
Abstract
Background
Cyclic nucleotide-gated channels (CNGCs) are Ca2+-permeable cation transport channels, which are present in both animal and plant systems. They have been implicated in the uptake of both essential and toxic cations, Ca2+ signaling, pathogen defense, and thermotolerance in plants. To date there has not been a genome-wide overview of the CNGC gene family in any economically important crop, including rice (Oryza sativa L.). There is an urgent need for a thorough genome-wide analysis and experimental verification of this gene family in rice.
Results
In this study, a total of 16 full length rice CNGC genes distributed on chromosomes 1–6, 9 and 12, were identified by employing comprehensive bioinformatics analyses. Based on phylogeny, the family of OsCNGCs was classified into four major groups (I-IV) and two sub-groups (IV-A and IV- B). Likewise, the CNGCs from all plant lineages clustered into four groups (I-IV), where group II was conserved in all land plants. Gene duplication analysis revealed that both chromosomal segmentation (OsCNGC1 and 2, 10 and 11, 15 and 16) and tandem duplications (OsCNGC1 and 2) significantly contributed to the expansion of this gene family. Motif composition and protein sequence analysis revealed that the CNGC specific domain “cyclic nucleotide-binding domain (CNBD)” comprises a “phosphate binding cassette” (PBC) and a “hinge” region that is highly conserved among the OsCNGCs. In addition, OsCNGC proteins also contain various other functional motifs and post-translational modification sites. We successively built a stringent motif: (LI-X(2)-[GS]-X-[FV]-X-G-[1]-ELL-X-W-X(12,22)-SA-X(2)-T-X(7)-[EQ]-AF-X-L) that recognizes the rice CNGCs specifically. Prediction of cis-acting regulatory elements in 5′ upstream sequences and expression analyses through quantitative qPCR demonstrated that OsCNGC genes were highly responsive to multiple stimuli including hormonal (abscisic acid, indoleacetic acid, kinetin and ethylene), biotic (Pseudomonas fuscovaginae and Xanthomonas oryzae pv. oryzae) and abiotic (cold) stress.
Conclusions
There are 16 CNGC genes in rice, which were probably expanded through chromosomal segmentation and tandem duplications and comprise a PBC and a “hinge” region in the CNBD domain, featured by a stringent motif. The various cis-acting regulatory elements in the upstream sequences may be responsible for responding to multiple stimuli, including hormonal, biotic and abiotic stresses.
Similar content being viewed by others


Background
Calcium signal transduction through calcium channels is a fundamental mechanism used by plants to sense and respond to endogenous and environmental stimuli [1], including hormone responses [1], plant–pathogen interaction [2], development [3], symbiosis [4], salt stress [5], light signaling [6], and circadian rhythm [7]. One of the potential pathways for the uptake of Ca2+ ions in signal transduction is via cyclic nucleotide-gated ion channels (CNGCs) [8]. CNGCs, functionally defined as ligand-gated protein channels, are nonselective cation channels, gated by the direct binding of cyclic nucleotides, and are present in both animals and plants system [9–12]. In animals, their biological roles and regulation have been well studied, however, plant CNGCs have only been investigated much more recently, and corresponding regulatory mechanisms are just starting to be discovered [13, 14]. Studies have revealed that CNGCs may function as a pathway for Ca2+ conduction into the cytosol as an early event during pathogen defense signaling cascades [15], and plant response to other biotic and abiotic stresses [16].
Plant CNGC ion channels were first identified in a screen for calmodulin (CaM) binding partners in barley [17]. A large family of CNGCs composed of 20 members have been identified in Arabidopsis genome [8] which are classified into four groups (groups I–IV) and two sub-groups “IV-A and IV-B” [18]. These CNGCs are characterized by general structural resemblance to animal CNGCs [8], having a predicted structure of six transmembrane domains (S1–S6) with a pore domain (P loop) between S5 and S6, C-terminal Cyclic nucleotide-binding domain (CNBD) and CaM-binding domains (CaMBD) [8, 13, 19, 20]. In the presence of Ca2+, CaM binds to the CNGC at the αC helix of the CNBD and thus blocks channel gating by cNMPs [21]. CNBD being most conserved region of the CNGC with a phosphate binding cassette (PBC) and a “hinge” region (adjacent to PBC). Where, the PBC binds to the sugar and phosphate moieties of the cyclic nucleotide (cNMP/ Cyclic nucleotide-monophosphate) ligand [22], and the hinge region contributes to ligand binding efficacy and selectivity [23]. In Arabidopsis, CNGC genes are differentially expressed in all tissues and their functions critically depend on the presence of cAMP and/or cGMP that function as signaling molecules [24–26]. Physiological processes in which these signaling molecules are believed to be involved include various developmental processes, photo-morphogenesis and tolerance to salt stress [27, 28], gibberellic acid-induced signaling in barley [29] and phytochrome signaling [30].
Approximately 5% of the Oryza sativa genome appears to encode membrane transport proteins. Many of these proteins are classified and several hundred putative transporters have not yet been assigned to families, including the CNGC gene family [18, 26]. The early investigations on rice genome, revealed a clue about the existence of putative CNGC fragments, as suggested by Bridges et al. [31] and Ramanjaneyulu et al. [29]. However, no comprehensive study has yet been undertaken, which can lead to the proper identification, characterization and functional verification of the CNGC family in rice.
Taking privilege from the accessibility of recent release of entire genome sequences of rice and information available from A. thaliana, we performed a genome-wide identification of CNGC family in rice in the present study. We found that the rice genome contains 16 CNGC full length genes which are classified into four major classes and two sub-groups as in Arabidopsis. Evolutionary history reconstruction via comparison with CNGCs from other plant species was accomplished. Furthermore, comprehensive analyses were performed to characterize these genes and protein sequence features e.g., domain, motif, phylogenetic relationships, gene structure, multiple alignment, cis-acting regulatory elements etc. To verify their functions, we analyzed the expression pattern of rice CNGC genes by quantitative PCR (qPCR) in response to various hormonal, biotic and abiotic stresses. The present work represents the first comprehensive study of CNGC genes in rice and offers a solid base for further functional investigation of this important gene family in rice.
Results and discussion
Identification of CNGC genes in rice genome
To obtain a complete overview of CNGC gene family in rice, we conducted a genome-wide analysis by using various bioinformatics resources. Considering the fact that the Arabidopsis CNGC gene family is fully characterized, we used the amino acid (aa) sequences of 20 Arabidopsis CNGC genes as the queries in BLAST searches and the keyword ‘cyclic nucleotide-gated ion channel’ in the putative function search tool of rice database (RAP). Seventeen non-redundant putative gene sequences were retrieved in rice with five genes (LOC_Os02g15580, LOC_Os09g38580, LOC_Os06g08850, LOC_Os02g53340 and LOC_Os06g10580) having potential alternative splice forms.
Since plant CNGCs, are characterized by the presence of CNBD, specifically phosphate binding cassettes and hinge region [8, 11, 32, 33], thus their presence in a protein sequence is a validation criteria for these genes. The sequence searches of databases based on annotation are not completely accurate and could potentially miss some bonafide CNGC sequences or inaccurately assign certain sequences as CNGCs [34]. Therefore, the deduced protein sequences of all the 17 putative genes were further analyzed to confirm the presence of CNBD/Cyclic Nucleotide-Monophosphate Binding Domain (cNMP, cNMP_bd or cNMP_bd like), Cap Family Effector Domain (CAP_ED), RmlC-like jelly roll fold (RmlC), and ion transport domains. We found that LOC_Os06g33600, previously designated as “genomic cyclic nucleotide-gated ion channel 1”, was identified as “Cyclic nucleotide-gated channel C (Fragment)”, and was eradicated from analysis due to lack of above cited domains. However, a 217 aa short fragment, LOC_Os06g33610 (latterly designated as CNGC3) contained the CNGC characteristic CNBD domain, with phosphate binding cassettes and hinge region as suggested by Zelman et al. [11], was recognized as bonafide CNGC. These identifications were purely based on the presence of primary CNBD domain, and the validation of the consensus motif derived by Zelman et al. [11]. We noticed that blast search of Arabidopsis CNGC also resulted into gene from potassium AKT /KAT channels (Shaker type) as homologs of CNGCs, due to the presence of transmembrane region, CNBD and ion transport domains and additional ankyrin repeats [35]. Such unrelated genes were rejected from analysis. Finally, 16 full length CNGC genes were confirmed to contain the specific domains in their proteins sequences, and hence were identified as CNGC genes in rice (Table 1).
OsCNGCs chromosomal localization and diversification
Chromosome localization analysis demonstrated that the OsCNGCs are located on eight rice chromosomes (1, 2, 3, 4, 5, 6, 9 and 12) (Figure 1). To better reflect the orthologous relationship between the rice and Arabidopsis CNGC genes, the nomenclature of respective rice CNGC genes was annotated according to their order in phylogenies, with Os abbreviating O. sativa (Table 1).

Genomic localization and duplication of CNGC genes in rice chromosomes. Chromosome numbers are indicated at the top of each chromosome. Genes are marked in Abbreviations i.e. C stands for CNGC; those present on duplicated segments of genome are connected by red lines and tandem duplicated genes are marked in blue.
Arabidopsis has been reported to have 20 CNGC genes (Mäser et al. 2001) [18]. Conversely, in rice that has a genome size nearly three times as that of Arabidopsis (Project IRGS 2005, Vij et al. 2006) [36, 37], the number of CNGC genes was found to be only 16. The reason for this could be the variable status of whole genome duplications in Arabidopsis and rice (Paterson et al. 2004, Yu et al. 2005) [38, 39]. In this study, both segmental and tandem duplication events were investigated for elucidating the potential mechanism of evolution of OsCNGC gene family in rice. Analysis of PGDD revealed that three genes pairs, OsCNGC1 and OsCNGC2, OsCNGC10 and OsCNGC11, as well as OsCNGC15 and OsCNGC16 located on different chromosomes regions, might have been induced by segmental duplication, and could be assigned to RGAP segmental duplication blocks (Figure 1). In addition, one gene pair, OsCNGC2 and OsCNGC3 were located at the adjacent positions on chromosome 2 and separated by 3 genes only. Hence suggested, that these two genes were generated from tandem duplication event (Figure 1). These results indicate that gene duplication not only expanded the number of genes in the rice CNGC family but also increased its functional diversity (see Gene expression analysis).
