
Abstract
Background
The main components of the spatial genetic structure of the populations are neighbourhood size and isolation by distance. These may be inferred from the allele frequencies across a series of populations within a region. Here, the spatial population structure of Proclossiana eunomia was investigated in two mountainous areas of southern Europe (Asturias, Spain and Pyrenees, France) and in two areas of intermediate elevation (Morvan, France and Ardennes, Belgium).
Results
A total of eight polymorphic loci were scored by allozyme electrophoresis, revealing a higher polymorphism in the populations of southern Europe than in those of central Europe.
Isolation by distance effect was much stronger in the two mountain ranges (Pyrenees and Asturias) than in the two areas of lower elevation (Ardennes and Morvan). By contrast, the neighbourhood size estimates were smaller in the Ardennes and in the Morvan than in the two high mountain areas, indicating more common movements between neighbouring patches in the mountains than in plains.
Conclusion
Short and long dispersal events are two phenomena with distinct consequences in the population genetics of natural populations. The differences in level of population differentiation within each the four regions may be explained by change in dispersal in lowland recently fragmented landscapes: on average, butterflies disperse to a shorter distance but the few ones which disperse long distance do so more efficiently. Habitat fragmentation has evolutionary consequences exceeding by far the selection of dispersal related traits: the balance between local specialisation and gene flow would be perturbed, which would modify the extent to which populations are adapted to heterogeneous environments.
Similar content being viewed by others

Background
Spatial models of genetic population structure generally refer either (i) to populations isolated in space, and connected by immigration and emigration [1], or to (ii) individuals distributed through space within a population [2, 3]. However in numerous cases natural populations are distributed in clusters that may differ in their connectivity depending on landscape structure and configuration. Connectivity of a given landscape is species-specific, as exemplified by inter-species comparisons of dispersal within the same area (e.g. [4]). Moreover, connectivity depends on the evolutionary interaction between dispersal strategies on the one hand and landscape structure and configuration on the other hand, which is predicted to be species- and landscape-specific [5]. Such differences in dispersal ability among various landscapes are the result of selection of phenotypic traits linked to movement behaviour. This situation is nicely exemplified by species with a large distribution range, which end up being present in different habitat types. The nature and patchiness of their preferred habitat may then differ between different areas of their distribution range, which led to contrasted dispersal strategies in the various landscape types they occupied [6, 7]. Habitat loss and fragmentation by human activities are another source of intraspecific dispersal variability. Man-induced patchiness of habitats modifies the balance between landscape structure and configuration on the one hand, and dispersal strategies on the other hand. Theory predicts that evolutionary changes in dispersal according to habitat fragmentation would be complex and non-linear [8], sometimes even maladaptive [9]. Empirical studies indeed document repeatedly various phenotypic changes according to habitat fragmentation at each of the three stages of the dispersal process (emigration from suitable habitats, displacement in the matrix and immigration in a new habitat)(review in [5]). However, the question remains about the evolutionary consequences of this phenotypic variation.
Here we address this question by comparing the effective dispersal among four different landscape types in the butterfly Proclossiana eunomia. Ecological studies previously showed that behavioural changes occurred in this species according to landscape structure, leading to a dispersal depression in fragmented landscapes [10]. In this study, we investigate whether such behavioural changes affect population genetic structures in landscapes differing in their structure and configuration.
A convenient way to describe dispersal strategies between species is to distinguish patchy populations from metapopulations [11]. However, these two cases of population structure are the extremes of a continuum, which depends on the proportion of individuals leaving their natal patch [12]. Locally, the area within which the individuals intermix freely has been defined as the genetic neighbourhood [2]. At a broader scale, if the differentiation between populations depends on the distance between them, as a result of equilibrium between migration and genetic drift, there is an isolation by distance effect [13].
Neighbourhood size and isolation by distance grasp two complementary levels of population spatial structure, as those parameters are informative about effective short- and long-distance dispersal respectively. Long-distance dispersal is inherently difficult to study, and various methods are now available, but all require large data sets, because of the rarity of long distance dispersal events [14]. Large data sets are more and more used to infer dispersal, either using classical FST methods, based on Wright's island model, which per se are inadequate to estimate the number of migrants, as the hypothesis of the model rarely if ever holds in natural situations [15]. It is possible to lift the hypothesis of the island model, but this in turn requires data on effective population sizes of each population [16], which is very difficult to infer in field situations. Nevertheless, for comparative purposes, the island model approach remains a useful tool [15, 17].
