
Abstract
Flow duration curve represents the percentage of time that a river flow is equal to or greater. As these curves provide a direct response to the behavior of water resources in a basin, which is used widely in hydropower projects, it is important to predict flow duration curves in no metering basins, named “ungagged basins.” The geostatistical approach to predict the values of these curves in non-measured stations shows the expansion of the range of studies in this topic. The aim of this study is to predict the flow duration curve over long periods of time in a basin with ungauged regions using probability kriging, inverse distance weighting (IDW) and maximum likelihood (ML) methods. Flow data from 38 flow measuring stations in the Dez Basin were used to map different discharges of the flow duration curve, and as a result, in order to complete their values, zone and quantify them, three different values of Q10, Q50 and Q90 of the flow duration curve acquired. The results show that as the flow rate increases (or the time percentage decreases), the amount of computational error increases and in all cases, the probability kriging method has a smaller error (0.96) than the IDW (1.65) and ML (1.15) methods.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
The flow duration curve (FDC) is the percentage of time or duration that a river’s flow over a historical period, is equal to or greater. This curve, as a signature of hydrological behavior of a basin, is used as an indicator of climate, morphology, soil permeability and other factors. FDC represents the characteristics of a basin based on the amount of runoff from a specific point of the river. This curve shows the frequency of occurrence of different amounts of flow at a specific point, which is widely used in the management of hydropower projects (Goodarzi et al. 2020). So is of great importance in the hydrological study of the basin. Flow continuity curves are used to investigate several hydrological issues related to hydropower generation, hydropower projects management, river and reservoir sedimentation, water quality assessment, water use assessment and water allocation. The FDC’s parameters are different in various river flows. The most important indices of low flows derive from FDCs parameters, such as Q75, Q80, Q90 and Q95. In addition to FDC, low-flow frequency curves display the ratio of years, which the discharge exceeds (in other words, Q10 is the most commonly used indices in the USA. (Goodarzi et al. 2022).
In many parts of the world, there are many basins where the discharge has not been measured regularly and accurately or it has not been measured at all. They are called ungauged basins. FDCs are one of the useful and applicable ways to estimate and compare the river parameters. In 2021, six indices were extracted and used from FDCs. The parameters, which are called signatures are as follows: runoff ratio (RR), high-segment volume (FHV), low-segment volume (FLV), mid-segment slope (FMS), mid-range flow (FMM) and maximum peak discharge (DiffMaxPeak). These signature indices are extremely important because they act as sorts of fingerprints representing differences in the hydrological behavior of the basin (Fatehifar et al. 2021).
In order to achieve major advances in the field of forecasting in ungauged basins, many researchers focused on analyzing and forecasting in basins where discharge has not been measured or in some cases did not have enough measuring stations. Sivapalan in collaboration with the International Association of Hydrological Sciences (IHAS) conducted statistical analysis. In their studies, they pointed to new and innovative methods for hydrological forecasting in ungauged basins in different parts of the world with a significant reduction in forecast uncertainty and showing the value of data on the results required for forecasting in unexplored basins (Sivapalan et al. 2003). Investigation of regional flow duration curves based on reliability for ungauged basins was another study that used statistical, parametric and graphical methods of data from 51 stations to estimate ungauged areas. The results of mean error of these three methods were compared with each other, among which the statistical method showed the best results (Castellarin et al. 2004). In a similar study, ungauged basins in eastern Italy were investigated by regionalizing the stochastic flow index model using regression method, and the Nash–Sutcliffe efficiency coefficient (NSE) was obtained for different basin parameters (Castellarin et al. 2007). Mohamoud (2008) stating that the methods based on flow duration curves are a great step for flow prediction in ungauged basins, applied the multiple regression method for the curve continuity of daily and monthly flow by analyzing data from 29 basins in the US Appalachian Plateau and calculated Nash efficiency coefficient. In 2010, Li et al. proposed a regional method called the index model describing a wide range of functions either linear or nonlinear, which prevents possible errors usually occurs as a result of using normal linear regression. By predicting flow continuity curves in 227 basins on the southeastern Australia using the index model and comparing the results of regional models with linear regression, nearest neighbor and hydrological similarity, they concluded that the index model had the most accurate prediction with