
Abstract
Objectives
We systematically reviewed the current literature evaluating the ability of fully-automated deep learning (DL) and semi-automated traditional machine learning (TML) MRI-based artificial intelligence (AI) methods to differentiate clinically significant prostate cancer (csPCa) from indolent PCa (iPCa) and benign conditions.
Methods
We performed a computerised bibliographic search of studies indexed in MEDLINE/PubMed, arXiv, medRxiv, and bioRxiv between 1 January 2016 and 31 July 2021. Two reviewers performed the title/abstract and full-text screening. The remaining papers were screened by four reviewers using the Checklist for Artificial Intelligence in Medical Imaging (CLAIM) for DL studies and Radiomics Quality Score (RQS) for TML studies. Papers that fulfilled the pre-defined screening requirements underwent full CLAIM/RQS evaluation alongside the risk of bias assessment using QUADAS-2, both conducted by the same four reviewers. Standard measures of discrimination were extracted for the developed predictive models.
Results
17/28 papers (five DL and twelve TML) passed the quality screening and were subject to a full CLAIM/RQS/QUADAS-2 assessment, which revealed a substantial study heterogeneity that precluded us from performing quantitative analysis as part of this review. The mean RQS of TML papers was 11/36, and a total of five papers had a high risk of bias. AUCs of DL and TML papers with low risk of bias ranged between 0.80–0.89 and 0.75–0.88, respectively.
Conclusion
We observed comparable performance of the two classes of AI methods and identified a number of common methodological limitations and biases that future studies will need to address to ensure the generalisability of the developed models.
Similar content being viewed by others


Key points
-
Fully-automated and semi-automated MRI-based AI algorithms show comparable performance for differentiating csPCa/iPCa.
-
DL and TML papers share common methodological limitations discussed in this review.
-
Consensus on datasets, segmentation, ground truth assessment, and model evaluation are needed.
Background
The introduction of pre-biopsy multiparametric magnetic resonance imaging (mpMRI) has considerably improved the quality of prostate cancer (PCa) diagnosis by reducing the number of unnecessary biopsies and increasing the detection of clinically significant disease compared to the conventional PSA-transrectal ultrasound (TRUS) pathway [1,2,3]. However, the high dependence of the diagnostic performance of mpMRI on reader experience [4, 5] and image quality [6], coupled with the need to balance the time-consuming delineation of biopsy targets against the increasing pressure on radiology departments [7], limits the population-based delivery of high-quality mpMRI-driven PCa diagnosis.
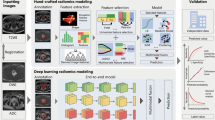
The recent joint position paper by the European Society of Urogenital Radiology (ESUR) and European Association of Urology (EAU) Section of Urological Imaging (ESUI) has highlighted the importance of developing robust and clinically applicable artificial intelligence (AI) methods for overcoming the aforementioned limitations and facilitating the successful deployment of the mpMRI-driven PCa diagnostic pathway [8] to the community. Importantly, the authors suggest the use of AI as a triage tool to detect and delineate areas suspicious for clinically significant PCa (csPCa), where its accurate differentiation from indolent PCa (iPCa) and benign conditions determines the need for subsequent biopsy and defines the diagnostic accuracy of mpMRI. While several recent systematic [9,10,11,12] and narrative [13] reviews have described the performance of AI methods for detecting csPCa on MRI, little is known about the comparative performance of fully-automated and semi-automated approaches when applied to this specific clinical task. The rationale for this comparison is based on several inherent differences between the two approaches. Specifically, fully-automated methods rely on learned deep radiomic features and do not require human input following initial training and validation, which underpins their disruptive potential for significantly reducing the radiologists’ clinical workload. Conversely, semi-automated methods, most commonly based on hand-engineered radiomic features, require manual delineation and image pre-processing that may increase the radiologists’ time while not adding significant diagnostic benefit.
Therefore, the primary objective of this systematic review was to analyse the current literature on fully-automated and semi-automated AI methods to differentiate csPCa from iPCa and benign disease on MRI. In addition, we aimed to both identify and offer prospective solutions to common methodological limitations and biases of the existing studies. Addressing these issues going forward will facilitate the development of robust, generalisable, and clinically applicable MRI-derived AI models for PCa diagnosis.
Materials and methods
To avoid bias, the review protocol was agreed by all authors and registered with PROSPERO (CRD42021270309) before the start of the review process.
Search strategy
Data collection and reporting were conducted following the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) [14], with a complete PRISMA 2020 checklist presented in Additional file 2: Table S1. We performed a computerised bibliographic search of published and unpublished studies indexed in MEDLINE/PubMed, arXiv, medRxiv, and bioRxiv between 1 January 2016 and 31 July 2021. The full search strategy is summarised in Additional file 1.
Eligibility criteria
The population of interest included treatment-naïve patients who underwent MRI of the prostate that was subsequently processed using either fully-automated or semi-automated AI methods for lesion detection and subsequent binary classification as (a) csPCa or (b) iPCa or benign disease. The performance of AI methods (index test) was referenced against histopathological assessment of MRI target lesions, with csPCa defined as International Society of Urogenital Pathology (ISUP) grade group ≥ 2 disease and iPCa defined as ISUP grade group 1 disease. The outcome measures included the diagnostic performance of AI approaches for differentiating csPCa from iPCa and benign disease measured as an area under the receiving operator characteristic curve (AUC), sensitivity, specificity, accuracy, positive predictive value (PPV), and negative predictive value (NPV). Only studies written in English and presenting original results were included in this review.
