
Abstract
We developed a tool to guide decision-making for early triage of COVID-19 patients based on a predicted prognosis, using a Korean national cohort of 5,596 patients, and validated the developed tool with an external cohort of 445 patients treated in a single institution. Predictors chosen for our model were older age, male sex, subjective fever, dyspnea, altered consciousness, temperature ≥ 37.5 °C, heart rate ≥ 100 bpm, systolic blood pressure ≥ 160 mmHg, diabetes mellitus, heart disease, chronic kidney disease, cancer, dementia, anemia, leukocytosis, lymphocytopenia, and thrombocytopenia. In the external validation, when age, sex, symptoms, and underlying disease were used as predictors, the AUC used as an evaluation metric for our model’s performance was 0.850 in predicting whether a patient will require at least oxygen therapy and 0.833 in predicting whether a patient will need critical care or die from COVID-19. The AUCs improved to 0.871 and 0.864, respectively, when additional information on vital signs and blood test results were also used. In contrast, the protocols currently recommended in Korea showed AUCs less than 0.75. An application for calculating the prognostic score in COVID-19 patients based on the results of this study is presented on our website (https://nhimc.shinyapps.io/ih-psc/), where the results of the validation ongoing in our institution are periodically updated.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Introduction
Since the World Health Organization (WHO) declared the coronavirus disease 2019 (COVID-19) a pandemic in March 2020, it has been raging on, taking the lives of many people (over 4.4 million as of Aug 24, 2021)1. Since effective vaccines were recently developed, more than 5 billion doses have been administered worldwide. Still, however, more than 5 million people are being diagnosed with COVID-19 every week1. The treatment of COVID-19 mainly relies on symptomatic relief and supportive care, oxygen therapy, and critical care, depending on the disease severity. Thus, it is crucial to triage COVID-19 patients rapidly and efficiently so that limited medical resources, including quarantine facilities, hospital beds, and critical care equipment, can be allocated appropriately.
The current protocols recommended for triage and referral of COVID-19 patients in many countries or by WHO are based on known risk factors and expert opinion but have not been validated on the actual patient data2,3,4,5. Furthermore, since sudden disease progression in initially mild or asymptomatic COVID-19 patients is not rare with reported incidences of 6–12%6,7,8,9, we should base the triage and referral of COVID-19 patients on the worst severity expected during the disease course, rather than the severity at the time of diagnosis.
Data about the pandemic has now accumulated sufficiently to enable development of a data-driven prediction model for patient triage decision-making. Several prediction models for disease severity in COVID-19 patients have been proposed10,11,12,13,14,15,16,17,18,19,20. There may be limitations, however, to applying these models for COVID-19 patient triage under some real-world circumstances. Most of these models require patients’ information obtained from a blood test or imaging study. However, we often need to triage and refer COVID-19 patients immediately after the diagnosis with limited information depending on the situation.
Therefore, we aimed to develop and validate an easy-to-use tool for COVID-19 patient triage based on a predicted prognosis, with the flexibility to adapt to variable availability. We categorized variables into four groups—demographics and symptoms, underlying diseases, vital signs, and laboratory findings—and develop separate algorithms for different combinations of the variable groups. We compared the performance of our models with the currently used triage protocols. Lastly, we validated the final model in an independent external cohort.
Results
Patients
Of the total 5,596 COVID-19 patients in the model development cohort, approximately half of the patients (52.1%) were 50 years or older, while people aged younger than 20 years accounted for only 4.9% (Table 1). The two most common age groups were 20–29 years (19.8%) and 50–59 years (20.4%). The ratio of males to females was 5.9:4.1. Most (85.4%) recovered without particular therapy, 9.1% of the patients required oxygen therapy, and the remaining 5.4% fell into severe conditions such as respiratory or multi-organ failure and required critical care such as mechanical ventilation or extracorporeal membrane oxygenation (ECMO). The overall mortality from COVID-19 infection was 1.1% (63/5,596). The mean time between diagnosis and recovery or death was 25.6 days, with a standard deviation (SD) of 11.0 days. Patients who were older, male, under-weight or obese, or with symptoms (except for diarrhea), underlying diseases (except for autoimmune disease), abnormal vital signs (except for diastolic blood pressure), or abnormal blood test results tended to fall into more severe conditions (Table 1). The training and internal validation subcohorts comprised 3940 and 1656 patients, respectively. There was no significant difference in variables between the two subcohorts (Supplementary Table S1).
