
Abstract
Background
Despite numerous molecular and computational advances, roughly half of patients with a rare disease remain undiagnosed after exome or genome sequencing. A particularly challenging barrier to diagnosis is identifying variants that cause deleterious alternative splicing at intronic or exonic loci outside of canonical donor or acceptor splice sites.
Results
Several existing tools predict the likelihood that a genetic variant causes alternative splicing. We sought to extend such methods by developing a new metric that aids in discerning whether a genetic variant leads to deleterious alternative splicing. Our metric combines genetic variation in the Genome Aggregate Database with alternative splicing predictions from SpliceAI to compare observed and expected levels of splice-altering genetic variation. We infer genic regions with significantly less splice-altering variation than expected to be constrained. The resulting model of regional splicing constraint captures differential splicing constraint across gene and exon categories, and the most constrained genic regions are enriched for pathogenic splice-altering variants. Building from this model, we developed ConSpliceML. This ensemble machine learning approach combines regional splicing constraint with multiple per-nucleotide alternative splicing scores to guide the prediction of deleterious splicing variants in protein-coding genes. ConSpliceML more accurately distinguishes deleterious and benign splicing variants than state-of-the-art splicing prediction methods, especially in “cryptic” splicing regions beyond canonical donor or acceptor splice sites.
Conclusion
Integrating a model of genetic constraint with annotations from existing alternative splicing tools allows ConSpliceML to prioritize potentially deleterious splice-altering variants in studies of rare human diseases.
Similar content being viewed by others


Background
The diagnosis of Mendelian disease patients has progressed substantially owing to continued improvement of DNA sequencing technologies and software development for variant analysis. However, the diagnostic rate for these patients is still around 50% [1,2,3,4], leaving numerous patients with a diagnostic odyssey that persists indefinitely and results in financial, emotional, and physical burdens. Interpreting the effects of genetic variation outside of protein-coding exons is arguably one of the greatest challenges that remains. Discerning the impact of the non-canonical splice-site subset [5,6,7,8,9] of these deleterious genetic variants is especially difficult. Consequently, potential splicing variants lying within introns or exons are commonly ignored during clinical diagnosis.
Up to 95% of all protein-coding genes in humans are predicted to undergo alternative splicing [5, 6]. Alternative splicing is a conserved process that expands the functional potential of nascent transcripts [10,11,12] and requires tight regulation by the spliceosome, a large RNA and protein complex [13,14,15,16,17]. Previous work has identified highly conserved DNA sequences that facilitate spliceosome assembly, function, and regulation [10, 16, 18]. For example, variants at canonical di-nucleotide donor or acceptor splice sites lead to mis-splicing and are frequently deleterious. Disruption of alternative splicing is known to underlie numerous diseases [8, 9, 19,20,21,22,23,24]. Therefore, variants impacting canonical donor or acceptor sites should be considered as strong evidence for pathogenicity according to the guidelines established by the American College of Medical Genetics (ACMG). [25]
Early experiments estimated that about 15% of disease-causing point mutations affect pre-mRNA splicing, [26]. More recent studies predict that between one-third to one-half of disease-causing variants disrupt splicing [19, 27,28,29]. These estimates are based on evidence of splice-altering variants occurring beyond the exon–intron junctions. Variants at important splicing motifs such as the intronic donor, acceptor, branch point, and polypyrimidine track sites would potentially lead to mis-splicing [8, 9, 20]. Mis-splicing can also be caused by variants that affect splicing regulatory regions such as exonic and intronic splicing enhancers or silencers [30,31,32,33,34]. Since most splicing occurs co-transcriptionally [35,36,37,38,39,40], variants that affect transcriptional processing may also alter splicing. For example, variants that alter the elongation rate and transcription kinetics of RNA polymerase II [41,42,43], RNA secondary structure, [44,45,46,47], or nucleosome positioning [48, 49] could affect splicing during transcription. Furthermore, synonymous and non-synonymous variants in exonic regions affect splicing [22]. Additional work has estimated that an individual exome-sequencing will harbor more than 500 potential splice-affecting variants of unknown significance [50] and that up to 10% of the exonic disease-causing variants may also affect splicing [22]. These findings suggest that current gaps in understanding, detecting, and interpreting splicing across the entire coding and non-coding body of protein-coding genes likely contribute to the low diagnostic rate of rare diseases.
Multiple software tools have been developed that improve the prediction and identification of splice-altering variants [31, 32, 43, 50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76]. For example, SpliceAI is a deep residual neural network that uses only the primary nucleotide sequence to yield accurate alternative splicing predictions [76]. For each reference and possible alternative allele combination, SpliceAI provides four predictions. These predictions describe whether the variant may cause an acceptor loss, acceptor gain, donor loss, or donor gain. Similarly, SQUIRLS uses a Random Forest approach to predict whether a variant causes alternative splicing with similar performance as SpliceAI [77]. SQUIRLS differs in that it uses various features such as conservation scores from phyloP [78], sequence context parameters such as local distance from an exon and canonical splice sites, models of changes in spliceosome free energy binding, and other prediction tools such as ESRSeq [79]. However, these and other existing approaches provide little to no guidance as to whether or not the variant is deleterious. Consequently, there is a need for improved methods that guide the prioritization of the subset of variants that may lead to deleterious alternative splicing to improve the diagnosis of rare diseases. This gap motivates our development of ConSpliceML, an ensemble machine learning method that combines regional measures of splicing constraint with computational predictions of the potential for genetic variants to cause alternative splicing. We demonstrate that ConSpliceML more efficiently prioritizes deleterious splicing variants in genic regions outside of canonical donor or acceptor sites.
Results
A statistical model of genetic constraint against deleterious splicing variants
We sought to develop a model of splicing constraint within protein-coding genes, motivated by the logic that owing to purifying selection, genomic regions leading to deleterious splicing will exhibit depletion of genetic variation in a large cohort of ostensibly healthy individuals. Using the single-nucleotide variants (SNVs) detected among 76,156 individuals in v3.1.1 of gnomAD [80], we estimated substitution probabilities among protein-coding genes (Methods). We refined the substitution probabilities by estimating each substitution's probability of leading to alternative splicing by binning the sum of the SpliceAI scores provided for each reference nucleotide (Additional file 1: Fig. S1A, Fig. 1A, Methods). Each SpliceAI score estimates the potential for novel donor or acceptor sites if each of the three possible substitution alleles arose at a given reference position. Since SpliceAI's deep neural network incorporates flanking sequence when modeling the cryptic splicing potential for each reference allele, its scores indirectly provide local sequence context to the resulting substitution probability matrix. As expected, we observe an overall decrease in the substitution probabilities as the sum of SpliceAI scores increases, indicating that variants predicted to alter splicing by SpliceAI are depleted in a healthy population (Fig. 1A, Additional file 1: Fig. S1B). However, since SpliceAI predicts whether a single allele will cause alternative splicing, our goal is to measure regional depletion of splicing variation to identify loci exhibiting genetic constraint against deleterious splicing.

Overview of the regional splicing constraint model. A The per-site splicing substitution rate by reference allele and Sum SpliceAI score bin across autosomal protein-coding genes. The rate of no substitutions across all SpliceAI score bins for each reference allele is A > A = 0.9003, C > C = 0.8565, G > G = 0.8433, and T > T = 0.9347 B Calculating an Observed over Expected (O/E) ratio for a genomic region by counting the number of variants in that region from gnomAD and the number of expected variants with a given SpliceAI score. C The O/E score distribution. Smaller O/E scores indicate higher constraint against splicing, while larger O/E scores indicate lower constraints against splicing. (O/E plot truncated at -2000 to 2000 for visibility) D Representation of regional splicing constraint O/E scores across a hypothetical gene. The presence of gnomAD variants, in gray and the SpliceAI prediction for each position in the gene, in shades of red influences the splicing-specific observed and expected counts in a region. gnomAD variants with higher SpliceAI scores show evidence for more tolerance against splicing variation. In contrast, sites with a higher SpliceAI score and no gnomAD variant show evidence for less tolerance against splicing. Pathogenic splicing variants, in black, are commonly absent from gnomAD and have predictions of alternative splicing from SpliceAI. In this example, the regional constraint model identifies constraint signals at regions that harbor pathogenic splicing variants, such as at canonical splice regions (^) and cryptic splice regions (^^). All genomic positions in C without a SpliceAI score should be recognized as sites with a SpliceAI score < 0.1
With this goal in mind, we compare the observed count of variation in gnomAD to what is expected (Fig. 1B, Methods) across either entire genes or arbitrary regions within a gene. The expected counts for a given genomic region are derived from the substitution probability matrix (Additional file 1: Table S1, S2), where the substitution probability for each nucleotide in that region is determined by the nucleotide’s reference allele, and SpliceAI summed score. The sum of the substitution probabilities for each nucleotide in the region yields the region’s expected substitution counts. We calculate a final ratio of the observed (O) to expected (E) variant counts that are further weighted based on each bin’s likelihood to contribute to alternative splicing events (Fig. 1C, Methods). The null expectation for the O/E ratio was normalized to zero with an unbounded lower and upper limit to allow for a continuous spectrum of constraint (Methods). As a result, genomic regions less tolerant of splicing will have lower O/E ratios, as fewer splicing variants were observed in gnomAD than expected (a hypothetical example is depicted in Fig. 1D). Finally, we transform O/E ratios to normalized scores ranging from 0.0 to 1.0, with 0.0 being the least constrained (tolerant) regions and 1.0 being the most constrained (intolerant) regions to splicing.
Characterizing intolerance to aberrant splicing at the gene level
Gene-based genetic constraint scores such as the probability of loss-of-function intolerance (pLI) [81] and LOEUF [80] predict a gene's intolerance to putative loss-of-function (pLoF) mutations. However, such metrics only include pLoF splicing mutations at the canonical donor and acceptor splice sites and are thus likely to miss deleterious splicing mutations. We were interested in characterizing each gene's global intolerance to aberrant splicing mutations. Therefore, we measured splicing constraint using regions defined by the genomic interval defining each gene.
As a positive control, we tested expected patterns of constraint using gene sets known to underlie Autosomal Recessive (AR), Autosomal Dominant (AD), and Haploinsufficient (HI) disorders. Based on the evidence of strong or moderate sensitivity to heterozygous or homozygous pLoF variants [80, 82], respectively, we hypothesized that the AD and HI genes would exhibit high predicted splicing constraint. In contrast, the distribution of splicing constraint for AR genes would be broader. We based these expectations on the notion that a single LoF variant arising on AD and HI genes may cause disease, while disease phenotypes on AR genes require LoF variants on both haplotypes. We included Olfactory Receptor (OR) genes as a negative control since these genes are known to be tolerant to pLoF variants [83]. Since the majority of OR genes are single exons genes which are not expected to undergo splicing, we included genes shown to be non-essential for cell viability in CRISPR screens as a second negative control [84]. As expected, both the AD and HI genes are more constrained against aberrant splicing; AR genes have a wide distribution across the score range, with OR genes and CRISPR non-essential genes less constrained (Fig. 2A). Using several other gene sets, we identify similar patterns of expected splicing constraint in genes known to be involved in developmental delay and intellectual disability [85,86,87,88,89,90], genes shown to be essential in CRISPR screens [84], and genes shown to be tolerant to at least one homozygous pLoF mutation [81] (Additional file 1: Fig. S2, S3).

Patterns of genic splicing constraint. A The proportion of OR genes, CRISPR Non-essential genes, AR genes, AD genes, and HI genes across the splicing constraint deciles. Color corresponds to the gene set. B The distribution of VG values by splicing constraint deciles (p-value = 2.488e−31). Significance determined using ordinary least squares linear regression. The boxes' interquartile range (IQR) ranges from the 25th to 75th percentile. The horizontal black line in each box represents the median VG value for that decile. The whiskers are 1.5X the IQR. Outliers are not plotted. C The proportion of genes in each splicing constraint decile that had zero significant sOutliers (p-value = 8.832e−06, Adjusted R2 = 0.916). Significance determined using ordinary least squares linear regression. The dark blue line represents the linear regression line. Light blue shade represents the 95% confidence interval. OR Olfactory Receptor, AR Autosomal Recessive, AD Autosomal Dominant, HI Haploinsufficient, sOutliers splicing outliers
The patterns of splicing constraint for these gene sets are strongly correlated with the constraint on coding sequence measured by LOEUF and moderately correlated with pLI (Additional file 1: Fig. S4). We expect such correlations since genes under selective pressure should be broadly intolerant of any pLoF variant. For example, a pLoF nonsense variant in a gene with an AD inheritance pattern should have a similar constraint against a pLoF variant that leads to aberrant splicing. However, we also expected differences in constraint patterns since the splicing constraint model combines constraint in both coding and non-coding regions of a gene, whereas LOEUF and pLI focus solely on coding regions. Additionally, we anticipated the observed differences in constraint as the splicing constraint model is based on splicing predictions while pLI and LOEUF integrate all types of pLoF variation (Additional file 1: Fig. S4).