In this paper we would like (i) to compare neighbourhood size and isolation by distance effect in the butterfly Proclossiana eunomia in four different parts of its range, and (ii) from the resulting data compare the dispersal ability of the species in the respective parts of its range. We infer both neighbourhood size and isolation by distance effect from estimates of FST and geographic distances between populations in two mainly natural (mountain) and two mainly man-shaped (fragmented) landscapes.
Results
The genetic polymorphism of P. eunomia populations varied between the studied regions (Table 1; [see Additional file 1]). The Morvan is the region where P. eunomia shows the lowest number of polymorphic loci (three); this is due to the fact that the populations there originated from introduction performed in 1970 and 1974 from individuals coming from the Ardennes where only four polymorphic loci could be found [18–20]. Populations in the Asturias and the Pyrenees were the most variable ones with eight polymorphic loci.
Mean FST values per region showed that the differentiation between populations within each of the regions are moderate (sensu [2]), ranging from 0.080 for the Ardennes to 0.123 for the Asturias (Table 2). Pairwise comparisons of slopes and intercepts revealed significant differences in most cases (Table 2). The analysis of Isolation by Distance effect, with regressions of log() on log(distance), showed marked differences between the regions (Figure 1). In the Morvan area, the regression (and hence the slope) is not significant. In the Ardennes area, the slope is weak but significant (0.0073; [21]) whereas in the Pyrenees and the Asturias the slope was remarkably stronger (0.656 and 0.948 respectively; Table 3), indicating a stronger Isolation by distance effect in these regions (Table 1; Figure 1). The Isolation by Distance effect may then be ranked between the regions as nil in the Morvan, weak in the Ardennes, strong in the Pyrenees and strongest in the Asturias. The intercept of the log-log curves, on the other hand, indicated the reverse tendency, with the Morvan left out, as the relationship was not significant there, thus indicating an increasing neighbourhood size from the Ardennes to the Pyrenees to the Asturias.

Frequencies of distances between the source and the assigned population, according to the allele frequencies. (a) Observed frequencies. (b) Frequencies of distances between the source and a randomly assigned population for each individual.
The approach advocated by Porter & Geiger [22], the intercept of FST = a+b/(4x+1), for x being the geographical distances between populations, provided the same ranking of regions (Table 2). The stress between the 2-dimensional configuration of pairwise FST values and pairwise geographical distances between populations varied greatly between the four regions. It was the lowest for the Asturias (< 0.0001), the highest for the Morvan (27.58), with the Ardennes (0.01035) and the Pyrenees (14.09) being intermediate.
The percentage of correctly assigned individuals to their population, varied between the four regions, from 8.3% in the Ardennes to 40.4% in the Asturias (Table 2). In the Ardennes, the data set with the highest number of populations (26), the procedure assigned mostly to nearby populations when the source population was not chosen as the most likely (Figure 2). As in the Morvan there is no isolation by distance (see below), the distribution of assigned individuals does not differ from the randomly assigned individuals (Wilcoxon Rank Sum Test, P = 0.95), whereas in the three other regions the assigned populations are significantly closer to the source populations than randomly assigned ones (P < 0.001).

Estimated number of migrants per generation between pairs of populations (Nm) plotted against distances in km between populations for P. eunomia in the four regions studied; both with log scales. The significance levels were given by Mantel test.
Discussion
Our results show that the spatial structure of P. eunomia varied strongly among the four studied regions. The FST values per region all fall above the median value of FST for European butterfly populations (reviewed in [23]). The comparison of the slope of the estimated number of effective dispersal events vs. geographic distance provided a ranking of the effect of isolation by distance, which was lacking in the Morvan, weak in the Ardennes and increasingly higher in the Pyrenees and the Asturias respectively; this may be related to the higher altitude range in these areas, as well as to population connectivity. The Morvan is the area with the highest recorded connectivity; it has indeed been colonised within 15 years from just two points of origin [20, 24], and the populations there may not have reached an equilibrium yet (sensu Slatkin [13]), even if the genotypes of the individuals already show differentiation occurring within the region [19]. The slope of the pairwise log FST vs log geographical distance gives an index of the Isolation by Distance effect. For the three landscapes where it could be investigated, the neighbourhood size showed a trend opposite to the one of the isolation by distance effect, being smallest in the Ardennes and largest in the Asturias, with the Pyrenees being intermediate.