Gene structure and features of OsCNGC proteins
Comparisons between genomic DNA sequences with corresponding cDNA sequences showed that coding sequences of OsCNGC genes are interrupted by introns. Introns may interrupt the reading frame of a gene between two consecutive codons (phase 0 introns), between the first and second nucleotide of a codon (phase 1 introns), or between the second and the third nucleotide (phase 2 introns) [40]. Gene structural analysis showed that the rice CNGCs had different gene structures as compared to Arabidopsis CNGCs, with a variable number of introns and lengths. The numbers of introns in Arabidopsis CNGCs ranged from 4 to 10 introns, while rice CNGC ranged from 1 to 11 introns. Unlike the Arabidopsis CNGCs, introns of all OsCNGCs belong to phase 0 and 2 (Additional file 1; Additional file 2), while, Arabidopsis CNGC6 contained, four phase 1 introns. This suggests that all CNGCs with introns did not ascend from a retrotransposition event, and the different numbers may be caused by the insertion and loss of introns during their evolution [41].
The 16 OsCNGC proteins range in length from 217 (OsCNGC3) to 772 (OsCNGC12) amino acids (aa), with an average of 661 aa. ExPASy analysis showed that OsCNGC proteins vary greatly in isoelectric point (pI) values (ranging from 5.81 to 9.71) and molecular weights (ranging from 25.4 to 88,353 kDa). According to their instability index values, only 1 (OsCNGC8) of 16 OsCNGC proteins can be considered as stable with an instability index of < = 40 (Table 2) [42].
The subcellular localization of each OsCNGC was predicted by PSORT analysis. Our results evidenced that thirteen OsCNGCs (OsCNGC1-2, OsCNGC4-6, OsCNGC9-10, and OsCNGC12-16) are predicted to be localized in plasma membrane, while the others i.e., OsCNGC3, OsCNGC7 and OsCNGC11 to be in cytoplasm, chloroplast thylakoid membrane and mitochondrial inner membrane, respectively (Table 2). All relevant experiments in the past have indicated that plant CNGC proteins are specifically localized to the plasma membrane [11]. The presence of OsCNGC3 in cytoplasm is not clear, which needs further experimental elucidation. Arabidopsis CNGC proteins, when analyzed revealed that 11 out of 20 CNGC proteins were localized in plasma membrane, while the other 9 in chloroplast thylakoid membrane (data not shown).
Translated proteins are often subjected to post–translational modifications (PTMs) to become functionally active. PTMs are the chemical modification of a protein after its translation, and have wide effects on broadening its range of functionality [43]. CNGC channels can be controlled by variations in the phosphorylation state catalyzed by Ser/Thr kinases [44] and phosphatases [45]. When analyzed in ScanProsite, multiple putative phosphorylation sites were revealed in OsCNGC protein sequences, which may act as substrates for several kinases in the form of casein kinase II, protein kinase C, tyrosine kinase and cAMP/cGMP kinases [46]. Francis and Corbin [47] demonstrated that cAMP/cGMP-dependent protein kinases are major intracellular receptors for these nucleotides (cAMP/cGMP), and the actions of these enzymes account for much of the cellular responses to increased levels of cAMP or cGMP.
As a special class of PTMs, several proteins including CNGCs could be covalently altered by a range of lipids, such as myristate and palmitate, a phenomenon known as lipidation [47]. Protein N-myristoylation can alter the lipophilicity of the target protein and facilitate its interaction with membranes thereby affecting its subcellular localization [48–50]. Our bioinformatics analysis revealed that all OsCNGC proteins bear potential N-myristoylation/ N-glycosylation motif sites. The maximum number of N-myristoylation sites is present in OsCNGC15 and OsCNGC16 (16), while OsCNGC8 contain highest number (7) of N-glycosylation sites. In mammals, N-myristoylated proteins include protein kinases, phosphatases, guanine nucleotide-binding proteins (such as CNGCs), and Ca2+-binding proteins, many of which participate in signal transduction pathways [48, 51, 52]. Similarly, N-glycosylation, post-translational modification that occur in many eukaryotic proteins exposed to the extracellular medium (including trans-membrane proteins), is reported to play various roles, including facilitating the folding, trafficking and function of the protein as well as protecting it from an extracellular medium, which, in plants, is acidic and rich in proteases [53]. In a recent study, Meighan et al. [54] demonstrated that extracellular Ca2+ and Zn2+-dependent proteases (known as matrix metalloproteinase, MMP) increase the ligand sensitivity of rod and cone CNG channels, and prolonged exposure of CNG channels to MMP even caused the channels to become nonconductive due to MMP-dependent proteolysis. They have further indicated that presence of glycosylation sites may defend CNG channels from MMP-dependent proteolysis, and prevent the CNGC channels to become nonconductive [54]. Therefore the PTMs and other sequence-specific features such as N-myristoylation and N-glycosylation in rice CNGCs are likely to be necessary for their proper functioning, localization and regulation (Table 2).
Motif composition analysis
A functional motif-based recognition of CNGC proteins can contribute to understanding the evolutionary history of this gene family including possible role of genome and gene duplication events [55]. Motif search by the MEME/MAST identified 19 conserved motifs in rice CNGC proteins (Figure 2). Among these, five motifs (1, 3, 4, 8 and 19) were identified in rice, and found to be associated with functionally defined domains (Figure 2; Additional files 3 and 4). All the OsCNGC proteins share a conserved binding domain for cyclic nucleotides (CNBD) in the central region, referred to as motif 1. Plant CNGCs are believed to be activated by direct and reversible binding of nucleotides cGMP and cAMP to the CNBD, which allosterically causes the channel to open [19]. In the presence of calcium, CaM binds to the CaMBD and prevents the binding of cyclic nucleotides to the CNBD, and thereby stops the activation of CNGCs by cyclic nucleotides [19, 56]. This competitive regulation by cyclic nucleotides and CaMs was predicted [21] and experimentally verified for AtCNGC2 [19]. The CaM-binding site was recently mapped to an isoleucine glutamine (IQ) motif by Fischer et al. [57]. Our results also identified IQ as a functional motif (motif 3) within CaMBD, downstream of the CNBD (Figure 2; Additional file 3). IQ motifs have been investigated in detail in animal proteins, which often bind CaM in a Ca2+-dependent manner, while Ca2+ induces the displacement of the CaM ligand [58]. Fischer et al. [57] showed that IQ motif is conserved among plant CNGCs, this motif enhances the variability of Ca2+-dependent channel control mechanisms featuring the functional diversity within this multigene family. However, in rice, IQ motifs were present in less than 50% of the members of OsCNGC family, mainly in the members of group 2, 3 and 4 (OsCNGC4-6, OsCNGC9-10, and OsCNGC12-14, respectively) (Figure 2), suggesting that other regulators may alter the channel opening and for gating control of plant CNGCs which lack these motifs [57]. Other functional motifs denoted as motif 4, and 8, associated with prenyltransferase and squalene oxidase repeat, and ion transport, respectively, was found to be conserved in all OsCNGC proteins except OsCNGC3. The functions of other motifs identified in OsCNGC proteins 2, 5–7, 9–18, and 20 have not been reported in any plant or animal so far. Moreover, the sequence logo of three potential motifs, CNBD, IQ and ion transport one can determine not only the consensus sequence but also the relative frequency of bases and the information content (measured in bits) at every position in a site or sequence. The logo displays both significant residues and subtle sequence patterns (Additional file 3).

Distribution of Conserved motifs in rice CNGC proteins identified using MEME search tool. Schematic representation of motifs composition in OsCNGC protein sequences using MEME motif search tool for each groups given separately. Each motif is represented by a number in colored box. Length of box does not correspond to length of motif. Order of the motifs corresponds to position of motifs in individual protein sequence.
We also performed MEME analysis on 20 Arabidopsis CNGC proteins for comparison. The diagram of AtCNGC motifs, their details and the sequence logo of functional motifs is given in Additional files 4, 5, and 6. The numbers of motifs are designated similarly in both rice and Arabidopsis CNGC proteins, each corresponding to the position/location of the respective motif. In Arabidopsis, only three motifs (motif 1.1, 1.2 and 3) were identified representing the CNBD domain, and IQ motif, where CNBD domain was represented by two motifs (motif 1.1 and 1.2) interrupted by 4 non-functional motifs. Interestingly, motifs associated with ion transport, zinc finger, prenyltransferase and squalene oxidase repeat were absent in Arabidopsis (Additional files 5 and 6). Though, individual scan of AtCNGC proteins revealed the presence of ion transport domain in some members (data not shown).
As mentioned earlier, an essential structural feature of plant CNGCs is their CNBD, a direct binding site for cAMP/cGMP to modify the channel opening [59]. The most conserved feature of CNBD domain is the PBC that makes direct contact with cAMP [60], and the hinge region, essential for the capping of cAMP by the C-helix of the CNBD [61]. No plant CNGC-specific motifs had been reported until Zelman et al. [21] aligned the PBC and hinge regions for 20 AtCNGC proteins, from which the following consensus motif was derived: ([21]-X(2)-[GS]-X-[FYIVS]-X-G-X(0,1)-[DE]-LL-X(8,25)-[1]-X(9)-[VLIT]-E-X-F-[62]). Similarly we aligned the CNBD region of rice CNGCs (Individually and with Arabidopsis CNGCs) and identified a putative PBC and a hinge (Figure 3; Additional file 7). We identified a conserved (100%) glycine (G), acidic residue glutamate (E) followed by two aliphatic leucines (L) and aromatic tryptophan (W) inside the PBCs (Figure 3). We also detected that the putative hinge also comprises a conserved (100%) aromatic phenylalanine (F), aliphatic alanine (A) and leucines (L) (Figure 3). A neutral residue, threonine (T) was also found to be conserved (100%) near the hinge region. We successively built a stringent motif: (LI-X(2)-[GS]-X-[FV]-X-G-[DE]-ELL-X-W-X(12,22)-SA-X(2)-T-X(7)-[EQ]-AF-X-L) that recognizes the 16 rice CNGCs specifically. The rice PBC and hinge regions differed from the conserved residues of Arabidopsis. For example, residues E, W and T within PBCs, and residues A and L in hinges were found be conserved at 100% in rice CNGCs only. The diversity of motif patterns between the rice and Arabidopsis indicate the functional divergence across the species and individual groups.

