
Abstract
Background
Maintenance hemodialysis (MHD) patients often suffer from sarcopenia, which is strongly associated with their long-term mortality. The diagnosis and treatment of sarcopenia, especially possible sarcopenia for MHD patients are of great importance. This study aims to use machine learning and medical data to develop two simple sarcopenia identification assistant tools for MHD patients and focuses on sex specificity.
Methods
Data were retrospectively collected from patients undergoing MHD and included patients’ basic information, body measurement results and laboratory findings. The 2019 consensus update by Asian working group for sarcopenia was used to assess whether a MHD patient had sarcopenia. Finally, 140 male (58 with possible sarcopenia or sarcopenia) and 102 female (65 with possible sarcopenia or sarcopenia) patients’ data were collected. Participants were divided into sarcopenia and control groups for each sex to develop binary classifiers. After statistical analysis and feature selection, stratified shuffle split and Synthetic Minority Oversampling Technique were conducted and voting classifiers were developed.
Results
After eliminating handgrip strength, 6-m walk, and skeletal muscle index, the best three features for sarcopenia identification of male patients are age, fasting blood glucose, and parathyroid hormone. Meanwhile, age, arm without vascular access, total bilirubin, and post-dialysis creatinine are the best four features for females. After abandoning models with overfitting or bad performance, voting classifiers achieved good sarcopenia classification performance for both sexes (For males: sensitivity: 77.50% ± 11.21%, specificity: 83.13% ± 9.70%, F1 score: 77.32% ± 5.36%, the area under the receiver operating characteristic curves (AUC): 87.40% ± 4.41%. For females: sensitivity: 76.15% ± 13.95%, specificity: 71.25% ± 15.86%, F1 score: 78.04% ± 8.85%, AUC: 77.69% ± 7.92%).
Conclusions
Two simple sex-specific sarcopenia identification tools for MHD patients were developed. They performed well on the case finding of sarcopenia, especially possible sarcopenia.
Similar content being viewed by others


Explore related subjects
Find the latest articles, discoveries, and news in related topics.Introduction
The prevalence and medical resource consumption of chronic kidney disease (CKD) are rapidly increasing with the incidence of diabetes mellitus (DM), obesity, and hypertension. Furthermore, CKD plays an important role in increasing the prevalence of cardiovascular diseases and patient mortality. The criteria for CKD is that there are markers of kidney damage or glomerular filtration rate < 60 ml/min per 1.73 m2 for > 3 months. Its latest classification includes cause of disease, level of GFR (6 categories), and level of albuminuria (3 categories) [1]. When CKD progresses to kidney failure (glomerular filtration rate < 15 ml/min per 1.73 m2), renal replacement therapies, including kidney transplantation and dialysis, should be performed. Maintenance hemodialysis (MHD) is the usual choice for dialysis. However, it is not a treatment measure. Moreover, patients undergoing MHD suffer from many comorbidities and nutritional problems, which is becoming a common challenge worldwide [2]. MHD also increases whole-body and muscle proteolysis rates and elevates the net whole-body and muscle protein loss [3], resulting in sarcopenia. Sarcopenia is defined as age-related loss of muscle mass, plus low muscle strength, and/or low physical performance [4]. Additionally, in the latest 2019 sarcopenia consensus updated by Asia working group for sarcopenia (AWGS 2019), possible sarcopenia was introduced and defined as low muscle strength or physical performance. There is also a similar term and definition in the sarcopenia consensus published by European Working Group on Sarcopenia in Older People [5]. It is proven that sarcopenia is strongly associated with long-term mortality and cardiovascular events in MHD patients [6]. Furthermore, the average prevalence of sarcopenia in dialysis patients is 28.5% [7].
Though possible sarcopenia is recommended for using in primary health care and preventive services, MHD patients are more prone to suffering from sarcopenia and the poorer physical function is worse for their survival. A longitudinal study of patients with kidney failure has shown that low muscle strength predicts mortality better than low muscle mass [8]. Therefore, the diagnosis and treatment of sarcopenia, especially possible sarcopenia for MHD patients are very important [9]. Identifying possible sarcopenia cases may help clinicians identify potential underlying causes and provide appropriate personalized interventions for patients to reverse possible sarcopenia.
Bioimpedance analysis and dual-energy x-ray absorptiometry are two recommended methods for measuring skeletal muscle mass in AWGS 2019 [4]. But the instruments are expensive and not suitable for all MHD patients to measure. Handgrip strength (HGS) and physical performance examinations are easy to perform in outpatient and community. However, some biochemical indices that have been reported to be related to sarcopenia are ignored in sarcopenia assessment. As modern clinical medical systems have recorded many health and medical data, secondary use of medical data may bring discoveries and understanding about illness and treatment, enhance healthcare experiences, and increase the efficiency of healthcare systems [10]. Additionally, MHD patients are asked to undergo centralized examinations regularly. Hence, they own many normalized medical data with potential medical values. The cohort is relatively fixed because MHD patients undergo regular dialysis, making it easier to conduct long-term observations and research.
Machine learning, one of the main methods for data mining in our daily life, has been widely applied in medical data analysis with the development of information technology and artificial intelligence [11]. It can assist in clinical tasks such as aided diagnosis, disease and prognosis prediction, and other decision-making tasks. Clinicians can take the results of machine learning as additional references and react to disease identification and development, or any possible poor prognosis accordingly [12]. Electronic medical record data, nutrition intake, physical activity performance measurement results, medical history, socio-demographic and primary care data have been used to develop machine learning risk prediction or identification models and also find the risk factors about sarcopenia [13, 14].
Similarly, the medical data of MHD patients can be used to conduct relative research, too. However, few studies have been conducted so far. In order to help clinicians know MHD patients’ sarcopenia states early and accurately and get references for clinical decision making in sarcopenia treatment, this study aims to use machine learning methods to develop simple and accurate sarcopenia assistant identification tools for MHD patients of both sexes.
