
Abstract
Medical image categorization is essential for a variety of medical assessments and education functions. The purpose of medical image classification is to organize medical images into useful categories for the purpose of illness diagnosis or study, making it one of the most pressing issues in the field of image recognition. On the other hand, traditional methods have plateaued in their effectiveness. Additionally, a substantial amount of time and energy is required when employing them to extract and choose categorization features. Alzheimer’s disease is one of the most frequent sources of dementia in elderly patients. Metabolic diseases affect a huge population worldwide, and henceforth, there is a vast scope of applying machine learning to find treatments to these diseases. As a relatively new machine learning technique, deep neural networks have shown great promise for a variety of categorization problems. In this research, a model for diagnosing and tracking the development of Alzheimer’s disease that is both accurate and easy to understand has been developed. By following the developed procedure, medical professionals may make deliberations with solid justification. Early diagnosis utilizing these machine learning algorithms has the potential to minimize mortality rates associated with Alzheimer’s disease. This research work has developed a convolutional neural network using a shallow convolution layer to identify Alzheimer’s disease in medical image patches. The total accuracy of proposed classifications is around 98%, which is greater than the accuracy of the most popular existing approaches.
Similar content being viewed by others


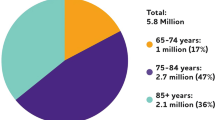
Introduction
Medical imaging is the process of photographing the inside of the body so that scientists, doctors, and clinicians may research, treat, and observe how the body’s tissues function. This procedure attempts to identify and resolve the issue. It generates a database of how organs should typically appear and function, making it simple to identify issues. Furthermore, this procedure employs both organic and radiological imaging techniques, including X-rays and gamma rays, sonography, magnetic imaging, scopes, thermal imaging, and isotope imaging.
There are several different methods for tracking where and what the body is doing. These approaches have a number of issues as compared to modulates that create pictures. Every year, billions of photographs are taken throughout the world for various diagnostic objectives. Approximately half of them employ modulators, which mix ionizing radiation with other forms of radiation. Medical imaging allows doctors to view into the body without having to cut it open. These images are created using a combination of fast computers and a mathematical and logical method of converting energy into signals. Here impulses are subsequently converted into digital images. These signals represent the functioning of various tissues in the body and are mapped into digital images. The use of a computer to modify images is referred to as “medical imaging processing.” Obtaining a photograph, saving it, showing it to someone, and interacting with them are all part of this operation. MRIs and CT scans enable doctors to analyze how well the treatment is working and make changes as needed [1]. Medical imaging is essential for monitoring the progression of a long-term disease. Medical imaging gives patients better, more complete care because it provides clinicians with more information. Medical image processing involves the use and analysis of 3D picture collections of the human body. These records, which are frequently collected via a computed tomography (CT) or magnetic resonance imaging (MRI) scanner, are used to diagnose diseases, plan medical operations like surgery, and perform research.
Medical imaging is becoming increasingly crucial for early illness detection, diagnosis, and treatment as patients want faster and more precise results. The resolution and precision of medical imaging improves as physics, electrical engineering, computer science, and technology advances, and additional image modalities become available and as a result, at the same time, many more medical images available than there were previously. Imaging modalities such as X-ray, CT, MRI, PET/CT, and ultrasound are often employed in hospitals and clinics these days. Both obtaining a precise diagnosis and deciding on the best treatment strategy rely greatly on accurate interpretation of medical images. However, because the findings drawn from image interpretation by doctors with varying degrees of precision are so dependent on the doctors own subjective judgment, the results might vary greatly. In recent years, major advancements in the precision of classification of images, identification of target, and segmentation of image have emerged from the spread of massive annotated natural image datasets and the advent of computer vision deep learning. Many studies on early sickness identification and diagnosis have used supervised learning.
