
Abstract
Quantum computing technologies are in the process of moving from academic research to real industrial applications, with the first hints of quantum advantage demonstrated in recent months. In these early practical uses of quantum computers, it is relevant to develop algorithms that are useful for actual industrial processes. In this work, we propose a quantum pipeline, comprising a quantum autoencoder followed by a quantum classifier, which are used to first compress and then label classical data coming from a separator, i.e., a machine used in one of Eni’s Oil Treatment Plants. This work represents one of the first attempts to integrate quantum computing procedures in a real-case scenario of an industrial pipeline, in particular using actual data coming from physical machines, rather than pedagogical data from benchmark datasets.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
We are currently witnessing a time of intense growth and investments into quantum computing technologies, both from academic and private sectors, aimed at a fast pace of advancement in the quest for computational advantage brought by the practical use of quantum information processing. In particular, it is believed we are now experiencing what has been termed the Noisy Intermediate Scale Quantum (NISQ) Computing era, i.e., quantum processing units (QPU) are available with a number of non-error corrected qubits scaling between 50 and 1000 (Preskill 2018). While not allowing to perform fault tolerant quantum computing, these devices are becoming worldwide available to explore the frontiers of quantum algorithms, which exploit inherent quantum mechanical features such as superposition and entanglement to produce a radically different approach to computational problems (Nielsen and Chuang 2010).
There are several fields of application in which new quantum algorithms have been analyzed: quantum chemistry (Sokolov et al. 2020; Barkoutsos et al. 2018; Peruzzo et al. 2014; Kivlichan et al. 2018), optimization problems (Farhi et al. 2014; Hadfield et al. 2019), machine learning (Biamonte et al. 2017; Havlíček et al. 2019; Abbas et al. 2021), solution of linear problems (Harrow et al. 2009; Bravo-Prieto et al. 2020; Xu et al. 2019) and differential equations (Childs and Liu 2020). To overcome the problems due to the limited number of qubits available and to the absence of efficient error correction techniques, several proof-of-principle demonstrations have been carried out by focusing on so-called variational quantum algorithms, characterized by a hybrid approach in which the quantum processing units (QPU) is seen as an accelerator alongside the classical CPU (McClean et al. 2016; Cerezo et al. 2020; Bharti et al. 2021). Several of these studies also fall within the emerging field of Quantum Machine Learning (Biamonte et al. 2017; Benedetti et al. 2019; Mangini et al. 2021), which has even triggered the birth of dedicated quantum machine learning software (Bergholm et al. 2020; Broughton et al. 2020; Abraham et al. 2019). Currently, most quantum machine learning algorithms are based on parametrized quantum circuits, and leverage an approach in which the optimization over the variational parameters is done on the classical CPU (Benedetti et al. 2019; Mangini et al. 2021). Indeed, these parametrized quantum circuits, often referred to as quantum neural networks (Schuld et al. 2014; Mangini et al. 2021; McClean et al. 2018) prove robust even in the presence of noise (McClean et al. 2016; Sharma et al. 2020; Gentini et al. 2020), which is inevitable in current implementation of quantum hardware, and are thus well-suited for near-term NISQ devices.
Here we test the use of quantum machine learning algorithms on a specific industrial use case. In particular, we propose the application of a newly formulated quantum pipeline comprising a quantum autoencoder algorithm (Romero et al. 2017; Bravo-Prieto 2021; Lamata et al. 2018; Khoshaman et al. 2018) followed by a quantum classifier, applied to real data coming from a first stage water/oil separator of one of Eni’s oil treatment plant. This algorithm is compared to the performance of a classical autoencoder to compress the original data, which are then used to implement a classification task. It is particularly relevant to notice that these quantum autoencoding algorithms can be run on presently existing quantum hardware, thus making such quantum machine learning algorithm readily usable with actual input data coming from a realistic source of industrial interest. While various models of variational autoencoders in the quantum domain have been proposed in the literature, for example for generative modelling tasks (Khoshaman et al. 2018) and for the study of entanglement in quantum states (Chen et al. 2021), our implementation of the quantum autoencoder directly follows the architecture proposed by authors in Romero et al. (2017), which is often studied as a prototypical model in the quantum machine learning literature (Cerezo et al. 2021), and it was also even extended to feature input redundancy (Pérez-Salinas et al. 2020), as discussed in Bravo-Prieto (2021).
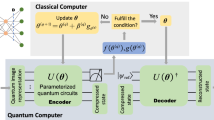
The manuscript is organized as follows. In Section 2 we explain and give the specifics of the industrial case study considered in this work. In Section 3 we introduce the classical neural network model of the autoencoder, and also discuss the clustering algorithm used to create the two classes for the classification problem. In Section 4 we review the quantum algorithm developed for a continuously valued input neuron (Mangini et al. 2020), from which the quantum algorithm for the quantum autoencoder is derived. In Section 5 we show the results obtained for the data compression task, comparing them with those obtained with the purely classical autoencoder. At last in Section 5.2, we use the compressed data to implement a quantum classifier used to label the original data in a binary classification problem.
2 Case study
The industrial case study discussed in this work aims at testing classical and quantum machine learning approaches to analyze data coming from industrial equipment within one of Eni’s Oil Treatment plants, showed in Fig. 1.
The equipment is a separator, i.e., a vessel receiving a stream of high pressure, high temperature crude oil (left part of the figure, indicated with a black stream), and exploits gravity to separate three output streams: Water (the heaviest component), indicated in the figure with a light blue stream; Oil (intermediate component), in the lower part of the figure indicated with a black stream; and Gas (lightest component), indicated with a light gray stream. The separator is regulated with three controllers: a pressure controller for the output gas stream, and two-level controllers for the water and the oil stream. Notice that the controllers use PID (proportional-integral-derivative) controller equations to regulate the opening of valves on the output streams.

Snapshot of the separator. The separator is regulated with three controllers: a pressure controller for the output gas stream, and two-level controllers for the water and the oil stream. The controllers use PID controller equations to regulate the opening of valves on the output streams
In a realistic machine learning problem, we might wish to use all the measurements coming from the sensors installed on this component, as well as on some of the components installed upstream, in order to predict if the behavior of the equipment is normal or faulty (i.e., working in a degraded mode). However, due to the limitation in the complexity of the problems that can currently be faced with quantum computing, we will focus on a simplified problem, involving only 4 variables, which are:
-
the oil level (LIC),
-
the oil output flow (FT),
-
the pressure (PI),
-
the opening of the oil output valve (FRC).
Sensor measurements are sampled every 10 s and stored into data tables to be used for the training of the neural networks.