Compared to high mountains, the genetic structure of P. eunomia populations in the lowlands of central Europe corresponds to (i) a lower dispersal rate leading to a lower neighbourhood size, and (ii) for the individuals which do disperse to a more efficient dispersal power preventing thus isolation by distance in lowland areas of relative high connectivity. The relation between dispersal ability and population genetic structure was firmly established on the basis of intrageneric but interspecific comparison [25]. At the intraspecific level, a direct relation between connectivity and gene flow was previously documented in the butterfly Parnassius smintheus [26]. However, here we definitely go further by showing that altogether, the pattern of genetic differentiation we observed is in line with results of mechanistic studies showing the evolution of dispersal polymorphism along a gradient of habitat fragmentation [27]. Indeed, behavioural studies demonstrated that flying individuals actively refuse to cross habitat boundaries in recently fragmented landscapes [27], which generate significantly lower dispersal emigration rates among fragmented populations [10]. This lower dispersal rate corresponds to the lower neighbourhood size among populations from lowland areas. However, individuals deciding to disperse in fragmented landscapes survive dispersal better than those dispersing in continuous landscapes [10]. This better performance has to be related to changes in the dispersal behaviour itself, dispersing butterflies in fragmented landscapes switching from routine, exploratory movements with a slow, tortuous trajectory, to special directed movements designed for net dispersal [28, 29]. The absence of isolation by distance in fragmented landscapes coincides with the existence of such long-distance dispersal movements [30].
The latter point suggests that habitat fragmentation might have selected some phenotypic traits conferring better performances to dispersing individuals. Admittedly, a recent study elegantly showed that the frequency of a PGI allele was higher in more mobile Melitatea cinxia butterflies. Genotypes with this allele had elevated metabolic rate, which suggests selection on PGI or a closely related locus for better dispersal performance [31]. However, the main message of our paper is that changes in dispersal according to habitat fragmentation have evolutionary consequences exceeding by far such selection of dispersal related traits. We show here that isolation by distance vanished in fragmented landscapes, which corresponds to higher gene flow between local populations. Accordingly, we expect that the balance between local specialisation and gene flow should be perturbated, which would modify the extent to which populations are adapted to heterogeneous environments [32].
In lowland areas, long distance dispersal may lead to successful gene flow, as in the Ardennes the frequency of distance between populations is relatively high until 90 km. In contrast, in the Pyrenees and the Asturias, frequencies of pairwise distances drops dramatically at 30 km (Figure 2), leaving little chance to long distance dispersal, given the rarity of suitable habitat patches at that distance. Short distance dispersal, however, are favoured in these regions, leading to a higher neighbourhood size than in the Ardennes or the Morvan.
Conclusion
The opposite trend of neighbourhood size and isolation by distance effect seems paradoxical. As individuals tend to move more, one would expect that the neighbourhood size will increase and the isolation by distance effect will get weaker. In which conditions would such opposite trends occur? Dispersal kernels do not usually follow a simple inverse exponential equation [33], the populations may be considered polymorphic as to the tendency of emigration among the individuals, and consequently the curve of the frequencies of the distances between the location of birth and the location of reproduction may be seen as the sum of curves of the different dispersal genotypes, weighted by their frequencies. Furthermore "The existence of dispersal functions valid as species-specific traits is most probably a myth [34]," so that they should be better viewed as population-specific. In the studied cases, these curves could be modelled like in figure 3. Most of the individuals tend to stay within the area classically defined as the neighbourhood size (shaded probability surface). This area is larger for the "Mountain" region (nm) than for the "Hill" region (nh). The individuals which move away from the neighbourhood area may move very far; however, their probability of leading to long distance dispersal, say of distance d, is smaller in the "Mountain" region than in the "Hill" region. Such a result may analytically be viewed as the sum of two negative exponential kernels, one for small distances, up to the range of the neighbourhood size, and another one for long distance dispersal.

