
Abstract
Variants of the Newton method are very popular for solving unconstrained optimization problems. The study on global convergence of the BFGS method has also made good progress. The q-gradient reduces to its classical version when q approaches 1. In this paper, we propose a quantum-Broyden–Fletcher–Goldfarb–Shanno algorithm where the Hessian is constructed using the q-gradient and descent direction is found at each iteration. The algorithm presented in this paper is implemented by applying the independent parameter q in the Armijo–Wolfe conditions to compute the step length which guarantees that the objective function value decreases. The global convergence is established without the convexity assumption on the objective function. Further, the proposed method is verified by the numerical test problems and the results are depicted through the performance profiles.
Similar content being viewed by others


1 Introduction
Several numerical methods have been developed extensively for solving unconstrained optimization problems. The gradient descent method is one of the most simplest and commonly used method in the field of the optimization [1]. This method is globally convergent, but suffers from the slow convergence rate as the iterative point approaches the minimizer. In order to improve the convergence rate, optimizers use the Newton method [1]. This method is one of the most popular methods due to its quadratic convergence. A major disadvantage of the Newton method is its slowness or non-convergence for the starting point not being taken close to an optima, and it also requires one to compute the inverse of the Hessian at every iteration, which is rather costly. The components of the Hessian matrix are constructed using the classical derivative, which is positive definite at every iteration. In quasi-Newton methods, instead of computing the actual Hessian, an approximation of the Hessian is considered [1]. These methods use only first derivatives to make an approximation whose computing costs are low.
The Broyden–Fletcher–Goldfarb–Shanno (BFGS) method is the type of quasi-Newton methods for solving unconstrained nonlinear optimization problems which came into existence from the independent work of Broyden [2], Fletcher [3], Goldfarb [4], and Shanno [5]. Since the 1970s the BFGS method became more and more popular and today it is accepted as one of the best quasi-Newton methods. Along these years, many attempts have been made to improve the performance of the quasi-Newton methods [6–18].
The global convergence of the BFGS method have been studied by several authors [5, 12, 19–21] under the convexity assumption on the objective function. An example was given in [22] to fail the standard BFGS method for non-convex functions with inexact line search [12]. A modified BFGS method was developed to converge globally without a convexity assumption on the objective function [23]. In the reference, Li et al. concerned with the open problem of whether the BFGS method with inexact line search converges globally when applied to non-convex unconstrained optimization problems [23]. We propose a cautious BFGS update and prove that the method with either a Wolfe-type or an Armijo-type line search converges globally if the function to be minimized has Lipschitz continuous gradients. The q-calculus, particularly known as quantum calculus, has gained a lot of interest in various fields of science, mathematics [24], physics [25], quantum theory [26], statistical mechanics [27] and signal processing [28], etc., where the q-derivative is employed. It is also known as the Jackson derivative, as the concept was first introduced by Jackson [29]; it was further studied in the case of a q-difference equation by Carmichael [30], Mason [31], Adams [32] and Trjitzinsky [33]. The word quantum usually refers to the smallest discrete quantity of some physical property and it comes from the Latin word “quantus”, which literally means how many. In mathematics, the quantum calculus is referred as the calculus without limits and it replaces the classical derivative by a difference operator.
A q-version of the steepest descent method was first developed in the field of optimization to solve single objective nonlinear unconstrained problems. The method was able to escape from many local minima and reach the global minimum [34]. The q-LMS (Least Mean Square) algorithm is proposed by employing the q-gradient to compute the secant of the cost function instead of the tangent [28]. The algorithm takes the larger steps towards the optimum solution and achieves a higher convergence rate. An improved version of q-LMS algorithm was developed based on a new class of stochastic q-gradient methods. The proposed approach shows the high convergence rate by utilizing the concept of error correlation energy, and normalization of signal [35]. Global optimization using the q-gradient was further studied in [36], where the parameter q is a dilation that is used to control the degree of localness of the search, solving several multimodal functions. Furthermore, a modified Newton method based on a deterministic scheme using the q-derivative was proposed [37, 38]. Recently, a mathematical package for q-series and partition theory applications has been developed using MATHEMATICA software [39].