the highest efficiency coefficients; hence, it is followed by linear regression method (Li et al. 2010). The flow duration curve for 379 discharge stations was analyzed using linear regression and random forest methods in a region in New Zealand, and the results showed that the probability distribution functions method is the most accurate method for estimating flow duration curves at unexplored and ungauged sites across New Zealand. Subsequent study shows that geostatistical methods have replaced regional regression methods to estimate the flow duration curve (Booker and Snelder 2012). In a study conducted by (Castellarin 2014) in two regions in Italy, the flow continuity curve was interpolated using kriging geostatistical method, and the results showed that 3D kriging is a reliable and robust approach that works better than traditional regional models. In particular, this approach works significantly better than conventional methods for predicting low currents (currents with long duration) in ungauged basins. In a basin in eastern Italy, the flow duration curve was standardized with the annual average flow index through examining the data of 18 flow measuring stations, and the total negative deviation of the curves from this, the value is calculated. These values are then obtained using the kriging method to express the hydrological similarity between interpolation basins and the Nash efficiency coefficient, which was a proof for proper performance of the kriging method (Pugliese et al. 2014). Kriging and regression methods were compared using available statistics for 182 stations in South America, and concluded that these two methods have similar performance by comparing it with Nash efficiency coefficient (Pugliese et al. 2016). In another similar study conducted on the Danube basin, it was concluded that comparing the kriging geostatistical method with the regression method and calculating the Nash efficiency coefficient, the kriging method has a higher accuracy (Castellarin et al. 2018). Researchers achieved new and applicable methods to estimate parameters, which are used to estimate the river flow. Niazkar et al. introduces a new straightforward flow-dependent scheme, which is capable of estimating the Manning’s coefficient due to grain and form roughness (Niazkar et al. 2019) estimating Manning’s coefficient due to grain and form roughness, is introduced. A large data are utilized to calibrate and testify the new scheme.
Worland et al. (2019) interpolated the flow continuity curve for all parts of the southeastern United States using Copula theory, with 74 stations, and concluded that Copula approaches will achieve better performance compared with previous methods based on the flow curve. Through a national project in Brazil, meta-basin data including 81 measuring stations in an area of 96,000 square kilometers data in places without measuring stations or stations with incomplete data were investigated with the support of the Brazilian National Water Agency and were interpolated using kriging geostatistical method to extract data for the required points. They also compared Kling–Gupta efficiency (KGE) values among the results of kriging and regression geostatistical approaches and concluded that geostatistical models outperform regression methods (Wolff and Duarte 2021). Researchers have investigated the new and more powerful methods like genetic programming and artificial neural networks. By introducing an equation with four parameters and application of ensemble machine learning (ML) as well as ensemble empirical models, the aspects of improving the accuracy, modifying the simple rating curve equation was investigated and declared that the machine learning simple average ensemble models and the empirical-based nonlinear ensemble models achieved the lowest root-mean-square error as well as mean absolute error (Niazkar and Zakwan 2023).
However, recent studies show that predicting flow duration curves in basins with low or no metering is important. The lack of statistics in basins without stations has seriously challenged researchers and, in many cases, has discouraged them from continuing the research process on these issues. On the other hand, geostatistical approaches are of proper effectiveness. The geostatistical approach to predict the values of these curves in ungauged stations shows the expansion of the scope of studies in this field of research and along with the expansion of research fields with geostatistical approaches, the diversity of these methods can also be a challenge for the users of these approaches. Geostatistical methods perform better than regression methods.
In this paper, using the kriging geostatistical method and IDW method, the flow duration curve in Dez river basin in the South West of Iran is interpolated, and error values are calculated and compared with each other. To examine the correlation of geostatistical methods and evaluate them, maximum likelihood relationships have been used, and the errors were compared with the geostatistical approaches.
The 7Q10 index approached 0.008 m3/s and zero for the SDSM model and change factor, respectively, for the future period; these values were 0.724 and 1.429 m3/s in the corresponding historical periods, respectively. Furthermore, Q80 decreased from 4.27 to 0.1 for SDSM and from 5.3 to 0.3 m3/s for the change factor method in future projection studies.
