
Abstract
The proximal alternating direction method of multipliers (P-ADMM) is an efficient first-order method for solving the separable convex minimization problems. Recently, He et al. have further studied the P-ADMM and relaxed the proximal regularization matrix of its second subproblem to be indefinite. This is especially significant in practical applications since the indefinite proximal matrix can result in a larger step size for the corresponding subproblem and thus can often accelerate the overall convergence speed of the P-ADMM. In this paper, without the assumptions that the feasible set of the studied problem is bounded or the objective function’s component \(\theta_{i}(\cdot)\) of the studied problem is strongly convex, we prove the worst-case \(\mathcal{O}(1/t)\) convergence rate in an ergodic sense of the P-ADMM with a general Glowinski relaxation factor \(\gamma\in(0,\frac{1+\sqrt{5}}{2})\), which is a supplement of the previously known results in this area. Furthermore, some numerical results on compressive sensing are reported to illustrate the effectiveness of the P-ADMM with indefinite proximal regularization.
Similar content being viewed by others


1 Introduction
Let \(\theta_{i}:\mathcal{R}^{n_{i}}\rightarrow(-\infty, +\infty]\ (i=1,2)\) be two lower semicontinuous proper (not necessarily smooth) functions. This work aims to solve the following two-block separable convex minimization problem:
where \(A_{i}\in\mathcal{R}^{l\times n_{i}}\ (i=1,2)\), \(b\in\mathcal{R}^{l}\). If there are convex set constraints \(x_{i}\in\mathcal{X}_{i}\ (i=1,2)\), where \(\mathcal{X}_{i}\subseteq\mathcal{R}^{n_{i}}\ (i=1,2)\) are some simple convex set, such as the nonnegative cones or positive semi-definite cones, etc. Then, we can define the indicator function as \(I_{\mathcal {X}_{i}}(\cdot)\) (\(I_{\mathcal{X}_{i}}(x_{i})=0\) if \(x_{i}\in\mathcal{X}_{i}\); otherwise, \(I_{\mathcal{X}_{i}}(x_{i})=+\infty\)), by which we can incorporate the constraints \(x_{i}\in\mathcal{X}_{i}\ (i=1,2)\) into the objective function of (1), and get the following equivalent form:
Then, we can further introduce some auxiliary variables and functions to rewrite the above problem as problem (1) (Please refer to [1] for more details). Therefore, problem (1) is quite general, and in fact problems like (1) come from diverse applications, such as the latent variable graphical model selection [2], the sparse inverse covariance selection [3], stable principal component pursuit with nonnegative constraint [4], and robust alignment for linearly correlated images [5], etc.
As one of the first-order methods, the following Algorithm 1, that is proximal alternating direction method of multipliers (P-ADMM) [6–8] is quite efficient for solving (1) or related problems, especially for large scale case.

The P-ADMM for (1)
The parameter γ in the P-ADMM is called the Glowinski relaxation factor in the literature, and \(\gamma>1\) can often accelerate the P-ADMM [9]. Due to its high efficiency, the P-ADMM has been intensively studied during the past few decades, and many scholars presented a lot of customized variants of the P-ADMM for some concrete separable minimization problems [10–12].
In this paper, we only focus our attention on the P-ADMM. In fact, the theory developed in this work can easily be extended to its various variants. Now, let us briefly analyze the structure advantages of the P-ADMM. Obviously, the P-ADMM fully utilizes the separable structure inherent to the original problem (1), which decouples the primal variable \((x_{1},x_{2})\) and get two subproblems with lower-dimension. Then, at each iteration, the computation of P-ADMM is dominated by solving its two subproblems. Fortunately, the two subproblems in (2) often admit closed-form solutions provided that \(\theta_{i}(\cdot)\ (i=1,2)\) are some the functions (such as \(\theta_{i}(\cdot)=\Vert \cdot \Vert _{1}\), \(\Vert \cdot \Vert _{2}\) or \(\Vert \cdot \Vert _{*}\)) and the matrices \(A_{i}\ (i=1,2)\) are unitary (i.e. \(A_{i}^{\top}A_{i}\ (i=1,2)\) are the identity matrices). Even if \(A_{i}\ (i=1,2)\) are not unitary, we can judiciously set \(G_{i}=rI_{n_{i}}-\beta A_{i}^{\top}A_{i}\) with \(r>\beta \Vert A_{i}^{\top}A_{i}\Vert \ (i=1,2)\), and then the two subproblems in the P-ADMM also have closed-form solutions in many practical applications. The global convergence of the P-ADMM with \(\gamma=1\) has been proved in [10, 11] for some concrete models of (1), and in [13], Xu and Wu presented an elegant analysis of the global convergence of the P-ADMM with \(\gamma\in(0,\frac{1+\sqrt{5}}{2})\) for the general model (1). Quite recently, He et al. [14] have further studied the P-ADMM and get some substantial advances by relaxing the matrix \(G_{2}\) in the proximal regularization term of its second subproblem to be indefinite. This is quite preferred in practical applications since the indefinite proximal matrix can result in a larger step size for the subproblem and thus maybe accelerate the overall convergence speed of the P-ADMM.
