
Abstract
In multi-attribute group decision-making (MAGDM), the attributes can be placed into independent groups based on their properties through partitioning. First, the partitioned dual Hamy mean (PDHM) operator is introduced, along with its essential properties. This operator integrates these separate groups while preserving the relationships between the attributes within each group. Furthermore, the partitioned Hamy mean (PHM) and the PDHM operators are also constructed in the generalized orthopair fuzzy environment, namely the q-rung orthopair fuzzy PHM (q-ROFPHM), the q-rung orthopair fuzzy PDHM (q-ROFPDHM), and their weighted forms. Their essential properties are verified to ensure the validity of the proposed aggregation operators (AOs). Subsequently, a new MAGDM approach is developed, employing the proposed AOs. The MAGDM problem of selecting the best person is examined. Moreover, the research includes a sensitivity analysis in three directions and a comparative analysis of the proposed MAGDM approach with five different approaches. The findings indicate that applying attribute partitioning in the proposed approach mitigates the adverse impact of irrelevant attributes, leading to more feasible and reliable outcomes. Additionally, a practical case study focuses on selecting a suitable industry for investment among the five available options. This case study demonstrates the approach’s effectiveness by considering five distinct qualities and results that make the Internet industry the best place to invest. Furthermore, a comparative analysis with four similar papers is also performed, indicating that the developed method’s results are more reliable and consistent.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
MAGDM is a prominent decision-making methodology to get an optimal choice from a set of feasible choices that depend on more than one attribute. In a group decision-making (GDM) problem, several decision-makers (DMs) initially evaluate these alternatives. Researchers need help solving such MAGDM problems: extracting information and its fusion. Real-world decision-making is sophisticated, and human understanding has its limits. Therefore, it can be challenging to extract the accompanying information accurately. Thus, information extraction becomes an ambiguous process, which can be tackled by fuzzy sets (FSs). Zadeh formulated FS [49] through his enlightened work known as fuzzy set theory. Its various extensions, like type-2 FS, intuitionistic fuzzy set (IFS), interval-valued IFS, neurotrophic FS, hesitant FS, q-rung orthopair fuzzy set (q-ROFS), and many others, have been introduced by various researchers and successfully employed in decision-making [9, 31, 47]. After quantifying the uncertainty through an appropriate approach, the next goal is to find an optimal alternative among all possible choices. An optimal alternative in any MAGDM problem can be found using either classical approaches, such as TOPSIS, AHP, ELECTRE, PROMETHEE, VIKOR, and others, or aggregation operator (AO)-based approaches [8, 31, 42]. The advantage of AO-based approaches is that they evaluate the comprehensive value of alternatives by fusing the associated information through an aggregation process and then ranking the alternatives accordingly. There are various classical AOs available in the literature, including arithmetic mean (AM), geometric mean (GM), Bonferroni mean (BM), and many others, which are used to integrate the information in a meaningful way [8]. Hence, the final decision depends on the method of uncertainty quantification and the aggregation procedure used to fuse the quantified information. Evaluating real-life engineering complex problems, such as urban mobility governance, is very awkward and complicated considering classical information.
In the context of decision sciences, FSs can represent information by quantifying its uncertainty through a membership function. This membership function reflects DMs’ satisfaction levels between 0 and 1. However, the classical FS cannot measure the sense of dissatisfaction. Therefore, Atanassov [6] introduced the concept of IFS, which handles both satisfaction and dissatisfaction through membership (\(\mu \)) and non-membership (\(\nu \)) degrees, respectively, where \(\mu ,\nu \in [0,1]\) and \(0\le \mu +\nu \le 1\). Over the years, numerous research articles have been published that study the concept of IFS and its usefulness in decision sciences [10, 39, 44]. Due to the conditions imposed on \(\mu \) and \(\nu \) as mentioned above, IFS provides a restricted space of \(\mu \) and \(\nu \), and as a consequence, it is not suited for much real-world decision-making problems. To address this problem, Yager [46] proposed the idea of a Pythagorean fuzzy set (PFS), which provides a larger feasible decision space compared to IFS by modifying the above conditions as \(\mu ,\nu \in [0,1];~0\le \mu ^2+\nu ^2\le 1\). Still, it does not provide sufficient decision space to tackle all such problems efficiently. Therefore, in 2017, Yager [47] further extended IFS by defining the notion of a generalized orthopair fuzzy set with more generalized conditions \(0\le \mu ^q+\nu ^q\le 1;~\mu ,\nu \in [0,1]\), where the enhancement in the decision space is controlled by the parameter q, and thus, the set is also known as a q-ROFS.
In 1890, Hamy [17] introduced a well-known symmetric function called the Hamy symmetric function, which was further extended to an rth-order means, i.e., the Hamy mean (HM). Furthermore, Hara et al. [18] established a critical refinement of AM and GM inequality in 1998, demonstrating that HM and its dual will monotonically lie between AM and GM. The Muirhead mean (MM), Maclaurin symmetric mean (MSM), and HM are types of AOs that provide the correlation between multiple arguments and the mean value of fused arguments. Because the MM and MSM operators do not normalize the correlated values as precisely as HM does, the HM operator presents a more accurate picture of the interrelationship among attributes. As a result, HM is the best choice for further investigation.
Motivations and contributions of the study
The motivation and contribution of the study can be explained in three phases. Inspiration for the first phase of the proposed work came from [13, 24, 34], where the partitioning concept was integrated with various AOs. Therefore, as the HM operator has a dual form [18, 45], the above references spiritualize us to introduce partitioning in dual HM (DHM). This new AO, partitioned DHM (PDHM), can intuitively and logically model the interrelationships among attributes. In the second phase, we were encouraged by the fact that work has yet to be presented on partitioned HM (PHM) for the orthopair family of fuzzy sets that include IFS, PFS, and q-ROFS. Therefore, the following papers [7, 34, 48, 51] motivated us to introduce the PHM and PDHM operators for generalized orthopair fuzzy sets. Based on these extensions, the proposed AOs are named q-ROFPHM, q-ROFWPHM, q-ROFPDHM, and q-ROFWPDHM. Finally, motivated by the role of multiple experts in real-world decision-making scenarios, as studied in the following papers [13, 15, 20, 22], this paper contributes an MAGDM approach for handling real-world decision-making problems by applying two new AOs, q-ROFWPHM and q-ROFWPDHM.
Innovative aspects of this work
Firstly, PDHM’s introduction addresses the need to handle attribute partitioning in MAGDM. This operator can effectively integrate attribute groups while preserving the internal relationships within each group, enabling more accurate decision outcomes. Furthermore, the extension of PDHM and PHM operators to the generalized orthopair fuzzy environment, leading to the development of the q-ROFPHM, q-ROFWPHM, q-ROFPDHM, and q-ROFWPDHM, introduces novel methodologies for dealing with fuzzy and uncertain information. The proposed MAGDM approach, utilizing the innovative AOs, also presents a novel framework for solving decision problems involving multiple attributes and group preferences. This approach addresses a significant gap in the existing MAGDM research and provides decision-makers with a robust methodology for complex decision scenarios. Moreover, the practical case study conducted in this research, focusing on selecting a suitable industry for investment, demonstrates the practical applicability and effectiveness of the proposed approach.
Overall, the innovations presented in this research contribute to the advancement of MAGDM. These contributions enhance the accuracy, reliability, and feasibility of decision outcomes in complex scenarios. Therefore, it can be useful for solving urban logistics problems, opening up new possibilities for effective decision-making in supply chain management and various other domains.
Organization of this study
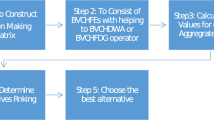
The concise structure of this paper is as follows: First, a brief overview of related literature has been provided in the section “Literature review”. Some fundamental definitions of the q-ROFS, HM, DHM, and PHM operators are given in the section “Preliminaries”. Then, the section “Partitioned dual Hamy mean (PDHM)” introduces the PDHM operator, its desirable properties, and the refinement of partition mean inequality. The section “q-Rung orthopair fuzzy partitioned Hamy mean operators” presents PHM, while the section “q-Rung orthopair fuzzy partitioned dual Hamy mean operators” proposes PDHM AOs under the q-ROF environment and names these AOs as q-ROFPHM, q-ROFWPHM, q-ROFPHM, and q-ROFWPHM. These AOs are defined in decision-making, where all attributes may or may not be correlated. The essential properties of these AOs are also discussed in their respective sections. Furthermore, an MAGDM approach based on q-ROFWPHM and q-ROFWPDHM operators is present in the section “An MAGDM approach based on the q-ROFWPHM and q-ROFWPDHM operators”. The section Some practical applications of the proposed methodology” provides the application of the presented approach by analyzing two MAGDM problems adopted from [24] and [34] with detailed sensitivity and comparative analyses. Finally, the section “Conclusion” delivers the conclusion of the paper and some recommendations for future work. The structure of the proposed study is also presented in Fig. 1.

Brief structure of the proposed study
Literature review
In this section, a brief literature overview has been provided for q-ROFS and HM related decision-making approaches.
Literature on q-ROFS-related decision-making
The generality of q-ROFS over IFS and PFS makes it a popular research topic in decision sciences. Using an AO-based decision-making approach, q-ROFS has been successfully integrated with several mean-type operators to evaluate multi-attribute decision-making (MADM) or MAGDM problems. Specifically, Liu and Wang [27] constructed some basic arithmetic operations for q-rung orthopair fuzzy numbers (q-ROFNs), and in addition to that, the AM and GM for q-ROFNs are also introduced with a new MADM approach. Liu and Liu [25] developed algebraic norms-based BM operators under a q-ROF environment for MAGDM problems, while Liang et al. [21] extended the Choquet integral for q-ROFNs and determined fuzzy measures using entropy and cross-entropy. Wang et al. [43] constructed the HM and DHM operators for q-ROFNs and used them to solve MADM problems. Xing et al. [45] extended Wang et al.’s work [43] by employing the interactional operational laws of q-ROFNs. Garg and Chen [15] introduced some q-ROF neutral weighted averaging AOs by fusing the interaction between membership degrees and membership coefficient sum. Zhang et al. [50] studied the q-ROFSs within the multi-granularity three-way decisions approach and developed a novel MAGDM method. To model the conjunctive and disjunctive behavior of q-ROFNs, Rawat and Komal [36] utilized Hamacher T-norm (TN) and T-conorm (TC) and introduced a family of MM-based AOs for q-ROF-MADM problems. Deveci et al. [11] utilized the q-ROF-CODAS method to identify the best rehabilitation strategy after the closure of a mining site. Tang et al. [41] constructed the q-ROF Zhenyuan integral and used BWM and optimization-based Shapley values to develop a new decision-making model. Recently, Senapati et al. [40] constructed Aczel–Alsina (AA) TN and TC-based average AOs under a q-ROF environment and studied an MADM problem of appropriate global partner selection for companies. Further, Akram et al. [2] infuse the concept of prioritization with the AA TN and TC and develop two robust AOs for a GDM problem related to energy resource selection. Farid and Riaz [14] utilized the AA TN and TC and linear programming to develop a new MAGDM method. Some other recent work on q-ROFSs-based decision-making and discussed paper are summarized in Table 1.