Materials and methods
Study area
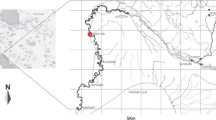
Dez river basin is located in the west and southwest of Iran. This basin is a grade 3 basin and a subset of the large Karun basin. The Dez Basin is also in a larger subdivision under the Persian Gulf and the Sea of Oman. Dezful, Andimeshk and Shoush can be mentioned as important cities in this basin. In the highlands of the western and southwestern slopes of the Zagros, which are part of the rainy regions of the country, most of the rainfall in the autumn, and winter is snow and their melting from late winter to late spring provides most of the annual surface runoff water. The basin is located in the range of longitude 32° 35′ to 34° 7′ north and geographical slope of 48° 20′ to 50° 20′ east in Lorestan and Khuzestan provinces. Figure 1 shows the shape and geographical location of the Dez Basin.

Situation of Dez basin in Iran
Cezar and Bakhtiari are the two main tributaries of the Dez River. The Cezar River flows in the north part of the Dez Basin and consists of three tributaries: Marbare, Tire and Sabze. The joining of several waterways, including the Azna river in the Aligudarz region, forms the Marbare river, which flows westward toward the city of Dorud in Lorestan province. This river drains a high but moderate slope catchment. The other tributary of the Cezar river is called the Tire river, which consists of the tributaries of Galerud, Silakhor, Absardeh and Biatun. The source of the Tire river is Boroujerd region and then this river flows in the east toward Dorud and here, the two rivers of Tire and Marbare join. From here, the direction of water flow is generally from north to south and southwest. 20 km south of Dorud, the Sabze river, which originates from the southern and western slopes of Oshtrankooh, is connected to this stream and the Cezar river is formed. About 25 km south west, the Vask river, and a short distance from the left bank, the Zaz river joins the Cezar river and continues in a southwest direction. The small Sorkhab river also joins the Cezar river from the right bank.
Bakhtiari river is the second main tributary of Dez river, which joins the Cezar river 40 km south of Sorkhab river. The Bakhtiari river originates from the southern heights of Oshtrankooh and initially flows as a river called Daredaei in the general direction from northwest to southeast. Then, after receiving water from the smaller tributaries, the river changes direction to the west, and in this part it is known as Zalaki. It then gathers with a relatively large tributary that joins it from the north and joins the Cezar river, after which it flows into the Dez river. Location of important rivers of Dez basin is shown in Figure 1.
Table 1 shows the characteristics of stations in the region, including geographical location, altitude and year of establishment. From the year of establishment of each station, the number of recorded statistical years can be understood.
Investigation of spatial variations by kriging geostatistical method
One method of estimation is based on the logic of weighted moving average. Kriging is a geostatistical method of interpolate the data based on spatial variance. In kriging, spatial variance is known as a function of distance, and this estimate is defined as follows.
where Z(Si) is the measured value for the i sample, λi is the weight of the i sample, S0 is the prediction location and N is the number of values measured (Castellarin 2014).
In the kriging method, each known sample in estimating the unknown point depends entirely on the spatial structure of the environment. In other methods, the weights depend only on one geometric characteristic, such as distance, and do not change as the spatial structure of the specimen changes, and as the spatial structure weakens, the role of the specimen decreases. In other words, the amplitude of the effect of the known variable on the unknown points depends on the maximum and minimum distance of the samples, so in using this method, the spatial distribution of the samples and the range of their effect must be considered. There are several methods for estimating values based on kriging:
Ordinary kriging The most common and widely used method among various available methods is ordinary kriging interpolation model. In this method, it is assumed that the constant mean is uncertain and will be justified until a scientific reason is found to reject it.
Universal kriging In cases where the trend is observed in the statistical community, and we have to remove the trend from the data for kriging operation, another way is to use general kriging. General kriging assumes that there is a trend in the data, but its function is not fully understood.
Simple kriging In this method, the average of the desired variable is known. However, the assumption that the mean is independent of the coordinates, and that there is no trend must be maintained.
