
Abstract
Background
Population segmentation permits the division of a heterogeneous population into relatively homogenous subgroups. This scoping review aims to summarize the clinical applications of data driven and expert driven population segmentation among Type 2 diabetes mellitus (T2DM) patients.
Methods
The literature search was conducted in Medline®, Embase®, Scopus® and PsycInfo®. Articles which utilized expert-based or data-driven population segmentation methodologies for evaluation of outcomes among T2DM patients were included. Population segmentation variables were grouped into five domains (socio-demographic, diabetes related, non-diabetes medical related, psychiatric / psychological and health system related variables). A framework for PopulAtion Segmentation Study design for T2DM patients (PASS-T2DM) was proposed.
Results
Of 155,124 articles screened, 148 articles were included. Expert driven population segmentation approach was most commonly used, of which judgemental splitting was the main strategy employed (n = 111, 75.0%). Cluster based analyses (n = 37, 25.0%) was the main data driven population segmentation strategies utilized. Socio-demographic (n = 66, 44.6%), diabetes related (n = 54, 36.5%) and non-diabetes medical related (n = 18, 12.2%) were the most used domains. Specifically, patients’ race, age, Hba1c related parameters and depression / anxiety related variables were most frequently used. Health grouping/profiling (n = 71, 48%), assessment of diabetes related complications (n = 57, 38.5%) and non-diabetes metabolic derangements (n = 42, 28.4%) were the most frequent population segmentation objectives of the studies.
Conclusions
Population segmentation has a wide range of clinical applications for evaluating clinical outcomes among T2DM patients. More studies are required to identify the optimal set of population segmentation framework for T2DM patients.
Similar content being viewed by others

Background
Rationale and objective
The global disease burden for type 2 diabetes mellitus (T2DM) is rising, with projected healthcare expenditures incurred by governments worldwide to exceed U.S.$ 2.3 trillion by 2030 [1]. Despite the advent of new drug therapeutics and improvement in diabetic care processes, the management of T2DM remains suboptimal and it remains one of the leading causes for non-traumatic lower extremity amputations, blindness and end-stage renal disease requiring renal replacement therapy [2].
With the rising prevalence of T2DM and its associated healthcare costs, the development and delivery of healthcare models from a population health perspective are becoming increasingly relevant. Population health refers to “the health outcomes of a group of individuals, including the distribution of such outcomes within the group” [3]. Within the field of population health analytics, population segmentation forms an important pillar where a data-driven segregation approach applied to a heterogeneous population cohort can generate meaningful and relatively homogenous sub-groups with similar healthcare needs [4]. This in turn allows healthcare administrators to navigate large and complex databases efficiently and synthesize essential patient factors which contribute to the health related outcome of interest such as healthcare utilization [5].
There are two distinctive approaches to population segmentation which are namely expert-driven and data-driven approaches. The derivation of patient segments using expert-driven approach is pre-determined by an expert panel (e.g. judgemental splits or prescribed binning criteria), while data-driven approaches perform specialized statistical techniques such as latent class analysis (LCA) on a dataset to derive the patient segments [6]. An example of an expert-driven framework is the “Bridges to Health” model which divides a patient population into eight segments comprising of patients without health issues to dying patients with rapid deterioration [7]. It has been suggested as an aid to guide the planning and allocation of healthcare resources tailored for each patient segment [7]. On the other hand, data-driven approaches have been used to profile patient segments by their healthcare utilization and clinical outcomes. An example is a study by Yan et al. which utilized LCA to identify six classes of primary care utilizers with differential healthcare utilization and mortality [8].
Among T2DM patients, data-driven population segmentation methodologies have also been leveraged to identify subgroups of patients with differential risk of diabetes related complications, healthcare utilization and clinical trajectories in large administrative patient databases [9]. A study by Jiang et al. identified four unique profiles of patients where patients in the “high morbidity / moderate treatment” group was shown to have the highest rates of inpatient admissions, all-cause healthcare costs and risk for diabetic nephropathy progression [10]. Another study by Karpati et al. derived three clusters of patients with differing Hba1c trajectories, where patients in both increasing and decreasing Hba1c trajectory clusters were to have higher prevalence of microvascular and macrovascular complications [11].
While reviews have summarized the applications of use-based [10] and healthcare needs based population segmentation [5] among general patient populations, there is no review which has evaluated the clinical applications of population segmentation among T2DM patients. It is important to note that T2DM patients form a high-priority target patient population as the comprehensive coverage and optimization of diabetes care involve a constellation of psychosocial, economic and demographical determinants, and requires a multi-pronged approach ranging from disease maintenance to prevention of its complications. Notably, care models designed for T2DM often serve as a model for the management of other chronic diseases. Coupled with the high prevalence of T2DM and its implications on the development of multi-organ complications, this makes T2DM patients highly amendable to reap the benefits of population segmentation so as to optimise patient outcomes. Hence, we aim to summarize the literature on the clinical applications of population segmentation among T2DM patients.
Methods
A scoping review was conducted for studies which applied the use of population segmentation techniques among T2DM patients and was reported using the Preferred Reporting Items for Systematic review and Meta-Analysis extension for Scoping Reviews (PRISMA-ScR) checklist [12].
Protocol and registration
The protocol for the search strategy was registered on Open Science Framework (https://doi.org/10.17605/osf.io/ay6uc).
Eligibility criteria and information sources
The literature search was performed in Medline®, Embase®, SCOPUS® and PsycInfo®. We included peer-reviewed studies in English language which applied data-driven or expert-driven approaches population segmentation among adult patients (age ≥ 18 years old) with T2DM. We excluded studies that included patients with type 1 diabetes mellitus or maturity onset diabetes of the young, as well as articles that were not in the English language. Randomized controlled trials, cross-sectional, case-control, cohort and record linkage studies were included. Case studies, case series, meta-analyses and other reviews were excluded. In situations where the subtype of diabetic patients studied was not clearly specified, we contacted the authors of the study for clarifications. The search was current as of September 2019. As this review did not include human subjects, institutional review board approval was exempted.
Search, selection of sources of evidence, data charting process and data items
The search terms included concepts and strategies utilized to segregate patients in population segmentation which were adapted from a review by Yan et al. [10], and key T2DM related terms. The details of the full search strategy are listed in Supplementary File 1. A pilot exercise for the screening of articles was performed by two independent reviewers (SJJB and AM) for the first 200 records (based on title and abstract). Thereafter, the same reviewers screened the titles and abstracts of all retrieved articles. After a second pilot exercise to screen the first 20 full-text articles, the full-texts of identified articles were evaluated by SJJB and AM independently for inclusion in the review. All disagreements in the inclusion process were discussed to reach a consensus. In the event that discrepancies could not be resolved, discussion with a third independent reviewer (YHK) was performed. Hand-searching of references in included articles was conducted.
The references and abstracts identified from the literature search were pooled in EndNote X9 software, which was utilized to remove the duplicated references. The removal of duplicated references was performed using the automated function in Endnote X9 and manual screening thereafter. Screening of the title, abstract and full-text was performed using a standardized Microsoft Excel spreadsheet which contained checkboxes for each inclusion and exclusion criteria. Conflicts during the screening process were automatically flagged by the software, using formulas embedded within the spreadsheet. All members of the research team involved in the screening of articles were trained to use the screening form. Thereafter, data of included articles were extracted independently by the two reviewers into a separate standardized Microsoft Excel spreadsheet. This information included the study’s title, publication year, sample size and characteristics of patient population, objectives of population segmentation, variables used for segmentation of patients, number/categories of patient segments derived and funding sources. In addition, the funding sources of included studies were extracted and reported, as per recommendations from AMSTAR-2 [13]. The full list of variables collected are reported in Supplementary Files 2 and 3.
Critical appraisal of individual sources of evidence
Critical appraisal of the risk of bias for included studies was not performed as this was not the objective of this scoping review.
Summary and synthesis of results
Descriptive statistics were used to summarize the characteristics of included studies which encompassed the study design, population, segmentation methods and variables used. The results were tabulated or presented in graphical charts to map the literature. A narrative summary of the population segmentation methodologies and variables used was presented. The segmentation methods identified from each study were mapped into two key themes - data-driven and expert-driven approaches [14]. Prescribed binning and judgemental splitting are examples of expert-driven population segmentation strategies. Prescribed binning utilizes a set of “off-the-shelf” binning rules, which are pre-determined by experts to divide a patient cohort into pre-defined segments [14]. On the other hand, judgemental splitting segregates patients based on one or more explanatory variables, which is determined by the judgement or documented experiences of healthcare practitioners or experts [14]. With regards to data-driven strategies, they can be grouped into decision trees and cluster-based segmentation [14]. Decisions trees utilize an objective classification strategy where patients are divided at successive decision nodes containing the explanatory variables and mimic the extension of branches in a tree [14]. An example is Breiman’s Classification and Regression Tree (CART) model which employs a binary recursive partitioning algorithm on the covariate space of a patient cohort [15]. Lastly, cluster based segmentation refer to a group of unsupervised modelling methods such as k-means and LCA which seeks to identify homogenous subgroups within a population.
