
Abstract
Background and objective
Sepsis is a heterogeneous disease and identification of its subclasses may facilitate and optimize clinical management. This study aimed to identify subclasses of sepsis and its responses to different amounts of fluid resuscitation.
Methods
This was a retrospective study conducted in an intensive care unit at a large tertiary care hospital. The patients fulfilling the diagnostic criteria of sepsis from June 1, 2001 to October 31, 2012 were included. Clinical and laboratory variables were used to perform the latent profile analysis (LPA). A multivariable logistic regression model was used to explore the independent association of fluid input and mortality outcome.
Results
In total, 14,993 patients were included in the study. The LPA identified four subclasses of sepsis: profile 1 was characterized by the lowest mortality rate and having the largest proportion and was considered the baseline type; profile 2 was characterized by respiratory dysfunction; profile 3 was characterized by multiple organ dysfunction (kidney, coagulation, liver, and shock), and profile 4 was characterized by neurological dysfunction. Profile 3 showed the highest mortality rate (45.4%), followed by profile 4 (27.4%), 2 (18.2%), and 1 (16.9%). Overall, the amount of fluid needed for resuscitation was the largest on day 1 (median 5115 mL, interquartile range (IQR) 2662 to 8800 mL) and decreased rapidly on day 2 (median 2140 mL, IQR 900 to 3872 mL). Higher cumulative fluid input in the first 48 h was associated with reduced risk of hospital mortality for profile 3 (odds ratio (OR) 0.89, 95% CI 0.83 to 0.95 for each 1000 mL increase in fluid input) and with increased risk of death for profile 4 (OR 1.20, 95% CI 1.11 to 1.30).
Conclusion
The study identified four subphenotypes of sepsis, which showed different mortality outcomes and responses to fluid resuscitation. Prospective trials are needed to validate our findings.
Similar content being viewed by others


Introduction
Sepsis is one of the leading causes of mortality and morbidity in the patients admitted to intensive care units (ICU). Despite evolving concepts and advances in management, the mortality associated with sepsis remains unexpectedly high. Many large clinical trials have been conducted aiming to test whether any drugs (for example, corticosteroids and ulinastatin) or other interventions (such as early goal-directed therapy, fluid strategy) could reduce the mortality but have yielded conflicting results [1,2,3,4,5,6]. One of the possible reasons that these sepsis trials failed to identify positive results was the problem of the case mix. Sepsis encompasses a heterogeneous population with respect to the site of infection, type of organism, genetic background, and coexisting conditions of the host. Thus, it is recommended that the individualized patient care be mandatory to improve survival outcome [7]. The concept of individualized medicine is to identify subphenotypes of patients who present with distinct clinical characteristics and respond to personalized interventions. For example, Calfee et al. identified subphenotypes of acute respiratory distress syndrome which showed distinct clinical characteristics [8]. In sepsis, many efforts have been made to identify endotypes by using genomics and transcriptomics [9]. However, genotyping is not routinely performed in daily clinical practice and thus such practice remains in the research stage. It is also suggested that individualized fluid strategy be implemented for sepsis [10]. However, there is a lack of empirical evidence on how to individualize patients with sepsis on the basis of clinical variables. The study aimed to analyze data to see whether subgroups could be detected. Electronic health-care records (EHRs) were employed for the study; the indicator variables for building a latent profile model were readily available in daily clinical practice. Furthermore, the identified profiles were compared for their different responses to fluid input.
Methods
Critical care database
The critical care big data Medical Information Mart for Intensive Care (MIMIC-III) was employed for this study. MIMIC-III is a large, single-center database comprising information relating to patients admitted to ICUs at a large tertiary care hospital [11, 12]. MIMIC-III integrates de-identified, comprehensive clinical data of patients admitted to the Beth Israel Deaconess Medical Center in Boston, MA, USA, from June 1, 2001 to October 31, 2012. There were 53,423 distinct hospital admissions for adult patients (16 years or above) admitted to ICUs during the study period [11]. This study was an analysis of the third-party anonymized databases with pre-existing institutional review board (IRB) approval; thus, IRB approval from our institution was exempted.
