
Abstract
Background
This study aims to determine predictors of food insecurity in a typical setting where resilience of population is weakened as a result of protracted crises. South Sudan is used as a case study. The rationale of the study is anchored on the perception that food insecurity risk is a function of weak resilience, which in turn is a function of the absence of a combination of certain characteristics and livelihood endowments of a household or a population. Analysis explores the use of SAS® SURVEYLOGISTIC procedure, as it has been established to be useful in analysis of data from sample surveys. The procedure is known for its valid statistical inference.
Results
Employing a survey logistic model with generalised logit link function determined all fitted fixed effects to be statistically significant. Analysis showed that characteristics of households and agriculture (including livestock and fishing) were typically associated with acceptable level of food consumption and implying that the absence of these factors demonstrated weakened resilience and thus increased risk of food insecurity. Analysis also examined the odds of each level of fixed effect compared to the reference level in relation to the food consumption score (the response or outcome variable). Findings were interesting, but largely confirmed what was expected (see Table 5). For instance, it was found out that households headed by younger adults aged 17 years or less fared three times worse than those aged 60 years and above. It was also shown that smaller households fared better than larger ones. The odds of a household with three or less members were twice as worse as those with seven or more members.
Conclusion
We conclude that the method exerted reasonable statistical efficiency for fulfilling the study end, thus providing sufficient evidence for food security analysts and development policy makers in the course of developing appropriate interventions for early preparedness and crises response.
Similar content being viewed by others


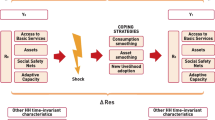
Introduction and motivation of the study
It is out of question that populations in conflict situations bear the brunt of food insecurity vulnerabilities, as their resilience is tremendously weakened. Protracted emergencies particularly render vulnerable populations hopeless, deplete their asset base and, at the lower end, often force them to resort to extreme coping mechanisms. Populations in distressful and protracted emergencies are plunged into extreme poverty and chronic food insecurity, as their resilience gets severely corroded. Instead of involving in developmental and life promoting activities such as investment, entrepreneurship and innovation, they are bogged down to fare for subsistence and survival from their physical insecurity.
The 36th Session of the Committee on World Food Security (CFS) describes protracted crisis as situations in which crises are prolonged and recurrent and that their manifestations, among others, “include disruption of livelihoods and food systems; increasing rates in morbidity and mortality; and increased displacements” [1]. In these situations, large numbers of people or entire communities are displaced and affected by food and malnutrition, thus often require enormous amount of resources and relief interventions.
It is on these grounds that the CFS recently produced the “Framework for Action for Food Security and Nutrition in Protracted Crises” (CFS-FFA). The Framework outlines and describes ten principles for informing and guiding policy on food security and nutrition mitigation in settings mired by protracted crises. Of particular relevance to this paper is CFS-FFA Principle 1 headed “Meet humanitarian and development needs and build resilient livelihoods”. It recommends seven policy and interventional areas, among which is the need to “align humanitarian and development approaches using the existing capacities and strategies of households and communities as entry points for policy and actions, particularly in situations of weak governance and state fragility” [1].
Often times populations living or forced to live in protracted food emergency settings can inadvertently become a cause for conflict and the vicious cycle continues. CFS-FFA Principle 8 states: “Address food security and nutrition in a conflict-sensitive manner … to ensure that food security and nutrition related interventions do not inadvertently cause or exacerbate tensions or conflict” [1]. Severe food insecurity causes anxiety, which in turn causes desperation, which in turn causes households to resort to extreme or even unthinkable forms of survival or coping strategies. In situations where firearms are rampant, extreme coping strategies might be in the form of banditry, armed robbery and rustling of cattle—a practice existing amongst pastoralist communities of South Sudan.
The need to shift from concentrating measurement of food insecurity and malnutrition to measuring resilience of populations in situations of distress is fast becoming relevant and urgent, as experience over the last three decades has shown that food insecurity and what causes it keeps escalating. Otherwise, it is like concentration on measuring the magnitude of ill health, while neglecting the factors that make people become resistant to diseases and ill health and, thereby, informing authorities to allocate more resources to the areas that improve those positive influencing factors. Against the dim light of economic, man-made and natural shocks or strains gaining momentum, it is utterly critical to concentrate efforts on measuring resilience, given its intrinsic value of cushioning against future vulnerability. In general, resilience enhancement is more a developmental strategy than the traditional humanitarian relief and rehabilitation. For more arguments along this line, see Barret and Maxwell [2], Barrett and Heisey [3] and Maxwell [4].
