
Abstract
Extensive research has shown that phonological awareness including phoneme awareness skills are vital when children acquire literacy skills in alphabetic languages especially in English. Furthermore, research on developmental dyslexia (DD) especially in English has been conducted with research-informed/well-established definitions of DD. This is because compared to other languages, the prevalence of DD in English is high, and thus children with DD form a large minority group. These dyslexia research encompasses cognitive-behavioural, neuroimaging, behavioural and molecular-genetic studies. There seems to be a consensus amongst these researchers that DD manifests itself as a phonological deficit, and thus the phonological deficit hypothesis (as well as naming disfluency) for DD has become prominent in the alphabetic languages, especially in English. This is because print-to-sound or sound-to-print mappings in English are not always one-to-one and thus opaque/inconsistent. Now important questions arise in discussing how children acquire reading skills in non-alphabetic languages especially in Japanese where logographic Kanji and 2-forms of syllabic Kana are used: (i) are phonological awareness skills vital when children learn to read in Japanese? (ii) can the phonological deficit hypothesis explain DD in Japanese? These questions will be addressed in this paper by comparing the behavioural and some neuroimaging studies in alphabetic languages and Japanese Kanji and Kana as well as Chinese, another non-alphabetic languag. It seems that phonological awareness may not be as important for non-alphabetic languages such as Chinese or Japanese at the start of literacy acquisition. Phonological awareness become important skills in Chinese and Japanese only when children are older. Instead of phonological awareness other metalinguistic awareness skills are important for acquisition of reading in Chinese and Japanese such as orthographic or morphological awareness (Chinese), vocabulary size (Japanese), visuo-spatial processing (Chinese and Japanese) and visual-motor integration (Chinese and Japanese) skills. Also available neuroimaging studies will be used to uncover the behavioural dissociation and the neural unity in an English-Japanese bilingual adolescent boy with monolingual dyslexia in English.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Definition of developmental dyslexia
Developmental dyslexia (DD) is a specific learning disability that is neurobiological in origin (Eden & Moats, 2002), and is highly heritable with genetic link (Fisher & DeFries, 2002).
A working definition of DD which is in current use in the UK was proposed in the Rose Review (2009) as follows: “DD is a learning difficulty (LD) that primarily affects the skills involved in accurate and fluent word reading and spelling. Characteristic features of dyslexia are difficulties in phonological awareness, verbal memory and verbal processing speed” (p.9).
Phonological awareness is the awareness of the sound of a word, one aspect of metalinguistic knowledge, and is explicit knowledge about our language processes. Phonological awareness skills are often measured by phoneme segmentation, counting, blending, deletion and reversal, and rhyme judgement, etc. In addition, the prevalence of Developmental Dyslexia (DD) is said to vary across different languages.
In this paper a particular focus is placed on how DD manifests itself in non-alphabetic languages in particular in Japanese, including how reading acquisition takes place as well as cognitive processes involved in reading in Japanese, compared to those of alphabetic languages such in English. It is hoped that this will lead to a plausible answer for the different prevalent rates of DD.
Prevalence of DD in different languages
In the English-speaking world, the prevalence of dyslexia is around 10–12% (Snowling, 2000; Shaywitz et al., 1990), thus forming a large minority group. In contrast, this is lower in consistent orthographies where print-to-sound correspondence is consistent such as in Italian, which is around 3–4% (Barbiero et al., 2012). In non-alphabetic language such as Japanese, the prevalence of reading difficulties differs across different scripts: 0.2% in consistent syllabic Hiragana, 1.4% in consistent syllabic Katakana and 6.9% in inconsistent logographic and morphographic Kanji (Uno et al., 2009)Footnote 1. A high or low incidence of developmental dyslexia seems to depend on the characteristics of the given languages (but see the results of a recent meta-analysis by Yang et al. (2022)Footnote 2, who found no significant difference in the prevalence rates across different writing systems).
Therefore, it is still interesting to investigate if these differences could partially be due to the key characteristics of alphabetic and non-alphabetic orthographies.
Characteristics of alphabetic orthographies
Alphabetic script is used in English and other European languages. The basic unit represented by a grapheme (a letter or a letter cluster, e.g., ‘ch’ in cheese) is a phoneme (the smallest speech sound unit which is required for reading alphabetic languages). For example, the word ‘cat’ has three graphemes (letters), ‘c’, ‘a’ and ‘t’ and three phonemes, /c/, /a// and /t/, which are then blended into the word /cat/. Synthesizing and segmenting phonemes are part of phonological awareness (phoneme) awareness.
English has 44 phonemesFootnote 3 and 1120 ways (graphemes) of representing 44 phonemes and hence the Grapheme-Phoneme-Correspondence (GPC) or Phoneme-Grapheme-Correspondence (PGC) in English is one-to-many and inconsistent (Nyikos, 1988). For example, the phoneme /f/ has seven spelling alternatives, ‘fan’, ‘cliff’, ‘phone’, ‘laugh’, ‘calf’, and ‘often’. English monosyllabic words can be categorised into four different types: (1) consistent regular words where the pronunciation of the word-body, ‘ink’ is invariant across different words with the same word-body (e.g., ink, link, pink or mink), (2) consistent irregular words (e.g., hint, mint, tint vs. pint) where the word-body int is pronounced the same except for one whose pronunciation is irregular, (3) Inconsistent words (e.g., beak, leak and peak) vs. bread (head and spread) vs. steak vs. learn (earn) where the word-body ea has four different pronunciations and (4) Exception words (e.g., through, thorough, bough, cough or dough) where the word-body ough is pronounced differently in every word with the same word-body ough or words such as yacht or colonel are truly exceptional as they violate the English GPC. Thus, it can be said that English has one of the most complicated grapheme-phoneme-correspondences requiring finer phonological in particular phoneme awareness skills.
In contrast, Italian has 33 graphemes and 25 phonemes, and GPC in Italian are one-to-one, and hence consistent. Because of this consistent/transparent GPC and PGC, research has shown that Italian children acquire reading and writing skills more easily and faster than English children. For example, Marinelli et al. (2015) compared Italian and English children’s spelling acquisition and found that Italian children were very accurate in spelling in Italian after only 2 years of schooling, while English children were still not accurate at spelling in English after 5 years of schooling. Moreover, as with Wimmer’s (1993) findings in German with a relatively consistent orthography (see also Wimmer & Mayringer, 2002), Zocolotti et al. (1999) found from their four case studies of Italian boys (aged 11.10–15.7) with reading difficulty that their reading difficulty lied in reading speed, while their reading accuracy was retained. Zocolotti et al. stated, “The most pervasive reading symptom was severe slowness” (p. 191). Thus, reading speed is a better indicator for reading skills in transparent/consistent orthographies.
Recently, Provazza et al. (2022) investigated the nature of visual and phonological processing in DD in transparent/consistent Italian and opaque/inconsistent English. Their focus was on the characterisation of visual processing deficits in relation to orthographic depth. Four different groups of participants—18 participants with DD and 18 control participants in English and 18 participants with DD and 18 control participants in Italian underwent two visual discrimination tasks—checkerboard and Kanji with each stimulus condition having target, probe and foil which were displayed vertically. The participants were asked to respond if the target was the same as the foil as well as the phonological task which was a forward and backward digit span task. The results showed that DD in English and Italian performed worse than their controls in both visual and phonological tasks. It was also revealed that both DD participants showed a deficit in processing visual stimuli. The Italian DD group performed significantly worse than the English DD and TDR groups in the visual tasks, and these differences were particularly evident in the visually complex and similar conditions. Provazza et al. (2022) suggested that the impaired reading and associated deficits observed in DD are anchored by dual impairments to visual and phonological mechanisms that underpin reading, with the magnitude of the visual deficit varying according to orthographic depth, i.e., the transparent/consistent Italian orthography was worse off. This means that DD researchers should also incorporate visual tasks such as Provazza et al.’s more to investigate finer visual processing skills.
Characteristics of Japanese orthography
Japanese orthography consists of two qualitatively different writing systems: logographic and morphographic Kanji, derived from Chinese characters, which are also logographic, and two forms of syllabic (linguistically known as moraic) Kana–Hiragana and Katakana, whose visual forms are derived from Kanji characters (see Sampson, 1985; Wydell and Butterworth, 1999; Wydell et al., 1995; Wydell et al., 1993, for more details). It is interesting to note that Chinese and Japanese are linguistically different from each other: Japanese is a Subject-Object-Verb (S-O-V) agglutinating language with limited number of subtle pitch accent, e.g., the pitch accent on the first mora (syllable like unit), /a-me/ (rain) versus the pitch accent on the second mora, /a-me/ (candy). It has 110 Japanese moraic or syllabic speech sounds. In contrast Chinese is a tonal language with a S-V-O ordering with four tones in Mandarin and nine tones in Cantonese.
Chinese characters are said to be introduced to Japan during 4th and 5th centuries (though from an antient tomb from Yayoi-era in the first century, Chinese coins with Chinese characters engraved have been found). Subsequently, Chinese characters were adopted into Japanese as Kanji characters where the Chinese reading of the characters became the ON-reading (without tonal information), and the Japanese reading of the same characters, the KUN-reading was given to the characters from the meaning (e.g., 花 meaning ‘flower’ is /ka/ in ON-reading as in 花瓶/ka-bin/ meaning ‘vase’, while /hana/ in KUN-reading as in 花束/hana-taba/ meaning ‘bouquet’). Hence most of the Kanji characters have both an ON-reading (of Chinese origin) and a KUN-reading (of Japanese origin) (Takebe, 1979).
Initially Japanese sentences were written in S-V-O like Chinese, which made it difficult for non-scholastic Japanese readers to read and write in Japanese. In order to transcribe the Japanese language appropriately syllabic Kana characters were thus invented/ derived from Chinese characters to fit the Japanese S-O-V language (Takebe, 1979).
Each Kana character was derived from parts of Chinese characters, e.g., 安 /a/ -> あ /a/ in Hiragana, and ア/a/ in Katakana. Initially Katakana, known as 男手 /otokode/ (male hand) was born to facilitate reading in Japanese. Then Hiragana, known as 女手/onnade/ (female hand) was born as females were forbidden to use Kanji characters. Since then both Kana forms have been used.
Both Kana characters, each corresponding to 110 Japanese moraic/syllabic sounds, can transcribe all Japanese words, however each transcribes different classes of words, i.e., Hiragana is mainly for function words, the inflections of the verbs, adjectives and adverbs as well as uncommon Kanji nouns, while Katakana is used for transcribing foreign loan words (see below).
Hiragana for
Function words, e.g., しかし/shi-ka-shi/ (but); the inflections of verbs, e.g., 歩く/aru-ku/ (walk), adjectives, e.g., 優しい /yasa-shi-i/ (gentle) and adverbs, e.g., 優しく/yasa-shi-ku/ (gently); and for uncommon Kanji words, e.g., なだれ (雪崩) /nadare/ (avalanche)—this would be analogous to exception words in English (e.g., colonel or yacht) as this particular Kanji word has to be learned as a whole word. /nadare/ is a Japanese word and Kanji characters 雪/yuki/ in KUN-reading and /setsu/ in ON-reading (snow) and崩 /hou/ (collapse) were assigned to /nadare/ from the meaning.
Katakana for
Foreign loan words in contemporary Japanese, e.g., アイス/a-i-su/ (ice); transcribing onomatopoetic words, e.g., ザーザー/zaa-zaa/ (raining hard) or キラキラ/ki-ra-ki-ra/ (a star or a diamond is sparkling) as well as sending telegrams (though not many people send telegrams nowadays).
