
Abstract
Introduction
The massive-transfusion concept was introduced to recognize the dilutional complications resulting from large volumes of packed red blood cells (PRBCs). Definitions of massive transfusion vary and lack supporting clinical evidence. Damage-control resuscitation regimens of modern trauma care are targeted to the early correction of acute traumatic coagulopathy. The aim of this study was to identify a clinically relevant definition of trauma massive transfusion based on clinical outcomes. We also examined whether the concept was useful in that early prediction of massive transfusion requirements could allow early activation of blood bank protocols.
Methods
Datasets on trauma admissions over a 1 or 2-year period were obtained from the trauma registries of five large trauma research networks. A fractional polynomial was used to model the transfusion-associated probability of death. A logistic regression model for the prediction of massive transfusion, defined as 10 or more units of red cell transfusions, was developed.
Results
In total, 5,693 patient records were available for analysis. Mortality increased as transfusion requirements increased, but the model indicated no threshold effect. Mortality was 9% in patients who received none to five PRBC units, 22% in patients receiving six to nine PRBC units, and 42% in patients receiving 10 or more units. A logistic model for prediction of massive transfusion was developed and validated at multiple sites but achieved only moderate performance. The area under the receiver operating characteristic curve was 0.81, with specificity of only 50% at a sensitivity of 90% for the prediction of 10 or more PRBC units. Performance varied widely at different trauma centers, with specificity varying from 48% to 91%.
Conclusions
No threshold for definition exists at which a massive transfusion specifically results in worse outcomes. Even with a large sample size across multiple trauma datasets, it was not possible to develop a transportable and clinically useful prediction model based on available admission parameters. Massive transfusion as a concept in trauma has limited utility, and emphasis should be placed on identifying patients with massive hemorrhage and acute traumatic coagulopathy.
Similar content being viewed by others


Introduction
Hemorrhage is responsible for more than 40% of all trauma deaths and therefore represents an important target for improving outcomes after severe injury. The concept of massive transfusion has existed for more than half a century and was developed to highlight the dilutional complications occurring when administering large volumes of packed red blood cells (PRBCs) or other fluids, which could be addressed by the use of massive-transfusion protocols. Such protocols are not immediately activated but typically require either the presence of abnormal laboratory tests of coagulation [1, 2] or the prior administration of a certain number of units of PRBCs [3].
It is now clear that standard massive-transfusion algorithms are less effective in trauma hemorrhage [4, 5]. Primarily, this is due to the presence of an endogenous coagulopathy very early in the clinical course of trauma patients, due to the presence of shock and tissue hypoperfusion [6]. This acute traumatic coagulopathy (ATC) may be established by the time the patient arrives in the emergency department [7–10] and is strongly associated with the need for large volumes of blood transfusion [10]. New damage-control resuscitation protocols targeted at ATC call for earlier plasma and blood-component regimens [11], and significant improvements in outcome may be achievable with such strategies [12–14].
In the absence of validated near-patient diagnostic tools for ATC, some centers are moving to empiric transfusion protocols activated early on the basis of clinical judgment [3]. Prediction models for massive transfusion have been developed in both civilian [15–17] and military [18–20] settings, although in general, these published tools have only moderate performance. In clinical use, where sensitivity rates of more than 90% would be important, these tools have very low specificities of around 50%. These models were developed in specific populations and remain largely unvalidated outside of their original datasets.
We designed this international multicenter study to reappraise the utility of massive transfusion as a clinical concept in modern trauma care. The first aim of the study was to assess whether a clinically relevant definition of massive transfusion existed in terms of a clinical outcome. The second aim was to assess by predictive modeling whether transfusion therapy can be rapidly and appropriately instituted by using parameters potentially available on trauma center admission.
Materials and methods
Datasets on trauma admissions were obtained from the trauma registries of a research network of major trauma centers. Participating trauma centers were the Royal London Hospital, London, UK; Oslo University Hospital Ulleval, Norway; Academic Medical Centre, Amsterdam, the Netherlands; and San Francisco General Hospital, San Francisco, California, USA. Data from The Trauma Registry of the Deutsche Gesellschaft für Unfallchirurgie (TR-DGU) [21, 22] from Germany, which covers more than 100 hospitals, were also included. The datasets included information over a 1-year period (2007) except the Oslo dataset covering 2 years (from June 2005). The data included patient age, sex, penetrating injury (yes/no), time from injury to emergency department arrival, admission systolic blood pressure, base deficit, prothrombin time (PT) and Injury Severity Score (ISS) [23], number of packed red blood cells (PRBCs) transfused in the first 24 hours, and in-hospital or 30 day (Oslo) mortality. The authors confirm that each trauma registry of the network is approved by a local review board and is in compliance with the institutional and/or national legal frameworks and data-protection requirements. Informed consent was not required, according to institutional, local and national guidelines. All data collection and analysis was performed anonymously.
