
Abstract
As one of the operator splitting methods, the Peaceman-Rachford splitting method (PRSM) has attracted considerable attention recently. This paper proposes a generalized PRSM for structured variational inequalities with positive orthants. In fact, we apply the well-developed LQP regularization to regularize the subproblems of the recently proposed strictly contractive PRSM, thus the resulting subproblems reduce to two nonlinear equation systems, which are much easier to solve than the subproblems of PRSM. Furthermore, these two nonlinear equations are allowed to be solved inexactly. For the new method, we prove its global convergence and establish its worst-case convergence rate in the ergodic sense. Numerical experiments show that the proposed method is quite efficient for the traffic equilibrium problems with link capacity bound.
Similar content being viewed by others
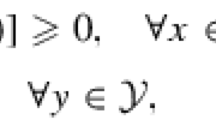


1 Introduction
In this paper, we focus on the variational inequalities with separable structures and positive orthants. That is, find \(u^{*}\in\Omega\) such that
with
where \(f:\mathcal{X}\rightarrow\mathcal{R}^{m}\) and \(g:\mathcal {Y}\rightarrow\mathcal{R}^{n}\) are continuous and monotone operators; \(A\in\mathcal{R}^{l\times m}\) and \(B\in\mathcal {R}^{l\times n}\) are given matrices; \(b\in\mathcal{R}^{l}\) is a given vector. Problem (1) is a standard mathematical model arising from several scientific fields and admits a large number of applications in network economics, traffic assignment, game theoretic problems, etc.; see [1–3] and the references therein. Throughout, we assume that the solution of Problem (1) (denoted by \(\Omega^{*}\)) is nonempty.
By attaching a Lagrange multiplier vector \(\lambda\in\mathcal{R}^{l}\) to the linear constraints \(Ax+By=b\), Problem (1) can be equivalently transformed into the following compact form, denoted by \(\operatorname{VI}(\mathcal{W},Q)\): Find \(w^{*}\in \mathcal{W}\), such that
where
We denote by \(\mathcal{W}^{*}\) the solution of \(\operatorname{VI}(\mathcal{W},Q)\). Obviously, \(\mathcal{W}^{*}\) is nonempty under the assumption that \(\Omega ^{*}\) is nonempty. In addition, due to the monotonicity of \(f(\cdot)\) and \(g(\cdot)\), the mapping \(Q(\cdot)\) of \(\operatorname{VI}(\mathcal{W},Q)\) is also monotone.
A simple but powerful operator splitting algorithm in the literature is the alternating direction method of multipliers (ADMM) proposed in [4–6]. For the developments of ADMM on structured variational inequalities (2), we refer to [7–9]. Similar to ADMM, the Peaceman-Rachford splitting method (PRSM) is also a simple algorithm for Problem (2); see [10–12]. For solving (2), the iterative scheme of PRSM is
where \(\beta>0\) is a penalty parameter. Different from the ADMM, the PRSM updates the Lagrange multiplier twice at each iteration. However, the global convergence of PRSM cannot be guaranteed without any further assumptions on the model (2). To solve this issue, He et al. [13] developed the following strictly contractive PRSM (SC-PRSM):
where \(r\in(0,1)\) is an underdetermined relaxation factor. The global convergence of SC-PRSM is proved via the analytic framework of contractive type methods in [13].
