
Abstract
Background
The most diverse marine ecosystems, coral reefs, depend upon a functional symbiosis between cnidarian hosts and unicellular dinoflagellate algae. The molecular mechanisms underlying the establishment, maintenance, and breakdown of the symbiotic partnership are, however, not well understood. Efforts to dissect these questions have been slow, as corals are notoriously difficult to work with. In order to expedite this field of research, we generated and analyzed a collection of expressed sequence tags (ESTs) from the sea anemone Aiptasia pallida and its dinoflagellate symbiont (Symbiodinium sp.), a system that is gaining popularity as a model to study cellular, molecular, and genomic questions related to cnidarian-dinoflagellate symbioses.
Results
A set of 4,925 unique sequences (UniSeqs) comprising 1,427 clusters of 2 or more ESTs (contigs) and 3,498 unclustered ESTs (singletons) was generated by analyzing 10,285 high-quality ESTs from a mixed host/symbiont cDNA library. Using a BLAST-based approach to predict which unique sequences derived from the host versus symbiont genomes, we found that the contribution of the symbiont genome to the transcriptome was surprisingly small (1.6–6.4%). This may reflect low levels of gene expression in the symbionts, low coverage of alveolate genes in the sequence databases, a small number of symbiont cells relative to the total cellular content of the anemones, or failure to adequately lyse symbiont cells. Furthermore, we were able to identify groups of genes that are known or likely to play a role in cnidarian-dinoflagellate symbioses, including oxidative stress pathways that emerged as a prominent biological feature of this transcriptome. All ESTs and UniSeqs along with annotation results and other tools have been made accessible through the implementation of a publicly accessible database named AiptasiaBase.
Conclusion
We have established the first large-scale transcriptomic resource for Aiptasia pallida and its dinoflagellate symbiont. These data provide researchers with tools to study questions related to cnidarian-dinoflagellate symbioses on a molecular, cellular, and genomic level. This groundwork represents a crucial step towards the establishment of a tractable model system that can be utilized to better understand cnidarian-dinoflagellate symbioses. With the advent of next-generation sequencing methods, the transcriptomic inventory of A. pallida and its symbiont, and thus the extent of AiptasiaBase, should expand dramatically in the near future.
Similar content being viewed by others

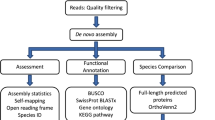
Background
Many biological systems rely on symbiotic interactions between different organisms. One of the most dramatic examples is the coral reef ecosystem, which has at its heart a mutualistic partnership between corals and endosymbiotic, dinoflagellate algae. The dinoflagellates are classified in a single genus, Symbiodinium, but molecular methods have revealed a high genetic diversity in this genus [1, 2]. The onset of these symbioses has been shown to display flexibility, but a range of specificity, i.e. from highly flexible to highly specific, is apparent during its maintenance [3–8]. This process is likely to involve early recognition mechanisms [9, 10] and an evasion of the hosts' digestive and immune systems [11], as well as adaptations to diverse ecological niches [12, 13] and physiological acclimation [14, 15]. There have also been controversial discussions of whether Symbiodinium populations may shift toward more heat-tolerant types as a consequence of thermal stress ("bleaching") in order to adapt to environmental changes [16–18] such as increasing seawater temperatures. In light of global climate change, this subject, i.e. cnidarian bleaching, has received much attention as devastating mass bleaching events have increased both in frequency and geographic extent [19]. Nonetheless, our knowledge of the underlying cellular and molecular mechanisms that facilitate the recognition between the partners, and determine the specificity, dynamics, and collapse of cnidarian-dinoflagellate symbioses, is limited.
The cellular and molecular interactions between host and symbiont cells are important targets for genetic and genomic dissection, but corals are notoriously difficult to work with. For example, corals form large, slow-growing colonies that are difficult and costly to maintain in the laboratory, and their handling for microscopy and amenability to other cell biological, biochemical, and genetic methods is complicated by the calcareous skeleton precipitated by reef-building corals. What is needed to make rapid advances in this field is a model system that possesses the key characteristics of coral symbiosis, but allows more facile laboratory investigation (for a detailed review see [20]). The sea anemone Aiptasia represents a good candidate system [20], as it possesses the same mutualistic relationship with Symbiodinium spp., but lacks the calcareous skeleton that hinders cellular-level work. It is widely distributed, and found in shallow tropical marine environments worldwide. Sequence characterized amplified region (SCAR) data indicate that the vast majority of Aiptasia worldwide (encompassing two described species, A. pallida and A. pulchella), appear to be genetically homogeneous (Santos Lab at Auburn University, pers. comm.). The one exception is a closely related, but genetically distinct, lineage potentially restricted to the Florida Keys. Data from the Santos Lab also indicate that natural populations of Aiptasia from the Florida Keys preferentially host Symbiodinium spp. comprised of only clade A or both clades A and B, whereas those from the remaining global range host clade B exclusively. Typically considered a pest organism by seawater aquarists, Aiptasia is hardy and proliferates rapidly by asexual reproduction. Individual polyps can be maintained in a symbiotic or aposymbiotic state (i.e., with and without symbionts, respectively), experimentally re-infected with a variety of Symbiodinium strains [21, 22], and cultured at low cost [23]. In fact, numerous studies have addressed symbiosis-related questions using A. pallida and its sister species A. pulchella by applying multiple tools ranging from microscopy to RNA-interference methods [24–29]. The generation of genomic resources for Aiptasia would therefore greatly advance research addressing the understanding of symbioses at a molecular, cell-biological, and genomic level.