Compared with the study of the global convergence of the P-ADMM, the research of its convergence rate is quite insubstantial in the literature. In [14, 15], under the assumption that the feasible set of (1) is bounded, He et al. have proved the worst-case \(\mathcal{O}(1/t)\) convergence rate of the P-ADMM with \(\gamma=1\), where t denotes the iteration counter. In [1], Lin et al. have presented a parallel version of the P-ADMM with the adaptive penalty β, and proved that the convergence rate of their new method is also \(\mathcal{O}(1/t)\). In addition, Goldstein et al. [16] proved a better convergence rate than \(\mathcal{O}(1/t)\) for the P-ADMM scheme with \(\gamma=1\) and \(G_{1}=0, G_{2}=0\) under the assumption that \(\theta_{i}(\cdot)\ (i=1,2)\) are both strongly convex, which is usually violated in practice, and thus excludes many practical applications of the P-ADMM. Then, by introducing some free parameters \(\alpha_{k}\) and \(\gamma_{k}\), Xu [17] developed a new variant of the P-ADMM for (1), which refined the results in [16]. In fact, only under the assumption that the function \(\theta_{2}(\cdot)\) is strongly convex, Xu [17] proved that the new method has \(\mathcal{O}(1/t)\) convergence rate with constant parameters and enjoys \(\mathcal {O}(1/t^{2})\) convergence rate with adaptive parameters.
In this paper, we aim to further improve the above results by removing the assumptions of the strong convexity of \(\theta_{2}(\cdot)\) and the boundedness of the feasible set of (1), and prove that the P-ADMM for the convex minimization problem (1) has a worst-case \(\mathcal{O}(1/t)\) convergence rate in an ergodic sense, which partially improves the results in [8, 13–15, 17].
The remaining of the paper is organized as follows. Section 2 gives some useful preliminaries. In Section 3, we prove the convergence rate of the P-ADMM in detail. In Section 4, a simple experiment on compressive sensing is conducted to demonstrate the effectiveness of the P-ADMM.
2 Preliminaries
In this section, we summarize some basic concepts and preliminaries that will be used in the later discussion.
First, we list some notation to be used in this paper. \(\langle\cdot ,\cdot\rangle\) denotes the inner product of \(\mathcal{R}^{n}\); \(G\succ0\) (or \(G\succeq0\)) denotes that the symmetric matrix G is positive definite (or positive semi-definite); If G is symmetric, we set \(\Vert x\Vert _{G}^{2}=x^{\top}Gx\) though G maybe not positive definite. The effective domain of a function \(f: \mathcal{X} \rightarrow(-\infty ,+\infty]\) is defined as \(\operatorname{dom}(f):= \{x\in\mathcal{X}|f(x) < +\infty\}\). The set of all relative interior points of a given nonempty convex set \(\mathcal{C}\) is denoted by \(\operatorname{ri}(\mathcal{C})\).
A function \(f:\mathcal{R}^{n}\rightarrow\mathcal{R}\) is convex iff
Then, if \(f:\mathcal{R}^{n}\rightarrow\mathcal{R}\) is convex, we have the following first-order necessary condition:
where \(\partial f(y)=\{\xi\in\mathcal{R}^{n}:f(\bar{y})\geq f(y)+\langle \xi,\bar{y}-y\rangle,\ \mathrm{for all}\ \bar{y}\in\mathcal{R}^{n}\}\) denotes the subdifferential of \(f(\cdot)\) at the point y.
