
Abstract
Investigating the interaction of water resources such as rainfall, river flow and groundwater level can be useful to know the behavior of water balance in a basin. In this study, using the rainfall, river flow and groundwater level deficiency signatures for a 60-day duration, accuracy of vine copulas was investigated by joint frequency analysis. First, while investigating correlation of pair-variables, tree sequences of C-, D- and R-vine copulas were investigated. The results were evaluated using AIC, Log likelihood and BIC statistics. Finally, according to the physics of the problem and evaluation criteria, D-vine copula was selected as the best copula and the relevant tree sequence was introduced. Kendall’s tau test was used to evaluate the correlation of pair-signatures. The results of the Kendall’s tau test showed that pair-signatures studied have a good correlation. Using D-vine copula and its conditional structure, the joint return period of groundwater deficiency signature affected by rainfall and river flow deficiency signatures was investigated. The results showed that the main changes in the groundwater level deficiency is between 0.3 and 2 m, which due to the rainfall and the corresponding river flow deficiency, return periods will be less than 5 years. Copula-based simulations were used to investigate the best copula accuracy in joint frequency analysis of the studied signatures. Using copula data of the studied signatures, the groundwater deficiency signature was simulated using D-vine copula and a selected tree sequence. The results showed acceptable accuracy of D-vine copula in simulating the copula values of the groundwater deficiency signature. After confirming the accuracy of D-vine copula, the probability of occurrence of groundwater deficiency signature was obtained from the joint probability of occurrence of other signatures. This method can be used as a general drought monitoring system for better water resources management in the basin.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Since hydrological phenomena are usually described by more than one dependent variables, multivariate statistical and dependency analysis is required. The main subject of probabilistic multivariate analysis is to create a dependence structure for random variables. (Li and Zhang 2016). For multivariate modeling of different meteorological and hydrological values, multivariate distribution functions have been investigated in various studies (Salvadori and De Michele 2007). In multivariate hydrological analyses, mainly items such as showing the importance and framework of multivariate, fitting appropriate multivariate distribution and studying multivariate return periods are considered. (Chebana and Ouarda 2011). The most widely used copula cumulative joint distribution function (CDF) is Gaussian. To overcome it, a bivariate distribution with margins such as gamma bivariate distribution, exponential bivariate distribution and extreme values bivariate distribution was proposed (Adamson et al. 1999; Yue et al. 2001; Favre et al. 2002). Favre et al. (2004) summarized the drawbacks of this type of distribution: (1) marginal distribution should be from the same family, (2) for the case of more than two variables, it is not clear and expressive and (3) marginal distribution parameters are also used for dependency model between random variables. In order to overcome these deficiencies, copulas, which are the latest mathematical tools for analyzing multivariate phenomena, were used in hydrological analysis (Xiau et al. 2008). The advantages of using a copula distribution over joint distribution methods are: (1) flexibility in selection of appropriate marginal distribution and dependence structure; (2) Increase the dimension to more than two variables and (3) marginal distribution analysis and dependence structure (Serinaldi et al. 2009; Salvadori et al. 2007).
During the past years, copula functions have been used for analysis the multivariate hydrological time series. Favre et al. (2004) used bivariate copulas to describe the relationship between flood peak flow and flood volume. In another study, Shiau et al. (2006) used copula functions to investigate joint frequency of flood peak flow and flood volume. Zhang and Singh (2006) used Archimedean functions for two-dimensional distribution of flood characteristics (pair variables of peak flow and flood volume, pair variables of flood peak flow and flood duration, and pair variables of flood volume and flood duration). Also Grimaldi and Serinaldi (2006a, b) provided a three-dimensional distribution of flood variables using general and asymmetric Archimedean complex functions and performed extensive simulations to highlight differences. Salvadori and De Michele (2007) developed some hydrological modeling such as calculating joint probabilities and joint return periods of two different events by using copula functions. Zhang and Singh (2007a) used another model of Coppola called Gumbel–Hougaard to investigate the three-dimensional distribution of flood peak flow, volume, and flood duration. Kao and Govindaraju (2008) investigated the Plackett copula and used it for the temporal distribution of extreme rainfall.
The use of copula functions in water resources and hydrology can be named as follows: frequency analysis of rainfall (De Michele and Salvadori 2003; Grimaldi and Serinaldi 2006a; Kao and Govindaraju 2007; Kuhn et. al. 2007; Zhang and Singh 2007a; Keef et al. 2009), in field of frequency analysis of flood can be named study of Favre et al. (2004), Shiau et al. (2006), Renard and Lang (2007), and Zhang and Singh (2006 and 2007b). The use of copula function in field of frequency analysis of drought also can be named research of Shiau (2006), Serinaldi et al. (2009), Kao and Govindaraju (2010), and Song and Singh (2010). Also in field of analysis of sea storm, De Michele et al. (2007), in field of flow simulation, Chen et al. (2015), in field of multivariate analysis the characteristics of rainfall, Salvadori and De Michele (2007) and Zhang et al. (2013), in field of multivariate analysis the characteristics of drought, Salvadori and De Michele (2004), Mirakbari et al. (2010), Mirabbasi Najafabadi et al. (2013), Abdi et al. (2017), Ramezani et al. (2019) and Tahroudi et al. (2020a), in field of groundwater level simulation, Tahroudi et al. (2020b) and some field of multivariate extreme events can be named Salvadori et al. (2007) and Salvadori and De Michele (2010). Therefore, copula functions are effective tools for analyzing and simulating multivariate hydrological phenomena (Calvo and Savi 2009; Chen et al. 2014; Fan et al. 2016). Hydrological prediction is a non-structural measure to deal with floods and droughts and an essential principle for flood warning and reservoir operation (Zhang et al. 2015; Liu et al. 2016; Wu et al. 2017). Predictive models that have been widely used in recent years are mostly definitive.