A sequence \({q^{k}}\) is introduced instead of using a fixed positive number q in the Newton and limited memory BFGS schemes in [37, 40]. After some large value of k, it is obvious that the Hessian becomes almost the same as the exact Hessian of the objective function. The concept of q-gradient, in contrast to the classical gradient in the q-least mean squares algorithm [28], provides extra freedom to control the performance of the algorithm, which we adopt in our proposed method.
In this article, we propose a method using the q-derivative for solving unconstrained optimization problems. This algorithm is different from the classical BFGS algorithm as the search process moves from global in the beginning to local at the end. We utilize an independent parameter \(q \in (0,1)\) in Armijo–Wolfe conditions for finding the step length. The proposed algorithm with the Armijo–Wolfe line search is globally convergent for general objective functions. Then we compare the new approach with the existing method.
his paper is organized as follows: In the next section, we give the preliminary idea about the q-calculus. In Sect. 3, we present the q-BFGS (quantum-Broyden–Fletcher–Goldfarb–Shanno) method, using q-calculus. In Sect. 4, the global convergence of proposed algorithm is proved. In Sect. 5, we report some numerical experiments. Finally, we present a conclusion in the last section.
2 Preliminaries
In this section, we present some basic definitions of q-calculus. Given value of \(q\neq 1\), we present the q-integer \([n]_{q}\) [41] by
for \(n \in \mathbb{N}\). The q-derivative \(D_{q} [f]\) [42] of a function \(f : \mathbb{R} \to \mathbb{R}\) is given by
whenever scalar \(q\in (0, 1)\), \(x\ne 0\) and \(D_{q}[f](0) = f'(0)\) provided \(f'(0)\) exists. Note that
if f is differentiable. The q-derivative of a function of the form \(x^{n}\) is
Let \(f(x)\) be a continuous function on \([a, b]\). Then there exists \(\hat{q} \in (0, 1)\) and \(x \in (a,b)\) [43] such that
for \(q \in (\hat{q}, 1) \cup (1, \hat{q}^{-1})\). The q-partial derivative of a function \(f : \mathbb{R}^{n} \to \mathbb{R}\) at \(x\in \mathbb{R}^{n}\) with respect to \(x_{i}\), where scalar \(q \in (0,1)\), is given as [34]
We now choose the parameter q as a vector, that is,
Then the q-gradient vector [34] of f is
Let \(\{ q^{k}_{i} \}\) be a real sequence defined by
for each \(i=1,\dots ,n\), where \(k \in \{0\}\cup \mathbb{N}\) and \(q^{0}_{i} \in (0, 1)\) is a fixed starting number, then the sequence \(\{q^{k}_{i}\}\) converges to \((1,\dots ,1)^{T}\) as \(k \to \infty \) [38]. Thus, the q-gradient reduces to its classical version. For the sake of convenience, we represent the q-gradient vector of f at \(x^{k}\) as
Example 1
Consider a function \(f : \mathbb{R}^{2} \to \mathbb{R}\) as \(f(x) = x_{1}^{2} x_{2} + x_{2}^{2}\). Then the q-gradient is given as
We focus our attention on solving the following unconstrained optimization problems:
where \(f : \mathbb{R}^{n} \to \mathbb{R}\) is a continuously q-derivative. In the next section, we present the q-BFGS algorithm.
