
Abstract
Background
Bayesian mixture models in which the effects of SNP are assumed to come from normal distributions with different variances are attractive for simultaneous genomic prediction and QTL mapping. These models are usually implemented with Monte Carlo Markov Chain (MCMC) sampling, which requires long compute times with large genomic data sets. Here, we present an efficient approach (termed HyB_BR), which is a hybrid of an Expectation-Maximisation algorithm, followed by a limited number of MCMC without the requirement for burn-in.
Results
To test prediction accuracy from HyB_BR, dairy cattle and human disease trait data were used. In the dairy cattle data, there were four quantitative traits (milk volume, protein kg, fat% in milk and fertility) measured in 16,214 cattle from two breeds genotyped for 632,002 SNPs. Validation of genomic predictions was in a subset of cattle either from the reference set or in animals from a third breeds that were not in the reference set. In all cases, HyB_BR gave almost identical accuracies to Bayesian mixture models implemented with full MCMC, however computational time was reduced by up to 1/17 of that required by full MCMC. The SNPs with high posterior probability of a non-zero effect were also very similar between full MCMC and HyB_BR, with several known genes affecting milk production in this category, as well as some novel genes. HyB_BR was also applied to seven human diseases with 4890 individuals genotyped for around 300 K SNPs in a case/control design, from the Welcome Trust Case Control Consortium (WTCCC). In this data set, the results demonstrated again that HyB_BR performed as well as Bayesian mixture models with full MCMC for genomic predictions and genetic architecture inference while reducing the computational time from 45 h with full MCMC to 3 h with HyB_BR.
Conclusions
The results for quantitative traits in cattle and disease in humans demonstrate that HyB_BR can perform equally well as Bayesian mixture models implemented with full MCMC in terms of prediction accuracy, but with up to 17 times faster than the full MCMC implementations. The HyB_BR algorithm makes simultaneous genomic prediction, QTL mapping and inference of genetic architecture feasible in large genomic data sets.
Similar content being viewed by others

Background
Genomic prediction of genetic merit, using SNP markers, is now routinely used in animal and plant breeding to identify superior breeding individuals and so accelerate genetic gain [1–3]. Genomic prediction methodology is also increasingly used in human disease studies for the inference of genetic architecture, the identification of causal mutations (QTL mapping), and prediction of disease risk [4–8].
Genomic predictions are often implemented using linear prediction models, especially best linear unbiased prediction (BLUP) or Genomic BLUP (GBLUP), which assume that all the SNPs contribute small effects to the trait and these effects are derived from a normal distribution [1, 4, 9]. While BLUP based genomic predictions have certainly been successful in increasing genetic gain in livestock and crops [10, 11], this approach does have some limitations. One limitation is that the prediction accuracy does not persist well across multiple generations, because the severe shrinkage in these models results in the effect of causative mutation being “smeared” across many markers encompassing long chromosome segments – in other words a linear combination of effects of a large number of markers is used to capture the effect of a QTL. After several generations, the association between markers and QTL might be broken down by recombination, thereby reducing prediction accuracy. The smearing of effect of causative mutations across many SNP also results in imprecise QTL mapping with BLUP methods.
To address these problems, Bayesian mixture models (nonlinear prediction e.g. Bayes A, B, C, and R) [1, 6, 12–15] assume non-normal prior distributions of SNP effects. One example of a flexible approach, BayesR [14] defines a mixture model with SNP effects following a mixture of four normal distributions with zero, very small, small and moderate variances. In practice, the prediction accuracy of Bayesian mixture models (including BayesR) has been shown to be equal or superior to that of GBLUP for both human diseases and dairy cattle milk production traits [15–25].
In addition to the prediction of breeding values and future phenotypes using genotype data, Bayesian models (such as BayesR) can be used to map the causal polymorphisms (quantitative trait loci or QTL). For this purpose they have some advantages over traditional single SNP regression, which is commonly used to analyse genome wide association studies (GWAS) [16–24]. Single SNP regression fits one SNP at a time as a fixed effect and tests the significance of the association between the SNP and the trait, while ignoring all other SNPs. To protect against performing multiple tests, stringent P-values (P < 5*10−8) are used. This method of analysis has three limitations:1) The effect of those SNPs declared significant is usually over-estimated; 2) multiple SNPs in linkage disequilibrium with the same QTL may show an association with the trait leading to imprecision in mapping the QTL; 3) many QTL are not detected at all because no SNP reaches the stringent P-value for association with the trait. By comparison, Bayesian mixture models fit all SNPs simultaneously by treating the SNP effects as random effects drawn from a prior distribution. For example, the BayesR model has been implemented for QTL detection in the dairy cattle genome and for human disease traits [15]. The results show that BayesR can increase the power of identifying the known genes in contrast with GBLUP and GWAS.
Even though nonlinear models are attractive, one limitation is that nonlinear models typically require long computational times. Due to the hierarchical estimation of posterior distributions of SNP effects and their variances, nonlinear models have usually been implemented with Markov Chain Monte Carlo (MCMC). This requires a large number of iterations with time per iteration scaled linearly with the number of markers (m) and the number of individuals (n). Genomic data sets are now often very large and are rapidly becoming larger. For human, 300,000 to 9 million SNPs arrays genotyped on up to 253 K individuals [26, 27] are available for association studies and disease/fitness prediction. In dairy cattle, whole genome sequence data including 39 million variants has been published by the 1000 bull genomes project [28]. When confronted with such huge genomic data, Bayesian methods can be so computationally expensive that it is not possible to use them.
Two approaches have been used to develop more computationally efficient algorithms for implementing Bayesian mixture models. One is to modify MCMC with speed-up schemes. For example, Moser et al. [8] introduced a “500SNPs” scheme to pick 500 SNPs with non-zero effects to be updated instead of all the SNPs. Such modification schemes could reduce the running time by 3 ~ 6 fold. Calus et al. [29] proposed a right-hand-side updating algorithm to cluster multiple SNPs (similar to a haplotype) to be updated as one during MCMC iterations. The results on 50 K SNP panels demonstrated up to 90 % reduction in computational time without reducing prediction accuracy. The other approach is to introduce heuristic methods (e.g. iterated conditional expectation, ICE; expectation maximisation, EM) as an alternative to MCMC. There are a wide range of fast versions of Bayesian approaches to genomic prediction using these methods (including fastBayesB, emBayesB, emBayesR) [30–35], which are several orders faster than MCMC implementations. However, none of these algorithms gives consistently as high prediction accuracy as their MCMC counterparts. The EM method of Wang et al. [30], emBayesR, gave higher accuracy than ICE based methods but still had a reduction in accuracy of 5 % ~ 7 % for traits with mutations of moderate to large effect. In other words, the heuristic approximations works best when there are no mutations of moderate to large effect, otherwise accuracy can be compromised. This is undesirable, especially when the largest advantage of the non-linear Bayesian methods over BLUP is observed when there are mutations of moderate to large effect (where moderate effect can mean a QTL explaining 1 % of the variance if the data set is large)!
Motivated by the deficiency of both MCMC (long computing terms) and fast versions of nonlinear models (lower prediction accuracy with some genetic architectures), we hypothesise that a hybrid scheme, beginning with EM iterations and finishing with MCMC sampling iterations, would give similar prediction accuracy to a full MCMC implementation, while having a significant speed advantage. Here we propose a hybrid algorithm (termed HyB_BR) of Expectation-Maximisation (EM) (emBayesR) and MCMC under the BayesR model. The algorithm also incorporates a speed-up scheme where only a proportion of SNP continue to be sampled in MCMC iterations. In comparison with emBayesR [30], the main improvement is that HyB_BR introduces a limited number of MCMC iterations after EM to improve the solutions from emBayesR.
To evaluate the predictive ability and computational efficiency of HyB_BR, prediction accuracy was compared with BayesR and GBLUP in two data sets. The first data set was 800 K SNP genotypes in 16,214 Holstein and Jersey bulls and cows. The prediction accuracy within these breeds and in a third breed (Aussie Red) was evaluated. The results showed that HyB_BR achieved very similar prediction accuracy to BayesR, while reducing the running time by up to 17 fold, and overcoming the limitations of slightly reduced accuracy of emBayesR. As a result of running the algorithm, the posterior probability of each SNP being in the model was derived, and this was used for QTL mapping. The resulting QTL regions were compared between the approaches and with previous literature reports. The results demonstrated that HyB_BR has enough power to detect the major known genes affecting milk production traits in dairy cattle as well as some novel regions. HyB_BR was also evaluated in a second data set - the Welcome Trust Case Control Consortium (WTCCC) human disease data set [27]. The results demonstrated that HyB_BR is a promising method for risk prediction and genetic architecture inference for human disease traits as well.
