
Abstract
When individuals in a community develop an infectious disease, it may quickly spread through personal contacts. Modeling the progression of such a disease is equivalent to modeling a branching process in which an infected person may infect others in a small time interval. It is also possible for some immigrants to enter the community with the disease and thus contribute to an increase in the number of infections. There exist various modeling approaches for dealing with this type of infectious disease data collected over a long period of time. However, there are certain infectious diseases which require very quick remedy by health professionals to prevent it from spreading further due to the dangerous nature of the disease. Such interventions require an understanding of the pattern of the disease in a short period of time. As a result, the spread of such infectious diseases only occur over a short period of time. The modeling of this type of infections that last only for a short period of time across several communities or countries is not, however, adequately discussed in the literature. In this paper, we develop a branching process with immigration to model this type of infectious disease data collected over a short period of time and provide consistent estimates of the parameters involved in the proposed model. We note that the model and inferences exploited in this paper are also applicable to infectious disease data obtained over a long period of time. We discuss a generalization of the proposed model under the assumption that the data may be affected by unobservable random community effects.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Modeling the spread of infectious diseases is an important epidemiological issue. Since the pioneering work of Kermack and Mckendrick (1927) several mathematical models have been developed for the number of infectives at time t starting at an initial time t = 0. We refer to a recent book edited by Ma and Li (2009) and the references therein for some widely used epidemiological models. See also the epidemic models discussed by Andersson and Britton (2000), Diekmann and Heesterbeek (2000), and Daley and Gani (1999), among others. For example, consider the so-called Kermack and Mckendrick SIS (susceptible-infectives-susceptible) (Ma and Li, 2009, §1.4.2, eqn. (1.22)) dynamic model
where y(t) is the total number of infectives at time t, y(0)P(t) is the number of infectives who were infected at time t = 0 and have not been recovered until time t, P(t − u) is the probability that the individuals who were infectives at time t = u have not been recovered after the time period t − u, and \(\tilde{\beta}S(u)y(u)\) is the number of secondary infections during the time period [u, u + du].
Note that the aforementioned models for infectious diseases were developed mainly to deal with infectious disease time series data obtained over a long period of time. For example, one may refer to the weekly mortality data (Choi and Thacker, 1981a, b) for pneumonia and influenza, pooled over 121 cities throughout the United States and covering the 15-year period from 1962 to 1979. In this example, there are 121 communities where mortality data were collected at 52 ×15 = 780 time points. Models have also been developed to deal with infectious disease data collected in the form of a time series of moderate length from a single community. One such example is the data from the October/November 1967 epidemic of respiratory disease in Tristan da Cunha (Shibli et al., 1971), which contains number of infections and number of susceptibles over a period of 16 time points. This type of data can be analyzed by using models similar to the model given in (1.1).
In this paper, we revisit the infectious disease problems modeled by (1.1) and provide an alternative modeling based on a recently developed dynamic model for repeated count data (Sutradhar, 2011, Chapter 6). Note that in the proposed model, we consider that an individual once infected may infect none or a few individuals following a binomial probability distribution where no record of recovery is available. We also note that even though our alternative model can handle infectious disease time series data of long duration that can be analyzed by models similar to that of (1.1), our main objective is to develop models for infectious diseases collected from a large number of independent communities, but over a small period of time. For an example of an infectious disease of this type, one may refer to the Severe Acute Respiratory Syndrome (SARS) epidemic of 2003 which lasted for only a short duration, such as T = 5, 6, or 7 weeks, involving many communities across Asia and secondary cases in large cities in different countries. The modeling of this type of infections that last only for a short period of time across several countries is not, however, adequately discussed in the literature. We remark that our proposed model would be suitable to deal with such longitudinal data. We also note that the inferential techniques we are proposing to develop in this paper based on data for small number of time points is also appropriate for dealing with time series type data obtained over a long period. In this special case, one will simply set the number of communities to one. In fact, it is important to examine whether the inference works for a small number of time points, since it would naturally work better if more time points are considered.