In the above-studied papers, it is assumed that all the attributes depend on each other without classifying their characteristics. However, in real-life MADM problems, there are situations when all the attributes can be classified into several independent groups according to their characteristics. Also, attributes in a particular group may interact with each other in the form of interdependency, which needs to be addressed appropriately. It is worth noticing that the interdependency between attributes can be reflected through the correlation between corresponding arguments in the aggregation process. For such a scenario, Dutta and Guha [13] introduced the partitioned BM, which avoids the unwanted influence of irrelevant attributes in the aggregation process. This has inspired many researchers and has used the concept of attribute partitioning in decision-making through various AOs, such as BM, HM, MSM, MM, and Heronian mean [7, 23, 24, 30, 34, 48, 51]. A brief literature review on HM is also presented in the following section.
Studies on Hamy mean and its extensions
Due to the advantages of HM, many researchers have analyzed real-life MADM or MAGDM problems through this function. There are several extensions to HM. Specifically, Qin [33] investigated it for symmetric triangular interval type-2 fuzzy numbers. Rong et al. [38] explored HM for hesitant fuzzy linguistic numbers, Ali et al. [4] constructed HM in a complex interval-valued q-ROF environment, and recently, Akram et al. [1] introduced HM for two-tuple linguistic complex q-ROFNs. These HM operators are also utilized for AO-based decision-making approaches in their papers. Liu and Liu [26] adopted linguistic IFS to develop HM-based AOs for GDM problems. Under the generalized orthopair fuzzy environment, Wang et al. [43] introduced HM and DHM operators, while Xing et al. [45] proposed interactional HM and DHM operators. Liu et al. [29] presented a normal wiggly hesitant fuzzy linguistic term set, and under this environment, some power HM operators were also developed. Using the concept of partitioning, Liu et al. [30] constructed the PHM under an interval-valued intuitionistic uncertain linguistic environment and investigated a plant location selection problem.
Preliminaries
The section provides some fundamentals of q-ROFS and definitions of some classical mean operators, including HM, DHM, and PHM.
Generalized orthopair fuzzy set [47]
A generalized orthopair fuzzy set or q-ROFS A is a collection of elements from a domain of discourse say X, with their membership grades and is written as follows:
where \(q\ge 1\) and \(\mu _A(x),\nu _A(x):X \rightarrow [0,1]\) are membership grade functions whose values represent the levels of agreement and disagreement for membership of x in A, respectively. The term \(\pi _A(x) = \left( 1-\mu ^q_A(x)-\nu ^q_A(x)\right) ^{1/q}\) is known as the degree of hesitancy of x in A. The orthopair \((\mu _A(x),\nu _A(x))\) is a q-ROFN and conveniently written as \((\mu ,\nu )\).
Basic operations and properties of q-ROFNs [27]
Given \(\alpha _1= (\mu _1,\nu _1)\) and \(\alpha _2= (\mu _2,\nu _2)\) are q-ROFNs. The probabilistic sum and product based operations on these two q-ROFNs are
-
(a)
\(\alpha _1 \oplus \alpha _2 =\left( (\mu _1^q + \mu _2^q - \mu _1^q\mu _2^q)^{1/q}, \nu _1\nu _2\right) \),
-
(b)
\(\alpha _1 \otimes \alpha _2 = \left( \mu _1 \mu _2, (\nu _1^q + \nu _2^q - \nu _1^q\nu _2^q)^{1/q}\right) \),
-
(c)
\(\lambda \alpha _1 = \left( (1-(1-\mu _1^q)^\lambda )^{1/q}, \nu _1^\lambda \right) \),
-
(d)
\(\alpha _1^\lambda = \left( \mu _1^\lambda ,(1-(1-\nu _1^q)^\lambda )^{1/q}\right) \).
Some useful fundamental properties of these operations are as follows:
-
(a)
\(\alpha _1 \oplus \alpha _2 = \alpha _2 \oplus \alpha _1\),
-
(b)
\(\alpha _1 \otimes \alpha _2 = \alpha _2 \otimes \alpha _1\),
-
(c)
\(n(\alpha _1 \oplus \alpha _2) = n\alpha _1 \oplus n\alpha _2\),
-
(d)
\((\alpha _1 \otimes \alpha _2)^n = \alpha _1^n \otimes \alpha _2^n\),
-
(e)
\(n_1\alpha _1 \oplus n_2\alpha _1 = (n_1+n_2)\alpha _1\),
-
(f)
\(\alpha _1^{n_1} \otimes \alpha _1^{n_2} = \alpha _1^{n_1+n_2}\).
Score and accuracy functions [27]
For a q-ROFN \(\alpha _i = (\mu _i, \nu _i)\), the score function (S) is given by Eq. (2) and its range is \(S(\alpha _i) \in [-1,1]\)
If two q-ROFNs having the same score values, then find their accuracy values through a function called accuracy function \(H(\alpha )\in [0,1]\) and it is defined by Eq. (3)
The following method is commonly used to provide the ordering between any two q-ROFNs, say \(\alpha _1 = (\mu _1, \nu _1)\) and \(\alpha _2 = (\mu _2, \nu _2)\):
-
(a)
For \(S(\alpha _1) > S(\alpha _2)\), it implies \(\alpha _1 > \alpha _2\).
-
(b)
However, if \(S(\alpha _1) = S(\alpha _2)\), then compare their accuracy values, that is
-
(i)
For \(H(\alpha _1) > H(\alpha _2)\), it conclude \(\alpha _1 > \alpha _2\).
-
(ii)
Further, if \(H(\alpha _1) = H(\alpha _2)\), it means that \(\alpha _1\) and \(\alpha _2\) are equal.
-
(i)
Hamy mean (HM) [17]
Given any set \(A=\{a_1,a_2, \ldots ,a_n\} \subset \mathbb {R}_+\) and a natural number \(k \le n\), the HM operator on A is defined by Eq. (4)
where, \(i_1, i_2, \ldots ,i_k\) are k natural numbers, such that \(1\le i_1< \cdots <i_k\le n\) and \(C_n^k=\frac{n!}{k!(n-k)!}\). The parameter k is also known as a granularity parameter. The \(\mathbb {R}_+\) is the set of non-negative real numbers.
Dual Hamy mean (DHM) [18, 45]
Given any set \(A=\{a_1,a_2, \ldots ,a_n\} \subset \mathbb {R}_+\) and a natural number \(k \le n\), the DHM operator on A is defined by Eq. (5)
where \(i_1, i_2, \ldots ,i_k\) are k natural numbers, such that \(1\le i_1< \cdots <i_k\le n\) and the value of \(C_n^k\) is \(\frac{n!}{k!(n-k)!}\).
Partitioned Hamy mean (PHM) [30]
Suppose, a set \(A=\{a_1,a_2, \ldots ,a_n\} \subset \mathbb {R}_+\) is partitioned into d-number of groups \(P_1, P_2, \ldots , P_d\), such that \(P_i\cap P_j=\emptyset \) and \(\cup _{t=1}^{d}P_t=A\), then the PHM operator on A is defined by Eq. (6)
where \((i_1, i_2, \ldots , i_{k_t})\) is \(k_t\)-tuple full combination of \((1,2, \ldots , |p_t|)\), \(k_t= 1, 2, \ldots ,|P_t|\) is the granularity parameter for the partition \(P_t\), and \(|P_t|\) denotes the cardinality of \(P_t\).
Partitioned dual Hamy mean (PDHM)
The section introduces the new PDHM operator, which includes the concept of partitioning and correlation for independent and dependent criteria, respectively. The section also discusses some imperative properties of the proposed operator.
The PDHM operator
Suppose, a set \(\{a_1,a_2, \ldots ,a_n\} \subset \mathbb {R}_+\) is partitioned into d-number of groups \(P_1, P_2, \ldots , P_d\), then the PDHM operator on a given set is defined as follows:
where \(i_1, i_2, \ldots ,i_{k_t}\) are \(k_t\) natural numbers, such that \(1\le i_1< \cdots <i_{k_t}\le |P_t|\), \(k_t= 1, 2, \ldots ,|P_t|\) is the granularity parameter for the partition \(P_t\), \(|P_t|\) denotes the cardinality of \(P_t\) (tth partition), and \(C_{|P_t|}^k=\frac{|P_t|!}{k!(|P_t|-k)!}\). Figure 2 depicts the functioning and structure of the PDHM operators.

Partition relationship structure among attributes
The calculation process for the proposed PDHM operator can be explain through a example: Consider \(A=\{0.4,0.7,0.1,0.9,0.3,0.5\}\) be the set of six input arguments which is partitioned into two groups \(P_1=\{a_1,a_2,a_5\}=\{0.4,0.7,0.3\}\) and \(P_2=\{a_3,a_4,a_6\}=\{0.1,0.9,0.5\}\). Therefore, \(|P_1|=3\) and \(|P_2|=3\). Taking the granularity values \(k_1=k_2=2\), the aggregated value of A by applying PDHM operator is computed as follows:
Now, using the traditional DHM operator as shown in Eq. (5), we get
It is observed that the aggregated values obtained from the PDHM and DHM operators differ, because the traditional DHM operator does not consider partitioning of inputs, whereas the PDHM operator splits the given set and provides a more refined and appropriate result.
Some fundamental properties of the PDHM operator
In this section, some fundamental properties, such as boundedness, monotonicity, and idempotency for PDHM operator, are verified. The section also proved that \(PDHM ^{k_t}\) is non-decreasing and \(PHM ^{k_t}\) is non-increasing in nature with respect to \(k_t\).