However, food aid organisations seem to shy away from determining resilience assessments and enhancement interventions, apparently on three grounds. First, resilience building requires a multi-dimensional and multi-sector approach. Improving resilience is mostly a function of long-term developmental strategies, rather than short-term actions, in order to bear impact. It is, therefore, seen to fall within the domain of long-term state development plans. Secondly, resilience enhancement measures and activities are seen to fall outside the fundamental mandate of humanitarian aid organisations. Third, humanitarian aid organisations are more concerned with addressing and arresting the severe cases of food emergency such as famine, severe malnourishment and deaths (The Johns Hopkins and the International Federation of Red Cross and Red Crescent Societies, 2004). This then makes measurement and monitoring of vulnerability more appealing than measuring resilience. Yet, according to Mousseau [5], “food aid undermines local agricultural production”, among several other effects.
As the continent’s population is predominantly dependent on agriculture, it only makes a lot of sense that the sector is enabled to boost social protection and vice versa. For this reason, partners in food security and nutrition, led by the Food and Agriculture Organisation of the United Nations (FAO), saw the need to conceptualise how the two sectors, agriculture and social development can be conjoined to benefit each other. The process started with multi-stakeholder consultations from 2013 and still ongoing. One of the outcomes of these stakeholder consultations led to commissioning of a team of researchers comprised of Slater et al. [6], which produced an analytical framework on cohesion between agriculture and social protection. This work builds on an earlier work titled, “Strengthening Coherence in FAO’s Initiatives to Fight Hunger” [7]. The paper states that efforts to address long-term solutions to fight hunger more aggressively are often thwarted by lack of political will, as resources are not made available. The paper proceeds by recommending multi-faceted responses for helping people, majority of whom are in rural settings, break out of hunger and prevent them from being caught in hunger traps. It further recommends support to safety net programmes and a two-tract approach that combines promoting rural and agricultural growth as a measure to protect those who cannot produce food themselves.
Furthermore, within the context of the Comprehensive Africa Agriculture Development Programme [8], the Framework for Africa’s Food Security under its objective “Increased economic opportunities for the vulnerable”, recommends a set of medium and long-term options for improving resilience of the vulnerable. Such durable resilience enhancing developmental options augment and improve on the framework’s other objectives of improved risk management, increased supply of affordable commodities and increased quality of diets among target groups [9]. Indeed, the focus on durable and forward-looking options to build resilience of the vulnerable seems to feature prominently more than ever before in contemporary food security and nutrition frameworks.
As the recommendations and plans for integrating socioeconomic and rural development objectives with humanitarian efforts to mitigate vulnerability and strengthen resilience of vulnerable population are gaining momentum, the need for producing evidence for monitoring the state of resilience of populations in distressful food insecurity situations, equality becomes of interest. Current measures based on periodically conducted household surveys are still centred on determining vulnerability for the purpose of relief and rehabilitation, rather than for boosting resilience and prevent future vulnerabilities and the devastating after-shock effects. In other words, there is need to establish measures for determining the probability of future risk, which resilience-based measures offer.
The purpose of the study is, therefore, to find statistically robust and efficient measures that identify the set of factors that determine and predict the risk to food insecurity. Resilience-based measures seem to provide the answer to this question.
In food security parlance, vulnerability is exposure to risk, shocks and stress. It is characterised by several dimensions of deprivation such as physical weakness, isolation and poverty [10]. For rural populations, vulnerability can come as a result of depletion of such livelihood assets, capitals and/or endowments as harvest failure, death of livestock due to disease or drought and, in the case of fishing and forest dependent communities, displacement. The South Sudan Food Security Monitoring Survey reports sporadic displacement and conflict-related instability caused depletion of harvests, lack of planting selling off of assets and livestock in exchange for food [11].
Sample and data
The study dataset is from the Food Security Monitoring Survey (FSMS), which was conducted at the peak of the conflict that sparked in South Sudan in mid-December 2013. The sample size was 3692 households, which covered all ten states of South Sudan. The sampling technique used in this study was based on multi-stage stratified random sampling involving selection of census enumeration areas, then clusters of villages, then households.
