
Abstract
Quantum machine learning seeks to exploit the underlying nature of a quantum computer to enhance machine learning techniques. A particular framework uses the quantum property of superposition to store sets of parameters, thereby creating an ensemble of quantum classifiers that may be computed in parallel. The idea stems from classical ensemble methods where one attempts to build a stronger model by averaging the results from many different models. In this work, we demonstrate that a specific implementation of the quantum ensemble of quantum classifiers, called the accuracy-weighted quantum ensemble, can be fully dequantised. On the other hand, the general quantum ensemble framework is shown to contain the well-known Deutsch-Jozsa algorithm that notably provides a quantum speedup and creates the potential for a useful quantum ensemble to harness this computational advantage.
Similar content being viewed by others

References
Bellman R (1966) Dynamic programming. Science 153(3731):34–37
Benedetti M, Realpe-Gómez J, Perdomo-Ortiz A (2018) Quantum-assisted Helmholtz machines: a quantum–classical deep learning framework for industrial datasets in near-term devices. Quant Sci Technol 3(3):034007
Beyer K, Goldstein J, Ramkrishnan R, Shaft U (1999) When is “nearest neighbor” meaningful?. In: International conference on database theory. Springer, pp 217–235
Bhattacharya RN (1977) Refinements of the multidimensional central limit theorem and applications. Ann Probab 5(1):1–27
Casella G, Robert CP, Wells MT, et al. (2004) Generalized accept-reject sampling schemes. In: A Festschrift for Herman Rubin. Institute of Mathematical Statistics, pp 342–347
Chandra A, Yao X (2006) Evolving hybrid ensembles of learning machines for better generalisation. Neurocomputing 69(7–9):686–700
Deutsch D, Jozsa R (1992) Rapid solution of problems by quantum computation. Proc R Soc London Series A 439:553–558
Farhi E, Goldstone J, Gutmann S (2014) A quantum approximate optimization algorithm. arXiv:1411.4028
Friedrich KO, et al. (1989) A Berry-Esseen bound for functions of independent random variables. Ann Stat 17(1):170–183
Gulde S, Riebe M, Lancaster GPT, Becher C, Eschner J, Häffner H, Schmidt-Kaler F, Chuang IL, Blatt R (2003) Implementation of the Deutsch–Jozsa algorithm on an ion-trap quantum computer. Nature 421(6918):48
Hansen LK, Salamon P (1990) Neural network ensembles. IEEE Trans Pattern Anal Mach Intell 10:993–1001
Havlíček V, Córcoles AD, Temme K, Harrow AW, Kandala A, Chow JM, Gambetta JM (2019) Supervised learning with quantum-enhanced feature spaces. Nature 567(7747):209
Hoeting JA, Madigan D, Raftery AE, Volinsky CT (1999) Bayesian model averaging: a tutorial. Stat Sci, 382–401
Klartag B (2010) High-dimensional distributions with convexity properties. Preprint, http://www.math.tau.ac.il/klartagb/papers/euro.pdf
Kübler JM, Muandet K, Schölkopf B (2019) Quantum mean embedding of probability distributions. arXiv:1905.13526
Madigan D, Raftery AE (1994) Model selection and accounting for model uncertainty in graphical models using Occam’s window. J Am Stat Assoc 89(428):1535–1546
Nielsen MA, Chuang I (2002) Quantum computation and quantum information
Peruzzo A, McClean J, Shadbolt P, Yung M-H, Zhou X-Q, Love PJ, Aspuru-Guzik A, O’brien JL (2014) A variational eigenvalue solver on a photonic quantum processor. Nat Commun 5:4213
Romero J, Olson JP, Aspuru-Guzik A (2017) Quantum autoencoders for efficient compression of quantum data. Quant Sci Technol 2(4):045001
Schapire RE (2003) The boosting approach to machine learning: an overview. In: Nonlinear estimation and classification. Springer, pp 149–171
Schuld M, Killoran N (2019) Quantum machine learning in feature Hilbert spaces. Phys Revi Lett 122 (4):040504
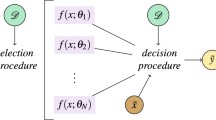
Schuld M, Petruccione F (2018) Quantum ensembles of quantum classifiers. Sci Rep 8(1):2772
Schuld M, Petruccione F (2018a) Supervised learning with quantum computers
Schuld M, Petruccione F (2018b) Supervised learning with quantum computers, vol 17. Springer
Shaft U, Ramakrishnan R (2006) Theory of nearest neighbors indexability. ACM Trans Datab Syst (TODS) 31(3):814–838
Simon DR (1997) On the power of quantum computation. SIAM J Comput 26(5):1474–1483
van Zwet R (1984) A Berry-Esseen bound for symmetric statistics. Zeitschrift für Wahrscheinlichkeitstheorie und verwandte Gebiete 66(3):425–440
Verdon G, Broughton M, Biamonte J (2017) A quantum algorithm to train neural networks using low-depth circuits. arXiv:1712.05304
Zhang C, Ma Y (2012) Ensemble machine learning: methods and applications. Springer
