
Abstract
In this paper a multi-criteria decision-making (MCDM) method is developed to rank a set of insurance companies. The proposed method is based on combining two MCDM methods: Extended Best–Worst (EBW) and Multiple Reference Point (MRP) methods. We formulate the problem of finding a priority vector from a set of interval pairwise comparisons applying an EBW method which allows the decision maker (DM) to use interval values in order to describe the relative importance of one criterion over another. The EBW method, using fuzzy set theory, can successfully handle the vagueness and ambiguity present in the judgments. Lastly, the MRP method is employed to obtain an overall score for each company using the weights established at the first stage. A case study is presented to rank Spanish non-life insurance companies based on the constructed model. Since the evaluation of insurance companies involves a great number of indicators, it is a complex MCDM issue. The results show the effectiveness of the proposed method and offer an insightful reference for an evaluation of the insurance industry.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The insurance market plays a key role in the financial markets and the economy of any country. Insurers provide security to companies and individuals who transfer their risks to them in exchange for the payment of a premium (Rejikumar et al. 2019). At the same time, insurance companies collect the premiums and invest them in the financial markets contributing in this way to economic development (Akyüz et al. 2020). Thus, insurance functions can be resumed in assurance and intermediation.
Assurance is the main service provided by insurers. It is related to risk-pooling and risk bearing services, as well as to the “real” financial service (Cummins and Nini 2002; Cummins and Rubio-Misas 2006; Leverty and Grace 2010). Insurers use the premiums received to pay claims. For this purpose, they incur actuarial and subscription expenses that, together with the capital reserve for extraordinary claims, allow the creation of value added. Real financial service is related to financial advisory services, risk management or loss prevention. Within the intermediation function, insurers obtain funds from their policyholders through premiums and invest them in financial markets in order to guarantee the payment of claims when they occur. This service is especially relevant in life insurance, where the moment of collection of the premiums and the payment of the claim are, normally, separated in time. Furthermore, this type of insurance guarantees an additional interest.
The competitiveness of insurance companies relies on their ability to maximise profits and improve the quality of their services. That is why the efficiency of insurance companies has long been studied in the literature (see, e.g., Eling and Luhnen 2010; Cummins and Weiss 2013 for a review). Efficiency measures the ability of companies to obtain the maximum output with a given amount of input, or conversely, use the least amount of inputs to achieve a certain level of output. The models to study efficiency are the non-parametric Data Envelopment Analysis (DEA) model and the parametric Stochastic Frontier Analysis (SFA) model. Both models in their different variations have been applied to the insurance market and allow a ranking of companies according to their level of efficiency. This allows companies to know their positions relative to their competitors. But although efficiency and profitability are usually related, only considering efficiency suffers the weakness that it does not guarantee profitability (Ventakateswarlu et al. 2016), nor financial strength (Eckles and Pottier 2011).
Meanwhile, the profitability of a company is related to its ability to make its income exceed its expenses and it can be measured through financial ratios which are widely used in the literature. It is related to its financial strength, given that better financial health is interpreted as presenting a greater likelihood that the company will meet all its obligations, thereby bearing a lower risk of insolvency and a greater likelihood of profit (Eckles and Pottier 2011). Analysing different financial ratios to rank companies for better performance, allows the introduction of different criteria such as profitability, liquidity, solvency, among others.
Therefore, in order to find the best non-life insurance companies from a pool, it is necessary to consider multiple but usually conflicting criteria. Thus, a company may perform well against one criterion and may perform poorly with respect to another criterion. The aggregation of these opposing performances can be achieved by applying multi-criteria methods.
Several studies exist that develop methods for ranking insurance companies (see Ecer and Pamucar 2021 and references therein). These works have applied various methods such as Analytical Hierarchy Process (AHP) (Toloie et al. 2011; Ksenija et al. 2017; Mandić et al. 2017; Beiragh et al. 2020) and Best–Worst Method (Torbati and Sayadi 2018; Akyüz et al. 2020) for determining the importance level of selected criteria. Alternatively, in order to score insurance firms, use has been made of Technique for Order of Preference by Similarity to Ideal Solution (TOPSIS) (Toloie et al. 2011; Abdolvand and Rahpeima 2013; Akhisar and Tunay 2015; Ksenija et al. 2017; Akyüz et al. 2020; Pattnaik et al. 2021), DEA (Sabet and Fadavi 2013; Nourani et al. 2018; Beiragh et al. 2020), Preference Ranking Organization Method for Enrichment of Evaluations (PROMETHEE) (Doumpos et al. 2012; Kazemi and Bardeji 2016), Measurement of Alternatives and Ranking according to Compromise Solution (MARCOS) (Ecer and Pamucar 2021), among others. Although the numerous methods used each have their advantages and disadvantages, it is universally accepted that reliable and robust models are needed to address the ambiguity and vagueness of judgements that arise when assessing insurers.
These studies support the DM in their choice of the best insurance companies and share two main phases: (i) a weighting process to determine the relative importance of the evaluation criteria, and (ii) an aggregation method for obtaining a score representative of the composite performance of each company which allows a ranking of the companies.
The classic AHP is the most used Multi-Criteria Decision Making (MCDM) technique in determining the weights of criteria (Govindan et al. 2014 and Alizadeh and Yousefi 2019) from pairwise comparisons and matrix calculus. Psychology sustains that it is easier and more accurate to express pairwise judgements than opinions simultaneously for all the elements of decision-making. AHP uses a ratio scale, which requires no units for the comparison. The preference scale is composed of the integers 1 to 9 and their reciprocals in order to compare the relative importance of one criterion over another. This linear scale has received criticism and several alternatives have been proposed in the literature (see discussion and references about this issue in Ishizaka and Labib 2011) but according to Saaty (1980, 1990), this scale is the best one for representing weight ratios. Other AHP extensions related to the way pairwise comparisons are expressed have been aimed at offering tools that represent the vagueness, ambiguity and imprecision/uncertainty present in a human's subjective judgments. In this context, interval pairwise comparison judgements have been proposed (Mikhailov 2003, 2004; Chen and Xu 2015; Ren 2018, among others) for overcoming situations where DMs find difficulties in using exact numerical numbers. Once the scale and the mathematical tool representing the pairwise comparisons (crisp numbers, interval values, fuzzy numbers, intuitionist fuzzy numbers, among others) have been chosen, it is necessary to address a key problem of MCDM models: priorities derivation from a pairwise comparison matrix. Different approaches have been proposed based on simple matrix calculus: the method mean of the row, the method of the principal eigenvector (see references in Ishizaka and Labib 2011 and Zhang et al. 2021). In contrast to the aforementioned approaches, most of the prioritisation methods are based on the distance minimisation between the empirical pairwise priority ratio and the corresponding theoretical pairwise priority ratio. Zhang et al. 2021 present a revision of the most famous methods and they propose a novel methodology implying both additive and multiplicative deviation relations. Their approach introduces two norms giving rise to four conic programming models.
In our paper, this first phase of the proposed hybrid MCDM methodology is carried out by an extension of the prioritisation method used in AHP. We work with the linear scale proposed by Saaty (1977) and interval values are used to represent the pairwise comparisons. We extend the Best–Worst (BW) method (Rezaei 2015, 2016; Lahri et al. 2021) for constructing the incomplete interval comparison matrix. This new methodology, introduced as Extended Best–Worst (EBW), is based on a modification of Mikhailov’s approach (2004) for obtaining the priority vector. It consists in solving a minimax problem that gives both the optimal weights and a measure of the consistency between the proposed ratios and the achieved ratios. The second phase, related to the aggregation process, is addressed by applying the Multiple Reference Point (MRP) method which performs two tasks. Firstly, a normalisation of the scores of the companies based on several reference points is carried out, permitting the DMs intervention for the purpose of setting the latter reference points. Secondly, several aggregation procedures based on fully compensatory, non-compensatory and partially compensatory operators allow to obtain a unique global score for the joint performance of each company. These scores share the same interpretation as the scale defined by the set reference points.