Suppose that K independent communities are at risk of an infectious disease. Also, suppose that at the initial time point, t = 1, y i1 individuals in the ith (i = 1, ..., K) community developed the disease. It is reasonable to assume that y i1 follows the Poisson distribution with mean parameter \(\mu_{i1} = \mbox{exp}({\bf x}_{i1} ^{\prime} {\boldsymbol\beta})\). That is,
where \({\bf x}_{i1} = (x_{i11}, x_{i12}, \ldots, x_{i1u}, \ldots, x_{i1})^{\prime}\) is a p-dimensional covariate vector representing p demographic and/or socioeconomic characteristics of the ith community such as its age (new or old), population density (low or high), apparent economic status (poor, middle class, or wealthy). In the restricted case, where each of the y i1 individuals are thought to have infected none or only one individual within a given time interval, one may model the next infected count at time t = 2 as
where b j (ρ) is a binary variable such that Pr[b j (ρ) = 1] = ρ and Pr[b j (ρ) = 0] = 1 − ρ. Here, d i2 is considered an immigration variable which follows a suitable Poisson distribution, and d i2 and y i1 are independent. In general, for t = 1, 2, ..., T, one may write,
Beginning with Sutradhar (2003, §4) (see also McKenzie, 1988), this model (1.2) has been used for modeling count data over time which follow an autoregressive, of order 1, type Poisson process. When y i,t − 1 is considered as an offspring variable at time t − 1 and d it is the immigration variable, the model (1.2) represents a branching process with immigration. In a time series context, that is for K = 1 and large T, this model was recently considered by Sutradhar, Oyet, and Gadag (2010) as a special case of a negative binomial branching process with immigration. In the present set up, the binary outcome based model (1.2) is not appropriate. This is because, each of the infected individuals y i,t − 1 at time t − 1 may infect none, one, or more than one individuals. Suppose that each of the y i,t − 1 patients can infect up to n t individuals. Then, these y i,t − 1 individuals will infect a total of \(\sum_{j=1} ^{y_{i,t-1}} B_j (n_t,\rho)\) individuals, where as opposed to (1.2), B j (n t ,ρ) is a binomial variable with parameters n t and ρ such that n t = 1 yields the model (1.2). That is,
for c j = 0,1, ..., n t .
The proposed binomial variable based extended model is discussed in Section 2. A method for consistent estimation of the parameters, namely \({\boldsymbol\beta}\) and ρ, is also given in Section 2. In Section 3, we provide a further generalization under the assumption that apart from community related covariates x it , the infected counts may also be influenced by an unobservable community effect. Let γ i represent this latent effect for the ith community. Under the assumption that \(\gamma_i \stackrel{iid}{\sim } N(0, \sigma_{\gamma} ^2)\), in Section 3, we develop an estimation method that provides consistent estimates for the parameters \({\boldsymbol\beta}\), ρ, and \(\sigma_{\gamma} ^2\).
2 Proposed fixed model for counts over time
Because an infected individual may infect more than one individual in a given time interval, and also because there may be other infected individuals arriving from other communities, we shall model the number of infected persons at time t (t = 2,3, ..., T) as
which accommodates (1.2) with n t = 1. In (2.1) we make the following assumptions:
-
Assumption 1. \(y_{i1} \sim \mbox{Poi}(\mu_{i1} = \mbox{exp}({\bf x}_{i1} ^{\prime} {\boldsymbol\beta}))\).
-
Assumption 2. \(d_{it} \sim \mbox{Poi}(\mu_{it} - \rho n_t \mu_{i,t-1})\), for t = 2, ..., T with \(\mu_{it} = \mbox{exp}({\bf x}_{it} ^{\prime} {\boldsymbol\beta})\), for all t = 1, ...,T.
-
Assumption 3. d it and y i,t − 1 are independent for t = 2, ..., T.
Note that the model (2.1) has some similarities with the Kermack and Mckendrick (1927) SIS model given in (1.1). In (2.1), y i1 is the initial number of infectives in the ith community at initial time t = 1, which is the same as y(0) in (1.1). The dynamic summation in (2.1) is similar to the integral in (1.1). The number of secondary infectives in (2.1) is d it , whereas \(\tilde{\beta}S(u)y(u)\) is the number of secondary infectives in (1.1), and so on.
Now turning to the statistical properties of the model (2.1), it is clear, from Assumption 1 above, that E(Y i1) = μ i1. Then, by successive expectation, it follows that for t = 2, ..., T,
Hence, E(Y it ) = μ it for all t = 1, 2, ..., T. Next, for t = 2, ..., T one may obtain a recursive relationship for the variance of y it in terms of the variance of y i,t − 1. To be specific, by using the model (2.1), one writes
By (2.2), it then follows that for t = 2, ..., T,
with \(var(Y_{i1}) = \mu_{i1} = \mbox{exp}({\bf x}_{i1} ^{\prime} {\boldsymbol\beta})\) by Assumption 1. After some algebra, we obtain the following formulas for variances, for all t = 1, 2, ..., T as
with n 1 = 1. Similarly, for lag k = 1, ..., t − 1, because
one obtains the covariance between y it and y i,t − k as
where σ i,tt is given by (2.3). It then follows that the lag k correlation between the infected counts y it at time t and y i,t − k at time t − k, has the formula
Note that when n t = 1, for all t = 1, 2, ..., T, the variance of y it in (2.4) and the correlation between y it and y i,t − k given in (2.6) reduce to
respectively, which are the same expressions for the binary sum (binomial thinning) based count data model considered by Sutradhar (2010, eqns. (15)–(16), p. 178). Thus, the present binomial sum based count data model (2.1) is an important generalization of the binary sum based count data model discussed by Sutradhar (2010, eqn. (14), p. 178). It is also clear that unlike the existing binomial thinning based count data models, the present model is suitable for modeling the spread of infectious diseases.