The first step of the case study is the implementation of a dimensionality reduction procedure to compress the 4-dimensional input vector \(\mathbf {x}=(x_\text {FRC},\, x_\text {FT},\, x_\text {LIC},\, x_\text {PI})\) into a 2-dimensional vector. This is done both via a standard classical neural network autoencoder and a quantum autoencoder, introduced in Section 3 and 4 respectively.
The second step will be to implement a classifier using the 2-dimensional latent vector from the compression step to classify the status of the component. In order to do so, we need a labeled training dataset associating an input \(\mathbf {x}_i\) to a label \(y_i=\{0,1\}\) corresponding to the “ok” or “faulty” state respectively. However, since 4 variables are too few to label the working status of the separator as “ok” or “faulty”, we followed a different approach, as explained in the upper left panel of Fig. 2. We run a binary clustering algorithm on the initial variables, in order to identify two categorical states, named as “Class A” and “Class B”, and then used these categorical states as the labels for the classification task. So, the latent vector from the encoder is used as input for the classifier, which is trained to correctly predict the “Class A” and “Class B” states. The clustering algorithm used is the KMeans algorithm as implemented in the scikit-learn library (Pedregosa et al. 2011). This algorithm takes as input the desired number of clusters, in our case two, and tries to split the data in groups of equal variance. The centroids of the clusters were initialized uniformly at random. In Fig. 2 we show the result of the clustering procedure, where for ease of plotting we show only three of the four variables. This categorical dataset is then used to train a classical and quantum classifier, whose implementation details and results are discussed in Section 5.2.
In Table 1 we summarize the findings of our work, showing the key figures (compression error and classification accuracy) for the classical and quantum pipelines considered in the case study.

(a) The approach followed in this project: a clustering algorithm was used to define two categorical classes (Class A and Class B). Then, an autoencoder was used to reduce the dimensionality of the problem. Finally, a classifier was used to predict Class A and Class B identified with the clustering algorithm. (b) Results of the clustering algorithm KMeans on the input data. In particular, only the features FRC, FT and LIC are shown. The different color indicates the different label (or class) assigned to the data. (c) Plot of the decoded data on top of the original validation data averaged by day. Here the features were rescaled to their original range
3 Neural network autoencoder
The most common use case of artificial neural networks is supervised learning, where the network is asked to learn a mapping from an input to an output space, by having access to an example set of input-output pairs. One prominent example are classification tasks, where the network is presented a labeled dataset \(\mathcal M=(({\mathbf x}_1,y_1),({\mathbf x}_2,y_2),\dots,({\mathbf x}_M,y_M))\subset\mathbb{R}^n\times\{0,1\dots,c\}\) consisting of a set of inputs \(\mathbf {x}_i\) and the corresponding correct labels \(y_j\), with c being the total number of classes the inputs can be divided into (see upper left side of Fig. 3). Using this dataset, called training set, a neural network can be trained in a supervised fashion to learn the relationship between the input variables and the expected classification results. When the training is complete, the neural network model can be used for inference, which is for labeling previously unseen data. This property of neural networks, called generalization, is ultimately the key figure that distinguishes them from standard fitting techniques, making them incredibly powerful tools (Goodfellow et al. 2016; LeCun et al. 2015; Hastie et al. 2009; Mnih et al. 2015).
When dealing with real-world problems, such as classifying the operational status of a plant as “ok” or “faulty” based on the measurements from the sensors installed on the plant, it is often the case that a large number of input variables are available. In fact, measurements coming from tens of sensors need to be analyzed not only on their instantaneous values, but also on additional features computed on time intervals, such as moving averages, and minimal/maximal values trends. This leads to a situation where too many input variables are available in the dataset, and it is often ineffective to directly feed them into the neural network classifier. With such a large number of variables, correlation analysis and feature engineering are often performed to focus only on the most influencing variables, and only after these pre-processing steps the neural network can be used effectively. Another strategy is to use a dimensionality reduction approach, consisting in computing a new set of variables, smaller than the initial one, incorporating most—ideally all—of the information contained in the original data. These new compressed data are then used as inputs to the classifier, as shown in Fig. 3a.

(a) Reducing the dimensionality of a classification problem. (b) Using Autoencoders to reduce the dimensionality of a problem and solving the classification problem on the reduced variable set. (c) Schematic representation of the neural network autoencoder architecture. The input neurons in red are mapped to a hidden layer (in green) of lower dimension, storing the compressed information. Then, an output layer with the same number of neurons as the input one tries to restore the original data with low error
In order to reduce the problem dimensionality, methods such as PCA (Principal Component Analysis) or SVD (Singular Value Decomposition) Hastie et al. (2009) are typically used. However, these methods are based on linear decomposition of the initial variable space, and they could not be suitable when nonlinear relationships between the variables need to be kept into account.
3.1 Classical autoencoders
An alternative method to reduce the dimensionality of the problem is to use Autoencoders (Goodfellow et al. 2016), as shown in Fig. 3c. An autoencoder is a neural network composed of two modules, called encoder and decoder, designed in such a way that the subsequent application of the encoder and the decoder to the input data results into an output that is as close as possible to the input, i.e., the discrepancy between output and input is minimized. With such an approach, the encoder builds a compressed representation of the input data to be eventually used by the decoder to fully (and as faithfully as possible) reconstruct the input. This means that the compressed representation built by the encoder (often referred to as latent vector) contains the same information of the initial input space, or at least minimum information is lost.
Once the autoencoder has been trained to reconstruct the input, the latent vector can be used as the input space for the classifier. Therefore, the classification problem can be described as shown in Fig. 3b.
In our case study, we consider a neural autoencoder as shown in Fig. 3c. The original input variables are fed to the input neurons, which are then passed to an intermediate hidden level (shown in green) consisting of a number of neurons much smaller than the input. Finally, there is an output layer (shown in red) with the same number of neurons as the input. The neural network is trained in an unsupervised fashion in order to generate an output that is as close as possible to the input. Thus, if it is possible to reconstruct the input (with a minimum loss of fidelity) starting from the inner layer, this means that the inner layer contains the same information as the input, and therefore we can use the compressed layer as an input for the classifier. The presence of nonlinear activation functions within the neural network, such as the Rectified Linear Unit \(\text {ReLU}(x) = \max (0, x)\), or sigmoid \(s(x) = 1/(1+e^{-x})\), ensures that the network can better capture nonlinear relationships in the input variables compared to PCA or SVD.