The methodology contributions of this study, represented by the Extended Best–Worst Multiple Reference Point (EBW-MRP) method, provides new tools for analysing the global performance of insurance companies. We see the EBW results as a foundation for prioritising criteria in an understanding and easy way for DMs. In addition, the application of a MRP method helps to rank the best alternatives according to expert knowledge.
We apply our methodology to the Spanish non-life insurance market. Since the 1980s, the Spanish insurance market has suffered a restructuring and consolidation process. The consequences of the latter have been studied in papers such as Cummins and Rubio Misas (2006) or Cummins et al (2017) for example. We have chosen the Spanish insurance market, because despite the high impact of the financial crisis in Spain, the non-life insurance sector has managed to grow by more than 6.5% over the period 2007–2017 (Mapfre 2018). This highlights the interest in studying the financial assessment of companies operating in the Spanish non-life insurance market. Between 80 and 83 insurers are considered during the period from 2009 to 2017. The criteria were chosen based on the academic literature and on the data published annually by the Dirección General de Seguros y Fondos de Pensiones (DGSFP).
The rest of the paper is organised as follows. Section 2 presents the proposed methodology, an Extended Best–Worst Multiple Reference Point Method. The next section is devoted to the empirical application. Our database consists of Spanish non-life insurance companies evaluated with respect to eight criteria. The main results of our real application are discussed in Sect. 4, with nine rankings obtained that allow an assessment for the period analysed. Finally, conclusions are discussed in Sect. 5.
2 Extended best–worst multiple reference point method
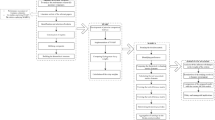
Throughout this section, it will be assumed that we are managing a set of \(M\) units \(\left\{ {U_{1} ,U_{2} ,...,U_{M} } \right\}\) and \(N\) criteria, \(\left\{ {C_{1} ,C_{2} ,...,C_{N} } \right\}\), which play an important role in evaluating the units in order to arrive at a decision. To do this, we formulate an Extended Best–Worst Multiple Reference Point (EBW-MRP) method considering the most important criterion (best) and the least important criterion (worst) for the DM. The procedure is divided into two phases, which are described in detail. In the first phase, a novel BW method is proposed to calculate the criterion weights considering that the relative preference of the i-th criterion over the j-th criterion is not precisely expressed by the expert since their judgment is imprecise. These weights are incorporated into a MRP model (Ruiz et al. 2020), in the second phase, to obtain the global scores of the units from which a ranking can be obtained (see Fig. 1).

Extended best–worst multiple reference point method
Phase 1. Extended Best–Worst (EBW) method
In the classic BW model (see Table 1), it is assumed that the preference value on the i-th criterion to the j-th criterion determined by experts is accurate. However, in some uncertain/imprecise situations the DM may not be able to provide exact point judgements and she/he expresses her/his preferences through linguistic labels, such as ‘approximately or about \(a\)’, instead of exact numerical values \(a\). The use of fuzzy logic tools (Zadeh 1965; Bellman and Zadeh 1970) may be useful to attempt at mechanisation or formalisation of human reasoning. Some research has been developed to handle vague and uncertain information in the BW method. For example, Mou et al. (2016, 2017) propose an intuitionistic fuzzy multiplicative BW model for multi-criteria group decision making and use the graph theory to find the best and worst criteria; Guo and Zhao (2017) extend the BW method to a fuzzy environment and describe the reference comparisons for the best criterion and for the worst criterion by triangular fuzzy numbers; Aboutorab et al. (2018) address the problem of the uncertainty of real world decisions with Z numbers that integrate in a BW method and obtain triangular fuzzy weights; Pamučar et al (2018) presents a new BW approach where the treatment of uncertainty is based on interval-valued fuzzy-rough numbers; Ren (2018) develop an interval BW method for determining the interval weights of the evaluation criteria and the relative performances of the alternatives with respect to the soft criteria; Ali and Rashid (2019) investigate a BW method in which the uncertain evaluation values are represented by hesitant linguistic term sets; Mi and Liao (2019) implement the weight-determining process by a hesitant fuzzy BW model; Fei et al. (2020) propose an evidential BW model based on the theory of belief functions, which is employed for evaluating hospital service quality.
In this paper, the uncertain/imprecise judgements are represented by interval ratios (Mikhailov 2003, 2004; Arbel and Vargas 2007; Wang and Elhag 2007; Yue, 2012; Ahn 2017; Ren 2018; Acuña-Soto et al. 2019). A novel weighting problem is then formulated and solved as a max–min mathematical programming problem for obtaining an optimal crisp weighting vector that maximises the overall degree of satisfaction of the DM.
To derive priorities from uncertain judgements, Saaty and Vargas (1987) construct an interval reciprocal comparison matrix of the type:
where \(a_{ij} = \left[ {l_{ij}^{{}} ,u_{ij}^{{}} } \right]\) represents the relative preference of criterion \(i\) to criterion \(j\), which is an interval judgement.\(l_{ij}^{{}}\) and \(u_{ij}^{{}}\) are the lower and the upper bounds of the interval. The range of bounds is assumed to be between \(1/9\) and \(9\) inclusive (Saaty 1977), taking into account that \(a_{ij} = a_{ji}^{ - 1}\) and the operations on closed intervals we have:
Definition 1
An interval pairwise comparison \(a_{ij}\) is defined as a reference comparison if \(i\) is the best criterion and/or \(j\) is the worst criterion.
According to Rezaei (2015), \(N(N - 1)/2\) interval pairwise comparisons are not needed to obtain the complete interval comparison matrix and it is sufficient to determine the \(2N - 3\) reference comparisons. This is the basis principle of the interval weighting method that we are going to formulate below.
The steps of the EBW method that can be used to obtain the weights of the \(N\) criteria, \(\left( {w_{1}^{*} ,w_{2}^{*} ,...,w_{N}^{*} } \right)\), are described in what follows:
Step 1. Determine the best criterion, \(C_{B}\), and the worst criterion, \(C_{W}\).
Step 2. Determine the preference of the best criterion over all the other criteria by mean of interval judgements. The resulting best-to-others interval-vector would be:
where \(a_{Bj} = \left[ {l_{Bj}^{{}} ,u_{Bj}^{{}} } \right]\) indicates the interval preference of the best criterion \(C_{B}\) over the criterion \(j\).
Step 3. Determine the preference of all the criteria over the worst criterion by mean of interval judgements. The resulting others-to-worst interval-vector would be:
where \(\left[ {l_{jW}^{{}} ,u_{jW}^{{}} } \right]\) indicates the interval preference of the criterion \(j\) over the worst criterion \(C_{W}\).
Step 4. Find the optimal crisp weights vector \(w^{*} = \left( {w_{1}^{*} ,w_{2}^{*} ,...,w_{N}^{*} } \right)\).
In this work, a crisp priority vector \(w = \left( {w_{1}^{{}} ,w_{2}^{{}} ,...,w_{N}^{{}} } \right)\) is admissible with respect to the best-to-others interval-vector, \(A_{B}\), and the others-to-worst interval-vector, \(A_{W}\), if it verifies
where \(\tilde{ \le }\) denotes the fuzzified version of \(\le\) and reads ‘approximately less than or equal to’.
The weights \(w_{1}^{*} ,w_{2}^{*} ,...,w_{N}^{*}\) will be optimal if they satisfy the fuzzy inequalities (5) and (6) with the highest degree of membership. Therefore, in order to find the optimal weights a fuzzy nonlinear problem must be solved.