1. Idempotency: Given a set, \(\{a_1,a_2, \ldots ,a_n\}\), such that \(a_i=a\) \(\forall \) \(i \in N=\{1,2, \ldots ,n\}\). The \(PDHM ^{k_t}(a_1,a_2, \ldots ,a_n)=a\).
Proof
Given that \(a_1=a_2=\cdots =a_n=a\), then
\(\square \)
2. Monotonicity: Given two sets, \(\{a_1,a_2, \ldots ,a_n\}\) and \(\{b_1,b_2, \ldots ,b_n\}\), such that \(a_i\le b_i\) \(\forall \) \(i \in N\). The \(PDHM ^{k_t}(a_1,a_2, \ldots ,a_n) \le PDHM ^{k_t}(b_1,b_2, \ldots ,b_n)\).
Proof
We have \(a_i\le b_i\) \(\forall \) \(i \in N\), then
that is,
\(\square \)
3. Boundedness: Given a set \(\{a_1,a_2, \ldots ,a_n\}\), whose \(\min _i a_i\) \(= a^-\) and \(\max _i a_i=a^+\), where \(i \in N\). We have \(a^- \le PDHM ^{k_t}(a_1,a_2, \ldots ,a_n) \le a^+.\)
Proof
From the idempotency of PDHM operator, we can claim
Now, making use of monotonicity of PDHM operator, we have
\(\square \)
Theorem 1
(Refinement of the partitioned mean inequality) Given a set \(S=\{a_1,a_2, \ldots ,a_n\}\) \(\subset \mathbb {R}_+\), which is divided into d-distinct groups \(P_1\),\(P_2\), ...,\(P_d\), such that \(\cup _{t=1}^{d}P_t=\cup _{t=1}^{d}\{a_{t_1}, a_{t_2}, \ldots , a_{t_{|P_t|}}\}=S\) and \(P_i \cap P_j=\) \(\{a_{i_1}, a_{i_2}, \ldots , a_{i_{|P_i|}}\} \cap \{a_{j_1}, a_{j_2}, \ldots ,a_{j_{|P_j|}}\}=\emptyset \). Then, \(PDHM ^{k_t}\) is non-decreasing with respect to \(k_t=1,2, \ldots ,k\), where \(k=\min _t |P_t|\).
Proof
From the refinement of the classical AM and GM inequality [18], we can have the following:
Now, aggregate these grouped value for the same granularity parameter. This will provide us the following inequalities:
Further, the normalization of these aggregated values results in the following conclusion:
Hence, \(PDHM ^{k_t}\) is non-decreasing w.r.t. \(k_t\) up to k. Similarly, it can be prove that \(PHM ^{k_t}\) is non-increasing w.r.t. \(k_t\) upto k and can be stated as a corollary of Theorem 1. \(\square \)
Corollary 1
The \(PHM ^{k_t}\) is non-increasing w.r.t. \(k_t=1,2, \ldots ,\) k under the same input environment as Theorem 1.
Remark For \(k_t=1~\forall ~t\), the PHM reduces to the partitioned AM (PAM) and the PDHM to the partitioned GM (PGM). Further, if \(k_t=1~\forall ~t\) and the cardinality of all partition (\(|P_t|\)) are same, then the PHM and PDHM will reduce to the AM and GM, respectively.
q-Rung orthopair fuzzy partitioned Hamy mean operators
This section proposes two new AOs: (i) the q-ROFPHM and (ii) the q-ROFWPHM. In addition, the section also discusses some properties that are satisfied by these AOs.
The q-ROFPHM operator
Given a set \(\{\alpha _1,\alpha _2, \ldots ,\alpha _n\}\) of q-ROFNs corresponding to the attributes set \(\{\gamma _1, \gamma _2, \ldots , \gamma _n\}\) which can be partitioned into d-number of groups \(P_1, P_2, \ldots , P_d\). Then, the q-ROFPHM operator is a map from \(\left( \alpha _1,\alpha _2, \ldots ,\alpha _n\right) \) to \(\left( [0,1],[0,1]\right) \) and defined as
where \(|P_t|\) denotes the cardinality of tth partition \(P_t=\{\gamma _{t_1}, \gamma _{t_2}, \ldots , \gamma _{t_{|P_t|}}\}\); \(k_t= 1, 2, \ldots ,|P_t|\) is the granularity parameter of partition \(P_t\); \(i_1, i_2, \ldots ,i_{k_t}\) are \(k_t\) natural numbers taken from the set \(\{1, 2, \ldots , |P_t|\}\) and \(C_{|P_t|}^{k_t}=\frac{|P_t|!}{k_t!(|P_t|-k_t)!}\) is the binomial coefficient.
Theorem 2
For a collection \(\{\alpha _1,\alpha _2, \ldots ,\alpha _n\}\) of q-ROFNs, where each \(\alpha _i = (\mu _i, \nu _i)\). Then, the aggregated value of these q-ROFNs by utilizing the q-ROFPHM operator is again a q-ROFN and has the expression:
Proof
Utilizing the arithmetic operations of q-ROFNs, we have
and
then
Now 54 b t4td
Adding all the partitioned values, we get
Finally
Now, on the basis of a definition of q-ROFS, the following inequalities can be easily justify:
Since, \(0\le (\mu _{i_j})^q + (\nu _{i_j})^q \le 1\) or \(0\le (\mu _{i_j})^q \le 1- (\nu _{i_j})^q\), therefore
Hence, the resultant value by utilizing the q-ROFPHM operator is again a q-ROFN.
Some essential properties of the q-ROFPHM operator are analyzed and discussed hereafter. \(\square \)
1. Idempotency: For a set \(\{\alpha _1,\alpha _2, \ldots ,\alpha _n\}\) of q-ROFNs with \(\alpha _i= \alpha =(\mu ,\nu ),~\forall ~i \in N\). The \(q-ROFPHM ^{k_t}(\alpha _1,\alpha _2, \ldots ,\alpha _n)=\alpha .\)
Proof
We have \(\alpha _i= \alpha =(\mu ,\nu ),~\forall ~i \in N\); using it, we get
\(=(\mu ,\nu )=\alpha \).
2. Monotonicity: Given two sets \(\{\alpha _1,\alpha _2, \ldots ,\alpha _n\}\) and \(\{\alpha _1',\alpha _2', \ldots ,\alpha _n'\}\) of q-ROFNs, such that \(\alpha _i \le \alpha _i'\) i.e., \((\mu _i,\nu _i) \le (\mu _i',\nu _i')\) or \(\mu _i\le \mu _i'\) and \(\nu _i\ge \nu _i'\), \(\forall ~i \in N\). The \(q-ROFPHM ^{k_t}(\alpha _1,\alpha _2, \ldots ,\alpha _n)\) \(\le \) \(q-ROFPHM ^{k_t}(\alpha _1',\alpha _2', \ldots ,\alpha _n')\).
Proof
Statement suggest that \(\mu _i\le \mu _i'\) and \(\nu _i\ge \nu _i'\) \(\forall ~i \in N\). Therefore
Similarly, the inequality for the non-membership part is straightforward to conclude from what is presented here
Hence
\(\square \)
3. Boundedness: Given a set of q-ROFNs \(\{\alpha _1,\alpha _2, \ldots ,\alpha _n\}\), whose \(\left( \min _i \mu _i,~\max _i \nu _i \right) =\alpha ^-\) and \(\left( \max _i\mu _i,~\min _i \nu _i\right) =\alpha ^+\), where \(i \in N\). We have \(\alpha ^-\le q-ROFPHM ^{k_t}(\alpha _1,\alpha _2, \ldots ,\) \(\alpha _n)\le \alpha ^+\).
Proof
The idempotency of q-ROFPHM operator implies that
Now, utilizing monotonicity of the q-ROFPHM operator, we get
In addition, the q-ROF Hamy mean (q-ROFHM), the q-ROF averaging (q-ROFA), and the q-ROF geometric average (q-ROFGA) operators are some specific cases of the developed q-ROFPHM operator.
Case 1: For \(d=1\), that is \(k_t=k\) and \(|P_t|=n\), the q-ROFPHM operator converts to the q-ROFHM operator
Case 2: For \(d=1\) and \(k_t=k=1\), the q-ROFPHM operator converts to the q-ROFA operator
Case 3: For \(d=1\) and \(k_t=k=n\), the q-ROFPHM operator converts to the q-ROFGA operator
There are situations in the real world where judgements are based on the relevance of the attributes. In such cases, the DMs typically select the optimal option in accordance with the features of the attributes and the nature of the problem. To address this issue, the following section proposes the q-ROFWPHM operator, which assesses the significance of attributes. \(\square \)
The q-ROFWPHM operator
Given a set \(\{\alpha _1,\alpha _2, \ldots ,\alpha _n\}\) of q-ROFNs corresponding to the attributes set \(\{\gamma _1, \gamma _2, \ldots , \gamma _n\}\) which can be partitioned into d-number of groups \(P_1, P_2, \ldots , P_d\). Let \(w_i\in [0,1]\) represents the importance of the ith attribute (\(\gamma _i\)), such that \(\sum _{i=1}^nw_i=1\). The q-ROFWPHM operator is a map from \((\alpha _1,\alpha _2, \ldots ,\alpha _n)^n\) to ([0, 1], [0, 1]) and defined as
where \(|P_t|\) denotes the cardinality of tth partition \(P_t=\{\gamma _{t_1}, \gamma _{t_2}, \ldots , \gamma _{t_{|P_t|}}\}\); \(k_t= 1, 2, \ldots ,|P_t|\) is the granularity parameter of the partition \(P_t\); \(i_1, i_2, \ldots ,i_{k_t}\) are \(k_t\) natural numbers taken from the set \(\{1, 2, \ldots , |P_t|\}\) and \(C_{|P_t|}^{k_t}=\frac{|P_t|!}{k_t!(|P_t|-k_t)!}\) is the binomial coefficient.
