
Abstract
Background
All animals are anatomically constrained in the number of discrete call types they can produce. Recent studies suggest that by combining existing calls into meaningful sequences, animals can increase the information content of their vocal repertoire despite these constraints. Additionally, signalers can use vocal signatures or cues correlated to other individual traits or contexts to increase the information encoded in their vocalizations. However, encoding multiple vocal signatures or cues using the same components of vocalizations usually reduces the signals' reliability. Segregation of information could effectively circumvent this trade-off. In this study we investigate how banded mongooses (Mungos mungo) encode multiple vocal signatures or cues in their frequently emitted graded single syllable close calls.
Results
The data for this study were collected on a wild, but habituated, population of banded mongooses. Using behavioral observations and acoustical analysis we found that close calls contain two acoustically different segments. The first being stable and individually distinct, and the second being graded and correlating with the current behavior of the individual, whether it is digging, searching or moving. This provides evidence of Marler's hypothesis on temporal segregation of information within a single syllable call type. Additionally, our work represents an example of an identity cue integrated as a discrete segment within a single call that is independent from context. This likely functions to avoid ambiguity between individuals or receivers having to keep track of several context-specific identity cues.
Conclusions
Our study provides the first evidence of segmental concatenation of information within a single syllable in non-human vocalizations. By reviewing descriptions of call structures in the literature, we suggest a general application of this mechanism. Our study indicates that temporal segregation and segmental concatenation of vocal signatures or cues is likely a common, but so far neglected, dimension of information coding in animal vocal communication. We argue that temporal segregation of vocal signatures and cues evolves in species where communication of multiple unambiguous signals is crucial, but is limited by the number of call types produced.
Similar content being viewed by others

Background
Nonhuman-animals (hereafter referred to as animals) have finite vocal repertoires and are anatomically constrained in the number of different call types they can produce [1, 2]. These constraints limit the variation of a species' vocal repertoire and may have played an important role in the evolution of meaningful combinations of calls [3, 4]. Another possible way to encode senders' related information in vocalizations is through vocal signatures (specifically for individual identity and/or group membership) and/or cues (related to all other individual traits or context; hereafter we refer to both signatures and cues as vocal cues) [5–8].
Although individual identity is the most commonly reported vocal cue [8], animal vocalizations have also been shown to contain cues for group identity [8–12], size [13–15], male quality, [14, 16, 17], sex [18, 19], and reproductive state [20]. Animals can encode vocal cue information using two general sets of acoustic properties. Firstly, spectral features, such as fundamental frequency or harmonic-to-noise ratio, can differ between individuals to encode for instance individuality [8]. Additionally, a number of recent studies have shown that filter-related formants are a reliable indication of body size and male quality [13–15, 21]. The importance of these formants has mainly been shown in larger mammals, such as rhesus macaques (Macaca mulatta) [13], dogs (Canis familiaris), red deer (Cervus elaphus) [14, 22] or fallow deer (Dama dama) [15]. Secondly, vocal cue information can be encoded in vocalizations through temporal features. Individual cues encoded by variance in the temporal features, such as duration or temporal arrangement of frequency elements have been reported for species such as the big brown bat (Eptesicus fuscus), pallid bat (Antrozous pallidus), and cricket species (Gryllidae spp.) [8]. All of these vocal cues potentially provide useful information to the receiver whenever variation between categories is larger than the within-category variation.
Many animal calls contain combinations of multiple different vocal cue types [5–8]. The expression of these multiple vocal cues typically correlates with different frequency-related acoustic parameters. The individualistic grunts of baboons (Papio spp.) are, for instance, audibly distinct in different behavioral contexts [23–25]. However, acoustic space is limited and many acoustic parameters are correlated with one another. Therefore, the amount of frequency related variation that can be used by signalers to encode different vocal cues is ultimately constrained. This constraint can result in a trade-off between the various kinds of information and typically reduces reliability of at least one of the vocal cues [26, 27]. For instance, the use by signalers of available variation for individual recognition conflicts with the need for stereotypic characteristics for group recognition in bird song [26]. Briefer et al. [27] showed a similar trade-off between the vocal cues for identity (stable over time) and male quality (variable over time) in fallow deer. Segregation of information could partially resolve this trade-off by expressing functionally different cues in temporally distinct call segments or in different acoustic features [26, 27]. In the white-crowned sparrow (Zonotrichia leucophrys pugetensis), for example, individual identity and group membership are segregated into the distinct note complex and trill phrases of its song respectively, thus avoiding a trade-off in reliability between the vocal cues [28]. Similar segregation of information (though not specifically referred to) has been shown in the songs of meadow pipits (Anthus pratensis) [29], rock hyraxes (Procavia capensis) [30], humpback whales (Megaptera novaeangliae) [31] and killer whales (Orcinus orca) [32]. Although this principle was proposed by Marler in 1960 [26], currently no studies have shown temporal segregation in the form of segmental concatenation within a single syllable call type. Such within-syllable encoding would have analogues with 'phonological' or segmental concatenation used in human language [33].