However, a hydrological prediction model is only for simulating hydrological which is usually incomplete (Wetterhall et al. 2013; Ravines et al. 2008) that accept different hydrological and meteorological input and use the parameters of the conceptual model; and these complex factors are due to unreliability in hydrological predictions (Freer et al. 1996; Montanari and Grossi 2008; Montanari 2007). The principle of logical decision-making in uncertainty shows that when a definite prediction is wrong, the consequences are likely worse than in a situation where no prediction is available (Krzystofowicz 1999; Wetterhall 2013; Ramos et al. 2013). Therefore, the logical decision maker who wants to make the desired decisions should be explicitly predicted with uncertainty (Verkade and Werner 2011; Ramos et al. 2013). Hydrological prediction seeks to provide probabilistic prediction rather than definitive prediction. For example, Nazeri Tahroudi et al. (2021) attempted to flood routing via a copula-based approach. They used vine copulas to simulation the flood hydrographs. The results of their study showed that copula-based approach has acceptable accuracy and performance. Khashei-Siuki et al. (2021) used vine copulas to simulate the potential evapotranspiration. By introducing the best dependence structure and tree sequence, the results of simulation of potential evapotranspiration showed that the efficiency of C-vine copula in dependence analysis and simulation of potential evapotranspiration is good, which indicates the ability of vine copulas in multivariate analysis.
The researches on copula functions are limited to bivariate frequency analysis. Copula-based simulations have also been developed in recent years. But this study seeks to provide a copula-based approach to determining the three-variable return period. The aim of the present study, while analyzing the tree sequences of vine copulas in determining the joint return period and the joint probability of occurrence, is to model and simulate three-dimensional water resources signatures. In order to achieve this, C-, D- and R-vine copulas and their conditional density were used.
Materials and methods
Study area
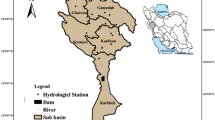
The study area in this study is Tapik basin located in the west of Lake Urmia basin. Lake Urmia is located 1267 m above sea level and directs runoff of heights around the basin. In this study, data on rainfall, river flow and groundwater level in Tapik basin during the statistical period of 1977–2019 have been used. Tapik aquifer is an unconfined aquifer. In the study basin, a rain gauge station was selected to indicate rainfall, a hydrometric station was selected to indicate river flow and a piezometric well was selected to show groundwater level changes. A summary of the statistical characteristics of the data studied in this study can be seen in Table 1 and the location of the study area as shown in Fig. 1.

Geographical location of Tapik basin in Iran and Lake Urmia basin
Selection of indicator rain gauge station/piezometric well
In this study, to select indicator rain gauge station/piezometric well, the entropy theory was used. Since there are several rain gauge stations and piezometric wells in the study basin and their distribution is uniform throughout the basin, so instead of using thiessen polygon or weighted average, entropy theory was used. In this method, the rain gauge station/piezometric well that transfers more information with other stations is selected as the indicator rain gauge station/piezometric well. In this method, entropy indices are first calculated according to the probability tables and the interaction of the rain gauge stations/piezometric wells. The rain gauge stations/piezometric wells were classified and ranked according to entropy indices and finally based on information transfer index of entropy theory, introduced as the indicator rain gauge station/piezometric well. The rain gauge station/piezometric well that has the highest rank is selected as the indicator rain gauge station/piezometric well. In this study, Tapik rain gauge station/Nazloo piezometric well selected as the indicator rain gauge station/piezometric well in the basin. For more information on entropy theory, see Mogheir et al. 2006 and Tahroudi et al. 2019a.
Extraction of water resources signatures
The rainfall, river flow and groundwater level deficiencies, which are referred to as water resources signatures in this study, based on the proposed method of Tahroudi et al (2019b) are extracted for a 60-day duration. The values generated are hereinafter referred to as "signature".
The rainfall deficiency means deficiency for 1- to n-day consecutive durations of rainfall compared to its mean long-term which are extracted from the daily rainfall. At the first step, the mean individual daily long-term period (MIDLP) is calculated using Eq. (1) for every day of the year. In fact, the number of MIDLPs will be equal to the number of days in a year (365). (Besharat et al. 2014; Tahroudi et al. 2019b).
In the next step, to obtain the new data, the daily rainfall data were subtracted from corresponding MIDLPs. The aim of present study is to find consecutive deficiency periods between 1 and n-day duration (Nazeri Tahroudi et al. 2019b). In this study, the above method was used to calculate river flow and groundwater level deficiency signatures.
Copula functions
The first topics related to copula functions and their application were introduced by Sklar (1959). Copulas are functions that connect the marginal distribution of one-dimensional variables to create a multivariate distribution (Nelson 2006). This function is able to show dependence structure between random variables and has recently emerged as a practical and efficient method for dependency modeling and dependency analysis of multivariate series. The results of studies by Joe (1997) and Kurowicka and Cooke (2007) indicated that a simple building block cascade called pair-copula can model multivariate series. Consider \(X = (X_{1} ,...,X_{n} )\) vector of random variables with \(f(x_{1} ,...,x_{n} )\) combined density function. This density is as follows:
this decomposition is unique until it reaches the reproduction of variables. Each joint distribution function implicitly includes the marginal behavior of individual variables and their dependence structure. The copula provides a way to isolate their dependence structure. A copula is the multivariate distribution C with the uniform distribution margins U (0,1) in [0,1]. Sklar theory states that any multivariate distribution F with margins F1(x1),…,F2(x2) can be written as follows:
For some multidimensional (n-dimensional) C copulas, the above equation is actually corrected as follows.
where \(F_{n}^{ - 1} (u_{n} )\) is the inverse of marginal distribution functions. According to the joint density function f, for incremental continuous F values, the continuous marginal densities F1,…,F2 are estimated using the following chain law for some n-variable copula densities \(c_{1...n} (.)\):
For the bivariate example, Eq. (5) is simplified as follows:
where \(c_{12} (.)\) is suitable pair-copula density for the pair of converted variables F1(x1) and F2(x2). For conditional density, the following can be done, which is the same for all pair-copulas.