Theorem 3
For a collection \(\{\alpha _1,\alpha _2, \ldots ,\alpha _n\}\) of q-ROFNs, where each \(\alpha _i = (\mu _i, \nu _i)\). If \(w_i\in [0,1]\) is the weight associated with ith attribute (\(\gamma _i\)), such that \(\sum _{i=1}^nw_i=1\). Then, the aggregated value of these q-ROFNs by utilizing the q-ROFWPHM operator is again a q-ROFN and has the expression:
Proof
Utilizing the arithmetic operations of q-ROFNs, we have
and
then
Now
Adding all the partitioned values, we get
Finally
Furthermore, it is easy to show that \(q-ROFWPHM ^{k_t}(\alpha _1, \alpha _2, \) \(\ldots ,\alpha _n)\) is a q-ROFN, as we proved for the q-ROFPHM operator in Theorem 2. \(\square \)
Corollary 2
If \(w=(\frac{1}{n},\frac{1}{n}, \ldots ,\frac{1}{n})^T\), then \(q-ROFWPHM ^{k_t}(\alpha _1,\alpha _2, \ldots ,\alpha _n)=q-ROFPHM ^{k_t}(\alpha _1,\alpha _2,\) \( \ldots ,\alpha _n)\).
All three essential properties of an AO are satisfied by the q-ROFWPHM operator and can be easily proved.
q-Rung orthopair fuzzy partitioned dual Hamy mean operators
In this section, the q-ROFPDHM and the q-ROFWPDHM operators are developed with their desirable properties.
The q-ROFPDHM operator
Given a set \(\{\alpha _1,\alpha _2, \ldots ,\alpha _n\}\) of q-ROFNs corresponding to the attributes set \(\{\gamma _1, \gamma _2, \ldots , \gamma _n\}\) which can be partitioned into d-number of groups \(P_1, P_2, \ldots , P_d\). Then, the q-ROFPDHM operator is a map from \(\alpha _1,\alpha _2, \ldots ,\alpha _n\) to \(\left( [0,1],[0,1]\right) \) and defined as
where \(|P_t|\) denotes the cardinality of tth partition \(P_t=\{\gamma _{t_1}, \gamma _{t_2}, \ldots , \gamma _{t_{|P_t|}}\}\); \(k_t= 1, 2, \ldots ,|P_t|\) is the granularity parameter of the partition \(P_t\); \(i_1, i_2, \ldots ,i_{k_t}\) are \(k_t\) natural numbers taken from the set \(\{1, 2, \ldots , |P_t|\}\) and \(C_{|P_t|}^{k_t}=\frac{|P_t|!}{k_t!(|P_t|-k_t)!}\) is the binomial coefficient.
Theorem 4
For a collection \(\{\alpha _1,\alpha _2, \ldots ,\alpha _n\}\) of q-ROFNs, where each \(\alpha _i = (\mu _i, \nu _i)\). Then, the aggregated result of these q-ROFNs by utilizing the q-ROFPDHM operator is again a q-ROFN and has the expression:
Proof
The proof is analogous to that of Theorem 2. \(\square \)
Some elemental properties of the q-ROFPDHM operator are discussed hereafter:
1. Idempotency: For a set \(\{\alpha _1,\alpha _2, \ldots ,\alpha _n\}\) of q-ROFNs with \(\alpha _i=\alpha =(\mu ,\nu )\), \(\forall ~i \in N\). The \(q-ROFPDHM ^{k_t}(\alpha _1,\alpha _2, \ldots ,\) \(\alpha _n)=\alpha \).
2. Monotonicity: Given two sets, \(\{\alpha _1,\alpha _2, \ldots ,\alpha _n\}\) and \(\{\alpha _1',\alpha _2', \ldots ,\alpha _n'\}\) of q-ROFNs, such that \(\alpha _i \le \alpha _i'\) i.e., \((\mu _i,\nu _i) \le (\mu _i',\nu _i')\) or \(\mu _i\le \mu _i'\) and \(\nu _i\ge \nu _i'\), \(\forall ~i \in N\). The \(q-ROFPDHM ^{k_t}(\alpha _1,\alpha _2, \ldots ,\alpha _n)\) \(\le \) \(q-ROFPDHM ^{k_t}(\alpha _1',\alpha _2', \) \(\ldots ,\alpha _n')\).
3. Boundedness: Given a set of q-ROFNs, \(\{\alpha _1,\alpha _2, \ldots ,\alpha _n\}\) whose \(\left( \min _{i} \mu _i,~\max _{i}\nu _i \right) =\alpha ^-\) and \(\left( \max _{i}\mu _i,~\min _{i}\nu _i\right) =\alpha ^+\), where \(i \in N\). We have \(\alpha ^-\le q-ROFPDHM ^P(\alpha _1,\alpha _2, \ldots ,\) \(\alpha _n)\le \alpha ^+\).
In addition, the q-ROF dual Hamy mean (q-ROFDHM), the q-ROF geometric average (q-ROFGA), and the q-ROF averaging (q-ROFA) operators are some specific cases of the developed q-ROFPHM operator.
Case 1: For \(d=1\), that is \(k_t=k\) and \(|P_t|=n\), the q-ROFPDHM operator converts to the q-ROFDHM operator
Case 2: For \(d=1\) and \(k_t=k=1\), the q-ROFPHM operator converts to the q-ROFA operator
Case 3: For \(d=1\) and \(k_t=k=n\), the q-ROFPHM operator converts to the q-ROFGA operator
The q-ROFWPDHM operator
Given a set \(\{\alpha _1,\alpha _2, \ldots ,\alpha _n\}\) of q-ROFNs corresponding to the attributes set \(\{\gamma _1, \gamma _2, \ldots , \gamma _n\}\) which can be partitioned into d-number of groups \(P_1, P_2, \ldots , P_d\). Let \(w_i\in [0,1]\) represents the importance of the ith attribute (\(\gamma _i\)), such that \(\sum _{i=1}^nw_i=1\). The q-ROFWPDHM operator is a map from \((\alpha _1,\alpha _2, \ldots ,\alpha _n)\) to ([0, 1], [0, 1]) and defined as
where \(|P_t|\) denotes the cardinality of tth partition \(P_t=\{\gamma _{t_1}, \gamma _{t_2}, \ldots , \gamma _{t_{|P_t|}}\}\); \(k_t= 1, 2, \ldots , |P_t|\) is the granularity parameter of the partition \(P_t\); \(i_1, i_2, \ldots ,i_{k_t}\) are \(k_t\) natural numbers taken from the set \(\{1, 2, \ldots , |P_t|\}\) and \(C_{|P_t|}^{k_t}=\frac{|P_t|!}{k_t!(|P_t|-k_t)!}\) is the binomial coefficient.
Theorem 5
For a collection \(\{\alpha _1,\alpha _2, \ldots ,\alpha _n\}\) of q-ROFNs, where each \(\alpha _i = (\mu _i, \nu _i)\). If \(w_i\in [0,1]\) is the weight associated with ith attribute (\(\gamma _i\)), such that \(\sum _{i=1}^nw_i=1\). Then, the aggregated value of these q-ROFNs by utilizing the q-ROFWPDHM operator is again a q-ROFN and has the expression:
Proof
The proof is analogous to that of Theorem 3. \(\square \)
Corollary 3
If \(w=(\frac{1}{n},\frac{1}{n}, \ldots ,\frac{1}{n})^T\), then \(q-ROFWPDHM ^{k_t}\) \((\alpha _1,\alpha _2, \ldots ,\alpha _n)=q-ROFPDHM ^{k_t}(\alpha _1,\) \(\alpha _2, \ldots ,\alpha _n)\).
All three essential properties of an AO are satisfied by the q-ROFWPDHM operator and can be proved easily.
An MAGDM approach based on the q-ROFWPHM and q-ROFWPDHM operators
In any MAGDM problem under a generalized orthopair fuzzy environment, multiple DMs, say \(\{D_1,D_2, \ldots ,D_l\}\), provide the assessment data in the form of matrices with q-ROF values. The input values are given based on their expertise to choose the suitable alternative among m feasible alternatives \(X_1,X_2, \ldots ,X_m\) concerning n dependent or independent attributes \(\gamma _1,\gamma _2, \ldots ,\gamma _n\). To formulate the problem, let us suppose that the kth DM (\(D_k\)) provides its assessment values in a matrix form \(M_{m\times n}^k =[\alpha _{ij}^k]_{m\times n}\), where \(\alpha _{ij}^k=(\mu _{ij}^k,\nu _{ij}^k)\) is an assessment value for the alternative \(X_i\) corresponding to attribute the \(C_j\) provided by kth DM. The importance of an attribute \(\gamma _j\) in terms of weight \(w_j\) is defined with the conditions \(w_j\in [0,1]\) and \(\sum _{j=1}^nw_j=1\). Similarly, the preference of an expert is represented by \(\omega _k\) with the conditions \(\omega _k\in [0, 1]\) and \(\sum _{k=1}^l\omega _k=1\). Since the attributes \(\gamma _1,\gamma _2, \ldots ,\gamma _n\) may be dependent or independent in nature, so based on their characteristics, they may be grouped into say d number of partitions \(P_1,P_2, \ldots ,P_d\) with conditions \(P_i\cap P_j=\varnothing \) and \(\cup _{t=1}^dP_t=\{\gamma _1,\gamma _2, \ldots ,\gamma _n\}\). In each partition \(P_t,~t=1,2, \ldots ,d\), the associated attributes are interrelated. The procedural steps of this MAGDM approach based on q-ROFWPHM and q-ROFWPDHM operators are discussed hereafter.
Step 1. The selected attributes that will be used in decision-making are either the benefit type or the cost type. To assess these two kinds of attributes simultaneously, each decision matrix needs to be normalized using the formula
Normalization of given inputs is needed only when the considered attribute set contains both benefit and cost types of attributes.
Step 2. The proposed q-ROFWPHM or q-ROFWPDHM operators can be used to get the comprehensive value \(({\tilde{\alpha }}_i^k)\) for alternative \(X_i\) corresponding to the DM-\(D_k\) by varying all the n attributes as follows:
Step 3. After step 2, we have comprehensive value \(({\tilde{\alpha }}_i^k)\) for alternative \(X_i\) corresponding to the DM-\(D_k\). Now, to get the collective decision information \({\tilde{\alpha }}_i\) for all the m alternatives, the group of DMs can be partitioned into \(d'\) number of partitions with granularity value \(k_t'\). Then, taking \(d'\) and \(k_t'\), the collective decision information \({\tilde{\alpha }}_i\) for all the m alternatives can be obtained by aggregating the comprehensive values \(({\tilde{\alpha }}_i^k); k=1,2, \ldots ,l\) using q-ROFWPHM or q-ROFWPDHM operators accordingly with the following equations:
or
or
Step 4. Using Eqs. (2) and (3) for each alternative and find the score \(S({\tilde{\alpha }}_{i})\) and accuracy \(H({\tilde{\alpha }}_{i})\) values of collective decision information (\({\tilde{\alpha }}_{i}\)).