Hiragana and Katana both have an almost one-to-one Kana-to-sound conversion, and its sound value does not change whether the character appears in the first position, the middle position, or at the end of a multi-syllable word, e.g., かきね /ka-ki-ne/ (hedge), みかん /mi-ka-n/ (tangerine) andえんか /e-n-ka/ (Japanese ballad). Therefore, the relationship between character and pronunciation is very transparent/consistentFootnote 4, unlike English where grapheme (letter or letter clusters) to phoneme (smallest speech sound unit in English) translation is opaque/inconsistent, e.g., ‘hint, lint, mint vs. pint’ or ‘head vs. bead vs. steak’
Kanji
In contrast, Kanji is used for nouns, which are not inflected in Japanese, e.g., 本 /hon/ (book); 着物 /kimono/ (Japanese Kimono) and for the root morphemes of inflected verbs, e.g., 歩く/aru-ku/ (study), adjectives, and adverbs.
Unlike Kana, the relationship between character and pronunciation in Kanji is very opaque/inconsistentFootnote 5. Kanji and Kana sit at the opposite ends of the transparency/consistency continuum. This is because each Kanji character is a morphographic element that cannot phonetically be decomposed, as there are no separate components of a character that correspond to the individual phonemes (see Wydell et al., 1995, for more details). Kanji Words have one to five characters, however, two is the modal number, and 2.4 is the mean (Yokosawa & Umeda, 1988). Moreover, most Kanji characters have one or more ON-readings (of Chinese origin) and a KUN-reading (of Japanese origin). For example, 歌 /uta/ (song) is a KUN-reading single-character word and 歌声 /uta-goe/ (singing voice) is a KUN-reading two-character word, while 歌手 /ka-shu/ (singer) is an ON-reading two-character word.
Furthermore, when the Chinese characters and words were introduced into the Japanese language, they lost their original Chinese tones and accents as previously mentioned Japanese is not a tonal language. Therefore, there are many homophones in ON-reading Kanji characters and words, which in the original Chinese could be distinguished from each other by tones and accents to greater extent, e.g., the character pronunciation, /ki/ has over 100 different homophonic characters: 希, 生, 樹, 紀, 貴, 輝, 季, 来, 大, 姫, 喜, 妃, 來, 稀, etc.
Like Chinese characters, some Kanji characters have phonetic or semantic or both radicals. However, the phonetic radicals do not necessarily lead to the correct pronunciation. For example, the phonetic radicals give no clue at all to KUN-reading (of Japanese origin). Saito et al. (1995) analysed 1668 commonly used Kanji characters and found that only 32 per cent have ON-readings identical to their phonetic radicals. Similarly, semantic radicals do not necessarily lead to the actual meanings of characters (this is the same for Chinese). For example, the character, 魚 meaning “fish” (/sakana/ in KUN-reading and /gyo/ in ON-reading) can be a semantic radical seen in many fish-related Kanji words, e.g., 鮪 /maguro/ (tuna) or 鯛/tai/ (seabream). Thus, all one can say is that all these characters and words are something to do with “fish. However, the “fish” radical cannot lead us to the correct names of the fish.
Since the syllabic (moraic) Kana and morphographic Kanji link to spoken Japanese through different character-to-pronunciation mappings, it is reasonable to assume Kana and Kanji require different weightings for the whole-word-level and the sub-word-level contributions in the computation of phonology from Kana and Kanji (see Uema et al. (2022) for a similar reading, which was considered to reflect the difference in the transparency/consistency of orthography-to-phonology mapping.)
So, 猫 /neko/ (cat) in Kanji is a two-syllable (mora) single character word, while ねこ/ne-ko/ in Hiragana, andネコ/ne-ko/ in Katakana are two-syllable (mora) two-character words. Currently a mixture of three scripts, Kanji, Hiragana and Katakana is in use in Japan.
Learning to read in Kana
Because of the transparent/consistent Kana character-to-pronunciation relationship, children master both Kana writing systems very quickly, as indicated by Sambai et al. (2012). That is, each Kana syllabary has a basic 46 characters and both Hiragana and Katakana syllabaries have the same 46 sounds (pronunciations). Each character has a unique pronunciation which does not vary whether it appears in the first, middle or last position of a word, for example, the sound of /ka/ does not change in these three words containing the character and sound /ka/ in かきね/ka-ki-ne/ (hedge)、 みかん/mi-ka-n/(orange)、へんか /he-n-ka/ (change). Therefore, learning to read/write in Kana is easy and once the 46 Hiragana or Katakana characters and their associated sounds are learned, with diacritical marks (e.g., か/ka/ ->が/ga/; は/ha/ ->ぱ/pa/, etc.) the 46 characters can now be extended to 110 characters and their associated sounds (pronunciations). Most children learn Hiragana even before they start primary-school education (Gibson & Levin, 1975; Makita, 1968; Muraishi, 1972; Sakamoto & Makita, 1973).
Cognitive behavioural studies of Kana reading with Japanese adults and children as participants showed that both whole-word lexical reading and sequential character-by-character sub-lexical reading processes are taking place in reading Kana (e.g., Besner & Hilderbrandt, 1987; Rastle et al., 2009; Sambai et al., 2012). For example, Besner and Hilderbrandt (1987) showed that reading latencies for Katakana real words, e.g., テレビ /te-re-bi/ (TV) were significantly shorter than pronounceable Katakana nonwords, thus showing a significant lexicality effect in reading Katakana. Similarly, Rastle et al. (2009) showed the effects of lexicality and word-frequency in Hiragana and Katakana words and non-words reading, thus showing a word-level familiarity effect in both Hiragana and Katakana reading. Reading latencies for real words in Hiragana and Katakana were significantly shorter than those for Hiragana transcriptions of Katakana words and Katakana transcriptions of Hiragana words, thus showing lexicality effects. In addition, reading latencies for high-frequency words were shorter than those for low-frequency words in reading Hiragana and Katakana respectively. Altogether Rastle et al. showed a whole-word level processing in reading Hiragana and Katakana.
Rastle et al. also revealed significant length effects in reading Katakana and Hiragana words as well as Katakana and Hiragana transcriptions in reading Hiragana and Katakana. The character lengths of the stimuli were 3, 4, 5, and 6 characters for words and transcriptions. The length effect was significantly larger for Katakana or Hiragana transcriptions than Hiragana or Katakana real words. Rastle et al. concluded that if the length effects were caused by a sequential character-by-character sub-lexical process, then this could explain why a particularly large length effect was observed for transcriptions of Hiragana or Katakana.
Sambai et al. (2012) investigated length and lexicality effects in reading Hiragana and Katakana high-familiar words and nonwords with Japanese Pre-School, First-Grade, Second-Grade, Third-Grade, and Fifth and Six-Grade typically developing children as well as Fifth and Six-Grade children with DD. The both Hiragana and Katakana stimuli were divided into two length conditions—2-character stimuli and 5-character stimuli. The results revealed that while typically developing Pre-School children made significantly more errors in reading than typically developing Fifth and Sixth-Grade children, no difference was found among other typically developing children. The authors stated that the typically developing children almost fully acquired Kana-to-sound conversion rules by the end of the first school year. This is because the Kana-to-sound conversion is transparent/consistent, and hence it is easy to acquire. Reading latency data revealed that all the typically developing children showed length effects for both words and nonwords. However, RTs for Second-Grade, Third-Grade and Fifth and Six Grade children showed that the length effect was modulated by the lexicality effect. A larger length effect was observed with nonwords than words amongst older children. Sambai et al. thus argued that the Japanese typically developing children acquire a lexical reading strategy for Kana as early as in the Second Grade. In contrast, the Fifth and Sixth-Grade children with DD showed reading characteristics similar to those of normal ability Pre-School and First-Grade children, in that they did not show a significant interaction between length and lexicality.
Because of the transparent/consistent relationship between Kana character and its pronunciation, it is reasonable to assume that the optimal reading strategy for Kana is sub-word syllabic processing, which is reliable and requires no orthographic segmentation or phonological blending (Wydell & Butterworth, 1999; Sambai et al., 2012). Therefore, it is said that Japanese children do not usually show reading difficulties in Kana.
The modulation of the length effect by the lexicality effect was also observed in transparent/consistent Italian. Zoccolotti et al. (2005) asked typically developing First-Grade, Second-Grade, and Third-Grade Italian primary school children as well as Third-Grade children with DD to read around words in four different letter-lengths, i.e., 2-letter, 3-letter, 4-letter and 5-letter words. The results revealed that while typically developing First-Grade children showed a large linear length effect, Grade-2 and 3 children showed very much attenuated length effects. Interestingly, Third-Grade children with DD showed a similar large linear length effect to that of First-Grade typically developing children, the results of which are very similar to those of Sambai et al.’s (2012) study. Similarly, Zoccolotti et al. argued that typically developing readers in an orthographically transparent/consistent language such as Italian adopt a lexical strategy early in their learning. In contrast, just like the Japanese children with DD, Italian children with DD seem unable to learn lexical strategy and continue to use a sub-lexical reading procedure.
Learning to read in Kanji
It is thought that Kanji character learning is at the level of whole characters and words. Kanji learning is essentially by rote: children are introduced to new Kanji characters in texts. The leaning method commonly used by Japanese primary school children is repeated writing (Kusumi, 1992; Naka & Naoi, 1995). Repeated writing, which is often accompanied by reciting the Kanji character or word they are writing, allows children to (1) develop a motor memory of the correct sequence of strokes for any given Kanji character and (2) learn how to pronounce the character or word that the child is writing repeatedly at the same time. This strategy is often observed amongst Japanese children learning new Kanji characters and words (e.g., Mann, 1985; Onose, 1987; 1988).
Further, it has been reported that in Chinese skilled reading is significantly and positively correlated with handwriting performance in primary school children (e.g., McBride et al., 2022; Tan et al., 2005). Just like Chinese, Kanji reading is also highly correlated with Kanji writing (e.g., Uno et al., 2009). This must be the consequence of how the Japanese (and Chinese) children learn to read new Kanji characters and words.
Moreover, Japanese children are not taught to analyse the components of Kanji characters such as phonetic radicals or semantic radicals until they are at Junior High School level (aged 13–15). This is partly because the children learn simple Kanji characters first where often they do not contain phonetic or semantic radicals. Besides these radicals do not necessarily lead to the correct pronunciation or the correct meaning of a Kanji word (Saito et al., 1995).
Japanese compulsory education (6 years of primary school and 3 years of junior high school) uses the common core curriculum across all the schools in Japan. Children during primary-school education are introduced to 996 different Kanji characters, which are prescribed in the GAKUNENBESU KANJI HAITO HYO [the list of Kanji characters to be learned by Japanese primary-school children for each grade from Grade-1 to Grade-6] by the Japanese Ministry of Education and Science. By the end of compulsory education (aged 15–16), a total of just over 2,000 Kanji characters, known as JYOYO KANJI, have been learned, but always from context. However, 3,000 Kanji characters are necessary for adults to lead everyday literacy activities, e.g., reading a national newspaper (National Language Research Institute, 1976; KANJI BUNKA SHIRYOUKAN, 2008).