Methods
The mixture data model
The overall model at the level of the data for HyB_BR (independent of MCMC and EM implementation) including all the relevant parameters and priors is described first. The model assumes that y, the phenotypic records of n individuals, is a linear model of fixed effects (β), SNP effect (g), random polygenic effects (v) and environmental errors (e):
where,
β = vector of p fixed effects, following uninformative priors.
g = vector of m SNP effects. For each SNP, \( {g}_i\sim b\left(i,1\right)\times N\left(0,0*{\sigma}_g^2\right)+b\left(i,2\right)\times N\left(0,0.0001*{\sigma}_g^2\right)+b\left(i,3\right)\times N\left(0,0.001*{\sigma}_g^2\right)+b\left(i,4\right)\times N\left(0,0.01*{\sigma}_g^2\right), \)in which σ 2 g is the genetic variance of the trait and b(i, k) is a scalar with two possible values {0, 1}, determining whether or not the effect of the i th SNP is derived from the k th distribution.
Pr = vector of probabilities where Pr k = scalar with the value range between 0 and 1. The parameter Pr defines the proportion of all the SNPs following each of four normal distributions k. Pr k is assumed to follow a Dirichlet distribution with the parameter α = (1, 1, 1, 1)T.
v = vector of q polygenic effects (breeding values, for the proportion of variance not explained by the SNP), with v ~ N(0, A σ 2 a ), A is the q × q pedigree-based relationship matrix, σ 2 a is the polygenic variance, q is the number of individuals in the pedigree.
e = vector of n residual errors. For cattle data, e ~ N(0, Eσ 2 e ), where E is a n × n diagonal matrix so that the error variance associated with different records can vary. For example, for bulls, the phenotype would be daughter yield deviations, which would have a lower error variance than the trait deviations (TD) of cows [36]. For human data where all phenotypes have the same magnitude of error, E matrix can be replaced by the identity matrix I.
X = n × p design matrix, allocating phenotypes y to fixed effects β.
Z = a n × m genotype matrix with elements \( {\mathbf{z}}_{\mathrm{ij}}=\left({\mathbf{s}}_{\mathrm{ij}}-2{p}_i\right)/\sqrt[2]{2{p}_i\left(1-{p}_i\right)} \), in which s ij is the genotypes of the j th individual for the i th SNP (0, 1 or 2 copies of the second allele), and p i is the allele frequency of each SNP i.
W = n × q design matrix, aims at allocating the q × 1 vector of polygenic effects to y.
Note that model (1) extends the model used by Wang et al. [30] to include fixed effects, polygenic effects and weights.
The prior distribution of each SNP effect g i conditional on b(i, k) is
Where, δ(gi) denotes the Dirac delta function with all probability mass at gi = 0.
The joint distribution p(g i , b(i, k)|Pr k ) (i.e. conditional on Pr k ) can be written as:
The implementation of HyB_BR with the mixture model defined above consists of two components: 1) The Expectation-Maximization module. HyB_BR first implements the EM iterations under the mixture Gaussian model (Eq. 2) to give approximations for the parameter set including SNP effects g, proportion of SNP in each distribution Pr, error variance σ 2 e , and polygenic variance σ 2 a . For the estimation of each SNP effect, the PEV (predicted error variance) correction is introduced to account for the errors which are generated from the estimations of all other SNP effects (detailed in Additional file 1). 2) MCMC module. Once the EM steps are converged, the output values of the parameters are used in the modified MCMC iterations as the start values. For the final step, a MCMC scheme is implemented with a limited number of iterations.
EM module
In the following EM modules, the parameter set θ = {g, Pr, β, v, σ 2 e } will be estimated by their maximum a posteriori (MAP) value. Similar to emBayesR [30], all the parameters θ were estimated according to the expectation-maximisation process with steps:
-
i)
Define the log likelihood f(y|θ) of the data under the data model (1).
-
ii)
Derive the log posterior function of the parameters using Bayes’ theorem. Following Bayes’ theorem, the log posterior distribution of the parameter sets θ is based on the rule logp(θ|y) ∝ logf(y|θ) + logp(θ), with p(θ) the prior for the parameter.
-
iii)
Take the expectation on the posterior function over the missing data.
-
iv)
Differentiate the expected posterior function and solve for this equal to zero to obtain MAP (Maximum A Posterior) of the parameter set θ.
In the Expectation-maximization implementation, the posterior distributions for each parameter p(θ|y) are obtained while “integrating out” the other parameters. For example, for the estimation of each SNP effect g i (SNP i in the vector g), we maximize the posterior distribution of each SNP effect p(g i |y, b(i, k), Prk, β, v, σ 2 e ) by integrating out the other SNP effects g j ≠ i , the parameters b(i, k), β, v, but we fix the proportion parameter Prk and the error variance σ 2 e at their maximum posterior estimates. In the following, we will detail the inference process for several key parameters including SNP effects (g), the mixing parameters (Pr k ), fixed effects (β), polygenic effects (v) and the error variance (σ 2 e ) separately:
-
1)
Estimation of SNP effects g
As in our EM version of BayesR [30], in HyB_BR we will update the estimated effect of SNPs one at a time. Therefore, we rewrite Zg in Eq. (1) as the sum of the effect of the current SNP Z i g i and the combined effect of all other SNP effects u i (u i = ∑ j ≠ i Z j g j ). We rewrite the model (1) as:
where, g i (the effect of SNP i) is the i th element of the vector g, and u i = ∑ j ≠ i Z j g j .
We estimate of ĝ i by the value of g i that maximises the posterior probability \( \mathrm{P}\left({g}_i\Big|\mathbf{y},\widehat{\mathbf{P}}\mathbf{r},\widehat{\upsigma_e^2}\right) \) where \( \widehat{\mathbf{P}}\mathbf{r} \) and \( \widehat{\upsigma_e^2} \) are the MAP estimates of Pr and σ 2 e conditional on y.
To perform this, we first introduce “missing data” (b(i, k), β, v, u i ), and then “integrate them out” via the Expectation-Maximisation steps. In detail, the marginal posterior distribution of each SNP effect g i can be written as:
\( p\left({g}_i,b\left(i,k\right)\Big|\mathbf{y},\boldsymbol{\upbeta}, \mathbf{v},{\mathbf{u}}_{\boldsymbol{i}},\widehat{\upsigma_{\mathrm{e}}^2},\ {\widehat{Pr}}_k\right)\propto p\left(\mathbf{y}\Big|{g}_i,b\left(i,k\right),\boldsymbol{\upbeta}, \mathbf{v},{\mathbf{u}}_{\boldsymbol{i}},\widehat{\upsigma_{\mathrm{e}}^2},\ {\widehat{Pr}}_k\right)p\left({g}_i,b\left(i,k\right)\Big|{\widehat{Pr}}_k\right). \)
Under the model (3), the first term \( p\left(\mathbf{y}\Big|{g}_i,b\left(i,k\right),\boldsymbol{\upbeta}, \mathbf{v},{\mathbf{u}}_{\boldsymbol{i}},\widehat{\upsigma_{\mathrm{e}}^2},\ {\widehat{Pr}}_k\right) \) is obtained according to the following normal distribution:
y − Xβ − Z i g i − Wv − u i ~ N(0, Eσ 2e ),
which can be transformed as:
Where, e* = y − Xβ − Wv − u i .
Therefore, the term \( p\left(\mathbf{y}\Big|{g}_i,b\left(i,k\right),\boldsymbol{\upbeta}, \mathbf{v},{\mathbf{u}}_{\boldsymbol{i}},\widehat{\upsigma_{\mathrm{e}}^2},\ {\widehat{Pr}}_k\right) \) can be written as: \( p\left(\mathbf{y}\Big|{g}_i,{\mathbf{u}}_{\boldsymbol{i}},b\left(i,k\right),\boldsymbol{\upbeta}, \mathbf{v},\widehat{\upsigma_{\mathrm{e}}^2},\ {\widehat{Pr}}_k\right)=\frac{1}{{\left(2\pi \widehat{\sigma_e^2}\right)}^{\frac{n}{2}}}\frac{1}{\left|\mathbf{E}\right|} exp\left[-\frac{1}{2\widehat{\sigma_e^2}}\left({\mathbf{e}}^{*}-{\mathbf{Z}}_{\mathrm{i}}{g}_i\right)\mathit{\hbox{'}}\;{\mathbf{E}}^{-1}\left({\mathbf{e}}^{*}-{\mathbf{Z}}_{\mathrm{i}}{g}_i\right)\right] \)
Then the log likelihood function is:
Ignoring an additive constant, the second term \( p\left({g}_i,b\left(i,k\right)\Big|{\widehat{Pr}}_k\right) \) is defined in the Eq. (2). Then the log of \( p\left({g}_i,b\left(i,k\right)\Big|{\widehat{Pr}}_k\right) \) is:
Treating (e*, b(i, k)) as missing data and omitting the terms without g i , the expectation of the log marginal posterior of each SNP effect is:
According to Eq (4), the expectation of the first term is:
According to the Eq. (5), the expectation of the second term is:
Where, \( P\left(i,k\right)=E\left(b\left(i,k\right)\Big|\mathbf{y},\ {\widehat{Pr}}_k\right) \). The term P(i, k) can be derived as in the Additional file 2.