Suggested dispersal kernels in the two types of studied regions: Hills and Mountains. Shaded areas have the same probability surface between the regions. The neighbourhood size nh for hill regions is smaller than the one for mountain areas, nm. Long distance dispersal is more frequent in hill regions (dh) than in mountain areas (dm).
Our study shows that dispersal behaviour by individuals may hardly be modelled using a single one-parameter function, however convenient this may be. For free flying insects, the factors affecting dispersal at small distances, such as mate-locating or mate-avoidance behaviour [35] or feeding behaviour, may be quite different from factors affecting long distance dispersal, such as the large scale habitat structure [36]. Furthermore, a comparison of four different habitat networks showed that the inter-patch dispersal abilities of P. eunomia varied according to the level of habitat fragmentation [10]. Our genetic data confirm this result and add that dispersal between neighbouring patches (i.e. short distance) may be affected differently from long-distance dispersal.
Methods
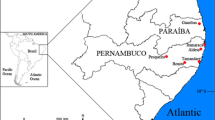
Between 1990 and 1995, a total of 53 populations of Proclossiana eunomia were sampled using butterfly nets [37, 38] in four regions: the Ardennes (N. France and S. Belgium [21]), the Morvan (central France [19]), the Pyrenees (France and Spain) and the Asturias mountains (Spain)(Figure 4). In each population at least 30 individuals were captured, and frozen at -80°C until analysis. Allozyme electrophoreses were performed on these samples; a total of 13 loci were tested, and of these eight proved polymorphic in the studied area (PGI, PGM, 6PGD, G6PDH, HBDH, AAT, MPI, AK). Microsatellites were not used, as loci usable for population genetic studies are generally few and difficult to identify in Lepidoptera [39, 40]. Genotypic analysis was performed using allozyme electrophoresis, as described in [21], adapted from [41].

Map showing the European distribution of P. eunomia (from [24, 48]), indicating the four sampled regions: (1) Ardennes, (2) Morvan, (3) Pyrenees, (4) Asturias.
Within the Ardennes and the Morvan, the populations were closer to each other than in the mountain areas of the Pyrenees and the Asturias, where each population was more isolated (Figure 2). If we make the hypothesis that each population inhabits a small suitable habitat surface within an unsuitable uniform area, we may compute the connectivity of each population within each region as [10], with (habitat patches are all the same size), and D ij the geographic distances between population i and population j. A value of 4 for α was found to be realistic for the Ardennes populations [10]. For each region the populations showed different degrees of connectivity (Table 1).
F statistics were calculated with the GENEPOP software [42]. Isolation by distance effect within each region was also tested by GENEPOP using a Mantel test between the matrices of pairwise FST between populations and geographic distances between the same locations. The strength of the effect was estimated as the slope of the regression of the log-log relationship between these variables [13]. A comparison of slopes and intercepts between regions was made using dummy variables in the REG procedure, then comparing AIC between different models [43]. The fit of the genetic differentiation matrix to the geographic distance matrix was tested using multidimensional scaling. For each of the four regions, matrices of pairwise FST were input into a 2-dimensional model, using R's mds procedure [44]. The resulting 2-dimensional structures were then compared to the geographic structure using Kruskal's Non-metric Multidimensional Scaling.
Neighbourhood size could be estimated by two methods. (i) Slatkin [13] suggested that the intercept of the log-log relationship between estimated number of migrant () between two populations and the geographical distance between them is related to the genetic neighbourhood. (ii) The migration between populations (Nm) may be estimated by the relationship [13].
Neighbourhood area may then be estimated by the intercept of the function of the pairwise FST = a+b/(4x+1), where x is the geographical distance between populations, and a and b the fitted parameter values [22].
This approach on dispersal was complemented by tests of assignments. GeneClass2 [45] was used for this purpose. The Bayesian method [46] was used to calculate the probability of individual assignment to source and non-source populations, based on allele frequencies in the original populations [47]. The distance between the source population and the population assigned with the highest probability was then compared with the distance between source populations and population assigned at random within each studied region. As assignment methods accuracy depend on the polymorphism of the studied populations, the procedure was performed first with the four loci which were polymorphic in each region (PGM, PGI, 6PGD and AK). For the Pyrenees and the Asturias datasets, the whole procedure was then repeated with the full data sets.
Abbreviations
- D ij :
-
geographical distance between populations i and j.
