
Abstract
Background
Child sexual abuse (CSA) is a considerable public health problem. Less focus has been paid to the role of community level factors associated with CSA. The aim of this study was to examine the association between neighbourhood-level measures of social disorganization and CSA.
Methods
We applied multiple multilevel logistic regression analysis on Demographic and Health Survey data for 6,351 adolescents from six countries in sub-Saharan Africa between 2006 and 2008.
Results
The percentage of adolescents that had experienced CSA ranged from 1.04% to 5.84%. There was a significant variation in the odds of reporting CSA across the communities, suggesting 18% of the variation in CSA could be attributed to community level factors. Respondents currently employed were more likely to have reported CSA than those who were unemployed (odds ratio [OR] = 2.05, 95% confidence interval [CI] 1.48 to 2.83). Respondents from communities with a high family disruption rate were 57% more likely to have reported CSA (OR=1.57, 95% CI 1.14 to 2.16).
Conclusion
We found that exposure to CSA was associated with high community level of family disruption, thus suggesting that neighbourhoods may indeed have significant important effects on exposure to CSA. Further studies are needed to explore pathways that connect the individual and neighbourhood levels, that is, means through which deleterious neighbourhood effects are transmitted to individuals.
Similar content being viewed by others

Background
Numerous studies from Africa and the rest of the world had shown that child sexual abuse (CSA) is a considerable public health problem[1]. However, until recently little attention has been paid to CSA in sub-Saharan Africa (SSA). Most of the peer-reviewed research on the sexual abuse of children in SSA is largely confined to the Republic of South Africa[2] while other reported studies in SSA are in the context of school. The current data on Africa from the World Health Organization Global School-based Student Health Survey estimated lifetime prevalence of sexual abuse among primary students aged between 13–15 years in the five countries surveyed in SSA to range from 9% to 33%[3]. In a cross study comparison of prevalence of CSA in South Africa, between 3.2% and 7.1% of all respondents report experiencing unwanted or forced sexual intercourse as a child[2]. In Swaziland, the prevalence of sexual violence before 18 years of age was 33.2% among participants aged 13–24 years[1]. While the understanding of the burden of sexual abuse in children and its relationship with adverse health behaviour has increased globally, such studies in children are nonexistent in Africa. In addition, the nature and causes of CSA is complicated due to many factors, including sexual behaviours.
When dealing with sexual behaviours, it is widely believed that focusing on individual levels ignores the broader social context within which sexual behaviour occurs. Previous studies that have investigated factors affecting CSA in SSA were based solely on the assessment of the impact of individual level variables[4–10]. However, other violence research has indicated the importance of community level factors as well as measures of social disorganization and experience of sexual violence[11]. It is important to examine whether this relationship is applicable to CSA. Thus, this study draws upon social disorganization theory[12] to examine and better understand community characteristics that may predict CSA. Although originally concerned with community conditions like delinquency and crime, social disorganization theory offers potentially important insights concerning how the characteristics of communities might be related to sexual violence. This study relies on a framework centred on the social disorganization theory (or model) to investigate the impact of neighborhood level factors on childhood sexual abuse. The framework conceptualises CSA as a multifaceted phenomenon based on interplay of individual, family, community and societal factors. In addition, the model takes into account measures of social disorganization and their role in influencing CSA.
Social disorganization identifies neighbourhood poverty, residential instability, family disruption, population density and proximity to urban areas as key structural factors that diminish community-level self-regulatory capacity[12]. The social disorganization thesis argues that communities with strong informal social networks are able to monitor and regulate sexual violent behavior[13]. Consequently, structural factors that increase the complexity of community social organization and undermine informal social networks enhance the range of sexual violent behaviours pursued by residents[14, 15]. Poverty reduces the resources necessary to sustain basic institutions like the family and organizations in neighbourhoods[16]. Social disorganization theory hypothesizes that the disruptive effects of immigration, industrialisation and urbanisation lead to changes in the social structure of neighbourhoods via ethnic diversity, residential instability and neighbourhood poverty. The resulting structural changes diminish the social cohesion of neighbourhoods and reduce the power of the social norm and the informal social control required to regulate deviant behaviour. This can result in CSA. The theory proposed that high ethnic diversity gives rise to social isolation[17]. This in turn leads to structural barriers and cultural adaptations that undermine social organization. Shaw and McKay[12] also traced social disorganization to conditions endemic to the urban areas that were the only places the newly arriving poor could afford to live, resulting in a high rate of turnover in the population (residential instability). These high levels of residential turnover can disrupt existing social networks. Urbanisation has been found to be negatively associated with the coherency of the normative environment[18]. Increasing urbanisation may give rise to an environment facilitating higher levels of sexual violent activity by creating greater anonymity with minimal risk of being “found out”[18]. Non-traditional family structures, such as female-headed (matriarchal) households for example, have been linked to social disorganization. Social disorganization has received support from research conducted on extramarital sexual activity of Zambian men[13]. Research on extramarital sex is supported by Bishai and colleageus[14] who found Ugandan men in ethnically heterogeneous communities to be more likely to report such activities.
