
Abstract
Host-microbiome interactions are recognized for their importance to host health. An improved understanding of the molecular underpinnings of host-microbiome relationships will advance our capacity to accurately predict host fitness and manipulate interaction outcomes. Within the plant microbiome research field, unlocking the functional relationships between plants and their microbial partners is the next step to effectively using the microbiome to improve plant fitness. We propose that strategies that pair host and microbial datasets—referred to here as holo-omics—provide a powerful approach for hypothesis development and advancement in this area. We discuss several experimental design considerations and present a case study to highlight the potential for holo-omics to generate a more holistic perspective of molecular networks within the plant microbiome system. In addition, we discuss the biggest challenges for conducting holo-omics studies; specifically, the lack of vetted analytical frameworks, publicly available tools, and required technical expertise to process and integrate heterogeneous data. Finally, we conclude with a perspective on appropriate use-cases for holo-omics studies, the need for downstream validation, and new experimental techniques that hold promise for the plant microbiome research field. We argue that utilizing a holo-omics approach to characterize host-microbiome interactions can provide important opportunities for broadening system-level understandings and significantly inform microbial approaches to improving host health and fitness.
Video abstract
Similar content being viewed by others

Introduction
The host microbiome has emerged as a crucial determinant of host health and an important modulator of host interaction with its abiotic environment [1]. In effect, the microbial genes in the microbiome augment the host’s own genetic repertoire and can act to improve the host’s adaptation to environmental perturbation [2], or, in some cases, prevent it from doing so [3]. In humans, it is increasingly recognized that the microbiome can influence a wide range of pathologies, including cancer, cardio-metabolic diseases, allergies, and obesity [4]. Similarly, it is now recognized that much of plant fitness depends on interactions with the plant microbiome [5], which not only includes susceptibility to diseases [6] but also survivability under both biotic and abiotic stress [7, 8]. Recent research suggests that these interactions depend on complex molecular exchanges involving the host’s perception of its microbial partners, microbial perception of the host, and microeconomics revolving around nutrients and resources important for survival of both [9,10,11,12,13]. Additionally, new findings indicate that final outcomes for host fitness can be dependent not only on the exchange of goods between the host and microbe, but on signaling and metabolic interactions among members of the microbiome themselves [14,15,16]. Collectively, these studies demonstrate that understanding the plant microbiome will likely require an examination of these relationships at the level of functional capacity, activity, and molecular exchange for both host and microbe.
Currently, we lack this necessary functional insight into plant microbiome interactions. This is in part due to the complexity of the system. Unlike the animal gut, the plant microbiome is assembled from and resides within one of the most diverse surrounding environments on the planet, the soil itself [1, 17]. Soils harbor a vast microbial ecosystem including bacteria, viruses, fungi, archaea, and protists, which all interact with each other [18] in complex trophic exchange networks. These soil microbiomes can shift drastically in abundance, composition, and activity over short physical distances, timeframes, and in response to seasonal environmental factors, which increases the source diversity from which plants draw their microbiomes [19,20,21]. As an added layer of complexity, it is also known that metabolites present within and exuded by the plant feed the microbiome [22], and that these metabolites can shift dramatically in composition and quantity over the course of plant development and from tissue to tissue, leading to differential recruitment of microbial taxa across time and space. Furthermore, specific microbial lineages are known to trigger the systemic exudation of specific plant metabolites [23], potentially creating feed forward loops in microbiome development. Collectively, these factors produce a dynamic and interconnected biological system that has challenged our ability to decipher the basal molecular mechanisms that create and sustain it.
However, perhaps a greater cause of our slow rise to functional insight on plant microbiome interactions lies in our choice of tools. The field of plant microbiome research thus far has largely relied on descriptive investigations of community structure using amplicon-based sequencing, such as 16S rRNA sequencing for bacteria and ITS sequencing for fungi [19, 20]. While it is true that these data have led to considerable insight into the general forces that act to shape the broad structure of the plant microbiome and the relative strength of their impact [24, 25], they typically fall short of providing mechanistic insight into relationships with the host. More recently, a greater number of studies have begun to explore other microbiome features, such as activity and functional capacity, through the inclusion of metatranscriptomics and shotgun metagenomics [26, 27]. Despite this increase, at present there remains a shortage of studies which take the additional step of linking plant microbiome data to plant physiology, genetics, metabolism, and other host processes [28], which could provide missing data from this underrepresented side of plant-microbiome interactions.
To achieve a more integrated perspective on plant microbiome function, we argue for experimental designs which pair host-centered omic strategies, such as transcriptomics, metabolomics, epigenomics, and proteomics, with the more commonly used microbial-focused techniques, such as amplicon sequencing, shotgun metagenomic, metatranscriptomics, and exometabolomics. Nyholm et al. recently coined the phrase “holo-omics” to describe such experiments that incorporate data across multiple omic levels from both host and microbiota domains [29]. We propose that such holo-omic studies have the power to resolve the functionality of a plant microbiome ecosystem by generating an image of what is being expressed, translated, and produced during plant-microbiome interactions [19]. This multifaceted image can help winnow results obtained from each individual dataset to meaningful biological signals, and to help build support for specific hypotheses with data gathered through orthogonal approaches. In this review, we build upon the conceptual framework introduced by Nyholm et al. with a specific exploration of holo-omics in the field of plant microbiome research. We first discuss experimental design considerations for plant holo-omics studies, focusing on the value of including longitudinal designs and careful consideration of sampling strategy. Next, we present a recent case study of plant holo-omics that investigates the interaction between drought stress and the development of the sorghum microbiome, followed by several other recent examples of holo-omic studies targeting the plant microbiome. Finally, we summarize current challenges in the analysis of holo-omics datasets and explore newly developed tools for analyzing holo-omics datasets, concluding with our perspective on the importance of downstream validation and the future of holo-omics in plant microbiome research.
Experimental design of holo-omics studies
A number of experimental design considerations (Fig. 1) are crucial for obtaining accurate and meaningful results from microbiome studies that involve holo-omics [29,30,31]. First, we propose that longitudinal studies—used here to refer to studies in which sampling occurs across plant development, though not always from the same individual host—offer distinct advantages for holo-omic studies over their end-point counterparts. In end-point microbiome experiments, researchers’ sample at typically a single defined time point in the experiment to find differences in microbial communities between different experimental treatments. However, selecting the appropriate time point presents a challenge, as there is often little or no a priori knowledge of when host and microbiome responses will occur. More importantly, patterns in each data type, even when biologically connected or correlated, may not occur within a single temporal window.