Given that deleterious, splice-altering variants commonly trigger nonsense-mediated decay (NMD) [91], which often reduces gene expression, we compared our gene-wide splicing constraint estimates to a measure of dosage sensitivity. We hypothesized that a gene’s sensitivity to changes in expression would be correlated with a gene’s constraint against splicing. To test this hypothesis, we used the expected genetic variation in gene expression (VG) [92] calculated from the RNA-seq expression data in the Genotype-Tissue Expression (GTEx) project [93, 94] to measure a gene’s sensitivity to expression variation. VG measures each gene’s expression variance and represents how tolerant a gene is to genetic variants that change expression. As expected, splicing constraint is significantly negatively correlated with VG (p-value = 2.488e−31, Fig. 2B) and remains significant after controlling for the number of exons per gene (p-value = 5.99e−26, Additional file 1: Fig. S5). Genes in the highest constraint decile have a mean of 4.23-fold less variance in gene expression than genes in the lowest decile. Furthermore, the distribution of VG is significantly different across splicing constraint bins after FDR correction (Additional file 1: Fig. S5).
Since most genes are alternatively spliced, we hypothesized that genes less tolerant to variation in alternative splicing events would have a higher genic splicing constraint than genes more tolerant to alternative splicing variation. We used alternative splicing events detected in GTEx by Ferraro et al. [95] to test our hypothesis of observing a depletion in alternative splicing for genes under higher splicing constraint. To estimate alternative splicing tolerance, we used the alternative splicing events that were significant outliers from the population distribution of alternative splicing events in a gene (sOutliers). As expected, there is a significant positive correlation with the proportion of genes having zero significant sOutliers and the splicing constraint for those genes. This observation indicates that genes more intolerant to alternative splicing have significantly fewer sOutliers (p-value = 8.83e-06, Fig. 2C, Additional file 1: Fig. S6). Additionally, we observe a negative correlation between splicing constraint and the proportion of genes having at least one significant sOutlier, indicating genes more intolerant to alternative splicing have significantly fewer sOutliers (p-value = 8.83e−06, Additional file 1: Fig. S6).
A regional model of splicing constraint
Genic loci outside of canonical splice junctions are involved in splicing [8, 12, 18, 23, 39, 50, 96]. While a gene-wide measure of splicing constraint reveals global constraint against splicing, it is insufficient for identifying the focal origins of constraint, especially when motifs drive the signal outside of exon–intron junctions. For example, we expect the highest levels of splicing constraint to be localized to regions of genes that are critical to splicing. It is thus reasonable to consider an intragenic regional model of constraint that identifies focal regions within a gene that are most intolerant of aberrant splicing. Indeed, regional constraint metrics such as Constrained Coding Regions (CCR) [97] highlight regional variability in constraint against pLoF variation within protein-coding genes. In the case of diagnosing rare diseases, it is imperative to identify and prioritize the deleterious causal variant, and using a regional level metric allows one to estimate where causal splicing variants would lie within a gene. Therefore, we created multiple regional splicing constraint models using various window sizes to determine the optimal region size to predict the pathogenicity of a splicing variant. We used window sizes that balanced smaller sizes with more spatial resolution with larger sizes that would contain more expected variants and therefore give more power to detect a difference between observed and expected splicing variation (Methods, Additional file 1: Fig. S7).
As a positive control, we evaluated the regional splicing constraint model at various region sizes around exon features using a set of constitutive exons (exons present in every isoform of a gene) and cassette exons (exons alternatively spliced in or out of a gene depending on the expressed isoform) defined by Busch et al. [98] We hypothesized that the splicing constraint at exons should generally be higher than in the surrounding 5′ and 3′ introns of those exons. This hypothesis comes from the fact that coding regions, in general, are more constrained than non-coding regions and that the exon boundaries are determined by splicing definition. As expected, we observe an increase in constraint as we move towards the 5′ end of an exon and a decrease in constraint as we move away from the 3′ end (Fig. 3A, Additional file 1: Fig. S8). Additionally, as expected, we see that a genetic constraint model unaware of splicing has a similar constraint pattern around exons. However, the change in constraint is much less dramatic than the splicing aware constraint model (Additional file 1: Fig. S9). This observation further suggests that the model captures specific constraints beyond the difference in constraint between coding and non-coding regions of genes. Finally, we observe differences in the magnitude of constraint-driven by the inclusion rate of an exon, where exons with a higher inclusion rate are slightly more constrained than exons with a moderate rate. This observation supports previous high-inclusion cassette exons being characteristically identical to constitutive exons. [98, 99]

Splicing constraint around exon features. A The pattern of splicing constraint at and around exon features including constitutive exons (Full Inclusion Exons) and cassette exons (Moderate Inclusion Exons and High Inclusion Exons). Full Inclusion Exons have an inclusion rate of 100%. High Inclusion Exons have an inclusion rate > = 90% and < 100%. Moderate Inclusion Exons have an inclusion rate < 90%. Plots are oriented 5′ to 3′ from left to right. Vertical dotted lines represent the relative start (left) and end (right) position of exons. Colors represent exon class based on inclusion rate. Dark lines for each exon class represent the median regional constraint score along the relative region around exons. The lighter shaded regions around the line represent the 95% CI determined by 1000 bootstrap iterations for each exon class. Oriented by the window size with the 2000 bp model on the top, 500 bp model in the middle, and 50 bp model on the bottom. Figure color legend is located to the right of the top plot. B, C Regional constraint score profiles for a poison exon in (B) and a randomly selected canonical SCN1A exon (C). The red horizontal bars in B represent the poison exon, and the dark blue horizontal bars in C represent the canonical exon. The gene track around the exon feature is shown below the regional constraint score profile with the GRCh38 3’ and 5’ (left and right, respectively) genomic coordinates for that exon feature above the gene track. SCN1A is on the negative strand; therefore 5′ to 3′ is from right to left in B and C. The regional constraint score track represents the splicing constraint profile using the 50 bp regional model
We note the difference in constraint profiles based on the size of the constraint region. As the region size decreases, the difference between exon classes as a whole diminishes, while the specificity of the feature driving the constraint increases. For example, we see an increase in the specificity of the 5′ and 3′ canonical splicing motifs as we move from the 2000 bp splicing constraint model to the 50 bp model (Fig. 3A, Additional file 1: Fig. S8). This result indicates that we can define an optimal region size based on the feature of interest. Splicing is primarily driven by small regulatory motifs such as the canonical acceptor and donor motifs, the polypyrimidine tract, and enhancer or silencer motifs. Therefore, an ideal region size would capture splicing motifs while excluding irrelevant adjacent nucleotides around the motifs that do not participate in splicing. However, the region also needs to encompass a sufficient number of nucleotides to calculate a robust O/E signal. Therefore, the region’s size needs to balance the size of a splicing motif and a region with a sufficient number of nucleotides to establish a robust O/E signal (Additional file 1: Fig. S7, Methods). Empirically testing this hypothesis further supports a smaller region size as the optimal size for detecting focal splicing constraint within genes. Specifically, we found that the 50 bp regional splicing constraint model was sufficiently large to encompass splicing motifs and capture O/E signal, while also small enough to identify focal constraint, likely driven by the splicing motifs (Fig. 3A, Additional file 1: Figs. S7, S8, S10, Methods).
Beyond annotated exons, the regional splicing model also captures constraint against splicing at poison exons, which are conserved, alternatively spliced exons that lead to nonsense-mediated decay (NMD) caused by a premature termination codon located in the poison exon [100]. While many poison exons are important regulatory features of the genome, others, when expressed, cause deleterious effects [100]. For example, multiple deleterious poison exons have been found in SCN1A, leading to Dravet Syndrome (DRVT [MIM: 607208]), a severe neurodevelopmental disorder marked by epileptic encephalopathies [96, 101, 102]. The 50 bp regional model detects each of the three poison exons in SCN1A with constraint scores at or above 0.95. The poison exons rank in the top 8th percentile and are in the top 2% of noncoding regions in SCN1A. Additionally, two of the three poison exons have higher constraint scores than the median constraint seen in coding regions of SCN1A, with the third having a constraint score of 0.017 below the median. (Additional file 1: Fig. S11). These poison exons also have similar constraint profiles as the annotated exons in SCN1A (Fig. 3B,C; Additional file 1: Fig. S12; Additional file 1: Table S3), which replicates the pattern seen for constitutive and cassette exons (Fig. 3A).
Interpreting pathogenic splicing variation with a regional model of splicing constraint
We next evaluated how well the regional splicing constraint model was able to identify pathogenic splice-altering variants. We curated 376 pathogenic splice altering variants from literature, where each variant has some functional support for its effect on splicing (Additional file 2: Table S4). Additionally, each variant was associated with a disease, such as Hereditary Hemorrhagic Telangiectasia (HHT2 [MIM: 600376]) [103,104,105,106,107,108,109,110], Stickler Syndrome(STL1 [MIM: 108300]) [111,112,113,114,115], Optic Atrophy 1 (OPA1 [MIM: 165500]) [116, 117], Marfan Syndrome (MFS [MIM: 154700]) [118, 119], Retinoblastoma (RB1 [MIM: 180200]) [120, 121], and Neurofibromatosis type 1 (NF1 [MIM: 162200]) [122, 123]. The regional constraint model placed 86% of the 376 variants at or above a constraint score of 0.95, indicating strong constraint against alternative splicing. For example, it classified 89% of intronic non-canonical splice-altering variants in ACVRL1, a gene that has well-characterized intronic splice-altering variants that cause Hereditary Hemorrhagic Telangiectasia (HHT2 [MIM: 600376]), with constraint scores at or above 0.88 (Fig. 4A–C).

Splicing constraint for pathogenic alternative splicing variants. A Regional constraint profile for the ACVRL1 gene with pathogenic splice-altering variants that cause HHT. The pathogenic variants are labeled as orange lollipops on the gene track and the corresponding splicing constraint region is circled in orange on the ConSplice track. The ConSplice score is provided below the variant lollipop. The y-axis depicts the regional constraint score log10 scale. B-C Zoomed-in view of the genomic regions that harbor the pathogenic variants in ACVRL1 seen in A. D The distribution of the manually curated pathogenic variants relative to the exonic position. The blue bar represents an exon while the gray bars represent introns around the exon. Oriented 5′ to 3’ from left to right, with the acceptor side on the left and the donor side on the right. Any variant > 10 bp away from the exon–intron junction in the intron or exon are labeled “Deep Intronic” or “Deep Exonic”, respectively. Canonical acceptor and donor sites = A-1, A-2., D + 1, D + 2. E The distribution of scores assigned by each method to the pathogenic variants in the set. The IQR of the boxes ranges from the 25th to 75th percentile. The vertical black line in each box represents the median score for that method. The whiskers are 1.5X the IQR. Outliers are not plotted
We excluded variants at canonical donor and acceptor splice sites from this list of pathogenic splicing variants to evaluate the performance of the splicing constraint model outside of regions that are commonly used when prioritizing variants in rare disease clinical diagnosis (Fig. 4D). We also included SpliceAI [76], SQUIRLS [77], and CADD v1.6 [124] to compare our performance to state-of-the-art splicing prediction and interpretation methods. We excluded other splicing prediction software because they cannot score all of the deep intronic variants in the set. Furthermore, many tools have been previously compared to SpliceAI, SQUIRLS, or CADD.
Although SpliceAI, SQUIRLS, and CADD perform well, the regional constraint model significantly scores these variants much higher than each of these tools (Fig. 4E).