To the best of our knowledge, there has been no multilevel study performed to date that examined the association between community-level measures of social disorganization and experience of CSA in the context of SSA.
Thus, the aim of this study is to answer the following research questions:
-
1.
Do neighbourhoods and countries differ in terms of the risks of CSA?
-
2.
Are neighbourhood-level measures of social disorganization associated with self-reported CSA after adjustment for individual-level variables?
Methods
The study used data from the Demographic and Health Surveys (DHS) conducted in six countries in sub-Saharan Africa (Ghana, Liberia, Nigeria, Uganda, Zambia and Zimbabwe) between 2006 and 2008. The six countries were chosen because they met the selection criteria of recent surveys during the past 10 years and the availability of data sets on sexual violence. DHS surveys were designed to collect good quality, nationally representative data on demographic and health indicators of women and members of their households. They are usually well conducted with a high response rate (average of 96%). Methods and data collection procedures have been published elsewhere[19]. Briefly, the survey utilised a two-stage cluster sampling design. The first stage involved taking up enumeration areas from census files while in the second stage, a sample of households is drawn from a current an updated list of households within each enumeration area. Every survey is stratified by urban and rural status and additionally by country-specific geographic or administrative regions. A standardised questionnaire was administered by interviewers to all female participants aged between 15 and 49 years in the selected households. To ensure standardisation and comparability across sites and time, DHS surveys employ intense interviewer training, standardised measurement tools and techniques, an identical core questionnaire and instrument pretesting[20]. The number of women included in the six DHS surveys ranged from 4,916 in Ghana to 33,885 in Nigeria. The DHS survey was implemented by respective national implementing agencies with technical assistance from ICF Macro International Inc (Calverton, MD).
Outcome variable
To be included in the analysis, the respondents were required to meet the following two criteria: The respondents must be 18 years or younger and must be principle resident at the place where the survey interview was conducted. Furthermore, for this study, CSA was defined as sexual violence on or before the age of 18 years. To assess if participants were sexually abused in childhood, all eligible women were asked the following questions: “At any time in your life, as a child or as an adult, has anyone forced you in any way to have sexual intercourse or perform any other sexual acts?” The two possible outcomes for the questions were “yes” or “no”. Respondents who said yes were then asked questions about the age at which this first happened and the person who committed the act. Respondents who gave an affirmative reply and if the violence occurred when they were under the age of 18 years, were considered as cases of CSA and coded as “1” while those who gave a negative response or if the abuse occurred after the age of 18 years, formed the other group of the dichotomy and were coded “0”. All the women who did not respond to the question were excluded.
Independent variables
Individual level factors
The following individual-level factors were included: education (no education, primary, secondary or higher); marital status (never married, currently married and formerly married) and occupation (working or not working). DHS did not collect direct information on household income and expenditure. We used DHS wealth index as a proxy indicator for socioeconomic position. The methods used in calculating DHS wealth index have been described elsewhere[21–23]. Briefly, an index of economic status for each household was constructed using principal components analysis based on the following household variables: number of rooms per house, ownership of car, motorcycle, bicycle, fridge, television and telephone as well as any kind of heating device. From these criteria the DHS wealth index quintiles (poorest, poor, middle, rich, and richest) were calculated and used in the subsequent modelling.
Community-level factors
where:
-
1.
Neighbourhood poverty: percentage of households below 20% of wealth index [24].
-
2.
Female-headed households (family disruption), expressed as percentages of households headed by a female in an area.
-
3.
Residential mobility/instability was defined as the proportion of households occupied by persons who had moved from another dwelling during the previous 5 years [25, 26].
-
4.
Place of residence was defined as either urban or rural, as administratively defined by each country.
-
5.
Population density (average household size) was operationalised as the median household size in a community.
-
6.