Researcher Ciresan [2] evaluated medical images using deep neural networks, which considerably benefited in skin cancer classification, breast cancer identification, and brain tumor segmentation. Then, researcher Hinton improved the deep convolutional neural network and utilized it to analyze medical images. One of the most important uses of this technology is deep learning. Deep learning is a type of artificial intelligence that can think and act in the same way as humans do. Most of the time, the system will be configured with hundreds or even thousands of input data points in order to accelerate and improve the “training” experience. It begins by “training” on all of the data that was provided to it in some fashion. Many machine learning methods have also been used to sort images. However, machine learning (ML) may be superior in other aspects. As a result, the deep learning system will be busy identifying images. Machine vision has its own picture categorization setting. This technology can search images of persons, items, places, activities, and text. Image categorization can be done extremely successfully when artificial intelligence (AI) and machine vision technologies are utilized combined in software.
The primary purpose of image classification is to organize all images into meaningful groups or sectors. Grouping objects is simple for humans but difficult for machines. It is not the same as identifying an object and categorizing it since it contains patterns that cannot be identified. One may use image categorization technology to drive a car, control a robot, or obtain information from a long distance. It is still hard labor, and all it takes to improve it is a few more tools. For a long time, image categorization has been a major issue in machine vision. The photographs in each challenge class are significantly distinct in terms of color, size, context, and shape. There should be sufficiently enough annotated training images, and producing sufficient numbers of training images takes time and money [3]. There are several categorization systems, each with its own set of benefits and drawbacks. Even the most advanced learning algorithm will have difficulty overcoming the limitations of supervised learning. Neural networks (artificial), algorithms (genetic), induction rule, decision trees, recognition methods (statistical and pattern), k-nearest neighbors, classifiers like naive Bayes, and discriminating analysis are all examples of approaches in machine learning. This research mainly focuses on the description of a classification model that may be used in conjunction with deep learning to address image classification issues. The benefits and drawbacks of this strategy are discussed in this study. To do this, the document is structured as follows. The second part of the research focuses on evaluating the classifier. In the final section, testing of the proposed model has been explained. Findings and recommendations for further research in the study have been proposed in the final phase.
Review of literature
In the recent past, deep learning techniques have been increasingly applied to the Alzheimer’s disease (AD) classification using multimodal data of brain imaging. Several studies have proposed improved deep convolutional neural networks (CNNs) for the classification of Alzheimer’s disease, taking advantage of the rich information available from multiple imaging modalities. For example, Zhang et al. [4] proposed improved CNNs for classification of Alzheimer’s disease using multimodal data of brain imaging, while Dey et al. [5] developed a hybrid deep learning (DL) framework for early stage diagnosis and detection of Alzheimer’s disease. Kumar et al. [6] conducted a systematic review of deep learning-based medical image classification for diagnosis of Alzheimer’s disease, and Liu et al. [7] proposed multi-modality cascaded convolutional networks for prediction and detection of disease like Alzheimer. Past studies have investigated the implementation of deep learning for diagnosis of Alzheimer’s disease using MRI—magnetic resonance imaging—and PET—positron emission tomography images. For instance, Liu et al. [8] proposed a multimodal deep learning approach for diagnosis of Alzheimer’s disease using MRI and PET images. Furthermore, Ma and Liu [9] developed multi-scale attention-guided capsule networks for the classification of Alzheimer’s disease. Zhang et al. [10] proposed dual-pathway convolutional neural network for joint learning of MRI and PET images for diagnosis of Alzheimer’s disease, while Yan et al. [11] proposed a multi-scale feature fusion network for disease classification like Alzheimer using MRI data. Additionally, deep CNNs and other deep learning techniques such as generative adversarial networks (GANs) and stacked deep polynomial networks have also been explored for Alzheimer’s disease diagnosis. Li et al. [12] proposed a multi-modal fusion approach with GANs for Alzheimer’s disease diagnosis, and Liu et al. [13] developed multimodal deep polynomial networks (stacked) for the diagnosis of Alzheimer’s disease. Furthermore, studies have investigated the fusion of brain imaging data from multiple modalities, such as MRI and PET, for classification of Alzheimer’s disease. Huang et al. [14] proposed a fusion approach (multimodal) for the classification of Alzheimer disease using the data of brain imaging. Zhang et al. [10] developed a dual-pathway CNN for combined learning of MRI and PET images. However, one of the