
Abstract
We study Tikhonov regularization for possibly nonlinear inverse problems with weighted \(\ell ^1\)-penalization. The forward operator, mapping from a sequence space to an arbitrary Banach space, typically an \(L^2\)-space, is assumed to satisfy a two-sided Lipschitz condition with respect to a weighted \(\ell ^2\)-norm and the norm of the image space. We show that in this setting approximation rates of arbitrarily high Hölder-type order in the regularization parameter can be achieved, and we characterize maximal subspaces of sequences on which these rates are attained. On these subspaces the method also converges with optimal rates in terms of the noise level with the discrepancy principle as parameter choice rule. Our analysis includes the case that the penalty term is not finite at the exact solution (’oversmoothing’). As a standard example we discuss wavelet regularization in Besov spaces \(B^r_{1,1}\). In this setting we demonstrate in numerical simulations for a parameter identification problem in a differential equation that our theoretical results correctly predict improved rates of convergence for piecewise smooth unknown coefficients.
Similar content being viewed by others


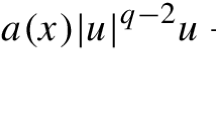
Avoid common mistakes on your manuscript.
1 Introduction
In this paper we analyze numerical solutions of ill-posed operator equations
with a (possibly nonlinear) forward operator F mapping sequences \(x=(x_j)_{j\in \varLambda }\) indexed by a countable set \(\varLambda \) to a Banach space \({\mathbb {Y}}\). We assume that only indirect, noisy observations \(g^\mathrm {obs}\in {\mathbb {Y}}\) of the unknown solution \(x^\dagger \in {\mathbb {R}}^\varLambda \) are available satisfying a deterministic error bound \({\Vert g^\mathrm {obs}-F(x^\dagger )\Vert _{{\mathbb {Y}}}\le \delta }\).
For a fixed sequence of positive weights \(( {\underline{r}} _j)_{j\in \varLambda }\) and a regularization parameter \(\alpha >0\) we consider Tikhonov regularization of the form
where \(D\subset {\mathbb {R}}^\varLambda \) denotes the domain of F. Usually, \(x^\dagger \) is a sequence of coefficients with respect to some Riesz basis. One of the reasons why such schemes have become popular is that the penalty term \(\alpha \sum _{j\in \varLambda } {\underline{r}} _j |x_j|\) promotes sparsity of the estimators \({\hat{x}}_\alpha \) in the sense that only a finite number of coefficients of \({\hat{x}}_\alpha \) are non-zero. The latter holds true if \(( {\underline{r}} _j)_{j\in \varLambda }\) decays not too fast relative to the ill-posedness of F (see Proposition 3 below). In contrast to [29] and related works, we do not require that \(( {\underline{r}} _j)_{j\in \varLambda }\) is uniformly bounded away from zero. In particular, this allows us to consider Besov \(B^0_{1,1}\)-norm penalties given by wavelet coefficients. For an overview on the use of this method for a variety linear and nonlinear inverse problems in different fields of applications we refer to the survey paper [26] and to the special issue [27].
Main contributions: The focus of this paper is on error bounds, i.e. rates of convergence of \({\hat{x}}_\alpha \) to \(x^\dagger \) in some norm as the noise level \(\delta \) tends to 0. Although most results of this paper are formulated for general operators on weighted \(\ell ^1\)-spaces, we are mostly interested in the case that \(x_j\) are wavelet coefficients, and
is the composition of a corresponding wavelet synthesis operator \(\mathcal {S}\) and an operator G defined on a function space. We will assume that G is finitely smoothing in the sense that it satisfies a two-sided Lipschitz condition with respect to function spaces the smoothness index of which differs by a constant \(a>0\) (see Assumption 2 below and Assumption 3 for a corresponding condition on F). The class of operators satisfying this condition includes in particular the Radon transform and nonlinear parameter identification problems for partial differential equations with distributed measurements. In this setting Besov \(B^{r}_{1,1}\)-norms can be written in the form of the penalty term in (1). In a previous paper [24] we have already addressed sparsity promoting penalties in the form of Besov \(B^0_{p,1}\)-norms with \(p\in [1,2]\). For \(p>1\) only group sparsity in the levels is enforced, but not sparsity of the wavelet coefficients within each level. As a main result of this paper we demonstrate that the analysis in [24] as well as other works to be discussed below do not capture the full potential of estimators (1), i.e. the most commonly used case \(p=1\): Even though the error bounds in [24] are optimal in a minimax sense, more precisely in a worst case scenario in \(B^s_{p,\infty }\)-balls, we will derive faster rates of convergence for an important class of functions, which includes piecewise smooth functions. The crucial point is that such functions also belong to Besov spaces with larger smoothness index s, but smaller integrability index \(p<1\). These results confirm the intuition that estimators of the form (1), which enforce sparsity also within each wavelet level, should perform well for signals which allow accuratele approximations by sparse wavelet expansions.
Furthermore, we prove a converse result, i.e. we characterize the maximal sets on which the estimators (1) achieve a given approximation rate. These maximal sets turn out to be weak weighted \(\ell ^t\)-sequences spaces or real interpolation spaces of Besov spaces, respectively.
Finally, we also treat the oversmoothing case that \(\sum _{j\in \varLambda } {\underline{r}} _j |x_j^\dagger |=\infty \), i.e. that the penalty term enforces the estimators \({\hat{x}}_\alpha \) to be smoother than the exact solution \(x^\dagger \). For wavelet \(B^r_{1,1}\) Besov norm penalties, this case may be rather unlikely for \(r=0\), except maybe for delta peaks. However, in case of the Radon transform, our theory requires us to choose \(r>\frac{1}{2}\), and more generally, mildly ill-posed problems in higher spatial dimensions require larger values of r (see Eq. (7a) below for details). Then it becomes much more likely that the penalty term fails to be finite at the exact solution, and it is desirable to derive error bounds also for this situation. So far, however, this case has only rarely been considered in variational regularization theory.
Previous works on the convergence analysis of (1): In the seminal paper [11] Daubechies, Defrise & De Mol established the regularizing property of estimators of the form (1) and suggested the so-called iterative thresholding algorithm to compute them. Concerning error bounds, the most favorable case is that the true solution \(x^\dagger \) is sparse. In this case the convergence rate is linear in the noise level \(\delta \), and sparsity of \(x^\dagger \) is not only sufficient but (under mild additional assumptions) even necessary for a linear convergence rate [21]. However, usually it is more realistic to assume that \(x^\dagger \) is only approximately sparse in the sense that it can be well approximated by sparse vectors. More general rates of convergence for linear operators F were derived in [4] based on variational source conditions. The rates were characterized in terms of the growth of the norms of the preimages of the unit vectors under \(F^*\) (or relaxations) and the decay of \(x^\dagger \). Relaxations of the first condition were studied in [15,16,17]. For error bounds in the Bregman divergence with respect to the \(\ell ^1\)-norm we refer to [5]. In the context of statistical regression by wavelet shrinkage maximal sets of signals for which a certain rate of convergence is achieved have been studied in detail (see [9]).
In the oversmoothing case one difficulty is that neither variational source conditions nor source conditions based on the range of the adjoint operator are applicable. Whereas oversmoothing in Hilbert scales has been analyzed in numerous papers (see, e.g., [22, 23, 30]), the literature on oversmoothing for more general variational regularization is sparse. The special case of diagonal operators in \(\ell ^1\)-regularization has been discussed in [20]. In a very recent work, Chen et al. [7] have studied oversmoothing for finitely smoothing operators in scales of Banach spaces generated by sectorial operators.
Plan of the remainder of this paper: In the following section we introduce our setting and assumptions and discuss two examples for which these assumptions are satisfied in the wavelet–Besov space setting (2). Sections 3–5 deal with a general sequence space setting. In Sect. 3 we introduce a scale of weak sequence spaces which can be characterized by the approximation properties of some hard thresholding operator. These weak sequence spaces turn out to be the maximal sets of solutions on which the method (1) attains certain Hölder-type approximation rates. This is shown for the non-oversmoothing case in Sect. 4 and for the oversmoothing case in Sect. 5. In Sect. 6 we interpret our results in the previous sections in the Besov space setting, before we discuss numerical simulations confirming the predicted convergence rates in Sect. 7.
2 Setting, assumptions, and examples
In the following we describe our setting in detail including assumptions which are used in many of the following results. None of these assumptions is to be understood as a standing assumption, but each assumption is referenced whenever it is needed.
2.1 Motivating example: regularization by wavelet Besov norms
In this subsection, which may be skipped in first reading, we provide more details on the motivating example (2): Suppose the operator F is the composition of a forward operator G mapping functions on a domain \(\varOmega \) to elements of the Hilbert space \({\mathbb {Y}}\) and a wavelet synthesis operator \(\mathcal {S}\). We assume that \(\varOmega \) is either a bounded Lipschitz domain in \({\mathbb {R}}^d\) or the d-dimensional torus \(({\mathbb {R}}/{\mathbb {Z}})^d\), and that we have a system \((\phi _{j.k})_{(j,k)\in \varLambda }\) of real-valued wavelet functions on \(\varOmega \). Here the index set \(\varLambda := \{(j,k) :j\in {\mathbb {N}}_0, k\in \varLambda _j\}\) is composed of a family of finite sets \((\varLambda _j)_{j\in {\mathbb {N}}_0}\) corresponding to levels \(j\in {\mathbb {N}}_0\), and the growths of the cardinality of these sets is described by the inequalities \(2^{jd}\le |\varLambda _j|\le C_\varLambda 2^{jd}\) for some constant \(C_\varLambda \ge 1\) and all \(j\in {\mathbb {N}}_0\).
For \(p,q \in (0,\infty )\) and \(s\in {\mathbb {R}}\) we introduce sequence spaces
with the usual replacements for \(p=\infty \) or \(q = \infty \). It is easy to see that \(b^{s}_{{p},{q}}\) are Banach spaces if \(p,q\ge 1\). Otherwise, if \(p\in (0,1)\) or \(q\in (0,1)\), they are quasi-Banach spaces, i.e. they satisfy all properties of a Banach space except for the triangle inequality, which only holds true in the weaker form \(\left\| {x+y} \right\| _{{ {\underline{\omega }} },{p}} \le C(\left\| {x} \right\| _{{ {\underline{\omega }} },{p}}+\left\| {y} \right\| _{{ {\underline{\omega }} },{p}})\) with some \(C>1\). We need the following assumption on the relation of the Besov sequence spaces to a family of Besov function spaces \(B^{s}_{{p},{q}}(\varOmega )\) via the wavelet synthesis operator \((\mathcal {S}x)({\mathbf {r}}) := \sum _{(j,k)\in \varLambda } x_{j,k} \phi _{j,k}({\mathbf {r}})\).
Assumption 1
Let \(s_\text {max}>0\). Suppose that \((\phi _{j.k})_{(j,k)\in \varLambda }\) is a family of real-valued functions on \(\varOmega \) such that the synthesis operator
is a norm isomorphism for all \(s \in (-s_\text {max}, s_\text {max})\) and \(p,q \in (0,\infty ]\) satisfying \({s \in (\sigma _p-s_\text {max}, s_\text {max})}\) with \(\sigma _p=\max \left\{ d\left( \frac{1}{p}-1\right) , 0 \right\} \).
Note that \(p\ge 1\) implies \(\sigma _p=0\), and therefore \(\mathcal {S}\) is a quasi-norm isomorphism for \(|s|\le s_\text {max}\) in this case.
We refer to the monograph [32] for the definition of Besov spaces \(B^{s}_{{p},{q}}(\varOmega )\), different types of Besov spaces on domains with boundaries, and the verification of Assumption 1.
As main assumption on the forward operator G in function space we suppose that it is finitely smoothing in the following sense:
Assumption 2
Let \(a>0\), \(D_G\subseteq B^{-a}_{{2},{2}}(\varOmega )\) be non-empty and closed, \({\mathbb {Y}}\) a Banach space and \(G :D_G \rightarrow {\mathbb {Y}}\) a map. Assume that there exists a constant \(L\ge 1\) with
Recall that \(B^{-a}_{{2},{2}}(\varOmega )\) coincides with the Sobolev space \(H^{-a}(\varOmega )\) with equivalent norms. The first of these inequalities is violated for infinitely smoothing forward operators such as for the backward heat equation or for electrical impedance tomography.