For example, \(f(x_{n - 1} |x_{n} )\), the right of Eq. (2), can be decomposed into \(c_{(n - 1)n} \left\{ {F_{n - 1} (x_{n - 1} ),F_{n} (x_{n} )} \right\}\) pair-copula and \(f_{n - 1} (x_{n - 1} )\) marginal densities. For the random variables X1, X2 and X3, \(c_{12|3}\) suitable pair-copula can be written \(F(x_{1} |x_{3} )\) and \(F(x_{2} |x_{3} )\) for converted to values:
Alternative decomposition is as follows:
where \(c_{13|2}\) differs from the pair-copula equation in (8). \(f(x_{1} |x_{2} )\) decomposition in Eq. (7) follows the following.
where two pair-copulas are present.
It is now clear that any of the terms in Eq. (2) can be decomposed into several suitable pair-copulas and marginal densities using a general formula for a d-dimension vector v.
where \(v_{j}\) is an optional component of v, \(v_{ - j}\) refers to the vector v that contains this component. As a result, under appropriate conditions, the multivariate conditional density, expressed as the product of the pair-copula, acts differently on various conditional probability distributions. Given that the structure is iterative, and according to a special classification, there are still many different parameters that the pair-copula structure includes F(x|v) marginal distribution functions. Joe (1997) showed that for each j:
where \(C_{ij|k}\) is the copula bivariate distribution function. For a special case where v is univariate:
\(h(x,v,\Theta )\) is also used to represent the conditional distribution function in cases where x and v are uniform. For example: F (x) = x and F (v) = v, then f (x) = f (v) = 1, in this case:
The second parameter of the expression h(.) has a perfect correspondence with the conditional variable and \(\Theta\) refers to the set of parameters of the joint distribution function x and v for the copula. In addition, \(h^{ - 1} (u,v,\Theta )\) the inverse of the function h, with respect to the first variable u or its equivalent, is equal to the inverse of the conditional distribution function.
In traditional multidimensional copulas, all series should have the same dependency. When the dimensions reach more, the accuracy of traditional methods is significantly reduced. Reciprocally, vine copulas allow all types of dependencies in different pairs. While a d-dimensional vine is made by d (d—1) a double copula as a tree. There are several ways to make a copula tree. C- and D-vine copulas are common types of trees. For example, in a C-vine tree, the dependency is modeled for a special variable (as the first root node) by bivariate copulas for each pair. According to this variable, the dependencies of the other pairs are selected according to the second variable. R-vine copula is more drawable than C or D type because it allows for a wider range of sequences. In order to increase sequence diversity, R-vine copula introduces a new concept. Two specific characteristics of vine tree were identified by Bedford et al. (2001). One of them is called drawable vine tree (D-vine) and the other is called canonical vine tree (C-vine). They are defined as follows:
A regular vine (R-vine) copula:
D-vine, if each node in T-1 tree has a maximum of two edges.
C-vine, if each tree in Ti has a special node with d-1 edge. The node with d-1 edge in Ti tree is called the root.
For higher dimension distribution, there is a significant number of possible pair-copula sequences. For example, there are 240 different sequences for the five-dimensional state (Aas et al. 2009). In order to help organize them, a graphical model called a regular vine was introduced. The regular copula class is very broad and includes a large number of possible pair-copulas. Each model offers a specific method for density analysis. C- and D-vine also belong to regular vines. Their characteristics may be in the form of, for example, a set of nested trees. Figure 2 shows characteristics of a five-dimensional vine that consists of four trees Tj, J = 1,…, 4. Tj tree has j-6 nodes and j-5 edges. Each edge with density belongs to the pair-copula and the edge label also belongs to the pair-copula density sample. For example, edge 14 | 23 belongs to the copula density C14|23(.). All analyses are defined by n (n-1) / 2 edge and marginal density of each variable. Tj tree node is only needed to determine the edge labels in Tj + 1 tree. As shown in Fig. 2, the two edges in Tj (which become nodes in Tj + 1) become one edge in Tj + 1 only if these edges have a common node in Tj. Note that a tree sequence is not absolutely necessary to apply the pair-copula method, but it does help to identify different pair-copula decompositions.

D-Vine with five variables, four trees and ten edges. Each edge may be associated with a pair-copula (Aas et al. 2009)
Bedford and Cooke (2001) assigned the density of an n-dimensional distribution of regular copulas to C- and D-vine copulas. f(x1,…,xn) density of D-vine copula is written as follows:
where j represents the trees that i runs around the edges of each tree. In D-Vine copula, no node in any of Tj trees is attached to more than two edges. In a regular vine copula, each Tj tree has a unique node attached to the n—j edge. Figure 3 shows C-vine copula with five variables. The next n density corresponding to C-vine copula is as follows:

C-vine copula with 5 variables, 4 trees and 10 edges (Aas et al. 2009)
Knowing that C-vine copula is appropriate may be useful when a special variable is the key variable that governs the interaction in the data set. Such conditions, it may decide to replace this variable at the root of C-vine copula (as is shown in Fig. 3 in the first tree with variable number 1).
Trivariate state
The common definition for the structure of both 3-D C- and D-vine copulas is as follows:
There are six allowed methods for changing x1, x2, and x3 in Eq. (17), but only three methods have different decompositions. In addition, each of the three decompositions includes C- and D-vine copulas.