Study population
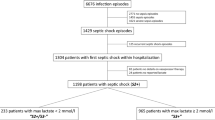
In the third sepsis definition, sepsis was defined as life-threatening organ dysfunction caused by a dysregulated host response to infection [13]. In this study, we screened patients with documented or suspected infection, plus the presence of organ dysfunction [14, 15]. The International Classification of Diseases, Ninth Revision, Clinical Modification (ICD-9-CM) codes for a bacterial or fungal infection were used to define infection (Additional file 1). A patient was defined to have organ dysfunction if he or she had ICD-9 code as follows: unspecified thrombocytopenia (287.5), hypotension (458.9), acute and subacute necrosis of liver (570), acute kidney failure (584.9), anoxic brain damage (348.1), shock without mention of trauma (785.59), encephalopathy (348.30), transient mental disorders due to conditions classified elsewhere (293.9), secondary thrombocytopenia (287.49), other and unspecified coagulation defects (286.9), defibrination syndrome (286.6), and hepatic infarction (573.4). If mechanical ventilation (procedures ICD code: 96.70, 96.71, 96.72) was required, it was also defined as organ dysfunction. The method was adapted from Angus DC [16], and the Structured Query Language (SQL) code could be found at https://github.com/MIT-LCP.
Multiple hospital admissions from the same patient were included as independent cases. Only the first ICU admission was included for analysis for patients who had multiple admissions to ICU.
Demographical and laboratory variables
The following variables were extracted from the MIMIC- III database: age at the time of hospital admission, gender, admission type, sequential organ failure assessment (SOFA) score, each component of SOFA score, use of vasopressors (including dopamine, epinephrine, norepinephrine, phenylephrine, and vasopressin), and renal replacement therapy (RRT). SOFA score was calculated within the first 24 h after the ICU admission. The laboratory variables included platelet count, activated partial thrombin time (aPTT), international normalized ratio (INR), and creatinine. Other clinical variables such as urine output (UO) for the first 24 h, Glasgow Coma Scale (GCS) score, mean blood pressure (BP), vasopressors, and arterial partial oxygen pressure (PaO2) were included. The median value was computed for variables measured more than once during the first 24 h after ICU admission. The lowest value of GCS score reported in the first 24 h was used in the study.
The primary endpoint was hospital mortality, which was defined as the status of patient survival at the time of hospital discharge. Secondary endpoints included length of stay (LOS) in the ICU and hospital. The 90-day mortality was also obtained by linking to the social security database by the database investigators.
Missing values
Variables with more than 40% missing values were excluded from the analysis (Additional file 1: Figure S1). Variables such as base excess, albumin, and calcium had missing values greater than 40% and were excluded from the study. Multiple imputation was performed for the remaining variables [17].
Latent profile analysis
Clinical variables were selected for constructing latent profiles as indicator variables. Platelet count, aPTT, and INR were used for the hematological system; creatinine and UO were used for the renal function; GCS score was used to assess the cerebral function, the circulatory system was measured by the mean BP and vasopressors, and respiratory function was measured by PaO2 and partial pressure of carbon dioxide (PaCO2). Multiple kinds of vasopressors (including dopamine, epinephrine, norepinephrine, phenylephrine, and vasopressin) were recorded in the MIMIC-III database. Therefore, their use was scaled by the standard deviation and centered at mean and then combined as one variable. Continuous variables were scaled to have similar variances. The distributions of included variables were examined before analysis, and severely skewed data would be transformed.
The goal of latent profile analysis (LPA) is to fit a mixture of distributions. The keys are that the underlying distributions must exist and the analyst must have the variables that best separate out those distributions [18,19,20]. In the study, the number of profiles was determined by Bayesian information criteria (BIC) and bootstrap likelihood ratio test (BLRT). Specifically, BIC was used to compare models with different numbers of clusters or specifying different parameterizations or both. Lower values of the BIC are indicative of better model fit. BLRT was used to assess the number of mixture components in a specific finite mixture model parameterization. The observed significance is approximated by using the bootstrap for the likelihood ratio test statistic (LRTS). BLRT computed P values for the comparison of k-class model with (k-1)-class model [21]. A P value of 0.05 was used to judge the statistical significance for the bootstrap likelihood ratio test. Furthermore, because the number of patients should be sizable in each latent profile, we pre-specified that the patient proportion should be greater than 5% in any of the latent profiles [22]. The clinical interpretation was also considered when determining the number of latent profiles. The LPA model was first fit by using patients admitted before 2008 and then validated in patients admitted after 2008. The final LPA model was fit on the whole dataset.