Frésard et al. recently used RNA-seq to identify a pathogenic splicing mutation around the 3′ end of exon 5 in ASAH1 that leads to exon 6 skipping and causes Spinal Muscular Atrophy with Progressive Myoclonic Epilepsy (SMAPME [MIM: 159950]) [125]. Motivated by this finding, we evaluated the splicing constraint model's ability to isolate such deleterious splicing events in the absence of RNA sequencing (RNA-seq) data. We find that it accurately identifies the splicing constraint of this region with a score of 0.989 (Additional file 1: Fig. S13A). Murdock et al. [126] used RNA-seq to identify deleterious changes in splicing and expression in a cohort of undiagnosed patients from the Undiagnosed Disease Network (UDN). They identified multiple deleterious splice-altering variants that explained disease pathology. The variants identified included: a deep intronic pathogenic splicing variant in PQBP1 that leads to an out-of-frame pseudoexon and causes X-linked recessive Renpenning Syndrome (RENS1 [MIM: 309500]); a deep intronic pathogenic splicing variant in HNRNPK that resulting in intron retention that caused Au-Kline Syndrome (AUKS [MIM: 616580]); and an intronic pathogenic splicing variant in RPL13 that lead to intron retention and causes Spondyloepimetaphyseal Dysplasia (SEMD [MIM: 618728]). Similarly, the splicing constraint model scored each region above 0.98 (Additional file 1: Fig. S13B–D).
Variant interpretation with ConSpliceML
While regional constraint identifies genomic regions harboring nucleotides with the potential for deleterious splicing when mutated, not all loci in each region are constrained. Consequently, solely using a region's constraint to prioritize individual residues will result in false-positive predictions of deleterious splicing. Therefore, we created ConSpliceML to provide a more accurate method for prioritizing individual genetic variants. ConSpliceML uses a Random Forest (RF) classifier to combine regional splicing constraint measures with per-nucleotide alternative splicing predictions from SpliceAI and SQUIRLS (Methods). We chose to use both SpliceAI and SQUIRLS since they each perform well at predicting alternative splicing [77], yet also capture variants missed by the other.
To train and evaluate ConSpliceML, we used the Human Gene Mutation Database (HGMD) [127,128,129], to collect 18,317 disease-causing, alternative splicing variants. In addition, we collected 48,978 benign variants from a collection of de novo mutations (DNMs) identified in whole-genome sequencing of multi-generational [130] and two generation [131] families from Utah and Iceland, respectively, as well as validated benign alternative splicing variants from GTEx curated by Jaganathan et al. [76] (Additional file 3: Table S5). We only included variants in protein-coding genes with SpliceAI, SQUIRLS, CADD, and regional splicing constraint scores. The final set represents 95% of the autosomal pathogenic variants and 36% of autosomal benign variants after filtering. Many of the benign variants are removed because they do not fall within protein-coding genes. We split this variant collection into a training set and test set using 60% of the variants for training and 40% for testing. To further avoid overfitting, we exlcuded variants in the training set if a variant in the test set was found in the same splicing constraint region. Furthermore, we performed training and validation using five-fold cross-validation with the training set to assess training accuracy performance and training consistency across different folds (Additional file 1: Fig. S14). To compare the performance between CADD, SpliceAI, SQUIRLS, and ConSpliceML, we trained the ConSpliceML model using the 60% training set and tested the performance of each method using the 40% test set.
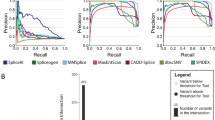
We analyzed each method’s precision and recall for differentiating pathogenic and benign splice-altering variants at various thresholds. With all the variants in the test set, we find that each method performs well, with ConSpliceML performing the best with an average precision of 0.97 and SpliceAI as the second best with an average precision of 0.96 (Additional file 1: Fig. S15). However, since variants at canonical donor and acceptor splicing sites are routinely prioritized without the need for annotations during rare disease clinical diagnosis, we evaluated how well each method could isolate deleterious splicing variants outside of the canonical splice sites. We find a moderate decrease in performance for each method, with ConSpliceML continuing to outperform all other methods (Fig. 5A).

Splicing prediction and interpretation performance. A–D Precision-Recall (PR) curves depicting the performance of CADD, SpliceAI, SQUIRLS, and ConSpliceML in differentiating pathogenic splice-altering variants from benign variants. The dotted horizontal line represents the baseline value, meaning a random chance prediction. The Precision-Recall Area Under the Curve (PR AUC) for each metric is given in the plot legend, along with a more accurate measurement of performance called the Average Precision Score (Avg. PR Score). A PR Curve for all pathogenic and benign variants in the test set, excluding the canonical donor and acceptor splice sites. 2273 pathogenic variants. 19,499 benign variants. B PR Curve for all pathogenic and benign variants in the test set, excluding variants in the splice region. 627 pathogenic variants. 19,278 benign variants. C All variants in the filtered test set with a SpliceAI score between 0.0 and 0.2. 477 pathogenic variants. 18,688 benign variants. D Same as C but excluding variants at the canonical acceptor and donor splice sites. 452 pathogenic variants. 18,686 benign variants. E The odds ratio enrichment of pathogenic versus benign variants across the ConSpliceML deciles uses all test set variants. Odds ratio values are highlighted in black above each bar. Error bars represent the 95% CI. The dotted horizontal line represents an odds ratio at 1
Furthermore, roughly 50% of rare, monogenic disease cases are diagnosed when prioritizing variants in coding sequence, canonical splice sites, or variants within the "splice region" defined by VEP [132] as eight bases into the intron and three bases into the exon at exon–intron junctions. We, therefore, measured the performance of each method outside the canonical splice sites and "splice regions" commonly used to prioritize variants in rare disease studies. Not surprisingly, we observed a decrease in performance by all methods, with CADD having the greatest drop in performance and ConSpliceML outperforming all other methods (Fig. 5B).
The authors of SpliceAI recommend prioritizing variants as potentially splice-altering if the SpliceAI score is greater than 0.2 [76, 133,134,135]. However, some pathogenic splicing variants fall below this threshold and, as a result, would be ignored in rare disease analyses. When evaluating performance for variants having a SpliceAI score less than 0.2, we observe that ConSpliceML outperforms all other methods when either canonical splice variants are included or not (Fig. 5C, D). We excluded the analysis of variants outside the splice region due to an insufficient number of pathogenic variants for evaluation. Although it is not clear why SpliceAI is underperforming for these variants, there is evidence that SpliceAI misses certain alternative splicing variants. For example, Chen et al. found that SpliceAI was unable to fully distinguish between deleterious or neutral splice-altering variants and non-splice-affecting variants at the + 2 position of splice donor sites. [136]
Lastly, we measured the enrichment of pathogenic versus benign variants observed across ConSpliceML score ranges to establish a rational scoring threshold for rare disease analyses (Fig. 5E, Additional file 1: Fig. S16). We observed a significant difference in the enrichment scores between pathogenic and benign variants starting at a ConSpliceML score of 0.5 (Fig. 5E). Further restricting variants to those outside of canonical sites and the splice region revealed a significant enrichment starting at a ConSpliceML score of 0.3 and 0.2, respectively (Additional file 1: Fig. S16A, B). Therefore, we recommend that when using ConSpliceML, a score of 0.5 be used as a preliminary cutoff to distinguish pathogenic and benign splice altering variants. Subsequent iteration could reduce the cutoff to a lower ConSpliceML score to improve the sensitivity of identifying deleterious deep intronic and exonic splicing variants outside the splice region.
Discussion
Splicing is a highly regulated cellular process that, when disrupted, can lead to disease. Beyond a few nucleotides around exon–intron junctions, variants that could yield aberrant splicing are typically ignored during clinical diagnosis. There is growing evidence that cryptic splicing variants may underlie unsolved cases of rare disease and is a factor in the low diagnostic yield. Although multiple tools have been developed to improve the identification and interpretation of splice-altering variants, they largely underperform when interpreting intronic and exonic splice-altering variants outside the splice region. We developed a model of genetic constraint against aberrant splicing that combines patterns of genetic variation observed in a large cohort of ostensibly healthy individuals with per-nucleotide splicing predictions from SpliceAI. To our knowledge, this model is the first constraint metric built specifically for aberrant splicing that can score the entire gene body rather than solely loci near coding regions.
However, since our model measures splicing constraint in genomic regions, it is insufficient to provide an accurate score at the nucleotide level for variant interpretation. Therefore, we created ConSpliceML, which combines regional constraint with per-nucleotide splicing predictions from SpliceAI and SQUIRLS, providing a per-nucleotide prediction of pathogenic splicing in protein-coding genes. ConSpliceML outperforms state-of-the-art splicing prediction methods at differentiating pathogenic and benign splice altering variants, demonstrating the impact of including constraint on measures of potential deleteriousness.
However, ConSpliceML has notable limitations. First, population datasets, such as gnomAD, are far from reaching saturation for splicing variation, a common problem for pLoF variants [80]. This limitation will lessen as the number of human genomes increases in population genomic datasets. Another benefit of increasing the number of individuals in the human population datasets is that it provides additional power to increase the resolution of regional constraint models, which will help identify more focalized regions in a gene driving the splicing constraint. Secondly, there is a limited number of available pathogenic splicing variants, especially in deep intronic and exonic regions, in our truth set. This small set of variants limits our ability to measure ConSpliceML’s performance outside of canonical splicing regions. Further evaluation of ConSpliceML and other methods will be necessary as the community identifies additional deep intronic and exonic splicing variants in studies of rare human diseases. Finally, the splicing constraint model is built using splice site gain and loss predictions from SpliceAI. Although the model does quite well in identifying constraint against splicing throughout the protein-coding genome, there are other genomic variants (e.g., splicing eQTLs or structuiral variants) that disrupt splicing. While such variants are not currently accounted for, our model has the potential for future improvement as new techniques are developed to predict the consequence of such alterations on splicing.
Conclusion
Genetic constraint facilitates the interpretation of genomic variants in rare disease studies. ConSpliceML outperforms other prediction and interpretation methods for splicing variants at the canonical donor and acceptor sites, in the splice region, and in deep intronic and exonic regions of protein-coding genes. We provide a command-line tool (https://github.com/mikecormier/ConSplice) that generates the splicing constraint model, trains ConSpliceML, and scores variants with both splicing constraint and ConSpliceML. We also offer a VCF [137] file with precomputed regional constraint score and ConSpliceML scores for all possible SNVs that could occur in protein-coding genes. We suggest an initial pathogenic cutoff of 0.5 when using ConSpliceML and subsequently reducing the cutoff for additional iterations to improve the sensitivity to identify deleterious splicing variants outside of the canonical splice regions. These resources allow for easy distribution of ConSpliceML to the research and clinical communities for improved splicing variant detection and interpretation. We anticipate that ConSpliceML will facilitate the clinical diagnoses for patients with rare diseases, as it identifies missing pathogenic variants driving disease pathology.
Methods
Estimating substitution probabilities
Observed variants used to construct the substitution probabilities were identified using the genetic variation found in 76,156 individuals from v3.1.1 of gnomAD [80]. Variants were used only if they passed the following filtering criteria: the variant was a single nucleotide variant (SNV), had a PASS filter, had an allele count > = 1, had a least 10X coverage in 50% of the samples, had a reference allele that matched the reference genome, was in a protein-coding gene determined by GENCODE [138, 139] v34 transcripts, had an associated SpliceAI score prediction, and was not in the pathogenic or benign variant truth set. Additionally, any self-chain or segmental duplication region with a 95% or more identity to another region of the genome was excluded from the splicing constraint model. Because of the difference in constraint between the autosome and the X chromosome, two separate substitution probability matrices and two separate splicing constraint models were generated representing the autosome and the X chromosome. The Y chromosome is excluded in these models.
Relative substitution probabilities were calculated by creating a substitution matrix that modeled each reference allele changing (or not) to any of the other alleles across all protein-coding genes. The reference to nonreference cells in the 4 × 4 matrix track the number of per-reference to alternative observed variants from gnomAD that pass the filters mentioned above, while the reference to reference cells tracked the number of sites in protein-coding genes that did not have a gnomAD variant. A reference-specific substitution probability was then calculated using the marginal distribution of counts for each reference allele, where the probability represents the normalized counts of reference to non-reference alleles, which is the normalized difference between the total number of sites and the number of sites with no gnomAD variant for that reference allele.
These substitution probabilities were further refined using SpliceAI [76] predictions, which provide an alternative splicing prediction for each nucleotide considered. SpliceAI allows us to consider the splicing specific substitution rate in coding and non-coding regions of genes where before only the canonical donor and acceptor splice sites could confidently be used. Thus, the substitution probabilities can be transformed into splicing aware expectations, utilizing every site in protein-coding genes. Furthermore, SpliceAI uses the local sequence context around a nucleotide, 5 kb upstream and 5 kb downstream, to predict the effect of each nucleotide on splicing, thus adding a broader sequence context to the expectation calculation. SpliceAI provides four predictions for each nucleotide, including Acceptor Gain (AG), Acceptor Loss (AL), Donor Gain (DG), and Donor Loss (DL). We chose to use the sum of the four SpliceAI scores, sum(AG, AL, DG, DL), at a single site to account for nucleotides that may contribute to more than one of the four alternative splicing scenarios based on sequence context. For a given reference allele, SpliceAI provides predictions for each possible alternative SNV allele at that site. For sites without a gnomAD variant that passed the filters mentioned above, the sum of the four SpliceAI scores for each reference to alternative allele at that position was calculated and the max sum SpliceAI score was selected. For sites with a variant, the sum SpliceAI score was calculated using the four SpliceAI scores for the variant's specific reference to the alternative allele.