Conditional independence and pair-copula decompositions
Conditional independence can simplify analysis by reducing the level of pair-copula decompositions. Consider the three-dimensional process by decomposing the pair-copula in Eq. (2). For certain values of X1 and X3 with respect to X2, then, c13|2(F(x1|x2), F(x3|x2)) = 1. Therefore, pair-copula decomposition in this regard is simplified as follows.
for any vector of V and two variables X and Y, they are conditionally independent (with respect to V) if:
In hierarchical modeling, a model is simplified only if the common density factor uses the assumed conditional independence. For example, if the decomposition f(x1,x2,x3) = f(x2|x1,x3)f(x1|x3)f3(x3) is used in cases where X1 and X3 have conditional independence with X2, the existence of all pair-copulas is essential.
Confidence interval
Confidence interval for estimates xi are constructed using the standard error SE (xi). Lower and upper limit of the confidence interval for xi are calculated from (Apel 2004):
where z1–α/2 = –z α/2 is standard normal variable for levels corresponding to confidence interval 1 – α. where zp is standard normal variable corresponding to probability of nonexceedance p.
Results and discussion
Rainfall deficiency signature (RDS), river flow deficiency signature (FDS) and groundwater deficiency signature (GDS) were extracted using the desired method for a 60-day duration. The results of extracting the deficiency signatures for 10, 30 and 60-day durations are showed in Figs. 4, 5, 6.

Results of rainfall deficiency signature at Tapik rain gauge station for 10, 30 and 60-day durations in statistical period of 1977–2019

Results of river flow deficiency signature at Tapik hydrometric station for 10, 30 and 60-day durations in statistical period of 1977–2019

Results of groundwater level deficiency signature in Nazloo piezometric well for 10, 30 and 60-day durations in statistical period of 2004–2019
The reason for choosing a 60-day duration is to consider the worst possible conditions for the study area. Because rainfall deficiency of more than 60 days not exist, this duration was selected as the final duration. As shown in the above Figures, concentration pattern distribution is the same for all three durations. As shown, the changes in rainfall deficiency signature have intensified in recent years. Due to changes in river flow in Lake Urmia basin mentioned in various studies including Khalili et al. (2016), Tahroudi et al. (2018) and Khozeymehnezhad and Tahroudi (2019), it is possible to observe the increasing trend of river flow deficiency signature. The change in the form of rainfall in recent years and the disappearance of snow reserves in the northern regions of Lake Urmia basin, as well as climate change, led to a reduction in rainfall and river flow. In recent years, river flow deficiency has changed the regime of rivers and permanent rivers have become seasonal rivers and even flood crossing. This will cause many problems for the West Azerbaijan Province of Iran and Lake Urmia, which are highly dependent on surface water. Reducing river flow and limiting the irrigation cycle of fields in this basin cause farmers to turn to groundwater and dig unauthorized wells, which causes serious damage to the aquifer. Inlet flow to Lake Urmia, in addition to surface water, includes groundwater. Reducing the inflow of surface water and groundwater to Lake Urmia increases its water salinity. This increase in salinity causes damage to the habitats of living things and aquatic animals. The results indicated that the groundwater deficiency signature has an increasing trend. Due to the shallow depth of groundwater in the study area, the rainfall and river flow have a direct effect on groundwater level and there is not much time delay between mentioned variables. With the increase of groundwater level deficiency and due to the size of the aquifer, a large volume of groundwater becomes unavailable, which is very difficult to compensate for the shortage of reservoir.
On the other hand, by increasing extreme values of rainfall and also groundwater level, the soil texture is gradually damaged, which is irreparable, and the soil structure gradually becomes irreversible, which will help increase the flood potential. In the next step, different marginal distributions are fitted to the data. The results of comparing the different distributions based on Kolmogorov–Smirnov and Anderson Darling goodness of fit tests are presented in Table 2.
In this study, in order to obtain the best marginal distribution function, the common statistical distribution functions with two, three and four variables in hydrology were used. One of the important steps for applying copula functions is to discuss marginal distribution functions.
Trivariate analysis of groundwater deficiency signature affected by river flow and rainfall deficiency signatures for a 60-day duration
The studied signatures for 10, 30 and 60-day durations as well as rainfall, river flow and groundwater level were presented as shown in Fig. 7.

4-dimensional display of the studied signatures in Tapik basin (a: GDS, b: FDS and c: RDS)
In this section, different vine copulas including C-, D- and R-vine copulas are investigated and the best copula is selected according to the criteria (AIC, BIC and Log likelihood). However, the use of vine copulas requires correlation between the studied signatures. Correlation is essential for using copula functions. If there is a poor correlation, copula functions will not be able to multivariate analysis. According to the results of Kendall’s tau, the correlation between the studied signatures is confirmed and the accuracy of multivariate analyses can be ensured. Various studies such as Zhang et al. (2018), Cooke et al. (2015), Kurowicka and Cooke (2007), Aas et al. (2009), Bezak et al. (2017), Bevacqua et al. (2017), Khan et al. (2019), Graler et al. (2013), Brunner et al. (2019) and Tahroudi et al. (2020a, b) also confirmed and recommended Kendall’s tau to investigate the correlation of pair-variables. The study results of correlation between the studied signatures in Tapik basin are presented in Fig. 8. In Fig. 8, the main diameter elements represent marginal histogram of copula data, top triangular elements represent pair-copula data, and lower triangular elements represent normalized empirical contour lines of copula data. The numbers presented indicate the correlation of Kendall’s tau between the studied signatures. In the next step, vine copulas are fitted.

Study of correlation of studied signatures using Kendall’s tau in Tapik basin
Another noteworthy point is the selection of fitting trees. Rainfall and river flow will affect the groundwater level. In other words, river flow is affected by rainfall and on the other hand, the groundwater level is affected by river flow and rainfall. One of the important issues is the multiplicity of tree sequences in the use of vine copulas. In order to obtain the optimal copula, all the different tree sequence states created with C-, D- and R-vine copulas were analyzed and the results for Tapik basin are presented in Table 3, 4, 5, 6. Determining of copula parameters in this study was based on the maximum likelihood estimation (MLE( method.
