
Abstract
This paper presents the use of two artificial intelligence modeling methods, namely genetic programming (GP) and adaptive neuro-fuzzy inference system (ANFIS), to predict pier scour depth based on clear water conditions of 320 data sets of laboratory and field data measurements. The scour depth was modeled as a function of five main dimensionless parameters: pier width, approaching flow depth, Froude number, standard deviation of grain size distribution, and channel open ratio. A functional relationship was established using the trained GP model, and its performance was verified by comparing the results with those obtained by the ANFIS model and seven conventional regression-based formulas. Numerical tests indicated that the GP model yielded much superior agreement than the ANFIS model or any other empirical equation. The advantage of the GP model was confirmed by applying the derived GP equation to predict the scour depth around the piers of Imbaba Bridge, Egypt.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Bridge scour is the result of the erosive action of flowing water, excavating and carrying away material from the bed and banks of streams and from around the piers and abutments of bridges (Richardson and Davis 2001). The scour is accountable for about 60% of bridge failures (Lagasse et al. 1997), resulting in loss of lives and huge economic losses. Designing the bridge foundation safely needs an accurate estimation of scour depth; underestimation may lead to bridge failure, while overestimation will lead to excessive construction costs (Azamathulla and Ghani 2010).
Pier scour attracted significant research interest for more than a century now, and numerous studies on this subject were published. Much of this research dealt with laboratory model studies of local scour. In this context, several reviews summarized equations for pier scour depths in Breusers et al. (1977), Dey (1997), and Melville and Sutherland (1988). However, these equations are often suitable only for conditions similar to those under which they were developed. Moreover, this empirical approach suffers from its associated simplified conditions and scale effects. When applying the existing empirical equations for predicting bridge pier scour to field cases, the scour depths are overpredicted (Babaeyan-Koopaei and Valentine 1999). This means increased construction and maintenance costs as the foundation levels are required to be deeper than it should be.
Soft computing tools gained importance in many fields as they differ from conventional hard computing in many ways, such as their robustness, low solution cost, and tolerance to imprecision (Chuan-Yi et al. 2013). Artificial intelligence methods, such as artificial neural networks (ANNs), adaptive neuro-fuzzy inference systems (ANFIS), genetic programming (GP), and linear genetic programming (LGP), are now widely used to predict scour around hydraulic structures and bridge piers. The American Society of Civil Engineers Task Committee (2000) reported the application of ANNs in different fields of hydrology. Deo et al. (2008) used GP to predict scour depth downstream of spillways. Azamathulla et al. (2008a, b) used ANNs and GP to determine scour depth downstream of ski-jump buckets. Guven et al. (2009) applied LGP for predicting scour depth at circular piles. ANFIS and genetic expression programming were used by Azamathulla et al. (2009a, b) to estimate scour below flip buckets. For scour below a submerged pipeline, Azamathulla et al. (2011) employed the LGP model. Najafzadeh and Barani (2011) compared the group method of data handling-based GP and the back-propagation system to predict scour depth around bridge piers.
Different from traditional physically based analytical or empirical approaches, this study investigates the utility of artificial intelligence modeling tools in predicting scour depth around bridge piers. The main objective of this research was to further enhance the available inductive modeling tools for predicting bridge scour by developing ANFIS and GP-based models for pier scour prediction utilizing available laboratory and field data and comparing their performance with several well-known bridge pier regression-based models. The already existing equations used in this study are Modified Laursen by Neill (1964), Shen et al. (1969), The Colorado State University (1975), Jain and Fischer (1979), Kothyari et al. (1992), Modified Froehlich by Fischenich and Landers (1999), and Richardson and Davis (2001). A further objective of this research was to find out which of the existing formulae works for the Nile River and how well the newly developed formula performs. Thus, the applicability of the GP model, provided that it yielded better prediction results, to large-scale models and field data was verified via applying the developed GP model to the case of Imbaba Bridge, Giza, Egypt.
Proposed artificial intelligence networks
Genetic programming (GP) and ANFIS being recently the most widely used branches of soft computing in hydraulic engineering were employed in this research as an alternative tool in the prediction of local scour around bridge piers.