Systematic review process
We deployed a three-stage process to identify papers suitable for inclusion in this review using Covidence [15] as a Web-based support tool. In the first stage, a team of two reviewers (N.S., L.R.) independently performed the title and abstract screening to ensure relevance, with conflicts resolved by the third reviewer (T.B.). In the second stage, the same two reviewers screened the full text of each paper for eligibility, with conflicts resolved by the same third reviewer. In the third stage, four reviewers (Team 1, N.S., NMDS; Team 2, L.R., M.Y.) evaluated the quality of the documentation of methodologies in the papers to assess the reproducibility of their results. Papers using fully-automated AI methods based on deep learning (DL) methods were assessed using the Checklist for Artificial Intelligence in Medical Imaging (CLAIM) [16], while studies deploying semi-automated AI approaches relying on traditional machine learning (TML) methods were evaluated using the Radiomics Quality Score (RQS) [17] as detailed in Additional file 1.
Risk of bias assessment
We used the Quality Assessment of Diagnostic Accuracy Studies (QUADAS-2) tool [18] to assess the risk of bias and applicability of studies included in this systematic review. In line with the QUADAS-2 guidance, we developed a review-specific protocol on how to assess each signalling question, which is summarised in Additional file 1. QUADAS-2 assessment was conducted by the same two teams of two reviewers, with each paper reviewed independently by the reviewers prior to conflict resolution by consensus of all four reviewers.
Data extraction
The data extraction criteria were agreed prior to the review commencement and then independently extracted by the same reviewer teams. The full list of extracted parameters is presented in Additional file 3, with the key diagnostic performance characteristics being AUC, sensitivity, specificity, accuracy, NPV and PPV for the internal holdout or external test sets (when available).
Data analysis
Given the substantial heterogeneity of patient characteristics, AI algorithms, ground truth assessment methods, and validation strategies used in the diagnostic accuracy studies included in this review, we chose narrative synthesis over meta-analysis of the pooled data to avoid a biased result [19].
Results
Study selection
The study selection process is presented in Fig. 1. Our initial search identified 314 papers, of which 4 were highlighted as duplicates by Covidence and removed by us following manual verification. 60/310 papers had titles or abstract deemed relevant to the review question; of those, 28 were retained for quality review after full-text screening. 12/28 papers deployed fully-automated AI methods based on DL methods and were therefore screened using CLAIM, while 16/28 papers used TML methods to develop semi-automated AI approaches and were assessed using RQS. Of these, 5/12 (42%) DL papers [20,21,22,23,24] and 12/16 (43%) TML papers [25,26,27,28,29,30,31,32,33,34,35,36] passed the quality screening and were subject to full QUADAS-2 assessment, data extraction, and narrative synthesis.

Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) 2020 flow diagram for literature search. csPCa, clinically significant prostate cancer; iPCa, indolent prostate cancer
Quality review
Three out of 12 DL studies (25%) [37,38,39] that underwent quality screening using CLAIM failed at least three pre-identified mandatory criteria, with 2/12 [40, 41] failing two, and 2/12 [42, 43] failing just one criterion. Four of the seven rejected papers (57%) [37,38,39, 43] did not describe data processing steps in sufficient detail (Q9), 4/7 [38,39,40, 42] did not explain the exact method of selecting the final model (Q26), and 3/7 [38, 40, 41] failed to provide enough details on training approach (Q25). Following the subsequent full CLAIM assessment of the remaining five papers, we found that none of them reported the following items: selection of data subsets (Q10), robustness or sensitivity analysis (Q30), validation or testing on external data (Q32), and failure analysis of incorrectly classified cases (Q37). The results of CLAIM quality screening and full assessment are presented in Additional file 1.
One out of 16 TML studies (6%) [44] that underwent quality screening using RQS scored 2/8, 1/16 [45] scored 6/8, and 2/16 [46, 47] scored 7/8, which led to their exclusion from subsequent full RQS assessment. None of the excluded papers had well-documented imaging protocols (Q1) and neither performed multiple segmentations by different radiologists nor conducted robustness analysis of image segmentations to region-of-interest (ROI) morphological perturbations (Q2). The mean RQS of the remaining 12 papers that underwent full assessment was 10.9 ± 2.0 (standard deviation) out of 36 points possible. None of the papers performed phantom studies to detect scanner-dependent features (Q3), reported calibration statistics (Q10), registered a prospective study (Q11), and reported on the cost-effectiveness of the clinical application of the proposed models (Q14). Only one (8%) paper [32] discussed a potential biological correlate for some radiomic features included in the final model (Q7), and only two papers [28, 36] performed external testing of their models (Q12). Furthermore, only six out of 12 (50%) papers [25, 26, 29,30,31,32] had image segmentation performed by multiple radiologists or instead assessed the robustness of radiomic features to ROI morphological perturbations (Q2). Eight out of 12 (67%) papers [25,26,27, 30,31,32, 34, 35] did not make available any images, code, or feature values used to train the models (Q16), and only 4/12 (33%) papers [30, 31, 34, 36] incorporated non-radiomic features into the multivariable analysis (Q6). The results of RQS screening and full assessment are presented in Additional file 3.