Considerations for design, analysis, and validation of holo-omic experiments. At left, design related considerations include intentional use of longitudinal designs, appropriate selection of sample types, and evaluation of optimal data types for the scientific questions addressed in the study. In the middle, analysis related challenges include selecting the appropriate range of biological and technical expertise, as well as the selection of appropriate analytical framework and tools for direct integration of diverse data types. At right, recommendations of techniques for downstream hypothesis testing and validation include use of direct and evolution-driven modifications of host genetic space, direct manipulation of microbial genetics, and bottom-up construction of reduced complexity synthetic communities
Longitudinal studies, by contrast, attempt to describe shifts in the microbiome over time. As a result, longitudinal studies allow for a type of pseudo-replication, since patterns observed over multiple time points are more likely to be the result of real biological processes instead of random noise, similar to the value added and purpose-driven aspects of true biological replicates. Secondly, longitudinal designs increase the likelihood of observing shifts that only occur in a narrow window of time post treatment. As mentioned above, samples collected only at one arbitrarily defined time point may not capture important treatment-dependent differences manifesting outside the selected temporal window. Additionally, a longitudinal design can be beneficial in identifying correlations between data types that are affected by a temporal delay [7]. The transduction and decoding of signals between host and microbe can take time [32, 33], as does the lag between shifts in transcription and downstream shifts in protein synthesis and metabolite production within the host [34,35,36]. The impact on microbiome composition and abundance, and the development of macroscopic host phenotypes is likely even more impacted by temporal delay. Finally, a longitudinal design may help to establish a clear hypothesis for causality between correlated features in orthogonal datasets. The advent of probabilistic time series modeling and its application in holo-omic designs could prove particularly useful in this regard, though at present these tools are still under development [36, 37]. Despite its advantages, a longitudinal design for holo-omics experiments does come with important constraints and considerations. For instance, due to the necessity of multiple rounds of sampling, the timing of sample collection should be planned carefully to ensure that new confounding variables, such as circadian variations [38, 39] and abiotic factors that vary over diurnal cycles (for example, temperature and light), are not introduced into downstream statistical analyses. When sampling large numbers of samples, especially in the field, many host-associated data types, such as transcriptomics, are sensitive to circadian cycles and will require that samples be collected in as narrow a window at a fixed time of day across the experimental design.
Secondly, when designing an integrated holo-omics study, it is critical to consider the limitations imposed by the samples and sampling process. For instance, one must carefully consider the suitability of each collected sample type for specific desired data types, which in some cases may require alterations to sampling strategy to become feasible. Leaf microbiome samples, for example, will contain exponentially more DNA, RNA, and proteins derived from the plant than from the microbes, so some microbial techniques may not be feasible without plant-derived contamination removal. For environments that have low microbial biomass, such as sandy soils under drought stress, one must collect a larger number of samples for nucleic acid extraction. Soil or rhizosphere samples with high humic acid content, on the other hand, may require special reagents for humic acid removal. Additionally, different plant tissues, such as roots and leaves, may require different collection methods or require different amounts of time to collect, and these differences can have inadvertent impacts on sample viability and data outcomes, especially for omics strategies that are highly sensitive to time and temperature (i.e., transcriptomics, metatranscriptomics). When a single collected sample will be used to produce multiple data types, it is important to identify a universal sampling strategy that will work for all of them. Lastly, detailed collection and reporting of sample metadata is important to better ensure reproducibility and biological relevance of findings.
Third, it is important to consider not only how anticipated data types impact sampling needs but also what questions are best addressed with specific data types within a holo-omic design, and whether a holo-omic design is in fact advantageous. While there are indeed many queries that can be posed within this framework, careful review is needed of what data type combinations are most suitable and achievable for the system being studied, lines of investigation pursued, and resources available for the project; this includes taking inventory of tools, databases and computational resources available, extent and quality of host genome annotations, and potential impacts of biotic and abiotic parameters on data acquisition [40]. For example, holo-omics may be particularly challenging in non-model plants, in comparison to other host organisms, due to large, deficiently annotated genomes, large metabolic diversity, multiple organelles, and complex interaction networks with both symbionts and pathogens [36]. This may in some cases preclude the useful inclusion of some data types on the host side, such as transcriptomics or epigenomics.
It is worth noting that due to the inclusion of multiple omics techniques, holo-omics designs are typically quite expensive to implement. Specific omics techniques remain relatively expensive, including both shotgun metagenomics and metatranscriptomics, while others (such as amplicon analysis) can cost at one to two orders of magnitude less per sample. Prior to undertaking a holo-omic study, we suggest that focused pilot surveys with less costly techniques, or alternatively with limited sampling scope, have been performed first to determine that microbial community dynamics are significantly impacted by the experimental factors in question to warrant further holo-omic investigation. This will also allow preliminary analyses of the system to be analyzed without the need for as wide a range of technical and biological expertise. Development of staging within the holo-omic studies, in which techniques requiring greater investment are implemented later, can in the case of longitudinal designs allow for reduced resource expenditure through selection of critical time points to focus on based on less costly early datasets. However, it’s worth noting that not all data types are equally amenable to this approach; some sample types require immediate or rapid processing (RNA, metabolites), whereas others (DNA) can be stored for later use for much longer periods of time.
A plant holo-omics case study
As a recent example of a holo-omics study of the plant microbiome [7], Xu et al. conducted a large-scale field study of sorghum and the associated root microbiome as it responds to drought stress. This work was carried out in the central valley of California, where a lack of summer rainfall and high temperatures virtually guarantees the ability to induce drought conditions during sorghum’s growing cycle without the need for rainout shelters [7, 41]. As plants respond to drought differently depending on their developmental stage [42], collection of time-series data in this drought experiment was employed to yield a more complete view of sorghum’s responses to water stress across growth stages. Such an approach also has value for exploring the plant microbiome; to our knowledge, very few longitudinal microbiome studies have been performed on crop systems in the field [7, 43], and even fewer exist in which the diversity, composition, and function of the plant microbial community is profiled alongside plant growth and development.