Methods
Data collection and measurements
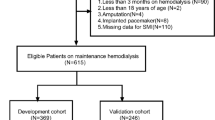
Data were retrospectively collected from patients undergoing MHD at Wenjiang Hemodialysis Center in the Department of Nephrology in West China Hospital, Sichuan University, Chengdu, China. All participants were over 18 years old without any mental disorder, and kept in-center maintenance hemodialysis for at least 3 months. Finally, a total of 140 male (49 with possible sarcopenia, 9 with sarcopenia or sever sarcopenia) and 102 female (53 with possible sarcopenia, 12 with sarcopenia or sever sarcopenia) MHD patients participated in this study. Sarcopenia diagnosis was carried out via AWGS 2019 [4]. The data set involved a total of 84 features, including patients’ basic information, body measurement results, and laboratory findings. Basic information was obtained through patients' medical archives, while body measurement results and laboratory findings came from the latest centralized examination at the hemodialysis center before data collection. HGS was tested by the arm without vascular access. Laboratory findings included routine blood examination, hepatic and renal function indicators, serum inorganic salts, and parathyroid hormone (PTH). Since urea and creatinine were measured again after hemodialysis, participants’ urea and creatinine after hemodialysis were also collected. All these features were carried forward as possible risk factors of sarcopenia in MHD patients.
Data processing
Similar to Hassler’s work [15], this study combined patients with different sarcopenia states as the sarcopenia group. In comparison, patients without sarcopenia were regarded as the control group to model a binary classifier for identifying whether a new patient had sarcopenia. The cutoff values of sarcopenia diagnosis measures differ between males and females due to the physical differences between both sexes. Hence, statistical analysis and classifier models were also studied separately for special reference to sex specificity.
All text results have been converted to digital classification values for subsequent processing. Sarcopenia cases were given the label “1” while controls were “0”. The original dataset had missing values (eight features and seven samples had missing values) because a few individuals had not taken all body measurements and blood examinations for various reasons. Hence, to process missing values, this study inferred missing values from the existing data to retain potentially valuable data as much as possible. For a sample with one missing value of a feature, other samples of the same sex and sarcopenia state that matched with the sample were selected. Then the missing value imputation was conducted using the mean of the selected samples’ same feature without missing values. After the imputation, the data format was unified into the original format.
Exploratory data analysis was then conducted to examine the unadjusted associations between sarcopenia and the risk factors in different sex groups. According to the distributions of different features, unadjusted tests for differences in each feature between sarcopenia and control groups were carried out via Chi-square test, Student’s t-test, or the Mann–Whitney U-test. Statistical analysis was performed in SPSS, version 16.0 (SPSS Inc., Chicago, IL, USA). P < 0.05 means that there is a statistically significant difference between two groups.
Feature selection
Sarcopenia can be assessed through several tests about muscle strength and mass and statistical analysis may find many features with P < 0.05. Using all these features to develop machine learning classifiers is not convenient enough to apply in clinical practice. Therefore, a simple and efficient machine learning identification model using a small number of features is preferred. Besides, the above statistical analysis only considered the relationship between a single feature and sarcopenia. Hence, the impact of combinations of different features on classifying sarcopenia is unclear. In order to develop a simple machine learning model, feature importance calculated by tree-based machine learning models, which represents features’ contribution to the classification model [16], was used for feature selection. The importance values based on Random Forest (RF) model with default hyper-parameters were calculated. Considering that feature importance values vary with tree-based machine learning models and different hyper-parameters, lasso regression, which does not depend on any machine learning models, was also used in this study. Feature importance calculation and lasso regression programs were all performed via Python 3.
Identification models based on machine learning
Ten commonly used binary machine learning methods were performed in this study, including K-Nearest Neighbor (KNN), Gaussian Naive Bayes (GaussianNB), Logistic Regression (LR), Support Vector Machine (SVM), Multi-layer Perceptron (MLP), and five tree-based models: Decision Tree (DT), Random Forest (RF), Adaptive Boosting (Adaboost), Gradient Boosting Decision Tree (GBDT), and Light Gradient Boosting Machine (LGBM). The complete sarcopenia classifier development process was shown in Fig. 1 and explained in detail as follows. Machine learning programs were all performed via Python 3.

The complete process of sarcopenia classifier development
Min–Max normalization was conducted to transfer feature values into a range of 0 to 1, making machine learning models converge more quickly and easily. Then, 80 percentage of the original data set of a total of 140 male samples and 102 female samples was divided into the training set and the rest was the test set, both retaining the same proportion of patients with sarcopenia as the original data set. The training set was used for doing a 5-fold grid search to find the best hyper-parameters of each machine learning method. The data size was a little small because the data did not come from a large-scale hemodialysis center. In addition, the participants were divided into two parts according to their sexes. Hence, the data size of one sex group became smaller. The results of one split and training may be less representative and unstable. Moreover, machine learning models may not gain good generation power using such a data set [17]. Therefore, stratified shuffle split method was used in model development and evaluation to reduce the influence of small data size. It is similar to cross-validation. However, the main difference is that it uses the sampling method with return and therefore one sample may be selected to compose the test set many times. The data set was split 10 times using stratified shuffle split method in this study. The data size ratio of the training set to test set was still set to four to one and the proportion of non-sarcopenia and sarcopenia cases retained the same.
