
Abstract
Water level prediction of rivers, especially in flood prone countries, can be helpful to reduce losses from flooding. A precise prediction method can issue a forewarning of the impending flood, to implement early evacuation measures, for residents near the river, when is required. To this end, we design a new method to predict water level of river. This approach relies on a novel method for prediction of water level named as RBF-FFA that is designed by utilizing firefly algorithm (FFA) to train the radial basis function (RBF) and (FFA) is used to interpolation RBF to predict the best solution. The predictions accuracy of the proposed RBF–FFA model is validated compared to those of support vector machine (SVM) and multilayer perceptron (MLP) models. In order to assess the models’ performance, we measured the coefficient of determination (R 2), correlation coefficient (r), root mean square error (RMSE) and mean absolute percentage error (MAPE). The achieved results show that the developed RBF–FFA model provides more precise predictions compared to different ANNs, namely support vector machine (SVM) and multilayer perceptron (MLP). The performance of the proposed model is analyzed through simulated and real time water stage measurements. The results specify that the developed RBF–FFA model can be used as an efficient technique for accurate prediction of water stage of river.
Similar content being viewed by others


1 Introduction
River flooding, as a natural disaster, occurs when rivers or streams overflow their banks. It could cause serious damage to people and the places in which they live and work. During the past decade, many solutions proposed to tackle river flooding, but it is clear that none of the proposed methods can solve this issue, completely. For example, in the United States, where flood mitigation is advanced, floods do about $6 billion worth of damage and kill about 140 people every year (National Geographic 2016). Prediction, as a part of statistical inference, is one of the useful approaches in this regard. A precise method of prediction of water stage of river can reduce losses from flooding using issue a forewarning for residents near the river, when is required (Chau 2006; Li and Tan 2015; Qi et al. 2013).
Over the last decade, metaheuristic optimization algorithms such as the Genetic Algorithm (GA), Ant Colony Optimization (ACO), Particle Swarm Optimization (PSO), Artificial Neural Networks (ANN) and Support Vector Machine (SVM) (Yang 2010a, b) were applied in prediction methods in different science. Also, there are various classes of ANN structure that many researchers have used them in their findings (Yang et al. 1996, 1997, 2009; Coulibaly et al. 2000, 2001; Daliakopoulose et al. 2005; Bhattacharjya and Datta 2005; Nayak et al. 2006; Nourani et al. 2008; Kentel 2009; Ghose et al. 2010; Mohanty et al. 2010; Emamgholizadeh 2012; Emamgholizadeh et al. 2013a; Emamgholizadeh et al. 2014; Akrami et al. 2014).
To overcome disadvantages of heuristic algorithms in isolation, hybrid heuristics algorithms also were widely used in different science, especially in hydrologic engineering. This is mainly because hybrid heuristic algorithms provide more ability to exploitation and exploration (Vasant 2012). Rogers et al. (1995) proposed the hybrid model include of the genetic algorithm and ANN which utilized the genetic algorithm for remedying optimal field-scale groundwater within ANN. Kisi et al. (2015) developed a novel method based on SVM coupled with firefly algorithm (FA) to predict water level of Urmia Lake. In this model, FA was applied to estimate the optimal SVM parameters. A hybrid approach using FA, PSO and GA is also proposed for sea water level prediction in (Long and Meesad 2013). Bazartseren et al. (2003) proposed a model based on ANN. They found that both ANN and neuro-fuzzy systems outperformed the other such as linear statistical models and they offered the results based on short-term water level predictions on two different river reaches in Germany. In order to predict water level of Shing Mun River, a neural network approach based on PSO also developed in (Chau 2006). Siddiquee and Hossain (2014) proposed a prediction method based on artificial neural network to provide an early flood warning system. This model predicts the water stage of Bahadurabad River in Bangladesh.