Risk of bias assessment
The full results of QUADAS-2 assessment are presented in Additional file 1, with their graphical summary provided in Table 1 and Fig. 2. Overall, 11/17 (65%) [12, 20,21,22,23, 25, 26, 29, 31, 34, 36], 1/17 [35], and 5/17 [24, 27, 30, 32, 33] papers had low, unclear, and high risk of bias, respectively. All papers had low applicability concerns. Inappropriate patient selection led to a high risk of bias in 3/5 (60%) studies [27, 30, 33], with two papers containing inappropriate exclusions and one study using a case–control design. One study [30] did not pre-specify a threshold prior to evaluation of the index test performance on the test set. One study [32] used transrectal ultrasound guided (TRUS) biopsy performed six weeks prior to MRI as a reference standard, which introduced a high risk of bias. Two (40%) papers [24, 32] had high risk of bias associated with data flow and timing between the index test (MRI) and reference standard (biopsy), with one paper using both surgical pathology and biopsy results as reference standards, and one paper reporting a six week interval between biopsy and MRI, which was below the recommended threshold of at least six months [48]. The only paper with an unclear risk of bias did not report any information regarding the timing between MRI and biopsy, as well as the specific type of biopsy and whether it was consistent in all patients in the study.

Summary QUADAS-2 risk of bias and applicability concerns assessment
Study characteristics
Summary demographic characteristics of patients included in the studies that passed the quality screening are presented in Table 2. Two out of five (40%) DL papers [20, 21] used patient data available as part of the open-source PROSTATEx challenge dataset [49], while the remaining three (60%) studies [22,23,24] used data from single institutions. Importantly, one paper [24] used radical prostatectomy and targeted biopsy interchangeably in one of its patient cohorts. None of the DL studies reported the time between MRI and biopsy, while all studies performed MRI using a single vendor. The number of readers annotating MR images varied between 1 and 4, with reader experience ranging between 0.5 and 20 years.
Ten out of 12 (83%) TML papers [12, 25, 26, 30,31,32,33,34,35,36] utilised non-publicly available institutional datasets, with the remaining 2/12 (17%) studies [27, 29] using the PROSTATEx challenge dataset [49]. In eight (67%) papers [25,26,27, 29,30,31,32, 34], the histopathological ground truth was obtained using targeted biopsy, while two studies [28, 33] relied on radical prostatectomy data, one [36] was a multi-institutional study relying on either biopsy (targeted or systematic) or prostatectomy data in different cohorts, and one [35] did not explicitly report the source of ground truth. Only two (17%) papers [31, 32] reported the time between biopsy and MRI; in these studies, biopsy was performed either three months [31] or six weeks [32] prior to MRI. Nine (75%) studies [25,26,27, 29, 30, 32,33,34,35] had one centre and one vendor each, while the remaining three studies [28, 31, 36] were multi-vendor. The number of readers varied between 1 and 5, with reader experience ranging between 0.5 and more than 25 years.
Predictive modelling characteristics
Summary predictive modelling characteristics of DL papers are presented in Table 3. All studies used different convolutional neural network (CNN) architectures, with 3/5 (60%) studies [20, 23, 24] proposing their own networks and 2 papers using off-the-shelf networks, including VGG16 [21] and U-Net [22]. None of the papers included non-imaging features for the purposes of predictive modelling and conducted external testing of the developed predictive models. All DL papers were designed as a classification task to distinguish csPCa from iPCa and benign lesions. Four (80%) studies [21,22,23,24] performed the analysis at the level of the whole prostate, and one study [20] separately analysed peripheral and transition zone lesions. Importantly, none of the DL studies validated their results using external datasets.
Similar predictive modelling characteristics of TML papers are summarised in Table 4. The three most commonly used ML models included random forests (50% papers), logistic regression (42% papers), and support vector machines (25% papers), with 7/12 studies testing several different models. Imaging features were extracted from apparent diffusion coefficient maps, T2-weighted images, and diffusion-weighted images with different b-values in 12/12 (100%) [25,26,27,28,29,30,31,32,33,34,35,36], 9/12 [25,26,27,28,29,30,31, 33, 36], and 7/12 [25,26,27,28,29, 32, 35] papers, respectively. In contrast to the DL papers, only 7/12 (58%) TML studies [25, 27, 29,30,31, 35, 36] differentiated csPCa from iPCa and benign lesions, whereas the remaining five studies (42%) [26, 28, 32,33,34] did not include benign disease, thereby focusing only on distinguishing csPCa from iPCa. Eight (67%) papers [26, 28, 30,31,32,33, 35, 36] performed the analysis at the level of the whole prostate, two [27, 34] reported the results for peripheral and transition zone lesions separately, one [25] developed models for the whole prostate as well as peripheral and transition zone lesions, and one [29] included peripheral zone tumours only. Seven (58%) studies [25,26,27, 29,30,31,32] validated their results using internal hold-out, three papers [33,34,35] used cross-validation, and the remaining two studies [28, 36] used either a mixed hold-out cohort or a fully external hold-out dataset.