Hence, in the Maximisation steps of EM, we differentiate Eqs. (6) and (7) with respect to ĝ i , and then obtain an estimate for the SNP effect as:
-
2)
Estimation of parameter Pr
This follows a common method for an EM algorithm to analyse a mixture of distributions. We introduce the ‘missing data’ b(i, k) which is the indicator variable that indicates which of the k = 4 distributions SNP effect i is drawn from. The posterior distribution of proportion parameter Pr is:
Where,
The term p(y|b) does not involve Pr. So when we differentiate with respect to Pr, this term will drop out and therefore can be ignored.
Therefore, the log posterior expression of Pr can be written as:
Treating b as the missing data and defining P(i, k) = E(b(i, k)|y, Pr k ), the expectation of the posterior can be written as:
Introducing Lagrange multiplier λ to account for the constraint that ∑ 4 k = 1 Pr k = 1 and differentiate with respect to Pr k , the parameter Pr can be estimated by:
The computation of P(i, k) is given in the Additional file 2.
-
3)
Estimation of fixed effects (β) and the error variance (σ 2 e )
Since fixed effects (β) and the error variance has uninformative priors, their posterior distribution is:
As \( \mathbf{y}-\mathbf{Z}\widehat{\mathbf{g}}-\mathbf{X}\boldsymbol{\upbeta } -\mathbf{W}\widehat{\mathbf{v}}=\mathbf{e} \), the full log likelihood based on this model is:
Treating e as the missing data, the expectation of the Eq. (11) can be expressed as
In theory, PEV(e) ≠ PEV(e*) due to e = e* + Z i g i . However, since each SNP effect is shrunk severely towards zero by GBLUP [4], we approximate PEV(e) ≅ PEV(e*). The calculation of the term PEV(e*) is detailed in the Additional file 1.
Therefore, differentiating the equation E e|y logp(σ 2 e , β, ĝ|y) with regard to σ 2e and b, we achieve:
-
4)
Estimation of polygenic effects (v)
Under the model (1), the conditional posterior density function of polygenic effects v is:
Where,
Therefore, the log posterior based on Eqs. (14) and (15) is:
According to the equation \( \mathbf{y}-\mathbf{Z}\widehat{\mathbf{g}}-\mathbf{X}\boldsymbol{\upbeta } -\mathbf{W}\widehat{\mathbf{v}}=\mathbf{e} \), the Eq. (16) can be written as:
Taking expectation over the missing data e, we get:
Differentiating the Eq. (18) with regards to v, we get:
Where, for simplicity, the variance σ 2a . will be fixed as the specified value from GBLUP estimation.
Table 1 lists all the parameters and their equation derived from EM steps.
Steps for EM module
The overall procedure of EM is described by means of the pseudo code, steps ①~⑦. Here we will detail these steps according to their sequence appearing in the pseudocode descriptions:
-
Step EM_①: Initialise the parameters g, Pr, σ 2 i and Construct X, A, G, E, W matrices. Similar to emBayesR [30], the starting values of g and Pr were set as g = 0.01 and Pr = {0.5, 0.487, 0.01, 0.003}, while σ 2 i = {0, 0.0001 * σ 2g , 0.001 * σ 2g , 0.01 * σ 2g }. The genetic variance σ 2g and polygenic variance σ 2a are obtained from GBLUP. Both variances won’t be updated during EM iterations.
The n × 3 matrix X is a design matrix, allocating the phenotypes to fixed effects. In our case, the matrix X is set up with the first column being the mean, the second and third columns defining the breeds (Holstein or Jersey) and sex (bulls or cows) of the cattle. For example, if the i th animal is a Holstein bull, then x i,2 = 1 with x i,3 = 0.
The Pedigree relationship matrix A is built using Henderson’s rules [37]; while the genomic relationship matrix G is constructed using the equation G = ZZ ' /n. Diagonal error matrix E is calculated following Garrick et al. [36], and the index matrix W maps individuals in the pedigree to the phenotypes if they have ones.
-
Step EM_②: Calculate the PEV matrix under model 1 (Additional file 1). Then using PEV matrix, calculate \( tr\left({\mathbf{E}}^{-1}{\mathbf{Z}}_{\mathbf{i}}{\mathbf{Z}}_{\mathbf{i}}^{\mathit{\hbox{'}}}{\mathbf{E}}^{-1}\mathbf{P}\mathbf{E}{\mathbf{V}}_{{\mathbf{u}}_1}\left(\mathbf{e}\right)\right) \) which is used in the equation for \( {E}_{e^{*}} logP\left(i,k\right) \) (Additional file 2). In theory, the calculation of this term should be updated each EM iteration, which is time consuming. To avoid huge computational burden, the PEV matrix is treated as constant value for the term \( tr\left({\mathbf{E}}^{-1}{\mathbf{Z}}_{\mathbf{i}}{\mathbf{Z}}_{\mathbf{i}}^{\mathit{\hbox{'}}}{\mathbf{E}}^{-1}\mathbf{P}\mathbf{E}{\mathbf{V}}_{{\mathbf{u}}_1}\left(\mathbf{e}\right)\right) \) in front of EM loop.
Then for each SNP i (i in 1 to m)
-
Step EM_③: Correct y for the effects of all other SNPs except current SNP i with equation \( {\mathbf{y}}^{\dagger }=\mathbf{y}-{\displaystyle {\sum}_{\mathrm{j}\ne \mathrm{i}}\kern0.5em {\mathbf{Z}}_{\mathbf{j}}}\kern0.5em {\widehat{\mathrm{g}}}_{\mathrm{j}}-\mathbf{X}\widehat{\mathbf{b}}-\mathbf{W}\widehat{\mathbf{v}}. \)
-
Step EM_④: Estimate the probability that the effect of SNP i is from one of four normal distributions \( {E}_{e^{*}} logP\left(i,k\right) \) with the equation (S3). After this, P(i, k) is calculated with the equation \( exp\left({E}_{e^{*}} log{P}_{ik}/{\displaystyle {\sum}_{k=1}^4 exp\kern0.5em }\left({E}_{e^{*}} log{P}_{ik}\right)\right) \) (S4).
-
Step EM_⑤: the SNP effect ĝ i is updated via Eq. (8).
After effects have been estimated for all SNP,
-
Step EM_⑥: Estimate σ 2 e with Eq. (12), fixed effects β with Eq. (13), update Pr k with Eq. (10), and update polygenic effects v with the Eq. (19).
-
Step EM_⑦: Assess convergence criterion (ĝ l − ĝ l − 1) ' (ĝ l − ĝ q − 1)/((ĝ l' ĝ l) ≤ 10− 10 with l being the EM iterations number. If not converged, then return to Step ③ for the next EM iteration; otherwise, exit the EM iterations and return the estimates of parameters from the final iterations.
Modified MCMC module with speed-up scheme
The outputs of the EM including SNP solutions, polygenic effects, error variance and genetic variance are used as starting values of parameters for the MCMC module, which allows MCMC to begin with no burn in.
The MCMC module of HyB_BR implements the same Gibbs sampling processes as BayesR [15] but modified with one speed-up scheme as follows. Over the first 500 iterations, the average probability that the SNP effect is zero (p(i, 1)) is calculated. If p(i, 1) ≥ a, then the SNP effect is set to zero and is not updated in future iterations.
The test for selecting a reasonable value of the parameter a was conducted as follows. The impact of value of a from 0.85 to 0.95 on prediction accuracy was investigated for the milk production traits and fertility, Fig. 1. The results show that criterion p(i, 1)≥, 1, is the lowest threshold which gives an accuracy very close to the maximum. The criterion means SNP i has more than 90 % probability of having no effect.