Adaptive neuro-fuzzy inference system
The ANFIS is a hybrid scheme which uses the learning capability of the ANN to derive the fuzzy if–then rules with appropriate membership functions worked out from the training pairs, leading finally to the inference (Tay and Zhang 1999). The difference between the common neural network and the ANFIS is that while the former captures the underlying dependency in the form of the trained connection weights, the latter does so by establishing the fuzzy language rules (Azamathulla et al. 2009a, b). The input in ANFIS is first converted into fuzzy membership functions, which are combined together and, after following an averaging process, used to obtain the output membership functions and finally the desired output (Mousavi et al. 2007).
The configuration of an adaptive network performs a static node function on its incoming signals to generate a single node output, and each node function is a parameterized function with modifiable parameters (Navneet et al. 2015). Thus, a trial-and-error method, where a range of different shapes, numbers, and types of membership functions, as well as various parameters used as input data, should be followed toward identifying the optimal ANFIS architecture.
Genetic programming
Genetic programming (GP) is an extension of John Holland’s genetic algorithms (GAs) proposed by Koza (1992). The major difference between GP and GAs is that the variable parse tree structure of GP replaces the fixed gene structure of GAs (Chuan-Yi et al. 2013). Genetic programming uses four steps to solve problems:
- 1.
Generate an initial population of random compositions of the functions and terminals of the problem (computer programs).
- 2.
Execute each program in the population and assign it a fitness value according to how well it solves the problem.
- 3.
Create a new population of computer programs.
- (a)
Copy the best existing programs.
- (b)
Create new computer programs by mutation.
- (c)
Create new computer programs by crossover.
- 4.
The best computer program that appeared in any generation, the best-so-far solution, is designated as the result of genetic programming (Koza 1992).
Based on the natural selection obtained by way of the evolutionary process, GP produces an optimal function set (formula). The use of this flexible coding system allows the algorithm to perform structural optimization (Chuan-Yi et al. 2013). This can be useful in solving many engineering problems. In the development of the GP model, the terminal set, functional set, fitness function, algorithm control parameters, and termination criterion are defined (Koza 1992). The first three components determine the algorithm search space, whereas the last two components affect the quality and speed of the search.
Pier scour parameters
The equilibrium local scour depth (ds) around a pier (Fig. 1) in a steady flow over a bed of uniform and non-cohesive sediment depends on numerous parameters including flow, fluid, sediment characteristics, and pier geometry. The factors affecting the magnitude of the local scour depth at piers are stated in Bateni et al. (2007) as follows: velocity of the approach flow, depth of flow, width of the pier, length of the pier if skewed to flow, size and gradation of bed material, angle of attack, and bed configuration.

Flow and local scour at bridge pier (Bateni et al. 2007)
Local scour depth at piers is a function of the following decision variables:
where U is the approach velocity, Y is the approach flow depth, ρ is the mass density of water, ρs is the mass density of sediment, g is the acceleration due to gravity, d50 is the particle mean diameter, D is the pier width, L is the length of the pier, σ is the standard deviation of grain size distribution, α is the opening ratio (= (B − D)/B), and B is the channel width. However, the influence of the Reynolds number Re is insignificant for a turbulent flow over rough beds (Melville and Coleman 2000). Considering uniform sediments, dimensional analysis of the variables in Eq. (1) reduces it to five dimensionless parameters as follows:
where Fr is the Froude number. These five parameters were used as decision variables in the development of the GP model.
Conventional regression models
Most of the pier scour prediction formulae available in the literature are based on conventional regression methods and most overpredict pier scour, resulting in an uneconomical bridge foundation design. In this section, a list is made of the bridge pier scour equations used in this study. In all the formulae listed below, it was assumed that the flow angle of the attack is negligible and that the pier shape is rectangular. Chang (1988) reported that the scour depth of circular piers is 90% of that for rectangular piers and 80% of that for sharp-nosed piers. It was also assumed that the effect of the flow angle of attack and the circular shape of the pier will mutually cancel each other. This is done because of the lack of information about these factors in the data.