A fractional polynomial was used to relate the odds of death to PRBCs received by logistic regression; these polynomials allow great flexibility by combining combinations of integer powers (such as squares and cubes) and noninteger powers such as one-half (square root), one third (cubic root), and others.
We then developed a logistic regression model for the prediction of massive transfusion, defined as 10 or more units of PRBCs. Missing data were a problem and were dealt with by using multiple imputation by chained equations [24, 25] under the assumption of missing at random [26]. Fifty imputed datasets were created (since time to emergency department was unobserved in 42% of patients) by using predictive mean matching, retaining imputed values obtained after 100 cycles. The imputation model was specified to be at least as complex as the prognostic model [27], including all candidate predictors. Normalizing transformations of the observed continuous variables were taken so that the distributions of imputed and observed values were similar. All candidate predictors potentially available on admission and thought to be associated with transfusion were considered. Center-specific effects were excluded to allow generalizability of results. Model parameters were estimated by combining across imputed datasets [28]. Backward elimination was used to select variables, with P > 0.1 as the elimination criterion. A shrinkage factor was applied to log odds ratios after model fitting before validation [29]. The same model was also fitted by using complete data without any imputation, to assess for any effects of imputation. The results were consistent with the multiple-imputation analysis, although the parameters were estimated with greater precision with imputation (data not shown). The Amsterdam data were not included in this complete analysis without imputation, because time to emergency department was not recorded at this center.
Two training-validation dataset scenarios were used. First, TR-DGU data from Germany were used for external validation [30], with all other data used for training. The German TR-DGU registry data contributed 1,705 patients, 30% of the total dataset, and was considered to be of a suitable size for validation. Further, no data were missing. As a second (internal) validation, data were split randomly with 60% of patients from each center in the training dataset and 40% in the validation dataset. Calibration [31] and receiver operating characteristic (ROC) plots were examined, along with sensitivity and likelihood ratio, at 90% specificity. The calibration plot was formed by predicting the likelihood of massive transfusion for each patient in the validation dataset [32]. Individuals were then grouped by predicted probability, and these groups were compared with the observed transfusions received. After validation, the model was evaluated with the full dataset. We examined between-center variation in the performance of the model to investigate the effect of center-specific transfusion practices. For these purposes, the model including variables chosen from the previous two analyses was fitted, and the predictive value was tested in each center separately to see how variable this was. All statistical analyses and graphics were produced in Stata version 10.1 (StataCorp, 4905 Lakeway Drive, College Station, TX, USA).
Results
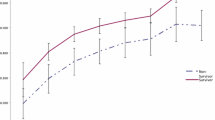
In total, 5,693 patient records were available for analysis. Patient demographics, injury characteristics, admission physiology, base deficit, and prothrombin times are shown in Table 1. Records of 2,497 (44%) patients had a complete set of observed covariates, whereas one covariate was missing in 1,788 (31%) and two (14%) in 850. Mortality increased as transfusion requirements increased (Figure 1). No threshold effect was seen at 10 units or any other value of PRBC transfusions. Mortality was 426 (9%) of 4,808 in patients who received none to five PRBC units, 82 (22%) of 367 in patients receiving six to nine PRBC units, and 217 (42%) of 518 in patients receiving 10 or more PRBC units. The fractional polynomial model for transfusion-associated probability of death, adjusting for any institution effect, is shown in Figure 2. The open dots above and below the fitted line (deviance residuals) represent patients who died (above) and survived (below). These serve to illustrate that transfusion for patients who died and survived extends over the range of PRBC transfusions up to 30. The model did not demonstrate any steps or plateaus: each additional unit of blood transfused was associated with an increased risk of death.

Transfusion-related mortality. Mortality by packed red blood cells (PRBCs) administered during the first 24 hours of admission.

Estimated probability of death per unit of packed red blood cells (PRBCs) administered (95% confidence interval in grey). Dots are deviance residuals. The band of dots above the line represents patients who died; the band below is those who survived.
