
Abstract
Charles Stein discovered a paradox in 1955 that many statisticians think is of fundamental importance. Here we explore its philosophical implications. We outline the nature of Stein’s result and of subsequent work on shrinkage estimators; then we describe how these results are related to Bayesianism and to model selection criteria like AIC. We also discuss their bearing on scientific realism and instrumentalism. We argue that results concerning shrinkage estimators underwrite a surprising form of holistic pragmatism.





Similar content being viewed by others

Notes
Here we assuming the variances are the same in the two cases.
X weakly dominates Y precisely when X’s risk is never higher than Y’s, and for some values of θ, X’s risk is lower. Inadmissible estimators are weakly dominated; they may or may not be strongly dominated.
In the theory of random walks, a similarly interesting transition happens when you move from two to three dimensions. Random walks in one or two dimensions are recurrent, meaning they have a probability of 1 of returning to their starting point. Random walks in dimensions greater than two are not recurrent. Brown (1971) discovered a connection between Stein’s result and this fact about random walks.
Although it’s unlikely, it’s possible for c to be a negative number.
The estimator that shrinks the ML estimates towards the sample mean is now standardly referred to as the “Efron-Morris estimator,” and we will follow this practice in our paper; however, it is worth pointing out that the Efron-Morris estimator was originally suggested by Dennis Lindley in the discussion section of Stein (1962).
The Laplace distribution is exponential like the normal distribution. The main difference between the two distributions is that in the Laplace distribution, the exponent is not squared; instead, its absolute value is taken.
Nor is Stein’s result in the case of the squared loss function attributable to the fact that the squared loss function is unbounded (James and Stein 1961, p. 367). The result also does not depend on the assumption that the measurements of the different means are independent of one another (Bock 1975).
We thank an anonymous reviewer for pointing this out to us.
This is not quite to say that inadmissibility suffices for refusing to use an estimator. You may know that E is inadmissible, but not know the identity of an estimator that weakly dominates E. This may lead you to think that E is better than nothing. We take no stand on whether you should use E or simply refuse to make an estimate.
The constant estimator E(X) = c has risk 0 for θ = c. Any estimator that weakly dominates E(X) = c must also have risk 0 for θ = c. But such an estimator will therefore have a variance of 0, which means (given any reasonable error distribution) that the estimator doesn’t vary given different data, and hence it must also be a constant estimator. Thus, any estimator that dominates E(X) = c must itself be a constant estimator, but a constant estimator with E(X) = d ≠ c can’t dominate E(X) = c. So all constant estimators of the form E(X) = c are admissible.
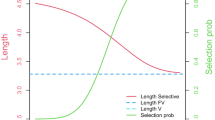
Suppose estimators E1 and E2 each weakly dominate the others you have considered, but neither dominates the other. You may have reason to prefer one over the other if you have reason to believe that some values of θ are more probable than others. Consider the relation of the mean and half-the-mean in Figure 1.
More precisely, the expected loss of estimate e relative to distribution p(θ | x) and loss function L is given by the formula \( {\sum}_{\theta}\kern0.15em p\left(\theta \Big|\mathrm{D}\right)L\left(\theta, e\right) \), where the sum is over all possible values of the parameter θ.
Note that this is a purely synchronic constraint on the conditional probability distribution.
Angers and Berger (1985, p. 5) emphasize that frequentist risk should be important even to pure Bayesians because frequentist risk gives an indication of the average posterior expected loss.
We thank Teddy Seidenfeld for pressing us on this point. We note that this point only makes sense given certain presuppositions. In particular, countable additivity must be discarded.
Perlman and Chaudhuri (2012) offer a different argument for a similar conclusion. They claim, without offering any explanation, that agents who use shrinkage estimation in the absence of prior information will unwittingly end up using a procedure that has the effect of reversing the Stein effect (see n24 for a description of the procedure).
In speaking of the “bias” and “variance” of models and estimators, we are following the (perhaps unfortunate) statistical practice of using these terms ambiguously. In the context of parameter estimation, “bias” and “variance” have precise technical meanings, as we also note in the text. In model selection, on the other hand, “bias” just means something like “the inability of a model to mimic the true curve, whatever the true curve happens to be.” For example, LIN is “biased” in this latter sense because it can adequately mimic the true curve only if the true curve happens to be roughly linear.
An anonymous reviewer pointed out to us that similar trade-offs also arguably occur outside of statistics, e.g. in the “Runge phenomenon” in numerical analysis.
