
Abstract
Pythagorean fuzzy set (PFS), disposing the indeterminacy portrayed by membership and non-membership, is a more viable and effective means to seize indeterminacy. Due to the defects of existing Pythagorean fuzzy similarity measures or distance measures (cannot obey third or fourth axiom; have no power to differentiate positive and negative difference; have no power to deal the division by zero problem), the major key of this paper is to explore the novel Pythagorean fuzzy distance measure and similarity measure. Meanwhile, some interesting properties of distance measure and similarity measure are proved. Some counterintuitive examples are presented to state their availability of similarity measure among PFSs.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Pythagorean fuzzy sets (PFSs) [2], initiatively introduced by Yager, have regarded as an efficient tool to describe the vagueness of the MADM issues. PFSs are also denoted by the degrees of membership and nonmembership, which their sum of squares is equal or less than one. In some special cases, PFSs can deal with issues in which IFSs fail. For instance, if a DM or expert presents the degree of nonmembership and membership as 0.5 and 0.7, respectively, it is just efficacious for the PFSs. That is to say, all the IFSs are a part of the PFSs, which reveals that the PFSs are more forceful for solving the indeterminate issues. Zhang and Xu [3] presented the particular mathematical language expression for PFSs and defined notion of PFN. Besides, they continued to propose a revised Pythagorean fuzzy TOPSIS (PF-TOPSIS) for dealing with the MCDM issue with PFNs. Peng and Yang [4] explored the subtraction and division operations for PFNs and initiated a Pythagorean fuzzy SIR (PF-SIR) algorithm to handle multi-criteria group decision-making (MCGDM) issue. Moreover, some extension models [5,6,7,8] of PFSs are rapidly developed. Meanwhile, some research hotspots are concentrated on the aggregation operators [9,10,11,12,13,14,15,16,17,18,19,20,21,22], decision-making methods [3, 23,24,25,26,27,28,29,30,31].
Similarity measure (distance measure) is a significant means for measuring the uncertain information. The fuzzy similarity measure (distance measure) is a measure that depicts the closeness (difference) among fuzzy sets. Zhang [33] proposed the Pythagorean fuzzy similarity measures for dealing the multi-attribute decision-making problems. Peng et al. [23] proposed the many new distance measures and similarity measures for dealing the issues of pattern recognition, medical diagnosis and clustering analysis, and discussed their transformation relations. Wei and Wei [32] presented some Pythagorean fuzzy cosine function for dealing with the decision-making problems. However, some existing similarity measures/distance measures cannot the obey third or fourth axiom, and also have no power to differentiate positive difference and negative difference or deal with the division by the zero problem. Due to the above counterintuitive phenomena [32,33,34, 36,37,38,39,40,41,42,43,44,45,46] of the existing similarity measures of PFSs, they may be hard for DMs to choose convincible or optimal alternatives. As a consequence, the goal of this paper is to deal with the above issue by proposing a novel similarity measure and distance measure for Pythagorean fuzzy set, which can be without counterintuitive phenomena.
For counting the distance measure and similarity measure of the two PFSs, we introduce a novel method to build the distance measure and similarity measure which rely on four parameters, i.e., a, b, t and p, where p is the \(L_p\) norm and a, b, t identify the level of vagueness. Meanwhile, their relation with the similarity measures for PFSs are discussed in detail.
The rest of the presented paper is listed in the following. In Sect. 2, the fundamental notions of PFSs and IFSs are shortly retrospected, which will be employed in the analysis in each section. In Sect. 3, some new distance measures and similarity measures are proposed and proved. In Sect. 4, some counterintuitive examples are given to show the effectiveness of Pythagorean fuzzy similarity measure. The paper is concluded in Sect. 5.
Preliminaries
In this section, we briefly review the fundamental concepts related to IFS and PFS.
Definition 1
[1] Let X be a universe of discourse. An IFS I in X is given by
where \(\mu _{I}:X\rightarrow [0,1]\) denotes the degree of membership and \(\nu _{I}:X\rightarrow [0,1]\) denotes the degree of nonmembership of the element \(x\in X\) to the set I, respectively, with the condition that \(0\le \mu _{I}(x)+\nu _{I}(x)\le 1\). The degree of indeterminacy \(\pi _{I}(x)=1-\mu _{I}(x)-\nu _{I}(x)\). For convenience, Xu and Yager [35] called \((\mu _I(x),\nu _I(x))\) an intuitionistc fuzzy number (IFN) denoted by \(i=(\mu _I,\nu _I)\).
Definition 2
[2] Let X be a universe of discourse. A PFS P in X is given by
where \(\mu _P:X\rightarrow [0,1]\) denotes the degree of membership and \(\nu _P:X\rightarrow [0,1]\) denotes the degree of nonmembership of the element \(x\in X\) to the set P, respectively, with the condition that \(0\le (\mu _P(x))^2+(\nu _P(x))^2\le 1\). The degree of indeterminacy \(\pi _P(x)=\sqrt{1-(\mu _P(x))^2-(\nu _P(x))^2}\). For convenience, Zhang and Xu [3] called \((\mu _P(x),\nu _P(x))\) a Pythagorean fuzzy number (PFN) denoted by \(p=(\mu _P,\nu _P)\).