As shown in Tables above, no significant difference was between AIC, BIC and Log likelihood statistics. Therefore, according to the physics of the problem as well as the calculated statistical parameters, D-vine copula was selected as the best copula. Finally, the selected tree is described in Fig. 9. It should be noted, however, that in the three-dimensional state, no difference was between C- and D-vine copulas in terms of tree sequence. But their parameters are different. In different studies, the dependence structure and tree sequence of vine copulas including C-, D- and R-vine have been investigated and their accuracy has been different for different data (depending on the physics of the problem). The results also indicate the ability of R-vine copula to analyze data and investigate uncertainty. This has also been confirmed and recommended in a study by Cooke et al. (2015). These models are able to manage large amounts of data and maintain the correlation of all executed values. Of course, R-vine copula functions have drawable sequences, but they have high complexity, which is the case mentioned in a study by Aas et al. (2009). On the other hand, Khan et al. (2019) by investigating the correlation structure of climatic variables showed that the accuracy of the two C- and D-vine copulas is almost close to each other.

Final tree of D-vine copula in three-dimensional structure analysis of groundwater level deficiency signature in Tapik basin
By introducing D-vine copula as the best copula for trivariate analysis of the studied signatures, the parameters of the internal copula functions for the joint analysis of the edges of pair-variables have also been calculated and presented. In the first tree, pair-variables, related copulas and edges are introduced and analyses are performed with selected copulas. In the second tree, according to the presented conditional structure, conditional and trivariate calculations are presented.
According to the selected sequences and edges, the analysis of the return period in "and" state of the groundwater deficiency signature affected by rainfall and river flow deficiency signatures was calculated and presented as shown in Fig. 10. The return period in "and" state is the state in which all three variables are less than a certain threshold. In the presented figures, the x-axis represents groundwater level deficiency signature, the y-axis represents rainfall deficiency signature, and the z-axis represents river flow deficiency signature. The color box to the right of the curves is also the 4th dimension. For example, increasing groundwater deficiency signature to about 0.5 m, which is affected by rainfall deficiency signature equal to 15 mm and river flow deficiency signature equal to 0.3 m3/s, has a return period of about 8 years.

Trivariate return period analysis of groundwater deficiency signature affected by river flow and rainfall deficiency signatures in "and" state for a 60-day duration
For the study basin, different states can be observed, each of which has a special return period. The curve presented in this section can be used as a complete reference for water resources management in terms of changes in rainfall, river flow and groundwater level. This curve shows the changes in the studied values during different return periods, each of which can be estimated to occur. These curves are in fact the evolved state of two-dimensional analysis that show the effect of rainfall changes on the river flow and groundwater level. Given that in the last tree, RDS60 | GDS60, FDS60 is established, river flow deficiency signature for a 60-day duration also depends on rainfall deficiency signature for a 60-day duration. As a result, changes in river flow and groundwater deficiency signatures can be considered as affected by rainfall deficiency signature. The accuracy of the calculations is acceptable according to the statistics used to investigate the tree sequence of the copulas. Because using AIC, BIC and Log likelihood statistics, the accuracy of the copulas was evaluated and the best copula was selected.
In this study, in order to investigate the efficiency of vine copulas for modeling and simulating the copula values of the studied signatures, the combination of conditional values of the selected copulas was used. According to the aim of this study, groundwater deficiency signature was simulated in the study area and the results of Pearson correlation between pair-variables were presented as shown in Fig. 11. It should be noted that red values indicate Kendall’s tau of measured data and black values indicate Kendall’s tau between simulated data (groundwater deficiency signature) and other signatures.

Results of groundwater level deficiency signature simulation in Tapik basin on the copula scale
The simulation was performed using vine copulas and selected internal copulas to evaluate the efficiency of the copulas for estimating the results. At this step, in order to estimate and determine the accuracy of the studied copulas, using conditional density of the copulas, the studied signatures were simulated for a 60-day duration. The other signature data were used to simulate the studied signatures. Thus, to simulate groundwater, river flow and rainfall deficiency signatures were used for a 60-day duration. Physically, in the case of groundwater level, it is possible to simulate groundwater level deficiency signature using rainfall and river flow deficiency signatures. But since groundwater level has no effect on river flow or rainfall, this simulation is physically rejected. However, simulation of rainfall and river flow deficiency signatures is presented only to investigate the accuracy of the copulas in the analyses. After simulating the studied signatures, the correlation of pair-signatures was investigated using Kendall’s tau test. The simulation results of studied pair-variables showed that correlation between rainfall and groundwater level deficiency signatures, and river flow and groundwater deficiency signatures at simulation stage reduced slightly. This reduction or increase in correlation values of the studied pair-copulas is not a reason for a reduction or increase in the accuracy of the copulas in the simulation of the studied signatures. RMSE and NSE statistics were used to investigate the accuracy and efficiency of the studied copulas in simulating the studied signatures. RMSE and NSE of the selected copulas for simulating groundwater deficiency signature for a 60-day duration due to rainfall and river flow deficiency signatures were 0.03 m and 70%, respectively. The results showed that vine copulas have high accuracy in simulating hydrological values. This has been the case mentioned and confirmed in various studies such as Aas et al. (2009) and Kurowicka and Cooke (2007). After simulating and confirming accuracy of the selected copula, joint frequency of the studied signatures was analyzed for a 60-day duration. The study results of the joint probability of occurrence of groundwater deficiency signature affected by rainfall and river flow deficiency signatures are presented in Fig. 12. For example, for this basin, the probability of increasing groundwater deficiency signature to more than 2.5 m, which is affected by rainfall deficiency signature equal to 300 mm and river flow deficiency signature equal to 2.5 m3/s, is about 90%.