Ethnic diversity - an index of ethnic diversity was created using a formula (equation 1) that captures both the number of different groups in an area and the relative representation of each group (23):
x i = population of ethnic group i of the area,
y = total population of the area,
n = number of ethnic groups in the area
Scores can range from 0 to approximately 1. For clarity of interpretation, each diversity index is multiplied by 100; the larger the index, the greater diversity there is in the area. If an area’s entire population belongs to one ethnic group, then an area has zero diversity. An area’s diversity index increases to 100 when the population is evenly divided into ethnic groups.
Country of residence was also included as a categorical variable. The country was included as a partial control variable to control for effects of unknown factors due to potential differences across the six countries.
Ethics
This study was based on an analysis of existing survey data with all identifier information removed. The survey was approved by the Ethics Committee of the ICF Macro at Calverton in the USA and by the National Ethics Committees in their respective countries. All study participants gave informed consent before participation and all information was collected confidentially.
Statistical analyses
Descriptive analyses
In the descriptive statistics the distribution of respondents by key variables were expressed as percentages. We used unadjusted logistic regression analyses to investigate the bivariate association between each variable and CSA.
Modelling approaches
We specified a 2-level multilevel model for binary outcome y, reporting childhood sexual abuse or not, for adolescents i (at level 1) living in a community j (at level 2) of form:
The probability of reporting CSA was related to a set of categorical predictor X and a random effect for each level by a logit-link function as:
The linear predictor on the right-hand side of the equation consisted of a fixed part (β 0 + β 1 X ij + β 2 X j ) estimating the conditional coefficients for the exposure variables and one random intercepts attributable to neighbourhoods (μ 0j ) assumed to have an independent and identical distribution and variance estimated at each level. We constructed two models. The first model, an empty or unconditional model without any exposure variables, was specified to decompose the amount of variance that existed between community levels. The second (full) model controlled for all the variables simultaneously.
Fixed effects (measures of association)
The results of fixed effects (measures of association) were shown as odds ratios (ORs) with their 95% confidence intervals (CIs).
Random effects (measures of variation)
The similarity between adolescents in the same community was measured using intra-community correlation (ICC). The ICC represents the percentage of the total variance in the probability of reporting CSA that is related to the area level, i.e. measure of clustering of odds of reporting CSA in the areas. The ICC was calculated by the linear threshold (latent variable method) according to the formula used by Snijders and Boskers Bosker[27]:
where is neighbourhood (area) variance. A high ICC in the empty model indicates high clustering CSA, in the area and thus suggesting a strong area effect on CSA. A low ICC, on the other hand, expresses the existence of a weak area influence on CSA.
Model fit and specifications
Regression diagnostics were used to judge the goodness-of-fit of the model. They included the tolerance test for multicollinearity, its reciprocal variance inflation factors (VIF)[28, 29], presence of outliers and estimates of adjusted R square of the regression model. The largest VIF greater than 10 or the mean VIF greater than 6, represent severe multicollinearity[30]. Regression estimates were calculated by means of the reweighted iterative generalised least square algorithm using MLwiN 2.20[31]. In the multilevel logistic regression models, second order penalized quazi-likelihood estimation was used[32]. The statistical significance of covariates was calculated using the Wald test[31]. All significance tests were two-tailed and statistical significance was defined at the 5% alpha level.
Results
Sample characteristics
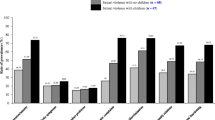
The countries, survey year and eligible samples are shown in Figure 1. The surveys were conducted between 2006 and 2008. The number of adolescents (18 years or younger) included in the study who were permanent residence of the place at the time of the survey ranged from 477 in Ghana and 2,956 in Nigeria. The number of communities sampled ranged from as few as 300 in Liberia to as many as 888 in Nigeria. The percentage of adolescents that had experienced CSA ranged from 1.04% in Liberia to 5.84% in Zambia. Table 1 shows the characteristics of the covariates and association with CSA. Almost half (47%) of the respondents included in the final pooled sample were from Nigeria. Most of the adolescents were not married (88%); had secondary or higher education (56%), and not working (68%). There was significant association between CSA, marital status, occupation and education, but not with wealth status. The test of overall differences in prevalence of reported CSA among the six countries showed that the differential in reported CSA across the countries was statistically significant (chi-squared test [degree of freedom 5] =45.2, p=0.0001).