In the external validation cohort of 445 patients, the mean age was 59 years (SD, 20 years) with the ratio of males to females of 4.7:5.3. Of these, 8.8% (39/445) required intensive treatment or died of COVID-19. The detailed characteristics are summarized in Supplementary Table S2.
Selected predictors for each model
The full results of predictor selection are in Supplementary Table S3.
Model 1: from history taking
The predictors selected from Tier 1 variables for Model 1 were age, sex, and symptoms of subjective fever, rhinorrhea, dyspnea, and altered consciousness. As opposed to other selected predictors, rhinorrhea was associated with a better prognosis.
Model 2A: from history taking with known underlying disease status
The predictors chosen for Model2A were age, sex, subjective fever, dyspnea, and altered consciousness from Tier 1 (rhinorrhea excluded), and underlying diseases of hypertension, diabetes mellitus (DM), heart disease, chronic kidney disease (CKD), cancer, and dementia from Tier 2 variables.
Model 2B: from history taking and physical examination with uncertain underlying disease
The predictors were age, sex, subjective fever, rhinorrhea, dyspnea, and altered consciousness from Tier 1, and high body temperature and tachycardia from Tier 3 variables.
Model 3: from history taking and physical examination with known underlying disease status
The predictors were age, sex, subjective fever, dyspnea, and altered consciousness from Tier 1 (rhinorrhea not included), severe hypertension (systolic blood pressure ≥ 160 mmHg), DM, heart disease, CKD, cancer, and dementia from Tier 2, and high body temperature and tachycardia from Tier 3.
Model 4: on admission
The predictors were age, sex, subjective fever, dyspnea, and altered consciousness from Tier 1, severe hypertension, DM, heart disease, CKD, cancer, and dementia from Tier 2, and high body temperature from Tier 3 (tachycardia excluded), and anemia, leukocytosis, lymphocytopenia, and thrombocytopenia from Tier 4 variables.
Variable effect size
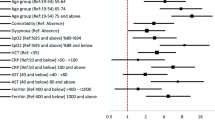
Older age, altered consciousness, dyspnea, lymphocytopenia, leukocytosis, CKD, temperature of ≥ 38.5 °C, dementia, thrombocytopenia, cancer, subjective fever, male sex, anemia, DM were associated independently with prognosis, in decreasing order of odds ratio (OR) from the multivariable ordinal logistic regression (OLR) in the entire cohort (Fig. 1 and Supplementary Table S4).

Forest plot showing the odds ratios of final predictors from multivariable ordinal logistic regression. The horizontal error bars indicated 95% confidence intervals. Note that the upper limit of 95% confidence interval is truncated for altered consciousness and age > 80. Detailed results are presented in Supplementary Table S4, including the odds ratios with confidence intervals from univariable and multivariable regression analyses.
Model performance
Conventional protocols
In predicting whether a patient will require more than supportive care, the Korea Medical Association (KMA) model showed an area under the curve (AUC) of 0.723 (95% confidence interval [CI], 0.693–0.753) with a sensitivity of 54.9 (48.3–61.4)% and a specificity of 7.6 (6.3–9.1)%, and the AUC, sensitivity, and specificity of the Modified Early Warning Score (MEWS) were 0.598 (0.563–0.633), 56.8 (50.1–63.4)%, and 23.5 (21.2–25.9)%, respectively, in the internal validation cohort (Table 2).