The trend of prediction accuracy according to a range of values of the threshold parameter a
The modified MCMC steps can then be described as follows:
-
Step MCMC_①: sampling the error variance \( {\widehat{\upsigma}}_{\mathrm{e}}^2 \) according to the distribution \( {\widehat{\upsigma}}_{\mathrm{e}}^2\sim Inv-{\upchi}^2\left(n-2,\frac{{{\mathbf{y}}^{*}}^{\hbox{'}}{\mathbf{E}}^{-1}{\mathbf{y}}^{*}}{n-2}\right) \), with \( {\mathbf{y}}^{*}=\left(\mathbf{y}-\mathbf{Zg}-\mathbf{X}\widehat{\boldsymbol{\upbeta}}-\mathbf{W}\widehat{\mathbf{v}}\right). \)
-
Step MCMC_②: sampling the fixed effects β from the distribution \( N\Big(\ {\boldsymbol{\upbeta}}_{\mu },{\left(\mathbf{X}\mathit{\hbox{'}}\;{\mathbf{E}}^{-1}\mathbf{X}\right)}^{-1}{\widehat{\upsigma}}_{\mathrm{e}}^2 \)), with \( {\boldsymbol{\upbeta}}_{\mu }={\left(\mathbf{X}\mathit{\hbox{'}}\;{\mathbf{E}}^{-1}\mathbf{X}\right)}^{-1}\mathbf{X}\mathit{\hbox{'}}\;{\mathbf{E}}^{-1}\left(\mathbf{y}-\mathbf{Z}\widehat{\mathbf{g}}-\mathbf{W}\widehat{\mathbf{v}}\right) \).
-
Step MCMC_③: Polygenic variance is sampled \( {\widehat{\upsigma}}_{\mathrm{a}}^2\sim Inv-{\upchi}^2\left(n-2,\frac{\widehat{\mathbf{v}}\mathit{\hbox{'}}\;{\mathbf{A}}^{-1}\widehat{\mathbf{v}}}{n-2}\right) \).
-
Step MCMC_④: The polygenic effects are sampled from normal distribution N(μ, s), with the mean \( \mu =\widehat{\mathbf{v}} \) from Eq. (19) and the variance\( s={\left(\mathbf{W}\mathit{\hbox{'}}\;{\mathbf{E}}^{-1}\mathbf{W}+{\mathbf{A}}^{-1}{\upsigma}_{\mathrm{e}}^2/{\upsigma}_{\mathrm{a}}^2\right)}^{-1}. \)
Then for each SNP i (i in 1 to m),
-
Step MCMC_⑤: Implement the speed-up scheme : if (iterations > 500) and (P(i, 1) > 0.9), then stop updating this SNP i.
Else,
-
Step MCMC_⑥: Estimate the log likelihood that the effect of SNP i is from one of four normal distributions L(g i |σ 2 i [k]). Following the derivation steps of Kemper et al. [15], the optimised equation of the log likelihood function is
\( \begin{array}{c}L\left({g}_i\Big|{\upsigma}_i^2\left[k\right]\right)=-\frac{1}{2}\left\{ \log \left({\upsigma}_i^2\left[k\right]{\mathbf{Z}}_{\mathbf{i}}^{\boldsymbol{\hbox{'}}}{\mathbf{Z}}_{\mathbf{i}}+{\upsigma}_{\mathrm{e}}^2\right)+{\left(\left({e}^{*}\right)\mathit{\hbox{'}}\;{\mathbf{E}}^{-1}{\mathbf{Z}}_{\mathbf{i}}\right)}^2{\upsigma}_i^2\left[k\right]{\upsigma}_{\mathrm{e}}^{-2}/\left({\upsigma}_i^2\left[k\right]{\mathbf{Z}}_{\mathbf{i}}^{\boldsymbol{\hbox{'}}}{\mathbf{E}}^{-1}{\mathbf{Z}}_{\mathbf{i}}+{\upsigma}_{\mathrm{e}}^2\right)\right\}\\ {}+ log{ \Pr}_{\mathrm{k}},\end{array} \)
with e* = y − Xβ − u − Wv.
After this, P(i, k) is calculated with the equation:\( exp\Big(L\left({g}_i\Big|{\upsigma}_i^2\left[k\right]\right)/{\displaystyle {\sum}_{k=1}^4 exp\kern0.5em }\left(L\left({g}_i\Big|{\upsigma}_i^2\left[k\right]\right)\right) \)
-
Step MCMC_⑦: Sample ĝ i with N(μ, s), \( \mu ={\left[{\mathbf{Z}}_{\mathrm{i}}^{\mathit{\hbox{'}}}{\mathbf{E}}^{-1}{\mathbf{Z}}_{\mathrm{i}}+\frac{\widehat{\upsigma_{\mathrm{e}}^2}}{\upsigma_i^2\left[k\right]}\right]}^{-1}\left[{\mathbf{Z}}^{\mathit{\hbox{'}}}{\mathbf{E}}^{-1}\ {e}^{*}\right] \), and \( s={\left[{\mathbf{Z}}_{\mathrm{i}}^{\mathit{\hbox{'}}}{\mathbf{E}}^{-1}{\mathbf{Z}}_{\mathrm{i}}+\frac{\widehat{\upsigma_{\mathrm{e}}^2}}{\upsigma_i^2\left[k\right]}\right]}^{-1} \).
-
Step MCMC_⑧: Update Pr ~ Dirichlet(β1 + 1, β2 + 1, β3 + 1, β4 + 1),where β1, β2, …, β4 are the number of SNPs in one of four normal distributions.
Return to MCMC step 1.
HyB_BR was written in the C++ programming language.
Data
Cattle
One thousand seven hundred forty-five Holstein and Jersey cattle and 114 Australian Red bulls were genotyped with the 777 K Illumina HD bovine SNP chip. 15,049 Holstein and Jersey bulls and cows, 249 Australian red bulls and cows were genotyped with the 54 K Illumina Bovine SNP array. After stringent quality control and SNP filtering described in [14], there were 632,003 SNPs remaining for animals genotyped with the 777 K SNP panel, and 43,425 SNPs remaining for animals genotyped with the 54 K SNP array. Animals genotyped with the 43,425 SNPs, were imputed to 632,003 SNP genotypes using Beagle 3.0 [38]. Therefore, the total data set was 17,157 cattle of three breeds with real or imputed genotypes for 632,003 SNP.
The phenotypes include milk yield, protein yield, fat percent(fat%), and cow fertility. The heritability of these traits varies from 0.33 (for milk yield, protein yield and fat%), to 0.03 (for cow fertility). The fertility (reproductive performance of dairy cows) is usually measured according to calving interval (CI, the number of days between successive calvings), days from calving to first service (CFS), pregnancy diagnosis, lactation length (LL), and survival to second lactation on Australian Holstein and Jersey cows [39, 40]. Here, the fertility phenotype was calving interval (CI). Here, the fertility phenotype is mainly derived from CI. The phenotypes for all the traits were daughter trait deviations (DTD) for bulls (the average of their daughters phenotypes, corrected for fixed effects), and trait deviations (TD) for cows (as described by Kemper et al. [15]). For genomic prediction, the data was separated into a reference set, where SNP effects were estimated, and validation sets, where the prediction accuracy was assessed, and the division of animals into reference and validation sets was by year of birth (youngest animals in validation set). The reference data includes bulls and cows from two breeds (Holstein and Jersey), and the predictions were evaluated in the other animals of the same breeds or in a breed (Aussie red) not included in the reference set. The exact number of individuals in these data sets for each trait is given in Table 2.
To compare the computational time required by the different genomic prediction methods, we also used three reference sets with increasing different numbers of animals; Ref 1_ CATTLE had 3049 Holstein bulls; Ref 2_CATTLE had 11,527 Holstein bulls and cows, while Ref 3_CATTLE was the complete reference data set with 16,214 animals.
For the EM module, estimates of three variance components (σ 2 e , σ 2 v , σ 2 g ) were required as the input. We ran Asreml4.0 [41] (which is implemented with GBLUP methods) on these data sets to estimate these variance parameters and the results are listed in Table 3.
The correlation between GEBV and DTD in the validation sets was used as a proxy for prediction accuracy. The regression of DTD on GEBV in the validation sets was used to investigate if any of the methods resulted in biased predictions.