Contact calls are among the most common vocalizations produced by both mammalian and bird species. In a variety of species, contact calls seem to function to coordinate movements and cohesion of individuals on a range of spatial scales, concurrently with various behaviors and in a variety of social systems [34, 35]. Contact calls have been shown to contain individual vocal cues [8, 12, 36] and group membership vocal cues [9, 11, 12, 37]. Contact calls can also contain multiple vocal cues as has been shown in baboons [23–25] and meerkats (Suricata suricatta) [12]. In some species contact calls seem to function predominantly over mid- to long-distance, while in others contact calls play a more important role in short-distance communication. It has been suggested that these short distance close calls, often low in amplitude and pitch and consisting of a single syllable, are better described as close calls [12, 38]. Such close calls have the potential to provide constant information about the individual characteristics of the signaler and are likely used to monitor changes in behavior and relative spatial positioning of members in social groups [12, 34, 35, 39, 40].
Cooperatively breeding banded mongooses (Mungos mungo) are small (≤ 2 kg) social carnivores that show high group cohesion. They live in mixed sex groups, with an average of around 20 individuals, but groups occasionally grow to more than 70 individuals [41]. They forage together as cohesive units and cooperate in pup care, predator avoidance and territory defense [41–43]. During foraging, banded mongooses move in and out of dense vegetation with many position shifts, both in distance to nearest neighbor and in relative position within the group. They regularly dig for food items in the soil with their heads down. Besides digging they also search for food on the surface, but this is mainly done in the thickets (see Table 1 for details). They are often visually constrained during foraging and, therefore vocalizations play a critical role in keeping individuals informed of changes in the social and ecological environment. Banded mongoose use a range of graded vocalizations to coordinate behaviors and to maintain group cohesion [44, 45]. One of the most commonly emitted call types is the close call and previous work has demonstrated the presence of an individual vocal cue within the call [46]. Subsequent field observations suggested additional graded variation in the close calls, which appeared to be related to the behavioral context experienced by the signaler (personal observations DJ). We, therefore, investigated whether banded mongooses' close calls contain multiple vocal cues and how these vocal cues are encoded in the temporal and frequency related aspects of this graded single syllable call type.
Results
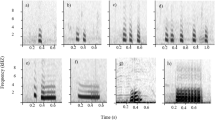
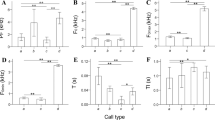
The acoustic structure of close calls in banded mongoose varied significantly between individuals and behavioral contexts. Specifically, the initial noisy segment of the call remained stable within an individual in all of the quantified behavioral contexts, while a gradation was detected in the subsequent harmonic tonal segment (Figure 1, Additional files 1, 2, 3). Close calls could be individually distinguished statistically in all four groups (total number of individuals = 36, range per group 7 to 14). Correct cross validation probabilities varied between 40% and 61% for the initial noisy segment and the whole call, and bootstrapping showed that all classification probabilities were much higher than that expected by chance (Table 2). The cross-validation probabilities for the harmonic part of the call were considerably lower at 11% to 25% and were not significantly different than expected by chance (Table 2). A group-specific vocal cue was found in the noisy segment of the call (number of correctly cross-classified elements (ncce) = 44.47, P = 0.038, n = 36), but not for the whole call (ncce = 38.08, P = 0.27), nor for the harmonic segment (ncce = 44.47, P = 0.038, n = 36). No evidence for a sex-specific vocal cue was found in either the whole call (ncce = 60.35, P = 0.54, n = 36), or the initial noisy part (ncce = 64.23, P = 0.19, n = 36).
A cross-classified permutated discriminant function analysis (pDFA) showed that, overall, close calls were correctly classified to the appropriate behavioral context (Table 1) based on their acoustic structure (ncce = 44.22, P <0.001, n = 20). Specifically, the harmonic extension of the close calls varied significantly and was correctly classified according to the behavioral context (ncce = 78.04, P = 0.009, n = 18), whereas the initial noisy segment of the call was not (ncce = 19.87, P = 0.79, n = 20). Thereby, the harmonic segment was either not present or of a very short duration in the digging context (mean ± sd; 0.01 ± 0.02 s), while its duration increased in the searching context (0.05 ± 0.03 s). The longest and most pronounced harmonic segments were observed in the moving context (0.08 ± 0.03 s). For pairwise comparisons of the acoustic structures between behavioral contexts, see Table 3.

Spectrograms of banded mongoose close calls. Spectrograms of close calls of the three individuals (in rows 1 to 3) associated with the three different behavioral contexts: a.) digging; b.) searching; c.) moving between foraging patches. The calls in the first and second row are of females, while calls in the third row are of a male. Calls of the individuals in the second and third row are from the same social pack. The solid black arrows indicate the individually stable foundation of the call, while the dashed arrows indicate the harmonic tonal segment (Hamming, FTT = 1024, overlap = 97.87%, frequency resolution = 43 h).
The calls used to generate the results of this article are available in the Labarchives repository http://dx.doi.org/10.6070/H4W37T8Q[47].
