
Abstract
Additive manufacturing (AM) processes, such as laser sintering (LS), are complex in parameter dependencies and process flow. To be able to analyse and potentially predict the quality of the manufactured parts, the monitoring of multiple process parameters along the process chain is necessary. Currently, there are standards defined for data exchange but there is no framework to store and analyse these data or enhance a system with additional sensors. Therefore, a generic software concept is required that allows a consistent process monitoring. In this publication, a generic workflow for AM including pre- and post-processing steps is presented and relevant communication interfaces as e.g. OPC-UA, and relevant data types to be collected are identified. The concept allows the use of different communication protocols, storing and evaluating process data and by its modularity the enhancement of a system with its hardware. The stored values can be analysed by further scripts. The architecture is applicated on LS and partial aspects are prototypically implemented as well as practically validated. Therefore, a generic modular software concept, based on a hardware independent Docker based architecture, is presented. A practical feasibility test shows that machine and image data can be decentralized tapped and recorded, cloud-based analysed and web-based visualized.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction to data management in AM
Additive manufacturing (AM), also known as 3D printing, is a manufacturing process, in which the part is built by layerwise deposition of material [1]. During the manufacturing process, many parameters affect the quality of the built part and their relation and even some of the affecting parameters itself are unknown yet. The result is fluctuating quality and time expensive post-processing verification [2]. To improve the part quality and develop a stable and reliable process the manufacturing process needs to be analysed, and therefore monitored, during the whole build process. Statements about the part quality can only be determined with a sufficient amount of data about the manufacturing process and an evaluation of it. Which data are the relevant one, needs to be identified based on the data of the process [3]. The amount of data collected during a process can be immense and the evaluation very complicated [4], so a sophisticated data management is required. With help of the current solutions, the relations between different process-affecting parameters cannot be identified, resulting in problems to understand the process and its optimization. The collected data are not standardised yet (standards are currently under development), suitable data management systems are not adopted to the use in AM and existing evaluation methods not sufficient.
1.1 State of the art
In modern times, AM is particularly used for end-used parts and functional prototypes [5]. The Wohlers Report shows that 31.5% of the companies using AM use it for end-use parts production and 25.2% of the companies for functional prototyping [5]. According to the survey, the industrial usage is rising; therefore, establishing standards for AM processes gets more and more important. For the named use cases, a constant quality of all produced parts is necessary and the need to know about process failures during the build process. To make sure, that the parts have the correct properties and quality, time-expensive post processing measurements are required to check the build part quality. Many companies, as EOS and Farsoon, are providing process-monitoring systems for their machines [6, 7]. The user can get access to live and design data, but the overall analysis of the data to get knowledge about the process itself is missing.
Companies such as 3YourMind provide Manufacturing Execution Systems (MES) tools, helping to organize build times, material consumption and order management [8]. Moreover, OQTON published a MES tool to monitor the build process, but this tool only provides monitoring of live data without analysing it [9]. Materialize has recently published developing the tool CO-AM with selected partners to manage and monitor the AM process [10]. The CO-AM tool is compatible only to the machines of the selected partners. The referenced systems do not collect the data in a holistic way to have a base for accurate quality assumptions and enhancement of process knowledge.
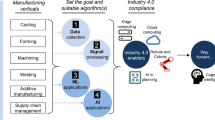
The interoperability of a monitoring and data management system is an important point in collecting data of different machines to enhance the knowledge about the process itself. A topic, which the Industry 4.0 working group is also working on. The Industry 4.0 working group, a committee of industrial and research partners [11], is going to try to establish standards for a proper data management in databases, organized in table structures [12]. The developed Asset Administration Shell (AAS) is a tool to provide a dictionary for standardisation of machine property descriptions, as energy consumption, power, machine type, etc. [12]. The AAS also provides a template of how to structure specific assets, like machines and parts of machines or factory items, for management and data acquisition in a standardised way so that it is compatible to other manufacturers’ machines [13].