In order to linearise the fuzzy problem, (5) and (6) are transformed into the following fuzzy linear inequalities:
The range of approximate satisfaction of (7) and (8) can be defined as extended intervals \(\left[ {0,d_{Bj}^{l} } \right]\), \(\left[ {0,d_{Bj}^{u} } \right]\), \(\left[ {0,d_{jW}^{l} } \right]\) and \(\left[ {0,d_{jW}^{u} } \right]\) where \(d_{Bj}^{l}\), \(d_{Bj}^{u}\), \(d_{jW}^{l}\) and \(d_{jW}^{u}\) are tolerance parameters for the corresponding intervals.Footnote 1
As the two constraints in (7) relate to the same interval, we can represent them as a linear satisfaction function (see Fig. 2) corresponding to the lower and upper bounds that expresses the DM’s satisfaction with its accomplishment (Mikhailov 2004; Chen and Xu 2015):

Linear satisfaction function
where \(m_{Bj} = \frac{{\frac{1}{{d_{Bj}^{l} }}l_{Bj} + \frac{1}{{d_{Bj}^{u} }}u_{Bj} }}{{\frac{1}{{d_{Bj}^{l} }} + \frac{1}{{d_{Bj}^{u} }}}}\) is the extended middle of the interval \(\left[ {l_{Bj}^{{}} ,u_{Bj}^{{}} } \right]\) where the greatest satisfaction is achieved.
This function has a maximum, \(\mu_{Bj}^{\max }\), when \({{w_{B} } \mathord{\left/ {\vphantom {{w_{B} } {w_{j} }}} \right. \kern-\nulldelimiterspace} {w_{j} }} = m_{Bj}\). In this case the DM should be ‘most satisfied’. Otherwise, the DM is ‘satisfied’ when \(l_{Bj} < {{w_{B} } \mathord{\left/ {\vphantom {{w_{B} } {w_{j} < u_{Bj} }}} \right. \kern-\nulldelimiterspace} {w_{j} < u_{Bj} }}\), and she/he is ‘partially satisfied’ when \({{w_{B} } \mathord{\left/ {\vphantom {{w_{B} } {w_{j} }}} \right. \kern-\nulldelimiterspace} {w_{j} }}\) takes a value within the admissible interval \(\left[ {l_{Bj} - {{d_{Bj}^{l} } \mathord{\left/ {\vphantom {{d_{Bj}^{l} } {w_{j} }}} \right. \kern-\nulldelimiterspace} {w_{j} }},u_{Bj} + {{d_{Bj}^{u} } \mathord{\left/ {\vphantom {{d_{Bj}^{u} } {w_{j} }}} \right. \kern-\nulldelimiterspace} {w_{j} }}} \right]\). Finally, \({{w_{B} } \mathord{\left/ {\vphantom {{w_{B} } {w_{j} }}} \right. \kern-\nulldelimiterspace} {w_{j} }} \notin \left[ {l_{Bj} - {{d_{Bj}^{l} } \mathord{\left/ {\vphantom {{d_{Bj}^{l} } {w_{j} }}} \right. \kern-\nulldelimiterspace} {w_{j} }},u_{Bj} + {{d_{Bj}^{u} } \mathord{\left/ {\vphantom {{d_{Bj}^{u} } {w_{j} }}} \right. \kern-\nulldelimiterspace} {w_{j} }}} \right]\) indicates ‘dissatisfaction’ with the pair \((w_{B} ,w_{j} )\).
We have a similar function for the two constraints in (8):
The function (10) has a maximum, \(\mu_{jW}^{\max }\), when \({{w_{j} } \mathord{\left/ {\vphantom {{w_{j} } {w_{W} }}} \right. \kern-\nulldelimiterspace} {w_{W} }} = m_{jW}\).Footnote 2 In this case the DM should be ‘most satisfied’. Otherwise, the DM is ‘satisfied’ when \(l_{jW} < {{w_{j} } \mathord{\left/ {\vphantom {{w_{j} } {w_{W} < u_{jW} }}} \right. \kern-\nulldelimiterspace} {w_{W} < u_{jW} }}\), and she/he is ‘partially satisfied’ when \({{w_{j} } \mathord{\left/ {\vphantom {{w_{j} } {w_{W} }}} \right. \kern-\nulldelimiterspace} {w_{W} }}\) takes a value within the admissible interval \(\left[ {l_{jW} - {{d_{jW}^{l} } \mathord{\left/ {\vphantom {{d_{jW}^{l} } {w_{W} }}} \right. \kern-\nulldelimiterspace} {w_{W} }},u_{jW} + {{d_{jW}^{u} } \mathord{\left/ {\vphantom {{d_{jW}^{u} } {w_{W} }}} \right. \kern-\nulldelimiterspace} {w_{W} }}} \right]\). Finally, \({{w_{j} } \mathord{\left/ {\vphantom {{w_{j} } {w_{W} }}} \right. \kern-\nulldelimiterspace} {w_{W} }} \notin \left[ {l_{jW} - {{d_{jW}^{l} } \mathord{\left/ {\vphantom {{d_{jW}^{l} } {w_{W} }}} \right. \kern-\nulldelimiterspace} {w_{W} }},u_{jW} + {{d_{jW}^{u} } \mathord{\left/ {\vphantom {{d_{jW}^{u} } {w_{W} }}} \right. \kern-\nulldelimiterspace} {w_{W} }}} \right]\) indicates ‘dissatisfaction’ with the pair \((w_{j} ,w_{W} )\).
Taking into account the above satisfaction functions, we can solve the weighting problem applying the Zimmermann fuzzy programming approach (1976). To do this, the feasible set of weighting vectors is defined:
The fuzzy subset \(\tilde{P}\), whose membership function \(\mu_{{\tilde{P}}} (w)\) is the intersection of the satisfaction functions defined in (9) and (10):
This membership function represents the overall satisfaction of the DM with a specific weighting vector \(w\).
Definition 2
A vector \(w^{*} = \left( {w_{1}^{*} ,w_{2}^{*} ,...,w_{N}^{*} } \right)\) is an optimal weighting vector with respect to the best-to-others interval-vector, \(A_{B}\), and the others-to-worst interval-vector, \(A_{W}\), if it maximises the overall degree of satisfaction \(\mu_{{\tilde{P}}} (w)\). i.e.,
As is well known, this problem is equivalent to solving the following linear program:
The optimal solution of (14) is a vector \(\left( {w^{*} ,\lambda^{*} } \right)\) whose first component represents the weighting vector that maximises the degree of membership of the aggregated function \(\mu_{{\tilde{P}}} (w)\), whereas \(\lambda^{*}\) measures the degree of overall satisfaction of the DM with the optimal solution \(w^{*}\).
The optimal value \(\lambda^{*}\) is also an indicator for measuring the consistency of the DM judgements and, for a given set of interval judgements, depends on the values of the tolerance parameters.
Definition 3
The DM interval judgements are strongly inconsistent if the optimal value \(\lambda^{*}\) of (14) is negative. In this case the solution ratios are outside the extended intervals.
The following proposition avoids the problems of strong inconsistency in the DM interval judgments.
Proposition 1
(Mikhailov 2004). The solution of (14) verifies \(\lambda^{*} \ge 0\), if all deviation parameters \(d_{Bj}^{l} ,d_{Bj}^{u} ,d_{jW}^{l} ,d_{jW}^{u}\) is greater than or equal to \(d^{*}\), where \(d^{*}\) is the solution of the following linear problem:
The weights obtained in this Phase 1 are incorporated into a Multiple Reference Point model (Ruiz et al. 2020; García-Bernabeu et al., 2021; Cabello et al. 2021; Boggia et al. 2022) for ranking and choosing the best unit.
Phase 2. Multiple Reference Point to calculate the global scores of the units (Ruiz et al., 2020).
Let us denote by \(x_{ij}\) the value of the \(i\)-th unit for the criterion \(j\)-th.
Step 1. Setting of the reference levels.
Let us denote by \(q_{j}^{0}\) and \(q_{j}^{n + 1}\), respectively, the minimum and maximum values that criterion \(j\) can take. For each criterion \(j\), the DM gives \(n\) reference levels, \(q_{j}^{1} ,q_{j}^{2} ,...,q_{j}^{n} ,\) which define the performance levels of criterion \(j\) (e.g., very low, low, medium, high, very high or very poor, poor, fairly good, very good). Wierzbicki et al. (2000) mention several ways for establishing these reference levels. They can be defined in an absolute way by experts, in a relative way, applying a statistical scheme, or by setting all the reference levels equal to certain percentages of their respective criteria ranges.