Cognitive behavioural studies on reading with Japanese adults as participants showed that both whole-word and character-level sub-word processing are involved in Kanji reading (e.g., Ami, Coltheart & Uno, 2018; Fushimi et al., 1999; 2003; Kondo and Wydell, 2011; Patterson et al., 1996; Patterson et al., 1995; Shibahara et al., 2003; Uema et al., 2022; Wydell et al., 1993; Wydell, Butterworth, & Patterson, Wydell et al., 1995), although the effect size of the former is substantially larger than the latter in Kanji word-naming or semantic-judgement experiments. In these experiments with Kanji significant word-frequency or word-familiarity effects were observed, indicating the involvement of whole-word processes.
For example, Shibahara et al. (2003) found not only a significant word-frequency effect but also a significantly larger imageability effect during naming of two-character Kanji words. Both word frequency and imageability effects are indicative of whole-word level processes in the computation of Kanji word phonology. In this paper, Shibahara et al. also cited a similar experiment conducted in English by Strain et al. (1995). Strain et al.’s results also showed a significant imageability effect in reading English but the effect was significantly weaker when compared to Shibahara et al.’s study in Kanji.
Uema et al. (2022) reported a case study of acquired phonological dyslexia in Japanese due to a left hemisphere infarction, who showed difficulty in reading two-character kanji nonwords (nonwords was created by replacing the first or second Kanji character of a 2-character word with other pronounceable Kanji character) and produced lexicalization errors. Uema et al. also observed the dissociation between normal Kana reading and impaired Kanji reading in this patient, and thus argued that the results reflected the difference in the transparency/consistency of orthography-to-phonology mapping.
Patterson et al. (1995) reported a case study of progressive aphasia in Japanese due to Alzheimer’s disease, revealing Legitimate Alternative Reading of Component (LARC) errors in naming two-character Kanji words, whereby the pronunciation of one or more components is inappropriate for the target word but is nonetheless legitimate, and often more typical ON-reading for words containing the character (e.g., 毛糸/ke-ito/ (wool yarn), a KUN-reading word was read as /mou-shi/ (which is in ON-reading but is a nonword) as in other ON-reading words, e.g., 純毛/jun-mou/ (pure wool), and as in 製糸/sei-shi/ (spinning). Fushimi et al. (2003; 2009) reported similar LARC errors in another Japanese progressive aphasic patient. These LARC errors thus indicate character-by-character sub-word reading processes (though neither Patterson et al. or Fushimi et al. interpreted their data in terms of the DRC model of reading. Their interpretation of the data is based on the connectionist models of reading (e.g., PDP or Triangle model of reading (e.g., Harm and Seidenberg (2004).
In contrast to Wydell et al., (1995) report on the null effect of print-to-sound consistency during reading of 2-character Kanji words, Fushimi et al. (1999) conducted a similar study and showed a small but statistically significant consistency effect. That is, those two-character Kanji words for which each constituent character has only a single ON-reading, revealed shorter reading latencies, and lower error rates than those two-character words for which either one or both characters have a KUN-reading, but a target word takes an ON-reading.
These studies with Japanese Kanji words as stimuli were spurred on by many studies in English that have addressed the effect of spelling-to-sound transparency/consistency in reading (e.g., Andrews, 1982; Glushko, 1979; Jared, 2002; Stanhope and Parkin, 1987; Taraban and McClelland, 1987). According to Glushko (1979), in English, ‘. . consistency rather than rule-defined regularity, provided a better account of empirical results. Although five may be a regular word “by rule”, its spelling-sound relationship is inconsistent with orthographically similar words such as give. . .’ (as cited in Wydell et al., 1995). The fact that inconsistent English words produced longer RTs and were more prone to errors during naming than consistent words suggests that sub-word level processing plays a significant role in the computation of word pronunciation.
The presence (Fushimi et al., 1999) or the absence (Wydell et al., 1995) of consistency effects in reading two-character Kanji words might largely result from differences in the experimental paradigms and subsequent statistical analyses. The statistically significant consistency effects in Fushimi et al. (1999) were obtained only when the analysis was conducted on the difference of RTs as well as error rates between the immediate-naming task and the delayed-naming task. In contrast, in their immediate-naming task a small but significant consistency effect was observed in the subject analysis but not in the item analysis. The discrepancy between the results obtained by Fushimi et al. and Wydell et al. seems to have been resolved by Kondo and Wydell (2011), who conducted immediate and delayed-naming experiments similar to those of Fushimi et al. (1999), but with 1,000 two-character Kanji word stimuli as opposed to the 120 two-character Kanji word stimuli in the Fushimi et al.’s study, varying the degree of word familiarity and consistency amongst several other variables. The use of the NTT Psycholinguistic Database Series (Amano & Kondo, 1999) made it possible to construct well-controlled Kanji stimuli. As with the results obtained by Fushimi et al. (1999), a small but statistically significant consistency effect in the reding latencies as well as the error rates was observed. However, more significantly and importantly, Kondo and Wydell (2011) also revealed that the effect size of word-level contribution such as the effects of word familiarity and frequency were far greater than that of sub-word level contribution in reading Kanji words.
Sambai et al. (2018) conducted three experiments investigating sub-lexical serial processing in reading 2-character Kanji words and nonwords with 46 Japanese university students. The stimuli were divided into three conditions—(1) typical-atypical words, where an inconsistent-atypical character-to-sound correspondence lay in the second Kanji character (2) atypical-typical words, where an inconsistent-atypical character-to-sound correspondence lay in the first Kanji character and (3) atypical-atypical words, where both 1st and 2nd Kanji characters have inconsistent character-to-sound correspondence. In Experiment 3, however, new two-character Kanji words, where both characters were typical – typical-typical words were added. Results showed that (i) in Experiment-1 when nonwords were included, RTs for the words in Condition (2), where atypical-characters were in the first position were significantly longer than RTs for the words in Condition (1), where atypical-characters were in the second position; (ii) In Experiment-2, however, when nonwords were excluded, there was no RT difference between the words in Condition (2) and Condition (1); (iii) In Experiment-3 when typical-typical words were added, the typicality effect was significant in the first-character position, but not in the second-character position. Ami et al. interpreted the data as (a) these position-of-atypicality effects indicate that sub-lexical processing of Kanji takes place serially and (b) the phonology of two-character Kanji words is generated from both a lexical whole word processing in parallel to a sub-lexical character-level processing.
Thus reading logographic and morphographic Kanji requires both lexical whole word and sub-lexical character level processing, though as was discussed earlier (see also Umema et al., 2022) reading Kanji may require a greater weighting for the whole-word-level contribution in the computation of phonology from orthography, as the relationship between Kanji and pronunciation is opaque/inconsistent. It is also reasonable to assume that learning to read in Kanji appears to be more laborious, and cognitively more demanding than that in Kana.
Now the relationship between reading acquisition and one of the metalinguistic skills, phonological awareness will be discussed in alphabetic (e.g., English) and non-alphabetic (e.g., Japanese Kana and Kanji; Chinese) languages.
Reading acquisition & phonological awareness
Wargner et al. (2022) asserted that “Phonological processing is a signature cognitive/linguistic skill that is essential for the development of reading regardless of the script …., and a deficit in phonological processing is regarded as a contributor to most cases of dyslexia …” (p.418). This assertion will now be closely examined in alphabetic and non-alphabetic languages.
In alphabetic languages
Many studies showed that phonological awareness skills including phoneme awareness, sometimes referred to as sub-lexical decoding skills are crucial for learning to read in English (e.g., Castle et al., 2018), and that phonological awareness skills are a reliable predictor of children’s reading success (e.g., Perfetti & Harris, 2019). For example, Stuart and Coltheart (1988) conducted a 4-year longitudinal study following children from nursery in the UK, whereby the reading errors that these children made were analysed in detail. It was revealed that (1) phonological awareness can play an important role in the very first stage of learning to read, (2) children with good phonological especially phoneme awareness will become not only good readers but also good spellers, and (3) phonological awareness and reading development in English have a reciprocal interactive causal relationship. The final point of the reciprocal interactive relationship between phoneme awareness and reading acquisition and development was also shown in Portuguese by Morais et al. (1986).
In non-alphabetic languages
Huang and Hanley (1995) examined the performance of 137 8-year-old primary school children from the UK, Hong Kong (Cantonese) and Taiwan (Mandarin) on tests of phonological awareness skills, visual skills and reading skills. The results showed that phonological awareness skills tested by rhyme and phoneme deletion tasks were significantly related to the reading ability of the children from the UK but not Chinese children from Hong Kong or Taiwan. Instead, visual skills tested by visual paired associates learning were significantly related to the reading ability of the Chinese children in Hong Kong and Taiwan, but not the children in the UK. Huang and Hanley thus concluded that phonological awareness skills are not as crucial when Chinese children learn to read as the British children.
Uno et al. (2009) tested individually nearly 500 Japanese primary school children from Grade-2 (aged 8) to Grade-6 (aged 12) in Japan on 16 cognitive tests. These 16 tests included not only reading and writing single characters and words in hiragana, Katakana and Kanji, vocabulary size (SCTAW; Haruhara and Kaneko, 2003), and IQ (RCPM; Raven, 1976), but also other cognitive skills such as arithmetic, visual-spatial, and phonological processing skills. Thus, Uno and colleagues were the first researchers to show the occurrence of Reading and Writing impairments amongst Japanese children across the three different writing scripts, i.e., Hiragana, Katakana and Kanji, through objective measures. The data are also indicative of the fact that reading Kanji may require different reading strategies, e.g., word-level rather than sub-word level of reading processes, or even different cognitive skills to those required for reading Kana.
In the study, Uno et al. conducted a series of regression analyses on the data from the typically developing children and from the children with reading and writing impairments (whose performance on reading and writing tests were below − 1.5SD) separately in order to ascertain which tests, i.e., cognitive skills were more closely related to Kanji word-reading or -writing skills. Data from the typically developing children revealed that in general, vocabulary size (SCTAW) was closely related to Kanji word reading performance across all the grades. An increase in vocabulary size led better performance in Kanji word reading. The results lend further support to a view that reading is a secondary linguistic skill (e.g., Mattingley, 1972), and that reading is acquired through spoken language development (e.g., Bowey and Patel, 1988). This is also more indicative of how Kanji is read. However, caution is needed in interpreting Uno et al.’s results as reading is acquired through spoken language development definitively, since regression results cannot indicate causation.
Despite the fact that many studies in English have established the strong relationship between phonological development and the reading and writing acquisition and development, i.e., better phonological awareness leads to better literacy skills, and vice versa (e.g., Stuart and Coltheart, 1988), in the Uno et al.’s study, a significant relationship between phonological skills (i.e., nonword repetition) and Kanji word reading was only seen in the older children in Grade-6 (aged 12). It is worth noting that the literate Japanese adults’ data revealed that phonological processing also takes place early on in Kanji word reading together with lexical and semantic processing (see Sakuma et al., 1998; Wydell et al., 1993 for more details). It can thus be said that the reading system in the Grade-6 children is maturing, and only with this maturation does phonological processing become important. This is very different from English children. As mentioned earlier, Japanese children adopt two different procedures for reading: for syllabic Kana, a simple character-to-pronunciation conversion is required, and for logographic Kanji, a whole Kanji word and its pronunciation has to be learned by rote and simultaneously and in parallel to writing. Moreover, Kanji characters cannot be decomposed phonemically unlike English words. That is, the optimal reading procedure for Kana is sub-lexical character-to-pronunciation conversion, though this does not preclude lexical whole word-level processing. In contrast the optimal reading procedure for Kanji is lexical whole word-level processing, though this does not preclude sub-lexical character-level processing, and the sub-lexical character-level reading can be afforded by older children and adults.