The substitution matrix was updated by separating the reference to alternative allele counts into eight SpliceAI score range bins (Additional file 1: Fig. S1A) for each of the four reference alleles changing (or not) to the four alternative alleles. The final substitution probabilities were calculated by merging all GENCODE protein-coding transcripts, separated by positive and negative strand, and counting the number of gnomAD variants or sites without gnomAD variants across the merged transcripts, separated by SpliceAI score prediction and reference allele to alternative allele combination. The substitution probabilities were calculated as mentioned above, which resulted in 32 substitution probabilities based on a reference allele and SpliceAI score combination (Fig. 1A, Additional file 1: Fig. S1B, Additional file 1: Table S1, S2). These substitution probabilities make up the global per-site expectation of seeing an alternative splicing variant based on the reference allele and SpliceAI score prediction for each nucleotide. Canonical GENCODE transcripts, segmental duplication annotations, and self-chain annotations were obtained from the Go Get Data [140] (GGD) data management system.
Building the regional model of splicing constraint
To calculate the genetic constraint against aberrant splicing in coding and non-coding regions of the genome, we sought to measure the degree to which the variation observed deviated from what would be expected given the relative substitution probability matrix. Observed counts for a region were measured by adding up the number of gnomAD variants that passed previously stated filters and separated into 32 bins based on each variant's reference allele and SpliceAI score prediction. Expected counts for the same region were based on the substitution probabilities for each nucleotide in the region, where each nucleotide was assigned an expectation from the substitution probability matrix based on the nucleotides reference allele and SpliceAI prediction, again separated into the 32 bins. Once observed and expected counts were collected for a region, the window was slid down the genome, and the observed and expected counts for the new region were collected. Finally, an Observed / Expected (O/E) ratio was calculated for each region using the region’s observed counts and expected counts. First, an O/E ratio was calculated for each of the 32 bins in a region separately, weighted by the likelihood of that bin contributing to splicing. We include a likelihood weight here to boost the signal for constraint against splicing in a given region and reduce the noise from irrelevant alleles in that same region. Each bin's likelihood weight was based on the proportion of sites in the genome with that reference allele and SpliceAI score range combination, where the weight was equal to one over the genome-wide proportion for that bin. Therefore, irrelevant alleles that do not contribute to splicing will be down-weighted, reducing noise, while relevant alleles that do contribute to splicing will be up-weighted, boosting the signal. Second, weighted O/E ratios for all 32 bins for a single region were summed together to get the final O/E ratio for that region.
-
32 bins = The 32 bins based on the combination of reference alleles and SpliceAI score ranges.
-
X = A weight based on the likelihood that bin i contributes to splicing (See below).
-
O = The observed counts at a specific reference allele + SpliceAI score range bin i.
-
E = The expected counts at a specific reference allele + SpliceAI score range bin i.
To normalize the observed and expected counts across each of the 32 bins per region, we set the observed and expected counts to a default value of 1.0. Using the equation above, these default values lead to a regional O/E distribution being centered at 0 rather than at 1. Additionally, these default values with the O/E equation above remove the lower limit of 0 seen in traditional O/E and chi-squared statistics to a continuous negative value lower limit, allowing for higher constraint to be represented by a larger negative value with a null O/E value expectation of 0.0, and higher O/E values representing an increase in constraint. The mean O/E value for single exon genes was arbitrarily increased in the positive direction to account for the absence of splicing in single-exon genes.
Once an O/E score was calculated for every region, the O/E scores were sorted from largest to smallest and assigned a normalized score between 0.0 and 1.0. A constraint score of 1.0 represents the most constrained region to splicing, while a constraint score of 0.0 represents the most tolerant region to splicing.
Due to the difference between the autosome and the X chromosome, substitution probabilities and splicing constraint models were generated separately for both the autosome and the X chromosome. The pseudoautosomal regions (PAR) on the X chromosome were excluded from the X chromosome model. (GRCh38) PAR 1 = chrX:10,000–2,781,479, PAR 2 = chrX:155,701,382–156,030,895.
Evaluation of likelihood weights and optimal region sizes
To determine the best weighting approach among the six different likelihood weights used to develop the constraint model, performance was compared across each of the different weights using the pathogenic variants from HGMD and the validated benign alternative splicing variants in the benign set from GTEx (see “Pathogenic and benign variant truth set” methods section below). We found that the regional constraint model performed best when using the 1 / Proportion weight (Additional file 1: Fig. S17–S19). Additional file 1: Fig. S17–S19 also shows that the linear weighted model performs better for larger regions.
Name of weight (X[i]) | X[i] = |
|---|---|
Unweighted | 1 |
Linear weighted | SpliceAI score at i |
Log weighted | − 10* log10(Proportion[i]) |
1—Proportion weighted | 1—Proportion[i] |
1/Proportion weighted | 1/Proportion [i] |
1/Substitution rate weighted | 1/Substitution probability at i |
Where Proportion[i] represents the total proportion of sites in protein-coding genes with a reference allele and SpliceAI prediction in bin i.
Both the genic and regional constraint models were developed using a window-based approach. The gene size defined the window sizes for the gene model. Intragenic regional models were defined by a window either equal to or smaller than the size of a gene. Specific regions were excluded from the model if there was less than 80% of the nucleotides in that region with a SpliceAI score. To maintain a sufficiently large window to calculate constraint, we only included windows that were above the significant cutoff for informative sites based on the critical value determined using the F distribution. The number of informative sites by window size was modeled with a Poisson distribution where lambda was set to the genome-wide proportion of sites in protein-coding genes that were predicted to affect splicing by SpliceAI with a SpliceAI score > 0.0 (Additional file 1: Fig. S1A, S7). The significance cutoff was based on the F distribution at an alpha value of 0.025 using 7 degrees of freedom representing the 8 proportion bins used to calculate the proportion of informative sites. The critical value from the F distribution table is 6.5415, meaning a window needs at least 6.5415 informative variants to be significant. Additional file 1: Fig. S7 shows the number of informative sites per window size. Based on the significance cutoff, a window size of 50 bp or greater was used to generate the constraint model. Additional file 1: Fig. S10 shows the performance of various windows sizes using the 1/Proportion weight constraint model, where performance is assessed using the HGMD pathogenic variants and validated splice-altering benign variants from GTEx in the truth set. Figure 3A and Additional file 1: Fig. S8 provide additional testing to evaluate the ability of each window size to capture focal constraint around 5′ and 3′ splice regions.
Regional splicing constraint score bins
For multiple analyses in this manuscript, the regional constraint scores are separated into decile bins. For each bin, any gene or variant with a regional constraint score within the bin’s range was included in that bin. For all but the last bin, genes and variants were included if their regional constraint score was equal to or greater than the lower value of the bin range and less than the upper value of the range. For the last bin, any gene or variant with a regional constraint score greater than or equal to the lower value of the bin range and less than or equal to the upper value of the range were included in that bin.
Gene sets used to assess and compare splicing constraint
We used multiple gene sets to evaluate the genic splicing constraint scores based on previously established constraint expectations for those gene sets.
Gene Sets:
-
Haploinsufficient genes We used a set of 294 genes determined to be dosage-sensitive in the ClinGen data set [141] and hosted on the Macarthur lab gene list GitHub page at https://github.com/macarthur-lab/gene_lists/blob/master/lists/clingen_level3_genes_2018_09_13.tsv.
-
Autosomal Dominant genes We used a combined set of 709 genes that were shown to follow an autosomal dominant inheritance pattern determined by Blekhman et al. [142] and Berg et al. [143] hosted on the Macarthur lab GitHub page at: https://github.com/macarthur-lab/gene_lists/blob/master/lists/berg_ad.tsv.
-
Autosomal Recessive genes We used a combined set of 1183 genes that were shown to follow an autosomal recessive inheritance pattern by Blekhman et al [142]. and Berg et al. [143] hosted on the Macarthur lab GitHub page at: https://github.com/macarthur-lab/gene_lists/blob/master/lists/all_ar.tsv.
-
Olfactory Receptor genes We used a set of 371 Olfactory Receptor genes from the Mainland et al. [144] paper hosted on the Macarthur lab GitHub page at: https://github.com/macarthur-lab/gene_lists/blob/master/lists/olfactory_receptors.tsv.
-
CRISPR Essential and Nonessential genes We used a set of 683 essential genes and 913 nonessential genes determined to be essential or nonessential, respectively, by CRISPR screens from Hart et al. [84] hosted on the Macarthur lab GitHub page at: essential genes: https://github.com/macarthur-lab/gene_lists/blob/master/lists/CEGv2_subset_universe.tsv, nonessential genes: https://github.com/macarthur-lab/gene_lists/blob/master/lists/NEGv1_subset_universe.tsv.
-
Homozygous LoF tolerant genes We used a set of 1815 genes tolerant to high confident homozygous loss of function mutations in at least one individual in gnomAD found in Supplemental Table S7 of the gnomAD paper [80]: https://static-content.springer.com/esm/art%3A10.1038%2Fs41586-020-2308-7/MediaObjects/41586_2020_2308_MOESM4_ESM.zip
-
Developmental Delay and Intellectual Disability (DD/ID) genes We obtained a set of 2072 genes collected across multiple Deciphering Developmental Delay (DDD) studies hosted on the Gene 2 Phenotype [90] website: https://www.ebi.ac.uk/gene2phenotype/, csv file: https://www.ebi.ac.uk/gene2phenotype/downloads/DDG2P.csv.gz.
Genes in the Haploinsufficient, Autosomal Dominant, Autosomal Recessive, Olfactory Receptor, DD/ID, CRISPR Essential, and CRISPR Nonessential gene sets were each normalized to a value of one across the genic splicing constraint score spectrum to compare the proportion/fraction of genes in each constraint decile bin. Genes in the Homozygous LoF tolerant gene set were separated into constraint decile bins. For each genic splicing constraint decile bin, the number of Homozygous LoF tolerant genes in a bin was divided by the total number of genes in that same bin to get the percent of Homozygous LoF tolerant genes by decile.
pLI and LOEUF constraint scores
The genic splicing constraint metric was compared to the probability of loss-of-function intolerance (pLI) [81] and the loss-of-function observed/expected upper bound fraction (LOEUF) [80] metrics to establish if the splicing constraint metric captured known patterns of constraint. pLI and LOEUF were downloaded from the gnomAD browser using the constraint download link https://gnomad-public-us-east-1.s3.amazonaws.com/legacy/exac_browser/forweb_cleaned_exac_r03_march16_z_data_pLI_CNV-final.txt.gz for pLI and the constraint download link https://gnomad-public-us-east-1.s3.amazonaws.com/release/2.1.1/constraint/gnomad.v2.1.1.lof_metrics.by_gene.txt.bgz for LOEUF. The “pLI” column and the “oe_lof_upper_bin” column were used for the pLI score and the LOEUF score in their respective files.
Splicing constraint and pLI scores are ranked from least to most constrained from 0.0 to 1.0. LOEUF scores are ranked in the opposite direction with the most constrained gene assigned a LEOUF decile of 0 and the least constrained gene assigned a LOEUF decile of 9. To compared LOEUF to pLI and splicing constraint, we reversed the LOEUF deciles so that the ranking was oriented in the same direction as pLI and splicing constraint, and relabeled the deciles to match the pLI and splicing constraint decile bins. Therefore, LOEUF deciles in this mansucript are as follows:
Original LOEUF decile | Reversed and relabeled LOEUF decile |
|---|---|
9 | 0.0–0.1 |
8 | 0.1–0.2 |
7 | 0.2–0.3 |
6 | 0.3–0.4 |
5 | 0.4–0.5 |
4 | 0.5–0.6 |
3 | 0.6–0.7 |
2 | 0.7–0.8 |
1 | 0.8–0.9 |
0 | 0.9–1.0 |
Comparing genic splicing constraint to gene dosage sensitivity using VG estimates from GTEx
To assess the correlation between splicing constraint and gene dosage, we used the average genetic variation in gene expression (VG) values created from GTEx data by Mohammadi et al. [92] located in their Additional file 1: Table S1. The average VG values are a per gene weighted harmonic mean across tissues in natural log units. We removed any outlier VG value that was > 10 standard deviations from the mean. We assigned each gene its cross-tissue average VG value and separated them into ConSplice score decile bins. We plotted the distribution of average VG values per constraint decile bin as box plots. The interquartile range (IQR) of the boxes ranges from the 25th to 75th percentile. The horizontal line in each box represents the median. The whiskers are 1.5X the IQR. Outlier values are not included in the plot.