In the setting of Assumptions 1 and 2 and for some fixed \(r\ge 0\) we study the following estimators
We recall two examples of forward operators satisfying Assumption 2 from [24] where further examples are discussed.
Example 1
(Radon transform) Let \(\varOmega \subset {\mathbb {R}}^d\), \(d\ge 2\) be a bounded domain and \({\mathbb {Y}}= L^2(S^{d-1}\times {\mathbb {R}})\) with the unit sphere \(S^{d-1}:=\{x\in {\mathbb {R}}^d:|x|_2=1\}\). The Radon transform, which occurs in computed tomography (CT) and positron emission tomography (PET), among others, is defined by
It satisfies Assumption 2 with \(a=\frac{d-1}{2}\).
Example 2
(Identification of a reaction coefficient) Let \(\varOmega \subset {\mathbb {R}}^d\), \(d\in \{1,2,3\}\) be a bounded Lipschitz domain, and let \(f:\varOmega \rightarrow [0,\infty )\) and \(g:\partial \varOmega \rightarrow (0,\infty )\) be smooth functions. For \(c\in L^{\infty }(\varOmega )\) satisfying \(c\ge 0\) we define the forward operator \(G(c):=u\) by the solution of the elliptic boundary value problem
Then Assumption 2 with \(a=2\) holds true in some \(L^2\)-neighborhood of a reference solution \(c_0\in L^{\infty }(\varOmega )\), \(c_0\ge 0\). (Note that for coefficients c with arbitrary negative values uniqueness in the boundary value problem (5) may fail and every \(L^2\)-ball contains functions with negative values on a set of positive measure, well-posedness of (5) can still be established for all c in a sufficiently small \(L^2\)-ball centered at \(c_0\). This can be achieved by Banach’s fixed point theorem applied to \(u = u_0+(-\varDelta + c_0)^{-1}(u(c_0-c))\) where \(u_0:=G(c_0)\) and \((-\varDelta + c_0)^{-1}{\tilde{f}}\) solves (5) with \(c=c_0\), \(f={\tilde{f}}\) and \(g=0\), using the fact that \((-\varDelta + c_0)^{-1}\) maps boundedly from \(L^1(\varOmega )\subset H^{-2}(\varOmega )\) to \(L^2(\varOmega )\) for \(d\le 3\).)
2.2 General sequence spaces setting
Let \(p\in (0,\infty )\), and let \( {\underline{\omega }} =( {\underline{\omega }} _j)_{j\in \varLambda }\) be a sequence of positive reals indexed by some countable set \(\varLambda \). We consider weighted sequence spaces \(\ell _{ {\underline{\omega }} }^{p}\) defined by
Note that the Besov sequence spaces \(b^{s}_{{p},{q}}\) defined in (3) are of this form if \(p=q <\infty \), more precisely \(b^{s}_{{p},{p}} =\ell _{ {\underline{\omega }} _{s,p}}^{p}\) with equal norm for \(( {\underline{\omega }} _{s,p})_{(j,k)}= 2^{j(s+\frac{d}{2}-\frac{d}{p})}\). Moreover, the penalty term in is given by \(\alpha \left\| {\cdot } \right\| _{{ {\underline{r}} },{1}}\) with the sequence of weights \({ {\underline{r}} } =( {\underline{r}} _j)_{j\in \varLambda }\). Therefore, we obtain the penalty terms \(\alpha \Vert {\cdot } \Vert _{{s},{1},{1}}\) in (4) for the choice \( {\underline{r}} _{j,k} := 2^{j(r-\frac{d}{2})}\).
We formulate a two-sided Lipschitz condition for forward operators F on general sequence spaces and argue that it follows from Assumptions 1 and 2 in the Besov space setting.
Assumption 3
\( {\underline{a}} =( {\underline{a}} _j)_{j\in \varLambda }\) is a sequence of positive real numbers with \({ {\underline{a}} _j {\underline{r}} _j^{-1}\rightarrow 0}\).Footnote 1 Moreover, \(D_F\subseteq \ell _{ {\underline{a}} }^{2} \) is closed with \(D_F\cap \ell _{ {\underline{r}} }^{1} \ne \emptyset \) and there exists a constant \(L>0\) with
for all \(x^{(1)},x^{(2)}\in D_F\).
Suppose Assumptions 1 and 2 hold true, and let
With \( {\underline{a}} _{j,k}:=2^{-ja}\) and \( {\underline{r}} _{j,k} := 2^{j(r-\frac{d}{2})}\) we have \(\ell _{ {\underline{a}} }^{2}= b^{-a}_{{2},{2}}\) and \(\ell _{ {\underline{r}} }^{1} = b^{r}_{{1},{1}}\). Then \( {\underline{a}} _{j,k} {\underline{r}} _{j,k}^{-1}\rightarrow 0\). As \(\mathcal {S}:b^{-a}_{{2},{2}} \rightarrow B^{-a}_{{2},{2}}(\varOmega )\) is a norm isomorphim \(D_F:= \mathcal {S}^{-1}(D_G)\) is closed, and \(F:=G\circ \mathcal {S}:D_F\rightarrow {\mathbb {Y}}\) satisfies the two-sided Lipschitz condition above.
In some of the results we also need the following assumption on the domain \(D_F\) of the map F.
Assumption 4
\(D_F\) is closed under coordinate shrinkage. That is \(x\in D_F\) and \(z\in \ell _{ {\underline{a}} }^{2}\) with \(|z_j|\le |x_j|\) and \({{\,\mathrm{sgn}\,}}z_j\in \{0,{{\,\mathrm{sgn}\,}}x_j\}\) for all \(j\in \varLambda \) implies \(z\in D_F. \)
Obviously, Assumption 4 is satisfied if \(D_F\) is a closed ball \(\{x\in \ell _{ {\underline{a}} }^{2} : \left\| {x} \right\| _{{ {\underline{\omega }} },{p}} \le \rho \}\) in some \(\ell _{ {\underline{\omega }} }^{p}\) space centered at the origin.
Concerning the closedness condition in Assumption 3, note that such balls are always closed in \(\ell _{ {\underline{a}} }^{2}\) as the following argument shows: Let \( x^{(k)}\rightarrow x\) as \(k\rightarrow \infty \) in \(\ell _{ {\underline{a}} }^{2}\) and \(\left\| { x^{(k)}} \right\| _{{ {\underline{\omega }} },{p}}\le \rho \) for all k. Then \(x^{(k)}\) converges pointwise to x, and hence \(\sum _{j\in \varGamma } {\underline{\omega }} _j^p |x_j|^p = \lim _{k\rightarrow \infty } \sum _{j\in \varGamma } {\underline{\omega }} _j^p |x_j^{(k)}|^p\le \rho ^p\) for all finite subsets \(\varGamma \subset \varLambda \). This shows \(\left\| { x} \right\| _{{ {\underline{\omega }} },{p}}\le \rho \).
In the case that \(D_F\) is a ball centered at some reference solution \(x_0\ne 0\), we may replace the operator F by the operator \(x\mapsto F(x+x_0)\). This is equivalent to using the penalty term \(\alpha \left\| {x-x_0} \right\| _{{ {\underline{r}} },{1}}\) in (1) with the original operator F, i.e. Tikhonov regularization with initial guess \(x_0\). Without such a shift, Assumption 4 is violated.
2.3 Existence and uniqueness of minimizers
We briefly address the question of existence and uniqueness of minimizers in (1). Existence follows by a standard argument of the direct method of the calculus of variations as often used in Tikhonov regularization, see, e.g., [31, Thm. 3.22]).
Proposition 3
Suppose Assumption 3 holds true. Then for every \(g^\mathrm {obs}\in {\mathbb {Y}}\) and \(\alpha >0\) there exists a solution to the minimization problem in (1). If \(D_F= \ell _{ {\underline{a}} }^{2}\) and F is linear, then the minimizer is unique.
Proof
Let \((x^{(n)})_{n\in {\mathbb {N}}}\) be a minimizing sequence of the Tikhonov functional. Then \(\left\| {x^{(n)}} \right\| _{{ {\underline{r}} },{1}}\) is bounded. The compactness of the embedding \(\ell _{ {\underline{r}} }^{1}\subset \ell _{ {\underline{a}} }^{2}\) (see Proposition 31 in the “Appendix”) implies the existence of a subsequence (w.l.o.g. again the full sequence) converging in \(\left\| {\cdot } \right\| _{{ {\underline{a}} },{2}}\) to some \(x\in \ell _{ {\underline{a}} }^{2}\). Then \(x\in D_F\) as \(D_F\) is closed. The second inequality in Assumption 3 implies
Moreover, for any finite subset \(\varGamma \subset \varLambda \) we have
and hence \(\left\| {x} \right\| _{{ {\underline{r}} },{1}}\le \liminf _n \left\| {x^{(n)}} \right\| _{{ {\underline{r}} },{1}}\). This shows that x minimizes the Tikhonov functional.
In the linear case the uniqueness follows from strict convexity. \(\square \)
Note that Proposition 3 also yields the existence of minimizers in (4) under Assumptions 1 and 2 and Eqs. (7).
If \(F=A:\ell _{ {\underline{a}} }^{2} \rightarrow {\mathbb {Y}}\) is linear and satisfies Assumption 3, the usual argument (see, e.g., [29, Lem. 2.1]) shows sparsity of the minimizers as follows: By the first order optimality condition there exists \(\xi \in \partial \left\| {\cdot } \right\| _{{ {\underline{r}} },{1}}({\hat{x}}_\alpha )\) such that \(\xi \) belongs to the range of the adjoint \(A^*\), that is \(\xi \in \ell _{ {\underline{a}} ^{-1}}^{2}\) and hence \( {\underline{a}} _j^{-1}|\xi _j|\rightarrow 0\). Since \( {\underline{a}} _j {\underline{r}} _j^{-1}\rightarrow 0\), we have \( {\underline{a}} _j \le {\underline{r}} _j\) for all but finitely many j. Hence, we obtain \(|\xi _j|<r_j\), forcing \( x_j=0\) for all but finitely many j.
Note that for this argument to work, it is enough to require that \( {\underline{a}} _j {\underline{r}} _j^{-1}\) is bounded from above. Also the existence of minimizers can be shown under this weaker assumption using the weak\(^*\)-topology on \(\ell _{ {\underline{r}} }^{1}\) (see [14, Prop. 2.2]).
3 Weak sequence spaces
In this section we introduce spaces of sequences whose bounded sets will provide the source sets for the convergence analysis in the next chapters. We define a specific thresholding map and analyze its approximation properties.
Let us first introduce a scale of spaces, part of which interpolates between the spaces \(\ell _{ {\underline{r}} }^{1}\) and \(\ell _{ {\underline{a}} }^{2}\) involved in our setting. For \(t\in (0,2]\) we define weights
Note that \( {\underline{\omega }} _1= {\underline{r}} \) and \( {\underline{\omega }} _2= {\underline{a}} \). The next proposition captures interpolation inequalities we will need later.
Proposition 4
(Interpolation inequality) Let \(u,v,t\in (0,2]\) and \(\theta \in (0,1)\) with \(\frac{1}{t}= \frac{1-\theta }{u} + \frac{\theta }{v}.\) Then
Proof
We use Hölder’s inequality with the conjugate exponents \(\frac{u}{(1-\theta ) t}\) and \(\frac{v}{\theta t}\):
\(\square \)
Remark 5
In the setting of Proposition 4 real interpolation theory yields the stronger statement \(\ell _{ {\underline{\omega }} _t}^{t} = (\ell _{ {\underline{\omega }} _u}^{u} , \ell _{ {\underline{\omega }} _v}^{v} )_{\theta ,t}\) with equivalent quasi-norms (see, e.g., [19, Theorem 2]). The stated interpolation inequality is a consequence.
For \(t\in (0,2)\) we define a weak version of the space \(\ell _{ {\underline{\omega }} _t}^{t}\).