Variables used for population segmentation were mapped into five broad domains which encompassed socio-demographic, diabetes related, non-diabetes medical related, psychological or psychological related and healthcare systems related variables.
Proposed framework for design of population segmentation studies for T2DM patients (PASS-T2DM)
A proposed framework, PopulAtion Segmentation Studies design framework for T2DM patients (PASS-T2DM), was constructed using population segmentation variables and outcomes identified from the review. The study design framework was divided into three phases: 1) Selection of study design; 2) Selection of population segmentation outcomes and population segmentation variables and 3) Evaluation of segments generated. The approaches to selection of study designs for population segmentation studies were divided into data-driven and expert driven approaches. The advantages and disadvantages of the approaches were listed in Supplementary File 4. With regards to the population segmentation variables, variables identified were categorized into three categories which were namely: Category A: important and accessible variables; Category B: important variables that are relatively accessible and Category C: important variables that may not be readily accessible. The derivation of these categories factored in the level of accessibility and importance of the variables where a variable is important is determined by its clinical relevance and need/usefulness in diabetic care as assessed by existing literature and expert opinion. The relative level of accessibility was determined from a health system perspective. The selection and assignment of variables to each category was discussed among population segmentation experts (LLL, TCS, JT) and endocrinologist (SBZ) within the team. All disagreements were resolved via further discussion to achieve consensus. With regards to the evaluation of segments generated, important criteria utilized commonly in consumer market segmentation and a review by Yan et al. was adapted for use [10, 16]. They were namely number of patient segments, internal and external validation, identifiability and interpretability, substantiality, stability and actionability. (Definitions in Supplementary File 5).
Data availability statement
All data analyzed in this study are included within the published article and its supplementary information files.
Results
Selection of sources of evidence
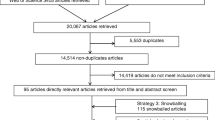
Figure 1 shows the flowchart for inclusion and exclusion of articles. After the exclusion of duplicated and irrelevant articles and, inclusion of 17 articles from hand-searching, a total of 148 articles were included in this review. The overall percentage of agreement between SJJB and AM during the screening of articles was 89.2% and all disagreements were resolved after discussion. Detailed information on the characteristics of individual studies is reported in Supplementary File 4. Thirty-seven studies (25%) received partial or full funding by private organizations while 47 studies (31.8%) were not funded. (Supplementary File 3). The remaining studies (n = 64, 43.2%) were funded by governmental agencies, professional organizations and/or research foundations.

Flowchart for retrieval of articles
Characteristics of sources of evidence
Table 1 shows the characteristics of the studies included in the review. Majority of the studies were conducted between 2011 and 2019 (n = 113, 76.4%) and in Asia (n = 58, 39.2%), Europe (n = 40, 27.0%) and North America (n = 40, 27.0%). Among these continents, the United States of America (USA) (n = 33, 22.3%) [10, 17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47], China (n = 17, 11.5%) [48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63] and Italy (n = 11, 7.4%) [64,65,66,67,68,69,70,71,72,73] were the three countries with the highest number of studies. The two most common study designs employed were cross sectional studies (n = 92, 62.1%) and cohort studies (n = 50, 33.8%). Most studies included fewer than 5000 patients (n = 101, 68.2%).
With regards to the subgroups of T2DM patients studied, adult T2DM patients (without age restriction) formed the most studied population (n = 137, 92.6%). Eight studies (5.4%) focused on elderly T2DM patients (≥65 years old) [24, 30, 32, 62, 74,75,76,77] while two studies (1.4%) [78, 79] focused on young T2DM patients (≤40 years old). Majority of the studies were conducted in tertiary healthcare settings (n = 68, 45.9%) and utilized secondary data sources (n = 76, 51.4%).
Synthesis of results
Population segmentation strategies utilized in studies
Figure 2 shows the details pertaining to population segmentation strategies employed. Expert-driven population segmentation was the most common approach utilized (n = 111, 75.0%) where all studies employed judgemental splits as the main strategy. With regards to data-driven population segmentation studies, cluster-based segmentation was the main strategy used (n = 37, 100%), of which cluster analysis (n = 15, 40.5%) and LCA (n = 12, 32.4%) were most frequently used.

Population segmentation strategies employed in studies (n = 148) a
Segmentation variables used
Table 2 shows the variables used for population segmentation. Across the five main domains of variables utilized, socio-demographic (n = 66, 44.6%), diabetes related (n = 54, 36.4%), non-diabetes medical related (n = 18, 12.2%) and psychiatric/psychological related variables (n = 16, 10.8%) were the most frequently utilized across studies. A total of 85 types of variables from 45 subdomains were utilized as population segmentation variables. A graphical overview of the common subtypes of population segmentation variables used was presented in Fig. 3. Within the domain of socio-demographic related variables, the use of race/ethnicity (n = 17, 11.5%) [23, 25, 36,37,38, 40, 44, 45, 79,80,81,82,83,84,85,86], patient’s age (n = 16, 10.8%) [26, 33, 39, 43, 45, 51, 88,89,90,91,92,93,94,95,96,97], gender (n = 12, 8.1%) [41, 56, 67, 72, 79, 92, 94, 97,98,99,100] and obesity/weight related (n = 7, 4.7%) [17, 49, 58, 59, 102,103,104] variables were most commonly studied.

Overview of variables used in population segmentation
Within the domain of diabetes related variables, Hba1c related (n = 14, 9.5%) [11, 67, 74,75,76, 103, 118,105,119,120,121,122,123,124, 126], diabetes related complications (n = 13, 8.8%) [10, 26, 30, 50, 54, 57, 68, 127, 129,130,131,132,133] and diabetes treatment related (n = 7, 4.7%) [10, 26, 31, 69, 134,135,136] variables were the most commonly utilized variables for population segmentation.
With regards to the domain of non-diabetes medical related variables, chronic kidney disease (n = 6, 4.1%) [10, 26, 56, 65, 68, 132], hypertension (n = 5, 3.4%) [71, 102, 149, 150], and cardiovascular disease related (n = 3, 2.0%) [50, 51, 102]. Pertaining to the domain of psychiatric / psychological related variables, depression/anxiety related (n = 9, 6.1%) [21, 27, 29, 35, 42, 46, 154,155,156] and other psychiatric disorders/symptoms related (n = 5, 3.4%) [22, 35, 42, 62, 131] variables were most commonly employed. Lastly for the health systems related domain, types of healthcare utilization (n = 2, 1.4%) [160, 161] and type/specialty of care providers (n = 2, 1.4%) [64, 77] related variables were most frequently used.
Objectives of population segmentation strategies and number of derived segments
Health grouping/profiling (n = 71, 48%), assessment of differential risk of diabetes related complications (n = 57, 38.5%), non-diabetes metabolic derangements (e.g. lipids and blood pressure) (n = 42, 28.4%) and diabetes control (n = 40, 27.0%) were the most frequent population segmentation objectives of the studies. (Table 3) The number of patient segments derived ranged from one to ten segments, of which two to four segments (n = 119, 80.4%) were most commonly derived number of segments. (Fig. 4).

Number of patient segments derived within included studies
PASS-T2DM framework
Figure 5 shows the proposed PASS-T2DM framework, which comprises of three phases: 1) Selection of study design; 2) Selection of population segmentation outcomes and variables and 3) Evaluation of segments generated. For Phase 2, there is generally no preferred order for the selection of population segmentation outcomes and variables. One exception lies in the use of CART which requires the segmentation outcome to be determined beforehand. For other methodologies, concurrent selection of segmentation variables and outcomes may be performed at the user’s discretion. Examples of commonly utilized segmentation outcomes for consideration include health profiling of patients or assessment of patients’ differential risk of T2DM related complications. For segmentation variables that were classified as “Category A: important and accessible variables”, these included patient’s age, gender, race / ethnicity, Hba1c levels, diabetes related complications, presence of non-psychiatric and psychiatric comorbidities. These variables were selected after careful evaluation of their clinical importance and relative accessibility. Additionally, they were among the most commonly used segmentation variables across studies.

Population Segmentation Studies design framework for T2DM patients (PASS-T2DM)
Discussion
Summary of evidence
Overall, this scoping review has summarized the clinical applications of population segmentation strategies among T2DM patients. To our best knowledge, this is also the first review which evaluated the clinical applications of population strategies for T2DM patients and proposed a framework for the design of population segmentation studies for T2DM patients.