Comparative performance of fully-automated and semi-automated AI methods
Three out of 5 (60%) DL studies [21,22,23] had clearly defined thresholds at which performance characteristics of the developed models were calculated; these are presented in Table 5. For studies combining peripheral and transition zone lesions for classification [21, 23, 24], the AUCs of the best-performing models reported in the test sets for differentiating csPCa from iPCa and benign disease ranged between 0.80 and 0.89. Importantly, the AUC range changed to 0.85–0.89 when a study by Seetharaman et al. [24] was excluded from the calculation due to its high risk of bias reported on QUADAS-2 assessment (Table 1). In a study by Wang et al. [20], AUCs for peripheral zone and transition zone lesions were 0.89 [0.86–0.93] and 0.97 [0.95–0.98], respectively, and a study by Schelb et al. [22] did not report AUC values. Four (80%) studies [21,22,23,24] did not report accuracy of the developed models, while Wang et al. [20] reported accuracy of 0.91 [0.86–0.95] and 0.89 [0.87–0.91] in the peripheral and transition zone lesions, respectively. All studies reported sensitivity and specificity of the proposed models, while only 2/5 (40%) [22, 23] studies presented NPV and PPV, with NPV being higher in both cases (Table 5).
Six out of 12 (50%) TML studies [25, 30,31,32, 34, 36] defined specific thresholds for diagnostic performance, with the resulting characteristics summarised in Table 5. The AUCs of the best-performing models for studies combining peripheral and transition zone lesions ranged between 0.75 and 0.98. The AUC range changed to 0.75–0.88 when five papers [27, 30, 32, 33, 35] with high or unclear risk of bias on QUADAS-2 (Table 1) were removed from the calculation. A study by Li et al. [30] (high risk of bias, see Table 1) was one of two papers reporting accuracy of the proposed model (0.90), in addition to a study by Hiremath et al. [36] where it reached 0.78; both studies applied their models to peripheral and transition zone lesions combined. 3/12 (25%) [27, 33, 35] papers did not report sensitivity and specificity of their models, and only one study by Li et al. [30] presented NPV and PPV of their model.
Discussion
This systematic review highlights the intensity of research efforts in developing both fully-automated and semi-automated MRI-derived AI methods for differentiating csPCa from iPCa and benign disease. While formal meta-analysis and direct comparison of the two approaches were not possible due to a substantial heterogeneity of studies included in this review, the narrative synthesis revealed their comparable performance that was marginally higher for fully-automated methods. If common methodological limitations outlined in this review are addressed, future studies will have the potential to make AI-driven expert-level prostate MRI assessment widely accessible and reproducible among multiple centres and readers with different experiences.
In keeping with this report, previous systematic and narrative reviews investigating the diagnostic performance of DL- and TML-based AI methods for PCa diagnosis [9, 11,12,13] have also highlighted substantial heterogeneity and poor reproducibility of the developed predictive models. While a meta-analysis by Cuocolo et al. [10] showed higher AUC of TML-based models compared to DL-based models, the authors drew the data from all studies included in the qualitative synthesis. Some of these studies had a high risk of bias and showed important differences among their patient populations, ground truth assessment methods, zonal distribution of predictive models, and other potential confounders. In our review, the addition of full CLAIM and RQS quality evaluation to QUADAS-2 assessment highlighted high methodological heterogeneity of both DL- and TML-based studies, which limited the reliability of their quantitative synthesis. The outcomes of qualitative synthesis, however, suggest that DL-based fully-automated AI methods may prove more clinically useful in the long run given their comparable performance to TML-based semi-automated methods. A crucial practical advantage of fully-automated approaches is its potential time-saving effect that is important in the context of an ever-increasing workload in radiology departments. That said, almost all DL papers included in this review still require even minimal manual interaction from the readers, including lesion identification as patches [20] or bounding boxes [22,23,24], thereby still introducing a known element of interobserver variability. However, a head-to-head comparison of DL- and TML-based AI methods in the same patient cohort presents a highly important area of unmet research need. If addressed, this has the capacity to directly answer the clinical question behind this review.
In this review, a combination of full CLAIM, RQS, and QUADAS-2 assessment revealed several common methodological limitations, some of which are applicable to both DL and TML studies. These common limitations fall into four distinct domains: (1) datasets used for model development, (2) methods used to ensure quality and reproducibility of image segmentation, (3) ground truth assessment methods, (4) strategies used for model evaluation. The following paragraphs summarise the key limitations within each of the four domains, with detailed recommendations for their prospective mitigation provided in Additional file 1.
First, the overwhelming majority of papers included in this review either utilised non-publicly available single-centre datasets or used the same open-source single-centre PROSTATEx challenge dataset [49]. The use of single-centre datasets, both public and private, without external testing presents a critical limitation to the clinical applicability of the developed models. Conversely, the use of a single public dataset without additional data encourages community-wide overfitting that limits the utility of the dataset itself.
Second, nearly half of the studies did not process images segmented by multiple radiologists, thus limiting the generalisability of the developed predictive models due to known interobserver variability even among experts [50,51,52]. The same applies to the original PROSTATEx dataset [49] that includes lesion coordinates based on the outlines provided by a single reader. While one DL study included in our review [20] used the original single-reader segmentations, another study [21] overcame this limitation by utilising segmentations validated by several readers in a dedicated study by Cuocolo et al. [53]. Even if trained on the same dataset and using the same AI methods, models developed using different segmentations will inevitably differ in their performance, which brings additional layer of heterogeneity to the field.