As a cost-effective alternative to sequencing the genome of an organism, the generation and analysis of expressed-sequence-tag (EST) libraries provides an efficient method for discovering novel genes, estimating gene content, and approximating levels of gene expression. Once established, these resources can be utilized for comparative genomics studies or the construction of gene expression microarrays [30]. Among cnidarians, the extensive genomic resources now available for the non-symbiotic sea anemone Nematostella vectensis have opened new perspectives on the study of basal metazoans [31], and several EST resources have been generated for symbiotic cnidarians (predominantly corals) and Symbiodinium spp. [32–34]. However, to date, only one small-scale project has generated ESTs (N = 870) for the symbiotic anemone Aiptasia pulchella [35].
In this study, we report the generation and analysis of 10,285 high-quality ESTs from a Symbiodinium clade A-hosting clonal population of Aiptasia pallida that was likely derived from an individual originating from the Florida Keys lineage, which were processed through a software pipeline [36] resulting in a user-friendly, queryable, web-accessible database named AiptasiaBase. A BLASTx-based approach was used to estimate the relative contributions of each partner to the mixed cDNA library, and we were able to identify numerous genes involved in key processes of cnidarian-dinoflagellate symbioses.
Results and Discussion
EST library construction and assembly
A total of 6,448 cDNA clones were bi-directionally sequenced, resulting in 12,896 raw chromatograms, which served as input for the processing pipeline. After base calling by phred [37], Lucy [38] discarded 2,556 low-quality sequences, short or insert-less sequences, and vector or polyA-only sequences. An additional 55 sequences were removed by seqclean [39], leaving 10,285 high-quality ESTs (from 5,450 cDNA clones) for further processing (success rate ~80%). Assembly of these ESTs by cap3 [40] resulted in the generation of 1,427 contigs, which ranged from 112 to 3,440 bp in length and contained 2 – 259 ESTs (mean: 4.8). Together with the remaining 3,498 singletons, a total of 4,925 unique sequences (UniSeqs) were generated. Because of the possibility that two (or more) UniSeqs originated from the same transcript, we also estimated the number of unique genes (unigenes) in our dataset by assembling only the reverse reads of the directionally cloned cDNAs. The resulting estimate of 2,564 unigenes compared to the 4,925 UniSeqs is likely to reflect the large average size (1.95 kb) of inserts in the cDNA library; thus, in many cases, UniSeqs represent the 3' and 5' ends of genes for which the central parts were not captured due to Sanger-sequencing length limitations (600–800 bp). In addition, different splice variants or alleles of the same gene may have contributed to the excess of UniSeqs over unigenes. Detailed pre-assembly statistics are summarized in Additional file 1: Quality control and assembly statistics.
Previously, a small-scale EST project was conducted in order to compare the abundance of transcripts between symbiotic and aposymbiotic Aiptasia pulchella polyps [35]. The present study included bi-directional sequencing, and the total number of ESTs is more than 14 times larger than in the earlier study. Therefore, the availability of almost 5,000 UniSeqs for about 2,500 unigenes represents a rich transcriptomic resource, previously unavailable at this scale, for a symbiotic anemone.
Annotation of unique sequences and implementation of AiptasiaBase
All UniSeqs were assigned putative identities based on BLASTx hits (E-value cutoff: 1e-5) to the UniProt Knowledgebase databases SwissProt and TrEMBL [41]. About 37% and ~63% of the UniSeqs found hits in SwissProt and TrEMBL, respectively, leaving ~36% of the UniSeqs without similarities to known proteins. Because the TrEMBL database contains protein sequences based on conceptual translations of all nucleotide sequence entries in EMBL/GenBank/DDBJ, we chose to annotate the UniSeqs according to the curated SwissProt entries. Assignments of gene ontologies (GO) could be made for about one third of UniSeqs in each of the GO categories: molecular function, biological process, and cellular component. Because our cDNA library represents the symbiotic, adult life-history stage of A. pallida, the GO resource generated in this study sets the stage for statistical assessments of over- or under-representation of specific GO-categories in libraries obtained from anemones under different conditions such as life-history stages, symbiotic state (symbiotic vs. aposymbiotic), or environmental conditions (temperature, salinity, nutrients, etc.). In addition to BLAST and GO annotations, all UniSeqs were screened for single-nucleotide polymorphisms (SNPs) and simple-sequence repeats (SSRs), providing resources for the investigation of gene polymorphisms between individuals and/or populations. The prediction of open reading frames within UniSeqs also provided the basis for domain annotations at the protein level. About 25% of UniSeqs matched a protein domain entry in the Pfam database [42].