Definition 3
[3] For any PFN \(p=(\mu ,\nu )\), the score function of p is defined as follows:
where \(s(p)\in [-1,1]\).
Definition 4
[5] For any PFN \(p=(\mu ,\nu )\), the accuracy function of p is defined as follows:
where \(a(p)\in [0,1]\).
For any two PFNs \(p_1,p_2\),
(1) if \(s(p_1)>s(p_2)\), then \(p_1\succ p_2\);
(2) if \(s(p_1)=s(p_2)\), then
(a) if \(a(p_1)>a(p_2)\), then \(p_1\succ p_2\);
(b) if \(a(p_1)=a(p_2)\), then \(p_1\sim p_2\).
Definition 5
[3, 4] If \(M,N\in \) PFSs, then the operations can be defined as follows:
\((1)~M^c=\left\{ \langle x,\nu _M(x),\mu _M(x)\rangle |x\in X\right\} \);
\((2)~M\subseteq N~~~\) iff \(~\forall x\in X, \mu _M(x)\le \mu _N(x)\) and \(\nu _M(x)\ge \nu _N(x)\);
\((3)~M=N~~~\) iff \(~\forall x\in X, \mu _M(x)=\mu _N(x)\) and \(\nu _M(x)=\nu _N(x)\);
\((4)~\varPhi _M=\left\{ \langle x,1,0\rangle |x\in X\right\} \);
\((5)~\emptyset _M=\left\{ \langle x,0,1\rangle |x\in X\right\} \);
\((6)~M\bigcap N=\Big \{\langle x,\mu _M(x)\bigwedge \mu _N(x),\nu _M(x)\bigvee \nu _N(x)\rangle |x\in X\Big \}\);
\((7)~M\bigcup N=\Big \{\langle x,\mu _M(x)\bigvee \mu _N(x),\nu _M(x)\bigwedge \nu _N(x)\rangle |x\in X\Big \}\);
\((8)~M\oplus N=\Big \{\langle x,\sqrt{\mu _M^2(x)+\mu _N^2(x)-\mu _M^2(x)\mu _N^2(x)},\nu _M(x)\nu _N(x)\rangle |x\in X\Big \}\);
\((9)~M\otimes N=\Bigg \{\langle x,\mu _M(x)\mu _N(x),\sqrt{\nu _M^2(x)+\nu _N^2(x)-\nu _M^2(x)\nu _N^2(x)}|x\in X\Bigg \}\);
\((10)~M\ominus N=\left\{ \langle x,\sqrt{\frac{\mu _M^2(x)-\mu _N^2(x)}{1-\mu _N^2(x)}},\frac{\nu _M(x)}{\nu _N(x)}\rangle |x\in X\right\} ,~ \text {if} \) \(\mu _M(x)\ge \mu _N(x),\) \(\nu _M(x)\le \text {min}\left\{ \nu _N(x),\frac{\nu _N(x)\pi _M(x)}{\pi _N(x)}\right\} \);
\((11)~M\oslash N=\left\{ \langle x,\frac{\mu _M(x)}{\mu _N(x)},\sqrt{\frac{\nu _M^2(x)-\nu _N^2(x)}{1-\nu _N^2(x)}}\rangle |x\in X\right\} ,~\text {if} \nu _M(x)\ge \nu _N(x)\), \(\mu _M(x)\le \text {min}\left\{ \mu _N(x),\frac{\mu _N(x)\pi _M(x)}{\pi _N(x)}\right\} \).
Definition 6
[34] Let M, N and O be three PFSs on X. A distance measure D(M, N) is a mapping \(D:PFS(X)\times PFS(X)\rightarrow [0,1]\), possessing the following properties:
\((D1)~0\le D(M,N)\le 1\);
\((D2)~D(M,N)=D(N,M)\);
\((D3)~D(M,N)=0\) iff \(M=N\);
\((D4)~D(M,M^c)=1\) iff M is a crisp set;
(D5) If \(M\subseteq N\subseteq O\), then \(D(M,N)\le D(M,O)\) and \(D(N,O)\le D(M,O)\).
Definition 7
[34] Let M, N and O be three PFSs on X. A similarity measure S(M, N) is a mapping \(S:PFS(X)\times PFS(X)\rightarrow [0,1]\), possessing the following properties:
\((S1)~0\le S(M,N)\le 1\);
\((S2)~S(M,N)=S(N,M)\);
\((S3)~S(M,N)=1\) iff \(M=N\);
\((S4)~S(M,M^c)=0\) iff M is a crisp set;
(S5) If \(M\subseteq N\subseteq O\), then \(S(M,O)\le S(M,N)\) and \(S(M,O)\le S(N,O)\).
Distance measure and similarity measure of PFSs
Theorem 1
Let M and N be two PFSs in X where \(X=\{x_1,x_2,\cdots ,x_n\}\), then D(M, N) is the distance measure between two PFSs M and N in X.
where p is the \(L_p\) norm, and t, a and b denote the level of uncertainty with the condition \(a+b\le t+1, 0<a,b\le t+1,t>0\).
