
Abstract
Educationally-oriented measures of handwriting fluency – tasks such as written alphabet recall and sentence copying – conflate graphomotor skill and various higher-level abilities. Direct measurement of pen control when forming letters requires analysis of pen-tip velocity associated with the production of sub-letter features that, in a skilled handwriter, are typically produced in a single, smooth movement. We provide a segmentation and coding scheme that identifies these features in manuscript letters and gives criteria for whether or not a feature is accurately formed. We demonstrate that, in skilled handwriters, these features are the product of smooth movements: The velocity profiles of adult writers (N = 27 performing a letter-copying task) producing straight-line features and curved features gave modal velocity-peak counts of 1 and 2 respectively. We then illustrate the utility of our segmentation and coding scheme by describing the velocity profiles of beginning writers (176 first grade students with minimal handwriting training). This sample produced the same features with less accuracy and with a substantially greater number of velocity peaks. Inaccurate features tended to be produced more slowly and less fluently.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Handwriting is now relatively rare as a means of communication for most adults. However, it remains the dominant writing modality in the vast majority of primary school classrooms. Developing the ability to produce neat, or at least legible, handwriting is therefore important. Handwriting neatness affects subjective ratings of text quality. Studies in which raters assess compositional quality of texts that are neatly or untidily written but are otherwise identical or matched have consistently found that lower, and often substantially lower, ratings are given to the untidy texts (Bull & Stevens, 1979; Chase, 1979; Klein & Taub, 2005, review by Graham et al., 2011). In the majority of educational settings untidy writing will result in teacher criticism. Danna et al. (2016) describe a vicious cycle in which criticism reduces self-esteem which results in handwriting avoidance, which again results in reduced opportunity to improve.
Developing handwriting automaticity is also important. As might be expected, the fluency with which children are able to form letters on the page affects their productivity when composing text (Berninger et al., 1997; Graham et al., 2000), and there is some evidence that it also affects the quality of the resulting composition (Alves et al., 2016). Handwriting ability is, therefore, needed not just for the production of aesthetically pleasing text. It is, in most educational contexts, a necessary precursor to effective written communication.
Researchers exploring handwritten production therefore need tools that allow assessment both of the written product – the neatness or at least accuracy with which letters are formed on the page – and also of the fluency with which the pen moves across the page when these letters are produced. Although accuracy and fluency are likely to be correlated, particularly in young children, developing an understanding of the writing process requires that these are assessed independently: Real-time handwriting data need to be analysed in such a way as to be able to distinguish not just fluent, neat writers from inaccurate disfluent writers, but also writers who are fluent but inaccurate, and those who are disfluent but accurate.
Our aim in the present paper is to describe and illustrate one such tool. We first review existing research-focussed approaches to handwriting assessment. We then give a detailed description of the approach that we have adopted in our own research. By segmenting the handwriting trace into sub-letter features this approach makes possible fine-grained analysis of writers’ ability to control their pen movements. In the final section of the paper, we illustrate the use of the tool with a comparison of children and adults forming single letters.
Research-focussed approaches to handwriting assessment
A range of tools have been developed to meet the needs of researchers and educators in identifying children whose handwriting is unusually poor and therefore requires remediation (see Feder & Majnemer, 2003 and Rosenblum & Weiss, 2006 for reviews). Most of these include measures of both the neatness of the handwritten product – the form of the pen-trace as it appears on the page – and a measure of rate or fluency of the process by which this is produced. In practice, these are inseparable. Product accuracy must be interpreted with reference to how fluently the text was produced, and vice versa. For ease of explanation, however, we will first discuss approaches to product assessment, and then approaches to measuring process.
Assessing the handwritten product
Tools for assessing the handwritten product can be described broadly as either holistic or analytic. Holistic assessment involves raters making a global judgement about the legibility (readability) of a handwriting sample. Ayres (1912) described a legibility measure based on how long it takes to read a text, averaging across several readers. Much more recently Larsen and Hammill (1989) developed the Test of Legible Handwriting based on matching handwriting samples to benchmark exemplars representing different levels of reading ease and neatness. Other measures elicit holistic ratings of legibility or of characteristics that are assumed to impact legibility. The Children’s Handwriting Evaluation Scale (Phelps & Stempel, 1988) rates samples for form, spacing and general appearance. The Handwriting Legibility scale (Barnett et al., 2018) scores texts for legibility and effort-to-read, and raters also provide a single, global score for how well letters are formed, defined as containing all necessary elements, i.e., having appropriate shape, being neatly closed, and being consistent in size and tilt. Several other similar tools exist (e.g., Amundson, 1995; Molfese et al., 2011; Ziviani & Watson-Will, 1998).