Definition 6
(Source sets) Let \(t\in (0,2)\). We define
with
Remark 7
The functions \( \Vert \cdot \Vert _{k_t}\) are quasi-norms. The quasi-Banach spaces \(k_t\) are weighted Lorentz spaces. They appear as real interpolation spaces between weighted \(L^p\) spaces. To be more precise [19, Theorem 2] yields \( k_t= (\ell _{ {\underline{\omega }} _u}^{u} , \ell _{ {\underline{\omega }} _v}^{v} )_{\theta ,\infty }\) with equivalence of quasi-norms for u, v, t and \(\theta \) as in Proposition 4.
Remark 8
Remarks 5 and 7 predict an embedding
Indeed the Markov-type inequality
proves \(\Vert \cdot \Vert _{k_t} \le \left\| {\cdot } \right\| _{{ {\underline{\omega }} _t},{t}} \).
For \( {\underline{a}} _j= {\underline{r}} _j=1\) we obtain the weak \(\ell _p\)-spaces \(k_t=\ell _{t,\infty }\) that appear in nonlinear approximation theory (see e.g. [8, 10]).
We finish this section by defining a specific nonlinear thresholding procedure depending on r and a whose approximation theory is characterized by the spaces \(k_t\). This characterization is the core for the proofs in the following chapters. The statement is [10, Theorem 7.1] for weighted sequence space. For sake of completeness we present an elementary proof based on a partition trick that is perceivable in the proof of [10, Theorem 4.2].
Let \(\alpha >0\). We consider the map
Note that
If \( {\underline{a}} _j {\underline{r}} _j^{-1}\) is bounded above, then \( {\underline{a}} _j^{-2} {\underline{r}} _j^{2}\) is bounded away from zero. Hence, in this case we see that the set of \(j\in \varLambda \) with \( {\underline{a}} _j^{-2} {\underline{r}} _j \alpha < |x_j|\) is finite, i.e. \(T_\alpha (x)\) has only finitely many nonvanishing coefficients whenever \(x\in \ell _{ {\underline{a}} }^{2}\).
Lemma 9
(Approximation rates for \(T_\alpha \)) Let \(0<t<p\le 2\) and \(x\in {\mathbb {R}}^\varLambda \). Then \(x\in k_t\) if and only if \(\gamma (x):= \sup _{\alpha >0} \alpha ^\frac{t-p}{p}\left\| {x-T_\alpha (x)} \right\| _{{ {\underline{\omega }} _p},{p}} < \infty \).
More precisely we show bounds
Proof
We use a partitioning to estimate
A similar estimation yields the second inequality:
\(\square \)
Corollary 10
Assume \( {\underline{a}} _j {\underline{r}} _j^{-1}\) is bounded from above. Let \(0<t<p\le 2\). Then \(k_t\subset \ell _{ {\underline{\omega }} _p}^{p}\). More precisely, there is a constant \(M>0\) depending on t, p and \(\sup _{j\in \varLambda } {\underline{a}} _j {\underline{r}} _j^{-1}\) such that \( \left\| {\cdot } \right\| _{{ {\underline{\omega }} _p},{p}}\le M \Vert \cdot \Vert _{k_t}\).
Proof
Let \(x\in k_t\). The assumption implies the existence of a constant \(c>0\) with \(c\le {\underline{a}} _j^{-2} {\underline{r}} _j^2\) for all \(j\in \varLambda .\) Let \(\alpha >0\). Then
Inserting \({\overline{\alpha }}:= 2 \Vert x\Vert _{k_t} c^{-\frac{1}{t}}\) implies \( {\underline{a}} _j^{-2} {\underline{r}} _j {\overline{\alpha }}\ge |x_j|\) for all \(j\in \varLambda .\) Hence, \(T_{{\overline{\alpha }}}(x)=0\). With \({C=2\left( 2^{p-t}-1\right) ^{-\frac{1}{p}}}\) Lemma 9 yields
\(\square \)
Remark 11
(Connection to best N-term approximation) For better understanding of the source sets we sketch another characterization of \(k_t\). For \(z\in {\mathbb {R}}^\varLambda \) we set \(S(x):= \sum _{j\in \varLambda } {\underline{a}} _j^{-2} {\underline{r}} _j^2 \mathbbm {1}_{ \{z_j \ne 0\} }.\) Note that for \( {\underline{a}} _j= {\underline{r}} _j=1\) we simply have \(S(x)= \# \mathrm {supp}(x)\). Then for \(N>0\) one defines the best approximation error by
Using arguments similar to those in the proof of Lemma 22 one can show that for \(t \in (0,2)\) we have \(x\in k_t\) if and only if the error scales like \(\sigma _N(x)=\mathcal {O}(N^{\frac{1}{2}-\frac{1}{t}})\).
4 Convergence rates via variational source conditions
We prove rates of convergence for the regularization scheme (1) based on variational source conditions. The latter are nessecary and often sufficient conditions for rates of convergence for Tikhonov regularization and other regularization methods [13, 25, 31]. For \(\ell ^1\)-norms these conditions are typically of the form
with \(\beta \in [0,1]\) and \(\psi :[0,\infty )\rightarrow [0,\infty )\) a concave, stricly increasing function with \(\psi (0)=0\). The common starting point of verifications of (9) in the references [4, 15, 16, 24], which have already been discussed in the introduction, is a splitting of the left hand side in (9) into two summands according to a partition of the index set into low level and high level indices. The key difference to our verification in [24] is that this partition will be chosen adaptively to \(x^\dagger \) below. This possibility is already mentioned, but not further exploited in [18, Remark 2.4] and [15, Chapter 5].
4.1 Variational source conditions
We start with a Bernstein-type inequality.
Lemma 12
(Bernstein inequality) Let \(t\in (0,2)\), \(x^\dagger \in k_t\) and \(\alpha >0\). We consider
and the coordinate projection \(P_\alpha :{\mathbb {R}}^\varLambda \rightarrow {\mathbb {R}}^\varLambda \) onto \(\varLambda _\alpha \) given by \((P_\alpha x)_j:= x_j\) if \(j\in \varLambda _\alpha \) and \({(P_\alpha x)_j:= 0}\) else. Then
Proof
Using the Cauchy–Schwarz inequality we obtain
\(\square \)
The following lemma characterizes variational source conditions (9) for the embedding operator \(\ell ^1_r\hookrightarrow \ell ^2_a\) (if \( {\underline{a}} _j {\underline{r}} _j^{-1}\rightarrow 0\)) and power-type functions \(\psi \) with \(\beta =1\) and \(\beta =0\) in terms of the weak sequence spaces \(k_t\) in Definition 6:
Lemma 13
(Variational source condition for embedding operator) Assume \(x^\dagger \in \ell _{ {\underline{r}} }^{1}\) and \(t\in (0,1)\). The following statements are equivalent:
-
(i)
\(x^\dagger \in k_t.\)
-
(ii)
There exist a constant \(K>0\) such that
$$\begin{aligned} \left\| {x^\dagger -x} \right\| _{{ {\underline{r}} },{1}} + \left\| {x^\dagger } \right\| _{{ {\underline{r}} },{1}} -\left\| {x} \right\| _{{ {\underline{r}} },{1}}\le K \left\| {x^\dagger -x} \right\| _{{ {\underline{a}} },{2}} ^\frac{2-2t}{2-t} \end{aligned}$$(10)for all \(x\in \ell _{ {\underline{r}} }^{1}.\)
-
(iii)
There exist a constant \(K>0\) such that
$$\begin{aligned} \left\| {x^\dagger } \right\| _{{ {\underline{r}} },{1}} -\left\| {x} \right\| _{{ {\underline{r}} },{1}}\le K \left\| {x^\dagger -x} \right\| _{{ {\underline{a}} },{2}} ^\frac{2-2t}{2-t}\end{aligned}$$for all \(x\in \ell _{ {\underline{r}} }^{1}\) with \(|x_j| \le |x^\dagger _j|\) for all \( j\in \varLambda .\)
More precisely, (i) implies (ii) with \(K=(2+4(2^{1-t}-1)^{-1}) \Vert x^\dagger \Vert _{k_t}^\frac{t}{2-t}\) and (iii) yields the bound \(\Vert x^\dagger \Vert _{k_t}\le K^\frac{2-t}{t}.\)
Proof
First we assume (i). For \(\alpha >0\) we consider \(P_\alpha \) as defined in Lemma 12. Let \(x\in D\cap \ell _{ {\underline{r}} }^{1}\). By splitting all three norm term in the left hand side of (10) by \(\left\| {\cdot } \right\| _{{ {\underline{r}} },{1}}=\left\| {P_\alpha \cdot } \right\| _{{ {\underline{r}} },{1}}+\left\| {(I-P_\alpha )\cdot } \right\| _{{ {\underline{r}} },{1}}\) and using the triangle equality for the \((I-P_\alpha )\) terms and the reverse triangle inequality for the \(P_\alpha \) terms (see [4, Lemma 5.1]) we obtain
We use Lemma 12 to handle the first summand
Note that \(P_\alpha x^\dagger = T_\alpha ( x^\dagger ).\) Hence, Lemma 9 yields
Inserting the last two inequalities into (11) and choosing
we get (ii).
Obviously (ii) implies (iii) as \(\left\| {x^\dagger -x} \right\| _{{ {\underline{r}} },{1}}\ge 0.\)
It remains to show that (iii) implies (i). Let \(\alpha >0\). We define
Then \(|x_j|\le |x^\dagger _j|\) for all \(j\in \varLambda \). Hence, \(x\in \ell _{ {\underline{r}} }^{1}\). We estimate
Rearranging terms in this inequality yields
Hence, \( \Vert x^\dagger \Vert _{k_t}\le K^\frac{2-t}{t}.\) \(\square \)
Theorem 14
(Variational source condition) Suppose Assumption 3 holds true and let \(t\in (0,1)\), \(\varrho >0\) and \(x^\dagger \in D\). If \(\Vert x\Vert _{k_t}\le \varrho \) then the variational source condition
holds true with \(C_\mathrm {vsc} = (2+4(2^{1-t}-1)^{-1}) L^{\frac{2-2t}{2-t}}\varrho ^\frac{t}{2-t}\).
If in addition Assumption 4 holds true, then (12) implies \(\Vert x\Vert _{k_t}\le L^{\frac{2-2t}{t}} C_\mathrm {vsc}^{\frac{2-t}{t}}\).
Proof
Corollary 10 implies \(x\in D\cap \ell _{ {\underline{r}} }^{1}\). The first claim follows from the first inequality in Assumption 3 together with Lemma 13. The second inequality in Assumption 3 together with Assumption 4 imply statement (iii) in Lemma 13 with \(K= L^\frac{2-2t}{2-t} C_\mathrm {vsc}.\) Therefore, Lemma 13 yields the second claim. \(\square \)
4.2 Rates of convergence
In this section we formulate and discuss bounds on the reconstruction error which follow from the variational source condition (12) by general variational regularization theory (see, e.g., [24, Prop. 4.2, Thm. 4.3] or [15, Prop.13., Prop.14.]).
Theorem 15
(Convergence rates) Suppose Assumption 3 holds true. Let \(t\in (0,1)\), \(\varrho >0\) and \(x^\dagger \in D_F\) with \(\Vert x^\dagger \Vert _{k_t}\le \varrho .\) Let \(\delta \ge 0\) and \(g^\mathrm {obs}\in {\mathbb {Y}}\) satisfy \(\Vert g^\mathrm {obs}-F(x^\dagger )\Vert _{\mathbb {Y}}\le \delta \).
-
1.
(error splitting) Every minimizer \({\hat{x}}_\alpha \) of (1) satisfies
$$\begin{aligned} \left\| {x^\dagger -{\hat{x}}_\alpha } \right\| _{{ {\underline{r}} },{1}}&\le C_e \left( \delta ^2 \alpha ^{-1}+ \varrho ^t \alpha ^{1-t} \right) \quad \text {and} \end{aligned}$$(13)$$\begin{aligned} \left\| {x^\dagger -{\hat{x}}_\alpha } \right\| _{{a},{2}}&\le C_e \left( \delta + \varrho ^\frac{t}{2} \alpha ^\frac{2-t}{2}\right) . \end{aligned}$$(14)for all \(\alpha >0\) with a constant \(C_{e}\) depending only on t and L.
-
2.