Joint probability of occurrence of groundwater deficiency signature for a 60-day duration in Tapik basin
The results of joint probability analysis of the studied signatures showed that the use of vine copulas as well as three-dimensional analysis can well show the changes in water resources signatures of the studied basin. The presented four-dimensional curves show the probability of occurrence of water resources signatures in the basin. Groundwater level in areas with surface water resources, such as Lake Urmia, is not dependent on rainfall as the only factor. For this reason, the use of trivariate analysis and the involvement of effective parameters such as rainfall and river flow deficiency signatures, increases the accuracy of groundwater deficiency signature estimation. Also, using the presented curves, the effect of each of rainfall and river flow deficiency signatures can be observed on groundwater level deficiency signature. This is also very important physically, because using the presented curves, the effect of rainfall can be directly and indirectly observed on groundwater level. The presented curves can be used as typical curves for water resources monitoring in the basin. The presented curves will act as a continuous monitoring system in the basin. Graler et al. (2013) in their studies on the multivariate flood return period showed that in the joint case, the probability of occurrence is closer to reality. On the other hand, the results of simulation also confirmed the performance of the selected copulas.
Conclusion
The combined, multivariate, or dependent events are multivariate extreme events that may not be limited in themselves, but their occurrence causes other events to occur. The conventional univariate statistical analysis in these cases cannot provide accurate information about the multivariate nature of these dependent events. Therefore, the risk associated with these events is not possible by univariate statistical analysis. Because the existing approaches are statistically different, from a scientific point of view, it is almost impossible to provide a suitable approach for estimating multivariate cases. Many practical models and approaches based on the concept of univariate return period have been proposed by researchers so far. But the multivariate return period has a different meaning. On the other hand, simulation using copulas is very helpful in investigating accuracy of selected copulas in the analyses performed. The results showed that in case of reduced rainfall in the study area, which is the first tangible factor in each basin, deficiency of other signatures can be estimated with different probabilities. This model is plotted using the many complexities that exist in terms of three-dimensional copula functions, parameter estimation, tree sequences, and conditional density. At later stages, future predictions can be very effective and there are no complexities in calculating curves. Given that each curve is specific to the relevant basin, these curves can be used as long as the changes in rainfall are not significant and there is no time of changing point in the data. These curves can be used to joint frequency analysis of water resources signatures in the study basin. For each rainfall deficiency signature (y axis), it is possible to observe river flow and groundwater level deficiency signatures affected by rainfall deficiency signature with different probabilities of occurrence. The results showed that by increasing rainfall deficiency signature, the joint probability of occurrence as well as groundwater level and river flow deficiency signatures increases. In the study basin, three-dimensional analysis of groundwater deficiency signature showed that with a reduction of more than 150 mm in rainfall, groundwater level increases significantly. In this case, river flow is reduced by about 2 m3/s. Groundwater level in this basin is highly dependent on rainfall changes. As rainfall deficiency signature in the study area increases, the decreasing trend of river flow increases. This is due to the seasonal rivers in this basin in recent years. The results showed that the probability of increasing groundwater level in trivariate state in the study basin is not less than 30%. The study results of the return periods of groundwater deficiency signature also showed that in the study basin, the increase in groundwater level every year is not far from expectation. In most cases, the return periods of groundwater deficiency signature in the basin are less than 5 years. 4-D curves of joint frequency analysis can be used in aquifer management, surface water and groundwater resources allocation, as well as water resources management in the basin.
Availability of data and material
Data collected by the author and secondary data are cited.
References
Aas K, Czado C, Frigessi A, Bakken H (2009) Pair-copula constructions of multiple dependence. Insur: Math Econ, 44(2): 182–198.
Abdi A, Hassanzadeh Y, Talatahari S, Fakheri-Fard A, Mirabbasi R (2017) Regional bivariate modeling of droughts using L-comoments and copulas. Stoch Env Res Risk Assess 31(5):1199–1210
Adamson PT, Metcalfe AV, Parmentier B (1999) Bivariate extreme value distributions: an application of the Gibbs sampler to the analysis of floods. Water Resour Res 35(9):2825–2832
Apel H, Thieken AH, Merz B, Blöschl G (2004) Flood risk assessment and associated uncertainty. Nat Hazard 4(2):295–308
Bedford T, Cooke R (2001) Probabilistic risk analysis: foundations and methods. Cambridge University Press
Besharat S, Khalili K, Tahrudi MN (2014) Evaluation of SAM and Moments methods for estimation of log Pearson type III parameters (Case Study: daily flow of rivers in Lake Urmia basin). J Appl Environ Biol Sci 4(S1):24–32
Bevacqua E, Maraun D, HobækHaff I, Widmann M, Vrac M (2017) Multivariate statistical modelling of compound events via pair-copula constructions: analysis of floods in Ravenna (Italy). Hydrol Earth Syst Sci 21(6):2701–2723
Bezak N, Rusjan S, KramarFijavž M, Mikoš M, Šraj M (2017) Estimation of suspended sediment loads using copula functions. Water 9(8):628
Brunner MI, Furrer R, Favre AC (2019) Modeling the spatial dependence of floods using the Fisher copula. Hydrol Earth Syst Sci 23(1):107–124
Calvo B, Savi F (2009) Real-time flood forecasting of the Tiber river in Rome. Nat Hazards 50(3):461–477
Chebana F, Ouarda TB (2011) Multivariate quantiles in hydrological frequency analysis. Environmetrics 22(1):63–78
Chen L, Singh VP, Guo S, Zhou J, Ye L (2014) Copula entropy coupled with artificial neural network for rainfall–runoff simulation. Stoch Env Res Risk Assess 28(7):1755–1767
Chen L, Singh VP, Guo S, Zhou J, Zhang J (2015) Copula-based method for multisite monthly and daily streamflow simulation. J Hydrol 528:369–384
Cooke RM, Kurowicka D, Wilson K (2015) Sampling, conditionalizing, counting, merging, searching regular vines. J Multivar Anal 138:4–18
De Michele C, Salvadori G (2003) A generalized Pareto intensity‐duration model of storm rainfall exploiting 2‐copulas. J Geophys Res: Atmos, 108(D2).