Zimek A, Schubert E, Kriegel H-P (2012) A survey on unsupervised outlier detection in high-dimensional numerical data. Statist Ana Data Min: ASA Data Sci J 5(5):363–387
Acknowledgements
This work is based upon research supported by the South African Research Chair Initiative of the Department of Science and Technology and National Research Foundation.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix 1: Analysis of the accuracy-weighted q-ensemble
Using the dequantised accuracy-weighted q-ensemble, we may study the behaviour of the algorithm. A problem occurs if it becomes difficult to select models with an accuracy greater than 0.5 for the ensemble. In particular, if models tend to an accuracy of 0.5 and the variance of these accuracies vanishes exponentially fast, both classical and quantum versions of the accuracy-weighted q-ensemble become intractable: exponentially more precision will be required to calculate the accuracies for the classical rejection criteria and the probabilities of the label in the quantum setting. Postselection is done on the |0〉-branch of the accuracy qubit in superposition \(|{A_{\theta }}\rangle = \sqrt {a_{\theta }}|{0}\rangle +\sqrt {1-a_{\theta }}|{1}\rangle \). Looking at the probabilities, \(p(\tilde {y}=-1) = {\sum }_{\theta \in \mathcal {E}^{+}} \frac {a_{\theta }}{E_{\mathcal {X}}}\) and \(p(\tilde {y}=1) = {\sum }_{\theta \in \mathcal {E}^{-}} \frac {a_{\theta }}{E_{\mathcal {X}}}\), if a𝜃 → 0.5 ∀ 𝜃 as \(d \to \infty \) with increasing certainty, one requires increasingly more resources to obtain the necessary precision to compute the probabilities of the label. The resources needed are directly dependent on the rate of convergence of models’ accuracies to 0.5 and ultimately determine the feasibility of this strategy. In this analysis, we examine this rate of convergence with linear, perceptron and neural network models under specific data assumptions.
Data and model assumptions
We explicitly define the accuracy of a model with a parameter set 𝜃 as
where f is a base model, f∗ is a specified “ground truth” model with parameters 𝜃∗ and a𝜃 may be interpreted as the proportion of correct classifications of M data points in a dataset \(\mathcal {D}\) containing d features. We can also define the average ensemble accuracy of n sampled models for a fixed dimension (i.e. a fixed number of features) d as \(A_{\theta |d} = \frac {1}{n} {\sum }_{i=1}^{n} a_{\theta _{i}}\). To examine the behaviour of model accuracy, we consider base models with simple data to provide an indication as to whether the accuracy-weighted strategy is indeed viable. The entries of the input vectors xm are drawn from a standard normal distribution and ℓ2 normalised. Again, for simplicity, the labels are assigned based on the first entry of each input vector. If the first entry of the m th input vector denoted by \(x_{m}^{(1)}\) is positive, f∗(xm; 𝜃∗) = 1, else f∗(xm; 𝜃∗) = − 1.
Model parameters 𝜃 contain entries drawn from a random uniform distribution over the interval [ − 1, 1] to create the respective ensembles. This follows directly from the accuracy-weighted q-ensemble routine in Schuld and Petruccione (2018) which assumes 𝜃 ∈ [a,b ] and initially encodes the parameter sets into a uniform superposition of computational basis states. Simulations are done with M = 10000 input vectors and labels, along with n = 100 parameter sets.
Accuracy in higher dimensions
Figure 1 plots A𝜃|d for d ≤ 1000 using linear models and Fig. 3 contains the same plot for single-layer perceptron models and neural networks with three hidden layers. These models all satisfy the point symmetric property assumed in the original accuracy-weighted q-ensemble and are commonly deployed in machine learning. For simulations in low dimensions (d < 10), the distribution of A𝜃|d has a relatively high dispersion around the mean value of 0.5 with all base models. This is desirable as it allows for models with accuracy a𝜃 > 0.5 to be easily accepted into the ensemble. As the dimension increases, however, the dispersion rapidly decreases and all models tend to an accuracy of 0.5 with less deviation, making it increasingly difficult to build a strong ensemble. The sharp decline in standard deviation is plotted on a log scale for linear models in Figs. 2 and 4 for the perceptron and neural network models. This occurrence is due to the sampling method for the parameter vectors and the ℓ2 normalisation of data which leads to “the curse of dimensionality” and “concentration of measure” phenomena discussed in Bellman (1966), Klartag (2010), and Beyer et al. (1999). Put briefly, most models become random guessers as the dimension increases.