Analytic approaches, by contrast, aim at direct measurement, on a letter-by-letter basis, of the degree to which a letter confirms to a neatly-written ideal. Helwig et al., (1976); see also Collins et al. (1980); Jones et al. (1977) described an approach to establishing accuracy when a writer is required to precisely copy model letters. Children copy letters onto paper with four guidelines: a baseline, upper and lower lines to guide maximum and minimum vertical extent, and a midline above the baseline. Inaccuracies are identified, using transparent overlays, where letter components deviate from the model by more than a set tolerance (1, 2 or 3 mm depending on researcher purpose). This provides a binary copying-accuracy measure for each sub-letter unit (is accurate or is not accurate, separately for, for example, the straight line and the curve in a lowercase h).
The strength of this approach, for research contexts, is that in contrast with holistic measures, it provides very precise diagnosis of which features a writer is not able to form precisely. The pen-control deficit of a child who, for example, struggles to keep letter height within bounds is potentially quite different from the deficit associated with producing malformed curves. The disadvantage, however, is that it necessarily requires precise copying not just of the form of a presented letter, but also its dimensions. This provides an overly-specific definition of what constitutes an accurately formed letter, both in terms of form – there is no possibility for variation in allograph – and in size.
The widely used Minnesota Handwriting Test (MHT; Reisman, 1993) also scores a sample of text on a letter-by-letter basis. However, unlike the transparent-overlay method, the sample text is a sentence that participants copy without the requirement to exactly reproduce letter form. In the manuscript version participants are, however, required to print rather than use cursive script to write within three guidelines. For each letter, scorers first determine whether or not it is possible to identify the letter out of context. If the letter passes this test, then it is given a binary score for form (for example whether gaps or overlaps within the letter are all less than 1.6 mm), for position relative to the printed baseline (must be within 1.6 mm), for size (all letter components must be positioned correctly relative to guidelines), and for letter and word spacing. Each legible letter is therefore given a score out of 5 representing its neatness.
The approach adopted by the MHT in scoring letter form is conceptually different from that implemented by the transparent-overlay method. The transparent-overlay method specifies a specific form for each letter, whereas the MHT applies the same neatness criteria across all letters. If the researcher requires by-child neatness scores – and this is the aim of the MHT – then this makes sense. However, if researchers need to know whether a specific letter was formed well, as might be the case for example in an experimental context, then letter-specific form criteria are required. The transparent-overlay method is one way to provide these. It is possible, however, to specify form individually for each letter without constraining size and allowing at least some flexibility in allograph choice. For example, the “criteria for letter formation” provided by Ziviani and Elkins (1984, Table II) specify necessary (but not sufficient) characteristics for each letter. For example, a lowercase m must comprise a “double smooth curve finishing on aligned base”.
Assessing production fluency
Handwriting fluency measures are, broadly, of two different types, delineated by implicit assumptions about the range of processes that are encompassed by the term “handwriting”. Educationally-focussed research that, for example, explores the effects of handwriting ability on the quality of children’s written compositions (e.g., Abbott & Berninger, 1993; Kim & Schatschneider, 2017; Limpo & Alves, 2013; review by Kent & Wanzek, 2016), tends to use tasks that capture a range of skills over-and-above the motor planning and execution necessary to form a letter. All of the studies reviewed by Kent and Wanzek measure fluency by recording the number of characters children wrote in a fixed period of time when recalling the alphabet or when copying a written sentence or paragraph. Both the MHT and the Detailed Assessment of Speed of Handwriting (Barnett et al., 2009), for example, involve copying an unfamiliar sentence that includes all of the letters in the English alphabet (although necessarily with unrepresentative letter and digraph frequencies). Rate of output when performing this task will depend upon motor planning ability and pen control. However, it will also require reading, short-term memory, attention, and orthographic retrieval.
More direct measures of the speed and fluency with which a writer can form known letters – i.e., of those components of the handwriting process that are directly related to planning and controlling pen movement – can be captured by participants writing on a digitising tablet (or, at lower resolution, with a smart pen). This permits a broad range of measures that describe how the pen moves across that page (see review by Danna et al., 2013). At minimum, measuring pen movement, unlike measures that just count characters produced in a fixed period, differentiates between time spent with the pen moving on the page and time spent with the pen lifted or stationary (e.g., Paz-Villagrán et al., 2014; Sumner et al., 2013). Pen lifts or stops will, for example, occur (probably) in sentence copying tasks when the writer is reading the next words to be copied (probably, but see Alamargot et al., 2007).
Measuring pen movement also permits a direct measure of mean pen-tip speed (Khalid et al., 2010; Kushki et al., 2011; Rosenblum et al., 2006; van Galen et al., 1993). For example, van Galen et al. found that 2nd to 4th graders identified by their teachers as having untidy handwriting moved the pen more quickly than peers. Kushki et al. (2011) found that 4th graders showed decreasing vertical velocity but increasing horizontal velocity as they progressed through composing a paragraph. Most obviously, competent adult writers show much faster mean pen-movement speed than beginning writers (writing single words: adults around 80 mm/s, Hepp-Reymond et al., 2009; 6-year-olds, around 10 mm/s, Séraphin-Thibon et al., 2019).