As shown in the review, a multitude of population segmentation strategies encompassing both data-driven and expert-riven population segmentation approaches have been utilized among T2DM patients. Importantly, each methodology carries its inherent advantages and disadvantages [10, 14, 16, 163]. The main merit of judgemental splitting, which is the most studied expert-driven methodology is its simplicity of use, where a patient population is divided into segments based on one or more explanatory variables [14]. Conversely, one of its disadvantages is non-objectivity, where the discriminatory properties of the target variable have not been actively sought [14]. Furthermore, the use of certain population segmentation variables may lead to excessive number of segments, which may have inadequate discriminatory properties [14]. For cluster based analysis which was the main data-driven population segmentation analyses employed, its chief advantage lies in its ability to manage multiple types of population segmentation variables, which can be continuous or categorical in nature [163, 164]. However, certain cluster based analyses techniques such as hierarchical analyses and k-means cluster analyses are affected by outliers [163]. In this review, there were no studies which have utilized decision trees analyses or prescribed binning criteria for the segmentation of T2DM patients. Future studies should consider the use of these strategies to evaluate their potential role in segmentation of T2DM patients. Currently, the optimal population segmentation methodology for T2DM patients has not been established. As such, researchers should be cognizant of the advantages and disadvantages of each population segmentation methodology when selecting an appropriate technique for their studies. Additional factors that should be considered during the selection process include the type of population segmentation variables to be used, the properties of the dataset, research questions and level of technical and statistical expertise of the researchers [165].
With regards to population segmentation variables used in T2DM studies, 85 sub-groups of variables were identified in our review. Given the wide array of population segmentation variables available, potential computation challenge exists when processing large number of segmentation variables and observations during the implementation of population segmentation strategies. Hence, careful selection and screening of variables needs to be performed to achieve a balance between number of patient segments derived and sufficient discriminatory properties from the derived segments. In the PASS-T2DM framework, variables which included patient’s age, gender, race / ethnicity, Hba1c levels, diabetes related complications, presence of non-psychiatric and psychiatric comorbidities e.g. hypertension, chronic kidney disease, anxiety and depression were classified as Category A variables which correspond to variables that are of high clinical importance and relative accessibility. Of note, these variables were also the most frequently utilized segmentation variables across included studies for the review.
Within the domain of socio-demographic variables, age is a well-recognized driver of the global rise in diabetes [166] and T2DM among older adults have been associated with increased mortality, poorer functional status and risk of hospitalisation [167]. On the other end of the spectrum, there is also a growing epidemic of early-onset T2DM among young adults, which has been attributed to complex interplay of lifestyle and genetic factors such as sedentary lifestyles and obesity [168]. For example, the SEARCH study showed that the incidence of T2DM among young people increased by 7.1% between 2002 and 2003 and 2011–2012 in the United States [169]. Unsurprisingly, studies which have employed age as a population segmentation variable were able to generate patient segments with differential risk of diabetes related complications, diabetes control and cardiovascular risk profiles [51, 88, 89]. With regards to the role of gender, sexual dimorphisms related to pathophysiological mechanisms of T2DM and its complications have been gaining interest in the recent years [170]. Gender differences in the clinical presentation of T2DM and risk of diabetes related complications have been postulated to involve a multitude of biological, cultural, lifestyle, environmental and socio-economic factors [170]. For example, a study by Logue et al. showed that diabetic men tend to be diagnosed at an earlier age and lower body mass index as compared to women [171]. Conversely, diabetic women tended to have higher risk of stroke related mortality when compared to their male counterparts [172]. For ethnicity, it has been implicated in the development of T2DM related lower extremity amputations and microvascular complications, where higher rates of these complications have been reported among minority ethnic groups [173]. The use of gender and ethnicity as segmentation variables have similarly generated distinctive patient segments with varying risk of diabetes related outcomes [25, 67, 80, 98].
With regards to diabetes related variables, Hba1c is a well-established measure of glycaemic control and has been shown in the Diabetes Control and Complications Trial (DCCT) to be quintessential for prevention of diabetes related complications [174]. In studies which segmented patients based on Hba1c levels, patients with poorer glycaemic control were consistently shown to have increased risk of diabetes related complications [76, 118]. A variant of this measure, Hba1c variability and its relationship with diabetic complications has been increasingly studied although there have been conflicting results [175]. While a recent study showed a positive correlation between increased Hba1c variability and all-cause mortality [176], a post-hoc analysis from the DCCT trial showed no association between glycaemic variability and developing adverse clinical outcomes [177]. Consequently, researchers who are designing population segmentation studies should consider the use of Hba1c variability for exploratory purposes until more evidence supporting its use emerges. For diabetes related complications, their association with morbidity and mortality, as well as their resultant impact on healthcare resource consumption and economic burden are well-established and recognized [9]. In studies where patients were segmented by the presence or severity of diabetes related complications, distinct patient segments were derived with differing healthcare utilization, mortality and morbidity [9, 133].
Pertaining to non-diabetes medical related and psychiatric/psychological related domains, the presence of co-morbidities such as hypertension, chronic kidney disease, depression and anxiety are common and often result in additional financial and psychological burden on patients [178]. Notably, these comorbidities may have profound impacts on the self-care ability of patients. For example, depression often results in significant impairment of patients’ functioning and may present as barriers to adherence to lifestyle modifications and treatment regimens [179]. Managing the healthcare needs of T2DM patients with varying types of multi-morbidities is challenging and there is a need for changes in the health system to meet the needs of these patients. Population segmentation is a valuable endeavour which can segregate T2DM patients into more manageable patient segments, to facilitate the design of targeted interventions.
As seen from this review, population segmentation has a wide range of clinical applications, ranging from health group profiling to assessing the differential risk of diabetes related complications and mortality. This highlights the versatility of population segmentation and its applications. With the rising use of electronic health records in big data analytics, future population segmentation studies may wish to leverage on the recent advancement in big data by streamlining and tailoring their study designs to population segmentation variables and outcomes which are readily available in the electronic health records or can be easily incorporated into electronic health records at routine clinical care touch points between patients and healthcare providers to reduce the burden placed onto healthcare professionals [5].
In this review, we identified 148 studies which have utilized data-driven and expert-driven population segmentation strategies to identify subgroups of T2DM patients with differential health related outcomes or healthcare utilization patterns. The main strength of this review was that the proposed PASS-T2DM framework provides a simple overview for future researchers to design population segmentation studies for T2DM patients.
Limitations
However, users of this framework should also be cognizant of its potential limitations. The segmentation variables included within the framework were restricted to those evaluated across included studies and should not be regarded as an exhaustive list. Researchers planning to utilize variables outside the list should evaluate these variables carefully prior to their inclusion. In addition, this highlights the need for more studies to explore the role of other potentially useful population segmentation variables not listed in the framework such as medication compliance rates. Furthermore, while the proposed framework in our study had categorized population segmentation variables on the basis of their relative clinical importance and accessibility, the optimal set and combination of population segmentation variables which is context specific for the different aims of population segmentation remains unclear. Nonetheless, our review serves as an important foundation for future researchers to evaluate and determine the optimal set of population segmentation variables that should be used. With regards to other limitations related to this review, the grey literature was not searched, which could have led to omission of potentially relevant articles. Future reviews which plan to update this topic should consider searching grey literature. Another limitation was that non-English articles as well as studies which included children or adolescents with T2DM were excluded. Lastly, a formal assessment of the methodological limitations of the evidence was not performed as it was not the objective of this study. Nonetheless, researchers conducting future systematic reviews to evaluate specific population segmentation methodologies should evaluate the risk of bias of included studies [180]. This will aid in identifying the optimal combination of population segmentation variables to be used for each methodology.
Conclusion
Population segmentation methodologies via data-driven or expert-driven approaches are important tools that can aid policymakers and healthcare administrators in evaluating a wide range of outcomes among different sub-groups of T2DM patients, ranging from health profiling to assessing the differential risk of diabetes related complications. While a large number of population segmentation variables have been used in literature, the optimal combination of population segmentation variables to be used remains unknown and should be explored in future studies. The proposed PASS-T2DM framework for the design of population segmentation studies will serve as an important guide for researchers to structure and design population segmentation studies for T2DM patients until the optimal framework has been established. More studies are required to explore the role of population segmentation variables not listed in the framework.
Availability of data and materials
All data generated or analyzed during this study are included in this published article and its supplementary information files.
Abbreviations
- CART:
-
Classification and regression tree
- LCA:
-
Latent class analyses
- PASS-T2DM:
-
PopulAtion Segmentation Studies design framework for T2DM patients
- T2DM:
-
Type 2 diabetes mellitus
References
Bommer C, Sagalova V, Heesemann E, Manne-Goehler J, Atun R, Barnighausen T, et al. Global economic burden of diabetes in adults: projections from 2015 to 2030. Diabetes Care. 2018;41(5):963–70.
International Diabetes Federation. IDF diabetes atlas. 8th ed. Brussels: International Diabetes Federation; 2017.
Kindig D, Stoddart G. What is population health? Am J Public Health. 2003;93(3):380–3.