The following equality is used frequently in the paper:
From now on, we denote
Throughout this paper, we make the following assumptions.
Assumption 2.1
The functions \(\theta_{i}(\cdot)\ (i=1,2)\) are both convex.
Assumption 2.2
There is a point \((\hat{x}_{1},\hat{x}_{2})\in\operatorname {ri}(\operatorname{dom}(\theta_{1})\times\operatorname{dom}(\theta_{2}))\) such that \(A_{1}\hat{x}_{1}+A_{2}\hat{x}_{2}=b\).
Then, under Assumption 2.2, it follows from Corollaries 28.2.2 and 28.3.1 in [18] that \(({x}_{1}^{*},{x}_{2}^{*})\in\operatorname{ri}(\operatorname {dom}{(\theta_{1})}\times\operatorname{dom}{(\theta_{2})})\) is an optimal solution to problem (1) iff there exists a Lagrangian multiplier \(\lambda^{*}\in\mathcal{R}^{l}\) such that \(({x}_{1}^{*},{x}_{2}^{*},\lambda^{*})\) is a solution of the following KKT systems:
The set of the solutions of (5) is denoted by \(\mathcal{W}^{*}\). By Assumption 2.1, (3), and (5), for any \(({x}^{*},\lambda^{*})=({x}_{1}^{*},{x}_{2}^{*},\lambda^{*})\in\mathcal{W}^{*}\), we have the following useful inequality:
Assumption 2.3
The solution set \(\mathcal{W}^{*}\) of the KKT systems (5) is nonempty, and at least one \(({x}_{1}^{*},{x}_{2}^{*},\lambda^{*})\in\mathcal{W}^{*}\) with \(\lambda^{*}\neq0\).
3 Convergence rate of the P-ADMM
In this section, we aim to prove the convergence rate of the P-ADMM, and to accomplish this, we need to make some restrictions of the matrices \(A_{i},G_{i}\ (i=1,2)\) included in the P-ADMM as follows.
Assumption 3.1
(1) The matrix \(G_{1}\succeq0\), and \(A_{1}\) is full-column rank if \(G_{1}=0\).
(2) The matrix \(G_{2}\) is set as \(G_{2}=\alpha\tau I_{n_{2}}-\beta A_{2}^{\top}A_{2}\) with \(\tau>\beta \Vert A_{2}^{\top}A_{2}\Vert \), \(\alpha\in(0,1]\), and \(\alpha \geq(5-\min\{\gamma,1+\gamma-\gamma^{2}\})/5\).
Remark 3.1
In [14], the parameter α can take any value of the interval \([0.8,1)\). Obviously, the parameter α in this paper can also obtain the lower bound 0.8 if \(\gamma=1\).
Let us introduce some matrices to simplify our notation in the subsequent analysis. More specifically, we set
and
Remark 3.2
From Assumption 3.1 and \(\gamma\in(0,\frac{1+\sqrt {5}}{2})\), we see that the matrices \(\bar{G}_{2}, M, N, H\) defined by (7) are all positive definite. However, the matrix \(G_{2}\) defined in Assumption 3.1 may be indefinite. For example, when \(\gamma=1, \alpha=0.8\), and \(\tau=1.01\beta \Vert A_{2}^{\top}A_{2}\Vert \), then \(G_{2}=-0.198\beta A_{2}^{\top}A_{2}\), which is obviously indefinite if the matrix \(A_{2}\) is full-column rank.
Remark 3.3
From the definitions of \(G_{2}\) and \(\bar{G}_{2}\), we have
Now, we start proving the convergence rate of the P-ADMM under Assumptions 2.1-2.3 and Assumption 3.1. Firstly, we prove three lemmas step by step.