The rice CNGC-specific motif spans the putative PBC and the hinge within the CNBD of the 16 OsCNGCs. The diagram at the top represents three regions of plant CNGCs: the six transmembrane domains (TM), a CNBD containing a PBC and the hinge, and CaMBD. The rice CNGC-specific amino acid motif is shown below the cartoon. In the square brackets “[]” are the amino acids allowed in this position of the motif, “X” represents any amino acid and the round brackets “()” indicate the number of amino acids. Below is the alignment of CNBD domains of 16 rice CNGCs. Residues in white highlighted in blue indicate 100% identity among the 16 rice CNGCs.
Phylogenetic analysis
Phylogenetic relationship between rice and ArabidopsisCNGC family genes
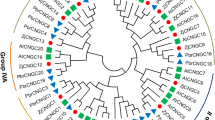
To determine the phylogenic relationship of CNGC family between rice and Arabidopsis, a maximum likelihood (ML) phylogenetic tree was constructed using full-length amino acid sequences. Four groups, as described by Mäser et al. [18] were identified containing representative gene of both rice and Arabidopsis. All the Arabidopsis CNGC proteins were found to lie in groups similar to those identified previously [18]. Of the four groups, three groups (Group I, II and III) are monophyletic, while one group (IV) is sub-divided into two distinct clades, named group IV-A and IV-B (Figure 4). Group I comprises three members from rice CNGCs (OsCNGC1 to OsCNGC3) and six from Arabidopsis (AtCNGC1, 3, 10, 11, 12 and 13). Similarly, Group II contains three rice CNGCs (OsCNGC4 to OsCNGC6) and five AtCNGCs (AtCNGC5 to AtCNGC9). However, Group III embraces five in rice (OsCNGC7 to OsCNGC11) and five in Arabidopsis (AtCNGC14 to AtCNGC18), thus form the largest group, with 10 members. Two CNGCs from each rice (OsCNGC12 and OsCNGC13) and Arabidopsis (AtCNGC19 and AtCNGC20) were assigned to group IV-A, while, three rice CNGCs (OsCNGC14 to OsCNGC16) and two Arabidopsis CNGCs (AtCNGC2 and AtCNGC4) segregated into group IV-B (Figure 4). A separate phylogenetic tree was also generated from conserved CNBD domains sequences of all the CNGC proteins in rice and Arabidopsis, which resulted into similar clustering pattern.

Phylogenetic tree of OsCNGC and AtCNGC proteins. The multiple alignment was performed by ClustalX program. MEGA 6.0 was used to create the maximum likelihood (ML) under the Jones-Taylor-Thornton (JTT) model. The bootstrap values from 1000 resampling are given at each node. The rice CNGC genes identified in this study are shown in red circles and Arabidopsis CNGCs are shown in blue squares. Rice CNGC genes were designated according to their order in phylogeny.
During the evolution of a gene family, gene duplication plays important roles in generating new members and creating novel gene functions, hence increasing numbers and diversifying functions of genes within a gene family [63, 64]. The phylogenetic analysis between rice and Arabidopsis following previously described model [64, 65] demonstrates the evolutionary trend of gene duplication in both taxa.
Phylogenetic data provide a framework for making more appropriate intergenomic comparisons, by determining whether chromosomal duplications within taxa pre-date or post-date divergence among taxa [65]. The current analysis shows that divergence of two taxa may have pre-dated the gene duplication events among them resulting in gene expansion within individual group [63] (Additional file 8). This is further strengthened by our detailed phylogenetic analysis among all plant lineages given ahead. The detailed phylogeny also points towards the duplication of CNGC genes occurring after speciation and after divergence of angiosperms into mono and dicots. Interestingly AtCNGC2 and OsCNGC14; AtCNGC15 and OsCNGC7 are not in congruence with the pattern of other sister groups. The existing anomaly between these taxa could not be reasoned out.
Phylogenetic analysis of the CNGCgenes in all plant lineages
For a better understanding of the evolutionary history of the CNGC gene family, we comprehensively analyzed the phylogeny and evolution of the CNGC gene family in all plant lineages. We used the amino acid sequences of rice and Arabidopsis CNGCs to query the OrthologDB, Gramene, TAIR, ConGenIE, NCBI, Phytozome and RGAP databases of plant species (see Materials and Methods). In order to obtain only specific CNGC sequences, we removed the hits with exact duplicates (same identifiers, same sequence and different identifiers, same sequence), annotated fragments, as well as any unrelated gene like AKT or KAT family channels from subsequent analyses (Additional file 9). We identified 235 CNGC-like sequences from 32 different species including green algae (8), bryophytes (4), lycophytes (4), gymnosperms (3), monocots (58) and dicots (158) [66, 67], whose protein sequences harbored typical domains and motifs of CNGC proteins, i.e. CNBD (essential), ion transport (optional) and IQ (optional). The copy number of CNGC gene family ranged from 1 to 28 amongst the species, where, Glycine max had the largest CNGC gene family containing 28 genes (Additional file 9). However, it should be indicated that the single CNGC in wild banana (Musa acuminata) may not reflect the true number of CNGC genes in this species; rather it is due to the limited availability of its genomic information.
A maximum likelihood tree was generated using amino acid sequences of the deduced full-length peptides with JTT (Jones, Taylor and Thornton) model. We used SYG1 from Saccharomyces cerevisiae as out-group [68]. According to the tree’s topology, CNGC gene family of all plant lineages clustered into four distinct groups (I-IV) with significant bootstrap values (Figure 5). Group II and group IV are subdivided into II-A/II-B and IV-A/IV-B. All the CNGCs from algae formed the basal lineage and clustered into same group (group VI-B), whereas those from the land plants grouped into several other groups (I–IV), showing that the CNGC family originated earlier than the separation of green algae and the ancestor of land plants. Among these four groups, only Group II was conserved in all land plants, showing that all CNGC genes from land plants shared a mutual ancestor after the divergence from aquatic plants. Group II-B was solely present in lower land plants including mosses (bryophytes) and lycophytes. Similarly, CNGCs from group I expanded in both mono- and dicotyledonous angiosperms, while group II-A and III was prevalent in all embryophytes (angiosperms and gymnosperms) (Figure 5). Group IV-A contain CNGCs from vascular plants i.e., embryophytes and lyophytes. These analyses revealed that all CNGC genes from land plants originated from a common ancestor, earlier than the split between lower and higher land plants [69], while the lineage specific expansion and divergence happened in higher land plants, particularly in dicots, after diversification from lower land plants, which lead to generation of group II-B in basal land plant and group I-IV in higher land plants. Moreover, CNGC genes from similar lineage, such as mosses, lycophytes, gymnosperms and angiosperms, inclined to be clustered together. Our interpretations are corroborated by the findings of previous studies [66, 68, 70, 71].

The maximum-likelihood (ML) phylogenetic tree of CNGC family genes in 235 representative plant species. The rooted maximum-likelihood (ML) phylogenetic tree was inferred from the amino acid sequences alignment of full length proteins using MEGA 6.0, under the Jones-Taylor-Thornton (JTT) model. The bootstrap values from 1000 resampling, and cut-off values >70% are given at each node. The node color specifies group i.e. pink = I, light green = II-A, aqua = II-B, red = III, blue = IV-A, and black = IV-B. Rice CNGC genes are shown in blue color. Plant lineages are shown by shapes with different colors, i.e. green circle = dicots, maroon diamond = monocots, green diamond = gymnosperms, Aqua blue square = lycophytes, pink square = moss, and black triangles = green algae.
In silicoprediction of potential cis-acting regulatory elements
The cis-acting regulatory elements are important molecular switches involved in the transcriptional regulation of genes during biotic and abiotic stress responses, and may be induced through independent signal transduction pathways [72]. The 5′ upstream noncoding sequences are not well conserved among the OsCNGC genes (data not shown), signifying that these genes may be differentially expressed in response to various stimuli, even if they encode identical proteins [34]. To obtain a preliminary clue about the regulatory function and the molecular mechanism of OsCNGC genes in transcriptional regulation, potential cis-acting regulatory elements in upstream (1000 bp) sequences of the CNGC genes were analyzed. Results exhibited that OsCNGC gene promoter sequences contain numerous cis-acting regulatory elements regulatory sites for hormones, different biotic and abiotic factors (Table 3; Additional file 10). Twenty different cis-acting regulatory elements are regulated by ABA; among them, MYB recognition site (MYB1AT) related to the drought- and ABA-induced gene expression [73], is conserved among 13 OsCNGC genes. Moreover, only 4 elements (ERELEE4, LECPLEACS2, GCCCORE and AGCBOXNPGLB) are regulated by ethylene, two elements (ARR1AT, CPBCSPOR) are regulated by cytokinin (Additional file 10). The patterns of cis-acting regulatory elements differed significantly among the OsCNGC genes. For example, the promoter of nine OsCNGCs (2, 6, 8, 9 and 11–15) contain elements that may respond to all these hormones, biotic and abiotic stress, while others lack the elements responsive to ethylene and cytokinin (Table 3). Comparatively, only three elements were found to be conserved and consistently present in the upstream region of all 16 OsCNGCs, i.e. two abiotic stress signaling related elements, consensus GT-1 binding site (GT1CONSENSUS) and MYC recognition site (MYCCONSENSUSAT), and WRKY transcription factor (WRKY71OS). The WRKY transcription factor (WRKY71OS) is reported as binding site of rice WRKY71, a transcriptional repressor of the gibberellin signaling pathway [74], and a core of TGAC-containing W-box in WRKY1, which plays an important role in the regulation of early defense-response genes in rice. The presence of most these cis-acting regulatory elements in OsCNGC gene promoters depicts their importance in regulation of this gene family (Table 3).
