
Abstract
Airborne Laser Scanning (ALS) is widely extended in forest evaluation, although photogrammetry-based Structure from Motion (SfM) has recently emerged as a more affordable alternative. Return cloud metrics and their normalization using different typologies of Digital Terrain Models (DTM), either derived from SfM or from private or free access ALS, were evaluated. In addition, the influence of the return density (0.5–6.5 returns m-2) and the sampling intensity (0.3–3.4%) on the estimation of the most common stand structure variables were also analysed. The objective of this research is to gather all these questions in the same document, so that they serve as support for the planning of forest management. This study analyses the variables collected from 60 regularly distributed circular plots (r = 18 m) in a 150-ha of uneven-aged Scots pine stand. Results indicated that both ALS and SfM can be equally used to reduce the sampling error in the field inventories, but they showed differences when estimating the stand structure variables. ALS produced significantly better estimations than the SfM metrics for all the variables of interest, as well as the ALS-based normalization. However, the SfM point cloud produced better estimations when it was normalized with its own DTM, except for the dominant height. The return density did not have significant influence on the estimation of the stand structure variables in the range studied, while higher sampling intensities decreased the estimation errors. Nevertheless, these were stabilized at certain intensities depending on the variance of the stand structure variable.
Similar content being viewed by others


Introduction
The sustainable management and conservation of forest resources require a deep knowledge of the stand characteristics, as well as their distribution and organization, necessary to define the forest structure (Spies and Franklin 1991; Smith et al. 1997; Zimble et al. 2003). From a static point of view, the most relevant features are the diametric classification, the size of the tree crown and their specific composition, considering their spatial distribution both vertical and horizontal (del Río et al. 2003).
Classic forest inventories play a key role in the Forest Management Plans (FMP), which are based on in situ measurements over a disperse sample of field plots all over the stand (Fankhauser et al. 2018). Then, these measurements are translated into stand variables, such as stand density, dominant height, basal area, volume or above-ground biomass. Finally, the population values are estimated throughout statistical operations. This traditional technique is effective, but it is not always efficient (Pascual et al. 2008), especially in those stands with irregular topography and adverse meteorology, where the field work is more demanding. In addition, the variability of the stand is not always correctly represented by the initial sampling (Meyer et al. 2013), which involves the necessity of alternative techniques to the traditional inventories.
Remote sensing offers ex-situ high-resolution information, more extensive both spatially and temporally than conventional inventories (Fankhauser et al. 2018). Initially, aerial images were used to complement the field measurements (Franklin 2001). Despite the subjectivity of this approach (Skidmore 1989; Franklin 2001; in Pascual et al. 2008), the field sampling design and the subsequent estimations improved (Magnussen et al. 2006). However, this 2D remote sensing technology (orthophotographs or satellite images) is not able to detect the complexity of forest stands. Therefore, other remote sensing techniques were required. Active sensors such as LiDAR (Light Detection and Ranging) or passive sensors such as photogrammetry are capable to generate 3D models of the forest, which increases the stand information (Fankhauser et al. 2018).
LiDAR is based on the emission of laser beam pulses and their return intervals, which together with an accurate geolocation and orientation of the sensor, allows to produce faithful representations of the reality in a point cloud form. The use of Aerial Laser Scanning (ALS) is common since the beginning of the twenty-first century, although it has some limitations associated with its high cost of acquisition and processing (Hummel et al. 2011), which makes these data sources cost-effective only on a relatively large scale (Koch 2013). However, some countries such as the United States of America (Veneziano et al. 2002; Cunningham et al.; 2004; in Jakubowski et al. 2013), or those within the framework established by the INSPIRE Directive of the European Union, have free access to large-scale ALS data, although with low-density (Jakubowski et al. 2013) and scarce periodicity (Iglhaut et al. 2019).
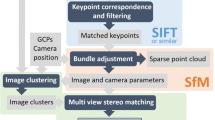
On the other hand, Digital Aerial Photogrammetry (DAP) techniques, such as Structure from Motion (SfM), are also able to create three-dimensional scenes, but more affordable (White et al. 2013), especially because of the improvements of the processing software (Probst et al. 2018) and the versatility of the measurement technology (Colomina and Molina 2014). SfM is based on overlapping photographs, so that the same scene is perceived from at least two points of view. These sensors could be equipped either in manned aircrafts to cover high range extensions or in compact Unmanned Aerial Systems (UAS) for small forest stands, which make them suitable to evaluate the dynamics of the forest frequently (Malambo et al. 2018). In contrast, the quality of the Digital Terrain Model (DTM) is their main limitation, especially in high density stands (Iglhaut et al. 2019).
In the last 20 years, an extensive bibliography has shown the potential of ALS for the evaluation of forest structure, either for individual tree parameters (Persson et al. 2002) or for stand properties (Means et al. 2000, Naesset 2002). In addition, it could be used in a wide range of forest ecosystems, such as boreal forests (Maltamo et al. 2006; Næsset 2007; Hyyppä et al. 2008), central Europe temperate forests (Hollaus et al. 2009; Latifi et al. 2010; Breidenbach et al. 2010), or even in tropical forest (Drake et al. 2002; Razak et al. 2013; Magdon et al. 2018) despite the inaccuracy of DTM (Salleh et al. 2015) and the rapid dynamics of the tropical stands (Razak et al. 2013) in the latter. Therefore, ALS is currently the most extended technology in terms of forest evaluation. Recently, small differences have been shown when estimating some stand structure variables, such as timber volume, canopy height and basal area, using either ALS or DAP (Nurminen et al. 2013; Straub et al. 2013; Pitt et al. 2014; Gobakken et al. 2015) even at large-scale areas (Rahlf et al. 2017). Those authors coincide in the normalization of the DAP point clouds using a DTM from ALS data. However, there are other possibilities, for example, to extract a DTM using the own DAP point cloud, since the latter could have similar accuracy than the former depending on the stand density (Wallace et al. 2016).
Return density is a relevant feature, regardless of its source. The acquisition cost for ALS data is directly related to the pulse density, especially for large areas of interest (Jakubowski et al. 2013). The effect that this parameter has on the evaluation of the stand structure variables has been widely studied (e.g. Treitz et al. 2012; Jakubowski et al. 2013; Singh et al. 2015). Furthermore, ALS data are in some countries free access, low-density return clouds intended mainly for the extraction of the DTM (Veneciano et al. 2002, Cunningham et al. 2004, IGN 2019). In general, there were no significant differences on the estimation of the stand structure variables when reducing the point cloud density (Goodwin et al. 2006; Takahashi et al. 2010; Tesfamichael et al. 2010), apart from those cases with a paltry number of points (0.004 points m−2), in which the errors increased exponentially (Magnusson et al. 2007).
On the other hand, the sampling intensity (sampled area in relation with the total area of the stand) has also an economic impact on the FMP. In Spain, for instance, every administrative region develops its own FMP based on the common guidelines established by the National Forest Plan (NFP), which is revised every 10 years. Some other countries also implement their own legal forest management documents (Lisańczuk et al. 2020), in which a maximum sampling error (es) is established to statistically evaluate the forest resources. That parameter is the first step of the sample size design, since it allows to calculate the minimum number of sampling plots needed as a function of both the stand variance and the level of confidence. A higher number of plots would be set up in terms of other characteristics, such as the objective of the sampling design or the availability of auxiliary information.
