
Abstract
Image inpainting is a critical area of research in computer vision with a broad range of applications, including image restoration and editing. However, current inpainting models often struggle to learn the specific painting styles and fine-grained brushstrokes of individual artists when restoring Chinese landscape paintings. To address this challenge, this paper proposes a novel inpainting model specifically designed for Chinese landscape paintings, featuring a hierarchical structure that can be applied to restore the famous Dwelling in the Fuchun Mountains with remarkable fidelity. The proposed method leverages an image processing algorithm to extract the structural information of Chinese landscape paintings. This approach enables the model to decompose the inpainting process into two separate steps, generating less informative backgrounds and more detailed foregrounds. By seamlessly merging the generated results with the remaining portions of the original work, the proposed method can faithfully restore Chinese landscape paintings while preserving their rich details and fine-grained styles. Overall, the results of this study demonstrate that the proposed method represents a significant step forward in the field of image inpainting, particularly for the restoration of Chinese landscape paintings. The hierarchical structure and image processing algorithm used in this model is able to faithfully restore delicate and intricate details of these paintings, making it a promising tool for art restoration professionals and researchers.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Classical Chinese landscape paintings are invaluable treasures of Chinese culture, but many of the surviving works have been damaged or defaced due to historical events and storage issues. Despite the effort that artists have made to restore them through imitation, they have struggled to replicate the original painters’ unique style due to individual painting habits. With recent advances in machine learning and image processing, leveraging such technologies to restore ancient Chinese landscape paintings has emerged as a promising solution, as is shown in Fig. 1.

The final restored Dwelling in the Fuchun Mountains. The original painting has a portion lost in a fire and is divided into two sections, i.e., WuYongShi Scroll and ShengShan Scroll
Image inpainting, which aims to fill in missing parts of images, is a typical method used to restore paintings. However, restoring Chinese landscape paintings presents three significant challenges that current inpainting approaches [1–10] cannot directly address. First, Chinese landscape paintings often comprise intricate natural scenes, such as trees and rocks, and thus generating missing regions based solely on the remaining parts of an image may lead to nonsensical results or disrupt the overall coherence of the painting. Second, Chinese landscape paintings are typically created using barely black ink, with brushstrokes determined by the ink’s intensity changes, which can be challenging for models to learn. Finally, there are usually very few surviving works of a given artist, therefore, learning their unique artistic style from limited data is a formidable challenge.
To address these challenges, we proposed an inpainting model for Chinese landscape paintings, especially concentrating on the restoration of the masterpiece Dwelling in the Fuchun Mountains, one of the most well-known classical Chinese landscape paintings by the early 14th century master Huang Gongwang (1269-1354). Our main idea is to hierarchically restore the missing parts, from object structure to stroke details. Therefore, we name our framework Hierarchical Painter, which not only restores the missing objects but also generates vivid strokes that represent the painter’s style. Specifically, we integrate the structure of a 17th century imitation copy of the original painting, the ZiMing Scroll, instead of generating out of the air to avoid nonsensical and inconsistent results. Our approach also utilizes well-designed edge detection as well as detail generation methods to accurately reflect the intensity of brushstroke ink. To enhance details and generate content with fine-grained styles, we segment trees, a key feature of Chinese landscape paintings, and generate them separately. In this way, we successfully generate the missing portion of Dwelling in the Fuchun Mountains and seamlessly merge the generated results with the existing portions to complete the restoration, as shown in Fig. 1. It is noteworthy that our framework only needs a single image to train, which outperforms many image inpainting methods that are data-hungry. This also makes our framework to be easily scalable to other broken Chinese landscape images.
In summary, our contributions are threefold:
-
1)
To the best of our knowledge, we first proposed an image inpainting model specially designed for restoring Chinese landscape paintings except for commercial tools. This broadens the traditional image inpainting task’s application and sets a strong baseline for future research.
-
2)
We designed an image processing algorithm that explores the edge detection method for better extraction of structural information from Chinese landscape paintings. We further utilized the estimated edges by designing a hierarchy-aware image-to-image translation algorithm, with which we restore fine-grained brushstrokes and painting styles without large-scale training.
-
3)
We conducted extensive experiments on Dwelling in the Fuchun Mountains, which demonstrated the effectiveness of the proposed method, especially in detail restoration and style preservation.
2 Related work
2.1 Image generation
Image generation in our case specifically means unsupervised learning [11] and seed-based image synthesis [12, 13]. Generative adversarial networks [14], or GANs, are typical tools used for this purpose [15–17]. Previous works have already shown the feasibility of this method [18–23] and have proposed improvements and adaptations. Deep convolutional generative adversarial networks [24], or DCGAN, introduces convolutional neural networks and batch normalization [25] into unsupervised learning. It is adapted in a wide variety of implementations [26–32] and their generative results show promising quality and diversity [33, 34].
StyleGAN [35] enhances controls on specific details of the synthesis of the image. Its style-based generator architecture [35] allows for better preservation of semantic details [13, 36, 37]. Its variation, StyleGAN3, fixes the unhealthy dependence on absolute pixel coordinates [38–40], solving aliasing in signal processing of image synthesis. StyleGAN-XL [41] utilizes super-resolution [42] and stem-leaf staged training [13] that can produce meticulous images up to \(1024\times 1024\) resolution.
Despite the outstanding performance of current state-of-the-art image generation models, they are not suitable for our Chinese landscape painting restoration task due to their uncontrollable results. Moreover, such models are often built upon extra-large datasets and intense training resources [24, 43], and are not suitable for our task with limited data.
2.2 Edge detection
Edge detection is used to determine the contours of objects in an image. Currently, there are two popular types of edge detection algorithms: gradient-based [44–48] and CNN-based [49–57]. Canny edge detector [46], a popular gradient-based algorithm, adopts a Gaussian filter to smooth the image, thresholding intensity gradient magnitude to avoid spurious response and applying a double threshold to find the potential edge. The rich convolutional features (RCF) method [50], which is categorized as a CNN-based approach, extracts features from both the final layer and the intermediate layers. However, both types are not suitable for direct use in our Chinese landscape painting restoration task because gradient-based methods fail to learn the complex brushstrokes, while CNN-based approaches need to be trained over massive datasets.
2.3 Image inpainting
Image inpainting aims to fill in missing or corrupted parts of an image with plausible content. Currently, it can be classified into three categories: patch-based, diffusion-based, and GAN-based methods. Criminisi et al. [58] first proposed a patch-based inpainting method by sampling patches from known parts of the image and finding the best match for the missing parts. Such an idea has been extended by several future approaches [1–3]. Diffusion-based approaches [4–6] render missing regions based on the appearance of neighboring regions. Both types are not suitable for our Chinese landscape painting restoration task since predicting an unknown portion of a painting from existing ones is an ill-posed problem.
Some later GAN-based methods [7, 8] reached state-of-the-art performance by leveraging the generative adversarial network [14]. A generator is utilized to synthesize the missing parts directly, while a discriminator is adopted during adversarial training to assess the realism of the generated results. However, it is impossible to use these GAN-based methods for restoring Chinese landmark paintings because they all need to be trained over massive datasets.
2.4 Image-to-image translation
Image-to-image translation refers to transforming an arbitrary given image from one domain to another, while the two images share a certain style or structure. Pix2Pix [59] introduces the conditional GAN [60] into image translation, which was upgraded by Wang et al. [61] with multi-scale and coarse-to-fine discriminators. CycleGAN [62] regards the unaligned training sets as style domains and reduces the difficulty of constructing datasets. StarGAN [63] allows multi-domain training at the same time. Apart from these GAN-based approaches, VAE [64] uses a deep generative deconvolutional network as a decoder and convolutional neural network as an encoder to realize both supervised and unsupervised image translation. Our method leverages Pix2Pix [59] for generating the missing region while several designs including choosing proper image domains and normalizing are proposed.
3 Methods
3.1 Overview
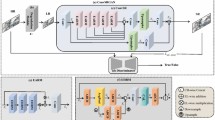
To address the challenge brought by the unique characteristics of Chinese landscape paintings, we propose the hierarchical painter, a multi-hierarchical inpainting model for Chinese landscape painting restoration. Figure 2 demonstrates the overall pipeline of the proposed method. First, we design a normalization algorithm for Chinese landscape painting including purifying backgrounds and eliminating noise, seals, and inscriptions (Sect. 3.2). Then, we separately generate background and details to ensure the restoration performance in both overall structure and detailed texture. Specifically, we offer distinct designs to efficiently extract the structure and obtain the segmentation of details (Sect. 3.3 and Sect. 3.4). Finally, we integrate the superposition of the background and details into the original image by inpainting models to maintain the overall consistency of the final restored image (Sect. 3.5).

