
Abstract
Background
Previous published prognostic models for COVID-19 patients have been suggested to be prone to bias due to unrepresentativeness of patient population, lack of external validation, inappropriate statistical analyses, or poor reporting. A high-quality and easy-to-use prognostic model to predict in-hospital mortality for COVID-19 patients could support physicians to make better clinical decisions.
Methods
Fine-Gray models were used to derive a prognostic model to predict in-hospital mortality (treating discharged alive from hospital as the competing event) in COVID-19 patients using two retrospective cohorts (n = 1008) in Wuhan, China from January 1 to February 10, 2020. The proposed model was internally evaluated by bootstrap approach and externally evaluated in an external cohort (n = 1031).
Results
The derivation cohort was a case-mix of mild-to-severe hospitalized COVID-19 patients (43.6% females, median age 55). The final model (PLANS), including five predictor variables of platelet count, lymphocyte count, age, neutrophil count, and sex, had an excellent predictive performance (optimism-adjusted C-index: 0.85, 95% CI: 0.83 to 0.87; averaged calibration slope: 0.95, 95% CI: 0.82 to 1.08). Internal validation showed little overfitting. External validation using an independent cohort (47.8% female, median age 63) demonstrated excellent predictive performance (C-index: 0.87, 95% CI: 0.85 to 0.89; calibration slope: 1.02, 95% CI: 0.92 to 1.12). The averaged predicted cumulative incidence curves were close to the observed cumulative incidence curves in patients with different risk profiles.
Conclusions
The PLANS model based on five routinely collected predictors would assist clinicians in better triaging patients and allocating healthcare resources to reduce COVID-19 fatality.
Similar content being viewed by others

Background
The novel coronavirus disease 2019 (COVID-19) has become a pandemic worldwide since its first outbreak in Wuhan, China since December 2019 [1]. As of July 3, 2020, more than 10 million cases are confirmed in over 200 countries, including 517,337 deaths [2]. Due to the high contagiousness and rapid progression of the disease, healthcare demand, in particular for critical care capacities, has often been overwhelming even in high-income areas [3]. Good support tools are needed for clinicians and other healthcare workers to respond promptly to urgent situations. It is crucial to accurately select severe patients for targeted treatment. For example, while it is essential to increase the intensive care unit (ICU) capacities and staff, ICU triage may be critical to prioritize severe patients for intensive care [4]. Therefore, early stratification of patients will facilitate targeted supportive care and appropriate allocation of medical resources.
Prognostic model that combines several clinical or non-clinical variables to estimate the future health outcomes of an individual could be a useful tool [5]. To respond quickly to the health crisis of COVID-19, a prognostic model based on robust evidence could be used as a simple and inexpensive tool to assist physicians in triaging the patients in the first place, which in turn may mitigate the burden of overwhelmed healthcare system and better allocate limited healthcare resources to reduce COVID-19 fatality [6]. Currently, several clinical prognostic models have been developed for COVID-19 patients [7, 8]. However, the quality of these models has been criticized and was prone to bias due to unrepresentativeness of patient population, lack of external validation, inappropriate statistical analyses, or poor reporting [7]. Two of these prognostic models have been constructed with promising predictive performance for predicting mortality [9, 10]. However, they may not be highly reliable due to relatively small derivation cohorts (189 to 296 patients) and external validation cohorts (19 to 165 patients). Several studies used a time-to-event analysis to allow for administrative censoring [11,12,13]. However, censoring for other reasons, such as being discharged alive because of quick recovery, were seldom considered to be analyzed in a competing risk framework. For example, the CALL score [11] predicted the disease progression in hospitalized COVID-19 patients by using the standard Cox model. In this study, the risk of progression would be over-estimated because the patients discharged alive are no longer at risk of disease progression while the standard Cox model assumes they are still at risk.
In this study, we aimed to develop and validate a prognostic model to predict in-hospital mortality in COVID-19 patients using routinely measured demographic and clinical characteristics.