4 Quantum data compression
In order to use a quantum pipeline to analyze the classical data coming from the sensors, we need to encode such data on a quantum state to be used as the input of the quantum autoencoder. While it is known from the recent literature (Abbas et al. 2021; Lloyd et al. 2020; Schuld et al. 2021; Gil Vidal and Theis 2020; LaRose and Coyle 2020; Mitarai et al. 2018) that choosing a good encoding scheme is of key importance to ensure good expressivity and representation power of variational quantum algorithms, there is still no standard procedure to do so. In our case, given the relatively simple and low dimensional nature of the data sets to be analyzed, we choose to use a phase encoding strategy (Tacchino et al. 2019; Mangini et al. 2020), which provides an effective way to load classical data into a quantum state, and also already proved useful in other machine learning tasks such as pattern-recognition (Tacchino et al. 2019; Mangini et al. 2020; Tacchino et al. 2020, 2021). In particular, given a data sample \(\mathbf x=(x_1,x_2,\dots,x_N)\in\mathbb{R}^N\), this is encoded on the quantum state of \(n=\log _2 N\) qubits as follows
where the data \(\mathbf {x}\) are first rescaled to fit into an appropriate range, such as \(x_i \in [0, \pi ]\). This class of states is also known as locally maximally entangled (LME) states (Kruszynska and Kraus 2009), and we refer to Refs. Mangini et al. (2020); Tacchino et al. (2019) for an extended discussion on these states for variational quantum procedures.
4.1 Quantum autoencoder
Having fixed a data encoding strategy, we now build a variational quantum algorithm for data compression. In particular, borrowing from the classical machine learning literature, our goal is to implement a quantum autoencoder (Romero et al. 2017; Lamata et al. 2018; Bravo-Prieto 2021). In classical autoencoders, the compression is built in the geometric structure of the neural network, since the input layer is followed by a much smaller hidden layer consisting of a number of neurons equal to the desired reduced dimension. This bottleneck forces the NN to learn a low dimensional representation of the inputs, which is stored in the intermediate hidden layer(s) of the network. However, this procedure cannot be straightforwardly applied to the quantum domain, because quantum computations follow a unitary, thus reversible, evolution. In fact, while classically it is possible to perform fan-in(fan-out) operations, which is arbitrarily reducing (increasing) the number of classical bits in the computation, such operations are irreversible, which prevents their direct implementation on a quantum computer. Alternatively said, it is not possible to eliminate or create new qubits during the execution of a quantum computation.
Nonetheless, it is possible to circumvent this issue as follows. Consider two quantum systems, denoted as system A and system B, and be \({|{\psi }\rangle }_{AB}\) the quantum state of the composite quantum system AB. Our goal is to compress the information stored in the composite state in a lower dimensional representation, for example given by the state of subsystem A only, with system B being safely discarded. We can formalize this intuition in the following way: denote with \(\mathcal {E}(\varvec{\theta })\) a quantum encoding (in the sense of compressing) operation depending on variational parameters (i.e., trainable weights) \(\varvec{\theta }\), then the desired compression task consists in the operation
where the state \({|{\psi }\rangle }_{AB}\) of the composite system AB is compressed on the state \({|{\phi }\rangle }_A\) of subsystem A only, and the system B is mapped to a fixed reference state of choice, called trash state, for example being the ground state \({|\text {trash}\rangle }_B = |0\rangle ^{\otimes |B|}\). It is clear that the goal of the encoder is to disentangle the two systems in such a way that one of them, i.e., the trash system, goes to the fixed reference state, and the other contains all the original information of from the full quantum state. In order to recover the original quantum state \(|{{\psi }\rangle }_{AB}\), it is then possible to act with a quantum decoder operation \(\mathcal {D}(\varvec{\theta })\), defined as \(\mathcal {D}(\varvec{\theta })=\mathcal {E}^{\dagger }(\varvec{\theta })\). This way, acting with the decoder on the compressed state yields the original state
Thus, suppose having compressed the information stored in the quantum state of a composite system into one of its subsystems. Then, it is always possible to retrieve the original information, if needed, by coupling such information-carrying system with some new qubits initialized in the \(|{\text {trash}}\rangle\) state, and then act on them with the quantum decoder operator, as schematically represented in Fig. 4.

Schematic representation of the generic quantum autoencoder algorithm. The input quantum state, \(|{\psi }\rangle _{AB}\), is disentangled and the state of the system B, defined “trash” system, is mapped to a reference quantum state, \(|{\varvec{0}}\rangle _B\). The action may then be reversed by applying a quantum decoder operation \(\mathcal {D}(\varvec{\theta }) = \mathcal {E}^\dagger (\varvec{\theta })\)
Of course, this only holds in the ideal case where the encoder perfectly manages to disentangle the subsystems A and B, i.e., by obtaining the product state in Eq. (2). In practice, this is never the case since the input state \(|{\psi }\rangle _{AB}\) depends on the classical input data via the phase encoding, and these states cannot be exactly disentangled, in general. In fact, after discarding the trash system B, the compressed state A is no more a pure state, rather a mixed state given by the density matrix \(\rho _A = \text {Tr}_B [(\mathcal {E}(\varvec{\theta })|{\psi _{AB}}\rangle ) (\langle {\psi _{AB}}|)\mathcal {E}(\varvec{\theta })^\dagger )]\). However, upon optimization of the variational parameters \(\varvec{\theta }\), the trained encoder tries to create a final state as close as possible to the target product state in Eq. (2).
The initial quantum state \(|{\psi }\rangle _{AB}\) is obtained by using phase encoding to load the classical information on the phase of the quantum state, with the following scheme. Be \(\mathcal X=\{{\mathbf x}_i\,\vert\,{\mathbf x}_i\in\mathbb{R}^N,i=1,\dots,M\}\) the set containing the classical data to be analyzed, then the quantum autoencoder is trained using the quantum states obtained as \(\mathcal {T} = \{|{\psi _{\mathbf {x}}}\rangle = \sum _i e^{i\,x_i}|{i}\rangle \,|\, \forall \mathbf {x} \in \mathcal {X}\}\). In our specific case, the classical data are four dimensional \(N=4\) and thus we only need \(n=\log _2 N = 2\) qubits to encode the data. This in turn implies that the compressed system A and the trash subsystem B consist of a single qubit each. Given the input data, the variational parameters \(\varvec{\theta }\) of the encoder are optimized in order to rotate the trash qubit as close as possible to the target trash state, which we choose to be \(|{\text {trash}}\rangle = |{0}\rangle\). This is achieved by means of a training procedure whose aim is to find optimal parameters \(|{\theta }\rangle ^*\) such that the loss function characterizing the task, \(\mathcal {L}(\varvec{\theta })\), is minimized. That is, the goal of training is to find
where we have defined
as the mean value of the Pauli operator \(Z=\text {diag}(1,-1)\) evaluated on the trash system B, after the encoder acted on the input quantum state, \(|{\psi _{\mathbf {x}_j}}\rangle\).