As part of this study, two genotypes of sorghum (RTx430 and BTx642) were grown in randomized blocks in an agricultural field at the Kearney Agricultural Research and Extension Center in Parlier, CA. Individual, randomized blocks were subjected to either drought stress or normal irrigation from the 2nd until the 8th week after seedling emergence [7, 44,45,46], at which point drought-stressed samples were watered again to explore the impact of renewed irrigation on host and microbiome processes. Samples were collected in a longitudinal fashion (once per week at a specific time of day) from leaf and root tissues, along with rhizosphere and bulk soil. This design allowed for the investigation of differences influenced by sample compartments (leaf, root, rhizosphere, and soil), by genotype (RTx430 and BTx642), by watering treatment (irrigation and drought), and by plant development (from seedling emergence to grain maturation) [44]. More importantly, the holo-omics approach described enabled exploration of connections between microbial and plant phenotypes across the diverse datasets.
First, an exploration of the impact of drought on root bacterial microbiome composition was undertaken. Amplicon sequencing (16S rRNA) revealed that the bacterial community in the sorghum root system strongly responds to early drought stress in a developmentally conditioned manner. Specifically, it was observed that drought delayed the normal development of the root and rhizosphere microbiome, and that this development is rapidly restored upon rewatering [7]. Notably, drought stress led to a strong enrichment of gram-positive bacteria, including Actinobacteria and Firmicutes, and lineages within the phylum Chloroflexi. Second, an exploration of microbiome transcriptional activity was used to look for potential causes on the microbial side for this broad, but clear, lineage-specific enrichment. Metatranscriptomics data from the rhizosphere revealed a strong drought-induced shift in microbial processes related to the transport and catabolism of carbohydrates, amino acids, and secondary metabolites, many of which are known to be present in the plant-produced root exudates that feed rhizosphere and root-associated microbes. By including metabolomics data derived from the host root tissue, we identified a strong overlap between drought-enriched root metabolites produced by the host and microbial transport pathways upregulated in the root microbiome during drought. An analysis of transcription levels through qPCR and RNA-Seq for several sorghum genes involved in these metabolic pathways revealed strong upregulation, demonstrating that the enriched metabolites were likely produced by the host and not the microbes themselves. Finally, genome-resolved metagenomics allowed for the development of partially complete genomic bins for many of the enriched and depleted taxa in the rhizosphere microbiome. A comparative genomics approach between these groups has demonstrated that microbes which are strongly enriched in drought stress have significantly more genes allocated to the transport and catabolism of many of the drought-enriched root metabolites. Based on the combined analysis of these individual datasets, we developed the hypothesis that drought leads to enrichment of specific microbes in the root microbiome through shifts in host exudate profiles that favor growth of these taxa due to substrate preference.
In addition to the bacterial community, this project also analyzed the impact of drought on sorghum’s fungal microbiome using ITS2 amplicon sequencing. The symbiosis between sorghum and arbuscular mycorrhizal fungi (AMF) was of particular interest [47], considering previous reports that AMF colonization improves drought resistance in certain plants, with speculation that fungal hyphae could improve water transport through the soil and that fungal symbionts are capable of altering their hosts’ stomatal conductance [48, 49]. In contrast, the sorghum root RNA-seq dataset found that while AMF community composition was not altered, AMF abundance decreased markedly, as assessed via qPCR of total fungal 18S rDNA and ITS2 amplicon sequencing to determine relative AMF abundance. Notably, the strongest, drought-induced change in transcription of host genes was the downregulation of the cluster previously identified as markers of AMF colonization. Transcription of these sorghum genes was strongly and broadly downregulated in both pre- and post-flowering drought and, in both cases, correlated closely with decreases in AM fungal abundance [45]. When irrigation was resumed following the pre-flowering drought, both AMF abundance and plant gene expression were restored to pre-drought levels. Furthermore, a variety of host datasets (metabolomics, proteomics, and RNA-Seq) revealed that photosynthesis, which produces the sugars used to sustain AMF partnerships, stalls during drought stress [45]. Researchers inferred from the individual analysis of these different datasets that sorghum, having lost photosynthetic output as a consequence of closing its stomata in response to drought, cannot make use of the mineral nutrients that it acquires from AMF and quits providing the sugars and lipids that it normally supplies to AMF in exchange for minerals. This experiment suggests that integrating host data with ITS amplicon data can offer profound and even surprising clarification to broad assumptions made about plant biology.
Holo-omics research in the field of plant biology
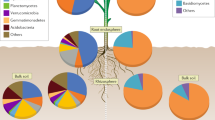
In addition to the case study described above, a growing number of publications highlight the adoption of holo-omics strategies in the plant microbiome field (Table 1, Fig. 2) [31]. At present, the most frequently included host data type is transcriptomics [50,51,52,53,54], which affords a broad and, in many cases, comparatively well-annotated perspective on host functionality. One clear advantage of this data type is that it is perhaps the most well-developed of all the plant omics techniques in terms of analytics; there are a comparatively large number of vetted tools available, and an array of plant-host specific expression atlases for downstream analyses. As an example of one such study that successfully employed host-transcriptomics in a holo-omics framework, Castrillo et al. explored the relationship between phosphate starvation response (PSR) and microbiome composition and function in Arabidopsis [55]. As a result of this design, researchers discovered that the plant immune system coordinates microbial recognition with nutritional cues during microbiome assembly; 16S rRNA compositional profiles indicated that the microbiomes of PSR mutants were distinct from those of wild type Arabidopsis [55]. Additionally, it was shown that synthetic community inoculation enhanced the activity of a master regulator of PSR (PHR1) under limited phosphate conditions, which confirmed that PHR1 directly regulates a functionally relevant set of plant-microbe recognition genes [55]. Genome-wide gene expression analysis of the Arabidopsis root demonstrated that the PHR1 mutant in Arabidopsis also directly represses the plant immune system by altering the expression of genes in the jasmonic and salicylic acid biosynthesis pathways [55]. Taken together, this holo-omic design demonstrated that the plant root microbiome directly connects phosphate stress response and the plant immune system [55].