Case/Control human disease trait data
For predicting human disease risk, seven disease traits of the Welcome Trust Case Control Consortium (WTCCC) genomic data [27] including bipolar disorder (BD), coronary artery disease (CAD), Crohn’s disease (CD), Hypertension (HT), rheumatoid arthritis (RA), type 1 diabetes (T1D), and type 2 diabetes (T2D) were used. Following the steps of strict QC on SNP data [7, 8, 42] with Plink [43], we had seven combined case/control data sets (one for each trait) with different number of markers and records listed in Table 4. The input parameters of seven datasets for HyB_BR including error variance and genetic variance were calculated by GCTA [44], given in Table 4. To assess prediction accuracy, for each disease, we randomly generated 20 splits of the data with 80 % of individuals for the reference set and 20 % for the validation set. To assess the prediction ability, the area under the ROC curve (AUC) [45] was calculated.
Results
Compute time comparison of HyB_BR and BayesR
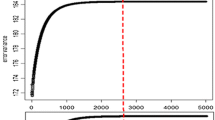
To compare computational efficiency, HyB_BR without the speed-up scheme (labelled as Hyb_BR_Orig), HyB_BR with the speed-up scheme and pure MCMC BayesR were implemented on three data sets with 632,003 markers but different numbers of records, varying from 3049 in Ref 1_CATTLE, 11,527 in Ref 2_CATTLE, to 16,214 in Ref 3_CATTLE. As used by Kemper et al. [15], pure MCMC BayesR required 40,000 iterations of complexity O(mn) with parameters estimated from samples from the posterior distributions (m is the number of markers and n is the number of individuals). The first 20,000 iterations were removed as burn in. The MCMC module of HyB_BR used only 4000 iterations and burn-in was replaced by the EM (400 iterations to convergence). 4000 cycles for the MCMC module were used after comparing results with increasing number of iterations. The results showed that 4000 were necessary to achieve maximum prediction accuracy (Fig. 2).

Prediction accuracy with an increasing number of MCMC iterations for BayesR
The prediction accuracy was evaluated for milk yield with a reference set containing the Holstein and Jersey bulls&cows data.
With the smallest data set (Ref 1_CATTLE), 5 h compute time was required for HyB_BR compared with 96 h for BayesR MCMC (Fig. 3); 35 h required by HyB_BR instead of 410 h of BayesR for Ref 2_CATTLE; And in Ref 3_CATTLE, 42 h for HyB_BR_sp but 720 h for BayesR. These results suggest HyB_BR is at least 10 times faster than BayesR MCMC, with the speed advantage increasing as data sets became larger (17 times faster with the largest data set). The HyB_BR speed up scheme reduced compute time by approximately 50 %, compared to HyB_BR_Orig without the speed up scheme (Fig. 3), with no reduction in the prediction accuracy (Tables 5, 6 and 7).

Computational time in hours required for BayesR, HyB_BR_Orig, and HyB_BR_sp on three reference sets (Ref 1_CATTLE, Ref 2_CATTLE, Ref 3_CATTLE)
These timings were recorded on a server with Intel E5-2680 2.7GHz processors and 384GB of 1333 MHz RAM.
The accuracy and bias of within-breeds, multi-breeds and across-breeds prediction for four complex dairy traits
Genomic prediction with a single breed reference
For the within-breed prediction (that is, when a Holstein reference was used to estimate SNP effects used for calculating GEBV in a Holstein validation set, and likewise for Jersey) in Table 5, HyB_BR performed as well as BayesR for all traits, including fat%. Both BayesR and HyB_BR had a 1 % ~ 6 % superiority of accuracy over GBLUP for Milk yield, Protein yield and Fat%, but had no advantage for fertility. Similarly, for the prediction of Jersey validation with Jersey reference, BayesR and HyB_BR had a consistent advantage over GBLUP for milk production traits, but not for fertility. Especially, for the trait Fat%, BayesR and HyB_BR gave very similar results, with a 17 % increase in accuracy (0.79 vs 0.73 in Holstein and 0.71 vs 0.54 in Jersey) of genomic prediction over GBLUP, as well as a 5 % increase in accuracy over emBayesR. HyB_BR and BayesR also gave regression coefficients closer to one than GBLUP for most traits.
Genomic prediction with a multi-breed reference
When predicting the Holstein or Jersey validation with the combined Holstein and Jersey reference, HyB_BR had the same accuracy as BayesR, Table 5. Compared with GBLUP, BayesR and HyB_BR gave consistently higher accuracy increase for the milk production traits, though this was not observed for fertility. And for the prediction of Jersey validation set, BayesR and HyB_BR improved accuracy for the milk production traits by 11 % compared with GBLUP. The results show that there are small but consistent accuracy improvements as a result of using the multi-breed reference (compare Tables 5 and 6), consistent with the results of Kemper et al. [15] and Hoze et al. [46].
Also, including polygenic effects (estimated using the pedigree) in the model can improve the prediction accuracy by 1 ~ 2 %, at least for milk production traits, Tables 5 and 6. However, for fertility the introduction of polygenic effects for all the prediction methods did not impact the accuracy at all.
Compared with GBLUP and emBayesR, BayesR and HyB_BR gave less biased predictions for milk production traits. However for fertility the regression values far from one indicate bias, from all methods – the low accuracy of fertility phenotypes, including in the validation set, likely contributes to this.
Genomic prediction across breeds
For predicting Australian Red validation bulls (an additional breed to those in the reference set), BayesR and HyB_BR gave higher accuracy than GBLUP for all traits (Table 7).
Across all the prediction results shown in Tables 5, 6 and 7, emBayesR had a 2 % ~ 5 % reduction in accuracy compared with BayesR and HyB_BR for fat%, while BayesR and HyB_BR gave almost identical accuracies in all cases.
Inferred genetic architecture and QTL mapping for dairy production and fertility traits
Bayes R described the genetic architecture of a trait by the posterior proportion of SNPs in each of the four different distributions. Table 8 reported the estimated proportion in each of four distributions from BayesR, emBayesR, and HyB_BR. The number of SNPs falling into the distribution with the largest variance was similar for all three methods. Compared with BayesR, HyB_BR tended to estimate more SNPs (up to 5 %) in the distribution with variance 0.001 * σ 2 g , and 0.0001 * σ 2 g . In contrast to HyB_BR, emBayesR tended to estimate that a higher proportion of SNPs have no effect than does BayesR. This may explain the lower accuracy it achieves.
QTL mapping for dairy production and fertility traits
Both BayesR and HyB_BR estimate the posterior probability that every SNP has a non-zero effect on the trait. This is useful for QTL mapping – SNP with very high posterior probabilities of having a non-zero effect should be strongly associated with causal mutations (e.g. Moser et al. [8], Kemper et al. [15]). Then, QTL mapping from BayesR and HyB_BR can be conducted by plotting the posterior probability of each SNPs having a non-zero effect on the trait by genome position, and then comparing the genome location of the effects with a high posterior probability of being in the largest distribution for each method.
The estimated posterior possibilities of all the SNPs (y axis) related to four different traits were plotted according to the positions (base pairs) of SNPs on the whole genome (x axis) in Figs. 4, 5, 6 and 7. The top SNPs with high posterior possibilities were picked up according to the number of SNPs in the variance 0.01 * σ 2 g (the total number of markers * Pr [4]). Table 9 listed all the top SNPs in the variance related to the previously reported genes with a effect on milk production including CSF2RB [47], GC [48], GHR/CCL28 [18], PAEP [17], MGST1 [49], and DGAT1 [16]. Both BayesR and HyB_BR identified all of these regions, which demonstrated that HyB_BR can perform QTL mapping with similar precision to BayesR. For example, HyB_BR could detect the DGAT1 as well as BayesR shown in Fig. 6 (Fat%).