The loss function used in Eq. (3) is referred to as Mean Absolute Error (MAE) in the classical machine learning literature, and together with the Mean Squared Error (MSE) is the one of the most commonly employed loss functions in supervised regression tasks, which is also our case. Note that the loss function is faithful, in the sense that it reaches its global minimum \(\mathcal {L}(\varvec{\theta }^*) = 0\), only when \(\langle Z_B\rangle_j=1,\,\forall j=1,\dots,M\), which is when the trash qubit is always and perfectly disentangled from the other qubit, and mapped to the target trash state \(|{0}\rangle\). A schematic representation of the quantum circuit used for the training procedure is explicitly shown in Fig. 5a.

(a) Quantum circuit used to train the quantum autoencoder. A register initialized in the ground state \(|{00}\rangle\) is first subject to the phase encoding operation denoted by \(P(\mathbf {x})\), and then goes through the quantum encoder \(\mathcal {E}(\varvec{\theta })\). Then the trash qubit is measured, and the mean value of the Pauli operator \(\langle {Z}\rangle\) is evaluated. Such value is then plugged into the loss function \(\mathcal {L}(\varvec{\theta })\) to drive the learning process. (b) Circuit representation of the quantum encoder \(\mathcal {E}(\varvec{\theta })\). Two layers of Pauli\(-y\) rotations and CNOT, are followed by a final layer of Pauli\(-y\) rotations. In total, the circuit has 6 trainable parameters. The decoder \(\mathcal {D}(\varvec{\theta })=\mathcal {E}^\dagger (\varvec{\theta })\) is obtained by reversing the order of the operations, and changing the sign of the rotations angles
Variational ansatz The actual quantum circuit implementation of the encoder \(\mathcal {E}(\varvec{\theta })\) (and hence the decoder) is arbitrary, and different variational ansatzes have been proposed in the quantum machine learning literature, in fact (Cerezo et al. 2020; Mangini et al. 2021; Bharti et al. 2021; McClean et al. 2016). In our case, we are dealing with only two qubits, and the most general ansatz consists of repeated applications of single qubit rotations and CNOT quantum gates. In fact, having in mind to keep the parameters count and the overall circuit complexity low, we hereby propose a minimal yet efficient variational autoencoder consisting of two layers of Pauli\(-y\) rotations \(R_y(\theta )=e^{i\sigma _y\theta /2}\) and a CNOT, followed by a final layer of rotations, as schematically depicted in Fig. 5b.
5 Experiments and results
In this section we discuss the experiments implementing the classical and quantum data analysis approaches described above for the data compression and classification tasks.
5.1 Data compression
Classical autoencoder The classical neural network autoencoder was implemented with the Keras library of TensorFlow (Abadi et al. 2015), and it consists of two dense layers in a 4-2-4 structure as in Fig. 3c, with sigmoid activation function. The input data consists of a time series with 2873893 samples, 25% of which are used as validation data, and the rest for training. Before training, features were transformed with a MinMax scaler, which scaled each feature to fit in the range [0, 1]. After the learning phase, the average reconstruction error \(\bar{e}\), evaluated as
amounts to 5%, and in Fig. 2 we show a comparison of the original against reconstructed data averaged by day, for the validation dataset. As we can see, the decoder shows quite good performance in the reconstruction of the input data for 3 of the 4 variables. For the “LIC” variable, the median of the distribution of the reconstructed data coincides with the one of the original data, though the fluctuations are not very well described. There is no obvious a priori reason for the imperfect reconstruction of this particular variable, and this may well be a shortcoming of the autoencoding approach, which focuses more on the other variables to achieve a good-enough reconstruction scheme.
In the following step we used the two variables from the compressed layer as input for a supervised classification algorithm, to predict the class assigned at the beginning through the clustering algorithm. We expect that, if the compressed vector is a suitable representation of the input data, a classification algorithm would be able to achieve very good performances.
Quantum autoencoder The quantum autoencoder was simulated using a combination of PennyLane (Bergholm et al. 2020) with the TensorFlow (Abadi et al. 2015) interface, as well as Qiskit 2019, and the optimization was thus performed using the automatic differentiation techniques implemented by these libraries. While this is only possible when performing a classical simulation of the quantum algorithm, in realistic scenarios of optimizing a quantum circuit on real quantum hardware one can resort to parameter-shift rules Schuld et al. (2019); Mitarai et al. (2018) to estimate gradients and optimize variational parameters.
The variational circuit was trained using the Adam optimizer (Kingma 2015) with learning rate set to 0.001, to update the six variational parameters \(\varvec{\theta } = (\theta _0, \theta _1, \theta _2, \theta _3, \theta _4, \theta _5)\). The training was performed using mini-batches of size 20 for a total training set consisting of 10040 samples. In Fig. 6 it is shown the optimization process across epochs of learning, both for the training loss, and for a validation set of 520 samples. Before the phase encoding process, the classical data \(\{\mathbf {x}_i\}_i\) were normalized as \(\mathbf {x}_i\leftarrow \pi \cdot \mathbf {x}_i/||\mathbf {x}_i||\). It is clear that the quantum encoder is effectively trained, with the loss reaching the minimum value of \(\mathcal {L}(\varvec{\theta }^*) = 0.0058\).

Optimization of the quantum encoder, \(\mathcal {E}(\varvec{\theta })\), showing the training and validation loss evaluated with data sets containing 10040 and 520 samples, respectively. The optimal loss is found at \(\mathcal {L}(\varvec{\theta }^*)=0.0058\)
With a trained encoder, we can now proceed to investigate the quality of the data compression provided by the algorithm. The state of the qubits A and B after the quantum encoder operator consists of a general two-qubit state
where, if the encoder has been successfully trained, the probability of measuring qubit B in state \(|{1}\rangle\), \(p_1 = |c|^2 + |d|^2\), is much smaller (ideally zero) than the probability of finding it in \(|{0}\rangle\), i.e., \(p_1\ll p_0 = |a|^2 + |b|^2\). Thus, in order to obtain a compressed pure state for qubit A instead of a mixed one, we could post-select state \(|{\Psi }\rangle _{AB}\) on measuring the trash qubit in state \(|{0}\rangle\). Be \(\hat{\Pi }^B_0 = {|0 \rangle \langle 0|}_B\) the projector on state \(|{0}\rangle\) for system B, then the composite state is projected to
If we wish to retrieve the original information, now stored in compressed form in the state \(|{\psi _c}\rangle _{A}\) of system A only, we can couple this system to a new qubit initialized in \(|{0}\rangle\), and then apply the quantum decoder, as shown in Fig. 4. An example of this procedure is shown in Fig. 7, where the reconstruction performances of the quantum autoencoder are evaluated on a test set consisting of \(M=1000\) samples coming from the original dataset. In the case of Fig. 7, the average reconstruction error (see Eq. (5)) amounts to \(\bar{e} = 5.4\%\), confirming that the quantum autoencoder can successfully compress and retrieve original information with low error.

