
Abstract
SINEUP is a new class of long non-coding RNAs (lncRNAs) which contain an inverted Short Interspersed Nuclear Element (SINE) B2 element (invSINEB2) necessary to specifically upregulate target gene translation. Originally identified in the mouse AS-Uchl1 (antisense Ubiquitin carboxyl-terminal esterase L1) locus, natural SINEUP molecules are oriented head to head to their sense protein coding, target gene (Uchl1, in this example). Peculiarly, SINEUP is able to augment, in a specific and controlled way, the expression of the target protein, with no alteration of target mRNA levels. SINEUP is characterized by a modular structure with the Binding Domain (BD) providing specificity to the target transcript and an effector domain (ED)—containing the invSINEB2 element—able to promote the loading to the heavy polysomes of the target mRNA. Since the understanding of its modular structure in the endogenous AS-Uchl1 ncRNA, synthetic SINEUP molecules have been developed by creating a specific BD for the gene of interest and placing it upstream the invSINEB2 ED. Synthetic SINEUP is thus a novel molecular tool that potentially may be used for any industrial or biomedical application to enhance protein production, also as possible therapeutic strategy in haploinsufficiency-driven disorders.
Here, we describe a detailed protocol to (1) design a specific BD directed to a gene of interest and (2) assemble and clone it with the ED to obtain a functional SINEUP molecule. Then, we provide guidelines to efficiently deliver SINEUP into mammalian cells and evaluate its ability to effectively upregulate target protein translation.
You have full access to this open access chapter, Download protocol PDF
Similar content being viewed by others

Key words
- SINEUP
- Long non-coding RNA
- Antisense
- Translational increase
- Physiological increase
- Therapeutic tool
- Haploinsufficiency
- Protein manufacturing
1 Introduction
The quantitative improvement of protein production in mammalian systems is a compelling need for the industrial manufacturing of commercially available enzymes, antibodies and supplements, but also for gene therapy-based treatments of medical conditions. Several technologies are available to address such a need, however, they usually consist of introducing exogenously constructs containing the protein of interest or directly the target peptide [1]. These approaches still struggle to overcome hazardous but invariable hurdles, especially when used as therapeutic tools, such as ectopic expression and protein quantity modulation, sometimes associated with toxicity [2]. As an alternative, newly identified RNA-based techniques such as small activating RNAs (RNAa) are able to target and upregulate endogenous gene transcription [3]. In 2012, Carrieri et al. discovered a new class of lncRNAs, belonging to the category of natural antisense transcripts (NATs), that have the property to increase the protein translation of the target mRNA [4]. These transcripts were named SINEUP based on their ability to upregulate target protein translation by means of an invSINEB2 repeat, leaving unaltered the transcriptional levels of the target mRNA. They were first discovered in mice, where AS-Uchl1 was found to have a post-transcriptional upregulating activity on its sense protein coding counterpart, Uchl1 mRNA [4]. Later studies confirmed and validated the expression of SINEUP in human cells [5, 6]. SINEUP molecular mechanism relies on its modular structure, composed of two fundamental domains: a Binding Domain (BD)—a region at the 5′ of the lncRNA overlapping head to head to the 5′ of the target mRNA—and an Effector Domain (ED)—constituted by an invSINEB2 repetitive element. The BD is crucial for target gene pairing and it confers molecular specificity, while the ED is the functional part of SINEUP required for loading the target transcript on polysomes and driving the translational increase [4].
The initial discovery was then supported by the crucial finding that the BD could be engineered in order to target a specific mRNA of interest, as first demonstrated with Green Fluorescent Protein (GFP) [4]. Additionally, miniSINEUP containing only the BD and a shorter version of the original ED were also proven to be effective [7]. This characteristic would enable to overcome the difficulties of long molecules delivery, especially for therapeutic purposes in which naked RNA molecules administration can be proposed. Recently, TranSINE Therapeutics Limited (Cambridge, UK) has been founded to translate the SINEUP technology into the clinics as therapeutics for haploinsufficiency.
All together, these findings qualified SINEUP as a flexible tool able to upregulate the protein production of virtually any mRNA target of interest, affecting solely the translational levels. As such, SINEUP molecules demonstrated to be a suitable tool for protein manufacturing, able to boost, for instance, the production of recombinant proteins and monoclonal antibodies in mammalian cells [8,9,10]. SINEUP molecules are also being studied from a therapeutic point of view, since their functional characteristics could confer advantages with respect to other gene therapy approaches. SINEUP molecules generally upregulate the endogenous protein of about two- to fivefold (almost within a physiologic range) and they are only effective in those districts where the target mRNA is physiologically expressed, therefore avoiding unspecific effects [10]. Finally, by targeting mRNA molecules, SINEUP does not introduce stable or unwanted changes in the host genome. Thus far, several synthetic SINEUP molecules were successfully designed and delivered as potential therapeutic molecules. For instance, synthetic SINEUP were designed and successfully used to increase the levels of disease-associated proteins in vitro, such as Parkinson’s disease-associated DJ-1 in three human neuronal cell lines [7] and Glial-cell derived neurotrophic factor (GDNF) in mouse cell line [11]. Moreover, SINEUP have been used to rescue frataxin levels in a cellular model of Friedreich’s Ataxia [12]. Concerning in vivo model systems, SINEUP could effectively rescue some phenotypes associated with microphthalmia with linear skin defects (MLS) syndrome in a medaka fish model of cox7B haploinsufficiency [13]. More recently, SINEUP targeting GDNF mRNA was tested in a neurochemical Parkinson’s disease (PD) mouse model [11]. Interestingly, SINEUP-GDNF increased endogenous GDNF level for at least 6 months which lead to an enhancement of dopamine release in the striatum and an amelioration of motor behavior and neurodegeneration, without affecting body weight or food intake, common side effects of the ectopic expression of GDNF [11].