- :
-
estimated number of migrants between two populations.
- N :
-
number of individuals in one or a set of populations
- m :
-
proportion of migrants.
- Studied alleles: PGI:
-
phosphoglocose isomerase E.C.5.3.1.9.
- PGM:
-
phosphoglucomutase E.C.2.5.7.1
- 6PGD:
-
6-phosphoclodonate dehydrogenase E.C.1.1.1.44
- G6PDH:
-
glucose 6-phosphate dehydrogenase E.C.1.1.1.49
- HBDH:
-
β-hydroxybutirate dehydrogenase E.C.1.1.1.30
- AAT:
-
aspartate aminotransferase E.C.2.6.1.1
- MPI:
-
mannose-phosphate isomerase E.C.5.3.1.8
- AK:
-
adenilate kinase E.C.2.7.4.3.
References
Gilpin M: The genetic effective size of a metapopulation. Biol J Linn Soc. 1991, 42: 165-175. 10.1111/j.1095-8312.1991.tb00558.x.
Wright S: Evolution and the Genetics of Populations. Variability within and among Natural Populations. 1978, Chicago: University of Chicago Press, 4:
Epperson BK: Geographical Genetics. 2003, Princeton: Princeton University Press
Baguette M, Petit S, Queva F: Population spatial structure and migration of three butterfly species within the same habitat network: consequences for conservation. J Appl Ecol. 2000, 37: 100-108. 10.1046/j.1365-2664.2000.00478.x.
Baguette M, Van Dyck H: Landscape connectivity and animal behavior: functional grain as a key determinant for dispersal. Landscape Ecol. 2007, 22: 117-1129. 10.1007/s10980-007-9108-4.
Britten HB, Brussard PF, Murphy DD, Ehrlich PR: A test for isolation-by-distance in central rocky mountain and great basin populations of Edith's checkerspot butterfly (Euphydryas editha). J Hered. 1995, 86: 204-210. [http://jhered.oxfordjournals.org/cgi/content/abstract/86/3/204]
Blondel J, Thomas DW, Charmantier A, Perret P, Bourgault P, Lambrechts MM: A thirty-year study of phenotypic and genetic variation of blue tits in Mediterranean habitat mosaics. Bioscience. 2006, 56: 661-673. 10.1641/0006-3568(2006)56[661:ATSOPA]2.0.CO;2.
Heino M, Hanski I: Evolution of migration rate in a spatially realistic metapopulation model. Am Nat. 2001, 157: 495-511. 10.1086/319927.
Kokko H, Lopez-Sepulcre A: From individual dispersal to species ranges: Perspectives for a changing world. Science. 2006, 313: 789-791. 10.1126/science.1128566.
Schtickzelle N, Mennechez G, Baguette M: Dispersal depression with habitat fragmentation in the bog fritillary butterfly. Ecology. 87: 1057-1065. 10.1890/0012-9658(2006)87[1057:DDWHFI]2.0.CO;2.
Harrison S: Metapopulation and Conservation. Large Scale Ecology and Conservation Biology. Edited by: Edwards PJ, May RM, Webb NR. 1994, Oxford: Blackwell Scientific Publications, 111-128.
Hanski I: Metapopulation Ecology. 1999, Oxford: Oxford University Press
Slatkin M: Isolation by distance in equilibrium and non-equilibrium populations. Evolution. 1993, 47: 264-279. 10.2307/2410134.
Nathan R, Perry G, Cronin JT, Strand AE, Cain ML: Methods for estimating long-distance dispersal. Oikos. 2003, 103: 261-273. 10.1034/j.1600-0706.2003.12146.x.
Whitlock MC, McCauley DE: Indirect measures of gene flow and migration: FST≠1/(4Nm+1). Heredity. 1999, 82: 117-125. 10.1038/sj.hdy.6884960.
Tufto J, Engen S, Hindar K: Inferring patterns of migration from gene frequencies under equilibrium conditions. Genetics. 1996, 144: 1911-1921.
Neigel JE: Is FST obsolete?. Conserv Genet. 2002, 3: 167-173. 10.1023/A:1015213626922.
Descimon H: L'acclimatation de lépidoptères: un essai d'expérimentation en biogéographie. Alexanor. 1976, 9: 195-204.