Methods
Study cohorts
Derivation cohort
The derivation cohort included 1008 COVID-19 patients admitted at Jinyintan Hospital (n = 763) and Union Hospital (n = 245) in Wuhan, China from January 1 to February 10, 2020. Patients were followed up to March 20, 2020. Patients who were still hospitalized until March 20, 2020 were not included in the analyses. The Jinyintan hospital had mostly severe patients while Union Hospital had mostly mild patients, thus providing a case-mix of mild-severe COVID-19 patients.
Validation cohort
The validation cohort included 1031 COVID-19 patients aged ≥18 years at Tongji Hospital in Wuhan, China from January 14 to March 8, 2020. Since this cohort was designed to assess the potential risk factors related to acute cardiac injury in COVID-19 patients, patients with stage of chronic kidney disease ≥4, chronic heart failure in the decompensatory stage, acute myocardial infarction during hospitalization, or having missing information on hypersensitive cardiac troponin I were excluded. Patients were followed up to March 30, 2020.
Data collection
A trained team of physicians retrospectively reviewed clinical electronic medical records and laboratory findings for all the patients. All patients met the diagnostic criteria according to the WHO interim guidance [14]. In the derivation cohort, we collected data on age, sex, the dates of admission and discharge or death, complete blood count at admission (neutrophil, lymphocyte, platelet count, haemoglobin), current smoking status (no, yes), chronic disease history (hypertension, digestive disease, kidney disease, coronary heart disease (CHD), chronic pulmonary disease, cerebrovascular disease, diabetes, thyroid disease, malignancy, and other diseases). In the validation cohort, we collected data on age, sex, the dates of admission and discharge or death, complete blood count at admission (neutrophil, lymphocyte, platelet count), chronic disease history (hypertension, diabetes, CHD). All data were reviewed and collected by two physicians and a third researcher adjudicated any difference in interpretation between the two physicians.
Outcome and candidate predictors
The end point of interest was the time from hospital admission until in-hospital death (event of interest) or discharged alive (competing event) or 30-day after hospital admission (censored), whichever came first. Discharged alive was treated as a competing event because the event of discharged alive precludes the event of in-hospital death. Since conventional survival methods, such as Kaplan-Meier method and Cox model, assume two competing events (in-hospital death and discharged alive) are independent, they are not valid any more and more advanced methods accounting for competing risks should be used. Candidate predictor variables included a set of demographic variables (age, sex, current smoking status), laboratory findings (neutrophil count, lymphocyte count, platelet count), and comorbidities (hypertension, CHD, diabetes, cerebrovascular disease, and malignancy), which were selected according to clinical knowledge, literature, [7, 15] and data availability. While current smoking status was not considered due to high proportion of missing data in the derivation cohort (46.3% missing), information on all other candidate predictor variables and outcome was complete for data analysis.
Model derivation
Fine-Gray models were used to develop the prognostic model, treating discharged alive from hospital as a competing event [16]. The prognostic model derivation consisted of a prognostic index (PI) that captured the effect of the predictor variables on cumulative incidence function (CIF) for death, and a baseline CIF that determined the cumulative mortality of an “average” patient, i.e., a patient with the average value of PI. First, uni-variable Fine-Gray models with fractional polynomials (maximum permissible degree 1) were performed to investigate the potential non-linear relationship between continuous variables and CIF for death. Second, a multivariable Fine-Gray model with all the predictors was built. Backward elimination was applied to do the variable selection with significant level setting to 0.05, resulting in a final model in this step. PI was then calculated based on the combination of β coefficients and values of the corresponding predictors. The baseline CIF CIF0(t) corresponds to the cumulative mortality of an “average” patient with the average value of PI. The CIF for death of other patients can be computed via the formula: \( {\mathrm{CIF}}_i(t)=1-{\left(1-{\mathrm{CIF}}_0(t)\right)}^{\exp \left({PI}_i-\overline{PI}\right)} \), where PIi is the PI of patient i and \( \overline{PI} \) is the average value of PI in the derivation cohort. Details about the implementation and estimates of the Fine-Gray model, see the Additional file 1: Appendix Text 1.