3 On q-BFGS algorithm
The BFGS method for solving optimization problems (4) generates a sequence \(\{x^{k}\}\) by the following iterative scheme:
for \(k=\{0\}\cup \mathbb{N}\), where \(\alpha _{k}\) is the step length, and \(d_{q^{k}}^{k}\) is the q-BFGS descent direction obtained by solving the following equation:
and, for \(k\ge 1\), we have
where \(W^{k}\) is the q-quasi-Newton update Hessian. The sequence \(\{W^{k}\}\) satisfies the following equation:
where \(y^{k}=g_{q^{k}}^{k+1} - g_{q^{k}}^{k}\). We call the famous BFGS (Broyden [2], Fletcher [3], Goldfarb [4], and Shanno [5]) updated formula in the context of q-calculus: q-BFGS. Thus, the Hessian \(W^{k}\) is updated by the q-BFGS formula:
where \(s^{k} = x^{k+1}- x^{k}\). A good property of Eq. (7) is that \(W^{k+1}\) should inherit the positive definiteness of \(W^{k}\) as long as \((y^{k})^{T} s^{k} >0\) and numerically support in the sense of classical BFGS update. The condition \((y^{k})^{T} s^{k} >0\) is guaranteed to hold if the step length \(\alpha _{k}\) is determined by the exact or inexact line search methods. For computing the step length, the modified Armijo–Wolfe line search conditions due to the q-gradient are presented as
and
where \(0<\sigma _{1}<\sigma _{2}<1\). The first condition (8) is called the Armijo condition; it ensures a sufficient reduction of the objective function while the second condition (9) is called the curvature condition which ensures the nonacceptance short step length.
The Armijo-type line search does not ensure the condition \((y^{k})^{T} s^{k} >0\) and hence \(W^{k+1}\) is not positive definite even if \(W^{k}\) is positive definite. In order to ensure positive definiteness of \(W^{k+1}\), the condition \((y^{k} )^{T} s^{k} >0 \) is sometimes used to decide whether or not \(W^{k}\) is updated. More specifically, we present the following update due to [23]:
where ϵ and β are positive constants.
It is not difficult to see from (10) that the updated matrix \(W^{k}\) is symmetric and positive definite for all k, which is in turn implies that \(\{ f(x^{k}) \}\) is a non-increasing sequence when the modified Armijo–Wolfe line search conditions (8) and (9) are used. On the basis of the above theory, we present the following q-BFGS Algorithm 1. In the next section, we shall investigate the global convergence of Algorithm 1.

q-BFGS algorithm
4 Global convergence
In this section, we present the global convergence of Algorithm 1 under the following two assumptions.
Assumption 1
The objective function \(f(x)\) has a lower bound on the level set
where \(x^{0}\) is the starting point of Algorithm 1.
Assumption 2
Let function f be a continuously q-derivative on Ω, and there exists a constant \(L>0\) such that \(\lVert g_{q^{k}}(x) - g_{q^{k}}(y) \rVert \le L(x-y)\), for each \(x,y\in \Omega \).
Since \(\{ f(x^{k}) \}\) is a non-increasing sequence, it is clear that the sequence \(\{ x^{k} \}\) generated by Algorithm 1 is contained in Ω. We present the index set as
We can again express (10) as
The following lemma is used to prove the global convergence of Algorithm 1 within the context of q-calculus.
Lemma 3
Let f be satisfied by Assumption 1and Assumption 2. Let \(\{x^{k}\}\) be generated by Algorithm 1, with \(q^{k}_{i} \in (0 , 1)\), where \(i=1,\dots ,n\). If there are positive constants \(\gamma _{1}\), and \(\gamma _{2}\) such that the inequalities
-
1)
\(\lVert W^{k} s^{k} \rVert \le \gamma _{1} \lVert s^{k} \rVert \),
-
2)
\((s^{k} )^{T} W^{k} s^{k} \ge \gamma _{2} \lVert s^{k} \rVert ^{2}\),
hold for infinitely many k, then we have
Proof
Since \(s^{k} = \alpha _{k} d_{q^{k}}^{k}\), using Part 1 of this lemma, and (6), we have
and
Substituting \(s^{k} = \alpha _{k} d_{q^{k}}^{k}\) in Part 2, we get
We present the case where the Armijo-type line search (8) is used with backtracking parameter ρ. If \(\alpha _{k} \ne 1\), then we have
From the q-mean value theorem, there is a \(\theta _{k} \in (0,1)\) such that
that is,
From Assumption 2, we get
From (17) and (18), we get for any \(k \in K\)
Since \(-g_{q^{k}}(x^{k})= W^{k} d_{q^{k}}^{k}\),
Using (16) in the above inequality we get
We now consider the case where the Wolfe-type line search (9) is used. From (9) and Assumption 2, we get
This implies that
Since \(-g_{q^{k}}^{k} = W^{k}d_{q^{k}}^{k}\),
Since \(W^{k} d_{q^{k}}^{k} \ge \gamma _{2} \lVert d_{q^{k}}^{k} \rVert ^{2}\),
The inequalities (19) together with (20) show that \(\{ \alpha _{k}\}_{ k\in K}\) is bounded below away from zero when we use the Armijo–Wolfe line search conditions. Moreover,
that is,
this gives
This together with (9) gives
Since \(g_{q^{k}}^{k} = -W^{k} d_{q^{k}}^{k}\),
This together with (15) and (16) implies (12). □
Lemma 3 indicates that to prove the global convergence of Algorithm 1, it suffices to show that there are positive constants \(\gamma _{1}\) and \(\gamma _{2}\) such that Part 1 and Part 2 hold for infinitely many k. For this purpose, we require the following lemma which may be proved in the light of [20, Theorem 2.1].