Indicator kriging This method can also be used for samples in which the observations are 0 or 1. For example, we can have a sampling that contains information such that the sampled point is a forest dwelling or a non-forest dwelling, in which the binary variables indicate the sample membership class. Using binary variables, marker kriging proceeds exactly to normal kriging performance.
Probability kriging Possible kriging tries to do the same as index kriging; yet, this method uses the same kriging in an effort to create something better.
Disjunctive kriging Kriging is an indicator of a special case of probable kriging. In the field of statistics, both the value and the indicator can be predicted by discrete kriging.
In this paper, the probability kriging method is used to measure and internalize information related to the flow continuity curve.
Flow duration curve
Flow duration curves (FDCs) represent the indicators of a catchment based on the amount of water flow from a specific point of a waterway or river. On the other hand, since they show the frequency of occurrence of different amounts of flow at a specific point, provide data on the flow characteristics of a river for a selected area under all recorded flows in the river. In addition, with the help of flow continuity curve, the percentage of availability time of each flow rate can be easily obtained. The symbol Q with an index from 0 to 100 is used to indicate the flow continuity curve. Daily, weekly or monthly flow values can be used to generate the flow continuity curve. Flow continuity curves formed using long-term flow data are more reliable and convenient due to their application. Q95 and Q90 currents are considered as low-flow indicators in academic works and public studies in different regions of the world. The most important advantage of flow continuity curve analysis is that it has a wide range of applications. In addition, different flow rates are proposed for different ecological processes.
The Tennett (Montana) method is the most common method of assessing ambient flow due to its rapid use. This method is the result of Tennett observations in 11 different rivers in Montana. During the study of the river, the Tennett of the river was studied physically, biologically and chemically. As a result of these observations, Tennett presented a graph that includes different average annual flow rates to protect river ecosystems and provide suitable living conditions for fish.
Investigation of flow duration curve parameters
Daily discharge data in 38 discharge measuring stations from Dez catchment area have been obtained from Lorestan and Khuzestan Regional Water Company. These data are between 25 and 60 years old, depending on the station age, access conditions, maintenance services and station location. The flow continuity curve was plotted using FDC 2.1 model using all available data, and the value of Q90 was extracted from. The reason for including Q90 for this basin is that some of the passages of this basin have not always been full of water during different times and even without water on some days. On the other hand, very few discharges have been obtained to study the climate of the basin in droughts. For this reason, Q90 is used, which indicates the amount of flow that is equal to or more than 90% of the time. They have been performed by geostatistical methods.
Flow duration curve interpolation by probability kriging method
To calculate Q90 in places that do not have enough information or generally do not have a flow measuring station, the interpolation method is used using the probability kriging method. Data from 38 stations were used for interpolation. In fact, these data were used by drawing the daily flow continuity curve including daily discharge data of discharge stations for a minimum of 25 years and a maximum of 60 years of available statistics for these stations. Eventually, interpolation was performed in the whole basin using the Geostatistical Analysis plugin in ArcGIS 10.6 model based on this data.
Inverse distance weighting (IDW) interpolation
To compare the results of different geostatistical methods, the values of flow rates of the flow continuity curve were measured using the inverse distance weighting method and their error was obtained. The following are diagrams of both probability kriging and inverse distance weighting methods.
The inverse distance weighting method is a definite exact geostatistical method that are interpolated by default. This interpolation method has various features, including simplicity and comprehensibility, ease and speed of calculations and lack of need for preprocessing data and basic assumptions.
Since the spatial relationship of the sample pair values is not a simple decreasing relation in terms of distance, a power is considered for the inverse distance method. Relationship used in this method is (Barbulescu 2016):
where
where Z is the measured value and by weighting w is inversely proportional to the spatial distance. In this paper, the flow continuity curves are calculated using two geometric methods of probability kriging and inverse distance weighting, and the error values are compared with each other.