Here, we describe in detail the fundamental steps in order to design, clone, and deliver SINEUP molecular tools in the cellular system of interest.
2 Materials
2.1 Design and Cloning of SINEUP
-
1.
Zenbu browser (https://fantom.gsc.riken.jp/zenbu/).
-
2.
Ensembl genome browser (https://www.ensembl.org/index.html).
-
3.
UCSC genome browser (https://genome.ucsc.edu/).
- 4.
-
5.
RNA Fold web server (http://rna.tbi.univie.ac.at/cgi-bin/RNAWebSuite/RNAfold.cgi).
-
6.
Salt free primers. Use primers to clone the Effector Domain from Carrieri et al. [4]:
-
(a)
For mAS Uchl1Δ5′: 5-CAGTGCTAGAGGAGGTCAGAAGAG-3
-
(b)
Rev mAS Uchl1 fl: 5-CATAGGAGTGTTTCATT-3
Or primers from Zucchelli et al. [7]:
-
(a)
FWD EcoRI invSINEB2: 5-TATAGAATTCCAGTGCTAGAGGAGG-3
-
(b)
3REV HindIII invSINEB2: 5-GAGAAAGCTTAAGAGACTGGAGC-3
-
(a)
-
7.
Ultrapure water.
-
8.
Mammalian expression plasmid vector of your choice.
-
9.
Restriction enzymes.
-
10.
T4 DNA ligase.
-
11.
E. coli competent cells.
-
12.
Luria-Bertani (LB-10 g/L Tryptone, 10 g/L NaCl, 5 g/L Yeast Extract) broth.
-
13.
Antibiotics of your choice.
-
14.
Maxiprep kit.
-
15.
Molecular grade agarose.
-
16.
DNA gel staining.
-
17.
DNA loading dye.
-
18.
DNA ladder.
-
19.
Electrophoresis apparatus.
2.2 SINEUP Delivery into Cellular Model
-
1.
Target cells of interest. In this protocol we used human iPS-derived neuronal progenitor cells (hiNPCs) [14].
-
2.
Poly-l-ornithine hydrobromide (20 μg/mL).
-
3.
Laminin (3 μg/mL).
-
4.
Dulbecco’s Modified Eagle’s Medium (DMEM).
-
5.
Ham’s F-12 Nutrient (HAM F12).
-
6.
B27.
-
7.
Penicillin-Streptomycin solution.
-
8.
l-Glutamine.
-
9.
EGF (20 ng/mL).
-
10.
bFGF (20 ng/mL).
-
11.
Heparin (5 μg/mL).
-
12.
hiNPCs culturing medium: 70% v/v DMEM completed with 30% v/v HAM F12, 2% v/v B27, 1% v/v Penicillin-Streptomycin solution, and 1% v/v l-Glutamine and supplemented with EGF (20 ng/mL), bFGF (20 ng/mL) and Heparin (5 μg/mL). Semi-confluent monolayers of hiNPCs were maintained in 5% CO2, 37 °C humidified incubator.
-
13.
Enzyme for adherent cellular culture detachment (e.g. TripLE in this example).
-
14.
Transfection solution (e.g. Nucleofector Solutions—Lonza).
-
15.
NucleofectorTM Device (Lonza).
2.3 RNA and Protein Analysis
-
1.
RadioImmunoPrecipitation Assay—RIPA—buffer.
-
2.
Protease and Phosphatase inhibitors (PI and PhI, respectively).
-
3.
Bicinchoninic acid (BCA) or Bradford protein assay kit.
-
4.
Bovine serum albumin (BSA) standard curve.
-
5.
Western blot apparatus.
-
6.
Specific antibody for the target protein and a housekeeping protein.
-
7.
Enhanced ChemiLuminescence (ECL) or equivalent assay.
-
8.
Eurofins PCR primer design tool or equivalent (https://eurofinsgenomics.eu/en/ecom/tools/pcr-primer-design/).
-
9.
ThermoFisher primer analyzer tool or equivalent (https://www.thermofisher.com/it/en/home/brands/thermo-scientific/molecular-biology/molecular-biology-learning-center/molecular-biology-resource-library/thermo-scientific-web-tools/multiple-primer-analyzer.html).
-
10.
DNAse.
-
11.
DEPC-treated (nuclease-free) water.
-
12.
Retro-transcriptase containing both oligo(dT) and Random Hexamer primers.
-
13.
SYBR Green or Taqman reagents.
3 Methods
Prepare all the solutions using analytical grade reagents with ultrapure water at room temperature, unless otherwise indicated. Solutions used with cells are filtered or sterilized at the beginning. Cells are handled under biological hoods while all the other reactions are performed on the bench . Follow safety instructions indicated by safety team in your institution.
3.1 Binding Domain Design and Cloning
-
1.
Retrieve the sequence of your transcript of interest from Zenbu browser (https://fantom.gsc.riken.jp/zenbu/) [15].