Model performance and internal validation
Model performance was assessed in terms of discrimination and calibration. Discrimination was assessed using the concordance statistic (C-index) [17]. Calibration was assessed jointly by calibration slope and calibration plot. Calibration slope is a measure to estimate the regression coefficient on the PI in the validation dataset [18]. In the calibration plot, the averaged predicted mortality curves estimated by the proposed prognostic model were compared with the averaged observed mortality curves across several risk groups. The risk group was based on patients’ PI (thresholds: 16th, 50th and 84th percentiles) [19].
We performed internal validation to estimate the optimism (the level of model overfitting) and adjusted measures of C-index and calibration slope by bootstrapping 1000 samples of the original data (a detailed description of implementation of bootstrap is provided in Additional file 1: Appendix Text 2). Average calibration slope in the internal validation was obtained to be a uniform shrinkage factor. We multiplied the shrinkage factor by the raw PI (PI in the model derivation step) to obtain optimism-adjusted PI. Lastly, we developed the final model by re-estimating the baseline CIF for death based on the optimism-adjusted PI.
External validation
The final model was applied to each patient in the external validation cohort. PI was then calculated based on the combination of β coefficients and the corresponding predictor values of every patient. The discriminative accuracy of the proposed model was evaluated using C-index and visually checked by the distribution of PIs. The calibration accuracy of the proposed model was assessed using calibration slope and visually checked by calibration plot.
Statements about reporting and evaluation of our prognostic model
The reporting of this prognostic model study followed Transparent Reporting of a multivariable prediction model for Individual Prognosis Or Diagnosis (TRIPOD) statement (Additional file 2) [20]. The risk of bias of the prognostic model was independently assessed by an expert (JW, who did not take part in the model development and validation) using PROBAST (prediction model risk of bias assessment tool) [21].
Results
Patient population
In the derivation cohort, the median age of 1008 patients was 55 (interquartile range [IQR] 44–65, youngest at 14 years of age and oldest at 98 years) and 43.6% patients were females. During a median length of stay (LOS) of 12 days (IQR 8–16), 211 patients died in total, and 4 of which died beyond 30 days. Seven hundred fifty-seven patients discharged alive from the hospital within 30 days. There were 438 (43.5%) patients with one or more comorbidities. Hypertension (N = 232, 23.0%), diabetes (N = 110, 10.9%), chronic digestive disease (N = 78, 7.7%), and chronic pulmonary disease (N = 40, 4.0%) were among the most frequent comorbidities (Table 1).
In the validation cohort, the 1031 patients included were older (63, IQR 52–70), had more females (47.8%), and were more prevalent with hypertension (N = 383, 37.1%), CHD (N = 83, 8.1%) and diabetes (N = 189, 18.3%), compared to the derivation cohort (Table 1). Patients had a longer LOS (19, IQR 11–27). The in-hospital mortality of patients in the validation cohort was slightly lower compared with the derivation cohort (Additional file 1: Appendix Fig. 1).
Coding of predictors
Categorical predictors (sex, hypertension, CHD, diabetes, cerebrovascular disease and malignancy) were coded as dummy variables. Among continuous predictors, we did not observe obvious violation of linearity assumption for age, neutrophil and platelet count. We observed a non-linear relation between outcome and lymphocyte count. Therefore, we included the transformed lymphocyte count (square root of the lymphocyte count) in the model according to the results of fractional polynomial analyses.
Model derivation and internal validation
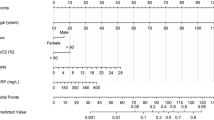
The PLANS model included five predictors: platelet count, lymphocyte count, age, neutrophil count, and sex. Cumulative incidence function for the in-hospital mortality was associated with older age, being male, higher neutrophil, lower lymphocyte and lower platelet count (Table 2). This model showed excellent apparent discriminative ability (C-index: 0.85, 95% CI: 0.83 to 0.88). After adjusting for overfitting, the model maintained excellent discriminative accuracy (optimism-adjusted C-index: 0.85, 95% CI: 0.83 to 0.87). The average calibration slope (uniform shrinkage factor) was 0.95 (95% CI: 0.82 to 1.08), suggesting little model overfit. The final PI was calculated as 0.95 (uniform shrinkage factor) times the raw PI and the formula for final PI was structured as
-
Platelet: × 109/L
-
Lymphocyte: × 109/L, transformed to lymphocyte ^ 0.5
-
Age: in years
-
Neutrophil: × 109/L
-
Sex: female = 0; male = 1
The distribution of final PI suggested good discriminative ability of our model (upper panel of Fig. 1). The relationship between PI and 7-day, 14-day and 30-day mortality are presented in Fig. 2. While we observed a slight underestimate of the mortality in the highest risk group, the agreement between predicted mortality curves and the observed mortality curves in the other risk groups suggested good calibration of our model (left panel of Fig. 3). The final formula for the PLANS model and a patient example of how it can be applied in the real clinical practice is depicted in Table 3. Furthermore, an online calculator can be accessed for this calculation: https://plans.shinyapps.io/dynnomapp/.