Development and internal validation of machine learning model
Machine learning models showed better performances than the conventional protocols (Table 2 and Supplementary Table S5). In the internal validation, with the OLR algorithm, the AUCs of Models 1, 2A, 2B, 3, and 4 were 0.880 (95% CI, 0.855–0.904), 0.889 (0.865–0.912), 0.866 (0.841–0.892), 0.894 (0.871–0.917), and 0.907 (0.884–0.929) in predicting whether a patient will require at least oxygen therapy, and 0.903 (0.869–0.937), 0.905 (0.869–0.940), 0.922 (0.892–0.953), and 0.927 (0.894–0.960) in predicting whether a patient will need critical care or die, respectively (Table 2). The other machine learning algorithms—random forest (RF), linear support vector machine (L-SVM), and SVM with a radial basis function kernel (R-SVC)—did not show superior performances to the OLR model (Supplementary Table S5).
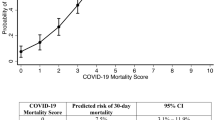
The sensitivity, specificity, accuracy, precision, and negative predictive value (NPV) at different cutoff probabilities for the OLR models are presented in Supplementary Table S6. The models showed good calibration in the training and testing, especially in the probability range of < 50% (Fig. 2). Figure 3 shows the nomogram of OLR Model 4 to predict the probability of recovering without particular treatment and the probability of requiring critical care or death from COVID-19 (see Supplementary Fig. S1 for the nomograms of all the five models).

Calibration plot.

Nomogram of ordinal logistic regression model using all the predictors (Model 4). The nomogram is used by first giving each variable a score on the ‘Point’ scale. The points for all variables are then added to obtain the total points and a vertical line is drawn from the ‘Total points’ row to estimate the probability of requiring treatment and that of requiring critical care or death. The nomograms of the other models can be found in Supplementary Fig. S1.
External validation
In the external validation, the AUCs of Models 1, 2A, 2B, 3, and 4 were 0.829 (95% CI, 0.786–0.869), 0.850 (0.809–0.895), 0.838 (0.796–0.879), 0.861 (0.822–0.902), and 0.871 (0.834–0.910) in predicting whether a patient will require at least oxygen therapy, and 0.827 (0.754–0.901), 0.833 (0.759–0.907), 0.833 (0.759–0.907), 0.851 (0.786–0.912), and 0.864 (0.802–0.916) in predicting whether a patient will need critical care or die, respectively (Table 3). The sensitivity, specificity, accuracy, precision, and NPV at the optimal cutoff probability for each model are presented in Table 3, and those at different cutoff probabilities can be interactively viewed on our website (https://nhimc.shinyapps.io/ih-psc/), where the results of validation ongoing in our institution are periodically updated; the results on the website will be different from those in this study after updates.
Discussion
Our results demonstrate that a data-driven model to predict prognosis can be a good tool for early triage of COVID-19 patients. A significant shortcoming of the triage protocols that are not based on data is that risk factors are not weighted appropriately based on their effects on the outcome. For example, the WHO algorithm for COVID-19 triage and referral regards age > 60 years and the presence of relevant symptoms or co-morbidities as risk factors, but it does not put different weights on them2. However, if not treated as a continuous variable, age should be divided into multiple categories with appropriate weights because the risk continues to increase with age even after 60 years. Different symptoms or co-morbidities must also be weighted according to their importance when assessing the patients’ status for triage. For example, in the current study, subjective fever, dyspnea, and altered consciousness were independent risk factors for severe illness, while other symptoms such as cough, sputum production, sore throat, myalgia, and diarrhea were not.
Our final prediction model used the OLR algorithm. We chose the OLR over the other machine learning algorithms (i.e., RF, L-SVM, and R-SVM) because it showed comparable performances to the other algorithms in the final evaluation. Furthermore, a linear model like the OLR is more interpretable and easier to use even without a computer device, as nomograms can be used instead. We also observed the linear model’s superiority in predicting COVID-19 prognosis in our previous study in which we developed a model to predict the risk of COVID-19 mortality based on demographics and medical claim data15.