Table 2 reports the regression coefficients from the logistic regression model. For the prediction of patients requiring massive transfusion, transformation toward a normal distribution for skewed continuous covariates was undertaken, as shown in column 1, Table 2. Log-odds and odds ratios for each variable are shown (log-odds can be more readily added together to calculate patient-specific probability of massive transfusion, and odds ratios are more meaningful for considering the impact of an individual predictor). The variables with the most weight in the model were systolic blood pressure (Figure 3a), base deficit (Figure 3b) and prothrombin time (Figure 3c). Age, penetrating injury, and time to emergency department were also identified as important dependent variables. Injury severity is known to be related to transfusion requirements (Figure 3d), but because accurate ISS scores are not directly available on admission, these measures were excluded from the final model, as shown. However, when a model including ISS was fitted, it was found that ISS was a significant predictor and gave more accurate predictions of massive transfusion (data not shown). For continuous variables, the odds ratios apply to a unit increase in the transformed variable (for example, √age). A patient's logit probability, A, of transfusion could be calculated by summing the intercept and appropriate log-odds ratios for their parameters by using Table 2. The probability of massive transfusion was then calculated from .

Scatterplots showing admission parameters and injury severity associated with transfusion requirements. Where covariates are missing for patient data, an average of imputed values has been substituted. (a) Packed red blood cells (PRBCs) transfusions by admission systolic blood pressure. (b) PRBC transfusions by admission base deficit. (c) PRBC transfusions by admission prothrombin time. (d) PRBC transfusions by injury-severity score.
The receiver operating characteristic (ROC) curve is shown in Figure 4a and has an area under the curve (AUC) of 0.81, externally validated on the German TR-DGU data. This model performed less well at intermediate and higher probabilities of 10+ PRBC transfusions (Figure 4b). At a sensitivity of 90%, specificity for massive transfusion was only 50%, with 58% of patients correctly classified. For the internal validation (60 to 40 split), the identical set of variables was selected; in this case, the AUC was 0.89 (95% confidence interval, 0.87 to 0.92), with a specificity of 70% at 90% sensitivity. The model varied in performance when applied to specific trauma centers. At a sensitivity of 90%, the specificity varied from 48% (San Francisco) to 91% (Amsterdam). Complete data analysis was entirely consistent with the multiple imputation analysis in terms of parameter estimates and confidence intervals (CIs). The only difference was reflected in less-precise parameter estimates, as would be expected. Because validation was on the German TR-DGU centers, and these had no missing data, the inferences were very similar to those using multiple imputation.

Performance of the massive-transfusion prediction tool. The performance of the model developed on non-German TR-DGU centers and validated on German TR-DGU registry data (see text). (a) Receiver operating characteristic plot. Area under the ROC curve, 0.81. (b) Calibration plot.
Discussion
This international multicenter study was conducted to evaluate the clinical applicability of massive transfusion as a concept in modern trauma care. The five trauma datasets represent a range of sizes and activities, which are likely to be generalizeable to many different trauma units worldwide. Any definition of massive transfusion should be useful in terms of its relevance to patient outcome. We have shown an association between transfusion and mortality, with a continuous increase in risk, and with a steeper increase in the lower ranges of the curve. We were not able to identify the traditional 10 units of PRBCs or any other specific threshold definition of massive transfusion, based on a mortality outcome. Patients receiving six to nine units of PRBCs had nearly 2.5 times the mortality of patients receiving none to five units. Management strategies targeted at patients receiving a threshold of 10 or more PRBC units will exclude a large proportion of patients receiving fewer transfusions but who still have a significant mortality. Research studies examining only massively transfused patients, according to this definition, will therefore exclude an important patient group. Moreover, therapeutic intervention studies will be confounded by any treatment effect that results in reduced PRBC requirements and therefore the inappropriate exclusion of patients from the study population. This may be one factor relevant to discussions about the internal validity of retrospective reports suggesting benefit with increased plasma and platelet transfusions in massively transfused patients [12–14, 33–35].