The Modified Laursen by Neill (1964) equation
Neill (1964) used Laursen and Toch’s (1956) design curve to obtain the following explicit formula for the scour depth:
where ds is the equilibrium scour depth, D is the obstruction width (or pier width), and Y is the approach water depth. This equation does not include the Froude number or in other words the velocity of the attacking stream.
Shen et al. (1969) formula
Shen et al. (1969) used the Froude number in their scour depth prediction in addition to the pier width as given as follows:
where Fr is the Froude number and the other variables are as defined before.
The Colorado State University (CSU) formula (1975)
This equation is developed as a best fit to the data (laboratory) available at the time. The formula is given as:
The CSU (1975) formula is similar in form to Shen et al. (1969) equation. Later on, correction factors were added for the effects of flow angle, pier shape, and bed conditions.
Jain and Fischer (1979) equations
Jain and Fischer (1979) developed a set of equations based on laboratory data. For (Fr − Fc) > 0.2, the formula reads as:
where Fc is the critical Froude number. For (Fr − Fc) < 0.2, the formula is:
Kothyari et al. (1992) formula
Kothyari et al. (1992) developed the following equation:
Modified Froelich by Fischenich and Landers (1999) formula
Fischenich and Landers (1999) modified Froelich’s (1988) equations for live-bed scour at bridge crossings as:
where \(\theta\) is the angle of flow attack (°). This equation does include a safety factor (+ 1.0) that accounts for contraction scour in most cases. To compare this formula with other formulae, this factor will not be considered, as only local bridge pier scour is considered herein.
Richardson and Davis (2001) formula
Originally, this formula was presented in HEC-18 (Richardson and Davis 2001) and was recently used by Mohamed et al. (2005) for comparison with other regression-based equations.
Different values for Ks and Kθ are reported by Simons and Senturk (1992).
Development of ANFIS and GP models
The experimental results of the laboratory study were used in training and testing sets of the proposed ANFIS and GP models. The data sets that were used were collected from the studies of Chabert and Engeldinger (1956), Verstappen (1978), Walker (1978), Melville and Chiew (1999), Mohamed et al. (2006) and Beg (2013). A total number of 150 datasets were collected. From the total 150 test sets, 110 sets were selected randomly for the training and the remaining 40 sets were used for validating the proposed two models. Table 1 presents the ranges of various parameters used in developing the two models. After training and validating the models, the field data (170 data sets) collected by Mueller and Wagner (2005) was employed to verify the developed models (Table 1).
ANFIS model
The ANFIS model was established using the MATLAB fuzzy logic toolbox. First, all data and input parameters were utilized in search of the best performing ANFIS structure. This involves running models (22 models) with various types of membership functions and the number of membership functions for each input parameter.
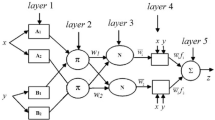
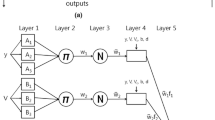
The ANFIS model network includes five layers and works according to Takagi and Sugeno (1985) as follows: In the first layer, let x and y be the typical input values fed at the two input nodes, which will then transform those values to the membership functions (say bell-shaped) and give the output as follows: note in general, w = output from a node; l = membership function, Ai, Bi = fuzzy sets associated with nodes x, y.
where a1, b1, and c1 = changeable premise parameters. Similar computations are carried out for the input of y to obtain \(\mu_{Bi} \left( y \right)\). The membership functions are thereafter multiplied in the second layer, e.g.,
Such products or firing strengths are then averaged in the third layer. Nodes of the fourth layer use the above ratio as a weighting factor, and using fuzzy if–then rules produces the output as below: (An example of the if–then rule is: If x is A1 and y is B1 then f1= p1x + q1y + r1.)
where p, q, r = changeable consequent parameters. The final network output f is produced by the node of the fifth layer as a summation of all incoming signals, exemplified in Eq. (13).