Therefore, the \((n + 2)\)-dimensional vector
contains all the information relative to the reference levels of the criterion \(j\). These reference levels can naturally define performance levels for each criterion, in absolute or relative terms, and the corresponding distance function measures the position of each unit with respect to these levels.
Step 2. Normalisation: the achievement function.
We assume a set of \(n + 2\) real values \(\alpha_{{}}^{0} ,\alpha_{{}}^{1} ,...,\alpha_{{}}^{n} ,\alpha_{{}}^{n + 1}\) which define a common measurement scale for all the criteria. A piece-wise linear achievement function is used to turn each criterion \(j\) to the scale defined by the values \(\alpha^{k}\).
If the j criterion is of type “the more, the better” we consider:
In this case \(s_{j} \left( {x_{ij} ,{\varvec{q}}_{{\varvec{j}}} } \right)\) is a an increasing piece-wise linear function. Therefore, the achievement function \(s_{j}\) of criterion \(j\) takes values between \(\alpha^{k - 1}\) and \(\alpha^{k}\) if the unit achieves values between \(q_{j}^{k - 1}\) and \(q_{j}^{k}\) for the criterion \(j\).
If the j criterion is of type “the lower, the better”
In this case \(s_{j} \left( {x_{ij} ,{\varvec{q}}_{{\varvec{j}}} } \right)\) is a decreasing piece-wise linear function. Therefore, the achievement function \(s_{j}\) of criterion \(j\) takes values between \(\alpha^{n + 1 - k}\) and \(\alpha^{n + 2 - k}\) if the unit achieves values between \(q_{j}^{k - 1}\) and \(q_{j}^{k}\) for the criterion \(j\).
Step 3. Final aggregation: global scores.
Considering the weights obtained in Phase 1, \(w^{*} = \left( {w_{1}^{*} ,w_{2}^{*} ,...,w_{N}^{*} } \right)\), and the achievement functions (17) and (18), we can build the global score of each unit. At this stage, we can obtain different types of composite measures.
The weak composite measure of unit \(i,\) \(WS_{i} ,\) allowing for full compensation among the criteria, is obtained using an additive weighted aggregation:
as \(\sum\nolimits_{j = 1}^{N} {w_{j}^{*} = 1}\) then \(WS_{i} \in \left[ {\alpha^{0} ,\alpha^{n + 1} } \right]\) which can be easily interpreted as the composite performance of the unit \(i\) with respect to the reference levels \({\varvec{q}}_{{\varvec{j}}}\).
The strong composite measure of unit \(i,\) \(SS_{i} ,\) does not allow any compensation. In this case, following Ruiz et al. (2020), it is possible to modify the achievement functions (17) and (18) so that poor performance on a given criterion is not so bad if the criterion is not very important to the DM. For this, a normalisation of the weights is used, so that the highest weight takes the value 1:
Then, the modified achievement function takes the form:
Making use of (21) it is possible to build the strong composite measure as:
Finally, we propose building new composite measures of unit \(i,\) \(PS_{i} ,\) for different compensation degrees considering the following convex linear combination of the weak and strong composite measure:
The coefficient \(\lambda_{i}\) associated to unit \(i\) is obtained as follows:
Step 1: Set a threshold \(0 < th \le 1\).
Step 2: Rank (decreasing order) the criteria according to their weights: \(C_{p(1)} ,C_{p(2)} ,...,C_{p(N)}\), where p is a permutation of \(1,2,...,N\).
Step 3: Identify the minimum set of “important” criteria, \(C_{p(1)} ,C_{p(2)} ,...,C_{p(H)} ,\) such that the sum of their weights is higher or equal to the threshold:
Step 4: Calculate the coefficient \(\lambda_{i}\) as below:
Indeed, \(0 \le \lambda_{i} \le 1\). Note that \(\lambda_{i}\) is close to 1 when the unit i achieves good results for the most important criteria, therefore the weighted mean \(WS_{i}^{{}}\) is a suitable composite measure of performance. On the contrary, \(\lambda_{i}\) is close to 0 when the unit i achieves bad results for the most important criteria and therefore, the compensation of the weighted mean should be corrected with a higher coefficient for the strong measure \(SS_{i}^{{}}\).
We observe \(PS_{i}^{{}} = \alpha^{n + 1}\) if and only if the unit i achieves the score \(\alpha^{n + 1}\) for all criteria and \(PS_{i}^{{}} = \alpha^{0}\) if and only if the unit i achieves the score \(\alpha^{0}\) for all criteria.
The value of the global score obtained with the above composite measures is influenced by the choice of the reference levels \({\varvec{q}}_{{\varvec{j}}}\).
The set of units can now be ranked according to the descending order of the global scores obtained by (19), (22) or (23).
In the next section we apply the proposed Extended Best–Worst Multiple Reference Point (EBW-MRP) method for ranking non-life insurance companies operating in Spain.
3 Case study: spanish non-life insurance companies
In 2017, the Spanish insurance market with a total volume of total direct premiums amounting to €62,451 million ($70,547 million) ranked 15th worldwide in front of other European countries such as Switzerland, Sweden, Belgium, Finland or Portugal, among others Footnote 3. Despite this, in line with other international insurance markets, the recent crisis had an important impact on the Spanish insurance market. Nevertheless, the Spanish sector has proved robust, managing to overcome this economic cycle in a solid way (Manzano 2017). This is reflected by the evolution of the different financial ratios that it has presented in recent years. Specifically, the Non-Life insurance market, has seen an accumulated growth of 6.8% over the period 2007–2017, while in parallel Spanish GDP grew by 7.7% (Mapfre 2018). This economic growth is linked to an increase in the consumption capacity of homes and companies, therefore contributing towards the growth of the Non-Life insurance business.
3.1 Database
The present research studies the performance of Non-Life Spanish insurers over the period 2009–2017 (see Table A1 in the Appendix). The data have been collected from the Balance Sheets and Accounts of insurance entities that the Spanish regulatory and supervisory authority, the Dirección General de Seguros y Fondos de Pensiones (DGSFP), publishes annually.
3.1.1 Non-life insurance companies
In Spain, insurance companies can operate in life, non-life or simultaneously in both life and non-life branches of insurance. In this paper, we focus on those firms that operate exclusively in non-life business between the years 2009–2017. This criterion has the advantage that it makes the insurers more comparable. But, at the same time, it has the disadvantage that insurers such as Mapfre, Mutua Madrileña, or Allianz among others, with important market shares in Spain, but operating simultaneously in the life and non-life business, can be omitted. Table 2 shows the number of firms considered each year. In 2009, 80 firms operate exclusively in non-life business in the Spanish market. In 2011, Segurcaixa is incorporated to this group because the firm split the business of life and non-life into two different insurers. The same happened with Sabadell in 2014 and Asisa in 2015.
In Spain, insurers can have two organizational forms: private (stocks) and mutuals. The literature has always considered this a determining aspect of insurers’ performance, with stocks being more profitable than mutuals, and with better performance (Cummins and Nini 2002; Gaganis et al. 2015). Given that among the companies analysed in our study, both types coexist (23 mutuals appear in our database for all years), we will also analyse whether or not our performance ranking supports this hypothesis.
3.1.2 Criteria
Similar to other research in the field (see Table 3), in order to approach the performance and profitability of insurers, different financial ratios have been calculated, all of which are typically used by international organisms such as The International Association of Insurance Supervisors or the OCDE to evaluate the global insurance market.
Premium growth ratio: it reflects the evolution of the yearly premium. If for an insurer company this ratio is above the mean of the market, it means that this insurer is expanding its share market.
Loss ratio: it indicates the percentage of premiums used to pay claims. The smaller the better. A high loss ratio would indicate poor risk management by the insurer and the need for greater control over future payments as well as the process of underwriting policies.