Our current model has a few differences compared to other proposed models. Above all, our main purpose was to develop an easy-to-use prediction model that can be used widely in various real-world fields. This was another reason that we preferred a linear prediction model to other complex machine learning algorithms; simply by knowing the coefficients of the linear model, anyone can calculate the predicted risk using various methods: the nomogram or web-based application we developed, or even paper-and-pencil calculation. Several published prognostic models have also used linear logistic regression and proposed nomograms possibly for the same reason10,13,16,17,20. However, those models were designed to be used for hospitalized patients, requiring information that is usually obtained after hospitalization such as laboratory test results or imaging studies. In contrast, our model is intended to be used in various situations, not only for hospitalized patients but also for early triage immediately after the diagnosis. Therefore, our model uses different algorithms depending on the available variable subsets. Health workers sometimes need to triage newly diagnosed COVID-19 patients even by a phone call alone, and patients commonly do not know their underlying disease exactly. Therefore, we expect that our model’s flexibility may make our model distinct from previous models and lead to a more widespread use. Lastly, we divided disease severity into three categories. This is more helpful than the binary categorization (i.e., recovery vs. mortality), because not all medical facilities capable of oxygen therapy can also provide critical care, such as mechanical ventilation or ECMO.
The predictors chosen in this study are not much different from the known risk factors of developing into critical conditions from COVID-1921. However, it was unexpected that chronic obstructive pulmonary disease (COPD), a known strong risk factor, was not selected as a predictor. We assume that this is because there were only 40 patients with COPD in the entire cohort, of whom 65% had dyspnea, and the disease severity of COPD might have varied widely. Thus, it is likely that the number of COPD cases was too small (became even smaller after the training-validation set split) to play a significant role independently from the other strong predictors.
There are limitations to our current model. First, since we trained and validated our model on Koreans’ data, it is unsure whether it can be generalizable to patient cohorts in other countries or races. We hope to be able to develop a triage model that can be used globally through collaboration. Second, we converted continuous variables such as blood test results into categorical variables, which may have resulted in some loss of information. Our intention was, however, to prevent small differences in continuous variables (which could be more of a noise than a true signal in terms of prediction) from overfitting models. Furthermore, all the variables categorized in this study have well-established cutoff values classifying them into categories (e.g., normal vs, abnormal). Third, our data lacked some important variables, such as smoking, respiratory rate, and oxygen saturation, and had missing values in some of the Tiers-2/3/4 variables, which may have affected the training and performance of the algorithms using those variables. We did not perform imputation for missing values because we did not want the uncertainty and potential bias from imputation, and imputation for missing values did not make significant differences in our preliminary analysis. Lastly, we did not experiment more machine learning algorithms such as extreme gradient boost. Thus, we cannot conclude that OLR is superior to all other machine learning algorithms.
In conclusion, we developed and validated a set of models that can be used for disease severity prediction and triage or referral of COVID-19 patients. Our prediction model showed a good performance with age, sex, symptoms, and the information on underlying disease used as predictors. The model performance was enhanced when further information on vital signs and blood test results were also used.
Materials and methods
Ethical approval
The Institutional Review Board of National Health Insurance Service Ilsan Hospital (NHIMC 2020-08-018 and 2021-02-023) approved this retrospective Health Insurance Portability and Accountability Act-compliant cohort study and waived the informed consent from the participants. We performed all methods in accordance with relevant guidelines and regulations.
Data source and patients
This study used two datasets. For model development and internal validation, we used a dataset containing the epidemiologic and clinical information of patients diagnosed with COVID-19 in South Korea, which the Korea Disease Control and Prevention Agency collected, anonymized, and provided to researchers for the public interest. The data included 5,628 patients who either were cured or died from COVID-19 infection by April 30, 2020. After excluding 32 patients who lacked the information on disease severity or the presence or absence of symptoms, a total of 5,596 patients comprised the model development cohort. The dataset was randomly divided into training and internal validation cohorts with a ratio of 7:3 while preserving the disease severity distribution. We trained and optimized models using the training cohort and validation them on the internal validation cohort.
