
Abstract
We use data from the British Household Panel Survey to analyse changes in poverty of self-reported health from 1991 to 2008. We use the indices recently introduced by Bennett and Hatzimasoura (Poverty measurement with ordinal data. Institute for International Economic Policy, IIEP-WP-2011-14, 2011), which can be interpreted as ordinal counterparts of the classical Foster et al. (Econometrica 52(3):761–766, 1984) poverty measures. We decompose changes in self-reported health poverty over time into within-group health poverty changes and population shifts between groups. We also provide statistical inference for the Bennett and Hatzimasoura’s (Poverty measurement with ordinal data. Institute for International Economic Policy, IIEP-WP-2011-14, 2011) indices. Results suggest that when “fair” self-reported health status is chosen as a health poverty threshold all of the used indices indicate the growth of health poverty in Britain. However, when the health poverty threshold is lower (“poor” self-reported health status) the increase in health poverty incidence was compensated by decreasing average health poverty depth and improving health inequality among those who are poor with respect to health. The subgroup decompositions suggest that the most important factors accounting for the changes in total health poverty in Britain include a rise of both health poverty and population shares of persons cohabiting and couples with no children as well as an increase of the population of retired persons.
Similar content being viewed by others
Introduction
In recent years there has been a growing interest in analysing the distribution of self-rated health statuses in a population and its changes over time. The problem that has received most attention is the appropriate measurement of health inequality that accounts for the ordinal nature of self-reported data (see, e.g., [1, 2, 5, 17]). A related, but different distributional problem of health poverty has been less studied.Footnote 1 As noticed by Allison and Foster [2], the most popular poverty measure using self-rated data is poverty headcount rate defined as the proportion of a population whose health status is below a chosen threshold.Footnote 2 In case of studies using data based on a five-point scale of self-assessed health with categories of “poor”, “fair”, “good”, “very good” and “excellent”, the health poverty headcount rate has been usually defined as the share of population with poor or fair health. However, such a simple measure takes into account only poverty incidence, but it is insensitive to poverty depth and distribution among the poor (poverty severity) as it weights respondents with poor and fair health equally. Poverty measurement literature delivers several families of poverty indices which are sensitive to the poverty incidence, depth and severity—most notably the Foster, Greer, Thorbecke (FGT) family, introduced in Foster et al. [7]. The FGT indices are, however, designed for cardinally measurable and interpersonally comparable variables like income and they are not meaningful when applied to ordinal data like self-rated health statuses [8].Footnote 3 The main reason for this is that they are not invariant to order-preserving transformations applied to the numerical values representing self-reported health statuses and the poverty threshold. To overcome this difficulty, Bennett and Hatzimasoura [3] recently proposed ordinal counterparts of the FGT poverty measures, which are invariant to order-preserving transformations and possess many attractive features of the original FGT measures. From the policy perspective, the most attractive feature of the FGT indices, both the original ones and their ordinal counterparts, is their subgroup decomposability. This property means that for any division of the population into nonoverlapping subgroups, total poverty measured by an FGT index can be expressed as a sum of the subgroup poverty indices weighted with population shares of subgroups.Footnote 4 The ordinal FGT indices of Bennett and Hatzimasoura [3] can be therefore used to identify the subgroups which are more affected by health poverty and to design policies that may be most effective in reducing overall health poverty.
The purpose of this paper is to analyse trends in self-reported health poverty in Britain using ordinal FGT measures of Bennett and Hatzimasoura [3] and data from the British Household Panel Survey (BHPS) for the period between 1991 and 2008. We also provide statistical inference for these ordinal FGT indices to verify if the observed changes in health poverty are due to sampling variability or if they correspond to the true changes in the population. Finally, we borrow from the literature on decomposing poverty indices using the Shapley value concept [12] to provide decompositions of changes in total self-rated health poverty in Britain between 1991 and 2008 into changes in subgroups’ population shares and changes in health poverty levels within subgroups.