3 GQL estimation of the parameters of the infectious disease model (3)
3.1 Estimation of β
Recall from (2.2) that the expectation of the infectious counts y it in the ith community at time t has the formula \(E(Y_{it}) = \mu_{it} = \mbox{exp}({\bf x}_{it} ^{\prime} \boldsymbol{\beta})\) which is a function of \(\boldsymbol{\beta}\). Let \(\boldsymbol{\mu}_i = (\mu_{i1}, \mu_{i2}, \ldots, \mu_{it}, \ldots, \mu_{iT})^{\prime}\) be the T-dimensional expectation vector of \({\bf y}_i = (y_{i1}, y_{i2}, \ldots, y_{it}, \ldots, y_{iT})^{\prime}\). Following Sutradhar (2010, eqn. (46)), one may then obtain a consistent and efficient estimate of \(\boldsymbol{\beta}\) by solving the so-called generalized quasi-likelihood (GQL) estimating equation
with
where \({\it A}_i = diag[\sigma_{i1}, \ldots, \sigma_{it}, \ldots, \sigma_{iT}]\) and \({\it C}_i\) is the T ×T correlation matrix defined as
with \( \rho_{i,t-k,t} = \left( \prod_{l=0} ^{k-1} n_{t-l} \right) \rho^k \sqrt{\frac{\sigma_{i,t-k,t-k}}{\sigma_{i,tt}}}\) by (2.6) for t = 2, ..., T, and k = 1, ..., t − 1. The GQL estimating equation (3.1) may be solved iteratively by using the Newton–Raphson iterative equation
where \(\hat{\boldsymbol\beta}(r)\) is the value of \({\boldsymbol\beta}\) at the rth iteration.
3.2 Estimation of the correlation index parameter ρ
Let S itt and S it,t + 1 be the standardized sample variance and the standardized lag 1 sample autocovariance defined as
Since
one may use the method of moments to obtain a consistent estimator of ρ given by
3.3 Forecasting
Once the parameters of the infectious disease model (2.1) have been estimated, one-step ahead forecasts can be obtained for the purpose of planning and control. In this section, we will derive the one-step ahead forecasting function and the variance of the forecast error.
From the model (2.1), it is clear that the conditional mean of Y it given y i,t − 1 is given by
If we define the l-step ahead forecasting function of y i,t + l as \(y_{i,t}(l) = \hat{y}_{i,t+l} = E(Y_{i,t+l}|y_{i.t+l-1})\), then, from (3.4) the one-step ahead forecasting function can be written as
where y it = y it (0) with forecast error
Using the fact that E[e it (1) | y it ] = 0 and that V(Y i,t + 1|y it ) = μ i,t + 1 − ρn t + 1 μ it + y it n t + 1 ρ(1 − ρ), one can easily verify that the variance of the one-step ahead forecast error is
In Section 3.4, we will examine the performance of the GQL estimation approach [(3.2) and (3.3)] discussed in Sections 3.1 and 3.2 through a simulation study. We will also examine the performance of the forecasting function (3.5).
3.4 A simulation study
3.4.1 Estimation performance of β and ρ
We begin our simulation study by generating data from (2.1) for various combinations of parameter values and simulation design. The parameter values used in the simulation were T = 5, K = 100, \({\boldsymbol\beta}^{\prime} \equiv (0.5,1), (1,1)\), and \({\bf n}^{\prime} = (n_1, n_2, n_3, n_4, n_5) \equiv (1,2,2,2,2), (1,2,2,3,2), (1,2,3,4,2), (1,2,2,2,3)\), (1,2,2,3,3), (1,2,3,4,3). We have used a time dependent covariate vector x it in order to study the nonstationary case. The components of the covariate vector \({\bf x}_{it} ^{\prime} = (x_{it1}, x_{it2})\) were generated as follows:
and
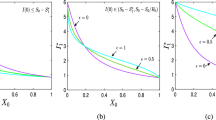
Note that even though we have chosen two covariates hypothetically, they however reflect the time dependent economic (x it1) and cleanliness (x it2) conditions of the K communities. For example, the covariate for economic conditions of the communities x it1 indicates that half of the communities had low income conditions (x it1 = − 1) at t = 1,2 and subsequently at \(t = 3,4 \mbox{ and } 5\), their economic condition improved (x it1 = 1). The rest of the communities also increasingly did better (x it1 = 0, 0.5 and 1.0) as time progressed. A similar pattern of improvement in the cleanliness conditions can be observed for the first and fourth quarter of the communities over time and the middle half of the communities also showed improved cleanliness conditions with regard to change in time. The roles of these covariates are highlighted through Figure 1(a), (b) and (c) for time dependent mean, variance, and correlation.