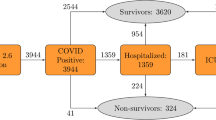
For external validation, we used a cohort of COVID-19 patients treated in National Health Insurance Service, Korea, between December 19, 2020 and March 16, 2021. After excluding 59 patients who were referred with severe conditions requiring oxygen therapy or mechanical ventilation at the time of admission, a total of 445 patients comprised this external validation cohort (Fig. 4).

Study flow.
The outcome variable was the worst severity during the disease course, determined by the type of treatment required: (1) none or supportive treatment, (2) oxygen therapy, (3) critical care such as mechanical ventilation or ECMO, or death from COVID-19 infection.
Variables in four different tiers based on accessibility
We intended to develop a model that can be used flexibly in real-world circumstances where some of the variables may not be available. Therefore, we categorized variables into four tiers based on their accessibility (Table 1 and Fig. 4).
Tier 1: basic demographics and symptoms
Tier 1 variables can be obtained by simply asking a patient questions: age, sex, body mass index, pregnancy, and symptoms. The symptoms included were subjective fever, cough, sputum, dyspnea, altered consciousness, headache, rhinorrhea, myalgia, sore throat, fatigue, nausea or vomiting, and diarrhea. We separated this group of variables from others because there could be times when we need to triage a patient quickly without physical contact.
Tier 2: underlying diseases
Tier 2 variables are underlying medical conditions: hypertension, DM, heart disease, asthma, COPD, CKD, chronic liver disease, cancer, autoimmune disease, and dementia. We categorized these variables into a separate group because sometimes patients may not know exactly their underlying medical conditions. In this case, further actions may be required, including reviewing medical records or other examinations.
Tier 3: vital signs
Tier 3 variables are blood pressure, body temperature, and heart rate. Our data lacked information on breathing rate. We separated these variables from the first two tiers because these can be obtained only when a patient visits a medical facility or can measure their vital signs on their own. Blood pressure and heart rate were transformed into binary categorical variables by merging categories that were not significantly associated with disease severity based on the preliminary results in the training cohort: severe hypertension (systolic blood pressure ≥ 160 mmHg) and tachycardia (heart rate ≥ 100 bpm). We assumed that many patients had their body temperature measured while taking antipyretics, although our data did not contain the information on such patients’ proportion.
Tier 4: Blood test results
Tier 4 variables are hemoglobin, hematocrit, white blood cell (WBC) count, lymphocyte count, and platelet count, which are available only after a blood test. As with Tier 3, these variables were also transformed into binary categorical variables: anemia (hematocrit < 40%), leukocytosis (WBC ≥ 11 × 103/µL), lymphocytopenia (lymphocyte < 1,000/µL), and thrombocytopenia (platelet < 150,000/µL).
Predictor selection
To identify robust and stable predictors, we repeated tenfold cross-validation (CV) 100 times with shuffling and choose variables that were selected more than 900 times out of 1,000 trials (> 90%) based on two algorithms: Least Absolute Selection and Shrinkage Operator (LASSO) and RF. A variable was selected if its coefficient was non-zero on LASSO, and its variable importance on RF was positive22,23.
Development of prediction models
We used four machine learning algorithms: OLR, multivariate RF, L-SVM, and R-SVM. For each algorithm, five models were created using one of the following five predictor sets: predictors chosen from the Tier 1 variables (Model 1), Tiers 1/2 variables (Model 2A), Tiers 1/3 variables (Model 2B), Tiers 1/2/3 variables (Model 3), and Tiers 1/2/3/4 variables (Model 4). We optimized the hyperparameters for RF and SVM through a tenfold CV with a grid search in the training cohort, using AUC as an evaluation metric.