Discussion
Banded mongoose close calls, consisting of a single syllable, were not only individually distinct, but also differed in their acoustic structure depending on the current behavior of the signaler. This acoustic variation depended on the behavioral context encoded within a harmonic extension of the basic noisy segment of the close call. To our knowledge this is the first example of temporal segmentation as a means of encoding multiple types of information within a call consisting of a single syllable in an animal vocalisation. Variation in spectral aspects (for example, fundamental frequency) of the more noisy call element verify previous findings of individual cues in close calls of banded mongoose [46]. In that study, Müller and Manser [46] showed, using playback experiments that pups are able to discriminate between close calls of their escorting adult and the close calls of other adults. Their results suggest that individual vocal cues of these close calls are meaningful to receivers. Additionally, here we found group specific vocal cues. Such cues of group identity may arise because the physical characteristics that determine vocal characteristics of an individual (for example, vocal fold length (for F0) and/or vocal tract length (for formants)) are, on average, more similar among group members than non-group members. Another possibility in species with vocal flexibility and where individuals change groups is that individuals converge to match the vocal group cue of the new group after switching [48, 49]. At present it is unknown which of these two processes is applicable for the banded mongoose. In contrast, temporal features (for example, duration) of the tonal harmonic segment of the call seem to encode the behavioral vocal cues. Future research using playback experiments will need to be conducted to investigate if behavioral context vocal cues are used by receivers.
While many animal signaling systems, including human speech, use concatenation of acoustically-separate syllables to enrich and extend the signaling space (for example, birdsong [28, 29], rock hyraxes (Procavia capensis) [30] or cetacean species [31, 32]), human speech also encodes information into individual syllables. By combining stop consonants with different vowels at a phonological level, syllables are created that have different meanings. Thus, a stop consonant like/b/versus/p/can be combined with a vowel like/a/or/o/to create a richer signaling unit than either class (that is, stop consonants or vowel) alone could provide. Such combinations (versus 'syntactic' concatenation of syllables and words) are a core feature of the phonological component of human spoken language [33]. The temporally segmented fashion in which banded mongooses encode multiple cues into a single syllable close call is analogous to this system. Moreover, our study provides an example of a discrete individual 'element' in a graded call containing information regarding individuality. The noisy, yet stable, segment of the close call, explained almost as much individual variation as the whole call. This implies that, despite the graded nature of the close call, individual identity is encoded in a discrete way.
The functional aspect of the discrete identity cue in combination with a graded behavioral cue seems analogous to human communicative contexts, when sender and receiver cannot see each other. For example, in the drum or whistle languages of tribes in the remote and isolated conditions of mountainous or densely forested areas, discrete signals are used to announce identity and other information to avoid ambiguity [50, 51]. Similarly, in radio conversations in aviation between pilots and control towers, identity and additional information are shared in a highly standardized order (that is, You Me Where What With; chapter 5, in [52]). Signals in these 'conversations' are intentionally chosen for their clarity to the receivers [53, 54]. In particular in species that are constantly moving as a cohesive unit, in their search for food or shelter, and where the identification of an individual cannot be based on its spatial position, acoustic individual identity may be a crucial aspect for the successful operation of the system. This is true for banded mongooses where coordination of foraging and movement facilitates the successful functioning of the overall social system. Temporal segregation of vocal cues may enable banded mongooses to reliably encode dual information sets regarding an individual's identity and its current behavioral context. Our study on banded mongoose close calls demonstrates temporal segregation within a single syllable call type. However, reviewing spectrograms of other species' calls, available in the literature, reveal that our findings may not be unique to banded mongooses. For example, the well-known 'whine-chuck' advertisement call of the túngara frog (Physalaemus pustulosus) provides another example of segregation of information within a single syllable, where whines encode the species identity and the chucks refer to male quality [55, 56]. Such a system is highly advantageous in providing detailed reliable information in an otherwise ambiguous graded system. Human speech [6, 54, 57, 58], and elements of some other species' vocal repertoires such as Barbary macaque (Macaca sylvanus) [59, 60], chimpanzee (Pan troglodytes) [61, 62] and Japanese macaque (Macaca fuscata) [54] are, from the production side, classified as a graded system, yet perceived by the receivers as discrete [6, 59–61, 63]. Graded signals have the potential to convey subtle and complex information, but potentially suffer from heightened ambiguity [54, 64]. This ambiguity can partly be resolved by meaningful, within-category, classification of a graded signal into perceptually discrete signals [64, 65]. It has been hypothesized that this perception of a graded continuum as a series of discrete units was a crucial stage in the evolution of human language [63, 64]. This analogous ability in banded mongoose demonstrates that animal communication systems also have the potential to convey a rich set of information in an acoustically sophisticated way.
Recent studies have shown that some free ranging primates use meaningful call- and element-combinations to vastly increase the range of information that can be decoded by listeners [3, 4, 66–71]. This may be particularly important for forest species living in dense vegetation, where no visual cues can be used to verify the information content or context of the signal [3, 4]. In the same way, we suggest that species that use vocal cues ultimately benefit from an increased informational repertoire and, therefore, similar species demonstrating combinatorial calling behavior could be expected to make use of multiple vocal cues and benefit from temporal segregation of information. Vocal cues predominantly encode individual related cues of the sender (for example, identity or male quality) and we, therefore, predict temporal segregation to evolve when signalers could benefit from unambiguous multiple vocal cues. Call combinations have been hypothesized to occur in response to discrete external events (for example, alarm calls) or behavioral contexts, but not directly related to characteristics of the signaler [3, 71]. Species with graded vocal systems would especially benefit from the use of unambiguous vocal cues, since these would; i) avoid the lack of clarity that generally occurs in graded vocalizations, and ii) potentially enhance the reliability of categorization by receivers of graded signals into discrete units.