Description of demographic and health surveys data 2006–2008 in Sub-Saharan Africa by country, survey year, sample size, eligible sample and reported childhood sexual abuse (CSA).
Measures of variability (random intercept models)
The result of the random-intercept model is shown in Table 2. The empty model (null model) shows that there was a significant variation in the odds of reporting CSA across the communities (area variance [] =0.74, p=0.017). The intra-community correlation coefficient as implied by the intercept component variance, specified that 18% of the variation in CSA could be attributed to the community level factors. After adjusting for all the variables in the full model (Model 2), more than half (54%) of the variance in the odds of reporting CSA across communities was explained by all the variables included. The variations across communities became not statistically significant after controlling for other variables in the full model.
Measures of associations (fixed effects)
The results of fitting the model including individual- and community-level variables, are also displayed in Table 2. The odds of reporting CSA decreased with illiteracy. Respondents with no education were 84% less likely to have reported CSA than those with a formal education (OR = 0.16, 95% CI 0.07 to 0.39). Respondents currently employed were more likely to have reported CSA than those unemployed (OR=2.05, 95% CI 1.48 to 2.83). Compared with adolescents from Nigeria, adolescents from Uganda (OR = 0.44, 95% CI 0.21 to 0.90) were significantly less likely to have reported CSA and adolescents from Zimbabwe (OR = 1.71, 95% CI 1.14 to 2.57) and Zambia (OR = 2.48, 95% CI 1.53 to 4.02) were significantly more likely to have reported CSA. There was no evidence of differential in the odds of reporting CSA among respondents from Nigeria, Liberia and Ghana in the adjusted model. However, the test of overall differences in prevalence of reported CSA among the six countries showed that the differential in reported CSA across the countries is statistically significant (chi-squared test [degree of freedom 5] =31.54, p=0.0001). Only one community-level factor was statistically significantly associated with CSA. Respondents from communities with a high family disruption rate were 57% more likely to have reported CSA (OR=1.57, 95% CI 1.14 to 2.16).
Discussion
To the best our knowledge, this is the first study that examined the association between both individual-level and community-level social disorganization and CSA in sub-Saharan Africa. Our results suggest that the level of family disruption in the community is associated with exposure to CSA. The associations between CSA and other measures of social disorganization were not statistically significant after adjusting for individual level factors.
Our findings are consistent with previous research carried out elsewhere, outside Africa, which had examined the association between CSA and family disruption[33–36]. There is a growing body of literature that suggests that children who experience multiple transitions in family structure may experience worse development and health outcomes compared to children raised in stable two-parent families and perhaps even worse than children raised in stable, single-parent families[34].
Results of this study suggests that family instability, especially family disruption (as a measure of community social disorganization) affects children as much as (or even more than) changes in family structure[34]. Unlike most previous studies that examined factors associated with CSA, we found evidence of significant geographical clustering in exposure to CSA. Respondents from the same area may be more similar to each other in relation to their exposure to CSA than to people from other areas[37]. Respondents living in the same neighbourhood tend to have similar exposure to CSA, which may be in part because people in the same neighbourhood are prone to common contextual influences.
This study has some caveats: Firstly, the cross-sectional nature of the data limits our ability to draw causal inferences. Secondly, the communities used in the analyses were administrative boundaries, which may not adequately capture the social context important for individual exposure to CSA. However, due to high community-level variance observed, the communities used seem to be appropriate to capture social context. DHS collects sexual violence data from females only. It would have been better if data for male victims were also available to enable comparisons between the two groups. Finally, we used self-reported measures, though the reliability and validity of this instrument is yet to be established. Despite these limitations, the strengths of the study are significant. It is a large, population-based study with national coverage from six countries with high response rates. The DHS have some important advantages when compared with other surveys. They are often nationally representative, allowing for conclusions that cover the entire nation. In addition, the same variable is operationalised in the same way and thereby making it possible for numerical values to be comparable across countries.
Conclusion
This study found that exposure to CSA is associated with high community level of family disruption, suggesting that neighbourhoods may indeed have important effects on exposure to CSA. Further studies are needed to investigate the pathways through which neighbourhood factors interact with individual factors to influence CSA. A better understanding of the mechanisms involved might be important for designing public health interventions aimed at reducing CSA in Sub-Saharan Africa.
Abbreviations
- CSA:
-
Childhood sexual abuse
- CI:
-
Confidence intervals
- DHS:
-
Demographic and health surveys
- ICC:
-
Intra-community correlation
- OR:
-
Odds ratio
- SSA:
-
Sub-Saharan Africa
- VIF:
-
Variance inflation factor.