To test for a significant negative correlation between the splicing constraint of a gene and its estimated genic expression, we ran an ordinary least squares (OLS) linear regression using the splicing constraint scores and VG values. We also controlled for the number of exons per gene in the regression to rule out any covariant significance driven by the number of splicing events in a gene. The mean fold difference of variance in gene expression between the lowest and highest constraint decile bins was calculated by taking the mean VG value in the 0.0–0.1 decile and dividing by the mean VG values in the 0.9–1.0 decile. We further tested for a significant difference in VG distributions between different constraint bins. We compared each bin to every other bin in a pair-wise manner using a t-test of independence. The p-values were adjusted using the Benjamini Hochberg approach with an alpha value of 0.01. FDR adjusted p-values can be found in Additional file 1: Fig. S4.
Comparing genic splicing constraint to GTEx splicing outliers
Splicing Outliers from Ferraro et al. [95] were obtained from the GTEx portal within the version 8 data release file named “gtexV8.sOutlier.stats.globalOutliers.removed.txt.gz” under the “Outlier Calls” heading: https://storage.googleapis.com/gtex_analysis_v8/outlier_calls/GTEx_v8_outlier_calls.zip. The data within the sOutiler file represent the per gene cross-tissue p-values for splicing outliers found for each GTEx sample, where the p-values were determined using the SPOT [95] metric. For a sOutlier to be included in this dataset for a sample, it needed to have been present in multiple tissues based on the requirements from Ferraro et al. These events represent a highly confident set of sOutliers.
Ferraro et al. determined that a p-value cutoff of 0.0027 was adequate to determine whether or not a cross-tissue splicing outlier was significant or not. We used the same p-value cutoff and designated significant sOutliers as those with a p-value < 0.0027. For each gene, we counted the number of individuals in GTEx that had a significant cross-tissue sOutlier p-value.
Using the gene designation within the sOutlier file, we added the associated constraint scores. We counted the number of genes with 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, and > 10 sOutliers per each constraint decile bin. That is, how many genes within a constraint decile bin have zero significant sOutilers, one significant sOutlier, and so on. We then normalized the total number of sOutlier genes (i.e., genes from the sOutlier file) for each constraint decile bin. The total normalized number of sOultier genes in a constraint decile bin will sum to 1. Figure 3C shows the normalized values for genes with zero sOutliers per constraint bin. Additional file 1: Fig. S5B shows the normalized values for the genes with at least one sOutlier. Significance was determined using OLS linear regression.
Assessing regional constraint in constitutive vs cassette exons
We used constitutive and cassette exons from the HEXEvent database [98] to evaluate the regional splicing constraint metric around exons. Exon definitions were downloaded from the HEXEvent website http://hexevent.mmg.uci.edu/cgi-bin/HEXEvent/HEXEventWEB.cgi for the GRCh38 genome build. For each exon, HEXEvent provides a measure of exon inclusion called the constitutive level (constLevel). The inclusion level for each exon provided by HEXEvent was used to determine “Full Inclusion” constitutive exons, “High Inclusion” cassette exons, and “Moderate Inclusion” cassette exons. High inclusion cassette exons were defined as exons with an inclusion > = 90% and < 100% based on previous work defining a 90% cutoff [98, 99]. Moderate inclusion cassette exons included all exons with an inclusion rate < 90%.
For each exon, a regional constraint score was identified at 25 bp intervals from the 5′ and 3′ ends of the exon, moving upstream and downstream of the exon into the intron, respectively. These intervals continued until the upstream and downstream exon had been reached. The list of regional scores for exons on the negative strand was re-oriented to match the positive strand in a 5′ to 3′ manner. Solid lines represent the median ConSplice score at each 25 bp interval. The opaque shading around the solid lines represents the 95% confidence interval calculated using bootstrap with 1000 iterations.
Splicing unaware model of constraint
To determine if the regional model of splicing constraint was identifying the constraint of coding regions compared to non-coding regions alone or identifying the signal of splicing beyond coding regions, we created multiple regional models of constraint unaware of splicing to compare to the splicing aware models of constraint. The same approach already described for the splicing constraint model was used to create the splicing unaware model of constraint. The difference between the two models lies in the inclusion or exclusion of SpliceAI predictions to inform the model, where the splicing aware model of constraint uses the SpliceAI prediction and the splicing unaware model of constraint excludes the SpliceAI predictions. Additionally, since SpliceAI predictions are excluded from the splicing unaware model of constraint, the splicing likelihood weights used to calculate constraint were also excluded, representing an unweighted model.
Assessing regional constraint in poison exons
Genomic coordinates for the three poison exons in SCN1A seen in Fig. 3B and Additional file 1: Fig. S12 that cause nonsense-mediated decay (NMD) leading to Dravet Syndrome (DRVT [MIM: 607208]) were collected from Steward et al. [101], (Additional file 1: Table S3). IGV [145] was used to visualize the constraint score profiles around each exon feature. Constraint scores reflect the 50 bp regional constraint model. Additional file 1: Table S3 also contains the coordinates of the three randomly selected exons in SCN1A seen in Fig. 3C and Additional file 1: Fig. S12. To identify the ranking for each poison exon in SCN1A, all constraint scores in SCN1A were sorted and assigned a score between 0.0 and 1.0. The max constraint score that overlapped each poison exon was at or above the 92nd percentile for SCN1A constraint scores.
Coding sequencing (CDS) annotations were used to distinguish coding and noncoding sequences in SCN1A. Canonical splice sites were determined based on the − 1, − 2, + 1, and + 2 positions around each CDS exon, excluding the − 1 and − 2 positions of the first exon and the + 1 and + 2 positions of the last exon which do not participate in splicing. The distribution of regional constraint scores was plotted based on if the region overlapped a CDS region or not, or a canonical splice site (Additional file 1: Fig. S11). IQR of the boxes ranges from the 25th to 75th percentile. The horizontal line in each box represents the median. The whiskers are 1.5X the IQR. The max regional constraint score for each poison exon is plotted as points along the distribution. The max regional constraint score for each poison exon was in the top 2% of scores for noncoding regions in SCN1A, and is similar to the constraint in both CDS regions and canonical splice site regions.
Manually curated pathogenic splice altering variants
We identified 376 autosomal noncanonical pathogenic splice altering variants by reviewing scientific medical literature. Each variant in this list has functional support for its effect on splicing and an association with a Mendelian disorder. Variants at the canonical donor and acceptor splice sites were explicitly excluded from this set. For each variant, we include PubMed ids for the papers the describe the variant, dbSNP [146] RS ids, Clinvar [147] ids along with review status, gnomAD v2 and v3 allele frequencies, online mendelian inheritance of man (OMIM) [148] ids, the relative exonic position, and the number of bases from the nearest exon–intron junction. Each variant also has a SpliceAI score, a SQUIRLS score, a CADD v1.6 score, and a 50 bp regional constraint score. (Additional file 2: Table S4).
IGV was used to visualize the regional constraint profiles in ACVRL1 found in Fig. 4A–C. The variant position was plotted on the gene track as a red lollipop. The 50 bp constraint region containing the variant is circled in red. The regional constraint score for each variant is listed below the variant lollipop in red. The right y-axis shows the regional constraint score. The left y-axis shows the log scaled constraint scores using the following equation: − 10 * log10(1—constraint score). The constraint profile is plotted using the log scaled scores. Variants in Additional file 1: Fig. S13 were identified from Frésard et al. [125] and Murdock et al. [126] and plotted using the same approach for the ACVRL1 gene described above.
The count of variants from the set at each relative exonic position was plotted in the 5’ to 3’ direction from left to right. Variants greater than 10 bp away from the exon–intron junction were labeled as deep intronic and deep exonic variants. The distribution of scores for each variant in the set from CADD-Splice (the splicing version of CADD v1.6), SpliceAI, SQURILS, and regional constraint are plotted as boxplots with the IQR ranging from the 25th to the 75th percentile, median scores represented by the black vertical line in each box, and the whiskers 1.5X the IQR. Outliers beyond the whiskers are not plotted.
The 50 bp regional constraint model was used for all analyses in this section.
Pathogenic and benign variant truth set
The 18,317 filtered variants in the pathogenic truth set were identified from the Human Gene Mutation Database [127,128,129] (HGMD). Each pathogenic variant leads to deleterious splicing and was labeled as a disease-causing mutation (DM) by HGMD. Variants were downloaded from Q1 of 2021. Variants not on the autosome and that did not have a CADD score, SpliceAI score, SQUIRLS score, and regional constraint score were excluded from the analysis. The relative exonic position was identified using the combination of the “type” and “location” columns in the dataset. Due to licensing agreements with HGMD, we are not allowed to share these variants publicly. For those who do have an HGMD commercial license, we provide the MySQL command to download the HGMD variants in the “Availability of Data and Materials” section WGS below.
The 48,978 filtered variants in the benign truth set come from a combination of de novo mutations (DNM) from whole-genome sequencing of multi-generational [130] and two generation [131] families, and a set of validated benign splice altering variants in GTEx [76]. Second and third-generation DNMs from the multi-generational family study were downloaded from https://github.com/quinlan-lab/ceph-dnm-manuscript. These DNMs were lifted over from GRCh37 to GRCh38. DNMs from 1,548 two-generation trios were downloaded from Supplemental Table 4 of the Jónsson et al. paper [131]. These DNMs were already in GRCh38. Validated benign splice altering variants seen in 1–4 individuals in the GTEx RNA-seq data were downloaded from Jaganathan et al. [76] Variants were lifted over from GRCH37 to GRCh38.
Variants in the benign truth set outside of protein-coding genes were filtered out of the set. All remaining variants were then scored with CADD, SpliceAI, SQUIRLS, and regional constraint. Any variant that did not have a score from CADD, SpliceAI, SQUIRLS, and regional constraint was removed from the set. The relative exonic position was added to each variant using the canonical transcripts in GENCODE v34. This benign set is available in Additional file 3: Table S5.
The ConSpliceML model
The ConSpliceML model is deployed using a Random Forest (RF) ensemble machine learning approach, a supervised classification machine learning algorithm based on a collection of decision trees, implemented using the scikit-learn [149] python API. The RF uses the regional constraint, SpliceAI, and SQUIRLS scores as a feature vector with a pathogenic or benign label for each variant to create the decision trees that make up the model. ConSpliceML is made up of 1000 decision trees. The ConSpliceML model provides a prediction at a per-base resolution on a range from 0.0 to 1.0, describing the probability that a variant is a pathogenic splice-altering variant. The model used in this manuscript can be found in the manuscript GitHub repository at https://github.com/mikecormier/ConSplice-manuscript and is implemented as a python module found at https://github.com/mikecormier/ConSplice. The precomputed ConSpliceML scores in the vcf file we provide were generated using the ConSpliceML python module at https://github.com/mikecormier/ConSplice, where the model was trained using the full collection of pathogenic and benign variants in the truth set.
Scoring variants
We used CADD v1.6, also known as the splicing version of CADD called CADD-Splice, for the CADD scores used in our dataset. GRCh38 CADD v1.6 scores for all possible SNVs were downloaded from the CADD website at https://cadd.gs.washington.edu/download. Variants were assigned a CADD score based on the genomic position, reference allele, and alternative allele.
GRCh38 SpliceAI v1.3.1 pre-computed scores for SNVs in protein-coding genes were downloaded following the instructions found on SpliceAI’s GitHub page at https://github.com/Illumina/SpliceAI. Variants were assigned a SpliceAI score using the genomic position, reference allele, alternative allele, and gene name.
SQUIRLS version 1.0.0 was downloaded following the instructions outlined in the SQUILRS documentation at https://squirls.readthedocs.io/en/latest/. Variants were scored using the GRCh38 SQUIRLS CLI.
The regional splicing constraint score was assigned to each variant using the ConSplice CLI: https://github.com/mikecormier/ConSplice.
ConSpliceML scores were generated using the trained RF with the ConSplice, Max SpliceAI, and Max SQUIRLS scores from each test variant as the input feature vector. ConSpliceML then provides a pathogenic probability score that ranges from 0.0 to 1.0.