Conclusion
Our results show that considerable acoustic variation underlies the close calls of banded mongooses with specific information in temporarily segregated vocal cues. Through the segregation of acoustic information, the potential trade-off in reliability between vocal cues can be avoided. Many nonhuman-animals have small vocal repertoires [3, 4, 72] and call combinations are one way animals can get around the limited information content of a finite vocal repertoire. Here we demonstrate that temporarily distinct acoustic segments relating to specific vocal cues provide an equally effective and reliable solution to this problem and represent an additional dimension to the complexity underlying information coding in animal vocal communication. To what extent these are used throughout the animal kingdom is an important question to be addressed in the future, as it may help us to identify the selective pressures that gave rise to these kinds of abilities in non-human animals and potentially also in humans.
Methods
Study population
The study site was located in Uganda, in the Queen Elizabeth National park (0°12S; 29°54E). The study site and the habituated population have been described in detail elsewhere [41, 73]. During the period of data collection (February 2009 to July 2011), the study population consisted of six habituated groups and three semi-habituated groups, with group sizes ranging from 6 to 50+ individuals. In five groups, most individuals were habituated to a level that allowed us to follow them with a microphone and to do detailed focal watches. As part of the Banded Mongoose Research Project long-term data collection protocol, all animals were tagged with subcutaneous transponders (TAG-P-122GL, Wyre Micro Design Ltd., UK), whereas for field identification individuals were given small hair cuts or, for less habituated fully grown adults, color-coded plastic collar (weight ≤ 1.5 g, regularly checked to ensure a loose fit) [73].
Recording methods
All close calls used in the acoustic analysis were recorded from well-habituated adult (≤ 1 year) banded mongooses at a distance of approximately 1 to 2 m, using a Sennheiser directional microphone (ME66/K6 and a MZW66 pro windscreen, frequency response 40-20000 Hz ± 2.5 dB, Old Lyme, Connecticut, U.S.A.) connected to a Marantz PMD-660 solid state (Marantz Japan Inc.) or a M-Audio Microtrack II (Avid Technology USA Inc.). Calls were recorded in wav format with 16 bits and 44.1 kHz sample rate. Calls were recorded as part of detailed behavioral focal watches or during ad libitum sampling recording sessions. In 2009, audio recordings were made at the same time as video focal watches to record behavior (Canon HF100); in 2010/11, commentaries on behavior were added to the audio recording. It was noted whether the individual was a.) digging, b.) searching, or c.) moving within the foraging patch of the group (Table 1 and for details of behavior see [74]). For the acoustic analysis, calls with high signal-to-noise ratio were selected, using Avisoft SASLab Pro 5.18 (R. Specht, Berlin, Germany) [75]. Only individuals for which we had at least five calls in at least two of the behavioral contexts were included in the analysis. For individuals where more than five calls were available, we randomly selected five calls [76]. The calls are available in the Labarchives repository http://dx.doi.org/10.6070/H4W37T8Q[47].
Acoustic analysis
A 1,024-point fast Fourier transformation (Hamming window; time step: 0.07 ms; overlap: 96.87%; frequency range: 44.1 kHz; frequency resolution: 43 Hz) was conducted for all calls, using Avisoft. We manually assigned labels to the whole call, the noisy base of the call and, if present, the harmonic part of the call (Figure 1). We then used a batch processing option to obtain automatic measurements for 12 parameters (Table 4). The minimum frequency is the lowest frequency of the amplitude exceeding this threshold (-20 dB), while the maximum frequency is the highest frequency of the amplitude exceeding this threshold. The bandwidth is the difference between minimum and maximum frequency. These quartile variables characterize the distribution of energy across the spectrum and indicate the frequency below which 25, 50 or 75%, respectively, of the energy can be found. The distance between quartile 75% and quartile 25% is a measure of the pureness of the sound. The 50% quartile also indicates the mean frequency. All mean frequency measures were obtained from the mean spectrum of each call or call component, while the three quartiles were also measured from the point within the call or call component that had the maximum amplitude [75]. We also calculated the transition onset (fundamental frequency (F0) at the onset of call minus F0 at the middle of the call) and offset (F0 at the middle of the call minus F0 at the end of the call) [12]. The automatic measurements were checked by visual inspection of the graphic results of the measurements in the spectrograms.