The pipeline of the proposed hierarchical painter. Both the imitation image and the original image are pre-processed. The background and details of the painting are generated separately before the generated image is connected with the original portion to get the final restored image
3.2 Image pre-processing
Chinese landscape paintings share a common attribute in that their contents are grayscale, and the background is typically blank. However, due to technological limitations in the conservation of paintings during ancient times, many surviving works have backgrounds that contain unwanted noise. These noise artifacts can have a detrimental effect on the performance of our model. To address this challenge, we pre-processed the input images by reducing or eliminating irrelevant noise and unifying the background color. This allowed us to achieve more accurate and precise inpainting results, even in the presence of challenging noise artifacts.
We first calculated the mean value μ of the gray images. Then, we set a threshold value \(\epsilon =\mu +3\), with 3 being a hyperparameter of compensation. ϵ is used in the filter \(F_{\epsilon}\) to eliminate the noise in the background and unify its color purity. For each pixel \(a_{ij}\), we apply
To normalize each input image, the background should be unified to white, while the color-depth relationship of the content within each image should also be preserved. Thus, we design a linear function \(\Phi _{\gamma ,\epsilon}\) to set the background to be pure white:
where \(\gamma =255\), the value of white in RGB. To enlarge the contrast among lines, a mapping needs to be designed so that points that are greater than μ should be mapped to where close to γ, while the points that are smaller than μ should be mapped to where close to 0. Inspired by [65], we design a mapping to enlarge the image color contrast:
where φ is a parameter that controls the mapping range. The effect of such transformation is shown in Fig. 3 from (a) to (c).

Demonstration of the image pre-processing process
Figure 4 compares images generated through the method given in Sect. 3.5 using datasets with and without pre-processing. We find that the output image without preprocessing displays evident inconsistencies in colors, which provides evidence for the necessity of pre-processing to keep colors consistent.

Comparison between the results using datasets with and without pre-processing
3.3 Background generation
Background generation is a key component of our proposed model, as it aims to transfer the style of objects in the background of the imitation copy to those in the original painting. In our specific case, it is critical to preserve the content’s structure in the background of the ZiMing Scroll, including the trend of mountains and rivers, while also translating the style of the content, such as shading, ink techniques, and stroke texture, to match the original painting’s style. By incorporating these factors into our background generation algorithm, we were able to achieve highly realistic and faithful restorations of Chinese landscape paintings.
Conventional methods for style translation often result in blurred outputs and difficulty in constructing large training datasets [61].
To address this, we split this process into two stages: structure extraction and style translation. This method ensures a smooth and consistent style translation, preserving the integrity and continuity of the artwork. To be more specific, we first transform the imitation image to its edge map (structure extraction), then we convert this map to the style of the original image (style translation).
Selecting the appropriate edge maps is crucial. The algorithm to generate the edge maps should be designed to have the following characteristics:
-
1)
Be able to extract the structure of the main content in the painting, such as the trends of lines composing mountains and rivers.
-
2)
Be able to abstract the content and filter style information, including shading, ink techniques, and stroke texture.
-
3)
Be able to create a reversible mapping model between the edge map and the original painting based on existing research.
-
4)
Be able to keep the entire consistency between images after combination.
In the following subsections, we will present a comprehensive approach for selecting an appropriate edge map and will explain its functionality in detail. Additionally, we describe the methodology used for achieving style translation based on previous research.
3.3.1 Structure extraction
Chinese landscape paintings are renowned for their unique composition, which consists solely of lines that form complex shapes and structures. However, extracting the structure of these paintings is a challenging task that cannot be accomplished easily using common edge detection methods, such as Canny, or CNN-based methods, like RCF. The reason for this difficulty is that these methods typically detect the contours of objects in an image, rather than the lines themselves. In the case of Chinese landscape paintings, the lines represent the structure of the painting, making it challenging to apply traditional edge detection techniques. To overcome this challenge, we investigated the XDoG algorithm [65], which can directly extract the lines from the painting, resulting in a more accurate representation of its structure. By incorporating this algorithm into our proposed model, we were able to achieve highly faithful and detailed restorations of Chinese landscape paintings.
XDoG [65] applies two layers of Gaussian-blur functions \(G_{\sigma}\) with different kernel sizes σ and kσ to determine the edge of an image, where k is a preset constant. Intuitively, regardless of how large the σ is, the blurred image will always preserve the rough location and structure information of the main body within an image, and the difference between the two blurred images with different kernel sizes σ and kσ, i.e. \(\Delta G_{\sigma , k} = G_{k\sigma} - G_{\sigma}\), provides some information about the main body while clearing details and noise [65]. With a larger kernel size difference, the output of the main body will be more abstract so that more structure information will be reserved, while details will be removed [66]. With suitable (σ, k), the shape of the lines will be modified, losing details of the style features, but making the outline of the structure simpler and more abstract, as demonstrated in Fig. 3(d).
XDoG can extract the content’s structure of the painting clearly with a controllable level of abstraction. In addition, one advantage of XDoG is that it can work on an entire high-resolution image, and the abstraction process takes the whole painting into consideration. This attribute ensures the entire structure and abstraction consistency. Therefore, we choose XDoG as the algorithm for structure extraction in our model. In Sect. 5.4, we will describe in detail its advantages over other common edge detection methods in structure extraction.
3.3.2 Style translation
In this step, we translate the edge map to painting images and choose Pix2Pix [59] as our prototype.
Technically, an encoder-decoder with skip connections between mirrored layers is applied to the generator and the Markovian discriminator (PatchGAN) is used for the discriminator. In our task, the inputs are the edge-mapped imitation images, and the outputs are the fake images in the original images’ style, as displayed in Fig. 5.