Expenses ratio: it reflects that part of the premium employed to pay the underwriting expenses, including acquisitions cost, commissions, administrative and general management expenses. This ratio reflects an insurer's ability to manage its daily activity. The lower this ratio is, the more efficient is the insurer is in its management, this enabling it to obtain greater benefits.
Combined ratio: it is the sum of the loss and expenses ratios. This ratio shows a first approximation to the technical profitability of the insurer. Lower values of this ratio would imply that the entity chooses its policyholders well and manages expenses better. If the ratio is greater than 1, it implies that the expenses are greater than the premiums, which means that the insurer is not obtaining benefits with its underwriting activity; either because it has many claims or because expenses are too high. Insurers should compensate these losses with income derived from financial investments, which in non-life insurance have a less relevant role than in life insurance.
Return on equity (ROE): This ratio explains the relation of profit to shareholder capital. It is one of the ratios commonly used in the financial analysis of any firm. High values of this ratio indicate that the company is able to generate a lot of profit with less capital.
Technical ratio: This measures how much profit the insurer makes in relation to the premiums. It indicates the performance of the insurer derived solely from its underwriting activity. The higher the ratio, the greater its financial strength, as the company can generate more profit per income received, thus indicating good management and business efficiency.
Number of Insurance Business Lines: among Non-Life Insurance, up to 19 different lines of business can be distinguished: health, dependency, automobile, home … This variable includes the number of business lines in which each observed insurer operates. It gives us a proxy of the diversification grade of the insurer.
Table 4 shows the main statistics of the criteria calculated for the Spanish Non-Life Insurance market for the period 2009–2017.Footnote 4
Figure 3 shows the evolution of the different criteria throughout the analysed period. An important decrease in premium growth is observed between 2010 and 2013, coinciding with the economic crisis lived by Spain. In 2014 there was a change in the trend of premium growth which continued in 2017, as stated in the Mapfre (2018) report. The evolution of the variations in market shares confirms this trend given that, in recent years, many companies have improved their market share, probably due to the increase in the premiums written linked to the upturn of the Spanish economy.

Evolution of the different criteria from 2009 to 2017
The analysis of the Combined Ratio shows an efficient and healthy non-life insurance sector, as its mean values remained below 1 over the whole period. The big drop of this ratio in 2016 is explained by an important decrease in claims for this year also seen in the loss ratio. At the same time, the expenses ratio has seen an increase since 2004, parallel to the increase in premium writing in the market.
The profitability of non-life insurers can be approximated through their Technical Ratio and ROE. Both measures indicate that Spanish non-life insurers are good managers, generating an average profitability of 10% throughout the period, both on equity (ROE) and in terms of technical activity (Technical Ratio). In 2010, the effects of the economic crisis were felt in the Spanish insurance market and a significant drop in both the ROE and technical ratio occurred. Despite this, profitability levels recovered from 2011 onwards, once again demonstrating the financial strength of the sector.
Figure 3 (graphic 8) shows the number of business lines in which non-life insurers operate. This variable is stable along the period, with almost 60% of companies only working in up to 3 branches. This is probably due to a large number of companies being specialised in specific branches such as: health, credit and surety or legal defence, among others.
3.2 Extended Best–Worst multiple reference point method for the non-life insurance companies
3.2.1 Extended Best–Worst (EBW) Method to calculate the criteria weights.
In order to determine the weights of each criterion, model (14) will be solved. To do this, preferential parameters should be set. The ranking of the importance of the decision criteria is established according to expert opinion and is shown in the first column of Table 5 in descending order, the best criterion is the ROE and the worst is the number of business lines. Reference interval preferential ratios used for solving (14) are displayed in Table 5.
The weights obtained by (14) using the deviation parameterFootnote 5\(d = 0.1\) are displayed in the last column of Table 6, the optimum value, \(\lambda^{*} ,\) is equal to 0.75 showing that the obtained ratios are within the extended intervals but not in the strict intervals. The value used for the deviation parameter d assures a degree of overall satisfaction \(\lambda\) greater than zero because the solution for model (15) gives a lower bound for the parameter d equal to 0.0254. In order to visualise the results of the EBW method in our application, Table 6 shows the preferential intervals established and the achieved ratios as well as the left and right spreads corresponding to these intervals.
On inspection of Table 6, we conclude that in the process of weighting the criteria for ranking Spanish non-life insurance companies, the most important criterion for the expert, ROE, has a weight of 0.279 and the worst, number of business lines, 0.032.
3.2.2 Multiple reference point to calculate the global scores of the non-life insurance companies.
Phase 2 of the process requires setting the reference levels. We have used three reference points \((n = 3)\) for each criterion established according to both statistical values and expert knowledge. Specifically, the reference levels corresponding to Premium Growth, ROE, Technical Ratio and Number of Business Lines are obtained according to the three first quartiles of the data distributions (see Tables 7, 8, 910). For the criteria of the Loss Ratio, Expense Ratio and Combined Ratio, reference levels were set by the DM according to the values displayed in Table 11.
4 Results
The global scores obtained by applying the proposed EBW-MRP(WS) model to our database, according to the composite measure, \(WS_{i} ,\) proposed in (19), are presented in Table A2 of the Appendix. We have applied the Jarque Bera test for the nine series and normality cannot be rejected at the 5% significance level for all of them. Table 12 summarises the distribution of the EBW-MRP(WS) scores for the four tranches. Few companies achieve good results simultaneously
for the eight criteria analysed. The same happens in the case of companies with poor results in all criteria This shows the conflict that exists between the different criteria that measure the comprehensive performance of the companies. For all the years the upper intermediate tranche includes more companies than the lower. Moreover, in most years there are more companies in the upper tranche than in the lower one. Therefore, we can point out a good performance of the Spanish non-life insurance market during the analysed period.
According to Table 13, sixteen firms remain above the mean of the EBW-MRP(WS) scores for all the periods analysed (from 2009 to 2017). On the other hand, fourteen companies remain below the corresponding means. From Table 13, we conclude that mutual insurers rank worse than stock companies, as only one mutuality always appears above the mean (out of 16 firms); while 7 of the 14 insurers that are always below the mean are mutual ones. The hypothesis that the proportion of mutual insurance companies above the score mean is lower than the same proportion for the stock companies is accepted at the 5% significance level (p-value = 0.03408). In addition, the hypothesis that the proportion of mutual insurers always below the score mean is greater than the same proportion for the stock companies is accepted at the 5% significance level (p-value = 0.04306). It means that, according to the EBW-MRP(WS) score, stocks firms perform better than mutual insurers, confirming the results of previous research (Cummins and Nini 2002; Gagarnis et al., 2015).
Table A3 in the Appendix displays the top 10 insurers for each year according to our scoring. For 2010, 2012, 2014, 2015, 2016 and 2017 years it is possible to accept at the 5% significance level the hypothesis that the proportion of mutual insurers is less than the proportion of stock companies in the top ten of the best firms. We focus on the 7 insurers that score in this top 10 at least 5 times, their main financial ratios appearing in Fig. 4. Undoubtedly, EXPERTIA appears as the best firm during all the observed period, ranking first for 5 years. Surprisingly, it is not one of the largest insurers and represented only 0.015% of the market share in 2017, because it only operates in two business lines -assistance and death insurance-. Nevertheless, being a smaller insurer is not a factor which impairs efficiency, profitability or an overall good performance. Looking at the financial health of EXPERTIA, we observe an important decrease of the Combined Ratio over the whole period due to an improvement in both the loss and the expenses ratios. This reveals an enhancement of the insurer’s ability to manage risk and daily activity, which can also be seen in the positive evolution of its ROE.

Financial ratios for the seven insurers that score in the top 10 at least 5 times
The second-best firm is CAI, ranking 8 out of 9 years amongst the 10 best firms according to our scores. It had a market share of 0.048% in 2017 despite operating in up to 7 lines of business. As can be seen in Fig. 4.2, CAI experienced an improvement in its financial health since 2009. It diminished its Combined Ratio and improved its ROE and Technical Ratio. This indicates an important improvement in the capacity of the insurer to generate profits efficiently.