-
2.
In Zenbu, select the organism in which you will perform the experiments (e.g. human or mouse) and search for the target gene of interest (see Note 1 and Fig. 1a).
-
3.
Check how many TSS have been characterized for your gene and in which tissue/cell line they are expressed (Fig. 1b) by selecting the “CAGE libraries” (or other libraries in which you are interested).
-
4.
Expand the window in the 5′UTR region containing the TSS in order to better appreciate how many TSS have been identified. You will see a bar plot in which each bar represents a TSS (Fig. 1b); in the window below, the tracks expressing your transcript will be displayed (Fig. 1c). Among them, you can select the tissue/cells/organ of your interest.
-
5.
In the identified TSS and the 5′UTR region, design an efficient SINEUP molecule in which the BD overlaps the Translational Initiation Site (TIS) and expands in the upstream region characterized for your transcript.
-
6.
Further test the expression of your transcript(s) using genome browsers such as Ensembl genome browser (https://www.ensembl.org/index.html), UCSC genome browser (https://genome.ucsc.edu/), or NCBI (https://www.ncbi.nlm.nih.gov/genome/).
-
7.
Design forward primer (FW) on the 5′UTR and reverse primer (RV) on coding DNA sequence (CDS) downstream Translational Initiation Site (TIS).
-
8.
Dissolve salt free quality primers in ultrapure water to obtain equal molarity for each primer to a final concentration of 10 μM.
-
9.
Confirm the expression of your target transcript(s) by PCR in your selected model system.
-
10.
Run the PCR product onto agarose gel to confirm amplicon size, purify PCR product, and sequence with both FW and RV primers to validate transcript identity and specificity (see Note 2).
-
11.
The BD will be designed spanning the TIS of the transcript of interest. You can start selecting the “canonical” target sequence corresponding to 40 bases upstream and 4 bases downstream the TIS (−40/+4) in which 0 correspond to the A of the TIS ATG (see Note 3).
-
12.
Additional sequences of different length can be designed both on the TIS and in region(s) targeting downstream , in-frame methionines (see Note 4 and Fig. 2a). A full list of published BDs is reported in Table 1.
-
13.
On the target region of interest where the BD will be designed, evaluate the GC content and the mRNA secondary structure using RNA Fold web server (http://rna.tbi.univie.ac.at/cgi-bin/RNAWebSuite/RNAfold.cgi—Fig. 2b, see Note 5) [19, 20].
-
14.
Further analysis can be performed to understand if other lncRNA(s) are generated endogenously from the same genetic locus. Albeit not mandatory, this information can give you an idea of the specific gene’s structure as well as highlight possible competition in SINEUP binding to the target TIS.
-
15.
Once selected BDs of interest, perform off-targets prediction by interrogating Basic local Alignment (BLAST, https://blast.ncbi.nlm.nih.gov/Blast.cgi) or BLAT (https://genome.ucsc.edu/cgi-bin/hgBlat). This information can help to avoid SINEUP off-target issues and to prioritize experiments with the more specific molecules (see Note 6).
-
16.
When you select the region of the transcript in which you want to design the BD, you must reverse complement the sense mRNA sequence to obtain a SINEUP able to interact with the target gene (Fig. 2a).
-
17.
For each BD of interest, synthetize the FW primer in a sense orientation (5′–3′ orientation) with the restriction enzyme needed for insertion into the chosen vector at its 5′ end. On the other hand, synthetize the RV primer in an inverted orientation (3′-5′) with the compatible restriction site at the 5′ end, in order to allow primer annealing.
-
18.
Equimolar concentration of both primers must be denatured for 5′ at 100 °C and cooled slowly (1 °C every minute) to obtain double stranded DNA (dsDNA) BD.
-
19.
By taking advantage of the restriction sites present in the BD and in the selected plasmid of interest, clone every BD upstream of the AS-Uchl1 ED. A shorter version of ED called miniSINEUP, which still comprehends the invSINEB2 element present in AS-Uchl1, should preferentially be used to obtain shorter SINEUP (see Note 7) in expression plasmid (e.g. pcDNA 3.1 vector from Clontech, Fig. 2c) using T4 DNA ligase (Fig. 2b). If necessary, inducible or tissue specific promoters can be used.