Statistical analysis
We conducted all analyses in R, version 2.14 (R Development Core Team 2010), using the software packages 'car' [77], 'kla' [78], 'lme4' [79], and 'MASS' [80]. The analyses described below were done on the whole call, on the 'noisy' segment of the call, and if present, on the 'harmonic segment' of the call (Figure 1). We performed linear mixed effect models (lmer) on the acoustic variables to calculating variance inflation factors and obtaining a subset of acoustic parameters that was free from multicollinearity as this is essential for the proper functioning of the discriminant function analysis (DFA). It has been argued that conventional DFA provides grossly inflated levels of overall significance of discriminability when using multiple samples of the same individual [76] and that in such cases a permuted discriminant function analysis (pDFA) should be used. We controlled for repeated sampling of groups and individuals by fitting 'individual' nested in 'group' as a random factor [81]. We used an adapted form of the variance inflation factors (VIF) analysis that worked directly on predictors in lmer models (Austin Frank, pers. comm.) to detect multicollinearity in the acoustic parameters. Only parameters with a VIF ≤ 2.5 were included in the analyses. The remaining parameters were entered into a DFA to determine the correct classification probabilities of close calls to i.) behavior while controlling for individual and ii.) individuals while controlling for behavior. DFA identifies linear combinations of predictor variables that best characterize the differences among groups and combines the variables into one or more discriminant functions, depending on the number of groups to be classified [78, 80]. This method of analyses provides a classification procedure that assigns each call to its appropriate class (correct assignment) or to another class (incorrect assignment). A stepwise variable selection was performed for the DFA. The initial model consisted of the parameters that remained after the selection with the linear effect model and the VIF analysis; in subsequent steps new models were generated by either including or excluding single variables in the model. This resulted in a performance measure for these models that were estimated by cross-validation, and if the maximum value of the chosen criterion was better than the previous model, the corresponding variable was included or excluded. This procedure was stopped once the new best value, after including or excluding any variable, did not exceed a 5% improvement. The number and type of variables included in the analysis differed per analysis and sub-analysis. Duration was included in all behavioral context specific tests. The number of variables included was smaller than the number of individuals included in the test [76]. For external validation, we used a leave-one-out cross-validation procedure and estimated the significance levels for correct statistical assignment of calls using post hoc 'bootstrapping' analyses. This method determined the probability that a cross-validated correct assignment value was achieved by chance [46]. Our data for behavioral, group, and sex vocal cues were two factorial (test factor and individual) and contained five call examples per individual, we, therefore, used a crossed pDFA (Mundry, pers. comm.). Furthermore, to ensure no differences resulted from variation in sex or group, we also performed pDFAs while keeping these two additional variables constant. We performed four pDFAs to test for overall and the pairwise comparison between behavioral contexts. In addition, we performed two additional pDFAs to test for the group cue and sex cues (both while controlling for individual). From one of the groups, we did not have calls from a large enough number of individuals to perform a classification analysis, and, therefore, the group vocal cue analysis was conducted on four groups only.
Ethical note
This research was carried out under license from the Uganda National Council for Science and Technology, and all procedures were approved by the Uganda Wildlife Authority. Trapping and marking procedures, which are part of the long-term research program, followed the guidelines of the Association for the Study of Animal Behavior [43, 73].
Abbreviations
- DFA:
-
discriminant function analysis
- F0:
-
fundamental frequency
- lmer:
-
linear mixed effect models
- ncce:
-
number of correctly cross-classified elements
- pDFA:
-
permutated discriminant function analysis
- VIF:
-
variance inflation factors.
References
Fitch WT: Skull dimensions in relation to body size in nonhuman primates: the causal bases for acoustic allometry. Zoology. 2000, 103: 40-58.
Hammerschmidt K, Fischer J: Constraints in primate vocal production. The evolution of Communicative Creativity: From Fixed Signals to Contextual Flexibility. Edited by: Griebel U, Oller K. 2008, Cambridge, MA: The MIT Press, 93-119.
Arnold K, Zuberbühler K: The alarm-calling system of adult male putty-nosed monkeys, Cer-copithecus nictitans martini. Anim Behav. 2006, 72: 643-653. 10.1016/j.anbehav.2005.11.017.
Arnold K, Zuberbühler K: Meaningful call combinations in a non-human primate. Curr Biol. 2008, 18: R202-R203. 10.1016/j.cub.2008.01.040.
Bradbury JW, Vehrencamp SL: Principles of Animal Communication. 1998, New York: Sinauer Associates
Hauser MD: The Evolution of Communication. 1996, Cambridge, MA: MIT Press
Maynard-Smith J, Harper D: Animal Signals. 2003, New York: Oxford University Press
Shapiro AD: Recognition of individuals withing social group: signature vocalizations. Handbook of Mammalian Vocalization. Edited by: Brudzynski SM. 2010, Oxford: Elsevier Academic Press, 495-503.
Briefer E, Aubin T, Lehongre K, Rybak F: How to identify dear enemies: the group signature in the complex song of the skylark Alauda arvensis. J Exp Biol. 2008, 211: 317-326. 10.1242/jeb.013359.
Crockford C, Herbinger I, Vigilant L, Boesch C: Wild chimpanzees produce group-specific calls: a case for vocal learning?. Ethology. 2004, 110: 221-243. 10.1111/j.1439-0310.2004.00968.x.
Boughman JW, Wilkinson GS: Greater spear-nosed bats discriminate group mates by vocalizations. Anim Behav. 1998, 55: 1717-1732. 10.1006/anbe.1997.0721.