Wei et al. (2014) addressed the same question in Chinese (another mophographic orthography), “Are phonological awareness skills important when learning to read in Chinese?”. They tested 400 Chinese children (from pre-school to Grade-3 primary school) on their metalinguistic awareness skills including phonological awareness skills (e.g., in the phoneme deletion task, say /miano2/ without the /i/ sound), morphological awareness skills (e.g., Prime sentence—“Early in the morning we can see the sun rising” -> “This is called a sunrise”. Test sentence—“At night, we might also see the moon rising” -> “What could we call this?”—moonrise) and orthographic awareness skills (e.g., chose a character which is more like a real character between a pseudo-character which was made up based on the rules of Chinese orthography and a non-character which violated orthographic structures). Their results showed that the orthographic skills best predicted younger children’s reading performance, that the morphological awareness skills better predicted older children’s reading performance than younger children’s and that the phonological skills became an important predictor variable for reading performance only when the children were older, i.e., Grade-3. Thus, the phonological awareness skills become important in Chinese and Japanese only when children are older—aged 9.11 (Grade-3) for Chinese and aged 12 (Grade-6) for Japanese (Uno et al., 2009) children. The aforementioned argument applies here, i.e., the sub-lexical character-level (phonological) reading can be afforded by older children and adults.
It seems then that rather than phonological awareness skills, other metalinguistic awareness skills are more important at the beginning of acquisition of reading in Chinese and Japanese, such as for example, orthographic awareness (Chan et al. 2006; Ho et al., 2004; Wei et al., 2014) and morphological awareness (Liu, Li, & Wong, 2017; Wei et al., 2014) in Chinese, vocabulary size in Japanese (Uno et al., 2009), and in both languages visuo-spatial processing (Huang & Hanley, 1995; Uno et al., 2002) as well as visual-motor integration skills in Chinese (Meng, Wydell & Bi, 2018) which are necessary to combine the visual spatial information of the character and finger-hand motor component.
Therefore, we could only accept a weaker version of Wargner et al.’s (2022) assertion on the importance of phonological processing for development of reading. Unlike English-speaking children, this is not at the very beginning of learning to read for Chinese and Japanese children.
Developmental dyslexia (DD) in different languages
As mentioned earlier, research showed that the prevalence of developmental dyslexia (DD) varies across different languages. In this section we will discuss why this is the case, and also how DD manifests itself in different languages.
DD in alphabetic languages
There is a consensus amongst researchers that a phonological processing deficit, measured by various phonological awareness skills tests, underlies DD and thus the phonological deficit hypothesis has been predominant for over 30 years or so to account for DD in alphabetic languages (e.g., Snowling, 2000; Shaywitz et al., 1990; Ramus, 2003; Ramus et al., 2003) over the visual deficit hypotheses such as Stein’s Magnocellular abnormality (e.g., Stein, 2001; Stein and Walsh, 1997) or Valdois’ Visual Attention Span deficit (e.g., Bosse et al., 2007).
From the available empirical studies, Ramus (2003) reviewed auditory processing deficit (e.g., Tallal, 1980), visual stress (e.g., Wilkins, 1995), magnocellular dysfunction (e.g., Stein, 2001), motor difficulties, i.e., cerebellar dysfunction (e.g., Fawcett et al., 2001) and phonological deficit hypotheses (e.g., Ramus et al., 2003), and concluded: “…… the case for phonological deficit’s causal role in the aetiology of the reading and writing disability of the great majority of dyslexic children is overwhelming” (p.216).
Furthermore, adults with childhood diagnosis of dyslexia have shown persistent phonological deficits (Felton et al., 1990; Paulesu et al., 1996; Shapiro et al., 2009). Felton et al. (1990) found that dyslexic adults were impaired when compared to controls on rapid automatised naming (RAN) (Denckla, & Rudel, 1974), phoneme awareness skills tests (e.g., phoneme deletion, counting or blending) and non-word reading. Paulesu et al. (1996) found that even the well compensated dyslexic adults (who were mainly undergraduate or postgraduate students with only cognitive deficit being in phonological processing) showed residual phonological deficits especially on phoneme deletion and Spoonerising (given a pair of words [sad, cat], participants are asked to swap the initial sound (phoneme) of each word -> [cad, sat]).
More recently, however, Huettig et al. (2018) in their review paper posited that “we conjecture that the dyslexia research community should take seriously the possibility that a common factor could be a lack of reading experience” (p.342), after having reviewed empirical studies on “categorical perception, phonological awareness, verbal short-term memory, pseudoword repetition, RAN, prediction in spoken language processing and mirror invariance as well as results from structural and functional brain imaging” (p.4). One of the papers that Huettig et al. reviewed was Morais et al.’s (1986) study, where illiterate and literate Portuguese speaking children were asked to participate in a phoneme manipulation task. Their results showed that the illiterate Portuguese found it difficult to manipulate phonemes in adding and deleting to the starts of nonwords (e.g., ‘bremp’ <=> ‘remp’; ‘tebol’ <=> ‘ebol’), thus suggesting phoneme awareness skills and literacy have a reciprocal relationship. Given Morais et al.’s results along with other empirical studies that Huettig et al., reviewed, they questioned if the phonological awareness deficits in individuals with DD are a likely cause of DD or not.
Further, according to Huettig et al., both cortical structural imaging studies and functional neuroimaging studies revealed abnormalities in illiterate individuals compared to literate individuals. For example, voxel-based morphometry on structural MRI data revealed greater white matter density in the corpus collosum with the literate participants compared to the illiterate participants, which is thought to be the consequence of “undergoing extensive myelination during the critical period of reding acquisition aged 6–10 (Thompson et al., 2000). Also, a functional neuroimaging study with PET (Peterson et al., 2007) for example showed that the literate individuals were more left-lateralised in the inferior parietal lobules during reading, while the illiterate individuals showed a more bilateral activations. Huettig et al. further pointed out that many studies have found that increased bilateral processing is associated with reading disorders such as DD. However, Huettig et al. also suggested that “bilateral processing of written materials is related to the relative lack of reading experience and not necessarily diagnostic of a reading disorder such as dyslexia” (p.340). They added that reduced reading experience, and inefficient reading strategies impede the development of proficient general language skills. The author of this manuscript still thinks that this is a chicken and egg situation, and there is a clear need for further research, in particular, possible further molecular genetic research on DD.
Wydell in Shapiro et al. (2009) found similar results in adolescent pupils (aged 14–15) in a highly academic school in the UK. 158 pupilsFootnote 6 were tested on reading and writing skills, phonological awareness skills (i.e., rhyme judgements in words and nonwords; homophone judgements in words and nonwords; phonological lexical decisions -> YES to brane), orthographic skills (orthographic lexical decisions -> YES to brain) as well as visuo-spatial processing skills (Rey–Osterrieth complex figure (ROCF) test). Results revealed that 16 out of 158 pupils showed significantly poorer performance on reading and writing and phonological awareness skills tests when compared to the rest of pupils. Interestingly these 16 pupils in this highly academic school had never been diagnosed as dyslexic, and the teachers (and possibly these pupils themselves) were not aware that these pupils might be dyslexic. It is interesting but perhaps typical that some teachers noticed discrepancies between articulate oral language and poor written language in some of these pupils, however the teachers thought this could be due to some “teenagers’ behavioural problems.
DD in non-alphabetic languages
Phonological deficit may be a contributing factor to account for DD in Chinese or Japanese but to a much lesser extent compared to alphabetic languages. Instead, it seems that other metalinguistic skills could better account for DD in Chinese or Japanese.
In Chinese, Siok et al. (2004) showed that DD in Chinese manifests itself by two deficits: (1) orthography-to-syllable-conversion (e.g., homophone judgements in Chinese), and (2) orthography-to-semantics-mapping (e.g., lexical decisions in Chinese).
Further, Meng, Wydell and Bi (2018) revealed that Chinese dyslexic children (aged 8–9) showed a significant visual motor integration deficit compared to the age matched as well as reading-age matched controls over and above other metalinguistic skills including phonological awareness skills (e.g., phoneme deletions).
McBride et al. (2022) found that deficits in RAN tend to predict subsequent DD in Hong Kong children, stating “Arguably, RAN tests tap the product of visual-verbal paired-associate learning since the participant has to retrieve a name for a visual stimulus that must reflect arbitrary rote learning….Therefore, it is perhaps not surprising that RAN is a strong correlate of Chinese reading abilities in studies conducted ….” (p.362). The RAN tests administered in Chinese are typically single-digit numbers (e.g., from 0 to 9 in Meng et al. (2018).
In Japanese rather than group studies, single case(s) studies of children with reading and writing impairments have been reported (e.g., Kaneko et al., 1997; 1998). These children’s reading and writing impairments were attributed to visual or visuospatial processing deficits rather than phonological deficits. Uno et al. (2002) revealed that 100% of 22 Japanese dyslexic children reported in the study had visuospatial processing deficits, while 72.7% of these children also had phonological deficits. Further, although Uno et al. (2009) showed that the vocabulary size was the single most potent variable to explain Kanji word reading performance for neurotypical Japanese primary school children (aged 8–12), for the neuroatypical children with reading and writing impairments in the same study, only arithmetic skills were significantly correlated with Kanji word reading performance.
Monolingual DD in a bilingual individual–behavioural dissociation
Thus far it has been shown that different cognitive and metalinguistic skills are involved in reading in different orthographies which are primarily due to the different characteristics inherent within a given orthography. These differences give rise to different prevalence rates of developmental dyslexia.
It is therefore theoretically possible to see good reading skills in Japanese but poor reading skills in an English-Japanese bilingual individual. Indeed, Wydell and Butterworth (1999) found such an individual named AS (aged 16). His reading skills in Japanese were equal to those of Japanese university student, while his reading skills as well as phonological awareness skills in English were poorer than those of English and Japanese controls. Wydell and her colleagues reported on AS in several studies, which include behavioral (Wydell & Butterworth, 1999; Wydell & Kondo, 2003), neuroimaging (Magnetoencephalography-MEG: Wydell and Kondo, 2015) and computer-simulation (Ijuin & Wydell, 2018) studies as well as in reviews (Wydell, 2012; 2019). In these studies, in order to account for the dissociation between AS’s impaired reading skills in English and his superior reading skills in Japanese, the Hypothesis of Granularity and Transparency (Wydell & Butterworth, 1999) was postulated. The following Fig. 1 illustrates the hypothesis.

Hypothesis of Granularity and Transparency (Adapted from Wydell & Butterworth, 1999)
In the Figure, the X-axis represents the transparency of print-to-sound translation (from transparent to opaque). The Y-axis represents the granularity of the speech sound required for a given language (from fine to coarse), that is, whether the smallest speech sound unit is at the phoneme level, syllable level or at the whole character or word level. Thus, different languages map print onto sound in different ways, and thus languages differ in the preferred size of the key unit that emerges while learning to read. Languages with consistent orthographies, “ … it is possible to make systematic use of smaller units (i.e., phonemes) and hence older children come to rely on simple Grapheme-Phoneme-Correspondence without needing to develop reading by analogy based on rimes .” (Harley, 2014, p.246).