This plot contains the average accuracy of sampled parameter sets for linear models over increasing dimensions d. As d increases, it becomes more noticeable that models in the ensemble have accuracies close to 0.5 with declining dispersion represented by one standard deviation above and below the mean in yellow shading

Declining standard deviation of average accuracies for linear models plotted on a log scale per dimension
Since A𝜃|d is an average of the sum of random variables a𝜃, by the central limit theorem, A𝜃|d tends to a normal distribution as more random variables are added. The mean and standard deviation of this distribution depend on a𝜃 which depends on the dimension of the data. We show in Appendix ?? that the mean of a𝜃 is equal to 0.5 and the standard deviation tends to 0 as d increases to infinity for perceptron and linear models. Numerical simulations suggest the same behaviour for three-layer neural networks as seen in Fig. 3. The crucial issue is the rate of convergence of a𝜃 (and hence A𝜃|d) to 0.5 which depends on the statistical properties of the input data. For i.i.d data drawn from a standard normal distribution as done so here, by the Berry-Esseen theorem, the rate of convergence is \(\mathcal {O}(d^{-\frac {1}{2}})\) (Friedrich et al. 1989; van Zwet 1984). For more realistic data, the convergence rate may differ. When data is represented as matrices, an expository survey of rates of convergence and asymptotic expansions in the context of the multi-dimensional central limit theorem may be found in Bhattacharya (1977). In short, the rates of convergence vary and are generally calculated (or estimated) on a case by case basis unless specific assumptions around the input data may be made. For the simple models deployed in this analysis, overall the results indicate convergence rates that are polynomial in d, and hence, the accuracy-weighted q-ensemble remains tractable (Fig. 4). This, however, does not say anything about whether the accuracy-weighted q-ensemble (even if computationally tractable) is a useful method. As such, we continue with the same data assumptions, making use of the known tractability, and build the accuracy-weighted ensemble for a high-dimensional dataset.