Connecting plant and microbial omics techniques. Recent examples from the plant microbiome research field of holo-omics studies employing paired datasets from host data types (in green) and associated microorganism data types (in blue). Lines between techniques indicate individual studies that integrate across the pair of indicated techniques. All studies reference here are also listed with additional detail in Table 1
Metabolites represent the downstream products of multiple interactions between genes, transcripts, and proteins [56] and serve as an important component of the functional interface of host-microbe interactions. An advantage of including metabolomics data in holo-omics studies is that many of the experimental, analytical, and data integration requirements that are essential for metabolomics studies are actually fully compatible with inclusion of genomics, transcriptomics and proteomics studies; for this reason, it has been suggested that metabolomics can provide a “common denominator” to the design and analysis of many holo-omics experiments [56, 57]. As an example, by combining microbiome profiling, primary metabolite quantification, host defense-gene expression, herbivore growth assays, and microbial complementation analysis, Hu et al. found that Benzoxazinoids (BXs), a class of defensive secondary metabolites that are released by the roots of cereals such as wheat and maize, create feedback loops with soil microbial communities that can alter future generations of crop performance [58]. Metabolomics was used to identify and quantify specific plant produced BX classes as they moved to soils, and amplicon analysis in several elegant experimental designs revealed that exudation of these compounds alter root-associated fungal and bacterial communities for the host and subsequent generations of the host, even following periods of overwintering. Finally, host phenomics and host gene expression analysis demonstrated that these conditioned shifts in soil microbiota led to altered host defense in the subsequent generation, including altered levels of phytohormones known to regulate herbivory [58]. An additional study in this system confirmed has suggested a role for BXs as gatekeepers to the root endosphere, allowing specific microbial lineages access to the host [59]. Despite the many advantages of using metabolomic data for holo-omic studies, some challenges remain, namely, that many peaks are not identifiable as specific metabolites and studies typically require greater replication due to noise in the data [60]. Additionally, the number of identifiable metabolites is far more limited than identifiable genes and transcripts from the genome or transcriptome layer, and as a consequence use of metabolomics data may limit the “search space” and thereby limit the interpretation of the final results [56].
Host genomic datasets have also been used recently in combination with genome-wide association style analyses to investigate the genetic underpinnings of microbial recruitment [61,62,63,64,65]. An analysis of a population-level microbiome analysis of the rhizospheres of 200 sorghum genotypes indicated that rhizosphere-associated bacteria exhibiting heritable associations with plant genotypes, and certain host loci showed a correlation with the abundance of specific subsets of the rhizosphere microbiome [61]. There is an opportunity to expand the use of other data types in holo-omics research as well, such as epigenomics [66], proteomics, ionomics [67], phenomics [67], exometabolomics [68], metaproteomics [69,70,71,72], and metatranscriptomics; improving analytical methodology and methods of holo-omics integration will help facilitate this expansion.
Challenges in holo-omics analysis
Taken together, the above examples indicate how collecting a combination of microbial and host data is a promising approach to further unraveling plant and bacterial community interactions through generating mechanism-based questions and testable hypotheses. However, analysis of holo-omics comes with its own challenges (Fig. 1). One clear hurdle is that holo-omics approaches will typically require a broad range of expertise to implement, and collaborations should include not only a team of plant and microbial biologists for interpreting and decoding connections within and between kingdom-specific pathways and genes but also statisticians and computational biologists to identify and implement the approaches with appropriate statistical rigor [73]. Integrative analyses for holo-omics require intensive computational resources, including suitable means for storing, processing, analyzing data, and workflows with appropriate quality control measures and modeling selections. Another significant challenge is the current lack of fully developed analytical methodology, and there is significant need for continued development of informative and robust bioinformatic tools. For those tools that do exist, it can be difficult to know which to select, as some will be generalizable to all data types and experiments, while others will depend on the particular questions under investigation [31]. Generally, there is much more software tailored for multi-omic analysis of either the host or microbiome in isolation [36, 74,75,76,77,78], as opposed to tools for integrating datasets from both simultaneously [79, 80]. For instance, gNOMO is a bioinformatic pipeline that is specifically designed to process and analyze non-model organism samples of up to three meta-omics levels—metagenomics, metatranscriptomics, and metaproteomics—in an integrative manner [81], but analysis does not extend to the host.
A second challenge is the development and implementation of statistical methods that directly integrate orthogonal datasets within a single analytical framework. Currently, the majority of plant microbiome studies that employ a holo-omic design, including the examples highlighted in this study, focus on separate omic analyses first and then integrate results from seperate layers later based on the available data and prior knowledge [82, 83]. This approach, while comparatively straightforward to implement, may miss important associations among multiple omics layers [84, 85]. In this respect, the plant microbiome research community may benefit from recent advances made in the human microbiome field; a number of recent human gut holo-omics studies have begun to use direct integration of data from different omics levels, for instance through implementation of correlation analyses (such as Spearman’s rank correlation), to directly resolve microbial taxa that correlate with specific environmental or host features [86]. It has also been suggested that more recently developed strategies, such as kernel- and network-based approaches [82], as well as Network-free non-Bayesian and Network-free Bayesian [87] approaches, may more completely uncover the non-linear relationships in host-microbe interactions [88].
As an example of tools useful for a direct integration approach, the recently developed Transkingdom network (TransNet) analysis is designed to integrate and interrogate holo-omics data. TransNet allows for the construction of networks using correlations between differentially expressed elements (e.g., genes, microbes) and integration of high throughput data from different taxonomic kingdoms. In addition, TransNet analysis can be applied to integrate any “Transomics” data between, as well as within, taxonomic kingdoms. Examples of data types suitable for TransNet include miRNAs and gene expression, proteins and metabolites, bacterial and host gene expression, and methylation data [89]. A second such example is the use of multivariate predictive modeling with the Elastic Net algorithm through stacked generalization. A recent study in humans obtained samples of the immunome, transcriptome, microbiome, proteome, and metabolome simultaneously from the same patients in order to measure the ability of each dataset to predict gestational age [90]. While at present this list remains relatively short, as holo-omics research continues to grow as a field, we anticipate the development of new models, statistical and visualization tools, and methods for omics data integration and analysis that is powerful enough to understand the underlying principles that govern complex plant microbiome systems. One last, additional area of importance is the continued development of means to incorporate non-omic data with holo-omic analyses; a recent study suggest a joint modeling approach [91], in order to further advance our understandings of how the interplay of host and the microbial world impacts not only host fitness and health, but potentially broader environmental and evolutionary change as well.