In many practical situations, the main concern is making accurate and timely predictions at specific locations. A simple “black-box” model is then preferred in identifying a direct mapping between inputs and outputs. In recent years, many nonlinear approaches, such as the artificial neural network ANN, genetic algorithm GA, and fuzzy logic approaches, have been used in solving flood forecasting problems. The following Table 1 shows the discussion of previous works.
In this work, a hybrid method comprised of RBF and FFA is developed for river stage prediction. RBF performs structural minimization whereas the traditional techniques use the process of the minimization of the errors. Therefore, in the proposed hybrid method, while RBF is used to carry out structural minimization, the FFA searches the optimal hyper parameters for RBF thus giving more reliable and accurate forecasts.
This combination of RBF and FFA is unique and thus has enhanced the performance of the proposed RBF-FFA model compared with the other existing popular models. To the best of our knowledge, this algorithm has never been applied to hydrological and water resources problems. The new contributions made by this paper are the application of these two algorithms on flood forecasting problems in real prototype cases and the comparison of their performances with support vector machine (SVM) and multilayer perceptron (MLP) which are two typical methods that have been widely applied to many real world applications. Figure 1 presents schematic diagram of the proposed RBF–FFA model. It is then used to predict water levels in the Selangor River of Malaysia. To evaluate proposed method, the level of river, measured by four existing stations during 24 hours, is applied.

Diagram of RBF–FFA model
The outline of this paper is as follows: First, the study area is described in Section 2. In Section 3, the proposed prediction method based on RBF–FFA is explained. Then, in Section 4 the different neural modelling methods are introduced for performance evaluation. Section 5 analyzes and discusses the performance of the algorithm through simulation results. Finally, section 6 concludes the paper.
2 Region and Data Description
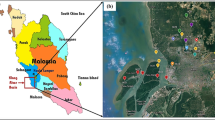
These hydrographs presents daily records of water level from Selangor River. This river is a major river in Selangor, Malaysia. As shown in Fig. 2, it runs from Kuala Kubu Bharu in the east and empties into the Straits of Malacca at Kuala Selangor in the west. We extract the required information from the hydrograph for different stations includes Sg. Buloh (as Station1), Sg. Klang (as Station2), Sg. Rawang (as Station3) and Sg. Penchala (as Station4) on Selangor River. The hydrograph presents statistics of the daily water level with specific color on different positions (see Fig. 2). According to the existing hydrograph on 27 February 2016, the average water level measured by Station1 is about 26.48188. This value is about 2.832708, 33.04167 and 18.30313 that measured by Station2, Station3 and Station4, respectively Online flood information website (2016)). Table 2 represents 48 samples of the river level value that measured by four stations during 24 hours on this date.

Map of Selangor River
2.1 Radial basis function (RBF)
Artificial Neural Network (ANN) has been related to develop, optimize, estimate, predict and monitor of complicated systems. A new and effective feed forward neural network with three layers called radial basis function (RBF) neural network, which has fine characteristics of approximation performance and the global optimum (Ansong et al. 2013). Generally speaking, the RBF network consists of the input layer, the hidden layer and the output layer. Each neuron in the input layer is responsible to transfer the recorded signal to the hidden layer. In the hidden layer, we often use the radial basis function as the transfer function, while we usually adopt a simple linear function in the output layer. The RBF program was implemented in MATLAB. The main reasons for choosing RBF are its good computationally performance, simplicity, reliability, high level of adaptation to optimization and other adaptive methods and also its adaptability in handling parameters which are very complicated (Yu et al. 2011).
Basically, the RBF network consists of the three layers includes input layer, the hidden layer and the output layer. ANN executes nominal computation to offer an output. Computation comprises one-pass arithmetic steps. No iterative and nonlinear computations are complicated in offering an output. We have chosen RBF networks because this method is simple design that it has just three layers. In this study, the number of neurons in the hidden layer is set to 15; the Mean Squared Error (MSE) is 0.1 according to the actual training process and σ (sigma) parameter is width of RBF by 0.02.