(rates with a-priori choice of \(\alpha \)) If \(\delta >0\) and \(\alpha \) is chosen such that
$$\begin{aligned} c_1 \varrho ^\frac{t}{t-2} \delta ^\frac{2}{2-t} \le \alpha \le c_2 \varrho ^\frac{t}{t-2} \delta ^\frac{2}{2-t} \quad \text {for } 0<c_1<c_2,\end{aligned}$$then every minimizer \({\hat{x}}_\alpha \) of (1) satisfies
$$\begin{aligned} \left\| {x^\dagger -{\hat{x}}_\alpha } \right\| _{{ {\underline{r}} },{1}}&\le C_p \varrho ^\frac{t}{2-t}\delta ^\frac{2-2t}{2-t} \quad \text {and} \end{aligned}$$(15)$$\begin{aligned} \left\| {x^\dagger -{\hat{x}}_\alpha } \right\| _{{ {\underline{a}} },{2}}&\le C_p \delta . \end{aligned}$$(16)with a constant \(C_{p}\) depending only on \(c_1, c_2, t\) and L.
-
3.
(rates with discrepancy principle) Let \(1\le \tau _1\le \tau _2\). If \({\hat{x}}_\alpha \) is a minimizer of (1) with \(\tau _1 \delta \le \Vert F({\hat{x}}_\alpha )-g^\mathrm {obs}\Vert _{\mathbb {Y}}\le \tau _2 \delta \), then
$$\begin{aligned} \left\| {x^\dagger -{\hat{x}}_\alpha } \right\| _{{ {\underline{r}} },{1}}&\le C_d \varrho ^\frac{t}{2-t}\delta ^\frac{2-2t}{2-t} \quad \text {and} \end{aligned}$$(17)$$\begin{aligned} \left\| {x^\dagger -{\hat{x}}_\alpha } \right\| _{{ {\underline{a}} },{2}}&\le C_d \delta . \end{aligned}$$(18)Here \(C_d>0\) denotes a constant depending only on \(\tau _2\), t and L.
We discuss our results in the following series of remarks:
Remark 16
The proof of Theorem 15 makes no use of the second inequality in Assumption 3.
Remark 17
(Error bounds in intermediate norms) Invoking the interpolation inequalities given in Proposition 4 allows to combine the bounds in the norms \(\left\| {\cdot } \right\| _{{ {\underline{r}} },{1}}\) and \(\left\| {\cdot } \right\| _{{ {\underline{a}} },{2}}\) to bounds in \(\left\| {\cdot } \right\| _{{ {\underline{\omega }} _p},{p}}\) for \(p\in (t,1]\). In the setting of Theorem 15(2.) or (3.) we obtain
with \(C=C_p\) or \(C=C_d\) respectively.
Remark 18
(Limit \(t\rightarrow 1\)) Let us consider the limiting case \(t=1\) by assuming only \(x^\dagger \in \ell _{ {\underline{r}} }^{1}\cap D_F\). Then it is well known, that the parameter choice \(\alpha \sim \delta ^2\) as well the discrepancy principle as in Theorem 15.3. lead to bounds \(\left\| {x^\dagger -{\hat{x}}_\alpha } \right\| _{{ {\underline{r}} },{1}} \le C \left\| {x^\dagger } \right\| _{{ {\underline{r}} },{1}} \) and \(\Vert F(x^\dagger )-F({\hat{x}}_\alpha )\Vert _{\mathbb {Y}}\le C \delta \). As above, Assumption 3 allows to transfer to a bound \(\left\| {x^\dagger -{\hat{x}}_\alpha } \right\| _{{ {\underline{a}} },{2}}\le {\tilde{C}} \delta .\) Interpolating as in the last remark yields
Remark 19
(Limit \(t\rightarrow 0\)) Note that in the limit \(t\rightarrow 0\) the convergence rates get arbitrarily close to the linear convergence rate \(\mathcal {O}(\delta )\), i.e., in contrast to standard quadratic Tikhonov regularization in Hilbert spaces no saturation effect occurs. This is also the reason why we always obtain optimal rates with the discrepancy principle even for smooth solutions \(x^\dagger \).
As already mentioned in the introduction, the formal limiting rate for \(t\rightarrow 0\), i.e. a linear convergence rate in \(\delta \) occurs if and only if \(x^\dagger \) is sparse as shown by different methods in [21].
We finish this subsection by showing that the convergence rates (15), (17), and (19) are optimal in a minimax sense.
Proposition 20
(Optimality) Suppose that Assumption 3 holds true. Assume furthermore that there are \(c_0>0\), \(q\in (0,1)\) such that for every \(\eta \in (0,c_0)\) there is \(j\in \varLambda \) satisfying \({q\eta \le {\underline{a}} _j {\underline{r}} _j^{-1}\le \eta }\). Let \(p\in (0,2]\), \(t\in (0,p)\) and \(\rho >0\). Suppose D contains all \(x\in k_t\) with \(\Vert x\Vert _{k_t}\le \varrho .\) Consider an arbitrary reconstruction method described by a mapping \(R:{\mathbb {Y}}\rightarrow \ell ^1_r\) approximating the inverse of F. Then the worst case error under the a-priori information \(\Vert x^\dagger \Vert _{k_t}\le \varrho \) is bounded below by
for all \(\delta \le \frac{1}{2}L\varrho c_0^\frac{2-t}{t}\) with \(c=q^\frac{2p-2t}{pt} (2L^{-1})^{\frac{2}{p}\frac{p-t}{2-t}}\).
Proof
It is a well-known fact that the left hand side in (20) is bounded from below by \(\frac{1}{2}\varOmega (2\delta ,\varrho )\) with the modulus of continuity
(see [12, Rem. 3.12], [34, Lemma 2.8]). By Assumption 3 we have
By assumption there exists \(j_0\in \varLambda \) such that
Choosing \(x_{j_0}=\varrho a_{j_0}^\frac{2-2t}{t}r_{j_0}^\frac{t-2}{t}\) and \(x_j=0\) if \(j\ne j_0\) we obtain \( \Vert x\Vert _{k_t}=\varrho \) and \( \left\| {x} \right\| _{{ {\underline{a}} },{2}} \le 2 L^{-1}\delta \) and estimate
\(\square \)
Note that for \(\varLambda ={\mathbb {N}}\) the additional assumption in Proposition 20 is satisfied if \( {\underline{a}} _j {\underline{r}} _j^{-1}\sim {\tilde{q}}^j\) for \({\tilde{q}}\in (0,1)\) or if \( {\underline{a}} _j {\underline{r}} _j^{-1}\sim j^{-\kappa }\) for \(\kappa >0\), but violated if \( {\underline{a}} _j {\underline{r}} _j^{-1}\sim \exp (-j^2)\).
4.3 Converse result
As a main result, we now prove that the condition \(x^\dagger \in k_t\) is necessary and sufficient for the Hölder type approximation rate \(\mathcal {O}(\alpha ^{1-t})\):
Theorem 21
(Converse result for exact data) Suppose Assumption 3 and 4 hold true. Let \(x^\dagger \in D_F\cap \ell _{ {\underline{r}} }^{1}\), \(t\in (0,1)\), and \((x_\alpha )_{\alpha >0}\) the minimizers of (1) for exact data \(g^\mathrm {obs}= F(x^\dagger ).\) Then the following statements are equivalent:
-
(i)
\(x^\dagger \in k_t.\)
-
(ii)
There exists a constant \(C_2>0\) such that \(\left\| {x^\dagger -x_\alpha } \right\| _{{ {\underline{r}} },{1}}\le C_2 \alpha ^{1-t}\) for all \(\alpha >0\).
-
(iii)
There exists a constant \(C_3>0\) such that \(\Vert F(x^\dagger )-F(x_\alpha )\Vert _{\mathbb {Y}}\le C_3 \alpha ^\frac{2-t}{2}\) for all \(\alpha >0.\)
More precisely, we can choose \(C_2:= c \Vert x^\dagger \Vert _{k_t}^t\), \(C_3:= \sqrt{2C_2}\) and bound \(\Vert x^\dagger \Vert _{k_t}\le c C_3^\frac{2}{t}\) with a constant \(c>0\) that depends on L and t only.
Proof
- \(\mathrm{{(i)}}\Rightarrow \mathrm{{(ii)}}\)::
-
By Theorem 15(1.) for \(\delta =0.\)
- \(\mathrm{{(ii)}}\Rightarrow \mathrm{{(iii)}}\)::
-
As \(x_\alpha \) is a minimizer of (1) we have
$$\begin{aligned} \frac{1}{2} \Vert F(x^\dagger )-F(x_\alpha )\Vert _{\mathbb {Y}}^2 \le \alpha \left( \left\| {x^\dagger } \right\| _{{ {\underline{r}} },{1}} - \left\| {x_\alpha } \right\| _{{ {\underline{r}} },{1}}\right) \le \alpha \left\| {x^\dagger -x_\alpha } \right\| _{{ {\underline{r}} },{1}}\le C_2 \alpha ^{2-t}. \end{aligned}$$Multiplying by 2 and taking square roots on both sides yields (iii).
- \(\mathrm{{(iii)}}\Rightarrow \mathrm{{(i)}}\)::
-
The strategy is to prove that \(\Vert F(x^\dagger )-F(x_\alpha )\Vert _{\mathbb {Y}}\) is an upper bound on \(\left\| {x^\dagger -T_\alpha (x^\dagger )} \right\| _{{ {\underline{a}} },{2}}\) up to a constant and a linear change of \(\alpha \) and then proceed using Lemma 9.
As an intermediate step we first consider
The minimizer can be calculated in each coordinate separately by
Hence,
Comparing \(z_\alpha \) with \(T_\alpha (x^\dagger )\) yields \( |x^\dagger -T_\alpha (x^\dagger )_j|\le |x^\dagger _j- (z_\alpha )_j|\) for all \(j\in \varLambda \). Hence, we have \( \left\| {x^\dagger -T_\alpha (x^\dagger )} \right\| _{{ {\underline{a}} },{2}} \le \left\| {x^\dagger -z_\alpha } \right\| _{{ {\underline{a}} },{2}}\).
It remains to find a bound on \( \left\| {x^\dagger -z_\alpha } \right\| _{{ {\underline{a}} },{2}}\) in terms of \(\Vert F(x^\dagger )-F(x_\alpha )\Vert _{\mathbb {Y}}\).
Let \(\alpha >0\), \(\beta :=2 L^2\alpha \) and \(z_\alpha \) given by (21). Then
Using Assumption 3 and subtracting \(\alpha \left\| {z_\alpha } \right\| _{{ {\underline{r}} },{1}}\) yield
Due to Assumption 4 we have \(z_\alpha \in D_F\). As \(x_\beta \) is a minimizer of (1) we obtain
Using the other inequality in Assumption 3 and subtracting \(\beta \left\| {z_\alpha } \right\| _{{ {\underline{r}} },{1}}\) and dividing by \(\beta \) we end up with
We insert the last inequality into (22), subtract \(\frac{1}{4} \left\| {x^\dagger - z_\alpha } \right\| _{{ {\underline{a}} },{2}}^2\), multiply by 4 and take the square root and get \(\left\| {x^\dagger -z_\alpha } \right\| _{{ {\underline{a}} },{2}} \le \sqrt{2} L \Vert F(x)-F(x_\beta )\Vert _{\mathbb {Y}}.\) Together with the first step, the hypothesis (iii) and the definition of \(\beta \) we achieve
Finally, Lemma 9 yields \(x\in k_t\) with \(\Vert x^\dagger \Vert _{k_t}\le c C_3^\frac{2}{t}\) with a constant c that depends only on t and L. \(\square \)
5 Convergence analysis for \(x^\dagger \notin \ell _{ {\underline{r}} }^{1}\)
We turn to the oversmoothed setting where the unknown solution \(x^\dagger \) does not admit a finite penalty value. An important ingredient of most variational convergence proofs of Tikhonov regularization is a comparison of the Tikhonov functional at the minimizer and at the exact solution. In the oversmoothing case such a comparison is obviously not useful. As a substitute, one may use a family of approximations of \(x^\dagger \) at which the penalty functional is finite. See also [22, 23] where this idea is used and the approximations are called auxiliary elements. Here we will use \(T_{\alpha }(x^\dagger )\) for this purpose. We first show that the spaces \(k_t\) can not only be characterized in terms of the approximation errors \(\left\| {(I-T_{\alpha })(\cdot )} \right\| _{{ {\underline{\omega }} _p},{p}}\) as in Lemma 9, but also in terms of \(\left\| {T_\alpha \cdot } \right\| _{{ {\underline{r}} },{1}}\):
Lemma 22
(Bounds on \(\left\| {T_\alpha \cdot } \right\| _{{ {\underline{r}} },{1}}.\)) Let \(t\in (1,2)\) and \(x\in {\mathbb {R}}^\varLambda \). Then \(x\in k_t\) if and only if \(\eta (x):= \sup _{\alpha >0} \alpha ^{t-1}\left\| {T_\alpha (x)} \right\| _{{ {\underline{r}} },{1}} <\infty \).