Style translation through XDoG and Pix2Pix-based models
Notably, we do not choose more advanced models such as Pix2Pix HD [61] and CycleGAN [62]. While these models have made significant improvements such as supporting non-aligned training sets, reducing the need for paired data, and optimizing image resolution by using coarse-to-refined generators, they suffer from the problem of excessive output content freedom. In our pipeline, the original images are cropped into patches for training due to the large resolution of the original image. Therefore, in the test phase, the generation results need to be composed to generate the final output image. Consequently, if the output image has too much freedom, it can easily result in discontinuity in content, as shown in Fig. 6. In addition, as the background images in our dataset contain details, it is not suitable to use those models that require great constraints on detailed information. In summary, we simply adopt a Pix2Pix-based model because it finds the balance between structure conservation and style translation.

Examples of the stitching effect tested on (a) ZiMing Scroll (left) and (b) WuYongShi Scroll (right) using CycleGAN
3.4 Details generation
The image-to-image translation model is effective in natural image processing but less effective in restoring Chinese landscape paintings due to the complex structure of foreground trees, which is more like a blocky entity. The current model is unable to identify each stroke separately within the blocks. Additional image processing and model learning are required to learn the color transition within trees, considering their unique characteristics.
To address this issue, we propose a solution that includes creating a segmentation mapping to classify each pixel within the images and provide more information on how the color transitions within each stroke. Then, we employ the SPADE [67] model to learn the color style within each class and how the color transitions between classes.
3.4.1 Segmentation mapping
To learn how to transit color from light to dark within each stroke, especially in determining the stroke style of trees inside the painting, stroke information should be extracted and classified from the perspective of color depth. Segmentation mapping is designed to map each pixel \(a_{ij}\) to a color class: shallow class \(c_{s}\), transition class \(c_{t}\), dark class \(c_{d}\), and background class \(c_{b}\), i.e. \(a_{ij}\mapsto \{c_{s}, c_{t}, c_{d}, c_{b}\}\). With the mean value μ of the image and two preset thresholds \(\epsilon _{1}\) and \(\epsilon _{2}\), the model will map each pixel \(a_{ij}\) to different color-depth features with mapping \(\rho _{\epsilon _{1},\epsilon _{2},\mu}\):
If \(\rho _{\epsilon _{1},\epsilon _{2},\mu}\) is applied on the normalized images, we will obtain the result as shown in Fig. 7(b). There will be many isolated points due to the discontinuity of pixel values. Such points should all be considered noise and should be reclassified. Based on Fig. 7(b), we apply Gaussian blur \(G_{\sigma}\) and then calculate \(\rho _{\epsilon _{1},\epsilon _{2},\mu}\) again, and we will obtain the result as displayed in Fig. 7(c). Most of the noise in both the orange and blue squares is removed. Such a process could reflect strokes more clearly and tell which part of the painting should have a darker stroke and how each stroke should transit in color in a more fluent way. Using this process, the normalized input is mapped to a segmentation image as illustrated in Fig. 3(e). We call this process “double classification”.

Demonstration of double classification using Gaussian blur
The advantage of this algorithm is that it ignores the noise within each stroke and generates a continuous boundary between dark parts and light parts. With this algorithm, each stroke can have a more complete structure in color transition, giving more precise guidance to the downstream generation model.
3.4.2 Mapping guided generation
Chinese landscape paintings are known to have marvelous alternating details with the trace of ink and the hardness of each stroke of the brush. Inspired by SPADE [67], we design a structure-aware generation framework that preserves and recovers the magnitude of integrity and style of the original painter. The model takes in segmentation mappings and trains each segmentation class in parallel with their class indexes. Similar to Pix2Pix, SPADE is trained with an initial learning rate of 0.0002 for 50 epochs and then a linearly decreasing learning rate for another 1000 epochs. It normally takes a day for the loss curve to saturate.
As depicted in Fig. 8, our model takes in the segmentation maps instead of plain RGB pictures. Each patch stands for a particular segmentation class and is colorized for visualization purposes. To ensure that the delicate details of the brush traces are preserved and translated accurately, we further design the following steps for the input segmentation maps.

Input segmentation mask with class labels
To provide better structure guidance for the generation model, a three-step segmentation mapping based on the XDoG edge map is introduced. First, the sketches are split into two classes based on the brightness of each pixel, and these classes are trained in parallel. Second, an extra transition layer is added between the two existing layers to create a smooth and natural transition between the hard and shallow strokes. Finally, Gaussian blur is applied to the image to merge discrete pixels into large continuous patches. This pipeline aims to provide more accurate and solid structure guidance for the generation model.
3.5 Inpainting integration
To improve the integration of the generated part with the original image, we intentionally inserted a mask between the joined parts and applied image inpainting to fill it. This approach allows the generated result to consider the overall consistency with the original image rather than solely relying on the structure from the imitation image.
We apply a model similar to CTSDG [68], which focuses on regenerating defective regions within an image while preserving its overall consistency. The model first transforms the input image into an edge map, and then fills the corrupted part based on the edge map to ensure the structural correctness of the fill content. Finally, the filled edge map is added with the texture of the original image. After research on several edge detection methods, we change the edge detection model in CTSDG from canny detection to RCF to further emphasize the structure and preserve some space for random generation.
To integrate the generated part seamlessly into the original image, we begin by placing the generated image into the missing part of the original image. Next, we add rectangle masks to the edge of the missing part with a fixed width. These masks are later filled with textures and structures generated by the inpainting model. The process is illustrated in Fig. 9. This allows the generated result to blend well with the original image and maintains overall consistency.

Added masks and generated results
4 Results
Our methods of Chinese landscape painting restoration (Fig. 1) has displayed outstanding performance. The restored image reveals fine-grained details in a full resolution of 2363 pixels in height. Moreover, the layout of the restoration figures is consistent with the imitation painting, providing fundamental evidence of rationality and authenticity. Courtesy of customized inpainting methods, our restoration reconciles seamlessly with the original painting. Our finetuned styles for the trees are also unified in coherence with the original, both in sketches and in colorization styles.
To further validate the effectiveness of our methods, we compare our result with the restoration result of a commercial tool WENXINFootnote 1 created by Baidu.
To combat the inconsistencies between the generated image and the original ones, WENXIN leaves a space much wider than the actual missing part from the original painting, as shown in the arrow below the overall figure in Fig. 10. Its model is based purely on unsupervised image generation and pays little attention to the shape or style of the original image. Our research finds that WENXIN’s generation results are similar to a refracted copy of another sector of the painting from ZiMing Scroll. When interacting with users through sketch inputs, WENXIN also achieves less satisfactory results with respect to the coherence and consistency of objects.