Training and testing ConSpliceML
We used 60% of the truth set for training the ConSpliceML model and 40% for testing. The test set was excluded from all training of the ConSpliceML model and represents an independent set of variants for testing. We eliminated possible overfitting based on variants in the training and test set not falling in the same splicing constraint region. The variants within a region that containes multiple variants in the truth set were randomly assigned to either the training set or tests set using the 60/40% split. This approach eliminates any variants in the training set falling in the same splicing constraint region as those in the test set. With the training set, we used a stratified five-fold cross-validation approach to train and validate the training accuracy of the ConSpliceML model. Each of the five folds had a distinct 20% of pathogenic and benign variants not shared by any of the other folds used for validation. The variants used to train each fold used the 80% remaining variants in the training set not found in the validation set for that fold. The number of pathogenic and benign variants in each fold was consistent across all folds. Pathogenic and benign variants were labeled as such. Due to a large difference in the number of pathogenic to benign variants, Precision-Recall (PR) was assessed, as it is more suitable for imbalanced datasets. PR curves were generated and compared across each of the five folds to evaluate the training accuracy, stability, and consistency of the ConSpliceML model (Additional file 1: Fig. S14). The combined average performance across all five folds was also assessed in the same plot.
Finally, the ConSpliceML model was trained using the training set, and the performance of CADD, SpliceAI, SQUIRLS, and ConSpliceML was assessed using the hold-out test set. The area under the precision-recall curve (PR AUR) and the average precision score (Ave. PR Score) are provided for each PR curve. The Ave. PR Score is a weighted mean of precision occurring at each threshold weighted by the difference in recall from the previous threshold and is a more accurate measure of performance.
-
Pi = The precision at the ith threshold.
-
Ri = The recall at the ith threshold.
The dotted horizontal baseline in each PR plot represents the random chance prediction and is calculated as follows:
-
P = The number of pathogenic variants
-
B = the number of benign variants
Odds ratio enrichment
To measure the enrichment of pathogenic to benign variants along the ConSpliceML score range, we measure the ratio of pathogenic variants to benign variants in a ConSpliceML decile divided by the ratio of pathogenic to benign variants not in the decile. That is, we calculate the odds ratio (OR) of pathogenic to benign variants at each ConSpliceML decile.
-
ORi = The odds ratio of pathogenic to benign variants for the ConSpliceML decile i.
-
Ai = The number of pathogenic variants in the ConSpliceML decile i.
-
Bi = The number of benign variants in the ConSpliceML decile i.
-
Cnot i = The number of pathogenic variants not in the ConSpliceML decile i.
-
Dnot i = The number of benign variants not in the ConSpliceML decile i.
We calculate the 95% confidence interval (CI) for each OR as follows:
OR by decile was plotted as bar plots with whiskers as the 95% CI. The OR values for each decile are indicated above each bar. The dotted line at an OR of 1 indicates no difference in the ratio of pathogenic to benign variants.
Availability of data and materials
The ConSplice CLI, including a module for splicing constraint and a module for ConSpliceML, is an open-source and publicly available project under an MIT license. The ConSplice CLI can be found at https://github.com/mikecormier/ConSplice and contains the code necessary to recreate the regional constraint model. Additionally, it contains information on the data required to create the ConSplice model along with how to download and use the data. The GRCh38 gnomAD [80] v3.1.1 vcf file for each chromosome and the per-base sequencing coverage file were downloaded from the gnomAD browser website at https://gnomad.broadinstitute.org/downloads. The separate chromosome vcf files were merged together into one file, decomposed, and normalized. Any gnomAD variant in the truth set was removed from the final gnomAD vcf file to ensure that the splicing constraint model was not trained and tested on the same variants. The precomputed GRCh38 SpliceAI [76] v1.3.1 raw SNV vcf files were downloaded from the illumina basespace portal at https://basespace.illumina.com/s/otSPW8hnhaZR following the information available on the SpliceAI GitHub repo at https://github.com/Illumina/SpliceAI. The GRCh38 gene features from GENCODE [138, 139] v34 used to create the splicing constraint model were downloaded using the GGD [140] CLI under the GGD data package name “grch38-canonical-transcript-features-gencode-v1”. (https://gogetdata.github.io/recipes/genomics/Homo_sapiens/GRCh38/grch38-canonical-transcript-features-gencode-v1/README.html). The segmental duplications and self-chain genomic repeat bed files used to create the splicing constraint model were downloaded using the GGD cli under the GGD data package names “grch38-segmental-dups-ucsc-v1” and “grch38-self-chain-ucsc-v1”, respectively. (https://gogetdata.github.io/recipes/genomics/Homo_sapiens/GRCh38/grch38-segmental-dups-ucsc-v1/README.html, https://gogetdata.github.io/recipes/genomics/Homo_sapiens/GRCh38/grch38-self-chain-ucsc-v1/README.html). The GGD [140] documentation can be found at https://gogetdata.github.io/. Gene sets used to test the genic splicing constraint model were obtained from the following resources: Gene 2 Phenotype [90]: https://github.com/macarthur-lab/gene_lists/blob/master/lists/homozygous_lof_tolerant_twohit.tsv. Haploinsufficient Genes [141]: https://github.com/macarthur-lab/gene_lists/blob/master/lists/clingen_level3_genes_2018_09_13.tsv. Autosomal Dominant Genes [142, 143]: https://github.com/macarthur-lab/gene_lists/blob/master/lists/berg_ad.tsv. Autosomal Recessive Genes [142, 143]: https://github.com/macarthur-lab/gene_lists/blob/master/lists/all_ar.tsv. Olfactory Receptor Genes [144]: https://github.com/macarthur-lab/gene_lists/blob/master/lists/olfactory_receptors.tsv. CRISPR Essential Genes [84]: https://github.com/macarthur-lab/gene_lists/blob/master/lists/CEGv2_subset_universe.tsv. CRISPR Non-essential Genes [84]: https://github.com/macarthur-lab/gene_lists/blob/master/lists/NEGv1_subset_universe.tsv. Homozygous LoF Genes from supplemental Table S7 of the gnomAD paper [80]: https://static-content.springer.com/esm/art%3A10.1038%2Fs41586-020-2308-7/MediaObjects/41586_2020_2308_MOESM4_ESM.zip. VG values created from GTEx data were downloaded from Additional file 1: Table S1 in the Mohammadi et al. [92] paper. Splicing Outliers from Ferraro et al. [95] were obtained from the GTEx portal https://www.gtexportal.org/home/ within the version 8 data release file named “gtexV8.sOutlier.stats.globalOutliers.removed.txt.gz” under the “Outlier Calls” heading: https://storage.googleapis.com/gtex_analysis_v8/outlier_calls/GTEx_v8_outlier_calls.zip. The GRCh38 constitutive and cassette exons were downloaded from the HEXEvent website http://hexevent.mmg.uci.edu/cgi-bin/HEXEvent/HEXEventWEB.cgi.
The manually curated noncanonical pathogenic splicing variants are available in Additional file 2: Table S4 of this manuscript. SQUIRLS v1.0.0 was downloaded following the instructions outlined in the SQUIRLS documentation: https://squirls.readthedocs.io/en/latest/. The disease-causing, splice-altering variants from HGMD were downloaded from the HGMD website http://www.hgmd.cf.ac.uk/ under the HGMD commercial license using version Q1 of 2021. Due to HGMD commercial licensing, we are not allowed to share these variants publicly, but we provide the following SQL command for reproducibility if you obtain an HGMD commercial license. Variants were downloaded using the following MySQL command from the MySQL import of HGMD 2021q1 SQL dump: SELECT*FROM splice INNER JOIN hgmd_hg38_vcf ON acc_num = hgmd_hg38_vcf.id. The set of benign variants used in this manuscript are available in Additional file 3: Tables S5 of this manuscript. Scripts, data requirements, and other information that can be used to reproduce the results in this manuscript can be found at the ConSplice manuscript GitHub repo https://github.com/mikecormier/ConSplice-manuscript.
Abbreviations
- ACMG:
-
American College of Medical Genetics
- AD genes:
-
Autosomal dominant genes
- AG:
-
Acceptor gain
- AL:
-
Acceptor loss
- AR genes:
-
Autosomal recessive genes
- AUKS:
-
Au-Kline syndrome
- Avg. PR Score:
-
Average precision score
- CDS:
-
Coding sequencing
- CI:
-
Confidence interval
- CLI:
-
Command line interface
- ConSplice:
-
Constrained splicing
- constLevel:
-
Constitutive level
- DD/ID:
-
Developmental delay and intellectual disability
- DG:
-
Donor gain
- DL:
-
Donor loss
- DM:
-
Disease-causing mutations
- DNA-seq:
-
DNA sequencing
- DNMs:
-
De novo mutations
- DRVT:
-
Dravet syndrome
- FDR:
-
False discovery rate
- GGD:
-
Go get data
- gnomAD:
-
Genome aggregate database
- GTEx:
-
Genotype-tissue expression
- HI genes:
-
Haploinsufficient genes
- HGMD:
-
Human gene mutation database
- HTT2:
-
Hereditary hemorrhagic telangiectasia
- IQR:
-
Interquartile range
- LOEUF:
-
Loss-of-function observed/expected upper-bound fraction
- MFS:
-
Marfan syndrome
- NF1:
-
Neurofibromatosis type 1
- NMD:
-
Nonsense-mediated decay
- O/E:
-
Observed over expected
- OLS:
-
Ordinary least squares
- OPA1:
-
Optic atrophy 1
- OMIM or MIM:
-
Online Mendelian inheritance of man
- OR:
-
Odds ratio
- OR genes:
-
Olfactory receptor genes
- PAR:
-
Pseudoautosomal region
- pLI:
-
Probability of loss-of-function intolerance
- pLoF:
-
Putative loss-of-function
- PR:
-
Precision-recall
- PR AUC:
-
Precision-recall area under the curve
- RB1:
-
Retinoblastoma
- RENS1:
-
Renpenning syndrome
- RF:
-
Random forest
- RNA-seq:
-
RNA sequencing
- SEMD:
-
Spondyloepimetaphyseal dysplasia
- SMAPME:
-
Spinal muscular atrophy with progressive myoclonic epilepsy
- SNV:
-
Single nucleotide variant
- sOutliers:
-
Splicing outlier
- STL1:
-
Stickler syndrome
- UDN:
-
Undiagnosed disease network
- VG :
-
Expected genetic variation in gene expression
References
Eilbeck K, Quinlan A, Yandell M. Settling the score: variant prioritization and Mendelian disease. Nat Rev Genet. 2017;18:599–612.
Boycott KM, et al. International cooperation to enable the diagnosis of all rare genetic diseases. Am J Hum Genet. 2017;100:695–705.
Ewans LJ, et al. Whole-exome sequencing reanalysis at 12 months boosts diagnosis and is cost-effective when applied early in Mendelian disorders. Genet Med. 2018;20:1564–74.
Lionel AC, et al. Improved diagnostic yield compared with targeted gene sequencing panels suggests a role for whole-genome sequencing as a first-tier genetic test. Genet Med. 2018;20:435–43.
Wang ET, et al. Alternative isoform regulation in human tissue transcriptomes. Nature. 2008;456:470–6.
Pan Q, Shai O, Lee LJ, Frey BJ, Blencowe BJ. Deep surveying of alternative splicing complexity in the human transcriptome by high-throughput sequencing. Nat Genet. 2008;40:1413–5.
Xiong HY, et al. RNA splicing. The human splicing code reveals new insights into the genetic determinants of disease. Science. 2015;347:1254806.
Scotti MM, Swanson MS. RNA mis-splicing in disease. Nat Rev Genet. 2016;17:19–32.
Anna A, Monika G. Splicing mutations in human genetic disorders: examples, detection, and confirmation. J Appl Genet. 2018;59:253–68.
Black DL. Mechanisms of alternative pre-messenger RNA splicing. Annu Rev Biochem. 2003;72:291–336.
Xing Y, Lee C. Alternative splicing and RNA selection pressure–evolutionary consequences for eukaryotic genomes. Nat Rev Genet. 2006;7:499–509.
Park E, Pan Z, Zhang Z, Lin L, Xing Y. The expanding landscape of alternative splicing variation in human populations. Am J Hum Genet. 2018;102:11–26.
Matlin AJ, Clark F, Smith CWJ. Understanding alternative splicing: towards a cellular code. Nat Rev Mol Cell Biol. 2005;6:386–98.
Will CL, Lührmann R. Spliceosome structure and function. Cold Spring Harb Perspect Biol. 2011;3:a003707.