Usually, the sample size is evaluated in absolute terms rather than in relative values (sampling intensity). For instance, Gobakken et al. (2013) established a minimum sample size of 40 plots of 250 m2 in a mixed Norway spruce (Picea abies (L.) Karst.) and Scots pine (Pinus sylvestris L.) forest of 1000 ha. Bouvier et al. (2019) agreed with the number of plots but differed in size (530 m2) to estimate the above-ground biomass in Maritime pine (Pinus pinaster Aiton) stands of 6000 and 8000 ha. Finally, Stereńczak et al. (2018) did not find significant differences in sample sizes higher than 100 plots of 500 m2 in 8500 ha of mixed forest dominated by Scots pine. The main problem of considering the absolute value of sample size is that the results are difficult to apply in other areas of interest, since the design depends on the extent of the stand. Therefore, it is more suitable to use relative results, for comparison among studies.
The objective of this study is to compare ALS and SfM data sources for the estimation of the main stand structure variables: above-ground biomass (AGB), volume over bark (V), stand density (N), quadratic mean diameter (QMD), Hart’s dominant height (Ho), and stand basal area (G) to establish a basis for the decision making and design of remote sensing-assisted field inventories. Moreover, the normalization of the point clouds with different DTM typologies was analysed: private high-density ALS, public low-density ALS and SfM. Finally, the effect of the return density and sampling intensity, as well as the associated errors were evaluated.
Materials and methods
Study area
The study area, with an extension of 141.91 ha, was located in the western hillside of the Fuenfria Valley (40°45ʹN, 4°5ʹW), in the northwest of Madrid, Spain (Fig. 1). Elevation ranged between 1300 and 1820 m above sea level, with an average slope of 42%. The mean annual temperature was 9.4 °C and mean precipitation was 1180 mm/year. Scots pine (Pinus sylvestris L.) was the dominant species throughout the study area, which was accompanied by Pyrenean oak (Quercus pyrenaica Willd.), especially in the lower part of the hillside. As the elevation increases, the forest was less dense and rocky outcrops with Cytisus scoparius (L.) Link., C. oromediterraneus Rivas Mart. et al. and Genista florida L. shrubs appear. Most of the area faced east.

Study area with the location of the 60 field sampling plots measured in 2013. Fuenfría Valley, Cercedilla, Madrid (Spain)
Data
Field inventory
A systematic sampling was carried out to measure 60 circular sample plots (r = 18 m), covering the study area (Fig. 1). The first plot was randomly located, while the others were set up according to a regular grid with 150 m of separation between contiguous plots. The total sampling area amounted to 6.11 ha, which represented a sampling intensity of 4.34%. Field measurements were conducted between October 2013 and January 2014. On each sample plot, slope, orientation, shrub cover, and regeneration were recorded, and the diameter at breast high (DBH) of all trees over 1.3 m in height was calipered. In addition, both the total height and the height to the first live branch of four trees (three dominant and one co-dominant trees) were measured with a Häglof Vertex III hypsometer. Finally, the species and the phytosanitary status for each tree were recorded. The coordinates of each plot were first accurately obtained with a differential GPS (Topcon HiperPro) and then processed and corrected. With all this information, six typical stand structure variables were identified for each plot. The above-ground biomass (AGB) was computed based on the formulas described in Montero et al. (2005). On the other hand, the volume over bark (V) required the design of some regression models to relate that variable to the DBH. The computes were performed according to Tordesillas (2014; Eq. 1 for pine and Eq. 2 for oak). The four remaining variables were stand density (N), quadratic mean diameter (QMD), Hart’s dominant height (Ho), and stand basal area (G). A general description of the stand structure variables is presented in Table 1.
where \(V\) is the volume over bark in dm3 and \({\rm DBH}\) is the Diameter at Breast Height in cm.
Remote sensing data
ALS data were collected in July 2011 using a Leica ALS70-HP laser scanning system with a 200 kHz pulse rate and a 21 Hz scan frequency. The flight was composed of 7 passes at an elevation range between 625 and 1200 m above-ground, with a scan angle (FOV) of 14°. Every pass covered an average width of 400 m. All these configurations resulted in a total covered area of 220.3 ha with an average scan density of 24.88 returns m−2. On the other hand, the SfM point cloud was generated by processing 17 free-access and high-quality pictures using Agisoft Photoscan software. These pictures were published by the National Geographic Institute of Spain (IGN) in 2011 along with the National Aerial Orthography Plan (PNOA). The number of control points used for image referencing over the study area, according to the Agisoft photoscan software procedure, was six. This procedure provided a root-mean-square error (RMSE) of 0.16 m (RMSE in Z = 0.15 m), which were considered sufficient. SfM point cloud had an average density of 8.13 returns m−2 (Table 2).
Digital terrain models
Both ALS and SfM data were normalized with three different types of DTM. Two of them were generated from ALS data, our private ALS flight (DTMALS) and the free-access PNOA ALS (DTMPNOA), while the third one was derived from the SfM point cloud (DTMSfM). The DTMALS was generated with the highest point cloud density (Table 2) with a spatial resolution of 1 m, while the DTMPNOA, which came from a 0.5 returns m−2 cloud, had a spatial resolution of 5 m. The DTMSfM was compared with the public DTMPNOA, by means of height difference (Z) in each of the cells. The average (± standard deviation) height difference between DTMSfM and DTMPNOA was 0.53 ± 1.77 m, which was considered acceptable, taking into account the low resolution of the DTMPNOA and the high slope of the study area (42%). The spatial resolution of the DTMSfM was 0.37 m (Table 2).
Data processing
Reduction in point cloud density
Since ALS and SfM files had different scan densities, both were decimated to a homogeneous density of 6.5 returns m−2. From this start return density, both datasets were recursively decimated by thinning them a 50% at each step until they reached a scan density of 0.5 returns m−2. In this way, five density files were derived for each point cloud (6.5, 4, 2, 1 and 0.5 returns m−2), to study the effects of scan densities on the stand properties. A minimum density of 0.5 returns m−2 was established in this analysis to make it coincident with the PNOA public data. The decimation process was automatized using RStudio (R core team 2019) with “lasfilterdecimate” function of the “lidR” package. At each step of decimation, the highest scan density file (6.5 returns m−2) was used to derive the subsequent ones, in order to minimize the errors in future stages. A maximum error of 0.01 returns m−2 in the average density was established to obtain each file.
Calculation of return metrics
For the calculation of return metrics, two successive stages were developed in Fusion 3.80. First, the sample plots were extracted for each data file using “clipdata” function. Once this was completed, all metrics were obtained with “cloudmetrics” function. A height break of 3.5 m was set up to exclude trees with DBH lower than 7.5 cm. This process was repeated and automatized for each data and density file with RStudio. As a result, 93 return, height and intensity metrics were obtained.