Statistical analysis
Continuous variables were expressed as the mean (standard deviation) or median (interquartile range, or IQR) as appropriate and were compared between the different profiles of sepsis using analysis of variance [23]. The CBCgrps package was employed for the statistical description and bivariate inference [24]. Clinical outcomes such as the mortality rate, LOS in the ICU, and the entire hospitalization were compared between latent profiles.
The multivariable logistic regression model was employed to investigate the independent association of fluid input and mortality outcome, and an interaction between fluid input and latent profiles was included. Other covariates included in the models were SOFA score, age, gender, admission type, ethnicity, ICU types, and the use of RRT. The covariates were selected because they were potential confounders as determined by subject-matter knowledge. Odds ratio (OR) and relevant 95% confidence interval (CI) were reported for the impact of each 2000 mL increase in fluid input on mortality outcome.
All statistical analyses were performed by using R package (version 3.4.3). A P value less than 0.05 was considered to be statistically significant.
Results
Choose the number of latent classes
A total of 14,993 patients fulfilled the inclusion criteria for the analysis. Models with different number of profiles were compared. In patients enrolled before 2008, the best number of profiles was 4, which was validated in patients admitted after 2008 (Additional file 1: Tables S1 and S2). Then the LPA model was fit to the whole dataset. The BIC and AIC values decreased from 3-class model rapidly to the 4-profile model (dropped by 10,000) and remained relatively stable from 4- to 5-profile (decreased by 3000). The entropy dropped remarkably from 4- to 5-profile model. The number of patients in each profile was less than 5% for the 6- and 7-profile models. Taken together, the 4-profile model was chosen as the best one (Table 1).
Different clinical features between profiles
Clinical features of all the four profiles are shown in Tables 2 and 3. Profile 1 (69%) was the largest group and had the lowest mortality rate (16.9%) and was considered the baseline type; profile 2 (9%) was characterized by respiratory dysfunction (low PaO2 and high PaCO2); profile 3 (11%) was characterized by multiple organ dysfunction (kidney, coagulation, liver, and shock); and profile 4 (11%) was characterized by neurological dysfunction (low GCS score) (Fig. 1). Table 2 shows that profile 3 has the largest amount of vasopressor use and the lowest BP.

Characteristics of latent profile groups. The y-axis shows the standardized mean for each variable (that is, each variable is centered at the sample mean and scaled by its standard deviation). Abbreviations: aPTT activated partial thrombin time, BP blood pressure, GCS Glasgow Coma Scale, INR international normalized ratio, RR respiratory rate, UO urine output, VR vasopressor rate, WBC white blood cell count
Profile 3 showed the highest mortality rate (45.4%), and profile 1 showed the lowest mortality rate (16.9%). Profile 1 showed the longest LOS in the hospital (P <0.001; Table 3). Profile 3 had the highest SOFA score on day 1 (median 9, IQR 6 to 12), followed by profile 4 (median 8, IQR 5 to 10). Profile 1 had the lowest SOFA score (median 4, IQR 2 to 6).
Fluid input
Overall, the amount of fluid input was the largest on day 1 (median 5115 mL, IQR 2662 to 8800 mL) and decreased rapidly on day 2 (median 2140 mL, IQR 900 to 3872 mL). Patients in profile 2 received less fluid input than all other profiles, and those in the profile 3 received the largest amount of fluid input on day 1 (Table 3). In the multivariable regression model by adjusting for SOFA score, age, gender, admission type, ethnicity, ICU type, and the use of RRT, higher cumulative fluid input in the first 48 h was associated with reduced risk of hospital death for profile 3 (OR 0.89, 95% CI 0.83 to 0.95 for each 1000-mL increase in fluid input) and with increased risk of death for profile 4 (OR 1.20, 95% CI 1.11 to 1.30). Of note, more fluid inputs were associated with improved outcome in profile 3, which was consistent with the fact that this profile was characterized by circulatory shock (lowest mean BP and elevated requirement of vasopressor).
Clinical outcomes
By using profile 1 as reference, profile 3 (OR 2.16, 95% CI 1.88 to 2.47) was associated with increased risk of hospital morality (Table 4). In the Cox regression model investigating independent predictors of 90-day survival (Additional file 1: Table S4), profile 2 (hazard ratio (HR) 1.15, 95% CI 1.02 to 1.28) and 3 (HR 1.79, 95% CI 1.63 to 1.97) showed increased risk of 90-day mortality as compared with profile 1.