Notice that the class distribution of the original data set was a little imbalanced (the prevalence of sarcopenia was 41.43%, 58/140 in males and 63.73%, 65/102 in females). Hence, a resampling method for the minority class, Synthetic Minority Oversampling Technique (SMOTE) was conducted to increase the data size and keep the data distribution balanced. It manually generates minority class samples by interpolating between several neighboring minority class examples instead of simply creating copies [18], which lets machine learning models pay balanced attention to sarcopenia and control groups and can avoid over-generalization in some degree. SMOTE did not change the true prevalence in the original data set significantly because the proportion of these two groups was not too imbalanced. Moreover, SMOTE was only done on the training set but not the original data set because using real-world data in test set to reflect the performance of machine learning classifiers in clinical practice is more preferred. After SMOTE, ten machine learning algorithms used their best hyper-parameters tuned by the 5-fold grid search to develop sarcopenia classifiers.
The true disease states of the patients in test set were used to obtain the true-negative rates (TNR, also called specificity), precision scores (the proportion of people classified as sarcopenia cases to those who are really assessed as sarcopenia cases) and true-positive rates (TPR, also called recall score and sensitivity) of ten models. Sensitivity, specificity, F1 score (2 * precision * sensitivity / (precision + sensitivity)) and the area under the receiver operating characteristic curve (AUC), were used together to evaluate classifiers’ performance. Other evaluation metrics for classification included the accuracy of training set and test set and the absolute of accuracy difference between these two sets. The absolute of accuracy difference was used to judge whether a model occurs overfitting. Machine learning models achieve their best performance when all metrics’ values are 1, except the absolute of accuracy difference is expected to be as close to 0 as possible [19]. If the absolute value of accuracy difference is too large, it indicates that this model occurs overfitting or has poor generalization power, and this model should be abandoned. Others with poor classification evaluation metrics will also be excluded.
After each split and modeling, every machine learning model’s performance was evaluated via the metrics mentioned above. For one metric, each model had 10 values. Therefore, the mean and SD values of these metrics were calculated. Notice that each model has different performance with various feature sets and models may not perform very well with such a data size, which makes it inconvenient to compare the classification performance of kinds of feature sets. Hence, in order to combine kinds of machine learning classifier methods, improve the final performance, and find the best feature set, the voting classifiers were proposed. The voting classifiers calculated the average probabilities that each model judged every sample as sarcopenia case in test set. If a mean value was larger than or equal to 0.5, the voting classifiers would consider the sample as a sarcopenia case. The voting classifiers combined several machine learning classifiers’ results, and also had the same evaluation metrics.
Results
Table 1 reported descriptive statistics on the male and female MHD patients’ basic information, body measurement results and laboratory findings, stratified by sarcopenia cases versus controls. Continuous and summary statistics were expressed as mean ± standard deviation (SD) for normally distributed features and as median with interquartile range (IQR) when the normality assumption was violated. Classification statistics were expressed as n (%). Unadjusted statistical analysis found 19 features with statistically significant differences between two male groups and 13 in two female groups.
After calculating the feature importance values and absolute weights of lasso regression of 84 features, the average ranking was gotten. The ranking results of features in two sex groups shown in Table 2 were in descending order of the average ranking. Only top 15 ranking results were given.
The 6-m walk and HGS were considered to be the most two important features for identifying possible sarcopenia and sarcopenia after feature selection, and P values also showed statistically significant differences of these two features in both sexes. According to AWGS 2019, possible sarcopenia can be assessed by any one of these two items’ test results, confirming the reliability of the feature importance and weight ranking method in degrees.
Among the top 15 features sorted by average ranking, some features, like age, pre-dialysis creatinine (pre-CRE), and post-dialysis creatinine (post-CRE), had significant differences. Meanwhile, other features with P > 0.05, such as anion gap (AG), total protein (TP), and triglyceride (TG), might also be helpful to the development of the machine learning classifier because of their high average rankings. Therefore, to obtain a simple and efficient machine learning identification model different from existing means of diagnosis, top 3, 4, 5 feature and top 3, 4, 5 feature with statistically significant differences (P < 0.05) after excluding 6-m walk, HGS, and skeletal muscle index (SMI) in Table 2, were selected for modeling. Their performance was compared to find the best feature set for sarcopenia identification.
After abandoning models occurring overfitting and unacceptable bad performance, all evaluation metrics of voting classifiers using top 3, 4, 5 feature sets and top 3, 4, 5 feature sets with P < 0.05 about 10 splits were shown in Table 3 and Table 4. The sensitivity, specificity, F1 score and AUC of voting classifiers were draw into a box plot as shown in Fig. 2 and Fig. 3. Notice that the top 4 features of male patients in Table 2 all had statistically significant differences. Hence, only 4 kinds of feature sets were compared in male MHD patients.

The box plot of voting classifier’s evaluation metrics about six feature sets in males. × : the mean value mark. ○: the outliers

The box plot of voting classifier’s evaluation metrics about six feature sets in females. × : the mean value mark. ○: the outliers
In Fig. 2, the top 4 feature set and top 5 feature set (P < 0.05) both had low F1 scores. Thus, these two sets were not recommended for sarcopenia identification. The top 3 feature set seemed to have a similar performance to the top 5 feature set. But in Table 3, the top 3 feature set achieved a little higher F1 score and AUC with lower SD than the top 5 feature set. Besides, using less features is more popular because it is easier to measure them and explain how the classifier works. Therefore, top 3 feature set became the best feature set for classifying sarcopenia in male MHD patients.
When males only used 3 features to identify sarcopenia accurately, females needed more. In Fig. 3, none of the voting classifier performed as well as the voting classifier using top 3 features in males. Only top 4 and top 5 feature sets (P < 0.05) got an average specificity over 70%. Compared with top 5 feature set (P < 0.05), the top 4 feature set (P < 0.05) had an advantage in all metrics except the absolute of accuracy difference. Though it had a larger IQR of specificity, it achieved better results of several classification evaluation metrics at once. Overall, the top 4 feature set (P < 0.05) was considered to be better than other feature sets.