The main advantage is that RBF has a hidden layer that includes nodes named RBF units. Each RBF has main factors that designate the location, deviation or width of the function’s center. The hidden component processes the distance from input data vector and the center of its RBF. If the distance from specific center to the input data vector is zero then RBF has own peak and if the distance increases then the peak of RBF will be declined steadily.
In RBF, hidden layer have different sets of weights that divided into the two sets. These weights can connect the hidden layer to the input layer and the hidden layer to the output layer as linkages. The subjects of the basis functions fixed into the weights those connect to the input layer. The issues of the network outputs fixed into the weights those connect to the hidden layer to the output layer. Since the hidden units are nonlinear, the outputs of the hidden layer can be merged linearly and subsequently processing is fast. The output of the network is resultant from (Foody 2004).
where N , in Eq (1), is the number of basic functions, \( {w}_{k_j} \)represents a weighted connection between the basis function and output layer, x the input data vector, and ∅ j is the nonlinear function of unit j, which is typically a Gaussian of the form (Foody 2004).
where x and μ are the input and the center of RBF unit, respectively. In Eq (2), the spread of the Gaussian basis function Foody (2004) shows by σ j . The weights can be optimized by least mean square LMS algorithm once the centers of RBF units are determined. The centers are selected randomly or through clustering algorithms.
2.2 Firefly Optimization Algorithm
Firefly Algorithm (FFA) is a meta-heuristic search algorithm, which is based on the social dashing behavior of fireflies in nature (Łukasik and Żak 2009;Yang 2010a, 2010b). In the FA, there are two important issues: the difference of light intensity and formulation of the attractiveness. We can consider that the attractiveness of a firefly is assessed by its light intensity that in turn is related with the encoded objective function. For simplicity, the light intensity L(d) varies with the distance d monotonically and exponentially based on Eq (3):
Where light intensity and absorption coefficient are presented by L 0 and γ respectively. The light intensity L(r) varies with distance r monotonically and exponentially. Where L 0 the original light intensity and γ is the light absorption coefficient.
As a firefly’s attractiveness is proportional to the light intensity seen by adjacent fireflies, we can now define the attractiveness β of a firefly by Eq. (4):
Where β0 is the attractiveness at d = 0. β0 is their attractiveness at r = 0 i.e. when twofireflies are found at the same point of search space. In general β0 ∈ [0, 1] should be usedand two limiting cases can be defined: whenβ0 = 0, that is only non-cooperative distributed random search is applied and when β0 = 1 which is equivalent to the scheme of cooperative local search with the brightest firefly strongly determining other fireflies positions, especially in its neighborhood. The value of γ determines the variation of attractiveness with increasing distance from communicated firefly. Using γ = 0 corresponds to no variation or constant attractiveness and conversely setting γ → ∞ results in attractiveness being close to zero which again is equivalent to the complete random search. In general γ ∈ [0, 10] could be suggested (Yang 2008).
The distance between any two fireflies i and j at xi and xj can be the Cartesian distance d ij = ‖x i − x j ‖2 or the 2-norm. The movement of a firefly i is attracted to another more attractive (brighter) firefly j is determined by Eq. (5):
Where the second term is due to the attraction, while the third term is randomization with the vector of random variables ϵ i being drawn from a Gaussian distribution.
The optimal solution found by FFA is far better than the best solution obtained previously in literature. FFA is a population based search algorithm inspired by the flashing behavior of fireflies. It has been successfully employed to solve the nonlinear and non-convex optimization problems [10–12]. Recent research shows that FFA is a very efficient and could outperform other metaheuristic algorithms. The superiority of FFA over ABC and PSO has also been reported in the literature (Fister et al. 2013).