Distribution of the prognostic index of the prognostic model in the derivation and validation cohort; Upper part: derivation cohort; Lower part: validation cohort

Prediction of 7-day, 14-day and 30-day mortality versus the prognostic index based on the PLANS model (red line); Prediction of 7-day, 14-day and 30-day mortality versus a smooth function of the prognostic index using generalized additive model (black line) together with the 95% confidence band; Upper part: derivation cohort; Lower part: validation cohort

Predicted vs. Observed cumulative incidence curves per risk group in the derivation and validation cohort (Risk groups were defined based on PI. PI range from low risk tp high risk group: ≤ − 0.81, − 0.81 to 0.50, 0.50 to 2.03, and > 2.03. Two lowest group were combined due to the limited death)
External validation
We applied the PLANS model to the independent cohort of 1031 patients from Tongji Hospital. The distribution of the PIs in the validation cohort was very similar to that in the derivation cohort, suggesting that the excellent discriminative accuracy of our model maintained in the validation cohort (Fig. 1). The resulting C-index showed excellent discriminative accuracy of our model (C-index: 0.87, 95% CI: 0.85 to 0.89). Regarding the calibration accuracy, our model slightly overestimated mortality in each risk group (right panel of Fig. 3). Details about the thresholds and corresponding proportion and death toll included in each risk group are provided (Additional file 1: Appendix Table 2). Jointly considering a close-to-one calibration slope (1.02, 95% CI: 0.92 to 1.12) and good agreement between predicted and observed cumulative incidence curves, our model still suggested good calibration accuracy in the validation cohort.
Model update
The proposed model may not be directly applied to other areas where the distribution of predictive factors may be different from that in Wuhan. For instance, New York of USA and Lombardy of Italy could have a different distribution of preditor variables compared with Wuhan. Therefore, we used entropy balancing to update proposed model to generalize to their settings [22]. Details about the two updated model, see the Additional file 1: Appendix Text 3.
Methodology quality assessment
According to the PROBAST, the proposed model was rated as low risk of bias in all four domains: 17 of the total signaling questions were “Yes” and 3 were “Probably Yes”. Rationales of answers were shown in Additional file 1: Appendix Table 6.
Discussion
We developed a prognostic model (PLANS), using clinical readily available measures of platelet count, lymphocyte count, age, neutrophil count, and sex, to predict in-hospital mortality for COVID-19 patients using two retrospective cohorts in Wuhan, China. This model was first internally validated using bootstrap and then externally validated in an independent cohort in Wuhan. The PLANS model showed excellent discriminative and calibration accuracy.
All the five predictors are routinely collected and some of them have been already well established as the risk factors for in-hospital mortality in previous studies [23]. Recent studies from Italy, the USA, and China [24,25,26] have also reported that advanced age was a strong predictor of in-hospital mortality as suggested in our study. Compared to previous studies, [27, 28] our study had a more balanced gender composition. Our finding that male gender was associated with increased in-hospital mortality provided further evidence to support the hypothesis of male’s vulnerability to COVID-19 [29, 30]. Our study further confirmed that poor prognosis was associated with higher neutrophil and lower lymphocyte count [31]. On top of that, lymphopenia was found to have a non-linear relation with in-hospital mortality. A meta-analysis of nine studies had reported that thrombocytopenia was significantly associated with the severity of COVID-19 disease, but heterogeneity between studies was high [32]. Given a relatively large sample size and longer follow-up, our study indicated thrombocytopenia was associated with a higher risk of in-hospital mortality. Other studies have shown that several comorbidities (hypertension, diabetes, and coronary heart disease) were associated with poor prognosis [24, 33]. While none of the comorbidities were included in our model, we found that diabetes status would be incorporated when we excluded age from our model. It is plausible as the prevalence of most comorbidities, in particular diabetes, increases with age [25].