Barascud B, Martin JF, Baguette M, Descimon H: Genetic consequences of an introduction-colonization process in an endangered butterfly species. J Evol Biol. 1999, 12: 697-709. 10.1046/j.1420-9101.1999.00069.x.
Descimon H, Zimmermann M, Cosson E, Barascud B, Nève G: Diversité génétique, variation géographique et flux géniques chez quelques Lépidoptères Rhopalocères français. Gen Sel Evol. 2001, 33 (suppl 1): S223-S249.
Nève G, Barascud B, Descimon H, Baguette M: Genetic structure of Proclossiana eunomia populations at the regional scale (Lepidoptera, Nymphalidae). Heredity. 2000, 84: 657-666. 10.1046/j.1365-2540.2000.00699.x.
Porter AH, Geiger H: Limitations to the inference of gene flow at regional geographic scales – an example from the Pieris napi group (Lepidoptera: Pieridae) in Europe. Biol J Linn Soc. 1995, 54: 329-348. 10.1111/j.1095-8312.1995.tb01041.x.
Nève G: Population genetics of butterflies. The Ecology of Butterflies in Europe. Edited by: Settele J, Shreeve TG, Dennis RLH, Van Dyck H. Cambridge: Cambridge University Press,
Nève G, Barascud B, Hughes R, Aubert J, Descimon H, Lebrun P, Baguette M: Dispersal, colonization power and metapopulation structure in the vulnerable butterfly Proclossiana eunomia (Lepidoptera, Nymphalidae). J Appl Ecol. 1996, 33: 14-22. 10.2307/2405011.
Louy D, Habel JC, Schmitt T, Assmann T, Meyer M, Müller P: Strongly diverging population genetic patterns of three skipper species: the role of habitat fragmentation and dispersal ability. Conserv Genet. 2007, 8: 671-681. 10.1007/s10592-006-9213-y.
Keyghobadi N, Roland J, Strobeck C: Genetic differentiation and gene flow among populations of the alpine butterfly, Parnassius smintheus, vary with landscape connectivity. Mol Ecol. 2005, 14: 1897-1909. 10.1111/j.1365-294X.2005.02563.x.
Schtickzelle N, Baguette M: Behavioural responses to habitat patch boundaries restrict dispersal and generate emigration-patch area relationship in fragmented landscapes with low quality matrix. J Anim Ecol. 2003, 72: 533-545. 10.1046/j.1365-2656.2003.00723.x.
Schtickzelle N, Joiris A, Van Dyck H, Baguette M: Quantitative analysis of changes in movement behaviour within and outside habitat in a specialist butterfly. BMC Evol Biol. 2007, 7: 4-10.1186/1471-2148-7-4.
Van Dyck H, Baguette M: The behavioural nature of dispersal in fragmented landscapes: routine or special movements?. Basic App Ecol. 2005, 6: 535-545. 10.1016/j.baae.2005.03.005.
Keyghobadi N, Unger KP, Weintraub JD, Fonseca DM: Remnant populations of the Regal Fritillary (Speyeria idalia) in Pennsylvania: Local genetic structure in a high gene flow species. Conserv Genet. 2006, 7: 309-313. 10.1007/s10592-006-9127-8.
Haag CR, Saastamoinen M, Marden JH, Hanski I: A candidate locus for variation in dispersal rate in a butterfly metapopulation. P Roy Soc B-Biol Sci. 2005, 272: 2449-2456. 10.1098/rspb.2005.3235.
Bohonak AJ: Dispersal, gene flow and population structure. Q Rev Biol. 1999, 74: 21-45. 10.1086/392950.
Clobert J, Lebreton JD: Estimation of demographic parameters in bird populations. Bird Populations Studies, Relevance to Conservation and Management. Edited by: Perrins CM, Lebreton JD, Hirons GJM. 1991, Oxford: Oxford University Press, 75-104.
Clobert J, Ims R, Rousset F: Causes, mechanisms and consequences of dispersal. Ecology, genetics and evolution of metapopulation. Edited by: Hanski I, Gaggiotti OE. 2004, Amsterdam: Academic Press, 307-335.
Baguette M, Convié I, Nève G: Male density effect on female spatial behaviour in the butterfly Proclossiana eunomia. Acta Œcol. 1996, 17: 225-232.