Step 5. Now, using the ranking methodology as described in the section “Score and accuracy functions”, rank the alternatives \(X_1,X_2, \ldots ,X_m\) based on their score \(S({\tilde{\alpha }}_{i})\) and accuracy \(H({\tilde{\alpha }}_{i})\) values.
To implement this approach, MATLAB codes have been run on a system whose specifications are as follows: Processor-12th Gen Intel(R) Core(TM) i5-1240P 1.70 GH, RAM-16 GB. A comprehensive graphical flowchart of the discussed approach is presented in Fig. 3. This flowchart visually represents the various steps involved in our approach.

Flowchart of the proposed MAGDM approach
The benefits and drawbacks of the proposed method are discussed in Table 2.
Some practical applications of the proposed methodology
In this section, two MAGDM problems have been investigated. One is related to selecting the best personnel in the intuitionistic fuzzy (IF) environment, and another is prioritizing the potential investment options in the q-ROF environment.
Problem 1: an illustrative example related to selecting best personnel
To illustrate the suggested MAGDM approach, an MAGDM problem of selecting the best personnel from Liu et al. [24] has been considered for the discussion. In this problem, four feasible alternatives, \(X_1, X_2, X_3,\) and \(X_4\), are there, which will be evaluated based on seven different attributes that capture the competency framework of teachers. All these benefit type attributes are learning ability \((\gamma _1)\), management innovation ability \((\gamma _2)\), communication and coordination ability \((\gamma _3)\), professional quality \((\gamma _4)\), moral character \((\gamma _5)\), professional knowledge level \((\gamma _6)\), and legal awareness \((\gamma _7)\). The weights \(w_j,~j=1,2,..,7\) assign to these attributes are 0.1, 0.1, 0.1, 0.2, 0.2, 0.2, and 0.1, respectively. Now, considering their interrelationship pattern, attributes’ set can be partitioned into two groups \(P_1\) and \(P_2\), where \(P_1=\{\gamma _1,\gamma _2,\gamma _3,\gamma _6\}\) and \(P_2=\{\gamma _4,\gamma _5,\gamma _7\}\) representing the individual ability level and the personal accomplishment, respectively. There are three DMs, \(D_1,D_2\), and \(D_3\), with their preference weights \(\omega _1=0.4, \omega _2=0.3\), and \(\omega _3=0.3\), respectively. The DM (\(D_k\)) evaluates each alternative \(X_i\) in accordance to every attribute \(\gamma _j\) and construct the decision matrices of q-ROFNs denoted by \(M^k=[\alpha _{ij}^k]=[(\mu _{ij}^k,\nu _{ij}^k)]_{4\times 7},~i=1,2,3,4;~j=1,2,..,7\) and \(k=1,2,3\). The decision matrices associated with three DMs are shown in Tables 3, 4, and 5, respectively. Now, the discussed MAGDM method has been applied to analyze this problem. The procedural steps are listed hereafter.
Step 1. Normalization of decision matrices:
The attributes of the selected problem are all benefit types. As a result, decision matrix normalization is not required.
Step 2. Calculation of comprehensive values \(({\tilde{\alpha }}_i^k)\):
Using Eqs. (18) and (19), calculate the comprehensive value \(({\tilde{\alpha }}_i^k)\) for each alternative \(X_i\) corresponding to DM-\(D_k\) using matrix \(M^k=[\alpha _{ij}^k]\), where j varies from \(1,2, \ldots ,n\). Here, we are given \(d=2\), \(|P_1|=4\) and \(|P_2|=3\). Since all the \(\alpha _{ij}^k\) are orthopair fuzzy numbers for \(1\le q<\infty \), so without loss of generality, choose \(q=1\). Also, the granularity parameter \(k_1=2\) and \(k_2=2\) are selected for computation. The computed values of \(({\tilde{\alpha }}_i^k)\) are provided in the Table 6 for q-ROFWPHM and q-ROFWPDHM operators, respectively.
Step 3. Computation of collective decision information \(({\tilde{\alpha }}_i)\):
As per the considered problem, there is no partitioning in the group of DMs, so \(d'=1\). For the computation, we have taken \(q=1\) and \(k_t'=2\). Then, apply the q-ROFWPHM and q-ROFWPDHM operators using Eqs. (20) and (21) to get a collective decision information \(({\tilde{\alpha }}_i)\) for the alternatives \(X_i\). The collective information is provided in Table 7.
Step 4. Calculation of score \(S({\tilde{\alpha }}_{i})\) and accuracy \(H({\tilde{\alpha }}_{i})\) values:
Use Eq. (2) to compute the score value \(S({\tilde{\alpha }}_{i})\) for each \({\tilde{\alpha }}_i\). The computed values are shown in Table 8.
Here, every score value is distinct, so we can proceed to the next step without calculating their accuracy values.
Step 5. Ranking of alternatives:
Utilizing the methodology described in the section “Score and accuracy functions”, rank the alternatives. The final ordering of alternatives based on the score values is summarized in Table 8.
The calculated results demonstrate that the suggested MAGDM strategy using the q-ROFWPHM and q-ROFW PDHM operators yields the same optimum choice (\(X_2\)) for the problem under consideration. Also, it is worth noticing that the score value of an alternative obtained by using the q-ROFWPDHM operator is higher than the score value from the q-ROFWPHM operator, which concludes that for optimistic types of decision preference, the q-ROFWPDHM operator can be applied. The q-ROFWPHM operator, the other operator, can aggregate all the information of a pessimistic nature. It signifies the role of the AOs in the proposed MAGDM method in the sense of flexibility based on DM preferences. The expert’s decision-making nature clearly impacts the final ordering of alternatives, which can be seen in Table 8.
Sensitivity analysis
This section investigates the flexibility and efficiency of the constructed MAGDM technique by varying the parameters q, \(1\le k_1 \le |P_1|\), \(1\le k_2 \le |P_2|\), and \(1\le k_1' \le 3\) and analyzing the ranking order of alternatives accordingly. Among many possible variations, we have done sensitivity analysis in three different directions, which are as follows:
-
1.
In the first direction, we have analyzed the variational trend in the score values of \(\alpha _i\) by fixing the parameter \(q=1\) and taking the other three parameters as \(k_1=k_2=k_1'=1,2,\) and 3. The results for q-ROFWPHM and q-ROFWPDHM operators are tabulated in Tables 9 and 10, respectively. These results suggest that by increasing the values of association granularity \(k_1, k_2, k_1'\), the score of each alternative obtained from the q-ROFWPHM operator decreases, while the q-ROFWPDHM operator shows an increasing tendency. Also, for the first case, i.e., \(k_1=k_2=k_1'=1\), the score values of \(\alpha _i\) obtained from the q-ROFWPHM operator are higher than those obtained from the q-ROFWPDHM operator. This shows an unexpected trend, because it is expected that the q-ROFWPHM operator will provide lower values (pessimistic results) in comparison to the values obtained from the q-ROFWPDHM operator (optimistic results) for a particular alternative, as seen in the other two cases. This unexpected trend is due to the underlying structure of the q-ROFWPHM and q-ROFWPDHM operators. The best and worst alternatives are \(X_2\) and \(X_3\), respectively, irrespective of the considered variation.
-
2.
In the second direction, we chose \(q=1\) and all 12 possible combinations of the different granularity parameters \(k_1\in \{1,2,3,4\}\) and \(k_2\in \{1,2,3\}\) to account for all the possible correlations among attributes in the selected MAGDM problem. Herein, \(k_1'\) may take values of 1, 2, or 3. If we select \(k_1'=1\) and \(k_1'=3\), the implicit nature of the proposed AOs, which are q-ROFWPHM and q-ROFWPDHM, is lost in the averaging and geometric averaging means. Therefore, to differentiate the proposed AOs, we have fixed \(k_1'=2\) for all the above 12 possible combinations in both AOs. The results for both AOs are tabulated in Tables 11 and 12, respectively, and their graphical depiction is provided in Fig. 4. From these results, it is clearly seen that the best and worst alternatives are always \(X_2\) and \(X_3\), respectively, for both AOs and for all the feasible combinations considered in the analysis.
-
3.
In the third direction, we have selected \(k_1=k_2=k_1'=2\) and taken different values of \(q\in [1,10]\). The computed results are tabulated in Tables 13 and 14 for q-ROFWPHM and q-ROFWPDHM operators, respectively, and also plotted in Fig. 5. By increasing the values of q, the score values show a decreasing tendency for each alternative, irrespective of the AO applied. Subsequently, the ranking order is almost unaffected for both the AOs. Thus, we can say that the variation in the parameter q values does not provide any significant advantage in making concrete decisions for the considered problem. However, this may increase computational efforts. The results show that the best and worst alternatives are unanimous \(X_2\) and \(X_3\), respectively.

Score values for different cases of (\(k_1,k_2\)) computed by a q-ROFWPHM and b q-ROFWPDHM operators

Score versus q-values for a q-ROFWPHM and b q-ROFWPDHM operators
Based on sensitivity analysis, the following points are noted:
-
(a)
For a neutral attitude of the DM toward risk preference, the value of \(k_t\) can be taken as \(\left[ \frac{|p_t|}{2}\right] \); \(t=\{1,2, \ldots ,d\}\), where [ ] is the greatest integer function. For q-ROFWPHM operator, the value \(k_t < \left[ \frac{|p_t|}{2}\right] \) represents the optimistic preference, whereas \(k_t > \left[ \frac{|p_t|}{2}\right] \) reflects the pessimistic preference nature of the DM. Contrary to the q-ROFWPHM operator, the value \(k_t < \left[ \frac{|p_t|}{2}\right] \) represents the pessimistic preference, whereas \(k_t > \left[ \frac{|p_t|}{2}\right] \) shows the optimistic preference nature of the DM for the q-ROFWPDHM operator. Therefore, the appropriate value of \(k_t\) can be selected by the DM according to the actual needs and his preferential nature in decision-making.