Note that the computational load of SC-PRSM (4) relies on the resulting two complementarity problems, which are computationally expensive, especially for large-scale problems. Therefore, how to alleviate the difficulty of these subproblems deserves intensive research. In this paper, motivated by well-developed logarithmic-quadratic proximal (LQP) regularization proposed in [14], we regularize the two complementarity problems in (4) by LQP, which forces the solutions of the two complementarity problems to be interior points of \(\mathcal{R}^{m}_{+}\) and \(\mathcal{R}^{n}_{+}\), respectively, thus the two complementarity problems reduce to two easier nonlinear equation systems. On the other hand, it is well known that the generalized ADMM [15, 16] includes the classical ADMM as a special case, and it can numerically accelerate the original ADMM with some values of the relaxation factor. Therefore, inspired by the above analysis, we get the following iterative scheme:
where \(\alpha\in(0,2)\), \(r\in(0,2-\alpha)\), and \(\mu\in(0,1)\) are three constants, and \(R=\operatorname{diag}(r_{1},r_{2},\ldots, r_{m})\in\mathcal {R}^{m\times m}\) and \(S=\operatorname{diag}(s_{1},s_{2},\ldots,s_{n})\in\mathcal {R}^{n\times n}\) are symmetric positive definite matrices, \(P_{k}=\operatorname {diag}(1/x^{k}_{1},1/x^{k}_{2},\ldots,1/x^{k}_{m})\), \(Q_{k}=\operatorname{diag}(1/y^{k}_{1},1/y^{k}_{2},\ldots,1/y^{k}_{n})\), and \((x^{k+1})^{-1}\) (or \((y^{k+1})^{-1}\)) is a vector whose jth element is \(1/x^{k+1}_{j}\) (or \(1/y^{k+1}_{j}\)). By Lemma 2.2 (see Section 2), the new iterate \((x^{k+1}, y^{k+1})\) generated by (5) lies in the interior of \(\mathcal{R}^{m+n}\), provided that the previous iterate \((x^{k}, y^{k})\) does. Therefore, the two complementarity problems in (5) can reduce to the nonlinear equation systems, and we get the following iterative scheme:
Obviously, the above iterative scheme includes two nonlinear equations, which are not easy to solve exactly in many applications. This motivates us to propose the following inexact version:
where \(\{v_{k}\}\) is a nonnegative sequence satisfying \(\sum_{k=0}^{\infty}v_{k}<+\infty\), and \(x_{*}^{k+1}\), \(y_{*}^{k+1}\) satisfy
Here \(\lambda_{*}^{k+\frac{1}{2}}=\lambda^{k}-r\beta(Ax_{*}^{k+1}+By^{k}-b)\).
The rest of this paper is organized as follows. In Section 2, we summarize preliminaries which are useful for further discussion, and we present the new method. In Section 3, the global convergence and the worst-case convergence rate in the ergodic sense of the new method are proved. In Section 4, we apply the proposed method to solve the traffic equilibrium problems with link capacity bound. Finally, some concluding remarks are made in Section 5.
2 Preliminaries
In this section, we first of all summarize some notations and lemmas which are used frequently in the sequent analysis, and then present our proposed method in detail.
First, we define four matrices as follows:
and
The four matrices M, P, N, H just defined satisfy the following assertions.
Lemma 2.1
If \(\mu\in(0,1)\), \(\alpha\in(0,2)\), \(r\in(0,2-\alpha)\), and R, S are symmetric positive definite, then we have:
-
(1)
The matrices M, P, H defined, respectively, in (7), (8) have the following relationship:
$$ HM=P. $$(9) -
(2)
The two matrices H and \(\tilde{H}:=P^{\top}+P-M^{\top}HM-2N\) are symmetric positive definite.
Proof
Item (1) holds evidently. As for item (2), it is obvious that H and H̃ are symmetric. Now, we prove that they are positive definite. Note that \(\mu\in(0,1)\), \(\alpha\in(0,2)\), and \(r\in(0,2-\alpha)\). Then for any \(w=(x,y,\lambda)\neq0\), we get
where the inequality follows from the Cauchy-Schwartz inequality. If \(x\neq0\) or \(y=0\), then from (10), we have \(w^{\top}Hw>0\). Otherwise \(x=0\), \(y=0\), and \(\lambda\neq0\), then we have \(w^{\top}Hw=\frac {\|\lambda\|^{2}}{\beta(r+\alpha)}>0\). Thus, H is positive definite. As for H̃, using (9), we have
Therefore H̃ is positive definite. The proof is complete. □
The following lemma lists a fundamental assertion with respect to the LQP regularization, which was proved in [17].
Lemma 2.2
Let \(\bar{P}=\operatorname{diag}(p_{1},p_{2},\ldots,p_{t})\in \mathcal{R}^{t\times t}\) be a positive definite diagonal matrix, \(q(u)\in\mathcal{R}^{t}\) be a monotone mapping of u with respect to \(\mathcal{R}^{t}_{++}\), and \(\mu\in(0,1)\). For a given \(\bar{u}\in\mathcal{R}^{t}_{++}\), we define \(\bar{U}:=\operatorname {diag}(\bar{u}_{1},\bar{u}_{2},\ldots,\bar{u}_{t})\). Then the equation
has the unique positive solution u. In addition, for this positive solution \(u\in\mathcal{R}^{t}_{++}\) and any \(v\in\mathcal{R}^{t}_{+}\), we have
Now we present the generalized PRSM with LQP regularization for solving the Problem (2).
Remark 2.1
Note that Algorithm 1 includes many LQP-type methods as special cases, such as:
-
If \(r=0\) and \(v_{k}=0\) (∀k), we obtain the generalized alternating direction method with LQP regularization proposed in [18].