Maximum likelihood estimation
In statistical science, estimating maximum likelihood is a method for estimating the parameters of a statistical model. When operating on a set of data, a statistical model is obtained, then the maximum likelihood can provide an estimate of the model parameters. The maximum likelihood method is similar to many known statistical estimation methods. Suppose that information about height is important to us in a population and we cannot measure height of individual due to limitations. On the other hand, we know that these lengths follow the normal distribution but do not know the mean and variance of the distribution. Now, using the maximum likelihood with data from a limited sample of the population can provide an estimate of the mean and variance of this distribution. This is done by ignoring the variance and the mean and then assigning values to them that are most likely given the information available. In general, the maximum likelihood method for a given set of data is to assign values to the model parameters, resulting in a distribution that most likely attributes to the observed data, i.e., values of the parameter that maximize the likelihood function. Here, a clear estimation mechanism is provided, which works well for the normal distribution and many other distributions. Yet, in some cases problems arise, such as whether maximum likelihood estimators are inadequate or non-existent.
Results and discussion
Basin data including daily discharges recorded at stations were analyzed using FDC2.1 model, and Q90 values were obtained. These values were then interpolated using ArcGIS10.6 model using geostatistical methods, and the zoning map was drawn. Figure 2 shows the zoning diagrams based on the probability kriging methods and the inverse distance weighting method for Q90. In Fig. 2, we can notice the spatial interpolation and distribution of Q90 in the basin, which helps us to estimate Q90 in ungauged stations.

Q90 value zoning diagrams based on IDW method (a) and kriging method (b)
The root-mean-square error (RMSE) obtained in the probability kriging method is less than inverse distance weighting method. This error is 0.85 in the probability kriging method and 0.95 in the inverse distance weighting method.
Having examined and compared other flows of the flow continuity curve, the errors obtained by each method in different flows can be analyzed. Figure 3 shows the zoning diagrams for Q50 values with probability kriging and inverse distance weighting methods.

Q50 value zoning diagrams based on IDW method (a) and kriging method (b)
Similarly, Fig. 4 shows the zoning diagrams for Q10 values with probability kriging and inverse distance weighting methods.

Q10 value zoning diagrams based on IDW method (a) and kriging method (b)
From Figs. 2, 3, and 4, we can notice the areas that have higher Q90, Q50 and Q10.
The researchers who have investigated in the same field have argued that low flow in FDCs vary from 70 to 99%. The authors used the FL (frequent low) method, which is one of the five low-flow managing approaches used in St. Johns River in Florida. In order to achieve that, first, the 7Q10 values fit intense low-flow situations occurring 95–99% of the FDC, which shows that it happens over severe short-term dry years and drought and has a wide recurrence interval. Besides, the FL approach is within the low-flow selection range, so FL levels have considered low-flow effects (Goodarzi and Faraji 2022).
Table 2 shows the error values of the kriging and inverse distance weighting methods for different flow rates of the flow continuity curve. In this table, the error changes can be compared with the change in flow rate.
The results, as the discharge index in the flow continuity curve decreases, which is an indicator of high discharges and occurs during floods, the amount of computational error also increases; however, the error rate of probability kriging method in all cases is less than inverse distance weighting method. Figures 5, 6 and 7 compare the error diagrams obtained through kriging, IDW and maximum likelihood methods. Each figure compares two methods with each other, and the R2 coefficient shows the relationship between the two methods.

Comparison of error diagrams of maximum likelihood method with kriging method (R2 = 0.98)

Comparison of error diagrams of kriging method with IDW method (R2 = 0.91)

Comparison of IDW method error diagram with maximum likelihood method (R2 = 0.93)
Figure 5 compares the error diagrams obtained through probability kriging and maximum likelihood methods with the R-square coefficient of 0.98, which shows a very good relationship.
Figure 6 compares the error diagrams obtained through probability kriging and IDW methods with the R-square coefficient of 0.91.
Similarly, Fig. 7 compares the error diagrams obtained through IDW and maximum likelihood methods with the R-square coefficient of 0.93.