The mean and SD of metrics about machine learning classifiers involved in voting classifier using the best feature set were calculated as shown in Table 5. The average sensitivity of LR was larger than Adaboost and LGBM as it identified more males with sarcopenia, while its precision, specificity and F1 score were the lowest. The performance of Adaboost was similar to LGBM’s. However, LGBM had the largest accuracy difference, which means it was not very robust. After combining these models, the voting classifier got improvement on them and kept a low absolute of accuracy difference. Its F1 score and AUC all exceeded other three models and it reduced their SD simultaneously. Besides, the voting classifier also kept high specificity as these models. The difference between voting classifier’s average specificity and sensitivity was less than 6%. Therefore, it was considered to classify sarcopenia and non-sarcopenia male patients in a balanced way. Overall, the voting classifier showed better classification performance than any single model.
In female group, SVM got the best classification performance. However, the voting classifier’s performance would become worse if SVM was combined with other models. Therefore, the voting classifier only used SVM to identify sarcopenia in female MHD patients. Though its results were not as good as the classifier for males, its F1 score of 78.04% also suggested that it could provide assistance in identification.
The ROC curves of each classifier listed in Table 5 were shown in Fig. 4 and Fig. 5. Considering that a ROC curve can be plotted after each split, it is hard to evaluate several classifiers’ performance through 10 ROC curves intuitively. Therefore, an approximate ROC curve to represent 10 splits’ “average” performance of one classifier was provided. According to the principle of ROC curve, the threshold set was redesigned to obtain the FPR and TPR sequences which were used for drawing the “average” ROC curve. The mean values of FPR sequences of 10 splits were calculated to get the value series of x axis of the ROC curve, while the mean and SD values of TPR sequence were calculated as y values. Finally, according to Fig. 4, the ROC curve of voting classifier about male MHD patients was more convex to the upper left, which means a larger AUC value. Meanwhile, it retained a small TPR dispersion in degrees, that is, a low SD of sensitivity.

The “average” ROC curves of four classifiers using the best feature set about male patients. The solid line represents the mean value of sensitivity, and the light area can be regarded as SD values

The “average” ROC curves of two classifiers using the best feature set about female patients. The solid line represents the mean value of sensitivity, and the light area can be regarded as SD values
Discussion
In this study, two binary classification models for the identification of sarcopenia, especially possible sarcopenia in male and female MHD patients were developed separately using features collected from the medical system. Sex-specific classifiers and features in two classifiers were mainly discussed as follows.
Sex-specific classifiers
Previous studies on sarcopenia prediction or identification models usually do not consider sex as a very important grouping indicator, but as a risk factor. Therefore, males and females used the same risk factors in one model, and the classification performance may be not satisfactory [20]. However, studies have shown that sex-specific aging patterns involve muscle mass and quality changes [21]. Though the diagnostic methods are the same in AWGS 2019, the diagnostic cutoff values vary with sex. It is also the same in the consensus published by European Working Group on Sarcopenia in Older People [5]. Inspired by Kang’s work [13], this study focused on sex specificity and developed two classifiers. They may raise greater attention to sarcopenia among MHD patients and promote the implementation of simply sex-specific diagnosis and identification methods for sarcopenia in clinic. The hyperparameter values found through grid search and machine learning model performance were not the same for different sexes and feature sets. Therefore, the voting classifier used different feature sets and models for two sexes, reflecting the physiological differences in the onset and diagnosis of sarcopenia between males and females. However, if there is a sex-insensitive model which can identify sarcopenia in MHD patients very precisely, it will be more convenient and popular in clinical practice and is an aim of further research.
Features in two classifiers
The features in two classifiers were selected by feature selection. Feature selection plays an important role in compressing the data processing scale. Medical data contains a large variety of examination results, medical history, nutrition intake, psychological states and so on, which are often high-dimensional. As not all data features are strongly related to the onset of sarcopenia, some unnecessary and irrelevant features need to be removed before model development. Feature selection can pre-process machine learning algorithms. Moreover, good feature selection results can improve models’ accuracy, reduce learning time, and also simplify learning results [22]. Well selected features help clinicians understand the possible underlying mechanism of sarcopenia and carry out corresponding intervention treatments. Since AWGS 2019 has recommended the sarcopenia diagnosis methods and cutoff values, it is meaningless to use the items proposed in the consensus and let machine learning to learn the existing classification rules. Therefore, HGS, 6-m walk, and SMI were excluded before developing machine learning models in this study. The features used in each classifier after feature selection were discussed as follows.
Age is a common key feature for identification in two sex groups. Sarcopenia itself is defined as an age-related geriatric syndrome [4]. It refers to the gradual decline in muscle mass, strength, and quality noted with advancing age [23]. The sarcopenia incidence increases with age [24].
In addition to age, FBG and PTH are also the most two suitable features for classification in males. Skeletal muscle is the largest insulin-sensitive tissue in the body. Hence, low muscle mass seems to result in a reduced capacity for glucose metabolism ability [25], and patients with sarcopenia have higher FBG levels [26, 27]. Other studies have shown that people with type 2 diabetes have a higher risk of developing sarcopenia [28, 29], and higher FBG levels are also a symptom of DM. Therefore, the hidden relationship between DM and sarcopenia may be explained by FBG levels. Meanwhile, according to Table 1, male patients with sarcopenia had lower PTH levels. As basal PTH levels can be modified by s-IP [30], MHD patients are prone to be at high s-IP levels [31], resulting in increased PTH secretion and possible secondary hyperparathyroidism [32]. However, male patients with sarcopenia had lower s-IP levels, which may be attributed to too little protein intake. The content of phosphorus in food is proportional to proteins, and the intake of certain proteins can help treat sarcopenia [33]. This result is consistent with the result of another study on sarcopenia in MHD patients [34].