The main purpose of the FSMS was to provide essential information to help as baseline for monitoring the food security situation in South Sudan as the conflict escalated. The survey was also aimed at determining the seriousness of food security situation in order to mitigate effective and efficient humanitarian interventions, early warning and preparedness. In fact, led by the World Food Programme of the United Nations (WFP), the survey helped in production of the South Sudan Food Security Monitoring—a situation update [11]. Twenty other organisations, including UN agencies, government line ministries, international NGOs and the South Sudan Food Security Technical Secretariat (FSTS) contributed to the survey.
Data collected included a range of demographic variables (age, sex, and household size) and livelihood sustaining essentials, namely; whether or not a household cultivated crops in the preceding season, whether a household member did fishing and whether a household owned livestock and main source of income. The two-stage stratified sampling method was used to select households for the study based on cartographic data (maps, clusters and enumeration areas) of the 2008 Population and Housing Census, which provided the sampling frame. The sample was then drawn from all ten states, 150 clusters, although five clusters were dropped due to non-accessibility. The datasets analysed have mixed structure with fixed and random effects (clusters).
The outcome variable Food Consumption Score (FCS) was calculated as described in Lokosang et al. [12] and the World Food Programme, Vulnerability Analysis and Mapping Branch [13]. FCS in the datasets takes the form of ordered polytomous (or multinomial categories: “poor”, “borderline” and “acceptable” consumption. Since the aim of the study was to predict how the explanatory variables contributed to household food insecurity, the categories “poor” and “borderline” food consumption score were taken to combine as the reference category, henceforth referred to as ‘worse’ food consumption level. The frequency profile of the food consumption score is as given in Table 1 below.
Methods
The statistical technique applied
Stratification and clustering of the complex sample design as done in most researches generally have an impact on the accuracy of both the model variance estimates and the test statistics. It is of essence examining whether or not the parameter estimates will change when the complexity of the survey design is taken into account by fitting a main effect model using survey logistic technique. A distinct measure in the procedure is that it accommodates sample weights.
As data for this study were drawn from a stratified survey sampling, the survey logistic regression model was used to model data from a complex survey design [14]. The method is known to account for the complexity of survey design, that is, it takes into account the effects of stratification, clustering used in the survey design and unequal assignment of sampling weights. The theory of both the survey logistic regression model and the ordinary logistic regression model are the same. The only difference is in the estimation of variances. If the data are drawn from a simple random sampling then the survey logistic and the ordinary logistic give identical estimates of the variances. But, if the data are from a complex survey design the estimates of the coefficients and the standard errors will be different due to the effects of stratification and clustering. The effects of both sampling-survey design and weights on the data structure are discussed in the next section of the paper. Application of the method follows in the works of Cox and Snell [15], Walker and Duncan [16], Morel [17], Rao et al. [18], and Roberts et al. [19]. A member of the exponential family [20], the procedure fits linear logistic regression models for survey data with discrete responses based on the maximum likelihood estimation. For more and exhaustive review of the statistical theory and mathematical formulation, please refer to Rao [18], Heeringa et al. [21], Walker and Duncan [16], Cox and Snell [15] and McCullagh [22].
Estimation and test of hypothesis
Significant or non-significant estimates determine whether to reject or not to reject the null hypothesis. In the case of this study, the null hypothesis stated that each parameter value contributed zero in its relationship with food consumption score. For an estimate to differ significantly from zero, its value must be less than the significance level of 0.05.
Model evaluation
The model was evaluated using the Akaike’s Information Criteria (AIC) and the Schwarz Criteria (SC). These criteria were used to impose penalties to the likelihood ratio statistic −2 log L [23]. Generally, the decision on either whether the AIC or the SC criterion is the best, depends on the objectives of the study and the more appealing model; thus if the interest is in the consistency of the approximation and the model fit, a model based on AIC is preferred. However, if interest is in the order of the model, then a model based on SC is preferred. For further discussion on model selection refer to Buckland et al. [24], Burnham and Anderson [25].
Results of goodness-of-fit tests were not presented. Due to the complex sampling designs, existing software was not yet developed or implemented for these tests based on the logistic regression. According to Archera et al. [26], available software usually takes the form of simulation studies in which results of analysis were compared with ordinary goodness-of-fit statistics. For instance, the Hosmer and Lemeshow goodness-of-fit test statistic, the Pearson residual, and the deviance residual test are not yet incorporated in the Survey Logistic procedure. Thus, for the assessment of the goodness-of-fit of the model used in the study, the Akaike Information Criterion (AIC), the Schwarz Criterion (SC), and the −2 log likelihood statistic were used as approximations for the goodness-of-fit test.