For imparting faster training and adjusting the network parameters to the above network, a two-step process is used. In the first step, the premise parameters are kept fixed and the information is propagated forward in the network to layer 4, where a least-squares estimator identifies the consequent parameters. In the second step, the backward pass, the consequent parameters are held fixed while the error is propagated, and the premise parameters are modified using the gradient descent.
It was realized that using three or more membership functions not only results in overtraining, but also is exponentially more costly in time required to train the model (e.g., the time required for training the model with four membership functions per input was 50 times greater than for the model employing only three). The optimum value of the cluster radius was determined by the trial-and-error method based on the criterion of the maximum correlation coefficient and minimum root-mean-square error. An optimum value of 0.58 was realized for the cluster radius, for which the optimum number of rules obtained was 6. Thus, using two membership functions per input, subtractive clustering with six rules, and testing for different types of membership functions ranging from triangular to sigmoid, the Gaussian was found to obtain the best accuracy, with good generalization ability. The prediction of the ANFIS model versus the actual experimental values for the training and testing sets is shown in Figs. 2 and 3.

ANFIS- and GP-predicted values of ds/D versus measured values for training sets

ANFIS- and GP-predicted values of ds/D versus measured values for testing sets
GP model
In this study, the GP model for scour depth prediction was developed using the epochX, a powerful Java software computing package. The function set consisted of eight basic arithmetic operators (+, −, × , ÷, √, log, exp, and power) and constants. The terminal set included five fundamental groups of hydraulic parameters of ds, as expressed in Eq. (14). The terminal set encompasses the dimensionless relationships obtained from the variables influencing ds, as expressed by Eq. (2).
In this study, the operations of crossover and mutation were selected as 0.30–0.70 and 0.01–0.10, respectively. The population size considered was 500–1000 members. The total number of generations was 1000–10,000, and the maximum depth of the parse tree structure was allowed during 20–25 generations. The restriction in the maximum depth of the parse tree structure is aimed at achieving a balanced accuracy of the solutions and the parsimony problem in GP. The parsimony problem indicates the diverging growth of population size without an associated increase in fitness during the process of obtaining best-fit optima. The fitness function was the sum of absolute differences (SAD= Σ Pi − mi) between the measured values and the estimated values present in the database. The program was run for a number of generations and was stopped when there was no improvement in fitness function value or coefficient of determination. The optimum result found through the GP development and program was obtained when the population size was 700 members with a total of 5500 generations having crossover 0.6 and mutation 0.05. The prediction of the proposed GP formula versus the actual experimental values for the training and testing sets is shown in Figs. 2 and 3. It is a common result that the predictions of training sets are slightly better than the results for the testing sets. These figures show that the proposed GP formula can learn very well the nonlinear relationship between parameters and also provide high generalization capacity. The generated prediction formula of GP for ds/D is given in Eq. (15) as follows:
Results and discussion
The comparison of ds/D predicted using the ANFIS model and Eq. (15) derived from the GP model with that predicted using empirical equations proposed by various researchers is presented in Figs. 4, 5, 6, 7, 8, 9, and 10 and in Table 2. For this comparison, the experimental data given in Table 1 are used. The performance of these formulas is validated in terms of the common statistical measures of the root-mean-square error (RMSE), mean absolute percentage error (MAPE), and correlation coefficient (R). The results indicated that the GP model (Eq. 15) has a superior performance to the ANFIS model and the empirical pier scour equations furnished in "Conventional regression models" section for all the experimental data considered. The values of RMSE, MAPE, and R for the proposed GP formula considering all data (Table 2) are 0.29, 19.85%, and 0.89, respectively, which are better than those of other equations in this study. The equations of Richardson and Davis (2001) and The Colorado State University (1975) resulted in larger errors than did the other equations.