In female group, arm without vascular access (AWVA), total bilirubin (TBIL), and post-CRE are the most three suitable features for classification besides age. AWVA between control and sarcopenia group is of statistically significant difference and has a high ranking in Table 2. Studies have shown that the HGS of AWVA is larger than the arm with vascular access [35, 36]. Although the vascular access is usually built in the non-dominant arm, varying with the vascular condition of the upper limbs and other factors, the vascular access may be built in the dominant arm. The dominant arm of each patient has not been investigated in this study. Hence, the relationship between sarcopenia and the trend of using the left arm to test HGS in female patients is unclear. Limited by this single-center study, AWVA may not be applicable for other different populations. Meanwhile, bilirubin is a potent endogenous antioxidant with anti-inflammatory, immunomodulatory and so on [37]. Low TBIL levels may lead to chronic-inflammation, and the phenomenon of chronic-inflammation or inflamm-aging is a contributor to sarcopenia [38]. The female group with sarcopenia of this study had lower TBIL levels, which is consistent with previously proven knowledge.
Female patients with sarcopenia had lower post-CRE levels in Table 1 and other studies have also shown similar results [34, 39]. Creatinine comes from both the metabolism of creatine in muscles and the meat intake. Hence, low serum creatinine levels may be regarded as a proxy for low muscle mass and protein-energy wasting, which is associated with adverse outcomes in MHD patients [40]. In both males and females, the pre-CRE and post-CRE levels of sarcopenia groups were significantly lower than those of the control groups. However, only the post-CRE level in females was selected after feature selection.
Besides, other research has shown that the modified creatinine index (mCI) and sarcopenia index (serum creatinine / CysC × 100) can be better indicators of sarcopenia [41,42,43]. However, after replacing the post-CRE in the top 4 features (P < 0.05) with the sarcopenia index and applying the same voting classifier, the classifier’s performance was not significantly improved. The voting classifier’s performance on two feature sets was shown in Table 6. It may be that CysC had no statistical difference in this study. Therefore, it did not help the model classify more accurately when it was combined with post-CRE.
Meanwhile, previous studies have rarely discussed whether the pre-CRE or post-CRE is more useful. MHD patients are required to measure pre-CRE and post-CRE before and after dialysis, respectively. Hence, the use of a combination of these two indicators may bring new breakthroughs. The creatinine generation rate calculated from pre-dialysis and post-dialysis blood examinations positively correlates with skeletal muscle mass [44]. However, this study only used data directly extracted from the medical system and did not conduct related research due to limited time and effort.
In order to obtain a simple classification model, the number of features less than six was only considered. Other features may also be related to sarcopenia identification. For example, the relationship between dialysis duration and sarcopenia varies with study cohorts [7, 45]. Limited by the small data size, population, and requirements for model convenience, some features showed little or no help in identification. But they can be involved or replace some existing features in classifiers if appropriate.
Limitation and development
The primary task of the classifier is to divide MHD patients into non-sarcopenia and sarcopenia groups. Generally, failing to identify a patient with sarcopenia leads to subsequent adverse events and prognoses, greatly destroying the doctor-patient relationship and making the patient question the classifier’s ability. Therefore, finding features with high sensitivity is the main aim of the best feature set selection. However, clinical diagnosis always pursues both higher sensitivity and specificity as much as possible. Hence, better feature sets and models still need to be found in further research.
Studies have shown that sarcopenia and frailty share many commonalities in the proposed underlying mechanisms involving a complex interplay between multiple systems and pathophysiologic processes [46]. Furthermore, physical performance is a common item to assess them. Sarcopenia and frailty are interrelated and both can increase the risk of adverse outcomes and mortality [6, 47]. Therefore, further understanding of the potential relationship between sarcopenia and frailty in MHD patients may help identify and diagnose these two diseases simultaneously. However, this study only focused on sarcopenia and considered two common comorbidities (DM and hypertension). Whether frailty could help identify sarcopenia was not considered. The role of frailty states in sarcopenia identification assistant tools for MHD patients remains unclear. Therefore, some convenient and available clinical frailty assessment results, such as clinical frailty scale results and hospital frailty risk score [48], should be included in data collection and model development in future research.
In this study, the voting classifier combing LR, Adaboost, and LGBM achieved an average AUC of more than 85% with only three features for males. However, the performance of SVM was the only acceptable one for females. The SD of the voting classifier’s metrics after stratified shuffle split were a little large because of the relatively small amount of data in one single hemodialysis center. Integrated tree-based models, which are more suitable for processing a large number of high-dimensional data [16], performed not as well as LR and SVM based on relatively simple theories. However, with the increase of the data amount, integrated tree-based models may show their advantages. Meanwhile, if there are big data available, deep learning models may be able to get better classification results.
Currently, there is no unified diagnostic standard for sarcopenia. Owing to the study population and geographical area limitations, this study only used AWGS 2019 as the criterion for sarcopenia diagnosis and true sample labels for model evaluation. This study aims to develop a sarcopenia identification tool for MHD patients, not a new diagnostic method. Therefore, the results may only be applied to populations who use the same consensus. It is still necessary to check the classifiers’ performance on other sarcopenia consensuses, and multi-regional or multi-center research.
Conclusion
In this study, two simple sex-specific sarcopenia identification assistant tools for MHD patients using machine learning methods were developed. They performed well on the case finding of sarcopenia, especially possible sarcopenia assessed by the methods proposed in AWGS 2019. They can promote the early diagnosis and identification of sarcopenia among MHD patients and improve their quality of life. Limited by the single hemodialysis center research, the data size was relatively small after grouping by sex, and classifiers have not been applied in clinical practice. More samples are needed in further research. Moreover, the models and features that voting classifiers use should be adjusted to make classifiers more robust. The classifiers’ results on other sarcopenia consensuses, regions and populations should be verified, too.