More precisely, we can bound
Proof
As in the proof of Lemma 9 we use a partitioning. Assuming \(x\in k_t\) we obtain
Vice versa we estimate
Hence, \(\Vert x\Vert _{k_t}\le \eta (x)^\frac{1}{t}.\) \(\square \)
The following lemma provides a bound on the minimal value of the Tikhonov functional. From this we deduce bounds on the distance between \(T_\alpha (x^\dagger )\) and the minimizers of (1) in \(\left\| {\cdot } \right\| _{{ {\underline{a}} },{2}}\) and in \(\left\| {\cdot } \right\| _{{ {\underline{r}} },{1}}.\)
Lemma 23
(Preparatory bounds) Let \(t\in (1,2)\), \(\delta \ge 0\) and \(\varrho >0\). Suppose 3 and 4 hold true. Assume \(x^\dagger \in D_F\) with \(\Vert x^\dagger \Vert _{k_t}\le \varrho \) and \(g^\mathrm {obs}\in {\mathbb {Y}}\) with \(\Vert g^\mathrm {obs}-F(x^\dagger )\Vert _{\mathbb {Y}}\le \delta .\) Then there exist constants \(C_{t}\), \(C_{a}\) and \(C_{r}\) depending only on t and L such that
for all \(\alpha >0\) and \({\hat{x}}_\alpha \) minimizers of (1).
Proof
Due to Assumption 4 we have \(T_\alpha ( x^\dagger )\in D\). Therefore, we may insert \(T_\alpha ( x^\dagger )\) into (1) to start with
Lemma 22 provides the bound \( \alpha \left\| {T_\alpha ( x^\dagger )} \right\| _{{ {\underline{r}} },{1}}\le C_1 \varrho ^t \alpha ^{2-t}\) for the second summand on the right hand side with a constant \(C_1\) depending only on t.
In the following we will estimate the first summand on the right hand side. Let \(\varepsilon >0\). By the second inequality in Assumption 3 and Lemma 9 we obtain
with a constant \(C_2\) depending on L and t. Inserting into (26) yields (23) with \(C_{t}:=C_1+C_2\).
We use (27), the first inequality in Assumption 3 and neglect the penalty term in (23) to estimate
with \(C_{a}:= 4L^2(C_2+C_{t})\).
Lemma 22 provides the bound \( \left\| {T_\alpha (x^\dagger )} \right\| _{{ {\underline{r}} },{1}} \le C_3 \varrho ^t \alpha ^{1-t}\) with \(C_3\) depending only on t. Neglecting the data fidelity term in (23) yields
with \(C_r:=C_t+C_3.\)
\(\square \)
The next result is a converse type result for image space bounds with exact data. In particular, we see that Hölder type image space error bounds are determined by Hölder type bounds on the whole Tikhonov functional at the minimizers and vice versa.
Theorem 24
(Converse result for exact data) Suppose Assumption 3 and 4 hold true. Let \(t\in (1,2)\), \(x^\dagger \in D_F\) and \((x_\alpha )_{\alpha >0}\) a choice of minimizers in (1) with \(g^\mathrm {obs}=F(x^\dagger )\). The following statements are equivalent:
-
(i)
\(x^\dagger \in k_t\).
-
(ii)
There exists a constant \(C_2>0\) such that \(\frac{1}{2}\Vert F(x)-F(x_\alpha )\Vert _{{\mathbb {Y}}}^2 +\alpha \left\| {x_\alpha } \right\| _{{ {\underline{r}} },{1}} \le C_2 \alpha ^{2-t}.\)
-
(iii)
There exists a constant \(C_3\) such that \(\Vert F(x)-F(x_\alpha )\Vert _{{\mathbb {Y}}}\le C_3 \alpha ^\frac{2-t}{2}\).
More precisely, we can choose \(C_2 = C_t \Vert x^\dagger \Vert _{k_t}^t\) with \(C_t\) from Lemma 23, \(C_3=\sqrt{2C_2}\) and bound \(\Vert x^\dagger \Vert _{k_t}\le c C_3^\frac{2}{t}\) with a constant c that depends only on t and L.
Proof
- \(\mathrm{{(i)}}\Rightarrow \mathrm{{(ii)}}\)::
-
Use (23) with \(\delta =0\).
- \(\mathrm{{(ii)}}\Rightarrow \mathrm{{(iii)}}\)::
-
This implication follows immediately by neglecting the penalty term, multiplying by 2 and taking the square root of the inequality in the hypothesis.
- \(\mathrm{{(iii)}}\Rightarrow \mathrm{{(i)}}\)::
-
The same argument as in the proof of the implication (iii) \(\Rightarrow \) (i) in Theorem 21 applies.
\(\square \)
The following theorem shows that we obtain order optimal convergence rates on \(k_t\) also in the case of oversmoothing (see Proposition 20).
Theorem 25
(Rates of convergence) Suppose Assumptions 3 and 4 hold true. Let \(t\in (1,2)\), \(p\in (t,2]\) and \(\varrho >0.\) Assume \(x^\dagger \in D_F\) with \(\Vert x^\dagger \Vert _{k_t}\le \varrho \).
-
1.
(bias bound) Let \(\alpha >0\). For exact data \(g^\mathrm {obs}= F(x^\dagger )\) every minimizer \(x_\alpha \) of (1) satisfies
$$\begin{aligned} \left\| {x^\dagger -x_\alpha } \right\| _{{ {\underline{\omega }} _p},{p}} \le C_b \varrho ^\frac{t}{p} \alpha ^\frac{p-t}{p} \end{aligned}$$with a constant \(C_{b}\) depending only on p, t and L.
-
2.
(rate with a-priori choice of \(\alpha \)) Let \(\delta >0\), \(g^\mathrm {obs}\in {\mathbb {Y}}\) satisfy \(\Vert g^\mathrm {obs}-F(x^\dagger )\Vert _{\mathbb {Y}}\le \delta \) and \(0<c_1<c_2\). If \(\alpha \) is chosen such that
$$\begin{aligned} c_1 \varrho ^\frac{t}{t-2} \delta ^\frac{2}{2-t} \le \alpha \le c_2 \varrho ^\frac{t}{t-2} \delta ^\frac{2}{2-t},\end{aligned}$$then every minimizer \({\hat{x}}_\alpha \) of (1) satisfies
$$\begin{aligned} \left\| {{\hat{x}}_\alpha - x^\dagger } \right\| _{{ {\underline{\omega }} _p},{p}} \le C_c \varrho ^\frac{t(2-p)}{p(2-t)}\delta ^\frac{2(p-t)}{p(2-t)} \end{aligned}$$with a constant \(C_{c}\) depending only on \(c_1, c_2, p, t\) and L.
-
3.
(rate with discrepancy principle) Let \(\delta >0\) and \(g^\mathrm {obs}\in {\mathbb {Y}}\) satisfy \(\Vert g^\mathrm {obs}-F(x^\dagger )\Vert _{\mathbb {Y}}\le \delta \) and \(1<\tau _1\le \tau _2\). If \({\hat{x}}_\alpha \) is a minimizer of (1) with \(\tau _1 \delta \le \Vert F({\hat{x}}_\alpha )-g^\mathrm {obs}\Vert _{\mathbb {Y}}\le \tau _2 \delta \), then
$$\begin{aligned} \left\| {{\hat{x}}_\alpha - x^\dagger } \right\| _{{ {\underline{\omega }} _p},{p}}\le C_d \varrho ^\frac{t(2-p)}{p(2-t)}\delta ^\frac{2(p-t)}{p(2-t)}. \end{aligned}$$Here \(C_d>0\) denotes a constant depending only on \(\tau _1\), \(\tau _2\), p, t and L.
Proof
-
1.
By Proposition 4 we have \(\left\| {\cdot } \right\| _{{ {\underline{\omega }} _p},{p}} \le \left\| {\cdot } \right\| _{{ {\underline{a}} },{2}} ^\frac{2p-2}{p} \left\| {\cdot } \right\| _{{ {\underline{r}} },{1}}^\frac{2-p}{p}.\) With this we interpolate between (24) and (25) with \(\delta =0\) to obtain
$$\begin{aligned}\left\| {T_\alpha (x^\dagger )-x_\alpha } \right\| _{{ {\underline{\omega }} _p},{p}} \le K_1 \varrho ^\frac{t}{p} \alpha ^\frac{p-t}{p} \end{aligned}$$with \(K_1:=C_a^\frac{p-1}{p} C_r^\frac{2-p}{p}\). By Lemma 9 there is a constant \(K_2\) depending only on p and t such that
$$\begin{aligned} \left\| {x^\dagger - T_\alpha (x^\dagger )} \right\| _{{ {\underline{\omega }} _p},{p}} \le K_2\varrho ^\frac{t}{p} \alpha ^\frac{p-t}{p}. \end{aligned}$$(29)Hence
$$\begin{aligned} \left\| {x^\dagger -x_\alpha } \right\| _{{ {\underline{\omega }} _p},{p}}&\le \left\| {x^\dagger - T_\alpha (x^\dagger )} \right\| _{{ {\underline{\omega }} _p},{p}} + \left\| {T_\alpha (x^\dagger )-x_\alpha } \right\| _{{ {\underline{\omega }} _p},{p}} \\&\le (K_1+K_2) \varrho ^\frac{t}{p} \alpha ^\frac{p-t}{p}. \end{aligned}$$ -
2.
Inserting the parameter choice rule into (24) and (25) yields
$$\begin{aligned} \left\| { T_\alpha (x^\dagger ) - {\hat{x}}_\alpha } \right\| _{{ {\underline{a}} },{2}}&\le (8L^2+C_a c_2^{2-t})^\frac{1}{2} \delta \quad \text {and} \\ \left\| { T_\alpha (x^\dagger ) - {\hat{x}}_\alpha } \right\| _{{ {\underline{r}} },{1}}&\le (c_1^{-1}+ C_r c_1^{1-t}) \varrho ^\frac{t}{2-t}\delta ^\frac{2(1-t)}{2-t}. \end{aligned}$$As above, we interpolate these two inequalities to obtain
$$\begin{aligned}\left\| {T_\alpha (x^\dagger )-{\hat{x}}_\alpha } \right\| _{{ {\underline{\omega }} _p},{p}} \le K_3 \varrho ^\frac{t(2-p)}{p(2-t)}\delta ^\frac{2(p-t)}{p(2-t)}. \end{aligned}$$with \(K_3:= (8L^2+C_a c_2^{2-t})^\frac{p-1}{p} (c_1^{-1}+ C_r c_1^{1-t})^\frac{2-p}{p}\). We insert the parameter choice into (29) and get \(\left\| {x^\dagger - T_\alpha (x^\dagger )} \right\| _{{ {\underline{\omega }} _p},{p}} \le K_2 c_2^\frac{p-t}{p}\varrho ^\frac{t(2-p)}{p(2-t)}\delta ^\frac{2p-2t}{p(2-t)}.\) Applying the triangle inequality as in part 1 yields the claim.
-
3.