Lemma 3.1
Let \(\{(x^{k},\lambda^{k})\}=\{(x_{1}^{k},x_{2}^{k},\lambda^{k})\} \) be the sequence generated by the P-ADMM. Under Assumptions 2.1-2.3, for any \((x_{1},x_{2},\lambda)\in\mathcal{R}^{n_{1}+n_{2}+l}\) such that \(A_{1}x_{1}+A_{2}x_{2}=b\), we have
Proof
Note that the optimality condition for the first subproblem (i.e., the subproblem with respect to \(x_{1}\)) in (2) is
where \(\nabla\theta_{1}(x_{1}^{k+1})\) is a subgradient of \(\theta_{1}(\cdot)\) at \(x_{1}^{k+1}\), \(\tilde{\lambda}^{k}=\lambda^{k}-\beta (A_{1}x_{1}^{k+1}+A_{2}x_{2}^{k+1}-b)\), and the second equality uses the updating formula for λ in (2). Then (10) can be rewritten as
where the inequality comes from the convexity of \(\theta_{1}(\cdot)\) and (3). Similarly, the optimality condition for the second subproblem (i.e., the subproblem with respect to \(x_{2}\)) in (2) gives
i.e.,
where the inequality follows from the convexity of \(\theta_{2}(\cdot)\) and (3). Then, adding (11) and (12), we obtain
where the last equality comes from the identity (4). Now, let us deal with the term \(\langle Ax^{k+1}-b,-\tilde{\lambda }^{k}\rangle\) on the right side of (13). Specifically, from the updating formula for λ in (2) again, we can get
where the second equality comes from \(\lambda^{k+1}=\lambda^{k}-\gamma (\lambda^{k}-\tilde{\lambda}^{k})\), and the last equality uses the identity (4). Then, substituting (14) into (13) yields (9). This completes the proof. □
The following lemma aims to further refine the crossing term \(\beta \langle Ax^{k+1}-b,A_{2}x_{2}^{k}-A_{2}x_{2}^{k+1}\rangle\) on the right side of (9).
Lemma 3.2
Let \(\{(x^{k},\lambda^{k})\}=\{(x_{1}^{k},x_{2}^{k},\lambda^{k})\} \) be the sequence generated by the P-ADMM. Under Assumptions 2.1-2.3, for any \((x_{1},x_{2},\lambda)\in\mathcal{R}^{n_{1}+n_{2}+l}\) such that \(A_{1}x_{1}+A_{2}x_{2}=b\), we have
Proof
Setting \(x_{2}=x_{2}^{k}\) in (12), we get
That is,
Similarly, taking \(x_{2}=x_{2}^{k+1}\) in (12) for \(k:=k-1\), and thus we have
That is,
Adding (16) and (17), we obtain
We have
Substituting the above equality into (18), we obtain
Then, substituting (19) into (9) yields (15). The proof is completed.
Now, let us deal with the term \(\frac{2-\gamma}{2\beta\gamma^{2}}\Vert \lambda ^{k+1}-\lambda^{k}\Vert ^{2} +(1-\gamma)\beta\langle A_{2}(x_{2}^{k}-x_{2}^{k+1}),A_{1}x_{1}^{k}+A_{2}x_{2}^{k}-b\rangle+\frac{\beta}{2}\Vert A_{2}x_{2}^{k+1}-A_{2}x_{2}^{k}\Vert ^{2}\) on the right side of (15). □
Lemma 3.3
Let \(\{(x^{k},\lambda^{k})\}=\{(x_{1}^{k},x_{2}^{k},\lambda^{k})\} \) be the sequence generated by the P-ADMM. Then, we have
where \(\varrho=\min\{\gamma,1+\gamma-\gamma^{2}\}\).
Proof
Obviously, by the updating formula for λ in (2), we have
Then, applying the Cauchy-Schwartz inequality, we can get
Then, substituting the above two inequalities into (21), and by some simple manipulations, we obtain
which is the same as the assertion (20), and the lemma is thus proved.