Furthermore, ASTM is establishing standards for data in AM. In [14] existing norms and terminology are presented and different information of relevant modules of the AM process are defined, including their corresponding variables and datatypes. In the German industry, the OPC UA working group was set up by the VDMA. Within the topic of OPC UA machine communication different specialised working groups, e.g. one specialised on AM, were set up [15]. The working group is establishing OPC UA as interoperable communication interface within industrial machines, including AM tools, and defining the requirements to this communication interface [15, 16].
1.2 Needs of data management for process control and analysis
Depending on the amount of data collected by different sensors and different machines, the collected data becomes a huge amount and it gets complex to analyse all these data. Therefore, it is necessary to structure and manage the collected data by an automated tool. The data need to be sorted and assigned to each other for finding the dependencies, identifying the impacts and other facts about the build process(es) [17]. Using the results of these data analysis, the process might be optimized and understood more in detail. This paper presents a data structure concept for an extensive analysis of data in AM.
2 Conception
For a holistic analysis of process data the acquisition, proper sorting and saving of data are necessary. Data, which cannot be assigned to other recorded values, cannot be used to identify the impact on the process and other parameters.
2.1 User groups and use cases
To define requirements and needs of the database management system, it is useful to name the probable user and their use cases, meaning what should be done with the data in the database. It needs to be considered, what is necessary for machine users, scientific analysis or quality control. In Table 1, different user groups and their specific use cases are listed.
The use cases differ on the user group. A scientist has other requirements to the database framework than a machine worker or software developer. However, most of the use cases and related requirements to the database system result in the same solution: a standardised structure with an expandable layout and an interoperable application.
2.2 Database and data structure
The data management system is included in the process chain of data transfer and connected to the programmable logic controls (PLC) of the machines and frontend applications as user visualization. Figure 1 shows the concept of the general data transfer from the machine PLC to and within the data management system. Different machines with specific process chains send the data from their PLC to a client, which represents the interface between database and machine and is specific for every PLC of the machinery. Depending on the machinery and ability to react on input data, information can also be sent to the machinery by the client pool. The clients of the pool can be of different communication frameworks, including the OPC UA approach of [15] or other standards as MTConnect. The client processes the data of the machines to the exchange format needed for the database. This format also needs to be standardized to make the collected data consistent and give simple rules for the extension to other systems. It is important that every entry is well defined and there is no space for interpretation. As reference point for a consistent syntax the approach of the AAS in [11] can be considered. The database system is storing all the data points, meaning sensor values, which are then the entries in the database, getting from the clients. Different software applications access the database system to load and exchange with other systems or analyse the data on specific properties and relationships. The results can be pushed to the database system again or given to the clients for exchange with other systems. Integrating commonly used communication clients and an open source approach for the database system give the opportunity to extend and enhance the current system by further parties and might be helpful for security reasons to comprehend the system. Furthermore, an open source approach allows to avoid lock-in effects and to develop solutions, tailored to application-specific requirements.

Integration of data management system in AM workflow
Along the process chain of an AM process, different data types are used. All of them affect the process and might be relevant for an analysis, so they need to be stored in the database system. Data beside the printing process itself are, for e.g., the STL files of the printed parts or build job files incl. positions in the build volume. Within the printing process, the PLC of the machine gets different variable types by the sensors. Depending on the type of data acquisition device (sensor, camera, etc.), the PLC gets different variable and data types. All of these types need to be considered to store when choosing the database, the interface format and developing a suitable database system.
2.2.1 Interface format
The JavaScript Object Notation (JSON) format is a common format to structure data for exchange. Most programming languages support the JSON format as universal standard [18], hence it is used in this work as well. The concept includes the clustering of the collected process data in single JSON strings, one data value per JSON string with related properties as tags.
As an example the JSON string can look like

The number of tags beside the listed ones need to be adjusted to all relevant properties of the process parameter to reach a holistic analysis. Properties means related process data as material or build job and describing parameters as the unit of the value.
The machine specific clients collect the process data from different sources (PLC, user entries, etc.) and sort them into the defined JSON string. This JSON string is the standardized exchange format to the database system.