Since the outbreak of COVID-19 in Wuhan, a number of prognostic models have been established [7]. A comprehensive systematic review conducted by Wynants and colleagues found that most of these models were of high risk of bias due to several methodological limitations from participant domain to analysis domain [7]. Compared to the previous models, the PLANS model has several strengths. Our derivation cohort had a relatively large sample size with complete information on candidate predictors. While duration of follow up was unclear in most of the previous studies, the patients in our study were followed over a relatively long period, allowing us to perform a time-to-event analysis to predict in-hospital mortality. Furthermore, a competing risk analysis treating discharged alive as a competing event was done in this study to avoid overestimation of mortality. The similar distribution of age and sex in our study to recent large international reports [34, 35] indicates good representativeness of the patient population. External validation of the PLANS model to a large sample of patients showed excellent discrimination and calibration accuracy, indicating the generalizability of the PLANS model in the same city. Furthermore, we explored the possibility of generalizing the PLANS model to New York and Lombardy by using the published summary statistics. Though the adapted models are not recommended being applied before external validation, it might still be a good initiative to develop them and make use of them in the areas where the pandemic is still prevailing. The PLANS model was developed following high methodological standard and rated as low risks of bias in all four domains using PROBAST. Therefore, the PLANS model might be more reliable than most of the published prognostic models in making clinical decisions.
Several limitations should be noted. First, like most of the previous datasets and two main initiatives which created protocols for the investigators, namely, the ‘International Severe Acute Respiratory and emerging Infectious Consortium (ISARIC)’ and the ‘Lean European Open Survey on SARS-CoV-2 Infected Patients (LOESS)’, we only include closed (discharged or dead) COVID-19 cases. However, the resulting bias of unrepresentative sample could be largely offset by the long period of follow-up time. Second, we did have missing data on current smoking status for some patients. Inclusion of smoking status into the current model might improve the model performance. However, a reliable mechanism under the association between smoking and negative progression of COVID-19 is still missing [36]. Third, some potential risk factors confirmed by previous studies, such as D-dimer [31], C-reactive protein [37], lactate dehydrogenase [27, 38], and interleukin-6 [27], were not available in our study. Respiration symptoms were not available either, and inclusion of which might improve the predictive accuracy. However, considering the practicality and validity in clinical application, a simple and interpretable model is usually preferred [39]. In addition, our model showed promising performances with five routinely available predictors, balancing the trade-off between model performance and model practicality.
Implication for practice
The availability of a prognostic model that can accurately predict in-hospital mortality in COVID-19 patients upon admission to hospital has important implications for practice and policy. The PLANS model may assist physicians to early stratify the patients according to the estimated mortality at 7-day (14-day or 30-day) after admission, thus giving patients targeted supporting care and better allocating the limited medical facilities (e.g. ventilators), especially when critical care capacities are overwhelmed. Several studies showed that physicians have been experiencing guilt when they make clinical decisions that contravene the morals of those making them, e.g. one ventilator, two patients [40, 41]. The PLANS model might be useful to be incorporated into a protocol to assist physicians in making those difficult decisions. Our findings from the model update suggest that our model might be generalized to different countries as well. The model could be validated in the first place and then be used directly if it performs well or after being updated according to local settings [42].
Conclusions
In summary, the PLANS model can be a guidance model for Chinese hospitals in case of the resurgence of COVID-19. It can also be a useful tool for predicting mortality or triage patients in the countries where COVID-19 is still a pandemic after being validated in their settings. Future studies are warranted about the impact of the PLANS model on clinical practice and decision.
Availability of data and materials
The datasets analyzed during the current study are available from the corresponding author on reasonable request.