The utility of the massive-transfusion concept may better apply for its therapeutic potential, and it may have a role in the activation of major hemorrhage protocols. Damage-control resuscitation strategies require early administration of blood-component therapy along with the first units of PRBCs [11], and attempts have been made to develop prediction algorithms for massive transfusion [15–20]. Our prediction model has been robustly validated across multiple centers, a larger sample size, and a wider geographic area, and uses variables that are potentially available soon after arrival in the emergency department. However, the performance of the model was only moderate, and the AUC of our tool of 0.81 is consistent with other prediction tools (0.68 to 0.85) [15–20]. Setting the sensitivity at a clinically useful threshold of 90% (at which 10% of actively bleeding patients will be missed initially), the tool has a specificity of only 50%. [15–20]. The consequences of lower specificity is the risk of inappropriate activations of transfusion protocols, wasting of blood products, and increased exposure of patients to adverse events related to transfusion. The potentially harmful effects of PRBCs in trauma patients, especially in relation to storage age, have been documented [36]. This will have increasing impact as protocols move toward much higher doses of plasma, platelets, fibrinogen, and cryoprecipitate.
One of the reasons for the difficulties in developing any models with high specificity and sensitivity is likely to be the heterogeneity in patient populations of trauma. Existing transfusion practices may also limit its utility in clinical practice. This study shows that the reliable prediction of massive transfusion from standard admission physiology alone is difficult. The components of the prediction model were heavily weighted toward systolic blood pressure, base deficit, and the prothrombin time, which are the main features driving the development of ATC [6].
The performance of the tool might be improved if a better near-patient measure of the severity of the coagulopathy were available (for example, functional tests of coagulation such as thromboelastometry or thromboelastography) [37, 38]. Injury severity is also a strong dependent variable for the prediction of ATC and massive transfusion [6–9], but is not immediately available. Whether it is possible to develop an alternative but comparable measure for ISS that is available soon after admission remains unclear. Currently, no biomarkers of tissue injury are available, but such a rapidly available measure might also significantly improve prediction algorithms for ATC, massive hemorrhage, and patient care. Future work must look at these alternative approaches to developing a clinically useful prediction tool, because even across multiple datasets and with the application of several validation techniques, this study was not able to develop a reliable prediction tool.
Some limitations exist in this study. It is a retrospective review of registry data in which a variable proportion of records contained missing data, but this is inevitable to a degree in analyses of multiple registries. Multiple imputation assumes that missing data are random, having accounted for observed covariates, but this may not have been the case if variables that predict missing data were not recorded. However, the model performed well against the German TR-DGU data, which were more plentiful, indicating geographic transportability [30]. Entry criteria for the datasets were also recognized to be different. The San Francisco dataset included only patients with a higher-level trauma team activation, whereas the German TR-DGU included only patients with an ISS of 9 or higher. It was not possible to standardize the measurements of PT between the centers, as different thromboplastins were used, each with a different laboratory-specific Mean Normal Prothrombin Time (MNPT) and International Specificity Index (ISI), although in this study, the variations in reference ranges and results for PT were small, and the majority of results were normal or only marginally increased [39].
The mortality model may also be confounded because, as for patients dying within 24 hours, the rate of PRBC transfusion may have been higher than indicated in the data [40]. In addition, it is difficult to exclude an effect due to censoring for death, as some patients may die before sufficient time to receive blood. The rate of bleeding is not available from standard registry data but has been identified as an important confounder in the retrospective high-dose plasma studies [3]. Another limitation is the lack of information between centers on indications for transfusing PRBCs, the variation in transfusion practices, and the use of hemostatic drugs such as antifibrinolytics or even recombinant activated factor VIIa [41]. Massive transfusion not only is the result of a set of clinical parameters but it also is a function of the clinical response to them.
Conclusions
In summary, current definitions of massive transfusion are not supported by clinical outcomes and are not useful for guiding management. Rather, mortality increases with each PRBC unit required, although not linearly. The robust prediction of massive transfusion from standard admission parameters remains difficult. The concept of massive hemorrhage may be more useful than is massive transfusion for modern trauma care. New approaches are required for the early diagnosis of patients with acute traumatic coagulopathy who are actively bleeding and will go on to require significant blood-component transfusions.
Key messages
-
Red cell requirements in trauma correlate with mortality.
-
No clinically relevant threshold defines massive transfusion in terms of clinical outcomes.
-
Red cell transfusion requirements cannot reliably be predicted on the basis of standard physiological variables available on admission.
-
Attention should be focused on identifying patients with massive hemorrhage.
-
New diagnostic modalities are needed for the early identification of acute traumatic coagulopathy.