main challenges in using DL for classification of medical images including Alzheimer’s disease is the limited availability of labeled training samples. Hai Tang [15] demonstrated the use of semi-supervised learning for classification of images, which further required the pathologically tagged data of the image for training the network model. Wang and Dong [16] also showed that fine-tuning can enhance the classification performance of DL models, especially when training samples are limited. Hai Tang [15] focused his study on demonstrating how images can be sorted using semi-supervised learning. To train the network model, this technique just requires a modest amount of pathologically tagged image data. When it comes to identifying images, the neural network surpasses the CNN and other baseline models, according to this data. Wang and Dong [16] researched the main problem of using DL to sort medical images that there are not enough labeled training samples. It shows that fine-tuning makes it a lot easier to classify liver lesions, especially when the training samples are small. Satya Eswari Jujjavarapuand [14] researched about different applications, such as figuring out what kind of cancer is in a medical image or extracting and choosing features. The authors use the above applications to explain how to evaluate different machine learning methods in a fair way. Nadar [17] studied patient hyperspectral images to create an algorithm based on DL for an automated, computer-aided oral cancer diagnosis system. Yi Zhou [18] provided a collaborative learning technique that blends semi-supervised learning with a mechanism to enhance illness grading and lesion segmentation. After developing early predictions of lesion maps for a large amount of image-level annotated data, it constructs a lesion-aware disease grading model. This enhances the accuracy with which it classifies illness severity. Hossam H. Sultan [19] presented a CNN-based DL model for brain tumor classification utilizing two publically accessible datasets. The best overall accuracy for the proposed network structure was 96.13% in one study and 98.7% in the other. The results proved that the model can be used to distinguish between types of brain tumors. Laleh Armi [20] in his paper looks at combinatorial methods that are well-known; the “Results” section of this paper has a list of the pros and cons of well-known image texture descriptors. All of the methods that have made it this far are based on how well they can tell things apart, how hard they are to figure out, and how well they can handle noise, rotation, etc. Standard classifiers for texture images are also briefly discussed. Dongyun Lin [21] described a novel deep neural network design that uses transfer learning to recognize photographs taken with a microscope.
Based on proposed research of 2D-Hela and PAP-smear datasets, it can be concluded that proposed network structure outperforms the neural network structure that is mostly based on characteristics provided by a single CNN and a few standard classification methods. Allugunti [22] illustrated the similarities between DL and the more traditional non-parametric approach to machine learning, i.e., CNN demonstrates that the proposed approach performs better than the “state of the art” methods currently employed to deliver precise diagnoses. H. H. A. and Zahraa Sh. Aaraji [23] investigated how MRI brain scans and sections of those pictures are used to build and evaluate various deep learning architectures. After processing these photographs, it became simpler to distinguish between AD and CN (cognitively normal) in four distinct patterns. In terms of prediction, the ResNet architecture fared the best (90.83% for raw brain pictures and 93.50% for processed images). Ali Mohammad Alquadah [24] proved that the SVM classifier puts each image into a “good” or “bad” group. By looking at histopathology as a whole, the system can be used to find where in the body cancer is. Overall, the proposed method was 91.12% correct, 85.2% sensitive, and 94.01% specific. That is more than any other system has ever had. Afshar and Mohammadi [25] utilized Caps Nets to determine how to categorize brain cancers, implemented new architecture to improve classification accuracy, further analyzed the over-fitting problem of Caps Nets by applying it to a real-world dataset of MRI images, also tested whether Caps Nets can give a better match for whole-brain imaging or simply the segmented tumor, and finally developed a unique display paradigm for Caps Nets output.
Our findings imply that the suggested approach outperforms CNNs in determining the type of brain tumor a patient has. Jianliang GaoAnd [26] evaluated using T1-weighted MRI data from the Autism Brain Imaging Data Exchange I (ABIDE I) utilizing tenfold cross validation. Based on the assessment results, it can be concluded that the proposed solution for classification of autism spectrum disorder/total communication has an accuracy of 90.39% and an AUC (area under the curve) of 0.9738. The proposed solution performs a range of cutting-edge ASD/TC classification algorithms, according to the findings. Monika Bansal [27] has enhanced the performance of picture classification by fusing deep features extracted with a well-known deep CNN (VGG19) with a wide variety of manually-designed feature extraction methods. When compared to other classifiers and algorithms developed by different authors, random forest is generally more accurate (93.73%) (Fig. 1).