Vuik SI, Mayer EK, Darzi A. Patient segmentation analysis offers significant benefits for integrated care and support. Health Aff (Millwood). 2016;35(5):769–75.
Chong JL, Lim KK, Matchar DB. Population segmentation based on healthcare needs: a systematic review. Syst Rev. 2019;8(1):202.
Low LL, Yan S, Kwan YH, Tan CS, Thumboo J. Assessing the validity of a data driven segmentation approach: a 4 year longitudinal study of healthcare utilization and mortality. PLoS One. 2018;13(4):e0195243.
Lynn J, Straube BM, Bell KM, Jencks SF, Kambic RT. Using population segmentation to provide better health care for all: the “bridges to health” model. Milbank Q. 2007;85(2):185–208 discussion 9-12.
Yan S, Seng BJJ, Kwan YH, Tan CS, Quah JHM, Thumboo J, et al. Identifying heterogeneous health profiles of primary care utilizers and their differential healthcare utilization and mortality - a retrospective cohort study. BMC Fam Pract. 2019;20(1):54.
Seng JJB, Kwan YH, Lee VSY, Tan CS, Zainudin SB, Thumboo J, et al. Differential health care use, diabetes-related complications, and mortality among five unique classes of patients with type 2 diabetes in Singapore: a latent class analyses of 71,125 patients. Diabetes Care. 2020;43(5):1048–56.
Jiang R, Law E, Zhou Z, Yang H, Wu EQ, Seifeldin R. Clinical trajectories, healthcare resource use, and costs of diabetic nephropathy among patients with type 2 diabetes: a latent class analysis. Diabetes Ther. 2018;9(3):1021–36.
Karpati T, Leventer-Roberts M, Feldman B, Cohen-Stavi C, Raz I, Balicer R. Patient clusters based on HbA1c trajectories: a step toward individualized medicine in type 2 diabetes. PLoS One. 2018;13(11):e0207096.
PRISMA. Extension for scoping reviews (PRISMA-ScR): checklist and explanation. Ann Intern Med. 2018;169(7):467–73.
Shea BJ, Reeves BC, Wells G, Thuku M, Hamel C, Moran J, et al. AMSTAR 2: a critical appraisal tool for systematic reviews that include randomised or non-randomised studies of healthcare interventions, or both. BMJ. 2017;j4008:358.
Wood RM, Murch BJ, Betteridge RC. A comparison of population segmentation methods. Oper Res Health Care. 2019;22:100192.
Breiman L. Classification and regression trees. New York: Routledge; 2017.
Wedel M, Kamakura WA. Market segmentation: conceptual and methodological foundations: Springer US; 1997.
Fink JT, Magnan EM, Johnson HM, Bednarz LM, Allen GO, Greenlee RT, et al. Blood pressure control and other quality of care metrics for patients with obesity and diabetes: a population-based cohort study. High Blood Press Cardiovasc Prev. 2018;25(4):391–9.
Schillinger D, Grumbach K, Piette J, Wang F, Osmond D, Daher C, et al. Association of health literacy with diabetes outcomes. Jama. 2002;288(4):475–82.
Okosun IS, Annor F, Dawodu EA, Eriksen MP. Clustering of cardiometabolic risk factors and risk of elevated HbA1c in non-Hispanic white, non-Hispanic black and Mexican-American adults with type 2 diabetes. Diabetes Metab Syndr. 2014;8(2):75–81.
Li C, Ford ES, Mokdad AH, Jiles R, Giles WH. Clustering of multiple healthy lifestyle habits and health-related quality of life among U.S. adults with diabetes. Diabetes Care. 2007;30(7):1770–6.
Coleman SM, Katon W, Lin E, Von Korff M. Depression and death in diabetes; 10-year follow-up of all-cause and cause-specific mortality in a diabetic cohort. Psychosomatics. 2013;54(5):428–36.
Egede LE, Gebregziabher M, Zhao Y, Dismuke CE, Walker RJ, Hunt KJ, et al. Differential impact of mental health multimorbidity on healthcare costs in diabetes. Am J Manag Care. 2015;21(8):535–44.
Chan KS, Gaskin DJ, Dinwiddie GY, McCleary R. Do diabetic patients living in racially segregated neighborhoods experience different access and quality of care? Med Care. 2012;50(8):692–9.
Griffiths RI, Danese MD, Gleeson ML, Valderas JM. Epidemiology and outcomes of previously undiagnosed diabetes in older women with breast cancer: an observational cohort study based on SEER-Medicare. BMC Cancer. 2012;12:613.
Emanuele N, Sacks J, Klein R, Reda D, Anderson R, Duckworth W, et al. Ethnicity, race, and baseline retinopathy correlates in the veterans affairs diabetes trial. Diabetes Care. 2005;28(8):1954–8.
Li L, Cheng WY, Glicksberg BS, Gottesman O, Tamler R, Chen R, et al. Identification of type 2 diabetes subgroups through topological analysis of patient similarity. Sci Transl Med. 2015;7(311):311ra174.
Kalsekar ID, Madhavan SS, Amonkar MM, Douglas SM, Makela E, Elswick BL, et al. Impact of depression on utilization patterns of oral hypoglycemic agents in patients newly diagnosed with type 2 diabetes mellitus: a retrospective cohort analysis. Clin Ther. 2006;28(2):306–18.
Morris NS, MacLean CD, Littenberg B. Literacy and health outcomes: a cross-sectional study in 1002 adults with diabetes. BMC Fam Pract. 2006;7:49.
O'Donnell A, de Vries McClintock HF, Wiebe DJ, Bogner HR. Neighborhood social environment and patterns of depressive symptoms among patients with type 2 diabetes mellitus. Community Ment Health J. 2015;51(8):978–86.
Escalada J, Liao L, Pan C, Wang H, Bala M. Outcomes and healthcare resource utilization associated with medically attended hypoglycemia in older patients with type 2 diabetes initiating basal insulin in a US managed care setting. Curr Med Res Opin. 2016;32(9):1557–65.
de Vries McClintock HF, Morales KH, Small DS, Bogner HR. Patterns of adherence to oral hypoglycemic agents and glucose control among primary care patients with type 2 diabetes. Behav Med. 2016;42(2):63–71.
Lee PG, Ha J, Blaum CS, Gretebeck K, Alexander NB. Patterns of physical activity in sedentary older individuals with type 2 diabetes. Clin Diabetes Endocrinol. 2018;4:7.
Berkowitz SA, Meigs JB, Wexler DJ. Age at type 2 diabetes onset and glycaemic control: results from the National Health and Nutrition Examination Survey (NHANES) 2005-2010. Diabetologia. 2013;56(12):2593–600.
Gucciardi E, Mathew R, Demelo M, Bondy SJ. Profiles of smokers and non-smokers with type 2 diabetes: initial visit at a diabetes education centers. Prim Care Diabetes. 2011;5(3):185–94.
Gunzler D, Sajatovic M, McCormick R, Perzynski A, Thomas C, Kanuch S, et al. Psychosocial features of clinically relevant patient subgroups with serious mental illness and comorbid diabetes. Psychiatr Serv. 2017;68(1):96–9.
de Rekeneire N, Rooks RN, Simonsick EM, Shorr RI, Kuller LH, Schwartz AV, et al. Racial differences in glycemic control in a well-functioning older diabetic population: findings from the health, aging and body composition study. Diabetes Care. 2003;26(7):1986–92.
Wang Y, Katzmarzyk PT, Horswell R, Zhao W, Li W, Johnson J, et al. Racial disparities in cardiovascular risk factor control in an underinsured population with type 2 diabetes. Diabet Med. 2014;31(10):1230–6.
Osborn CY, Trott HW, Buchowski MS, Patel KA, Kirby LD, Hargreaves MK, et al. Racial disparities in the treatment of depression in low-income persons with diabetes. Diabetes Care. 2010;33(5):1050–4.
Johnson JF, Parsa R, Bailey RA. Real-world clinical outcomes among patients with type 2 diabetes receiving canagliflozin at a specialty diabetes clinic: subgroup analysis by baseline HbA1c and age. Clin Ther. 2017;39(6):1123–31.
Kaplan SH, Billimek J, Sorkin DH, Ngo-Metzger Q, Greenfield S. Reducing racial/ethnic disparities in diabetes: the coached care (R2D2C2) project. J Gen Intern Med. 2013;28(10):1340–9.
Zhao W, Katzmarzyk PT, Horswell R, Wang Y, Johnson J, Hu G. Sex differences in the risk of stroke and HbA(1c) among diabetic patients. Diabetologia. 2014;57(5):918–26.
Li H, Ji M, Scott P, Dunbar-Jacob JM. The effect of symptom clusters on quality of life among patients with type 2 diabetes. Diabetes Educ. 2019;45(3):287–94.