Model analysis
Elimination of atypical field plots
Those sampling plots out of range for each stand structure variables were considered as an outlier and were previously removed from the model analysis. The range limits were established by 1.5 times the interquartile range (IQR) below and above the first and third quartiles, respectively, according to the Tukey’s method (Tukey 1977), since the data sets were normally distributed (Seo 2006).
Selection of explanatory variables
Intensity return metrics were not considered as predictor variables (PV) in this analysis, since they need calibration before use (García, et al. 2010). The PV selection was realized according to two criteria: i) the highest Pearson’s correlation with the response variable; (ii) non-collinearity among predictors. The process was automatized in RStudio in a loop form. First, the program evaluated the Pearson’s correlation of all PV with the response variable and selected that with the highest coefficient. Then, the correlations among the selected predictor and the other ones were performed. The selection threshold of noncollinear PV was set at a Pearson’s correlation coefficient of ≤ 0.7. All the predictor candidates are presented in Table 3.
Design of regression models
The best multiple linear regression model (MLRM) was searched for every stand structure variable on each combination of data source and DTM. For that, the metrics from the maximum return density file (6.5 returns m−2) of all sample plots, excluding the outliers, were used in RStudio. MLRM were carried out according to a stepwise ordinary least squares (OLS) regression (“ols_step_both_p” function of the “olsrr” package), removing from the models any PV with a partial F statistic with a significance level greater than 0.05 (Gobakken and Naesset 2008). In addition, both the original explanatory variable and its logarithmic transformation were considered as different scenarios of the model design, correcting in this last case the bias of predictions (Strimbu et al. 2018). Finally, the normality, heteroscedasticity and independence test of residuals were, respectively, analysed according to Kolmogorov–Smirnov (KS test; “ks.test” function; “stats” package), Breusch–Pagan (BP test; “bptest” function; “lmtest” package) and Durbin–Watson (DW test; “dwtest” function; “lmtest” package) at 0.05 significance level.
Bootstrap
Every MLRM was validated in a 1000 repetitions bootstrap analysis for each return density in different sampling intensity scenarios (0.3, 0.7 1 1.4 2 2.7 and 3.4%), obtaining in each repetition the adjusted coefficient of determination (r2) and RMSE. A simple random sample of plots (training plots) referring to the required sampling intensity was taken for each repetition of the model re-calculation, which was validated using the remaining plots (testing plots) based on a cross-validation analysis. Previously, it was verified that the sample of training plots had the same distribution as the plots used during the model design, by means of the Kolmogorov–Smirnov test. Given that the re-calculated model was only applicable in the same range of values of training plots, those testing plots out of that range were not considered for the validation process. Apart from assessing the factor effect, two relative error parameters were calculated: i) simple random sampling error, \({e}_{\mathrm{SRS}}\) (Eq. 3); (ii) regression sampling error, \({e}_{\mathrm{r}}\) (Eq. 4).
where \({S}_{y}\) was the sampling standard deviation of variable y; \(n\) was the sample size; \(f\) was the proportion between the sample size and the population; \({t}_{\alpha ; n-1}\) was the Student t-distribution parameter with \(\alpha\) = 0.05 significance level and \(n-1\) degrees of freedom; \(r\) was the Pearson’s correlation coefficient, and \(mean\) is the average sample value of each variable. In this analysis, \(f\) was disregarded, while just the Pearson’s correlation between the explanatory forest structure variable and the first predictor was considered.
Analysis of variance
To assess the effects of the different factors on the estimation of each stand structure variable, two types of analysis of variance (ANOVA) tests were performed. Firstly, a simple ANOVA test was carried out to evaluate significant differences (95% level of confidence) between \({e}_{SRS}\) and \({e}_{r}\) (for both ALS and SfM regression models). Secondly, that same test was used to assess the influence of return density on the estimation of the stand structure variables. Finally, a multiple ANOVA test was developed to evaluate the influence of sampling intensity, data source and DTM, as well as their interactions. ANOVA used the F statistic to assess the significance of the parameters, while the Fisher’s Least Significant Difference test (LSD) was used to establish the confidence interval and to evaluate the differences between each parameter level. These computations were carried out in Statgraphics Centurion 18 (v. 18.1.13).
Results
Base models
Regardless of the combination of data source and DTM normalization, the models of both N and QMD showed the poorest fits (Table 4). The former presented a r2 range from 0.50 to 0.56, while the latter ranged between 0.45 and 0.57. In addition, the DW p values were lower than 0.05 in all the N and in half of the QMD models, meaning collinearity at a 95% confidence level. The BP p value of the QMD model with ALS predictors normalized with DTMPNOA (ALSPNOA) was also lower than the significance threshold (Table 4). Therefore, both stand structure variables were not considered in this study.
On the other hand, the remaining stand structure variables produced suitable MLRM. They did not present problems either in normality, in heteroscedasticity or in collinearity of their residuals, since the KS, BP and DW p values were higher than 0.05 (Table 4). In general, the ALS predictors produced significantly better estimations than the SfM ones. The MLRM for V carried out the best fits, with r2 in the range of 0.85–0.87 with ALS and 0.81–0.83 with SfM predictors, closely followed by Ho, which produced the best MLRM with ALS predictors normalized with both the DTMALS and the DTMPNOA (r2 = 0.81; Table 4). However, the alternative exponential model (logarithmic transformation of the response variable) was used in three of the six study cases (ALSSfM, SfMALS and SfMPNOA), to solve the collinearity (DW p values < 0.05) of the residuals produced after the regression with the non-transformed Ho variable. Finally, both the G and the AGB models also showed better estimations using the ALS rather than the SfM metrics (Table 4). Basal area produced MLRM with the same r2 values for all the ALS study cases (r2 = 0.80), which was subsequently translated into small differences in RMSE (15.49%-15.67%), while the SfM models showed r2 in the range of 0.72–0.75 (Table 4). Similarly, the AGB regression models were better for ALS (r2 = 0.78–0.79; RMSE = 16.42–16.77%) than for SfM point cloud metrics as predictor variables (r2 = 0.74–0.78; RMSE = 16.68–17.92%; Table 4).
Regarding the point cloud normalization, no significant differences in the LSD test were found between the DTMALS and the DTMPNOA, which had similar r2 for most of the MLRM, but higher than the SfM models (Table 4). The greatest differences between the point cloud normalization with a LiDAR-based instead of the DTMSfM were found in the Ho models, with r2 = 0.81 in the ALSALS and the ALSPNOA models, clearly higher than the ALSSfM model (r2 = 0.67). The RMSE% values were inversely proportional to the r2 results in all the study cases, being the Ho the variable that produced the lowest errors (Table 4). However, a remarkable effect was found when using the DTMSfM: ALSSfM models were less accurate than the ALSALS and ALSPNOA regressions, while normalizing the SfM point cloud with its own DTM produced better estimations than normalizing it with a LiDAR-based DTM. For instance, r2 values of 0.75 and 0.83 were found for the SfMSfM models of G and V, respectively, higher than 0.72 and 0.81 shown by the SfMALS and SfMPNOA models (Table 4).