Proof
For two PFSs M and N, we have
(D1) \(|(t+1-a)(\mu _{M}^2(x_i)-\mu _{N}^2(x_i))-a(\nu _{M}^2(x_i)-\nu _{N}^2(x_i))| =|((t+1-a)(\mu _{M}^2(x_i)-a\nu _{M}^2(x_i))-((t+1-a)\mu _{N}^2(x_i)-a\nu _{N}^2(x_i))|\),
\(|(t+1-b)(\nu _{M}^2(x_i)-\nu _{N}^2(x_i))-b(\mu _{M}^2(x_i)-\mu _{N}^2(x_i))| =|((t+1-b)(\nu _{M}^2(x_i)-b\mu _{M}^2(x_i))-((t+1-b)\nu _{N}^2(x_i)-b\mu _{N}^2(x_i))|\).
Since \(0\le \mu _M(x_i),\mu _N(x_i), \nu _M(x_i),\nu _N(x_i) \le 1\), we can have
\(-a\le (t+1-a)(\mu _{M}^2(x_i)-a\nu _{M}^2(x_i) \le t+1-a\), \(-(t+1-a)\le -((t+1-a)\mu _{N}^2(x_i)-a\nu _{N}^2(x_i)) \le a\).
Therefore, we have \(-(t+1)\le ((t+1-a)(\mu _{M}^2(x_i)-a\nu _{M}^2(x_i))-((t+1-a)\mu _{N}^2(x_i)-a\nu _{N}^2(x_i)) \le t+1\).
It means that \(0\le |((t+1-a)(\mu _{M}^2(x_i)-a\nu _{M}^2(x_i))-((t+1-a)\mu _{N}^2(x_i)-a\nu _{N}^2(x_i))|^p\le (t+1)^p\).
Similarly, we can have \(0\le |((t+1-b)(\nu _{M}^2(x_i)-b\mu _{M}^2(x_i))-((t+1-b)\nu _{N}^2(x_i)-b\mu _{N}^2(x_i))|^p\le (t+1)^p\).
Hence, by the above Eq. (5), we can obtain \(0\le D(M,N)\le 1\).
(D2) This is straightforward from Eq. (5).
(D3) Firstly, we suppose that \(M=N\), which implies that \(\mu _M(x_i)=\mu _N(x_i)\) and \(\nu _M(x_i)=\nu _N(x_i)\) for \(i=1,2,\cdots ,n\). Thus, by Eq. (5), we can have \(D(M,N)=0\).
Conversely, assuming that \(D(M,N)=0\) for two PFSs M and N, this implies that
and
After solving, we can obtain
\(\mu _M^2(x_i)-\mu _N^2(x_i)=0,\nu _M^2(x_i)-\nu _N^2(x_i)=0\), which implies \(\mu _M(x_i)=\mu _N(x_i)\), \(\nu _M(x_i)=\nu _N(x_i)\).
Consequently, \(M=N\). Hence \(D(M,N)=0\) iff \(M=N\).
(D4) \(D(M, M^c)=1\Leftrightarrow \root p \of {\frac{1}{n}\sum \nolimits _{i=1}^n |\mu _M^2(x_i)-\nu _M^2(x_i)|^p}=1 \Leftrightarrow |\mu _M^2(x_i)-\nu _M^2(x_i)|=1\Leftrightarrow \mu _M(x_i)=1,\nu _M(x_i)=0\) or \(\mu _M(x_i)=0,\nu _M(x_i)=1\) \(\Leftrightarrow M\) is a crisp set.
(D5) According to the formula of the distance measure, we have
Since \(|(t+1-a)(\mu _{M}^2(x_i)-\mu _{N}^2(x_i))-a(\nu _{M}^2(x_i)-\nu _{N}^2(x_i))| =|((t+1-a)(\mu _{M}^2(x_i)-a\nu _{M}^2(x_i))-((t+1-a)\mu _{N}^2(x_i)-a\nu _{N}^2(x_i))|\),
\(|(t+1-b)(\nu _{M}^2(x_i)-\nu _{N}^2(x_i))-b(\mu _{M}^2(x_i)-\mu _{N}^2(x_i))| =|((t+1-b)(\nu _{M}^2(x_i)-b\mu _{M}^2(x_i))-((t+1-b)\nu _{N}^2(x_i)-b\mu _{N}^2(x_i))|\),
\(|(t+1-a)(\mu _{M}^2(x_i)-\mu _{O}^2(x_i))-a(\nu _{M}^2(x_i)-\nu _{O}^2(x_i))| =|((t+1-a)(\mu _{M}^2(x_i)-a\nu _{M}^2(x_i))-((t+1-a)\mu _{O}^2(x_i)-a\nu _{O}^2(x_i))|\),
\(|(t+1-b)(\nu _{M}^2(x_i)-\nu _{O}^2(x_i))-b(\mu _{M}^2(x_i)-\mu _{O}^2(x_i))| =|((t+1-b)(\nu _{M}^2(x_i)-b\mu _{M}^2(x_i))-((t+1-b)\nu _{O}^2(x_i)-b\mu _{O}^2(x_i))|\).