Based on the JSON string the data should be inserted in the database system. To make sure all initial relations between the data of the process are recorded, the JSON string includes all information for every data set, meaning all information to one sensor value. It is then sorted to the databases of the database system depending on the content. The tags of the JSON string get a hierarchical order, from global information to more detailed and process run specific ones. Global information is in a small application for example the machine type. Going more into detail and process specific information, follows next the used material, then the specific build job, next the single layers and so on.
2.2.2 Database system
The database system should efficiently store the collected data, as well as results of analysis, so all data sets are reachable and usable for further work. The data in the database system correlates to each other in different ways: sensor data of the same timestamp, data related to a build job or analysis results and so on. Depending on the data, the relationship between it is a many-to-many or one-to-many relationship. Storing all related data points in one row would result in redundancy, if the data point relates to multiple data points. This would result in a high demand for storage space, especially for large files as CAD files (STL, 3MF, etc.) and image files even when stored as generic binary objects. To avoid the redundancy of stored information and save storage space, different databases for the information can be used and the entries linked together by bridge tables. Figure 2 shows the database system, consisting of multiple databases, to store and link sensor data and analysis results. These databases can be of different type, but it is easier to handle (clients and bridge tables) if they are of the same type. Sensor data and analysis results are linked in a many-to-many relationship. Many different sensor data are used for many different calculations of specific analysis results. The results should not be stored with every sensor data it is linked to, but instead a bridge table can be used to save this link. Every row in a database is marked with an ID and includes one dataset, e.g. the data of a temperature sensor with name, value and timestamp or one result of an analysis for e.g. a specific time range. This ID is then written to the bridge table, as primary key. The combinations of IDs represent every combination of relationships between data points.

Related databases with bridge table
There are more than these data sets, which belong to many data points, so a system of more databases and bridge tables is needed. Figure 3 shows a part of this database system with example entries. A database for sensor data collected e.g. every second, one for image data, collected every layer, one for CAD files, collected every build job, one for analysis results, collected every computation. The relationships to the others are different for the databases. One image belongs per timestamp to many sensor values, one CAD file belongs to many images and sensor values of a build job, many analysis computations uses many sensor values and images. The IDs identify the data set in the database. The bridge table then sets the relationship between the IDs and by this, between the data points of different databases. For this constellation, it does not matter how many rows and columns each table of the database has compared to the others. Furthermore, new rows can be added to the system, without any retroactive changes on the existing bridge tables. The existing ones can be easily extended by new relationships in further rows. Further databases can be integrated to the system by adding further bridge tables. The database itself is preferably a relational database. There are two common different types of databases: relational and non-relational ones [19]. To prevent non-consistent rows in a database and additional costs in configuration for indexing of columns and IDs, for this concept a relational database is proposed, but nevertheless a non-relational one can even be used with a bit more effort. Every entry in a row represents one property of a data point of the process.

Database system managed by bridge tables
To transfer the datasets to the database system, first, a row for the new dataset needs to be added to the sensor database and the ID for this row created, which is then used for the representation of relationships in the bridge tables. For the proper sorting of the relationships, the JSON string is checked on the tags in the hierarchical order explained earlier (e.g. machine or material etc.) and the content filled to the databases or the ID to the bridge tables. If an information did not exist yet, a new row in the associated database is added, an ID created and written to the bridge table. Otherwise the ID of the searched content is copied and written in new rows to the bridge table. Then the ID of related dataset is written next to it and the relationship completed.
3 Prototypic realization in the LS process chain
As LS machine, an EOS Formiga P100 is used. The powder supply is part of the automated process chain and includes a powder management system, which mixes old and new powder in an individually defined proportion and pumps it to the LS machine. In the powder management system, as well as the LS machine, different sensors are integrated to track the powder mixture, supply and the build process. A camera is installed on top of the process chamber of the LS machine to take an image of every layer. The used computational system for initial tests of the database system is a Raspberry Pi 4B. An USB device of 8 GB enhances the storage of it.