Results
In the first step of the analysis, two models fitted based on the choice were compared: cumulative logit link function and generalised logit link function. Results of type 3 analysis of effects or the cumulative link function are presented in Table 2.
Table 2 shows that all fixed effects were significant factors except fishing, which was marginally non-significant. This result shows that fishing might not have influenced the level of food consumption and that households with at least one member involved in fishing did not statistically differ significantly from those with no member who did fishing. The score Chi-square for testing the proportional odds assumption is 93,300.1007, which is highly significant (probability <0.0001). This indicates that the cumulative logit model might not adequately fit the data. An alternative model is to use the generalised logit model (i.e. fitting a model with glogit option). The second model resulted in the Type 3 analysis which is presented in Table 3.
The generalised logit model resulted in all effects contributing significantly. We proceeded to examine parameter estimates of the model effects based on the maximum likelihood and the related Wald test of hypothesis. The model fit statistics and prediction of model accuracy power is presented in Table 4.
The influence of each predictor variable on food consumption score was determined by examining the coefficients of each factor. It is important to note that a factor level with a higher coefficient indicates a greater probability of being in one of the upper level categories of the cumulative response. A factor with a negative sign indicates that its level had a negative effect on the corresponding category of the response variable. Conversely, a factor with a positive sign corresponding to a category (e.g. male for gender) indicates a positive association with the reference category of the response variable.
The maximum likelihood estimates showed that households headed by males aged 60 years or less, had six members or less, cultivated crops, owned livestock, had a member who did fishing and earned incomes from sale of livestock or animal products, had better chance of associating with ‘acceptable’ food consumption score compared to those headed by females who were over 60 years, had seven or more members, did not cultivate crops, did not own livestock and lived mainly on agriculture and wages. This means that in practice the listed factors were typical determinants of how a household fared in consuming food. Crop cultivation for food and income and ownership of livestock improved the consumption levels, vis-à-vis coping with or resilient to food insecurity strains. In general, estimation of model parameters based on test of hypothesis as stated in “Methods” section led to six of the seven variables having levels with significant values compared to reference (or constrained) levels.
The next step was to determine the relationships between each of the fitted fixed effects and the likelihood of corresponding to ‘worse’ FCS, controlling for other household- and cluster-level characteristics. We examined the parameter estimates for each fixed effect which the glogit model generated (see Table 5). These values were transformed into proportional odds to allow comparisons of between-level relationships in terms of associations of the fixed effects with the ‘worse’ FCS level.
In Table 5 each fixed effect category was compared with the reference category and the point estimate of the odds ratio obtained. An odds ratio value greater than one indicates that the given level of the fixed effect associated more with the ‘worse’ FCS score compared to the reference category. The bigger the odds ratio value the more significant is the relationship between the levels of the fixed effect with the ‘worse’ category of the outcome variable. For instance it was shown that the odds for a household head aged 17 years or less associating with ‘worse’ food consumption score were about three times those of a household headed by a person aged sixty years or above. This finding augurs well with common knowledge. Younger household heads are not experienced enough to fend for family support. The very high odds ratio value corresponding with livestock ownership indicated with >999.999 is due to the large Wald Chi-square estimate of fixed effect ‘livestock’. It simply signifies that the odds of a household owning livestock compared to one not owning were extremely large or over 1000 times. This finding begs the question, where pastoralist households extremely worse off than non-pastoralist communities? Much as this could be investigated further, the reality of the situation in South Sudan at the time of data collection suggested that non-crop farming communities fared badly compared to peasant communities. The armed conflict, which had raged for months and throughout the survey, could have only made matters worse for this category of the population.
Finally, we examined the model fit (see Table 6). Note that the aim of fitting an ordinal logistic regression model was to predict the ordinal outcome of the response variable Food Consumption Scores with three categories: ‘poor’, ‘borderline’ and ‘acceptable’ consumption. The model determined all seven variables as possible predictors of food consumption score. The variable fishing was determined to be statistically significant after fitting the generalised logit model.
Generally, the model showed reasonably satisfactory goodness-of-fit statistics with both the Pearson’s Chi-square and Deviance Chi-square values being non-significant, which indicated that the observed data and the model predictions were similar.
Discussion
To perform estimation, the procedure modifies the standard likelihood equations in order to cater for the case of weighted observations. Thus, the method called pseudo-maximum likelihood estimation (PML) is used instead such that the clustering effects of the model are properly accounted for [17, 19, 27, 28].