Sensitivity analysis
It is of concern that the elevated aPTT in profile 3 might be explained by the use of heparin. Thus, sensitivity analysis was performed by restricting to patients without heparin (Additional file 1: Table S3). A subclass characterized by elevated aPTT and vasopressor requirement was identified (Additional file 1: Figure S2). The underlying subphenotypes were also verified by using latent class analysis. As shown in Additional file 1: Table S5, the best number of classes was 4 as judged by entropy. Characteristics of the four classes are shown in Fig. 2. Consistent with the result obtained by LPA, class 1 was characterized by respiratory dysfunction, class 2 was the baseline type, class 3 was characterized by neurological dysfunction, and class 4 was characterized by multiple organ dysfunction. Note that owing to the random process, the class number may not be consistent with the LPA model .

Characteristics of classes identified by latent class analysis. The response category of 1 to 4 is the quartile category by cutting continuous variables into four quartile categories. Category 1 refers to the lowest value and category 4 is the highest value. The vertical axis is the proportion of each response category. Abbreviations: aPTT activated partial thrombin time, BP blood pressure, GCS Glasgow Coma Scale, INR international normalized ratio, RR respiratory rate, UO urine output, VR vasopressor rate, WBC white blood cell count
Discussion
This study identified four subclasses of sepsis: profile 1 was the baseline group characterized by low mortality outcome; profile 2 was characterized by respiratory dysfunction; profile 3 was characterized by multiple organ dysfunction involving kidney, liver, coagulation, and circulatory failure; and profile 4 was characterized by neurological dysfunction. Whereas profile 1 showed the lowest mortality rate, profile 3 had the highest mortality rate. Since the profile 3 was characterized by hemodynamic instability, an increased amount of fluid input in the first two days was associated with improved mortality outcome, after adjustment for multiple confounding factors. For profile 4, more fluid input was associated with worse outcome.
The study employed LPA to identify subphenotypes of patients. There are a number of ways to perform agnostic clustering, such as latent variable mixture modeling, K-means clustering, and latent class analysis (LCA) [25,26,27]. Whereas LCA allows only categorical variables, the LPA allows continuous indicator variables. The main difference between LPA and other clustering algorithms is that LPA provides a “model-based clustering” approach that derives clusters using a probabilistic model that describes distribution of the data. So instead of looking for clusters with some arbitrary chosen distance measure, LPA fits a model that describes distribution of the data and based on this model you assess probabilities that certain patients are members of certain latent profiles. Because LPA uses a statistical model, assessing goodness of fit (GOF) is possible. The clustering method does not allow the assessment GOF. Furthermore, we had assumed that there were some processes or “latent structure” underlying the structure of our data. Thus, LPA seemed to be an appropriate choice since it allowed us to model the latent structure behind the data (rather than just looking for similarities).
Several studies have focused on the identification of subgroups of sepsis on the basis of the genomic and transcriptomic data [28,29,30]. In the pediatric septic shock, three subgroups were identified with subtype A showing a higher mortality rate, pediatric risk of mortality (PRISM) score, pediatric sepsis biomarker risk model (PERSEVERE)-based mortality risk, and maximum number of organ failures compared with other subtypes [31]. Sweeney et al. investigated subtypes of sepsis by using transcriptomics [32]. The study identified three subtypes of sepsis, which were coined “coagulopathic”, “adaptive”, and “inflammopathic” subtypes. In our study, coagulopathy was found to be present in profile 3, coexisting with other organ dysfunctions. Consistent with our study, the coagulopathic type showed the highest mortality rate. The adaptive subtype was equivalent to profile 1 in our study, which showed the best clinical outcome. However, transcriptomics are not routinely obtained in real clinical practice, which limited its widespread applicability. To the best of our knowledge, our study is the first to explore subphenotypes of the sepsis by using the clinical variables obtained from EHR, which would facilitate application of the results to daily clinical practice. Since the different subclasses showed different clinical presentations and responses to the fluid strategy, our sepsis classification could be used to design future trials. However, it is largely unknown whether tailored treatment according to the classification system is beneficial for patients with sepsis, and further trials are required to test this hypothesis.