Sampling errors
Both eSRS and er were inversely proportional to the sampling intensity (Fig. 2). However, the former was significantly higher than the latter in every variable of interest (F statistic p value < 0.05). Therefore, the auxiliary information from both SfM and ALS let to reduce the sampling error as compared to that of the field inventory alone. Considering ALS regression, er was 51% for G (Fig. 2A), 58% for V and Ho (Fig. 2B and C, respectively) and 44% for AGB (Fig. 2D) lower than the eSRS. On the other hand, those differences were smaller when SfM was considered, specifically 44% for G, 46% for V, 50% for Ho and 37% for AGB. On the other hand, the er for ALS were 12% lower for G 22% for V 15% for Ho and 11% for AGB in comparison with the SfM (Fig. 2). However, no significant differences in the LSD test were found between ALS and SfM.

Relative simple random sampling error (Classic inventory) and sampling regression error (ALS and SfM) vs. sampling intensity for each stand structure variable of interest
Effect of the parameters of interest
No significant differences on the estimation of the stand structure variables regarding the return density were found, since all the F statistic p values were higher than 0.05 (Table 5). The average value for both the coefficient of determination and the RMSE narrowly ranged (Table 5). The maximum differences in r2 were 0.02 for G and AGB, being them even more insignificant for V and Ho (r2 = 0.01). Finally, the relative RMSE amplitude was less than 1% for all the variables of interest, considering a return density reduction from 6.5 to 0.5 returns·m−2, or from 100 to 7.7% in relative values (Table 5).
On the other hand, the sampling intensity, the data source and the DTM normalization, as well as their interactions, had a significant influence on the estimation of the stand structure variables. First, the decrease in accuracy when reducing the sampling intensity was evident (Figs. 3 and 4). This factor produced significant differences for every stand structure variable (p value < 0.05). Thus, the lower the sampling intensity, the worse the estimation of the variables. The MLRM were equally explanatory from certain values of sampling intensities depending on the stand structure variable, which was reflected in their coefficients of determination (Fig. 3). For instance, the average r2 was 0.76 for the Ho models designed by sampling intensities higher than 1%, and 0.84 when the sampling intensity was higher than 2% for volume estimation. On the other hand, no significant r2 values for G (0.75–0.76) and AGB (0.76–0.77) were found, when the sampling intensity exceeded 1.4%. In addition, the RMSE were both significantly and exponentially higher when sampling intensity was reduced. However, certain stabilization of them was observed when sampling intensity reached 1% (Fig. 4).

Coefficients of determination (r2), with 95% confidence intervals, vs. sampling intensity (%) for each combination of data source (ALS and SfM) and DTM normalization (ALS, PNOA and SfM). PNOA: DTM provided by the National Aerial Orthography Plan

Relative Root-Mean-Square Error (RMSE%), with 95% confidence intervals, vs. sampling intensity (%) for each combination of data source (ALS and SfM) and DTM normalization (ALS, PNOA and SfM). PNOA: DTM provided by the National Aerial Orthography Plan
The data source and the DTM showed significant differences between the considered alternatives (p value < 0.05). First, the ALS metrics fitted better to the stand structure variables, producing higher r2 in these MLRM than those designed with the SfM variables (Table 6; Fig. 3). Consequently, the former produced estimations with lower RMSE than the latter (Table 6; Figs. 4 and 5). More disparate results in the DTM normalization were found, depending on the variable of interest. Firstly, the MLRM for V and Ho fitted better when the point cloud was normalized using DTMALS or DTMPNOA, whereas G and AGB showed the opposite response, since their regressions were better when the DTMSfM was used for the normalization process (Table 6; Fig. 3). Finally, there were no significant differences between the point cloud normalization with DTMALS and DTMPNOA for G, V and AGB, while the Ho regressions were better when the point cloud was normalized with DTMALS (Table 6).

Relative Root-Mean-Square Error (RMSE%) with 95% confidence intervals for each combination of data source (ALS and SfM) and DTM normalization (subindices ALS, PNOA and SfM). PNOA: DTM provided by the National Aerial Orthography Plan
In addition, both the pairwise and the triple factor interaction were evaluated in the multiple ANOVA test. The interaction between the data source and the DTM was significant in all study variables both in the evaluation of r2 and RMSE (p value < 0.05; Fig. 5). The LSD test showed that the relative RMSE for V (Fig. 5B), Ho (Fig. 5C) and AGB (Fig. 5D) were equally lower in the ALSALS and ALSPNOA than in the ALSSfM combinations. In contrast, the G models with the ALS metrics were equally explanatory, regardless of the DTM (Fig. 3A) and the relative RMSE were significantly lower when the ALS cloud was normalized with the DTMSfM (Fig. 5A). On the other hand, the SfM metrics produce better regressions when the point cloud was normalized with its own ground file (DTMSfM) rather than with the LiDAR-based DTMs (Fig. 3). Therefore, the relative RMSE were lower in those cases (Fig. 5A, B and C). Only in the case of the dominant height, no significant differences in the LSD test were found between the combinations of the SfM models, which produced lower relative RMSE in the SfMALS and SfMPNOA than in the SfMSfM combinations (Fig. 5C). In addition, the Ho models using ALSSfM presented worse fits than those designed with the SfM metrics (Fig. 3C), while the worst ALS model was always better that the best SfM for the remaining variables (Figs. 3A, B and C). Finally, an irregular response was found for some of the variables of interest when the sampling intensity decreased. The estimation of the basal area was better both for ALSALS and ALSPNOA combinations at higher sampling intensities. However, when these were lower than 0.5%, both produced higher RMSE than the remaining combinations (Fig. 4A).
Discussion
Base models
The MLRM for G, V, Ho and AGB showed high precision in the fit, as reflected in their r2 (Table 4). However, N and QMD produced models with poor fits, in accordance with previous studies (Table 7), not only because of their low r2 values, but also because they did not meet the basic assumptions of the correlation of residuals in many cases (Table 4). One possible reason for this phenomenon lies in smaller trees, which come to represent a high percentage in some sampling plots. These trees, being dominated by other individuals, would be unnoticed in the point cloud, especially with SfM. On the other hand, the smaller trees had a low influence on G, V, AGB and Ho calculation. That may be why the other models did have a good fit (Tordesillas 2014).
Our r2 values were similar to those obtained in other studies (Table 7), although some of them have been carried out under very homogeneous and even-aged forest stands (Næsset 2002 and 2004). In contrast, our study area was an uneven-aged stand, with heterogeneity conditions (Pascual 2008). Treitz et al. (2012) obtained the best r2 values for each stand structure variable considering all the study areas of their research study, which translated into high-precise model fits because the stands were classified and differentiated according to its type and characteristics. However, N and QMD also showed worse fits than the remaining stand structure variables. In contrast, Gonzalez-Ferreiro et al. (2012) did not consider these variables, even though the forest was a Pinus radiata plantation.