El-Kebbi IM, Cook CB, Ziemer DC, Miller CD, Gallina DL, Phillips LS. Association of younger age with poor glycemic control and obesity in urban african americans with type 2 diabetes. Arch Intern Med. 2003;163(1):69–75.
Harris MI. Racial and ethnic differences in health care access and health outcomes for adults with type 2 diabetes. Diabetes Care. 2001;24(3):454–9.
Harris MI, Eastman RC, Cowie CC, Flegal KM, Eberhardt MS. Racial and ethnic differences in glycemic control of adults with type 2 diabetes. Diabetes Care. 1999;22(3):403–8.
Demmer RT, Gelb S, Suglia SF, Keyes KM, Aiello AE, Colombo PC, et al. Sex differences in the association between depression, anxiety, and type 2 diabetes mellitus. Psychosom Med. 2015;77(4):467–77.
Prentice JC, Graeme Fincke B, Miller DR, Pizer SD. Primary care and health outcomes among older patients with diabetes. Health Serv Res. 2012;47(1 Pt 1):46–67.
Tao X, Li J, Zhu X, Zhao B, Sun J, Ji L, et al. Association between socioeconomic status and metabolic control and diabetes complications: a cross-sectional nationwide study in Chinese adults with type 2 diabetes mellitus. Cardiovasc Diabetol. 2016;15:61.
Liu H, Wu S, Li Y, Sun L, Huang Z, Lin L, et al. Body mass index and mortality in patients with type 2 diabetes mellitus: a prospective cohort study of 11,449 participants. J Diabetes Complicat. 2017;31(2):328–33.
Cheng Y, Zhang H, Chen R, Yang F, Li W, Chen L, et al. Cardiometabolic risk profiles associated with chronic complications in overweight and obese type 2 diabetes patients in South China. PLoS One. 2014;9(7):e101289.
Yang W, Cai X, Han X, Ji L. Clinical characteristics of young type 2 diabetes patients with atherosclerosis. PLoS One. 2016;11(7):e0159055.
Xu ZR, Molyneaux L, Wang YZ, Jing H, Liu Y, McGill M, et al. Clustering of cardiovascular risk factors with diabetes in Chinese patients: the effects of sex and hyperinsulinaemia. Diabetes Obes Metab. 2001;3(3):157–62.
Yeung RO, Cai JH, Zhang Y, Luk AO, Pan JH, Yin J, et al. Determinants of hospitalization in Chinese patients with type 2 diabetes receiving a peer support intervention and JADE integrated care: the PEARL randomised controlled trial. Clin Diabetes Endocrinol. 2018;4:5.
Zheng W, Chen L. Factor analysis of diabetic nephropathy in Chinese patients. Diabetes Metab Syndr. 2011;5(3):130–6.
Xu D, Fang H, Xu W, Yan Y, Liu Y, Yao B. Fasting plasma glucose variability and all-cause mortality among type 2 diabetes patients: a dynamic cohort study in Shanghai, China. Sci Rep. 2016;6(1):39633.
Lu B, Song X, Dong X, Yang Y, Zhang Z, Wen J, et al. High prevalence of chronic kidney disease in population-based patients diagnosed with type 2 diabetes in downtown Shanghai. J Diabetes Complicat. 2008;22(2):96–103.
Wang X, Chen J, Liu X, Gao F, Zhao H, Han D, et al. Identifying patterns of lifestyle behaviors among people with type 2 diabetes in Tianjin, China: a latent class analysis. Diabetes Ther. 2017;8(6):1379–92.
Cheng XB, Hsieh YT, Tu ST, Hsieh MC. Obesity and low target attainment rates in Chinese with type 2 diabetes. Eur J Intern Med. 2012;23(4):e101–5.
Zhou X, Ji L, Ran X, Su B, Ji Q, Pan C, et al. Prevalence of obesity and its influence on achievement of cardiometabolic therapeutic goals in Chinese type 2 diabetes patients: an analysis of the nationwide, cross-sectional 3B study. PLoS One. 2016;11(1):e0144179.
Zou X, Zhou X, Ji L, Yang W, Lu J, Weng J, et al. The characteristics of newly diagnosed adult early-onset diabetes: a population-based cross-sectional study. Sci Rep. 2017;7:46534.
Zhang XL, Fu HJ, Yang GR, Wan G, Li D, Zhu LX, et al. The effects of cardiovascular risk factor combined anti-platelet therapy and the risk of cerebrovascular events in patients with T2DM in an urban community over 96-months follow-up: the Beijing communities diabetes study 19. Diabetes Res Clin Pract. 2018;144:236–44.
Gao Y, Xiao Y, Miao R, Zhao J, Cui M, Huang G, et al. The prevalence of mild cognitive impairment with type 2 diabetes mellitus among elderly people in China: a cross-sectional study. Arch Gerontol Geriatr. 2016;62:138–42.
Ji L, Weng J, Lu J, Guo X, Yang W, Jia W, et al. Hyperglycemia and duration of diabetes as risk factors for abnormal lipids: a cross sectional survey of 19,757 patients with type 2 diabetes in China. J Endocrinol Investig. 2014;37(9):843–52.
Bruno G, Cavallo-Perin P, Bargero G, Borra M, D'Errico N, Macchia G, et al. Cardiovascular risk profile of type 2 diabetic patients cared for by general practitioners or at a diabetes clinic: a population-based study. J Clin Epidemiol. 1999;52(5):413–7.
Ravera M, Noberasco G, Re M, Filippi A, Gallina AM, Weiss U, et al. Chronic kidney disease and cardiovascular risk in hypertensive type 2 diabetics: a primary care perspective. Nephrol Dial Transplant. 2009;24(5):1528–33.
Genovese S, Bazzigaluppi E, Goncalves D, Ciucci A, Cavallo MG, Purrello F, et al. Clinical phenotype and beta-cell autoimmunity in Italian patients with adult-onset diabetes. Eur J Endocrinol. 2006;154(3):441–7.
Penno G, Solini A, Bonora E, Fondelli C, Orsi E, Zerbini G, et al. Gender differences in cardiovascular disease risk factors, treatments and complications in patients with type 2 diabetes: the RIACE Italian multicentre study. J Intern Med. 2013;274(2):176–91.
De Cosmo S, Rossi MC, Pellegrini F, Lucisano G, Bacci S, Gentile S, et al. Kidney dysfunction and related cardiovascular risk factors among patients with type 2 diabetes. Nephrol Dial Transplant. 2014;29(3):657–62.
Bo S, Castiglione A, Ghigo E, Gentile L, Durazzo M, Cavallo-Perin P, et al. Mortality outcomes of different sulphonylurea drugs: the results of a 14-year cohort study of type 2 diabetic patients. Eur J Endocrinol. 2013;169(1):117–26.
Amato MC, Pizzolanti G, Torregrossa V, Panto F, Giordano C. Phenotyping of type 2 diabetes mellitus at onset on the basis of fasting incretin tone: results of a two-step cluster analysis. J Diabetes Investig. 2016;7(2):219–25.
Solini A, Zoppini G, Orsi E, Fondelli C, Trevisan R, Vedovato M, et al. Resistant hypertension in patients with type 2 diabetes: clinical correlates and association with complications. J Hypertens. 2014;32(12):2401–10 discussion 10.
Vitale M, Masulli M, Cocozza S, Anichini R, Babini AC, Boemi M, et al. Sex differences in food choices, adherence to dietary recommendations and plasma lipid profile in type 2 diabetes - the TOSCA.IT study. Nutr Metab Cardiovasc Dis. 2016;26(10):879–85.
Muggeo M, Zoppini G, Bonora E, Brun E, Bonadonna RC, Moghetti P, et al. Fasting plasma glucose variability predicts 10-year survival of type 2 diabetic patients: the Verona diabetes study. Diabetes Care. 2000;23(1):45–50.
Sakurai T, Kawashima S, Satake S, Miura H, Tokuda H, Toba K. Differential subtypes of diabetic older adults diagnosed with Alzheimer’s disease. Geriatr Gerontol Int. 2014;14(Suppl 2):62–70.
Ravona-Springer R, Heymann A, Schmeidler J, Moshier E, Godbold J, Sano M, et al. Trajectories in glycemic control over time are associated with cognitive performance in elderly subjects with type 2 diabetes. PLoS One. 2014;9(6):e97384.
Twito O, Ahron E, Jaffe A, Afek S, Cohen E, Granek-Catarivas M, et al. New-onset diabetes in elderly subjects: association between HbA1c levels, mortality, and coronary revascularization. Diabetes Care. 2013;36(11):3425–9.
Escobar C, Blanes I, Ruiz A, Vinuesa D, Montero M, Rodriguez M, et al. Prevalence and clinical profile and management of peripheral arterial disease in elderly patients with diabetes. Eur J Intern Med. 2011;22(3):275–81.
Chan JC, Lau ES, Luk AO, Cheung KK, Kong AP, Yu LW, et al. Premature mortality and comorbidities in young-onset diabetes: a 7-year prospective analysis. Am J Med. 2014;127(7):616–24.