De Michele C, Salvadori G, Passoni G, Vezzoli R (2007) A multivariate model of sea storms using copulas. Coast Eng 54(10):734–751
Fan YR, Huang GH, Li YP, Wang XQ, Li Z (2016) Probabilistic prediction for monthly streamflow through coupling stepwise cluster analysis and quantile regression methods. Water Resour Manage 30(14):5313–5331
Favre AC, Musy A, Morgenthaler S (2002) Two-site modeling of rainfall based on the Neyman-Scott process. Water Resour Res 38(12):43–51
Favre A C, El Adlouni S, Perreault L, Thiémonge N, Bobée B (2004) Multivariate hydrological frequency analysis using copulas. Water Resour Res, 40(1).
Freer J, Beven K, Ambroise B (1996) Bayesian estimation of uncertainty in runoff prediction and the value of data: An application of the GLUE approach. Water Resour Res 32(7):2161–2173
Gräler B, van den Berg M, Vandenberghe S, Petroselli A, Grimaldi S, De Baets B, Verhoest N (2013) Multivariate return periods in hydrology: a critical and practical review focusing on synthetic design hydrograph estimation. Hydrol Earth Syst Sci 17(4):1281–1296
Grimaldi S, Serinaldi F (2006a) Asymmetric copula in multivariate flood frequency analysis. Adv Water Resour 29(8):1155–1167
Grimaldi S, Serinaldi F (2006b) Design hyetograph analysis with 3-copula function. Hydrol Sci J 51(2):223–238
Guo S, Zhang H, Chen H, Peng D, Liu P, Pang B (2004) A reservoir flood forecasting and control system for China/Un système chinois de prévision et de contrôle de crue en barrage. Hydrol Sci J, 49(6).
Joe H (1997) Multivariate models and multivariate dependence concepts: Chapman and Hall/CRC.
Kao S C, Govindaraju R S (2007) A bivariate frequency analysis of extreme rainfall with implications for design. J Geophys Res: Atmos, 112(D13).
Kao S C, Govindaraju R S (2008) Trivariate statistical analysis of extreme rainfall events via the Plackett family of copulas. Water Resour Res, 44(2).
Kao SC, Govindaraju RS (2010) A copula-based joint deficit index for droughts. J Hydrol 380(1–2):121–134
Keef C, Svensson C, Tawn JA (2009) Spatial dependence in extreme river flows and precipitation for Great Britain. J Hydrol 378(3–4):240–252
Khalili K, Tahoudi MN, Mirabbasi R, Ahmadi F (2016) Investigation of spatial and temporal variability of precipitation in Iran over the last half century. Stoch Env Res Risk Assess 30(4):1205–1221
Khan F, Spöck G, Pilz J (2019) A novel approach for modelling pattern and spatial dependence structures between climate variables by combining mixture models with copula models. Int J Climatol 40(2):1049–1066
Khashei‐Siuki A, Shahidi A, Ramezani Y, Nazeri Tahroudi M (2021) Simulation of potential evapotranspiration values based on vine copula. Meteorol Appl, 28(5): e2027.
Khozeymehnezhad H, Tahroudi MN (2019) Annual and seasonal distribution pattern of rainfall in Iran and neighboring regions. Arab J Geosci 12(8):1–11
Krzysztofowicz R (1999) Bayesian theory of probabilistic forecasting via deterministic hydrologic model. Water Resour Res 35(9):2739–2750
Kuhn G, Khan S, Ganguly AR, Branstetter ML (2007) Geospatial–temporal dependence among weekly precipitation extremes with applications to observations and climate model simulations in South America. Adv Water Resour 30(12):2401–2423
Kurowicka D, Cooke RM (2007) Sampling algorithms for generating joint uniform distributions using the vine-copula method. Comput Stat Data Anal 51(6):2889–2906
Li F, Zheng Q (2016) Probabilistic modelling of flood events using the entropy copula. Adv Water Resour 97:233–240
Liu XF, Wang SX, Zhou Y, Wang FT, Yang G, Liu WL (2016) Spatial analysis of meteorological drought return periods in China using copulas. Nat Hazards 80(1):367–388
Mirabbasi R, Anagnostou EN, Fakheri-Fard A, Dinpashoh Y, Eslamian S (2013) Analysis of meteorological drought in northwest Iran using the joint deficit index. J Hydrol 492:35–48
Mirakbari M, Ganji A, Fallah S (2010) Regional bivariate frequency analysis of meteorological droughts. J Hydrol Eng 15(12):985–1000
Mogheir Y, Singh VP, De Lima JLMP (2006) Spatial assessment and redesign of a groundwater quality monitoring network using entropy theory, Gaza Strip. Palestine Hydrogeol J 14(5):700–712
Montanari A (2007) What do we mean by ‘uncertainty’? The need for a consistent wording about uncertainty assessment in hydrology. Hydrol Proc: an Int J 21(6):841–845
Montanari A, Grossi G (2008) Estimating the uncertainty of hydrological forecasts: a statistical approach. Water Resour Res, 44(12).
NazeriTahroudi M, Ramezani Y, De Michele C, Mirabbasi R (2021) Flood routing via a copula-based approach. Hydrol Res 52(6):1294–1308
Nelsen R B (2006) An introduction to copulas, ser. Lecture Notes in Statistics. New York: Springer.