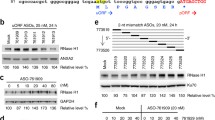
Zenbu genome browser interrogation of transcript of interest showing TSS usage in selected model system. (a) Zenbu genome browser screenshot showing the genomic location of the gene of interest (in this example GJB2) in the human genome assembly 19 (hg19), green arrow identifies the Translation Initiation Site (TIS). RefSeq accession number for the transcript of interest (NM_004004, in this case) is also visible. In the enlargement in (b) alternative TSS usage identified by FANTOM5 CAGE library (reported as purple bar plots) is shown. Both TSSs in the same orientation (reverse strand, purple bar plots) and in the opposite orientation (forward strand, green bar plots) of the gene are depicted. The purple box highlights the chosen region in which interrogates the browser about the expression of your target transcript. Main TSSs, TSS1, TSS2, and TSS3, are indicated by purple arrows. (c) Displays the tracks (experiments) in which the transcript is more expressed

SINEUP modular structure: Binding domain (BD) design and cloning. (a) Representation of the modular structure of SINEUP and the design strategy to obtain BD oriented head to head to its target gene. BDs, in light purple, targeting the gene of interest (as an example, the CDS of EGFP is depicted in light green), untranslated region (UTR) in gray, Transcriptional Start Site (TSS) in black, and Transcriptional Initiation Site (TIS) in yellow, are shown. Different suggested lengths for BD are reported. SINEUP effector domain (ED) in light blue, with the antisense region, overlapping TIS is depicted in black-shadowed yellow. Adenine (A) of the TIS is set as 0, BDs lengths vary between −40 from the A and +32 nucleotides, −40 and +4 nucleotides, and −14 and +4 nucleotides, respectively. (b) Example of RNA folding prediction results using RNA Fold web server (http://rna.tbi.univie.ac.at/cgi-bin/RNAWebSuite/RNAfold.cgi) with default parameters, here reported for EGFP transcript. The blue box displays an enlargement of the TIS (in yellow AUG) surrounding region, in which packed structures without big hairpin-loop are reported. Minimum free energy (MFE) prediction is used to create the output, with base-pair probability in form of a dot plot it depicted. Scale bar reports both base-pair and unpair probability for every base colored dot, with 1 highest probability that the base pair as well as 1 highest probability that the base unpair with the neighbors (c). (Schematic representation of pcDNA 3.1 vector structure obtained from Carrieri C. et al. 2012 [4], BD is depicted in light purple followed by ED in light blue are under CMV promoter)
3.2 Effector Domain Design and Cloning
You can design the ED and insert in a different plasmid as needed. The ED comprehends an invSINEB2, free right Alu monomer (FRAM) or MIRb (Mammalian-wide Interspersed Repeat type b) transposable element sequence from natural SINEUP (see Note 8). Virtually any of those elements can present SINEUP activity, however, the element present in AS-Uchl1 was previously inserted in miniSINEUP vectors and it was the most widely characterized. For this reason, in this section, we will refer to invSINEB2 cloning as ED.
-
1.
To amplify ED from AS-Uchl1 you can use primers “For mAS Uchl1Δ5′”and “Rev mAS Uchl1 fl” from Carrieri et al. [4]. Moreover, to obtain a 170 bp long ED, primers “FWD EcoRI invSINEB2” and “REV HindIII invSINEB2” from Zucchelli et al. [7] which produce a shorter SINEUP called miniSINEUP, can be selected. Albeit miniSINEUP retains only the invSINEB2 and not the Alu element, this construct was successfully used to increase GFP translation [7].
-
2.
Add restriction enzymes sites at the 5′ end to the primers of interest to clone the ED into the desired vector.
-
3.
After performing PCR, purify the amplicon and confirm the correct sequence.
-
4.
Clone the purified ED in the vector of interest downstream the BD.
-
5.
Transform the ligation product into E. coli competent cells.
-
6.
Cultured the bacteria in LB broth at 37 °C supplemented with the antibiotic required for selection (e.g. kanamycin sulfate).
-
7.
The empty vector and/or a vector containing only the ED (in the case you clone only the BD targeting the gene of interest in the vector already containing the ED) must be produced as control for ligation.
-
8.
Verify positive clones by restriction analysis or colony PCR and sequencing.
-
9.
Produce and purify the plasmids containing SINEUP for the gene of interest and the empty vector.
-
10.
Analyze plasmids integrity on agarose gel and confirm again the presence of the insert and its correct orientation by restriction map and sequencing.
3.3 SINEUP Delivery into Cellular Model
Different methods such as transfection, electroporation, or viral vectors transduction , can be chosen to deliver your plasmid into the cells of choice. The selected method should meet a criterion of high plasmid internalization efficiency (>60–70% positive cells). In fact, SINEUP molecules upregulate protein translation in a physiologic range (approximately two- to fivefold) so if few cells receive the plasmid this effect can be hidden or under-estimated. Here, we describe the method which best fits our expectations in hiNPCs [14]. For additional information on SINEUP delivery in animal and cellular models see Note 9.
In this protocol we focused on our target cells of choice, hiNPCs, for which electroporation represents an optimal method of transfection for transient expression. For this purpose, we used Nucleofector™ Device (Lonza) and selected the recommended protocol for our specific cell line, as well as the advised program (A033) of the device. Dealing specifically with SINEUP, we recommend the following:
-
1.
Start by using 1 μg of SINEUP for every one million cells (see Note 10).
-
2.
Prepare the electroporation mix using the recommended electroporation solution and each SINEUP you want to deliver as well as a solution containing the empty vector as negative control.
-
3.
Resuspend the cellular pellet with the electroporation mix and electroporate with the device and program of choice (e.g. Nucleofector™ Device, Lonza program A033 for hiNPCs).
-
4.
Collect the electroporated cells and seed them in a mix of 1:2 = old:new pre-warmed medium. We recommend seeding the cells to reach roughly 40% confluency.
-
5.
Replace the medium after 6 h of incubation (be careful that cells are attached on the well) with new, pre-warmed medium.
-
6.
If any fluorescent protein (e.g. GFP) reporter gene is present, check the fluorescence levels to evaluate delivery efficiency (Fig. 3a).
-
7.
We recommend harvesting the electroporated cells after 24–48 h, when cells have fully recovered and are transiently expressing the delivered constructs (containing SINEUP or empty control).