Conclusions and perspective
The crosstalk among multiple molecular layers, within and between both host and associated microbiome, cannot be properly assessed solely by a reductionist approach that analyzes individual omics layers in isolation. While holo-omics has the power to help unlock the molecular dynamics at play within the plant microbiome [29], it is worth noting that we anticipate the primary function of such large-scale holo-omics studies is to be the generation, rather than testing, of hypotheses about functional relationships in the plant microbiome. While it has been argued that null-hypothesis testing is actually an outdated method for performing ecology studies [92], to reach a functional understanding of the molecular mechanisms at play in the plant microbiome, validation experiments that follow a traditional hypothesis-driven approach will be necessary (Fig. 1) [93]. Fortunately, a wide variety of new technical approaches in both plant and microbial biology have been developed that are well suited to the purpose of hypothesis testing in the plant microbiome. The use of CRISPR/Cas9 engineering to create plant hosts altered in core functions represents one such powerful approach that has been used for validation [94]. Additionally, use of large plant germplasm collections and mapping populations has potential power to dissect genetic loci involved in the recruitment of specific microbes through microbiome-based GWAS [61,62,63, 95] and related approaches. On the microbial side, the use of synthetic communities to dissect microbial contributions to host phenotype is an approach that derives its power from creating microbial communities that can mimic in form and function as the native plant microbiome, but with a level of diversity that makes manipulation manageable [93]. Similarly, randomly barcoded transposon mutagenesis sequencing (RB-TnSeq) has also been shown to be capable of identifying microbial genes involved in root colonization [96], and could prove invaluable for developing more complete bacterial genome annotations as well as experimental validation of gene function. Another promising technique for in situ manipulation and study of the plant microbiome is the use of CRISPR/Cas9-derived, sequence-specific antimicrobials [97]. This environmental CRISPR/Cas9 system could be used to remove certain species or even certain alleles within a species from a complex community in order to study its effect on the plant microbiome as a whole.
In conclusion, holo-omics represents a useful tool to be used in our efforts to develop an improved understanding into the basic biology of plant-microbiome interactions. Adoption of this strategy will in turn necessitate and fuel the development of alternative sequencing-data integration analysis techniques that may have benefit outside the realm of plant biology. Finally, we believe pursuit of this path will encourage microbial and plant biologists, as well as ecologists, statisticians, and computer scientists, to work together to develop unified experimental frameworks that integrate diverse scientific perspectives. It is this process of technical and conceptual harmonization of methodologies across the scientific community that remains perhaps the greatest challenge to affording us a more holistic view of our natural world.
Availability of data and materials
The datasets used and/or analyzed during the current study are available from the corresponding author on reasonable request.
References
Compant S, Samad A, Faist H, Sessitsch A. A review on the plant microbiome: ecology, functions, and emerging trends in microbial application. J Advert Res. 2019;19:29–37.
López-Mondéjar R, Kostovčík M, Lladó S, Carro L, García-Fraile P. Exploring the plant microbiome through multi-omics approaches. In: Kumar V, Kumar M, Sharma S, Prasad R, editors. Probiotics in Agroecosystem. Singapore: Springer Singapore; 2017. p. 233–68.
Douglas AE, Werren JH. Holes in the hologenome: why host-microbe symbioses are not holobionts. MBio. 2016;7:e02099.
Hadrich D. Microbiome research is becoming the key to better understanding health and nutrition. Front Genet. 2018;9:212.
Singh BK, Trivedi P, Egidi E, Macdonald CA, Delgado-Baquerizo M. Crop microbiome and sustainable agriculture. Nat Rev Microbiol. 2020;18:601–2.
Saikkonen K, Nissinen R, Helander M. Toward comprehensive plant microbiome research. Front Ecol Evol. 2020;8:e1002352.
Xu L, Naylor D, Dong Z, Simmons T, Pierroz G, Hixson KK, et al. Drought delays development of the sorghum root microbiome and enriches for monoderm bacteria. Proc Natl Acad Sci U S A. 2018;115:E4284–93.
Rodriguez PA, Rothballer M, Chowdhury SP, Nussbaumer T, Gutjahr C, Falter-Braun P. Systems biology of plant-microbiome interactions. Mol Plant. 2019;12:804–21.
Finkel OM, Salas-González I, Castrillo G, Spaepen S, Law TF, Teixeira PJPL, et al. The effects of soil phosphorus content on plant microbiota are driven by the plant phosphate starvation response. PLoS Biol. 2019;17:e3000534.
Stassen MJJ, Hsu S-H, Pieterse CMJ, Stringlis IA. Coumarin communication along the microbiome–root–shoot axis. Trends Plant Sci. 2020; Available from: http://www.sciencedirect.com/science/article/pii/S1360138520302867
Campos-Soriano L, Bundó M, Bach-Pages M, Chiang S, Chiou T, San Segundo B. Phosphate excess increases susceptibility to pathogen infection in rice. Mol Plant Pathol. 2020;21:555–70.
Cotton TEA, Pétriacq P, Cameron DD, Meselmani MA, Schwarzenbacher R, Rolfe SA, et al. Metabolic regulation of the maize rhizobiome by benzoxazinoids. ISME J. 2019;13:1647–58.
Huang AC, Jiang T, Liu Y-X, Bai Y-C, Reed J, Qu B, et al. A specialized metabolic network selectively modulates Arabidopsis root microbiota. Science. 2019;364. Available from: https://doi.org/10.1126/science.aau6389
Finkel OM, Salas-González I, Castrillo G, Law TF, Conway JM, Jones CD, et al. Root development is maintained by specific bacteria-bacteria interactions within a complex microbiome. Cold Spring Harbor Laboratory. 2019 [cited 2020 Nov 6]. p. 645655. Available from: https://www.biorxiv.org/content/10.1101/645655v1.full-text
Harbort CJ, Hashimoto M, Inoue H, Niu Y, Guan R, Rombolà AD, et al. Root-secreted coumarins and the microbiota interact to improve iron nutrition in Arabidopsis. Cell Host Microbe. 2020; Available from: https://doi.org/10.1016/j.chom.2020.09.006
Durán P, Thiergart T, Garrido-Oter R, Agler M, Kemen E, Schulze-Lefert P, et al. Microbial Interkingdom Interactions in Roots Promote Arabidopsis Survival. Cell. 2018;175:973–83 e14.