Lemma 4
If there are positive constants \(\gamma _{1}\) and \(\gamma _{2}\) such that, for each \(k\ge 0\),
then there exist constants \(\gamma _{1}\) and \(\gamma _{2}\) such that, for any positive integer t, Part 1 and Part 2 of Lemma 3hold for at least \(\lceil \frac{t}{2}\rceil \) values of \(k\in \{1,\dots ,t\}\).
From Lemma 3 and Lemma 4, we now prove the global convergence for Algorithm 1.
Theorem 5
Let f satisfy Assumption 1and Assumption 2, and \(\{x^{k}\}\) be generated by Algorithm 1. Then Eq. (12) holds.
Proof
If K is finite then \(W^{k}\) remains constant after a finite number of iterations. Since \(W^{k}\) is symmetric and positive definite for each k, it is obvious that there are constants \(\gamma _{1}\), and \(\gamma _{2}\) such that Part 1 and Part 2 of Lemma 3 hold for all k sufficiently large. If K is infinite, then for the sake of contradiction (12) is not true. Then there exists a positive constant δ such that for all k
Since \((y^{k})^{T}s^{k}\ge \epsilon \delta ^{\alpha }\lVert s^{k} \rVert ^{2}\),
We know that \(\lVert y^{k} \rVert ^{2} \le L^{2}\lVert s^{k} \rVert ^{2}\). Thus, we get
From Assumption 2, we get
for each \(k\ge 0\), where \(M =\frac{L^{2}}{ \epsilon \delta ^{\alpha }}\). Applying Lemma 4 to the matrix subsequence \(\{ W^{k}\}_{k\in K}\), we conclude that Part 1 and Part 2 of Lemma 3 hold for infinitely many k. There exists a subsequence of \(\{ x^{k} \}\) converging to the q-critical point of (4). As \(k \to \infty \), since \(q^{k}\) approaches \((1,1,\ldots , 1)^{T}\), a q-critical point eventually approximates a critical point. If the objective function f is convex then every local minimum point is a global minimum point. Since the sequence \(\{f(x^{k})\}\) converges, every accumulation point of \(\{x^{k}\}\) is a global optimal solution of (4). Then Lemma 3 completes the proof. □
The above theorem proved the global convergence of q-BFGS algorithm without the convexity assumption on the objective function.
5 Numerical experiments
This section reports some numerical experiments with Algorithm 1. We teated on some test problems taken from [44]. Our numerical experiments are performed on a Laptop with Intel(R) Core(TM) CPU (i3-4005U@1.70 GHz) and 4 GB RAM, with MATLAB (2017a).
We used the condition
as the stopping criterion. The program stops if the total iteration number is larger than 400. For each problem we choose the initial matrix \(W^{0}=I_{n}\), where \(I_{n}\) is an identity matrix. First, we find the q-gradient of the following problem when the parameter q is not fixed.