ANFIS- and GP-predicted values of ds/D versus Modified Laursen (1964) values

ANFIS- and GP-predicted values of ds/D versus Shen et al. (1969) values

ANFIS- and GP-predicted values of ds/D versus CSU (1975) values

ANFIS- and GP-predicted values of ds/D versus Jain and Fischer (1979) values

ANFIS- and GP-predicted values of ds/D versus Kothyari et al. (1992) values

ANFIS- and GP-predicted values of ds/D versus Modified Froelich (1999) values

ANFIS- and GP-predicted values of ds/D versus Richardson and Davis (2001) values
A comparison between the proposed GP equation (Eq. 15), ANFIS model results, and all other pier scour equations (Table 2) for different ranges of D/d50 and Y/D was carried out. For all ranges of D/d50 and Y/D, the proposed GP performance gives the best results that are quantitatively reflected in all statistical parameters, i.e., RMSE, MAPE, and R. GP followed by ANFIS outperforms in high-value predictions for the conditions of D/d50 > 100, D/d50≦ 40, Y/D > 2, Y/D ≦ 1, compared to all other traditional equations. It should be noted that GP is more effective at extreme ranges of D/d50 and Y/D.
The results confirmed that none of the conventional regression equations give acceptable results, as reflected in higher RMSE and MAPE and lower R for D/d50 ≦ 100. At D/d50 > 100, only the equation by Kothyari et al. (1992) gave good results. Also, for dimensionless approaching flow depth Y/D < 1, the equation of Kothyari et al. (1992) performed well, as reflected in lower RMSE and MAPE. However, at 1 < Y/D, all of them gave reasonable results because the depth was difficult to measure for this range. The comparison of ANFIS and GP performance with other empirical equations presented in Figs. 4, 5, 6, 7, 8, 9, and 10 illustrates that the pier scour equations of Modified Froelich by Fischenich and Landers (1999) and Richardson and Davis (2001) over-estimated scour depth (Figs. 9, 10) because these formulas are based on high safety factors and envelop curves to data. Therefore, the correlation coefficient R for these two equations is lower in some selected ranges of D/d50 and Y/D, indicating poor performance. However, the equation of Shen et al. (1969) overpredicted the scour depth to some extent (Fig. 5) but performed well under the conditions of D/d50 > 100, 0 < Y/D ≤ 1. Contrary to this, the equations of Jain and Fischer (1979) under-predicted the scour depth at some ranges (Fig. 7). Furthermore, the equation of Kothyari et al. (1992) has an advantage over the other equations, as it is based on a large data range, which was used for regression analysis, but with minimal R in some selected ranges. The correlation coefficient R is lower, showing that there is a wide variation in the prediction of scour depth.
The robustness of ANFIS and GP was further verified and evaluated with the field data of (Mueller and Wagner 2005), which were not used in developing the ANFIS and GP models. Table 2 furnishes details of the data. The RMSE, MAPE, and R values using the ANFIS and GP models for these data are listed in Table 2. The statistical parameters show that the prediction performance of both ANFIS and GP is satisfactory. Hence, the two models can be used with a wide range of data because the data of Mueller and Wagner (2005) consist of large-scale pier models. Figure 11 shows the comparison of scour depth as predicted by the GP and ANFIS models and respective field data.

ANFIS- and GP-predicted values of ds/D versus field data values
The relatively inferior performance of the regression-based models further strengthens the notion that such models are not always suitable for effectively predicting bridge pier scour depth.
GP model application to Imbaba Bridge, Egypt
According to the results discussed above, the GP model proved to provide a better prediction of the local scour depth around bridge piers other than the ANFIS model and other empirical formulas. Hence, it is used to investigate the local scour around bridge piers for the Nile River conditions. In Egypt, many investigators have worked on this important subject, but most have built their findings on laboratory data that have simplified conditions and scale effects. Therefore, the developed GP equation was employed to predict the local scour around the piers of the Imbaba Bridge. The results of the GP equation were then compared to those revealed by the seven regression equations illustrated earlier in "Conventional regression models" section.