Expression analysis of OsCNGCs
Plant CNGC genes have been implicated in diverse aspects of plant growth and development, including responses to hormonal, abiotic and biotic stress [75]. In past, many plant mutants of CNGCs, and transgenic plants expressing full-length or mutant CNGCs, were characterized to explore their role in plants [16]. These researches mainly focused on Arabidopsis CNGCs and found that CNGC mutants exhibit various phenotypes and multi-functional behaviors. Briefly, AtCNGC1 are probably involved in Ca2+ uptake into plants [76], AtCNGC2, 4, 11 and 12 in plant defense and disease resistance pathway [77], AtCNGC3 in homeostasis [24, 78], and AtCNGC2, 4, 7, 8, 10, 16, and 18 in plant development [79–81]. To obtain information about potential differential gene functions in rice, we employed bioinformatics and experimental approaches to assess the role of OsCNGCs in plant development, and expression patterns in response to various stress.
Expression of OsCNGCsin development
The expression profile of rice leaves obtained from public database RiceXPro exhibited that most of OsCNGC genes showed their maximum expression in late vegetative and early reproductive stage (from day 41 to day 62) during life cycle of rice in field conditions, while, OsCNGC5 had its highest expression level at early vegetative stage. Overall, highest expression was observed for OsCNGC14 at 118th day during late reproductive stage, while lowest expression was noted for OsCNGC8 at 20th day of rice growth in field conditions (Additional file 11).
Expression of OsCNGCs in rice seedlings
By using quantitative real-time PCR (qPCR) analysis, the expression level of OsCNGC genes was investigated in leaves of the rice cultivar Nipponbare (O. sativa L. ssp. japonica). The results indicated there were tremendous variations among the OsCNGC genes (Figure 6). OsCNGC8 and 13 were highly expressed and had transcripts abundances of 441 and 518 times that of OsCNGC5, while OsCNGC11 had the lowest transcripts abundances (Figure 6).

Expression profiles of OsCNGC genes in 4 weeks old rice leaves. The expression patterns of OsCNGC genes under hormonal (ABA, ETH, IAA, and KN), biotic (Xoo and P. fuscovaginae) and abiotic (cold) stresses are depicted in figure. Gene expression was perforemd by qPCR, 4 h after each treatment and non-treated CK. The Y-axis indicates the relative experssion levels (in folds) of treated versus untreated (control) for each gene and X axis shows OsCNGC genes. The error bars were calculated based on three biological repliactes using standard deviation. *significant difference at p < 0.05, **means very significant difference p < 0.01.
Response to hormonal stresses
To examine the expression pattern of OsCNGCs in response to different plant hormones, qPCR analysis were performed using the total RNA extracted from leaves of the rice cultivar Nipponbare (O. sativa L. ssp. japonica), subjected to ABA (abscisic acid), ETH (ethylene), IAA (indole acetic acid) and KN (kinetin). Primers used for RT-PCR analysis are listed in Table 4.
The expression of several CNGC genes in rice is regulated by plant hormones. In general, more genes were up-regulated by ABA (12) and IAA (11) as compared to KN (2) and ETH (6). In sharp contrast, twelve and 6 genes were significantly down-regulated by KN and ETH, respectively, while none and 3 genes were down-regulated by ABA and IAA, respectively (Figure 6). The CNGC genes belonging to different phylogenetic groups showed different expression levels from each other, depending on the treatment type, while the genes in the same group showed a similar expression pattern. For example, the expression of OsCNGC7 and OsCNGC10 (belonging to same phylogenetic group III) was simultaneously up-regulated by all but ETH treatments (Figure 6). It has been proposed that the proteins classified in the same classes may have similar functions [82, 83]. Similar conclusion has been drawn by Ma et al. [84], while studying the expression of the C3HC4-type RING finger gene family in rice.
Response to biotic and abiotic stress
To determine OsCNGCs role in disease resistance, we quantified gene expression levels in 4 weeks old rice seedlings, inoculated with two phytopathogens, Xanthomonas oryzae pv. oryzae (Xoo) and Pseudomonas fuscovaginae, that cause a serious blight and bacterial sheath brown rot of rice, respectively. The expression of the OsCNGC family genes at 4 hpi (hour post-inoculation) are shown in Figure 6. The data depicted that large number of OsCNGC genes were significantly up-regulated after infection with each pathogen within 4 h. Fourteen OsCNGCs were significantly up-regulated by P. fuscovaginae inoculation with OsCNGC13 being at the highest relative level of expression. The expression of OsCNGC5 and 6 were not affected (Figure 6). Similarly 11 OsCNGCs were up-regulated by Xoo, where the expression of OsCNGC6 and 10 increased by 12.5 and 15.3-folds respectively. Previous genetic approaches have identified three CNGCs in Arabidopsis (AtCNGC2 and 4) exhibited alterations in defense responses and reported to be involved in plant immunity [14]. These two mutants are reported to have successfully managed the lower growth rates of P. syringae, accomplished by sustaining high levels of salicylic acid, leading to constitutive expression of pathogenesis-related (PR) genes, and other defense responses [85]. It is noteworthy to mention that AtCNGC2 & 4 are the closest homologue of the members of rice CNGCs from group IV, which showed highest expression levels in response to P. fuscovaginae, suggesting that these OsCNGC genes are early responsive and sensitive to biotic stress, and their regulation plays an important role in plant defense.
Similarly, the expression levels of the OsCNGC family genes under cold stress condition were also investigated. The results indicated that 10 OsCNGCs were up-regulated under cold stress. It was noted that the expression of OsCNGCs belonging to phylogenetic group I, II and III were significantly induced by cold stress, with fold range of 5–102 for group I (OsCNGC1-3), 3–192 for group II (OsCNGC5 and 6), and 4–39 folds for group III (OsCNGC7-11), respectively (Figure 6). On other hand, OsCNGCs from group IV (OsCNGC14-16) showed relatively lower expression under cold stress. Overall, OsCNGC6 gene showed the highest expression level (192-folds increase) in response to cold stress, while OsCNGC16 showed the lowest level expression (−2-fold decrease) (Figure 6).
Interestingly, six of 16 gene pairs located on duplicated chromosomal segments showed differential expression patterns, suggesting that most duplicated gene pairs were under the diverse transcriptional controls. For example, OsCNGC1 and OsCNGC2 localized on duplicated segments exhibit similar expression patterns in response to both pathogenic and abiotic stresses (ABA & IAA), indicating their overlapping functions. This finding was similar to previous results showing that the expression of duplicated genes frequently diverges compared to that of their ancestors, suggesting that duplication was a major reason for the enrichment of the functions of this family during the long course of evolution [63, 86, 87]. It is proposed that a change in a duplicated locus of two genes might not exhibit the same morphological and/or physiological phenotypes. However, when gene duplication occurs, some genes may retain their original functions and expression patterns [22]. No close correlation was observed between cis-acting regulatory elements in upstream sequences of rice CNGC genes and their qPCR expression levels. It is probable that the differential response of genes to different stimuli is due to different upstream sequences and introns. These results suggest that many of the OsCNGC genes play discrete roles in development, response to stress and plant defense related functions in rice. However, further studies based on gene knockout techniques are required to properly identify and explore their functions.
Conclusions
There are 16 CNGC genes in rice, which are classified into 4 groups (I-IV) and two sub-groups (IV-A and IV- B); this gene family appears to have expanded through both chromosomal segmentation and tandem duplications. The CNGCs from all plant lineages are also clustered into four groups, with group II being conserved in all land plants. All the OsCNGC protein sequences contain a CNGC specific domain CNBD that comprises a PBC and a “hinge” region, featured by a stringent motif: (LI-X(2)-[GS]-X-[FV]-X-G-[DE]-ELL-X-W-X(12,22)-SA-X(2)-T-X(7)-[EQ]-AF-X-L). Various cis-acting regulatory elements were identified in the upstream sequences present on both positive and negative strands. In addition, the genes transcripts significantly respond to multiple stimuli, as demonstrated by their expression patterns to exogenous hormonal (abscisic acid, indoleacetic acid, kinetin and ethylene), biotic (P. fuscovaginae and Xoo) and abiotic (cold) stresses.
Methods
Bioinformatics analysis
Identification of CNGC genes in rice
To identify members of CNGC gene family, multiple database searches were performed. The Arabidopsis CNGC (AtCNGCs) gene sequences obtained from the TAIR database [88] were used as queries to perform repetitive blast searches against MSU Rice Genome Annotation Project database (RGAP/ RAP-DB) [89]. Additionally, all protein sequences were then used as queries to perform multiple database searches against proteome and genome files downloaded from these databases. Stand-alone versions of BLASTP and TBLASTN available from Basic Local Alignment Search Tool [90] were used with the e-value cutoff set to 1e-003. All retrieved non-redundant sequences were collected from phytozome database v9.1 [91], and subjected to domain analysis by using six different domain analysis programs: the Pfam 27.0 [92], CDD [93], SMART [94], PROSITE profiles [95], supfam [96] and Gene3D [97], with the default cut off parameters. Genes without CNGC-specific CNBD domains or having a size of below < 200 amino acids domains were rejected.
Chromosomal localization and gene duplication
Positional information on the rice CNGC genes was provided by the rice genome databases, RGAP and GRAMENE [98]. Rice TOGO Browser was used to locate each gene on a chromosome [99]. The Plant Genome Duplication Database (PGDD) was utilized to analyze the duplication of each gene with a maximum distance of 500 kb permitted between collinear genes [100].
Prediction of gene structure and cis-acting regulatory elements
The gene structure (Exon-intron distribution) analyses of the CNGC families of rice and Arabidopsis were carried out using the Gene Structure Display Server (GSDS) with default settings [101].