The best predictions were for V and Ho, while N and QMD showed the worst results (Table 7). There are two main reasons which could affect the regression model adjustments: i) the forest field work and the ALS flight were two years apart, considering the stand growth of the stand between 2011 and 2013 negligible as other authors did (Andersen et al. 2005; Næsset and Gobakken 2008; Breidenbach and Astrup 2012); (ii) the tree height was just measured for three dominant and co-dominant trees, while estimating the height of the remaining trees by regression. These conditions explained the differences between the r2 values in Cercedilla forest with the other authors, especially for the Ho regression models, since Treitz et al. (2012) and Gonzalez-Ferreiro et al. (2012) measured all the tree heights within the field plots at the same time as the ALS data was taken.
Sampling errors
The sampling intensity could be reduced by incorporating auxiliary information from both SfM and ALS. The stand structure variables considered in this study showed disparate response to the use of auxiliary information, being the V and the Ho the variables that improved more with this technique, due to their correlation with the point cloud metrics. This supports the good fits of the regression models for these variables (Table 7). In practice, considering a 10% sample error, the required sampling intensity is approximately 0.7% for Ho, 5% for G and AGB, 3.5% for V in a classical forest inventory (Fig. 2). However, in ALS-assisted forest inventories, the sampling intensity could be reduced up to 0.7% for G and V 1% for AGB and less than 0.3% for Ho, significantly increasing the efficiency of field work (Fig. 2).
On the other hand, the sampling errors would be reduced considering auxiliary information in a fixed sample size. For example, with a sampling intensity of 1% the relative error decreased from 15.8 to 7.8% for G, from 19.1 to 8.0% for V, from 8.1 to 3.4% for Ho and from 16.1 to 9.1% for AGB using ALS auxiliary information (Fig. 2). These results are in accordance with Philip and Lam (1997), who showed the improvement of sampling error when the correlation between X and Y was higher than 0.4.
Regarding the supplementary data source, SfM metrics were less correlated with the forest variables than the ALS, which means that a higher sampling intensity is required to get the same sampling error (Fig. 2). However, these differences were not significant and each of them could be used to improve the field work in the same dimension.
ALS density
According to González-Ferreiro et al. (2012), various LiDAR flight configuration, especially different flight height and scan angles, would be ideal to assess the real influence of the point cloud density reduction on the estimation of the stand structure variables. However, this could be substituted by randomly decreasing the return density. In this sense, this study supports the good estimations of stand structure variables in a wide range of ALS densities, from 0.5 to 6.5 returns m−2, being similar to those historically reported (Table 8).
Relative RMSE obtained in the G models were slightly lower than those obtained by González-Ferreiro et al. (2012) in stands of Pinus radiata in Galicia (Table 8), but considerably higher than those in Treitz et al. (2012). Nevertheless, the differences were lower than 1%, similarly to González-Ferreiro et al. (2012), for ALS densities from 0.5 to 8 pulses m−2, and Treitz et al. (2012) in intolerant hardwood stands of Romeo Mallette Forest, using ALS densities from 0.5 to 3.2 pules·m−2. This supports the idea of Stephens et al. (2007), who did not find significant differences in G estimation for densities above 0.1 pulses m−2.
The estimations for V produced relative RMSE values from 19.30 to 20.11%, which were similar to those reported by Valbuena et al. (2018) in a study area close to the one analysed in this study. On the other hand, González-Ferreiro et al. (2012) reported a relative RMSE higher than those obtained in this study improving in 5% the estimations by increasing the density from 0.5 to 8 pulses·m−2, while the estimations of Treitz et al. (2012) were again better, with a maximum relative RMSE difference of 2.2% in black spruce stands (Treitz et al. 2012).
Ho was the variable with the best estimations. This could be understandable since the information in the point cloud is height above the DTM. In this sense, the relative RMSE values were similar to those obtained by González-Ferreiro et al. (2012) with approximate values of 8%. In contrast, the estimations of Treitz et al. (2012) were highly precise, with relative RMSE around 2–3%. However, the differences between ALS densities were almost negligible, being less than 1% in all studies, in agreement with Stephens et al. (2007), who demonstrated the insignificance of LiDAR density for dominant height estimation up to 0.1 pulses m−2 and significant loses only for lower densities.
Finally, the relative RMSE obtained in AGB models were similar in all studies, except for black spruce stands (Treitz et al. 2012; Table 8). In this study, the relative RMSE was slightly higher than those obtained by Hernando et al. (2019), who reported a relative RMSE of 16.72% in Scots pine-dominated forest in Valsaín (Spain). The differences between the ALS densities were lower than 1% in this study, similarly to intolerant hardwood stands (Treitz et al. 2012). On the other hand, the differences were higher than 2% in the black spruce stand (Treitz et al. 2012) and higher than 7% in Pinus radiata in Galicia (González-Ferreiro et al. 2012). This is related with the differences in the coefficients of determination of their models (Table 8).
Sampling intensity
The sampling intensity is a crucial factor in forest inventory planning, since it will determine the minimum area needed to be measured in the field. This is related not only with the variability of the stand and the total error expected (González et al. 1993), but also with the availability of auxiliary information such as ALS or SfM as previously discussed in 4.2.
There were significant differences between all the sampling intensities considered in relation with the estimation error, which means that the higher the sampling intensity, the lower the RMSE obtained. In contrast, the coefficients of determination of the regression models were not significant, while reaching a specific sampling intensity value depending on the stand structure variable. This proves the above-mentioned relationship between the variability of stand and the sampling intensity. Ho showed the lowest variability (SD = 19.03%), followed by the G (SD = 37.30%), AGB (SD = 38.96%) and, finally V (SD = 46.97%). This increasing trend-line is also present when analysing the signification threshold for the sampling intensity. In this sense, no significant differences were found for values higher than 1% in sampling intensity for the estimation of Ho 1.4% for both G and AGB, and 2% for V. Therefore, the higher the variance of the target variable, the higher the sampling intensity to get a good regression for its estimation.
Data source and DTM normalization
The estimation of the stand structure variables was significantly more accurate using ALS information rather than SfM (Table 6; Figs. 3, 4 and 5). One of the reasons is that LiDAR can penetrate through the canopy, reaching the lower vegetation and the ground, which means more representativity of the understorey. In contrast, the trees which are not visible in the aerial pictures, are not represented by the SfM point cloud. Therefore, V and AGB showed higher RMSE differences between ALS and SfM than Ho and G, due to the non-detection of the smaller trees (Table 6). In some plots, this type of vegetation represents a high percentage, with greater influence over V and AGB. On the other hand, those smaller trees do not have so much influence on the G calculation, because they usually have low DBH values. In addition, when calculating the Ho, just the 100 tallest trees per hectare are considered, i.e. the 10 tallest trees per plot (area = 0.1 ha). Therefore, the undetected trees usually have small influence, and the differences are related to the accuracy of the return’s height.
The point cloud normalization produced more discrepancies between the DTM considered. First, both the DTMALS and the DTMPNOA did not produce significant differences in the normalization of the point clouds (Table 6). This reinforces the no-influence of LiDAR density within the range considered here, this time for the DTM processing. However, the DTMALS had 5-times more resolution than the DTMPNOA (Table 2), which means much more accuracy, although superfluous even considering such a great slope. As an exception, the dominant height was more sensible to the DTM typology, being the DTMALS the best option to normalize the point cloud (Table 6).