Let \(\varepsilon =\frac{\tau _1^2-1}{2}\). Then \(\varepsilon >0\). By Lemma 9 there exists a constant \(K_4\) depending only on t such that \(\left\| {x^\dagger -T_\beta (x^\dagger )} \right\| _{{ {\underline{a}} },{2}}^2 \le K_4 \varrho ^t \beta ^{2-t}\) for all \(\beta >0.\) We choose
$$\begin{aligned} \beta :=(\delta ^2\varepsilon (1+\varepsilon ^{-1})^{-1}L^{-2} K_4^{-1}\varrho ^{-t} )^\frac{1}{2-t}. \end{aligned}$$Then
$$\begin{aligned} \left\| {x^\dagger -T_\beta (x^\dagger )} \right\| _{{ {\underline{a}} },{2}}^2 \le \varepsilon (1+\varepsilon ^{-1})^{-1}L^{-2}\delta ^2. \end{aligned}$$(30)We make use of the elementary inequality \( (a+b)^2 \le (1+\varepsilon )a^2 +(1 +\varepsilon ^{-1})b^2\) which is proven by expanding the square and applying Young’s inequality on the mixed term. Together with the second inequality in Assumption 3 we estimate
$$\begin{aligned}&\frac{1}{2} \Vert g^\mathrm {obs}- F(T_\beta (x^\dagger )) \Vert _{\mathbb {Y}}^2 \\&\le \frac{1}{2} (1+\varepsilon ) \Vert g^\mathrm {obs}- F(x^\dagger )\Vert _{\mathbb {Y}}^2+ \frac{1}{2}(1+\varepsilon ^{-1}) L^2 \left\| {x^\dagger -T_\beta (x^\dagger )} \right\| _{{ {\underline{a}} },{2}}^2 \\&\le \frac{1}{2} (1+2\varepsilon ) \delta ^2 = \frac{1}{2} \tau _1^2 \delta ^2. \end{aligned}$$By inserting \(T_\beta (x^\dagger )\) into the Tikhonov functional we end up with
$$\begin{aligned} \frac{1}{2} \tau _1^2 \delta ^2 + \alpha \left\| {{\hat{x}}_\alpha } \right\| _{{ {\underline{r}} },{1}}&\le \frac{1}{2} \Vert g^\mathrm {obs}-F({\hat{x}}_\alpha )\Vert _{\mathbb {Y}}^2 + \alpha \left\| {{\hat{x}}_\alpha } \right\| _{{ {\underline{r}} },{1}} \\&\le \frac{1}{2} \Vert g^\mathrm {obs}-F(T_\beta (x^\dagger )) \Vert _{\mathbb {Y}}^2 +\alpha \left\| {T_\beta (x^\dagger )} \right\| _{{ {\underline{r}} },{1}}\\ {}&\le \frac{1}{2} \tau _1^2 \delta ^2 + \alpha \left\| {T_\beta (x^\dagger )} \right\| _{{ {\underline{r}} },{1}}. \end{aligned}$$Hence, \(\left\| {{\hat{x}}_\alpha } \right\| _{{ {\underline{r}} },{1}} \le \left\| {T_\beta (x^\dagger )} \right\| _{{ {\underline{r}} },{1}}\). Together with Lemma 22 we obtain the bound
$$\begin{aligned} \left\| {T_\beta (x^\dagger )-{\hat{x}}_\alpha } \right\| _{{ {\underline{r}} },{1}} \le 2 \left\| {T_\beta (x^\dagger )} \right\| _{{ {\underline{r}} },{1}} \le K_5 \varrho ^\frac{t}{2-t}\delta ^\frac{2-2t}{2-t} \end{aligned}$$with a constant \(K_5\) that depends only on \(\tau \), t and L. Using (30) and the first inequality in Assumption 3 we estimate
$$\begin{aligned}&\left\| {T_\beta (x^\dagger )-{\hat{x}}_\alpha } \right\| _{{ {\underline{a}} },{2}} \\&\le \left\| {x^\dagger - T_\beta (x^\dagger )} \right\| _{{ {\underline{a}} },{2}}+\left\| {x^\dagger -{\hat{x}}_\alpha } \right\| _{{ {\underline{a}} },{2}} \\&\le \left\| {x^\dagger - T_\beta (x^\dagger )} \right\| _{{ {\underline{a}} },{2}}+L \Vert F(x^\dagger )-F({\hat{x}}_\alpha )\Vert _{\mathbb {Y}}\\&\le \left\| {x^\dagger - T_\beta (x^\dagger )} \right\| _{{ {\underline{a}} },{2}}+L \Vert g^\mathrm {obs}- F(x^\dagger )\Vert _{\mathbb {Y}}+L \Vert g^\mathrm {obs}-F({\hat{x}}_\alpha )\Vert _{\mathbb {Y}}\\&\le K_6 \delta \end{aligned}$$with \(K_6= \varepsilon ^\frac{1}{2}(1+\varepsilon ^{-1})^{-\frac{1}{2}}L^{-1}+L+L\tau _2.\) As above, interpolation yields
$$\begin{aligned}\left\| {T_\beta (x^\dagger )-{\hat{x}}_\alpha } \right\| _{{ {\underline{\omega }} _p},{p}} \le K_7 \varrho ^\frac{t(2-p)}{p(2-t)}\delta ^\frac{2p-2t}{p(2-t)} \end{aligned}$$with \(K_7:= K_6 ^\frac{2p-2}{p} K_5^\frac{2-p}{p}\). Finally, Lemma 9 together with the choice of \(\beta \) implies \(\left\| {x^\dagger -T_\beta (x^\dagger )} \right\| _{{ {\underline{\omega }} _p},{p}} \le K_8 \varrho ^\frac{t(2-p)}{p(2-t)}\delta ^\frac{2p-2t}{p(2-t)}\) for a constant \(K_8\) that depends only on \(\tau \), p, t and L and we conclude
$$\begin{aligned} \left\| {x^\dagger -{\hat{x}}_\alpha } \right\| _{{ {\underline{\omega }} _p},{p}}&\le \left\| {x^\dagger -T_\beta (x^\dagger )} \right\| _{{ {\underline{\omega }} _p},{p}} +\left\| {T_\beta (x^\dagger )-{\hat{x}}_\alpha } \right\| _{{ {\underline{\omega }} _p},{p}} \\&\le (K_8+K_7) \varrho ^\frac{t(2-p)}{p(2-t)}\delta ^\frac{2p-2t}{p(2-t)}. \end{aligned}$$
\(\square \)
6 Wavelet regularization with Besov spaces penalties
In the sequel we apply our results developed in the general sequence space setting to obtain obtain convergence rates for wavelet regularization with a Besov r, 1, 1-norm penalty.
Suppose Assumptions and 1 and 2 and Eqs. (7) hold true. Then \(F:=G\circ \mathcal {S}\) satisfies Assumption 3 on \(D_F:=\mathcal {S}^{-1}(D_G) \subseteq \ell _{ {\underline{a}} }^{2}= b^{-a}_{{2},{2}}\) as shown in Sect. 2.
Recall that \( {\underline{a}} _{(j,k)}= 2^{-ja}\) and \( {\underline{r}} _{(j,k)}=2^{j(r-\frac{d}{2})}\). Let \(s\in [-a,\infty )\). With
we obtain \(b^{s}_{{t_s},{t_s}}=\ell _{ {\underline{\omega }} _{t_s}}^{t_s}\) with equal norm for \( {\underline{\omega }} _{t_s}\) given by (8). For \(s\in (0,\infty )\) we have \(t_s\in (0,1)\).
The following lemma defines and characterizes a function space \(K_{t_s}\) as the counterpart of \(k_{t_s}\) for \(s>0\). As spaces \(b^{s}_{{p},{q}}\) and \(B^{s}_{{p},{q}}(\varOmega )\) with \(p<1\) are involved let us first argue that within the scale \(b^{s}_{{t_s},{t_s}}\) for \(s>0\) the extra condition \(\sigma _{t_s}-s_\text {max}< s\) in Assumption 1 is always satisfied if we assume \(a+r> \frac{d}{2}\). To this end let \(0<s<s_\text {max}\). Then
Hence, \(\sigma _{t_s}- s_\text {max}< 0 <s\).
Lemma 26
(Maximal approximation spaces \(K_{t_s}\)) Let \(a,s>0\) and suppose that Assumption 1 and Eqs. (7a) and (7b) holds true. We define
with \(t_s\) given by (31). Let \(s<u < s_\text {max}\). The space \(K_{t_s}\) coincides with the real interpolation space
with equivalent quasi-norms, and the following inclusions hold true with continuous embeddings:
Hence,
Proof
For \(s<u<s_\text {max}\) we have \(k_{t_s}=(b^{-a}_{{2},{2}},b^{u}_{{t_u},{t_u}} )_{\theta ,\infty }\) with equivalent quasi-norms (see Remark 7). By functor properties of real interpolation (see [3, Thm. 3.1.2]) this translates to (32). As discussed above, we use \(a+r> \frac{d}{2}\) (see (7a)) to see that \(u\in (\sigma _{t_s}- s_\text {max},s)\) such that \(\mathcal {S}:b^{u}_{{t_u},{t_u}} \rightarrow B^{u}_{{t_u},{t_u}}(\varOmega )\) is well defined an bijective. By Remark 8 we have \(b^{s}_{{t_s},{t_s}}\subset k_{t_s}\) with continuous embedding, implying the first inclusion in (33). Moreover, we have \(t_u\le \frac{2a+2r}{2a+r}\le 2\). Hence, the continuous embeddings \( B^{-a}_{{2},{2}}(\varOmega ) \subset B^{-a}_{{2},{\infty }}(\varOmega )\subset B^{-a}_{{t_u},{\infty }}(\varOmega )\) (see [33, 3.2.4(1), 3.3.1(9)]). Together with (32) and the interpolation result
(see [33, 3.3.6 (9)]) we obtain the second inclusion in (33) using [33, 2.4.1 Rem. 4]. Finally, the last statement follows from \(t_u\rightarrow t_s\) for \(u\searrow s\) and again [33, 3.3.1(9)]. \(\square \)
Theorem 27
(Convergence rates) Suppose Assumptions 2 and 1 hold true with \(\frac{d}{2}-r<a<s_\text {max}\) and \(b^{r}_{{1},{1}} \cap \mathcal {S}^{-1}(D_G)\ne \emptyset \). Let \(0<s<s_\text {max}\) with \(s\ne r\), \(\varrho >0\) and \(\Vert \cdot \Vert _{L^p}\) denote the usual norm on \(L^p(\varOmega )\) for \(1\le p:=\frac{2a+2r}{2a+r}\). Assume \(f^\dagger \in D_G\) with \(\Vert f^\dagger \Vert _{K_{t_s}}\le \varrho \). If \(s<r\) assume that \(D_F:=\mathcal {S}^{-1}(D_G)\) satisfies Assumption 4. Let \(\delta >0\) and \( g^\mathrm {obs}\in {\mathbb {Y}}\) satisfy \(\Vert g^\mathrm {obs}-F(f^\dagger )\Vert _{\mathbb {Y}}\le \delta .\)
-
1.
(rate with a-priori choice of \(\alpha \)) Let \(0<c_1<c_2\). If \(\alpha \) is chosen such that
$$\begin{aligned} c_1 \varrho ^{-\frac{a+r}{s+a}} \delta ^\frac{s+2a+r}{s+a}\le \alpha \le c_2 \varrho ^{-\frac{a+r}{s+a}} \delta ^\frac{s+2a+r}{s+a},\end{aligned}$$then every \({\hat{f}}_\alpha \) given by (4) satisfies
$$\begin{aligned} \left\| f^\dagger -{\hat{f}}_\alpha \right\| _{L^p} \le C_a \varrho ^\frac{a}{s+a}\delta ^\frac{s}{s+a}. \end{aligned}$$ -
2.
(rate with discrepancy principle) Let \(1 < \tau _1 \le \tau _2 \). If \({\hat{f}}_\alpha \) is given by (4) with
$$\begin{aligned} \tau _1 \delta \le \Vert F({\hat{x}}_\alpha )-g^\mathrm {obs}\Vert _{\mathbb {Y}}\le \tau _2 \delta , \end{aligned}$$then
$$\begin{aligned} \left\| f^\dagger -{\hat{f}}_\alpha \right\| _{L^p} \le C_d \varrho ^\frac{a}{s+a}\delta ^\frac{s}{s+a}. \end{aligned}$$
Here \(C_a\) and \(C_{d}\) are constants independent of \(\delta ,\) \(\varrho \) and \(f^\dagger \).