Promoter sequences (−1000 bps) of OsCNGC family genes were obtained from the RGAP database. The upstream 1000 bp sequence of CNGC genes were searched for a variety of cis-acting regulatory elements by ‘Signal Scan Search’ program in the PLACE database [40].
Prediction of rice CNGC protein sequence features
Protein sequences of putative OsCNGC members collected from the RGAP database were analyzed using ExPASy proteomics Server [102]. The information in number of amino acids, isoelectric points, molecular weights and instability index were obtained. The proteins having instability index of >40 were considered as unstable. The cellular localization of each CNGC protein was identified using the PSORT online program [103]. The post-translational modifications such as phosphorylation sites casein kinase II, protein kinase C, tyrosine kinase, cAMP- and cGMP-kinase, N-Myristoylation, N-Glycosylation, were predicted at ScanProsite tool [104].
Phylogenetic analysis of CNGC genes in Arabidopsisand rice
To identify the number of groups formed by rice CNGC genes in comparison to Arabidopsis, the amino acid sequences of full length of 20 CNGCs from A. thaliana and 16 CNGCs from O. sativa were aligned by using ClustalX 2.01 program [105] with default settings. The MUSCLE (Multiple Sequence Comparison by Log-Expectation) program (version 3.52) was also used to perform multiple sequence alignments to confirm the ClustalX data output [106]. A complete phylogenetic analysis between rice and Arabidopsis was also carried out. Individual protein sets were aligned using MAFFT v7.017 with the L-INS-i model [107]. The protein sequence of outgroups Amborella trichopoda and Selaginella moellendorffii was downloaded from Amborella Genome Database [108] and Phtyozome [91] respectively. The alignment was further used to construct a maximum likelihood Newick-formatted phylogenetic tree by FastTree [109] keeping the default settings.
Furthermore, we carried out phylogenetic investigation of CNGCs in all plant lineages to comprehend the evolutionary patterns followed by these genes. For this purpose, the amino acid sequences from Arabidopsis CNGCs were used as queries against GRAMENE [98], OrthologDB [110], Phytozome [92], UniProt [111], MSU-RGAP [87], TAIR [88], ConGenIE [112] and GeneBank [90] of plant. These sequences were subsequently submitted to Pfam for analysis and confirmation of CNGC-specific functional domain [92]. Afterwards, 235 typical identified CNGC proteins were subjected to multiple alignments using MUSCLE (version 3.52) as mentioned above.
Finally, phylogenetic trees were constructed based on alignments using maximum likelihood (ML) method of MEGA 6.0 (Molecular Evolutionary Genetics Analysis) with complete deletion option parameters engaged [113]. The reliability of the trees was tested using bootstrapping with 1000 replicates. Then, to build the condensed tree it was selected a cut-off value equal to 50%, where the values >70% are displayed on each clade. Images of the phylogenetic trees were also drawn using MEGA 6.0.
Motif composition analysis of OsCNGC proteins
The conserved protein motifs of all CNGC protein sequences from the rice and Arabidopsis were analyzed using the MEME 4.6.1 and MAST motif search tool [114] with the following parameters: number of different motifs as 10, minimum motif width as 6 and a maximum motif width set to 50. The functional annotation of these motifs was analyzed by Pfam program.
Moreover, the CNBD domain regions of 20 Arabidopsis and 16 rice CNGC proteins were aligned to construct rice CNGC specific motif. First, the amino acid sequences of all 36 CNGCs were subjected to Pfam database, to determine the position of CNBD regions. Alignments were performed using the default parameters of ClustalX (version 1.83) and subsequently examined and edited in GeneDoc [115]. Finally, a detailed diagram was constructed for in depth sequence analysis.
Experimental verification
Plant materials for expression analysis
Rice seeds of Nipponbare (O. sativa L. ssp. japonica) were surface-sterilized with 3% sodium hypochlorite for 30 min, germinated at 28°C for 3 days, and then grown in nutrient solution under controlled conditions of 14 h light 30°C/10 h dark 22°C and 70% relative humidity. The rice seedlings at the three-leaf stage (approx. 4 weeks old) were subjected to different stresses. For hormonal treatment, rice leaves were sprayed with six different hormones including 100 μM ABA, 10 mM ETH, 100 μM IAA, 100 μM KN and sterilized water as control. For cold stress treatment, seedlings were incubated at 4°C for 4 h.
For pathogen inoculation, the bacterial pathogen P. fuscovaginae and Xoo were incubated overnight at 28°C on LB medium plates containing rifampicin (50 μg/mL) and kanamycin (50 μg/mL), inoculated on LB broth. The bacterial cells were collected by centrifugation and then diluted into suspensions to a concentration of OD600 = 0.002 and 0.5, using 10 mM of MgCl2 buffer or sterilized ddH2O, respectively. The prepared bacterial solution was infiltrated into leaves of 4 weeks old rice plants. Sterile MgCl2 buffer or sterilized ddH2O was served as controls. A pool of leaves from ten rice seedlings were collected as one biological replicate, and each stress treatment was repeated three times. The samples were placed in liquid nitrogen immediately after sampling and stored at −80°C for total RNA isolation.
Gene expression analysis with quantitative real-time PCR
Samples were ground in liquid nitrogen using a mortar and pestle. Total RNA (4 mg) was isolated using RNAiso (Takara) and treated with RNase-free DNase I (Takara) for 15 min to eliminate possible contaminating DNA. The resulting cDNA was reverse transcribed using the PrimeScript RT regent kit (TAKARA, Japan) and used for gene expression analysis through qPCR. The qPCRs were conducted in Step One Real-Time PCR System (Applied Biosystems, USA) using SYBER Premix Ex Taq reagents (TAKARA, Japan) following the program: 95°C for 30 seconds, 95°C for 5 seconds, and 60°C for 45 seconds for 40 cycles. Relative gene expression values were calculated using the 2-△△Ct method [116], based on the data from three biological replicates for each treatment. To normalize the samples variance, 18S rRNA and Ubiquitin 5 (UBQ5) genes served as internal control, as recommended by many researchers [117–120]. The experiments were conducted three times, each containing three replicates for all genes. For the statistical analysis of the gene expression data, ANOVA (analysis of variance) analysis was performed with SAS software Version 9.2 [121]. The resultant expression profiles are plotted in the form of graphs (Figure 6; Additional file 12).
Furthermore, the CDs of all CNGC genes were subjected to Rice XPro microarray expression database [122] to obtain microarray data derived from leaves at various stages of development under natural field conditions.
References
Jammes F, Hu HC, Villiers F, Bouten R, Kwak JM: Calcium‒permeable channels in plant cells. FEBS J. 2011, 278: 4262-4276. 10.1111/j.1742-4658.2011.08369.x.
Qi Z, Verma R, Gehring C, Yamaguchi Y, Zhao Y, Ryan CA, Berkowitz GA: Ca2+ Signaling by Plant Arabidopsis Thaliana Pep Peptides Depends on AtPepR1, a Receptor With Guanylyl Cyclase Activity, and cGMP-Activated Ca2+ Channels. Proc. Natl. Acad. Sci. U.S.A. 2010, 107: 21193-21198. 10.1073/pnas.1000191107.
Frietsch S, Wang Y-F, Sladek C, Poulsen LR, Romanowsky SM, Schroeder JI, Harper JF: A Cyclic Nucleotide-Gated Channel is Essential for Polarized tip Growth of Pollen. Proc. Natl. Acad. Sci. U.S.A. 2007, 104: 14531-14536. 10.1073/pnas.0701781104.
Kosuta S, Hazledine S, Sun J, Miwa H, Morris RJ, Downie JA, Oldroyd GE: Differential and Chaotic Calcium Signatures in the Symbiosis Signaling Pathway of Legumes. Proc. Natl. Acad. Sci. U.S.A. 2008, 105: 9823-9828. 10.1073/pnas.0803499105.
Tracy FE, Gilliham M, Dodd AN, Webb AA, Tester M: NaCl‒induced changes in cytosolic free Ca2+ in Arabidopsis thaliana are heterogeneous and modified by external ionic composition. Plant Cell Environ. 2008, 31: 1063-1073. 10.1111/j.1365-3040.2008.01817.x.
Harada A, Sakai T, Okada K: Phot1 and phot2 Mediate Blue Light-Induced Transient Increases in Cytosolic Ca2+ Differently in Arabidopsis Leaves Proc. Natl. Acad. Sci. U.S.A. 2003, 100: 8583-8588. 10.1073/pnas.1336802100.
Dodd AN, Gardner MJ, Hotta CT, Hubbard KE, Dalchau N, Love J, Assie J-M, Robertson FC, Jakobsen MK, Gonçalves J: The Arabidopsis circadian clock incorporates a cADPR-based feedback loop. Science. 2007, 318: 1789-1792. 10.1126/science.1146757.
Talke IN, Blaudez D, Maathuis FJ, Sanders D: CNGCs: prime targets of plant cyclic nucleotide signalling?. Trends Plant Sci. 2003, 8: 286-293. 10.1016/S1360-1385(03)00099-2.
Becchetti A, Gamel K, Torre V: Cyclic Nucleotide–gated Channels Pore Topology Studied through the Accessibility of Reporter Cysteines. J Gen Physiol. 1999, 114: 377-392. 10.1085/jgp.114.3.377.
Kaupp UB, Seifert R: Cyclic nucleotide-gated ion channels. Physiol Rev. 2002, 82: 769-
Zelman AK, Dawe A, Gehring C, Berkowitz GA: Evolutionary and Structural Perspectives of Plant Cyclic Nucleotide-Gated Cation Channels. 2012, Plant Sci: Front, 3-
Yuen CC, Christopher DA: The group IV-A cyclic nucleotide-gated channels, CNGC19 and CNGC20, localize to the vacuole membrane in Arabidopsis thaliana. AoB Plants. 2013, 5: plt012-
Chin K, Moeder W, Yoshioka K: Biological roles of cyclic-nucleotide-gated ion channels in plants: What we know and don’t know about this 20 member ion channel family. Botany. 2009, 87: 668-677. 10.1139/B08-147.