Abbreviations
- COVID-19:
-
Coronavirus disease 2019
- ICU:
-
Intensive care unit
- CHD:
-
Coronary heart disease
- PI:
-
Prognostic index
- CIF:
-
Cumulative incidence function
- IQR:
-
Interquartile range
- LOS:
-
Length of stay
References
Guan WJ, Ni ZY, Hu Y, Liang WH, Ou CQ, He JX, et al. Clinical characteristics of coronavirus disease 2019 in China. N Engl J Med. 2020;382(18):1708–20.
World Health Organization. Coronavirus disease (COVID-19) Pandemic. https://www.who.int/emergencies/diseases/novel-coronavirus-2019. Accessed 3 July 2020.
Kissler SM, Tedijanto C, Goldstein E, Grad YH, Lipsitch M. Projecting the transmission dynamics of SARS-CoV-2 through the postpandemic period. Science. 2020:eabb5793.
Phua J, Weng L, Ling L, Egi M, Lim CM, Divatia JV, et al. Intensive care management of coronavirus disease 2019 (COVID-19): challenges and recommendations. Lancet Respir Med. 2020;8(5):506–17.
Moons KG, Royston P, Vergouwe Y, Grobbee DE, Altman DG. Prognosis and prognostic research: what, why, and how? BMJ. 2009;338:b375.
Coslovsky M, Takala J, Exadaktylos AK, Martinolli L, Merz TM. A clinical prediction model to identify patients at high risk of death in the emergency department. Intensive Care Med. 2015;41(6):1029–36.
Wynants L, Van Calster B, Bonten MMJ, Collins GS, Debray TPA, De Vos M, et al. Prediction models for diagnosis and prognosis of covid-19 infection: systematic review and critical appraisal. BMJ. 2020;369:m1328.
Wang K, Zuo P, Liu Y, Zhang M, Zhao X, Xie S, et al. Clinical and laboratory predictors of in-hospital mortality in patients with COVID-19: a cohort study in Wuhan, China. Clin Infect Dis. 2020.
Xie J, Hungerford D, Chen H, Abrams ST, Li S, Wang G, et al. Development and external validation of a prognostic multivariable model on admission for hospitalized patients with COVID-19. 2020.
Gong J, Ou J, Qiu X, Jie Y, Chen Y, Yuan L, et al. A Tool to Early Predict Severe 2019-Novel Coronavirus Pneumonia (COVID-19) : A Multicenter Study using the Risk Nomogram in Wuhan and Guangdong, China. preprint. Public and Global Health; 2020 2020/03/20/.
Ji D, Zhang D, Xu J, Chen Z, Yang T, Zhao P, et al. Prediction for Progression Risk in Patients with COVID-19 Pneumonia: the CALL Score. Clin Infect Dis. 2020:ciaa414.
Bello-Chavolla OY, Bahena-López JP, Antonio-Villa NE, Vargas-Vázquez A, González-Díaz A, Márquez-Salinas A, et al. Predicting Mortality Due to SARS-CoV-2: A Mechanistic Score Relating Obesity and Diabetes to COVID-19 Outcomes in Mexico. J Clin Endocrinol Metab. 2020;105(8):2752–61.
Wang S, Zha Y, Li W, Wu Q, Li X, Niu M, et al. A fully automatic deep learning system for COVID-19 diagnostic and prognostic analysis. Eur Respir J. 2020;56(2):2000775.
World Health Organization. Clinical management of severe acute respiratory infection when COVID-19 is suspected. https://www.who.int/publications-detail/clinical-management-of-severe-acute-respiratory-infection-when-novel-coronavirus-(ncov)-infection-is-suspected. Accessed March 6, 2020..
Martins-Filho PR, Tavares CSS, Santos VS. Factors associated with mortality in patients with COVID-19. A quantitative evidence synthesis of clinical and laboratory data. Eur J Intern Med. 2020;76:97–9.
Austin PC, Lee DS, D'Agostino RB, Fine JP. Developing points-based risk-scoring systems in the presence of competing risks. Stat Med. 2016;35(22):4056–72.
Harrell FE Jr, Lee KL, Mark DB. Multivariable prognostic models: issues in developing models, evaluating assumptions and adequacy, and measuring and reducing errors. Stat Med. 1996;15(4):361–87.
van Houwelingen HC. Validation, calibration, revision and combination of prognostic survival models. Stat Med. 2000;19(24):3401–15.