Underlying this variation in speed is the extent to which letter components are formed with smooth single movements. This is illustrated in Fig. 1, which shows the velocity profile and final product for a competent adult producing a lower-case letter h. The upright is formed in a single, ballistic movement. The velocity curve for this feature – the first peak in the speed plot – is smooth, formed by a single acceleration and deceleration. Contrast this with the much less fluent velocity profile for the corresponding feature produced by a child in the lower panel. Whilst the adult produced this feature in a little over 300 ms, the child took over three times longer. This difference in speed and fluency is even more marked in the formation of the curved feature of the h.

Speed (tangential velocity) of pen tip, omitting in-air movement, and the final product for an adult and a beginning writer producing lowercase h. Solid circles are locations where the pen was either stationary or lifted. Unfilled circles represent velocity peaks. Velocity is smoothed with a 10 Hz Butterworth filter
A range of indices have been suggested for measuring pen-tip movement disfluency (Broderick et al., 2009; Khalid et al., 2010; Rosenblum et al., 2006; Smits-Engelsman & Van Galen, 1997). One relatively straightforward approach is to smooth the velocity trace to some extent, as is the case in Fig. 1, and then simply count the number of times that velocity reaches a local maximum (a velocity peak; e.g., Overvelde & Hulstijn, 2011). Average velocity and velocity peak-count are strongly correlated, at least in beginning writers (Fitjar et al., 2021), but velocity peaks are causally prior to slow production: The child in Fig. 1 produced the two components of the h much more slowly than the adult because their pen accelerated and decelerated multiple times.
Two other characteristics of the velocity profiles shown in Fig. 1 are important to note. First, the disfluency in the child’s pen movement was particularly marked when producing the curve. This is to be expected. The motor planning associated with forming a straight line has two degrees of freedom – length and direction. Curves add the need to manage angular change. This adds considerable complexity to both planning and execution (see Morasso & Mussa Ivaldi, 1982, for a computational model and Habas & Cabanis, 2008, for fMRI evidence). Séraphin-Thibon et al. (2019) found that pseudowords composed of letters that contained more curves were written with a larger number of velocity peaks than otherwise-matched pseudowords with fewer curves.
Second, maximal fluency does not mean zero velocity peaks. Drawing a straight line necessarily involves starting and finishing with the pen stationary and so, at minimum, there must be one velocity maximum between these two points. This is the case for the adult writer in Fig. 1. Similar constraints apply to curved features: Edelman and Flash (1987) showed that both open and closed loops (hook, cup and gamma strokes, in their terminology) necessarily involve two velocity peaks, yet are still produced with maximum fluency. This again can be seen in the adult’s formation of the curve (inverted cup) of the h.
Product segmentation for process analysis
Determining the extent to which a specific sample of real-time handwriting data represent fluent production involves, therefore, making a comparison between the velocity profile for the sample and the theoretical maximally-fluent velocity profile for the production of the same text. One approximation to this is simply to make comparisons between groups who have, a priori, been identified as poor or good handwriters on the basis of the neatness of their handwriting (e.g., Di Brina et al., 2008; Rosenblum & Werner, 2006; van Galen et al., 1993). It is also possible to make a priori assumptions about differences in the bandwidth of velocity spikes that constitute disfluency and those that are an essential to fluent production (Danna et al., 2013; Meulenbroek & van Galen, 1986). Danna et al., for example, counted velocity peaks after low-pass filtering of pen-tip speed at 10 Hz (as in Fig. 1) and then subtracted a count of velocity peaks after low-pass filtering at 5 Hz on the grounds that the latter were likely to be a necessary characteristic of competent, fluent production. This permits estimates of pen-movement fluency across extended text.
A more fine-grained approach is to segment letters into standard features that in competent, fluent writers could be produced as a single stroke – i.e. as a pen movement bounded by points where the pen-tip is stationary or near-stationary and / or lifted (e.g., Meulenbroek & van Galen, 1990). These features then provide a basic unit of analysis when comparing pen movement across writers or experimental conditions. This is the approach that we have taken in our discussion of the fluency of production of the letter h shown in Fig. 1. By segmenting the letter h into two features – a straight line and a curve – it was possible to make direct comparison between the adult and child samples.
For an approach based on marking up pen traces into features to be an effective research tool it needs to meet the following criteria:
First, and most obviously, it must be universally applicable: The segment delineation for a specific letter must be applicable across a wide range of different attempts at forming that letter by different writers.
Second, segmentation must be possible on the basis of the written product, without reference to information about how the letter was formed. Automatic segmentation based on process – dividing up letters into components based on units that are composed in single strokes – is possible, of course (see, for example Rosenblum et al., 2006). However, this will identify different segments depending on whether a letter is produced fluently or disfluently. The reason for this can be clearly seen in Fig. 1 by considering the different location of the pen stops and lifts in the adult and child letters. If the purpose of segmenting the letter is to then establish the fluency with which the segments are produced, then the procedure by which segmentation is achieved must itself be independent of fluency.