Expected results when SINEUP positively increases target mRNA translation without altering its transcriptional level in human induced neural progenitor cells (hiNPCs). (a) Representative image of hiNPCs expressing EGFP after electroporation with control vector (SINEUP −) or with SINEUP targeting EGFP (SINEUP +). (b) Western Blot image reports target protein expression relative to a chosen reference protein in the presence (+) or absence (−) of SINEUP against the target mRNA, EGFP, in this example. (c) Bar graph representing fold change quantification of target protein from WB experiments in (b). (d) Bar graphs representing normalized expression level of target mRNA upon SINEUP administration (− control SINEUP, + SINEUP against target EGFP mRNA). SINEUP presence is depicted in (e). Transcripts expression was obtained from qPCR quantification and normalized with a chosen reference gene
3.4 SINEUP Efficacy Assessment: Transcription and Translation Evaluation
Successful SINEUP function needs to be assessed by transcriptional and translational analysis, such as qPCR and WB, respectively. In particular, an increase in protein production between two- and fivefold changes is expected (Fig. 3b, c) without dysregulation of the target mRNA expression (Fig. 3d) when SINEUP is present (Fig. 3e).
-
1.
Apply protocols you routinely use in your lab to extract proteins from the electroporated cells. We used commercial RIPA buffer supplemented with Protease and Phosphatase inhibitors (PI and PhI, respectively).
-
2.
Carefully quantify your proteins using BCA or Bradford protein assay kit. Always include the BSA standard curve for protein quantification. It is fundamental reliable quantification in order to appreciate standard two- to fivefold changes in the protein level due to SINEUP delivery.
-
3.
Perform Western blot experiments using a protocol you are familiar with; the optimization of WB depends on the target protein of interest.
-
4.
Load the same amount of protein (e.g. 20 μg) for all the samples.
-
5.
It is crucial to use specific antibodies to recognize the protein isoform of interest targeted by SINEUP. In particular, the resolved band of the target gene (Fig. 3b) should be clearly distinguishable after WB analysis to perform a correct quantification of the protein of interest (Fig. 3c).
-
6.
Be careful with your choice of ECL or equivalent assay. If the reagent is not sensitive enough you will not see the band of interest; on the other side, many sensitive reagents will not allow you to appreciate subtle changes in protein level due to saturated bands.
-
7.
Albeit in standard experiments three/five biological replicates are considered enough to achieve robust results and to assess reproducibility, in this case you may need more replicates (see Note 11).
-
8.
Design Quantitative Polymerase Chain Reaction (qPCR) primers for the target of interest, a housekeeping gene and SINEUP ED by using Eurofins PCR Primer Design online tool (https://eurofinsgenomics.eu/en/ecom/tools/pcr-primer-design/), but equivalent systems could also be employed (see Note 12).
-
9.
All primers should be tested for hairpin and primer dimer formation. Here we used multiple primer analyzer (ThermoFisher; https://www.thermofisher.com/it/en/home/brands/thermo-scientific/molecular-biology/molecular-biology-learning-center/molecular-biology-resource-library/thermo-scientific-web-tools/multiple-primer-analyzer.html) and Oligo Calc (Northwestern; http://biotools.nubic.northwestern.edu/OligoCalc.html), but similar tools might also be evaluated.
-
10.
Apply protocols you routinely use in your lab to obtain high quality RNA from the electroporated cells.
-
11.
Preferentially, perform DNase treatment on your RNA samples before proceeding with retro-transcription in order to avoid issues due to DNA contamination.
-
12.
Always resuspend RNA in DEPC-treated (nuclease-free) water.
-
13.
To retro-transcribe RNA to produce cDNA we used a mix containing both oligo(dT) and Random Hexamer primers.
-
14.
For qPCR, the Master Mix reagents should be preferred to DNA polymerase in order to minimize errors. You can use SYBR Green or Taqman systems equally.
-
15.
Perform qPCR assay with the cDNA using primers or Taqman probes targeting a reference housekeeping gene (such as ACTB), the target transcript(s) and SINEUP to assess correct expression.
-
16.
Calculate the relative mRNA expression level of the target gene by normalizing treated samples with SINEUP against the empty vector and by using 2−ΔΔCt method [21].
-
17.
Normalize the empty vector against the SINEUP sample for SINEUP expression (see Note 13).
-
18.
Stable mRNA expression from your target transcript should be observed (Fig. 3d) when SINEUP is expressed (Fig. 3e).
4 Notes
-
1.
The first step is to identify the specific transcript isoform(s) of your transcript of interest that is expressed in the selected model system. This step is necessary since your target might express alternative isoforms that differ from cell to cell and in different tissues. Moreover, the expressed isoform in your cell model/tissue would not necessarily be the most characterized. Zenbu browser is an on-demand freely available interface that allows visualizing data, such as RNA-seq, CAGE (cap analysis of gene expression), short-RNA-seq, and ChIP-seq (chromatin immunoprecipitation) in the chosen model system. The broad spectrum of systems that are annotated could give information especially on annotated promoters and transcriptional starting sites (TSS) usage. However, not all the systems have been characterized and reported in Zenbu [15]. Additional information about how to use Zenbu genome browser, as well as methods to detect and analyze SINEUP in cell culture can be found in Takahashi et al. [22].
-
2.
When you design SINEUP BD, it is important to seek for possible Single Nucleotide Variants (SNV) that might hamper the annealing capability of SINEUP or the expression of your target.