FFA is simple, flexible and versatile, which is very efficient in solving a wide range of diverse real-world problems. FFA has an ability to control its modality and adapt to problem landscape by controlling its scaling parameter. For any meta-heuristic algorithm, a good balance between exploitation and exploration during search process should be maintained to achieve good performance. FFA being a global optimizing method is designed to explore the search space and most likely gives an optimal/near-optimal solution if used alone (Fister et al. 2013).
In this study, we have developed a novel algorithm for prediction water stage of river to reduce the risk of river flooding via hybridization of RBF and Firefly Algorithm (FFA). We used Firefly Algorithm (FFA) for determining optimal RBF solutions. To achieve this, four stations on the Selangor River to analyze the influence of water level on the capability of the developed method.
3 RBF Parameters Selection Using FFA
In this study, FFA is used to interpolation RBF. In other words, we want to train RBF by FFA as an optimization problem to forecast river flooding using water stage of river. FFA was implemented in this study to optimize the connection weights of the RBF system.
Artificial neural network with radial basis function (RBF) based on FFA have been utilized to interpolation RBF in order to approximate the solution and RBF is combined with firefly optimization algorithm to estimate level of water. In this section, the explanation of experiment by RBF–FFA model is shown. It should be mentioned that here, number of kernel RBFs was set to 10. Also, the mean square error (MSE) was used as cost function in the FFA. The ability of the RBF-FFA to make good predictions is related on input parameters selection. The water level of river will be considered as inputs into RBF-FFA in order to examine the best prediction by this method. In this combination, we train the RBF by FFA. In other words, in order to improve the accuracy of the prediction, the responsibility of RBF’s training.
4 Model Performance Evaluation
Different neural modelling methods namely support vector machine (SVM) and multilayer perceptron (MLP) are tested to model RBF–FFA. The support vector is a supervised learning method that is used for classification and regression analysis. A multilayer perceptron is a feedforward artificial neural network model that maps sets of input data onto a set of appropriate outputs. In this study, MLP with a single hidden layer is used, as a general approximation when enough number of hidden neurons are employed. To evaluate the performance of proposed model and two famous prediction methods MLP and SVM; some statistical indicators were examined as root mean squared error (RMSE), coefficient of determination (R 2), correlation coefficient (r) and mean absolute percentage error (MAPE). Structurally, the evaluated networks consist of a single input and output layers; a single hidden layers for MLP, RBF–FFA and SVM. We have postponed an evaluation and comparison of the approaches until Section 5.
5 Results and Discussions
In this section, we try to show the importance of each independent input variable on the output. Some experimental works were executed to do the evaluation of proposed model. Root-mean-square error (RMSE), coefficient of determination (R 2), correlation coefficient (r) and mean absolute percentage error (MAPE) served to evaluate the differences between the predicted and actual values for both SVMs models. Table 4 shows the comparison of RBF–FFA with SVM and MLP.
The radial basis artificial neural network model was trained to minimize the mean squared error (MSE) with parameter (water level of river) as input and the desired output (predicted water level). To design and verify the reliability of the proposed model, the dataset was divided into two different sets includes of training and test data that are 80% and 20% of the total data, respectively. The test data are not presented to the network in the training process. Afterwards, when the training process is done, the reliability and over fitting of the network was verified with test data. The overall performance of the proposed models in estimating the water stage of four stations has been graphically depicted in Fig. 3.

Overall performance of RBF–FFA for Station1, Station2, Station3, and Station4
In order to acquire correct assessment, RBF–FFA model are tested with data set that have not been used during the training process. The real and predicted water stage values for four stations during 48 times have been stated in Table 3. By looking at this table, we can observe that the RBF–FFA model can estimate this value very quickly about 700 ms before the actual time.