Comparison of the overall effect and detail between WENXIN’s restoration result and ours
The style of the trees is also prone to be less consistent. In many cases, WENXIN generates merely a chaotic cloud of black ink where there should be trees. The trees it generates depict a vastly different style than the original. Our results, on the other hand, are built directly upon the imitation ZiMing Scroll, which guarantees that the general layout and object structure are coherent with the original image.
We also conduct a group t-test on the average score. The t-statistic results are presented in Table 1. Except for the style consistency, our model outperformed WENXIN in terms of statistical significance, with a p-value of less than 0.001.
To further evaluate our restoration result, we conducted a parallel comparison survey with WENXIN’s result. We distributed the survey to a diverse group of subjects and invited them to rate our model and WENXIN on four dimensions: structural integrity, style consistency, the naturalness of transition, and detail restorations such as tree strokes. We used a scale of 1 to 10 for each dimension and collect confidence intervals for each rating.
A total of 233 subjects (except for our group members) were involved in the survey, including 27% who are specialists in the field of arts, as shown in Fig. 11. As art specialists have more professional knowledge about Chinese landscape painting, as is reflected in Fig. 12, their scores in the comparison survey are more convincing and credible. To ensure the balance between objectivity and professionalism, we weighed the ratings from these specialists by a factor of 1.5.

Statistics of the survey on the comparison between WENXIN’s restoration result and ours. A total of 233 participants completed the survey, including 67 experts, students, practitioners of art, and 170 other non-art-related individuals

Score distributions of participants’ knowledge of Chinese landscape painting. Both sample groups are normally distributed in terms of scores. Generally, experts, students, and practitioners of art have higher scores than others, thus are able to offer more convincing scores in the comparison survey
According to the statistics in Fig. 11, both groups in general give higher scores on our result in the perspective of overall consistency, style consistency, transition interpretation, and detail restoration (in trees). Especially, art specialists give much higher scores on our results than on WENXIN’s. Such a rating indicates that our model has better performance on image restoration than WENXIN.
It is worth noting that WENXIN relies on traditional methods of training a large model with a vast amount of data, which is a luxury for those with limited datasets. In contrast, our research is only based on the original painting and the imitation copy. The survey result (Fig. 11) confirms that through careful designing our model, despite a smaller dataset and limited computing power, our results are superior to those of WENXIN in all the four aspects, including overall effect, style consistency, transition, and details. It is also worth mentioning that our style is not only consistent within the generated image, but also coherent with the style of the original Dwelling in the Fuchun Mountains, which can be illustrated by the gray-scale histogram analysis shown in Fig. 13.

Gray-scale histogram analysis
5 Experiments
5.1 Experimental setup
We conduct our experiments on the Chinese landscape painting Dwelling in the Fuchun Mountains, which contains two original parts and an imitation work.
WuYongShi Scroll and ShengShan Scroll are two sections from the original painting, with the middle part lost. These two parts act as the ground truth in our experiments. Our work mainly focuses on mimicking the style and gestures of these two paintings. Our electronic copy of WuYongShi Scroll has a resolution of \(89{,}911\times 4854\) pixels, while ShengShan Scroll has a resolution of \(8253\times 5197\) pixels.
ZiMing Scroll is a complete copy of the original painting, which was mimicked by an unknown artist in the 17th century or earlier. This painting is intact in image form, but it compromises the style of the original by mixing in this artist’s own painting style. This image has a resolution of \(41{,}588\times 2363\) pixels.
We crop the large paintings into \(256\times 256\) or \(512\times 512\) pixel images with a 75% overlap with each other. Smaller images are designed for rapid learning of calligraphic details and larger images are designed for further enhancements of structural integrity, as a tree can typically be covered completely in a \(512\times 512\) patch. We also apply basic data-enrichment methods such as flipping, rotating, and multi-scaling to further enrich the training sets. A combination of the OpenCV detection algorithm and OCR engine is utilized to remove the stamps and calligraphy on the painting to prevent irrelevant information from being fed into training. After image cropping and data augmentation, we created a dataset of 19,074 patches. Self-contained training on our own datasets guarantees the consistency and authenticity of the restoration, as Chinese landscape paintings vary greatly in style, even in the scope of the same author.
5.2 Implementation detail
We split the pipeline into image translation, image inpainting, and detail enhancement. All the experiments are conducted with 4 NVIDIA GeForce RTX 3090 GPUs.
The style translation model is used to transform the style of the imitation copy into that of the original image. This model requires an aligned dataset. We feed the \(256\times 256\) image pairs into the model and set the starting learning rate to 0.0002. After training for 100 epochs, we linearly decrease the learning rate to 0 in approximately 1000 epochs. This process takes approximately 18 hours.
The mapping guided generation model is used for detail enhancements. The number of base filters for the generator and discriminator is reduced to 48 to accommodate our small dataset.
The image inpainting model is introduced for the connection of the generated image and the original ones. This model first connects the edge map and then colorizes the sketches to restore the original style. This model is trained with an initial learning rate of 0.0002 and a fine-tuned learning rate of 0.00005, and requires approximately 40,000 epochs to saturate.
5.3 Evaluation metrics
Our main objective is to ensure that the imitation that we have generated reconciles with the originals. Although commonly used quantitative evaluation metrics such as FID [69] and SSIM [70–72] exist, they are not appropriate for our goal because the patch we are seeking to generate lacks a ground truth to which we may compare it. Finally, the subjective evaluation approach is adopted, where we assess the degree to which the generated part is consistent with the originals based on human perception. When evaluating our results, we emphasize the overall integrity, style consistency, transition coherency, and details of the trees.
5.4 Ablation study
As our painter is hierarchical, we conduct ablation studies in each step to verify their effectiveness.
5.4.1 Structure extraction
The XDoG algorithm is chosen as our structure extraction tool. Among the common edge detection methods [52, 73–78], we perform comparative analysis with some of the most typical models, i.e., Canny and RCF. All the datasets processed by each of the edge detection methods are fed into Pix2Pix and are trained with the same parameters.
Figure 14 depicts the comparative results. The leftmost column shows the patches from the original copy and those from similar locations on the imitation copy. We select three representative objects for comparison, including stones, houses, and mudflats. The results reveal that XDoG outperforms the other two methods in terms of style translation. This is because XDoG gives better control in detail selection from the perspective of structural extraction. It enhances the contour of the objects while omitting some surrounding decorative strokes. Such selection enables Pix2Pix to better interpret the style translation of the objects and leaves the model with enough degrees of freedom to imitate and generate decorative strokes. We can see that the style translation in the stones succeeds in learning the style of strokes and generating the surroundings. In contrast, the Canny algorithm fails to determine the surrounding edges of small objects. The continuity and integrity of the edges are poor, not to mention the neglected abstractions, resulting in inadequate translation and color displacements. The RCF model, on the other hand, preserves too much structure information, which limits the model’s explanatory freedom, resulting in noisy outputs that contain information irrelevant to the original copy.