Third, only 80% of DL and 67% of TML papers used MRI-targeted biopsy specimens as a source of ground truth. The remaining studies either relied on radical prostatectomy data or included mixed patient cohorts where the ground truth was obtained using different methods. While radical prostatectomy specimens offer definitive assessment of lesion morphology, the resulting predictive models will have very limited clinical applicability due to overrepresentation of patients with intermediate-risk disease. If predictive models are trained to differentiate between iPCa and csPCa and therefore help clinicians decide on the need for subsequent biopsy, then MRI-targeted biopsy using cognitive, US/MRI fused, or in-bore approaches present an appropriate standard for ground truth assessment.
Fourth, none of the DL papers and only two TML papers used external testing to assess the generalisability of the developed predictive models [54]. Given the intrinsically low reproducibility and repeatability of MRI-derived radiomic features [55, 56], the lack of robust external testing and prior assessment of feature robustness to scanning parameters present major obstacles to the clinical use of any MRI-based AI algorithms. However, even if external testing becomes the norm, it is also important to avoid common mistakes in reporting standard measures of discrimination that help evaluate model performance. These often include the lack of clearly identified operating points at which they were calculated and confidence intervals that reflect the uncertainty in the estimate. Ideally, the operating points should reflect the expected performance of expert radiologists, with the pooled NPV of 97.1% (95% CI 94.9–98.7%) [2] being the key clinical benchmark that has established mpMRI as a diagnostic test that can effectively rule out csPCa. Importantly, a thorough failure analysis of incorrectly classified cases is key to understanding and communicating diagnostic pitfalls of the developed models, which is paramount to their safe and evidence-based clinical use. Finally, despite pointing out the above pitfalls, we acknowledge the overall high quality of publications in the field of applying AI methods to mpMRI-driven PCa diagnosis. Improving their methodological quality, the next steps will require a consolidated international and multi-institutional effort, the success of which will primarily depend on the quality of data used for training and validating AI algorithms.
This review has several limitations. The introduction of stringent CLAIM and RQS methodological screening led to the exclusion of several high-quality papers published in high-impact journals, such as Journal of Magnetic Resonance Imaging, European Radiology, and Cancers. This approach, which we previously adopted for another review [57], allowed us to only include studies that are reproducible. It is, however, important to acknowledge that the CLAIM requirements are harder to fulfil compared to the RQS ones. We also acknowledge that some relevant studies may not have been included, particularly those published between our search and publication of this review. Due to the considerable heterogeneity of studies, we did not pool the data for a formal comparison of the diagnostic accuracy of fully-automated and semi-automated AI methods. This was, however, compensated by an extensive narrative synthesis that identified common pitfalls and inconsistencies of the included studies that formed the basis of their heterogeneity.
Conclusions
In conclusion, we observed comparable performance of fully-automated and semi-automated MRI-derived AI methods for differentiating csPCa from iPCa and benign disease. In-depth CLAIM and RQS methodological quality assessment of the studies included in this review revealed several important pitfalls that limit clinical applicability and generalisability of the vast majority of the proposed predictive models. These include, but are not limited to, the use of single-centre datasets without external test cohorts, lack of multi-reader image segmentation, use of inappropriate ground truth assessment methods, and insufficient reporting of model evaluation metrics that can inform their interpretability and clinical applicability. Future studies that address these limitations will help to unlock the disruptive potential of AI and harness the benefits of expert-quality mpMRI-driven PCa diagnosis for the wider community.
Availability of data and materials
All data generated or analysed using this study are included in this published article and its supplementary information files.
Abbreviations
- ADC:
-
Apparent diffusion coefficient
- AI:
-
Artificial intelligence
- AUC:
-
Area under the receiver operating characteristic curve
- CART:
-
Classification and regression trees
- CLAIM:
-
Checklist for Artificial Intelligence in Medical Imaging
- CNN:
-
Convolutional neural network
- csPCa:
-
Clinically significant prostate cancer
- DL:
-
Deep learning
- GLCM:
-
Grey level co-occurrence matrix
- HP:
-
Histopathology
- iPCa:
-
Indolent prostate cancer
- LASSO:
-
Least absolute shrinkage and selection operator
- LinR:
-
Linear regression
- LQDA:
-
Linear and quadratic discriminant analysis
- LR:
-
Logistic regression
- mpMRI:
-
Multiparametric MRI
- NB:
-
Naïve Bayes
- NPV:
-
Negative predictive value