Third, because there is potential for a trade-off between speed and precision, the segmentation procedure also needs to take some account of the accuracy with which a segment is formed. To compare like-with-like it is necessary to know whether a feature is well shaped and positioned.
Finally, the segmentation procedure must allow for the possibility of variation in allograph. Again, this is illustrated in Fig. 1. Although we have been talking as though the curved component of the h is comparable across the adult and child samples this is, arguably, not the case: In the classification used by Edelman and Flash (1987), the adult forms a cup whereas the child forms a hook. The production demands of these two features may well be different. Segmentation must therefore differentiate between various allographs that represent the same letter but comprise different features. In practice this means that common allographs of the same letter will require their own segment codes, but obviously also that the coding scheme must identify these different allographs as representations of the same letter.
The coding scheme that is the focus of this paper aims to meet these criteria. We describe a formal, though we believe intuitive, schema for segmenting Latin lower and uppercase letters into sub-letter features, and for then determining whether or not the feature is formed and positioned with adequate precision. This develops the “criteria for letter formation” (Ziviani & Elkins, 1984) approach to coding the handwritten trace into a rigorous formalism for segmenting letters into sub-letter units that can then be directly compared in terms of kinematics of their production. In the next section of this paper, we give a detailed description of our letter-segmentation and coding scheme. In the final section we provide evidence for its value in comparing production fluency across writers.
A scheme for letter segmentation and accuracy coding
Our coding scheme specifies, for each letter, a set of rules that (a) segments letters into sub-letter features, based on the shape of the pen trace, (b) provides criteria for deciding whether or not the feature is well formed. These are illustrated, for upper case R, in Table 1 and given in full in the appendix. The descriptions in the appendix describe common allographs of both upper- and lower-case printed letters. This is intended as illustrative rather than definitive and should be adapted by researchers to suit local context and their research needs.
Segmentation
Our strategy for identifying sub-letter features within a particular writer’s output depends just on the pen trace – the shape that the writer forms – and does not make reference to how the writer produced the feature. A feature is identified if it corresponds, within specified tolerances, to a feature as defined in our coding scheme (see example in Table 1). However, decisions about what constitutes a feature in a prototypical letter form – the decision, for example, to identify 3 distinct features in R is process-based. In developing the coding scheme, we identified features in a letter as the minimum number of components in an allograph such that, in maximally-fluent handwriting, each feature could be produced with a smooth velocity profile and without the pen either stopping or lifting (i.e., as a single pen stroke). Under this definition the letter C comprises a single feature, T comprises two features, N comprises three features, and so forth. Features may be either straight, as is the case for both features in T, or curved, as in feature R3 of R (see Table 1).
Marking up a specific pen trace into segments – identifying feature boundaries – is, as we have said, independent of the process by which that trace was produced. So, although in a skilled writer a feature will normally start and end with a pen stop or lift, this information is not used when deciding for a particular pen trace where a feature starts and ends. We defined features based on the spatial characteristics of acceptable letter forms – i.e., how the letter appears on the page – and then look for pen trace segments that, alone or combined, match these characteristics. As we discussed above, identifying features independently of how they were produced allows comparison of the kinematics of production of the same features across writers with varying graphomotor ability.
We use MarkWrite v 0.4.9 (Simpson et al., 2021) to segment and code handwriting traces. MarkWrite takes as input data captured in real time from a digitising tablet or, at lower resolution, a smart pen. It requires just that data provide, at minimum, time and coordinates for each pen-location sample. The MarkWrite interface is illustrated in Fig. 2. Sequences of samples that comprise a feature, as defined by the coding scheme, are selected either by cursor movement or by keyboard shortcut. Then the feature is annotated with a feature label and, if it is inaccurate, one or more codes to indicate how it deviates from well-formed.

Screenshot from the MarkWrite program showing selection Feature R1 from a child’s copying an uppercase R. The upper right panel shows change in y-axis location (upper plot) and pen-tip speed (lower plot) over the period when this feature was produced. The black trace in the spatial view is a selected set of samples that represent a single feature (annotated as R1). The grey trace represents in-air movements
Accuracy
Once features are identified, the coding scheme then allows a binary decision about whether or not a handwritten feature was produced accurately. By accurately, we mean the extent to which the pen-trace corresponds to an acceptable representation of the target feature with regards to shape, size and position. In our coding, this decision is made without regard to aesthetics – we define relatively broad criteria for acceptable feature representation – and as with segmenting into features, accuracy coding is agnostic about the kinematics of the feature’s production. Decisions about accuracy (and / or neatness) criteria will depend on research purposes. The criteria we present here are illustrative rather than prescriptive. In our own implementation we applied a general tolerance of 1/6 of letter or feature height or width in determining whether or not features deviated from the shape, proportion or size defined by their allograph. This corresponds approximately to the 1.5 mm tolerance on 9.5 mm ruled paper allowed by the Minnesota Handwriting Test (Reisman, 1993). Our approach differs from the MHT, however, in that we allowed for variation in absolute letter size, and therefore applied proportional rather than absolute tolerance criteria.