References
Reza A, Breiding MJ, Gulaid J, Mercy JA, Blanton C, Mthethwa Z: Sexual violence and its health consequences for female children in Swaziland: a cluster survey study. Lancet. 2009, 373: 1966-1972. 10.1016/S0140-6736(09)60247-6.
Lalor K: Child sexual abuse in sub-Saharan Africa: a literature review. Child Abuse Negl. 2004, 28: 439-460. 10.1016/j.chiabu.2003.07.005.
Brown DW, Riley L, Butchart A, Meddings DR, Kann L, Harvey AP: Exposure to physical and sexual violence and adverse health behaviours in African children: results from the Global School-based Student Health Survey. Bull World Health Organ. 2009, 87: 447-455. 10.2471/BLT.07.047423.
Vogeltanz ND, Wilsnack SC, Harris TR, Wilsnack RW, Wonderlich SA, Kristjanson AF: Prevalence and risk factors for childhood sexual abuse in women: national survey findings. Child Abuse Negl. 1999, 23: 579-592. 10.1016/S0145-2134(99)00026-5.
Kenny MC, McEachern AG: Racial, ethnic, and cultural factors of childhood sexual abuse: a selected review of the literature. Clin Psychol Rev. 2000, 20: 905-922. 10.1016/S0272-7358(99)00022-7.
Ko Ling C, Yan E, Brownridge DA, Tiwari A, Fong DY: Childhood sexual abuse associated with dating partner violence and suicidal ideation in a representative household sample in Hong Kong. J Interpers Violence. 2011, 26: 1763-1784. 10.1177/0886260510372943.
Martin A, Najman JM, Williams GM, Bor W, Gorton E, Alati R: Longitudinal analysis of maternal risk factors for childhood sexual abuse: early attitudes and behaviours, socioeconomic status, and mental health. Aust N Z J Psychiatry. 2011, 45: 629-637. 10.3109/00048674.2011.587395.
Mennen FE: Evaluation of risk factors in childhood sexual abuse. J Am Acad Child Adolesc Psychiatry. 1993, 32: 934-939. 10.1097/00004583-199309000-00007.
O’Leary PJ, Barber J: Gender differences in silencing following childhood sexual abuse. J Child Sex Abus. 2008, 17: 133-143. 10.1080/10538710801916416.
Pineda-Lucatero AG, Trujillo-Hernandez B, Millan-Guerrero RO, Vasquez C: Prevalence of childhood sexual abuse among Mexican adolescents. Child Care Health Dev. 2009, 35: 184-189. 10.1111/j.1365-2214.2008.00888.x.
Pinchevsky GM, Wright EM: The Impact of Neighborhoods on Intimate Partner Violence and Victimization. Trauma Violence Abuse. 2012, 13: 112-132.
Shaw CR, McKay HD: Juvenile Delinquency in Urban Areas. 1942, Chicago: University of Chicago Press
Benefo KD: Determinants of Zambian men’s extra-marital sex: a multi-level analysis. Arch Sex Behav. 2008, 37: 517-529. 10.1007/s10508-007-9243-7.
Bishai D, Patil P, Pariyo G, Hill K: The Babel effect: community linguistic diversity and extramarital sex in Uganda. AIDS Behav. 2006, 10: 369-376. 10.1007/s10461-006-9097-3.
Browning CR, Olinger-Wilbon M: Neighborhood structure, social organization and the number of short-term sexual partnerships. J Marriage Fam. 2003, 65: 730-745. 10.1111/j.1741-3737.2003.00730.x.
Browning CR: The span of collective efficacy: extending social disorganisation theory to partner violence. J Marriage Fam. 2002, 64: 833-850. 10.1111/j.1741-3737.2002.00833.x.
Putnam RD: E Pluribus Unum: Diversity and community in the twenty-first century: the 2006 Johan Skytte Prize lecture. Scand Polit Stud. 2007, 30: 137-174. 10.1111/j.1467-9477.2007.00176.x.
Billy JOG, Moore DE: A Multilevel Analysis of Marital and Nonmarital Fertility in the U.S. Soc Forces. 1992, 70: 977-1011.