Clinical variables employed for modeling LPA in the study included indicator variables for major organ dysfunctions that are typically involved in sepsis. The LPA model showed that the organ dysfunctions were related to each other with special patterns. For example, profile 3 was characterized by the multiple organ failure and circulatory shock, supporting the notion that multiple organ failures have common underlying pathophysiological process of circulatory shock. There is evidence that the circulatory shock usually coexists with coagulopathy and the latter is a good prognostic marker for survival outcome [33, 34]. Sepsis-associated encephalopathy (SAE) is an important complication of sepsis [35] and can occur in up to 82% of patients with sepsis [36]. SAE presents with varying severity ranging from mild confusion to coma. In this study, we identified a subgroup of sepsis patients who were characterized by the severe SAE with a median GCS score of 7 points. The mortality rate of this subclass was the second highest despite preserved functions of other organs, indicating the importance of neurological injury in sepsis.
Several limitations must be acknowledged in this study. First, this study used EHR data which were produced by routine clinical practice. Thus, having missing values is a big problem. Although there are many sophisticated methods to deal with missing values, significant bias may be introduced for those with missing rates greater than 40% [17, 37]. Thus, these variables were excluded from analysis. Multiple imputations were performed for variables containing missing values. Second, although restricting the variables used for modeling to those available in clinical practice is reasonable, it may limit the separation of classes. It would be better to use biomarkers and genomics as well. However, the biomarkers not routinely obtained were not available in the database. Third, the study was limited by the lack of external validation and thus the results need to be validated in other external datasets. However, we performed internal validation by splitting the whole dataset. The LPA model was first fit in patients enrolled before 2008 and then the model was validated in patients admitted after 2008. Fourth, fluid responsiveness was assessed observationally, as one of several exposures among several subgroups; hence, this association is less robust than if this were done within a randomized trial context. Finally, LPA does not provide a definitive class membership but instead provides posterior probabilities of each class and assigns the class with the highest posterior probability. Because of this, there is uncertainty regarding class membership (for example, patient A has 90% probability of being in class 1, 2% in class 2, 4% in class 3, and 4% in class 4).
Conclusion
This study identified four subphenotypes of sepsis, which showed different mortality outcomes and responses to fluid resuscitation. The subphenotypes need to be validated in external datasets.
Abbreviations
- aPTT:
-
Activated partial thrombin time
- BIC:
-
Bayesian information criteria
- BLRT:
-
Bootstrap likelihood ratio test
- BP:
-
Blood pressure
- CI:
-
Confidence interval
- EHR:
-
Electronic health-care record
- GCS:
-
Glasgow Coma Scale
- GOF:
-
Goodness of fit
- HR:
-
Hazard ratio
- ICD:
-
International Classification of Diseases
- ICU:
-
Intensive care unit
- INR:
-
International normalized ratio
- IQR:
-
Interquartile range
- IRB:
-
Institutional review board
- LCA:
-
Latent class analysis
- LOS:
-
Length of stay
- LPA:
-
Latent profile analysis
- MIMIC-III:
-
Medical Information Mart for Intensive Care
- OR:
-
Odds ratio
- PaCO2 :
-
Partial pressure of carbon dioxide
- PaO2 :
-
Arterial partial oxygen pressure
- RRT:
-
Renal replacement therapy
- SAE:
-
Sepsis-associated encephalopathy
- SOFA:
-
Sequential organ failure assessment
- UO:
-
Urine output
References
Rivers E, Nguyen B, Havstad S, Ressler J, Muzzin A, Knoblich B, et al. Early goal-directed therapy in the treatment of severe sepsis and septic shock. N Engl J Med. 2001;345:1368–77.
ARISE Investigators, ANZICS Clinical Trials Group, Peake SL, Delaney A, Bailey M, Bellomo R, et al. Goal-directed resuscitation for patients with early septic shock. N Engl J Med. 2014;371:1496–506.
Uchida M, Abe T, Ono K, Tamiya N. Ulinastatin did not reduce mortality in elderly multiple organ failure patients: a retrospective observational study in a single center ICU. Acute Med Surg. 2018;5:90–7.
Zhang Z, Chen L, Ni H. The effectiveness of Corticosteroids on mortality in patients with acute respiratory distress syndrome or acute lung injury: a secondary analysis. Sci Rep. 2015;5:17654.