In Fig. 3 we illustrate six versions of the letter R, all of which have at least one inaccurate feature.

Different inaccurate versions of the letter R
Shape
Shape accuracy depends on the straightness for straight features and curvedness for curved features. Decisions about straightness were made relative to the feature’s length and without reference to other features in the letter. The rule is that the feature is coded as inaccurate if the pen trace deviates from the straightest path between the ends of the feature with more than 1/6 of the feature length. In Fig. 3 the first R (I), the feature R1 (highlighted in solid black) is inaccurately shaped. Curvedness requires the pen trace to deviate from the straightest path between endpoints with more than 1/6 of feature width without the trajectory crossing itself. Thus, the feature length (measured between endpoints and bottom of the curve) must be at least 1/6 of feature width (measured between the two most extreme points to each side of the endpoints). All the curved features in Fig. 3 are sufficiently curved. In our data, lack of curvedness was generally not a problem.
As shown in Table 1, curves can be either open or closed. Open curves need an opening that is at least 1/6 of feature width. Closed curves can have a gap or overlap between endpoints that corresponds to 1/6 of feature width. For letters with only one option, such as U, a gap smaller than 1/6 of feature width means that the letter is not accurately shaped. Likewise, the letter O can only be written with a closed curve and a gap larger than 1/6 means the letter is not accurately shaped.Footnote 1 For letters with options, such as R2 in Table 1, this distinction has two purposes. First, it makes letter description easier. Second, this is a scheme intended for exploring handwriting fluency and we recognise that other researchers may have an interest in curved features in particular. Although we have not pursued this further at the moment, other researchers might find this useful.
Position
Positioning of features refers to spatial orientation of features as well as gaps and overlaps between features. For open curves spatial orientation refers to the direction of the open end – left, right, upwards and downwards – and is described for each letter. Straight lines can be either vertical, diagonal or horisontal. In this coding scheme, the tolerances for gaps/overlaps are 1/6 of letter height, or feature height in case of curves. In Fig. 3, the top arm of the R2 feature of R (III) does not meet the top of R1 as specified in the table. The horizontal overlap is within the 1/6 tolerance for overlap between features that should meet. The vertical overlap exceeds the 1/6 tolerance and is coded as inaccurate for position. The R3 feature in the same letter does not meet R2 and is therefore coded as inaccurate for position. The R3 in R(IV) and R(II) are not diagonal, slanting bottom to right, and are therefore coded as inaccurate for position. The R2 and R3 in R(VI) are both inaccurately positioned as both are placed to the left of R1.
Size
For a feature to be accurate it also needs to meet relative size criteria. Criteria for size are letter specific. These are described in Appendix 1. To illustrate, in the letter R the vertical straight feature must be proportional to the other two features and vice versa. The rule is that the length of R1 is twice the width of the curve in R2. The length of the curve, R2, must be shorter or similar to length of R1, and the width must half the length of R1. Unless specified the tolerance for size difference is 1/6 of the previously produced feature. In Fig. 3, the curved feature R2_1 in the R(V) is too big in comparison with the previously produced feature, as the width of the curve is almost the same as the length of R1.
Alternative allographs
All letters have several legal allographs, depending on whether it is an upper-case or lower-case, block or cursive version. In addition, some letters have several allographs within these categories. As Fig. 4 shows, the upper-case A is an example of a letter with two allographs; one has two straight features slanting towards each other at the top while in the other the straight features are replaced by one curved feature. The scheme is open-ended and may need to be adapted and augmented in specific contexts.

Two handwritten allographs for the letter A, one has one curved and one straight feature and the other has three straight features
One feature – multiple segments
A feature may be produced with a single stroke (e.g., the h open curve – feature h2 in our coding scheme – produced by the adult in Fig. 1). A feature can also be produced with multiple pen-stops as is the case for the child’s production of the h open curve in Fig. 1. It may be produced in two or more distinct movements. The bar of the T – feature T2 in our coding scheme – would typically be produced by a skilled writer in a single stroke. Figure 5 shows this feature, T2, being produced, by a beginning writer, in two distinct movements. The numbers represent the sequence in which these were generated, and arrows indicate approximate initial direction of pen trajectory. The movement is separated by a pen lift and in-air move, and with the pen moving in different directions to produce each segment. It is not even the case that a feature must be produced with consecutive movements as illustrated with the g in Fig. 5. The feature g1 – in our coding scheme – is produced in three distinct and non-consecutive movements.

Handwritten letters in which features are produced with multiple actions. Different line shades represent pen traces bounded by pen lifts. Numbers represent the sequence in which these were generated. Arrows indicate approximate initial direction of pen trajectory. The feature g1, for example, was, therefore, produced in three separate non-consecutive movements – segments 1, 3 and 5. Data are digitally-sampled pen movements by a Norwegian child who was just starting to learn how to handwrite
Handwriting fluency in adults and beginning handwriters
Our purpose in this section is to illustrate how the segment and coding scheme can be used as the basis for a detailed analysis of the kinematics of single letter production in a sample of very early writers, and of competent adults.