In order to assess the performance of fit in our RBF–FFA, residual analysis has been changed and used. This is to justify in what way the RBF–FFA can predict new water stage values, with a great degree of certainty, resulting from extremely variable data (water level) collected from stations on Selangor River. To evaluate the performance of the RBF–FFA, three statistical estimators that are the mean squared error (MSE) in Eq. (6), coefficient of determination (R 2) in Eq. (7) and root mean square error (RMSE), that if RMSE is zero then the method has outstanding performance, in Eq. (8) were used:
Where r the number of points is, v pi is the estimated value, v ai is the actual value, and v av is the average of the actual values. The coefficient of determination, R 2, of the linear regression line between the estimated values of the neural network model and the required output was also used as a measure of performance. The use of R 2, the coefficient of determination, also called the multiple correlation coefficient, is well established in classical regression analysis (Rao 1973). Its definition as the proportion of variance 'explained' by the regression model makes it useful as a measure of success of predicting the dependent variable from the independent variables. The closer the R2 value is to 1, the better the model fits to the actual data (Goudarzi et al. 2015). Express differently, R-square is the square of the correlation between the response values and the predicted response values. It is also named the square of the multiple correlation coefficients and the coefficient of multiple determinations. Also, the root-mean-square error (RMSE) is a frequently used measure of the differences between values (sample and population values) predicted by a model or an estimator and the values actually observed. This measurement processes how successful the fit is in describing the change of the data. The Mean Squared Error (MSE) is a measure of how close a fitted line is to data points. For every data point, we take the distance vertically from the point to the corresponding y value on the curve fit (the error), and square the value. The smaller the Mean Squared Error, the closer the fit is to the data. Table 3 shows more details for four Station1, Station2, Station3 and Station4. Note that in suitable selection of initial weights may cause the local minimum data. In order to prevent of this unfavorable phenomenon, 30 runs for each method were applied and in each run different random values of initial weights were measured. Finally, in RBF the best-trained network, which had minimum MSE of validation data, was selected as the trained network. The estimation performance of RBF–FFA, SVM and MLP are assessed by R 2 and MSE the output values are stated in Table 4. This table shows the results in 30 different running times with Iteration = 100.
Table 4 shows R 2 values of all data sets for the RBF–FFA, SVM and MLP. It is clear that the fit is rationally suitable for all data sets with R-values about 1 for the RBF–FFA. The SVM and MLP were found to be as sufficient for estimation of the water stage, whereas the RBF–FFA model showed a significantly high degree of accuracy in the estimation of R 2 between 0.97 and 0.99. Also, root of MSE was founded that the smaller the RMSE of the test data set, the higher is the predictive quality. The assessment of the aforementioned models shows the suitable predictive capabilities of RBF–FFA model.
In continue, we show the results of comparison based on correlation coefficient (r) and mean absolute percentage error (MAPE) that MAPE is the mean absolute percentage error, i.e., the average absolute error in predicting cumulative data, divided by the actual cumulative data (Lam et al. 2001). This comparison is served to evaluate the differences between the predicted and actual values for RBF–FFA, SVM and MLP models. Table 4 shows the results of comparison based on (r) and (MAPE).
Where n the number of points is, v pi is the estimated value, v ai is the actual value, and \( \overline{v_{pi}} \) and \( \overline{v_{ai}} \)are the mean value of v pi and v ai respectively. The smaller value of MAPE has the better performance model and vice versa in the case of r.
Tables 4 and 5 indicate that the RBF–FFA model has the best capabilities of estimating the water stage of river. Based on the results of comparisons we can find that the performance of proposed model is different between the two considered approaches. The main point is that we compared RBF–FFA model to the SVM and MLP and obtained better results and the results expressed that is the superior method.
6 Conclusion
In this study, a novel hybrid prediction model is proposed. For this purpose, in order to improve the prediction accuracy, we integrated (FFA) to train the (RBF). The simulation studies measured stage of water obtained from four stations on Selangor River. The main idea of the study focuses on examination of the feasibility of the proposed hybrid technique in comparison with other techniques. To validate the precision of developed RBF–FFA model its performance is compared to (SVM) and (MLP) models. After the analysis we could show that proposed model has better performance. The statistical indicator used for performance evaluation of the proposed model indicates lower values of RMSE and MAPE and higher values of R2 and r when compared to SVM and MLP models for all the nodes considered. The achieved results revealed that the proposed hybrid RBF–FFA approach would be an appealing option to predict water level since the results were favorable for all 30 running times studies despite different nodes characterizes. Based on these, the proposed RBF–FFA model can therefore be allocated an efficient approach for accurate prediction of water level. In addition, other techniques to solve Water level prediction of rivers such as reinforcement learning will also be considered in the future.