Moeder W, Urquhart W, Ung H, Yoshioka K: The role of cyclic nucleotide-gated ion channels in plant immunity. Mol Plant. 2011, 4: 442-452. 10.1093/mp/ssr018.
Ma W, Berkowitz GA: Ca2+ conduction by plant cyclic nucleotide gated channels and associated signaling components in pathogen defense signal transduction cascades. New Phytol. 2011, 190: 566-572. 10.1111/j.1469-8137.2010.03577.x.
Kaplan B, Sherman T, Fromm H: Cyclic nucleotide-gated channels in plants. FEBS Lett. 2007, 581: 2237-2246. 10.1016/j.febslet.2007.02.017.
Schuurink RC, Shartzer SF, Fath A, Jones RL: Characterization of a Calmodulin-Binding Transporter from the Plasma Membrane of Barley Aleurone. Leaves. Proc. Natl. Acad. Sci. U.S.A. 1998, 95: 1944-1949. 10.1073/pnas.95.4.1944.
Mäser P, Thomine S, Schroeder JI, Ward JM, Hirschi K, Sze H, Talke IN, Amtmann A, Maathuis FJ, Sanders D: Phylogenetic relationships within cation transporter families of Arabidopsis. Plant Physiol. 2001, 126: 1646-1667. 10.1104/pp.126.4.1646.
Hua B-G, Mercier RW, Zielinski RE, Berkowitz GA: Functional interaction of calmodulin with a plant cyclic nucleotide gated cation channel. Plant Physiol Biochem. 2003, 41: 945-954. 10.1016/j.plaphy.2003.07.006.
Köhler C, Neuhaus G: Characterisation of calmodulin binding to cyclic nucleotide-gated ion channels from Arabidopsis thaliana. FEBS Lett. 2000, 471: 133-136. 10.1016/S0014-5793(00)01383-1.
Arazi T, Sunkar R, Kaplan B, Fromm H: A tobacco plasma membrane calmodulin‒binding transporter confers Ni2+ tolerance and Pb2+ hypersensitivity in transgenic plants. Plant J. 1999, 20: 171-182. 10.1046/j.1365-313x.1999.00588.x.
Cukkemane A, Seifert R, Kaupp UB: Cooperative and uncooperative cyclic-nucleotide-gated ion channels. Trends Biochem Sci. 2011, 36: 55-64. 10.1016/j.tibs.2010.07.004.
Young EC, Krougliak N: Distinct structural determinants of efficacy and sensitivity in the ligand-binding domain of cyclic nucleotide-gated channels. J Biol Chem. 2004, 279: 3553-3562.
Balagué C, Lin B, Alcon C, Flottes G, Malmström S, Köhler C, Neuhaus G, Pelletier G, Gaymard F, Roby D: HLM1, an essential signaling component in the hypersensitive response, is a member of the cyclic nucleotide–gated channel ion channel family. Plant Cell. 2003, 15: 365-379. 10.1105/tpc.006999.
Leng Q, Mercier RW, Hua B-G, Fromm H, Berkowitz GA: Electrophysiological analysis of cloned cyclic nucleotide-gated ion channels. Plant Physiol. 2002, 128: 400-410. 10.1104/pp.010832.
Ramanjaneyulu G, Seshapani P, Naidu B, Rayalu DJ, Raju CP, Kumari JP: Genome wide analysis and identification of genes related to cyclic nucleotide gated channels (CNGC) in Oryza sativa. Bulletin of Pure & Applied Sciences-Botany. 2010, 29: 83-91.
Maathuis FJ: cGMP modulates gene transcription and cation transport in Arabidopsis roots. Plant J. 2006, 45: 700-711. 10.1111/j.1365-313X.2005.02616.x.
Rubio F, Flores P, Navarro JM, Martınez V: Effects of Ca2+, K+ and cGMP on Na+ uptake in pepper plants. Plant Sci. 2003, 165: 1043-1049. 10.1016/S0168-9452(03)00297-8.
Penson SP, Schuurink RC, Fath A, Gubler F, Jacobsen JV, Jones RL: cGMP is required for gibberellic acid-induced gene expression in barley aleurone. Plant Cell. 1996, 8: 2325-2333. 10.1105/tpc.8.12.2325.
Bowler C, Neuhaus G, Yamagata H, Chua N-H: Cyclic GMP and calcium mediate phytochrome phototransduction. Cell. 1994, 77: 73-81. 10.1016/0092-8674(94)90236-4.
Bridges D, Fraser ME, Moorhead GB: Cyclic nucleotide binding proteins in the Arabidopsis thaliana and Oryza sativa genomes. BMC Bioinformatics. 2005, 6: 6-10.1186/1471-2105-6-6.
Ward JM, Mäser P, Schroeder JI: Plant ion channels: gene families, physiology, and functional genomics analyses. Annu Rev Physiol. 2009, 71: 59-82. 10.1146/annurev.physiol.010908.163204.
Zhorov BS, Tikhonov DB: Potassium, sodium, calcium and glutamate‒gated channels: pore architecture and ligand action. J Neurochem. 2004, 88: 782-799. 10.1111/j.1471-4159.2004.02261.x.
Zhao Y, Liu W, Xu Y-P, Cao J-Y, Braam J, Cai X-Z: Genome-wide identification and functional analyses of calmodulin genes in Solanaceous species. BMC Plant Biol. 2013, 13: 70-10.1186/1471-2229-13-70.
Su H, Golldack D, Katsuhara M, Zhao C, Bohnert HJ: Expression and stress-dependent induction of potassium channel transcripts in the common ice plant. Plant Physiol. 2001, 125: 604-614. 10.1104/pp.125.2.604.
Project IRGS: The map-based sequence of the rice genome. Nature. 2005, 436: 793-800. 10.1038/nature03895.
Vij S, Gupta V, Kumar D, Vydianathan R, Raghuvanshi S, Khurana P, Khurana JP, Tyagi AK: Decoding the rice genome. Bioessays. 2006, 28: 421-432. 10.1002/bies.20399.
Paterson A, Bowers J, Chapman B: Ancient Polyploidization Predating Divergence of the Cereals, and its Consequences for Comparative Genomics. Leaves. Proc. Natl. Acad. Sci. U.S.A. 2004, 101: 9903-9908. 10.1073/pnas.0307901101.
Yu J, Wang J, Lin W, Li S, Li H, Zhou J, Ni P, Dong W, Hu S, Zeng C: The genomes of Oryza sativa: a history of duplications. PLoS Biol. 2005, 3: e38-10.1371/journal.pbio.0030038.
PLACE: A database of plant Cis-acting regulatory DNA elements. http://www.dna.affrc.go.jp/PLACE/signalscan.html,
Sun J, Xie D-W, Zhao H-W, Zou D-T: Genome-wide identification of the class III aminotransferase gene family in rice and expression analysis under abiotic stress. Genes Genom. 2013, 35: 1-12. 10.1007/s13258-013-0064-x.
Guruprasad K, Reddy BB, Pandit MW: Correlation between stability of a protein and its dipeptide composition: a novel approach for predicting in vivo stability of a protein from its primary sequence. Protein Eng. 1990, 4: 155-161. 10.1093/protein/4.2.155.
Khoury GA, Baliban RC, Floudas CA: Proteome-wide post-translational modification statistics: frequency analysis and curation of the swiss-prot database. Sci Rep. 2011, 1: 1-5. doi:10.1038/srep00090
Müller F, Bönigk W, Sesti F, Frings S: Phosphorylation of mammalian olfactory cyclic nucleotide-gated channels increases ligand sensitivity. J Neurobiol. 1998, 18: 164-173.
Gordon SE, Brautigan DL, Zimmerman AL: Protein phosphatases modulate the apparent agonist affinity of the light-regulated ion channel in retinal rods. Neuron. 1992, 9: 739-748. 10.1016/0896-6273(92)90036-D.
Jami SK, Clark GB, Ayele BT, Roux SJ, Kirti P: Identification and characterization of annexin gene family in rice. Plant Cell Rep. 2012, 31: 813-825. 10.1007/s00299-011-1201-0.
Nadolski MJ, Linder ME: Protein lipidation. FEBS J. 2007, 274: 5202-5210. 10.1111/j.1742-4658.2007.06056.x.
Resh MD: Fatty acylation of proteins: new insights into membrane targeting of myristoylated and palmitoylated proteins. Biochim Biophys Acta. 1999, 1451: 1-16. 10.1016/S0167-4889(99)00075-0.
Batistič O, Sorek N, Schültke S, Yalovsky S, Kudla J: Dual fatty acyl modification determines the localization and plasma membrane targeting of CBL/CIPK Ca2+ signaling complexes in Arabidopsis. Plant Cell. 2008, 20: 1346-1362. 10.1105/tpc.108.058123.
Benetka W, Mehlmer N, Maurer-Stroh S, Sammer M, Koranda M, Neumüller R, Betschinger J, Knoblich JA, Teige M, Eisenhaber F: Experimental testing of predicted myristoylation targets involved in asymmetric cell division and calcium-dependent signalling. Cell Cycle. 2008, 7: 3709-3719. 10.4161/cc.7.23.7176.
O’Callaghan D, Burgoyne R: Role of myristoylation in the intracellular targeting of neuronal calcium sensor (NCS) proteins. Biochem Soc Trans. 2003, 31: 963-965. 10.1042/BST0310963.
Utsumi T, Ohta H, Kayano Y, Sakurai N, Ozoe Y: The N‒terminus of B96Bom, a Bombyx mori G‒protein‒coupled receptor, is N‒myristoylated and translocated across the membrane. FEBS J. 2005, 272: 472-481. 10.1111/j.1742-4658.2004.04487.x.
Lerouge P, Cabanes-Macheteau M, Rayon C, Fischette-Lainé A-C, Gomord V, Faye L: N-glycoprotein biosynthesis in plants: recent developments and future trends. Plant Mol Biol. 1998, 38: 31-48. 10.1023/A:1006012005654.