Participants and task
Our child sample comprised 176 Norwegian children tested within the first four weeks of first grade (mean age 6.2 years, 86 girls). Early childhood care and education in Norway (Barnehage / Kindergarten) is attended by 97.6% of 5 year olds (Norwegian Directorate for Education & Training, 2019).Footnote 2 Children in kindergarten do not, however, follow a set curriculum and, in particular there is no requirement to learn handwriting before the start of primary (elementary) school. Many of the children in our sample were, therefore, at the very start of learning how to handwrite. Our adult sample comprised faculty and other staff at a Norwegian university (N = 27, 23 women). We did not record age.
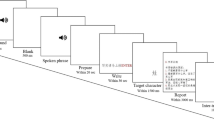
Both children and adults copied the letters A M d h T d g R. Letters were displayed on cards presented one-at-a-time by a researcher.Footnote 3 Participants copied these within pre-printed 2.5 cm square boxes. They were instructed to “write the letter as they saw it”, without a requirement to exactly copy its form.
All participants were asked to write with their dominant hand. Adults then completed the task again, writing with their non-dominant hand. This provided a direct motor-control manipulation, holding all other factors that might affect production fluency constant.
Participants wrote with an inking ballpoint stylus on paper overlayed on a Wacom Intuos XL digitising tablet connected to an HP Elitebook i5 laptop. Pen-tip locations were sampled at intervals of around 7.5 ms (133 Hz) and with a spatial resolution of at least 330 lines/cm. Software for pen-movement capture and analysis was provided by the OpenHandWrite suite of programs (Simpson et al., 2021) which provide a digitising tablet interface for PsychoPy (Peirce et al., 2019).
Data from the child sample are a subset of data previously reported in Fitjar et al., (2021), although the analyses reported in this paper are new. Adults were sampled specifically for this paper.
Processing handwritten data
Pen traces were segmented and coded according to the segmentation and coding scheme presented in the previous section. If copied accurately, using most-common allographs, these 8 letters segment into a total of 20 features. We additionally classified these as either straight or curved. The motor plan for producing a curved line is more complex than a straight line and these different motor plans are reflected in different kinematic profiles (Habas & Cabanis, 2008; Morasso & Mussa Ivaldi, 1982). This means that the effects of graphomotor difficulty, in writers with impaired or not-yet-developed graphomotor ability, are more likely to be exhibited when drawing curves than when drawing straight lines (e.g., Fitjar et al., 2021). The letters for the present task – reproduced with the most common allograph, gave 8 curved and 12 straight features.
The digitised pen traces were first segmented into features, with boundaries at the first visible (non-zero pressure) sample that was part of the pen-trace associated with an identifiable feature. We then calculated tangential velocity (speed) of the pen tip at each sample point and then filtered the resulting velocity timecourse with a 10 Hz 4th order low-pass Butterworth filter. The 10 Hz filter removes measurement noise. We then counted remaining velocity maxima for each feature (see, for example, Khalid et al., 2010; Overvelde & Hulstijn, 2011; Smits-Engelsman et al., 2001).
Results
We present analysis of these data as follows: We describe the distribution of velocity maxima for straight and curved features produced by adults writing with their dominant hand and with their non-dominant hand and children. We then provide examples of fluency and accuracy for participants producing the three features of an upper-case letter R. We finally provide inferential analysis across all stimulus letters and both adult and child samples to determine differential effects of handwriting skill on the production of curved and straight features.
Fluency distributions
Figure 6 shows frequency distributions for the three groups producing straight and curved features. As we suggested in our introduction, modal number of velocity peaks for adults producing straight lines was one, and for producing a curve was two. For straight line, and for many curves, these represent the minimum possible number of velocity peaks. Adults writing with their dominant hand tended, as might be expected, to be maximally fluent. Interestingly, even though the distribution had a longer tail when adults wrote with their non dominant hands, modal number of velocity peaks remained similar in number to those for writing with their dominant hand, and substantially fewer than for our child sample. Given that handwriting with a non-dominant hand is not something that our adult sample will have practiced, this finding is consistent with the assumption that the motor plans underlying competent handwriting are effector-independent (Wing, 2000).

Distribution of count of velocity maxima (velocity peaks remaining after 10 Hz low-pass filtering) for adults and children producing straight and curved features
An example: upper-case R
Table 2 gives some summary statistics for adults and children producing the three features of the letter R. The adult sample produced all three of these features accurately in all cases, and inaccuracy was also rare in children. This resulted partly from how the task was set. Both adults and children had the shape of the letter that they were to produce visible in front of them as they wrote. It is also a feature of the coding scheme: The parameters within which a feature must lie are deliberately quite broad, so as to capture any successful attempt at production. Only a subset of these would also be perceived as having been produced neatly.