Performances of the quantum autoencoder in a compression and decoding task. Each plot shows one of the input features labeled “FRC”, “FT”, “LIC”, “PI”, as reconstructed by the quantum autoencoder (“decoded”) confronted with the original sample (“original”). These plots are evaluated on a test set consisting of \(M=1000\) samples. The average reconstruction error \(\bar{e}\) as defined in the main text (Eq. (5)), amounts to \(\bar{e}=5.4\%\). This results were obtained using the IBM Qiskit statevector_simulator
However, it is important to stress that these results were obtained using the Qiskit statevector_simulator from IBM, which allowed us to have direct access to the amplitudes of the quantum states, and thus recover the final phases of the decoded state, \(|{\varphi _\text {decoder}}\rangle =\mathcal {D}(|{\theta }\rangle )(|{0}\rangle \otimes |{\psi _c}\rangle _{A})\). In fact, in a real-case scenario with quantum hardware, it is not possible to perfectly retrieve the phases of the decoded state \(|{\varphi _\text {decoder}}\rangle\), since one would need to perform quantum tomography of such state, and even in that case results could only be obtained up to an arbitrary constant, due to quantum measurement outcomes following Born’s rule. Thus, while such reconstruction test would prove much harder to be performed on a real device, the results in Fig. 7 obtained with the simulator are still relevant in checking the inner working of the quantum autoencoder, and check that it is actually able to perform the task it was designed for, even if it is not currently accessible by a real experimenter.
There is a second possible approach, which albeit being indirect does not require state tomography and is thus more readily compatible with actual runs on quantum processors. The performances of the quantum autoencoder can be tested measuring the fidelity (Wilde 2017) \(F(\rho _{\mathbf {x}},\sigma ^{\varvec{\theta }}_{\mathbf {x}})=\text {Tr}[\rho _{\mathbf {x}}\,\sigma ^{\varvec{\theta }}_{\mathbf {x}}]\) between the initial pure state \(\rho _{\mathbf {x}} = |{\psi _{\mathbf {x}}}\rangle \langle {\psi _{\mathbf {x}}}|\) obtained through phase encoding (Eq. (1)), and the generally mixed state obtained through the quantum circuit autoencoder (see Fig. 4)
where E\((\varvec{\theta })\) and D\((\varvec{\theta })\) represents the superoperator corresponding to the encoder \(\mathcal {E}(\varvec{\theta })\) and decoder \(\mathcal {D}(\varvec{\theta })\) operators, respectively. Clearly, the larger the fidelity the better, since it corresponds to the quantum autoencoder being able to recreate states that are very close to the initial ones. Using this figure of merit, post-selecting on the trash subsystem B is not necessary, since qubit A can be directly coupled to a new qubit initialized in \(|{0}\rangle\) to act with the decoder, and then proceed to evaluating \(\text {Tr}[\rho _{\mathbf {x}}\,\sigma ^{\varvec{\theta }}_{\mathbf {x}}]\). There are various techniques to evaluate state overlaps on quantum hardware (Cincio et al. 2018; Mangini et al. 2020), the most common one being the SWAP test, and here we use leverage the so-called compute-uncompute method, whose circuit is shown in Fig. 8.

Circuit to evaluate the fidelity \(F(\rho _{\mathbf {x}},\sigma ^{\varvec{\theta }}_{\mathbf {x}}) = \text {Tr}[\rho _{\mathbf {x}}\,\sigma ^{\varvec{\theta }}_{\mathbf {x}}]\) between the initial pure state \(\rho _{\mathbf {x}} = {|\psi _{\mathbf {x}}\rangle \langle \psi _{\mathbf {x}}|}\) and the generally mixed state \(\sigma ^{\varvec{\theta }}_{\mathbf {x}}\), obtained through the autoencoding procedure. The fidelity is obtained by counting the number of \(|{00}\rangle\) outcomes. In fact, dropping the subscripts for simplicity, one has \(\text {Tr}[P^\dagger \sigma P {|\varvec{0}\rangle \langle \varvec{0}|}] = \text {Tr}[\sigma P {|\varvec{0}\rangle \langle \varvec{0}|}P^\dagger ]= \text {Tr}[\sigma {|\psi \rangle \langle \psi |}]\)
Using a test set of \(M=1000\) samples, a simulation of the trained quantum autoencoder, even including stochastic measurement outcomes with \(10^4\) shots, yields an average fidelity
which confirms again that the proposed variational quantum autoencoder is able to compress and later decode information.
5.2 Classification
Classical classifier The supervised classification algorithm used is the KNeighborsClassifier as implemented in scikit-learn. KNeighborsClassifier assigns the class to a point from a simple majority vote based on the k nearest neighbors of that point. The number of nearest neighbors is a parameter of the algorithm, and after some trials we fixed it at \(k=100\), which correspond to an optimal trade-off between performances and computational efficiency. The lowest panel of Fig. 9 shows the results of the classification, which is now anticipated but discussed later in comparison with the quantum algorithm results. In red and blue are the points correctly classified, while in yellow and green are those which were misclassified. The classification accuracy, evaluated as the percentage of correctly classified data, reaches a remarkably high value of \(89.7\%\), indicating that the compressed vector is able to summarize the information carried by the input data.
Single qubit quantum classifier Once the quantum autoencoder has been trained to learn a compressed representation of the original information, the compressed quantum state can be used as input for a classification task. We expect that, if the compressed information is a suitable representation of the input data, the classification algorithm would be able to learn the classes assigned to the full-size input data through the clustering algorithm described in Section 2. To do so, we can use the information-carrying qubit obtained with the encoder \(\mathcal {E}(\varvec{\theta })\), as input to a quantum classifier which is trained to learn the desired clustering of the original data. A quantum classifier is made of two parts: a trainable parametrized operation, U, which tries to map inputs belonging to different classes in two distant regions of the Hilbert space; and a final measurement, which is used to extract and assign the label. Since we are dealing with a single qubit classifier, the most general transformation on a qubit is represented by the unitary matrix
Thus, it is reasonable to use such operation as the trainable block of the classifier, since it ensures the greatest flexibility. Actually, as discussed later, the angle \(\beta\) in Eq. (9) does not influence the measurement statistics of the qubit; hence, it has no influence on the training of the classifier. For this reason, it is kept fixed at \(\beta =0\), and the actual trainable gate used is \(U(\alpha ,0,\gamma )=U(\alpha , \gamma )\).