Meighan SE, Meighan PC, Rich ED, Brown RL, Varnum MD: Cyclic nucleotide-gated channel subunit glycosylation regulates matrix metalloproteinase-dependent changes in channel gating. Biochemistry. 2013, 52: 8352-8362. 10.1021/bi400824x.
Seoighe C, Gehring C: Genome duplication led to highly selective expansion of the Arabidopsis thaliana proteome. Trends Genet. 2004, 20: 461-464. 10.1016/j.tig.2004.07.008.
Yuen CL, Christopher D: The Role of Cyclic Nucleotide-Gated Channels in Cation Nutrition and Abiotic Stress. Ion Channels and Plant Stress Responses. Edited by: Demidchik V, Maathuis F. 2010, Berlin Heidelberg: Springer, 137-157.
Fischer C, Kugler A, Hoth S, Dietrich P: An IQ domain mediates the interaction with calmodulin in a plant cyclic nucleotide-gated channel. Plant Cell Physiol. 2013, 54: 573-584. 10.1093/pcp/pct021.
Rhoads AR, Friedberg F: Sequence motifs for calmodulin recognition. FASEB J. 1997, 11: 331-340.
DiFrancesco D, Tortora P: Direct activation of cardiac pacemaker channels by intracellular cyclic AMP. Nature. 1991, 351: 145-147. 10.1038/351145a0.
Diller T, Madhusudan X, Xuon NH, Taylor SS: Molecular basis for regulatory subunit diversity in cAMP-dependent protein kinase: crystal structure of the type II beta regulatory subunit. Structure. 2001, 9: 73-82. 10.1016/S0969-2126(00)00556-6.
Jackson HA, Marshall CR, Accili EA: Evolution and structural diversification of hyperpolarization-activated cyclic nucleotide-gated channel genes. Physiol Genomics. 2007, 29: 231-245. 10.1152/physiolgenomics.00142.2006.
Munemasa S, Oda K, Watanabe-Sugimoto M, Nakamura Y, Shimoishi Y, Murata Y: The coronatine-insensitive 1 mutation reveals the hormonal signaling interaction between abscisic acid and methyl jasmonate in Arabidopsis guard cells. Specific impairment of ion channel activation and second messenger production. Plant Physiol. 2007, 143: 1398-1407. 10.1104/pp.106.091298.
Cannon SB, Mitra A, Baumgarten A, Young ND, May G: The roles of segmental and tandem gene duplication in the evolution of large gene families in Arabidopsis thaliana. BMC Plant Biol. 2004, 4: 10-10.1186/1471-2229-4-10.
Chauve C, Doyon J-P, El-Mabrouk N: Gene family evolution by duplication, speciation, and loss. J Comput Biol. 2008, 15: 1043-1062. 10.1089/cmb.2008.0054.
Bowers JE, Chapman BA, Rong J, Paterson AH: Unravelling angiosperm genome evolution by phylogenetic analysis of chromosomal duplication events. Nature. 2003, 422: 433-438. 10.1038/nature01521.
Du H, Wang Y-B, Xie Y, Liang Z, Jiang S-J, Zhang S-S, Huang Y-B, Tang Y-X: Genome-wide identification and evolutionary and expression analyses of MYB-related genes in land plants. DNA Res. 2013, 20: 437-448. 10.1093/dnares/dst021.
Maruyama S, Suzaki T, Weber AP, Archibald JM, Nozaki H: Eukaryote-to-eukaryote gene transfer gives rise to genome mosaicism in euglenids. BMC Evol Biol. 2011, 11: 105-10.1186/1471-2148-11-105.
He L, Zhao M, Wang Y, Gai J, He C: Phylogeny, structural evolution and functional diversification of the plant PHOSPHATE1 gene family: a focus on Glycine max. BMC Evol Biol. 2013, 13: 103-10.1186/1471-2148-13-103.
Li W, Liu B, Yu L, Feng D, Wang H, Wang J: Phylogenetic analysis, structural evolution and functional divergence of the 12-oxo-phytodienoate acid reductase gene family in plants. BMC Evol Biol. 2009, 9: 90-10.1186/1471-2148-9-90.
Gomez-Porras JL, Riaño-Pachón DM, Benito B, Haro R, Sklodowski K, Rodríguez-Navarro A, Dreyer I: Phylogenetic Analysis of K + Transporters in Bryophytes, Lycophytes, and Flowering Plants Indicates a Specialization of Vascular Plants. 2012, Plant Sci: Front, 3-
Sze H, Geisler M, Murphy AS: Linking the Evolution of Plant Transporters to Their Functions. 2013, Plant Sci: Front, 4-
Nakashima K, Ito Y, Yamaguchi-Shinozaki K: Transcriptional regulatory networks in response to abiotic stresses in arabidopsis and grasses. Plant Physiol. 2009, 149: 88-95. 10.1104/pp.108.129791.
Abe H, Urao T, Ito T, Seki M, Shinozaki K, Yamaguchi-Shinozaki K: Arabidopsis AtMYC2 (bHLH) and AtMYB2 (MYB) function as transcriptional activators in abscisic acid signaling. Plant Cell. 2003, 15: 63-78. 10.1105/tpc.006130.
Zhang Z-L, Xie Z, Zou X, Casaretto J, Ho T-hD, Shen QJ: A rice WRKY gene encodes a transcriptional repressor of the gibberellin signaling pathway in aleurone cells. Plant Physiol. 2004, 134: 1500-1513. 10.1104/pp.103.034967.
Tunc-Ozdemir M, Tang C, Ishka MR, Brown E, Groves NR, Myers CT, Rato C, Poulsen LR, McDowell S, Miller G: A cyclic nucleotide-gated channel (CNGC16) in pollen is critical for stress tolerance in pollen reproductive development. Plant Physiol. 2013, 161: 1010-1020. 10.1104/pp.112.206888.
Ma W, Ali R, Berkowitz GA: Characterization of plant phenotypes associated with loss-of-function of AtCNGC1, a plant cyclic nucleotide gated cation channel. Plant Physiol Biochem. 2006, 44: 494-505. 10.1016/j.plaphy.2006.08.007.
Clough SJ, Fengler KA, Yu I-C, Lippok B, Smith RK, Bent AF: The Arabidopsis dnd1 “Defense, no Death” Gene Encodes a Mutated Cyclic Nucleotide-Gated ion Channel Leaves. Proc. Natl. Acad. Sci. U.S.A. 2000, 97: 9323-9328. 10.1073/pnas.150005697.
Gobert A, Park G, Amtmann A, Sanders D, Maathuis FJ: Arabidopsis thaliana cyclic nucleotide gated channel 3 forms a non-selective ion transporter involved in germination and cation transport. J Exp Bot. 2006, 57: 791-800. 10.1093/jxb/erj064.
Borsics T, Webb D, Andeme-Ondzighi C, Staehelin LA, Christopher DA: The cyclic nucleotide-gated calmodulin-binding channel AtCNGC10 localizes to the plasma membrane and influences numerous growth responses and starch accumulation in Arabidopsis thaliana. Planta. 2007, 225: 563-573. 10.1007/s00425-006-0372-3.
Bock KW, Honys D, Ward JM, Padmanaban S, Nawrocki EP, Hirschi KD, Twell D, Sze H: Integrating membrane transport with male gametophyte development and function through transcriptomics. Plant Physiol. 2006, 140: 1151-1168. 10.1104/pp.105.074708.
Frietsch S: PhD Thesis. The Role of Cyclic Nucleotide-Gated Channels (CNGC) in Plant Development and Stress Responses in Arabidopsis Thaliana. 2006, Germany: Ulm University
Nicole M-C, Hamel L-P, Morency M-J, Beaudoin N, Ellis BE, Séguin A: MAP-ping genomic organization and organ-specific expression profiles of poplar MAP kinases and MAP kinase kinases. BMC Genomics. 2006, 7: 223-10.1186/1471-2164-7-223.
Nuruzzaman M, Manimekalai R, Sharoni AM, Satoh K, Kondoh H, Ooka H, Kikuchi S: Genome-wide analysis of NAC transcription factor family in rice. Gene. 2010, 465: 30-44. 10.1016/j.gene.2010.06.008.
Ma K, Xiao J, Li X, Zhang Q, Lian X: Sequence and expression analysis of the C3HC4-type RING finger gene family in rice. Gene. 2009, 444: 33-45. 10.1016/j.gene.2009.05.018.
McAinsh MR, Roberts SK, Dubovskaya LV: Calcium Imaging of the Cyclic Nucleotide Response. Methods and Protocols. Cyclic Nucleotide Signaling in Plants. Volume 1016. Edited by: Gehring C. 2013, NewYork: Springer, 107-119. ISBN: 978-1-62703-440-1 (Print) 978-1-62703-441-8 (Online)
Arora R, Agarwal P, Ray S, Singh AK, Singh VP, Tyagi AK, Kapoor S: MADS-box gene family in rice: genome-wide identification, organization and expression profiling during reproductive development and stress. BMC Genomics. 2007, 8: 242-10.1186/1471-2164-8-242.
Boutrot F, Chantret N, Gautier M-F: Genome-wide analysis of the rice and Arabidopsis non-specific lipid transfer protein (nsLtp) gene families and identification of wheat nsLtp genes by EST data mining. BMC Genomics. 2008, 9: 86-10.1186/1471-2164-9-86.