-
3.
Most of the efficient SINEUP BDs characterized until now have been designed in this region in order to specifically recognize the target gene. Specific recognition of transcript originating from the gene of interest allows increase in translation of the full-length target. We recommend designing BD of different lengths. Optimization of the Binding Domain sequence and length is an important step in designing the experiment [17]. Among others, we suggest −40/+32, −40/+4, and 14/+4 BD regions as the most promising target to be chosen for the experiments (as reported in Fig. 2a).
-
4.
Additional SINEUP targeting in-frame, internal methionine can be design if the TIS surrounding region is poorly accessible. Although many more experimental evidences support the importance of targeting the TIS, the internal, in-frame methionine of the Frataxin gene was successfully tested and provided efficient upregulation of Frataxin protein [12]. In fact, SINEUP mechanism is not completely characterized and we cannot exclude that target mRNA can be loaded on polysomes by internal bait which does not interfere with translational initiation. Moreover, alternative translation might occur to downstream AUG codon in the presence of internal ribosomal entry site (IRES) [23]. In summary, we prompt researchers to explore also the possibility of targeting internal in-frame methionines.
-
5.
As mentioned in the methods, packed secondary structures can impair the sense-antisense pairing of SINEUP molecules, decreasing its efficacy. In addition, GC rich region and stem-and-loop structures might inhibit translation by blocking ribosome binding [23]. RNA fold web server predicts in vitro secondary structure of single stranded nucleic acid by energy minimization and/or minimum entropy. This analysis will provide hints on the accessibility of the transcript area in order to optimize SINEUP binding. Although RNA fold tool can be a useful tool, it only mimics the complex physiological condition of RNA fold present in vivo. Recently, a novel approach called icShape (in vivo click selective 2-hydroxyl acylation and profiling experiment) was established to capture the RNA structure in vivo in order to overcome the RNA Fold tool issues [24]. Although not essential for SINEUP design, we recommend analysing icShape data to better understand the binding capacity of SINEUP to the target area of interest.
-
6.
While performing off-target analysis, keep in mind that the possible off-target transcripts need also to be expressed in the model system of your choice to be targeted by SINEUP. On the other hand, the TIS or the internal in-frame methionine you choose to design SINEUP must be present in the transcript(s) expressed in the tissue of interest for translation to occur.
-
7.
To clone SINEUP you can use a mammalian expression plasmid vector of your choice. Since the aim is to obtain an abundant and efficient production of SINEUP, the expression should be driven by a suitable promoter, Cytomegalovirus (CMV) or SV40, frequently employed in mammalian cells plasmids. An inducible/tissue specific promoter may be used, if needed.
-
8.
Long sequences of in vitro synthesized RNA molecules can generate issues especially during delivery in cells. For this reason, starting from the original complete sequence containing the invSINEB2, Alu sequence, and 3′ tail of the natural AS-Uchl1, a short functional version was created, called miniSINEUP, encompassing only the invSINEB2 [7, 17]. We suggest performing the SINEUP experiment using miniSINEUP construct, composed by the specific BD and 170 nucleotides length ED of invSINEB2 element. Notably, the human transcriptome does not present invSINEB2 sequences, but functional SINEUP were discovered in human containing embedded FRAM and MIRb transposable element. These two functional domains worked as Eds [5]. Although ED can be designed either with invSINEB2, FRAM, and MIRb domains, we recommend to generate initially ED by using invSINEB2 motif that has been extensively and successfully used to increase protein translation in different cell lines, in vivo in Medaka fish and in a mouse model for Parkinson Disease [4,5,6, 10,11,12,13]. Notably, by nuclear magnetic resonance (NMR) analysis, it was observed that the secondary structure of the invSINEB2 motif is crucial for its function. For this reason, when designing the ED containing invSINEB2, it is important to include the region between 43 and 58 stem-loop structure since this region is likely to be vital for SINEUP function [25].
-
9.
In vitro and in vivo delivery can be optimized and changed if needed. To date, successful SINEUP deliveries were previously reported in vitro using Lipofectamine and lentiviral particles in human derived fibroblasts [12], in vivo by RNA injection in zebrafish embryo [13] and AAV9 vectors injection in the dorsal striatum of adult mice [11]. For both in vitro and in vivo, the delivery method can vary according to the model of choice, the stage and the time window of interest (e.g. transient expression, conditional expression or stable expression). The methods described here for BD design, cloning and SINEUP efficacy assessment steps in cellular models also apply for animal systems. However, concerning the delivery step in vivo, SINEUP molecules can be delivered and expressed in animal models similarly to other RNA-based therapeutics, e.g. by viral vectors. Moreover, it is possible to administer in vitro transcribed SINEUP targeting the transcript of interest instead of the plasmid carrying it. If this method is used, you should chemically modify the in vitro transcribed SINEUP to better stabilize the molecule, by replacing CTP with 5-methylcytidine-50-triphosphate (m5C); and replacing UTP with pseudouridine-50-triphosphate (Ψ) or N1-methylpseudouridine-50-triphosphate (N1mΨ) [18]. In our experience, it is best to test whether the experimental cell system chosen for the experiment is positively responding to SINEUP administration. For this reason, we suggest testing the previously characterized SINEUP against GFP [4, 7], before moving to SINEUP targeting the gene of interest. To analyze the SINEUP efficacy on GFP translation, WB analysis as well as imaging analysis with semi-automatic detection methods can be performed [22]. Of importance, to underlie that protein translation is increased due to SINEUP mechanism, qPCR should be conducted and report stable expression of the target transcript.