Matera AG, Wang Z. A day in the life of the spliceosome. Nat Rev Mol Cell Biol. 2014;15:108–21.
Lee Y, Rio DC. Mechanisms and regulation of alternative pre-mRNA splicing. Annu Rev Biochem. 2015;84:291–323.
Ule J, Blencowe BJ. Alternative Splicing regulatory networks: functions, mechanisms, and evolution. Mol Cell. 2019;76:329–45.
Wang Z, Burge CB. Splicing regulation: from a parts list of regulatory elements to an integrated splicing code. RNA. 2008;14:802–13.
Singh RK, Cooper TA. Pre-mRNA splicing in disease and therapeutics. Trends Mol Med. 2012;18:472–82.
Caminsky N, Mucaki EJ, Rogan PK. Interpretation of mRNA splicing mutations in genetic disease: review of the literature and guidelines for information-theoretical analysis. F1000Res. 2014;3:282.
Sibley CR, Blazquez L, Ule J. Lessons from non-canonical splicing. Nat Rev Genet. 2016;17:407–21.
Soemedi R, et al. Pathogenic variants that alter protein code often disrupt splicing. Nat Genet. 2017;49:848–55.
Vaz-Drago R, Custódio N, Carmo-Fonseca M. Deep intronic mutations and human disease. Hum Genet. 2017;136:1093–111.
Dong X, Chen R. Understanding aberrant RNA splicing to facilitate cancer diagnosis and therapy. Oncogene. 2020;39:2231–42.
Richards S, et al. Standards and guidelines for the interpretation of sequence variants: a joint consensus recommendation of the American College of Medical Genetics and Genomics and the Association for Molecular Pathology. Genet Med. 2015;17:405–24.
Krawczak M, Reiss J, Cooper DN. The mutational spectrum of single base-pair substitutions in mRNA splice junctions of human genes: causes and consequences. Hum Genet. 1992;90:41–54.
López-Bigas N, Audit B, Ouzounis C, Parra G, Guigó R. Are splicing mutations the most frequent cause of hereditary disease? FEBS Lett. 2005;579:1900–3.
Wang G-S, Cooper TA. Splicing in disease: disruption of the splicing code and the decoding machinery. Nat Rev Genet. 2007;8:749–61.
Daguenet E, Dujardin G, Valcárcel J. The pathogenicity of splicing defects: mechanistic insights into pre-mRNA processing inform novel therapeutic approaches. EMBO Rep. 2015;16:1640–55.
Cartegni L, Chew SL, Krainer AR. Listening to silence and understanding nonsense: exonic mutations that affect splicing. Nat Rev Genet. 2002;3:285–98.
Wang Z, et al. Systematic identification and analysis of exonic splicing silencers. Cell. 2004;119:831–45.
Smith PJ, et al. An increased specificity score matrix for the prediction of SF2/ASF-specific exonic splicing enhancers. Hum Mol Genet. 2006;15:2490–508.
Goren A, et al. Comparative analysis identifies exonic splicing regulatory sequences—the complex definition of enhancers and silencers. Mol Cell. 2006;22:769–81.
Wang Z, Xiao X, Van Nostrand E, Burge CB. General and specific functions of exonic splicing silencers in splicing control. Mol Cell. 2006;23:61–70.
Görnemann J, Kotovic KM, Hujer K, Neugebauer KM. Cotranscriptional spliceosome assembly occurs in a stepwise fashion and requires the cap binding complex. Mol Cell. 2005;19:53–63.
Listerman I, Sapra AK, Neugebauer KM. Cotranscriptional coupling of splicing factor recruitment and precursor messenger RNA splicing in mammalian cells. Nat Struct Mol Biol. 2006;13:815–22.
Merkhofer EC, Hu P, Johnson TL. Introduction to cotranscriptional RNA splicing. Methods Mol Biol. 2014;1126:83–96.
Custódio N, Carmo-Fonseca M. Co-transcriptional splicing and the CTD code. Crit Rev Biochem Mol Biol. 2016;51:395–411.
Herzel L, Ottoz DSM, Alpert T, Neugebauer KM. Splicing and transcription touch base: co-transcriptional spliceosome assembly and function. Nat Rev Mol Cell Biol. 2017;18:637–50.
Neugebauer KM. Nascent RNA and the coordination of splicing with transcription. Cold Spring Harb Perspect Biol. 2019;11:a032227.
Roberts GC, Gooding C, Mak HY, Proudfoot NJ, Smith CWJ. Co-transcriptional commitment to alternative splice site selection. Nucleic Acids Res. 1998;26:5568–72.
Kornblihtt AR. Promoter usage and alternative splicing. Curr Opin Cell Biol. 2005;17:262–8.
Lim KH, Ferraris L, Filloux ME, Raphael BJ, Fairbrother WG. Using positional distribution to identify splicing elements and predict pre-mRNA processing defects in human genes. Proc Natl Acad Sci U S A. 2011;108:11093–8.
Hertel KJ. Combinatorial control of exon recognition. J Biol Chem. 2008;283:1211–5.
Shepard PJ, Hertel KJ. Conserved RNA secondary structures promote alternative splicing. RNA. 2008;14:1463–9.
Zhang J, Kuo CCJ, Chen L. GC content around splice sites affects splicing through pre-mRNA secondary structures. BMC Genom. 2011;12:90.
Taube JR, et al. PMD patient mutations reveal a long-distance intronic interaction that regulates PLP1/DM20 alternative splicing. Hum Mol Genet. 2014;23:5464–78.
Luco RF, et al. Regulation of alternative splicing by histone modifications. Science. 2010;327:996–1000.
Kim S, Kim H, Fong N, Erickson B, Bentley DL. Pre-mRNA splicing is a determinant of histone H3K36 methylation. Proc Natl Acad Sci. 2011;108:13564–9.
Jagadeesh KA, et al. S-CAP extends pathogenicity prediction to genetic variants that affect RNA splicing. Nat Genet. 2019;51:755–63.
Shapiro MB, Senapathy P. RNA splice junctions of different classes of eukaryotes: sequence statistics and functional implications in gene expression. Nucleic Acids Res. 1987;15:7155–74.
Brunak S, Engelbrecht J, Knudsen S. Prediction of human mRNA donor and acceptor sites from the DNA sequence. J Mol Biol. 1991;220:49–65.
Hebsgaard SM, et al. Splice site prediction in Arabidopsis thaliana pre-mRNA by combining local and global sequence information. Nucleic Acids Res. 1996;24:3439–52.
Reese MG, Eeckman FH, Kulp D, Haussler D. Improved splice site detection in Genie. J Comput Biol. 1997;4:311–23.
Rogozin IB, Milanesi L. Analysis of donor splice sites in different eukaryotic organisms. J Mol Evol. 1997;45:50–9.
Burge C, Karlin S. Prediction of complete gene structures in human genomic DNA. J Mol Biol. 1997;268:78–94.
Pertea M, Lin X, Salzberg SL. GeneSplicer: a new computational method for splice site prediction. Nucleic Acids Res. 2001;29:1185–90.
Fairbrother WG, Yeh R-F, Sharp PA, Burge CB. Predictive identification of exonic splicing enhancers in human genes. Science. 2002;297:1007–13.
Knudsen B, Hein J. Pfold: RNA secondary structure prediction using stochastic context-free grammars. Nucleic Acids Res. 2003;31:3423–8.
Cartegni L, Wang J, Zhu Z, Zhang MQ, Krainer AR. ESEfinder: a web resource to identify exonic splicing enhancers. Nucleic Acids Res. 2003;31:3568–71.
Zuker M. Mfold web server for nucleic acid folding and hybridization prediction. Nucleic Acids Res. 2003;31:3406–15.
Brendel V, Xing L, Zhu W. Gene structure prediction from consensus spliced alignment of multiple ESTs matching the same genomic locus. Bioinformatics. 2004;20:1157–69.
Carmel I, Tal S, Vig I, Ast G. Comparative analysis detects dependencies among the 5’ splice-site positions. RNA. 2004;10:828–40.
Yeo G, Burge CB. Maximum entropy modeling of short sequence motifs with applications to RNA splicing signals. J Comput Biol. 2004;11:377–94.
Kol G, Lev-Maor G, Ast G. Human-mouse comparative analysis reveals that branch-site plasticity contributes to splicing regulation. Hum Mol Genet. 2005;14:1559–68.
Dogan RI, Getoor L, Wilbur WJ, Mount SM. SplicePort–an interactive splice-site analysis tool. Nucleic Acids Res. 2007;35:W285–91.
Desmet F-O, et al. Human splicing finder: an online bioinformatics tool to predict splicing signals. Nucleic Acids Res. 2009;37: e67.
Divina P, Kvitkovicova A, Buratti E, Vorechovsky I. Ab initio prediction of mutation-induced cryptic splice-site activation and exon skipping. Eur J Hum Genet. 2009;17:759–65.
Corvelo A, Hallegger M, Smith CWJ, Eyras E. Genome-wide association between branch point properties and alternative splicing. PLoS Comput Biol. 2010;6: e1001016.
Lorenz R, et al. ViennaRNA Package 2.0. Algorithms Mol Biol. 2011;6:26.
Raponi M, et al. Prediction of single-nucleotide substitutions that result in exon skipping: identification of a splicing silencer in BRCA1 exon 6. Hum Mutat. 2011;32:436–44.
Lim KH, Fairbrother WG. Spliceman–a computational web server that predicts sequence variations in pre-mRNA splicing. Bioinformatics. 2012;28:1031–2.
Piva F, Giulietti M, Burini AB, Principato G. SpliceAid 2: a database of human splicing factors expression data and RNA target motifs. Hum Mutat. 2012;33:81–5.
Erkelenz S, et al. Genomic HEXploring allows landscaping of novel potential splicing regulatory elements. Nucleic Acids Res. 2014;42:10681–97.
Shibata A, et al. IntSplice: prediction of the splicing consequences of intronic single-nucleotide variations in the human genome. J Hum Genet. 2016;61:633–40.
Jaganathan K, et al. Predicting splicing from primary sequence with deep learning. Cell. 2019;176:535-548.e24.
Danis D et al. Interpretable prioritization of splice variants in diagnostic next-generation sequencing. bioRxiv (2021). https://doi.org/10.1101/2021.01.28.428499.
Hubisz MJ, Pollard KS, Siepel A. PHAST and RPHAST: phylogenetic analysis with space/time models. Br Bioinform. 2011;12:41–51.
Soukarieh O, et al. Exonic splicing mutations are more prevalent than currently estimated and can be predicted by using in silico tools. PLoS Genet. 2016;12: e1005756.
Karczewski KJ, et al. The mutational constraint spectrum quantified from variation in 141,456 humans. Nature. 2020;581:434–43.
Lek M, et al. Analysis of protein-coding genetic variation in 60,706 humans. Nature. 2016;536:285–91.
Cassa CA, et al. Estimating the selective effects of heterozygous protein-truncating variants from human exome data. Nat Genet. 2017;49:806–10.
Pierron D, Cortés NG, Letellier T, Grossman LI. Current relaxation of selection on the human genome: tolerance of deleterious mutations on olfactory receptors. Mol Phylogenet Evol. 2013;66:558–64.
Hart T, et al. Evaluation and design of genome-wide CRISPR/SpCas9 knockout screens. G3. 2017;7:2719–27.
Firth HV, Wright CF, & DDD Study. The deciphering developmental disorders (DDD) study. Dev Med Child Neurol. 2011;53:702–703.
Deciphering Developmental Disorders Study. Large-scale discovery of novel genetic causes of developmental disorders. Nature. 2015;519:223–8.
Wright CF, et al. Genetic diagnosis of developmental disorders in the DDD study: a scalable analysis of genome-wide research data. Lancet. 2015;385:1305–14.
Deciphering Developmental Disorders Study. Prevalence and architecture of de novo mutations in developmental disorders. Nature. 2017;542:433–8.
Wright CF, et al. Making new genetic diagnoses with old data: iterative reanalysis and reporting from genome-wide data in 1,133 families with developmental disorders. Genet Med. 2018;20:1216–23.
Thormann A, et al. Flexible and scalable diagnostic filtering of genomic variants using G2P with Ensembl VEP. Nat Commun. 2019;10:2373.
Kurosaki T, Popp MW, Maquat LE. Quality and quantity control of gene expression by nonsense-mediated mRNA decay. Nat Rev Mol Cell Biol. 2019;20:406–20.
Mohammadi P, et al. Genetic regulatory variation in populations informs transcriptome analysis in rare disease. Science. 2019;366:351–6.