References
Akrami SA, Nourani V, Hakim SJS (2014) Development of nonlinear model based on wavelet-ANFIS for rainfall forecasting at Klang gates dam. Water Resour Manag 28:2999–3018
Ansong, Mary Opokua, Yao, Hong-Xing, & Huang, Jun Steed. (2013). Radial and sigmoid basis function neural networks in wireless sensor routing topology control in underground mine rescue operation based on particle swarm optimization. International Journal of Distributed Sensor Networks, 2013.
Bazartseren B, Hildebrandt G, Holz K-P (2003) Short-term water level prediction using neural networks and neuro-fuzzy approach. Neurocomputing 55(3):439–450
Bhattacharjya RK, Datta B (2005) Optimal management of coastal aquifers using linked simulation optimization approach. Water Resour Manag 19:295–320
Chau KW (2006) Particle swarm optimization training algorithm for ANNs in stage prediction of Shing Mun River. J Hydrol 329(3):363–367
Coulibaly P, Anctil F, Bobee B (2000) Daily reservoir inflow forecasting using artificial neural networks with stopped training approach. J Hydrol 230:244–257
Coulibaly P, Anctil F, Aravena R, Bobee B (2001) Artificial neural network modeling of water table depth fluctuations. Water Res 37:885–896
Daliakopoulose NI, Colibaly P, Tsanis KI (2005) Groundwater level forecasting using artificial neural networks. Hydrol 309:229–240
Emamgholizadeh S (2012) Neural network modeling of scour cone geometry around outlet in the pressure flushing. Glob Nest J 14:540–549
Emamgholizadeh S, Bateni SM, Jeng DS (2013a) Artificial intelligence-based estimation of flushing half-cone geometry. Eng Appl Artif Intell 26:2551–2558
Emamgholizadeh S, Moslemi K, Karami G (2014) Prediction the groundwater level of bastam plain (Iran) by artificial neural network (ANN) and adaptive neuro-fuzzy inference system (ANFIS). Water Resour Manag 28(15):5433–5446
Fister I, Fister I, Yang XS, Brest J (2013) A comprehensive review of firefly algorithms. Swarm Evolut Comput 13:34–46
Foody GM (2004) Supervised image classification by MLP and RBF neural networks with and without an exhaustively defined set of classes. Int J Remote Sens 25(15):3091–3104
Ghose D, Panada S, Swain P (2010) Prediction of water table depth in western region. Orissa using BPNN and RBFN neural networks J Hydr:296–304
Goudarzi, Shidrokh, Hassan, Wan Haslina, Soleymani, Seyed Ahmad, Anisi, Mohammad Hossein, & Shabanzadeh, Parvaneh. A Novel Model on Curve Fitting and Particle Swarm Optimization for Vertical Handover in Heterogeneous Wireless Networks.(2015)
Kentel E (2009) Estimation of river flow by artificial neural networks and identification of input vectors susceptibble to producing unreliable flow estimates. J Hydrol:481–488
Kisi O, Shiri J, Karimi S, Shamshirband S, Motamedi S, Petković D, Hashim R (2015) A survey of water level fluctuation predicting in Urmia Lake using support vector machine with firefly algorithm. Appl Math Comput 270:731–743
Lam KF, Mui HW, Yuen HK (2001) A note on minimizing absolute percentage error in combined forecasts. Comput Oper Res 28(11):1141–1147
Li J, Tan S (2015) Nonstationary Flood Frequency Analysis for Annual Flood Peak Series, Adopting Climate Indices and Check Dam Index as Covariates. Water Resour Manag 29(15):5533–5550
Long, Nguyen Cong, & Meesad, Phayung. (2013). Meta-heuristic algorithms applied to the optimization of type-1 and type 2 TSK fuzzy logic systems for sea water level prediction. Paper presented at the Computational Intelligence & Applications (IWCIA), 2013 I.E. Sixth International Workshop on.