As for the label assignment, since the measurement process of a qubit has only two possible outcomes, these are interpreted to be the two possible values for the labels, that is, “Class A” and “Class B” described in Section 2. More in detail, a label is assigned based on a majority vote on multiple shots of the same quantum circuit: an input is assigned to “Class A” if the majority of measurement gave \(|{0}\rangle\) as outcome, “Class B” otherwise. Formally, be \(\rho ^A_{\mathbf {x}} = \text {Tr}_B [\mathcal {E}(\varvec{\theta })(|{\psi _{\mathbf {x}}\rangle \langle \psi _{\mathbf {x}}})\mathcal {E}(\varvec{\theta })^\dagger ]\), the compressed quantum qubit, then the label is assigned following the decision rule:
where \(p_0\) denotes the probability that the measurement yields \(|{0}\rangle\) outcome. As mentioned earlier, one can check easily that \(p_0\) does not depend on the angle \(\beta\) of the unitary \(U(\alpha , \beta , \gamma )\), and for this reason it is set to zero, yielding the variational unitary \(U(\alpha ,0,\gamma )=U(\alpha , \gamma )\).
The loss function used to drive the training of the unitary \(U(\alpha , \gamma )\) is the categorical cross entropy, defined as
where \(y_i\) is the correct label, and \(\hat{y}_i\) is the label assigned by the quantum classifier, and the optimizer used is COBYLA (Powell 1994) as implemented in SciPy’s python package (Virtanen et al. 2020).
Figure 9 shows the results of the classification obtained after the optimization of the variational parameters \((\alpha , \gamma )\), for a test set of \(M=10^3\) samples. The accuracy, measured as the ratio of correctly classified to total samples, is measured to be 87.4% when evaluated with exact simulation of the quantum circuit. As clear from the figure, the misclassified data are only those located near the edge connecting the two classes. In fact, in this region, the samples are not neatly divided but rather a blurred border exists. On the contrary, the quantum classifier, given its relatively simple structure, learns essentially a straight cut of the data in this region, thus committing some labeling errors. This should not come as a surprise however, since it is known from the literature that, if not using expressivity enhancement techniques like data re-uploading, a single qubit classifier can only learn simple functions (i.e., sine functions) of the input data (Schuld et al. 2021; Pérez-Salinas et al. 2020; LaRose and Coyle 2020; Gratsea and Huembeli 2021; Lloyd et al. 2020). In addition, remind that the classical data are loaded onto the quantum states by means of rotations, hence the dependence of the classification on the original classical data is strictly nonlinear, with the presence of the encoder scrambling information even more. It is interesting to notice that the classification performances remain stable even when including sources of noise, such as stochastic measurement outcomes. In this case, using \(n_{shots}=1024\), the accuracy amounts to about \(82.5\%\), with the uncertainty due to the stochastic nature of the simulation. In addition, the classifier proves robust even with tests performed on real quantum hardware. In fact, the circuit for the trained classifier was tested against IBM’s ibmq_x2 quantum chip (accessed May 2021) but with a smaller test set of 75 samples, due to limitations in the device usage. In this case, using 1024 shots per circuit, and averaging on 5 executions with different test samples, the classification accuracy (evaluated again as the percentage of correctly classified data) was found to be \((82.3\pm 1.3)\%\), indeed very close to the simulation including only measurement noise, and not much different from the noiseless result.

Results of the classification task performed by the quantum classifier, for a test set of size \(10^3\) samples. (a) Plot of the original data with the color indicating the two different classes. Note that for simplicity, only the FRC and FT features are shown. (b) Label assigned by the trained quantum classifier. (c) Focus on the data that are mislabeled by the classifier. The color indicates the label assigned by the quantum classifier, and the “cross” marker means that the data were misclassified. Note that these samples lay on the border of separating the two classes. The accuracy, evaluated as the percentage of correctly classified data, amounts to \(87.4\%\). (d) Result of the classification using the classical autoencoder followed by a KNN clustering procedure. Note that the axis is different from the quantum case due to normalization of the features. In this case the classification accuracy amounts to \(89.7\%\)
6 Summary and outlook
We have presented a direct comparison between quantum and classical implementations of a neural network autoencoder, followed by a classifier algorithm, applied to sample real data coming from one of Eni’s plants, in particular from a first stage separator. While the achievement of a clear quantum machine learning advantage with variational algorithms is still disputed (Huang et al. 2021b, a; Abbas et al. 2021), this work sets a milestone in the field of quantum machine learning, since it is one of the first examples of direct application of quantum computing software and hardware to analyze real data sets from industrial sources.
As a first step, we have implemented and analyzed the performance of a variational quantum autoencoder to compress and subsequently recover the input data. We verified its performances using full simulation of the wavefunction, which allowed us to evaluate the average reconstruction error to about \(\bar{e}=5\%\) —essentially identical to the classical autoencoder—thus confirming the capability of the quantum autoencoder to effectively store a compressed version of the original data set, and then being able to recover it. In addition, we also checked the correctness of the quantum autoencoding procedure by evaluating the quantum fidelity between original and decoded quantum states, which were again found to be very similar to each other even in the presence of simulated stochastic measurement noise. Once the optimal parameters for the quantum autoencoder were determined during the training phase, we used the compressed quantum state as input to a quantum classifier, with the goal of performing a binary classification task. The algorithm achieved an accuracy above \(87\%\), absolutely comparable to that achieved in the classical setting using the neural network autoencoder followed by a nearest-neighbors classifier, thus indicating again that the quantum algorithm is able to correctly compress the relevant information of the input data. We also tested the performance of the full quantum pipeline (given by the quantum autoencoder plus the classifier) on actual and currently available IBM quantum hardware, obtaining a classification accuracy of \(82\%\), which is only slightly smaller than the ideal result.
The small size of current quantum devices and their relatively high noise levels make it hard to run actually relevant and large-scale computations, thus making an effective quantum advantage out of reach. We provided, on the other hand, a successful proof-of-concept demonstration that an original quantum autoencoder and a quantum classifier can actually reach the same level of accuracy as standard classical algorithms, on a data set that is sufficiently low dimensional to be handled on actual near-term quantum devices. In addition, it is worth emphasizing that the quantum autoencoder allows to obtain results that are quantitatively comparable to the classical algorithm by using only 6 parameters instead of 16, thus displaying an increased efficiency in terms of number of trainable parameters already reached on NISQ devices. With continuing progress in quantum technologies and quantum information platforms, we envision the execution of the very same quantum algorithms on larger scales, possibly reaching the threshold for a classically intractable problem. We believe these results take the first foundational steps towards the application of usable quantum algorithms on NISQ devices for industrial data.