Some languages are plotted against transparency and granular size in the figure: Italian, German, English, and DanishFootnote 7 (as phoneme-based languages); then Japanese Kana (syllable-based script) and Japanese Kanji and Chinese (as logography-based script). If print-to-sound translation of a language is transparent (i.e., one-to-one), then regardless of granular size, albeit, phoneme, syllable or word, phonological dyslexia (i.e., DD due to phonological deficits) is rare in this language (e.g., Italian). If the smallest orthographic unit representing sound is coarse, i.e., larger grain size such as syllable or whole character or whole word in opaque language, phonological dyslexia is also rare in this language (e.g., Chinese or Japanese Kana and Kanji). Therefore, if any language comes under the grey area in the figure, phonological dyslexia may not be common in these languages. From the figure it can be predicted that phonological dyslexia is not very common in Japanese Kana or Japanese Kanji. Thus, it is not just a theoretical possibility to see an English-Japanese bilingual individual who may be dyslexic only in English.
AS in English (Wydell and Butterworth, 1999; Wydell and Kondo, 2003)
Wydell and Butterworth (1999) showed that AS’s results from phoneme categorizations (e.g., /pea/ - /key) were well within the normal range, and thus AS had no auditory processing deficits.

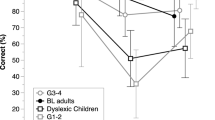
Performance of AS and his English and Japanese Controls on Reading and Reading-related tests in English (accuracy) adapted from Wydell and Kondo (2003) Note: Rhyme Rhyme judgements; PLDT Phonological Lexical Decision Task; OLDT Orthographic Lexical Decision Task; Reading Reading in English
Figure 2 shows the summary data from Wydell and Kondo’s (2003) follow-up study where his fundamental phonological deficit, which led to his phonological dyslexia still persisted as with other studies in English (e.g., Felton et al., 1990; Paulesu et al., 1996; Shapiro et al., 2009). This was despite the fact that he was successfully taking a BSc course after a 12-month intensive intervention programme (and subsequently awarded a BSc) in an English-speaking country. AS’s performance on reading and reading-related tests in English (reading words and nonwords; phoneme deletion; rhyme judgement, phonological lexical decision (YES to pseudo-homophones, e.g., ‘brane’); orthographic lexical decision (YES to the correctly spelled words), and Spoonerising) was significantly poorer than that of not only the age-matched and education matched English controls but also the Japanese controls. Thus, these results clearly suggested that AS was a typical phonological dyslexic in English. Now we will look at AS’s reading skills in Japanese Kana and Kanji.
AS in Japanese (Wydell and Butterworth, 1999)
AS’s Kanji reading performance, both in accuracy and reaction times, was equal to or better than the Japanese university students, except for JUKUJIKUN (Exception words like ‘yacht’ in English). One cannot pronounce these exception Kanji words unless one knows them. AS was then 16 years old, and the university students were in their 20s. If AS had stayed on in Japan and had gone to a Japanese university, he would be reading these exception words easily (see Wydell and Butterworth (1999) for more details).
Similarly, AS’s performance on Kana reading was equal to that of the Japanese university students (both AS and the controls were almost at a ceiling level) (see Wydell and Butterworth (1999) for more details).
Why does the dissociation between the two languages exist?
As predicted by the Hypothesis of Granularity and Transparency, the behavioural dissociation between superior reading skills in Japanese Kana and Kanji and poor reading skills in English arose because computation of phonology from orthography (G-P-C) is more demanding in English as its granular size is small, i.e., at the level of phoneme and G-P-C is not transparent, i.e., inconsistent. In contrast the granular size of Japanese is coarser at a level of syllable (Kana) or whole character or word (Kanji) with no demanding computation of phonology being required. It is also because phonological processing including phoneme awareness skills are crucial in learning to read successfully in English (phoneme-based alphabet) (e.g., Stuart and Coltheart, 1988), while these skills are not the most important metalinguistic awareness skills especially at the beginning of learning to read in Japanese (e.g., Uno et al., 2009) or Chinese (syllable-based-morphography) (e.g., Meng et al., 2018; Wei et al., 2014).
According to the Hypothesis of Granularity and Transparency phonological dyslexia is rare in Japanese Kana and Kanji, while phonological dyslexia is common in English. Thus, the behavioural dissociation between AS’s impaired reading in English and his superior reading in Japanese was accounted for.
Interestingly, Haruhara et al. (2014) reported six cases of Japanese–English bilingual postgraduate students with DD in English at an art college in the UK (diagnoses were made while they were at this art college). They had all been educated in Japan until at least their undergraduate degrees. Haruhara et al. conducted a series of tests on these bilingual postgraduate students, including reading English, Kana, and Kanji as well as phonological awareness and other cognitive skills. Also, 202 Japanese senior-high-school pupils (aged 18) and a small number of postgraduate art and design students were tested as controls, who all reside in Japan. It was found that three out of these six bilingual students showed no impairments in reading Japanese Kana and Kanji, and thus they were just like AS—a bilingual with monolingual dyslexia in English, since they too were dyslexic only in English.
However, the other three bilingual students were significantly poorer at RAN (Rapid Automatized Naming) task than even the senior-high-school pupils, who were similar to the Chinese dyslexic children with RAN deficit in Hong Kong described by McBride et al. (2022). However, their RAN deficit did not lead to reading impairments in reading Japanese Kana and Kanji. Please note that the RAN test used by Haruhara et al. was a mixture of single-digit numbers from 1 to 9 and 10 simple black and white line-drawings of animate and inanimate objects, e.g., cat, dog, hat, pencil, umbrella, etc. Moreover, two out of these three bilingual students took significantly longer in reading Hiragana and Katakana than the senior-high-school neurotypical pupils. The data from these bilingual students seem to suggest that they might have some phonological deficit. However, the reading impairments (their fluency was affected just like Italian dyslexic individuals (e.g., Paulesu et al., 2001) in Japanese Kana manifested in these two bilinguals appear not to have warranted concern for remediation while they were at school and university in Japan, as the impairments might have been rather subtle, and thus have been overlooked. Thus, the Hypothesis of Granularity and Transparency illustrated in Fig. 3 successfully accounted for the data from Haruhara et al., i.e., phonological dyslexia is rare in Japanese Kana and Kanji (Wydell & Butterworth, 1999).
Neural correlates of reading in different orthography (universality–biological unity vs. specificity—cultural diversity of reading processes)
One of the most influential studies on the neural correlates of reading in different orthographies was conducted by Paulesu et al. (2000). In their behavioural and neuroimaging with PET (Positron Emission Tomography) studies English and Italian university students were asked to read words and nonwords. Their ingenious five different word and nonword stimuli in ‘inconsistent’ English and ‘consistent’ Italian consisted of (i) words in English for English participants or words in Italian for Italian participants, (ii) nonwords derived from Italian, (iii) nonwords derived from English, (iv) international words conforming to Italian (e.g., pasta), and (v) international words confirming to English (e.g., business).
Paulesu et al. found a common distributed brain network of activation across the two languages including inferior frontal and premotor cortex, superior middle and inferior temporal gyri and fusiform gyrus on the left, and superior temporal gyrus on the right, thus showing the language universality aspect of reading. Furthermore, Italian showed greater activation in the left superior temporal regions, which are often implicated with (sub-word) phonological processing. In contrast English showed greater activations in the left posterior inferior temporal and anterior inferior frontal gyri, which are known to be associated with word retrieval (whole-word processing) during reading, thus showing the language-specificity aspect of reading.
Wydell et al. (2003) conducted a neuroimaging study employing a magnetoencephalography (MEG) during reading Finnish, another consistent language like Italian. Finnish is represented by 21 phonemes (d.f., 44 phonemes in English), and G-P-C is one-to-one. Finnish is also an agglutinating language with many different forms or cases, e.g., ‘talo’ (house),’ talossa’ (in the house) and ‘taloissa’ (in the houses) with each form representing a single word. Hence like Italian, the optimal reading strategy is sub-word level phonological processing (Leinonen et al., 2001). However, this does not preclude whole-word lexical contribution during reading in Finnish, similar to Italian (Notarnicola et al., 2011).
Wydell et al. manipulated length (4-letter string vs. 8-letter-string) and lexicality (word or nonword) in the study. It was found that at 100 ms from the stimulus onset the initial activation was seen in the occipital lobes in the peak amplitude (nAm) (that is the strength of the cortical activation). Regardless of the lexical status of the stimuli, the mean peak amplitude of 8-letter-strings were significantly greater than that of 4-letter-strings, hence showing a significant length effect. Between 200 ms and 600 ms sustained cortical activation was seen in the left superior temporal lobe (L-STG). This time, the mean duration of cortical activation (ms) for each stimulus type was measured as well as the amplitude with words showing a smaller effect than nonwords. A significant lexicality effect was also evident in this time window, with stronger and longer duration for nonwords than words, thus showing the length and lexicality interaction. The reduced length effect for the real words is likely to reflect the influence of lexical-semantic processing, lending support to other imaging data particularly in this time window, i.e., 200-600 ms (e.g., Helenius et al., 1998). Pugh et al. (1996) maintain that phonological and semantic processing together make greater demands on the left superior temporal gyrus than phonological processing alone, suggesting multi-functionality. Overall, the neural correlates of reading in Finnish (Wydell et al., 2003) seem to be similar to those of reading in Italian rather than English (Paulesu et al., 2000).
Paulesu et al. (2001) conducted another PET study with English, French and Italian participants with and without DD. On a consistency continuum, Italian sits at the consistent end, while English sits at the inconsistent end, and French sits between Italian and English but closer to English. The behavioural data showed that the participants with DD in the three language groups all performed significantly poorer on reading and phonological awareness tasks (though Italian dyslexics were more accurate, as has been reported, i.e., Italian dyslexics tend to show a deficit in fluency rather than accuracy (e.g., Paulesu et al., 2001). The neuroimaging data showed that when the participants with DD from the three language groups were compared, all the participants with DD showed reduced activation in the left middle, inferior, and superior temporal cortex and in the middle occipital gyrus. According to Paulesu et al., this shows that DD “has a universal basis in the brain and can be characterised by the same neurocognitive deficit” (p.2167), thus showing the biological unity.
Another influential neuroimaging study with fMRI (functional magnetic resonance imaging) was conducted by Siok et al. (2004) in Chinese (morphographic and morphosyllabic orthography) with Chinese children with and without DD (average age of 11), which refuted the biological unity hypothesis of DD. Siok et al. found that the left middle frontal gyrus (L-MFG) was crucial to successful Chinese reading, as the L-MFG is assumed to function as a “centre for fluent Chinese reading” (p.71) where typically reading processes in Chinese are mediated, i.e., the conversion of a Chinese character to a syllable, and mapping orthography (Chinese characters) to semantics. However, the children with DD showed reduced activation in the L-MFG, and greater activation in the left inferior prefrontal gyrus when compared to neurotypical Chinese controls. In contrast, previous fMRI research in English with a similar experimental paradigm consistently showed reduced activation in left temporoparietal regions (e.g., Paulesu et al., 2001; Aylward et al., 2003). Thus Siok et al.’s neuroimaging data showed a language-specific aspect of neural correlates, i.e., cultural diversity.
Interestingly Wydell and Kondo (2015) showed biological unity and behavioural dissociation in the before mentioned AS: an English-Japanese bilingual with monolingual dyslexia. As with Wydell et al., (2003) MEG study in Finnish, Wydell and Kondo measured the neural activation using MEG when AS and English and Japanese controls made phonological lexical decisions in English (YES to ‘brane’ – sounds like a real word) and in Japanese Katakana (YES to Katakana transcriptions of Kanji words, e.g., YES to ‘ガクセイ’ for ‘学生’ /gakusei/ (student) respectively.