-
(b)
For the considered problem, the variation in the values of q does not affect the final decision too much. However, that may affect the final decision significantly if we consider any other problems.
Quantitative and qualitative comparative analyses
This section compares the constructed MAGDM methodology with five other existing decision-making methodologies, including Liu et al. [23], Rong et al. [37], Rahman et al. [35], Liu and Chen [22], and Liu et al. [24] based on quantitative and qualitative analyses. The quantitative analysis results are tabulated in Table 15 and plotted in Fig. 6. In addition, a detailed comparative analysis has been done with the Liu et al.’s [24] method by taking five different cases, and their results are shown in Table 16. The comparison between the presented and the existing approaches, as mentioned above, based on their characteristics is done qualitatively, and the findings are tabulated in Table 17. A detailed discussion of the qualitative comparison between the presented and existing approaches is provided hereafter.
(a) Comparison based on quantitative analysis
Since the above-cited five decision-making methods are working on IFS to perform a meaningful quantitative comparison, the same IF environment has been created for the proposed method by taking \(q=1\). The methods of the Liu et al. [23] and Liu and Chen [22] methods can capture the correlation between any two attributes. Therefore, for the Liu et al.’s [24] method, the granularity parameter \(k=2\) is used, whereas \(k_t=2\) is used for the proposed method to provide an identical working environment. To apply the Rong et al.’s [37] method, their method parameters’ values are taken as \(\lambda =1\) and \(\gamma =1\), while for the Rahman et al. [35] method, the parameter \(\lambda =1\) is selected. Among the considered methods, Liu et al. [23], Liu et al. [24], and proposed methods consider partitioning, while Rong et al. [37], Rahman et al. [35], and Liu and Chen [22] approaches do not consider partitioning of attributes. The final ordering by Liu et al. [23], Liu et al. [24], and the proposed approach with the q-ROFWPHM operator is the same as \(X_2\succ X_4\succ X_1\succ X_3\), because they take partitioning into account, as can be seen from Table 15. On the contrary, Rong et al. [37], Rahman et al. [35], Liu and Chen [22], and the proposed method with q-ROFWPDHM operator provide slightly different order \(X_2\succ X_1\succ X_4\succ X_3\). This is because the Rong et al. [37], Rahman et al. [35], and Liu and Chen [22] methods do not eliminate the influence of irrelevant attributes, while the proposed method with q-ROFWPDHM operator is dual. The computed score values of each alternative by utilizing these methods are depicted in a radar graph (Fig. 6). Figure 6 shows that the alternatives \(X_1\) (red) and \(X_4\) (blue) are sensitive, and their ranking orders depend on the AO applied, while \(X_2\) (green) and \(X_3\) (gray) have the same ranking orders irrespective of AOs applied. All these methods’ results concluded that \(X_2\) is the best among all the available alternatives.
The computational results presented in Table 15 show that under the same IF environment, the developed MAGDM method gives almost the same ranking order as the other existing approaches. However, the proposed method outperforms the existing methods in the decision space, partitioning, and correlation between attributes by providing a range of solutions to the DM, who can choose an appropriate solution depending on the problem’s requirements.

Radar graph of AOs used in various MAGDM approaches
Furthermore, the suggested technique using q-ROFWPHM and q-ROFWPDHM operators is compared to the Liu et al.’s [24] method using five distinct sets of values for the parameters \(k=k_t\) and \(s=d\), while keeping the other parameters \(q=1\) and \(k_1'=2\) fixed. The computed values are given in Table 16. The results indicate that for \(s=d=1\), when no partitioning of attributes is considered, the proposed and Liu et al.’s [24] approaches provide the same ranking behavior. When attributes are partitioned into two groups using the values \(s=d=2\) and the granularity parameters \(k=k_t=1,2,3\), it is discovered that the ranking orders differ slightly due to differences in the underlying structure of the operators engaged in their techniques. However, both of these approaches, \(X_3\) and \(X_2\), are always the worst and best alternatives, demonstrating the consistency of the proposed method.
(b) Qualitative comparison based on their characteristics
Qualitative comparison of the suggested MAGDM approach with five existing methods as discussed in the previous section [22,23,24, 35, 37] has been made based on their characteristics, including capability in handling uncertainty, the correlation between numerous attributes of the same group, partitioning of irrelevant attributes, flexibility in handling various levels of granularity between attributes in different partitions, and the power of considering multiple DMs to make decisions. The findings are provided in Table 17 which suggests that the developed MAGDM approach is superior to the selected MAGDM approaches.
Problem 2: a real-world problem of prioritizing the potential investment options
The proposed MAGDM method is illustrated through a numerical example, adapted from [34], which involves selecting the most suitable industry for investment among five available options. This example serves to showcase the application and effectiveness of the proposed method.
To fully utilize dormant capital, the company’s board of directors made a strategic decision to invest in a new industry. Following preliminary research, five potential industries were identified as viable investment options. These alternatives encompass the medical industry (\(X_1\)), real-estate development industry (\(X_2\)), Internet industry (\(X_3\)), education and training industry (\(X_4\)), and manufacturing industry (\(X_5\)). To determine the optimal industry for investment, the board of directors assembled a panel of experts consisting of four individuals: \(D_1\), \(D_2\), \(D_3\), and \(D_4\). The relative significance of these experts was quantified using a weight vector \(\omega =(0.30, 0.22, 0.28, 0.20)\). Each of the four experts was tasked with evaluating the five alternative industries based on five attributes: capital profit potential (\(\gamma _1\)), market potential (\(\gamma _2\)), risk of capital loss (\(\gamma _3\)), growth potential (\(\gamma _4\)), and policy stability (\(\gamma _5\)). The weight vector \(w=(0.20, 0.20, 0.15, 0.25, 0.20)\) was utilized to assess the relative importance of these attributes. Based on the interrelationship structure, the five criteria were categorized into two partitions: \(P_1 = \{\gamma _1, \gamma _3, \gamma _5\}\) and \(P_2 = \{\gamma _2, \gamma _4\}\). Interrelationships were found among the three attributes within \(P_1\) and the two attributes within \(P_2\), while \(P_1\) and \(P_2\) remained independent. To allow for sufficient flexibility in evaluating the values of the attributes for each alternative industry, the experts were permitted to employ q-ROFNs. The evaluation outcomes provided by the four experts are individually documented in the following four matrices, as shown in Tables 18, 19, 20, and 21.
Now, the suggested MAGDM approach has been applied to analyze this problem. The procedural steps are listed hereafter.
Step 1. Normalization of decision matrices:
In this problem, four attributes \(\gamma _1\), \(\gamma _2\), \(\gamma _4\), and \(\gamma _5\) are of benefit types and one attribute \(\gamma _3\) is of cost type. Hence, the normalization of given data is essential and completed by utilizing Eq. 17.
Step 2. Calculation of comprehensive values \(({\tilde{\alpha }}_i^k)\):
Compute the comprehensive value \(({\tilde{\alpha }}_i^k)\) for each alternative \(X_i\) corresponding to DM \(D_k\) by utilizing the matrix \(M^k=[\alpha _{ij}^k]_{5\times 5}\) and Eqs. (18) and (19). Here, we are given \(d=2\), \(|P_1|=3\) and \(|P_2|=2\). Since the given information satisfy the orthopair fuzzy numbers condition for \(q\ge 3\), so without loss of generality, select \(q=3\). Also, select the granularity parameter \(k_1=2\) and \(k_2=2\). The computed values of \(({\tilde{\alpha }}_i^k)\) are provided in Tables 22 and 23 for q-ROFWPHM and q-ROFWPDHM operators, respectively.
Step 3. Computation of collective decision information \(({\tilde{\alpha }}_i)\):
As there is no partitioning of DMs group suggested in the problem, so implies \(d'=1\). For the further calculations, the values of parameters are \(q=3\) and \(k_t'=2\). Employ the q-ROFWPHM and q-ROFWPDHM operators using Eqs. (20) and (21) to get a collective decision information \(({\tilde{\alpha }}_i)\) for the alternatives \(X_i\). The collective information is provided in Table 24.
Step 4. Calculation of score \(S({\tilde{\alpha }}_{i})\) and accuracy \(H({\tilde{\alpha }}_{i})\) values:
Compute the score value \(S({\tilde{\alpha }}_{i})\) for each \({\tilde{\alpha }}_i\) using the score function mention in Eq. (2). The resultant values are shown in Table 25.
Step 5. Ranking of alternatives:
Using the approach discussed in the section“Score and accuracy functions”, rank the alternatives. The final ordering of alternatives is based on the score values and is summarized in Table 25.
Based on the computed results of problem 2, it is observed that the proposed MAGDM approach with either the q-ROFWPHM operator or the q-ROFWPDHM operator identifies the same best alternative, which is the Internet industry (\(X_2\)) following the medical industry (\(X_1\)). Internet industry investment offers significant growth potential, competitive advantages, favorable financial performance, expanding user engagement, and effective risk management strategies. However, it is important to note that investment decisions should also be tailored to individual risk tolerance, financial goals, and the specific investment opportunities available. Furthermore, comparing results between the q-ROFWPDHM operator and the q-ROFWPHM operator reveals a distinction between optimistic and pessimistic decision preferences. Specifically, the results obtained from the q-ROFWPDHM operator are higher than those obtained from the q-ROFWPHM operator, highlighting the differing optimism and pessimism inherent in the two operators.

Rankings of alternative through different partitioning-based decision-making approaches
Comparison of the proposed approach with similar existing work
This section compares the developed approach with some existing similar works on partitioning, such as Bai et al.’s MAGDM method based on the q-ROFWPPMSM operator [7], Zhong et al.’s MAGDM method based on the q-ROFDWPPHM operator [51], Qin et al.’s MAGDM method based on the q-ROFWAPPMM operator [34], and Yang and Pang’s MADM method based on the q-ROFPGWBM operator [48]. All these AOs, including the proposed one, can capture the interactions among input arguments. This implies that they can effectively measure the internal interactions among attributes. As a result, it is valuable to analyze the resultant values derived from these operators in the context of real-world decision-making problems.