Substituting (20) into (15), we get the following important inequality:
Now, let us deal with all the terms related with the variable \(x_{2}\) on the right side of (22). From the definition of the matrices \(G_{2}, N\) and (8), we have
Then, substituting the above inequality into (22), we can obtain
where the inequality comes from \(\alpha\in(0,1]\) and \(\alpha\geq\frac {5-\varrho}{5}\). Based on (23), we can prove the worst-case \(\mathcal {O}(1/t)\) convergence rate in an ergodic sense of the P-ADMM. □
Theorem 3.1
Suppose that Assumptions 2.1-2.3 and Assumption 3.1 hold. Let \(\{(x^{k},\lambda^{k})\}=\{(x_{1}^{k},x_{2}^{k},\lambda^{k})\}\) be the sequence generated by the P-ADMM and let \(\bar{x}^{t}=\frac{1}{t}\sum_{k=1}^{t}x^{k+1}\), where t is a positive integer. Then,
where \((x^{*},\lambda^{*})=(x_{1}^{*},x_{2}^{*},\lambda^{*})\) with \(\lambda^{*}\neq0\) is a point satisfying the KKT conditions in (5), and D is a constant defined by
Proof
Setting \(x=x^{*}\) in the inequality (22) and summing it over \(k= 1, 2,\ldots,t\), we obtain
which together with the convexity of the function \(\theta(\cdot)\) implies
Using the Lemmas 2.2 and 2.3 of [17] with \(\rho=2\Vert \lambda^{*}\Vert \) (ρ is a parameter defined in Lemmas 2.2 and 2.3 of [17]), we can get (24). This completes the proof. □
Remark 3.4
From (24) and (25), we can conclude that larger values of γ is more beneficial for accelerating the convergence of the P-ADMM, as the larger γ, the smaller D, which controls the upper bounds of \(\vert \theta(\bar{x}^{t})-\theta(x^{*})\vert \) and \(\Vert A\bar{x}^{t}-b\Vert \).
4 Numerical experiments
In this section, we apply the P-ADMM to solve the compressive sensing, a concrete problem of the general model (1). The codes were written by Matlab R2010a and conducted on a ThinkPad notebook with Pentium(R) Dual-Core CPU T4400@2.2 GHz, 2 GB of RAM using Windows 7.
Let us briefly review the compressive sensing. Compressive sensing (CS) is to recover a sparse signal \(\bar{x}\in\mathcal{R}^{n}\) from an undetermined linear system \(y=A\bar{x}\), where \(A\in\mathcal {R}^{m\times n}(m\ll n)\) is a linear mapping and \(y\in\mathcal{R}^{m}\) is an observation. An important decoding model of CS is
where the parameter \(\nu>0\) is used to trade off both terms for minimization. This is a special case of the general two-block separable convex minimization model (1). In fact, setting \(x_{1}=x, x_{2}=x\), (26) can be recast as
which is a special case of (1) with
and thus, the P-ADMM can be used to solve CS.
In our experiment, the stopping criterion of the P-ADMM is set as
where \(f_{k}\) denotes the function value of (26) at the iterate \(x_{1}^{k}\). The initial points of \(x_{1},x_{2},\lambda\) are all set as \(A^{\top}y\), and due to the limit of EMS memory of our computer, we only test a medium scale of (26) with \(n=1{,}000, m=300\), \(k=60\), where k is the number of random nonzero elements contained in the original signal. In addition, we set
and \(\nu=0.01\), \(G_{1}=\tau I_{n}-\beta A^{\top}A\) with \(\tau=2, \beta =\operatorname{mean}(\operatorname{abs}(b))\). In the literature, the relative error (RelErr) is usually used to measure the quality of recovered signal and is defined by
where x̃ and x̄ denote the recovered signal and the original signal, respectively.
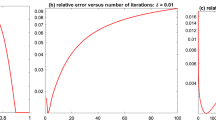
First, let us illustrate the sensitivity of γ for the P-ADMM. We choose different values of γ in the interval [0.1, 1.6] (More specifically, we take \(\gamma =0.10,0.15,\ldots,1.60\)). The numerical results of the objective value of (26) and the CPU time in seconds requited by the P-ADMM are depicted in Figure 1, and the numerical results of the numbers of iteration and the RelErr required by P-ADMM are depicted in Figure 2.

Objective value and CPU time with different γ .

Numbers of iteration and relative error with different γ .
According to the curves in Figures 1-2, we can see that the relaxation factor γ works well for a wide range of values and, based on this experiment, the values greater than 0.5 are more preferred.
Now let us test the effectiveness of the P-ADMM with the indefinite proximal matrix \(G_{2}=(\alpha\tau-\beta)I_{n}\). Here we set \(\alpha=0.8, \tau=1.1\), \(\beta=1\), and \(\gamma=1\). The numerical results of one experiment are as follows: the objective value is 0.4291; the CPU time is 1.0920; the numbers of iteration is 378 and the RelErr is 5.75%. The original signal, the measurement and the signal recovered by the P-ADMM for this test scenario are given in Figure 3. The recovered results are marked by a red circle in the third subplot of Figure 3, which shows clearly that almost the original signal is recovered with high precision. This indicates that the P-ADMM is effective though the proximal matrix \(G_{2}\) is indefinite.