Example 2
Consider a function \(f : \mathbb{R}^{2} \to \mathbb{R}\) such that
We need to find the q-gradient vector at \(x=(2, 3)^{T}\) and \(x=(-4, 5)^{T}\). This function uses the sequence \(\{q^{k}\}\) with an initial vector of
In fact, Tables 1 and 2 show the computational values of \(f(x)\), \(f(q^{k}x)\) and the q-gradient, where \(g_{q^{k}}(1)\) and \(g_{q^{k}}(2)\) are the first and second component of q-gradient. We obtain the q-gradient as
for \(x=(2, 3)^{T}\) and \(x=(-4, 5)^{T}\), respectively, where
at \(k= 30\). From Fig. 1, one can observe that \(q_{1}^{k}\) and \(q_{2}^{k} \in (0,1)\) for \(k=1,\dots ,30\). As \(q^{k}\to (1,1)\), the q-gradient reduces to the classical gradient. For this case, we have
for \(x=(2, 3)^{T}\) and \(x=(-4, 5)^{T}\), respectively.

Example 3
Consider an unconstrained objective function [45] \(f : \mathbb{R} \to \mathbb{R}\) such that
This function has the unique minimizer \(x^{*} = 1\). We run Algorithm 1 with a starting point \(x^{0}=9.0\) and get the minimum function value
at minimizer \(x^{*} = 1.0\) in 7 iterations, which can be seen in Fig. 2. With different starting points 15, 17 and 19, the algorithm converges to the solution point 1.00, 0.9999 and 0.9998 in iterations 7, 4 and 5, respectively.

Iteration points of Example 3
Example 4
Consider an unconstrained optimization function \(f : \mathbb{R}^{2} \to \mathbb{R}\) such that
The Rosenbrock function is a non-convex function, introduced by Rosenbrock in 1960. We consider this function to measure the performance of Algorithm 1. In this case, a starting point
is taken. The function converges in 20 iterations to get the minimum function value
at minimizer
while we run the Algorithm used in the methodology of [23], the function converges in 29 iterations to get the minimum function value
at minimizer
in 29 iterations that are shown in Fig. 3. Of course, Fig. 3(a) shows that our proposed method takes larger steps to converge due to the q-gradient.

With different starting points, we compare our algorithm with [23] on the Rosenbrock function. The numerical results is shown in Tables 3 and 4 where the columns ‘it’, ‘fe’, and ‘ge’ indicate the total numbers of iterations, the total number of function evaluations, and the total number of gradient evaluations, respectively. Note the total number of q-gradient evaluations for q-BFGS and total number of gradient evaluations for BFGS use the same notation.
Dolan and Moré [46] presented an appropriate technique to demonstrate the performance profiles, which is a statistical process. The performance ratio is presented as
where \(r_{(p,s)}\) refers to the iteration, function evaluations and q-gradient evaluations, respectively for solver s spent on problem p and \(n_{s}\) refers to the number of problems in the model test. The cumulative distribution function is expressed as
where \(P_{s}(\tau )\) is the probability that a performance ratio \(\rho _{(p,s)}\) is within a factor of τ of the best possible ratio. That is, for a subset of the methods being analyzed, we plot the fraction \(\rho _{s}(\tau )\) of problems for which any given method is within a factor τ of the best. We use this tool to show the performance of Algorithm 1. Here, Fig. 4(a), Fig. 4(b) and Fig. 4(c) show that q-BFGS method solves about 82%, 59% and 89% of Rosenbrock test problem with the least number of iterations, function evaluations and gradient evaluations, respectively.

Example 5
Consider an unconstrained optimization problem \(f : \mathbb{R}^{2} \to \mathbb{R}\) such that
With a starting point \(x^{0}=(0.5 , 0.5)^{T}\), the function converges to \(x^{*}=(2 , 2)^{T}\) that is shown in Fig. 5(a). The global minima of this function can also be observed in Fig. 5(b).