-
10.
SINEUP molecule can act in a dose dependent manner to control protein translation without affecting transcript level [7]. To assess the optimal efficiency, different concentrations of SINEUP should be tested.
-
11.
SINEUP delivery experiments as well as WB and qPCR analysis should be performed at least in triplicate to observe statistically significant changes. However, depending on the model system used, additional experiments may be needed to reach significance. The crucial step is the WB quantification: if the band of your target(s) and the reference proteins are not well resolved, changes ascribed to SINEUP positive upregulation can be difficult to examine. In our experience it is better to set specific conditions for WB detection in the chosen model system before performing SINEUP experiment.
-
12.
Primers or Taqman probes for target gene(s) of interest and stable housekeeping gene(s) must be designed in order to assess the stability of the target gene(s) upon SINEUP administration. In addition, primers or probes targeting SINEUP ED must be designed in order to check the correct expression of SINEUP into the chosen model system after plasmid delivery (if the chosen ED contain the invSINEB2 and Alu elements the desired primer can be found in Zucchelli et al. [7]). Primers for qPCR should be designed in regions spanning exon-exon junctions to minimize DNA residual contamination, maximize PCR efficiency and specificity.
-
13.
The different methods for analysing SINEUP and the target mRNA expression is needed since for SINEUP, the quantification in qPCR of the empty vector should be close to the detection limit of the instrument since little signal can be recorded by using the SINEUP specific primer or probes. On the contrary, SINEUP expression is expected to be high upon delivery of the plasmid containing SINEUP sequence, hence that amount is set as default condition one, whereas the empty vector quantification should be close to zero (Fig. 3e).
References
Wahlestedt C (2013) Targeting long non-coding RNA to therapeutically upregulate gene expression. Nat Rev Drug Discov 12(6):433–446. https://doi.org/10.1038/nrd4018
Wang D, Gao G (2014) State-of-the-art human gene therapy: part I. Gene delivery technologies. Discov Med 18(97):67–77
Li LC (2017) Small RNA-guided transcriptional gene activation (RNAa) in mammalian cells. Adv Exp Med Biol 983:1–20. https://doi.org/10.1007/978-981-10-4310-9_1
Carrieri C, Cimatti L, Biagioli M, Beugnet A, Zucchelli S, Fedele S, Pesce E, Ferrer I, Collavin L, Santoro C, Forrest AR, Carninci P, Biffo S, Stupka E, Gustincich S (2012) Long non-coding antisense RNA controls Uchl1 translation through an embedded SINEB2 repeat. Nature 491(7424):454–457. https://doi.org/10.1038/nature11508
Schein A, Zucchelli S, Kauppinen S, Gustincich S, Carninci P (2016) Identification of antisense long noncoding RNAs that function as SINEUPs in human cells. Sci Rep 6:33605. https://doi.org/10.1038/srep33605
Zucchelli S, Cotella D, Takahashi H, Carrieri C, Cimatti L, Fasolo F, Jones MH, Sblattero D, Sanges R, Santoro C, Persichetti F, Carninci P, Gustincich S (2015) SINEUPs: a new class of natural and synthetic antisense long non-coding RNAs that activate translation. RNA Biol 12(8):771–779. https://doi.org/10.1080/15476286.2015.1060395
Zucchelli S, Fasolo F, Russo R, Cimatti L, Patrucco L, Takahashi H, Jones MH, Santoro C, Sblattero D, Cotella D, Persichetti F, Carninci P, Gustincich S (2015) SINEUPs are modular antisense long non-coding RNAs that increase synthesis of target proteins in cells. Front Cell Neurosci 9:174. https://doi.org/10.3389/fncel.2015.00174
Patrucco L, Chiesa A, Soluri MF, Fasolo F, Takahashi H, Carninci P, Zucchelli S, Santoro C, Gustincich S, Sblattero D, Cotella D (2015) Engineering mammalian cell factories with SINEUP noncoding RNAs to improve translation of secreted proteins. Gene 569(2):287–293. https://doi.org/10.1016/j.gene.2015.05.070
Sasso E, Latino D, Froechlich G, Succoio M, Passariello M, De Lorenzo C, Nicosia A, Zambrano N (2018) A long non-coding SINEUP RNA boosts semi-stable production of fully human monoclonal antibodies in HEK293E cells. MAbs 10(5):730–737. https://doi.org/10.1080/19420862.2018.1463945
Zucchelli S, Patrucco L, Persichetti F, Gustincich S, Cotella D (2016) Engineering translation in mammalian cell factories to increase protein yield: the unexpected use of long non-coding SINEUP RNAs. Comput Struct Biotechnol J 14:404–410. https://doi.org/10.1016/j.csbj.2016.10.004