Proof
If \(s>r\) (hence \(t_s\in (0,1)\)) we refer to Remark 17. If \(s<r\) (hence \(t\in (1,2)\)) to Theorem 25 for the bound
for the a-priori choice \( \alpha \sim \varrho ^\frac{t_s}{t_s-2} \delta ^\frac{2}{2-t_s}= \varrho ^{-\frac{a+r}{s+a}} \delta ^\frac{s+2a+r}{s+a} \) as well as for the discrepancy principle. With Assumption 1 and by the well known embedding \(B^{0}_{{p},{p}}(\varOmega ) \subset L^p\) we obtain
Together with (34) this proves the result. \(\square \)
Remark 28
In view of Remark 18 we obtain the same results for the case \(s=r\) by replacing \(K_{t_s}\) by \(B^{r}_{{1},{1}}(\varOmega )\).
Theorem 29
Let \(r=0\). Suppose Assumptions 2, 1 and 4 hold true with \(s_\text {max}>a>\frac{d}{2}\). Let \(f^\dagger \in D_G\cap B^{0}_{{1},{1}}(\varOmega )\), \(s>0\) and \((f_\alpha )_{\alpha >0}\) the minimizers of (4) for exact data \(g^\mathrm {obs}=F(f^\dagger )\). The following statements are equivalent:
-
(i)
\(f^\dagger \in K_{t_s}.\)
-
(ii)
There exists a constant \(C_2>0\) such that \(\Vert {f^\dagger -f_\alpha } \Vert _ {B^{0}_{{1},{1}}} \le C_2 \alpha ^\frac{s}{s+2a}\) for all \(\alpha >0\).
-
(iii)
There exists a constant \(C_3>0\) such that \(\Vert F(f^\dagger )-F(f_\alpha )\Vert _{\mathbb {Y}}\le C_3 \alpha ^\frac{s+a}{s+2a}\) for all \(\alpha >0.\)
More precisely, we can choose \(C_2:= c \Vert f^\dagger \Vert _{K_t}^{t_s}\), \(C_3:= c C_2^\frac{1}{2}\) and bound\({\Vert f^\dagger \Vert _{K_t}\le c C_3^\frac{2}{t_s}}\) with a constant \(c>0\) that depends only on L and t and operator norms of \(\mathcal {S}\) and \(\mathcal {S}^{-1}\).
Proof
Statement (i) is equivalent to \(x^\dagger =\mathcal {S}^{-1}f^\dagger \in k_t\) and statement (ii) is equivalent to a bound \(\Vert {x-x_\alpha } \Vert _{{0},{1},{1}}\le \tilde{C_2} \alpha ^\frac{s}{s+2a}\). Hence, Theorem 21 yields the result. \(\square \)
Example 30
We consider functions \(f^{\mathrm {jump}}, f^{\mathrm {kink}}:[0,1]\rightarrow {\mathbb {R}}\) which are \(C^{\infty }\) everywhere with uniform bounds on all derivatives except at a finite number of points in [0, 1], and \(f^{\mathrm {kink}}\in C^{0,1}([0,1])\). In other words, \(f^{\mathrm {jump}}, f^{\mathrm {kink}}\) are piecewise smooth, \(f^{\mathrm {jump}}\) has a finite number of jumps, and \(f^{\mathrm {kink}}\) has a finite number of kinks. Then for \(p\in (0,\infty )\), \(q\in (0,\infty ]\), and \(s\in {\mathbb {R}}\) with \(s>\sigma _p\) with \(\sigma _p\) as in Assumption 1 we have
if \(q<\infty \) and
To see this, we can use the classical definition of Besov spaces in terms of the modulus of continuity \(\Vert \varDelta _h^m f\Vert _{L^p}\) where \((\varDelta _hf)(x) := f(x+h)-f(x)\) and \(\varDelta _h^{m+1}f:= \varDelta _h(\varDelta _h^m f)\), see, e.g., [32, Eq. (1.23)]. Elementary computations show that \(\Vert \varDelta _h^m f^{\mathrm {jump}}\Vert _{L^p}\) decays of the order \(h^{1/p}\) as \(h\searrow 0\) if \(m\ge 1/p\), and \(\Vert \varDelta _h^m f^{\mathrm {kink}}\Vert _{L^p}\) decays as \(h^{1/p+1}\) if \(m\ge 2/p\). Therefore, as \(t_s<1\) describing the regularity of \(f^{\mathrm {jump}}\) or \(f^{\mathrm {kink}}\) in the scale \(B^{s}_{{t_s},{t_s}}(\varOmega ) \subset K_{t_s}\) as in Theorems 27 and 29 allows for a larger value of s and hence a faster convergence rate than describing the regularity of these functions in the Besov spaces \(B^s_{1,\infty }\) as in [24]. In other words, the previous analysis in [24] provided only suboptimal rates of convergence for this important class of functions. This can also be observed in numerical simulations we provide below.
Note that the largest set on which a given rate of convergence is attained can be achieved by setting \(r=0\) (i.e. no oversmoothing). This is in contrast to the Hilbert space case where oversmoothing allows to raise the finite qualification of Tikhonov regularization. On the other hand for larger r convergence can be guaranteed in a stronger \(L^p\)-norm.
7 Numerical results
For our numerical simulations we consider the problem in Example 2 in the form
The forward operator in the function space setting is \(G(c):=u\) for the fixed right hand side \(f(\cdot )=\sin (4\pi \cdot )+2\).
The true solution \(c^\dagger \) is given by a piecewise smooth function with either finitely many jumps or kinks as discussed in Example 30.
To solve the boundary value problem (35) we used quadratic finite elements and an equidistant grid containing 127 finite elements. The coefficient c was sampled on an equidistant grid with 1024 points. For the wavelet synthesis operator we used the code PyWavelets [28] with Daubechies wavelet of order 7.
The minimization problem in (4) was solved by the Gauß-Newton-type method \(c_{k+1}= \mathcal {S}x_{k+1}\),
with a constant initial guess \(c_0=1\). In each Gauß-Newton step these linearized minimization problems were solved with the Fast Iterative Shrinkage-Thresholding Algorithm (FISTA) proposed and analyzed by Beck and Teboulle in [2]. We used the inertial parameter as in [6, Sec. 4]. We did not impose a constraint on the size of \(\Vert {x-x_0} \Vert _{{0},{2},{2}}\), which is required by our theory if Assumption 3 does not hold true globally. However, the size of the domain of validity of this assumption is difficult to assess, and such a constraint is likely to be never active for a sufficiently good initial guess.
The regularization parameter \(\alpha \) was chosen by a sequential discrepancy principle with \(\tau _1=1\) and \(\tau _2=2\) on a grid \(\alpha _j=2^{-j}\alpha _0\). To simulate worst case errors, we computed for each noise level \(\delta \) reconstructions for several data errors \(u^{\delta }-G(c^\dagger )\), \(\Vert u^{\delta }-G(c^\dagger )\Vert _{L^2}=\delta \), which were given by sin functions with different frequencies.

Left: true coefficient \(c^\dagger \) with jumps in the boundary value problem (5) together with a typical reconstruction at noise level \(\delta = 3.5\cdot 10^{-5}\). Right: Reconstruction error using \(b^{0}_{{1},{1}}\)-penalization, the rate \(\mathcal {O}(\delta ^{2/5})\) predicted by Theorem 27 (see Eq. (36)), and the rate \(\mathcal {O}(\delta ^{1/3})\) predicted by the previous analysis in [24]
For the piecewise smooth coefficient \(c^\dagger \) with jumps shown on the left panel of Fig. 1, Example 30 yields
Here \(t_s=\frac{4}{s+4}\). Hence,Theorem 27 predicts the rate
In contrast, the smoothness condition \(c^\dagger \in B^s_{1,\infty } ((0,1))\) in our previous analysis in [24], which was formulated in terms of Besov spaces with \(p=1\) is only satisfied for smaller smoothness indices \(s\le 1\), and therefore, the convergence rate in [24] is only of the order \(\left\| {\widehat{c}}_{\alpha }-c^\dagger \right\| _{L^1}= \mathcal {O}\left( \delta ^{\frac{1}{3}}\right) \). Our numerical results displayed in the right panel of Fig. 1 show that this previous error bound is too pessimistic, and the observed convergence rate matches the rate (36) predicted by our analysis.

Left: true coefficient \(c^\dagger \) with kinks in the boundary value problem (5) together with a typical reconstruction at noise level \(\delta = 3.5 \cdot 10^{-5}\). Right: Reconstruction error using \(b^{0}_{{1},{1}}\)-penalization, the rate \(\mathcal {O}(\delta ^{4/7})\) predicted by Theorem 27 (see Eq. (37)), and the rate \(\mathcal {O}(\delta ^{1/2})\) predicted by the previous analysis in [24]
Similarly, for the piecewise smooth coefficient \(c^\dagger \) with kinks shown in the left panel of Fig. 2, Example 30 yields
with \(t_s=\frac{4}{s+4}\). Hence, Theorem 27 predicts the rate
which matches with the results of our numerical simulations shown on the right panel of Fig. 2. In contrast, the previous error bound \(\left\| {\widehat{c}}_{\alpha }-c^\dagger \right\| _{L^1}=\mathcal {O}\left( \delta ^\frac{1}{2}\right) \) in [24] based on the regularity condition \(c^\dagger \in B^2_{1,\infty } ((0,1))\) turns out to be suboptimal for this coefficient \(c^\dagger \) even though it is minimax optimal in \(B^2_{1,\infty }\)-balls.

Left: true coefficient \(c^\dagger \) with jumps in the boundary value problem (5) together with reconstructions for \(r=0\) and \(r=2\) at noise level \(\delta = 3.5\cdot 10^{-5}\) for the same data. Right: Reconstruction error using \(b^{2}_{{1},{1}}\)-penalization (oversmoothing) and the rate \(\mathcal {O}(\delta ^{3/10})\) predicted by Theorem 27 (see Eq. (38)). This case is not covered by the theory in [24]
Finally, for the same coefficient \(c^\dagger \) with jumps as in Fig. 1, reconstructions with \(r=0\) and \(r=2\) are compared in the left panel of Fig. 3. Visually, the reconstruction quality is similar for both reconstructions. For \(r=2\) the penalization is oversmoothing, and Example 30 yields
with \(t_s=\frac{8}{s+6}\). Hence, Theorem 27 predicts the rate
which once again matches with the results of our numerical simulations shown on the right panel of Fig. 3. This case is not covered by the theory in [24].
8 Conclusions
We have derived a converse result for approximation rates of weighted \(\ell ^1\)-regularization. Necessary and sufficient conditions for Hölder-type approximation rates are given by a scale of weak sequence spaces. We also showed that \(\ell ^1\)-penalization achieves the minimax-optimal convergence rates on bounded subsets of these weak sequence spaces, i.e. that no other method can uniformly perform better on these sets. However, converse results for noisy data, i.e. the question whether \(\ell ^1\)-penalization achieves given convergence rates in terms of the noise level on even larger sets, remains open. Although it seems likely that the answer will be negative, a rigorous proof would probably require uniform lower bounds on the maximal effect of data noise.
A further interesting extension concerns redundant frames. Note that lacking injectivity the composition of a forward operator in function spaces with a synthesis operator of a redundant frame cannot meet the first inequality in Assumption 3. Therefore, the mapping properties of the forward operator in function space will have to be described in a different manner. (See [1, Sec. 6.2.] for a related discussion.)
We have also studied the important special case of penalization by wavelet Besov norms of type \(B^r_{1,1}\). In this case the maximal spaces leading to Hölder-type approximation rates can be characterized as real interpolation spaces of Besov spaces, but to the best of our knowledge they do not coincide with classical function spaces. They are slightly larger than the Besov spaces \(B^s_{t,t}\) with some \(t\in (0,1)\), which in turn are considerably larger than the spaces \(B^s_{1,\infty }\) used in previous results. Typical elements of the difference set \(B^s_{t,t}\setminus B^s_{1,\infty }\) are piecewise smooth functions with local singularities. Since such functions can be well approximated by functions with sparse wavelet expansions, good performance of \(\ell ^1\)-wavelet penalization is intuitively expected. Our results confirm and quantify this intuition.
Notes
This notion means that for every \(\varepsilon >0\) all but finitely many \(j\in \varLambda \) satisfy \( {\underline{a}} _j {\underline{r}} _j^{-1}\le \varepsilon \).