Visualization of Example 5
Example 6
Consider the following Rastrigin function:
The Rastrigin function is a non-convex. The visualization of in an area from −1 to 1 is shown in Fig. 6(a) with many local minima, and the global optimum at \((0 , 0)^{T}\) in an area from −1 to 1 is shown in Fig. 6(b) with successive iterative points. The numerical results of this function is shown in Table 5.

Visualization of Example 6
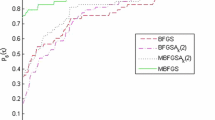
We have used the 19 test problems as shown in Table 6 with attributes problem number, problem’s name and starting point, respectively. Table 7 shows the computational results for q-BFGS and BFGS method [23] on small scale test problems. Of course, Fig. 7(a), Fig. 7(b) and Fig. 7(c) show that the q-BFGS method solves about 95%, 79% and 90% of the test problems with the least number of iterations, function evaluations and gradient evaluations, respectively. Therefore, this is concluded that the q-BFGS performs better than the BFGS of [23] and improves the performance in fewer iterations, function evaluations, and gradient evaluations, respectively.

Performance profiles based on the number of iterations, the number of function evaluations and the number of gradient evaluations given in Table 7
6 Conclusion
We have proposed a q-BFGS update and shown that the method converges globally with the Armijo–Wolfe line search conditions. The variant of the proposed method behaves like the classical BFGS method in limiting case where the existence of second-order partial derivatives at every point is not required. First-order q-differentiability of the function is sufficient to prove the global convergence of the proposed method. The q-gradient enables the q-BFGS quasi-Newton search process to be carried out in a more diverse set of directions and takes larger steps to converge. The reported numerical results show that the proposed method is efficient in comparison to the existing method for solving unconstrained optimization problems. However, other modified BFGS methods using the q-derivative are yet to study.
Availability of data and materials
Data sharing not applicable to this article as no datasets were generated or analyzed during the current study.
References
Mishra, S.K., Ram, B.: Introduction to Unconstrained Optimization with R. Springer, Singapore (2019). https://doi.org/10.1007/978-981-15-0894-3
Broyden, C.G.: The convergence of a class of double-rank minimization algorithms. IMA J. Appl. Math. 6(1), 76–90 (1970). https://doi.org/10.1093/imamat/6.1.76
Fletcher, R.: A new approach to variable metric algorithms computer. Comput. J. 13(3), 317–322 (1970). https://doi.org/10.1093/comjnl/13.3.317
Goldfarb, A.: A family of variable metric methods derived by variational means. Math. Comput. 24(109), 23–26 (1970). https://doi.org/10.1090/S0025-5718-1970-0258249-6
Schanno, J.: Conditions of quasi-Newton methods for function minimization. Math. Comput. 24(111), 647–650 (1970). https://doi.org/10.1090/S0025-5718-1970-0274029-X
Salim, M.S., Ahmed, A.R.: A quasi-Newton augmented Lagrangian algorithm for constrained optimization problems. J. Intell. Fuzzy Syst. 35(2), 2373–2382 (2018). https://doi.org/10.3233/JIFS-17899
Hedayati, V., Samei, M.E.: Positive solutions of fractional differential equation with two pieces in chain interval and simultaneous Dirichlet boundary conditions. Bound. Value Probl. 2019, 141 (2019). https://doi.org/10.1186/s13661-019-1251-8
Dixon, L.C.W.: Variable metric algorithms: necessary and sufficient conditions for identical behavior of nonquadratic functions. J. Optim. Theory Appl. 10, 34–40 (1972). https://doi.org/10.1007/BF00934961