One of the primary challenges of sequencing ESTs from a mixed transcriptome originating from two or more partners is to assign sequences to the proper genome of origin. Taking a bioinformatic approach to this problem, we constructed taxon-specific databases representing either "Cnidaria-only" or "Alveolata-only" (i.e., dinoflagellates and their relatives) sequences from GenBank, and then performed BLASTx-searches against those databases as well as the complete non-redundant database (see Methods). We then employed a best-BLASTx-hit (BBH) approach (Additional file 2: Flow diagram illustrating BBH approach) to estimate the numbers of ESTs that originated from A. pallida and Symbiodinium spp., respectively, at various levels of confidence (Table 1). Irrespective of the confidence level, about one quarter of ESTs had no BLASTx-hit (E-value cutoff 1e-5). At the different levels of confidence, 56 – 70% and 1.7 – 6.4% were predicted to originate from the anemone and the Symbiodinium genomes, respectively (Additional file 3: Detailed EST (N = 10,285) distribution and assignment). The relatively small fraction of Symbiodinium ESTs could be expected given that Symbiodinum spp. are spatially restricted to the endodermal tissue layer of the host and that no special effort was made to disrupt the algal cell walls during the preparation of the RNA (see Methods). Furthermore, the number of UniSeqs without a significant BLASTx hit may be higher for Symbiodinium transcripts. However, the uncertainty about the origin of non-annotated sequences represents a current limitation to our approach. Ongoing and future genome-sequencing projects for symbiotic cnidarians and their dinoflagellate endosymbionts should soon become available and help to uncover the origins of sequences without currently known homologs in other organisms. This will provide an interesting opportunity to revisit our data set to look further at these perhaps taxonomically restricted genes.
Using an EST-processing software (EST2uni) [36], we stored all ESTs, UniSeqs, and annotations in a queryable database named AiptasiaBase (database = AiptasiaBase_v1), which is accessible through the URL: http://aiptasia.cs.vassar.edu/AiptasiaBase/index.php. In addition to the results generated by the software, we have included the annotation of UniSeqs according to KEGG, which provides a convenient way to explore pathway components that were identified in this study.
Analysis of the most highly abundant transcripts
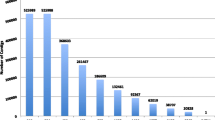
We identified the contigs containing the greatest numbers of ESTs, which we used as a proxy for the most abundant transcripts. Although the numbers of ESTs in contigs that are predicted to originate from Symbiodinium were too low to be analyzed (data not shown), many of the most abundant host-derived transcripts represented genes that are involved in the processes of protein biosynthesis, extracellular-matrix formation, and oxidative-stress response (Table 2).
Kuo et al. (2004) reported that the most highly expressed gene in symbiotic A. pulchella was ferritin (11.7%), whereas we found only 4 ESTs (0.04%) that represented this gene. Although differences in the preparations of the cDNA libraries (e.g. insert size-selection) and sequencing depths (474 vs. 10,285 ESTs) pose an obstacle for a direct comparison, the discrepancy in the numbers of ferritin transcripts appears to be noteworthy. In a recent study that investigated the effect of increased temperature and UV levels on the symbiotic anemone Anthopleura elegantissima, Richier et al. (2008) observed a more than 17-fold up-regulation of ferritin expression upon thermal stress, but not UV stress [43]. Given this observation, it seems possible that the anemones in the study by Kuo et al. (2004) were under elevated thermal stress at the time of sampling, which, taken together with the methodological differences mentioned above, makes any further comparative analyses unfeasible. This result has important implications, i.e., how culturing conditions of organisms as well as methodological differences between studies may have an impact on the transcriptome, and by extension, the interpretation of gene expression analyses.
The highly abundant sequences with the highest uncertainties for correct annotation (highest E-values), apolipophorin and the CUB and zona pellucida-like domain-containing protein 1, were further scrutinized by similarity searches in additional databases. These searches revealed that the best hit for CUB and zona pellucida-like domain-containing protein 1 in the GenBank non-redundant database (nr) was mesoglein, a protein that is proposed to be a structural element of the extracellular matrix of the mesoglea in the jellyfish Aurelia aurita [44]. The sequence annotated as apolipophorin contains a von Willebrand factor type-D domain, and was reported to be involved in forming lipoprotein particles that bind lipoproteins and lipids [45]. Two other highly abundant sequences had no homologs among previously characterized proteins, suggesting that they are novel, and a third contig with no BLASTx-hit was identified as an artifact due to misassembled sequences. These results illustrate some of the caveats to automated sequence assembly and annotation and highlight the necessity for corroboration after automated sequence processing when focusing on single genes or groups of genes of interest.
Candidate genes with potential relevance to cnidarian-dinoflagellate symbioses
We generated a candidate gene list of groups containing UniSeqs that are likely to be of relevance to cnidarian-dinoflagellate symbioses (Table 3). Among these, the cellular antioxidant-response system could be most comprehensively reconstructed (see below). Genes related to the innate immune system and sugar-binding proteins gave rise to a partial gene inventory (Fig. 1; Table 3). Other genes that are likely to play a role in the cellular events surrounding the breakdown of symbiosis (exocytosis, host-cell detachment, apoptosis and/or autophagy [46–52]) were also identified.