The main limitation of SfM is the reconstruction of the ground surface, being this only well-defined where large vegetation gaps exist (Iglhaut et al. 2019). Nevertheless, the ground return density was sufficient to get a good DTMSfM in this study. In addition, it had a resolution of 0.37 cm, much higher than the DTMALS and DTMPNOA (Table 2). That resulted in not so notorious differences but significantly better estimations for G and AGB using SfM, instead of ALS (Table 6). However, these results were affected not only by the individual effect of DTM, but also by its combination with the data source. Attending the graphics in Fig. 5, two results are necessary to highlight.
Firstly, the improvement of the G estimations using the ALS metrics was remarkable when normalizing with DTMSfM as compared with DTMALS or DTMPNOA (Fig. 5A), since the remaining variables of interest showed the opposite effect (Fig. 5A, B and C). The explanatory variables in the G regression models are mostly related with the first returns, both in absolute and relative values, while the remaining variables used height percentiles as the main independent variable in their regression relationships. Therefore, the basal area seems to be more affected by the crown size than by tree height (Manzanera et al. 2016). This is also shown by the low relative RMSE differences between the ALS and SfM data sources (Table 6). Although ALS metrics were clearly better estimators than SfM metrics in general, an exception was observed in the G estimation (Table 6, Fig. 4A), since the SfM can provide great accuracy on the visible tree tops and crowns, even higher than the ALS (Iglhaut et al. 2019). However, the point cloud normalization with an ALS-based DTM provided higher accuracy in the canopy height (Wallace et al. 2016), which was useful on the estimation of V, Ho and AGB.
Secondly, despite the high precision of the DTMALS and DTMPNOA, the SfM metrics produced better results if they were normalized with the DTMSfM, that is, with their own-generated DTM for most of the variables of interest, except for the dominant height (Fig. 5). In fact, normalization of the ALS point cloud with the DTMSfM was worse than estimating the Ho using the SfM metrics for each case of DTM normalization (Figs. 3C and 4C). This showed the sensibility of Ho to the accurate normalization of the point cloud.
The significance of the triple interaction
The irregular response of G estimations when reducing the sampling intensity is explained by the characteristics of their MLRM. The explanatory variables were related with first returns in absolute value for ALSALS and ALSPNOA, while they were related to relative first returns for the SfM combinations (Table 4). The regressions were designed with the maximum sampling intensity, which better represents the stand variety. However, low sampling intensity values are less representative, even worse in absolute than in relative metrics, since the latter are more homogeneous in the whole stand. Therefore, the G estimation with the SfM (relative explanatory metrics) showed a more consistent response than the ALSALS and ALSPNOA (absolute explanatory metrics). On the other hand, the estimation of Ho using the ALSSfM produced the same results in all the sampling intensities tested. These considerations explain the significance of the triple interaction for Ho.
Conclusions
This study reveals that both Airborne Laser Scanning (ALS) and Structure from Motion (SfM) have similar capabilities for the evaluation of forest structure. Both are equally able to decrease the sampling intensity in field work inventories or to decrease the sampling error while maintaining the sample size. However, ALS produced significantly better subsequent estimations for most of the common stand structure variables. As an exception, the basal area was more affected by the crown size than by the height of the trees. Therefore, the SfM was able to accurately estimate that variable. In contrast, the point cloud normalization with ALS-based DTM was significantly better than with the SfM-based DTM, although the latter produced better results when normalizing its own point cloud. On the other hand, the lowest return density (0.5 returns m−2) was equally explanatory than the maximum return density (6.5 returns m−2). Therefore, low density public ALS data would be satisfactory to evaluate the most common stand structure variables, although the main limitation is the temporal resolution. Thus, the SfM is a good alternative to the ALS technology. Finally, the sampling intensity should be carefully designed to obtain the admissible estimation error. However, no significant differences were found if the sampling intensity was higher than 1% for the dominant height 1.4% for the total basal area and the above-ground biomass and 2% for the stand volume, depending on the variance of the respective stand structure variables.
Data availability
The datasets generated and analysed during the current study are available from the corresponding author on reasonable request.
Code availability
The codes generated and analysed during the current study are available from the corresponding author on reasonable request.
References
Andersen H, McGaughey RJ, Reutebuch SE (2005) Estimating forest canopy fuel parameters using LIDAR data. Remote Sens Environ. https://doi.org/10.1016/j.rse.2004.10.013
Bouvier M, Durrieu S, Fournier RA, Saint-Geours N, Guyon D, Grau E, de Boissieu F (2019) Influence of sampling design parameters on biomass predictions derived from airborne lidar data. Can J Remote Sens. https://doi.org/10.1080/07038992.2019.1669013
Breidenbach J, Astrup R (2012) Small area estimation of forest attributes in the Norwegian National forest inventory. Eur J Forest Res. https://doi.org/10.1007/s10342-012-0596-7
Breidenbach J, Nothdurft A, Kändler G (2010) Comparison of nearest neighbour approaches for small area estimation of tree species-specific forest inventory attributes in central Europe using airborne laser scanner data. Eur J Forest Res. https://doi.org/10.1007/s10342-010-0384-1
Colomina I, Molina P (2014) Unmanned aerial systems for photogrammetry and remote sensing: a review. ISPRS J Photogramm Remote Sens. https://doi.org/10.1016/j.isprsjprs.2014.02.013
Cunningham R, Gisclair D, Craig J (2004) The Louisiana statewide lidar project. Louisiana State University:12
Del Río M, Montes F, Cañellas I, Montero G (2003) Revisión: Índices de diversidad estructural en masas forestales. Investigación agraria: Sistemas y recursos forestales
Drake JB, Dubayah RO, Clark DB, Knox RG, Blair JB, Hofton MA, Chazdon RL, Weishampel JF, Prince S (2002) Estimation of tropical forest structural characteristics using large-footprint lidar. Remote Sens Environ. https://doi.org/10.1016/S0034-4257(01)00281-4