Measures of self-rated health poverty
Bennett and Hatzimasoura’s [3] ordinal FGT family of poverty indices may be defined in the context of self-rated health data as follows. Let self-rated health of a population consisting of n persons be represented by a vector of S ordered categories Y = (y 1, y 2,…, y S ), with y i > y j if and only if health status i is preferred to health status j. In practice y 1 may represent, for example, poor self-rated health status, while y S may represent excellent self-rated health status. If category k is chosen as a poverty threshold, then Bennett and Hatzimasoura [3] propose the following class of ordinal poverty measures:
where p j is the share of population with self-rated health y j and α ≥ 0 is a parameter. Notice that p j can be interpreted as a probability of having self-rated health y j and hence Eq. (1) can be viewed as a weighted sum of the probabilities of having self-rated health below the chosen health poverty threshold with weights determined by k (the number of self-rated health categories below or equal to the poverty threshold) and the parameter α. If α = 0, then Eq. (1) reduces to the standard poverty headcount rate, while if α > 0, then Eq. (1) gives more weight to the categories with lower self-rated health. For example, when k = 2 and α = 1, the weights for p 1 and p 2 are, respectively, 1 and 1/2. Higher values of parameter α lead to lower weights attached to p 2,…, p k . Using an alternative representation of Eq. (1) in terms of normalized health ranks, Bennett and Hatzimasoura [3] show that the ordinal FGT measures are sensitive both to depth (when α > 0) and depth and distribution (when α > 1) of health poverty.
Statistical inference
The family of ordinal FGT poverty indices (1) is a linear function of k population parameters, p = (p 1,…, p k )T. In particular, it takes the form
with \( c = \left[ {1,\left( {\frac{k - 1}{k}} \right), \ldots ,\left( \frac{1}{k} \right)^{\alpha } } \right] \). For a random sample of n individuals, the maximum likelihood estimator of a population share p i is simply the sample proportion, \( \hat{p}_{i} = a_{i} /n\), where a i is the number of persons with self-rated health status y i in the sample. The maximum likelihood estimator of \( \pi_{\alpha } (Y;k) \) is therefore given by
where \( \hat{p} \) is a column vector of sample estimates of p i . From the central limit theorem, \( \hat{\pi }_{\alpha } (Y;k) \) is (asymptotically) normally distributed with a covariance matrix, which can be obtained using the delta method. The covariance matrix of p is given by
Therefore, the variance of Eq. (2) is given by
The sample estimate of Eq. (5), \( \widehat{\text{Var}}(\hat{\pi }_{\alpha } (Y;k)), \) can be obtained by replacing in Eq. (4) each p i by its sample estimate \( \hat{p}_{i} . \)
The variance estimator of \( \hat{\pi }_{\alpha } (Y;k) \) can be used to construct confidence intervals for estimated self-rated health poverty indices and to test hypotheses about the estimated indices. In particular, in order to test the hypothesis that two distributions of self-rated health, X and Y, have the same value of a given ordinal FGT index, we may use the following statistic:
If the samples X and Y are independent, the covariance term in the denominator of Eq. (6) is zero. However, the samples taken from two different waves of the BHPS are dependent as the BHPS is a longitudinal survey, which interviews annually the same individuals belonging to a representative sample chosen in 1991. The dependence of two BHPS samples taken from two different survey waves is only partial owing to sample attrition and inclusion of new entrants after wave 1 (see [13]). An appropriate method of accounting for partial sample dependency was proposed by Zheng [16] in the context of the inference for continuous additively separable poverty measures (including the continuous FGT indices).Footnote 5 In this paper, we use Zheng’s [16] approach to calculate the covariance term in Eq. (6).