Proportion of population affected by AD according to their ages in 2020
Methods
Our proposed method for categorizing and collecting images is described in Fig. 2 for a high-level diagram of our proposed procedure. This chart depicts the five main stages of the proposed procedure.

Full process diagram of proposed approach
Dataset
This MRI scanner data is made freely available to the scientific community via the open access series of imaging studies (OASIS). OASIS has made available MRI datasets from a wide range of subjects; cross-sectional OASIS-1 and longitudinal OASIS-2 have since been used in numerous studies. The OASIS-3 database is an upgrade to previous versions. There are 1098 people in total, ranging in age from 42 to 95. Six hundred and nine persons are linked to moderate cognitive decline (normal), whereas another 489 are linked to more severe forms of the condition. More than two thousand MRI pictures were used to construct the OASIS-3 dataset, which included structural and functional characteristics. Figure 3 displays the results of the dataset consisting of four types of MR images. Dataset is also available on Kaggle.

Sample images from the dataset
Pre-processing
The steps of feature extraction and image recognition follow the pre-processing of images. Whatever methods of picture capture are used; the resulting photographs never live up to expectations. Image noise, blurry focal plane, unwanted object interference, and similar issues are all examples of such drawbacks. Pre-processing techniques vary depending on the final use of the picture. The paper’s pre-processing phase consists of the following procedures: resizing and segmentation. Resize the all images into width: 196 and height: 196. After that, apply the image segmentation technique to the pre-processed images (Fig. 4).

Pre-processing diagram
Optical Thresholding Using Maximum Variance (OTSU) segmentation
In order to determine the segmentation threshold, the OTSU method maximizes the interclass variance of the grayscale picture. The two-dimensional OTSU technique generates a two-dimensional grayscale value variorum from the original grayscale image’s pixel points’ grayscale values and their grayscale values after the neighborhood smoothing procedure (Fig. 5).

OTSU thresholding
Proposed approach to OTSU segmentation:
-
Step 1: Image preparation: Prepare image for thresholding. Convert the image to grayscale and apply pre-processing, such as noise reduction and contrast enhancement.
-
Step 2: Histogram calculation: Compute the histogram of the grayscale image. The histogram represents the distribution of pixel intensities. Histogram is a plot for the number of pixels at each intensity level.
-
Step 3: Variance calculation: Calculate “between-class” variance and “within-class” variance from the histogram. The between-class variance is the measure of separation between the two classes of pixels, and the within-class variance is the measure spread of pixels within each class. Then, calculate the variances for all possible threshold values.
-
Step 4: Threshold selection: Select a threshold value that maximizes the between-class variance or minimizes the within-class variance as the “optimal threshold” and then iterate through all threshold values from step 3 and choose the one with the highest between-class variance and the lowest within-class variance.
-
Step 5: Image segmentation: Once the threshold is selected, segment the image into background and foreground regions on the basis of threshold value. Pixels with intensities above threshold were classified as foreground, while pixels with intensities below the threshold were classified as background.
Same threshold has been applied to all images. And we found that the OTSU method is excellent for images with bimodal intensity distributions or images with distinct peaks in the histogram representing the two classes of pixels. OTSU automatically found the threshold that best separates these two classes and gave us accurate image segmentation (Figs. 6, 7, and 8).

OTSU process flow

Images after pre-processing

Data distribution graph
Deep learning (DL)
DL is a subfield of ML which employs more modern and well-documented approaches. Since its inception, its purpose has been to bring ML one step closer to its ultimate, exclusive goal: AI. As its name implies, DL makes use of complex neural networks. In the past, neural networks were only two layers deep since building larger systems was not computationally feasible. These days, networks of neurons with tens of layers, and even hundreds of layers are being designed and built. These kinds of systems are referred to as “deep neural systems.” It shows that the system has several levels, making it quite complex.