Availability of data and materials
The datasets used and/or analysed during the current study are available from the corresponding author on reasonable request.
Change history
26 April 2023
A Correction to this paper has been published: https://doi.org/10.1186/s12882-023-03139-9
Abbreviations
- MHD:
-
Maintenance hemodialysis
- CKD:
-
Chronic kidney disease
- AWGS:
-
Asia Working Group for Sarcopenia
- SD:
-
Standard deviation
- IQR:
-
Interquartile range
- KNN:
-
K-Nearest Neighbor
- GaussianNB:
-
Gaussian Naive Bayes
- LR:
-
Logistic Regression
- SVM:
-
Support Vector Machine
- MLP:
-
Multi-layer Perceptron
- DT:
-
Decision Tree
- RF:
-
Random Forest
- Adaboost:
-
Adaptive Boosting
- GBDT:
-
Gradient Boosting Decision Tree
- LGBM:
-
Light Gradient Boosting Machine
- SMOTE:
-
Synthetic Minority Oversampling Technique
- TNR:
-
True-negative rates
- TPR:
-
True-positive rates
- AUC:
-
The area under the receiver operating characteristic curves
- DM:
-
Diabetes mellitus
- HTN:
-
Hypertension
- AVF:
-
Arteriovenous fistula
- CVC:
-
Central venous catheter
- DM:
-
Dialysis duration
- SARC-F:
-
Strength,assistance with walking,rise from a chair,climb stairs and falls
- CC:
-
Calf circumference
- WC:
-
Waist circumference
- HC:
-
Hip circumference
- AWVA:
-
Arm without vascular access
- HGS:
-
Handgrip strength
- SMI:
-
Skeletal muscle index
- BMI:
-
Body mass index
- RBC:
-
Red blood cell count
- HGB:
-
Hemoglobin
- HCT:
-
Hematocrit
- MCV:
-
Mean corpuscular volume
- MCH:
-
Mean corpuscular hemoglobin
- MCHC:
-
Mean corpuscular hemoglobin concentration
- RDW-CV:
-
Red blood cell distribution width—coefficient of variation
- RDW-SD:
-
Red blood cell distribution width—standard deviation
- PLT:
-
Platelet count
- WBC:
-
White blood cell count
- NEUT%:
-
Neutrophil percentage
- LY%:
-
Lymphocyte percentage
- MO%:
-
Monocyte percentage
- EOS%:
-
Eosimophil percentage
- BASO%:
-
Basophil percentage
- ANC:
-
Absolute neutrophil count
- ALC:
-
Absolute lymphocyte count
- AMC:
-
Absolute monocytes count
- AEC:
-
Absolute eosinophils count
- ABC:
-
Absolute basophil count
- TBIL:
-
Total bilirubin
- DBIL:
-
Direct bilirubin
- IBIL:
-
Indirect bilitubin
- ALT:
-
Alanine amiotransferase
- AST:
-
Aspartate aminotransferase
- AST/ALT:
-
Aspartate aminotransferase/Alanine amiotransferase
- TP:
-
Total protein
- ALB:
-
Albumin
- GLOB:
-
Globulin
- A/G:
-
Albumin/globulin
- FBG:
-
Fasting blood glucose
- pre-URE:
-
Pre-dialysis urea
- pre-CRE:
-
Pre-dialysis creatinine
- CysC:
-
Cystatin C
- UA:
-
Uric acid
- TG:
-
Triglyceride
- CHOL:
-
Cholesterol
- HDL-C:
-
High density lipoprotein cholesterol
- LDL:
-
Low density lipoprotein
- ALP:
-
Alkaline phosphatase
- GGT:
-
γ-Glutamyl transpeptadase
- s-Na:
-
Serum sodium
- s-K:
-
Serum potassium
- s-Cl:
-
Serum chloride
- CO2CP:
-
Carbon dioxide combining power
- AG:
-
Anion gap
- β-HBA:
-
Serum β-hydroxybutyrate
- s-Ca:
-
Serum calcium
- s-Mg:
-
Serum magnesium
- s-IP:
-
Serum inorganic phosphorus
- s-I:
-
Serum iron
- TIBC:
-
Total iron binding capacity
- TSAT:
-
Transferrin saturation
- PTH:
-
Parathyroid hormone
- s-Fe:
-
Serum ferritin
- CRP:
-
C-reactive protein
- β2-MG:
-
β2-Microglobulin
- post-URE:
-
Post-dialysis urea
- post-CRE:
-
Post-dialysis creatinine
- mCI:
-
Modified creatinine index
References
Levey AS, Eckardt KU, Dorman NM, Christiansen SL, Hoorn EJ, Ingelfinger JR, et al. Nomenclature for kidney function and disease: report of a Kidney Disease: Improving Global Outcomes (KDIGO) consensus conference. Kidney Int. 2020;97(6):1117–29.
Slee A, McKeaveney C, Adamson G, Davenport A, Farrington K, Fouque D, et al. Estimating the prevalence of muscle wasting, weakness, and sarcopenia in hemodialysis patients. J Ren Nutr. 2020;30(4):313–21.
Ikizler TA, Pupim LB, Brouillette JR, Levenhagen DK, Farmer K, Hakim RM, et al. Hemodialysis stimulates muscle and whole body protein loss and alters substrate oxidation. Am J Physiol Endocrinol Metab. 2002;282(1):E107–16.
Chen LK, Woo J, Assantachai P, Auyeung TW, Chou MY, Iijima K, et al. Asian working group for sarcopenia: 2019 consensus update on sarcopenia diagnosis and treatment. J Am Med Dir Assoc. 2020;21(3):300-7 e2.
Cruz-Jentoft AJ, Bahat G, Bauer J, Boirie Y, Bruyere O, Cederholm T, et al. Sarcopenia: revised European consensus on definition and diagnosis. Age Ageing. 2019;48(1):16–31.