Townsend SW, Hollen LI, Manser MB: Meerkat close calls encode group-specific signatures, but receivers fail to discriminate. Anim Behav. 2010, 80: 133-138. 10.1016/j.anbehav.2010.04.010.
Fitch WT: Vocal tract length and formant frequency dispersion correlate with body size in rhesus macaques. J Acoust Soc Am. 1997, 102: 1213-1222. 10.1121/1.421048.
Reby D, McComb K: Anatomical constraints generate honesty: acoustic cues to age and weight in the roars of red deer stags. Anim Behav. 2003, 65: 519-530. 10.1006/anbe.2003.2078.
Vannoni E, McElligott AG: Low frequency groans indicate larger and more dominant fallow deer (Dama dama) males. PloS One. 2008, 3: e3113-10.1371/journal.pone.0003113.
Clutton-Brock TH, Albon SD: The roaring of red deer and the evolution of honest advertising. Behaviour. 1979, 69: 145-170. 10.1163/156853979X00449.
Fischer J, Kitchen DM, Seyfarth RM, Cheney DL: Baboon loud calls advertise male quality: acoustic features and relation to rank, age, and exhaustion. Behav Ecol Sociobiol. 2004, 56: 140-148. 10.1007/s00265-003-0739-4.
Charlton BD, Zhang Z, Snyder RJ: Vocal cues to identity and relatedness in giant pandas (Ailuropoda melanoleuca). J Acoust Soc Am. 2009, 126: 2721-2732. 10.1121/1.3224720.
Mathevon N, Koralek A, Weldele M, Glickman SE, Theunissen FE: What the hyena's laugh tells: Sex, age, dominance and individual signature in the giggling call of Crocuta crocuta. BMC Ecol. 2010, 10: 9-10.1186/1472-6785-10-9.
Charlton BD, Keating JL, Li R, Yan H, Swaisgood RR: Female giant panda (Ailuropoda melanoleuca) chirps advertise the caller's fertile phase. Proc Biol Sci. 2010, 277: 1101-1106. 10.1098/rspb.2009.1431.
Riede T, Fitch WT: Vocal tract length and acoustics of vocalization in the domestic dog Canis familiaris. J Exp Biol. 1999, 202: 2859-2867.
Reby D, Joachim J, Lauga J, Lek S, Aulagnier S: Individuality in the groans of fallow deer (Dama dama) bucks. J Zool. 1998, 245: 79-84. 10.1111/j.1469-7998.1998.tb00074.x.
Owren MJ, Seyfarth RM, Cheney DL: The acoustic features of vowel-like grunt calls in chacma baboons (Papio cyncephalus ursinus): implications for production processes and functions. J Acoust Soc Am. 1997, 101: 2951-2963. 10.1121/1.418523.
Rendall D, Seyfarth RM, Cheney DL, Owren MJ: The meaning and function of grunt variants in baboons. Anim Behav. 1999, 57: 583-592. 10.1006/anbe.1998.1031.
Rendall D: Acoustic correlates of caller identity and affect intensity in the vowel-like grunt vocalizations of baboons. J Acoust Soc Am. 2003, 113: 3390-3402. 10.1121/1.1568942.
Marler P: Bird song and mate selection. Animal Sounds and Communication. Edited by: Lanyon W, Tavalga W, Port Jervis. 1960, NY: Lubrecht & Cramer, 348-367.
Briefer E, Vannoni E, McElligott AG: Quality prevails over identity in the sexually selected vocalisations of an ageing mammal. BMC Biol. 2010, 8: 1-15. 10.1186/1741-7007-8-1.
Nelson DA, Poesel A: Segregation of information in a complex acoustic signal: individual and dialect identity in white-crowned sparrow song. Anim Behav. 2007, 74: 1073-1084. 10.1016/j.anbehav.2007.01.018.
Elfstörm ST: Responses of territorial meadow pipits to strange and familiar song phrases in playback experiments. Anim Behav. 1990, 40: 786-788. 10.1016/S0003-3472(05)80712-2.
Koren L, Geffen E: Complex call in male rock hyrax: a multi-information distributing channel. Behav Ecol Sociobiol. 2009, 63: 581-590. 10.1007/s00265-008-0693-2.
Payne RS, McVay S: Songs of humpback whales. Science. 1971, 173: 57-64.
Ford JKB: Acoustic behavior of resident killer whales (Orcinus orca) off Vancouver Island, British Columbia. Can J Zool. 1989, 67: 727-745. 10.1139/z89-105.
Hauser MD, Fitch WT: Language Evolution: The States of the Art. Language Evolution: The States of the Art. Edited by: Christiansen M, Kirby S. 2003, Oxford: Oxford University Press, 317-337.
Kondo N, Watanabe S: Contact calls: information and social function. Jpn Psychol Res. 2009, 51: 197-208. 10.1111/j.1468-5884.2009.00399.x.
DaCunha RGT, Byrne RW: The use of vocal communication in keeping the spatial cohesion of groups: intentionality and specific functions. South American Primates: Comparative Perspectives in the Study of Behavior, Ecology, and Conservation. Edited by: Garber PA, Estrada A, Bicca-Marques JC, Heymann E, Strier K. 2008, New York: Springer, 341-363.