Samei, M.E., Yang, W.: Existence of solutions for k-dimensional system of multi-term fractional q-integro-differential equations under anti-periodic boundary conditions via quantum calculus. Math. Methods Appl. Sci. 43(7), 4360–4382 (2020). https://doi.org/10.1002/mma.6198
Powell, M.J.D.: On the convergence of the variable metric algorithm. IMA J. Appl. Math. 7(1), 21–36 (1971). https://doi.org/10.1093/imamat/7.1.21
Ahmadi, A., Samei, M.E.: On existence and uniqueness of solutions for a class of coupled system of three term fractional q-differential equations. J. Adv. Math. Stud. 13(1), 69–80 (2020)
Dai, Y.H.: Convergence properties of the BFGS algoritm. SIAM J. Optim. 13(3), 693–701 (2002). https://doi.org/10.1137/S1052623401383455
Samei, M.E., Hedayati, V., Rezapour, S.: Existence results for a fraction hybrid differential inclusion with Caputo–Hadamard type fractional derivative. Adv. Differ. Equ. 2019, 163 (2019). https://doi.org/10.1186/s13662-019-2090-8
Samei, M.E., Hedayati, V., Ranjbar, G.K.: The existence of solution for k-dimensional system of Langevin Hadamard-type fractional differential inclusions with 2k different fractional orders. Mediterr. J. Math. 17, 37 (2020). https://doi.org/10.1007/s00009-019-1471-2
Aydogan, M., Baleanu, D., Aguilar, J.F.G., Rezapour, S. Samei, M.E.: Approximate endpoint solutions for a class of fractional q-differential inclusions by computational results. Fractals 28, 2040029 (2020). https://doi.org/10.1142/S0218348X20400290
Baleanu, D., Darzi, R., Agheli, B.: Fractional hybrid initial value problem featuring q-derivatives. Acta Math. Univ. Comen. 88, 229–238 (2019)
Baleanu, D., Shiri, B.: Collocation methods for fractional differential equations involving non-singular kernel. Chaos Solitons Fractals 116, 136–145 (2018). https://doi.org/10.1016/j.chaos.2018.09.020
Shiri, B., Baleanu, D.: System of fractional differential algebraic equations with applications. Chaos Solitons Fractals 120, 203–212 (2019). https://doi.org/10.1016/j.chaos.2019.01.028
Byrd, R., Nocedal, J., Yuan, Y.: Global convergence of a class of quasi-Newton methods on convex problems. SIAM J. Numer. Anal. 24(5), 1171–1189 (1987)
Byrd, R.H., Nocedal, J.: A tool for the analysis of quasi-Newton methods with application to unconstrained minimization. SIAM J. Numer. Anal. 26(3), 727–739 (1989). https://doi.org/10.1137/0726042
Wei, Z., Li, G.Y., Qi, L.: New quasi-Newton methods for unconstrained optimization problems. Appl. Math. Comput. 175(2), 1156–1188 (2006). https://doi.org/10.1016/j.amc.2005.08.027
Mascarenhas, W.F.: The bfgs method with exact line searches fails for non-convex objective functions. Math. Program. 99(1), 49–61 (2004). https://doi.org/10.1007/s10107-003-0421-7
Li, D.H., Fukushima, M.: On the global convergence of the BFGS method for nonconvex unconstrained optimization problems. SIAM J. Optim. 11(4), 1054–1064 (2001). https://doi.org/10.1137/S1052623499354242
Cieśliński, J.L.: Improved q-exponential and q-trigonometric functions. Appl. Math. Lett. 24(12), 2110–2114 (2011). https://doi.org/10.1016/j.aml.2011.06.009
Ernst, T.: A method for q-calculus. J. Nonlinear Math. Phys. 10(4), 487–525 (2003). https://doi.org/10.2991/jnmp.2003.10.4.5
Tariboon, J., Ntouyas, S.K.: Quantum calculus on finite intervals and applications to impulsive difference equations. Adv. Differ. Equ. 2013, 282 (2013). https://doi.org/10.1186/1687-1847-2013-282
Borges, E.P.: A possible deformed algebra and calculus inspired in nonextensive thermostatistics. Phys. A, Stat. Mech. Appl. 340(1–3), 95–101 (2004). https://doi.org/10.1016/j.physa.2004.03.082
Al-Saggaf, U.M., Moinuddin, M., Arif, M., Zerguine, A.: The q-least mean squares algorithm. Signal Process. 111, 50–60 (2015)