-
If \(\alpha=1\), we obtain a method similar to the method proposed in [19], and their difference only lies in the latter is designed for the separable convex programming.

A generalized PRSM with LQP regularization for \(\operatorname{VI}(\mathcal{W},Q)\)
Remark 2.2
Obviously, by the relationship of the PRSM and the generalized ADMM presented in [20], the iterative scheme (6) is equivalent to
where \(\mu=\alpha-1+r\) and \(y_{**}^{k+1}\) satisfy
Obviously, when \(\alpha=1\), \(r=0\), that is, \(\tilde{\lambda}^{k+\frac {1}{2}}={\lambda}_{*}^{k+\frac{1}{2}}=\lambda^{k}\), the above iterative scheme reduces to the first inexact ADMM with LQP in [21].
3 Global convergence and convergence rate
In this section, we aim to prove the global convergence of Algorithm 1, and establish its worst-case convergence rate in a nonergodic sense.
To prove the global convergence, we need to define some auxiliary sequences as follows:
and
Thus, based on (6) and (12), we immediately have
Lemma 3.1
The sequence \(\{w_{*}^{k}\}\) defined by (12) and the sequence \(\{w^{k}\}\) generated by Algorithm 1 satisfy the following inequality:
where \(\rho>0\) and H is defined by (8).
Proof
By the definitions of \(\lambda^{k+1}\) and \(\lambda _{*}^{k+1}\), we have
This and (6), (12) imply (14) immediately. The lemma is proved. □
Lemma 3.2
If \(w^{k}=w^{k+1}\), then \(w^{k+1}=(x^{k+1},y^{k+1},\lambda^{k+1})\) produced by Algorithm 1 is a solution of \(\operatorname{VI}(\mathcal{W},Q)\).
Proof
For any \(x\in\mathcal{R}^{m}_{+}\), applying Lemma 2.2 to the x-subproblem of (6) by setting \(\bar{u}=x^{k}\), \(u=\hat{x}^{k}\), \(v=x\), and
in (11), we have
from which we get
For any \(y\in\mathcal{R}^{n}_{+}\), applying Lemma 2.2 to the y-subproblem of (6) by setting \(\bar{u}=y^{k}\), \(u=\hat{y}^{k}\), \(v=y\), and
in (11), we have
from the above inequality and \(\lambda_{*}^{k+\frac{1}{2}}-\beta(\alpha A\hat{x}^{k}-(1-\alpha)(B\hat{y}^{k}-b)+B\hat{y}^{k}-b)=\hat{\lambda }^{k}+(1-r-\alpha)(\lambda^{k}-\hat{\lambda}^{k})-\beta B(\hat{y}^{k}-y^{k})\), we get
In addition, from (12) again, we have
Then, combining (15), (16), (17), for any \(w=(x,y,\lambda)\in\mathcal {W}\), we have
Then, recalling the definitions of P in (7) and N in (8), the above inequality can be written as
In addition, if \(w^{k}=w^{k+1}\), then we have \(w^{k}=\hat{w}^{k}\), which together with (18) indicates that
This implies that \(\hat{w}^{k}=(\hat{x}_{1}^{k},\hat{x}_{2}^{k},\hat{\lambda}^{k})\) is a solution of \(\operatorname{VI}(\mathcal{W},Q)\). Since \(\hat{w}^{k}=w^{k+1}\), therefore \(w^{k+1}\) is also a solution of \(\operatorname{VI}(\mathcal{W},Q)\). This completes the proof. □
The next lemma further refines the right term of (17) and express it in terms of some quadratic terms, and its proof is motivated by Lemma 3.3 in [13].
Lemma 3.3
Let the sequence \(\{w^{k}\}\) be generated by Algorithm 1. Then, for any \(w\in\mathcal{W}\), we have
Proof
Taking \(a=w\), \(b=\hat{w}^{k}\), \(c=w^{k}\), \(d=w_{*}^{k+1}\) in the identity
we get
which combined with (9) and (13) yields
For the last term of (20), we have
Substituting it in (20), we obtain (19). The proof is complete. □
The following theorem indicates the sequence generated by Algorithm 1 is Fejèr monotone with respect to \(\mathcal{W}^{*}\).