Convolutional neural network (CNN)
It is made up of neurons that have previously been adjusted for their individual inputs, just like an artificial neural network (ANN), and it also delivers non-linear transformations. The convolutional neural network is preferred for image identification tasks because it encodes picture-specific characteristics into the network’s design. This CNN contains the following five layers: input, convolutional, non-linear, pooling, and fully connected. There are five main tenets that define the operation of a convolution neural network. All of the image’s pixel values are stored in the input layer. The input convolution computation is carried out at the convolutional layer. The outputs from the preceding layer are sent into the non-linear layer, where they undergo a non-linear modification. With the pooling layer, the number of activation parameters may be decreased via sampling the inputs. Class scores derived from activations are shown in the fully linked layer and utilized for sorting (Table 1).
The values for all of the parameters in our proposed approach are listed in Table 2.
Results and discussion
The proposed model is trained effectively using a backpropagation strategy that adjusts the learning rate and pauses the model as it reaches an accuracy (maximum) criterion, given that the learning rate is a critical controllable hyper-parameter for model accuracy as well as for processing time. The OASIS-3 dataset was created using 2168 unique MRI scanners. There are 1734 training shots and 434 validation photos available. Eighty percent of the photos were used for training and 20% for testing. Table 1 depicts the accuracy and loss of suggested models across a number of epochs.
Non-demented, very mild demented, mild dementia, and moderate dementia can all be identified with 98% accuracy and loss-free using the suggested model trained on CNN. Table 3 displays the outcome of the system performance based on the values of the training accuracy, training loss, validation accuracy, validation loss, and the epochs (Fig. 9).

Model accuracy and loss plot
Measurements
In the field of machine learning, classification challenges are frequently validated by specificity, precision, accuracy, F1-score, recall, and other metrics, particularly to quantify the performance of a system or to understand the generalization potential of models.
-
• The entire amount of correct predictions (TP + TN) divided by the total number of datasets (P + N) yields the accuracy.
$$Accuracy=\frac{TP+TN}{TP+TN+FP+FN}$$(1) -
• By dividing the overall number of accurate positive predictions (TP + FP) by the total number of correct positive predictions, precision is calculated (TP).
$$Precision=\frac{TP}{TP+FP}$$(2) -
• F1-score. It is a single indication that combines precision and sensitivity. The maximum and minimum values are 1 and 0.
$$F1=\frac{2TP}{2TP+FP+FN}$$(3) -
• Recall is the proportion of correctly predicted positive observations to all actual class observation (Table 4).
$$Recall=\frac{TP}{TP+FN}$$(4)
Commonly, a confusion matrix is used to assess the classifier’s efficacy. This table is used to display the true classes, the classes that the classifier predicted, and the types of errors that the classifier produced. Figure 10 depicts a confusion matrix for the diagnosis of Alzheimer’s. According to the confusion matrix, the following are the four different types of terminologies used:
-
• When a classifier returns a “1” as a “true positive,” it signifies the prediction was accurate.
-
• When a classifier returns a result of “true negative,” it signifies the prediction was indeed negative.
-
• If a classifier returns a “1” for a positive result when it should return a “0,” this is a false positive (FP).
-
• When a classifier returns a false negative (FN), it is indicating that the prediction was incorrect.

Confusion matrix
Among the most crucial performance indicators for a classification model are the ones derived from the confusion matrix itself: accuracy, precision, and recall. The result of our model is shown in the classification report in Table 5.
Future scope
DL inAD research is continuously being enhanced for improved performance and transparency. Research on the diagnostic categorization of AD using deep learning is moving away from hybrid approaches and towards a model that purely employs deep learning algorithms. Getting enough, accurate, and brain-balanced information on Alzheimer’s disease is one of the key obstacles. However, strategies still need to be developed to incorporate totally diverse forms of data in a deep learning network. Knowing that good, noise free data is a key obstacle, we propose the following approaches for future work:
-
1. Research methods focused on using a feature selector before using a CNN
-
2. Approaches using Manifold-based deep learning algorithms
-
3. AD classification using sparse regression models
-
4. Methods that use deep learning segmentation, introduced into the process, to mark out the regions of activity
All of the above approaches could potentially open up new avenues for AD prediction and classification.