ACUNSA only operates in 2 lines of business, related with health insurance. It has a 0.39% of the market share. The behaviour of the financial ratios for ACUNSA is stable over the whole period and reveals a good performance and efficient management. The high value of the loss ratio is noteworthy, probably because the coverage provided is very costly (it is the Navarra Clinic insurance company, an expert in cancer and experimental treatments). Despite the latter, all the financial ratios of this insurer are close to the expected values for a financially healthy firm.
National-Nederlanden is the Spanish Non-life division of the international company of the same name. In our sample it represents 0.174% of the market share and operates in up to 8 lines of business. Its financial health is good throughout the period. It should be noted that the ROE practically doubles its value, but the Technical Ratio, although it increases, does not do so to the same extent, indicating that a significant part of the company's profit does not come from the underwriting activity. In addition, there is an increase in the Loss Ratio from 2010 onwards which, although it always remains at very acceptable levels, indicates that the company could improve its risk management.
ERGO is the most important insurer in travel insurance, operating in 7 lines with 0.066% of market share in our sample. Although its financial health is good, its behaviour is unstable over time. Until 2013 all ratios improved, although from that moment on the trend changed and the ratios showed a worse performance, mainly derived from an increase in claims. There is also a drop in the ROE, greater than that for the Technical Ratio, which indicates a decrease in the earnings from non-underwriting activity.
Sanitas has the largest market share of those companies appearing at least 5 times in the top 10, with 9.785%. Its insurance activity is focused on 4 health-related business lines. Its financial health is good, and the evolution of its ratios is similar to that of ACUNSA (a company also focused on the health business), with a high value for the Loss Ratio. It should be noted that Sanitas, together with Línea Directa, is the one with the best ROE, standing at around 6%.
Línea Directa also appears 5 times in the top 10 and is the second by market share with 5.924%. It is the most diversified company, operating in up to 10 business lines with differing coverage: auto, home, health, etcetera. Although its financial performance has always been good, as of 2014 there has been a significant increase in the ROE reaching in 2017 a value higher than 0.6%. Furthermore, throughout the period an improvement in risk management translates itself into a decrease in the loss ratio and, consequently, in the Combined Ratio.
To sum up, the seven insurers that appear 5 or more times in our top 10, perform well and present good financial health, being efficient in terms of their business management and profitability. None of them is a mutuality, which reinforces the idea that mutual insurers perform worse than stock insurers. Finally, it seems that market share, and size is not necessary to guarantee a good performance, as most of the firms in this top 10 are not the biggest or those with the largest market share (see Table 14).
Table 15 and Fig. 5 show the most important firms by share market for our sample. Even those insurers usually large firms, with important amounts of gross premium, are not necessarily ranked as the best ones. These insurers usually operate in up to 13 lines of business, so they are very diversified. Nevertheless, diversification does not indicate good performance or greater profit. In fact, as Cummins and Xie (2013) conclude: “the benefits of diversification come at a cost”. González-Fernández et al (2020), also argue that while diversification allows earning more profits, reducing risk, achieving scope economies and providing higher revenues due to market size, diversification is also related to large and more complex organizations, that incur more management and underwriting costs, which can have a negative impact on profit and performance.

EBW-MRP(WS) rankings for the most important firms by share market
Kendall’s (tau) and Spearman’s (rho) rank correlation coefficients are calculated in order to analyse the relation between company rankings in different years. We have chosen for comparison those pairs of years in which the analysed insurers coincided. As observed in Table 16, a meaningful relation between the performance rankings is revealed with the latter analysis. There is a significant correlation between the performance rankings obtained through the EBW-MRP(WS) method for the different years. This shows that the resulting rankings are close to each other for each pair of years compared.
Table 17 shows the ranking of the top 10 insurers, for the year 2017, according to the different composite measures, \(WS_{i}\), \(SS_{i}\) and \(PS_{i}\), proposed in (19), (22) and (23), respectively. The last three columns of Table 17 correspond to the partial compensatory measure when we consider three different thresholds 0.65, 0.55 and 0.3. EXPERTIA appears as the best firm when applying the weighted mean \(WS_{i}\), but surprisingly this firms is not in the top 10 when applying the strong composite measure \(SS_{i}\). This is due to EXPERTIA being a non-diversified insurer with a very low value for the number of business lines criterion. When we consider a partial compensatory measure, this firm is not so penalized and again ranks in the top 10. Table 18 shows the Spearman and Kendall correlation coefficients between the insurers’ rankings obtained for the different composite measures. There are high and significant correlations between the rankings obtained through the weighted mean \(WS_{i}\) and the partial compensatory measures \(PS_{i}\) for all the thresholds considered. When the relationship between \(SS_{i}\) and \(WS_{i}\) is analysed, the Spearman and Kendall correlation coefficients are lower. The top 10 insurers prove different for both measures. In addition to EXPERTIA, another three insurers disappear for the \(SS_{i}\) ranking. We also observe that when applying the \(PS_{i}\) measure, the correlation with the \(WS_{i}\) measure rises as does the threshold considered.
4.1 Sensitivity analysis
The sensitivity of the EBW-MRP(WS) model is analysed via changes in several parameters. We have modified the interval comparisons between pairs of criteria in line with Table 19. Here, keeping ROE as the most important criterion, the Loss Ratio is the second most important criterion, followed by the Technical and Combined Ratios. The resulting weights (last column in Table 19) reflect these preferences. In addition, the parameter \(d_{W}\) has been set equal to 0.05. The value achieved by \(\lambda^{*}\) is, in this case, equal to 0.641, therefore achieving consistency within the extended intervals. The Spearman correlation coefficient between the scores of the original and disturbed models is equal to 0.977 (Kendall coefficient equal to 0.887). The top ten companies remain for both rankings except La Fe which goes up five places and ranks among the top ten in the disturbed model.
The other sensitivity exercise carried out consisted in using the reference points arising from the statistical values (the three first quartiles), for all criteria. In this situation, the Spearman correlation between the scores of the original and disturbed models is equal to 0.99, therefore signifying that results are highly correlated.
5 Conclusions
The paper proposes a model for ranking non-life insurance companies based on combining the most relevant financial ratios and indicators into one overall score, thereby measuring the composite performance of each firm.
We have attempted to resolve two issues associated with such scoring approaches that may preclude decision making. The pairwise comparisons are useful tools for identifying the relative importance between the decision elements. The study takes advantage of this suitability, well referenced in the literature, and proposes an approach for overcoming two ongoing problems, such as the imprecision in judgements and the difficulty for making many paired comparisons. The first issue is addressed by interval values that are extended by tolerance thresholds. The second one is overcome by restricting paired comparisons to those where one element of the pair is the most (least) important of the decision criteria. This approach extends the Best–Worst method and is addressed by fuzzy set theory. The aggregation procedure chosen uses both knowledge expert and statistical values, facilitating a good balance between objective and subjective information. In addition, the MRP methodology gives global scores within the scale set by the DM making them meaningful for the DM. The proposal is comfortable for the DM because it is based on easily obtainable expert knowledge as well as easily understandable results. Mathematically, the proposal is within a linear framework.
Several findings are obtained from the implementation of the model for a Spanish database spanning the years 2009 to 2017. The distribution of the score obtained allows us to conclude that the Spanish non-life insurance market performance is reasonably good given that most of the companies are located in the upper tranches.
The results reveal, as expected, that stock (private) companies perform better and are more profitable than mutual companies. At the same time, small companies score higher than large ones, revealing that size and diversification does not offer a real advantage. Maybe management inefficiencies and the increase in cost make large firms underperform when compared with smaller firms. Nevertheless, the financial study made for the Spanish non-life insurance market, allows us to affirm that it benefits from good financial health, based on the financial ratios analysed. Although over the whole period premium growth was positive, the financial crisis caused a slowdown in the latter from 2010 onwards. The impact of the financial crisis is also observed via the decrease of the ROE and technical ratio in 2010, although these ratios recuperate during the period analysed, albeit not reaching their previous values. The positive evolution of these ratios as well as the Combined Ratio reveals a favourable trend for the Spanish non-life insurance market.