Subgroup decomposition of changes in self-reported health poverty over time
In order to identify how various subgroups contribute to changes in self-reported health poverty over time, we can use “dynamic” decompositions of poverty changes proposed in the distributional literature concerned with continuous outcome variables. For subgroup decomposable ordinal FGT measures defined in Eq. (1), changes in total poverty over time from t 1 to t 2 can be written as follows:
where v i and \( \pi_{\alpha }^{i} \) are, respectively, population share and poverty level of subgroup i ∈ (1,…, h). Accounting for the change in total poverty over time, Δπ α can be expressed in terms of changes in poverty within subgroups, \( \Delta \pi_{\alpha }^{i} = \pi_{\alpha }^{i} (Y_{{t_{2} }} ;k) - \pi_{\alpha }^{i} (Y_{{t_{1} }} ;k), \) i ∈ (1,…, h), and changes in population shares of subgroups, \( \Delta v^{i} = v^{i} (t_{2} ) - v^{i} (t_{1} ), \) i ∈ (1,…, h). Shorrocks [12] has shown that an exact decomposition of this kind can be performed using the Shapley value concept taken from the cooperative game theory.Footnote 6 According to the Shapley value based decomposition, Eq. (7) becomes
Within-subgroup effects, W i, measure the contribution of poverty changes within subgroups to changes in total poverty weighted by the subgroups’ population shares averaged over time. Between-subgroup population shift effects, P i, are defined as contributions of changes in subgroups’ population shares to changes in total poverty weighted by the subgroup levels of poverty averaged over time. A poverty change decomposition similar to that given by Eq. (8), but with weights coming from the initial period (t 1), was initially proposed by Ravallion and Huppi [11]. However, their decomposition was inexact as it contained an interaction term between \( \Delta \pi_{\alpha }^{i} \,{\text{and}}\,\Delta v^{i} \). Shapley value based decomposition in Eq. (8) does not suffer from this drawback.
Data
We use data from waves 1–18 of the BHPS. The BHPS was designed as a nationally representative annual survey of the adult (aged 16+) population of Great Britain [13]. It re-interviews annually the same individuals belonging to the initial sample of more than 5,000 households as well as their adult co-residents. The BHPS collects rich information about respondents’ household structure, health, incomes, labour market status, housing conditions, education and socio-economic values. In this paper, we are mainly interested in cross-sectional analysis of trends in self-reported health in Britain. For this reason, we use information on all respondents giving the full interview in a given year weighted with cross-sectional weights available in the BHPS that adjust for inclusion of new entrants and for within household nonresponse. We also use information about clustering and stratification of the BHPS sample (see [13]) in estimating covariance matrix Σ in Eq. (3). The total number of observations ranges from 9,790 in 1991 to 7,125 in 2008.
The self-rated health status is measured in the BHPS using an answer to the question: “Please think back over the last 12 months about how your health has been. Compared to people of your own age, would you say your health has on the whole been excellent, good, fair, poor or very poor?”Footnote 7 Table 1 presents the distribution of self-rated health for 1991 and 2008. For the purposes of decomposing health poverty we use also information on individual marital status, household type and labour market status. The distributions of these variables in 1991 and 2008 are given in Table 3.
Poverty of self-reported health in Britain, 1991–2008
Trends in self-rated health poverty
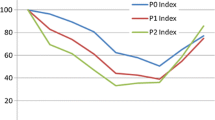
Figure 1 shows trends in poverty of self-rated health using ordinal FGT indices of Bennett and Hatzimasoura [3] with different values of α and different poverty thresholds k. The lowest possible poverty threshold k = 1 is certainly unreasonable as people reporting higher self-rated health status still consider it to be “poor”.

Trends in ordinal FGT poverty indices for the BHPS data with different health poverty thresholds (k = 1, 2, 3)
For more reasonable poverty thresholds, we observe that health poverty as measured by poverty headcount rate (\( \pi_{0} \)) increased between 1991 and 2008 by 13.7 % and by 18.9 % for k = 2 (“poor” self-rated health status) and k = 3 (“fair” self-rated health status), respectively. The growth of health poverty was smaller in the case of \( \pi_{1} \)—7.2 % (k = 2) and 15.6 % (k = 3). Finally, self-reported health poverty as measured by \( \pi_{2} \) did not change when k = 2 and increased by 10.6 % when k = 3. Table 2 presents estimates of health poverty indices for k = 2 and 3 together with their standard errors and 95 % confidence intervals.Footnote 8 It also gives results of significance tests on pairwise health poverty comparisons between 1991 and 2008.