Kim JK, Kim SG, Oh JE, Lee YK, Noh JW, Kim HJ, et al. Impact of sarcopenia on long-term mortality and cardiovascular events in patients undergoing hemodialysis. Korean J Intern Med. 2019;34(3):599–607.
Shu X, Lin T, Wang H, Zhao Y, Jiang T, Peng X, et al. Diagnosis, prevalence, and mortality of sarcopenia in dialysis patients: a systematic review and meta-analysis. J Cachexia Sarcopenia Muscle. 2022;13(1):145–58.
Giglio J, Kamimura MA, Lamarca F, Rodrigues J, Santin F, Avesani CM. Association of sarcopenia with nutritional parameters, quality of life, hospitalization, and mortality rates of elderly patients on hemodialysis. J Ren Nutr. 2018;28(3):197–207.
Ueshima J, Maeda K, Shimizu A, Inoue T, Murotani K, Mori N, et al. Diagnostic accuracy of sarcopenia by “possible sarcopenia” premiered by the Asian Working Group for Sarcopenia 2019 definition. Arch Gerontol Geriatr. 2021;97:104484.
Safran C, Bloomrosen M, Hammond WE, Labkoff S, Markel-Fox S, Tang PC, et al. Toward a national framework for the secondary use of health data: an American Medical Informatics Association White Paper. J Am Med Inform Assoc. 2007;14(1):1–9.
Deo RC. Machine Learning in Medicine. Circulation. 2015;132(20):1920–30.
Bellazzi R, Zupan B. Predictive data mining in clinical medicine: current issues and guidelines. Int J Med Inform. 2008;77(2):81–97.
Kang YJ, Yoo JI, Ha YC. Sarcopenia feature selection and risk prediction using machine learning: A cross-sectional study. Medicine (Baltimore). 2019;98(43):e17699.
Castillo-Olea C, Garcia-Zapirain Soto B, Zuniga C. Evaluation of prevalence of the sarcopenia level using machine learning techniques: case study in Tijuana Baja California, Mexico. Int J Environ Res Public Health. 2020;17(6):1917.
Hassler AP, Menasalvas E, Garcia-Garcia FJ, Rodriguez-Manas L, Holzinger A. Importance of medical data preprocessing in predictive modeling and risk factor discovery for the frailty syndrome. BMC Med Inform Decis Mak. 2019;19(1):33.
Breiman L. Random forests. Mach Learn. 2001;45(1):5–32.
Schnack HG, Kahn RS. Detecting neuroimaging biomarkers for psychiatric disorders: sample size matters. Front Psychiatry. 2016;7:50.
Chawla NV, Bowyer KW, Hall LO, Kegelmeyer WP. SMOTE: Synthetic minority over-sampling technique. J Artif Intell Res. 2002;16:321–57.
Sokolova M, Lapalme G. A systematic analysis of performance measures for classification tasks. Inf Process Manage. 2009;45(4):427–37.
Tseng TG, Lu CK, Hsiao YH, Pan SC, Tai CJ, Lee MC. Development of Taiwan Risk Score for Sarcopenia (TRSS) for sarcopenia screening among community-dwelling older adults. Int J Environ Res Public Health. 2020;17(8):2859.
Di Monaco M, Castiglioni C, Vallero F, Di Monaco R, Tappero R. Sarcopenia is more prevalent in men than in women after hip fracture: a cross-sectional study of 591 inpatients. Arch Gerontol Geriatr. 2012;55(2):e48-52.
Cai J, Luo J, Wang S, Yang S. Feature selection in machine learning: A new perspective. Neurocomputing. 2018;300:70–9.
Kamel HK. Sarcopenia and aging. Nutr Rev. 2003;61(5):157–67.
Han P, Zhao J, Guo Q, Wang J, Zhang W, Shen S, et al. Incidence, risk factors, and the protective effect of high body mass index against sarcopenia in suburb-dwelling elderly Chinese populations. J Nutr Health Aging. 2016;20(10):1056–60.
Scott D, de Courten B, Ebeling PR. Sarcopenia: a potential cause and consequence of type 2 diabetes in Australia’s ageing population? Med J Aust. 2016;205(7):329–33.
Ogama N, Sakurai T, Kawashima S, Tanikawa T, Tokuda H, Satake S, et al. Association of glucose fluctuations with sarcopenia in older adults with type 2 diabetes mellitus. J Clin Med. 2019;8(3):319.
He Q, Wang X, Yang C, Zhuang X, Yue Y, Jing H, et al. Metabolic and nutritional characteristics in middle-aged and elderly sarcopenia patients with type 2 diabetes. J Diabetes Res. 2020;2020:6973469.
Chan LC, Yang YC, Lin HC, Wahlqvist ML, Hung YJ, Lee MS. Nutrition counseling is associated with less sarcopenia in diabetes: A cross-sectional and retrospective cohort study. Nutrition. 2021;91–92:111269.
Massimino E, Izzo A, Riccardi G, Della Pepa G. The impact of glucose-lowering drugs on sarcopenia in type 2 diabetes: current evidence and underlying mechanisms. Cells. 2021;10(8):1958.
Felsenfeld AJ, Rodriguez M, Aguilera-Tejero E. Dynamics of parathyroid hormone secretion in health and secondary hyperparathyroidism. Clin J Am Soc Nephrol. 2007;2(6):1283–305.
Block GA, Hulbert-Shearon TE, Levin NW, Port FK. Association of serum phosphorus and calcium x phosphate product with mortality risk in chronic hemodialysis patients: A national study. Am J Kidney Dis. 1998;31(4):607–17.
Silver J, Levi R. Regulation of PTH synthesis and secretion relevant to the management of secondary hyperparathyroidism in chronic kidney disease. Kidney Int. 2005;67:S8–12.