Pen movement in adults was very much more fluent than in children, even when adults were writing (accurately) with their non-dominant hand (see also Fig. 9). 74% of adults writing with their dominant hand achieved the minimum-possible number of velocity peaks for both features R1 and R2.Footnote 4
Fluency decreased when adults wrote R with their non-dominant hand but, as we have already noted, only slightly. This effect can be clearly seen in the example in Fig. 7. Non-dominant handwriting was definitely slower than when adults wrote normally, and mid-curve deceleration was more pronounced. However, the velocity profile maintained a similar shape to normal production and did not come close to the level of disfluency seen in our child sample.

Examples of velocity profiles for each feature of the letter R – R1 (vertical straight), R2_1 (open curve), R3 (diagonal straight) – for a child, and an adult writing with both non-dominant and dominant hand. Open circles in the trace represent locations of velocity peaks. Filled circles represent stops or lifts. Velocity is smoothed with a 10 Hz Butterworth filter
One question worth asking concerns the relationship between accuracy and fluency. Figure 8 gives velocity plots from four different child writers producing feature R2. This demonstrates again, very clearly, the importance of exploring fluency alongside accuracy. On the basis of their pen traces the children in the top two panels would be identified as skilled handwriters, and the children in the bottom two panels might be identified as being in need of remedial intervention. This is despite the fact that the child in the second panel took 8 times as long to produce the same feature as the child in the first panel. The bottom two panels show faster production suggesting an accuracy fluency trade-off: Inaccuracy in older children is often associated with greater rather than less fluency (van Galen et al., 1993). Analysis of just the child data from the present sample – children at an earlier stage of learning to handwrite than those sampled by van Galen, reported in Fitjar et al., (2021) – did not find this effect, however. We found, instead, that inaccurate features were produced with, on average, 3 more velocity peaks than accurately produced features.

Pen velocity (smoothed with 10 Hz Butterworth filter) for examples of children producing Feature R2 either correctly or incorrectly, and the resulting trace. Filled circles represent pen lifts or stops. Unfilled circles represent velocity maxima
Effects of feature shape on child and adult fluency
The descriptive statistics and illustrations that we have reported so far suggest that, as might be expected, curved features present a greater graphomotor challenge than straight features, particularly in the early stages of learning to handwrite. In this section we test that hypothesis with data from both adult and child samples. To this end we compared nested linear mixed effects models (e.g., Baayen et al., 2008) predicting velocity peak count and implemented in the lme4 R package (Bates et al., 2015). Model comparison was by likelihood ratio χ2 test. Statistical significance for parameter estimates for models was established by evaluating against a t distribution with Satterthwaite approximation for denominator degrees of freedom (implemented in lmerTest; Kuznetsova et al., 2017). We started with an intercept-only model, and then added main effects for condition (child, adult dominant-hand, adult non-dominant hand) and whether the feature was straight or curved as fixed effects. This model gave significantly better fit (χ2(1) = 70.4, p < 0.001). We then added the interaction between these factors (Model 2 vs. M1, χ2(1) = 49.3, p < 0.001). This final model gave an estimated marginal R2 of 0.17 (Nakagawa & Schielzeth, 2013), and intra-class correlations of 0.26 for random effects of child and 0.16 for random effects of item.
The effects found by the best-fit model can be clearly seen in Fig. 9. Relative to adult writers writing with their dominant hand there was some evidence of a reduction in fluency when adults write with their non-dominant hand (estimated velocity peak increase = 1.0, 95% CI [0.01,2.0], p = 0.047) but with no significant additional effect of the feature being curved. Children were substantially less fluent for straight features (5.8 [4.5, 7.2], p < 0.001) with a substantial additional effect of 7.9 velocity peaks (95% CI [5.7, 9.9], p < 0.001) for children producing curved features.

Observed velocity peak count, after 10 Hz Butterworth smoothing. Error bars represent one standard deviation
Conclusion
The aim of this paper was to describe and illustrate a method for segmenting handwritten letter pen-traces into sub-letter features that can then form the basis for an analysis of handwriting fluency. The scheme that we have described also necessarily identifies whether or not a feature has been produced with an acceptable degree of accuracy.
The details of our specific implementation of the approach – our 1/6 tolerance principle and, particularly, our set of acceptable allographs – can and should be varied by users to fit specific research questions, populations, and educational contexts. Our contribution boils down to two observations. First, that if researchers want to make comparisons across writers in handwriting kinesthetics then this must be across features that are, to some meaningful extent, spatially equivalent and that are identified independently of how they are produced. Second, that it is possible to develop a rigorous approach to identifying these features that allows both for variation in absolute size of letter that writers may represent letters using different allographs.