Comparison of style translation in background detail (stone, house, and mudflat) with different edge detection algorithms. Row a is the original content in ZiMing Scroll. Row B is the similar content in WuYongShi Scroll to show the original style. The row edge shows the edge detection results using Canny, RCF, and XDoG, and the row output shows the corresponding results through Pix2Pix
In terms of the efficiency of preprocessing the datasets, XDoG also expresses superiority by extracting the structure in its entirety. In the preprocessing phase, XDoG can directly process the entire high-resolution painting, while RCF is limited by its excessive RAM occupation. Figure 15 depicts an example of inconsistencies in RCF edges on the boundaries of patches.

Comparison of the consistency of the boundaries. There is an evident trace at the center of the RCF’s result
5.4.2 Style translation
To quantitatively evaluate the effectiveness of our style translation model, we visualize the image features with the gray-scale histogram. The x-axis of the histogram represents the gray value ranging from 0 to 255, while the y-axis represents the number of pixels. As depicted in Fig. 13, the gray-scale histogram of the original image has a smoother overall contour than that of the imitation copy. The concave-convex positions are also different, with the original and generated images demonstrating convexity at approximately 130 gray levels, while the imitation image demonstrates concavity. Additionally, the pixel counts in specific gray values reach unexpected peaks, which are critical indicators of the painting style, including ink characteristics and brushstrokes, according to experts in the field of Chinese landscape painting.
Our ablation study reveals that our generated image demonstrates a smoother contour compared to the imitation copy. Moreover, the gray values of the unexpected pixel peaks in the generated image become closer to those of the original one. The distributions of the gray histograms between the generated and original images are similar. As a result, our style translation model has produced promising pixel value distribution results.
5.4.3 Detail generation model
Our prior steps have already generated promising results. However, due to the efficacy of their edge detection techniques, their capacity is too limited to generate tree representations that should exhibit diverse forms and styles. More specifically, they fail to discern and isolate the density and concentration of ink strokes in individual sections of the trees. Considering this, we further incorporate another generative layer to pursue more detailed results.
To enhance the performance of our model, we design a 3-layer segmentation map accompanied by a layer of Gaussian blur. Figure 16 illustrates the comparison of different segmentation mapping processes, where (A) is the benchmark testing by inputting the segmentation map directly into Pix2Pix; (B) introduces our model with one segmentation map for the trees; and (C) differentiates stems from the leaves. From (A) and (B), it can be observed that our model outperforms its predecessor Pix2Pix. However, with the horizontal shadings’ information eliminated, this configuration fails to recover the horizontal brushstrokes of the trees. Segregating into two classes allows for discrepancies between shallow and dark brushstrokes, yet the transition is too stiff to be considered as a natural transition. A third layer is thus added to smoothen the transition between classes. Finally, the Gaussian layer merges the discrete pixels into continuous patches, which is crucial since the traces left by the brushstrokes should be continuous. The generated results also demonstrate significantly improved consistency and resistance against large chunks of trees, as demonstrated in (D4) and (E4) in Fig. 16. Through the three classes and the Gaussian layer, we manage to make the segmentation mapping remarkably close to the actual looks of brushstrokes.

Different stages of using the detail generation model: (A) is the benchmark testing by inputting the segmentation map directly into Pix2Pix; (B) introduces our model with one segmentation map for the trees; (C) differentiates stems from the leaves; (D) surrounds a transition layer around the border of the layers; (E) adds a Gaussian layer to introduce a more continuous result
The ablation test reveals the superiority of our segmentation layering design, which ensures smooth connections between hard and soft calligraphical strokes. Moreover, the extra Gaussian blur layer significantly enhances the structural integrity and fluency, resulting in high-quality synthesized images with impeccable details. Designing segmentation mapping in this way guarantees a good restoration patch that is faithful to the original.
5.4.4 Image inpainting
The image inpainting model is adopted to ease the transition between the original painting and the translated painting after stitching them together. The transition parts are cropped separately into \(256\times 256\) images with a 75% overlap. Masks that take up 15%, 30% and 45% of the width of the cropped images are generated and tested. The results are demonstrated in Fig. 17. The leftmost column displays our input images cropped directly from the joint parts of the stitched image, where the seams are easy to spot. The three columns on the right show the results generated by the model with masks of different widths. These generated images are a good illustration of our inpainting model’s ability to coherently connect the contents of both ends of the mask together, eliminating the rigidity at the joints caused by direct stitching. However, when we scrutinize the detailed images, we find that while the results of wider masks are more coherent, it has difficulty in generating detailed objects such as trees, stones, and houses that can match both sides of the mask. Thus, we concluded that the inpainting model achieves a better effect when the width of masks is 15%.

Comparison of inpainting results with masks of different widths (15%, 30% and 45%)
5.5 Model comparison
To demonstrate the superiority of our model, we fed the same set of images into other state-of-the-art inpainting models for comparison. Figure 18 is the result of the stable diffusion inpainting model [9]. Figure 19 is the result of the LAMA-Fourier model [10]. Both models fail to achieve our goal of restoring Chinese landscape paintings because they are unable to achieve a high degree of consistency in the trend of mountains and the intricate shapes of trees. Traditional inpainting models either directly copy another patch from other parts of the painting, or merely stretch and extend existing resources. These actions will inevitably bring inconsistencies to the overall style and coherence of the painting. In comparison, our model, with results displayed in Fig. 20, achieves an outstanding performance from both perspectives.

