
Abstract
The aim of this paper was to investigate the impact of the fly ash concentration on the infiltration process and to assess the potential of five soft computing techniques such as artificial neural network, Gaussian process, support vector machine (SVM), random forest, and M5P model tree and compare with two popular conventional models, SCS and Kostiakov mode, to estimate the cumulative infiltration of fly-ash-mixed soils. Laboratory experiment was carried out with the different combinations of the sand, clay, and fly ash by using mini disk infiltrometer. The combination consists of the different concentrations of sand (25–45%), clay (25–45%), and fly ash (10–50%). The total observation consists of the 138 field measurement. The cumulative infiltration increase with an increment in the concentration of the fly ash, but it decreases when fly ash concentration increases 40–50% in the soil. On the other hand, the cumulative infiltration increases with the decrease in the concentration of clay in samples. The predictive modeling technique, SVM with RBF kernel, is the best technique to predict the cumulative infiltration with minimum error. Results suggest that SVM with RBF kernel is the best-fit modeling technique among other soft computing techniques as well as conventional models to find the impact of fly ash on infiltration characteristics for the given combination of the sand, clay and fly ash.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Infiltration is the vital property of the water. It is the process in which surface water such as precipitation, flood, and snowfall percolate into the soil. Infiltration is the most affecting process during irrigation actions which is to be considered for scheduling of irrigation, irrigation system design and optimization, and management of irrigation system (Al-Azawi 1985; Bhave and Sreeja 2013). It separates the water into two parts: groundwater flow and surface flow (Singh et al. 2018a). There are many parameters such as density, texture, and type of soil and moisture content that affect the infiltration process (Angelaki et al. 2013). The estimation of the infiltration characteristics is also useful to evaluate the performance of the hydrogeological investigations (Pedretti et al. 2012).
Various researchers analyzed the infiltration data and gave some infiltration model for solving the problem related to the infiltration. These models are Green and Ampt, Harton, Philip, Kostiakov, Holton, modified Kostiakov and novel model. Mishra et al. (2003) divided these models into three categories: physical, semiempirical, and empirical models. Sihag et al. (2017a) used four infiltration rate models and found that novel model was the best-suited model for the soil of NIT Kurukshetra campus. Vand et al. (2018) also found the novel model was the best-fit model in two provinces (Lorestan and Ilam) in Iran. Sihag and Singh (2018) also investigated about these models using double-ring infiltrometer and found that Mezencev and modified Kostiakov model can be used to evaluate the infiltration rate of the soil for the given study area. Chowdary et al. (2006) have studied the infiltration process under different experimental conditions. Singh et al. (2018a) compares the four infiltration model and found that modified Philip’s model is the best-fit model among other selected models to calculate the infiltration rate of the soil.
Soft computing techniques such as random forest, adaptive neuro-fuzzy inference system, gene expression programming, support vector machine, generalized neural network, Gaussian process regression, artificial neural network fuzzy logic, and M5P model tree have been widely used in civil and water resources engineering problems. Many researchers used these soft computing techniques in civil and water resources engineering-related problem successfully (Haghiabi et al. 2018; Parsaie et al. 2016a, Parsaie et al. 2017a, b, 2018a, b; Tiwari et al. 2018; Parsaie and Haghiabi 2014b, 2015a, 2017a, b; Haghiabi et al. 2017a; Tiwari et al. 2017; Nain et al. 2018; Azamathulla et al. 2016) and found that these techniques are less time consuming and gave good result. Also, these techniques have the very less optimum user-defined parameters. Sihag et al. (2018b, 2017b) used the different proportion of sandy soil and analyzed the infiltration characteristics in the laboratory. Thus, the aim of this study is to analyze the impact of fly ash in the cumulative infiltration of the soil. The major objective is to compare the performance of various soft computing techniques to predict the cumulative infiltration of the fly ash mixed in the soil.
Soft computing techniques
Artificial neural network
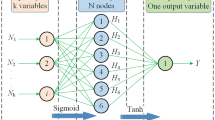
Artificial neural network (ANN) is the most common computing technique which is based on the nerve cells of the human brains. ANN is successfully used in hydrological and water resources problems (Sihag 2018; Sihag et al. 2018d; Haghiabi et al. 2017b; Sihag et al. 2017c; Parsaie et al. 2016b; Parsaie and Haghiabi 2014a, 2015b). Neurons are arranged in the form of layers. Every layer carries out the different kinds of transformations on their inputs. Multiple transformations occurred during signals pass through the first input layer to the last output layer. ANNs have three interconnected layers. The first layer consists of input neurons which receive the input data. Received input data from the first layer are forwarded to the second layer which consists of different hidden layers. After processing of data in hidden layers, they are transferred to the third layer which consists of output neurons. Training an artificial neural network involves choosing from allowed models for which there are several associated algorithms. For further explanation about ANN, readers are referred to Haykin (2004) and Tiwari and Sihag (2018).