Annane D, Renault A, Brun-Buisson C, Megarbane B, Quenot J-P, Siami S, et al. Hydrocortisone plus Fludrocortisone for Adults with Septic Shock. N Engl J Med. 2018;378:809–18.
Marik PE, Linde-Zwirble WT, Bittner EA, Sahatjian J, Hansell D. Fluid administration in severe sepsis and septic shock, patterns and outcomes: an analysis of a large national database. Intensive Care Med. 2017;43:625–32.
László I, Trásy D, Molnar Z, Fazakas J. Sepsis: From Pathophysiology to Individualized Patient Care. J Immunol Res Hindawi. 2015;2015:510436–13.
Calfee CS, Delucchi K, Parsons PE, Thompson BT, Ware LB, Matthay MA, et al. Subphenotypes in acute respiratory distress syndrome: latent class analysis of data from two randomised controlled trials. Lancet Respir Med. 2014;2:611–20.
Seymour CW, Gomez H, Chang C-CH, Clermont G, Kellum JA, Kennedy J, et al. Precision medicine for all? Challenges and opportunities for a precision medicine approach to critical illness. Crit Care. 2017;21:257.
Jozwiak M, Hamzaoui O, Monnet X, Teboul J-L. Fluid resuscitation during early sepsis: a need for individualization. Minerva Anestesiol. 2018;84:987–92.
Johnson AEW, Pollard TJ, Shen L, Lehman L-WH, Feng M, Ghassemi M, et al. MIMIC-III, a freely accessible critical care database. Sci Data. 2016;3:160035.
Zhang Z. Accessing critical care big data: a step by step approach. J Thorac Dis. 2015;7:238–42.
Singer M, Deutschman CS, Seymour CW, Shankar-Hari M, Annane D, Bauer M, et al. The Third International Consensus Definitions for Sepsis and Septic Shock (Sepsis-3). JAMA. 2016;315:801–10.
Zhang Z, Hong Y. Development of a novel score for the prediction of hospital mortality in patients with severe sepsis: the use of electronic healthcare records with LASSO regression. Oncotarget. 2017;8:49637–45.
Zhang Z, Hong Y, Liu N, Chen Y. Association of do-not-resuscitate order and survival in patients with severe sepsis and/or septic shock. Intensive Care Med. 2017;43:1–3.
Angus DC, Linde-Zwirble WT, Lidicker J, Clermont G, Carcillo J, Pinsky MR. Epidemiology of severe sepsis in the United States: analysis of incidence, outcome, and associated costs of care. Crit Care Med. 2001;29:1303–10.
Zhang Z. Multiple imputation with multivariate imputation by chained equation (MICE) package. Ann Transl Med. 2016;4:30.
Pastor DA, Barron KE, Miller BJ, Davis SL. A latent profile analysis of college students’ achievement goal orientation. Contemp Educ Psychol. 2007;32:8–47.
Collins LM, Lanza ST. Latent Class and Latent Transition Analysis: With Applications in the Social, Behavioral, and Health Sciences. Latent Class and Latent Transition Analysis: With Applications in the Social, Behavioral, and Health Sciences. Hoboken: Wiley; 2010. p. 1–295.
Zhang Z, Abarda A, Contractor AA, Wang J, Dayton CM. Exploring heterogeneity in clinical trials with latent class analysis. Ann Transl Med. 2018;6:119–9.
Nylund KL, Asparouhov T, Muthén BO. Deciding on the Number of Classes in Latent Class Analysis and Growth Mixture Modeling: A Monte Carlo Simulation Study. Struct Equ Modeling. 2007;14:535–69.
Nasserinejad K, van Rosmalen J, de Kort W, Lesaffre E. Comparison of Criteria for Choosing the Number of Classes in Bayesian Finite Mixture Models. PLoS One. 2017;12:e0168838.
Zhang Z. Univariate description and bivariate statistical inference: the first step delving into data. Ann Transl Med. 2016;4:91–1.
Zhang Z, Gayle AA, Wang J, Zhang H, Cardinal-Fernández P. Comparing baseline characteristics between groups: an introduction to the CBCgrps package. Ann Transl Med. 2017;5:484–4.
Lanza ST, Rhoades BL. Latent class analysis: an alternative perspective on subgroup analysis in prevention and treatment. Prev Sci. 2013;14:157–68.