Abbreviations
- ATC:
-
acute traumatic coagulopathy
- AUC:
-
area under the curve
- ISI:
-
international specificity index
- ISS:
-
injury severity score
- MNPT:
-
mean normal prothrombin time
- PRBC:
-
packed red blood cell
- PT:
-
prothrombin time
- ROC:
-
receiver operating characteristic
- TR-DGU:
-
Trauma Registry of the Deutsche Gesellschaft für Unfallchirurgie.
References
College of American Pathologists: Practice parameters for the use of fresh frozen plasma, cryoprecipitate and platelets. JAMA 1994, 271: 777-781. 10.1001/jama.271.10.777
British Committee for Standards in Haematology, Stainsby D, MacLennan S, Thomas D, Isaac J, Hamilton PJ: Guidelines on the management of massive blood loss. Br J Haematol 2006, 135: 634-641. 10.1111/j.1365-2141.2006.06355.x
Geeraedts LM Jr, Demiral H, Schaap NP, Kamphuisen PW, Pompe JC, Frölke JP: 'Blind' transfusion of blood products in exsanguinating trauma patients. Resuscitation 2007, 73: 382-388. 10.1016/j.resuscitation.2006.10.005
Gonzalez EA, Moore FA, Holcomb JB, Miller CC, Kozar RA, Todd SR, Cocanour CS, Balldin BC, McKinley BA: Fresh frozen plasma should be given earlier to patients requiring massive transfusion. J Trauma 2007, 62: 112-119. 10.1097/01.ta.0000250497.08101.8b
Ho AM, Karmakar MK, Dion PW: Are we giving enough coagulation factors during major trauma resuscitation? Am J Surg 2005, 190: 479-484. 10.1016/j.amjsurg.2005.03.034
Brohi K, Cohen MJ, Davenport RA: Acute coagulopathy of trauma: mechanism, identification and effect. Curr Opin Crit Care 2007, 13: 680-685. 10.1097/MCC.0b013e3282f1e78f
Brohi K, Singh J, Heron M, Coats T: Acute traumatic coagulopathy. J Trauma 2003, 54: 1127-1130. 10.1097/01.TA.0000069184.82147.06
MacLeod JB, Lynn M, McKenney MG, Cohn SM, Murtha M: Early coagulopathy predicts mortality in trauma. J Trauma 2003, 55: 39-44. 10.1097/01.TA.0000075338.21177.EF
Maegele M, Lefering R, Yucel N, Tjardes T, Rixen D, Paffrath T, Simanski C, Neugebauer E, Bouillon B, AG Polytrauma of the German Trauma Society (DGU): Early coagulopathy in multiple injury: an analysis from the German Trauma Registry on 8.724 patients. Injury 2007, 38: 298-304. 10.1016/j.injury.2006.10.003
Brohi K, Cohen MJ, Ganter MT, Matthay MA, Mackersie RC, Pittet JF: Acute traumatic coagulopathy initiated by hypoperfusion: modulated through the protein C pathway? Ann Surg 2007, 245: 812-818. 10.1097/01.sla.0000256862.79374.31
Holcomb JB, Jenkins D, Rhee P, Johannigman J, Mahoney P, Mehta S, Cox ED, Gehrke MJ, Beilman GJ, Schreiber M, Flaherty SF, Grathwohl KW, Spinella PC, Perkins JG, Beekley AC, McMullin NR, Park MS, Gonzalez EA, Wade CE, Dubick MA, Schwab CW, Moore FA, Champion HR, Hoyt DB, Hess JR: Damage control resuscitation: directly addressing the early coagulopathy of trauma. J Trauma 2007, 62: 307-310. 10.1097/TA.0b013e3180324124
Borgman MA, Spinella PC, Perkins JG, Grathwohl KW, Repine T, Beekley AC, Sebesta J, Jenkins D, Wade CE, Holcomb JB: The ratio of blood products transfused affects mortality in patients receiving massive transfusions at a combat support hospital. J Trauma 2007, 63: 805-813. 10.1097/TA.0b013e3181271ba3
Zink KA, Sambasivan CN, Holcomb JB, Chisholm G, Schreiber MA: A high ratio of plasma and platelets to packed red blood cells in the first 6 hours of massive transfusion improves outcomes in a large multicentre study. Am J Surg 2009, 197: 565-570. 10.1016/j.amjsurg.2008.12.014
Duchesne JC, Islam TM, Stuke L, Timmer JR, Barbeau JM, Marr AB, Hunt JP, Dellavolpe JD, Wahl G, Greiffenstein P, Steeb GE, McGinness C, Baker CC, McSwain NE Jr: Hemostatic resuscitation during surgery improves survival in patients with traumatic-induced coagulopathy. J Trauma 2009, 67: 33-37. 10.1097/TA.0b013e31819adb8e