It is worth noting that how you choose to bias your estimates is important. Perlman and Chaudhuri (2012) show that there are procedures for picking the point towards which you shrink that lead to a “reverse” Stein effect wherein the resulting shrinkage estimator does worse than MLE in expectation. In particular, the point you shrink towards needs to be relatively stable given different data sets; otherwise, your shrinkage estimator is not going to reduce total variance. Here’s an example: given data (x1, x2, …, xn) about parameters (θ1, θ2, …, θn), consider (x1, x2, …, xn) as the center of a sphere in n-dimensional space and then randomly pick some point within the sphere towards which you shrink your data. This procedure gives you an estimator that bounces around given different data sets, and that therefore doesn’t help you reduce overall variance.
The same point holds for AIC – realists can embrace this estimator so long as closeness to the truth is understood in the right way (Sober 2015).
It may seem that (2) contradicts the fact that MLE is admissible when you are estimating a single parameter. However, the fact that MLE is admissible just means that, given (normally distributed) data D and a single parameter p, there is no function of D that weakly dominates the ML estimator. This does not exclude the possibility that you can get a better estimate of p by lumping D with another data set D′ and using a shrinkage estimator on D&D′.
The measure of global inaccuracy that we have relied on so far in this paper implicitly places an equal weight on each of the individual estimation problems, since global inaccuracy is simply the unweighted sum of the inaccuracies in all the individual estimates. It may, however, happen that getting accurate estimates for some of the parameters is more important than getting accurate estimates for others. Brown (1975) models this by weighting each inaccuracy term (xi-θi)2 by a factor ci that measures the importance of getting an accurate estimate of θi, and he shows that Stein’s result is surprisingly robust across different assignments of weights (although he does not propose explicit estimators corresponding to the different weightings of the local estimation problems). In a similar vein, Efron and Morris (1972) introduce “compromise estimators” that aim at lowering total inaccuracy while at the same time limiting the loss in accuracy at the level of individual estimates.
There is a parallel situation for AIC. Consider NULL and DIFF as claims about how the mean heights in two (or more) human populations are related. NULL says they have the same mean height; DIFF says that the heights may differ. Since NULL says there is a single mean height that characterizes each population, it has a single adjustable parameter. DIFF has one adjustable parameter for each population. AIC tells you to prefer NULL if the sample means are close together and DIFF when they are very far apart, where the question “how close is close enough?” is answered by considering how the two models differ in their numbers of adjustable parameters. NULL lumps whereas DIFF splits.
This is not to say that the puzzling quality of Stein’s result derives entirely from the assumption that estimating a quantity and assigning a probability to a proposition are closely connected projects.
In thinking about how assigning a probability to a proposition is related to estimating a quantity, it is important to note that an estimation problem must involve infinitely many possible values if shrinkage estimators are to have lower expected error than MLE (Guttmann 1982).
References
Angers, J.-F. and Berger, J. O. (1985) The stein effect and bayesian analysis: A reexamination. Technical Report #85–6. Department of Statistics, Purdue University.
Baranchik, A. J. (1964) Multiple regression and estimation of the mean of a multivariate normal distribution. Technical Report 51. Department of Statistics, Stanford University.
Blyth, C. (1951). On minimax statistical decision procedures and their admissibility. The Annals of Mathematical Statistics, 22(1), 22–42.
Bock, M. E. (1975). Minimax estimators of the mean of a multivariate distribution. Annals of Statistics, 3(1), 209–218.
Brown, L. D. (1966). On the admissibility of invariant estimators of one or more location parameters. Annals of Mathematical Statistics, 37(5), 1087–1136.
Brown, L. D. (1971). Admissible estimators, recurrent diffusions, and insoluble boundary value problems. The Annals of Mathematical Statistics, 42(3), 855–903.
Brown, L. D. (1975). Estimation with incompletely specified loss functions (the case of several location parameters). Journal of the American Statistical Association, 70(350), 417–427.
Carnap, R. (1950). Empiricism, semantics, and ontology. Revue Internationale de Philosophie, 4(2), 20–40.
Edwards, A. W. F. (1974). The history of likelihood. International Statistical Review, 42.
Efron, B. (2013). Large-scale inference: empirical Bayes methods for estimation, testing, and prediction. Cambridge: Cambridge University Press.
Efron, B., & Morris, C. (1972). Limiting the risk of Bayes and empirical Bayes estimators – part II: the empirical Bayes case. Journal of the American Statistical Association, 67(337), 130–139.
Efron, B., & Morris, C. (1973). Stein’s estimation rule and its competitors – an empirical Bayes approach. Journal of the American Statistical Association, 68(341), 117–130.