The result generated using the Stable Diffusion Inpainting model: (A) is WuYongShi Scroll; (B) is generated; (C) is ShengShan Scroll

The result generated using the LAMA-Fourier model: (A) is WuYongShi Scroll; (B) is generated; (C) is ShengShan Scroll

The result generated using our model: (A) is WuYongShi Scroll; (B) is generated; (C) is ShengShan Scroll
6 Conclusion
In this paper, we present a novel hierarchical painter that aims to restore Chinese landscape paintings. Our proposed framework is capable of generating high-quality inpainting results and fine-grained details that closely resemble the original painting. By separating the background and details of the image, our model ensures that the overall structure is consistent while the details can exhibit stroke effects that mimic the brushwork of the original artist. Moreover, we discover an effective method for generating structures and translating styles that are specific to Chinese landscape painting. Our experimental results demonstrate that our hierarchical painter can successfully restore damaged Chinese landscape paintings to their original glory.
7 Discussion
Although our proposed method achieves satisfying results in restoring Chinese landscape paintings, there are still limitations that need to be addressed. First, it is impossible to generate the missing part completely based on the original image without referring to the information provided by the imitation copy. Therefore, the style of the generated part may be affected by the imitation copy. Additionally, the in-painted part lacks details, which may result in failure to fill in concrete objects that can truly connect the generated part and the original painting. Future research can explore and solve these issues to better restore paintings using artificial intelligence.
Additionally, during our experiments, we encountered a challenge when generating detailed trees using the SPADE model. The model struggled to automatically optimize the edges of the selected area, resulting in the edges of the generated trees being restricted by the mask and containing many small irregular shapes. To address this issue, we explored recent developments in the field of visual intelligence, specifically the stable diffusion model (SDM). This model is a text-manipulated image synthesis model that builds upon the previous findings of the latent diffusion model [9]. The SDM can generate remarkably natural and delicate images, with the correct parameters and datasets to fine-tune an existing generator. Our experiments showed that the SDM can generate tree styles similar to those in the original painting, with smooth and streamlined edges (Fig. 21).