Our method is easily comprehensible and includes both hard and soft data. We hope that these features will give rise to a widespread use by practitioners. In terms of future research, the proposed method may be extended to include group decision-making involving more than one DM. In addition, the EBW method could be combined with other scoring methodologies. We also suggest applying the proposed method to other markets. In the context of the COVID-19 pandemic it is important to check how have changed the financial performance of the insurance companies. The future research could consider the impact of the COVID-19 pandemic on the global scores to find the correlation between periods before and after the pandemic.
Notes
Following Zimmermann (1976), an extended fuzzy linear membership function that expresses the DM’s satisfaction with the accomplishment of the soft constraints \(Ax\tilde{ \le }0\) is:
$$\mu (Ax) = 1 - \frac{Ax}{d},\quad {\text{if 0}} \le Ax \le d$$\(m_{jW} = \frac{{\frac{1}{{d_{jW}^{l} }}l_{jW} + \frac{1}{{d_{jW}^{u} }}u_{jW} }}{{\frac{1}{{d_{jW}^{l} }} + \frac{1}{{d_{jW}^{u} }}}}\)
For reasons of brevity, Table 4 shows the average of the different statistics for the observed period. Individual statistics for each year are available upon request.
Without loss of generality, we suppose that all the tolerance parameters are equal, \(d_{Bj}^{l} = d_{Bj}^{u} = d_{jW}^{l} = d_{jW}^{u} = d\).
References
Abdolvand MA, Rahpeima A (2013) Evaluating and ranking businesses’ branches, based on clients’ perception, a study in insurance industry. Res J Appl Sci Eng Technol 5(4):1323–1329. https://doi.org/10.19026/rjaset.5.4868
Aboutorab H, Saberi M, Asadabadi MR, Hussain O, Chang E (2018) ZBWM: the Z-number extension of best worst method and its application for supplier development. Expert Syst Appl 107:115–125
Acuña-Soto CM, Liern V, Pérez-Gladish B (2019) A VIKOR-based approach for the ranking of mathematical instructional videos. Manag Decis 57(2):501–522. https://doi.org/10.1108/MD-03-2018-0242
Ahn BS (2017) The analytic hierarchy process with interval preference statements. Omega 67:177–185. https://doi.org/10.1016/j.omega.2016.05.004
Akhisar I and Tunay N (2015) “Performance ranking of turkish life insurance companies using AHP and TOPSIS”, MIC: managing sustainable growth; proceedings of the joint international conference, may, Portorož, Slovenia, University of Primorska, Faculty of Management Koper, pp. 28–30.
Akuffo B, Okae-Adjei S, Gyasi-Agyei AK (2016) Fuzzy classification of life insurance companies in ghana using financial ratios. Africa Develop Resources Res Inst J 255(3):11–20
Akyüz G, Tosun Ö, Aka S (2020) Performance evaluation of non-life insurance companies with Best-Worst method and TOPSIS. Int J Manage Econ Business 16(1):108–125
Ali A, Rashid T (2019) Hesitant fuzzy best-worst multi-criteria decision-making method and its applications. Int J Intell Syst 34(8):1953–1967
Alizadeh A, Yousefi S (2019) An integrated Taguchi loss function–fuzzy cognitive map–MCGP with utility function approach for supplier selection problem. Neural Comput Appl 31(3):7595–7614
Arbel A, Vargas L (2007) Interval judgments and euclidean centers. Math Comput Model 46(7–8):976–984
Beiragh RG, Alizadeh R, Kaleibari SS, Cavallaro F, Zolfani SH, Bausys R, Mardani A (2020) An integrated multi-criteria decision making model for sustainability performance assessment for insurance companies. Sustainability 12(3):789–813. https://doi.org/10.3390/su12030789
Bellman R, Zadeh L (1970) Decision-making in a fuzzy environment. Manage Sci 17(4):141–164
Bilbao-Terol A, Arenas-Parra M, Alvarez-Otero S, Cañal-Fernández V (2019) Integrating corporate social responsibility and financial performance. Manag Decis 57(2):324–348
Boggia A, Fagioli FF, Paolotti L, Ruiz F, Cabello J, Rocchi L (2022) Using accounting dataset for agricultural sustainability assessment through a multi-criteria approach: an Italian case study. Int Trans Oper Res. https://doi.org/10.1111/itor.13141
Cabello JM, Ruiz F, Pérez-Gladish B (2021) An alternative aggregation process for composite indexes: an application to the heritage foundation economic freedom index. Soc Indicator Res 153:443–467. https://doi.org/10.1007/s11205-020-02511-8
Chen L, Xu Z (2015) A new fuzzy programming method to derive the priority vector from an interval reciprocal comparison matrix. Inf Sci 316:148–162. https://doi.org/10.1016/j.ins.2015.04.015
Cummins JD, Nini GP (2002) Optimal capital utilization by financial firms: evidence from the property-liability insurance industry. J Finan Serv Res 21(1–2):15–53
Cummins JD, Rubio-Misas M (2006) Deregulation, consolidation, and efficiency: evidence from the Spanish insurance industry. J Money, Credit, Bank 38(2):323–355
Cummins JD, Xie X (2013) Efficiency, productivity, and scale economies in the U.S. property-liability insurance industry. J Product Analys 39:141–164
Cummins JD, Weiss MA, Xiaoying X, Hongmin Z (2010) Economies of scope in financial services: A DEA efficiency analysis of the US insurance industry. J Bank Finance 34(7):1525–1539
Cummins JD, Rubio-Misas M, Vencappa D (2017) Competition, efficiency and soundness in European life insurance markets. J Financ Stab 28:66–78
Cummins JD, and Weiss MA (2013) “Analyzing firm performance in the insurance industry using frontier efficiency and productivity methods” Dionne, G (Ed), Handbook of insurance, Springer, New York, pp. 795–861.
Dar SA, Thaku IA (2015) A comparative analysis of financial performance of public and private non-life insurers in India. Int J Manag 6(1):507–526
Diacon SR, Starkey K, O’Brien C (2002) Size and efficiency in European long-term insurance companies: an international comparison. Geneva Papers Risk Insurance 27(3):444–466
Doumpos M, Gaganis C, Pasiouras F (2012) Estimating and explaining the financial performance of property and casualty insurers: a two-stage analysis. J CENTRUM Cathedra: Business Econ Res J 5(2):155–170
Ecer F, Pamucar D (2021) MARCOS technique under intuitionistic fuzzy environment for determining the COVID-19 pandemic performance of insurance companies in terms of healthcare services. Appl Soft Comput 104(2):107199. https://doi.org/10.1016/j.asoc.2021.107199
Eckles DL, Pottier SW (2011) Is efficiency an important determinant of A.M. best property-liability insurer financial strength ratings? J Insurance Issues 34(1):18–33
Eling M, Jia R (2019) Efficiency and profitability in the global insurance industry. Pacific-Basin Finance J 57:101190
Eling M, Luhnen M (2010) Frontier efficiency methodologies to measure performance in the insurance industry: overview, systematization and recent developments. Geneva Papers Risk Insurance - Issues Practice 35(2):217–265
Fei L, Lu J, Feng Y (2020) An extended best-worst multi-criteria decision-making method by belief functions and its applications in hospital service evaluation. Comput Ind Eng 142:106355. https://doi.org/10.1016/j.cie.2020.106355
Gaganis C, Liuling L, Pasiouras F (2015) Regulations, profitability and risk-adjusted returns of European insurers: an empirical investigation. J Finan Stabil 18(C1):55–77
Garcia-Bernabeu A, Cabello JM, Ruiz F (2021) A reference point-based proposal to build regional quality of life composite indicators. Soc Indicator Res. https://doi.org/10.1007/s11205-021-02818-0
Dirección general de seguros y fondos de pensiones (DGSFP). Available at: http://www.dgsfp.mineco.es/es/Paginas/Iniciocarrousel.aspx.