References
Abadi M, Agarwal A, Barham P, Brevdo E, Chen Z, Citro C, Corrado GS, Davis A, Dean J, Devin M, Ghemawat S, Goodfellow I, Harp A, Irving G, Isard M, Jia Y, Jozefowicz R, Kaiser L, Kudlur M, Levenberg J, Mané D, Monga R, Moore S, Murray D, Olah C, Schuster M, Shlens J, Steiner B, Sutskever I, Talwar K, Tucker P, Vanhoucke V, Vasudevan V, Viégas F, Vinyals O, Warden P, Wattenberg M, Wicke M, Yu Y, Zheng X (2015) TensorFlow: Large-scale machine learning on heterogeneous systems. https://www.tensorflow.org/, software available from tensorflow.org
Abbas A, Sutter D, Zoufal C, Lucchi A, Figalli A, Woerner S (2021) The power of quantum neural networks. Nature Computational Science 1:403
Abraham H, et al (2019) Qiskit: An open-source framework for quantum computing
Barkoutsos PK, Gonthier JF, Sokolov I, Moll N, Salis G, Fuhrer A, Ganzhorn M, Egger DJ, Troyer M, Mezzacapo A, Filipp S, Tavernelli I (2018) Quantum algorithms for electronic structure calculations: Particle-hole hamiltonian and optimized wave-function expansions. Phys Rev A 98:022322
Benedetti M, Lloyd E, Sack S, Fiorentini M (2019) Parameterized quantum circuits as machine learning models. Quantum Sci Technol 4:043001
Bergholm V, Izaac J, Schuld M, Gogolin C, Alam MS, Ahmed S, Arrazola JM, Blank C, Delgado A, Jahangiri S, McKiernan K, Meyer JJ, Niu Z, Száva A, Killoran N (2020) Pennylane: Automatic differentiation of hybrid quantum-classical computations. arXiv:1811.04968 [quant-ph]
Bharti K, Cervera-Lierta A, Kyaw TH, Haug T, Alperin-Lea S, Anand A, Degroote M, Heimonen H, Kottmann JS, Menke T, Mok WK, Sim S, Kwek LC, Aspuru-Guzik A (2021) Noisy intermediate-scale quantum (nisq) algorithms. arXiv:2101.08448 [quant-ph]
Biamonte J, Wittek P, Pancotti N, Rebentrost P, Wiebe N, Lloyd S (2017) Quantum machine learning. Nature 549:195–202
Bravo-Prieto C (2021) Quantum autoencoders with enhanced data encoding. arXiv:2010.06599 [quant-ph]
Bravo-Prieto C, LaRose R, Cerezo M, Subasi Y, Cincio L, Coles PJ (2020) Variational quantum linear solver. arXiv:1909.05820 [quant-ph]
Broughton M, Verdon G, McCourt T, Martinez AJ, Yoo JH, Isakov SV, Massey P, Niu MY, Halavati R, Peters E, Leib M, Skolik A, Streif M, Dollen DV, McClean JR, Boixo S, Bacon D, Ho AK, Neven H, Mohseni M (2020) Tensorflow quantum: A software framework for quantum machine learning. arXiv:2003.02989 [quant-ph]
Cerezo M, Arrasmith A, Babbush R, Benjamin SC, Endo S, Fujii K, McClean JR, Mitarai K, Yuan X, Cincio L, Coles PJ (2020) Variational quantum algorithms. arXiv:2012.09265 [quant-ph]
Cerezo M, Sone A, Volkoff T, Cincio L, Coles PJ (2021) Cost function dependent barren plateaus in shallow parametrized quantum circuits. Nature Communications 12:1791. https://doi.org/10.1038/s41467-021-21728-w
Chen Y, Pan Y, Zhang G, Cheng S (2021) Detecting quantum entanglement with unsupervised learning. Quantum Science and Technology 7:015005
Childs AM, Liu JP (2020) Quantum Spectral Methods for Differential Equations. Communications in Mathematical Physics 375:1427
Cincio L, Subaşı Y, Sornborger AT, Coles PJ (2018) Learning the quantum algorithm for state overlap. New Journal of Physics 20:113022
Farhi E, Goldstone J, Gutmann S (2014) A quantum approximate optimization algorithm. arXiv:1411.4028 [quant-ph]
Gentini L, Cuccoli A, Pirandola S, Verrucchi P, Banchi L (2020) Noise-resilient variational hybrid quantum-classical optimization. Phys Rev A 102:052414
Gil Vidal FJ, Theis DO (2020) Input redundancy for parameterized quantum circuits. Front Phys 8:297
Goodfellow I, Bengio Y, Courville A (2016) Deep Learning. MIT Press
Gratsea A, Huembeli P (2021) Exploring quantum perceptron and quantum neural network structures with a teacher-student scheme. arXiv:2105.01477 [quant- ph]
Hadfield S, Wang Z, O’Gorman B, Rieffel EG (2019) From the quantum approximate optimization algorithm to a quantum alternating operator ansatz. Algorithms 12. https://doi.org/10.3390/a12020034
Harrow AW, Hassidim A, Lloyd S (2009) Quantum algorithm for linear systems of equations. Phys Rev Lett 103:150502
Hastie T, Tibshirani R, Friedman J (2009) The Elements of Statistical Learning: Data Mining, Inference, and Prediction. Springer series in statistics, Springer
Havlíček V, Córcoles AD, Temme K, Harrow AW, Kandala A, Chow JM, Gambetta JM (2019) Supervised learning with quantum-enhanced feature spaces. Nature 567:209–212
Huang HY, Broughton M, Mohseni M, Babbush R, Boixo S, Neven H, McClean JR (2021) Power of data in quantum machine learning. Nature Communications 12:2631
Huang HY, Kueng R, Preskill J (2021) Information-theoretic bounds on quantum advantage in machine learning. Phys Rev Lett 126:190505
Khoshaman A, Vinci W, Denis B, Andriyash E, Sadeghi H, Amin MH (2018) Quantum variational autoencoder. Quantum Science and Technology 4:014001
Kingma DP, Ba J (2015) Adam: A method for stochastic optimization. In: 3rd International Conference on Learning Representations, ICLR
Kivlichan ID, McClean J, Wiebe N, Gidney C, Aspuru-Guzik A, Chan GKL, Babbush R (2018) Quantum simulation of electronic structure with linear depth and connectivity. Phys Rev Lett 120:110501
Kruszynska C, Kraus B (2009) Local entanglability and multipartite entanglement. Phys Rev A 79:052304
Lamata L, Alvarez-Rodriguez U, Martín-Guerrero JD, Sanz M, Solano E (2018) Quantum autoencoders via quantum adders with genetic algorithms. Quantum Science and Technology 4:014007
LaRose R, Coyle B (2020) Robust data encodings for quantum classifiers. Phys Rev A 102:032420