Fankhauser KE, Strigul NS, Gatziolis D (2018) Augmentation of traditional forest inventory and airborne laser scanning with unmanned aerial systems and photogrammetry for forest monitoring. Remote Sens. https://doi.org/10.3390/rs10101562
Franklin SE (2001) Remote sensing for sustainable forest management. CRC Press
Führer E (2000) Forest functions, ecosystem stability and management. For Ecol Manage. https://doi.org/10.1016/S0378-1127(00)00377-7
García M, Riaño D, Chuvieco E, Danson FM (2010) Estimating biomass carbon stocks for a Mediterranean forest in central Spain using LiDAR height and intensity data. Remote Sens Environ. https://doi.org/10.1016/j.rse.2009.11.021
Gobakken T, Bollandsås OM, Næsset E (2015) Comparing biophysical forest characteristics estimated from photogrammetric matching of aerial images and airborne laser scanning data. Scand J for Res. https://doi.org/10.1080/02827581.2014.961954
Gobakken T, Korhonen L, Næsset E (2013) Laser-assisted selection of field plots for an area-based forest inventory. Silva Fenn. https://doi.org/10.14214/sf.943
González C, Martínez-Falero E, Pardo M, Solana J (1993) Técnicas de Muestreo Forestal. Fundación del Conde del Valle de Salazar
González-Ferreiro E, Diéguez-Aranda U, Miranda D (2012) Estimation of stand variables in Pinus radiata D. Don plantations using different LiDAR pulse densities. Forestry. https://doi.org/10.1093/forestry/cps002
Goodwin NR, Coops NC, Culvenor DS (2006) Assessment of forest structure with airborne LiDAR and the effects of platform altitude. Remote Sens Environ. https://doi.org/10.1016/j.rse.2006.03.003
Hernando A, Puerto L, Mola-Yudego B, Manzanera JA, Garcia-Abril A, Maltamo M, Valbuena R (2019) Estimation of forest biomass components using airborne LiDAR and multispectral sensors. Forest-Biogeosci Forest. https://doi.org/10.3832/ifor2735-012
Hollaus M, Wagner W, Schadauer K, Maier B, Gabler K (2009) Growing stock estimation for alpine forests in Austria: a robust lidar-based approach. Can J for Res. https://doi.org/10.1139/X09-042
Hummel S, Hudak AT, Uebler EH, Falkowski MJ, Megown KA (2011) A comparison of accuracy and cost of LiDAR versus stand exam data for landscape management on the Malheur National Forest. J Forest. https://doi.org/10.1093/jof/109.5.267
Hyyppä J, Hyyppä H, Leckie D, Gougeon F, Yu X, Maltamo M (2008) Review of methods of small-footprint airborne laser scanning for extracting forest inventory data in boreal forests. Int J Remote Sens. https://doi.org/10.1080/01431160701736489
Iglhaut J, Cabo C, Puliti S, Piermattei L, O’Connor J, Rosette J (2019) Structure from motion photogrammetry in forestry: a review. Curr Forest Rep. https://doi.org/10.1007/s40725-019-00094-3
IGN PNOA. Plan Nacional de Ortografía Aérea. In: . https://pnoa.ign.es/. Accessed Oct 8 2019
Jakubowski MK, Guo Q, Kelly M (2013) Tradeoffs between lidar pulse density and forest measurement accuracy. Remote Sens Environ. https://doi.org/10.1016/j.rse.2012.11.024
Koch B (2015) Remote Sensing supporting national forest inventories NFA. FAO Knowledge Reference for National Forest Assessments; FAO: Rome, Italy: 77–92
Latifi H, Nothdurft A, Koch B (2010) Non-parametric prediction and mapping of standing timber volume and biomass in a temperate forest: application of multiple optical/LiDAR-derived predictors. Forestry. https://doi.org/10.1093/forestry/cpq022
Lisańczuk M, Mitelsztedt K, Parkitna K, Krok G, Stereńczak K, Wysocka-Fijorek E, Miścicki S (2020) Influence of sampling intensity on performance of two-phase forest inventory using airborne laser scanning. Forest Ecosyst. https://doi.org/10.1186/s40663-020-00277-6
Magdon P, González-Ferreiro E, Pérez-Cruzado C, Purnama ES, Sarodja D, Kleinn C (2018) Evaluating the potential of ALS data to increase the efficiency of aboveground biomass estimates in tropical peat–swamp forests. Remote Sens. https://doi.org/10.3390/rs10091344
Magnussen S, Allard D, Wulder MA (2006) Poisson Voronoi tiling for finding clusters in spatial point patterns. Scand J for Res. https://doi.org/10.1080/02827580600688178
Magnusson M, Fransson JE, Holmgren J (2007) Effects on estimation accuracy of forest variables using different pulse density of laser data. For Sci. https://doi.org/10.1093/forestscience/53.6.619
Malambo L, Popescu SC, Murray SC, Putman E, Pugh NA, Horne DW, Richardson G, Sheridan R, Rooney WL, Avant R (2018) Multitemporal field-based plant height estimation using 3D point clouds generated from small unmanned aerial systems high-resolution imagery. Int J Appl Earth Obs Geoinf. https://doi.org/10.1016/j.jag.2017.08.014
Maltamo M, Malinen J, Packalén P, Suvanto A, Kangas J (2006) Nonparametric estimation of stem volume using airborne laser scanning, aerial photography, and stand-register data. Can J for Res. https://doi.org/10.1139/x05-246
Manzanera JA, García-Abril A, Pascual C, Tejera R, Martín-Fernández S, Tokola T, Valbuena R (2016) Fusion of airborne LiDAR and multispectral sensors reveals synergic capabilities in forest structure characterization. Gisci Remote Sens. https://doi.org/10.1080/15481603.2016.1231605
Means JE, Acker SA, Fitt BJ, Renslow M, Emerson L, Hendrix CJ (2000) Predicting forest stand characteristics with airborne scanning lidar. Photogramm Eng Remote Sens 5:87
Meyer V, Saatchi SS, Chave J, Dalling JW, Bohlman S, Fricker GA, Robinson C, Neumann M, Hubbell S (2013) Detecting tropical forest biomass dynamics from repeated airborne lidar measurements. Biogeosciences. https://doi.org/10.5194/bg-10-5421-2013
Montero G, Ruiz-Peinado R, Munoz M (2005) Producción de biomasa y fijación de CO2 por los bosques españoles. INIA-Instituto Nacional de Investigación y Tecnología Agraria y Alimentaria …
Næsset E, Gobakken T (2008) Estimation of above-and below-ground biomass across regions of the boreal forest zone using airborne laser. Remote Sens Environ. https://doi.org/10.1016/j.rse.2008.03.004
Næsset E (2007) Airborne laser scanning as a method in operational forest inventory: status of accuracy assessments accomplished in Scandinavia. Scand J Res. https://doi.org/10.1080/02827580701672147
Næsset E (2004) Effects of different flying altitudes on biophysical stand properties estimated from canopy height and density measured with a small-footprint airborne scanning laser. Remote Sens Environ. https://doi.org/10.1016/j.rse.2004.03.009
Næsset E (2002) Predicting forest stand characteristics with airborne scanning laser using a practical two-stage procedure and field data. Remote Sens Environ. https://doi.org/10.1016/S0034-4257(01)00290-5
Nurminen K, Karjalainen M, Yu X, Hyyppä J, Honkavaara E (2013) Performance of dense digital surface models based on image matching in the estimation of plot-level forest variables. ISPRS J Photogramm Remote Sens. https://doi.org/10.1016/j.isprsjprs.2013.06.005
Pascual C, García-Abril A, García-Montero LG, Martín-Fernández S, Cohen WB (2008) Object-based semi-automatic approach for forest structure characterization using lidar data in heterogeneous Pinus sylvestris stands. For Ecol Manage. https://doi.org/10.1016/j.foreco.2008.02.055