Janik VM, Dehnhardt G, Todt D: Signature whistle variation in a bottlenosed dolphin, Tursiops truncatus. Behav Ecol Sociobiol. 1994, 35: 243-248. 10.1007/BF00170704.
Jameson JW, Hare JF: Group-specific signatures in the echolocation calls of female little brown bats (Myotis lucifugus) are not an artefact of clutter at the roost entrance. Acta Chiropterol. 2009, 11: 163-172. 10.3161/150811009X465785.
Harcourt AH, Stewart KJ, Hauser MD: Functions of wild gorilla 'close' calls. 1. repertoire, context, and interspecific comparison. Behaviour. 1993, 124: 89-112. 10.1163/156853993X00524.
Townsend SW, Zoettl M, Manser MB: All clear? Meerkats attend to contextual information in close calls to coordinate vigilance. Behav Ecol Sociobiol. 2011, 65: 1927-1934. 10.1007/s00265-011-1202-6.
Townsend SW, Allen C, Manser MB: A simple test of vocal individual recognition in wild meerkats. Biol Lett. 2012, 8: 179-182. 10.1098/rsbl.2011.0844.
Cant MA: Communal breeding in banded mongooses and the theory of reproductive skew. PhD thesis. 1998, University of Cambridge, Cambridge
Rood AP: Population dynamics and food habits of the banded mongoose. East Afr Wildl J. 1975, 13: 89-111.
Cant MA: Social control of reproduction in banded mongooses. Anim Behav. 2000, 59: 147-158. 10.1006/anbe.1999.1279.
Messeri P, Masi E, Piayya R, Dessifulgheri F: A study of the vocal repetoire of the banded mongoose (Mungos mungo). Ital J Zool. 1987, 341-373. Suppl 22
Furrer RD: Leadership and group-decision-making in banded mongooses (Mungos mungo). PhD thesis. 2009, Zurich University, Zurich
Müller CA, Manser MB: Mutual recognition of pups and providers in the cooperatively breeding banded mongoose. Anim Behav. 2008, 75: 1683-1692. 10.1016/j.anbehav.2007.10.021.
Jansen DAWAM, Cant MB, Manser MB: Banded mongoose close calls. LabArchives. [http://dx.doi.org/10.6070/H4W37T8Q]
Briefer E, McElligott AG: Social effects on vocal ontogeny in an ungulate, the goat (Capra hircus). Anim Behav. 2012, 83: 991-1000. 10.1016/j.anbehav.2012.01.020.
Candiotti A, Zuberbühler K, Lemasson A: Convergence and divergence in Diana monkey vocalizations. Biol Lett. 2012, 8: 382-385. 10.1098/rsbl.2011.1182.
Stern T: Drum and whistle 'languages': an analysis of speech surrogates. Am Anthropol. 1957, 59: 487-506. 10.1525/aa.1957.59.3.02a00070.
Meyer J, Gautheron B: Whistled speech and whistled languages. Encyclopedia of Language and Linguistics, Volume 13. Edited by: Brown K. 2006, Elsevier, 573-576.
Todd SC: The Pilot's Handbook. 2009, Beverly, MA: Pilot Handbook Publishing
Ong WJ: African talking drums and oral noetics. New Literary Hist. 1977, 8: 411-429. 10.2307/468293.
Green S: Variation of vocal pattern with social situation in the Japanese monkey (Macaca fuscata): A field study. Primate Behavior, Developments in Field and Laboratory Research. 1975, 2: 1-102.
Ryan MJ: Frequency modulated calls and species recognition in a Neotropical frog. J Comp Physiol. 1983, 150: 217-221. 10.1007/BF00606371.
Ryan MJ: Sexual selection and communication in a Neotropical frog, Physalaemus pustulo- sus. Evolution. 1983, 39: 261-272.
Nelson DA, Marler P: Categorical perception of natural stimulus continuum: birdsong. Science. 1990, 244: 976-979.
Dooling RJ: Hearing in birds. The Evolutionary Biology of Hearing. Edited by: Webster DB, Fay RR, Popper AN. 1992, Berlin Heidelberg: Springer, 545-560.
Fischer J, Hammerschmidt K, Todt D: Factors affecting acoustic variation in Barbary-macaque (Macaca sylvanus) disturbance calls. Ethology. 1995, 101: 51-66.
Fischer J, Hammerschmidt K: Functional referents and acoustic similarity revisited: the case of Barbary macaque alarm calls. Anim Cogn. 2001, 4: 29-35. 10.1007/s100710100093.
Slocombe KE, Townsend SW, Zuberbühler K: Wild chimpanzees (Pan troglodytes schweinfurthii) distinguish between different scream types: Evidence from a playback study. Anim Cogn. 2009, 12: 441-449. 10.1007/s10071-008-0204-x.
Marler P, Mundinger PC: Vocalizations, social-organization and breeding biology of twite Acanthus avirostris. Ibis. 1975, 117: 1-6.