Gaussian process
Gaussian process (GP) is an artificial machine learning technique to build computer systems that can adapt and learn from their experience. Rasmussen and Williams (2006) assumed for the processing of GP regression model that the adjoining observations give knowledge to each other. This technique has emerged in recent years and currently successfully applied in various research fields of medicine, chemistry, construction, etc. Gaussian process is based on probability theorem which could make predictions on unknown input data as well as provide prediction exactness which highly increases the statistical significance in prediction. Also Gaussian processes are based on multivariate Gaussian distributions which extend it to infinite dimensionality. Formally, Gaussian process setups the data by using the domain which has any finite subset range following a multivariate Gaussian distribution. In this paper, radial basis kernel \(\left( {K\left( {x,x^{\prime}} \right)} \right) = e^{{ - \gamma \left| {x - x^{\prime}} \right|^{2} }} )\) and Pearson VII function kernel \(\left( {1/\left[ {1 + \left( {2\sqrt {x_{i} - x_{j}^{2} } \sqrt {2^{{\left( {1/\omega } \right)}} - 1} /\sigma } \right)} \right]^{\omega } } \right)\) is used, where γ, σ, and ω are kernel-specific parameters. For further explanation about GP, readers are referred to Kuss (2006) and Singh et al. (2018b).
Support vector machines
The support vector machines (SVMs) are based on statistical learning concept and structural risk minimization hypothesis. The basic concept of SVMs is to arrange the data sets from the input zone to infinite-dimensional feature zone by constructing set of hyper planes so that classification, regression, or other problems become simpler in the feature zone. The hyperplanes are defined as the set of points whose dot product with a vector is constant in that space. Support vector regression has been proposed by Vapnik et al. (1995) and it is a learning system using a high dimensional feature space. The model shaped by SVR depends only on a training dataset because any training data close to the model prediction are ignored by the function for generating the model. Various kernel functions are used with SVM-based regression approaches. In this study radial basis kernel \(\left( {K\left( {x,x^{\prime}} \right)} \right) = e^{{ - \gamma \left| {x - x^{\prime}} \right|^{2} }} )\) and Pearson VII function kernel \(\left( {1/\left[ {1 + \left( {2\sqrt {x_{i} - x_{j}^{2} } \sqrt {2^{{\left( {1/\omega } \right)}} - 1} /\sigma } \right)} \right]^{\omega } } \right)\) are used, where γ, σ and ω are kernel-specific parameter. For further explanation about SVM, readers are referred to Smola and Schölkopf (2004) and Sihag et al. (2018a).
Random forest
Random forests (Breiman 2001) are developed by a collection of tree-based models (Breiman et al. 1984) which can be used for categorization tasks in which the base models are classification trees or regression tasks which depend on base models of regression trees. The forest consists of various trees, which have any value between one to several thousand. To organize a new data set, data set of each condition is passed down every tree. All trees give a classification for that condition. Modeling of a single tree is highly sensitive and complicated. Small changes in the training data turn out a high variation in single classification trees and often lead to rather low classification accuracies (Breiman 1996). Random forests have been justified to be magnificent predictive models in regression tasks and several classifications. They are reasonably fast to obtain results and can be easily assimilated if more speed is required. For further explanation about the random forest, readers are referred to Singh et al. (2017) and Sihag et al. (2018c).
M5P model
M5P is the combined form of the conventional decision tree and the linear regression functions. The model tree algorithm applied in this paper is based on M5P algorithm. The aim of M5P algorithm is to establish a model that evaluates the relation between a target value of the training cases and the values of their input attributes. The performance of the model is checked by the accuracy parameters through which it predicts the values of the curtained cases.
M5P model combines the multiple linear regression and decision tree for data analysis. Decision tree makes relation between the observed inputs and the outputs by logic learning which is appropriate for categorized numerical input and outputs. Decision trees categorize the input dataset and output dataset by the maximized entropy to understand the regression and logical-type rules between inputs and outputs which unambiguously portray the patterns and relationships between data by the regression equations, while other models like SVR and ANN hide them. So, model trees are not only simple but also efficient and accurate technique for modeling and prediction of large data sets (Quinlan 1992).