The results suggest that for k = 2 a change in self-rated health poverty headcount is significant at the conventional 5 % significance level. However, if measures sensitive to depth (\( \pi_{1} \)) and depth and distribution of poverty (\( \pi_{2} \)) are applied, the results for k = 2 become statistically insignificant. This means that the observed increase in health poverty incidence as measured by \( \pi_{0} \) was accompanied by both the decrease in average health poverty depth and the decrease in inequality of health poverty. These additional insights would not be gained if health poverty was measured using poverty headcount index only.
When an even higher poverty threshold is used (k = 3), health poverty increases displayed by all poverty indices used are statistically significant.
Decomposition of health poverty changes
Table 3 presents results of subgroup decompositions of changes in self-rated health poverty in Britain between 1991 and 2008 when health poverty is measured by \( \pi_{2} \) with k = 3.Footnote 9 The total change in health poverty, denoted by δ, is 0.0073 or 10.6 % in relative terms. We perform decompositions for subgroups defined by marital status, household type and labour market status.Footnote 10
The decomposition based on marital status suggests that between-subgroup population shifts had overall an offsetting effect on changes in total poverty. The largest overall poverty-increasing effect among subgroups is due to increasing health poverty and population share of persons cohabiting. Turning to decompositions using subgroups defined by household type, we note that the within-subgroup population shifts accounted for as much as about 32 % of δ. Increases in the populations of single non-elderly persons and couples with no children each contributed to more than 25 % of δ. Health poverty increase among couples with no children accounted for about 35 % of the overall health poverty change, while a fall of health poverty among single non-elderly persons had a rather small poverty-decreasing effect. Finally, in case of decomposition for subgroups defined by labour market status 90 % of δ can be accounted for by within-subgroups poverty effects. However, detailed analysis of population shift effects reveals interesting facts. The population of retired persons in the BHPS increased between 1991 and 2008 from 19.5 % to 25.9 %, which accounts for as much as 97.5 % of the total health poverty increase. This large effect is, however, almost offset by significant decreases in the populations of inactive and unemployed persons. The biggest contributions to δ among the within-subgroup poverty effects can be assigned to deterioration in health among inactive persons (30.8 %) and full-time employees (20.8 %).
Conclusions
This paper used data from the BHPS to provide an analysis of trends in self-rated health poverty in Britain over 1991–2008. We used ordinal FGT poverty indices proposed recently by Bennett and Hatzimasoura [3], which are appropriate for the ordinal nature of self-rated health data. We have also extended the approach of Bennett and Hatzimasoura [3] by providing statistical inference for their ordinal FGT indices. Moreover, we have used the subgroup decompositions of health poverty changes borrowed from the literature on measuring income poverty.
Our results suggest that empirically there are additional insights from analysing health poverty with Bennett and Hatzimasoura’s [3] family of ordinal FGT indices, rather than using health poverty headcount rate only. The BHPS data show that when “fair” self-reported health status is chosen as a health poverty threshold all of the used ordinal FGT indices indicate the growth of health poverty in Britain. However, when health poverty threshold is lower (“poor” self-reported health status) only poverty headcount rate increases in a statistically significant way. For this threshold, the observed increase in health poverty incidence was accompanied by decreasing average health poverty depth and improving health inequality among those who are poor with respect to health.
More generally, we may expect that the ordinal FGT poverty indices of Bennett and Hatzimasoura [3] may be also useful in analysing data with more levels of self-reported health statuses. For example, it would be interesting to check if trends in poverty of satisfaction with health, which is measured in practice even on a 11-point ordinal scale (see, e.g., [9]), are robust to the choice of a poverty threshold.
Notes
In this paper, we use self-reported health as an indicator of overall health. Therefore, by “health poverty” we mean “self-reported health poverty”.
The only exception is poverty headcount rate, which is a member of the FGT class with poverty aversion parameter set to 0. However, as stated before, the poverty headcount rate is not sensitive to poverty depth and severity.