The original signal, noisy measurement and recovered results.
References
Lin, Z, Liu, R, Li, H: Linearized alternating direction method with parallel splitting and adaptive penalty for separable convex programs in machine learning. Mach. Learn. 95(2), 287-325 (2015)
Chandrasekaran, V, Parrilo, P, Willsky, A: Latent variable graphical model selection via convex optimization. Ann. Stat. 40(4), 1935-1967 (2012)
Banerjee, O, El Ghaoui, L, d’Aspremont, A: Model selection through sparse maximum likelihood estimation for multivariate Gaussian for binary data. J. Mach. Learn. Res. 9, 485-516 (2008)
Zhou, Z, Li, X, Wright, J, Candès, E, Ma, Y: Stable principal component pursuit. In: Proceedings of International Symposium on Information Theory (2010)
Peng, Y, Ganesh, A, Wright, J, Xu, W, Ma, Y: RASL: robust alignment by sparse and low-rank decomposition for linearly correlated images. IEEE Trans. Pattern Anal. Mach. Intell. 34, 2233-2246 (2012)
Glowinski, R, Marrocco, A: Sur l’approximation, par éléments fins d’ordren, et la résolution, par pénalisation-dualité, d’une classe de problèmes de Dirichlet nonlinéares. Rev. Fr. Autom. Inform. Rech. Oper. 9, 41-76 (1975)
Gabay, D, Mercier, B: A dual algorithm for the solution of nonlinear variational problems via finite-element approximations. Comput. Math. Appl. 2, 17-40 (1976)
He, B, Liao, L, Han, D, Yang, H: A new inexact alternating directions method for monotone variational inequalities. Math. Program., Ser. A 92, 103-118 (2002)
He, B, Wang, S, Yang, H: A modified variable-penalty alternating directions method for monotone variational inequalities. J. Comput. Math. 21, 495-504 (2003)
Wang, X, Yuan, X: The linearized alternating direction method of multipliers for Dantzig selector. SIAM J. Sci. Comput. 34, 2782-2811 (2012)
Zhang, X, Burger, M, Osher, S: A unified primal-dual algorithm framework based on Bregman iteration. J. Sci. Comput. 6, 20-46 (2010)
Sun, M, Liu, J: An inexact generalized PRSM with LQP regularization for structured variational inequalities and its applications to traffic equilibrium problems. J. Inequal. Appl. 2016 150 (2016)
Xu, M, Wu, T: A class of linearized proximal alternating direction methods. J. Optim. Theory Appl. 155, 321-337 (2011)
He, B, Ma, F, Yuan, X: Linearized alternating direction method of multipliers via positive-indefinite proximal regularization for convex programming. Manuscript (2016)
He, B, Yuan, X: On the \(\mathcal{O}(1/n)\) convergence rate of the Douglas-Rachford alternating direction method. SIAM J. Numer. Anal. 50, 700-709 (2012)
Goldstein, T, O’Donoghue, B, Setzer, S, Baraniuk, R: Fast alternating direction optimization methods. SIAM J. Imaging Sci. 7(3), 1588-1623 (2014)
Xu, Y: Accelerated first-order primal-dual proximal methods for linearly constrained composite convex programming. Manuscript (2016)
Rockafellar, R: Convex Analysis. Princeton University Press, Princeton (1970)
Acknowledgements
The authors gratefully acknowledge the helpful comments of the anonymous reviewers. This work is supported by the foundation of National Natural Science Foundation of China (No. 11601475, 11671228), the foundation of First Class Discipline of Zhejiang-A (Zhejiang University of Finance and Economics-Statistics), the Foundation of National Natural Science Foundation of Shandong Province (No. zr2016al05) and the Scientific Research Project of Shandong Universities (No. J15LI11).
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ contributions
The first author has proposed the motivations of the manuscript and the second author has proved the convergence rate. Both authors have equally contributed in the numerical results. All authors read and approved the final manuscript.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Sun, M., Liu, J. The convergence rate of the proximal alternating direction method of multipliers with indefinite proximal regularization. J Inequal Appl 2017, 19 (2017). https://doi.org/10.1186/s13660-017-1295-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13660-017-1295-1