Limitations
The suggested technique does have certain limitations that may need to be addressed.
-
1. All images must be scaled to the same dimensions.
-
2. Every image must be converted to grayscale.
-
3. CNN models are considerably slower as a result of procedures like maxpool.
-
4. Procedures like maxpool make CNN models significantly slower.
Conclusions
In recent years, deep learning has emerged as a central force in the automation of our daily lives, bringing about significant improvements in comparison to traditional AI calculations. The proposed work opted to investigate the application of CNN-based classification on a short MRI image dataset and assess its performance because of its significance of classifying medical images and the unique difficulty posed by the tiny dataset of Alzheimer’s disease-based images. For the best outcomes, using deep learning is the foremost requirement. If the convolution layer is defrosted, then the feature in question can acquire knowledge from the fresh data. Hence, the unique characteristic is a crucial element in achieving better precision. When compared to standard SVM, NB, and CNN models, the suggested methodology outperforms them all.
Availability of data and materials
All data generated or analyzed during this study are included in this article.
Abbreviations
- AD:
-
Alzheimer’s disease
- MRI:
-
Medical resonance imaging
- CT:
-
Computerized tomography
- PET:
-
Positron emission tomography
- ML:
-
Machine learning
- AI:
-
Artificial intelligence
- CNN:
-
Convolutional neural networks
- DL:
-
Deep learning
- GAN:
-
Generative adversarial networks
- CN:
-
Cognitively normal
- ABIDE I:
-
Autism Brain Imaging Data Exchange I
- AUC:
-
Area under the curve
- ACD:
-
Autism spectrum disorder
- OASIS:
-
Open Access Series of Imaging Studies
- OTSU:
-
Optical Thresholding Using Maximum Variance
- ANN:
-
Artificial neural network
References
Y. M. Y. A. and T. Alqahtani (2019) “Research in medical imaging using image processing techniques”. Available: https://www.researchgate.net/publication/334201999_Research_in_Medical_Imaging_Using_Image_Processing_Techniques
Dan Ciresan AG (2012) Deep neural networks segment neuronal membranes in electron microscopy images. Available: https://proceedings.neurips.cc/paper/2012/hash/459a4ddcb586f24efd9395aa7662bc7c-Abstract.html
I. H. Sarker, “Machine learning: algorithms, real-world applications and research directions,”
Zhang L, Peng Y, Sun J (2022) Improved deep convolutional neural networks for Alzheimer’s disease classification using multimodal brain imaging data. J Med Imaging 9(2):024501. https://doi.org/10.1117/1.JMI.9.2.024501
Dey S, Maity S, Mondal S, Dey N (2021) Early diagnosis of Alzheimer’s disease using a hybrid deep learning framework. J Med Syst 45(11):135. https://doi.org/10.1007/s10916-021-01875-6
Kumar A, Gupta A, Khanna A, Khanna P (2021) Deep learning-based medical image classification for Alzheimer’s disease diagnosis: a systematic review. J Healthcare Eng 2021:6646234. https://doi.org/10.1155/2021/6646234
Liu C, Liu Y, Shen D (2020) Multi-modality cascaded convolutional networks for Alzheimer’s disease prediction. NeuroImage 215:116806. https://doi.org/10.1016/j.neuroimage.2020.116806
Liu J, Zhang J, Luo S (2022) A multi-modal deep learning approach for Alzheimer’s disease diagnosis using MRI and PET images. J Med Image Anal 78:102210. https://doi.org/10.1016/j.media.2021.102210
Ma J, Liu W (2022) Multi-scale attention-guided capsule networks for Alzheimer’s disease classification. J Neurocomputing 510:167–180. https://doi.org/10.1016/j.neucom.2021.07.049
Zhang L, Zhang Y, Wang Y (2021) Joint learning of MRI and PET images for Alzheimer’s disease diagnosis using a dual-pathway convolutional neural network. J Pattern Recog 116:107985. https://doi.org/10.1016/j.patcog.2021.107985
Yan R, Han J, Huang L (2021) Multi-scale feature fusion network for Alzheimer’s disease classification. IEEE Transact Med Imag 41(9):2566–2577. https://doi.org/10.1109/TMI.2021.3059265