If \(M\subseteq N\subseteq O\), we have \(\mu _O\ge \mu _N(x_i) \ge \mu _M(x_i), \nu _O\le \nu _N(x_i) \le \nu _M(x_i).\)
Hence, \((t+1-a)\mu _{M}^2(x_i)-a\nu _{M}^2(x_i)\le (t+1-a)\mu _{N}^2(x_i)-a\nu _{N}^2(x_i) \le (t+1-a)\mu _{O}^2(x_i)-a\nu _{O}^2(x_i)\),
\((t+1-b)\nu _{O}^2(x_i)-a\mu _{O}^2(x_i)\le (t+1-b)\nu _{N}^2(x_i)-a\mu _{N}^2(x_i) \le (t+1-b)\nu _{M}^2(x_i)-a\mu _{M}^2(x_i)\).
Consequently,
Therefore, \(D(M,O)\ge D(N,O)\) and \(D(M,O)\ge D(M,N)\). \(\square \)
However, in most real environment, the diverse sets may possess diverse weights. Therefore, the weight \(w_i(i = 1, 2,\dots , n)\) of the alternative \(x_i\in X\) should be taken into consideration. We present a weighted distance measure \(D^w(M,N)\) between PFSs in the following.
where \(a+b\le t+1, 0<a,b\le t+1,t>0\), and \(w_i\) is the weights of the element \(x_i\) with \(\sum _{i=1}^n w_i=1\).
Theorem 2
\(D^w(M,N)\) is the distance measure between two PFSs M and N in X.
Proof
(D1) If we obtain the product of the inequality defined above with \(w_i\), then we can easily have
Furthermore, we can write the following inequality:
It is easy to know that \(\sum \limits _{i=1}^n w_i(t+1)^p\) is equal to \((t+1)^p\) since \(\sum \nolimits _{i=1}^n w_i=1\).
Hence, \(0\le \sum \nolimits _{i=1}^n w_i|(t+1-a)(\mu _{M}^2(x_i)-\mu _{N}^2(x_i))-a(\nu _{M}^2(x_i)-\nu _{N}^2(x_i))|^p \le (t+1)^p\),
\(0\le \sum \nolimits _{i=1}^n w_i|(t+1-b)(\nu _{M}^2(x_i)-\nu _{N}^2(x_i))-b(\mu _{M}^2(x_i)-\mu _{N}^2(x_i))|^p \le (t+1)^p\).
Hence, by Eq. (6), we can obtain \(0\le D^w(M,N)\le 1\).
(D2)–(D5) It is straightforward. \(\square \)
Theorem 3
If D(M, N) and \(D^w(M,N)\) are distance measures between PFSs M and N, then \(S(M,N)=1-D(M,N)\) and \(S^w(M,N)=1-D^w(M,N)\) are similarity measures between M and N, respectively.
Theorem 4
Let M and N be two PFSs, then we have
(1) \(D(M,M\otimes N)=D(N,M\oplus N)\);
(2) \(D(M,M\oplus N)=D(N,M\otimes N)\);
(3) \(S(M,M\otimes N)=S(N,M\oplus N)\);
(4) \(S(M,M\oplus N)=S(N,M\otimes N)\).
Proof
We only prove the (1), and (2)–(2) can be proved in a homologous way.
(1) According to Definition 5 and Eq. (5), and for \(D(M, M\bigotimes N)\) with \(\forall x_i\in X\), we can have
For \(D(N, M\bigoplus N)\) with \(\forall x_i\in X\), we can have
Consequently, we can obtain \(D_1(M,M\otimes N)=D_1(N,M\oplus N)\). \(\square \)
Theorem 5
Let M and N be two PFSs, and \(x_i\in X, \mu _M^2(x_i)+\mu _N^2(x_i)=1,\) \(\nu _M^2(x_i)+\nu _N^2(x_i)=1\), then we have
(1) \(D(M,M\oslash N)=D(N,N\ominus M),\mu _M(x_i)\le \mu _N(x_i),\nu _M(x_i)\ge \nu _N(x_i)\);
(2) \(D(M,M\ominus N)=D(N,N\oslash M),\mu _M(x_i)\ge \mu _N(x_i),\nu _M(x_i)\le \nu _N(x_i)\);
(3) \(S(M,M\oslash N)=S(N,N\ominus M),\mu _M(x_i)\le \mu _N(x_i),\nu _M(x_i)\ge \nu _N(x_i)\);
(4) \(S(M,M\ominus N)=S(N,N\oslash M),\mu _M(x_i)\ge \mu _N(x_i),\nu _M(x_i)\le \nu _N(x_i)\).
Proof
We only prove (1), and (2)–(2) can be proved in a homologous way.