The average accuracy of sampled parameter sets for ensembles over increasing dimensions d is depicted. Ensembles containing perceptron models are displayed in the top graph and neural networks with three hidden layers are contained in the bottom graph. The dispersion of model accuracies is represented by one standard deviation above and below the mean accuracies in the shaded orange and pink areas for perceptrons and neural networks respectively

Declining standard deviation of average accuracies per dimension d is plotted on a log scale for perceptron models in the top graph (in orange) and neural networks with three hidden layers in the bottom graph (in pink)
Poor performance of the accuracy-weighted ensemble on simple high-dimensional data
Using the perceptron as a base model, numerical simulations of the standard deviation of accuracies indicate that the rate of convergence is faster than the Berry-Esseen asymptotic convergence for \(d \leqslant 10000\) as plotted in Fig. 5. The standard deviation appears to level off for d ≥ 8000 and the rate of decay is notably not exponential. Thus, one may build an ensemble of weak classifiers in higher dimensions.

This plot contains the standard deviation of average accuracies of perceptron models in orange plotted on a log scale per dimension. The black line is the Berry-Essen asymptotic convergence
We construct the ensemble for d = 8000 to determine its empirical success using M = 10,000 training data points. With n = 30,000 sampled models, 14,903 models achieved an accuracy greater than 0.5. These models were then selected for the ensemble and tested on 2000 test samples. The overall test accuracy was found to be 0.50167. Using n = 100,000 sampled models did not appear to improve the result as 49,580 models passed the selection criteria and provided a test accuracy of 0.50165. It is interesting that even with non-exponential convergence of the standard deviation to zero, the accuracy-weighted ensemble strategy reveals poor performance on a simple dataset that should be easy to classify. On the other hand, this does not imply that the accuracy-weighted method will perform poorly for all high-dimensional datasets. If, for example, data actually follows a mixture of distributions where classes are composed of natural clusters that each follow their own distribution, the curse of dimensionality may no longer be an issue (Beyer et al. 1999; Zimek et al. 2012; Shaft and Ramakrishnan 2006).
Appendix 2: Modelling the behaviour of the perceptron ensemble in higher dimensions
The perceptron model may be written as follows
where σ is a thresholding function ensuring the prediction is 1 if the output is positive and − 1 otherwise. X is a M × d matrix where each row represents one data point and 𝜃 is a d × 1 column vector. The ground truth model in this example may be formulated with 𝜃∗ = [1, 0,..., 0 ]T for simplicity, although this may be any uniformly sampled 𝜃. One may now rewrite the accuracy of a model from Eq. (7) in terms of expectation values
Since \(X_{ij} \sim N(0,1)\) and \(\theta _{j} \sim U\ [-1,1\ ]\), σ(Xij𝜃j) = ± 1 with equal probability, and similarly for σ(Xij𝜃∗). Looking at all possible outcomes presented in Table 1, the distribution of accuracy is 1 and 0 with approximately equal occurrence. As \(d \to \infty \), by the law of large numbers, the distribution of accuracy contains an equal number of 0’s and 1’s with more certainty. Taking the expectation of this gives exactly 0.5 as confirmed by the simulated results
Using a similar logic, the variance of the accuracy of the perceptron model may be formulated as follows
The thresholding function applies to all f(X,𝜃) and so we leave it out of the notation for brevity but its effect is still present. The expectation of the squared accuracy is
Taking the expectation of each of the terms, it is clear that the first and last terms equal 0 as d increases to infinity since Xij and 𝜃j are independent with mean values of 0. The middle term may be further simplified using the fact that 𝜃∗ = [1, 0,..., 0 ]T
Using this along with the result from Eq. (10), the variance from Eq. (11) becomes
which holds for any uniformly sampled ground truth model.
Rights and permissions
About this article

Cite this article
Abbas, A., Schuld, M. & Petruccione, F. On quantum ensembles of quantum classifiers. Quantum Mach. Intell. 2, 6 (2020). https://doi.org/10.1007/s42484-020-00018-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42484-020-00018-6