Li Y, Chen C, Liu M (2020) Multi-modal fusion with generative adversarial networks for Alzheimer’s disease diagnosis. Comput Med Imag Graphics 82:101679. https://doi.org/10.1016/j.compmedimag.2020.101679
Liu M, Cheng D, Yan w (2019) Multi-modal neuroimaging feature learning with multimodal stacked deep polynomial networks for diagnosis of Alzheimer’s disease. J Neuroinform 17(3):393–404. https://doi.org/10.1007/s12021-019-09409-x
Huang L, Yang H, Wang L (2018) Multi-modal fusion of brain imaging data for Alzheimer’s disease classification. J Brain Imag Behav 12(4):1244–1255. https://doi.org/10.1007/s11682-017-9799-9
Hai Tang ZH (2020) Research on medical image classification based on machine learning. Available: https://ieeexplore.ieee.org/document/9091175
Wang W, Liang D et al (2020) Medical image classification using deep learning. Available:https://www.researchgate.net/publication/337362482_Medical_Image_Classification_Using_Deep_Learning
P. R. J. & E. R. S. Nadar ( 2019) “Computer-assisted medical image classification for early diagnosis of oral cancer employing deep learning algorithms” . Available: https://link.springer.com/article/10.1007/s00432-018-02834-7
X. H. et. a. Yi Zhou (2019) “Collaborative learning of semi-supervised segmentation and classification for medical images”. Available: https://openaccess.thecvf.com/content_CVPR_2019/html/Zhou_Collaborative_Learning_of_Semi-Supervised_Segmentation_and_Classification_for_Medical_Images_CVPR_2019_paper.html
N. M. S. et. a. Hossam H. Sultan (2020) “Multi-classification of brain tumor images using deep neural network” . Available: https://ieeexplore.ieee.org/document/8723045
Laleh Armi SFE (2019) Texture image analysis and texture classification methods - a review. Available: https://arxiv.org/abs/1904.06554
L. N. et. a. Dongyun Lin And (2018) “Deep CNNs for microscopic image classification by exploiting transfer learning and feature concatenation”. Available: https://www.researchgate.net/publication/324961229_Deep_CNNs_for_microscopic_image_classification_by_exploiting_transfer_learning_and_feature_concatenation
Allugunti VR (2021) A machine learning model for skin disease classification using convolution neural network. Available: https://www.researchgate.net/publication/361228242_A_machine_learning_model_for_skin_disease_classification_using_convolution_neural_network
Abbas HH, Aaraji ZSh (2022) “Automatic classification of Alzheimer’s disease using brain MRI data and deep convolutional neural networks. Available: https://arxiv.org/ftp/arxiv/papers/2204/2204.00068.pdf
A. A. Ali Mohammad Alqudah And (2018) “Sliding window based support vector machine system for classification of breast cancer using histopathological microscopic images” 2019. Available:https://www.tandfonline.com/DOI/abs/10.1080/03772063.2019.1583610?journalCode=tijr20
P. Afshar and A. et. a. Mohammadi (2018) “Brain tumor type classification via capsule networks”. Available: https://arxiv.org/pdf/1802.10200.pdf
Y. K. et. a. Jianliang GaoAnd (2018) “Classification of autism spectrum disorder by combining brain connectivity and deep neural network classifier”. Available: https://www.sciencedirect.com/science/article/abs/pii/S0925231218306234
Monika Bansal MK (2021) Transfer learning for image classification using VGG19: Caltech-101 imagedata set. Available: https://link.springer.com/article/https://doi.org/10.1007/s12652-021-03488-z
Acknowledgements
Not applicable.
Funding
Not applicable.
Author information
Authors and Affiliations
Contributions
SSB carefully reviewed and edited the paper; TV performed literature review and wrote the paper. All authors have read and approved the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Bamber, S.S., Vishvakarma, T. Medical image classification for Alzheimer’s using a deep learning approach. J. Eng. Appl. Sci. 70, 54 (2023). https://doi.org/10.1186/s44147-023-00211-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s44147-023-00211-x