The final assessment values from all approaches mentioned above are collected in a single table 26. All these compared AOs involve some parameters in their approaches that are fixed for this problem as follows: (i) The q-ROFWPPMSM operator [7] has the correlation parameter \(k_h\) and a Minkowski distance parameter \(p=3\). To aggregate the DMs assessment data, put \(k_h=k_1=1\) and calculate each alternative’s overall performance using \(k_h=(k_1,k_2)=(2,2)\). (ii) The q-ROFDWPPHM operator [51] involves interrelation parameters \(a=1\) and \(b=2\), Dombi parameter \(\lambda =1.5\), and the Minkowski distance parameter \(p=3\). (iii) The q-ROFWAPPMM operator is based on the Archimedean TN and TC, which involves generating functions (f and g); this AO also has a correlation parameter \(\Delta \) and a Minkowski parameter b [34]. For this analysis, we fixed them as \(f(t)=\ln \left( \frac{\lambda +(1-\lambda )t^q}{t^q}\right) \) and \(g(t)=\ln \left( \frac{\lambda +(1-\lambda )(1-t^q)}{(1-t^q)}\right) \) with \(\lambda =3\), \(\Delta =(1,0,0,0)\) to get a single decision matrix, \(\Delta =(\Delta _1,\Delta _2)=((1,2,3),(1,2))\) to compute the overall assessment values, and \(b=3\). (iv) The MADM method based on the q-ROFPFWBM operator is constructed for a single DM [48]. Therefore, to implement this operator, we need to add a step to their approach using their q-ROFPFWBM operator. The interrelation parameters of the q-ROFPFWBM operator are fixed at \(r=2\) and \(s=2\). The common parameter q for this problem is taken as 3. Moreover, the parameters involved in the proposed methodology are the same as in the previous section.
The ranking orders from the constructed MAGDM and Yang and Pang’s approaches [48] are identical and indicate that the alternative \(X_3\) (internet industry) is the best option, \(X_1\) (medical industry) is the second best option, and \(X_2\) (real-estate development industry) is the worst place for investment purposes. Both of them are based on weighted partitioned AO. Whereas the other three approaches are based on weighted power partitioned AO, and their final ranking orders are distinct. Bai et al.’s [7] and Qin et al.’s [34] approaches give \(X_1\) as the best and \(X_2\) as the worst alternatives. On the other hand, Zhong et al.’s [51] method provides the X2 as the best alternative. Yang and Pang’s [48] and the proposed method provide the \(X_3\) as the most suitable place to invest. The proposed method consistently prioritizes \(X_3\) as the top choice, followed by \(X_1\), \(X_5\), \(X_4\), and \(X_2\). The consistent high ranking of \(X_3\) highlights the distinct benefit of our method in recognizing the inherent strengths and advantages of \(X_3\) within the given problem context. The graphical representation of these results is also shown in Fig. 7.
Conclusion
This study presents a new partition-based decision-making approach to cope with MAGDM problems in a q-ROF environment. The paper proposed a new AO named PDHM, which not only partitions the irrelevant attributes but also considers various levels of granularity between attributes in different partitions. The advantage of the PDHM operator is that it converts to the DHM and PGM by assigning particular values to the granularity parameter \(k_t\). In addition, the existing PHM and the new PDHM operators are also constructed in a q-ROF environment. Some new AOs named q-ROFPHM, q-ROFWPHM, q-ROFPDHM, and q-ROFWPDHM have been developed. Finally, a new MAGDM approach has been proposed based on q-ROFWPHM and q-ROFWPDHM operators.
Further, two MAGDM problems have been analyzed by the developed MAGDM approach. The first problem is the IF-MAGDM problem related to the selection of the best personnel among four feasible alternatives (\(X_1\),\(X_2\), \(X_3\), \(X_4\)), and the second problem is a q-ROF-MAGDM problem, which aims to evaluate the most suitable investment alternative among five feasible options (\(X_1\), \(X_2\), \(X_3\), \(X_4\), \(X_5\)). The results from the suggested approach indicate that alternative \(X_2\) in the first problem and alternative \(X_3\) in the second problem are the best alternatives, respectively. A sensitivity analysis for the first problem is also conducted in three different directions to show the efficiency and flexibility of the developed approach.
Moreover, the comparative analysis for both MAGDM problems has been investigated. For comparison, five different IFS-based AOs and four q-ROFS-based partitioned AOs are selected in the first and second analyzed problems. Two of the five AOs used in the first problem’s comparative analysis are based on partitioning. On the other side, three AOs among the four partitioned AOs used in the comparison for the second problem are based on power weights. The results obtained from the sensitivity and comparative analyses confirm the following advantages over the existing methods:
-
The presence of parameter q in the q-ROF environment helps to raise the DMs’ assessment space.
-
Due to the underlying structure of the HM operator, the proposed approach allows us to consider the interrelationships between any number of input arguments.
-
The partitioning of attributes into several distinct groups helps to avoid the adverse impact of irrelevant attributes.
-
The proposed approach can consider various granularity levels between attributes in distinct partitions.
-
The proposed AOs-based MAGDM method provides more consistent results on real-world application problems.
Some limitations of the proposed work are as follows: (i) the conjunctive and disjunctive behavior of the proposed AOs is computed through a basic product and probabilistic sum; (ii) the proposed MAGDM methodology deals with only known weights provided by the DMs. Future research will extend the proposed methodology in various directions, including its extension in other uncertainty environments with new score functions, Archimedean TNs and TCs based on basic operational laws, partially known or fully unknown weights, etc. It would also be instructive to study the applicability of the developed AOs in the conventional MADM approaches, such as TOPSIS, VIKOR, and many others. These future developments would allow to contribute to the solution of complex real-life problems, such as decision-making with multiple stakeholders related to urban mobility governance and, more specifically, the urban logistics problems.
Data Availability
Not applicable.
Code Availability
Not applicable.
Abbreviations
- MAGDM:
-
Multi-attribute group decision-making
- AO:
-
Aggregation operator
- FS:
-
Fuzzy set
- IFS:
-
Intuitionistic fuzzy set
- PFS:
-
Pythagorean fuzzy Set
- q-ROFS:
-
q-Rung orthopair fuzzy set
- q-ROFN:
-
q-Rung orthopair fuzzy number
- TOPSIS:
-
Technique for order preference by similarity to ideal solution
- AHP:
-
Analytical hierarchy process
- ELECTRE:
-
ÉLimination et choix traduisant la realité
- PROMETHEE:
-
Preference ranking organization method for enrichment evaluation
- VIKOR:
-
Viekriterijumsko kompromisno rangiranje
- AM:
-
Arithmetic mean
- GM:
-
Geometric mean
- BM:
-
Bonferroni mean
- MSM:
-
Maclaurin symmetric mean
- MM:
-
Muirhead mean
- HM:
-
Hamy mean
- DHM:
-
Dual Hamy mean
- PHM:
-
Partitioned Hamy mean
- PDHM:
-
Partitioned dual Hamy mean
- q-ROFPHM:
-
q-Rung orthopair fuzzy partitioned Hamy mean
- q-ROFWPHM:
-
q-Rung orthopair fuzzy weighted partitioned Hamy mean
- q-ROFPDHM:
-
q-Rung orthopair fuzzy partitioned dual Hamy mean
- q-ROFWPDHM:
-
q-Rung orthopair fuzzy weighted partitioned dual Hamy mean
- TN:
-
Triangular norm
- TC:
-
Triangular conorm
- DM:
-
Decision maker
- MADM:
-
Multi-attribute decision-making
- GDM:
-
Group decision-making
- BWM:
-
Best–worst method
- CODAS:
-
Combinative distance-based assessment method
- TODIM:
-
Tomada de decisão iterativa multicritério
- EDAS:
-
Evaluation based on distance from average solution
- WASPAS:
-
Weighted aggregated sum product assessment
- CRITIC:
-
Criteria importance through intercriteria correlation
- IFWIPBM:
-
Intuitionistic fuzzy weighted interaction partitioned Bonferroni mean
- IFGHHWM:
-
Intuitionistic fuzzy generalized Hamacher hybrid weighted averaging
- GIFEWA:
-
Generalized intuitionistic fuzzy Einstein weighted averaging
- IFWAHA:
-
Intuitionistic fuzzy weight Archimedean Heronian aggregation
- IFWPMSM:
-
Intuitionistic fuzzy weighted partitioned Maclaurin symmetric mean
- q-ROFWPPMSM:
-
q-Rung orthopair fuzzy weighted power partitioned Maclaurin symmetric mean
- q-ROFDWPPHM:
-
q-Rung orthopair fuzzy Dombi weighted power partitioned Heronian mean
- q-ROFWAPPMM:
-
q-Rung orthopair fuzzy weighted Archimedean power partitioned Muirhead mean
- q-ROFPGWBM:
-
q-Rung orthopair fuzzy partitioned geometric weighted Bonferroni mean
- q-ROFWMM:
-
q-Rung orthopair fuzzy weighted Muirhead mean
- \(\mathbb {R}_+\) :
-
Set of non-negative real numbers
- \(\mu \) :
-
Membership degree
- \(\nu \) :
-
Non-membership degree
- q :
-
Adjustable parameter in q-ROFS
- \(\alpha \) :
-
q-Rung orthopair fuzzy number
- S :
-
Score function
- H :
-
Accuracy function
- \(C_n^k\) :
-
Binomial coefficient
- \(P_t\) :
-
tth partition of attributes
- \(k_t\) :
-
Granularity parameter for \(P_t\)
- \(k_t'\) :
-
Granularity parameter for DMs group
- \(D_k\) :
-
kth decision maker
- \(\omega _k\) :
-
Weight associated to the \(D_k\)
- \(X_i\) :
-
ith alternative
- \(\gamma _j\) :
-
jth attribute
- \(w_j\) :
-
Weight associated with the \(\gamma _j\)
- \(|P_t|\) :
-
Cardinality of \(P_t\)
- \(M^k\) :
-
Decision matrix provided by \(D_k\)
- []:
-
Greatest integer function
References
Akram M, Naz S, Edalatpanah SA, Samreen S (2023) A hybrid decision-making framework under 2-tuple linguistic complex q-rung orthopair fuzzy Hamy mean aggregation operators. Comput Appl Math 42:118