A plot of (a) values of nonstationary mean for t = 1 (solid line); t = 2 (dashed line), t = 3 (dotted line), t = 4 (dotted dashed line); (b) values of nonstationary variance for t = 1 (solid line); t = 2 (dashed line), t = 3 (dotted line), t = 4 (dotted dashed line); and (c) values of nonstationary lag 1 correlation for t = 1 (solid line); t = 2 (dashed line), t = 3 (dotted line); (d) average forecast overlaid on average of longitudinal data; (e) proportion of absolute values of forecast error that are 0 or 1 (solid lines) and > 1 (dashed line); by communities obtained from 1,000 simulations with ρ = 0.5, β = (1, 1)ʹ, nonstationary covariates (3.8)–(3.9) and n 1 = 1, n 2 = . . . = n 5 = 2.
Since the mean of the Poisson random variable d it given by E(d it ) = μ it − ρn t μ i, t − 1, must be positive, the values of ρ in our simulation were chosen to satisfy the condition \(\rho < \min \left\{\mu_{it}/n_t \mu_{i,t-1}, 1 \right\}\). As a result of the condition on ρ, the data generation process began with the computation of the covariate vector x it , i = 1, ...,K, t = 1, ..., T which we then used to evaluate the mean of y it , \(\mu_{it} = \exp({\bf x}_{it} ^{\prime} {\boldsymbol\beta})\) for a fixed value of \({\boldsymbol\beta}\), say for instance \({\boldsymbol\beta}^{\prime} = (0.5,1)\). Next, we used the values of μ it to compute the upper bound for ρ, given by \(\rho^* = \frac{\mu_{it}}{n_t \mu_{i,t-1}}\). We then choose ρ = ρ * − 0.1 or ρ = ρ * − 0.2 as the true value of ρ for the simulation. Once a value of ρ has been chosen, we generated y i1 and d it ’s from a Poisson distribution with means μ i1 and μ it − ρn t μ i, t − 1 respectively. The remainder of the observations, namely, y i2, y i3, y i4, y i5 were then generated from (2.1) for i = 1,2, ..., 100.
Using only the first four observations, y i1, y i2, y i3, y i4, i = 1,2, ..., 100, the GQL estimate of \({\boldsymbol\beta}\) and the method of moment estimate of ρ were iteratively computed from equations (3.2) and (3.3) respectively. This process was repeated 1,000 times for various combinations of n 1 = 1, n t , t = 2,3,4,5, \({\boldsymbol\beta}\), and ρ. The average of the estimated \({\boldsymbol\beta}\), ρ, and their standard errors \(s_{\hat{\boldsymbol\beta}}\) and s ρ over 1,000 simulations are reported in Table 1. The results in Table 1, show that the GQL method performed well in estimating the parameters of the infectious disease model (2.1). For instance, when \({\boldsymbol\beta}^{\prime} = (0.5,1)\), ρ = 0.3, and n 2 = n 3 = n 4 = 2 and n 5 = 3, the GQL estimate of \({\boldsymbol\beta}\) was (0.501,0.998) and the MM estimate of ρ was 0.292 with standard errors (0.055,0.62) and 0.045 respectively.
3.4.2 Forecasting performance
For the purpose of examining the performance of the model (2.1) in forecasting future infections, we used the parameter estimates obtained from using only the first four observations, in Section 3.4.1, and the forecasting function in (3.5) to compute a one-step ahead forecast of the fifth observation, y i5, i = 1, 2, ..., 100. We also computed the sum of squares of the forecast error (3.6) as well as the variance of the forecast error (3.7). These calculations were repeated 1,000 times for a fixed combination of parameter values. The average sum of squares of the forecast errors and the average variance of the forecast errors, denoted by ASS[e it (1)] and AV[e it (1)] respectively are reported in Table 2. From the results in Table 2, we see that the average sum of squares of the forecast errors closely estimates the average variance of the forecast errors irrespective of the combination of parameter values. This is an indication of the satisfactory performance of the estimation of the parameters of the model.
In practice, given the data y it , one may incorrectly assume that ρ = 0 and then estimate only the regression parameter \({\boldsymbol \beta}\). Results not reported here show that this assumption will not affect the GQL estimate of \({\boldsymbol \beta}\). However, the average sum of squares of the forecast errors when the incorrect assumption of ρ = 0 was used, given in Table 2 as ASS0[e it (1)] shows that this incorrect assumption will significantly inflate the variance of the forecast errors with the percentage of inflation ranging from 18% to 72%. The magnitude of the percentage of inflation appear to increase as the value of ρ increases. For instance when n 2 = n 3 = n 4 = n 5 = 2, and \({\boldsymbol \beta}^{\prime} = (.5,1)\), if one assumes that ρ = 0 when in fact ρ = 0.5 the average sum of squares of the forecast errors is inflated by approximately 72%; whereas if the true value of ρ were 0.3, the percentage inflation will only be about 30%.