Illustration of genes and pathways known or likely to be involved in cnidarian-dinoflagellate symbioses. Genes that were identified or missing in the EST library are highlighted by solid red lines or dashed black lines, respectively. Pathways or cellular processes that were partially represented are highlighted by dashed red lines. APx – ascorbate peroxidase, ATG – autophagy-related protein, AIF – apoptosis-inducing factor, CASP – caspases, CAT – catalase, DRAM – damage-regulated autophagy modulator, GCLC – glutamate-cysteine ligase catalytic subunit, GGT – gamma-glutamyltranspeptidase, GPx – glutathione peroxidase, GR – glutathione reductase, GS – glutathione synthetase, GST – glutathione-S-transferase, HSP – heat-shock protein, IAP – inhibitor of apoptosis, Prx – peroxiredoxin, SOD – superoxide dismutase, Sym – Symbiodinium spp..
Stress-induced photoinhibition and damage to algal photosystem II are thought to be responsible for an increased production of reactive oxygen species [53, 54] and consequently, diffusion of hydrogen peroxide (H2O2) through the membranes into the host cells [55]. The detoxification of H2O2 requires the activity of catalase or other peroxidases. Superoxide dismutase (SOD), which catalyzes the reduction of superoxide to H2O2, as well as glutathione peroxidase (GPx), which uses glutathione to detoxify H2O2, were both not found among the sequenced ESTs. One possibility is that the abundance of SOD transcripts in host cells was low, and the generation of superoxide spatially limited (inside the chloroplasts of Symbiodinium). In this case, superoxide may have been efficiently eliminated within the Symbiodinium cells, while excess H2O2 that was not detoxified (e.g., by Symbiodinium ascorbate peroxidase), could have diffused into the host cytosol and been reduced to H2O and O2 by catalase. Alternatively, methodological factors such as insert-size selection or general RNA processing may have prevented the detection of SOD. Other genes that had previously been reported in the context of cnidarian-dinoflagellate symbioses (Additional file 4: Genes that have been studied in the context of cnidarian-dinoflagellate symbiosis, but not found in this study) were also not detected, perhaps for same reasons as discussed above for SOD.
Conclusion
By analyzing >10,000 high-quality ESTs and generating a comprehensive database for the user community, we have provided a foundation of transcriptomic resources for a symbiotic anemone that is becoming an important model system for studying coral-dinoflagellate symbioses. The set of sequences identified constitutes a rich source of candidate genes that are likely to be involved in processes related to the onset, maintenance, and breakdown of symbiosis. In this context, we were able to reconstruct the oxidative-stress response, which we also found to be prominent during basal transcription. At the current depth of sequencing, we have identified two problems, namely (1) that some transcripts are represented by two (or more) contigs and (2) that we lack information on transcripts of low abundance. These issues will be addressed in the near future by using 454 sequencing, which, for example, has been successfully applied to sequence the coral larval transcriptome of Acropora millepora at 3 × coverage [56].
Methods
Generation and sequencing of a cDNA library from Aiptasia pallida and its dinoflagellate symbiont
A clonal line of Aiptasia pallida (clone CC7, available through the Pringle lab) hosting Symbiodinium of clade A was established from a single tiny propagule in a population obtained from Carolina Biological Supply (Burlington, NC) and grown into an abundant stock. Given the Symbiodinium clade harbored by this population, it is likely that the Aiptasia individual originated from the Florida Keys lineage. Approximately 500 anemones of various sizes were harvested from this stock under normal growth conditions (~26°C; salinity, ~33 ppt; light, ~40 μmol m-2 s-1 photosynthetic photon flux; 12-h light-dark cycle), blotted to remove excess water, and immediately frozen in liquid nitrogen. The anemones were then ground to a fine powder under liquid nitrogen using a ceramic mortar and pestle. The powder was weighed (~4 g) while still frozen and mixed with a proportional volume (50 ml) of TRIzol Reagent (Invitrogen, Carlsbad, CA); extraction was then performed in accordance with the manufacturer's instructions yielding ~5 mg of total RNA. This RNA was sent to Open Biosystems (Huntsville, AL), where it was tested for quality; mRNA was then isolated using oligo(dT)-coated magnetic particles (Seradyn, Indianapolis, IN), and cDNA was synthesized. Double-stranded cDNA was size fractionated to enrich for long reads, cloned into the vector pExpress1 (Express Genomics, Frederick, MD), and electroporated into E. coli strain DH10B. The resulting library was determined to contain ~96% recombinants with an average insert size of 1.95 kb. Sequencing was performed on 96-well capillary sequencing platforms (ABI 3700) at the DOE Joint Genome Institute (JGI, Walnut Creek, CA) and at the Genome Core Facility at the University of California, Merced, USA, CA.
Processing of ESTs and implementation of AiptasiaBase
Raw chromatogram files were used as input for the software pipeline EST2uni [36], which was implemented on an Ubuntu server (8.04 "Hardy Heron", Dual Intel Xeon 3.06 GHz) to generate the database named AiptasiaBase [57]. During the pipeline processing, raw EST reads were based-called by phred [37], and quality filtered and vector trimmed by the software Lucy [38]; low-complexity regions and repetitive elements were then removed by seqclean [39] and RepeatMasker [58], respectively. To remove unexpected vector sequences, seqclean additionally screened the processed ESTs using NCBI's UniVec database. All ESTs are available through GenBank accession numbers GH571982 – GH582266.