(1) According to Definition 5 and Eq. (5), and for \(D(M, M\oslash N)\) with \(\forall x_i\in X\), we can have
For \(D(N, M\ominus N)\) with \(\forall x_i\in X\) and \(\mu _M^2(x_i)+\mu _N^2(x_i)=1, \nu _M^2(x_i)+\nu _N^2(x_i)=1\), we can have
Consequently, we can obtain \(D(M,M\oslash N)=D(N,M\ominus N)\). \(\square \)
Apply the similarity measure between PFSs to pattern recognition
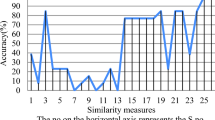
For stating the advantage of the explored similarity measure S, a comparison among the initiated similarity measure with the current similarity measures is established. Some existing similarity measures are presented in Table 1.
Next, we utilize six series of PFSs originally adopted from [45] to compare the decision results of the initiated similarity measure S with the existing similarity measures [32,33,34, 36,37,38,39,40,41,42,43,44,45,46] shown in Table 2. From Table 2, it is clear that the proposed similarity measure S, \(S_{BA}\) [46] and \(S_{CC}\) [38] can conquer the shortcomings of obtaining the illogical results of the existing similarity measures (\(S_{C}\) [37], \(S_{HY1}\) [39], \(S_{HY2}\) [39], \(S_{HY3}\) [39], \(S_{HK}\) [40], \(S_{LC}\) [41], \(S_{LX}\) [42], \(S_{L}\) [36], \(S_{LS1}\) [43], \(S_{LS2}\) [43], \(S_{LS3}\) [43], \(S_{M}\) [44], \(S_{Y}\) [45], \(S_{P1}\) [34], \(S_{P2}\) [34], \(S_{P3}\) [34], \(S_{Z}\) [33] and \(S_W\) [33]). We will state the five major shortcomings in detail in the following.
(1) It is easily seen that the third axiom of similarity measure (S3) is not satisfied by \(S_C, S_{LC},S_Y,S_W,S_{P1}\) since \(S_C(M,N)=S_{LC}(M,N)=S_Y(M,N)=S_W(M,N)=S_{P1}(M,N)=1\) when \(M= (0.3,0.3)\) and \(N=(0.4,0.4)\) (Case 1), which are indeed not equal to each other. Similarly, the third axiom of similarity measure (S3) is also not satisfied by \(S_C(M,N), S_{LC}(M,N)\) when \(M=(0.5,0.5), N= (0,0)\) and \(M= (0.4,0.2), N= (0.5,0.3)\). Moreover, we also can find that the fourth axiom of similarity measure (S4) is not satisfied by \(S_Z\) when \(M= (0.3,0.4)\) and \(N=(0.4,0.3)\)(Case 3) since \(S_Z(M,N)=0,\) which are indeed not a crisp number. Similarly, the fourth axiom of similarity measure (S4) is also not satisfied by \(S_{HY1}, S_{HY2}, S_{HY3}, S_{P2}\) when \(M=(1,0), N= (0,0)\) (Case 3) and \(S_{P2}\) when \(M=(0.5,0.5), N= (0,0)\) (Case 4).
(2) Some similarity measures [34, 36, 39, 40, 43, 44] have no power to differentiate positive and negative difference. For example, \(S_L(M,N)=S_L(M1, N2)=0.9\) when \(M= (0.3,0.3), N= (0.4,0.4)\) (Case 1), \(M1= (0.3,0.4)\) and \(N1= (0.4, 0.3)\) (Case 2). The same counter-intuitive example exists for \(S_{HY1},S_{HY2},S_{HY3}, S_{HK},S_{LS1}, S_{LS3},S_{M},S_{P2},S_{P3}\). Another type of counter-intuitive case occurs when \(M= (1, 0), N= (0, 0)\) (Case 3) and \(M1= (0.5, 0.5), N1= (0, 0)\) (Case 4). In this case, \(S_{HK}(M,N)=S_{HK}(M1,N1)=0.5\). The same counter-intuitive example exists for \(S_{LS1}, S_M, S_Z, S_{P2}\).
(3) The similarity measures have no power to deal with the division by zero problem. For example, \(S_Y\) and \(S_W\) when \(M=(1,0),N=(0,0)\) (Case 3) or \(M=(0.5,0.5), N=(0,0)\) (Case 4).
(4) Another kind of counter-intuitive example can be provided for the case where the similarity measures are \(S_{HY1}(M,N)=S_{HY1}(M1,N1)=0.9\) when \(M=(0.4,0.2), N=(0.5,0.3)\) (Case 5), \(M1=(0.4,0.2), N1=(0.5,0.2)\) (Case 6). The same counter-intuitive example also exists for \(S_{HY2},S_{HY3},S_{LX},S_{LS2}\).