3.1 Implementation
To build a platform, independent of the computational system it is running on, a local Docker application is set up. For every application in the system, such as client between machine and database, the databases, analysis tool and user interface, a separate container is build. To get access to the databases specifically to the database developed, pre-implemented clients and libraries are used and the ports opened between the containers. To share data between analysis tool and interface an OPC UA server and clients are set up. The analysis script, written in python, analyses the data of defined sensors in a defined time range. The results are send to a user interface written in node red.
The powder management system and the LS machine provide the sensor data using OPC UA, every sensor as single variable. The client script includes an OPC UA client and connects to the machine. The client collects the data, every second and writes it to the sensor database, which is an InfluxDB. The sensor database consists of multiple tables, one for each sensor, which are send at the same time to the client triggered by a timer, resulting in the same timestamp. The client sorts the values by the name of the sensor to the correct database in the InfluxDB. The camera takes an image every layer. In this application, the image is stored on the local file system on the external USB device of the raspberry, for later access without binary converting scripts. The path to the image is then stored to the image database, which is a MongoDB, as string. Another option would be to save the image as binary and then directly to the database.
A subset of the data can be defined by the user via the user interface by choosing a time range. A button on the interface triggers the start of the computation. The data are loaded from the database, analysed on different properties and the results displayed on the interface together with the images taken during the defined time range. In the current implementation, the results of the analysis are not written to the database yet.
4 Conclusion and discussion
A database management system consisting of different databases for process and analysis data and bridge tables is presented. The process data are sent to the database system in a JSON string included in machine specific clients. Using the defined tags in the JSON string, the data are then sorted to the databases and bridge tables save the relation between different process data, using database and row specific IDs.
The database system provides a structure for sorting and effective storing of data. Nevertheless, the database system can become complex by rising amount and size of databases and bridge tables.
The JSON string is an interoperable option to exchange data. For the communication not only from but also to the machine, the clients need to be adjusted to the machine needs. The sorting to the databases out of the JSON string and generating the bridge table entries is a highly critical step and needs to be reliably checked.
In the initial setup, the platform independent setup in Docker containers makes it easy to switch the database system to another computer and add or adjust the analysis applications. However, the used databases need to be compatible to a Docker application and images for the containers provided. Currently, the analysed data are not pushed back to the database. Likewise, the CAD files of the printed parts are missing in the database. These are tasks to be done in the near future.
Compared to the existing solutions the presented system gives the opportunity to be extended and adjusted according to the applications, not only in database storage amount, but also in number of databases, links between the collected data and analysing scripts. Especially the latter is missing yet in industrial solutions. Furthermore, the basic distinction of the presented approach compared to commercial solutions consists in the structural properties in addition to the technical ones. It is intended as an open approach that can be designed for specific applications and implemented with contemporary solutions. Ideally, an open standard can be established that is supported by a community and can avoid lock-in effects in the medium term.
With the presented approach, data of different machine types (AM systems incl. printers and periphery) can be collected and evaluated. On this basis, a holistic analysis of the available data can be implemented using a variety of scripts for different analysis tasks. Beside the implementation and integration of analysis scripts, one of the most challenging parts is the needed storage space. The presented approach can store the data in less redundancy, but depending on the type and time period of the stored data, the storage amount can be huge and still needs to be optimised.
5 Outlook
Further work includes tests to analyse the rising size of the database system should be executed. As reference, currently timestamps are used. This needs to be adjusted to IDs in bridge tables. Furthermore, the implementation needs to be enhanced to a more extensive database system with the missing data points. In addition, a cloud based version should be implemented and tested as well.
In future works, the client connection and used machinery can be adapted to the ability to react on process evaluations in situ, for that the communication from the database system and evaluation application to the machinery needs to be set up. Furthermore, the database system can be extended by artificial intelligence (AI) and other analysis applications using the database system for automated data analysis and evaluation.