Clustering of processed ESTs was performed by cap3 [40] with default settings resulting in unique sequences (UniSeqs), for which open reading frames were predicted by ESTScan [59]. Similar UniSeqs were found using BLASTn [60], resulting in clusters of similar UniSeqs [60]. Short-sequence-repeat microsatellites and sequence variations were predicted by Sputnik [61] and local algorithms [36], respectively. All UniSeqs were functionally annotated by BLASTx searches [60] in protein databases nr (GenBank – NCBI), TrEMBL, and SwissProt (Uniprot) [62]; HMMER [63] searches in pfam [42]; and GO-term associations (UniProt GOA, March 2008) [64]. The number of unique genes was estimated by clustering all reverse reads using the cap3 software with default settings.
BLAST-based prediction of UniSeq origin and KEGG annotation
In order to predict whether an EST originated from Aiptasia pallida or Symbiodinium spp., we performed a best-BLASTx-hit (BBH) approach (Additional file 2: Flow diagram illustrating BBH approach). First, all UniSeqs were BLASTx-searched (E-value cutoff: 1e-5) in a non-redundant protein database (nr, GenBank, NCBI). If the BBH was from a cnidarian or an alveolate species, the sequence was predicted to originate from Aiptasia pallida or Symbiodinium spp., respectively, with high confidence. Next, if the BBH was not from a cnidarian or alveolate species, we compared the E-values for the BBHs from a search against nr databases that were previously filtered for sequences from cnidarian (582,480) or alveolate (468,072) species. The organism for which the E-value was lower was assigned to the corresponding UniSeq with medium confidence. Finally, if the E-values for BBH searches in the cnidarian and alveolate databases were equal, we compared the percentage of identical amino acids in the sequence alignments. As in the E-value-based approach, the organism with the higher percentage of identical amino acids was assigned to the corresponding UniSeq (low confidence). In addition to the annotations described above, we used the Automatic Annotation Server provided by the Kyoto Encyclopedia of Genes and Genomes (KEGG) for all UniSeqs using the single-directional best-hit option.
References
LaJeunesse TC: Diversity and community structure of symbiotic dinoflagellates from Caribbean coral reefs. Marine Biology. 2002, 141 (2): 387-400. 10.1007/s00227-002-0829-2.
Rowan R, Powers DA: Ribosomal RNA sequences and the diversity of symbiotic dinoflagellates (zooxanthellae). Proc Natl Acad Sci USA. 1992, 89 (8): 3639-3643. 10.1073/pnas.89.8.3639.
Baird AH, Cumbo VR, Leggat W, Rodriguez-Lanetty M: Fidelity and flexibility in coral symbioses. Mar Ecol Prog Ser. 2007, 347: 307-309. 10.3354/meps07220.
Baker AC: Flexibility and specificity in coral-algal symbiosis: Diversity, ecology, and biogeography of Symbiodinium. Annu Rev Ecol Evol Syst. 2003, 34: 661-689. 10.1146/annurev.ecolsys.34.011802.132417.
Little AF, van Oppen MJ, Willis BL: Flexibility in algal endosymbioses shapes growth in reef corals. Science. 2004, 304 (5676): 1492-1494. 10.1126/science.1095733.
LaJeunesse TC: Diversity and community structure of symbiotic dinoflagellates from Caribbean coral reefs. Mar Biol. 2002, 141: 387-400. 10.1007/s00227-002-0829-2.
Santos SR, Shearer TL, Hannes AR, Coffroth MA: Fine-scale diversity and specificity in the most prevalent lineage of symbiotic dinoflagellates (Symbiodinium, Dinophyceae) of the Caribbean. Mol Ecol. 2004, 13 (2): 459-469. 10.1046/j.1365-294X.2003.02058.x.
Thornhill DJ, Lajeunesse TC, Kemp DW, Fitt WK, Schmidt GW: Multi-year, seasonal genotypic surveys of coral-algal symbioses reveal prevalent stability or post-bleaching reversion. Mar Biol. 2006, 148 (4): 711-722. 10.1007/s00227-005-0114-2.
Wood-Charlson EM, Hollingsworth LL, Krupp DA, Weis VM: Lectin/glycan interactions play a role in recognition in a coral/dinoflagellate symbiosis. Cell Microbiol. 2006, 8 (12): 1985-1993. 10.1111/j.1462-5822.2006.00765.x.
Rodriguez-Lanetty M, Wood-Charlson EM, Hollingsworth LL, Krupp DA, Weis VM: Temporal and spatial infection dynamics indicate recognition events in the early hours of a dinoflagellate/coral symbiosis. Marine Biology. 2006, 149 (4): 713-719. 10.1007/s00227-006-0272-x.
Fitt WK, Trench RK: Endocytosis of the symbiotic dinoflagellate Symbiodinium microadriaticum Freudenthal by endodermal cells of the scyphistomae of Cassiopeia xamachana and resistance of the algae to host digestion. J Cell Sci. 1983, 64: 195-212.