Royston P, Altman DG. External validation of a cox prognostic model: principles and methods. BMC Med Res Methodol. 2013;13:33.
Collins GS, Reitsma JB, Altman DG, Moons KG. Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD): the TRIPOD statement. Br J Surg. 2015;102(3):148–58.
Moons KGM, Wolff RF, Riley RD, Whiting PF, Westwood M, Collins GS, et al. PROBAST: a tool to assess risk of Bias and applicability of prediction model studies: explanation and elaboration. Ann Intern Med. 2019;170(1):W1–W33.
Hainmueller J. Entropy balancing for causal effects: a multivariate reweighting method to produce balanced samples in observational studies. Polit Anal. 2017;20(1):25–46.
Xu L, Yaqian M, Chen G. Risk factors for severe corona virus disease 2019 (COVID-19) patients : a systematic review and meta analysis. preprint. Infectious Diseases (except HIV/AIDS); 2020 2020/04/01/.
Richardson S, Hirsch JS, Narasimhan M, Crawford JM, McGinn T, Davidson KW, et al. Presenting characteristics, comorbidities, and outcomes among 5700 patients hospitalized with COVID-19 in the New York City area. JAMA. 2020;323(20):2052–9.
Grasselli G, Zangrillo A, Zanella A, Antonelli M, Cabrini L, Castelli A, et al. Baseline characteristics and outcomes of 1591 patients infected with SARS-CoV-2 admitted to ICUs of the Lombardy region, Italy. JAMA. 2020;323(16):1574–81.
Ruan S. Likelihood of survival of coronavirus disease 2019. Lancet Infect Dis. 2020;20(6):630–1.
Wu C, Chen X, Cai Y, Xia J, Zhou X, Xu S, et al. Risk factors associated with acute respiratory distress syndrome and death in patients with coronavirus disease 2019 pneumonia in Wuhan, China. JAMA Intern Med. 2020;180(7):1–11.
Zhou F, Yu T, Du R, Fan G, Liu Y, Liu Z, et al. Clinical course and risk factors for mortality of adult inpatients with COVID-19 in Wuhan, China: a retrospective cohort study. Lancet. 2020;395(10229):1054–62.
Wenham C, Smith J, Morgan R. Gender, group C-W. COVID-19: the gendered impacts of the outbreak. Lancet. 2020;395(10227):846–8.
Sama IE, Ravera A, Santema BT, van Goor H, Ter Maaten JM, Cleland JGF, et al. Circulating plasma concentrations of angiotensin-converting enzyme 2 in men and women with heart failure and effects of renin-angiotensin-aldosterone inhibitors. Eur Heart J. 2020;41(19):1810–7.
Terpos E, Ntanasis-Stathopoulos I, Elalamy I, Kastritis E, Sergentanis TN, Politou M, et al. Hematological findings and complications of COVID-19. Am J Hematol. 2020;95(7):834–47.
Lippi G, Plebani M, Henry BM. Thrombocytopenia is associated with severe coronavirus disease 2019 (COVID-19) infections: a meta-analysis. Clin Chim Acta. 2020;506:145–8.
Guan WJ, Liang WH, Zhao Y, Liang HR, Chen ZS, Li YM, et al. Comorbidity and its impact on 1590 patients with COVID-19 in China: a nationwideanalysis. Eur Respir J. 2020;55(5):2000547.
Novel Coronavirus Pneumonia Emergency Response Epidemiology T. The epidemiological characteristics of an outbreak of 2019 novel coronavirus diseases (COVID-19) in China. Zhonghua Liu Xing Bing Xue Za Zhi. 2020;41(2):145–51.
The Italian Department of Infectious Diseases and the IT Service. Integrated surveillance of COVID-19 in Italy. https://www.epicentro.iss.it/en/coronavirus/bollettino/Infografica_11maggio%20ENG.pdf Accessed May 12, 2020.
Cai H. Sex difference and smoking predisposition in patients with COVID-19. Lancet Respir Med. 2020;8(4):e20.