- NR:
-
Not reported
- PCa:
-
Prostate cancer
- PI-RADS:
-
Prostate imaging–reporting and data system
- PPV:
-
Positive predictive value
- PSA:
-
Prostate-specific antigen
- PSAd:
-
Prostate-specific antigen density
- PZ:
-
Peripheral zone
- QUADAS-2:
-
Quality Assessment of Diagnostic Accuracy Studies
- RF:
-
Random forests
- RQS:
-
Radiomics quality score
- SVM:
-
Support-vector machine
- TML:
-
Traditional machine learning
- TZ:
-
Transition zone
- WP:
-
Whole prostate
References
Drost FJH, Osses D, Nieboer D et al (2020) Prostate magnetic resonance imaging, with or without magnetic resonance imaging-targeted biopsy, and systematic biopsy for detecting prostate cancer: a cochrane systematic review and meta-analysis. Eur Urol 77:78–94
Sathianathen NJ, Omer A, Harriss E, et al (2020) Negative predictive value of multiparametric magnetic resonance imaging in the detection of clinically significant prostate cancer in the prostate imaging reporting and data system era: a systematic review and meta-analysis. Eur Urol 8(3):402–414
Kasivisvanathan V, Stabile A, Neves JB et al (2019) Magnetic resonance imaging-targeted biopsy versus systematic biopsy in the detection of prostate cancer: a systematic review and meta-analysis. Eur Urol 76:284–303. https://doi.org/10.1016/J.EURURO.2019.04.043
Hansen NL, Koo BC, Gallagher FA et al (2017) Comparison of initial and tertiary centre second opinion reads of multiparametric magnetic resonance imaging of the prostate prior to repeat biopsy. Eur Radiol 27:2259–2266. https://doi.org/10.1007/S00330-016-4635-5
Park KJ, Choi SH, Lee JS, Kim JK, Kim MH (2020) Interreader agreement with prostate imaging reporting and data system version 2 for prostate cancer detection: a systematic review and meta-analysis. J Urol 204:661–670. https://doi.org/10.1097/JU.0000000000001200
de Rooij M, Israël B, Tummers M et al (2020) ESUR/ESUI consensus statements on multi-parametric MRI for the detection of clinically significant prostate cancer: quality requirements for image acquisition, interpretation and radiologists’ training. Eur Radiol. https://doi.org/10.1007/s00330-020-06929-z
Sushentsev N, Caglic I, Sala E et al (2020) The effect of capped biparametric magnetic resonance imaging slots on weekly prostate cancer imaging workload. Br J Radiol 93:20190929. https://doi.org/10.1259/bjr.20190929
Penzkofer T, Padhani AR, Turkbey B et al (2021) ESUR/ESUI position paper: developing artificial intelligence for precision diagnosis of prostate cancer using magnetic resonance imaging. Eur Radiol. https://doi.org/10.1007/S00330-021-08021-6
Stanzione A, Gambardella M, Cuocolo R, Ponsiglione A, Romeo V, Imbriaco M (2020) Prostate MRI radiomics: a systematic review and radiomic quality score assessment. Eur J Radiol 129:109095
Cuocolo R, Cipullo MB, Stanzione A et al (2020) Machine learning for the identification of clinically significant prostate cancer on MRI: a meta-analysis. Eur Radiol 30:6877–6887. https://doi.org/10.1007/S00330-020-07027-W
Syer T, Mehta P, Antonelli M et al (2021) Artificial intelligence compared to radiologists for the initial diagnosis of prostate cancer on magnetic resonance imaging: a systematic review and recommendations for future studies. Cancers (Basel). https://doi.org/10.3390/CANCERS13133318
Castillo TJM, Arif M, Niessen WJ, Schoots IG, Veenland JF (2020) Automated classification of significant prostate cancer on MRI: a systematic review on the performance of machine learning applications. Cancers (Basel) 12:1–13. https://doi.org/10.3390/CANCERS12061606
Twilt JJ, van Leeuwen KG, Huisman HJ, Fütterer JJ, de Rooij M (2021) Artificial intelligence based algorithms for prostate cancer classification and detection on magnetic resonance imaging: a narrative review. Diagnostics (Basel). https://doi.org/10.3390/DIAGNOSTICS11060959
Page MJ, McKenzie JE, Bossuyt PM et al (2021) The PRISMA 2020 statement: an updated guideline for reporting systematic reviews. BMJ. https://doi.org/10.1136/BMJ.N71
Covidence Systematic Review Software (Veritas Health Innovation, 2021). https://www.covidence.org/. Accessed 14 Oct 2021
Mongan J, Moy L, Kahn CE (2020) Checklist for artificial intelligence in medical imaging (CLAIM): a guide for authors and reviewers. Radiol Artif Intell 2:e200029. https://doi.org/10.1148/RYAI.2020200029
Lambin P, Leijenaar RTH, Deist TM et al (2017) Radiomics: the bridge between medical imaging and personalized medicine. Nat Rev Clin Oncol 1412(14):749–762. https://doi.org/10.1038/nrclinonc.2017.141
QUADAS-2 | Bristol Medical School: Population Health Sciences | University of Bristol. https://www.bristol.ac.uk/population-health-sciences/projects/quadas/quadas-2/. Accessed 14 Oct 2021
Macaskill P, Gatsonis C, Deeks JJ, Harbord RM, Takwoingi Y (2010) Cochrane handbook for systematic reviews of diagnostic test accuracy chapter 10 analysing and presenting results. Available via http://methods.cochrane.org/sites/methods.cochrane.org.sdt/files/uploads/Chapter%2010%20-%20Version%201.0.pdf
Wang Y, Wang M (2020) Selecting proper combination of mpMRI sequences for prostate cancer classification using multi-input convolutional neuronal network. Phys Med 80:92–100. https://doi.org/10.1016/J.EJMP.2020.10.013
Fernandez-Quilez A, Eftestøl T, Goodwin M, Kjosavik SR, Oppedal K (2021) Self-transfer learning via patches: a prostate cancer triage approach based on bi-parametric MRI. Med Image Anal