OLR is a general term for logistic regression with (usually more than 2) ordinal outcomes. Among different OLR models, we used proportional odds model which assumes that the effects of input variables are proportional across the different outcomes, as interpretation under this model deemed logical and meaningful in our case. In case of the current study, as the outcome of each patient, denoted as Y here, is classified into one of three categories: supportive treatment (y1), oxygen therapy (y2), and critical care or death (y3), the dependency of Y on X (a vector of input variables of x1, x2, …, xp) can be expressed as:
where Pr(Y ≥ yj) is the cumulative probability of the outcome; αj is a respective intercept; and βi is a coefficient corresponding to the xi variable. Readers interested in more detailed explanation are referred to the paper by Singh et al.24.
In this study, the number of outcomes were more than two (not binary), which is considered multiclass or multinomial classification in machine learning. OLR and RF can perform multiclass classification inherently. With SVM, we performed multiclass classification using the one-vs.-rest scheme25.
Validation of prediction models in comparison with current protocols
We validated the optimized models in the internal validation cohort after fitting them onto the entire training dataset. Based on the probabilities for each outcome category, we assessed the diagnostic performance of each model for whether or not a patient will require treatment (Outcome 1 vs. 2/3), and whether or not a patient will require critical care or die (Outcome 1/2 vs. 3). Sensitivity, specificity, accuracy, precision, and NPV according to different probability cutoffs were calculated, in addition to AUC. We also drew calibration curves to compare the predicted and observed probabilities visually.
As a baseline for comparison, we also tested two protocols used to triage a newly diagnosed COVID-19 patient: a protocol proposed by the KMA and MEWS5,26. These are two of the protocols that the Korean government currently recommends using with some modifications depending on the situation5. Since we did not have information on smoking status, oxygen saturation, and respiratory rate, these variables were considered normal when applying the protocols. These protocols are described in detail in Supplementary Tables S7 and S8.
We tested the final model in the external validation cohort in the same manner as the internal validation. We also developed a web-based application for calculating the probability of requiring oxygen therapy or critical care based on the results of this study, where users also can view the ongoing validation results in our institution (https://nhimc.shinyapps.io/ih-psc/).
References
World Health Organization. Coronavirus (COVID-19) Dashboard. WHO, https://covid19.who.int/. Accessed 24 Aug 2021 (2021).
Algorithm for COVID-19 triage and referral: patient triage and referral for resource-limited settings during community transmission. WHO, https://apps.who.int/iris/handle/10665/331915. Accessed 24 Aug 2021 (2021).
Guidance for U.S. Healthcare Facilities about Coronavirus (COVID-19). CDC, https://www.cdc.gov/coronavirus/2019-ncov/hcp/us-healthcare-facilities.html. Accessed 24 Aug 2021 (2021).
Coronavirus (COVID-19) clinical triage support tool. NHS Digital, https://digital.nhs.uk/services/covid-19-clinical-triage-support-tool. Accessed 24 Aug 2021 (2021).
Coronavirus Disease-19, Republic of Korea. MOHW, http://ncov.mohw.go.kr/en/. Accessed 24 Aug 2021 (2021).
Chen, L. et al. Disease progression patterns and risk factors associated with mortality in deceased patients with COVID-19 in Hubei Province, China. Immun. Inflamm. Dis. 8, 584–594 (2020).
Suh, H. J. et al. Clinical characteristics of COVID-19: Clinical dynamics of mild severe acute respiratory syndrome coronavirus 2 infection detected by early active surveillance. J. Korean Med. Sci. 35, e297 (2020).
Wu, Z. & McGoogan, J. M. Characteristics of and important lessons from the coronavirus disease 2019 (COVID-19) outbreak in China: Summary of a report of 72 314 cases from the Chinese center for disease control and prevention. JAMA 323, 1239–1242 (2020).
Zhou, F. et al. Clinical course and risk factors for mortality of adult inpatients with COVID-19 in Wuhan, China: A retrospective cohort study. The Lancet 395, 1054–1062 (2020).
Feng, Z. et al. Early prediction of disease progression in COVID-19 pneumonia patients with chest CT and clinical characteristics. Nat. Commun. 11, 4968 (2020).
Liang, W. et al. Early triage of critically ill COVID-19 patients using deep learning. Nat. Commun. 11, 3543 (2020).