Efron, B., & Morris, C. (1977). Stein’s paradox in statistics. Scientific American, 236(5), 119–127.
Forster, M., & Sober, E. (1994). How to tell when simpler, more unified, or less ad hoc theories will provide more accurate predictions. British Journal for the Philosophy of Science, 45, 1–36.
Galton, F. (1888). Co-relations and their measurement, chiefly from anthropometric data. Proceedings of the Royal Society of London, 45, 135–145.
Gauss, C. F. (1823). Theoria Combination is Observationum Erroribus Minimis Obnoxiae: Pars Posterior. Translated (1995) as Theory of the Combination of Observations Least Subject to Error: Part One, Part Two, Supplement (Trans: Stewart, G. W.). Society for Industrial and Applied Mathematics.
Guttmann, S. (1982). Stein’s paradox is impossible in problems with finite sample space. Annals of Statistics, 10(3), 1017–1020.
Hodges, J., & Lehmann, E. (1951) Some applications of the Cramér-Rao inequality. In Proceedings of the Second Berkeley Symposium on Mathematical Statistics and Probability (pp. 13–22). Berkeley and Los Angeles, University of California Press.
James, W. (1896, 1979). The will to believe. In F. Burkhardt et al. (eds.), The will to believe and other essays in popular philosophy (pp. 291–341). Cambridge: MA, Harvard.
James, W., & Stein, C. (1961). Estimation with quadratic loss. Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability, 1, 361–379.
Jeffrey, R. (1956). Valuation and acceptance of scientific hypotheses. Philosophy of Science, 23(3), 237–246.
Jeffrey, R. (1983). The logic of decision (Second ed.). Cambridge: Cambridge University Press.
Lehmann, E. L. (1983). Theory of point estimation. New York: Wiley.
Miller Jr., R. G. (1981). Simultaneous statistical inference (Second ed.). New York: Springer.
Pascal, B. (1662). Pensées. Translated by W. Trotter. New York: J. M. Dent Co., 1958, fragments: 233–241.
Perlman, M. D., & Chaudhuri, S. (2012). Reversing the stein effect. Statistical Science, 27(1), 135–143.
Rudner, R. (1953). The scientist Qua scientist makes value judgments. Philosophy of Science, 20(1), 1–6.
Sober, E. (2008). Evidence and evolution – the logic behind the science. Cambrige: Cambridge University Press.
Sober, E. (2015). Ockham’s razors – a User’s manual. Cambridge: Cambridge University Press.
Spanos, A. (2016). How the decision theoretic perspective misrepresents Frequentist inference: ‘Nuts and Bolts’ vs learning from data. Available at https://arxiv.org/pdf/1211.0638v3.pdf.
Stein, C. (1956). Inadmissibility of the usual estimator for the mean of a multivariate normal distribution. Proceedings of the Third Berkeley Symposium on Mathematical Statistics and Probability, 1, 197–206.
Stein, C. (1962). Confidence sets for the mean of a multivariate normal distribution (with discussion). Journal of the Royal Statistical Society: Series B: Methodological, 24(2), 265–296.
Stigler, S. (1990). The 1988 Neyman memorial lecture: a Galtonian perspective on shrinkage estimators. Statistical Science, 5(1), 147–155.
Strawderman, W. E. (1971). Proper Bayes minimax estimators of the multivariate normal mean. Annals of Mathematical Statistics, 42(1), 385–388.
von Luxburg, U., & Schölkopf, B. (2009). Statistical learning theory: Models, concepts, and results. In D. Gabbay, S. Hartmann, & J. Woods (Eds). Handbook of the history of logic, Vol 10: Inductive Logic.
Wasserman, L. (2004). All of statistics: a concise course in statistical inference. New York: Springer.
White, M. (2005). A philosophy of culture: The scope of holistic pragmatism. Princeton University Press.
Acknowledgements
We thank Marty Barrett, Larry Brown, Jan.-Willem Romeijn, Teddy Seidenfeld, Mike Steel, Reuben Stern, and the anonymous referees for very useful comments. This paper is dedicated to the memory of Charles Stein (1920-2016).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Funding
No funding to declare.
Conflict of interest
We declare we have no conflicts of interest.
Rights and permissions
About this article

Cite this article
Vassend, O., Sober, E. & Fitelson, B. The philosophical significance of Stein’s paradox. Euro Jnl Phil Sci 7, 411–433 (2017). https://doi.org/10.1007/s13194-016-0168-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13194-016-0168-7