Espinoza S, Scarpato M, Damiani D, Manago F, Mereu M, Contestabile A, Peruzzo O, Carninci P, Santoro C, Papaleo F, Mingozzi F, Ronzitti G, Zucchelli S, Gustincich S (2020) SINEUP non-coding RNA targeting GDNF rescues motor deficits and neurodegeneration in a mouse model of Parkinson’s disease. Mol Ther 28(2):642–652. https://doi.org/10.1016/j.ymthe.2019.08.005
Bon C, Luffarelli R, Russo R, Fortuni S, Pierattini B, Santulli C, Fimiani C, Persichetti F, Cotella D, Mallamaci A, Santoro C, Carninci P, Espinoza S, Testi R, Zucchelli S, Condo I, Gustincich S (2019) SINEUP non-coding RNAs rescue defective frataxin expression and activity in a cellular model of Friedreich’s Ataxia. Nucl Acids Res 47(20):10728–10743. https://doi.org/10.1093/nar/gkz798
Indrieri A, Grimaldi C, Zucchelli S, Tammaro R, Gustincich S, Franco B (2016) Synthetic long non-coding RNAs [SINEUPs] rescue defective gene expression in vivo. Sci Rep 6:27315. https://doi.org/10.1038/srep27315
Sheridan SD, Theriault KM, Reis SA, Zhou F, Madison JM, Daheron L, Loring JF, Haggarty SJ (2011) Epigenetic characterization of the FMR1 gene and aberrant neurodevelopment in human induced pluripotent stem cell models of fragile X syndrome. PLoS One 6(10):e26203. https://doi.org/10.1371/journal.pone.0026203
Severin J, Lizio M, Harshbarger J, Kawaji H, Daub CO, Hayashizaki Y, Consortium F, Bertin N, Forrest AR (2014) Interactive visualization and analysis of large-scale sequencing datasets using ZENBU. Nat Biotechnol 32(3):217–219. https://doi.org/10.1038/nbt.2840
Yao Y, Jin S, Long H, Yu Y, Zhang Z, Cheng G, Xu C, Ding Y, Guan Q, Li N, Fu S, Chen XJ, Yan YB, Zhang H, Tong P, Tan Y, Yu Y, Fu S, Li J, He GJ, Wu Q (2015) RNAe: an effective method for targeted protein translation enhancement by artificial non-coding RNA with SINEB2 repeat. Nucl Acids Res 43(9):e58. https://doi.org/10.1093/nar/gkv125
Takahashi H, Kozhuharova A, Sharma H, Hirose M, Ohyama T, Fasolo F, Yamazaki T, Cotella D, Santoro C, Zucchelli S, Gustincich S, Carninci P (2018) Identification of functional features of synthetic SINEUPs, antisense lncRNAs that specifically enhance protein translation. PLoS One 13(2):e0183229. https://doi.org/10.1371/journal.pone.0183229
Toki N, Takahashi H, Zucchelli S, Gustincich S, Carninci P (2020) Synthetic in vitro transcribed lncRNAs (SINEUPs) with chemical modifications enhance target mRNA translation. FEBS Lett 594(24):4357–4369. https://doi.org/10.1002/1873-3468.13928
Gruber AR, Lorenz R, Bernhart SH, Neubock R, Hofacker IL (2008) The Vienna RNA websuite. Nucl Acids Res 36(Web Server Issue):W70–W74. https://doi.org/10.1093/nar/gkn188
Lorenz R, Bernhart SH, Honer Zu Siederdissen C, Tafer H, Flamm C, Stadler PF, Hofacker IL (2011) ViennaRNA Package 2.0. Algor Mol Biol 6:26. https://doi.org/10.1186/1748-7188-6-26
Segundo-Val IS, Sanz-Lozano CS (2016) Introduction to the gene expression analysis. Methods Mol Biol 1434:29–43. https://doi.org/10.1007/978-1-4939-3652-6_3
Takahashi H, Sharma H, Carninci P (2019) Cell based assays of SINEUP non-coding RNAs that can specifically enhance mRNA translation. J Vis Exp (144). https://doi.org/10.3791/58627
Kozak M (2002) Pushing the limits of the scanning mechanism for initiation of translation. Gene 299(1–2):1–34. https://doi.org/10.1016/s0378-1119(02)01056-9
Flynn RA, Zhang QC, Spitale RC, Lee B, Mumbach MR, Chang HY (2016) Transcriptome-wide interrogation of RNA secondary structure in living cells with icSHAPE. Nat Protoc 11(2):273–290. https://doi.org/10.1038/nprot.2016.011
Ohyama T, Takahashi H, Sharma H, Yamazaki T, Gustincich S, Ishii Y, Carninci P (2020) An NMR-based approach reveals the core structure of the functional domain of SINEUP lncRNAs. Nucl Acids Res 48(16):9346–9360. https://doi.org/10.1093/nar/gkaa598
Author information
Authors and Affiliations
Corresponding authors
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2022 The Author(s)
About this protocol

Cite this protocol
Arnoldi, M., Zarantonello, G., Espinoza, S., Gustincich, S., Di Leva, F., Biagioli, M. (2022). Design and Delivery of SINEUP: A New Modular Tool to Increase Protein Translation. In: Arechavala-Gomeza, V., Garanto, A. (eds) Antisense RNA Design, Delivery, and Analysis. Methods in Molecular Biology, vol 2434. Humana, New York, NY. https://doi.org/10.1007/978-1-0716-2010-6_4
Download citation
DOI: https://doi.org/10.1007/978-1-0716-2010-6_4
Published:
Publisher Name: Humana, New York, NY
Print ISBN: 978-1-0716-2009-0
Online ISBN: 978-1-0716-2010-6
eBook Packages: Springer Protocols