(5) Another charming counter-intuitive issue happens when \(M=(0.4, 0.2), N= (0.5, 0.3)\) (Case 5), \(M= (0.4, 0.2),N1= (0.5, 0.2)\) (Case 6). In such case, it is expected that the degree of similarity between M and N is bigger than or equal to the degree of similarity between M and N1, since they are ranked as \(N1\succ N\succ M\) by means of score function shown in Definition 3. However, the degree of similarity between M and N1 is bigger than the degree of similarity between M and N when \(S_{L},S_{HY1},S_{HY2},S_{HY3},S_{HK},S_{LC},S_{LX},S_{LS1},S_{LS2},S_C,S_{LS3},S_{M},S_{W},S_{Z},S_{P2}, S_{P3}\) are used, which does not seem to be reasonable. On the other hand, our proposed similarity measures \(S(M,N)=0.9625\) and \(S(M,N1)=0.9438\). Therefore, the developed similarity measure is the same as score function. The presented similarity measure S and the existing similarity measures (\(S_{CC}\) and \(S_{BA}\)) are the similarity measures that have no such counter-intuitive issues as stated in Table 2. To continue digging the defects of the existing similarity measures (\(S_{CC}\) and \(S_{BA}\)), we give the following tables for further discussion.
Meanwhile, \(S_{BA}\) [46] has the defects of obtaining unconscionable results in some special conditions which is shown in Table 3. In Table 3, we explore six sets of PFSs which are adopted from [38] to compare the decision results of the presented similarity measure S with the developed similarity measures [32,33,34, 36,37,38,39,40,41,42,43,44,45,46] shown in Table 3. From Table 3, we can conclude that the presented similarity measure S and \(S_{CC}\) [38], \(S_{P3}\) [34] can conquer the defects of obtaining the unconscionable results of the existing similarity measures \(S_{BA}\) [46], \(S_{C}\) [37], \(S_{HY1}\) [39], \(S_{HY2}\) [39], \(S_{HY3}\) [39], \(S_{HK}\) [40], \(S_{LC}\) [41], \(S_{LX}\) [42], \(S_{L}\) [36] , \(S_{LS1}\) [43], \(S_{LS2}\) [43], \(S_{LS3}\) [43], \(S_{M}\) [44], \(S_{Y}\) [45], \(S_{P1}\) [34], \(S_{P2}\) [34], \(S_Z\) [33] and \(S_W\) [32].
Nevertheless, \(S_{CC}\) [38] also has the defects of obtaining fallacious results in some special cases, which is shown in Table 4. In Table 4, we explore six series of PFSs to compare the results of the proposed similarity measure S and the existing similarity measures [32,33,34, 36,37,38,39,40,41,42,43,44,45,46] as shown in Table 4. From Table 4, we can see that the proposed similarity measure S with \(S_{P3}\) [34] can overcome the drawbacks of getting the unreasonable results of the existing similarity measures \(S_{BA}\) [46], \(S_{C}\) [37], \(S_{HY1}\) [39], \(S_{HY2}\) [39], \(S_{HY3}\) [39], \(S_{HK}\) [40], \(S_{LC}\) [41], \(S_{LX}\) [42], \(S_{L}\) [36] , \(S_{LS1}\) [43], \(S_{LS2}\) [43], \(S_{LS3}\) [43], \(S_{M}\) [44], \(S_{Y}\) [45], \(S_{P1}\) [34], \(S_{P2}\) [34], \(S_Z\) [33] and \(S_W\) [32].
Conclusion
The main contributions can be illustrated and reviewed in the following.
(1) The formulae of Pythagorean fuzzy similarity measures and distance measures are proposed, and their properties are proved. Meanwhile, the diverse desirable relations between the developed similarity measures and distance measures have also been elicited.
(2) A comparison with some existing literature [32,33,34, 36,37,38,39,40,41,42,43,44,45,46] is constructed in Tables 2, 3, 4 to state the availability of the proposed similarity measure.
In future, we will employ some similarity measures in other domains, such as medical diagnosis and machine learning. Besides, as this paper is just an applied research focusing on the similarity measures of PFSs, we will attempt to design some softwares to preferably realize the initiated information measure in daily life. Meanwhile, we also will take them into diverse fuzzy environment [47,48,49,50,51,52,53,54].