Schelb P, Kohl S, Radtke JP et al (2019) Classification of cancer at prostate MRI: deep learning versus clinical PI-RADS assessment. Radiology 293:607–617. https://doi.org/10.1148/RADIOL.2019190938
Deniffel D, Abraham N, Namdar K et al (2020) Using decision curve analysis to benchmark performance of a magnetic resonance imaging-based deep learning model for prostate cancer risk assessment. Eur Radiol 30:6867–6876. https://doi.org/10.1007/S00330-020-07030-1
Seetharaman A, Bhattacharya I, Chen LC et al (2021) Automated detection of aggressive and indolent prostate cancer on magnetic resonance imaging. Med Phys 48:2960–2972. https://doi.org/10.1002/MP.14855
Bonekamp D, Kohl S, Wiesenfarth M et al (2018) Radiomic machine learning for characterization of prostate lesions with MRI: comparison to ADC values. Radiology 289:128–137. https://doi.org/10.1148/RADIOL.2018173064
Min X, Li M, Dong D et al (2019) Multi-parametric MRI-based radiomics signature for discriminating between clinically significant and insignificant prostate cancer: Cross-validation of a machine learning method. Eur J Radiol 115:16–21. https://doi.org/10.1016/J.EJRAD.2019.03.010
Kwon D, Reis IM, Breto AL et al (2018) Classification of suspicious lesions on prostate multiparametric MRI using machine learning. J Med Imaging 5:1. https://doi.org/10.1117/1.JMI.5.3.034502
Castillo TJM, Starmans MPA, Arif M et al (2021) A multi-center, multivendor study to evaluate the generalizability of a radiomics model for classifying prostate cancer: high grade vs. low grade. Diagnostics (Basel) 11:369. https://doi.org/10.3390/DIAGNOSTICS11020369
Bleker J, Kwee TC, Dierckx RA, de Jong IJ, Huisman H, Yakar D (2020) Multiparametric MRI and auto-fixed volume of interest-based radiomics signature for clinically significant peripheral zone prostate cancer. Eur Radiol 30:1313–1324. https://doi.org/10.1007/S00330-019-06488-Y
Li M, Chen T, Zhao W et al (2020) Radiomics prediction model for the improved diagnosis of clinically significant prostate cancer on biparametric MRI. Quant Imaging Med Surg 10:368–379
Woźnicki P, Westhoff N, Huber T et al (2020) Multiparametric MRI for prostate cancer characterization: combined use of radiomics model with PI-RADS and clinical parameters. Cancers (Basel) 12:1–14. https://doi.org/10.3390/CANCERS12071767
Bevilacqua A, Mottola M, Ferroni F, Rossi A, Gavelli G, Barone D (2021) The primacy of high B-value 3T-DWI radiomics in the prediction of clinically significant prostate cancer. Diagnostics (Basel). https://doi.org/10.3390/DIAGNOSTICS11050739
Toivonen J, Perez IM, Movahedi P et al (2019) Radiomics and machine learning of multisequence multiparametric prostate MRI: towards improved non-invasive prostate cancer characterization. PLoS One. https://doi.org/10.1371/JOURNAL.PONE.0217702
Antonelli M, Johnston EW, Dikaios N et al (2019) Machine learning classifiers can predict Gleason pattern 4 prostate cancer with greater accuracy than experienced radiologists. Eur Radiol 29:4754–4764. https://doi.org/10.1007/S00330-019-06244-2
Yoo S, Gujrathi I, Haider MA, Khalvati F (2019) Prostate cancer detection using deep convolutional neural networks. Sci Rep. https://doi.org/10.1038/S41598-019-55972-4
Hiremath A, Shiradkar R, Fu P et al (2021) An integrated nomogram combining deep learning, Prostate Imaging-Reporting and Data System (PI-RADS) scoring, and clinical variables for identification of clinically significant prostate cancer on biparametric MRI: a retrospective multicentre study. Lancet Digit Heal 3:e445–e454. https://doi.org/10.1016/S2589-7500(21)00082-0
Sanyal J, Banerjee I, Hahn L, Rubin D (2020) An automated two-step pipeline for aggressive prostate lesion detection from multi-parametric MR sequence. AMIA Summits Transl Sci Proc 2020:552
Cao R, Zhong X, Afshari S et al (2021) Performance of deep learning and genitourinary radiologists in detection of prostate cancer using 3-T multiparametric magnetic resonance imaging. J Magn Reson Imaging 54:474–483. https://doi.org/10.1002/JMRI.27595
Hao R, Namdar K, Liu L, Haider MA, Khalvati F (2021) A comprehensive study of data augmentation strategies for prostate cancer detection in diffusion-weighted MRI using convolutional neural networks. J Digit Imaging 34:862–876. https://doi.org/10.1007/S10278-021-00478-7
Zhong X, Cao R, Shakeri S et al (2019) Deep transfer learning-based prostate cancer classification using 3 Tesla multi-parametric MRI. Abdom Radiol (NY) 44:2030–2039. https://doi.org/10.1007/S00261-018-1824-5
Zabihollahy F, Ukwatta E, Krishna S, Schieda N (2020) Fully automated localization of prostate peripheral zone tumors on apparent diffusion coefficient map MR images using an ensemble learning method. J Magn Reson Imaging 51:1223–1234. https://doi.org/10.1002/jmri.26913
Aldoj N, Lukas S, Dewey M, Penzkofer T (2020) Semi-automatic classification of prostate cancer on multi-parametric MR imaging using a multi-channel 3D convolutional neural network. Eur Radiol 30:1243–1253. https://doi.org/10.1007/s00330-019-06417-z
Kohl S, Bonekamp D, Schlemmer H-P et al (2017) Adversarial networks for the detection of aggressive prostate cancer. arXiv