Łukasik, Szymon, & Żak, Sławomir. (2009). Firefly algorithm for continuous constrained optimization tasks Computational Collective Intelligence. Semantic Web, Social Networks and Multiagent Systems (pp. 97-106): Springer.
Mohanty S, Jha K, Kumar A, Sudheer K (2010) Artificial neural network modeling for groundwater level forecasting in a river island of eastern India. J Water Resour Manag 24:1845–1865
National Geographic. (2016). Retrieved from http://environment.nationalgeographic.com/environment/natural-disasters/floods-profile/
Nayak P, SatyajiRao Y, Sudheer K (2006) Groundwater level forcasting in a shallow aquifer using artificial neural network. J Water Resour Manag 20:77–90
Nourani V, AsghariMoghaddam A, Nadiri A (2008) An ANN-based model for spatiotemporal groundwater level forcasting. J Hydrol Proc 22:5054–5066
Online flood information website. (2016). Retrieved from http://infobanjir.water.gov.my/real_time.cfm
Qi H, Qi P, M.S A (2013) GIS-Based Spatial Monte Carlo Analysis for Integrated Flood Management with Two Dimensional Flood Simulation. Water Resour Manag 27(10):3631–3645
Rao CR (1973) Linear statistical inference and its application. 2nd ed. Wiley, New York
Rogers LL, Dowla FU, Johnson VM (1995) Optimal field-scale groundwater remediation using neural networks and the genetic algorithm. Environ Sci Technol 29(5):1145–1155
Siddiquee, Mohammed Saiful Alam, & Hossain, Mollah Md Awlad. Development of a sequential Artificial Neural Network for predicting river water levels based on Brahmaputra and Ganges water levels. Neural Computing and Applications, 1-12. (2014)
Vasant, Pandian M. (2012). Meta-heuristics optimization algorithms in engineering, business, economics, and finance: IGI Global.
Yang XS (2008) Nature-Inspired Metaheuristic Algorithms. Luniver Press
Yang, Xin-She. (2010a). Engineering optimization: an introduction with metaheuristic applications: John Wiley & Sons.
Yang X-S (2010b) Firefly algorithm, stochastic test functions and design optimisation. International Journal of Bio-Inspired Computation 2(2):78–84
Yang CC, Prasher S, Lacroxi R (1996) Application of artificial neural network to simulate water-table depths under subirrigation. Cana Water Res J:1–12
Yang CC, Prasher SO, Lacroix R, Sreekanth S, Patni NK, Masse L (1997) Artificial neural network model for subsurfacedrained farmland. J Irrig Drain Eng 123:285–292
Yang ZP, Lu WX, Long YQ, Li P (2009) Application and comparison of two prediction models for groundwater levels; a case study in western Jilin province, China. J Arid Environ 73:487–492
Yu H, Xie T, Paszczynski S, Wilamowski BM (2011) Advantages of radial basis function networks for dynamic system design. Industrial Electronics, IEEE Transactions on 58(12):5438–5450
Acknowledgments
The authors thank University of Malaya for the financial support (UMRG Grant RP036A-15AET, RP036B-15AET, RP036C-15AET) and facilities to carry out the work.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Soleymani, S.A., Goudarzi, S., Anisi, M.H. et al. A Novel Method to Water Level Prediction using RBF and FFA. Water Resour Manage 30, 3265–3283 (2016). https://doi.org/10.1007/s11269-016-1347-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11269-016-1347-1