Jackson, F.H.: On q-definite integrals. Q. J. Pure Appl. Math. 41(15), 193–203 (1910)
Carmichael, R.D.: The general theory of linear q-difference equations. Am. J. Math. 34, 147–168 (1912)
Mason, T.E.: On properties of the solution of linear q-difference equations with entire fucntion coefficients. Am. J. Math. 37, 439–444 (1915)
Adams, C.R.: On the linear partial q-difference equation of general type. Trans. Am. Math. Soc. 31, 360–371 (1929)
Trjitzinsky, W.J.: Analytic theory of linear q-difference equations. Acta Math. 61, 1–38 (1933)
Sterroni, A.C., Galski, R.L., Ramos, F.M.: The q-gradient vector for unconstrained continuous optimization problems. In: Operations Research Proceedings 2010, pp. 365–370. Springer, Berlin (2010). https://doi.org/10.1007/978-3-642-20009-0_58
Diqsa, A., Khan, S., Naseem, I., Togneri, R., Bennamoun, M.: Enhanced q-least mean square. Circuits Syst. Signal Process. 38(10), 4817–4839 (2019). https://doi.org/10.1007/s00034-019-01091-4
Gouvêa, E.J., Regis, R.G., Soterroni, A.C., Scarabello, M.C., Ramos, F.M.: Global optimization using the q-gradients. Eur. J. Oper. Res. 251(3), 727–738 (2016). https://doi.org/10.1016/j.ejor.2016.01.001
Chakraborty, S.K., Panda, G.: q-Line search scheme for optimization problem (2017). arXiv:1702.01518
Chakraborty, S.K., Panda, G.: Newton like line search method using q-calculus. In: Mathematics and Computing: Third International Conference, Communications in Computer and Information Science, ICMC 2017, Haldia, India, pp. 196–208 (2017). https://doi.org/10.1007/978-981-10-4642-1_17
Ablinger, J., Uncu, A.K.: Functions—a mathematica package for q-series and partition theory applications (2019). arXiv:1910.12410
Lai, K.K., Mishra, S.K., Panda, G., Chakraborty, S.K., Samei, M.E., Ram, B.: A limited memory q-BFGS algorithm for unconstrained optimization problems. J. Appl. Math. Comput. 63, 1–2 (2020). https://doi.org/10.1007/s12190-020-01432-6
Aral, A., Gupta, V., Agarwal, R.P.: Applications of q-Calculus in Operator Theory. Springer, New York (2013). https://doi.org/10.1007/978-1-4614-6946-9
Jackson, F.H.: On q-functions and a certain difference operator. Trans. R. Soc. Edinb. 46, 253–281 (1909)
Rajković, P.M., Stanković, M.S., Marinković, S.D.: Mean value theorems in q-calculus. Mat. Vesn. 54, 171–178 (2002)
Moré, J.J., Garbow, B.S., Hillstrom, K.E.: Testing unconstrained optimization software. ACM Trans. Math. Softw. 7(1), 17–41 (1981)
Yuan, Y.X.: A modified bfgs algorithm for unconstrained optimization. IMA J. Numer. Anal. 11(3), 325–332 (1991). https://doi.org/10.1093/imanum/11.3.325
Dolan, E.D., Moré, J.J.: Benchmarking optimization software with performance profiles. Math. Program. 91(2), 201–213 (2002). https://doi.org/10.1007/s101070100263
Acknowledgements
The authors would like to thank the editors and the anonymous reviewers for their constructive comments and suggestions that have helped to improve the present paper. The fourth author was supported by Bu-Ali Sina University. This research was supported by the Science and Engineering Research Board (Grant No. DST-SERB- MTR-2018/000121) and the University Grants Commission (IN) (Grant No. UGC-2015-UTT-59235).
Funding
Not applicable.
Author information
Authors and Affiliations
Contributions
The authors declare that the study was realized in collaboration with equal responsibility. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Consent for publication
Not applicable.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Mishra, S.K., Panda, G., Chakraborty, S.K. et al. On q-BFGS algorithm for unconstrained optimization problems. Adv Differ Equ 2020, 638 (2020). https://doi.org/10.1186/s13662-020-03100-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13662-020-03100-2