See Chakravarty [4], for a recent overview of various poverty indices and their properties.
See also Zheng and Cushing [15] for the same procedure applied to inference on inequality with dependent samples.
For a textbook treatment of Shapley value based decompositions of poverty and inequality, see Duclos and Araar [6].
We do not include wave 9 of the BHPS in our analysis as there was a change in wording of the self-rated health question in this wave.
The health poverty change between 1991 and 2008 for k = 1 is 0.0037, which is not statistically significant with a p value of 0.116.
Results for \( \pi_{0} \) and \( \pi_{1} \) with k = 3 are in general qualitatively similar to those for \( \pi_{2} \) (k = 3).
Decompositions for subgroups defined by the number of children, education and income group are available upon request.
References
Abul Naga, R.H., Yalcin, T.: Inequality measurement for ordered response health data. J. Health Econ. 27(6), 1614–1625 (2008)
Allison, R.A., Foster, J.E.: Measuring health inequality using qualitative data. J. Health Econ. 23, 505–524 (2004)
Bennett, C., Hatzimasoura, C.: Poverty Measurement with Ordinal Data. Institute for International Economic Policy, IIEP-WP-2011-14 (2011)
Chakravarty, S.R.: Inequality, Polarization and Poverty: Advances in Distributional Analysis. Springer, New York (2009)
Cowell, F., Flachaire, E.: Inequality with ordinal data. In: Paper presented at the European Economic Association and Econometric Society Conference, Málaga, 2012
Duclos, J.-Y., Araar, A.: Poverty and Equity: Measurement, Policy and Estimation with DAD. Springer, New York (2006)
Foster, J., Greer, J., Thorbecke, E.: A class of decomposable poverty measures. Econometrica 52(3), 761–766 (1984)
Foster, J., Greer, J., Thorbecke, E.: The Foster–Greer–Thorbecke (FGT) poverty measure: 25 years later. J. Econ. Inequal. 8, 491–524 (2010)
Frijters, P., Haisken-DeNew, J.P., Shields, M.A.: The causal effect of income on health: evidence from German reunification. J. Health Econ. 24(5), 997–1017 (2005)
Madden, D.: Health and income poverty in Ireland, 2003–2006. J. Econ. Inequal. 9(1), 23–33 (2011)
Ravallion, M., Huppi, M.: Measuring changes in poverty: a methodological case study of Indonesia during an adjustment period. World Bank Econ Rev 5, 57–82 (1991)
Shorrocks, A.F.: Decomposition procedures for distributional analysis: a unified framework based on Shapley value. Department of Economics, University of Essex (1999)
Taylor, M.F., Brice, J., Buck, N., Prentice-Lane, E.: British Household Panel Survey User Manual, vol. A: Introduction, Technical Report and Appendices. Clochester, University of Essex (2010)
Van Doorslaer, E., Jones, A.: Inequalities in self-reported health: validation of a new approach to measurement. J. Health Econ. 22, 61–87 (2003)
Zheng, B., Cushing, B.J.: Statistical inference for testing inequality indices with dependent samples. J. Econom. 101(2), 315–335 (2001)
Zheng, B.: Poverty comparisons with dependent samples. J. Appl. Econom. 19(3), 419–428 (2004)
Zheng, B.: Measuring inequality with ordinal data: a note. Res. Econ. Inequal. 16, 177–188 (2008)
Acknowledgments
I would like to thank two anonymous referees for their comments and suggestions that helped to improve this paper.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution License which permits any use, distribution, and reproduction in any medium, provided the original author(s) and the source are credited.
About this article
Cite this article
Brzezinski, M. Accounting for trends in health poverty: a decomposition analysis for Britain, 1991–2008. Eur J Health Econ 16, 153–159 (2015). https://doi.org/10.1007/s10198-014-0561-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10198-014-0561-0
Keywords
- Health poverty
- Ordinal FGT measures
- Self-reported health
- Statistical inference
- British Household Panel Survey