Benhalima K, Wilmot E, Khunti K, Gray LJ, Lawrence I, Davies M. Type 2 diabetes in younger adults: clinical characteristics, diabetes-related complications and management of risk factors. Prim Care Diabetes. 2011;5(1):57–62.
Tan ED, Davis WA, Davis TM. Changes in characteristics and management of Asian and Anglo-Celts with type 2 diabetes over a 15-year period in an urban Australian community: the Fremantle diabetes study. J Diabetes. 2016;8(1):139–47.
Hermans MP, Dumont C, Buysschaert M. Clinical, biophysical and biochemical variables from African-heritage subjects with type 2 diabetes. Acta Clin Belg. 2002;57(3):134–41.
Chew BH, Mastura I, Lee PY, Wahyu TS, Cheong AT, Zaiton A. Ethnic differences in glycaemic control and complications: the adult diabetes control and management (ADCM), Malaysia. Med J Malaysia. 2011;66(3):244–8.
Wolffenbuttel BH, Herman WH, Gross JL, Dharmalingam M, Jiang HH, Hardin DS. Ethnic differences in glycemic markers in patients with type 2 diabetes. Diabetes Care. 2013;36(10):2931–6.
Cheong AT, Lee PY, Sazlina SG, Mohamad Adam B, Chew BH, Mastura I, et al. Poor glycemic control in younger women attending Malaysian public primary care clinics: findings from adults diabetes control and management registry. BMC Fam Pract. 2013;14:188.
Herman WH, Dungan KM, Wolffenbuttel BH, Buse JB, Fahrbach JL, Jiang H, et al. Racial and ethnic differences in mean plasma glucose, hemoglobin A1c, and 1,5-anhydroglucitol in over 2000 patients with type 2 diabetes. J Clin Endocrinol Metab. 2009;94(5):1689–94.
Hong CY, Chia KS, Hughes K, Ling SL. Ethnic differences among Chinese, Malay and Indian patients with type 2 diabetes mellitus in Singapore. Singap Med J. 2004;45(4):154–60.
Harris EL, Sherman SH, Georgopoulos A. Black-white differences in risk of developing retinopathy among individuals with type 2 diabetes. Diabetes Care. 1999;22(5):779–83.
Shamshirgaran SM, Mamaghanian A, Aliasgarzadeh A, Aiminisani N, Iranparvar-Alamdari M, Ataie J. Age differences in diabetes-related complications and glycemic control. BMC Endocr Disord. 2017;17(1):25.
Ki M, Baek S, Yun YD, Kim N, Hyde M, Na B. Age-related differences in diabetes care outcomes in Korea: a retrospective cohort study. BMC Geriatr. 2014;14:111.
Basanta-Alario ML, Ferri J, Civera M, Martinez-Hervas S, Ascaso JF, Real JT. Differences in clinical and biological characteristics and prevalence of chronic complications related to aging in patients with type 2 diabetes. Endocrinol Nutr. 2016;63(2):79–86.
Rosa MQM, Rosa RDS, Correia MG, Araujo DV, Bahia LR, Toscano CM. Disease and economic burden of hospitalizations attributable to diabetes mellitus and its complications: a nationwide study in Brazil. Int J Environ Res Public Health. 2018;15(2):294.
Al-Mukhtar SB, Fadhil NN, Hanna BE. General and gender characteristics of type 2 diabetes mellitus among the younger and older age groups. Oman Med J. 2012;27(5):375–82.
Toh MPHS, Wu CX, Leong HSS. Association of younger age with poor glycemic and cholesterol control in Asians with type 2 diabetes mellitus in Singapore; 2011.
Barrot-de la Puente J, Mata-Cases M, Franch-Nadal J, Mundet-Tuduri X, Casellas A, Fernandez-Real JM, et al. Older type 2 diabetic patients are more likely to achieve glycaemic and cardiovascular risk factors targets than younger patients: analysis of a primary care database. Int J Clin Pract. 2015;69(12):1486–95.
Bruce DG, Davis WA, Davis TM. Glycemic control in older subjects with type 2 diabetes mellitus in the Fremantle diabetes study. J Am Geriatr Soc. 2000;48(11):1449–53.
Gunathilake W, Song S, Sridharan S, Fernando DJ, Idris I. Cardiovascular and metabolic risk profiles in young and old patients with type 2 diabetes. Qjm. 2010;103(11):881–4.
Ezenwaka CE, Offiah NV. Differences in cardiovascular disease risk factors in elderly and younger patients with type 2 diabetes in the West Indies. Singap Med J. 2002;43(10):497–503.
Hanai K, Babazono T, Yoshida N, Nyumura I, Toya K, Hayashi T, et al. Gender differences in the association between HDL cholesterol and the progression of diabetic kidney disease in type 2 diabetic patients. Nephrol Dial Transplant. 2012;27(3):1070–5.
Duan JG, Chen XY, Wang L, Lau A, Wong A, Thomas GN, et al. Sex differences in epidemiology and risk factors of acute coronary syndrome in Chinese patients with type 2 diabetes: a long-term prospective cohort study. PLoS One. 2015;10(4):e0122031.
Gobl CS, Brannath W, Bozkurt L, Handisurya A, Anderwald C, Luger A, et al. Sex-specific differences in glycemic control and cardiovascular risk factors in older patients with insulin-treated type 2 diabetes mellitus. Gend Med. 2010;7(6):593–9.
Kautzky-Willer A, Kamyar MR, Gerhat D, Handisurya A, Stemer G, Hudson S, et al. Sex-specific differences in metabolic control, cardiovascular risk, and interventions in patients with type 2 diabetes mellitus. Gend Med. 2010;7(6):571–83.
Ernande L, Audureau E, Jellis CL, Bergerot C, Henegar C, Sawaki D, et al. Clinical implications of echocardiographic phenotypes of patients with diabetes mellitus. J Am Coll Cardiol. 2017;70(14):1704–16.
Safai N, Ali A, Rossing P, Ridderstrale M. Stratification of type 2 diabetes based on routine clinical markers. Diabetes Res Clin Pract. 2018;141:275–83.
Blak BT, Rigney U, Sternhufvud C, Davis J, Hammar N. Weight change and healthcare resource use in English patients with type 2 diabetes mellitus initiating a new diabetes medication class. Int J Clin Pract. 2016;70(1):45–55.
Vepsalainen T, Soinio M, Marniemi J, Lehto S, Juutilainen A, Laakso M, et al. Physical activity, high-sensitivity C-reactive protein, and total and cardiovascular disease mortality in type 2 diabetes. Diabetes Care. 2011;34(7):1492–6.
Ogihara T, Mita T, Osonoi Y, Osonoi T, Saito M, Tamasawa A, et al. Relationships between lifestyle patterns and cardio-renal-metabolic parameters in patients with type 2 diabetes mellitus: a cross-sectional study. PLoS One. 2017;12(3):e0173540.
Gariepy G, Malla A, Wang J, Messier L, Strychar I, Lesage A, et al. Types of smokers in a community sample of individuals with type 2 diabetes: a latent class analysis. Diabet Med. 2012;29(5):586–92.
Lim JH, Lee YS, Chang HC, Moon MK, Song Y. Association between dietary patterns and blood lipid profiles in Korean adults with type 2 diabetes. J Korean Med Sci. 2011;26(9):1201–8.
Bidel S, Hu G, Qiao Q, Jousilahti P, Antikainen R, Tuomilehto J. Coffee consumption and risk of total and cardiovascular mortality among patients with type 2 diabetes. Diabetologia. 2006;49(11):2618–26.
Sarmento RA, Antonio JP, de Miranda IL, Nicoletto BB, de Almeida JC. Eating patterns and health outcomes in patients with type 2 diabetes. J Endocr Soc. 2018;2(1):42–52.
Hsu CC, Jhang HR, Chang WT, Lin CH, Shin SJ, Hwang SJ, et al. Associations between dietary patterns and kidney function indicators in type 2 diabetes. Clin Nutr. 2014;33(1):98–105.
Ghane Basiri M, Sotoudeh G, Djalali M, Reza Eshraghian M, Noorshahi N, Rafiee M, et al. Association of major dietary patterns with general and abdominal obesity in Iranian patients with type 2 diabetes mellitus. Int J Vitam Nutr Res. 2015;85(3–4):145–55.
Spauwen PJ, Martens RJ, Stehouwer CD, Verhey FR, Schram MT, Sep SJ, et al. Lower verbal intelligence is associated with diabetic complications and slower walking speed in people with type 2 diabetes: the Maastricht study. Diabet Med. 2016;33(12):1632–9.
Rabi DM, Edwards AL, Svenson LW, Sargious PM, Norton P, Larsen ET, et al. Clinical and medication profiles stratified by household income in patients referred for diabetes care. Cardiovasc Diabetol. 2007;6:11.