References
DIN EN ISO/ASTM 52900:2022-03, Additive Fertigung_-Grundlagen_-Terminologie (ISO/ASTM 52900:2021); Deutsche Fassung EN_ISO/ASTM 52900:2021, Berlin
Hu Z, Mahadevan S (2017) Uncertainty quantification and management in additive manufacturing: current status, needs, and opportunities. Int J Adv Manuf Technol 93(5–8):2855–2874. https://doi.org/10.1007/s00170-017-0703-5
Köksal G, Batmaz İ, Testik MC (2011) A review of data mining applications for quality improvement in manufacturing industry. Expert Syst Appl 38(10):13448–13467. https://doi.org/10.1016/j.eswa.2011.04.063
Majeed A, Lv J, Peng T (2019) A framework for big data driven process analysis and optimization for additive manufacturing. Rapid Prototyp J 25(2):308–321. https://doi.org/10.1108/RPJ-04-2017-0075
Wohlers T, Campbell RI, Diegel O, Kowen J, Mostow N (2021) Wohlers report 2021: 3D printing and additive manufacturing: global state of the industry. Wohlers Associates, Fort Collins, Colorado
EOS GmbH (2022) Überwachung und Qualitätssicherung für Industriellen 3D Druck [Online]. Available: https://www.eos.info/de/additive-fertigung/software-3d-druck/monitoring-software-am. Accessed: 5 Sept 2022
FARSOON Technologies, Software Solutions for AM [Online]. Available: https://www.farsoon-gl.com/software/. Accessed 05 Sept 2022
3YourMind GmbH, Agile MES: Optimierte AM Produktion [Online]. Available: https://www.3yourmind.com/de/agile-mes. Accessed: 30 Aug 2022
OQTON, Track your end-to-end workflow with complete MES capabilities [Online]. Available: https://www.oqton.com/additive. Accessed 5 Sept 2022
Remziye Korner, Cloud-basierte CO-AM-Plattform von Materialise hilft bei Optimierung von 3D-Druck-Produktionsprozessen [Online]. Available: https://www.3d-grenzenlos.de/magazin/3d-software/materialise-co-am-plattform-neuvorstellung-27864253/. Accessed 30 Aug 2022
Platforms Alliance Industrie du Futur, Plattform Industrie 4.0 and Piano Nazionale Impresa 4.0, Ed., “The Structure of the Administration Shell: TRILATERAL PERSPECTIVES from France, Italy and Germany,” Federal Ministry for Economic Affairs and Energy (BMWi)
German Electrical and Electronic Manufacturers’ Association, “Examples of the Asset Administration Shell for Industrie 4.0 Components—Basic Part: Continuing Development of the Reference Model for Industrie 4.0 Components,” Apr 2017
Plattform Industrie 4.0, “Details of the Asset Administration Shell: Part1,” May 2022
Standard Practice for Additive Manufacturing General Principles Overview of Data Pedigree, F42 Committee, West Conshohocken, PA
VDMA, OPC UA: Eine gemeinsame Sprache für alle Maschinen [Online]. Available: https://www.vdma.org/opcua
Verein Deutscher Werkzeugmaschinenfabriken VDW, OPC UA for Machine Tools integriert Bestandssysteme, 2022. Accessed: 6 Sept 2022 [Online]. Available: https://vdw.de/opc-ua-for-machine-tools-integriert-bestandssysteme/
BrainStation, Big Data’s Role in 3D Printing. Accessed: 16 Aug 2022
Matthew Tyson, What is JSON? The Universal Data Format [Online]. Available: https://www.infoworld.com/article/3222851/what-is-json-a-better-format-for-data-exchange.html. Accessed: 30 Aug 2022
Jatana N, Puri S, Ahuja M, Kathuria I, Gosain D (2012) A survey and comparison of relational and non-relational database. Int J Eng Res Technol 1:1–5
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
This study has been financed by the Ministry of Economics, Labour and Housing of the State of Baden-Württemberg under Contract No. 3-4332.62-IPA/64 within the project “Zentrum für additive Produktion” (ZAM).
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The original online version of this article was revised: The ORCiD of Jan Janhsen was missing.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Michalkowski, C., Janhsen, J. & Springer, P. Concept for a generic modular software architecture for the integration of quality relevant data and sample implementation for a laser sintering system. Prog Addit Manuf 8, 67–73 (2023). https://doi.org/10.1007/s40964-022-00390-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40964-022-00390-8