LeCun Y, Bengio Y, Hinton G (2015) Deep learning. Nature 521:436–444
Lloyd S, Schuld M, Ijaz A, Izaac J, Killoran N (2020) Quantum embeddings for machine learning. arXiv:2001.03622 [quant-ph]
Mangini S, Tacchino F, Gerace D, Macchiavello C, Bajoni D (2020) Quantum computing model of an artificial neuron with continuously valued input data. Machine Learning: Science and Technology 1:045008
Mangini S, Tacchino F, Gerace D, Bajoni D, Macchiavello C (2021) Quantum computing models for artificial neural networks. EPL (Europhysics Letters) 134:10002
McClean JR, Romero J, Babbush R, Aspuru-Guzik A (2016) The theory of variational hybrid quantum-classical algorithms. New J Phys 18:023023
McClean JR, Boixo S, Smelyanskiy VN, Babbush R, Neven H (2018) Barren plateaus in quantum neural network training landscapes. Nat Commun 9:4812
Mitarai K, Negoro M, Kitagawa M, Fujii K (2018) Quantum circuit learning. Phys Rev A 98:032309
Mnih V, Kavukcuoglu K, Silver D, Rusu AA, Veness J, Bellemare MG, Graves A, Riedmiller M, Fidjeland AK, Ostrovski G, Petersen S, Beattie C, Sadik A, Antonoglou I, King H, Kumaran D, Wierstra D, Legg S, Hassabis D (2015) Human-level control through deep reinforcement learning. Nature 518:529
Nielsen MA, Chuang IL (2010) Quantum computation and quantum information, 10th edn. Cambridge, Cambridge University Press
Pedregosa F, Varoquaux G, Gramfort A, Michel V, Thirion B, Grisel O, Blondel M, Prettenhofer P, Weiss R, Dubourg V, Vanderplas J, Passos A, Cournapeau D, Brucher M, Perrot M, Duchesnay E (2011) Scikit-learn: Machine learning in Python. Journal of Machine Learning Research 12:2825
Pérez-Salinas A, Cervera-Lierta A, Gil-Fuster E, Latorre JI (2020) Data re-uploading for a universal quantum classifier. Quantum 4:226
Peruzzo A, McClean J, Shadbolt P, Yung MH, Zhou XQ, Love PJ, Aspuru-Guzik A, O’Brien JL (2014) A variational eigenvalue solver on a photonic quantum processor. Nature Communications 5:4213
Powell MJD (1994) A direct search optimization method that models the objective and constraint functions by linear interpolation. In: Gomez S, Hennart J-P (eds) Advances in Optimization and Numerical Analysis. Springer, Netherlands, Dordrecht, pp 51–67
Preskill J (2018) Quantum Computing in the NISQ era and beyond. Quantum 2:79
Romero J, Olson JP, Aspuru-Guzik A (2017) Quantum autoencoders for efficient compression of quantum data. Quantum Science and Technology 2:045001
Schuld M, Sinayskiy I, Petruccione F (2014) The quest for a quantum neural network. Quantum Inf Process 13:2567–2586
Schuld M, Bergholm V, Gogolin C, Izaac J, Killoran N (2019) Evaluating analytic gradients on quantum hardware. Phys Rev A 99:032331
Schuld M, Sweke R, Meyer JJ (2021) Effect of data encoding on the expressive power of variational quantum-machine-learning models. Phys Rev A 103:032430
Sharma K, Khatri S, Cerezo M, Coles PJ (2020) Noise resilience of variational quantum compiling. New Journal of Physics 22:043006
Sokolov IO, Barkoutsos PK, Ollitrault PJ, Greenberg D, Rice J, Pistoia M, Tavernelli I (2020) Quantum orbital-optimized unitary coupled cluster methods in the strongly correlated regime: Can quantum algorithms outperform their classical equivalents? The Journal of Chemical Physics 152:124107. https://doi.org/10.1063/1.5141835
Tacchino F, Macchiavello C, Gerace D, Bajoni D (2019) An artificial neuron implemented on an actual quantum processor. npj Quantum Information 5:26
Tacchino F, Barkoutsos P, Macchiavello C, Tavernelli I, Gerace D, Bajoni D (2020) Quantum implementation of an artificial feed-forward neural network. Quantum Sci Technol 5:044010
Tacchino F, Mangini S, Barkoutsos PK, Macchiavello C, Gerace D, Tavernelli I, Bajoni D (2021) Variational learning for quantum artificial neural networks. IEEE Transactions on Quantum Engineering 2:1
Virtanen P, Gommers R, Oliphant TE, Haberland M, Reddy T, Cournapeau D, Burovski E, Peterson P, Weckesser W, Bright J, van der Walt SJ, Brett M, Wilson J, Millman KJ, Mayorov N, Nelson ARJ, Jones E, Kern R, Larson E, Carey CJ, Polat İ, Feng Y, Moore EW, VanderPlas J, Laxalde D, Perktold J, Cimrman R, Henriksen I, Quintero EA, Harris CR, Archibald AM, Ribeiro AH, Pedregosa F, van Mulbregt P, SciPy 10 Contributors (2020) SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nature Methods 17:261
Wilde MM (2017) Quantum Information Theory. 2nd edn. Cambridge University Press
Xu X, Sun J, Endo S, Li Y, Benjamin SC, Yuan X (2019) Variational algorithms for linear algebra. arXiv:1909.03898 [quant-ph]
Acknowledgements
We acknowledge use of the IBM Quantum Experience for this work. The views expressed are those of the authors and do not reflect the official policy or position of IBM company or the IBM-Q team. We wish to thank Eni’s management, who gave the permission to publish this paper.
Funding
Open access funding provided by Università degli Studi di Pavia within the CRUI-CARE Agreement. This work was supported by Eni S.p.A. through the research program “Research, Development and Analysis Activities supporting the Innovation” under Contract No. 2500034935, and by the Italian Ministry of Education, University and Research (MIUR) through the “Dipartimenti di Eccellenza Program (2018-2022)”.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Mangini, S., Marruzzo, A., Piantanida, M. et al. Quantum neural network autoencoder and classifier applied to an industrial case study. Quantum Mach. Intell. 4, 13 (2022). https://doi.org/10.1007/s42484-022-00070-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42484-022-00070-4