Conventional models
Two conventional model SCS model and Kostiakov model were also used in this investigation. The empirical constants mentioned in the equation were found by implementing the least-square technique.
SCS model
Kostiakov model
where ‘I’ is cumulative infiltration, ‘t’ is time, ‘a’, ‘b’, ‘c’ and ‘d’ are dimensionless constant.
Measurement of cumulative infiltration
The cumulative infiltration was measured using a mini disk infiltrometer (MDI, Decagon Devices Inc., Pullman, Washington, USA) in a Hydraulic lab of National Institute of Technology, Kurukshetra, India. Figure 1 shows that it consists of two chambers (water reservoir and bubble chamber), connected via a Mariette tube to provide a constant water pressure head of − 0.5 to − 7 cm (equivalent to − 0.05 to − 0.7 kPa). A porous sintered steel disk of diameter 4.5 cm and thickness 3 mm is fitted at the bottom end of the infiltrometer. A suction rate of 1 cm was chosen for this study. The soil used for determination of cumulative infiltration is the mixture of fly ash, sand, and clay at different proportion. The moisture content of the soil samples was measured by the oven-dry method. A proctor (volume 1000 cm3) was used for measuring the density of the soil samples. All the initial conditions like suction head, dry density, moisture content, etc., were predetermined. Properties of the soil samples and details of the soil samples with their moisture content are listed in Tables 1 and 2, respectively.

(Infiltrometer User’s Manual 2014)
Mini disk infiltrometer
The water-filled infiltrometer (MDI) is placed upon the surface of soil resulting in infiltration of water into the soil and the volume of water in the reservoir chamber was recorded at regular interval. No rainfall occurred during the test period. Infiltration is computed from the cumulative infiltration records versus time following Sihag 2018 and Sihag et al. 2017c, according to Decagon Devices Inc. (2014), and fitted by the function of Eq. 5.
where I is the cumulative infiltration (cm), t is the time (s), and C1 (cm/s) and C2 (cm/s−0.5) are parameters. C1 is related to hydraulic conductivity and C2 is related to soil sorptivity.
Dataset
The collected dataset contains a total of 138 field measurement instances having six attributes. Out of 138 datasets, 96 datasets randomly selected for the training of the models whereas the remaining 42 datasets were selected for the testing. The input variables are time, sand, fly ash, clay, density, and moisture content (Mc), and the output variable is cumulative infiltration in this study. Statistical characteristics for input and output variables are shown in Table 3 for the entire dataset.
Flowchart of the research is given in Fig. 2. Initial step was the selection of the soil (clay and sand), impurity (fly ash), and instrument for experimentation. Total data were divided into two randomly selected parts of training and testing. Training data set was used to calibrate the conventional and soft computing-based infiltration models and testing data set was selected to validate the models. The step (optimum performance evaluation parameters) of flowchart was repeated till optimum users define parameters were achieved. The performance evaluation parameters such as R, RMSE, and NS were selected to compare the conventional and soft computing-based infiltration models.

Flowchart of the research
Results and discussion
The performance of soft computing models (SVM, GP, ANN, M5P model tree, and RF) were compared and evaluated by performance evaluation parameters. Three most frequent performance evaluation parameters were used such as root-mean-squared error (RMSE), coefficient of correlation (R), Nash–Sutcliffe efficiency coefficient (NSE) in this study. The optimum values for the RMSE, R, and NSE are 0, 1, and 0, respectively. The RMSE, R, and NSE can be calculated as:
m is the actual values, N is the predicted values, a is the number of observations, and \(\bar{m}\) is the average actual values.
Figures 3, 4, 5, 6, and 7 show the curves of cumulative infiltration for the different amount of fly ash at particular moisture content. Output from Figs. 3, 4, 5, 6, and 7 suggests that cumulative infiltration increases with increase in the concentration of the fly ash. Similarly, in case of the moisture content, cumulative infiltration increases with increase in the moisture content from 2 to 15%, but it starts to decrease when the moisture content increase from 15 to 20%. The cumulative infiltration was observed maximum when the concentration of the fly ash was 50% by weight and moisture content was 15%.