In Figure 1, we have overlaid a graph of the average of the forecast in 1,000 simulations over a scatterplot of the average of the observations y i5 (Figure 1(a)). The plot shows that the average forecast follows the general pattern of the infections at the fifth time point. In order to assess the accuracy of our forecasts, we have also displayed a graph showing the average of the proportion of the forecast error e it with absolute deviations 0, 1, and greater than 1. Figure 1(e) shows that deviations of magnitude 0 and 1 appear to be over 50% for the first 25 communities and over 80% for the remaining 75 communities. It is clear from Figure 1(d) that the number of infections for the first 25 communities range from 2.5 to 17.5 approximately. This large spread in the number of infections for the first 25 communities accounts for the 50% deviation of magnitude 0 and 1 in the absolute value of the forecast error for these 25 communities. Graphs showing the nonstationary patterns in the mean μ it , variance σ it,t , and the lag 1 correlation ρ i,t − 1,t are also shown in Figure 1. For the purpose of highlighting the differences between the stationary case and the nonstationary case, we constructed similar plots in Figures 2 and 3 for a stationary case obtained from data generated using the covariate components
and
The difference between Figures 2 and 3 is that in Figure 2 the maximum number of individuals that can be infected n t , t = 1, 2, ..., 5 is time dependent whereas in Figure 3, n t = 1, for all t = 1,2,3,4,5.

A plot of (a) values of stationary mean for t = 1, 2, 3, 4; (b) values of nonstationary variance for t = 1 (solid line); t = 2 (dashed line), t = 3 (dotted line), t = 4 (dotted dashed line); and (c) values of nonstationary lag 1 correlation for t = 1 (solid line); t = 2 (dashed line), t = 3 (dotted line); (d) average forecast overlaid on average of longitudinal data; (e) proportion of absolute values of forecast error that are 0 or 1 (solid lines) and > 1 (dashed line); by communities obtained from 1,000 simulations with ρ = 0.3, \({\boldsymbol\beta} =(1,1)^{\prime}\), stationary covariates (3.10)–(3.11) and n 1 = 1, n 2 = ... = n 5 = 2.

A plot of (a) values of stationary mean for t = 1,2,3,4; (b) values of stationary variance for t = 1,2,3,4; (c) values of stationary lag 1 correlation; (d) average forecast overlaid on average of longitudinal data; (e) proportion of absolute values of forecast error that are 0 or 1 (solid lines) and > 1 (dashed line); by communities k = 1,2,...,100 obtained from 1,000 simulations with \(\protect\rho =0.8\), \({\boldsymbol\beta } =(1,1)^{\prime }\), stationary covariates (3.10)–(3.11) and n 1 = n 2 = ... = n 5 = 1.
4 Extended model
4.1 Dynamic mixed model
In this section, we account for the fact that aside from the community related covariate x it , the number of infections generated by the model (2.1) may be influenced by some unobservable community effects. Suppose that for the ith community, \(\gamma_i \stackrel{iid}{\sim } N(0, \sigma_{\gamma} ^2)\) is this latent community effect. Then, conditional on the ith community effect γ i , a dynamic mixed model for the number of infections at time t, t = 2, ...,T, as a generalization of (2.1) can be written as
where,
-
Assumption 1. \(y_{i1} \left|_{\gamma_i} \right. \sim \mbox{Poi}(\mu_{i1} ^*)\).
-
Assumption 2. \(d_{it} \left|_{\gamma_i} \right. \sim \mbox{Poi}(\mu_{it} ^* - \rho n_t \mu_{i,t-1} ^*)\), for t = 2, ..., T, where \(\mu_{it} ^* = \exp({\bf x}_{it} ^{\prime} {\boldsymbol\beta} + \gamma_i)\), for all t = 1, ...,T.
-
Assumption 3. \(d_{it} \left|_{\gamma_i} \right. \) and \(y_{i,t-1} \left|_{\gamma_i} \right.\) are independent for t = 2, ..., T.
4.1.1 Basic properties of the dynamic mixed model
We note that in the present dynamic mixed model, the conditional means are denoted by \(\mu_{it} ^*\) whereas in the fixed model (2.1) the means were denoted by μ it , free from γ i . Because of the similarities between the fixed model (2.1) and the mixed model (4.1), following (2.2) and (2.3) or (2.4), the mean and variance of y it conditional on γ i can be written as
and
for t = 2, ..., T. Thus,
To understand the important properties of the data from the mixed model (4.1) it is now necessary to find the unconditional mean and variance of y it . They can be found by averaging (4.2) over the distribution of γ i . More specifically, from (4.2) we obtain
and using (4.2) and (4.3) we find that
Regarding the covariance between y it and y i,t + k we once again use the similarities between the fixed model (2.1) and the mixed model (4.1) to first write the conditional covariance of y it and y i,t + k given γ i in a form similar to (2.5) as
where \(\sigma_{i,tt} ^*\) is given by (4.3). We then average (4.6) over the distribution of γ i and use (4.2) to obtain the expression for the covariance between y it and y i,t + k as
where μ it and σ i,tt are given by (4.4) and (4.5) respectively, and \(h_{it} = \sigma_{i,tt} - \mu_{it} ^2 [\mbox{exp}(\sigma_{\gamma} ^2) - 1]\).