Persson A, Holmgren J, Soderman U (2002) Detecting and measuring individual trees using an airborne laser scanner. Photogramm Eng Remote Sens 6:513
Philip LH, Lam K (1997) Regression estimator in ranked set sampling. Biometrics. https://doi.org/10.2307/2533564
Pitt DG, Woods M, Penner M (2014) A comparison of point clouds derived from stereo imagery and airborne laser scanning for the area-based estimation of forest inventory attributes in boreal Ontario. Can J Remote Sens. https://doi.org/10.1080/07038992.2014.958420
Probst A, Gatziolis D, Strigul N (2018) Intercomparison of photogrammetry software for three-dimensional vegetation modelling. R Soc Open Sci. https://doi.org/10.1098/rsos.172192
Rahlf J, Breidenbach J, Solberg S, Næsset E, Astrup R (2017) Digital aerial photogrammetry can efficiently support large-area forest inventories in Norway. For: Int J Forest Res. https://doi.org/10.1093/forestry/cpx027
Razak KA, Santangelo M, Van Westen CJ, Straatsma MW, de Jong SM (2013) Generating an optimal DTM from airborne laser scanning data for landslide mapping in a tropical forest environment. Geomorphology. https://doi.org/10.1016/j.geomorph.2013.02.021
Salleh MRM, Ismail Z, Rahman MZA (2015) Accuracy assessment of lidar-derived digital terrain model (DTM) with different slope and canopy cover in tropical forest region. ISPRS Annal Photogrammetry, Remote Sens Spatial Inf Sci 3:81
Seo S (2006) A review and comparison of methods for detecting outliers in univariate data sets. Dissertation or Thesis, University of Pittsburgh
Simbaña PXM (2016) Geografía del carbono em alta resolución em bosque tropical amazónico del ecuador mediante sensores aerotransportados. Dissertation or Thesis, Universidad Politécnica de Madrid
Singh KK, Chen G, McCarter JB, Meentemeyer RK (2015) Effects of LiDAR point density and landscape context on estimates of urban forest biomass. ISPRS J Photogramm Remote Sens. https://doi.org/10.1016/j.isprsjprs.2014.12.021
Skidmore AK (1989) Expert system classifies eucalypt forest types using thematic mapper data and a digital terrain model. Photogramm Eng Remote Sens 3:23
Smith DM, Larson BC, Kelty MJ, Ashton PMS (1997) The practice of silviculture: applied forest ecology. Wiley
Spies TA, Franklin JF (1991) The structure of natural young, mature, and old-growth Douglas-fir forests in Oregon and Washington. Wildlife and vegetation of unmanaged Douglas-fir forests
Stephens PR, Watt PJ, Loubser D, Haywood A, Kimberley MO (2007) Estimation of carbon stocks in New Zealand planted forests using airborne scanning LiDAR
Sterenczak K, Lisanczuk M, Parkitna K, Mitelsztedt K, Mroczek P, Misnicki S (2018) The influence of number and size of sample plots on modelling growing stock volume based on airborne laser scanning. Drewno.Prace Naukowe.Doniesienia.Komunikaty. doi: https://doi.org/10.12841/wood.1644-3985.D11.04
Straub C, Stepper C, Seitz R, Waser LT (2013) Potential of UltraCamX stereo images for estimating timber volume and basal area at the plot level in mixed European forests. Can J Res. https://doi.org/10.1139/cjfr-2013-0125
Strimbu BM, Amarioarei A, McTague JP, Paun MM (2018) A posteriori bias correction of three models used for environmental reporting. Forest: Int J Forest Res. https://doi.org/10.1093/forestry/cpx032
Takahashi T, Awaya Y, Hirata Y, Furuya N, Sakai T, Sakai A (2010) Stand volume estimation by combining low laser-sampling density LiDAR data with QuickBird panchromatic imagery in closed-canopy Japanese cedar (Cryptomeria japonica) plantations. Int J Remote Sens. https://doi.org/10.1080/01431160903380623
Tesfamichael SG, Van Aardt J, Ahmed F (2010) Estimating plot-level tree height and volume of Eucalyptus grandis plantations using small-footprint, discrete return lidar data. Prog Phys Geogr. https://doi.org/10.1177/0309133310365596
Tordesillas A (2014) Estimación y evolución temporal de variables de variables forestales con tecnología LiDAR en el valle de la Fuenfría (Cercedilla, Madrid). Dissertation or Thesis, ETSI Montes, Forestal y del Medio Natural. Universidad Politécnica de Madrid
Treitz P, Lim K, Woods M, Pitt D, Nesbitt D, Etheridge D (2012) LiDAR sampling density for forest resource inventories in Ontario Canada. Remote Sens. https://doi.org/10.3390/rs4040830
Tukey JW (1977) Exploratory data analysis. Addison-Wesley Publishing Company
Valbuena R, Hernando A, Manzanera JA, Martínez-Falero E, García-Abril A, Mola-Yudego B (2018) Most similar neighbor imputation of forest attributes using metrics derived from combined airborne LIDAR and multispectral sensors. Int J Digital Earth. https://doi.org/10.1080/17538947.2017.1387183
Veneziano D, Hallmark S, Souleyrette R (2002) Comparison of lidar and conventional mapping methods for highway corridor studies. Center for Transportation Research and Education, Iowa State University:63
Wallace L, Lucieer A, Malenovský Z, Turner D, Vopěnka P (2016) Assessment of forest structure using two UAV techniques: A comparison of airborne laser scanning and structure from motion (SfM) point clouds. Forests. https://doi.org/10.3390/f7030062
White JC, Wulder MA, Vastaranta M, Coops NC, Pitt D, Woods M (2013) The utility of image-based point clouds for forest inventory: a comparison with airborne laser scanning. Forests. https://doi.org/10.3390/f4030518
Zimble DA, Evans DL, Carlson GC, Parker RC, Grado SC, Gerard PD (2003) Characterizing vertical forest structure using small-footprint airborne LiDAR. Remote Sens Environ. https://doi.org/10.1016/S0034-4257(03)00139-1
Acknowledgements
We thank Alberto Tordesillas for the field inventory, María Duarte for SfM data file and the Research Group for Sustainable Management SILVANET (UPM) for ALS data file and technical knowledge.
Funding
Open Access funding provided thanks to the CRUE-CSIC agreement with Springer Nature. Not applicable.
Author information
Authors and Affiliations
Contributions
Conceptualization was performed by AR-V, JAM, AG-C and AG-A. Methodology and investigation were performed by AR-V, JAM and SM-F. Software was performed by AR-Vand AG-C. Validation, data curation, writing—original draft preparation, visualization and project administration were performed by AR-V. Formal analysis was performed by AR-V and SM-F. JAM and AG-A collected resources. JAM, SM-F, AG-C and AG-Awere responsible for writing—review and editing. Supervision and funding acquisition were performed by JAM.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Communicated by Arne Nothdurft.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Rodríguez-Vivancos, A., Manzanera, J.A., Martín-Fernández, S. et al. Analysis of structure from motion and airborne laser scanning features for the evaluation of forest structure. Eur J Forest Res 141, 447–465 (2022). https://doi.org/10.1007/s10342-022-01447-7
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10342-022-01447-7