Walker JJ, Livingstone SJ, Colhoun HM, Lindsay RS, McKnight JA, Morris AD, et al. Effect of socioeconomic status on mortality among people with type 2 diabetes: a study from the Scottish Diabetes Research Network Epidemiology Group. Diabetes Care. 2011;34(5):1127–32.
Handisurya A, Bancher-Todesca D, Kamyar MR, Lemmens-Gruber R, Kautzky-Willer A. Clinical characteristics, modalities and complications of diabetic patients with migration background at a Central European University Clinic. Wien Med Wochenschr. 2011;161(5–6):128–35.
Kuznetsov VA, Yaroslavskaya EI, Bessonova MI, Bessonov IS, Zyrianov IP, Kolunin GV, et al. Clinical manifestations and risk factors of coronary artery disease in patients with diabetes mellitus in western Siberia. Int J Circumpolar Health. 2010;69(3):278–84.
Elissen AMJ, Hertroijs DFL, Schaper NC, Bosma H, Dagnelie PC, Henry RM, et al. Differences in biopsychosocial profiles of diabetes patients by level of glycaemic control and health-related quality of life: the Maastricht study. PLoS One. 2017;12(7):e0182053.
Elder DH, Singh JS, Levin D, Donnelly LA, Choy AM, George J, et al. Mean HbA1c and mortality in diabetic individuals with heart failure: a population cohort study. Eur J Heart Fail. 2016;18(1):94–102.
Siaw MY, Chew DE, Toh MP, Seah DE, Chua R, Tan J, et al. Metabolic parameters in type 2 diabetic patients with varying degrees of glycemic control during Ramadan: an observational study. J Diabetes Investig. 2016;7(1):70–5.
Klisic A, Kavaric N, Jovanovic M, Zvrko E, Skerovic V, Scepanovic A, et al. Association between unfavorable lipid profile and glycemic control in patients with type 2 diabetes mellitus. J Res Med Sci. 2017;22:122.
Walraven I, Mast MR, Hoekstra T, Jansen AP, van der Heijden AA, Rauh SP, et al. Distinct HbA1c trajectories in a type 2 diabetes cohort. Acta Diabetol. 2015;52(2):267–75.
Sidorenkov G, van Boven JFM, Hoekstra T, Nijpels G, Hoogenberg K, Denig P. HbA1c response after insulin initiation in patients with type 2 diabetes mellitus in real life practice: identifying distinct subgroups. Diabetes Obes Metab. 2018;20(8):1957–64.
Luo M, Lim WY, Tan CS, Ning Y, Chia KS, van Dam RM, et al. Longitudinal trends in HbA1c and associations with comorbidity and all-cause mortality in Asian patients with type 2 diabetes: a cohort study. Diabetes Res Clin Pract. 2017;133:69–77.
Penno G, Solini A, Bonora E, Fondelli C, Orsi E, Zerbini G, et al. HbA1c variability as an independent correlate of nephropathy, but not retinopathy, in patients with type 2 diabetes: the Renal Insufficiency And Cardiovascular Events (RIACE) Italian multicenter study. Diabetes Care. 2013;36(8):2301–10.
Ma WY, Li HY, Pei D, Hsia TL, Lu KC, Tsai LY, et al. Variability in hemoglobin A1c predicts all-cause mortality in patients with type 2 diabetes. J Diabetes Complicat. 2012;26(4):296–300.
Nakhjavani M, Morteza A, Jenab Y, Ghaneei A, Esteghamati A, Karimi M, et al. Gender difference in albuminuria and ischemic heart disease in type 2 diabetes. Clin Med Res. 2012;10(2):51–6.
Gao F, Chen J, Liu X, Wang X, Zhao H, Han D, et al. Latent class analysis suggests four classes of persons with type 2 diabetes mellitus based on complications and comorbidities in Tianjin, China: a cross-sectional analysis. Endocr J. 2017;64(10):1007–16.
Sheu SJ, Liu NC, Ger LP, Ho WL, Lin JY, Chen SC, et al. High HbA1c level was the most important factor associated with prevalence of diabetic retinopathy in Taiwanese type II diabetic patients with a fixed duration. Graefes Arch Clin Exp Ophthalmol. 2013;251(9):2087–92.
Wang Y, Ng MC, Lee SC, So WY, Tong PC, Cockram CS, et al. Phenotypic heterogeneity and associations of two aldose reductase gene polymorphisms with nephropathy and retinopathy in type 2 diabetes. Diabetes Care. 2003;26(8):2410–5.
Won JC, Im YJ, Lee JH, Kim CH, Kwon HS, Cha BY, et al. Clinical phenotype of diabetic peripheral neuropathy and relation to symptom patterns: cluster and factor analysis in patients with type 2 diabetes in Korea. J Diabetes Res. 2017;2017:5751687.
Loh PT, Toh MP, Molina JA, Vathsala A. Ethnic disparity in prevalence of diabetic kidney disease in an Asian primary healthcare cluster. Nephrology (Carlton). 2015;20(3):216–23.
Chen HL, Hsu WW, Hsiao FY. Changes in prevalence of diabetic complications and associated healthcare costs during a 10-year follow-up period among a nationwide diabetic cohort. J Diabetes Complicat. 2015;29(4):523–8.
Seok H, Jung CH, Kim SW, Lee MJ, Lee WJ, Kim JH, et al. Clinical characteristics and insulin independence of Koreans with new-onset type 2 diabetes presenting with diabetic ketoacidosis. Diabetes Metab Res Rev. 2013;29(6):507–13.
Gregoire JP, Sirois C, Blanc G, Poirier P, Moisan J. Persistence patterns with oral antidiabetes drug treatment in newly treated patients--a population-based study. Value Health. 2010;13(6):820–8.
Hari Kumar KV, Gupta AK, Kumar A. Clinical profile of patients using normal, high and very high insulin doses in type 2 diabetes. Diabetes Metab Syndr. 2014;8(2):72–4.
Amutha A, Datta M, Unnikrishnan R, Anjana RM, Mohan V. Clinical profile and complications of childhood- and adolescent-onset type 2 diabetes seen at a diabetes center in South India. Diabetes Technol Ther. 2012;14(6):497–504.
Zinman B, Kahn SE, Haffner SM, O'Neill MC, Heise MA, Freed MI. Phenotypic characteristics of GAD antibody-positive recently diagnosed patients with type 2 diabetes in North America and Europe. Diabetes. 2004;53(12):3193–200.
Yeung RO, Zhang Y, Luk A, Yang W, Sobrepena L, Yoon KH, et al. Metabolic profiles and treatment gaps in young-onset type 2 diabetes in Asia (the JADE programme): a cross-sectional study of a prospective cohort. Lancet Diabetes Endocrinol. 2014;2(12):935–43.
Kaukua J, Turpeinen A, Uusitupa M, Niskanen L. Clustering of cardiovascular risk factors in type 2 diabetes mellitus: prognostic significance and tracking. Diabetes Obes Metab. 2001;3(1):17–23.
Sancho-Mestre C, Vivas-Consuelo D, Alvis-Estrada L, Romero M, Uso-Talamantes R, Caballer-Tarazona V. Pharmaceutical cost and multimorbidity with type 2 diabetes mellitus using electronic health record data. BMC Health Serv Res. 2016;16(1):394.
Moehlecke M, Leitao CB, Kramer CK, Rodrigues TC, Nickel C, Silveiro SP, et al. Effect of metabolic syndrome and of its individual components on renal function of patients with type 2 diabetes mellitus. Braz J Med Biol Res. 2010;43(7):687–93.
Lee CL, Sheu WH, Lee IT, Lin SY, Liang WM, Wang JS, et al. Trajectories of fasting plasma glucose variability and mortality in type 2 diabetes. Diabetes Metab. 2018;44(2):121–8.
Mohan V, Shanthi Rani CS, Amutha A, Dhulipala S, Anjana RM, Parathasarathy B, et al. Clinical profile of long-term survivors and nonsurvivors with type 2 diabetes. Diabetes Care. 2013;36(8):2190–7.
Franch-Nadal J, Roura-Olmeda P, Benito-Badorrey B, Rodriguez-Poncelas A, Coll-de-Tuero G, Mata-Cases M. Metabolic control and cardiovascular risk factors in type 2 diabetes mellitus patients according to diabetes duration. Fam Pract. 2015;32(1):27–34.
Aguilar-Salinas CA, Reyes-Rodriguez E, Ordonez-Sanchez ML, Torres MA, Ramirez-Jimenez S, Dominguez-Lopez A, et al. Early-onset type 2 diabetes: metabolic and genetic characterization in the mexican population. J Clin Endocrinol Metab. 2001;86(1):220–6.
Lipscombe C, Burns RJ, Schmitz N. Exploring trajectories of diabetes distress in adults with type 2 diabetes; a latent class growth modeling approach. J Affect Disord. 2015;188:160–6.