Mapping all the SNPs’ posterior possibilities estimated from BayesR and HyB_BR across the whole chromosome related to milk yield. The posterior possibility is calculated based on the sum of the posterior possibilities P(i, k) of each SNP with non-zero variances written as ∑ 4 k = 2 P(i, k). The blue circle is the SNPs (picked up based on the high posterior possibility following in the distribution with largest variances) with location information mapped to known genes

Mapping all the SNPs’ posterior possibilities estimated from BayesR and HyB_BR across the whole chromosome related to protein yield. The posterior possibility is calculated based on the sum of the posterior possibilities P(i, k) of each SNP with non-zero variances written as ∑ 4 k = 2 P(i, k). The blue circle is the SNPs (picked up based on the high posterior possibility following in the distribution with largest variances) with location information mapped to known genes

Mapping all the SNPs’ posterior possibilities estimated from BayesR and HyB_BR across the whole chromosome related to Fat percent (Fat%). The posterior possibility is calculated based on the sum of the posterior possibilities P(i, k) of each SNP with non-zero variances written as ∑ 4 k = 2 P(i, k). The blue circle is the SNPs (picked up based on the high posterior possibility following in the distribution with largest variances) with location information mapped to known genes

Mapping all the SNPs’ posterior possibilities estimated from BayesR and HyB_BR across the whole chromosome related to fertility. The posterior possibility is calculated based on the sum of the posterior possibilities P(i, k) of each SNP with non-zero variances written as ∑ 4 k = 2 P(i, k). The blue circle is the SNPs (picked up based on the high posterior possibility following in the distribution with largest variances) with location information mapped to known genes
The application of HyB_BR to predict the risk of Human disease traits and infer genetic architecture for these traits
In the human data, cross validation was used to estimate the accuracy of HyB_BR. As there were 20 replicates of 20/80 split (validation/reference), we evaluated the mean of the AUC for each disease shown in Table 10. Analysis methods compared were GBLUP implemented in GCTA [44], BayesR from Moser et al. [8], and HyB_BR. The standard deviations of the accuracy (across the 20 replicates) were also listed in the parenthesis of Table 10. HyB_BR and BayesR performed equally well across all seven traits, with the same prediction accuracy for each trait. For the diseases of CD, RA, and T1D, BayesR and HyB_BR had significantly higher accuracy than GBLUP. Especially for T1D, BayesR and HyB_BR could have up to 12 % accuracy increase compared with GBLUP. However, for other traits including BD, CAD, HT, and T2D, BayesR and HyB_BR did not show any superiority over GBLUP. The underlying architecture of these traits might explained this, as suggested by Moser et al. [8]. In detail, for CD, RA and T1D, there are known mutations of moderate to large effect, and the mixture assumptions of BayesR and HyB_BR can take advantage of this. However, for four other diseases including BD, CAD, HT, and T2D, there are no known mutations of moderate to large effect, and this is reflected in the genetic architecture for these diseases inferred by HyB_BR.
The genetic architecture of human disease traits
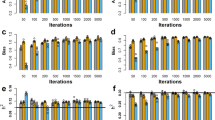
The inferred genetic architecture was different for each of the seven diseases (Table 11). For example, the genetic architecture of BD is controlled by many SNPs (9077 for HyB_BR; 9611 for BayesR) with small effects (the variance 0.0001σ 2 g ), but just 3 SNPs with large effects (the variance 0.01σ 2 g ). These numbers demonstrated the polygenic architecture of BD. On the contrary, for T1D, there was relatively smaller number of SNPs (3544 for HyB_BR; 2750 for BayesR) with small effects but many more SNPs (almost 200) with large effects. The proportion numbers from Fig. 8 also demonstrated this (in accordance with the results from Moser et al. [8]). Large proportion of SNPs with small effects (the variance 0.0001σ 2 g ) controlled the polygenic architecture of the diseases BD (98.76 % for HyB_BR; 99.55 % for BayesR), CAD (97.31 % for HyB_BR; 96.8 % for BayesR), HT (96.96 % for HyB_BR; 98.09 % for BayesR), and T2D (95.14 % for HyB_BR; 97.79 % for BayesR). For these diseases, the mixture model of BayesR and HyB_BR did not have much advantage. However, relatively larger proportions of SNPs with moderate effects (the variance 0.001σ 2 g ) existed for the traits RA (0.77 % for HyB_BR; 0.93 % for BayesR) and T1D(5.02 % for HyB_BR; 5.54 % for BayesR). For these two traits controlled by major genes, BayesR and HyB_BR gave substantially greater accuracy than GBLUP, which explained the results for prediction accuracy (Table 10).

The inferred genetic architecture of seven human diseases from BayesR and HyB_BR. The blue bar is the proportion of SNPs in Pr [2] (with the variance 0.0001 * σ 2 g ), which is estimated by the number of SNP in Pr [2] divided by the total number of SNPs with nonzero variance. The red bar is the proportion of SNPs with the variance 0.001 * σ 2 g , estimated by the number of SNP in Pr [3] divided by the total number of SNPs with nonzero variance. The green bar is the proportion of SNPs with the variances 0.01 * σ 2 g , estimated by the number of SNPs in Pr [2] divided by the total number of SNPs with nonzero variance
Compared with BayesR, HyB_BR detected the same number of SNPs with moderate variance (the variance 0.01 * σ 2 g ) but appeared to systematically detect more SNPs in the proportion of small variance (the variance 0.0001 * σ 2 g ), similar to the results observed for the comparison of BayesR and HyB_BR in in dairy cattle data (Table 8).
Discussion
We have presented a novel and computationally efficient algorithm termed HyB_BR for simultaneous genomic prediction and QTL mapping. A pure EM algorithm was less accurate for some traits, while pure MCMC requires very long computation times. Therefore, HyB_BR implements the EM algorithm followed by a limited number of MCMC iterations. In this way, the algorithm takes advantage of the features of an EM algorithm (rapid convergence) and the higher accuracy from MCMC implementations in a hybrid scheme. Our accuracies of genomic prediction for complex traits in human and cattle from HyB_BR are almost identical to those from the full MCMC implementation of the Bayesian mixture model, with a 10 fold or greater reduction in computing time required.
For the pure MCMC algorithm, the burn-in stage can account for up to 50 % of the total running time. One of the key advantages of HyB_BR is that the EM module effectively replaces the burn-in cycles that are usually required for MCMC. Based on the starting point from EM (with very limited number of iterations; less than 500 iterations), the running time of HyB_BR can be much reduced.
The pure EM algorithm, EmBayesR [30] has been demonstrated to be much faster than BayesR, but had lower accuracy for some traits, particularly those with mutations of moderate to large effect. For example, when implemented on the trait fat% in dairy cattle, emBayesR had a decreased accuracy of 5 % ~ 7 % compared to BayesR. One possible explanation is that emBayesR shrinks SNP effects too much (shown in Table 8). This could be because the PEV that is used to account for the error of the effects of all the other SNPs while estimating the effect of the current SNP is only an approximation. The introduction of PEV correction is based on one observation: previous fast algorithm studies (especially Iterative conditional expectation algorithms) assumed the effects of the other SNPs were estimated perfectly while estimating the effect of the current SNP, leading to poor performance [30]. Therefore, EmBayesR and the EM part of HyB_BR allow for the errors in the effect of other SNPs and other location parameters by using the PEV. The calculation of the PEV from GBLUP is carried out before the iterations to estimate the effects of each SNP. And since the normal priors from GBLUP model do not allow for SNPs of moderate to large effects, such PEV calculation is an approximation and this may be one reason for loss of accuracy in the EM. To deal with this, HyB_BR further implements a small number of MCMC iterations to improve the outcome of pure EM steps.
HyB_BR has three advantages. First, as the size of genomic data increases, the computational efficiency of HyB_BR without burn-in stage (a small number of O(mn) iterations), is greater than BayesR by full MCMC. And when implemented with the speed-up scheme described in the methods, computational time can be reduced even further, by sampling a reduced set of SNPs in the MCMC module, apparently with no loss of accuracy (but critically the information from the SNPs that are not sampled remains in the posterior proportions of SNPs in each distribution). Second, the prediction accuracy of HyB_BR is comparable to BayesR in all cases including dairy cattle and human disease prediction shown in Tables 5, 6 and 7, and Table 10. Third, HyB_BR, like BayesR, is flexible with respect to the genetic architecture of complex traits. As shown in Tables 5, 6 and 7, HyB_BR performs well on four different complex traits, with architecture ranging from highly polygenic architecture to genetic architecture controlled by major genes. In addition to the prediction on the continuous quantitative traits of dairy cattle, the investigation on the risk prediction of seven case/control human diseases with binary 0/1 phenotypes shows HyB_BR and BayesR perform on this type of data, Table 10. Finally, the posterior probabilities of SNP having a nonzero effect from HyB_BR can be used for QTL mapping, Fig. 6.
Implementing genomic prediction methods with whole genome sequence data may improve the prediction accuracy and accelerate the discovery of causal variants. However, for this to occur, more computationally efficient genomic prediction algorithms are required. Compared with BayesR, the predicted time of HyB_BR on different number of markers with the same reference phenotypesis listed in Table 12. The time is estimated linearly on the number of markers and individuals. When the number of markers reaches 30 million (the number of variants discovered in the 1000 bull genomes project, Daetwyler et al. [28]), the running time of BayesR is around 34,170 h, which is impractical. On the contrary, on the same data with 30 million of variants, HyB_BR is predicted to require 2010 h. It may be possible to reduce this further by optimising the code even more. Therefore, as the size of genomic data increases, HyB_BR will remain feasible well beyond the point where the use of BayesR is impractical.