Iglesias-Prieto R, Beltran VH, LaJeunesse TC, Reyes-Bonilla H, Thome PE: Different algal symbionts explain the vertical distribution of dominant reef corals in the eastern Pacific. Proc Biol Sci. 2004, 271 (1549): 1757-1763. 10.1098/rspb.2004.2757.
Rowan R, Knowlton N: Intraspecific diversity and ecological zonation in coral-algal symbiosis. Proc Natl Acad Sci USA. 1995, 92 (7): 2850-2853. 10.1073/pnas.92.7.2850.
Rowan R: Coral bleaching: thermal adaptation in reef coral symbionts. Nature. 2004, 430 (7001): 742-10.1038/430742a.
Berkelmans R, van Oppen MJ: The role of zooxanthellae in the thermal tolerance of corals: a 'nugget of hope' for coral reefs in an era of climate change. Proc Biol Sci. 2006, 273 (1599): 2305-2312. 10.1098/rspb.2006.3567.
Baker AC: Reef corals bleach to survive change. Nature. 2001, 411: 765-766. 10.1038/35081151.
Buddemeier RW, Fautin DG: Coral Bleaching as an Adaptive Mechanism. BioScience. 1993, 43 (5): 320-325. 10.2307/1312064.
Hoegh-Guldberg O, Jones RJ, Ward S, Loh WK: Communication arising. Is coral bleaching really adaptive?. Nature. 2002, 415 (6872): 601-602. 10.1038/415601a.
Hoegh-Guldberg O: Climate change, coral bleaching and the future of the world's coral reefs. Mar Freshw Res. 1999, 50: 839-866. 10.1071/MF99078.
Weis VM, Davy SK, Hoegh-Guldberg O, Rodriguez-Lanetty M, Pringle JR: Cell biology in model systems as the key to understanding corals. Trends Ecol Evol. 2008, 23 (7): 369-376. 10.1016/j.tree.2008.03.004.
Perez SF, Cook CB, Brooks WR: The role of symbiotic dinoflagellates in the temperature-induced bleaching response of the subtropical sea anemone Aiptasia pallida. J Exp Mar Biol Ecol. 2001, 256 (1): 1-14. 10.1016/S0022-0981(00)00282-3.
Belda-Baillie CA, Baillie BK, Maruyama T: Specificity of a model cnidarian-dinoflagellate symbiosis. Biol Bull. 2002, 202 (1): 74-85. 10.2307/1543224.
Clayton WS: Pedal Laceration by the Anemone Aiptasia pallida. Mar Ecol Prog Ser. 1985, 21 (1–2): 75-80. 10.3354/meps021075.
Chen MC, Hong MC, Huang YS, Liu MC, Cheng YM, Fang LS: ApRab11, a cnidarian homologue of the recycling regulatory protein Rab11, is involved in the establishment and maintenance of the Aiptasia-Symbiodinium endosymbiosis. Biochem Biophys Res Commun. 2005, 338 (3): 1607-1616. 10.1016/j.bbrc.2005.10.133.
Dunn SR, Phillips WS, Green DR, Weis VM: Knockdown of actin and caspase gene expression by RNA interference in the symbiotic anemone Aiptasia pallida. Biol Bull. 2007, 212 (3): 250-258.
Lesser MP: Elevated temperatures and ultraviolet radiation cause oxidative stress and inhibit photosynthesis in symbiotic dinoflagellates. Limnol Oceanogr. 1996, 41 (2): 271-283.
Nii CM, Muscatine L: Oxidative stress in the symbiotic sea anemone Aiptasia pulchella (Carlgren, 1943): Contribution of the animal to superoxide ion production at elevated temperature. Biol Bull. 1997, 192 (3): 444-456. 10.2307/1542753.
Perez S, Weis V: Nitric oxide and cnidarian bleaching: an eviction notice mediates breakdown of a symbiosis. J Exp Biol. 2006, 209 (14): 2804-2810. 10.1242/jeb.02309.
Sawyer SJ, Muscatine L: Cellular mechanisms underlying temperature-induced bleaching in the tropical sea anemone Aiptasia pulchella. J Exp Biol. 2001, 204 (20): 3443-3456.
Nagaraj SH, Gasser RB, Ranganathan S: A hitchhiker's guide to expressed sequence tag (EST) analysis. Brief Bioinform. 2007, 8 (1): 6-21. 10.1093/bib/bbl015.
Putnam NH, Srivastava M, Hellsten U, Dirks B, Chapman J, Salamov A, Terry A, Shapiro H, Lindquist E, Kapitonov VV, et al: Sea anemone genome reveals ancestral eumetazoan gene repertoire and genomic organization. Science. 2007, 317 (5834): 86-94. 10.1126/science.1139158.
Kortschak RD, Samuel G, Saint R, Miller DJ: EST analysis of the cnidarian Acropora millepora reveals extensive gene loss and rapid sequence divergence in the model invertebrates. Curr Biol. 2003, 13 (24): 2190-2195. 10.1016/j.cub.2003.11.030.