Marler P: Social organization, communication and graded signals: the chimpanzee and the gorilla. Growing Points in Ethology. Edited by: Bateson P, Hinde R. 1976, Cambridge:Cambridge University Press, 239-281.
Marler P: On the origin of speech from animal sounds. The Role of Speech in Language. Edited by: Kavanagh J, Cutting J. 1975, Cambridge, MA: MIT Press, 11-37.
Harnad S: Categorical Perception: the Groundwork of Cognition. 1987, Cambridge, UK: Cambridge University Press
Crockford C, Boesch C: Call combinations in wild chimpanzees. Behaviour. 2005, 142: 397-421. 10.1163/1568539054012047.
Clarke E, Reichard UH, Zuberbühler K: The syntax and meaning of wild gibbon songs. PLoS ONE. 2006, 1: e73-10.1371/journal.pone.0000073.
Schel AM, Tranquilli S, Zuberbühler K: The alarm call system of two species of black-and-white colobus monkeys (Colobus polykomos and Colobus guereza). J Comp Psychol. 2009, 123: 136-150.
Endress AD, Cahill D, Block S, Watumull J, Hauser MD: Evidence of an evolutionary precursor to human language affixation in a non-human primate. Biol Lett. 2009, 5: 749-751. 10.1098/rsbl.2009.0445.
Ouattara K, Lemasson A, Zuberbühler K: Anti-predator strategies of free-ranging Campbell's monkeys. Behaviour. 2009, 146: 1687-1708. 10.1163/000579509X12469533725585.
Ouattara K, Lemasson A, Zuberbühler K: Campbell's monkeys concatenate vocalizations into context-specific call sequences. Proc Natl Acad Sci USA. 2009, 106: 22026-22031. 10.1073/pnas.0908118106.
Zuberbühler K: Referential signaling in non-human primates: cognitive precursors and limitations for the evolution of language. Adv Stud Behav. 2003, 33: 265-307.
Jordan NR, Mwanguhya F, Kyabulima S, Rueedi P, Cant MA: Scent marking within and between groups of wild banded mongooses. J Zool. 2010, 280: 72-83. 10.1111/j.1469-7998.2009.00646.x.
Bousquet CAH, Sumpter DJT, Manser MB: Moving calls: a vocal mechanism underlying quorum decisions in cohesive groups. Proc Biol Sci. 2011, 278: 1482-1488. 10.1098/rspb.2010.1739.
Specht R: Avisoft SASLab Pro. User's Guide for Version 5.1. 2011, Avisoft Bioacoustics, Berlin
Mundry R, Sommer C: Discriminant function analysis with nonindependent data: consequences and an alternative. Anim Behav. 2007, 74: 965-976. 10.1016/j.anbehav.2006.12.028.
Fox J, Weisberg S: An R Companion to Applied Regression. 2011, Los Angeles, CA: Sage Publications, 2
Weihs C, Ligges U, Luebhe K, Raabem N: klaR Analyzing German Business Cycles. Data Analysis and Decision Support. Edited by: Baier D, Decker R, Schmidt-Thieme L. 2005, Berlin: Springer, 335-343.
Bates DM: lme4: Mixed-Effects Modeling with R. 2011, New York: Springer
Venables WN, Ripley BD: Modern Applied Statistics with S. 2002, Berlin Heidelberg: Springer, 4
Crawley MJ: The R Book. 2007, Chichester: John Wiley & Sons
Acknowledgements
We are grateful to Uganda Wildlife Authority (UWA) and the Uganda National Council of Science and Technology for permission to work in Queen Elizabeth National Park. We especially thank Aggrey Rwetsiba at UWA HQ, Conservation Area Managers, Tom Okello and Nelson Guma, and Research and Monitoring Warden, Margaret Dricuru, for support in the park. We thank Kenneth Mwesige, Francis Mwanguhya, Solomon Kyabulima and Robert Businge for their invaluable support during the field work. We also want to thank Jenni Sanderson, Emma Vitikainen and Corsin Müller, who were great co-workers in the field. We are grateful to Roger Mundry for providing pDFA scripts, Austin Frank for providing the script to work on collinearity diagnostics of mixed effect models and Raimund Specht of Avisoft for technical support. We thank Tim Clutton-Brock for discussions, and Simon Townsend, Christophe Bousquet, and Jennifer Krauser for comments on the manuscript. Finally, we would like to thank the anonymous reviewers for their valuable comments and suggestions to improve the quality of the paper. Financial support was provided by the University of Zurich. The long-term study site is supported by grants from the Natural Environment Research Council, UK.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors' contributions
DJ designed the study, collected data in the field, analyzed the data and wrote up of the paper. MC helped to write the paper and provided logistical support in the field. MM designed research and helped to write the paper. All authors read and approved the final manuscript.
Electronic supplementary material
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
{kind=link}
Rights and permissions
This article is published under license to BioMed Central Ltd. This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Jansen, D.A., Cant, M.A. & Manser, M.B. Segmental concatenation of individual signatures and context cues in banded mongoose (Mungos mungo) close calls. BMC Biol 10, 97 (2012). https://doi.org/10.1186/1741-7007-10-97
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1741-7007-10-97