Baguette M, Mennechez M, Petit S, Schtickzelle N: Effect of habitat fragmentation on dispersal in the butterfly Proclossiana eunomia. C R Biologies. 2003, 326: S200-S209. 10.1016/S1631-0691(03)00058-1.
Smithers C: Handbook of Insect Collecting, Collection, Preparation, Preservation and Storage. 1982, Newton Abbott: David and Charles
Nabokov V: From Nabokov's diary, June 25, 1966. Nabokov's Butterflies. Edited by: Boyd B, Pyle RM. 2000, London: Penguin, 640-
Meglécz E, Péténian F, Danchin E, d'Acier AC, Rasplus JY, Faure E: High similarity between flanking regions of different microsatellites detected within each of two species of Lepidoptera: Parnassius apollo and Euphydryas aurinia. Mol Ecol. 2004, 13: 1693-1700. 10.1111/j.1365-294X.2004.02163.x.
Meglécz E, Anderson A, Bourguet D, Butcher R, Caldas A, Cassel-Lundhagen A, d'Acier AC, Dawson AD, Faure N, Fauvelot C, Franck P, Harper G, Keyghobadi N, Kluetsch C, Muthulakshmi M, Nagaraju J, Patt A, Péténian F, Silvain JF, Wilcock HR: Microsatellite flanking region similarities among different loci within insect species. Insect Mol Biol. 2007, 16: 175-185. 10.1111/j.1365-2583.2006.00713.x.
Richardson BJ, Baverstock PR, Adams M: Allozyme Electrophoresis. 1986, Sydney: Academic Press
Rousset F: GENEPOP'007: a complete re-implementation of the GENEPOP software for Windows and Linux. Mol Ecol Res. 2008, 8: 103-106. 10.1111/j.1471-8286.2007.01931.x.
SAS Institute Inc: SAS/STAT(R) User's Guide. Version 6. 1990, Cary, NC: SAS Institute Inc, 4
R Development Core Team: R: A language and environment for statistical computing. Vienna: R Foundation for Statistical Computing. 2007, [http://www.R-project.org]
Piry S, Alapetite A, Cornuet JM, Paetkau D, Baudouin L, Estoup A: GeneClass2: a software for genetic assignment and first-generation migrant detection. J Hered. 2004, 95: 536-539. 10.1093/jhered/esh074.
Rannala B, Mountain JL: Detecting immigration by using multilocus genotypes. Proc Natl Acad Sci USA. 1997, 94: 9197-9221. 10.1073/pnas.94.17.9197.
Paetkau D, Slade R, Burden M, Estoup A: Genetic assignment methods for the direct, real-time estimation of migration rate: a simulation-based exploration of accuracy and power. Mol Ecol. 2004, 13: 55-65. 10.1046/j.1365-294X.2004.02008.x.
Jakšić P, van Swaay C, Đurić M: Boloria eunomia (Esper, 1799): a new species for Serbia (Nymphalidae). Nota lepid. 2007, 30: 64-70.
Acknowledgements
We wish to thank Ph. Lebrun (Université catholique de Louvain, Belgium) for his support to the Belgian study. GN was supported by a Belgian FRIA grant and BB by a French MRT grant. Thomas Schmitt and an anonymous reviewer provided constructive comments.
Author information
Authors and Affiliations
Corresponding author
Additional information
Authors' contributions
GN and BB carried out the allozyme electrophoreses. HD, now officially retired from his professorship at the University of Provence, and MB conceived the study. All authors contributed to the field work. GN carried out the data analysis and drafted the manuscript. All authors commented the manuscript and approved the final version.
Electronic supplementary material
12862_2007_653_MOESM1_ESM.txt
Additional file 1: List of sampled localities, with allele frequencies and sample size. For each locality, the coordinates are given in latitude and longitude (Greenwich coordinates) and xy coordinates in m within each region. (TXT 10 KB)
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Rights and permissions
This article is published under license to BioMed Central Ltd. This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Nève, G., Barascud, B., Descimon, H. et al. Gene flow rise with habitat fragmentation in the bog fritillary butterfly (Lepidoptera: Nymphalidae). BMC Evol Biol 8, 84 (2008). https://doi.org/10.1186/1471-2148-8-84
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1471-2148-8-84