Fitzpatrick CR, Salas-González I, Conway JM, Finkel OM, Gilbert S, Russ D, et al. The plant microbiome: from ecology to reductionism and beyond. Annu Rev Microbiol. Annual Reviews; 2020; Available from: https://doi.org/10.1146/annurev-micro-022620-014327
Wei Z, Gu Y, Friman V-P, Kowalchuk GA, Xu Y, Shen Q, et al. Initial soil microbiome composition and functioning predetermine future plant health. Sci Adv. 2019;5:eaaw0759.
Griffiths RI, Thomson BC, James P, Bell T, Bailey M, Whiteley AS. The bacterial biogeography of British soils. Environ Microbiol. 2011;13:1642–54.
Terrat S, Horrigue W, Dequiedt S, Saby NPA, Lelièvre M, Nowak V, et al. Mapping and predictive variations of soil bacterial richness across France. PLoS One. 2017;12:e0186766.
Chemidlin Prévost-Bouré N, Dequiedt S, Thioulouse J, Lelièvre M, Saby NPA, Jolivet C, et al. Similar processes but different environmental filters for soil bacterial and fungal community composition turnover on a broad spatial scale. PLoS One. 2014;9:e111667.
Jacoby RP, Chen L, Schwier M, Koprivova A, Kopriva S. Recent advances in the role of plant metabolites in shaping the root microbiome. F1000Res. 2020;9. Available from: https://doi.org/10.12688/f1000research.21796.1
Korenblum E, Dong Y, Szymanski J, Panda S, Jozwiak A, Massalha H, et al. Rhizosphere microbiome mediates systemic root metabolite exudation by root-to-root signaling. Proc Natl Acad Sci U S A. 2020;117:3874–83.
Coleman-Derr D, Desgarennes D, Fonseca-Garcia C, Gross S, Clingenpeel S, Woyke T, et al. Plant compartment and biogeography affect microbiome composition in cultivated and native Agave species. New Phytol. 2016;209:798–811.
Lundberg DS, Lebeis SL, Paredes SH, Yourstone S, Gehring J, Malfatti S, et al. Defining the core Arabidopsis thaliana root microbiome. Nature. 2012;488:86–90.
Crits-Christoph A, Diamond S, Butterfield CN, Thomas BC, Banfield JF. Novel soil bacteria possess diverse genes for secondary metabolite biosynthesis. Nature. 2018;558:440–4.
Antunes LP, Martins LF, Pereira RV, Thomas AM, Barbosa D, Lemos LN, et al. Microbial community structure and dynamics in thermophilic composting viewed through metagenomics and metatranscriptomics. Sci Rep. 2016;6:38915.
Brunel C, Pouteau R, Dawson W, Pester M, Ramirez KS, van Kleunen M. Towards unraveling macroecological patterns in rhizosphere microbiomes. Trends Plant Sci. 2020; Available from: https://doi.org/10.1016/j.tplants.2020.04.015
Nyholm L, Koziol A, Marcos S, Botnen AB, Aizpurua O, Gopalakrishnan S, et al. Holo-omics: integrated host-microbiota multi-omics for basic and applied biological research. iScience. 2020;23:101414.
Knight R, Vrbanac A, Taylor BC, Aksenov A, Callewaert C, Debelius J, et al. Best practices for analysing microbiomes. Nat Rev Microbiol. 2018;16:410–22.
Franzosa EA, Hsu T, Sirota-Madi A, Shafquat A, Abu-Ali G, Morgan XC, et al. Sequencing and beyond: integrating molecular “omics” for microbial community profiling. Nat Rev Microbiol. 2015;13:360–72.
Zhou W, Reza Sailani M, Contrepois K, Zhou Y, Ahadi S, Leopold SR, et al. Longitudinal multi-omics of host–microbe dynamics in prediabetes. Nature. 2019;569:663–71.
Fischbach MA, Segre JA. Signaling in host-associated microbial communities. Cell. 2016;164:1288–300.
Bradford KJ, Trewavas AJ. Sensitivity thresholds and variable time scales in plant hormone action. Plant Physiol. 1994;105:1029–36.
Swift J, Coruzzi GM. A matter of time — how transient transcription factor interactions create dynamic gene regulatory networks. Biochimica et Biophysica Acta (BBA) - Gene Regulatory Mechanisms. 2017:75–83 Available from: https://doi.org/10.1016/j.bbagrm.2016.08.007.
Jamil IN, Remali J, Azizan KA, Nor Muhammad NA, Arita M, Goh H-H, et al. Systematic Multi-omics integration (MOI) approach in plant systems biology. Front Plant Sci. 2020;11:944.
Jiang D, Armour CR, Hu C, Mei M, Tian C, Sharpton TJ, et al. Microbiome multi-omics network analysis: statistical considerations, limitations, and opportunities. Front Genet. 2019;10:995.
Hubbard CJ, Brock MT, van Diepen LT, Maignien L, Ewers BE, Weinig C. The plant circadian clock influences rhizosphere community structure and function. ISME J. 2018;12:400–10.
Thaiss CA, Levy M, Korem T, Dohnalová L, Shapiro H, Jaitin DA, et al. Microbiota diurnal rhythmicity programs host transcriptome oscillations. Cell. 2016;167:1495–1510.e12.
Lucaciu R, Pelikan C, Gerner SM, Zioutis C, Köstlbacher S, Marx H, et al. A bioinformatics guide to plant microbiome analysis. Front Plant Sci. 2019;10:1313.
Stokstad E. Deep deficit. Science. 2020;368:230–3.
Shi L, Wang Z, Kim WS. Effect of drought stress on shoot growth and physiological response in the cut rose “charming black” at different developmental stages. Horticulture Environ Biotechnol. 2019;60:1–8.
Edwards JA, Santos-Medellín CM, Liechty ZS, Nguyen B, Lurie E, Eason S, et al. Compositional shifts in root-associated bacterial and archaeal microbiota track the plant life cycle in field-grown rice. PLoS Biol. 2018;16:e2003862.
Gao C, Montoya L, Xu L, Madera M, Hollingsworth J, Purdom E, et al. Fungal community assembly in drought-stressed sorghum shows stochasticity, selection, and universal ecological dynamics. Nat Commun. 2020;11:34.