Cumulative infiltration versus time for varying fly ash at 2% moisture content

Cumulative infiltration versus time for varying fly ash at 5% moisture content

Cumulative infiltration versus time for varying fly ash at 10% moisture content

Cumulative infiltration versus time for varying fly ash at 15% moisture content

Cumulative infiltration versus time for varying fly ash at 20% moisture content
Soft computing modeling techniques such as GP, SVM, Random forest, and M5P had applied on observed data to evaluate the prediction efficiency. The user-defined parameters for the various soft computing techniques are summarized in Table 4. The values of sigma, noise, omega, and c were 1, 0.01, 2, and 50, respectively, for the SVM and GP techniques and values of m, k, I, hidden layer, learning rate, and momentum were 10, 1, 100, 7, 0.01, and 0.6 for M5P model tree, random forest and ANN, respectively, whose values the lesser error in prediction of the infiltration rate.
The details of the performance evaluation parameters for the different soft computing techniques are given in Table 5. The values of the R, RMSE, and NSE lie in the range of 0.9996–0.8936, 0.052–0.5919, and 0.9992–0.7868, respectively, for training dataset and 0.9817–0.7868, 0.2387–0.7611, and 0.9613–0.6070, respectively, for the testing dataset.
Table 5 suggests that all the soft computing techniques work well to predict the cumulative infiltration except M5P model tree. M5P model tree gave the worst result with lowest values of R and RMSE (0.7869 and 0.6070) and highest RMSE value (0.7611). SVM with RBF kernel was the best-fit model with the highest values of R and NSE (0.9817 and 0.9613) and lowest value of RMSE (0.2387). Figure 8 shows the agreement plot between actual cumulative infiltration and predicted cumulative infiltration. The output from Fig. 8 also suggests the similar trends that all the soft computing techniques work well except M5p model tree. Almost, all the scattered from M5P model tree lies outside from the ± 20% error line. Similarly, SVM with RBF kernel gave the best agreement with the ± 20% error line with minimum scattered lies outside the agreement line. The soft computing techniques others than SVM with RBF kernel and M5P model tree gave the almost similar result with the range of R, RMSE, and NSE in between 0.9800–0.9509, 0.2535–0.4007, and 0.9564–0.8910 respectively.


Actual values versus predicted values using different soft computing techniques using testing dataset
Table 6 gives the result of the SCS model and Kostiakov model. The values of R and NSE for these two conventional models were very low, and the value of the RMSE was very high for the training and testing period. Figure 9 shows the agreement diagram of two models (SCS and Kostiakov model). The scatters of these two equations did not lie in ± 50% error line. The output from Fig. 9 and Table 5 suggests that the two conventional model such as the SCS model and Kostiakov model fail to predict the cumulative infiltration rate.

Actual values versus predicted values of cumulative infiltration for the SCS model and Kostiakov model of the testing dataset
Figure 10 compares the predicted values and actual values of the cumulative infiltration for the various soft computing techniques and two conventional infiltration model which clearly suggest that all the scatters from conventional model and M5P model tree lies outside of ± 30% error line and almost of the scatters from other conventional model lies within the ± 30% error line. But SVM with RBF kernel gives the best-fit scatters. Hence, SVM with RBF kernel is the superior soft computing techniques and can be successfully used to predict the cumulative infiltration for the given combination of the soil.

Actual values versus predicted values using all model for the testing dataset
Conclusions
Infiltration process has been experimentally investigated on sand, clay, and fly ash mixed samples using mini disk infiltrometer. Various soft computing techniques such as SVM, GP, M5P model tree, random forest, and ANN for modeling the experimental result and prediction of the cumulative infiltration. The various conclusions drawn from this investigation are given as follows:
-
It is established from the test results that increment in the cumulative infiltration was observed with increment in the percentage of the fly ash. But there is a contradiction that it increases up to 40% of the fly ash and decreases when the percentage of the fly ash increases from 40 to 50%.
-
The cumulative infiltration also increases with the decrement in the percentage of the clay.
-
The prediction of the cumulative infiltration is tested by various soft computing techniques (SVM, GP, M5P model tree, random forest, and ANN), and SVM with RBF kernel was found best to predicting the cumulative infiltration followed by GP, random forest, ANN, and M5p Model Tree.
-
Obtained results suggest that the performance of conventional models, SCS model and Kostiakov model, is not satisfactory as compared to the soft computing techniques.