Conclusion
In this study, a method has been used to evaluate the network of discharge measuring stations in Dez area based on probability kriging geostatistical model as well as inverse distance weighting model. The interpolation of geostatistical methods was done using ArcGIS model and after statistical analysis of the data, they were checked to be normal. Thirty-seven stations were examined, and the results and errors obtained from different terrestrial methods came from the output of the software prepared and compared with each other. As shown in Table 2, the kriging method has the best performance with the mean RMSE of 0.96, which is less than other methods. Furthermore, to evaluate the performance of different geostatistical approaches, the errors obtained through both methods are adjusted and compared with each other using a maximum likelihood relationship in Table 2. Moreover, the error values of all three methods, probability kriging, inverse distance weighting and maximum likelihood are shown in pairs. For better comparison, it is possible to compare the errors of these methods are provided using line fitting through the data and determining the R-square coefficient (R2). The results show that probability kriging and maximum likelihood methods with R-square coefficient of 0.98 have the highest correlation with each other, and the inverse distance weighting method has a relatively good correlation with probability kriging method with R-square coefficient of 0.91 and good correlation with the maximum likelihood method with R-square coefficient of 0.93. Besides, comparing the errors of probability kriging methods and the maximum likelihood, it can be seen that in the low error rate that occurs in lower flow rates, the correlation rate of the graph is higher than the higher error rate.
References
Barbulescu A (2016) A new method for estimation the regional precipitation. Water Resour Manage 30:33–42. https://doi.org/10.1007/s11269-015-1152-2
Booker DJ, Snelder TH (2012) Comparing methods for estimating flow duration curves at un-gauged sites. J Hydrol 434–435:78–94. https://doi.org/10.1016/J.JHYDROL.2012.02.031
Burgan HI, Aksoy H (2020) Monthly flow duration curve model for un-gauged river basins. Water 12(2):1–19. https://doi.org/10.3390/w12020338
Castellarin A (2014) Regional prediction of flow-duration curves using a three-dimensional kriging. J Hydrol 513:179–191. https://doi.org/10.1016/J.JHYDROL.2014.03.050
Castellarin A, Galeati G, Brandimarte L, Montanari A, Brath A (2004) Regional flow-duration curves: reliability for un-gauged basins. Adv Water Resour 27(10):953–965. https://doi.org/10.1016/j.advwatres.2004.08.005
Castellarin A, Camorani G, Brath A (2007) Predicting annual and long-term flow-duration curves in un-gauged basins. Adv Water Resour 30(4):937–953. https://doi.org/10.1016/J.ADVWATRES.2006.08.006
Castellarin A, Persiano S, Pugliese A, Aloe A, Skøien JO, Pistocchi A (2018) Prediction of streamflow regimes over large geographical areas: interpolated flow-duration curves for the Danube region. Hydrol Sci J. https://doi.org/10.1080/02626667.2018.1445855
Cheremisinoff NP (1997) Relationship between groundwater and surface water. Groundw Remediat Treat Technol. https://doi.org/10.1016/b978-081551411-4.50004-1
Engelke MJ (1981) Hydrology of area 7. Eastern Coal Province, OHIO
Fatehifar A, Goodarzi MR, Montazeri Hedesh SS, Siahvashi Dastjerdi P (2021) Assessing watershed hydrological response to climate change based on signature indices. J Water Clim Change 12(6):2579–2593. https://doi.org/10.2166/wcc.2021.293
Frehs RR (1993) United States geological survey open-file report 93-458 Columbus, OHIO
Goodarzi M, Faraji A (2022) Analysis of low-flow indices in the era of climate change: an application of CanESM2 model. In: Chatterjee U, Akanwa AO, Kumar S, Singh SK, Dutta Roy A (eds) Ecological footprints of climate change. Springer Climate. Springer, Cham. https://doi.org/10.1007/978-3-031-15501-7_4