We note that when n t = 1, for all t = 1, ..., T, the variance of y it in (4.5) reduces to
which is the variance of a negative binomial random variable. In this case, h it in (4.7) simplifies to h it = μ it yielding a simplified version of the covariance between y it and y i,t + k in (4.7) as
4.2 Estimation of parameters
The dynamic mixed model (4.1) contains three unknown parameters, namely, \({\boldsymbol \beta}\), ρ, and \(\sigma_{\gamma} ^2\). Note that the mean μ it (4.4) and the variance (4.5) are functions of both β and \(\sigma_{\gamma} ^2\), whereas the covariances σ i,t,t + k (4.7) are functions of all three parameters \({\boldsymbol \beta}\), \(\sigma_{\gamma} ^2\), and ρ. It is then appropriate to jointly estimate β and \(\sigma_{\gamma} ^2\) by exploiting the first and the squared second order responses. Next, for known β and \(\sigma_{\gamma} ^2\), we use the method of moments to estimate ρ, where the unbiased moment functions are constructed from the cross products of the responses.
Alternatively, for known \(\sigma_{\gamma} ^2\), we may first exploit the first order responses to estimate β. Secondly, for known β, we exploit all second order responses to estimate \(\sigma_{\gamma} ^2\). Finally, for known β and \(\sigma_{\gamma} ^2\), only pairwise product responses are utilized to estimate ρ. In this section, we follow this alternative approach and solve a GQL estimating equation for the estimation of β for known \(\sigma_{\gamma} ^2\). The GQL approach is also used for the estimation of \(\sigma_{\gamma} ^2\), whereas the moment approach is used for the estimation of ρ.
4.2.1 Estimation of \({\boldsymbol \beta}\)
Recall that \({\boldsymbol \mu}_i ^{\prime} = (\mu_{i1}, \mu_{i2}, \ldots, \mu_{iT})\) is the mean of the response vector \({\bf y}_i ^ {\prime} = (y_{i1}, y_{i2}, \ldots, y_{iT})\). Because \({\Sigma}_i ({\boldsymbol \beta}, \rho, \sigma_{\gamma})\) is the covariance matrix of y i , it then follows from (3.1) that the GQL estimating equation for \({\boldsymbol\beta}\) has the form
Next, because
where \({\it X}_i ^{\prime} = ({\bf x}_{i1}, {\bf x}_{i2}, \ldots, {\bf x}_{iT})\) and \({\it U}_i = diag(\mu_{i1}, \mu_{i2}, \ldots, \mu_{iT})\), the GQL estimating equation can be written in the form
where the diagonal elements and off-diagonal elements of \({\Sigma}_i ({\boldsymbol \beta}, \rho, \sigma_{\gamma}) = cov({\bf Y}_i)\) are given by (4.5) and (4.7) respectively. The GQL estimating equation can now be solved iteratively using the Newton–Raphson iterative procedure, which in this case, is defined by
where \(\hat{\boldsymbol \beta}(r)\) is the value of \({\boldsymbol \beta}\) at the rth iteration.
4.2.2 Estimation of correlation parameter ρ
Similar to the approach in Section 3.2 we define the standardized variance and covariance as
For the dynamic mixed model (4.1) we can show that whereas E(S itt ) = 1, the expectation of the standardized covariance is given by
For known \({\boldsymbol \beta}\) and \(\sigma_{\gamma} ^2\), using the method of moments, we now solve for ρ in the expression S it,t + 1/S itt = E(S it,t + 1) to obtain the estimator
where \(h_{it} = \sigma_{i,tt} - \mu_{it} ^2 [\mbox{exp}(\sigma_{\gamma} ^2) - 1]\).