Leggat W, Hoegh-Guldberg O, Dove S, Yellowlees D: Analysis of an EST library from the dinoflagellate (Symbiodinium sp.) symbiont of reef-building corals. J Phycol. 2007, 43 (5): 1010-1021. 10.1111/j.1529-8817.2007.00387.x.
Schwarz JA, Brokstein PB, Voolstra C, Terry AY, Manohar CF, Szmant AM, Coffroth MA, Miller DJ, Medina M: Coral Life History and Symbiosis: functional genomic resources for two reef building Caribbean corals, Acropora palmata and Montastraea faveolata. BMC Genomics. 2008, 9: 97-10.1186/1471-2164-9-97.
Kuo J, Chen MC, Lin CH, Fang LS: Comparative gene expression in the symbiotic and aposymbiotic Aiptasia pulchella by expressed sequence tag analysis. Biochem Biophys Res Commun. 2004, 318 (1): 176-186. 10.1016/j.bbrc.2004.03.191.
Forment J, Gilabert F, Robles A, Conejero V, Nuez F, Blanca JM: EST2uni: an open, parallel tool for automated EST analysis and database creation, with a data mining web interface and microarray expression data integration. BMC Bioinformatics. 2008, 9: 5-10.1186/1471-2105-9-5.
Ewing B, Hillier L, Wendl MC, Green P: Base-calling of automated sequencer traces using phred. I. Accuracy assessment. Genome Res. 1998, 8 (3): 175-185.
Chou HH, Holmes MH: DNA sequence quality trimming and vector removal. Bioinformatics. 2001, 17 (12): 1093-1104. 10.1093/bioinformatics/17.12.1093.
The Gene Index project. [http://compbio.dfci.harvard.edu/tgi/software/]
Huang X, Madan A: CAP3: A DNA sequence assembly program. Genome Res. 1999, 9 (9): 868-877. 10.1101/gr.9.9.868.
Consortium TU: The Universal Protein Resource (UniProt). Nucleic Acids Res. 2008, 36: D190-D195. 10.1093/nar/gkm895.
Finn RD, Tate J, Mistry J, Coggill PC, Sammut SJ, Hotz HR, Ceric G, Forslund K, Eddy SR, Sonnhammer EL, et al: The Pfam protein families database. Nucleic Acids Res. 2008, 36: D281-288. 10.1093/nar/gkm960.
Richier S, Rodriguez-Lanetty M, Schnitzler CE, Weis VM: Response of the symbiotic cnidarian Anthopleura elegantissima transcriptome to temperature and UV increase. Comp Biochem Physiol D: Genomics Proteomics. 2008, 3 (4): 283-289. 10.1016/j.cbd.2008.08.001.
Matveev IV, Shaposhnikova TG, Podgornaya OI: A novel Aurelia aurita protein mesoglein contains DSL and ZP domains. Gene. 2007, 399 (1): 20-25. 10.1016/j.gene.2007.04.034.
Bogerd J, Babin PJ, Kooiman FP, André M, Ballagny C, Van Marrewijk WJA, Horst Van Der DJ: Molecular characterization and gene expression in the eye of the apolipophorin II/I precursor from Locusta migratoria. J Comp Neurol. 2000, 427 (4): 546-558. 10.1002/1096-9861(20001127)427:4<546::AID-CNE4>3.0.CO;2-H.
Downs CA, Kramarsky-Winter E, Martinez J, Kushmaro A, Woodley CM, Loya Y, Ostrander GK: Symbiophagy as a cellular mechanism for coral bleaching. Autophagy. 2009, 5 (2): 211-216.
Dunn SR, Schnitzler CE, Weis VM: Apoptosis and autophagy as mechanisms of dinoflagellate symbiont release during cnidarian bleaching: every which way you lose. Proc Biol Sci. 2007, 274 (1629): 3079-3085. 10.1098/rspb.2007.0711.
Gates RD, Baghdasarian G, Muscatine L: Temperature stress causes host cell detachment in symbiotic cnidarians: implications for coral bleaching. Biol Bull. 1992, 182: 324-332. 10.2307/1542252.
Chen MC, Cheng YM, Sung PJ, Kuo CE, Fang LS: Molecular identification of Rab7 (ApRab7) in Aiptasia pulchella and its exclusion from phagosomes harboring zooxanthellae. Biochem Biophys Res Commun. 2003, 308 (3): 586-595. 10.1016/S0006-291X(03)01428-1.
Lesser M, Stochaj W, Tapley D, Shick J: Bleaching in coral reef anthozoans: Effects of irradiance, ultraviolet radiation and temperature, on the activities of protective enzymes against active oxygen. Coral Reefs. 1990, 8: 225-232. 10.1007/BF00265015.
Merle PL, Sabourault C, Richier S, Allemand D, Furla P: Catalase characterization and implication in bleaching of a symbiotic sea anemone. Free Radic Biol Med. 2007, 42 (2): 236-246. 10.1016/j.freeradbiomed.2006.10.038.