References
Al-Azawi SA (1985) Experimental evaluation of infiltration models. J Hydrol (N Z) 24(2):77–88
Angelaki A, Sakellariou-Makrantonaki M, Tzimopoulos C (2013) Theoretical and experimental research of cumulative infiltration. Transp Porous Media 100(2):247–257
Azamathulla HM, Haghiabi AH, Parsaie A (2016) Prediction of side weir discharge coefficient by support vector machine technique. Water Sci Technol Water Supply 16(4):1002–1016. https://doi.org/10.2166/ws.2016.014
Bhave S, Sreeja P (2013) Influence of initial soil condition on infiltration characteristics determined using a disk infiltrometer. ISH J Hydraul Eng 19(3):291–296
Breiman L (1996) Bagging predictors. Mach Learn 24(2):123–140
Breiman L (2001) Random forests. Mach Learn 45(1):5–32
Breiman L, Friedman JH, Olshen RA, Stone CJ (1984) Classification and regression trees. Wadsworth International Group, Belmont, California, USA. LHCb collaboration
Chowdary VM, Rao MD, Jaiswal CS (2006) Study of infiltration process under different experimental conditions. Agric Water Manag 83(1–2):69–78
Decagon Devices Inc. (2014) Mini disk infiltrometer user’s manual, Version 9. Decagon Devices, Pullman (WA)
Haghiabi AH, Azamathulla HM, Parsaie A (2017a) Prediction of head loss on cascade weir using ANN and SVM. ISH J Hydraul Eng 23(1):102–110
Haghiabi AH, Parsaie A, Ememgholizadeh S (2017b) Prediction of discharge coefficient of triangular labyrinth weirs using adaptive neuro fuzzy inference system. Alex Eng J. https://doi.org/10.1016/j.aej.2017.05.005
Haghiabi AH, Nasrolahi AH, Parsaie A (2018) Water quality prediction using machine learning methods. Water Qual Res J 53(1):3–13
Haykin S (2004) Kalman filtering and neural networks, vol 47. Wiley, Hoboken
Kuss M (2006) Gaussian process models for robust regression, classification, and reinforcement learning. Doctoral dissertation, Technische Universität
Mishra SK, Tyagi JV, Singh VP (2003) Comparison of infiltration models. Hydrol Process 17(13):2629–2652
Nain SS, Sihag P, Luthra S (2018) Performance evaluation of fuzzy-logic and BP-ANN methods for WEDM of aeronautics super alloy. MethodsX. https://doi.org/10.1016/j.mex.2018.04.006
Parsaie A, Haghiabi AH (2014a) Evaluation of selected formulas and neural network model for predicting the longitudinal dispersion coefficient in river. J Environ Treat Tech 2(4):176–183
Parsaie A, Haghiabi AH (2014b) Assessment of some famous empirical equation and artificial intelligent model (MLP, ANFIS) to predicting the side weir discharge coefficient. J Appl Res Water Wastewater 1(2):74–79
Parsaie A, Haghiabi A (2015a) The effect of predicting discharge coefficient by neural network on increasing the numerical modeling accuracy of flow over side weir. Water Resour Manage 29(4):973–985
Parsaie A, Haghiabi AH (2015b) Predicting the longitudinal dispersion coefficient by radial basis function neural network. Model Earth Syst Environ 1(4):34. https://doi.org/10.1007/s40808-015-0037-y
Parsaie A, Haghiabi AH (2017a) Improving modelling of discharge coefficient of triangular labyrinth lateral weirs using SVM, GMDH and MARS techniques. Irrig Drain 66(4):636–654
Parsaie A, Haghiabi AH (2017b) Mathematical expression of discharge capacity of compound open channels using MARS technique. J Earth Syst Sci 126(2):20
Parsaie A, Najafian S, Shamsi Z (2016a) Predictive modeling of discharge of flow in compound open channel using radial basis neural network. Modeling Earth Systems and Environment 2(3):150. https://doi.org/10.1007/s40808-016-0207-6
Parsaie A, Najafian S, Yonesi H (2016b) Flow discharge estimation in compound open channel using theoretical approaches. Sustain Water Resour Manag 2(4):359–367
Parsaie A, Ememgholizadeh S, Haghiabi AH, Moradinejad A (2017a) Investigation of trap efficiency of retention dams. Water Sci Technol Water Supply 18(2):450–459. https://doi.org/10.2166/ws.2017.109
Parsaie A, Haghiabi AH, Saneie M, Torabi H (2017b) Predication of discharge coefficient of cylindrical weir-gate using adaptive neuro fuzzy inference systems (ANFIS). Front Struct Civil Eng 11(1):111–122