Theorem 3.1
Let \(\{w^{k}\}\) be the sequence generated by Algorithm 1. Then, for any \(w^{*}\in\mathcal{W}^{*}\), we have
Proof
From (18), (19), and the monotonicity of Q, we obtain
The assertion (21) follows immediately by setting \(w=w^{*}\in\mathcal {W}^{*}\) in (22). The theorem is proved. □
Now, we are ready to prove the global convergence of Algorithm 1.
Theorem 3.2
The sequence \(\{w^{k}\}\) generated by Algorithm 1 converges to some \(w^{\infty}\), which belongs to \(\mathcal{W}^{*}\).
Proof
First, by (21), for any given \(w^{*}\in\mathcal{W}^{*}\), we have
which together with (14) implies that
Therefore, for any \(l\leq k\), we have
Since \(\sum_{k=0}^{\infty}v_{k}<+\infty\), there is a constant \(C_{w^{*}}>0\), such that
Therefore the sequence \(\{w^{k}\}\) generated by Algorithm 1 is bounded. Furthermore, it follows from (14), (21), (23) that
Then, summing the inequality (24) over \(k=0,1,\ldots\) and by \(\sum_{k=0}^{\infty}v_{k}<+\infty\), we have
which implies that
Thus the sequence \(\{\hat{w}^{k}\}\) is also bounded, and thus it has at least one cluster point. Let \(w^{\infty}\) be a cluster point of \(\{\hat {w}^{k}\}\) and let the subsequence \(\{\hat{w}^{k_{j}}\}\) converge to \(w^{\infty}\). Then, by (18) and (25), we can get
That is,
which implies that \(w^{\infty}\in\mathcal{W}^{*}\). By (24), we have
From \(\lim_{k\rightarrow\infty}\|w^{k}-\hat{w}^{k}\|_{\tilde{H}}=0\) and \(\{\hat{w}^{k_{j}}\}\rightarrow w^{\infty}\), for any given \(\epsilon>0\), there exists an integer \(j_{0}\), such that
Therefore, for any \(k\geq k_{j_{0}}\), it follows from the above two equalities and (27) that
which combining with the positive definite of H̃ indicates that the sequence \(\{w^{k}\}\) converges to \(w^{\infty}\in\mathcal{W}^{*}\). This completes the proof. □
Now, we are going to establish the convergence rate of Algorithm 1 in a nonergodic sense.
Theorem 3.3
Let \(\{w^{k}\}\) be the sequence generated by Algorithm 1. Then, for any \(w\in\mathcal{W}\), we have
where \(\tilde{w}_{t}=(\sum_{k=0}^{t}\hat{w}^{k})/(t+1)\).
Proof
From (22), we have
It follows from (14) that
From the above two inequalities, we get
Summing the above inequality over \(k=0,1,\ldots,t\), we obtain
Using the notation of \(\tilde{w}_{t}\), we have
The assertion (28) follows from the above inequality immediately. The proof is completed. □
Remark 3.1
From the proof of Theorem 3.2, there is a constant \(D>0\), such that
Since \(\tilde{w}_{t}=(\sum_{k=0}^{t}\hat{w}^{k})/(t+1)\), thus, we also have \(\|\tilde{w}_{t}\|\leq D\). Denote \(E_{1}=\sum_{k=0}^{\infty}v_{k}<+\infty\). For any \(w\in\mathcal{B}_{\mathcal{W}}(\tilde{w}_{t})=\{w\in\mathcal{W}|\| w-\tilde{w}_{t}\|_{H}\leq1\}\), by (28), we get
Then, for any given \(\epsilon>0\), the above inequality shows that after at most \(\lceil(2D+1)(2D+1+2\rho E_{1})/(2\epsilon)-1\rceil\) iterations, we can get
This indicates that \(\tilde{w}_{t}\) is an approximate solution of \(\operatorname{VI}(\mathcal{W}, Q)\) with an accuracy of \(\mathcal{O}(1/t)\). Thus a worst-case \(\mathcal{O}(1/t)\) convergence rate of Algorithm 1 in the ergodic sense is established.
4 Numerical experiments
In this section, we apply Algorithm 1 to the traffic equilibrium problem with link capacity bound [22], which has been well studied in the literature of transportation. All codes were written by Matlab R2010a and conducted on a ThinkPad notebook with a Pentium (R) Dual-Core CPU T4400@2.2 GHz, 2GB of memory.
Consider a network \([\mathcal{N},\mathcal{L}]\) of nodes \(\mathcal{N}\) and directed links \(\mathcal{L}\), which is depicted in Figure 1, and consists of 20 nodes, 28 links and 8 O/D pairs.