This paper sets to answer one fundamental question, “is the strong statistical evidence to suggest the seven explanatory variables analysed in the model are predictors of household food consumption based on the survey sample?” Using the sampling weights and the generalised logit link function, the survey logistic procedure determined all seven as predictors of food consumption. Comparing the model with generalised logit link function and one with cumulative function both methods yielded almost similar coefficient estimates of the Wald test.
The negative coefficients in Table 4 corresponding to four factors (age and gender of household head, crop cultivation, fishing and main source of livelihood), however, indicate that the odds of these factors are in favour of the reference categories. Positive coefficient estimates to the contrary point to the odds being in favour of the corresponding category levels of the factors. It is shown that the very large coefficient estimates of the factor ‘owned livestock’ point to high odds of association with the reference category of the dependent variable, i.e. ‘acceptable’ food consumption score. It was clear that owning livestock associated highly significantly with ‘acceptable’ food consumption score. Thus, livestock could be singled out as a better means of resilience to households in chronic or protracted food insecurity settings. This finding is consistent with that by Ickowicz, et al. [29] who established that pastoral resilience is greater than agricultural resilience.
Of concern though, is the finding that the Chi-square test of the proportional odds assumption (the null hypothesis) gave the value 118,448.239, which is highly significant. This indicates that the cumulative logit model might not adequately fit the data. Thus, arguments for an alternative analysis such as those advanced by Williams [30] become relevant. He establishes a model (the Generalised Ordered Logit) that partially estimates the proportional odds assumption, which is quite often violated. Williams [30] argues that this partial proportional odds model (or gologit) is “more parsimonious and interpretable than those estimated by non-ordinal method, such as multinomial logistic regression”. The down side to this approach is that model convergence becomes an issue in presence of factors with missing data as is the case with survey data. This was the main constraint for not using the gologit technique.
Other limitations to the study could rest on the categories of the response variable as observed in Lokosang et al. [12] and World Food Programme [13]. Having a too wide or too narrow category of the response variable (in our case FCS) could result in inaccurate results. As shown in Table 1, the category ‘poor’ FCS amounted to only 11.6 % of the responses—thus too narrow, while the ‘Acceptable’ FCS was too wide at 59.6 %. Yet, another drawback is in the presence of missing responses in some of the selected variables for the study. This calls for employment of some of the pragmatic methods for imputing missing data so that analysis could lead to more accurate findings. This is, however, not in the scope of this study.
Conclusion and future direction
Data analysis explored in this paper featuring the Survey Logistic Model led to the conclusion that the technique is not only robust, but also appropriate for analysis of the type of data explored. The method proves to be relatively efficient and could thus be applied by food security analysts using similar datasets and for similar purposes. The results of the study may be useful evidence for crises response and disaster recovery interventions targeting populations in distressful situations. Good data that have no or insignificantly few missing case, can guarantee the power of the model.
Furthermore, it is important to note that the best strategy to buffer against humanitarian disaster risks is how much a population is able to withstand their serious impact. Therefore, the results give cause for reflection on what and where to prioritise for improving resilience of populations.
Finally, the technique could help governments in targeting areas identified to be at higher risk of food insecurity shocks with a set of resilience building interventions such as rural development programmes, social protections, among many other possible options. It is recommended that similar food security surveys as the one on which we have based our analysis should include collection of geographical information coordinates in order to enable spatial analysis.
References
Committee on World Food Security. Framework for action for food security and nutrition in protracted crises. Rome: FAO; 2015.
Barret CB, Maxwell DG. Food aid after fifty years: recasting its role (priorities for development economics). New York: Routeledge; 2005.
Barret CB, Heisey KC. How effectively does multilateral food aid respond to fluctuating needs? Food Policy. 2002;27:477–91.
Maxwell S. Food security: a post-modern perspective. Food Policy. 1996;21:155–70.
Mousseau F. Food AID or food sovereignty? Ending world hunger in our time. Oakland: The Oakland Institute; 2005.
Slater R, Harman L, Wiggins S, Ulrichs M. Coherence between agriculture and social protection: an analytical framework. Rome: FAO; 2015.
Strengthening coherence in FAO’s initiatives to fight hunger. http://www.fao.org/docrep/MEETING/007/J0710E.HTM.
New Partnership for Africa’s Development. Comprehensive Africa agriculture development programme. Rome: FAO; 2003.
New Partnership for Africa’s Development. CAADP pillar III framework for Africa’s food security (FAFS). Midrand: NEPAD Secretariat; 2009.