4.2.3 Estimation of the variance of the latent community effect \(\sigma_{\gamma} ^2\)
We note that the scale parameter \(\sigma_{\gamma} ^2\) is involved in the mean, variance and the covariances between y it and y i, t + k , for t = 1,2, ..., T, k = 1,2, ..., T − t. However, as first order responses were used for \({\boldsymbol\beta}\) estimation, we will be constructing an unbiased estimating function based on second order responses, where the expectation of these second order responses involve \(\sigma_{\gamma} ^2\). Let \({\bf z}_i ^{\prime} = (y_{i1} ^2, y_{i2} ^2, \ldots, y_{iT} ^2, y_{i1} y_{i2}, \ldots, y_{i1} y_{iT}, \ldots, y_{i,T-1} y_{iT})\) and \({\boldsymbol \lambda}_i = E({\bf z}_i)\), i = 1, ...,K with elements
leading to an unbiased estimating function \({\boldsymbol \lambda}_i - {\bf z}_i\), where μ it , σ i,tt , and σ i,ut are given by (4.4), (4.5), and (4.7) respectively. One can then solve the GQL estimating equation
for \(\hat{\sigma}_{\gamma} ^2\), where Ω i = Cov(z i ) and the elements of the vector \(\frac{\partial {\boldsymbol\lambda}_i ^{\prime}}{\partial {\boldsymbol\sigma_{\gamma} ^2}}\) are given by
Clearly, computing the matrix Ω i will require exact second order, third order, and fourth order joint moments of y it . However, unlike the computation for second order moments, computing third order and fourth order joint moments will require further distributional assumptions, which may not be practical. As a remedy, since the consistency of the estimator is not affected by the weight matrix Ω i , one can use certain suitable approximations to compute the required third and fourth order joint moments. Two possible approximations that can be used in the computation of the joint higher order moments are: (i) to pretend that the counts y it are normally distributed with the correct mean (4.4) and variance (4.5), (ii) to pretend that y it ’s are conditionally independent even if they are correlated. We remark here that the unbiased estimating function \({\boldsymbol\lambda}_i - {\bf z}_i\) is not affected by these approximations. In what follows, we have used the assumption of conditional independence to compute the components of Ω i .
Now, to begin the computation of the components of Ω i , we first use the assumption that \(\gamma_i \sim N(0, \sigma_{\gamma} ^2)\) to obtain
Then, by taking expectation over γ i and using (4.10) it can be shown that
Under the assumption of conditional independence we can now use the expectation of powers of \(\mu_{it} ^*\) in (4.11) to derive second and higher order joint moments of y it . Specifically, after some algebra, we found that the conditional second and higher order joint moments are given by
These conditional moments in (4.11) have been used in the computation of the elements of Ω i needed for estimating the variance of the latent community effect \(\sigma_{\gamma} ^2\). For instance,
The GQL estimating equation (4.9) can now be solved iteratively for \( \sigma_{\gamma} ^2\) using the Newton–Raphson iterative procedure, which in this case, is defined by
4.3 A simulation study
4.3.1 Estimation performance of β, \(\sigma_{\gamma} ^2\), and ρ
We observe that the dynamic mixed model has an additional parameter \(\sigma_{\gamma} ^2\) as compared to that of the dynamic fixed model discussed in Section 3. The simulation study conducted in Section 3.4.1 showed that the GQL estimation approach performs well in estimating the fixed model parameters \({\boldsymbol\beta}\) and ρ for various selected combinations of \({\bf n}^{\prime} = (n_1, n_2, n_3, n_4)\). In this section, we examine the performance of the GQL approach for estimating the parameters of the extended mixed model including \(\sigma_{\gamma} ^2\), the variance component of the latent community effect γ i . To be specific, the GQL estimates are obtained by solving the GQL estimating equation (4.7) iteratively for \({\boldsymbol\beta}\), and (4.12) for \(\sigma_{\gamma} ^2\) and the moment estimating equation (4.8) for ρ.
The data for our study was generated from model (4.1) with covariates previously defined in (3.8) and (3.9) for T = 4, K = 100 and various combinations of the parameter values \(\sigma_{\gamma} ^2 \equiv 0.25, 0.5, 0.75\) \({\boldsymbol\beta}^{\prime} \equiv (0.5,1), (1,1)\), and \({\bf n}^{\prime} = (n_1, n_2, n_3, n_4) \equiv (1,2,2,2), (1,2,2,3,), (1,2,3,4,)\). It is clear, from (4.1) that in order to generate the observed longitudinal data y it , (i = 1,2, ...,K; t = 1,2,..., T), we first had to generate values of the community effect \(\gamma_i \sim N(0, \sigma_{\gamma} ^2)\) which are then used in the computation of the conditional mean \(\mu_{it} ^* = \mbox{exp}({\bf x}_{it} ^{\prime} {\boldsymbol\beta} + \gamma_i)\) for fixed values of \(\sigma_{\gamma} ^2\) and the regression parameter vector \({\boldsymbol\beta}\). We then choose the correlation parameter ρ satisfying the condition \(\rho < \min \left\{ \frac{\mu_{it} ^*}{n_t \mu_{i,t-1} ^*}, 1 \right\}\), and generate d it conditional on γ i following Assumption 2 under model (4.1). Using the generated values of d i t and the conditional mean \(\mu_{i1} ^*\), the generation of y i1 and y it , t = 2, ..., T, and i = 1, ..., K followed directly from Assumption 1 and model (4.1) respectively.