Ramezani Y, NazeriTahroudi M, Ahmadi F (2019) Analyzing the droughts in Iran and its eastern neighboring countries using copula functions. Q J Hung Meteorol Serv 123(4):435–453
Ramos MH, Van Andel SJ, Pappenberger F (2013) Do probabilistic forecasts lead to better decisions? Hydrol Earth Syst Sci 17(6):2219–2232
Ravines RR, Schmidt AM, Migon HS, Rennó CD (2008) A joint model for rainfall–runoff: the case of Rio Grande basin. J Hydrol 353(1–2):189–200
Renard B, Kavetski D, Kuczera G, Thyer M, Franks S W (2010) Understanding predictive uncertainty in hydrologic modeling: the challenge of identifying input and structural errors. Water Resour Res, 46(5).
Renard B, Lang M (2007) Use of a Gaussian copula for multivariate extreme value analysis: some case studies in hydrology. Adv Water Resour 30(4):897–912
Salvadori G, De Michele C (2004) Analytical calculation of storm volume statistics involving Pareto‐like intensity‐duration marginals. Geophys Res Lett, 31(4).
Salvadori G, De Michele C (2010) Multivariate multiparameter extreme value models and return periods: a copula approach. Water Resour Res 46(10).
Salvadori G, De Michele C (2007) On the use of copulas in hydrology: theory and practice. J Hydrol Eng 12(4):369–380
Salvadori G, De Michele C, Kottegoda N T, Rosso R (2007) Extremes in nature: an approach using copulas (Vol. 56). Springer Science & Business Media.
Serinaldi F, Bonaccorso B, Cancelliere A, Grimaldi S (2009) Probabilistic characterization of drought properties through copulas. Phys Chem Earth, Parts a/b/c 34(10–12):596–605
Shiau JT, Wang HY, Tsai CT (2006) Bivariate frequency analysis of floods using COPULAS1. Jawra J Am Water Resour Assoc 42(6):1549–1564
Sklar M (1959) Fonctions de repartition an dimensions et leurs marges. Publ Inst Statist Univ Paris 8:229–231
Song S, Singh VP (2010) Frequency analysis of droughts using the Plackett copula and parameter estimation by genetic algorithm. Stoch Env Res Risk Assess 24(5):783–805
Tahroudi MN, Khalili K, Ahmadi F, Mirabbasi R, Jhajharia D (2018) Development and application of a new index for analyzing temperature concentration for Iran’s climate. Int J Environ Sci Technol 16(6):2693–2706
Tahroudi MN, Pourreza-Bilondi M, Ramezani Y (2019a) Toward coupling hydrological and meteorological drought characteristics in lake Urmia basin. Iran Theor Appl Climatol 138(3):1511–1523
Tahroudi MN, Siuki AK, Ramezani Y (2019b) Redesigning and monitoring groundwater quality and quantity networks by using the entropy theory. Environ Monit Assess 191(4):250
Tahroudi MN, Ramezani Y, De Michele C, Mirabbasi R (2020a) A new method for joint frequency analysis of modified precipitation anomaly percentage and streamflow drought index based on the conditional density of copula functions. Water Resour Manage 34(13):4217–4231
Tahroudi MN, Ramezani Y, De Michele C, Mirabbasi R (2020b) Analyzing the conditional behavior of rainfall deficiency and groundwater level deficiency signatures by using copula functions. Hydrol Res 51(6):1332–1348
Verkade JS, Werner MGF (2011) Estimating the benefits of single value and probability forecasting for flood warning. Hydrol Earth Syst Sci 15(12):3751–3765
Wetterhall F, Pappenberger F, Alfieri L, Cloke HL, Thielen-del Pozo J, Balabanova S, Cabrera-Tordera AJ (2013) HESS opinions" forecaster priorities for improving probabilistic flood forecasts". Hydrol Earth Syst Sci 17(11):4389–4399
Wu X, Wang Z, Guo S, Liao W, Zeng Z, Chen X (2017) Scenario-based projections of future urban inundation within a coupled hydrodynamic model framework: a case study in Dongguan City, China. J Hydrol 547:428–442
Xiao Y, Guo S, Liu P, Fang B (2008) A new design flood hydrograph method based on bivariate joint distribution. IAHS Publ-Ser Proc Rep 319:75–82
Yue S, Ouarda TBMJ, Bobee B (2001) A review of bivariate gamma distributions for hydrological application. J Hydrol 246(1–4):1–18
Zhang L, Singh V (2006) Bivariate flood frequency analysis using the copula method. J Hydrol Eng 11(2):150–164
Zhang L, Singh VP (2007a) Bivariate rainfall frequency distributions using Archimedean copulas. J Hydrol 332(1–2):93–109
Zhang L, Singh VP (2007b) Gumbel-Hougaard copula for trivariate rainfall frequency analysis. J Hydrol Eng 12(4):409–419
Zhang Q, Li J, Singh VP, Xu CY (2013) Copula-based spatio-temporal patterns of precipitation extremes in China. Int J Climatol 33(5):1140–1152
Zhang J, Chen L, Singh VP, Cao H, Wang D (2015) Determination of the distribution of flood forecasting error. Nat Hazards 75(2):1389–1402
Zhang D, Yan M, Tsopanakis A (2018) Financial stress relationships among Euro area countries: an R-vine copula approach. Eur J Finance 24(17):1587–1608
Acknowledgements
The authors would like to thank the Politecnico di Milano for providing the facilities to the first author as a visiting researcher. Also, the authors would like to thank the Iran Water Resources Management Company for providing the data.
Funding
The authors received no specific funding for this work.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
No conflicts of interest involved.
Ethics approval
In compliance with ethical standards.
Consent to participate
Consent by all authors.
Consent for publication
Consent by all authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Nazeri Tahroudi, M., Ramezani, Y., De Michele, C. et al. Trivariate joint frequency analysis of water resources deficiency signatures using vine copulas. Appl Water Sci 12, 67 (2022). https://doi.org/10.1007/s13201-022-01589-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s13201-022-01589-4