Deng Y, Liu W, Liu K, Fang YY, Shang J, Zhou L, et al. Clinical characteristics of fatal and recovered cases of coronavirus disease 2019 in Wuhan, China: a retrospective study. Chin Med J. 2020;133(11):1261–7.
Zhou F, Yu T, Du R, Fan G, Liu Y, Liu Z, et al. Clinical course and risk factors for mortality of adult inpatients with COVID-19 in Wuhan, China: a retrospective cohort study. Lancet. 2020;395(10229):1054–62.
Royston P, Moons KG, Altman DG, Vergouwe Y. Prognosis and prognostic research: developing a prognostic model. BMJ. 2009;338:b604.
Walton M, Murray E, Christian MD. Mental health care for medical staff and affiliated healthcare workers during the COVID-19 pandemic. Eur Heart J Acute Cardiovasc Care. 2020;9(3):241–7.
The Lancet. COVID-19: protecting health-care workers. Lancet. 2020;395(10228):922.
Moons KG, Altman DG, Vergouwe Y, Royston P. Prognosis and prognostic research: application and impact of prognostic models in clinical practice. BMJ. 2009;338:b606.
Acknowledgements
We would like to show our respect and gratitude to all the health workers who are at the front line of the outbreak response and fighting against COVID-19 in China.
Ethics approval and consent to participant
The study was approved by Jinyintan Hospital Ethics Committee (KY-2020-06.01), Union Hospital Ethics Committee (2020–0039), and the Institutional Review Board of Tongji Hospital, China (No. TJ-C20200140). Written informed consent was waived by these three Ethics Committees due to the emergence of this infectious diseases. Administrative permissions to access the raw data were granted by Jinyintan Hospital Ethics Committee, Union Hospital Ethics Committee, and the Institutional Review Board of Tongji Hospital. Data were anonymized for this study.
Funding
This study was funded by the National Nature Science Foundation of China (81870062 to Jinjun Jiang, 81900038 to Shujing Chen, 82073570 to Jiong Li, and 11871164 to Guoyou Qin), COVID-19 Emergency Response Project of Wuhan Science and Technology Department (2020020201010018 to Yin Shen), and National Key R&D Program of China (2017YFE0103400 to Yin Shen). The funding body had no role in the design of the study and collection, analysis, and interpretation of data and in writing the manuscript.
Author information
Authors and Affiliations
Contributions
JL, YC, SC, YS, JJ, and YY had the idea for and designed the study. SC, SW, DZ, HZ, YS and JJ collected the clinical data. JL, YC, SC, JW, GQ and YY analyzed and interpreted the data. JL, YC, YY drafted the manuscript. DP, GQ, YS, JJ and YY obtained funding and supervised the work. JL, YC, SC, SW, DZ, JW, DP, HZ, GQ, YS, JJ and YY critically revised the manuscript. The authors read and approved the final manuscript.
Corresponding authors
Ethics declarations
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Additional file 1:
. Appendix Text 1. Implementation and estimates of Fine-Gray model. Appendix Text 2. Internal validation by bootstrap. Appendix Text 3. Two updated models. Figure 1. Cumulative mortality for derivation and validation cohort. Figure 2. The Schoenfeld residual plots for each predictor, test of proportional hazards. Table 1. “Baseline”* mortality (Wuhan, China). Table 2. Thresholds and corresponding proportion and death toll included in each risk group. Table 3. Basic characteristics used in entropy balancing in Derivation cohort, New York cohort and Lombardy cohort. Table 4. “Baseline”* mortality (New York, USA). Table 5. “Baseline”* mortality (Lombardy, Italy). Table 6 Methodology quality assessment based on PROBAST risk of bias assessment tool
Additional file 2: TRIPOD Checklist
: Prediction Model Development
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Li, J., Chen, Y., Chen, S. et al. Derivation and validation of a prognostic model for predicting in-hospital mortality in patients admitted with COVID-19 in Wuhan, China: the PLANS (platelet lymphocyte age neutrophil sex) model. BMC Infect Dis 20, 959 (2020). https://doi.org/10.1186/s12879-020-05688-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12879-020-05688-y