Generated image of the stable diffusion model
However, a drawback of the SDM is that it is challenging to construct appropriate constraints for the model, and it may be necessary to manually select results from thousands of output images that match the shape and overlap of the generated terrain features. This workload significantly exceeds the limits of our team, so we were unable to integrate this method into our pipeline. Nonetheless, recent research on diffusion models [79] shows the feasibility of constructing such constraints. Thus, the SDM may hold the key to a smooth and natural image synthesis that can faithfully restore any painting, given an accurate and informative network guide.
Availability of data and materials
The datasets generated during the current study are not publicly available, but are available from the corresponding author on reasonable request.
Abbreviations
- CNN:
-
Convolutional Neural Networks
- CTSDG:
-
Image Inpainting via Conditional Texture and Structure Dual Generation
- GAN:
-
Generative Adversarial Networks
- OCR:
-
Optical Character Recognition
- RAM:
-
Random-Access Memory
- RCF:
-
Rich Convolutional Features
- SDM:
-
stable diffusion model
- SPADE:
-
Semantic Image Synthesis with Spatially-adaptive Normalization
- XDoG:
-
Extended Difference-of-Gaussions
References
Isogawa, M., Mikami, D., Iwai, D., Kimata, H., & Sato, K. (2018). Mask optimization for image inpainting. IEEE Access, 6, 69728–69741.
Liu, J., Yang, S., Fang, Y., & Guo, Z. (2018). Structure-guided image inpainting using homography transformation. IEEE Transactions on Multimedia, 20(12), 3252–3265.
Guo, Q., Gao, S., Zhang, X., Yin, Y., & Zhang, C. (2018). Patch-based image inpainting via two-stage low rank approximation. IEEE Transactions on Visualization and Computer Graphics, 24(6), 2023–2036.
Ballester, C., Bertalmío, M., Caselles, V., Sapiro, G., & Verdera, J. (2001). Filling-in by joint interpolation of vector fields and gray levels. IEEE Transactions on Image Processing, 10(8), 1200–1211.
Li, H., Luo, W., & Huang, J. (2017). Localization of diffusion-based inpainting in digital images. IEEE Transactions on Information Forensics and Security, 12(12), 3050–3064.
Sridevi, G., & Kumar, S. S. (2019). Image inpainting based on fractional-order nonlinear diffusion for image reconstruction. Circuits, Systems, and Signal Processing, 38(8), 3802–3817.
Yu, J., Lin, Z., Yang, J., Shen, X., Lu, X., & Huang, T. S. (2018). Generative image inpainting with contextual attention. arXiv preprint. arXiv:1801.07892.
Lin, C. H., Cheng, Y.-C., Lee, H.-Y., Tulyakov, S., & Yang, M.-H. (2022). InfinityGAN: towards infinite-pixel image synthesis. In Proceedings of the tenth international conference on learning representations (pp. 1–43). ICLR.
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., & Ommer, B. (2022). High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 10684–10695). Los Alamitos: IEEE.
Suvorov, R., Logacheva, E., Mashikhin, A., Remizova, A., Ashukha, A., Silvestrov, A., et al. (2022). Resolution-robust large mask inpainting with Fourier convolutions. In IEEE/CVF winter conference on applications of computer vision (pp. 2149–2159). Los Alamitos: IEEE.
Liu, M.-Y., Breuel, T., & Kautz, J. (2017). Unsupervised image-to-image translation networks. In I. Guyon, U. Von Luxburg, S. Bengio, et al. (Eds.), Advances in neural information processing systems (Vol. 30, pp. 700–708). Red Hook: Curran Associates.
Shamsolmoali, P., Zareapoor, M., Granger, E., Zhou, H., Wang, R., Celebi, M. E., et al. (2021). Image synthesis with adversarial networks: a comprehensive survey and case studies. Information Fusion, 72, 126–146.
Karras, T., Aila, T., Laine, S., & Lehtinen, J. (2017). Progressive growing of gans for improved quality, stability, and variation. arXiv preprint. arXiv:1710.10196.
Goodfellow, I. J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., et al. (2020). Generative adversarial networks. Communications of the ACM, 63(11), 139–144.
Wang, C., Xu, C., Yao, X., & Tao, D. (2019). Evolutionary generative adversarial networks. IEEE Transactions on Evolutionary Computation, 23(6), 921–934.
Roth, K., Lucchi, A., Nowozin, S., & Hofmann, T. (2017). Stabilizing training of generative adversarial networks through regularization. In I. Guyon, U. Von Luxburg, S. Bengio, et al. (Eds.), Advances in neural information processing systems (Vol. 30, pp. 2018–2028). Red Hook: Curran Associates.
Li, Y., Mo, Y., Shi, L., & Yan, J. (2022). Improving generative adversarial networks via adversarial learning in latent space. In S. Koyejo, S. Mohamed, A. Agarwal, et al. (Eds.), Advances in neural information processing systems (Vol. 35, pp. 8868–8881). Red Hook: Curran Associates.
Ho, L.-N., Tran, A. T., Phung, Q., & Hoai, M. (2021). Toward realistic single-view 3D object reconstruction with unsupervised learning from multiple images. In 2021 IEEE international conference on computer vision (pp. 12600–12610). Los Alamitos: IEEE.
Dalca, A. V., Yu, E., Golland, P., Fischl, B., Sabuncu, M. R., & Iglesias, J. E. (2019). Unsupervised deep learning for Bayesian brain MRI segmentation. In D. Shen, T. Liu, T. M. Peters, et al. (Eds.), Proceedings of the 22nd international conference on image computing and computer assisted intervention (pp. 356–365). Berlin: Springer.
Jakab, T., Gupta, A., Bilen, H., & Vedaldi, A. (2018). Unsupervised learning of object landmarks through conditional image generation. In S. Bengio, H. Wallach, H. Larochelle, et al. (Eds.), Advances in neural information processing systems (Vol. 31, pp. 4020–4031). Red Hook: Curran Associates.
Dosovitskiy, A., Springenberg, J. T., & Brox, T. (2015). Learning to generate chairs with convolutional neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1538–1546). Los Alamitos: IEEE.
Luo, Y., Zhu, J., He, K., Chu, W., Tai, Y., Wang, C., et al. (2022). Styleface: towards identity-disentangled face generation on megapixels. In S. Avidan, G. J. Brostow, M. Cissé, et al. (Eds.), Proceedings of 17th European conference on computer vision (pp. 297–312). Berlin: Springer.
Yan, Y., Xu, J., Ni, B., Zhang, W., & Yang, X. (2017). Skeleton-aided articulated motion generation. In Q. Liu, R. Lienhart, H. Wang, et al. Proceedings of the 2017 ACM on multimedia conference (pp. 199–207). New York: ACM.
Radford, A., Metz, L., & Chintala, S. (2015). Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv preprint. arXiv:1511.06434.
Ioffe, S., & Szegedy, C. (2015). Batch normalization: accelerating deep network training by reducing internal covariate shift. In F. R. Bach, & D. M. Blei (Eds.), Proceedings of the 32nd international conference on machine learning (pp. 448–456). JMLR.
Bian, Y., Wang, J., Jun, J. J., & Xie, X.-Q. (2019). Deep convolutional generative adversarial network (DCGAN) models for screening and design of small molecules targeting cannabinoid receptors. Molecular Pharmaceutics, 16(11), 4451–4460.
Wu, Q., Chen, Y., & Meng, J. (2020). DCGAN-based data augmentation for tomato leaf disease identification. IEEE Access, 8, 98716–98728.
Yu, Y., Gong, Z., Zhong, P., & Shan, J. (2017). Unsupervised representation learning with deep convolutional neural network for remote sensing images. In Y. Zhao, X. Kong, & D. Taubman (Eds.), Proceedings of the 9th international conference on image and graphics (pp. 97–108). Berlin: Springer.
Rawat, W., & Wang, Z. (2017). Deep convolutional neural networks for image classification: a comprehensive review. Neural Computation, 29(9), 2352–2449.
Puttagunta, M., Subban, R., & Nelson, K. B. C. (2022). A novel COVID-19 detection model based on DCGAN and deep transfer learning. Procedia Computer Science, 204, 65–72.
Curtó, J. D., Zarza, I. C., De La Torre, F., King, I., & Lyu, M. R. (2017). High-resolution deep convolutional generative adversarial networks. arXiv preprint. arXiv:1711.06491.
Xie, D., Deng, C., Li, C., Liu, X., & Tao, D. (2020). Multi-task consistency-preserving adversarial hashing for cross-modal retrieval. IEEE Transactions on Image Processing, 29, 3626–3637.
Zhu, J.-Y., Park, T., Isola, P., & Efros, A. A. (2017). Unpaired image-to-image translation using cycle-consistent adversarial networks. In 2017 IEEE international conference on computer vision (pp. 2223–2232). Los Alamitos: IEEE.
Gao, L., Zhu, J., Song, J., Zheng, F., & Shen, H. T. (2020). Lab2pix: label-adaptive generative adversarial network for unsupervised image synthesis. In C. W. Chen, R. Cucchiara, X.-S. Hua, et al. (Eds.), Proceedings of 28th ACM international conference on multimedia (pp. 3734–3742). New York: ACM.
Karras, T., Laine, S., & Aila, T. (2019). A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4401–4410). Los Alamitos: IEEE.
Zhou, B., Zhao, H., Puig, X., Xiao, T., Fidler, S., Barriuso, A., et al. (2019). Semantic understanding of scenes through the ADE20K dataset. International Journal of Computer Vision, 127(3), 302–321.
Johnson, J., Alahi, A., & Fei-Fei, L. (2016). Perceptual losses for real-time style transfer and super-resolution. In B. Leibe, J. Matas, N. Sebe, et al. (Eds.), Proceedings of 15th European conference on computer vision (pp. 694–711). Berlin: Springer.