Cruz-Jentoft AJ, Kiesswetter E, Drey M, Sieber CC. Nutrition, frailty, and sarcopenia. Aging Clin Exp Res. 2017;29(1):43–8.
Lin YL, Liou HH, Lai YH, Wang CH, Kuo CH, Chen SY, et al. Decreased serum fatty acid binding protein 4 concentrations are associated with sarcopenia in chronic hemodialysis patients. Clin Chim Acta. 2018;485:113–8.
Bucar Pajek M, Cuk I, Pajek J. Vascular access effects on motor performance and anthropometric indices of upper extremities. Ther Apher Dial. 2016;20(3):295–301.
Rehfuss JP, Berceli SA, Barbey SM, He Y, Kubilis PS, Beck AW, et al. The spectrum of hand dysfunction after hemodialysis fistula placement. Kidney Int Rep. 2017;2(3):332–41.
Inoguchi T, Sonoda N, Maeda Y. Bilirubin as an important physiological modulator of oxidative stress and chronic inflammation in metabolic syndrome and diabetes: a new aspect on old molecule. Diabetol Int. 2016;7(4):338–41.
Chhetri JK, de Souto BP, Fougere B, Rolland Y, Vellas B, Cesari M. Chronic inflammation and sarcopenia: a regenerative cell therapy perspective. Exp Gerontol. 2018;103:115–23.
Inaba M, Kurajoh M, Okuno S, Imanishi Y, Yamada S, Mori K, et al. Poor muscle quality rather than reduced lean body mass is responsible for the lower serum creatinine level in hemodialysis patients with diabetes mellitus. Clin Nephrol. 2010;74(4):266–72.
Park J, Mehrotra R, Rhee CM, Molnar MZ, Lukowsky LR, Patel SS, et al. Serum creatinine level, a surrogate of muscle mass, predicts mortality in peritoneal dialysis patients. Nephrol Dial Transplant. 2013;28(8):2146–55.
Yamamoto S, Matsuzawa R, Hoshi K, Suzuki Y, Harada M, Watanabe T, et al. Modified creatinine index and clinical outcomes of hemodialysis patients: an indicator of sarcopenia? J Ren Nutr. 2021;31(4):370–9.
Ren C, Su H, Tao J, Xie Y, Zhang X, Guo Q. Sarcopenia index based on serum creatinine and cystatin c is associated with mortality, nutritional risk/malnutrition and sarcopenia in older patients. Clin Interv Aging. 2022;17:211–21.
Osaka T, Hamaguchi M, Hashimoto Y, Ushigome E, Tanaka M, Yamazaki M, et al. Decreased the creatinine to cystatin C ratio is a surrogate marker of sarcopenia in patients with type 2 diabetes. Diabetes Res Clin Pract. 2018;139:52–8.
Mae Y, Takata T, Yamada K, Hamada S, Yamamoto M, Iyama T, et al. Creatinine generation rate can detect sarcopenia in patients with hemodialysis. Clin Exp Nephrol. 2022;26(3):272–7.
Ren H, Gong D, Jia F, Xu B, Liu Z. Sarcopenia in patients undergoing maintenance hemodialysis: incidence rate, risk factors and its effect on survival risk. Ren Fail. 2016;38(3):364–71.
Wong L, Duque G, McMahon LP. Sarcopenia and Frailty: Challenges in Mainstream Nephrology Practice. Kidney Int Rep. 2021;6(10):2554–64.
Garcia-Canton C, Rodenas A, Lopez-Aperador C, Rivero Y, Anton G, Monzon T, et al. Frailty in hemodialysis and prediction of poor short-term outcome: mortality, hospitalization and visits to hospital emergency services. Ren Fail. 2019;41(1):567–75.
Gilbert T, Neuburger J, Kraindler J, Keeble E, Smith P, Ariti C, et al. Development and validation of a hospital frailty risk score focusing on older people in acute care settings using electronic hospital records: an observational study. Lancet. 2018;391(10132):1775–82.
Acknowledgements
We gratefully acknowledge all the clinicians, statisticians, and technicians who contributed to this study.
Funding
We thank the National Key R&D Program of China (2020YFC2005600), National Natural Science Foundation of China (12102072), and Project of Sichuan Chengdu Science and Technology Bureau (2019-YF05-00622-SN).
Author information
Authors and Affiliations
Contributions
H.L.L., Y.J.Y., Y.C., and H.H.Y. prepared the manuscript, designed the study and organized the coordination. H.L.L., Y.J.Y., Y.Z., Y.Q., Y.C., and L.F.Z. searched literatures. Y.J.Y., Y.Z., Y.Q., Y.C., and L.F.Z. collected the data of MHD patients. H.L.L. and F.Y. analyzed the data. H.L.L. and Y.J.Y. are the major contributors in writing the manuscript. All authors read and approved the final manuscript.
Corresponding authors
Ethics declarations
Ethics approval and consent to participate
This study received approval from the Ethics Committee of Sichuan University (ethical approval number: 2020[1002]) and was performed in accordance with the principles of the Declaration of Helsinki. The requirement for informed consent was waived by the Ethics Committee of Sichuan University because this was an observational, cross-sectional study using a database from which the patients’ identifying information had been removed.
Consent for publication
Not applicable.
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The original version of this article was revised: the authors Hualong Liao, Yujie Yang, Ying Zeng, Ying Qiu, Yang Chen, Linfang Zhu, Yu Chen and Huaihong Yuan were incorrectly affiliated. The Fig. 3 has been updated.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Liao, H., Yang, Y., Zeng, Y. et al. Use machine learning to help identify possible sarcopenia cases in maintenance hemodialysis patients. BMC Nephrol 24, 34 (2023). https://doi.org/10.1186/s12882-023-03084-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12882-023-03084-7