Winkel DJ, Breit HC, Shi B, Boll DT, Seifert HH, Wetterauer C (2020) Predicting clinically significant prostate cancer from quantitative image features including compressed sensing radial MRI of prostate perfusion using machine learning: comparison with PI-RADS v2 assessment scores. Quant Imaging Med Surg 10:808–823
Chen T, Li M, Gu Y et al (2019) Prostate cancer differentiation and aggressiveness: assessment with a radiomic-based model vs PI-RADS v2. J Magn Reson Imaging 49:875–884. https://doi.org/10.1002/JMRI.26243
Algohary A, Shiradkar R, Pahwa S et al (2020) Combination of peri-tumoral and intra-tumoral radiomic features on Bi-parametric MRI accurately stratifies prostate cancer risk: a multi-site study. Cancers (Basel) 12:1–14. https://doi.org/10.3390/CANCERS12082200
Giannini V, Mazzetti S, Cappello G et al (2021) Computer-aided diagnosis improves the detection of clinically significant prostate cancer on multiparametric-MRI: a multi-observer performance study involving inexperienced readers. Diagnostics (Basel). https://doi.org/10.3390/DIAGNOSTICS11060973
Latifoltojar A, Dikaios N, Ridout A et al (2015) Evolution of multi-parametric MRI quantitative parameters following transrectal ultrasound-guided biopsy of the prostate. Prostate Cancer Prostatic Dis 184(18):343–351. https://doi.org/10.1038/pcan.2015.33
Litjens G, Debats O, Barentsz J, Karssemeijer N, Huisman H (2014) Computer-aided detection of prostate cancer in MRI. IEEE Trans Med Imaging. https://doi.org/10.1109/TMI.2014.2303821
Greer MD, Shih JH, Barrett T et al (2018) All over the map: an interobserver agreement study of tumor location based on the PI-RADSv2 sector map. J Magn Reson Imaging 48:482–490. https://doi.org/10.1002/JMRI.25948
Montagne S, Hamzaoui D, Allera A et al (2021) Challenge of prostate MRI segmentation on T2-weighted images: inter-observer variability and impact of prostate morphology. Insights Imaging. https://doi.org/10.1186/S13244-021-01010-9
Greer MD, Shih JH, Lay N et al (2019) Interreader variability of prostate imaging reporting and data system version 2 in detecting and assessing prostate cancer lesions at prostate MRI. AJR Am J Roentgenol 212:1197–1205. https://doi.org/10.2214/AJR.18.20536
Cuocolo R, Stanzione A, Castaldo A, De Lucia DR, Imbriaco M (2021) Quality control and whole-gland, zonal and lesion annotations for the PROSTATEx challenge public dataset. Eur J Radiol. https://doi.org/10.1016/J.EJRAD.2021.109647
Castiglioni I, Rundo L, Codari M et al (2021) AI applications to medical images: from machine learning to deep learning. Phys Med 83:9–24. https://doi.org/10.1016/J.EJMP.2021.02.006
Schwier M, van Griethuysen J, Vangel MG et al (2019) Repeatability of multiparametric prostate MRI radiomics features. Sci Rep 9:1–16. https://doi.org/10.1038/s41598-019-45766-z
Lee J, Steinmann A, Ding Y et al (2021) Radiomics feature robustness as measured using an MRI phantom. Sci Rep 111(11):1–14. https://doi.org/10.1038/s41598-021-83593-3
Roberts M, Driggs D, Thorpe M et al (2021) Common pitfalls and recommendations for using machine learning to detect and prognosticate for COVID-19 using chest radiographs and CT scans. Nat Mach Intell 33(3):199–217. https://doi.org/10.1038/s42256-021-00307-0
Funding
National Institute of Health Research Cambridge Biomedical Research Centre. Award Number: BRC-1215-20014|Recipient: Not applicable. Cancer Research UK. Award Number: C197/A16465|Recipient: Not applicable. Engineering and Physical Sciences Research Council Imaging Centre in Cambridge and Manchester. Award Number: None|Recipient: Not applicable. Cambridge Experimental Cancer Medicine Centre. Award Number: None|Recipient: Not applicable. The Mark Foundation for Cancer Research and Cancer Research UK Cambridge Centre. Award Number: C9685/A25177|Recipient: Not applicable. CRUK National Cancer Imaging Translational Accelerator (NCITA). Award Number: C42780/A27066|Recipient: Not applicable. Wellcome Trust Innovator Award. Award Number: 215733/Z/19/Z. Recipient: Not applicable.
Author information
Authors and Affiliations
Contributions
NS formulated the review concept, registered the review, contributed to all stages of the review process, and wrote the first draft of the manuscript. NMDS, MY, and TB contributed to the review registration and all stages of the review process. ES, MR, and LR oversaw the review conceptualisation, registration, and execution. All authors contributed equally to the preparation of the final version of the manuscript. All authors read and approved the final manuscript
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
N.M.D.S., M.R., and L.R. are Machine Learning Consultants for Lucida Medical. E.S is the Chief Medical Officer of Lucida Medical.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Additional file 1.
Master document summarising the review guidance and results of CLAIM, RQS, and QUADAS-2 assessment.
Additional file 2.
PRISMA-2020 checklist.
Additional file 3.
Supplementary Methods.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Sushentsev, N., Moreira Da Silva, N., Yeung, M. et al. Comparative performance of fully-automated and semi-automated artificial intelligence methods for the detection of clinically significant prostate cancer on MRI: a systematic review. Insights Imaging 13, 59 (2022). https://doi.org/10.1186/s13244-022-01199-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13244-022-01199-3