A directed network with 20 nodes and 28 links.
We use the following symbols. a: a link; p: a path; ω: an origin/destination (O/D) pair of nodes; \(\mathcal{P}_{\omega}\): the set of all paths connecting the O/D pair ω; Â: the path-arc incidence matrix; E: the path-O/D pair incident matrix; \(x_{p}\): the traffic flow on the path p; \(\hat{f}_{a}\): the link load on the link a; \(d_{\omega}\): the traffic amount between the O/D pair ω. Thus, the link-flow vector f̂ is given by
and the O/D pair-traffic amount vector d is given by
Let \(t(\hat{f})=\{t_{a},a\in\mathcal{L}\}\) be the vector of link travel costs, which is given in Table 1. For a given link travel cost vector t, the path travel cost vector θ is given by
Associated with every O/D pair ω, there is a travel disutility \(\eta_{\omega}(d)\), which is defined by
and the parameters \(m_{\omega}\), \(q_{\omega}\) are given in Table 2. Now, the traffic network equilibrium problem is to seek the path-flow pattern \(x^{*}\) [22]:
where
and b is the given link capacity vector. Using matrices  and E, a compact form of mapping is \(\hat {F}(x)=\hat{A}t(\hat{A}^{\top}x)-E\eta(E^{\top}x)\). Introducing a slack variable \(y\geq0\) and setting \(g(y)=0\), \(B=I\), the above problem can be converted into Problem (1). That is,
with
When \(v_{k}=0\) (\(\forall k\geq0\)), the implementation details of the two nonlinear equations of Algorithm 1 at each iteration are
For the y-subproblem, it is easy to get its solution explicitly [23]:
where
For the x-subproblem, we use the LQP-type method developed in [24] to solve it. In the test, we take \(x^{0}=(1,1,\ldots,1)^{\top}\), \(y^{0}=(1,1,\ldots,1)^{\top}\), and \(\lambda^{0}=(0,0,\ldots,0)^{\top}\) as the starting point. For the test problem, the stopping criterion is
where
In the test, we take \(\mu=0.01\), \(\beta=0.8\), \(r=0.8\), \(R=100I\), \(S=0.9I\). To illustrate the superiority of Algorithm 1, we also implement the inexact ADMM (denoted by IADMM) presented in [25] to solve this example under the same computational environment. The numerical results for different capacities (\(b=30\) and \(b=40\)) and different ϵ and α are listed in Table 1, where the numbers in the tuplet ‘\(\cdot/\cdot\)’ represents, respectively, the numbers of iterations (Iter.) and the CPU time in seconds. Numerical results in Table 3 indicate that Algorithm 1 is an efficient method for the traffic equilibrium problem with link capacity bound, and it is superior to the IADMM in terms of number of iteration and CPU time. Furthermore, the two criteria of Algorithm 1 decrease with respect to α, as one has pointed in [26].
In addition, for the test problem with \(b=40\), the optimal link-flow (Flow) vector \(\hat{A}x^{*}\) and the toll charge (Charge) on the congested link \(-\lambda^{*}\) are listed in Table 4.
5 Conclusions
In this paper, we have proposed an inexact generalized PRSM with LQP regularization for the structured variational inequalities, for which one only needs to solve two nonlinear equations approximately at each iteration. Under mild conditions, we have proved the global convergence of the new method and establish its convergence rate. Numerical results about the traffic equilibrium problem with link capacity bound indicate that the new method is quite efficient.