MEG data-AS with English and Japanese controls’cortical activation (in nAm) at 200–400 ms in L-STG during Phonological Lexical Decisions in English and Japanese Katakana
AS’s initial activation from the stimulus onset at the occipital cortices was normal. However as illustrated in Fig. 3, AS’s peak amplitude in nAm (strength of activation) was significantly weaker in the left superior temporal gyrus (L-STG) between 200 ms and 400 ms compared to that of English and Japanese controls. This area is often implicated in grapheme-phoneme-conversions (GPC) in alphabetic languages (Demonet et al., 1996; Paulesu et al., 2000; Wydell et al., 2003). His MEG also revealed significant activation in the left supramarginal gyrus (L-SMG) for Katakana at 220 ms, which was not observed with the Japanese controls. In the other neuroimaging studies this area is often associated with phonological processing when reading real words (e.g., Stoeckel et al., 2009).
Wydell and Kondo (2015) therefore argued that with the reduced L-STG activation augmented by the L-SMG, AS was still able to read Kana (and most likely in Kanji, though neuroimaging data are not available), because the cognitive demand for Kana character–pronunciation conversion (larger grain size) is less than that for English grapheme–phoneme conversion (smaller grain size) (and this would be the same for Kanji). They suggested that the L-SMG appeared to be able to process whole syllables with a coarser grain size as well as words and can assist an impaired L-STG for reading Kana pseudo-homophones but not English pseudo-homophones, where the smaller grain size requires the finer processing capability of the L-STG, thus indicating the existence of neural and biological unity but behavioural dissociation within one bilingual individual.
Recently, Richlan’s (2020) review article entitled, ‘The Functional Neuroanatomy of Developmental Dyslexia Across Languages and Writing Systems’, cited Martin et al., (2016) metanalysis investigating the universality and orthographic specificity in the predictions for dyslexics’ abnormal cortical activation during reading and reading related tasks between opaque/inconsistent (English) and transparent/consistent (Dutch, German, Italian and Swedish) languages. Those tasks included silent reading, reading aloud, phonological lexical decision, rhyme judgment, semantic judgement, and sentence comprehension. As shown by Paulesu et al. (2001) earlier, Martin et al. found all the dyslexic participants regardless of the languages revealed hypoactivation in the left occipito-temporal cortex, including the fusiform gyrus (L-FFG), inferior occipital gyrus (L-IOG), inferior temporal gyrus (L-IFG) and middle temporal gyrus (L-MTG), thus showing language universality, i.e., biological and neural unity. However, in the metanalysis the left superior temporal gyrus (L-STG) was not included unlike other studies (e.g., Paulesu et al., 2001; Wydell and Kondo, 2015).
Richlan’s review article also cited Bolger et al.’s (2005) metanalysis which extended to non-alphabetic languages including Japanese Kana and Kanji as well as Chinese with neurotypical readers, which identified ‘convergent reading-related activation’ (p.3) in a network of left STG, IFG, and OT cortical regions. Stronger L-STG activation seen in alphabetic and syllabic writing systems including Kana was due to the fact that these scripts map to more-fine-grained speech sound (phoneme and syllable). In contrast the stronger L-IFG observed in Chinese and Japanese Kanji was due to the fact that these scripts map to whole-word phonology, thus again showing biological and neural unity.
Further, Richlan singled out Siok et al., (2004) fMRI study introduced earlier in the current paper, stating that the first evidence for a language specificity, i.e., cultural diversity or non-biological or neural unity of cortical activation was seen in Chinese. As reported earlier, Siok et al. found that the left middle frontal gyrus (L-MEG) was significantly hypoactive in Chinese children with DD during homophone judgement and lexical decision tasks.
Interestingly, however, Hu et al.’s (2010) fMRI study where Chinese and English participants with and without DD underwent a semantic word matching task revealed that both participants with DD showed a similar pattern of cortical hypoactivation. These dyslexics showed that the left middle frontal gyrus (L-MFG), left temporo-parietal (L-TP) regions, left occipito-temporal (L-OT) were under active compared to their neurotypical controls. Richlan thus concluded that “functional neuroanatomical signature of developmental dyslexia in Chinese and English” (p. 4) appears to be more similar than Siok et al. depicted, at least during the semantic word matching task.
Moreover, Huettig et al.’s (2018) review paper reported earlier mentioned that voxel-based morphometry (VBM) showed significantly reduced white matter density in the illiterate individuals. In contrast, Richlan discussed VBM studies on grey matter (GM) density and found that in alphabetic language users with DD a consistent GM reduction was seen in the right superior temporal gyrus (R-STG) and in the left superior temporal sulcus (L-STS) (e.g., Hoeft et al., 2007). In contrast Chinese individuals with DD showed reduced GM volume in the left middle frontal gyrus (L-MFG). Ramus et al. (2018) pointed out that these discrepancies in reduced GM density in different cortical regions seen in dyslexics in different languages are due to relatively few and yet relatively heterogeneous participants being involved. This in turn lead to “a high number of false positive rates in the primary literature and, therefore, little replicability of results across independent studies” (p. 5). It is clear that further research is needed in this area.
Concluding comments
At the beginning of this paper the following questions were raised (i) and (ii) as follows:
-
(i)
Are phonological awareness skills vital at the beginning of literacy acquisition in Japanese?
-
(ii)
Can the phonological deficit hypothesis be applied to explain DD in Japanese?
Answers to these questions are ‘yes to some extent’. However, it is clear from the discussions above that phonological awareness skills are not as important in Japanese as in English especially at the beginning of literacy acquisition and development. It is also clear that the phonological deficit hypothesis cannot very well account for DD in Japanese (e.g., Kaneko et al., 1997; 1998; Haruhara et al., 2014; Uno et al., 2002; 2009; Wydell, 2019; Wydell & Butterworth, 1999; Wydell & Kondo, 2003; 2015).
Further, AS’s behavioural and neuroimaging data confirmed that AS has a phonological deficit and yet his phonological deficit only affected his reading in English and not in Japanese. As shown in this paper, due to the characteristics of the Japanese orthography, other cognitive and metalinguistic skills than phonological including phoneme processing skills are crucial in reading Japanese.
It is therefore strongly recommended that research on DD in Japanese should take the characteristics of the Japanese orthography into account, albeit behavioural, neuroimaging and behavioural genetic and molecular genetic researchFootnote 8. With the use of standardised screening tests for DD such as STRAW (Uno et al., 2006) and STRAW-R (Uno et al., 2018), children with suspected DD should be systematically tested for DD to ascertain which cognitive and metalinguistic skills are impaired in these children. The researchers on DD in Japanese should then be able to develop a Japanese-language appropriate definition as well as hypotheses to account for DD in Japanese. Subsequently, Japanese researchers, practitioners, and those in education should and could develop Japanese-language appropriate intervention programmes for children with DD in Japanese rather than borrowing those intervention programmes developed for alphabetic languages, especially for English. The author has no relevant financial or non-financial interests to disclose.
Notes
One of the reviewers rightly pointed out that different rates of DD could well be due to the different diagnostic criteria. Uno et al. (2009) used − 1.5SD following Shaywitz et al. (1990) study. Uno et al. commented in the paper, “Because we used the − 1.5 SD as the cut off, statistically speaking, 6.7% of the children in the cohort should be expected as RD or WD for any given reading and writing tests, when the data are normally distributed” (p.9).
They conducted systematic review and meta-analysis on prevalence of DD in primary school children aged 6–13 (Grade-1 to Grade-6) across different countries or regions such as African region, region of the Americas, Southeast Asia regions, European regions, Eastern Mediterranean region, and Western Pacific region. 6571 initial recorded studies that Yang et al. had gone through were reduced to 56 studies which met very strict criteria that Yang et al. set out. It is interesting to see out of 56 studies, 27 were alphabetic scripts, and 31 were logographic writing systems. It is well known that in general far more studies on DD have been conducted in alphabetic languages, especially in English than logographic languages, especially in Japanese. None of the 58 studies (instead of 56) listed in Fig. 2 includes Japanese studies. The authors claimed that their study showed an estimation of worldwide DD prevalence in primary school children as 7.10%). The prevalence was higher in boys (9.22%) than in girls (4.66%) and this gender difference was the same across different writing systems.
Bizzochi (2017) asserted that the number, 44 came from the fact that some authors erroneously considered clusters of sounds (e.g., diphthongs) as single phonemes, and that the actual number of phonemes in English is 35.
“transparent” and “consistent” are used interchangeably in the manuscript.
“opaque” and “inconsistent” are used interchangeably in the manuscript.
Those 15 years old pupils we tested were at a very academic grammar school in the UK where all the pupils had passed the 11 + entrance examination. At least they had above average reading skills when they sat for the examination. None of the pupils were identified as dyslexic at the time of testing.
Elbro et al. (1995) who conducted a qualitative (telephone interview) study with over 1100 Danish adults and a subsequent quantitative study (cognitive reading tests) with 445 Danish adults out of the original cohort who satisfied all the strict criteria that the authors had set. Elbo et al. found that 12% of the Danish adults (the 2nd cohort) showed reading impairments, i.e., dyslexia (9% of which had severe reading impairments).
Sugita et al. (2011) conducted a molecular genetic study on DD in Japanese with 15 DD participants, 22 non-DD family members of the DD participants and 60 control participants. They investigated the role of DYX1C1 gene mutations as a candidate gene for DD in Japanese children, as has been found in alphabetic languages (e.g., Taipale et al., 2003). The results, however, did not support the involvement of DYX1C1 gene variants in their sample of DD and their family members. It is not clear however how Sugita et al. chose these dyslexic individuals as their participants as no details were given.
References
Amano, S., & Kondo, T. (1999). Nihongo no goitokusei [Lexical properties of Japanese](NTT PsycholinguisticDatabase Series). Tokyo: Sanseidō.
Andrews, S. (1982). Phonological recoding: Is the regularity effect consistent? Journal of Memory and Cognition, 10, 565–575.
Aylward, E. H., Richards, T. L., Berninger, V. W., et al. (2003). Instructional treatment associated with changes in brain activation in children with dyslexia. Neurology, 61, 212–219.
Barbiero, C., Lonciari, I., Montico, M., Monasta, L., Penge, R., et al. (2012). The submerged dyslexia iceberg: How many school children are not diagnosed? Results from an italian study. PLOS One, 7, 10. https://doi.org/10.1371/journal.pone.0048082
Besner, D., & Hildebrandt, N. (1987). Orthographic and phonological code in theoralreadingof Japanese Kana. Journal of Experimental Psychology: Learning, Memory and Cognition, 13, 335–343.
Bizzochi, A. L. (2017). How many phonemes does the English language have? International Journal on studies in English Language and Literature, 5, 36–46.
Bolger, D. J., Perfetti, C. A., & Schneider, W. (2005). Cross-cultural effect on the brain revisited: universal structures plus writing system variation. Human Brain Mapping, 25, 92–104. https://doi.org/10.1002/hbm.20124.
Bosse, M. L., Tainturier, M. J., & Valdois, S. (2007). Developmental dyslexia: The visual attention span deficit hypothesis. Cognition, 104, 198–230.
Bowey, J. A., & Patel, R. K. (1988). Metalinguistic ability and early reading achievement. Applied Psycholinguistics, 9, 367–383.
Castles, A., Rastle, K., & Nation, K. (2018). Ending the reading wars: Reading acquisition from novice to expert. Psychological Science in the Public Interest, 19, 5–51. https://doi.org/10.1177/1529100618772271
Demonet, J. F., Fiez, J. A., Paulesu, E., Petersen, S. E., & Zatorre, R. J. (1996). REPLY—PET studies of phonological processing: A critical reply to Poeppel. Brain & Language, 55, 352–379.