MEASURE DHS: DHS Survey Organization manual. 2012,http://www.measuredhs.com/pubs/pdf/DHSM10/DHS6_Survey_Org_Manual_7Dec2012_DHSM10.pdf,
Macro O, Calverto M: Demographic and Health Survey Interviewer’s Manual. 2006, U.S.A: ORC Macro
Deon F, Pritchett LH: Estimating Wealth Effects without Expenditure Data-or Tears: An Application to Educational Enrollments in States of India. Demography. 2001, 38: 115-132.
Montgomery MR, Gragnolati M, Burke KA, Paredes E: Measuring Living Standards with Proxy Variables. Demography. 2000, 37: 155-174. 10.2307/2648118.
Vyas S, Kumaranayake L: Constructing socio-economic status indices: how to use principal components analysis. Health Pol Plann. 2006, 21: 459-468. 10.1093/heapol/czl029.
Rustein SO, Kiersten J: The DHS wealth index. 2004, Calverton, Maryland: ORC Macro, DHS comparative reports No. 6
Sampson RJ: Neighborhood and Crime: The Structural Determinants of Personal Victimization. J Res Crime Delinquen. 1985, 22: 7-40. 10.1177/0022427885022001002.
WARNER BD, PIERCE GL: Reexamining social disorganization theory using calls to the police as a measure of crime. Criminology. 1993, 31: 493-517. 10.1111/j.1745-9125.1993.tb01139.x.
Snijders T, Bosker R: Multilevel analysis- an introduction to basic and advanced multilevel modelling. 1999, London: SAGE publications, 2
Tu YK, Clerehugh V, Gilthorpe MS: Collinearity in linear regression is a serious problem in oral health research. Eur J Oral Sci. 2004, 112: 389-397. 10.1111/j.1600-0722.2004.00160.x.
Tu YK, Kellett M, Clerehugh V, Gilthorpe MS: Problems of Correlations between Explanatory Variables in Multiple Regression Analyses in the Dental Literature. Br Dent J. 2005, 199 (7): 457-461. 10.1038/sj.bdj.4812743.
Hocking RR: Methods and Applications of Linear Models. 1996, New York: Wiley
Rasbash J, Steele F, Browne W, Prosser B: A user’s guide to MLwin. [Version 2.10]. 2008, London: Center of Multilevel Modelling, Institute of Education, University of London
Goldstein H: Multilevel statistical models. 2003, London: Hodder Arnold, 3
Fergusson DM, Horwood LJ, Lynskey MT: Childhood sexual abuse, adolescent sexual behaviors and sexual revictimization. Child Abuse Negl. 1997, 21: 789-803. 10.1016/S0145-2134(97)00039-2.
Fomby P, Cherlin AJ: Family Instability and Child Well-Being. Am Sociol Rev. 2007, 72: 181-204. 10.1177/000312240707200203.
Li N, Ahmed S, Zabin LS: Association between childhood sexual abuse and adverse psychological outcomes among youth in Taipei. J Adolesc Health. 2012, 50: S45-S51.
Turner HA, Finkelhor D, Ormrod R, Hamby S, Leeb RT, Mercy JA: Family context, victimization, and child trauma symptoms: variations in safe, stable, and nurturing relationships during early and middle childhood. Am J Orthopsychiatry. 2012, 82: 209-219. 10.1111/j.1939-0025.2012.01147.x.
Merlo J, Chaix B, Yang M, Lynch J, Rastam L: A brief conceptual tutorial of multilevel analysis in social epidemiology: linking the statistical concept of clustering to the idea of contextual phenomenon. J Epidemiol Community Health. 2005, 59: 443-449. 10.1136/jech.2004.023473.
Pre-publication history
The pre-publication history for this paper can be accessed here:http://www.biomedcentral.com/1472-698X/13/33/prepub
Acknowledgements
The data used in this study were obtained from MEASURE DHS Archive and they were originally collected by the ICF Macro, Calverton USA. We will like to thank ICF Macro for allowing us to make use of the data.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ contributions
IY and GM were involved in the conception of the study. IY and OU set up the statistical analysis under the supervision of GM and JS. IY was involved in the drafting of the manuscripts with contributions from all the authors. All authors revised for content and style, and all have read and approved the final manuscript.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
This article is published under license to BioMed Central Ltd. This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Yahaya, I., Uthman, O.A., Soares, J. et al. Social disorganization and history of child sexual abuse against girls in sub-Saharan Africa: a multilevel analysis. BMC Int Health Hum Rights 13, 33 (2013). https://doi.org/10.1186/1472-698X-13-33
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1472-698X-13-33