References
Atanassov K (1986) Intuitionistic fuzzy sets. Fuzzy Sets Syst 20:87–96
Yager RR (2014) Pythagorean membership grades in multicriteria decision making. IEEE Trans Fuzzy Syst 22:958–965
Zhang XL, Xu ZS (2014) Extension of TOPSIS to multiple criteria decision making with Pythagorean fuzzy sets. Int J Intell Syst 29:1061–1078
Peng XD, Yang Y (2015) Some results for Pythagorean fuzzy sets. Int J Intell Syst 30:1133–1160
Peng XD, Yang Y (2016) Fundamental properties of interval-valued Pythagorean fuzzy aggregation operators. Int J Intell Syst 31:444–487
Zhang C, Li D, Ren R (2016) Pythagorean fuzzy multigranulation rough set over two universes and its applications in merger and acquisition. Int J Intell Syst 31:921–943
Liu ZM, Liu PD, Liu WL, Pang JY (2017) Pythagorean uncertain linguistic partitioned bonferroni mean operators and their application in multi-attribute decision making. J Intell Fuzzy Syst 32:2779–2790
Liang DC, Xu ZS (2017) The new extension of TOPSIS method for multiple criteria decision making with hesitant Pythagorean fuzzy sets. Appl Soft Comput 60:167–179
Peng XD, Yuan H (2016) Fundamental properties of Pythagorean fuzzy aggregation operators. Fund Inf 147:415–446
Garg H (2017) Confidence levels based Pythagorean fuzzy aggregation operators and its application to decision-making process. Comput Math Org Ther 23:546–571
Garg H (2017) Generalized pythagorean fuzzy geometric aggregation operators using einstein t-norm and t-conorm for multicriteria decision-making process. Int J Intell Syst 32:597–630
Ma ZM, Xu ZS (2016) Symmetric pythagorean fuzzy weighted geometric/averaging operators and their application in multicriteria decision-making problems. Int J Intell Syst 31:1198–1219
Peng XD, Yang Y (2016) Pythagorean fuzzy choquet integral based MABAC method for multiple attribute group decision making. Int J Intell Syst 31:989–1020
Wei G, Lu M (2018) Pythagorean fuzzy maclaurin symmetric mean operators in multiple attribute decision making. Int J Intell Syst 33:1043–1070
Khan MSA, Abdullah S, Ali A, Amin F (2018) Pythagorean fuzzy prioritized aggregation operators and their application to multi-attribute group decision making. Granul Comput. https://doi.org/10.1007/s41066-018-0093-6
Gao H, Lu M, Wei G, Wei Y (2018) Some novel Pythagorean fuzzy interaction aggregation operators in multiple attribute decision making. Fund Inf 159:385–428
Liu Y, Qin Y, Han Y (2018) Multiple criteria decision making with probabilities in interval-valued pythagorean fuzzy setting. Int J Fuzzy Syst 20:558–571
Zeng S (2017) Pythagorean fuzzy multiattribute group decision making with probabilistic information and OWA approach. Int J Intell Syst 32:1136–1150
Yang Y, Chen ZS, Chen YH, Chin KS (2018) Interval-valued Pythagorean Fuzzy frank power aggregation operators based on an isomorphic frank dual triple. Int J Comput Intell Syst 11:1091–1110
Qin J (2018) Generalized Pythagorean fuzzy maclaurin symmetric means and its application to multiple attribute SIR group decision model. Int J Fuzzy Syst 20:943–957
Yang Y, Li YL, Ding H, Qian GS, Lyu HX (2018) The pythagorean fuzzy Frank aggregation operators based on isomorphism Frank t-norm and s-norm and their application. Control Decis 33:1471–1480
Yang W, Pang Y (2018) New pythagorean fuzzy interaction maclaurin symmetric mean operators and their application in multiple attribute decision making. IEEE Access 6:39241–39260
Peng X, Dai J (2017) Approaches to Pythagorean Fuzzy stochastic multi-criteria decision making based on prospect theory and regret theory with new distance measure and score function. Int J Intell Syst 32:1187–1214
Liang DC, Xu ZS, Liu D, Wu Y (2018) Method for three-way decisions using ideal TOPSIS solutions at Pythagorean fuzzy information. Inf Sci 435:282–295
Xue W, Xu ZS, Zhang X, Tian X (2018) Pythagorean fuzzy LINMAP method based on the entropy theory for railway project investment decision making. Int J Intell Syst 33:93–125
Chen TY (2018) Remoteness index-based Pythagorean fuzzy VIKOR methods with a generalized distance measure for multiple criteria decision analysis. Inf Fusion 41:129–150
Chen TY (2018) An effective correlation-based compromise approach for multiple criteria decision analysis with Pythagorean fuzzy information. J Intell Fuzzy Syst 35:3529–3541
Peng X, Selvachandran G (2018) Pythagorean fuzzy set: state of the art and future directions. Artif Intell Rev. https://doi.org/10.1007/s10462-017-9596-9
Chen TY (2018) A novel VIKOR method with an application to multiple criteria decision analysis for hospital-based post-acute care within a highly complex uncertain environment. Neural Comput Appl. https://doi.org/10.1007/s00521-017-3326-8
Ren PJ, Xu ZS, Gou XJ (2016) Pythagorean fuzzy TODIM approach to multi-criteria decision making. Appl Soft Comput 42:246259
Chen TY (2018) An outranking approach using a risk attitudinal assignment model involving Pythagorean fuzzy information and its application to financial decision making. Appl Soft Comput 71:460–487
Wei G, Wei Y (2018) Similarity measures of Pythagorean fuzzy sets based on the cosine function and their applications. Int J Intell Syst 33:634–652
Zhang X (2016) A novel approach based on similarity measure for Pythagorean fuzzy multiple criteria group decision making. Int J Intell Syst 31:593–611