Akram M, Ullah K, Ćirović G, Pamucar D (2023) Algorithm for energy resource selection using priority degree-based aggregation operators with generalized orthopair fuzzy information and Aczel–Alsina aggregation operators. Energies 16:2816
Alamoodi A, Albahri O, Zaidan A, Alsattar H, Zaidan B, Albahri A (2023) Hospital selection framework for remote mcd patients based on fuzzy q-rung orthopair environment. Neural Comput Appl 35:6185–6196
Ali Z, Mahmood T, Pamucar D, Wei C (2022) Complex interval-valued q-rung orthopair fuzzy Hamy mean operators and their application in decision-making strategy. Symmetry 14:592
Alkan N, Kahraman C (2021) Evaluation of government strategies against covid-19 pandemic using q-rung orthopair fuzzy topsis method. Appl Soft Comput 110:107653
Atanassov KT (1986) Intuitionistic fuzzy sets. Fuzzy Sets Syst 20:87–96
Bai K, Zhu X, Wang J, Zhang R (2018) Some partitioned Maclaurin symmetric mean based on q-rung orthopair fuzzy information for dealing with multi-attribute group decision making. Symmetry 10:383
Beliakov G, Pradera A, Calvo T (2007) Aggregation functions: a guide for practitioners, vol 221. Springer, Berlin
Bustince H, Barrenechea E, Pagola M, Fernandez J, Xu Z, Bedregal B, Montero J, Hagras H, Herrera F, Baets BD (2016) A historical account of types of fuzzy sets and their relationships. IEEE Trans Fuzzy Syst 24:179–194
Dai J, Chen T, Zhang K (2023) The intuitionistic fuzzy concept-oriented three-way decision model. Inf Sci 619:52–83
Deveci M, Gokasar I, Brito-Parada PR (2022) A comprehensive model for socially responsible rehabilitation of mining sites using q-rung orthopair fuzzy sets and combinative distance-based assessment. Expert Syst Appl 200:117155
Deveci M, Pamucar D, Gokasar I, Koppen M, Gupta BB (2022) Personal mobility in metaverse with autonomous vehicles using q-rung orthopair fuzzy sets based OPA-RAFSI model. IEEE Transactions on Intelligent Transportation Systems, pp 1–10
Dutta B, Guha D (2015) Partitioned Bonferroni mean based on linguistic 2-tuple for dealing with multi-attribute group decision making. Appl Soft Comput 37:166–179
Farid HMA, Riaz M (2023) q-rung orthopair fuzzy Aczel–Alsina aggregation operators with multi-criteria decision-making. Eng Appl Artif Intell 122:106105
Garg H, Chen S-M (2020) Multiattribute group decision making based on neutrality aggregation operators of q-rung orthopair fuzzy sets. Inf Sci 517:427–447
Güneri B, Deveci M (2023) Evaluation of supplier selection in the defense industry using q-rung orthopair fuzzy set based EDAS approach. Expert Syst Appl 222:119846
Hamy M (1890) Sur le théorème de la moyenne. Bull Sci Math 14:103–104
Hara T, Uchiyama M, Takahasi S-E (1998) A refinement of various mean inequalities. J Inequal Appl 1998:932025
Krishankumar R, Nimmagadda SS, Rani P, Mishra AR, Ravichandran K, Gandomi AH (2021) Solving renewable energy source selection problems using a q-rung orthopair fuzzy-based integrated decision-making approach. J Clean Prod 279:123329
Kumar K, Chen S-M (2022) Group decision making based on q-rung orthopair fuzzy weighted averaging aggregation operator of q-rung orthopair fuzzy numbers. Inf Sci 598:1–18
Liang D, Zhang Y, Cao W (2019) q-rung orthopair fuzzy Choquet integral aggregation and its application in heterogeneous multicriteria two-sided matching decision making. Int J Intell Syst 34(12):3275–3301
Liu P, Chen S-M (2017) Group decision making based on Heronian aggregation operators of intuitionistic fuzzy numbers. IEEE Trans Cybern 47:2514–2530
Liu P, Chen S-M, Liu J (2017) Multiple attribute group decision making based on intuitionistic fuzzy interaction partitioned Bonferroni mean operators. Inf Sci 411:98–121
Liu P, Chen S-M, Wang Y (2020) Multiattribute group decision making based on intuitionistic fuzzy partitioned Maclaurin symmetric mean operators. Inf Sci 512:830–854
Liu P, Liu J (2018) Some q-rung orthopair fuzzy Bonferroni mean operators and their application to multi-attribute group decision making. Int J Intell Syst 33(2):315–347
Liu P, Liu X (2019) Linguistic intuitionistic fuzzy Hamy mean operators and their application to multiple-attribute group decision making. IEEE Access 7:127728–127744
Liu P, Wang P (2018) Some q-rung orthopair fuzzy aggregation operators and their applications to multiple-attribute decision making. Int J Intell Syst 33:259–280
Liu P, Wang Y (2020) Multiple attribute decision making based on q-rung orthopair fuzzy generalized Maclaurin symmetric mean operators. Inf Sci 518:181–210
Liu P, Xu H, Geng Y (2020) Normal wiggly hesitant fuzzy linguistic power Hamy mean aggregation operators and their application to multi-attribute decision-making. Comput Ind Eng 140:106224
Liu Z, Xu H, Liu P, Li L, Zhao X (2020) Interval-valued intuitionistic uncertain linguistic multi-attribute decision-making method for plant location selection with partitioned hamy mean. Int J Fuzzy Syst 22:1993–2010
Mardani A, Nilashi M, Zavadskas EK, Awang SR, Zare H, Jamal NM (2018) Decision making methods based on fuzzy aggregation operators: three decades review from 1986 to 2017. Int J Inf Technol Decis Making 17:391–466
Mardani A, Saberi S (2023) Industry 4.0 adoption drivers for sustainable supply chain in the manufacturing sector using a hybrid decision-making approach under q-rung orthopair fuzzy information. IEEE Transactions on Engineering Management, pp 1–18
Qin J (2017) Interval type-2 fuzzy Hamy mean operators and their application in multiple criteria decision making. Granul Comput 2:249–269
Qin Y, Qi Q, Scott PJ, Jiang X (2019) Multi-criteria group decision making based on Archimedean power partitioned Muirhead mean operators of q-rung orthopair fuzzy numbers. PLoS One 14:0221759
Rahman K, Abdullah S, Jamil M, Khan MY (2018) Some generalized intuitionistic fuzzy Einstein hybrid aggregation operators and their application to multiple attribute group decision making. Int J Fuzzy Syst 20:1567–1575
Rawat SS, Komal (2022) Multiple attribute decision making based on q-rung orthopair fuzzy Hamacher Muirhead mean operators. Soft Comput 26:2465–2487
Rong L, Liu P, Chu Y (2016) Multiple attribute group decision making methods based on intuitionistic fuzzy generalized Hamacher aggregation operator. Econ Comput Econ Cybern Stud Res 50:211–230
Rong Y, Pei Z, Liu Y (2020) Hesitant fuzzy linguistic Hamy mean aggregation operators and their application to linguistic multiple attribute decision-making. Math Probl Eng 2020:1–22
Senapati T, Chen G, Mesiar R, Yager RR (2023) Intuitionistic fuzzy geometric aggregation operators in the framework of Aczel–Alsina triangular norms and their application to multiple attribute decision making. Expert Syst Appl 212:118832
Senapati T, Martínez L, Chen G (2023) Selection of appropriate global partner for companies using q-rung orthopair fuzzy Aczel–Alsina average aggregation operators. Int J Fuzzy Syst 25:980–996
Tang G, Yang Y, Gu X, Chiclana F, Liu P, Wang F (2022) A new integrated multi-attribute decision-making approach for mobile medical app evaluation under q-rung orthopair fuzzy environment. Expert Syst Appl 200:117034
Triantaphyllou E (2000) Multi-criteria decision making methods: a comparative study, vol 44. Springer, New York
Wang J, Wei G, Lu J, Alsaadi FE, Hayat T, Wei C, Zhang Y (2019) Some q-rung orthopair fuzzy Hamy mean operators in multiple attribute decision-making and their application to enterprise resource planning systems selection. Int J Intell Syst 34:2429–2458
Xie D, Xiao F, Pedrycz W (2022) Information quality for intuitionistic fuzzy values with its application in decision making. Eng Appl Artif Intell 109:104568
Xing Y, Zhang R, Wang J, Bai K, Xue J (2020) A new multi-criteria group decision-making approach based on q-rung orthopair fuzzy interaction Hamy mean operators. Neural Comput Appl 32:7465–7488
Yager RR (2013) Pythagorean fuzzy subsets. IEEE, pp 57–61
Yager RR (2017) Generalized orthopair fuzzy sets. IEEE Trans Fuzzy Syst 25:1222–1230
Yang W, Pang Y (2019) New q-rung orthopair fuzzy partitioned Bonferroni mean operators and their application in multiple attribute decision making. Int J Intell Syst 34:439–476
Zadeh L (1965) Fuzzy sets. Inf Control 8:338–353
Zhang C, Ding J, Li D, Zhan J (2021) A novel multi-granularity three-way decision making approach in q-rung orthopair fuzzy information systems. Int J Approx Reason 138:161–187
Zhong Y, Gao H, Guo X, Qin Y, Huang M, Luo X (2019) Dombi power partitioned Heronian mean operators of q-rung orthopair fuzzy numbers for multiple attribute group decision making. PLoS One 14:e0222007
Zolfani SH, Krishankumar R, Pamucar D, Görçün Ömer Faruk (2022) The potentials of the southern and Eastern European countries in the process of the regionalization of the global supply chains using a q-rung orthopair fuzzy-based integrated decision-making approach. Comput Ind Eng 171:108405
Acknowledgements
The authors would like to thank the contributions of the different partners of the SENATOR project (https://www.senatorproject.eu/ (accessed on 21 March 2023)). The first author acknowledges the financial support from University Grant Commission (UGC), New Delhi, India (Ref. No. 211610046346).
Funding
This article was partially funded by the European Commission through the SENATOR project (H2020MG-2018–2020, RIA, Project No. 861540).
Author information
Authors and Affiliations
Contributions
All authors have contributed equally in preparing this manuscript.
Corresponding authors
Ethics declarations
Conflict of Interest
The authors have no conflicts of interest to declare that are relevant to the content of this article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Rawat, S.S., Komal, Liu, P. et al. A novel group decision-making approach based on partitioned Hamy mean operators in q-rung orthopair fuzzy context. Complex Intell. Syst. 10, 1375–1408 (2024). https://doi.org/10.1007/s40747-023-01201-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-023-01201-5