Barda, N. et al. Developing a COVID-19 mortality risk prediction model when individual-level data are not available. Nat. Commun. 11, 4439 (2020).
Gong, J. et al. A tool to early predict severe corona virus disease 2019 (COVID-19): A multicenter study using the risk nomogram in Wuhan and Guangdong, China. Clin. Infect. Dis. https://doi.org/10.1093/cid/ciaa443 (2020).
Yan, L. et al. An interpretable mortality prediction model for COVID-19 patients. Nat. Mach. Intell. https://doi.org/10.1038/s42256-020-0180-7 (2020).
An, C. et al. Machine learning prediction for mortality of patients diagnosed with COVID-19: A nationwide Korean cohort study. Sci Rep 10, 18716 (2020).
Her, A.-Y. et al. A clinical risk score to predict in-hospital mortality from COVID-19 in South Korea. J. Korean Med. Sci. 36, e108 (2021).
Chen, Y. et al. CANPT score: A tool to predict severe COVID-19 on admission. Front. Med. 8, 608107 (2021).
Gupta, R. K. et al. Development and validation of the ISARIC 4C deterioration model for adults hospitalised with COVID-19: A prospective cohort study. Lancet Respir. Med. 9, 349–359 (2021).
Haimovich, A. D. et al. Development and validation of the quick COVID-19 severity index: A prognostic tool for early clinical decompensation. Ann. Emerg. Med. 76, 442–453 (2020).
Wu, G. et al. Development of a clinical decision support system for severity risk prediction and triage of COVID-19 patients at hospital admission: An international multicentre study. Eur. Respir. J. 56, 2001104 (2020).
Liu, D. et al. Risk factors for developing into critical COVID-19 patients in Wuhan, China: A multicenter, retrospective, cohort study. Eclinicalmedicine 25, 100471 (2020).
Tibshirani, R. Regression shrinkage and selection via the lasso: A retrospective. J. R. Stat. Soc. Ser. B Stat. Methodol. 73, 273–282 (2011).
Bureau, A. et al. Identifying SNPs predictive of phenotype using random forests. Genet. Epidemiol. 28, 171–182 (2005).
Singh, V., Dwivedi, S. N. & Deo, S. V. S. Ordinal logistic regression model describing factors associated with extent of nodal involvement in oral cancer patients and its prospective validation. BMC Med. Res. Methodol. 20, 95 (2020).
Hong, J.-H. & Cho, S.-B. A probabilistic multi-class strategy of one-vs.-rest support vector machines for cancer classification. Neurocomputing 71, 3275–3281 (2008).
Subbe, C. P., Kruger, M., Rutherford, P. & Gemmel, L. Validation of a modified Early Warning Score in medical admissions. QJM. Int. J. Med. 94, 521–526 (2001).
Acknowledgements
This work was supported by a grant from National Health Insurance Service Ilsan Hospital (NHIMC2021-CR017). We conducted this research as part of the Ilsan Machine Intelligence with National health big Data (I-MIND) project. The authors would like to thank the Korea Disease Control and Prevention Agency for the support and data they kindly provided. The authors alone are responsible for the content of this article.
Author information
Authors and Affiliations
Contributions
C.A., J.H.C., S.J.O., H.C.O., and S.W.K. conceived the study. All authors designed the study. C.A. performed machine learning and statistical analysis. C.A., J.H.C., S.J.O., J.M.L., and C.H.H. interpreted the results of data analysis. C.A. drafted the original Article. All authors contributed to the editing of the Article. H.C.O. and S.W.K. supervised the study. All authors read and approved the final Article.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
An, C., Oh, H.C., Chang, J.H. et al. Development and validation of a prognostic model for early triage of patients diagnosed with COVID-19. Sci Rep 11, 21923 (2021). https://doi.org/10.1038/s41598-021-01452-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-01452-7
- Springer Nature Limited
This article is cited by
-
Triage body temperature and its influence on patients with acute myocardial infarction
BMC Cardiovascular Disorders (2023)