Parsaie A, Azamathulla HM, Haghiabi AH (2018a) Prediction of discharge coefficient of cylindrical weir–gate using GMDH-PSO. ISH J Hydraul Eng 24(2):116–123
Parsaie A, Haghiabi AH, Saneie M, Torabi H (2018b) Prediction of energy dissipation of flow over stepped spillways using data-driven models. Iran J Sci Technol Trans Civil Eng 42(1):39–53
Pedretti D, Barahona-Palomo M, Bolster D, Sanchez-Vila X, Fernàndez-Garcia D (2012) A quick and inexpensive method to quantify spatially variable infiltration capacity for artificial recharge ponds using photographic images. J Hydrol 430:118–126
Quinlan JR (1992) Learning with continuous classes. In: 5th Australian joint conference on artificial intelligence, vol 92, pp 343–348
Rasmussen CE, Williams CK (2006) Gaussian process for machine learning. MIT Press, Cambridge
Sihag P (2018) Prediction of unsaturated hydraulic conductivity using fuzzy logic and artificial neural network. Model Earth Syst Environ 4(1):189–198
Sihag P, Singh B (2018) Field evaluation of infiltration models. TEXHOГEHHO-EКOЛOГIЧHA БEЗПEКA. 4(2):3–12. http://repositsc.nuczu.edu.ua/handle/123456789/6842
Sihag P, Tiwari NK, Ranjan S (2017a) Estimation and inter-comparison of infiltration models. Water Sci 31(1):34–43
Sihag P, Tiwari NK, Ranjan S (2017b) Modelling of infiltration of sandy soil using Gaussian process regression. Model Earth Syst Environ 3(3):1091–1100
Sihag P, Tiwari NK, Ranjan S (2017c) Prediction of unsaturated hydraulic conductivity using adaptive neuro-fuzzy inference system (ANFIS). ISH J Hydraul Eng. https://doi.org/10.1080/09715010.2017.1381861
Sihag P, Jain P, Kumar M (2018a) Modelling of impact of water quality on recharging rate of storm water filter system using various kernel function based regression. Model Earth Syst Environ 4(1):61–68
Sihag P, Singh B, Sepah Vand A, Mehdipour V (2018b) Modeling the infiltration process with soft computing techniques. ISH J Hydraul Eng. https://doi.org/10.1080/09715010.2018.1464408
Sihag P, Tiwari NK, Ranjan S (2018c) Support vector regression-based modeling of cumulative infiltration of sandy soil. ISH J Hydraul Eng. https://doi.org/10.1080/09715010.2018.1439776
Sihag P, Tiwari NK, Ranjan S (2018d) Prediction of cumulative infiltration of sandy soil using random forest approach. J Appl Water Eng Res. https://doi.org/10.1080/23249676.2018.1497557
Singh B, Sihag P, Singh K (2017) Modelling of impact of water quality on infiltration rate of soil by random forest regression. Model Earth Syst Environ 3(3):999–1004
Singh B, Sihag P, Singh K (2018a) Comparison of infiltration models in NIT Kurukshetra campus. Appl Water Sci 8(2):63. https://doi.org/10.1007/s13201-018-0708-8
Singh B, Sihag P, Singh K, Kumar S (2018b) Estimation of trapping efficiency of vortex tube silt ejector. Int J River Basin Manag. https://doi.org/10.1080/15715124.2018.1476367
Smola AJ, Schölkopf B (2004) A tutorial on support vector regression. Stat Comput 14(3):199–222
Tiwari NK, Sihag P (2018) Prediction of oxygen transfer at modified Parshall flumes using regression models. ISH J Hydraul Eng. https://doi.org/10.1080/09715010.2018.1473058
Tiwari NK, Sihag P, Ranjan S (2017) Modeling of infiltration of soil using adaptive neuro-fuzzy inference system (ANFIS). J Eng Technol Educ 11(1):13–21
Tiwari NK, Sihag P, Kumar S, Ranjan S (2018) Prediction of trapping efficiency of vortex tube ejector. ISH J Hydraul Eng. https://doi.org/10.1080/09715010.2018.1441752
Vand AS, Sihag P, Singh B, Zand M (2018) Comparative evaluation of infiltration models. KSCE J Civil Eng. https://doi.org/10.1007/s12205-018-1347-1
Vapnik V, Guyon I, Hastie T (1995) Support vector machines. Mach Learn 20(3):273–297
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Sihag, P., Singh, B., Gautam, S. et al. Evaluation of the impact of fly ash on infiltration characteristics using different soft computing techniques. Appl Water Sci 8, 187 (2018). https://doi.org/10.1007/s13201-018-0835-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s13201-018-0835-2