Andrews RL, Currim IS. A Comparison of Segment Retention Criteria for Finite Mixture Logit Models. J Mark Res Am Market Assoc. 2003;40:235–43.
Berlin KS, Williams NA, Parra GR. An introduction to latent variable mixture modeling (part 1): overview and cross-sectional latent class and latent profile analyses. J Pediatr Psychol. 2014;39:174–87.
Wong HR, Cvijanovich N, Lin R, Allen GL, Thomas NJ, Willson DF, et al. Identification of pediatric septic shock subclasses based on genome-wide expression profiling. BMC Med. 2009;7:34.
Wong HR, Cvijanovich NZ, Allen GL, Thomas NJ, Freishtat RJ, Anas N, et al. Validation of a gene expression-based subclassification strategy for pediatric septic shock. Crit Care Med. 2011;39:2511–7.
Severino P, Silva E, Baggio-Zappia GL, Brunialti MKC, Nucci LA, Rigato O, et al. Patterns of gene expression in peripheral blood mononuclear cells and outcomes from patients with sepsis secondary to community acquired pneumonia. PLoS One. 2014;9:e91886.
Weiss SL, Cvijanovich NZ, Allen GL, Thomas NJ, Freishtat RJ, Anas N, et al. Differential expression of the nuclear-encoded mitochondrial transcriptome in pediatric septic shock. Crit Care. 2014;18:623.
Sweeney TE, Azad TD, Donato M, Haynes WA, Perumal TM, Henao R, et al. Unsupervised Analysis of Transcriptomics in Bacterial Sepsis Across Multiple Datasets Reveals Three Robust Clusters. Crit. Care Med. 2018;46:915–25.
Thiery-Antier N, Binquet C, Vinault S, Meziani F, Boisramé-Helms J, Quenot J-P, et al. Is Thrombocytopenia an Early Prognostic Marker in Septic Shock? Crit Care Med. 2016;44:764–72.
Koyama K, Katayama S, Muronoi T, Tonai K, Goto Y, Koinuma T, et al. Time course of immature platelet count and its relation to thrombocytopenia and mortality in patients with sepsis. PLoS One. 2018;13:e0192064.
Chaudhry N, Duggal AK. Sepsis Associated Encephalopathy. Adv Med Hindawi. 2014;2014:762320–16.
Molnár L, Fülesdi B, Németh N, Molnár C. Sepsis-associated encephalopathy: A review of literature. Neurol India. 2018;66:352–61.
Zhang Z. Missing values in big data research: some basic skills. Ann Transl Med. 2015;3:323.
Acknowledgments
None
Funding
ZZ received funding from the public welfare research project of Zhejiang province (LGF18H150005) and a scientific research project of the Zhejiang Education Commission (Y201737841).
Availability of data and materials
Data are available on request.
Author information
Authors and Affiliations
Contributions
ZZ conceived the idea and drafted the manuscript. LM performed data analysis. GZ and HG helped interpret the results and table preparation. YH helped data management and analysis. ZZ is the guarantor of the article, taking responsibility for the integrity of the work as a whole, from inception to published article. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
This study was an analysis of the third-party anonymized databases with pre-existing IRB approval.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Additional file
Additional file 1:
Figure S1. Missing rate for clinical and laboratory variables extracted from the database. Variables with missing rate greater than 40% were excluded from analysis. Figure S2. Characteristics of latent profile groups by restricting to patients without using heparin. Owing to the random process, the specific profile number may not be consistent with the main analysis. Abbreviations: aPTT activated partial thrombin time, BP blood pressure, GCS Glasgow Coma Scale, INR international normalized ratio, RR respiratory rate, UO urine output, VR vasopressor rate, WBC white blood cell count. Table S1. Latent profile analysis restricting to patients admitted after 2008. Table S2. Latent profile analysis restricting to patients admitted before 2008. Table S3. Sensitivity analysis restricting to patients who did not receive heparin. Table S4. Cox regression model to adjust for confounding for the 90-day survival. Table S5. Choosing the best number of classes by using latent class analysis. (DOCX 76 kb)
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Zhang, Z., Zhang, G., Goyal, H. et al. Identification of subclasses of sepsis that showed different clinical outcomes and responses to amount of fluid resuscitation: a latent profile analysis. Crit Care 22, 347 (2018). https://doi.org/10.1186/s13054-018-2279-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13054-018-2279-3