Goodarzi MR, Vagheei H, Mohtar RH (2020) The impact of climate change on water and energy security. Water Supply 20(7):2530–2546. https://doi.org/10.2166/ws.2020.150
Karakoyun Y, Yumurtaci Z, Dönmez AH (2018) Environmental flow assessment methods: a case study. Exergetic Energetic Environ Dimens. https://doi.org/10.1016/B978-0-12-813734-5.00060-3
Li M, Shao Q, Zhang L, Chiew FHS (2010) A new regionalization approach and its application to predict flow duration curve in un-gauged basins. J Hydrol 389(1–2):137–145. https://doi.org/10.1016/J.JHYDROL.2010.05.039
Mohamoud YM (2008) Prediction of daily flow duration curves and stream flow for un-gauged catchments using regional flow duration curves. Hydrol Sci J 53(4):706–724. https://doi.org/10.1623/hysj.53.4.706
Niazkar M, Zakwan M (2023) Developing ensemble models for estimating sediment loads for different times scales. Environ Dev Sustain. https://doi.org/10.1007/s10668-023-03263-4
Niazkar M, Talebbeydokhti N, Afzali SH (2019) Development of a new flow-dependent scheme for calculating grain and form roughness coefficients. KSCE J Civ Eng 23:2108–2116. https://doi.org/10.1007/s12205-019-0988-z
Pugliese A, Castellarin A, Brath A (2014) Geo-statistical prediction of flow-duration curves in an index-flow framework. Hydrol Earth Syst Sci 18(9):3801–3816. https://doi.org/10.5194/hess-18-3801-2014
Pugliese A, Farmer WH, Castellarin A, Archfield SA, Vogel RM (2016) Regional flow duration curves: geo-statistical techniques versus multivariate regression. Adv Water Resour 96:11–22. https://doi.org/10.1016/j.advwatres.2016.06.008
Reichl F, Hack J (2017) Derivation of flow duration curves to estimate hydropower generation potential in data-scarce regions. Water. https://doi.org/10.3390/w9080572
Rugumayo AI, Ojeo J (2006) Low flow analysis in Lake Kyoga basin-eastern Uganda. In Proceedings from the international conference on advances in engineering and technology. Woodhead Publishing Limited. https://doi.org/10.1016/b978-008045312-5/50078-9
Saket RK (2013) Design aspects and probabilistic approach for generation reliability evaluation of MWW based micro-hydro power plant. Renew Sustain Energy Rev 28:917–929. https://doi.org/10.1016/j.rser.2013.08.033
Sherwood, J. M. (1994). Estimation of peak-frequency relations, flood hydrographs, and volume-duration-frequency relations of ungaged small urban streams in Ohio. US Geological Survey Water-Supply Paper, 2432. https://doi.org/10.3133/ofr93135
Sivapalan M, Takeuchi K, Franks SW, Gupta VK, Karambiri H, Lakshmi V, Liang X, McDonnell JJ, Mendiondo EM, O’Connell PE, Oki T, Pomeroy JW, Schertzer D, Uhlenbrook S, Zehe E (2003) IAHS decade on predictions in un-gauged basins (PUB), 2003–2012: shaping an exciting future for the hydrological sciences. Hydrol Sci J 48(6):857–880. https://doi.org/10.1623/hysj.48.6.857.51421
Tarpanelli A, Domeneghetti A (2021) Flow duration curves from surface reflectance in the near infrared band. Appl Sci 11(8):3458. https://doi.org/10.3390/app11083458
Wolff W, Duarte SN (2021) Toward geo-statistical unbiased predictions of flow duration curves at un-gauged basins. Adv Water Resour 152:103915. https://doi.org/10.1016/j.advwatres.2021.103915
Worland SC, Steinschneider S, Farmer W, Asquith W, Knight R (2019) Copula theory as a generalized framework for flow-duration curve based streamflow estimates in ungaged and partially gaged catchments. Water Resour Res 55(11):9378–9397. https://doi.org/10.1029/2019WR025138
Zhao W, Guan X, Zhang Z, Wang Z, Wang L, Mamer EA (2021) Development of flow-duration-frequency curves for episodic low streamflow. Adv Water Resour 156:104021
Funding
Authors are required to disclose financial or non-financial interests that are directly or indirectly related to the work submitted for publication.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Goodarzi, M.R., Vazirian, M. A geostatistical approach to estimate flow duration curve parameters in ungauged basins. Appl Water Sci 13, 178 (2023). https://doi.org/10.1007/s13201-023-01993-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s13201-023-01993-4