The Arabidopsis Information Resource. http://arabidopsis.org/,
The MSU Rice Genome Annotation Project Database. http://rice.plantbiology.msu.edu/,
BLAST: Basic Local Alignment Search Tool. http://blast.ncbi.nlm.nih.gov/Blast.cgi,
Phytozome v9.1. http://www.phytozome.net/,
The Pfam database. http://pfam.sanger.ac.uk/,
CDD: a Conserved Domain Database. http://www.ncbi.nlm.nih.gov/Structure/cdd/wrpsb.cgi,
SMART: a Simple Modular Architecture Research Tool. http://smart.embl-heidelberg.de/,
PROSITE profiles. http://prosite.expasy.org/,
SUPERFAMILY. http://supfam.org/SUPERFAMILY/hmm.html,
Gene3D. http://gene3d.biochem.ucl.ac.uk/,
GRAMENE. http://www.gramene.org/,
Rice TOGO Browser. http://agri-trait.dna.affrc.go.jp/,
PGDD: The Plant Genome Duplication Database. http://chibba.agtec.uga.edu/duplication/,
GSDS: Gene Structure Display Server. http://gsds.cbi.pku.edu.cn/,
ExPASy: SIB Bioinformatics Resource Portal. http://www.expasy.org/,
PSORT. http://psort.hgc.jp/,
ScanProsite. http://prosite.expasy.org/scanprosite/,
Larkin M, Blackshields G, Brown N, Chenna R, McGettigan PA, McWilliam H, Valentin F, Wallace IM, Wilm A, Lopez R: Clustal W and Clustal X version 2.0. Bioinformatics. 2007, 23: 2947-2948. 10.1093/bioinformatics/btm404.
Edgar RC: MUSCLE: multiple sequence alignment with high accuracy and high throughput. Nucleic Acids Res. 2004, 32: 1792-1797. 10.1093/nar/gkh340.
Katoh K, Toh H: Recent developments in the MAFFT multiple sequence alignment program. Brief Bioinform. 2008, 9: 286-298. 10.1093/bib/bbn013.
Amborella Genome Database. http://www.amborella.org/,
Price MN, Dehal PS, Arkin AP: FastTree 2–approximately maximum-likelihood trees for large alignments. PLoS One. 2010, 5: e9490-10.1371/journal.pone.0009490.
Ortholog DB - Plant Genome Database Japan. http://pgdbj.jp/en/ortholog-db.html,
UniProt: Universal Protein Resource. http://www.uniprot.org/,
ConGenIE. http://congenie.org/,
Tamura K, Stecher G, Peterson D, Filipski A, Kumar S: MEGA6: Molecular Evolutionary Genetics Analysis Version 6.0. Mol Biol Evol. 2013, 30: 2725-2729. 10.1093/molbev/mst197.
The MEME Suite. http://meme.nbcr.net/meme/,
Nicholas KB, Nicholas HB, Deerfield DW: GeneDoc: analysis and visualization of genetic variation. EMBNEWNEWS. 1997, 4: 14-
Livark K, Schmittgen T: Analysis of relative gene expression data using real-time quantitative PCR and the 2 (−Delta Delta C (T) method. Methods. 2001, 25: 402-408. 10.1006/meth.2001.1262.
Thellin O, Zorzi W, Lakaye B, De Borman B, Coumans B, Hennen G, Grisar T, Igout A, Heinen E: Housekeeping genes as internal standards: use and limits. J Biotechnol. 1999, 75: 291-295. 10.1016/S0168-1656(99)00163-7.
Vandesompele J, De Preter K, Pattyn F, Poppe B, Van Roy N, De Paepe A, Speleman F: Accurate normalization of real-time quantitative qPCR data by geometric averaging of multiple internal control genes. Genome Biol. 2002, 3: 1-12. doi:10.1186/gb-2002-3-7-research0034
Valente V, Teixeira SA, Neder L, Okamoto OK, Oba-Shinjo SM, Marie SK, Scrideli CA, Paçó-Larson ML, Carlotti CG: Selection of suitable housekeeping genes for expression analysis in glioblastoma using quantitative qPCR. BMC Mol Biol. 2009, 10: 17-10.1186/1471-2199-10-17.
Jain M, Nijhawan A, Tyagi AK, Khurana JP: Validation of housekeeping genes as internal control for studying gene expression in rice by quantitative real-time PCR. Biochem Biophys Res Commun. 2006, 2: 646-651.
Institute S: SAS software, version 9.2. 2008, Cary, NC: SAS Institute
The Rice Expression Profile Database. http://ricexpro.dna.affrc.go.jp/,
Acknowledgements
The research was financially supported by the Special Funds for Agro-scientific Research in the Public Interest (201103007) by the Fundamental Research Funds for the Central Universities and Zhejiang Provincial Innovation Team of Nuclear Agricultural Science and Technology (2010R50033). We would like to convey our humble thanks to Professor Longjiang Fan, Director, Department of Agronomy and Professor of Bioinformatics James D. Watson Institute of Genome Sciences & Institute of Bioinformatics, Zhejiang University and Mr. Jie Qiu (Ph.D scholar) for their assistance in carrying out complete phylogenetic analysis between rice and Arabidopsis.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ contributions
ZN, KUK, MAS and Q-YS jointly conceived the study and collaborated on the study design. ZN and KUK performed all simulations, ran all analyses, and prepared all figures. ZN, KUK and MAS drafted the manuscript with critical input from Q-YS. All authors read and approved the final manuscript.
Zarqa Nawaz, Kaleem Ullah Kakar contributed equally to this work.
Electronic supplementary material
12864_2014_6538_MOESM1_ESM.png
Additional file 1: Schematic diagram representing structures of OsCNGC genes. Exons and introns are indicated as green boxes and black lines, respectively. Intron phase numbers 0, 1 and 2 are also shown at the beginning of the introns. The diagram is drawn to scale. The accession numbers for OsCNGC genes are listed in Figure 1. (PNG 108 KB)
12864_2014_6538_MOESM2_ESM.tiff
Additional file 2: Schematic diagram representing structures of CNGC genes of Arabidopsis. Exons and introns are indicated as black boxes and black lines, respectively. Intron phase numbers 0, 1 and 2 are also shown at the beginning of the introns. The diagram is drawn to scale. The accession numbers for AtCNGC genes are listed in Additional file 9. (TIFF 742 KB)
12864_2014_6538_MOESM3_ESM.png
Additional file 3: Sequence LOGOs for each motif of CNGC domains using the MEME algorithm. Motif 1: CNBD; Motif 3: IQ Motif 8: Ion transport. MEME motifs are displayed by stacks of letters at each position. The total height of the stack is the “information content” of that position in the motif in bits. The height of the individual letters in a stack is the probability of the letter at that position multiplied by the total information content of the stack. X- and Y-axis represents the width of motif and the bits of each letters, respectively. The details of motifs are given in Additional file 4. (PNG 621 KB)
12864_2014_6538_MOESM4_ESM.xlsx
Additional file 4: Comparison among motifs and domains of OsCNGC and AtCNGC proteins. OsCNGC protein motifs markedly differ from ATCNGCs. OsCNGC proteins contain a zinc finger domain in addition to conserved CNBD domains present in both taxa. (XLSX 11 KB)
12864_2014_6538_MOESM5_ESM.tiff
Additional file 5: Distribution of Conserved motifs in Arabidopsis CNGC proteins identified using MEME search tool. Schematic representation of motif composition in AtCNGC proteins sequences using MEME motif search tool for each groups given separately. Each motif is represented by a number in colored box. Length of box does not correspond to length of motif. Order of the motifs corresponds to position of motifs in individual protein sequence. (TIFF 649 KB)
12864_2014_6538_MOESM6_ESM.png
Additional file 6: Sequence LOGOs for each motif of Arabidopsis CNGC domains using the MEME algorithm. Motif 2: IQ; Motif 3 & 8: CNBD. MEME motifs are displayed by stacks of letters at each position. The total height of the stack is the “information content” of that position in the motif in bits. The height of the individual letters in a stack is the probability of the letter at that position multiplied by the total information content of the stack. X- and Y-axis represents the width of motif and the bits of each letters, respectively. (PNG 597 KB)
12864_2014_6538_MOESM7_ESM.png
Additional file 7: Multiple alignment profile of the CNBD domains of rice and Arabidopsis CNGCs obtained with ClustalX program. All the sequences show high level of amino acids conservation. Gaps (dashes) have been introduced to maximize the alignments. The most conserved feature of CNBD domain, the PBC and the hinge region are shown. The numbers at each end of the sequence show the start and stop positions of the region obtained from full length 36 CNGC protein. Followed by the names are the Residues highlighted in black indicate >100% conservation among the 36 CNGCs. Red highlighted residues indicates >70% identity. (PNG 1 MB)
12864_2014_6538_MOESM8_ESM.pdf
Additional file 8: Phylogenetic tree of CNGC genes belonging to rice and Arabidopsis. A multiple sequence alignment was performed by MAFFT v7.017 with the L-INS-i model. The alignment was further used to construct a maximum likelihood phylogenetic tree by FastTree keeping the default settings. (PDF 11 KB)
12864_2014_6538_MOESM11_ESM.xlsx
Additional file 11: A global expression profiles of rice CNGC genes at various stages of development. The data is obtained from RiceXPro [119]. The field/development datasets correspond to microarray data derived from leaves at various stages of development under natural field conditions. Each column represents the data of one replicate, as given in the database. (XLSX 565 KB)
12864_2014_6538_MOESM12_ESM.docx
Additional file 12: Expression profiles of OsCNGC genes in 4 weeks old rice leaves with UBQ5 internal control. Gene expression was perforemd by qPCR, 4 h after each treatment and non-treated CK. (A) Expression in response to different hormonal treatments. (B) Expression in response to pathogens inoculation with Xoo and P. fuscovaginae (biotic stress). (C) Expression in response to cold (abiotic stress). (DOCX 408 KB)
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
This article is published under an open access license. Please check the 'Copyright Information' section either on this page or in the PDF for details of this license and what re-use is permitted. If your intended use exceeds what is permitted by the license or if you are unable to locate the licence and re-use information, please contact the Rights and Permissions team.
About this article

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Cite this article
Nawaz, Z., Kakar, K.U., Saand, M.A. et al. Cyclic nucleotide-gated ion channel gene family in rice, identification, characterization and experimental analysis of expression response to plant hormones, biotic and abiotic stresses. BMC Genomics 15, 853 (2014). https://doi.org/10.1186/1471-2164-15-853
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1471-2164-15-853