Imbaba Bridge is located several kilometers upstream of the Delta Barrages (km 946 from HAD) north of Cairo. Imbaba Bridge is located in the backwater curve of Delta Barrage from about 150 years (HRI 1992). This bridge is a steel one, with two levels: one for railway and the other for roadway. It has seven piers; the second pier from the left bank is circular with 10.6 m diameter, and the other six piers are rectangular with 15 m length and 3.6 m width having rounded noses (Fig. 12). The scour holes of Imbaba Bridge have been going under detailed monitoring programs by The Hydraulics Research Institute (HRI) since 1981. The deep scour hole lies 97 m from the left bank and 32 m downstream of the centerline of the bridge with a bottom elevation of − 8.30 m (HRI 1992). Also, the mean velocity is not larger than 0.8 m/s since the bridge construction (HRI 1992). The monitoring programs revealed that the scour holes at Imbaba Bridge and are stable under current flow conditions after HAD (HRI 1997). This is because the peak flood flows released from HAD are dramatically reduced after its completion in 1968. Therefore, these scour holes are believed to be resulting from very large historic flows occurred before HAD. Table 3 shows the field data used in scour depth prediction at different piers of Imbaba Bridge.

View of Imbaba Bridge, Giza, Egypt
The sediment specific gravity is taken as 2.65, sediment porosity of 0.4, and bed material angle of repose of 300. In applying Jain and Fischer (1979) formula, a mean sediment diameter of 0.00017 m and D90 of 0.00035 m were taken from 1962 data (El-Motassem 1985) and the bed characteristics were fine sand as reported by HRI (1992). In this study, it was decided to investigate the worst condition (clear water scour). Table 4 illustrates the results of the local scour estimation for the six piers provided that Pier No. 7 was not included due to its location in a shallow area above the minimum water level.
The results of this table indicated that the GP equation gives very close local scour depth values to those of field measurements followed by Kothyari et al. (1992) and then Modified Froelich by Fischenich and Landers (1999). This coincides with the results of the statistical analysis presented in Table 2. Also, Table 4 shows that both Modified Laursen by Neill (1964) and Jain and Fischer (1979) overpredicted the scour depth compared to other regression equations. Table 5 demonstrates the accuracy of the developed GP equation in predicting the local scour depth for the Nile River conditions at Imbaba Bridge. The table shows that the percentage error of the derived GP equation in predicting the local scour depth around the piers of Imbaba Bridge varies between 2 and 9% with an average error of 6%.
Conclusions
This paper investigated the use of both ANFIS and GP-based inductive models for predicting relative bridge pier scour depth utilizing previously collected laboratory and field data, and their performance was compared with regression-based models. The following conclusions were drawn from this study:
The developed GP formula as given in Eq. (15) for the prediction of pier scour depth showed better agreement with experimental results than did the ANFIS model and the other regression equations considered in this study.
The proposed GP formula has a higher and more stable accuracy (smaller errors and greater R) in all ranges of pier scour parameters than the other empirical equations. The other equations work well only in some selected ranges of these conditions.
The study also validates the promise of ANFIS and GP as effective modeling tools for applications in hydraulic modeling.
The developed GP equation herein, Eq. (15), yielded very good agreement (6% average error) with field data than other existing empirical equations when applied to Imbaba Bridge Giza, Egypt. Thus, the GP equation is quite convenient for scour prediction in the Nile River conditions. For further studies, it is recommended to test the developed GP equation with several field data of Egyptian bridges such as El-Tahrir Bridge, El-Menyia Bridge, and Kafr El-Zayat Bridge.