Karras, T., Aittala, M., Laine, S., Härkönen, E., Hellsten, J., Lehtinen, J., et al. (2021). Alias-free generative adversarial networks. In M. Ranzato, A. Beygelzimer, Y. Dauphin, et al. (Eds.), Advances in neural information processing systems (Vol. 34, pp. 852–863). Red Hook: Curran Associates.
Azulay, A., & Weiss, Y. (2018). Why do deep convolutional networks generalize so poorly to small image transformations? arXiv preprint. arXiv:1805.12177.
Zhang, R. (2019). Making convolutional networks shift-invariant again. In K. Chaudhuri, & R. Salakhutdinov (Eds.), Proceedings of the 36th international conference on machine learning (pp. 7324–7334). JMLR.
Sauer, A., Schwarz, K., & Geiger, A. (2022). StyleGAN-XL: scaling stylegan to large diverse datasets. In M. Nandigjav, N. J. Mitra, & A. Hertzmann (Eds.), SIGGRAPH ’22: special interest group on computer graphics and interactive techniques conference (pp. 1–10). New York: ACM.
Liang, J., Cao, J., Sun, G., Zhang, K., Van Gool, L., & Timofte, R. (2021). SwinIR: image restoration using swin transformer. In 2021 IEEE international conference on computer vision (pp. 1833–1844). Los Alamitos: IEEE.
Brock, A., Donahue, J., & Simonyan, K. (2018). Large scale gan training for high fidelity natural image synthesis. arXiv preprint. arXiv:1809.11096.
Shrivakshan, G., & Chandrasekar, C. (2012). A comparison of various edge detection techniques used in image processing. International Journal of Computer Science Issues, 9(5), 269.
Saif, J. A., Hammad, M. H., & Alqubati, I. A. (2016). Gradient based image edge detection. International Journal of Engineering and Technology, 8(3), 153–156.
Ding, L., & Goshtasby, A. (2001). On the Canny edge detector. Pattern Recognition, 34(3), 721–725.
Gonzalez, R. C., & Wintz, P. (1987). Digital image processing. Boston: Addison Wesley Longman.
Vincent, O. R., & Folorunso, O. (2009). A descriptive algorithm for Sobel image edge detection. In Proceedings of Informing Science and IT Education Conference (pp. 97–107). Santa Rosa: ISI.
Xu, G. B., Zhao, G. Y., & Yin, Y. X. (2008). A CNN-based edge detection algorithm for remote sensing image. In 2008 Chinese control and decision conference (pp. 2558–2561). Los Alamitos: IEEE.
Liu, Y., Cheng, M.-M., Hu, X., Wang, K., & Bai, X. (2017). Richer convolutional features for edge detection. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 3000–3009). Los Alamitos: IEEE.
Shen, W., Wang, X., Wang, Y., Bai, X., & Zhang, Z. (2015). Deepcontour: a deep convolutional feature learned by positive-sharing loss for contour detection. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 3982–3991). Los Alamitos: IEEE.
Xie, S., & Tu, Z. (2015). Holistically-nested edge detection. In 2015 IEEE international conference on computer vision (pp. 1395–1403). Los Alamitos: IEEE.
Qin, Z., Lu, X., Nie, X., Liu, D., Yin, Y., & Wang, W. (2023). Coarse-to-fine video instance segmentation with factorized conditional appearance flows. Journal of Automatica Sinica, 10, 1.
Lu, X., Wang, W., Shen, J., Crandall, D. J., & Van Gool, L. (2022). Segmenting objects from relational visual data. IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(11), 7885–7897.
Lu, X., Wang, W., Ma, C., Shen, J., Shao, L., & Porikli, F. (2019). See more, know more: unsupervised video object segmentation with co-attention Siamese networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 3618–3627). Los Alamitos: IEEE.
Luo, Y., Zhang, Y., Yan, J., & Liu, W. (2021). Generalizing face forgery detection with high-frequency features. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 16312–16321). Los Alamitos: IEEE.
Zhang, N., & Yan, J. (2020). Rethinking the defocus blur detection problem and a real-time deep dbd model. In A. Vedaldi, H. Bischof, & T. Brox (Eds.), Proceedings of 15th European conference on computer vision (pp. 617–632). Berlin: Springer.
Criminisi, A., Perez, P., & Toyama, K. (2004). Region filling and object removal by exemplar-based image inpainting. IEEE Transactions on Image Processing, 13(9), 1200–1212.
Isola, P., Zhu, J.-Y., Zhou, T., & Efros, A. A. (2017). Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 5967–5976). Los Alamitos: IEEE.
Mirza, M., & Osindero, S. (2014). Conditional generative adversarial nets. arXiv preprint. arXiv:1411.1784.
Wang, T.-C., Liu, M.-Y., Zhu, J.-Y., Tao, A., & Kautz, J. (2018). Pix2pixhd: high-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 8798–8807). Los Alamitos: IEEE.
Zhu, J.-Y., Park, T., Isola, P., & Efros, A. A. (2017). Unpaired image-to-image translation using cycle-consistent adversarial networks. In 2017 IEEE international conference on computer vision (pp. 2242–2251). Los Alamitos: IEEE.
Choi, Y., Choi, M., Kim, M., Ha, J.-W., Kim, S., & Choo, J. (2018). Stargan: unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 8789–8797). Los Alamitos: IEEE.
Zhao, H., Shi, J., Qi, X., Wang, X., & Jia, J. (2017). Variational autoencoder for deep learning of images, labels and captions. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 6542–6550). Los Alamitos: IEEE.
Kyprianidis, H. W. E., & Olsen, S. C. (2012). XDoG: an extended difference-of-Gaussians compendium including advanced image stylization. Computers & Graphics, 36(6), 740–753.
Marr, D., & Hildreth, E. (1980). Theory of edge detection. Proceedings of the Royal Society of London. Series B, 207(1167), 187–217.
Park, T., Liu, M.-Y., Wang, T.-C., & Zhu, J.-Y. (2019). Semantic image synthesis with spatially-adaptive normalization. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 2337–2346). Los Alamitos: IEEE.
Guo, X., Yang, H., & Huang, D. (2021). Image inpainting via conditional texture and structure dual generation. In 2021 IEEE international conference on computer vision (pp. 14134–14143). Los Alamitos: IEEE.
Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., & Hochreiter, S. (2017). Gans trained by a two time-scale update rule converge to a local nash equilibrium. In I. Guyon, U. Von Luxburg, S. Bengio, et al. (Eds.), Advances in neural information processing systems (Vol. 30, pp. 6626–6637). Red Hook: Curran Associates.
Wang, Z., Bovik, A., Sheikh, H., & Simoncelli, E. (2004). Image quality assessment: from error visibility to structural similarity. IEEE Transactions on Image Processing, 13(4), 600–612.
Nilsson, J., & Akenine-Möller, T. (2020). Understanding SSIM. arXiv preprint. arXiv:2006.13846.
Hore, A., & Ziou, D. (2010). Image quality metrics: PSNR vs. SSIM. In Proceedings of the 20th international conference on pattern recognition (pp. 2366–2369). Los Alamitos: IEEE.
Poma, X. S., Riba, E., & Sappa, A. (2020). Dense extreme inception network: towards a robust CNN model for edge detection. In IEEE/CVF winter conference on applications of computer vision (pp. 1923–1932). Los Alamitos: IEEE.
Bi, C., Yuan, Y., Zhang, R., Xiang, Y., Wang, Y., & Zhang, J. (2017). A dynamic mode decomposition based edge detection method for art images. IEEE Photonics Journal, 9(6), 1–13.
Din, N. U., Javed, K., Bae, S., & Yi, J. (2020). A novel GAN-based network for unmasking of masked face. IEEE Access, 8, 44276–44287.
Pinto, F., Romanoni, A., Matteucci, M., & Torr, P. H. (2021). Seci-GAN: semantic and edge completion for dynamic objects removal. In Proceedings of the 25th international conference on pattern recognition (pp. 10441–10448). Los Alamitos: IEEE.
Xu, Z., Luo, H., Hui, B., & Chang, Z. (2018). Contour detection using an improved holistically-nested edge detection network. In Proceedings of global intelligence industry conference (Vol. 10835, pp. 7–13). Bellingham: SPIE.
Konishi, S., Yuille, A. L., Coughlan, J. M., & Zhu, S. C. (2003). Statistical edge detection: learning and evaluating edge cues. IEEE Transactions on Pattern Analysis and Machine Intelligence, 25(1), 57–74.
Zhang, L., & Agrawala, M. (2023). Adding conditional control to text-to-image diffusion models. arXiv preprint. arXiv:2302.05543.
Acknowledgements
We gratefully acknowledge the valuable cooperation of Jing Han for the support of knowledge in Chinese landscape paintings. We are also thankful for the support of the joint laboratory of SJTU-Montage Technology.
Author information
Authors and Affiliations
Contributions
ZX performed the experiments in the detailed generation model; HS contributed to the algorithms for structure extraction; SY was responsible for data preparation and survey analysis; RX contributed to style translation and inpainting integration; YY and YL designed the framework and provided technical and theoretical inspirations and support for the project; JH helped to perform the experiments; HCY and JZ provided constructive suggestions and analysis from the professional perspective of Chinese landscape paintings. All the authors contributed to the study and manuscript preparation. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Zhekai Xu, Haohong Shang, Shaoze Yang and Ruiqi Xu contributed equally to this work.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Xu, Z., Shang, H., Yang, S. et al. Hierarchical painter: Chinese landscape painting restoration with fine-grained styles. Vis. Intell. 1, 19 (2023). https://doi.org/10.1007/s44267-023-00021-y
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44267-023-00021-y