González-Fernández AI, Rubio-Misas M, Ruiz F (2020) Goal programming to evaluate the profile of the most profitable insurers: an application to the Spanish insurance industry. Int Trans Oper Res 27(6):2976–3006
Govindan K, Azevedo SG, Carvalho H, Cruz-Machado V (2014) Impact of supply chain management practices on sustainability. J Clean Prod 85:212–225
Guo S, Zhao H (2017) Fuzzy best-worst multi-criteria decision-making method and its applications. Knowl-Based Syst 121:23–31
Ishizaka A, Labib A (2011) Review of the main developments in the analytic hierarchy process. Expert Syst Appl 38(11):14336–14345
Kaya EO (2016) Financial performance assessment of non-life insurance companies traded in Borsa Istanbul via grey relational analysis. Int J Econ Financ 8(4):277–288
Kazemi M, Bardeji SF (2016) Application of combinational approach of FAHP and PROMETHEE in the insurance branches ranking. Int J Procurement Manage 9(5):548–567
Ksenija M, Boris D, Snežana K, Sladjana B (2017) Analysis of the efficiency of insurance companies in Serbia using the fuzzy AHP and TOPSIS methods. Econ Res-Ekonomska Istrazivanja 30(1):550–565
Kung CY, Yan TM, Chuang SC (2006) GRA to Assess the operating performance of non-life insurance companies in Taiwan. J Grey Sys 18(2):155–160
Lahri V, Shaw K, Ishizaka A (2021) Sustainable supply chain network design problem: using the integrated BWM, TOPSIS, possibilistic programming, and ε-constrained methods. Expert Syst Appl 168:114373
Leverty JT, Grace MF (2010) The robustness of output measures in property/liability insurance efficiency studies. J Bank Finance 34(7):1510–1524
Mandić K, Delibašić B, Knežević S, Benković S (2017) Analysis of the efficiency of insurance companies in Serbia using the fuzzy AHP and TOPSIS methods. Economic Res-Ekonomska Istraživanja 30(1):550–565
Manzano D (2017) Spain’s banking and insurance sector: a contrasting story. Spanish Econom Financial Outlook 6(4):79–84
Mapfre (2018) The Spanish insurance market in 2017, MAPFRE economic research, Fundación Mapfre.
Mi X, Liao H (2019) An integrated approach to multiple criteria decision making based on the average solution and normalized weights of criteria deduced by the hesitant fuzzy best worst method. Comput Ind Eng 133(5):83–94
Mikhailov L (2003) Deriving priorities from fuzzy pairwise comparison judgements. Fuzzy Sets Syst 134(3):365–385
Mikhailov L (2004) A fuzzy approach to deriving priorities from interval pairwise comparison judgements. Eur J Oper Res 159(3):687–704
Mou Q, Xu Z, Liao H (2016) An intuitionistic fuzzy multiplicative best-worst method for multi-criteria group decision making. Inf Sci 374:224–239
Mou Q, Xu Z, Liao H (2017) A graph based group decision making approach with intuitionistic fuzzy preference relations. Comput Ind Eng 110:138–150
Nourani M, Devadason ES, Chandran VGR (2018) Measuring technical efficiency of insurance companies using dynamic network DEA: An intermediation approach. Technol Econ Dev Econ 24(5):1909–1940
Pamučar D, Petrović I, Ćirović G (2018) Modification of the best-worst and MABAC methods: a novel approach based on interval-valued fuzzy-rough numbers. Expert Syst Appl 91:89–106
Pattnaik CR, Mohanty SN, Mohanty S, Chatterjee JM, Jana B, García-Díaz V (2021) A fuzzy multi-criteria decision-making method for purchasing life insurance in India. Bull Electric Eng Inform 10(1):344–356. https://doi.org/10.11591/eei.v10i1.2275
Rejikumar G, Raja Sreedharan V and Saha R (2019) “An integrated framework for service quality, choice overload, customer involvement and satisfaction: evidence from India’s non-life insurance sector”. Management Decision Vol. ahead-of-print No. ahead-of-print. https://doi.org/10.1108/MD-12-2018-1354.
Ren J (2018) Selection of sustainable prime mover for combined cooling, heat, and power technologies under uncertainties: An interval multicriteria decision-making approach. Energy Res 42(8):2655–2669
Rezaei J (2015) Best-worst multi-criteria decision-making method. Omega 53:49–57. https://doi.org/10.1016/j.omega.2014.11.009
Rezaei J (2016) Best-worst multi-criteria decision-making method: some properties and a linear model. Omega 64:126–130. https://doi.org/10.1016/j.omega.2015.12.001
Ruiz F, El Gibari S, Cabello JM, Gómez T (2020) MRP-WSCI: multiple reference point based weak and strong composite indicators. Omega 15:102060. https://doi.org/10.1016/j.omega.2019.04.003
Saaty TL (1977) A scaling method for priorities in hierarchical structures. J Math Psychol 15(15):234–281
Saaty TL (1980) The analytic hierarchy process. McGraw Hill, New York
Saaty TL (1990) How to make a decision: the analytic hierarchy process. Europ J Operat Res 48(1):9–26. https://doi.org/10.1016/0377-2217(90)90057-I
Saaty TL, Vargas LG (1987) Uncertainty and rank order in the analytic hierarchy process. Eur J Oper Res 32(1):107–117. https://doi.org/10.1016/0377-2217(87)90275-x
Sabet RJ, Fadavi A (2013) Performance measurement of insurance firms using a two-stage DEA method. Manage Sci Lett 3(1):303–308
Saeed U, Khurram N (2015) Factors influencing the financial performance of non-life insurance companies of Pakistan. Int J Empirical Finance 4(6):354–361
Toloie A, Nasimi M, Poorebrahimi A (2011) Assessing quality of insurance companies using multiple criteria decision making. Eur J Sci Res 54(3):448–457
Torbati AR, Sayadi MK (2018) A new approach to investigate the performance of insurance branches in Iran using Best-Worst Method and fuzzy inference system. J Soft Comput Decision Support Sys 5(4):13–18
Venkateswarlu R, Bishma Rao GSS (2016) Profitability evaluation and ranking of Indian non-life insurance firms using GRA and TOPSIS. European J Business Manage 8:2
Wang YM, Elhag TMS (2007) A goal programming method for obtaining interval weights from an interval comparison matrix. Eur J Oper Res 177(1):458–471
Wierzbicki AP, Makowski M, Wessels J (2000) Model-based decision support methodology with environmental applications. Kluwer Academic Publishers, Dordrecht
Yue ZL, Z.L. (2012) Extension of TOPSIS to determine weight of decision maker for group decision making problems with uncertain information. Expert Syst Appl 39(7):78–88
Zadeh LA (1965) Fuzzy sets. Inf Control 8(3):338–353
Zhang J, Kou G, Peng Y, Zhang Y (2021) Estimating priorities from relative deviations in pairwise comparison matrices. Inf Sci 552:310–327
Zimmermann HJ (1976) Description and optimisation of fuzzy systems. Int J Gen Syst 2:209–215
Funding
Open Access funding provided thanks to the CRUE-CSIC agreement with Springer Nature.This work was supported by Fundación para el Fomento en Asturias de la Investigación Científica Aplicada y la Tecnología (FICYT), Project AYUD/2021/50878.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Confict of interests
The authors declare that they have no confict of interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Bilbao-Terol, A., Arenas-Parra, M., Quiroga-García, R. et al. An extended best–worst multiple reference point method: application in the assessment of non-life insurance companies. Oper Res Int J 22, 5323–5362 (2022). https://doi.org/10.1007/s12351-022-00731-z
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12351-022-00731-z