Sunagawa S, Choi J, Forman HJ, Medina M: Hyperthermic stress-induced increase in the expression of glutamate-cysteine ligase and glutathione levels in the symbiotic sea anemone Aiptasia pallida. Comp Biochem Physiol B: Biochem Mol Biol. 2008, 151 (1): 133-138. 10.1016/j.cbpb.2008.06.007.
Jones RJ, Hoegh-Guldberg O, Larkum AWD, Schreiber U: Temperature-induced bleaching of corals begins with impairment of the CO2 fixation mechanism in zooxanthellae. Plant Cell Environ. 1998, 21 (12): 1219-10.1046/j.1365-3040.1998.00345.x.
Warner ME, Fitt WK, Schmidt GW: Damage to photosystem II in symbiotic dinoflagellates: A determinant of coral bleaching. Proc Natl Acad Sci USA. 1999, 96 (14): 8007-8012. 10.1073/pnas.96.14.8007.
Asada K, Takahashi M: Production and scavenging of active oxygen in photosynthesis. Topics in photosynthesis, Photoinhibition. Edited by: Kyle DJ, Osmond CB, Arntzen CJ . 1987, Amsterdam: Elsevier, 9: 227-287.
Meyer E, Aglyamova GV, Wang S, Buchanan-Carter J, Abrego D, Colbourne JK, Willis BL, Matz MV: Sequencing and de novo analysis of a coral larval transcriptome using 454 GS-Flx. BMC Genomics. 2009, 10 (1): 219-10.1186/1471-2164-10-219.
AiptasiaBase. [http://aiptasia.cs.vassar.edu/AiptasiaBase/index.php]
RepeatMasker. [http://www.repeatmasker.org]
Iseli C, Jongeneel CV, Bucher P: ESTScan: a program for detecting, evaluating, and reconstructing potential coding regions in EST sequences. Proc Int Conf Intell Syst Mol Biol. 1999, 138-148.
Altschul SF, Madden TL, Schaffer AA, Zhang J, Zhang Z, Miller W, Lipman DJ: Gapped BLAST and PSI-BLAST: a new generation of protein database search programs. Nucleic Acids Res. 1997, 25 (17): 3389-3402. 10.1093/nar/25.17.3389.
Sputnik – DNA microsatellite repeat search utility. [http://espressosoftware.com/sputnik/index.html]
TheUniProtConsortium: The universal protein resource (UniProt). Nucleic Acids Res. 2008, 36: D190-195. 10.1093/nar/gkm895.
HMMER: biosequence analysis using profile hidden Markov models. [http://hmmer.janelia.org]
Camon E, Magrane M, Barrell D, Binns D, Fleischmann W, Kersey P, Mulder N, Oinn T, Maslen J, Cox A, et al: The Gene Ontology Annotation (GOA) project: implementation of GO in SWISS-PROT, TrEMBL, and InterPro. Genome Res. 2003, 13 (4): 662-672. 10.1101/gr.461403.
Acknowledgements
We would like to thank Wayne Huang and Greg Priest-Dorman for system administration, Henry J. Forman for his input on oxidative-stress-related subjects, Elisha Wood-Charlson and two anonymous reviewers for providing constructive comments on the manuscript, and Josh Meisel for his assistance in preparation of the RNA used for library construction. Partial sequencing was donated by Eddy Rubin, director of the DOE Joint Genome Institute, through the sequencing quota allocated to the UC Merced Genome Biology course (BIS 142) in Spring 2007 and Spring 2008. Bioinformatics analyses were initiated by undergraduate students in the context of BIS 142 and courses BIOL325 and BIOL/CMPU353 taught at Vassar College. CC and JRP were partially supported by an Environmental Venture Project from the Woods Institute at Stanford University. VMW was partially supported by NSF grant IOB0542452. MM was partially supported by NSF awards (BE-GEN 0313708 and IOS 0644438) and startup funds from UC Merced. JS was supported by startup funds from Vassar College.
Author information
Authors and Affiliations
Corresponding author
Additional information
Authors' contributions
SS carried out the bioinformatics work, analyzed the data, implemented AiptasiaBase, and prepared the manuscript. ECW participated in the data analysis. MT, MLS, and JS participated in the implementation and web-design of AiptasiaBase. CC and JRP cultivated the anemones, and CC prepared the total RNA for cDNA-library construction. JRP, VMW, MM, and JS conceived of the study, coordinated its design, and helped in preparing the manuscript. All authors read and approved the final manuscript.
Electronic supplementary material
{kind=link}
12864_2009_2142_MOESM4_ESM.pdf
Additional file 4: Genes that have been studied in the context of cnidarian-dinoflagellate symbiosis, but not found in this study. (PDF 59 KB)
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
{kind=link}
Rights and permissions
Open Access This article is published under license to BioMed Central Ltd. This is an Open Access article is distributed under the terms of the Creative Commons Attribution License ( https://creativecommons.org/licenses/by/2.0 ), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Sunagawa, S., Wilson, E.C., Thaler, M. et al. Generation and analysis of transcriptomic resources for a model system on the rise: the sea anemone Aiptasia pallida and its dinoflagellate endosymbiont. BMC Genomics 10, 258 (2009). https://doi.org/10.1186/1471-2164-10-258
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1471-2164-10-258