Now, by using y it and associated x it , (t = 1,..., T; i = 1,2, ..., K), the method of moments estimate of ρ and the GQL estimates of \({\boldsymbol\beta}\) and \(\sigma_{\gamma} ^2\) were computed iteratively from (4.8), (4.7), and (4.12), respectively. The process of data generation and estimation was repeated 1,000 times. The average of the estimated parameters and their standard errors are reported in Table 3. From Table 3, we see that the method of moments and the GQL method perform well in estimating the true values of the parameters. For example, when n ′ = (1,2,2,3), the parameter values, namely, ρ = .307, \({\boldsymbol\beta}^{\prime} = (.5,1)\) and \(\sigma_{\gamma} ^2 = 0.75\) were estimated as \(\hat{\rho} = .310\), \(\hat{\boldsymbol\beta}^{\prime} = (.510,.989)\), and \(\hat{\sigma}_{\gamma} ^2 = 0.755\), respectively, showing that the estimates are very close to their corresponding true values. In a separate example, we took n ′ = (1,2,3,4) and estimated ρ = .205, \({\boldsymbol\beta}^{\prime} = (1,1)\) and \(\sigma_{\gamma} ^2 = 0.25\). The estimates were found to be \(\hat{\rho} = .224\), \(\hat{\boldsymbol\beta}^{\prime} = (.991,1.035)\), and \(\hat{\sigma}_{\gamma} ^2 = 0.229\) which are close to the respective parameter values.
5 Concluding remarks
In this paper, we have taken the first step in using branching processes with immigration to model the spread of an infectious disease in communities for the purpose of forecasting future spread and control. Because the model was developed mainly to deal with infectious disease data obtained over a short period of time, we have considered only a small number of time points, such as T = 5, in our simulation studies. This, however does not imply that the proposed methods are applicable only for small T. We have demonstrated that the GQL method performs well in estimating the parameters of the infectious disease model. The results also show that the estimated model can be used to obtain reasonable forecasts of future spread of the disease using the proposed forecasting function. We remark that the lag 1 dynamic models (2.1) and (4.1) show how individuals within communities with infections at time point t − 1 determine the number of new infections at time point t. However, there may be situations, in practice, where an individual who was infected at time point t − k, for k = 1, ..., t − 1, continue to infect others at future time points until he/she is discovered and treated. This higher order lag situation is a subject for future consideration.
References
Andersson, H. and Britton, T. (2000). Stochastic epidemic models and their statistical analysis. Springer, New York.
Choi, K. and Thacker, S.B. (1981a). An evaluation of influenza mortality surveillance, 1962–1979. I. Time series forecasts of expected pneumonia and influenza deaths. Am. J. Epidemiol., 113, 215–226.
Choi, K. and Thacker, S.B. (1981b). An evaluation of influenza mortality surveillance, 1962–1979. II. Percentage of pneumonia and influenza deaths as an indicator of influenza activity. Am. J. Epidemiol., 113, 227–235.
Daley, D.J. and Gani, J.M. (1999). Epidemic modelling: an introduction. Cambridge University Press, New York.
Diekmann, O. and Heesterbeek, J.A.P. (2000). Mathematical epidemiology of infectious diseases. John Wiley, New York.
Kermack, W.O. and Mckendrick, A.G. (1927). A contribution to the mathematical theory of epidemics. Proc. R. Soc. Lond. Ser. A, 115, 700–721.
Ma, Z. and Li, J. (2009). Dynamic modelling and analysis of epidemics. World Scientific Publishing, Singapore.
Mckenzie, E. (1988). Some ARMA models for dependent sequences of Poisson counts. Adv. in Appl. Probab., 20, 822–835.
Shibli, M., Gooch, S., Lewis, H.E. and Tyrell, D.A.J. (1971). Common colds on Tristan da Cunha. J. Hygiene, 69, 255–265.
Sutradhar, B.C. (2003). An overview on regression models for discrete longitudinal responses. Statist. Sci., 18, 377–393.
Sutradhar, B.C. (2010). Inferences in generalized linear longitudinal mixed models. Canad. J. Statist., 38, 174–196.
Sutradhar, B.C. (2011). Dynamic mixed model for familial longitudinal data. Springer, New York.
Sutradhar, B.C., Oyet, A.J. and Gadag, V.G. (2010). On quasi-likelihood estimation for branching processes with immigration. Canad. J. Statist., 38, 1–24.
Acknowledgement
This research was partially supported by grants from the Natural Sciences and Engineering Research Council of Canada.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Oyet, A.J., Sutradhar, B.C. Longitudinal modeling of infectious disease. Sankhya B 75, 319–342 (2013). https://doi.org/10.1007/s13571-012-0056-x
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13571-012-0056-x