Schafer I, Kuver C, Wiese B, Pawels M, van den Bussche H, Kaduszkiewicz H. Identifying groups of nonparticipants in type 2 diabetes mellitus education. Am J Manag Care. 2013;19(6):499–506.
Wan EY, Fung CS, Yu EY, Fong DY, Chen JY, Lam CL. Association of visit-to-visit variability of systolic blood pressure with cardiovascular disease and mortality in primary care Chinese patients with type 2 diabetes-a retrospective population-based cohort study. Diabetes Care. 2017;40(2):270–9.
Grenier J, Goodman SG, Leiter LA, Langer A, Teoh H, Bhatt DL, et al. Blood pressure management in adults with type 2 diabetes: insights from the diabetes mellitus status in Canada (DM-SCAN) survey. Can J Diabetes. 2018;42(2):130–7.
Marinho FS, Moram CB, Rodrigues PC, Franzoi AC, Salles GF, Cardoso CR. Profile of disabilities and their associated factors in patients with type 2 diabetes evaluated by the Canadian occupational performance measure: the Rio De Janeiro type 2 diabetes cohort study. Disabil Rehabil. 2016;38(21):2095–101.
Chao CT, Wang J, Chien KL. Both pre-frailty and frailty increase healthcare utilization and adverse health outcomes in patients with type 2 diabetes mellitus. Cardiovasc Diabetol. 2018;17(1):130.
Nunes S, Ribeiro L, Lobo C, Cunha-Vaz J. Three different phenotypes of mild nonproliferative diabetic retinopathy with different risks for development of clinically significant macular edema. Invest Ophthalmol Vis Sci. 2013;54(7):4595–604.
Bruce DG, Davis WA, Dragovic M, Davis TM, Starkstein SE. Comorbid anxiety and depression and their impact on cardiovascular disease in type 2 diabetes: the Fremantle diabetes study phase II. Depress Anxiety. 2016;33(10):960–6.
Nefs G, Pop VJ, Denollet J, Pouwer F. Depressive symptom clusters differentially predict cardiovascular hospitalization in people with type 2 diabetes. Psychosomatics. 2015;56(6):662–73.
Jeong JH, Um YH, Ko SH, Park JH, Park JY, Han K, et al. Depression and mortality in people with type 2 diabetes mellitus, 2003 to 2013: a nationwide population-based cohort study. Diabetes Metab J. 2017;41(4):296–302.
Wang RH, Lin KC, Hsu HC, Lee YJ, Shin SJ. Determinants for quality of life trajectory patterns in patients with type 2 diabetes. Qual Life Res. 2019;28(2):481–90.
Berry E, Davies M, Dempster M. Illness perception clusters and relationship quality are associated with diabetes distress in adults with type 2 diabetes. Psychol Health Med. 2017;22(9):1118–26.
Yoda N, Yamashita T, Wada Y, Fukui M, Hasegawa G, Nakamura N, et al. Classification of adult patients with type 2 diabetes using the temperament and character inventory. Psychiatry Clin Neurosci. 2008;62(3):279–85.
Chew BH, Shariff-Ghazali S, Lee PY, Cheong AT, Mastura I, Haniff J, et al. Type 2 diabetes mellitus patient profiles, diseases control and complications at four public health facilities- a cross-sectional study based on the adult diabetes control and management (ADCM) registry 2009. Med J Malaysia. 2013;68(5):397–404.
van Dijk CE, Hoekstra T, Verheij RA, Twisk JW, Groenewegen PP, Schellevis FG, et al. Type II diabetes patients in primary care: profiles of healthcare utilization obtained from observational data. BMC Health Serv Res. 2013;13:7.
Ustulin M, Woo J, Woo JT, Rhee SY. Characteristics of frequent emergency department users with type 2 diabetes mellitus in Korea. J Diabetes Investig. 2018;9(2):430–7.
Cook D, Swayne DF. Cluster analysis. Interactive and dynamic graphics for data analysis: with R and Ggobi. New York: Springer New York; 2007. p. 103–28.
Bittmann RM, Gelbard RM. Decision-making method using a visual approach for cluster analysis problems; indicative classification algorithms and grouping scope. Expert Syst. 2007;24(3):171–87.
Hofstetter H, Dusseldorp E, van Empelen P, Paulussen TW. A primer on the use of cluster analysis or factor analysis to assess co-occurrence of risk behaviors. Prev Med. 2014;67:141–6.
Kirkman MS, Briscoe VJ, Clark N, Florez H, Haas LB, Halter JB, et al. Diabetes in older adults. Diabetes Care. 2012;35(12):2650–64.
Brown AF, Mangione CM, Saliba D, Sarkisian CA. Guidelines for improving the care of the older person with diabetes mellitus. J Am Geriatr Soc. 2003;51(5 Suppl Guidelines):S265–80.
Wilmot E, Idris I. Early onset type 2 diabetes: risk factors, clinical impact and management. Ther Adv Chronic Dis. 2014;5(6):234–44.
Urakami T. Increased trend in the incidence of diabetes among youths in the USA during 2002-2012. J Diabetes Invest. 2017;8(6):748–9.
Kautzky-Willer A, Harreiter J, Sex PG. Gender differences in risk, pathophysiology and complications of type 2 diabetes mellitus. Endocr Rev. 2016;37(3):278–316.
Logue J, Walker JJ, Colhoun HM, Leese GP, Lindsay RS, McKnight JA, et al. Do men develop type 2 diabetes at lower body mass indices than women? Diabetologia. 2011;54(12):3003–6.
Peters SA, Huxley RR, Woodward M. Diabetes as a risk factor for stroke in women compared with men: a systematic review and meta-analysis of 64 cohorts, including 775,385 individuals and 12,539 strokes. Lancet. 2014;383(9933):1973–80.
Spanakis EK, Golden SH. Race/ethnic difference in diabetes and diabetic complications. Curr Diab Rep. 2013;13(6):814–23.
Nathan DM, Genuth S, Lachin J, Cleary P, Crofford O, Davis M, et al. The effect of intensive treatment of diabetes on the development and progression of long-term complications in insulin-dependent diabetes mellitus. N Engl J Med. 1993;329(14):977–86.
Ceriello A, Monnier L, Owens D. Glycaemic variability in diabetes: clinical and therapeutic implications. Lancet Diabetes Endocrinol. 2019;7(3):221–30.
Critchley JA, Carey IM, Harris T, DeWilde S, Cook DG. Variability in glycated hemoglobin and risk of poor outcomes among people with type 2 diabetes in a large primary care cohort study. Diabetes Care. 2019;42(12):2237–46.
Lachin JM, Bebu I, Bergenstal RM, Pop-Busui R, Service FJ, Zinman B, et al. Association of glycemic variability in type 1 diabetes with progression of microvascular outcomes in the diabetes control and complications trial. Diabetes Care. 2017;40(6):777–83.
Piette JD, Kerr EA. The impact of comorbid chronic conditions on diabetes care. Diabetes Care. 2006;29(3):725–31.
Ciechanowski PS, Katon WJ, Russo JE. Depression and diabetes: impact of depressive symptoms on adherence, function, and costs. Arch Intern Med. 2000;160(21):3278–85.
Munn Z, Peters MDJ, Stern C, Tufanaru C, McArthur A, Aromataris E. Systematic review or scoping review? Guidance for authors when choosing between a systematic or scoping review approach. BMC Med Res Methodol. 2018;18(1):143.
Yan S, Kwan YH, Tan CS, Thumboo J, Low LL. A systematic review of the clinical application of data-driven population segmentation analysis. BMC Med Res Methodol. 2018;18(1):121.
Acknowledgements
Nil
Funding
This research recieved grant funding from the Ministry of Health, Singapore National Innovation Challenge on Active and Confident Ageing - Chronic Disease Management (Grant number: MOH-CDM18Sep-0001). The funding sources had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
Author information
Authors and Affiliations
Contributions
LLL was the study’s principal investigator and was responsible for the conception and design of the study. SJJB, AM, YHK, SBZ, TCS and JT were the co-investigators. SJJB and AM were responsible for screening and the inclusion of relevant articles. SJJB and AM also performed the data extraction of All authors contributed to the interpretation of data. SJJB prepared the initial draft of the manuscript. All authors revised the draft critically for important intellectual content and agreed to the final submission.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable as this is a scoping review of existing literature.
Consent for publication
Not applicable as this is a scoping review of existing literature.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Additional file 1.
Details of full search strategy
Additional file 2.
Details of included studies
Additional file 3
Funding sources for included studies (n = 148)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Seng, J.J.B., Monteiro, A.Y., Kwan, Y.H. et al. Population segmentation of type 2 diabetes mellitus patients and its clinical applications - a scoping review. BMC Med Res Methodol 21, 49 (2021). https://doi.org/10.1186/s12874-021-01209-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12874-021-01209-w