Yücel N, Lefering R, Maegele M, Vorweg M, Tjardes T, Ruchholtz S, Neugebauer EA, Wappler F, Bouillon B, Rixen D, Polytrauma Study Group of the German Trauma Society: Trauma Associated Severe Hemorrhage (TASH)-Score: probability of mass transfusion as surrogate for life threatening hemorrhage after multiple trauma. J Trauma 2006, 60: 1228-1236. 10.1097/01.ta.0000220386.84012.bf
Nunez TC, Voskresensky IV, Dossett LA, Shinall R, Dutton WD, Cotton BA: Early prediction of massive transfusion in trauma: simple as ABC (assessment of blood consumption)? J Trauma 2009, 66: 346-352. 10.1097/TA.0b013e3181961c35
Kuhne CA, Zettl RP, Fischbacher M, Lefering R, Ruchholtz S: Emergency Transfusion Score (ETS): a useful instrument for prediction of blood transfusion requirement in severely injured patients. World J Surg 2008, 32: 1183-1188. 10.1007/s00268-007-9425-4
McLaughlin DF, Niles SE, Salinas J, Perkins JG, Cox ED, Wade CE, Holcomb JB: A predictive model for massive transfusion in combat casualty patients. J Trauma 2008,64(2 suppl):S57-S63. 10.1097/TA.0b013e318160a566
Schreiber MA, Perkins J, Kiraly L, Underwood S, Wade C, Holcomb JB: Early predictors of massive transfusion in combat casualties. J Am Coll Surg 2007, 205: 541-545. 10.1016/j.jamcollsurg.2007.05.007
Cancio LC, Wade CE, West SA, Holcomb JB: Prediction of mortality and of the need for massive transfusion in casualties arriving at combat support hospitals in Iraq. J Trauma 2008,64(2 suppl):S51-S55. 10.1097/TA.0b013e3181608c21
Ruchholtz S, Lefering R, Paffrath T, Oestern HJ, Neugebauer E, Nast-Kolb D, Pape HC, Bouillon B: Reduction in mortality of severely injured patients in Germany. Dtsch Arztebl Int 2008, 105: 225-231.
Maegele M, Lefering R, Paffrath T, Simanski C, Wutzler S, Bouillon B, Working Group on Polytrauma of the German Trauma Society (DGU): Changes in transfusion practice in multiply injury between 1993 and 2006: a retrospective analysis on 5.389 patients from the German Trauma Registry. Transfus Med 2009, 19: 117-124. 10.1111/j.1365-3148.2009.00920.x
Baker SP, O'Neill B, Haddon W Jr, Long WB: The injury severity score: a method for describing patients with multiple injuries and evaluating emergency care. J Trauma 1974, 14: 187-196. 10.1097/00005373-197403000-00001
Van Buuren S, Boshuizen HC, Knook DL: Multiple imputation of missing blood pressure covariates in survival analysis. Stat Med 1999, 18: 681-694. 10.1002/(SICI)1097-0258(19990330)18:6<681::AID-SIM71>3.0.CO;2-R
Royston P: Multiple imputation of missing values: further update of ice, with an emphasis on interval censoring. Stata J 2007, 7: 445-464.
Rubin DB: Inference and missing data. Biometrika 1976, 63: 581-592. 10.1093/biomet/63.3.581
Allison PD: Multiple imputation for missing data: a cautionary tale. Sociol Methods Res 2000, 28: 301-309. 10.1177/0049124100028003003
Rubin DB: Multiple Imputation for Non-response in Surveys. New York: John Wiley; 1987.
Copas JB: Regression, prediction and shrinkage. J R Stat Soc Series B Methodol 1983, 45: 311-354.
König IR, Malley JD, Weimar C, Diener HC, Ziegler A, German Stroke Study Collaboration: Practical experiences on the necessity of external validation. Stat Med 2007, 26: 5499-5511. 10.1002/sim.3069
Altman DG, Vergouwe Y, Royston P, Moons KG: Prognosis and prognostic research: validating a prognostic model. BMJ 2009, 338: b605. 10.1136/bmj.b1432
Altman DG, Royston P: What do we mean by validating a prognostic model? Stat Med 2000, 19: 453-473. 10.1002/(SICI)1097-0258(20000229)19:4<453::AID-SIM350>3.0.CO;2-5
Scalea TM, Bochicchio KM, Lumpkins K, Hess JR, Dutton R, Pyle A, Bochicchio GV: Early aggressive use of fresh frozen plasma does not improve outcome in critically injured trauma patients. Ann Surg 2008, 248: 578-584.