Abbreviations
- B :
-
Channel width (m)
- D :
-
Pier width (m)
- d s :
-
Equilibrium scour depth (m)
- d 50 :
-
Mean sediment size (m)
- D/d 50 :
-
Dimensionless pier width
- d s/D :
-
Dimensionless pier scour depth
- F r :
-
Froude number (dimensionless)
- g :
-
Gravitational acceleration (m/s2)
- L :
-
Length of pier (m)
- U :
-
Approach flow velocity (m/s)
- R :
-
Correlation coefficient
- Y :
-
Approach flow depth (m)
- Y/D :
-
Dimensionless approach flow depth
- α :
-
Channel open ratio
- θ :
-
Angle of attack (°)
- σ :
-
Standard deviation of grain size distribution
- ANFIS:
-
Adaptive neuro-fuzzy inference systems
- AI:
-
Artificial intelligence
- ANNs:
-
Artificial neural networks
- GAs:
-
Genetic algorithms
- GP:
-
Genetic programming
- HAD:
-
High Aswan Dam
- HRI:
-
Hydraulics Research Institute
- LGP:
-
Linear genetic programming
- MAPE:
-
Mean absolute percentage error
- MCM:
-
Million cubic meters
- RMSE:
-
Root-mean-square error
References
ASCE Task Committee (2000) Artificial neural networks in hydrology, I: preliminary concepts. J Hydrol Eng 5(2):115–123
Azamathulla HM, Ghani AA (2010) Genetic programming to predict river pipeline scour. J Pipeline Syst Eng Pract 1(3):127–132
Azamathulla HM, Deo MC, Deolalikar PB (2008a) Alternative neural networks to estimate the scour below spillways. Adv Eng Softw 38(8):689–698
Azamathulla HM, Ghani AA, Zakaria NA, Lai SH, Chan CK, Leow CS, Abuhasan Z (2008b) Genetic programming to predict ski-jump bucket spillway scour. J Hydrodyn 20(4):477–484
Azamathulla HM, Chang CH, Ghani AA, Ariffin J, Zakaria NA, Abu Hasan Z (2009a) An ANFIS-based approach for predicting the bed load for moderately sized rivers. J Hydro-environ Res 3:35–44
Azamathulla HM, Ghani AA, Zakari NA (2009) Prediction of scour below flip bucket using soft computing techniques. In: Proceedings of the 2nd international symposium on computational mechanics and the 12th international conference on the enhancement and promotion of computational methods in engineering and science, Hong Kong and Macau, vol 1233, pp 1588–1593
Azamathulla HM, Guven A, Demir YK (2011) Linear genetic programming to scour below submerged pipeline. Ocean Eng 38(8–9):995–1000
Babaeyan-Koopaei K, Valentine EM (1999) Bridge pier scour in self-formed laboratory channels. The XXVIII IA HR congress
Bateni SM, Borghei SM, Jeng DS (2007) Neural network and neuro-fuzzy assessments for scour depth around bridge piers. Eng Appl Artif Intell 20(3):401–414
Beg M (2013) Predictive competence of existing bridge pier scour depth predictors. Eur Int J Sci Technol 2(1):161–178
Breusers HNC, Nicollet G, Shen HW (1977) Local scour around cylindrical piers. J Hydraul Res 15(3):211–252
Chabert J, Engeldinger P (1956) Etude des affouillements autour des piles de ponts. Laboratoire National d’Hydraulique, Chatou
Chang HH (1988) Fluvial processes in river engineering. Wiley, Hoboken, p 13
Chuan-Yi W, Han-Peng S, Jian-Hao H, Rajkumar VR (2013) Prediction of bridge pier scour using genetic programming. J Mar Sci Technol 21(4):483–492
Colorado State University (1975) Highways in the river environment: Hydraulic and environmental design considerations. Prepared for the Federal Highway Administration, U.S. Department of Transportation
Deo O, Jothiprakash V, Deo MC (2008) Genetic programming to predict spillway scour. Int J Tomogr Stat 8(W08):32–45
Dey S (1997) Local scour at piers, part I: a review of development of research. Int J Sedim Res 12(2):23–46
Fischenich C, Landers M (1999) Computing scour: EMRRP Technical Notes Collection (ERDC TN-EMRRP-SR-05), U.S. Army Engineer Research and Development Center, Vicksburg, MS
Froelich DC (1988) Abutment scour prediction. 68th Transportation Research Board Annual Meeting, DC
Guven A, Azamathulla HM, Zakaria NA (2009) Linear genetic programming for prediction of circular pile scour. Ocean Eng 36(12–13):985–991