While HyB_BR performs well with computational efficiency and robust prediction accuracy, there are at least still two strategies that could be used to further improve efficiency. There is one key part of EM module that consumes running time and memory: the calculation of tr(E − 1 Z i Z ' i E − 1 PEV) for each SNP in front of EM iterations. In detail, the calculation of tr(E − 1 Z i Z ' i E − 1 PEV) requires the time complexity of \( O\left(\frac{1}{2}m{n}^2\right) \), which accounts for almost 2/3 of the computational time required for the EM module even though the calculation is made in front of the EM iterations. Therefore, a future task is to implement a multi-threaded version to improve speed. The threshold of limiting the number of SNPs to be updated requires further study. Currently we define the threshold as T: if(P(i, 1) > 0.9), which is applicable for the current data. However, it’s uncertain whether or not such a threshold is suitable for other types of data.
HyB_BR has some features in common with other mixture methods such as BSLMM [6], and BOLT-LMM [25]. All of these methods declared the merit of computational efficiency with time complexity O(mn) but under different mixture models. In detail, BSLMM assumed a large proportion of SNPs with small effects (under BLUP models), while others had large effects (under Bayesian sparse regression models; the mixture of two normal priors). Due to limited number of SNPs implemented for MCMC sampling (large proportion of SNPs are under GBLUP models), BSLMM could be computationally efficient. However, compared with the mixture of four normal distributions by BayesR which provided great flexibility with respect genetic architecture, the flexibility of BSLMM with respect to different genetic architectures required further investigation. Another algorithm is BOLT-LMM, which has been developed mainly for the association studies. BOLT-LMM incorporated Bayesian mixture models to improve the power of GWAS with appealing outcomes. Instead of MCMC sampling, BOLT-LMM implemented iterative conditional expectation (ICE) algorithm on a mixture of two normal distributions to improve the computational speed with the approximated computational complexity O(mn). There could be three limitations with this method: 1) ICE algorithms did not account for the PEVs from all other SNP effects during the estimation of current SNP effect. On practical data sets, ICE could lead to the loss of prediction accuracy. BOLT-LMM introduced LD score regression technique to calibrate the prediction errors. However, since the calibrating factor was constant across all the SNPs (the prediction error variance regarding each SNP differs according to our equation (E − 1 Z i Z ' i E − 1 PEV)), such calibration scheme seem not to be effective to solve the problem. 2) The leave-one-chromosome-out scheme implemented in BOLT-LMM might perform well for GWAS but not be suitable for simultaneous genomic prediction. 3) BOLT-LMM treated each SNP effect as a fixed effect for the association statistics. This combined with the stringent significance threshold for multiple testing, leaded to the over-estimation for SNP effects. Another efficient method for genomic prediction termed MultiBLUP [7] introduced SNPs clusters into BLUP models according to its adaptive algorithm. For each SNP class, the linear combination models (using genomic relationship matrix) similar to GBLUP were implemented. MultiBLUP has been demonstrated to be computationally efficient with robust prediction accuracy in the human data sets. However, when moved to dairy cattle genomic data sets, there is long Linkage disequilibrium (LD) between markers, which might be easily broken up by multiBLUP models.
Conclusions
In summary, HyB_BR is a computationally efficient method for simultaneous genomic prediction, QTL mapping and inference of genetic architecture. The hybrid scheme of MCMC and EM decreases computational time by a factor of at least 10 fold with no reduction in prediction accuracy. The HyB_BR algorithm makes simultaneous genomic prediction, QTL mapping and inference of genetic architecture feasible in extremely large genomic data sets including whole genome sequence data.
References
Meuwissen THE, Hayes BJ, Goddard ME. Prediction of total genetic value using genome-wide dense marker maps. Genetics. 2001;157(4):1819–29.
Goddard ME, Hayes BJ. Mapping genes for complex traits in domestic animals and their use in breeding programmes. Nat Rev Genet. 2009;10(6):381–91.
Meuwissen T, Hayes B, Goddard M. Accelerating improvement of livestock with genomic selection. Annu Rev Anim Biosci. 2013;1(1):221–37.
Yang J, Benyamin B, McEvoy BP, Gordon S, Henders AK, Nyholt DR, Madden PA, Heath AC, Martin NG, Montgomery GW, et al. Common SNPs explain a large proportion of the heritability for human height. Nat Genet. 2010;42(7):565–9.
de los Campos G, Gianola D, Allison DB. Predicting genetic predisposition in humans: the promise of whole-genome markers. Nat Rev Genet. 2010;11(12):880–6.
Zhou X, Carbonetto P, Stephens M. Polygenic modeling with Bayesian sparse linear mixed models. PLoS Genet. 2013;9(2):e1003264.
Speed D, Balding DJ. MultiBLUP: improved SNP-based prediction for complex traits. Genome Res. 2014;24(9):1550–7.
Moser G, Lee SH, Hayes BJ, Goddard ME, Wray NR, Visscher PM. Simultaneous discovery, estimation and prediction analysis of complex traits using a Bayesian mixture model. PLoS Genet. 2015;11(4):e1004969.
VanRaden PM. Efficient methods to compute genomic predictions. J Dairy Sci. 2008;91(11):4414–23.
VanRaden PM, Null DJ, Sargolzaei M, Wiggans GR, Tooker ME, Cole JB, Sonstegard TS, Connor EE, Winters M, van Kaam JBCHM, et al. Genomic imputation and evaluation using high-density holstein genotypes. J Dairy Sci. 2013;96(1):668–78.
Wolc A, Zhao HH, Arango J, Settar P, Fulton JE, O’Sullivan NP, Preisinger R, Stricker C, Habier D, Fernando RL, et al. Response and inbreeding from a genomic selection experiment in layer chickens. Genet Sel Evol. 2015;47:59.
Gianola D. Priors in whole-genome regression: the Bayesian alphabet returns. Genetics. 2013;194(3):573–96.
Habier D, Fernando RL, Kizilkaya K, Garrick DJ. Extension of the bayesian alphabet for genomic selection. BMC Bioinf. 2011;12(1):1–12.
Erbe M, Hayes BJ, Matukumalli LK, Goswami S, Bowman PJ, Reich CM, Mason BA, Goddard ME. Improving accuracy of genomic predictions within and between dairy cattle breeds with imputed high-density single nucleotide polymorphism panels. J Dairy Sci. 2012;95(7):4114–29.
Kemper KE, Reich CM, Bowman PJ, vander Jagt CJ, Chamberlain AJ, Mason BA, Hayes BJ, Goddard ME. Improved precision of QTL mapping using a nonlinear Bayesian method in a multi-breed population leads to greater accuracy of across-breed genomic predictions. Genet Sel Evol. 2015;47:29.
Grisart B, Coppieters W, Farnir F, Karim LCF, Berzi P, Cambisano N, Mni M, Reid S, Simon P, et al. Positional candidate cloning of a QTL in dairy cattle: identification of a missense mutation in the bovine DGAT1 gene with major effect on milk yield and composition. Genome Res. 2002;12(2):222–31.
Ng-Kwai-Hang K. A review of the relationship between milk protein polymorphism and milk composition/milk production. In: Proceedings of the international dairy federation seminar: 25–27 febuary, 1997 1997; palmerston north, New Zealand. 1997. p. 22–37.
Blott S, Kim J-J, Moisio S, Schmidt-Küntzel A, Cornet A, Berzi P, Cambisano N, Ford C, Grisart B, Johnson D, et al. Molecular dissection of a quantitative trait locus: a phenylalanine-to-tyrosine substitution in the transmembrane domain of the bovine growth hormone receptor is associated with a major effect on milk yield and composition. Genetics. 2003;163(1):253–66.
Wang X, Wurmser C, Pausch H, Jung S, Reinhardt F, Tetens J, Thaller G, Fries R. Identification and dissection of four major QTL affecting milk Fat content in the German holstein-friesian population. PLoS One. 2012;7(7):e40711.
Zhang Z, Ersoz E, Lai C-Q, Todhunter RJ, Tiwari HK, Gore MA, Bradbury PJ, Yu J, Arnett DK, Ordovas JM, et al. Mixed linear model approach adapted for genome-wide association studies. Nat Genet. 2010;42(4):355–60.
Lippert C, Listgarten J, Liu Y, Kadie CM, Davidson RI, Heckerman D. FaST linear mixed models for genome-wide association studies. Nat Meth. 2011;8(10):833–5.
Zhou X, Stephens M. Genome-wide efficient mixed-model analysis for association studies. Nat Genet. 2012;44(7):821–4.