Varoquaux N, Cole B, Gao C, Pierroz G, Baker CR, Patel D, et al. Transcriptomic analysis of field-droughted sorghum from seedling to maturity reveals biotic and metabolic responses. Proc Natl Acad Sci U S A. 2019; Available from: https://doi.org/10.1073/pnas.1907500116
Gao C, Montoya L, Xu L, Madera M, Hollingsworth J, Purdom E, et al. Strong succession in arbuscular mycorrhizal fungal communities. ISME J. 2019;13:214–26.
MacLean AM, Bravo A, Harrison MJ. Plant signaling and metabolic pathways enabling arbuscular mycorrhizal symbiosis. Plant Cell. 2017;29:2319–35.
Augé RM. Water relations, drought and vesicular-arbuscular mycorrhizal symbiosis. Mycorrhiza. 2001;11:3–42.
Augé RM, Toler HD, Saxton AM. Arbuscular mycorrhizal symbiosis alters stomatal conductance of host plants more under drought than under amply watered conditions: a meta-analysis. Mycorrhiza. 2015;25:13–24.
Salas-González I, Reyt G, Flis P, Custódio V, Gopaulchan D, Bakhoum N, et al. Coordination between microbiota and root endodermis supports plant mineral nutrient homeostasis. Science. 2020; Available from: https://doi.org/10.1126/science.abd0695
Zolti A, Green SJ, Sela N, Hadar Y, Minz D. The microbiome as a biosensor: functional profiles elucidate hidden stress in hosts. Microbiome. 2020;8:71.
Chialva M, Ghignone S, Novero M, Hozzein WN, Lanfranco L, Bonfante P. Tomato RNA-seq data mining reveals the taxonomic and functional diversity of root-associated microbiota. Microorganisms. 2019;8. Available from: https://doi.org/10.3390/microorganisms8010038
Ofek-Lalzar M, Sela N, Goldman-Voronov M, Green SJ, Hadar Y, Minz D. Niche and host-associated functional signatures of the root surface microbiome. Nat Commun. 2014;5:4950.
Li X, Jousset A, de Boer W, Carrión VJ, Zhang T, Wang X, et al. Legacy of land use history determines reprogramming of plant physiology by soil microbiome. ISME J. 2019;13:738–51.
Castrillo G, Teixeira PJPL, Paredes SH, Law TF, de Lorenzo L, Feltcher ME, et al. Root microbiota drive direct integration of phosphate stress and immunity. Nature. 2017;543:513–8.
Pinu FR, Beale DJ, Paten AM, Kouremenos K, Swarup S, Schirra HJ, et al. Systems biology and multi-omics integration: viewpoints from the metabolomics research community. Metabolites. 2019;9. Available from: https://doi.org/10.3390/metabo9040076
Schloss PD. Identifying and overcoming threats to reproducibility, replicability, robustness, and generalizability in microbiome research. MBio. 2018;9. Available from: https://doi.org/10.1128/mBio.00525-18
Hu L, Robert CAM, Cadot S, Zhang X, Ye M, Li B, et al. Root exudate metabolites drive plant-soil feedbacks on growth and defense by shaping the rhizosphere microbiota. Nat Commun. 2018;9:2738.
Kudjordjie EN, Sapkota R, Steffensen SK, Fomsgaard IS, Nicolaisen M. Maize synthesized benzoxazinoids affect the host associated microbiome. Microbiome. 2019;7:59.
Krumsiek J, Suhre K, Evans AM, Mitchell MW, Mohney RP, Milburn MV, et al. Mining the unknown: a systems approach to metabolite identification combining genetic and metabolic information. PLoS Genet. 2012;8:e1003005.
Deng S, Caddell D, Yang J, Dahlen L, Washington L. Genome wide association study reveals plant loci controlling heritability of the rhizosphere microbiome. BioRxiv. biorxiv.org; 2020; Available from: https://www.biorxiv.org/content/10.1101/2020.02.21.960377v1.abstract
Horton MW, Bodenhausen N, Beilsmith K, Meng D, Muegge BD, Subramanian S, et al. Genome-wide association study of Arabidopsis thaliana leaf microbial community. Nat Commun. 2014;5:5320.
Wallace JG, Kremling KA, Kovar LL, Buckler ES. Quantitative genetics of the maize leaf microbiome. Phytobiomes J. 2018;2:208–24.
Bergelson J, Mittelstrass J, Horton MW. Characterizing both bacteria and fungi improves understanding of the Arabidopsis root microbiome. Sci Rep. 2019;9:24.
Walters WA, Jin Z, Youngblut N, Wallace JG, Sutter J, Zhang W, et al. Large-scale replicated field study of maize rhizosphere identifies heritable microbes. Proc Natl Acad Sci U S A. 2018;115:7368–73.
Vílchez JI, Yang Y, He D, Zi H, Peng L, Lv S, et al. DNA demethylases are required for myo-inositol-mediated mutualism between plants and beneficial rhizobacteria. Nat Plants. 2020; Available from: https://doi.org/10.1038/s41477-020-0707-2
Ichihashi Y, Date Y, Shino A, Shimizu T, Shibata A, Kumaishi K, et al. Multi-omics analysis on an agroecosystem reveals the significant role of organic nitrogen to increase agricultural crop yield. Proc Natl Acad Sci U S A. 2020; Available from: https://doi.org/10.1073/pnas.1917259117
Zhalnina K, Louie KB, Hao Z, Mansoori N, da Rocha UN, Shi S, et al. Dynamic root exudate chemistry and microbial substrate preferences drive patterns in rhizosphere microbial community assembly. Nat Microbiol. 2018;3:470–80.
Keller M, Hettich R. Environmental proteomics: a paradigm shift in characterizing microbial activities at the molecular level. Microbiol Mol Biol Rev. 2009;73:62–70.
Rabus R. Environmental microbial proteomics: new avenues for a molecular understanding of the functional role of microorganisms in the natural environment. Proteomics. 2013;13:2697–9.
Broberg M, Doonan J, Mundt F, Denman S, McDonald JE. Integrated multi-omic analysis of host-microbiota interactions in acute oak decline. Microbiome. 2018;6:21.
Knief C, Delmotte N, Chaffron S, Stark M, Innerebner G, Wassmann R, et al. Metaproteogenomic analysis of microbial communities in the phyllosphere and rhizosphere of rice. ISME J. 2012;6:1378–90.