Hydraulic Research Institute (1992) Monitoring local scour in the Nile River at Imbaba Bridge, in Arabic, Cairo, Egypt
Hydraulic Research Institute (1997) Monitoring local scour in the Nile River at Imbaba and El-Tahreer Bridges, in Arabic, Cairo, Egypt
Jain SC, Fischer EE (1979) Scour around circular bridge piers at high Froude numbers. Rep. No. FHwa-RD-79-104, Federal Hwy. Administration (FHwa), Washington, DC
Kothyari UC, Garde RJ, Rangaraju KG (1992) Temporal variation of scour around circular bridge piers. J Hydraul Eng 118(8):1091–1106
Koza JR (1992) Genetic programming: on the programming of computers by means of natural selection. MIT Press, Cambridge
Lagasse PF, Richardson EV, Schall JD, Price GR (1997) Instrumentation for measuring scour at bridge piers and abutments. NCHRP Report 396: TRB, National Research Council, Washington, DC
Laursen EM, Toch A (1956) Scour around bridge piers and abutments. Bull. No. 4, Iowa Hwy. Res. Board, Ames, Iowa
Melville BW, Chiew YM (1999) Time scale for local scour at bridge piers. J Hydraul Eng 125(1):59–65
Melville BW, Coleman SE (2000) Bridge scour. Water Resources Publications, Fort Collins
Melville BW, Sutherland AJ (1988) Design method for local scour at bridge piers. J Hydraul Eng 114(1):1210–1226
Mohamed TA, Noor MJ, Ghazali AH, Huat BK (2005) Validation of some bridge pier scour formulae using field and laboratory data. Am J Environ Sci 1(2):119–125
Mohamed TA, Noor MJ, Halim AG, Yusuf B, Saed K (2006) Physical modelling of local scouring around bridge piers in erodible bed. J King Saud Univ 19(2):195–207
Motassem M (1985) Recognition of River Nile regime at Ekhsas flood. Nile Research Institute, Formerly Research Institute of the High Aswan Dam Side Effects, Cairo
Mousavi J, Ponnambalam K, Karray F (2007) Inferring operating rules for reservoir operations using fuzzy regression and ANFIS. Fuzzy Sets Syst 158:1064–1082
Mueller DS, Wagner CR (2005) Field observations and evaluations of streambed scour at bridges. Report No. FHWA-RD-03-052, U.S. Department U.S. Department of Transportation, Federal Highway Administration, Washington DC
Najafzadeh M, Barani GA (2011) Comparison of group method of data handling based genetic programming and back propagation systems to predict scour depth around bridge piers. Sci Iran Trans A Civ Eng 18(6):120–1213
Navneet W, Harsukhpreet S, Anurag S (2015) ANFIS: adaptive neuro-fuzzy inference system—a survey. Int J Comput Appl 123(8):32–38
Neill CR (1964) River bed Scour, a review for bridge engineers. Contract No. 281, Res. Council of Alberta, Calgary, Alberta, Canada
Richardson EV, Davis SR (2001) Evaluating scour at bridges. Report FHWA NHI 01-001, Hydraulic Engineering Circular No. 18 (HEC-18), US Department of Transportation, Federal Highway Administration, Washington, DC, USA
Shen HW, Schneider VR, Karaki S (1969) Local scour around bridge piers. J Hydraul Div Am Soc Civ Eng 95(6):1919–1940
Simons DB, Senturk (1992) Sediment transport technology. Water Resources Publications, Highlands Ranch
Takagi T, Sugeno M (1985) Fuzzy identification of systems and its application to modeling and control. IEEE Trans Syst Man Cybern 15(1):116–132
Tay JH, Zhang X (1999) Neural fuzzy modeling of anaerobic biological waste water treatment systems. ASCE J Environ Eng 125(12):1149–1159
Verstappen EL (1978) Non steady local scour at a cylindrical pier. ME Thesis, University of Canterbury, Christchurch, New Zealand
Walker BFG (1978) Scour at a cylindrical pier by translation waves. ME Thesis, University of Canterbury, Christchurch, New Zealand
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Abd El-Hady Rady, R. Prediction of local scour around bridge piers: artificial-intelligence-based modeling versus conventional regression methods. Appl Water Sci 10, 57 (2020). https://doi.org/10.1007/s13201-020-1140-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s13201-020-1140-4