Denckla, M. B., & Rudel, R. G. (1974). Rapid ‘automatized’ naming of pictured objects, colors, letters and numbers by normal children. Cortex, 10, 186–202.
Eden, G. F., & Moats, L. (2002). The role of neuroscience in the remediation of students with dyslexia. Nature Neuroscience Supplement, 5, 1080–1084. https://doi.org/10.1038/nn946
Elbro, C., Moller, S., & Nielsen, E. M. (1995). Functional reading difficulties in Denmark. Reading and Writing: An Interdisciplinary Journal, 7, 257–276.
Fawcett, A. J., Nicolson, R. I., & Maclagan, E. (2001). Cerebellar tests differentiate between groups of poor readers with and without IQ discrepancy. Journal of Learning Disabilities, 34, 119–135.
Felton, R. H., Naylor, C. E., & Wood, F. B. (1990). Neuropsychological profile of adult dyslexics. Brain & Language, 39, 485–497.
Fisher, S. E., & DeFries, J. C. (2002). Developmental dyslexia: Genetic dissection of a complex cognitive trait. Nature Review Neuroscience, 3, 767–780.
Fushimi, T., Ijuin, M., Patterson, K., & Tatsumi, I. F. (1999). Consistency, frequency, andlexicality effects in naming Japanese Kanji. Journal of Experimental Psychology: Human Perception and Performance, 25, 382–407.
Fushimi, T., Komori, K., Ikeda, M., Patterson, K., Ijuin, M., & Tanabe, H. (2003). Surface dyslexia in a Japanese patient withsemantic dementia: evidence for similarity-based orthography-to-phonologytranslation. Neuropsychologia, 41, 1644–1658.
Fushimi, F., Komori, K., Ikeda, M., Lambon Ralphd, M. A., & Patterson, K. (2009). The association between semantic dementia and surface dyslexia in japanese. Neuropsychologia, 47, 1061–1068.
Gibson, E. J., & Levin, H. (1975). Psychology of reading. MIT Press.
Glushko, R. J. (1979). The organization and activation of orthographic knowledge in reading aloud. JEP: HPP, 5(4), 674–691.
Harley, T. A. (2014). The psychology of Language: From data to theory (4th ed.). Routledge – Psychology Press.
Harm, M. W., & Seidenberg, M. S. (2004). Computing the meanings of words in reading: Cooperative division of labor between visual and phonological processes. Psychological Review, 111, 662–720. https://doi.org/10.1037/0033-295X.111.3.662
Haruhara, N., & Kaneko, M. (2003). Hyojun Chushogo Rikairyoku Kensa (in Japanese). In A. Uno (Ed.), The standardized comprehension test of abstract words. Tokyo: Intelna-Shuppan
Haruhara, N., Uno, A., Rankin, Q., & Wydell, T. N. (2014). Cognitive abilities and reading/writing attainment in Japanese of Japanese-English bilinguals with monolingual dyslexia in English. Paper presented at the British Dyslexia Association International Conference, Guildford, UK.
Helenius, P., Salmelin, R., Service, E., & Connolly, J. F. (1998). Distinct time courses of word and context comprehension in the left temporal cortex. Brain, 121, 1133–1142.
Ho, C. H. S., Chan, D., Lees, W. O., Tsang, S. M., & Luan, V. H. (2004). Cognitive profiling and preliminary subtyping in Chinese developmental dyslexia. Cognition, 91, 43–75. https://doi.org/10.1016/s0010-0277(03)00152-x
Hoeft, et al. (2007). Functional and morphometric brain dissociation between dyslexia and reading ability. Pnas, 104, 10, 4234–4239.
Hu, W., Lee, H. L., Zhang, Q., Liu, T., Geng, L. B., Seghier, M. L., Shakeshaft, C., Twomey, T., Green, D., Yang, Y. M., & Price, C. J. (2010). Developmental dyslexia in Chinese and English populations: Dissociating the effect of dyslexia from language differences. Brain, 133, 1694–1706. https://doi.org/10.1093/brain/awq106
Huang, H. S., & Hanley, J. R. (1995). Phonological awareness and visual skills in learning to read chinese and english. Cognition, 54(1), 73–98.
Huettig, F., Lachmann, T., Reis, A., & Petersson, K. M. (2018). Distinguishing cause from effect – many deficits associated with developmental dyslexia may be a consequence of reduced and suboptimal reading experience. Learning, Cognition and Neuroscience, 3, 333–350. Issue3: Special Issue: The effects of Literacy on Cognition and Brain Functioning. https://doi.org/10.1080/23273798.2017.1348528
Ijuin, M., & Wydell, T. N. (2018). A reading model from the perspective of japanese orthography: Connectionist approach to the hypothesis of granularity and transparency. Journal of Learning Disabilities, 5(5), 490–498.
Jared, D. (2002). Spelling-sound consistency and regularity effects in word naming. Journal of Memory and Language, 46, 723–750.
Kaneko, M., Uno, A., Matsuda, H., Inagaki, M., & Haruhara, N. (1997). Developmental Dyslexia and Dysgraphia: A case report (in japanese). No To Hattatsu (Brain & Child Development), 29, 249–253.
Kaneko, M., Uno, A., Matsuda, H., Inagaki, M., & Haruhara, N. (1998). Cognitive Neuropsychological and regional blood flow study of developmentally dyslexic japanese child. Journal of Child Neurology Brief Communication, 13, 9.
Kanji Bunka Shiryokan (2008). (in Japanese) [Kanji Culture Resource Centre online resource centre (https://kanjibunka.com)] Tokyo: Taishuu Shoten.
Kondo, T., & Wydell, T. N. (2011). Syllable effects during reading 1000 2-Character Kanji words: comparing ON-reading and KUN-reading words. Paper presented at the 14th Japanese Cognitive Neuropsychology Society Annual Conference (24th September 2011), Nagoya, Japan
Kusumi, T. (1992). Meta-memory. In Y. Anzai, S. Ishizaki, Y. Otsu, G. Hatano, & H. Mizogushi (Eds.), Handbook of cognitive science. Kyoritsu Shuppan.
Leinonen, S., Müller, K., Leppänen, P. H. T., Aro, M., Ahonen, T., & Lyytinen, H. (2001). Heterogeneity in adult dyslexic readers: Relating processing skills to the speed and accuracy of oral text reading. Reading & Writing, 14, 265–296.
Liu, D., Li, H., & Wong, K. S. R. (2017). The anatomy of the role of morphological awareness in chinese character learning: The mediation of vocabulary and semantic radical knowledge and the moderation of morpheme family size. Scientific Studies of Reading, 21(3), 210–224. https://doi.org/10.1080/10888438.2017.1278764.
Makita, K. (1968). The rarity of reading disability in japanese children. American Journal of Orthopsychiatry, 38, 599–614.
Mann, V. A. (1985). A cross-language perspective in the relation between temporary memory skills and earlyreading ability. Remedial and Special Education, 6, 37–42.
Marinelli, C., Romani, C., Brunai, C., & Zoccolotti, P. (2015). Spelling acquisition in English and Italian: A cross-linguistic study. Frontiers in Psychology, 6, 1843.
Martin, A., Kronbichler, M., & Richlan, F. (2016). Dyslexic brain activation abnormalities in deep and shallow orthographies: A meta-analysis of 28 functional neuroimaging studies. Human Brain Mapping, 37, 2676–2699.
Mattingley, I. G. (1972). Reading, the linguistic process, and linguistic awareness. In J. F. Kavanagh & I. G. Mattingley (Eds.), Language by ear and by eye. MIT Press.
McBride, C., Meng, X., Lee, J. R., & Pan, D. J. (2022). Reading and reading disorders in chinese. In M.J. Snowling, C. Hulme & K. Nation (Eds), The science of reading (2nd ed., pp. 354–371). Wiley Blackwell.
Meng, Z. L., Wydell, T. N., & Bi, H. Y. (2018). Visual-motor integration and reading chinese in children with/without dyslexia. Reading & Writing. https://doi.org/10.1007/s11145-018-9876-z
Morais, Bertelson, P., & Alegria, J. (1986). Literacy and speech segmentation. Cognition, 24, 45–64.
Muraishi, S. (1972). Acquisition of reading Japanese syllabic characters in pre-school children in Japan. Paper presented at the twentieth international congress of psychology, Tokyo.
Naka, M., & Naoi, H. (1995). The effect of repeated writing on memory. Journal of Memory and Cognition, 23, 201–212.
National Language Research Institute. (1976). Gendai Shinbun no Kanji [A study of Chinese characters in modernnewspapers], The National Language Research Institute Report, 56. Shuei-shuppan.
Notarnicola, A., Angelelli, P., Judica, A., & Zoccolotti, P. (2011). Development of spelling skills in a shallow orthography: The case of italian language. Reading and Writing, 25, 1171–1194. https://doi.org/10.1007/s11145-011-9312-0
Nyikos, J. (Linguistic Associations of Canada and the United States, Lake Bluff, Illinois, 1988). in The Fourteenth LACUS Forum 1987 (ed. Empleton, S.) 146–163.
Onose, M. (1987). The effect of tracing and copying practice on handwriting skills of japanese letters in preschool and first grade children. The Japanese Journal of Educational Psychology, 35, 9–16.
Onose, M. (1988). Effect of the combination of tracing and copying practices on handwriting skills of japanese letters in preschool and first grade children. The Japanese Journal of Educational Psychology, 36, 129–134.
Patterson, K., Suzuki, T., Wydell, T. N., & Sasanuma, S. (1995). Progressive aphasia and surface alexia in Japanese. Neurocase, 1, 155–165.
Patterson, K., Suzuki, T., & Wydell, T. N. (1996). Interpreting a case of japanese phonological alexia: The key is in phonology. Cognitive Neuropsychology, 13, 803–822.
Paulesu, E., Frith, U., Snowling, M., Gallagher, A., Morton, J., Frackowiak, R. S. J., & Frith, C. D. (1996). Is developmental dyslexia a disconnection syndrome? Evidence from PET scanning. Brain, 119, 143–157.
Paulesu, E., McCrory, E., Fazio, F., et al. (2000). A cultural effect on brain function. Nature Neuroscience, 3, 91–96.
Paulesu, E., Demonet, J. F., Fazio, F., et al. (2001). Dyslexia – Cultural diversity and biological unity. Science, 291, 2165–2167.
Perfetti, C., & Harris, L. (2019). Developmental dyslexia in English. In L. Verhoeven, C. Perfetti, & K. Pugh (Eds.), Developmental dyslexia across languages and writing systems. Cambridge University Press.
Petersson, K. M., Silva, C., Castro-Caldas, A., Ingvar, M., & Reis, A. (2007). Literacy: A cultural influence on functional left–right differences in the inferior parietal cortex. European Journal of Neuroscience, 26(3), 791–799. https://doi.org/10.1111/j.1460-9568.
Provazza, S., Carretti, B., Giofrè, D., Adams, A-M., Montesano, L. & Roberts, D. (2022). Shallow or deep? The impact of orthographic depth on visual processing impairments in developmental dyslexia. Annals of Dyslexia, 72, 171–196. https://doi.org/10.1007/s11881-021-00249-7.
Pugh, K., Shaywitz, B. A., Shaywitz, S. E., et al. (1996). Cerebral organization of component processes in reading. Brain, 119, 1221–1238.