Joyce AR, Palsson BØ. The model organism as a system: integrating “omics” data sets. Nat Rev Mol Cell Biol. 2006;7:198–210.
Chong J, Soufan O, Li C, Caraus I, Li S, Bourque G, et al. MetaboAnalyst 4.0: towards more transparent and integrative metabolomics analysis. Nucleic Acids Res. 2018;46:W486–94.
Rahnavard A, Hitchcock D, Pacheco JA, Deik A, Dennis C, Jeanfavre S, et al. netome: a computational framework for metabolite profiling and omics network analysis. Cold Spring Harbor Laboratory. 2018 [cited 2020 Oct 30]. p. 443903. Available from: https://www.biorxiv.org/content/10.1101/443903v1.full-text
Xia T, Hemert JV, Dickerson JA. OmicsAnalyzer: a Cytoscape plug-in suite for modeling omics data. Bioinformatics. 2010;26:2995–6.
Rohart F, Gautier B, Singh A, Lê Cao K-A. mixOmics: an R package for ’omics feature selection and multiple data integration. PLoS Comput Biol. 2017;13:e1005752.
Subramanian I, Verma S, Kumar S, Jere A, Anamika K. Multi-omics data integration, interpretation, and its application. Bioinform Biol Insights. 2020;14:1177932219899051.
Su X, Jing G, Zhang Y, Wu S. Method development for cross-study microbiome data mining: challenges and opportunities. Comput Struct Biotechnol J. 2020;18:2075–80.
Gui S, Yang L, Li J, Luo J, Xu X, Yuan J, et al. ZEAMAP, a comprehensive database adapted to the maize multi-omics Era. iScience. 2020;23:101241.
Muñoz-Benavent M, Hartkopf F, Bossche TVD, Piro VC, García-Ferris C, Latorre A, et al. gNOMO: a multi-omics pipeline for integrated host and microbiome analysis of non-model organisms. NAR Genom Bioinform. Oxford Academic; 2020 [cited 2020 Aug 31];2. Available from: https://academic.oup.com/nargab/article/2/3/lqaa058/5881268
Liu Z, Ma A, Mathé E, Merling M, Ma Q, Liu B. Network analyses in microbiome based on high-throughput multi-omics data. Brief Bioinform. 2020; Available from: https://doi.org/10.1093/bib/bbaa005
Limborg MT, Alberdi A, Kodama M, Roggenbuck M, Kristiansen K, Gilbert MTP. Applied Hologenomics: feasibility and potential in aquaculture. Trends Biotechnol. 2018;36:252–64.
Chen R, Mias GI, Li-Pook-Than J, Jiang L, Lam HYK, Chen R, et al. Personal omics profiling reveals dynamic molecular and medical phenotypes. Cell. 2012;148:1293–307.
Sun YV, Hu Y-J. Integrative analysis of multi-omics data for discovery and functional studies of complex human diseases. Adv Genet. 2016;93:147–90.
Hasin Y, Seldin M, Lusis A. Multi-omics approaches to disease. Genome Biol. 2017;18:83.
Bersanelli M, Mosca E, Remondini D, Giampieri E, Sala C, Castellani G, et al. Methods for the integration of multi-omics data: mathematical aspects. BMC Bioinformatics. 2016;17(Suppl 2):15.
Wang Q, Wang K, Wu W, Giannoulatou E, Ho JWK, Li L. Host and microbiome multi-omics integration: applications and methodologies. Biophys Rev. 2019;11:55–65.
Rodrigues RR, Shulzhenko N, Morgun A. Transkingdom networks: a systems biology approach to identify causal members of host-microbiota interactions. Methods Mol Biol. 2018;1849:227–42.
Ghaemi MS, DiGiulio DB, Contrepois K, Callahan B, Ngo TTM, Lee-McMullen B, et al. Multiomics modeling of the immunome, transcriptome, microbiome, proteome and metabolome adaptations during human pregnancy. Bioinformatics. 2019;35:95–103.
López de Maturana E, Alonso L, Alarcón P, Martín-Antoniano IA, Pineda S, Piorno L, et al. Challenges in the integration of omics and non-omics data. Genes. 2019;10. Available from: https://doi.org/10.3390/genes10030238
Stephens PA, Buskirk SW, Hayward GD, Martínez del Rio C. Information theory and hypothesis testing: a call for pluralism. J Appl Ecol. 2005;42:4–12.
Liu H, Brettell LE, Qiu Z, Singh BK. Microbiome-mediated stress resistance in plants. Trends Plant Sci. 2020; Available from: https://doi.org/10.1016/j.tplants.2020.03.014.
Rubin BE, Diamond S, Cress BF, Crits-Christoph A. Targeted genome editing of bacteria within microbial communities. bioRxiv. biorxiv.org; 2020; Available from: https://www.biorxiv.org/content/10.1101/2020.07.17.209189v2.abstract
Roman-Reyna V, Pinili D, Borja FN, Quibod IL, Groen SC, Alexandrov N, et al. Characterization of the leaf microbiome from whole-genome sequencing data of the 3000 rice genomes project. Rice. 2020;13:72.
Cole BJ, Feltcher ME, Waters RJ, Wetmore KM, Mucyn TS, Ryan EM, et al. Genome-wide identification of bacterial plant colonization genes. PLoS Biol. 2017;15:e2002860.
Bikard D, Euler CW, Jiang W, Nussenzweig PM, Goldberg GW, Duportet X, et al. Exploiting CRISPR-Cas nucleases to produce sequence-specific antimicrobials. Nat Biotechnol. 2014;32:1146–50.
Acknowledgements
Not applicable.
Funding
DOE EPICON (DE-SC0014081), US Department of Agriculture (CRIS 2030-21430-008-00D).
Author information
Authors and Affiliations
Contributions
LX conceived the study, performed the systematic review, and wrote the manuscript. G.P. and H.W. assisted in writing the manuscript. G.C., J.T., and P.L. provided intellectual input in the study and the manuscript. D.C.D generated the figures and revised the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Xu, L., Pierroz, G., Wipf, H.ML. et al. Holo-omics for deciphering plant-microbiome interactions. Microbiome 9, 69 (2021). https://doi.org/10.1186/s40168-021-01014-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s40168-021-01014-z