GTEx Consortium. The genotype-tissue expression (GTEx) project. Nat Genet. 2013;45:580–585.
GTEx Consortium et al. Genetic effects on gene expression across human tissues. Nature 2017;550:204–213.
Ferraro NM, et al. Transcriptomic signatures across human tissues identify functional rare genetic variation. Science. 2020;369:eaaz5900.
Carvill GL, et al. Aberrant inclusion of a poison exon causes dravet syndrome and related SCN1A-associated genetic epilepsies. Am J Hum Genet. 2018;103:1022–9.
Havrilla JM, Pedersen BS, Layer RM, Quinlan AR. A map of constrained coding regions in the human genome. Nat Genet. 2019;51:88–95.
Busch A, Hertel KJ. HEXEvent: a database of human EXon splicing events. Nucleic Acids Res. 2013;41:D118–24.
Shepard PJ, Choi E-A, Busch A, Hertel KJ. Efficient internal exon recognition depends on near equal contributions from the 3′ and 5′ splice sites. Nucleic Acids Res. 2011;39:8928–37.
Carvill GL, Mefford HC. Poison exons in neurodevelopment and disease. Curr Opin Genet Dev. 2020;65:98–102.
Steward CA, et al. Re-annotation of 191 developmental and epileptic encephalopathy-associated genes unmasks de novo variants in SCN1A. NPJ Genom Med. 2019;4:31.
Voskobiynyk Y, et al. Aberrant regulation of a poison exon caused by a non-coding variant in a mouse model of Scn1a-associated epileptic encephalopathy. PLoS Genet. 2021;17: e1009195.
Lesca G, et al. Molecular screening of ALK1/ACVRL1 and ENG genes in hereditary hemorrhagic telangiectasia in France. Hum Mutat. 2004;23:289–99.
Prigoda NL, et al. Hereditary haemorrhagic telangiectasia: mutation detection, test sensitivity and novel mutations. J Med Genet. 2006;43:722–8.
Argyriou L, et al. Novel mutations in the ENG and ACVRL1 genes causing hereditary hemorrhagic teleangiectasia. Int J Mol Med. 2006;17:655–9.
Xie G-L, Li Z-X, Li Z-X. Hereditary hemorrhagic telangiectasia caused by mutation in intron 4 of ALK1 gene: analysis of a HTT family. Zhonghua Yi Xue Za Zhi. 2007;87:249–52.
Fontalba A, et al. Mutation study of Spanish patients with hereditary hemorrhagic telangiectasia. BMC Med Genet. 2008;9:75.
Bayrak-Toydemir P, et al. Likelihood ratios to assess genetic evidence for clinical significance of uncertain variants: hereditary hemorrhagic telangiectasia as a model. Exp Mol Pathol. 2008;85:45–9.
Tørring PM, Brusgaard K, Ousager LB, Andersen PE, Kjeldsen AD. National mutation study among Danish patients with hereditary haemorrhagic telangiectasia. Clin Genet. 2014;86:123–33.
Wooderchak-Donahue WL, et al. Genome sequencing reveals a deep intronic splicing ACVRL1 mutation hotspot in hereditary haemorrhagic telangiectasia. J Med Genet. 2018;55:824–30.
Richards AJ, et al. High efficiency of mutation detection in type 1 stickler syndrome using a two-stage approach: vitreoretinal assessment coupled with exon sequencing for screening COL2A1. Hum Mutat. 2006;27:696–704.
Richards AJ, et al. Missense and silent mutations in COL2A1 result in Stickler syndrome but via different molecular mechanisms. Hum Mutat. 2007;28:639.
Richards AJ, et al. Stickler syndrome and the vitreous phenotype: mutations in COL2A1 and COL11A1. Hum Mutat. 2010;31:E1461–71.
Richards AJ, et al. Splicing analysis of unclassified variants in COL2A1 and COL11A1 identifies deep intronic pathogenic mutations. Eur J Hum Genet. 2012;20:552–8.
Bogaert R, et al. Expression, in cartilage, of a 7-amino-acid deletion in type II collagen from two unrelated individuals with Kniest dysplasia. Am J Hum Genet. 1994;55:1128–36.
Schimpf S, Schaich S, Wissinger B. Activation of cryptic splice sites is a frequent splicing defect mechanism caused by mutations in exon and intron sequences of the OPA1 gene. Hum Genet. 2006;118:767–71.
Ferré M, et al. Molecular screening of 980 cases of suspected hereditary optic neuropathy with a report on 77 novel OPA1 mutations. Hum Mutat. 2009;30:E692-705.
Comeglio P, et al. The importance of mutation detection in Marfan syndrome and Marfan-related disorders: report of 193 FBN1 mutations. Hum Mutat. 2007;28:928.
Stheneur C, et al. Identification of the minimal combination of clinical features in probands for efficient mutation detection in the FBN1 gene. Eur J Hum Genet. 2009;17:1121–8.
Nichols KE, et al. Sensitive multistep clinical molecular screening of 180 unrelated individuals with retinoblastoma detects 36 novel mutations in the RB1 gene. Hum Mutat. 2005;25:566–74.
Zhang K, Nowak I, Rushlow D, Gallie BL, Lohmann DR. Patterns of missplicing caused by RB1 gene mutations in patients with retinoblastoma and association with phenotypic expression. Hum Mutat. 2008;29:475–84.
Pros E, et al. Nature and mRNA effect of 282 different NF1 point mutations: focus on splicing alterations. Hum Mutat. 2008;29:E173–93.
Wimmer K, et al. AG-exclusion zone revisited: Lessons to learn from 91 intronic NF1 3’ splice site mutations outside the canonical AG-dinucleotides. Hum Mutat. 2020;41:1145–56.
Rentzsch P, Schubach M, Shendure J, Kircher M. CADD-Splice-improving genome-wide variant effect prediction using deep learning-derived splice scores. Genome Med. 2021;13:31.
Frésard L, et al. Identification of rare-disease genes using blood transcriptome sequencing and large control cohorts. Nat Med. 2019;25:911–9.
Murdock DR et al. Transcriptome-directed analysis for Mendelian disease diagnosis overcomes limitations of conventional genomic testing. J Clin Invest. 2021;131.
Stenson PD, et al. The human gene mutation database: building a comprehensive mutation repository for clinical and molecular genetics, diagnostic testing and personalized genomic medicine. Hum Genet. 2014;133:1–9.
Stenson PD, et al. The human gene mutation database: towards a comprehensive repository of inherited mutation data for medical research, genetic diagnosis and next-generation sequencing studies. Hum Genet. 2017;136:665–77.
Stenson PD, et al. The human gene mutation database (HGMD®): optimizing its use in a clinical diagnostic or research setting. Hum Genet. 2020;139:1197–207.
Sasani TA et al. Large, three-generation human families reveal post-zygotic mosaicism and variability in germline mutation accumulation. Elife 2019;8.
Jónsson H, et al. Parental influence on human germline de novo mutations in 1,548 trios from Iceland. Nature. 2017;549:519–22.
McLaren W, et al. The ensembl variant effect predictor. Genome Biol. 2016;17:122.
Vuckovic D, et al. The polygenic and monogenic basis of blood traits and diseases. Cell. 2020;182:1214-1231.e11.
Wai HA, et al. Blood RNA analysis can increase clinical diagnostic rate and resolve variants of uncertain significance. Genet Med. 2020;22:1005–14.
Riepe TV, Khan M, Roosing S, Cremers FPM, ‘t Hoen PAC. Benchmarking deep learning splice prediction tools using functional splice assays. Hum Mutat. 2021;42:799–810.
Chen J-M, et al. The experimentally obtained functional impact assessments of 5’ splice site GT’GC variants differ markedly from those predicted. Curr Genom. 2020;21:56–66.
Danecek P, et al. The variant call format and VCFtools. Bioinformatics. 2011;27:2156–8.
Harrow J, et al. GENCODE: the reference human genome annotation for the ENCODE project. Genome Res. 2012;22:1760–74.
Frankish A, et al. GENCODE reference annotation for the human and mouse genomes. Nucleic Acids Res. 2019;47:D766–73.
Cormier MJ, et al. Go get data (GGD) is a framework that facilitates reproducible access to genomic data. Nat Commun. 2021;12:2151.
Rehm HL, et al. ClinGen–the clinical genome resource. N Engl J Med. 2015;372:2235–42.
Blekhman R, et al. Natural selection on genes that underlie human disease susceptibility. Curr Biol. 2008;18:883–9.
Berg JS, et al. An informatics approach to analyzing the incidentalome. Genet Med. 2013;15:36–44.
Mainland JD, Li YR, Zhou T, Liu WLL, Matsunami H. Human olfactory receptor responses to odorants. Sci Data. 2015;2: 150002.
Thorvaldsdóttir H, Robinson JT, Mesirov JP. Integrative genomics viewer (IGV): high-performance genomics data visualization and exploration. Br Bioinform. 2013;14:178–92.
Sherry ST, Ward M, Sirotkin K. dbSNP-database for single nucleotide polymorphisms and other classes of minor genetic variation. Genome Res. 1999;9:677–9.
Landrum MJ, et al. ClinVar: improving access to variant interpretations and supporting evidence. Nucleic Acids Res. 2018;46:D1062–7.
Amberger JS, Bocchini CA, Schiettecatte F, Scott AF, Hamosh A. OMIM.org: online Mendelian inheritance in man (OMIM®), an online catalog of human genes and genetic disorders. Nucleic Acids Res. 2015;43:D789–98.
Pedregosa F, et al. Scikit-learn: machine learning in python. J Mach Learn Res. 2011;12:2825–30.
Acknowledgements
The authors wish to acknowledge Thomas Nicholas, Joe Brown, and Harriet Dashnow for reviews of and feedback on the manuscript.
Funding
Research reported in this publication was supported in part by funding to MJC from the National Center for Advancing Translational Sciences of the National Institutes of Health under Award Number UL1TR002538 and TL1TR002540, as well as NIH awards R01HG010757 and R01GM124355 to ARQ.
Author information
Authors and Affiliations
Contributions
M.J.C. and A.R.Q conceived the idea for the splicing constraint model and ConSpliceML. M.J.C developed the splicing constraint model, ConSpliceML, and performed all analyses and experiments. A.R.Q, B.S.P, and P.BT provided feedback and suggestion for the splicing constraint model and ConSpliceML. P.BT provided the pathogenic set of splice-altering mutations from HGMD. M.J.C. and A.R.Q. wrote and prepared the manuscript and figures. All authors reviewed the manuscript and provided feedback. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing Interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Additional file 1: Fig. S1.
Splicing constraint model context. Fig. S2. Patterns of splicing constraint for autosomal genes. Fig. S3. Patterns of splicing constraint for genes on the autosome and X chromosome. Fig. S4. Patterns of genic constraint by constraint method. Fig. S5. Gene expression variation across splicing constraint scores. Fig. S6. Genic splicing outliers. Fig. S7. Informative splicing nucleotides by range/window size. Fig. S8. Spicing constraint around exons. Fig. S9. Regional constraint around exon features. Fig. S10. Regional splicing constraint performance by window size. Fig. S11. SCN1A splicing constraint score distribution. Fig. S12. Spicing constraint at SCN1A exons. Fig. S13. Splicing constraint score profiles for deleterious splicing variants identified in RNA-seq data. Fig. S14. PR curves for ConSpliceML 5-fold cross-validation. Fig. S15 Splicing prediction and interpretation using the full test set. Fig. S16. Odds ratio enrichment of pathogenic to benign variants. Fig. S17. Regional splicing constraint performance for all HGMD pathogenic and benign alternative splicing GTEx variants by model weight. Fig. S18. Regional splicing constraint performance for non-canonical splice site HGMD pathogenic and benign alternative splicing GTEx variants by model weight. Fig. S19. Regional splicing constraint performance for non-splice region HGMD pathogenic and benign alternative splicing GTEx variants by model weight. Table S1. Autosomal splicing substitution rate by reference allele and SpliceAI score range. Table S2. X chromosome splicing substitution rate by reference allele and SpliceAI score range. Table S3. Three SCN1A poison exons and three SCN1A annotated exons
Additional file 2: Table S4.
Manually curated set of pathogenic variants
Additional file 3: Table S5.
Set of benign variants
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Cormier, M.J., Pedersen, B.S., Bayrak-Toydemir, P. et al. Combining genetic constraint with predictions of alternative splicing to prioritize deleterious splicing in rare disease studies. BMC Bioinformatics 23, 482 (2022). https://doi.org/10.1186/s12859-022-05041-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12859-022-05041-x