References
Kinderlehrer, D, Stampacchia, G: An Introduction to Variational Inequalities and Their Applications. SIAM, Philadelphia (2000)
Glowinski, R, Lions, JL, Tremolieres, R: Numerical Analysis of Variational Inequalities. Elsevier, Amsterdam (2011)
Bertsekas, DP, Gafni, EM: Projection method for variational inequalities with applications to the traffic assignment problem. Math. Program. Stud. 17, 139-159 (1987)
Gabay, D, Mercier, B: A dual algorithm for the solution of nonlinear variational problems via finite element approximations. Comput. Math. Appl. 2, 16-40 (1976)
Glowinski, R, Marrocco, A: Sur l’approximation par éléments finis d’ordre un et résolution par pénalisation-dualité d’une classe de problèmes non linéaires. Rev. Fr. Autom. Inform. Rech. Opér. , Anal. Numér. 9(2, 41-76 (1975)
Fortin, M, Glowinski, R: Augmented Lagrangian Methods: Applications to the Numerical Solutions of Boundary Value Problems. Studies in Mathematics and Its Applications. North-Holland, Amsterdam (1983)
Eckstein, J, Bertsekas, DP: On the Douglas-Rachford splitting method and the proximal point algorithm for maximal monotone operators. Math. Program. 55, 293-318 (1992)
Tseng, P: Applications of a splitting algorithm to decomposition in convex programming and variational inequalities. SIAM J. Control Optim. 29, 119-138 (1991)
Fukushima, M: The primal Douglas-Rachford splitting algorithm for a class of monotone mappings with application to the traffic equilibrium problem. Math. Program. 72, 1-15 (1996)
Gabay, D: Applications of the method of multipliers to variational inequalities. In: Fortin, M, Glowinski, R (eds.) Augmented Lagrange Methods: Applications to the Solution of Boundary-Valued Problems, pp. 299-331. North-Holland, Amsterdam (1983)
Lions, PL, Mercier, B: Splitting algorithms for the sum of two nonlinear operators. SIAM J. Numer. Anal. 16, 964-979 (1979)
Peaceman, DW, Rachford, HH Jr.: The numerical solution of parabolic and elliptic differential equations. J. Soc. Ind. Appl. Math. 3, 28-41 (1955)
He, BS, Liu, H, Wang, ZR, Yuan, XM: A strictly contractive Peaceman-Rachford splitting method for convex programming. SIAM J. Optim. 24(3), 1011-1040 (2014)
Auslender, A, Haddou, M: An interior proximal point method for convex linearly constrained problems and its extension to variational inequalities. Math. Program. 71, 77-100 (1995)
Gol’shtein, EG, Tret’yakov, NV: Modified Lagrangian in convex programming and their generalizations. Math. Program. Stud. 10, 86-97 (1979)
Eckstein, J: Approximate iterations in Bregman-function-based proximal algorithms. Math. Program. 83, 113-123 (1998)
Yuan, XM, Li, M: An LQP-based decomposition method for solving a class of variational inequalities. SIAM J. Optim. 21, 1309-1318 (2011)
Li, M, Li, XX, Yuan, XM: Convergence analysis of the generalized alternating direction method of multipliers with logarithmic-quadratic proximal regularization. J. Optim. Theory Appl. 164(1), 218-233 (2015)
Li, M, Yuan, XM: A strictly contractive Peaceman-Rachford splitting method with logarithmic-quadratic proximal regularization for convex programming. Math. Oper. Res. 40(4), 842-858 (2015)
He, BS, Ma, F, Yuan, XM: On the step size of symmetric alternating directions method of multipliers. http://www.optimization-online.org/DB_FILE/2015/05/4925.pdf
Li, M, Liao, LZ, Yuan, XM: Inexact alternating direction methods of multipliers with logarithmic-quadratic proximal regularization. J. Optim. Theory Appl. 159(2), 412-436 (2013)
Nagurney, A, Zhang, D: Projected Dynamical Systems and Variational Inequalities with Applications. Kluwer Academic, Dordrecht (1996)
Li, M: A hybrid LQP-based method for structured variational inequalities. Int. J. Comput. Math. 89(10), 1412-1425 (2012)
He, BS, Liao, LZ, Yuan, XM: A LQP-based interior prediction-correction method for nonlinear complementarity problems. J. Comput. Math. 24(1), 33-44 (2006)
He, BS, Liao, LZ, Han, DR, Yang, H: A new inexact alternating directions method for monotone variational inequalities. Math. Program., Ser. A 92, 103-118 (2002)
Deng, W, Yin, WT: On the global and linear convergence of the generalized alternating direction method of multipliers. J. Sci. Comput. 66(3), 889-916 (2016)
Acknowledgements
The authors gratefully acknowledge the helpful comments and suggestions of the anonymous reviewers. This work is supported by the National Natural Science Foundation of China (71371139, 11302188), the Shanghai Shuguang Talent Project (13SG24), the Shanghai Pujiang Talent Project (12PJC069), the foundation of Scientific Research Project of Shandong Universities (J15LI11).
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ contributions
The first author has designed the algorithm and the second author has proved its global convergence and convergence rate. The two authors have equally contributed in the numerical results. All authors read and approved the final manuscript.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Sun, M., Liu, J. An inexact generalized PRSM with LQP regularization for structured variational inequalities and its applications to traffic equilibrium problems. J Inequal Appl 2016, 150 (2016). https://doi.org/10.1186/s13660-016-1095-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13660-016-1095-z