References
Anzengruber, S.W., Hofmann, B., Ramlau, R.: On the interplay of basis smoothness and specific range conditions occurring in sparsity regularization. Inverse Probl. 29(12), 125002 (2013). https://doi.org/10.1088/0266-5611/29/12/125002
Beck, A., Teboulle, M.: A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM J. Imaging Sci. 2(1), 183–202 (2009). https://doi.org/10.1137/080716542
Bergh, J., Löfström, J.: Interpolation Spaces. An Introduction. Springer, Berlin (1976). Grundlehren der Mathematischen Wissenschaften, No. 223. https://doi.org/10.1007/978-3-642-66451-9
Burger, M., Flemming, J., Hofmann, B.: Convergence rates in \(\ell ^1\)-regularization if the sparsity assumption fails. Inverse Probl. 29(2), 025013 (2013). https://doi.org/10.1088/0266-5611/29/2/025013
Burger, M., Helin, T., Kekkonen, H.: Large noise in variational regularization. Trans. Math. Appl. 2(1), 1–45 (2018). https://doi.org/10.1093/imatrm/tny002
Chambolle, A., Dossal, C.: On the convergence of the iterates of the “fast iterative shrinkage/thresholding algorithm.’’. J. Optim. Theory Appl. 166(3), 968–982 (2015). https://doi.org/10.1007/s10957-015-0746-4
Chen, D.H., Hofmann, B., Yousept, I.: Oversmoothing Tikhonov regularization in Banach spaces. Inverse Probl. 37(8), 085007 (2021). https://doi.org/10.1088/1361-6420/abcea0
Cohen, A., Dahmen, W., DeVore, R.: Compressed sensing and best k-term approximation. J. Am. Math. Soc. 22(1), 211–231 (2009). https://doi.org/10.1090/S0894-0347-08-00610-3
Cohen, A., DeVore, R., Kerkyacharian, G., Picard, D.: Maximal spaces with given rate of convergence for thresholding algorithms. Appl. Comput. Harmon. Anal. 11(2), 167–191 (2001). https://doi.org/10.1006/acha.2000.0333
Cohen, A., DeVore, R..A., Hochmuth, R.: Restricted nonlinear approximation. Constr. Approx. 16(1), 85–113 (2000). https://doi.org/10.1007/s003659910004
Daubechies, I., Defrise, M., Mol, C..D.: An iterative thresholding algorithm for linear inverse problems with a sparsity constraint. Commun. Pure Appl. Math. 57(11), 1413–1457 (2004). https://doi.org/10.1002/cpa.20042
Engl, H.W., Hanke, M., Neubauer, A.: Regularization of Inverse Problems, Mathematics and Its Applications, vol. 375. Kluwer Academic Publishers Group, Dordrecht (1996). https://doi.org/10.1007/978-94-009-1740-8
Flemming, J.: Generalized Tikhonov Regularization and Modern Convergence Rate Theory in Banach Spaces. Shaker Verlag, Aachen (2012)
Flemming, J.: Convergence rates for \(\ell ^1\)-regularization without injectivity-type assumptions. Inverse Probl. 32(9), 095001 (2016). https://doi.org/10.1088/0266-5611/32/9/095001
Flemming, J., Gerth, D.: Injectivity and weak*-to-weak continuity suffice for convergence rates in \(\ell ^1\)-regularization. Inverse Ill-posed Probl. 26(1), 85–94 (2018). https://doi.org/10.1515/jiip-2017-0008
Flemming, J., Hegland, M.: Convergence rates in \(\ell ^1\)-regularization when the basis is not smooth enough. Appl. Anal. 94(3), 464–476 (2015). https://doi.org/10.1080/00036811.2014.886106
Flemming, J., Hofmann, B., Veselić, I.: On \(\ell ^1\)-regularization in light of Nashed’s ill-posedness concept. Comput. Methods Appl. Math. 15(3), 279–289 (2015). https://doi.org/10.1515/cmam-2015-0008
Flemming, J., Hofmann, B., Veselić, I.: A unified approach to convergence rates for \(\ell \)1-regularization and lacking sparsity. J. Inverse Ill-posed Probl. (2016). https://doi.org/10.1515/jiip-2015-0058
Freitag, D.: Real interpolation of weighted \({L}_p\)-spaces. Math. Nachr. 86(1), 15–18 (1978). https://doi.org/10.1002/mana.19780860103
Gerth, D., Hofmanm, B.: Oversmoothing regularization with \(\ell ^1\)-penalty term. AIMS Math. 4, 1223–1247 (2019). https://doi.org/10.3934/math.2019.4.1223
Grasmair, M., Haltmeier, M., Scherzer, O.: Necessary and sufficient conditions for linear convergence of \(\ell ^1\)-regularization. Commun. Pure Appl. Math. 64(2), 161–182 (2011). https://doi.org/10.1002/cpa.20350
Hofmann, B., Mathé, P.: Tikhonov regularization with oversmoothing penalty for non-linear ill-posed problems in Hilbert scales. Inverse Prob. 34(1), 015007 (2018). https://doi.org/10.1088/1361-6420/aa9b59
Hofmann, B., Plato, R.: Convergence results and low order rates for nonlinear Tikhonov regularization with oversmoothing penalty term. Electron. Trans. Numer. Anal. 53, 313–328 (2020). https://doi.org/10.1553/etna_vol53s313
Hohage, T., Miller, P.: Optimal convergence rates for sparsity promoting wavelet-regularization in Besov spaces. Inverse Probl. 35, 65005 (2019). https://doi.org/10.1088/1361-6420/ab0b15
Hohage, T., Weidling, F.: Characterizations of variational source conditions, converse results, and maxisets of spectral regularization methods. SIAM J. Numer. Anal. 55(2), 598–620 (2017). https://doi.org/10.1137/16M1067445
Jin, B., Maass, P.: Sparsity regularization for parameter identification problems. Inverse Probl. 28(12), 123001 (2012). https://doi.org/10.1088/0266-5611/28/12/123001
Jin, B., Maaß, P., Scherzer, O.: Sparsity regularization in inverse problems [preface]. Inverse Probl. 33(6), 060301 (2017). https://doi.org/10.1088/1361-6420/33/6/060301
Lee, G..R., Gommers, R., Waselewski, F., Wohlfahrt, K., O’Leary, A.: PyWavelets: a Python package for wavelet analysis. J. Open Source Softw. 4(36), 1237 (2019). https://doi.org/10.21105/joss.01237
Lorenz, D.A.: Convergence rates and source conditions for Tikhonov regularization with sparsity constraints. J. Inverse Ill-Posed Probl. 16(5), 463–478 (2008). https://doi.org/10.1515/JIIP.2008.025
Natterer, F.: Error bounds for Tikhonov regularization in Hilbert scales. Appl. Anal. (18), 29–37 (1984). https://doi.org/10.1080/00036818408839508
Scherzer, O., Grasmair, M., Grossauer, H., Haltmeier, M., Lenzen, F.: Variational Methods in Imaging. Applied Mathematical Sciences, vol. 167. Springer, New York (2009)
Triebel, H.: Function Spaces and Wavelets on Domains. EMS Tracts in Mathematics, vol. 7. European Mathematical Society (EMS), Zürich (2008). https://doi.org/10.4171/019
Triebel, H.: Theory of Function Spaces, reprint. edn. Modern Birkhäuser Classics. Springer, Basel (2010). Reprint of the 1983 edition
Weidling, F., Sprung, B., Hohage, T.: Optimal convergence rates for Tikhonov regularization in Besov spaces. SIAM J. Numer. Anal. (58), 21–47 (2020). https://doi.org/10.1137/18M1178098
Acknowledgements
Financial support by Deutsche Forschungsgemeinschaft (DFG, German Science Foundation) through Grant RTG 2088 is gratefully acknowledged.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
A Appendix
A Appendix
For a sequence \(( {\underline{\omega }} _j)_{j\in J}\) of positive real numbers, we write \( {\underline{\omega }} _j\rightarrow 0\) if for every \(\varepsilon >0\) the set \(\{ j\in \varLambda : {\underline{\omega }} _j > \varepsilon \}\) is finite.
Proposition 31
(Embeddings) Let \(1\le p \le q <\infty \) and \(s= (s_j)_{j\in \varLambda }\), \(r= ( {\underline{r}} _j)_{j\in \varLambda }\) sequences of positive reals.
-
(i)
There is a continuous embedding \(\ell _{r}^{p} \subset \ell _{s}^{q}\) iff \(s_j {\underline{r}} _j^{-1}\) is bounded.
-
(ii)
There is a compact embedding \(\ell _{r}^{p} \subset \ell _{s}^{q}\) iff \(s_j {\underline{r}} _j^{-1}\rightarrow 0\).
Proof
-
(i)
If there is such a continuous embedding, then there exists a constant \(C>0\) such that \({\left\| {\cdot } \right\| _{{s},{q}} \le C \left\| {\cdot } \right\| _{{r},{p}}.}\) Inserting unit sequences \(e_j:=(\delta _{jk})_{k\in \varLambda }\) yields \(s_j {\underline{r}} _j^{-1}\le C\). For the other implication we assume that there exists a constant \(C>0\) such that \(s_j {\underline{r}} _j^{-1}\le C\) for all \(j\in \varLambda \). Let \(x\in \ell _{r}^{p}\) with \( \left\| {x} \right\| _{{r},{p}}=1\). Then \(s_j |x_j|\le C {\underline{r}} _j |x_j| \le C \left\| {x} \right\| _{{r},{p}} \) implies
$$\begin{aligned}\left\| {x} \right\| _{{s},{q}}^q= & {} \sum _{j\in \varLambda } s_j^{q} |x_j|^q \le (C \left\| {x} \right\| _{{r},{p}})^{q-p} \sum _{j\in \varLambda } s_j^{p} |x_j|^{p} \\\le & {} C^q\left\| {x} \right\| _{{r},{p}}^{q-p} \sum _{j\in \varLambda } {\underline{r}} _j^p |x_j|^{p}= C^q \left\| {x} \right\| _{{r},{p}}^{q}.\end{aligned}$$Taking the q-th root shows \(\left\| {\cdot } \right\| _{{s},{q}} \le C \left\| {\cdot } \right\| _{{r},{p}}.\)
-
(ii)
Suppose \(s_j {\underline{r}} _j^{-1}\rightarrow 0\) is false. Then there exists some \(\varepsilon \) and a sequence of indices \((j_k)_{k\in {\mathbb {N}}}\) such that \(s_{j_k} r_{j_k}^{-1}\ge \varepsilon \) for all \(k\in {\mathbb {N}}.\) The sequence given by \(x_k=r_{j_k}^{-1}e_{j_k}\) is bounded in \(\ell _{r}^{p}\). But \(\left\| {x_k-x_m} \right\| _{{s},{q}} \ge 2^\frac{1}{q} \varepsilon \) for \(k\ne m\) shows that it does not contain a convergent subsequence in \(\ell _{s}^{q}\). To prove the other direction we assume \(s_j {\underline{r}} _j^{-1}\rightarrow 0\). Then \(s_j {\underline{r}} _j^{-1}\) is bounded and by part (i) there is a continuous embedding \(I:\ell _{r}^{p} \rightarrow \ell _{s}^{q}\). We define \(\varLambda _n=\{ j\in \varLambda :s_j {\underline{r}} _j^{-1}> \frac{1}{n}\}\). As \(\varLambda _n\) is finite the coordinate projection \(P_n:\ell _{r}^{p} \rightarrow \ell _{s}^{q}\) given by \((P_n x)_j= x_j\) if \(j\in \varLambda _n\) and \((P_n x)_j= 0\) else is compact. As \( s_j {\underline{r}} _j^{-1}\le \frac{1}{n}\) for all \(j\in \varLambda \setminus \varLambda _n\) part (i) yields
$$\begin{aligned} \left\| {(I-P_n)x} \right\| _{{s},{q}} \le \frac{1}{n} \left\| {(I-P_n)x} \right\| _{{r},{p}} \le \frac{1}{n} \left\| {x} \right\| _{{r},{p}} \quad \text {for all } x\in \ell _{r}^{p}.\end{aligned}$$Hence, \(\Vert I-P_n\Vert \le \frac{1}{n}\). Therefore, \(I=\lim _n P_n\) is compact.
\(\square \)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Miller, P., Hohage, T. Maximal spaces for approximation rates in \(\ell ^1\)-regularization. Numer. Math. 149, 341–374 (2021). https://doi.org/10.1007/s00211-021-01225-4
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00211-021-01225-4