Listgarten J, Lippert C, Kadie CM, Davidson RI, Eskin E, Heckerman D. Improved linear mixed models for genome-wide association studies. Nat Meth. 2012;9(6):525–6.
Yang J, Zaitlen NA, Goddard ME, Visscher PM, Price AL. Advantages and pitfalls in the application of mixed-model association methods. Nat Genet. 2014;46(2):100–6.
Loh P-R, Tucker G, Bulik-Sullivan BK, Vilhjalmsson BJ, Finucane HK, Salem RM, Chasman DI, Ridker PM, Neale BM, Berger B, et al. Efficient Bayesian mixed-model analysis increases association power in large cohorts. Nat Genet. 2015;47(3):284–90.
Wood AR, Esko T, Yang J, Vedantam S, Pers TH, Gustafsson S, Chu AY, Estrada K, Luan J, Kutalik Z, et al. Defining the role of common variation in the genomic and biological architecture of adult human height. Nat Genet. 2014;46(11):1173–86.
The Wellcome Trust Case Control Consortium. Genome-wide association study of 14,000 cases of seven common diseases and 3,000 shared controls. Nature. 2007;447(7145):661–78.
Daetwyler HD, Capitan A, Pausch H, Stothard P, van Binsbergen R, Brondum RF, Liao X, Djari A, Rodriguez SC, Grohs C, et al. Whole-genome sequencing of 234 bulls facilitates mapping of monogenic and complex traits in cattle. Nat Genet. 2014;46(8):858–65.
Calus MPL. Right-hand-side updating for fast computing of genomic breeding values. Genet Sel Evol. 2014;46:24.
Wang T, Chen Y-PP, Goddard ME, Meuwissen THE, Kemper KE, Hayes BJ. A computationally efficient algorithm for genomic prediction using a Bayesian model. Genet Sel Evol. 2015;47:34.
Meuwissen THE, Solberg TR, Shepherd R, Woolliams JA. A fast algorithm for BayesB type of prediction of genome-wide estimates of genetic value. Genet Sel Evol. 2009;41:2.
Yu X, Meuwissen THE. Using the pareto principle in genome-wide breeding value estimation. Genet Sel Evol. 2011;43:35.
Shepherd RK, Meuwissen THE, Woolliams JA. Genomic selection and complex trait prediction using a fast EM algorithm applied to genome-wide markers. BMC Bioinf. 2010;11(1):1–12.
Hayashi T, Iwata H. EM algorithm for Bayesian estimation of genomic breeding values. BMC Genet. 2010;11(1):1–9.
Sun X, Qu L, Garrick DJ, Dekkers JCM, Fernando RL. A fast EM algorithm for BayesA-like prediction of genomic breeding values. PLoS One. 2012;7(11):e49157.
Garrick D, Taylor J, Fernando R. Deregressing estimated breeding values and weighting information for genomic regression analyses. Genet Sel Evol. 2009;41(1):55.
Henderson C. Application of linear models in animal breeding. Canada: University of Guelph; 1984.
Browning BL, Browning SR. A unified approach to genotype imputation and haplotype-phase inference for large data sets of trios and unrelated individuals. Am J Hum Genet. 2009;84(2):210–23.
Haile-Mariam M, Bowman PJ, Pryce JE. Genetic analyses of fertility and predictor traits in Holstein herds with low and high mean calving intervals and in Jersey herds. J Dairy Sci. 2013;96(1):655–67.
Haile-Mariam M, Pryce JE, Schrooten C, Hayes BJ. Including overseas performance information in genomic evaluations of Australian dairy cattle. J Dairy Sci. 2015;98(5):3443–59.
Gilmour A, Cullis B, Welham S, Thompson R. ASReml reference manual 2nd edition, NSW agriculture biometrical bulletin 3. 2002.
Lee Sang H, Wray Naomi R, Goddard Michael E, Visscher Peter M. Estimating missing heritability for disease from genome-wide association studies. Am J Human Gen. 2011;88(3):294–305.
Purcell S, Neale B, Todd-Brown K, Thomas L, Ferreira MAR, Bender D, Maller J, Sklar P, de Bakker PIW, Daly MJ, et al. PLINK: a tool Set for whole-genome association and population-based linkage analyses. Am J Hum Genet. 2007;81(3):559–75.
Yang J, Lee SH, Goddard ME, Visscher PM. GCTA: a tool for genome-wide complex trait analysis. Am J Hum Genet. 2011;88(1):76–82.
Wray NR, Yang J, Goddard ME, Visscher PM. The genetic interpretation of area under the ROC curve in genomic profiling. PLoS Genet. 2010;6(2):e1000864.
Hozé C, Fritz S, Phocas F, Boichard D, Ducrocq V, Croiseau P. Efficiency of multi-breed genomic selection for dairy cattle breeds with different sizes of reference population. J Dairy Sci. 2014;97(6):3918–29.
Chamberlain AJ, Vander Jagt CJ, Hayes BJ, Khansefid M, Marett LC, Millen CA, Nguyen TTT, Goddard ME. Extensive variation between tissues in allele specific expression in an outbred mammal. BMC Genomics. 2015;16(1):1–20.
Sanders K, Bennewitz J, Reinsch N, Thaller G, Prinzenberg EM, Kühn C, Kalm E. Characterization of the DGAT1 mutations and the CSN1S1 promoter in the German angeln dairy cattle population. J Dairy Sci. 2006;89(8):3164–74.
Raven L-A, Cocks BG, Kemper KE, Chamberlain AJ, Jagt CJ, Goddard ME, Hayes BJ. Targeted imputation of sequence variants and gene expression profiling identifies twelve candidate genes associated with lactation volume, composition and calving interval in dairy cattle. Mamm Genome. 2015;27(1):81–97.
Pryce JE, Bolormaa S, Chamberlain AJ, Bowman PJ, Savin K, Goddard ME, Hayes BJ. A validated genome-wide association study in 2 dairy cattle breeds for milk production and fertility traits using variable length haplotypes. J Dairy Sci. 2010;93(7):3331–45.
Cole JB, Wiggans GR, Ma L, Sonstegard TS, Lawlor TJ, Crooker BA, Van Tassell CP, Yang J, Wang S, Matukumalli LK, et al. Genome-wide association analysis of thirty one production, health, reproduction and body conformation traits in contemporary U.S. Holstein cows. BMC Genomics. 2011;12(1):1–17.
McClure MC, Morsci NS, Schnabel RD, Kim JW, Yao P, Rolf MM, McKay SD, Gregg SJ, Chapple RH, Northcutt SL, et al. A genome scan for quantitative trait loci influencing carcass, post-natal growth and reproductive traits in commercial Angus cattle. Anim Genet. 2010;41(6):597–607.
Wickramasinghe S, Hua S, Rincon G, Islas-Trejo A, German JB, Lebrilla CB, Medrano JF. Transcriptome profiling of bovine milk oligosaccharide metabolism genes using RNA-sequencing. PLoS One. 2011;6(4):e18895.
Consortium TGP. A map of human genome variation from population-scale sequencing. Nature. 2010;467(7319):1061–73.
Acknowledgements
The authors acknowledge the support from Dairy Futures CRC project.
Availability of data and materials
The WTCCC data are available to researchers by application to the Welcome Trust Case Control Consortium Data Access Committee (http://www.wtccc.org.uk/info/access_to_data_samples.html), or contact egaadmin@ebi.ac.uk. Application is required to ensure proper protection of confidentiality of the participants.
For dairy cattle data, we can provide meta-analysis data related to our paper which can be easily used to conduct the analysis by other researchers.
The HyB_BR compiled program is available for request for non-commercial research.
Authors’ contributions
BJH and Y-PPC supervised this project; TW developed HyB_BR algorithm, analysed the data and drafted the manuscript; BJH gave important instructions on organizing and revising the manuscript. MEG contributed the valuable idea about hybrid scheme; PJB provided help with C++ programming. All authors read and approved the final manuscript.
Competing interests
The authors declare that they have no competing interests.
Author information
Authors and Affiliations
Corresponding author
Additional files
Additional file 1:
PEV calculation from GBLUP. (DOCX 16 kb)
Additional file 2:
Calculation of P(i, k). (DOCX 21 kb)
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Wang, T., Chen, YP.P., Bowman, P.J. et al. A hybrid expectation maximisation and MCMC sampling algorithm to implement Bayesian mixture model based genomic prediction and QTL mapping. BMC Genomics 17, 744 (2016). https://doi.org/10.1186/s12864-016-3082-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12864-016-3082-7