Kashuk JL, Moore EE, Johnson JL, Haenel J, Wilson M, Moore JB, Cothren CC, Biffl WL, Banerjee A, Sauaia A: Postinjury life threatening coagulopathy: is 1:1 fresh frozen plasma: packed red blood cells the answer? J Trauma 2008, 65: 261-270. 10.1097/TA.0b013e31817de3e1
Snyder CW, Weinberg JA, McGwin GSM Jr, George RL, Reiff DA, Cross JM, Hubbard-Brown J, Rue LW, Kerby JD: The relationship of blood product ratio to mortality: survival benefit or survival bias? J Trauma 2009, 66: 358-362. 10.1097/TA.0b013e318196c3ac
Spinella PC, Carroll CL, Staff I, Gross R, Mc Quay J, Keibel L, Wade CE, Holcomb JB: Duration of red blood cell storage is associated with increased incidence of deep vein thrombosis and in hospital mortality in patients with traumatic injuries. Crit Care 2009, 13: R151. 10.1186/cc8050
Rugeri L, Levrat A, David JS, Delecroix E, Floccard B, Gros A, Allaouchiche B, Negrier C: Diagnosis of early coagulation abnormalities in trauma patients by rotation thrombelastography. J Thromb Haemost 2007, 5: 289-295. 10.1111/j.1538-7836.2007.02319.x
Levrat A, Gros A, Rugeri L, Inaba K, Floccard B, Negrier C, David JS: Evaluation of rotation thrombelastography for the diagnosis of hyperfibrinolysis in trauma patients. Br J Anaesth 2008, 100: 792-797. 10.1093/bja/aen083
Horsti J: Has the Quick or the Owren prothrombin time method the advantage in harmonization for the international normalized ratio system? Blood Coagul Fibrinolysis 2002, 13: 641-646. 10.1097/00001721-200210000-00010
Hardy JF, de Moerloose P, Samana CM: The coagulopathy of massive transfusion. Vox Sang 2005, 89: 123-127. 10.1111/j.1423-0410.2005.00678.x
CRASH-2 trial collaborators, Shakur H, Roberts I, Bautista R, Caballero J, Coats T, Dewan Y, El-Sayed H, Gogichaishvili T, Gupta S, Herrera J, Hunt B, Iribhogbe P, Izurieta M, Khamis H, Komolafe E, Marrero MA, Mejía-Mantilla J, Miranda J, Morales C, Olaomi O, Olldashi F, Perel P, Peto R, Ramana PV, Ravi RR, Yutthakasemsunt S: Effects of tranexamic acid on death, vascular occlusive events, and blood transfusion in trauma patients with significant haemorrhage (CRASH-2): a randomised, placebo-controlled trial. Lancet 2010, 376: 23-32. 10.1016/S0140-6736(10)60835-5
Acknowledgements
The authors thank Teun Peter Saltzherr (Trauma Unit AMC Amsterdam, The Netherlands), Nils Oddvar Skaga and Morten Hestnes (Trauma Registry, Oslo University Hospital Ulleval, Norway), and Anita West (Royal London Hospital, London, UK) for their assistance in collecting the data used in this study. Furthermore, the authors acknowledge all centers and hospitals that are actively contributing data into the TR-DGU and Rolf Lefering (IFOM, Cologne, Germany) for data management. The authors confirm that no external funding existed for the study.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors' contributions
KB conceived the study, TM and TJ undertook the statistical analysis with SS and KB, and all other authors contributed to study design, data sharing, and writing of the manuscript.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
{kind=link}
Rights and permissions
This article is published under an open access license. Please check the 'Copyright Information' section either on this page or in the PDF for details of this license and what re-use is permitted. If your intended use exceeds what is permitted by the license or if you are unable to locate the licence and re-use information, please contact the Rights and Permissions team.
About this article
Cite this article
Stanworth, S.J., Morris, T.P., Gaarder, C. et al. Reappraising the concept of massive transfusion in trauma. Crit Care 14, R239 (2010). https://doi.org/10.1186/cc9394
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1186/cc9394