Ramus, F. (2003). Developmental dyslexia: Specific phonological deficit or general sensory motor dysfunction? Current Opinion in Neurobiology, 13, 212–218.
Ramus, Dakin, Day, Castelote, White, & Frith. (2003). Theories of developmental dyslexia: insights from a multiple case study of dyslexic adults. Brain, 126, 841–865.
Ramus, F., Altarelli, I., Jednoróg, K., Zhao, J., & di Covella, L. S. (2018). Neuroanatomy of developmental dyslexia: Pitfalls and promise. Neuroscience And Biobehavioral Reviews, 84, 434–452. https://doi.org/10.1016/j.neubiorev.2017.08.001
Rastle, K., Havelka, J., Wydell, T. N., Coltheart, M., & Besner, D. (2009). The cross-script lengtheffect: Further evidence challenging PDP models of reading aloud. Journal of Experimental Psychology: Learning, Memory and Cognition, 35, 238–246.
Raven, J. C. (1976). Coloured progressive matrices: SETS A, AB, B. OPP.
Richlan, F. (2020). The functional neuroanatomy of developmental dyslexia across languages and writing systems. Frontiers in Psychology, 11, 155. https://doi.org/10.3389/fpsyg.2020.00155
Rose, & Jim. (2009). Identifying and teaching children and young people with dyslexia and literacy difficulties: An independent report. Schools and Families (DCSF).
Saito, H., Kawakami, M., & Matsuda, H. (1995). Kanji kousei ni okeru buhin (bushu)-on’in taiouhyou [Variety of phonetic components of radical types incomplex left-rightKanji]. Jouhou Kagaku Kenkyu, 2, 89–115.
Sakamoto, T., & Makita, K. (1973). Japan. In J. Downing (Ed.), Comparative reading (pp. 440–465). Macmillan.
Sakuma, N., Sasanuma, S., Tatsumi, I. F., & Masaki, S. (1998). Orthography and phonology in reading japanese Kanji words: Evidence from the semantic decision task with homophones. Journal of Memory and Cognition, 26, 75–87.
Sambai, A., Uno, A., Kurokawa, S., Haruhara, N., Kaneko, M., Awaya, N., Kozuka, J., Goto, T., Tsutamori, E., Nakagawa, K., & Wydell, T. N. (2012). An investigation into kana reading development in normal and dyslexic japanese children using length and lexicality effects. Brain & Development, 34, 520–528.
Sambai, A., Coltheart, M., & Uno, A. (2018). The effect of the position of atypical character to-sound correspondences on reading kanji words aloud. Evidence for a sublexical seriallyoperating kanji reading process. Psychonomic Bulletin & Review, 25, 498–513.
Sampson, G. (1985). Writing systems. Stanford University Press.
Shapiro, L. R., Hurry, J., Masterson, J., Wydell, T. N., & Doctor, E. (2009). Classroom implications of recent research into literacy development: From predictors to assessment. Dyslexia, 15, 1–22.
Shaywitz, S. E., Shaywitz, B. A., Feltcher, J. M., & Escobar, M. D. (1990). Prevalenceofreading disability in boys and girls: Results of the connecticut longitudinal study. Journal of the American Medical Association, 264, 998–1002.
Shibahara, N., Zorzi, M., Hill, M. P., Wydell, T. N., & Butterworth, B. (2003). Semantic effects in word naming: Evidence from English and Japanese Kanji. Quarterly Journal of Experimental Psychology, 56A, 263–286.
Siok, W. T., Perfetti, C. A., Jin, Z., & Tan, L. H. (2004). Biological abnormality of impaired reading is constrained by culture. Nature, 431, 71–76.
Snowling, M. (2000). Dyslexia (2nd ed.). Blackwell.
Stanhope, N., & Parkin, A. J. (1987). Further explorations of the consistency effect in word and nonword pronunciation. Journal of Memory and Cognition, 15, 169–179.
Stein, J. (2001). The Magnocellular theory of developmental dyslexia. Dyslexia, 7, 12–36. https://doi.org/10.1002/dys.186
Stein, J., & Walsh, V. (1997). To see but not to read; the magnocellular theory of dyslexia. Trends in Neurosciences, 20, 147–152.
Stoeckel, C., Gough, P. M., Watkins, K. E., & Devlin, J. T. (2009). Supramarginal gyrus involvement in visual word recognition. Cortex; A Journal Devoted To The Study Of The Nervous System And Behavior, 45(9), 1091–1096.
Strain, E., Patterson, K., & Seidenberg, M. (1995). Semantic effects in single-word naming. Journal of Experimental Psychology: Learning, Memory, and Cognition, 21, 1140–1154.
Stuart, M., & Coltheart, M. (1988). Does reading develop in a sequence of stages? Cognition, 30, 2, 139–181.
Sugita, K., Uesaka, T., Nomura, J., Sugita, K., & Inagaki, M. (2011). A family-based association study does not support DYX1C1 as a candidate gene in dyslexia in Japan. International Medical Journal, 18, 2, 130–132.
Takebe, T. (1979). Nihongo no hyoki [The Japanese orthography]. Kadokawa.
Taipale, M., Kaminen, N., Nopola-Hemmi, J. et al. (2003). A candidate gene for developmental dyslexia encodes a nuclear tetratricopeptide repeat domain protein dynamically regulated in brain. PNAS, 100(20), 11553–11558
Tallal, P. (1980). Auditory temporal perception, phonics, and reading disabilities in children. Brian & Language, 9, 182–198.
Tan, L. H., Spinks, J. A., Eden, G. F., Perfetti, C. A., & Siok, W. T. (2005). Reading depends on writing, in Chinese. PNAS, 102, 8781–8785
Taraban, R., & McClelland, J. L. (1987). Conspiracy effects in word pronunciation. Journal of Memory and Language, 26, 608–631.
Thompson, P. M., Giedd, J. N., Woods, R. P., MacDonald, D., Evans, A. C., & Toga, A. W. (2000). Growth patterns in the developing brain detected by using continuum mechanical tensor maps. Nature, 404(6774), 190–193. https://doi.org/10.1038/35004593.
Uema, S., Uno, A., Hashimoto, K., & Sambai, A. (2022). A case of acquired phonological dyslexia with selective impairment of Kanji: Analysis of reading impairment mechanism using cognitive neuropsychological models for reading. Neurocase, 28(2), 173–180.
Uno, A., Kaneko, M., Haruhara, N., Matsuda, H., Kato, M., & Kasahara, M. (2002). Developmental dyslexia: Neuropsychological and cognitive-neuropsychological analysis (in Japanese). Shitsugoshoukenkyu, 22, 130–6.
Uno, A., Haruhara, N., Kaneko, M., & Wydell, T. N. (2006). Shougakusei no Yomikaki Screening Kensa—Screening test of reading and writing for Japaneseprimary school children (STRAW). Interuna Shuppan.
Uno, A., Wydell, T. N., Haruhara, N., Kaneko, M., & Shinya, N. (2009). Relationship between reading/writing skills and cognitive abilities among Japanese primary school children: Normal readers versus poor readers (dyslexics). Reading & Writing, 22, 755–789.
Uno, A., Haruhara, N., Kaneko, M., & Wydell, T. N. (2018). Hyojyun Yomikaki Screening test. Standardised test for assessing the reading and writing (seplling) attainment of japanese children and adolescents: Accuracy and fluency (STRAW-R).Interuna Shuppan.
Wargner, R. K., Zirps, F. A., & Wood, S. G. (2022). Developmental dyslexia. In M. J. Snowling, C. Hulme & K. Nation (Eds), The science of reading (2nd Ed., pp. 416–438). Wiley.
Wei, T. Q., Bi, H. Y., Chen, B. G., Liu, Y., Weng, X. U., & Wydell, T. N. (2014). Developmental changes in the role of different metalinguistic awareness skills in chinese reading acquisition from preschool to third grade. Plos One, 9(5), 1–11.
Wilkins, A. J. (1995). Visual stress. OUP.
Wimmer, H. (1993). Characteristics of developmental dyslexia in a regular writing system. Applied Psycholinguistics, 14, 1–33.
Wimmer, H., & Mayringer, H. (2002). Dysfluent Reading in the absence of spelling difficulties: A specific disability in regular orthographies. Journal of Educational Psychology, 94, 2, 272–277. https://doi.org/10.1037//0022-0663.94.2.272.
Wydell, T. N. (2012). Cross-Cultural/Linguistic Differences in the prevalence of developmental dyslexia and the Hypothesis of Granularity and Transparency. In Taeko N. Wydell & Liory Fern-Pollak (Eds.), Dyslexia – A Comprehensive and International Approach Intech.
Wydell, T. N. (2019). Developmental Dyslexia in Japanese. In L. Verhoeven, C. Perfetti, & K. Pugh (Eds.), Developmental Dyslexia across languages and writing systems. Cambridge University Press.
Wydell, T. N., & Butterworth, B. (1999). An English-Japanese bilingual with monolingual dyslexia. Cognition, 70, 273–305.
Wydell, T. N., & Kondo, T. (2003). Phonological deficit and the reliance on orthographic approximation for reading: A follow-up study on an English-Japanese bilingual with monolingual dyslexia. Journal of Research in Reading, 26(1), 33–48.
Wydell, T. N., & Kondo, T. (2015). Behavioral and neuroimaging research of reading: A case of Japanese. Current Developmental Disorders Reports, 2(4), 339–345.
Wydell, T., Patterson, K., & Humphreys, G. (1993). Phonologically mediated access to meaning for Kanji: Is a ROWSstill a ROSE in Japanese Kanji? J Exp Psychol: Learn Memory Cogn, 19, 491–514.
Wydell, T. N., Butterworth, B., & Patterson, K. (1995). The inconsistency of consistency effects in reading: The caseof Japanese Kanji. Journal of Experimental Psychology: Learning, Memory, and Cognition, 21, 1155–1168.
Wydell, T. N., Vuorinen, T., Helenius, P., & Salmelin, R. (2003). Neural correlates of letter-string length and lexicality during reading in a regular orthography. Journal of cognitive Neuroscience, 15, 7, 1052–1062.
Yang, L., Li, C., Li, X., Zhai, M., An, Q., Zhang, Y., Zhao, J., & Weng, X. (2022). Prevalence of developmental dyslexia in primary school children: A systematic review and meta-analysis. Brain Sciences, 12, 240. https://doi.org/10.3390/brainsci12020240
Yokosawa, K., & Umeda, M. (1988). Process in human Kanji word recognition. Proceedings of the 1988 IEEE International Conference on Systems, Man, and Cybernetics (pp. 377–380). Beijing: IEEE
Zoccolotti, P., de Luca, M., di Pace, E., Judica, A., Orlandi, M., & Spinelli, D. (1999). Markers of developmental surface dyslexia in a language (italian) with high grapheme–phoneme correspondence. Applied Psycholinguistics, 20, 191–216.
Zoccolotti, P., de Luca, M., Di Pace, E., Gasperini, F., Judica, A., & Spinelli, D. (2005). Word length effect in early reading and in developmental dyslexia. Brain & Language, 93, 369–373.
Author information
Authors and Affiliations
Contributions
I am the sole author of this review paper, and hence I wrote this whole manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The author has no competing interests to declare that are relevant to the content of this article.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wydell, T.N. Are phonological skills as crucial for literacy acquisition in Japanese as in English as well as in accounting for developmental dyslexia in English and in Japanese?. J Cult Cogn Sci 7, 175–196 (2023). https://doi.org/10.1007/s41809-023-00126-2
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s41809-023-00126-2