Peng X, Yuan H, Yang Y (2017) Pythagorean fuzzy information measures and their applications. Int J Intell Syst 32:991–1029
Xu ZS, Yager RR (2006) Some geometric aggregation operators based on intuitionistic fuzzy sets. Int J Gen Syst 35:417–433
Li Y, Olson DL, Qin Z (2007) Similarity measures between intuitionistic fuzzy (vague) sets: a comparative analysis. Pattern Recognit Lett 28:278–285
Chen SM (1997) Similarity measures between vague sets and between elements. IEEE Trans Syst Man Cyber 27:153–158
Chen SM, Chang CH (2015) A novel similarity measure between Atanssov’s intuitionistic fuzzy sets based on transformation techniques with applications to pattern recognition. Inf Sci 291:96–114
Hung WL, Yang MS (2004) Similarity measures of intuitionistic fuzzy sets based on Hausdorff distance. Pattern Recognit Lett 25:1603–1611
Hong DH, Kim C (1999) A note on similarity measures between vague sets and between elements. Inf Sci 115:83–96
Li DF, Cheng CT (2002) New similarity measures of intuitionistic fuzzy sets and application to pattern recognitions. Pattern Recognit Lett 23:221–225
Li F, Xu ZY (2001) Measures of similarity between vague sets. J Softw 12:922–927
Liang ZZ, Shi PF (2003) Similarity measures on intuitionistic fuzzy sets. Pattern Recognit Lett 24:2687–2693
Mitchell HB (2003) On the Dengfeng–Chuntian similarity measure and its application to pattern recognition. Pattern Recognit Lett 24:3101–3104
Ye J (2011) Cosine similarity measures for intuitionistic fuzzy sets and their applications. Math Comput Model 53:91–97
Boran FE, Akay D (2014) A biparametric similarity measure on intuitionistic fuzzy sets with applications to pattern recognition. Inf Sci 255:45–57
Huang HH, Liang Y (2018) Hybrid L1/2+2 method for gene selection in the Cox proportional hazards model. Comput Meth Prog Biol 164:65–73
Shen KW, Wang JQ (2018) Z-VIKOR method based on a new weighted comprehensive distance measure of Z-number and its application. IEEE Trans Fuzzy Syst. https://doi.org/10.1109/TFUZZ.2018.2816581
Peng HG, Wang JQ (2018) A Multicriteria Group Decision-Making Method Based on the Normal Cloud Model With Zadeh’s Z-numbers. IEEE Trans Fuzzy Syst. https://doi.org/10.1109/TFUZZ.2018.2816909
Liao HC, Xu ZS, Herrera-Viedma E, Herrera F (2018) Hesitant fuzzy linguistic term set and its application in decision making: a state-of-the-art survey. Int J Fuzzy Syst. https://doi.org/10.1007/s40815-017-0432-9
Alcantud JCR, Torra V (2018) Decomposition theorems and extension principles for hesitant fuzzy sets. Inf Fusion 41:48–56
Alcantud JCR, Mathew TJ (2017) Separable fuzzy soft sets and decision making with positive and negative attributes. Appl Soft Comput 59:586–595
Garg H (2018) Generalised Pythagorean fuzzy geometric interactive aggregation operators using Einstein operations and their application to decision making. J Exp Theor Artif Intell. https://doi.org/10.1080/0952813X.2018.1467497
Garg H (2018) New exponential operational laws and their aggregation operators for interval-valued Pythagorean fuzzy multicriteria decision-making. Int J Intell Syst 33(3):653–683
Garg H (2018) Some methods for strategic decision-making problems with immediate probabilities in Pythagorean fuzzy environment. Int J Intell Syst 33(4):687–712
Garg H (2018) Linguistic Pythagorean fuzzy sets and its applications in multiattribute decision-making process. Int J Intell Syst 33(6):1234–1263
Garg H (2018) Hesitant Pythagorean fuzzy sets and their aggregation operators in multiple-attribute decision-making. Int J Uncertain Quant 8:267–289
Nie RX, Tian ZP, Wang JQ, Hu JH (2018) Pythagorean fuzzy multiple criteria decision analysis based on Shapley fuzzy measures and partitioned normalized weighted Bonferroni mean operator. Int J Intell Syst. https://doi.org/10.1002/int.22051
Zhou H, Wang J, Zhang H (2017) Stochastic Multi-criteria decision-making approach based on SMAA-ELECTRE with extended grey numbers. Int Trans Oper Res. https://doi.org/10.1111/itor.12380
Tian ZP, Wang JQ, Zhang HY, Wang TL (2018) Signed distance-based consensus in multi-criteria group decision-making with multi-granular hesitant unbalanced linguistic information. Comput Ind Eng 124:125–138
Peng XD, Dai JG (2018) A bibliometric analysis of neutrosophic set: two decades review from 1998–2017. Artif Intell Rev. https://doi.org/10.1007/s10462-018-9652-0
Peng XD, Liu C (2017) Algorithms for neutrosophic soft decision making based on EDAS, new similarity measure and level soft set. J Intell Fuzzy Syst 32:955–968
Peng XD, Dai JG, Garg H (2018) Exponential operation and aggregation operator for q-rung orthopair fuzzy set and their decision-making method with a new score function. Int J Intell Syst. https://doi.org/10.1002/int.22028
Zhan J, Alcantud JCR (2018) A novel type of soft rough covering and its application to multicriteria group decision making. Artif Intell Rev. https://doi.org/10.1007/s10462-018-9617-3
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Ethical approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Peng, X. New similarity measure and distance measure for Pythagorean fuzzy set. Complex Intell. Syst. 5, 101–111 (2019). https://doi.org/10.1007/s40747-018-0084-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-018-0084-x