Chambers R. Vulnerability, Coping and Policy. IDS Bull. 2006;37:33–40.
World Food Programme. South Sudan food security monitoring, VAM food security analysis, round 13. Juba: WFP; 2014.
Lokosang L, Ramroop S, Hendriks SL. Establishing a robust technique for monitoring and early warning of food insecurity in post-conflict Southern Sudan using ordinal logistic regression. Agrekon. 2010;50:101–30.
World Food Programme VA and MB (ODAV). Food consumption analysis: calculation and use of the food consumption score in food security analysis. Rome: WFP; 2008.
SAS Institute. SAS/STAT 9.3 production GRIMMIX procedure for windows. Cary: SAS Institute Inc; 2011.
Cox DR, Snell EJ. The analysis of binary data. 2nd ed. London: Chapman and Hall; 1989.
Walker SH, Duncan DB. Estimation of the probability of an event as a function of several independent variables. Biometrika. 1967;54:167–79.
Morel JG. Logistic regression under complex survey designs. Surv Methodol. 1989;15:203–23.
Rao JNK, Wu CFJ, Yue K. Some recent work on resampling methods for complex surveys. Surv Methodol. 1992;18:209–17.
Roberts G, Rao JNK, Kumar S. Logistic regression analysis of sample survey data. Biometrika. 1987;74:1–12.
McCullagh P, Nelder JA. Generalized linear models. 2nd ed. London: Chapman and Hall; 1989.
Heeringa S, West B, Berglund PA. Applied survey data analysis. Boca Raton: Chapman and Hall; 2010.
McCullagh P. Regression models for ordinal Data (with discussion). J R Stat Soc B. 1980;42:42.
Agresti A. Analysis of ordinal categorical data. New York: Wiley; 2004.
Buckland ST, Burnham KP, Augustin NH. Model selection: an integral part of inference. Biometrics. 1997;53:603–18.
Burnham KP, Anderson DR. Model selection and multimodel inference: a practical information-theoretic approach. 2nd ed. New York: Springer; 2002.
Archera KJ, Lemeshow S, Hosmer DW. Goodness-of-fit tests for logistic regression models when data are collected using a complex sampling design. Comput Stat Data Anal. 2006;51:4450–64.
Skinner CJ, Holt D, Smith TMF. Analysis of complex surveys. New York: Wiley; 1989.
Chambers RL, Skinner CJ. Analysis of survey data. Chichester: Wiley; 2003.
Ickowicz A, Ancey V, Corniaux C, Duteurtre G, Poccard-Chappuis R, Touré I, Vall E, Wane A. Crop—livestock production systems in the Sahel—increasing resilience for adaptation to climate change and preserving food security. In: Meybeck A, Lankoski J, Redfern S, Azzu N, Gitx V, editors. Building resilience for adaptation to climate change in the agricultural sector. Rome: FAO; 2012.
Williams R. Generalized ordered logit/partial proportional odds models for ordinal dependent variables. Stata J. 2006;6:58–82.
Authors’ contributions
LL prepared the dataset for analysis, carried out the analysis in SAS version 9.3, made the necessary interpretations and drafted the initial manuscript. SR reviewed the entire manuscript and recommended changes especially in the results and discussion sections. TZ initiated the statistical technique used in the analysis, reviewed methods and tables and advised on some of the material cited. All authors read and approved the final manuscript.
Acknowledgements
The authors appreciate the cooperation of Mr. James Lemi Lugga and the management of the National Bureau of Statistics of South Sudan who provided the raw dataset. The study was made possible thanks to the University of KwaZulu-Natal’s research facilities and funding for its publication. The dataset was obtained without charge.
Competing interests
The authors categorically declare that they have no competing interests whatsoever in the conduct of the study save for purpose mentioned therein.
Ethical questions
The study used secondary data obtained from South Sudan Central Bureau of Statistics, which is an open source. The South Sudan Food Security Monitoring Survey (FSMS) was conducted in the latter trimester of 2014 with a collaboration of organisations and followed standard practice for eliciting respondent consent. For more information on the South Sudan FSMS, please refer to the survey report by the World Food Programme [11].
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Lokosang, L.B., Ramroop, S. & Zewotir, T. The effect of weakened resilience on food insecurity in protracted crisis: the case of South Sudan. Agric & Food Secur 5, 2 (2016). https://doi.org/10.1186/s40066-016-0051-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s40066-016-0051-y