Combined with analysis of movement fluency based on counts of velocity peaks our approach to segmentation and coding scheme therefore allows direct measurement of graphomotor performance. This will be of use to researchers who are directly interested in motor control, providing a more systematic and rigorous approach to pen-trace coding than we were able to find in the existing literature. It will also be of use to researchers who have a broader interest in the cognitive processes that underlie written production, and also in developing strategies for supporting children learning to write. Our approach contrasts, for example, with measures that count the number of characters that are produced in a fixed period of time. These necessarily confound handwriting fluency with time spend in other writing-related processing that occurs when the pen is stationary. Application of this method to real time data from, for example, sentence-copying or written alphabet recall, would allow disambiguation of the contribution of handwriting fluency, per se, to a writer’s overall fluency, and the contribution of processes – reading, message processing / stimulus recall, syntactic and orthographic retrieval – that are more likely to occur when the pen is lifted.
Notes
In copy and letter to dictation tasks it is clear what the target letter is. If the child saw or heard /u/ and produced a curve with a 1/6 gap between endpoints, then it is the letter u. If the scheme is applied to spelling words to dictation or free composition tasks researchers will need to make some additional decisions about letter interpretation.
92.8% of all children between 1 and 5 years old attend Barnehage (SSB, 2021).
As part of the same task participants also copied 4 unfamiliar letter-like symbols. We do not report data from these or the two practice items – one letter and one symbol – in this paper.
R3 does not fit this pattern, however, with only 33% of adults achieving maximum fluency. Inspection of the velocity profiles suggests that this was due to adults tending to add a final short pen movement at an acute angle to the end R3. This may be because adults' motor plans are adapted to writing cursively. It may also be because control of diagonal left-to-right finger movement is relatively complex in right-handed writers. Whatever their cause, our segmentation scheme, which was developed for use with children but then applied to adults, allowed for the inclusion of these final short movements. These little flicks were not big enough to break the rules of how features may deviate from prototype features. Bigger flicks would have been classified as inaccurate production of the feature. This highlights the need for carefully developing and testing feature definitions within a specific research context.
References
Abbott, R., & Berninger, V. (1993). Structural equation modeling of relationships among developmental skills and writing skills in primary- and intermediate-grade writers. Journal of Educational Psychology, 85(3), 478–508. https://doi.org/10.1037/0022-0663.85.3.478
Alamargot, D., Dansac, C., Chesnet, D., & Fayol, M. (2007). Parallel processing before and after pauses: a combined analysis of graphomotorand eye-movements during procedural text production. In M. Torrance, L. Van Waes, & D. Galbraith (Eds.), Writing and Cognition: Research and Applications (pp. 13–30). Elsevier.
Alves, R. A., Limpo, T., Fidalgo, R., Carvalhais, L., Pereira, L. Á., & Castro, S. L. (2016). The impact of promoting transcription on early text production: Effects on bursts and pauses, levels of written language, and writing performance. Journal of Educational Psychology, 108(5), 665–679. https://doi.org/10.1037/edu0000089
Amundson, S. J. (1995). Evaluation Tool of Children’s Handwriting: ETCH examiner’s manual. OT KIDS.
Ayres, L. P. (1912). A scale for measuring the quality of handwriting of school children. Russell Sage Foundation.
Baayen, R. H., Davidson, D. J., & Bates, D. M. (2008). Mixed-effects modeling with crossed random effects for subjects and items. Journal of Memory and Language, 59, 390–412. https://doi.org/10.1016/j.jml.2007.12.005
Barnett, A. L., Henderson, S. E., Scheib, B., & Schulz, J. (2009). Development and standardization of a new handwriting speed test: The Detailed Assessment of Speed of Handwriting. British Journal of Educational Psychology, 2(6), 137–157. https://doi.org/10.1348/000709909X421937
Barnett, A. L., Prunty, M., & Rosenblum, S. (2018). Development of the handwriting legibility scale (HLS): A preliminary examination of reliability and validity. Research in Developmental Disabilities. https://doi.org/10.1016/j.ridd.2017.11.013
Bates, D., Mächler, M., Bolker, B. M., & Walker, S. C. (2015). Fitting linear mixed-effects models using lme. Journal of Statistical Software. https://doi.org/10.18637/jss.v067.i01
Berninger, V. W., Vaughan, K. B., Abbott, R., Abbott, S. P., Rogan, L. W., Brooks, A., Reed, E., & Graham, S. (1997). Treatment of handwriting problems in beginning writers: Transfer from handwriting to composition. Journal of Educational Psychology, 89(4), 652–666. https://doi.org/10.1037/0022-0663.89.4.652
Broderick, M. P., Van Gemmert, A. W. A., Shill, H. A., & Stelmach, G. E. (2009). Hypometria and bradykinesia during drawing movements in individuals with Parkinson’s disease. Experimental Brain Research, 197(3), 223–233. https://doi.org/10.1007/s00221-009-1925-z
Bull, R., & Stevens, J. (1979). The effects of attractiveness of writer and penmanship on essay grades. Journal of Occupational Psychology, 52(1), 53–59. https://doi.org/10.1111/j.2044-8325.1979.tb00440.x
Chase, C. I. (1979). The Impact of Achievement Expectations and Handwriting Quality on Scoring Essay Tests. Journal of Educational Measurement, 16(1), 9–42.
Collins, F. L., Baer, G. R., Walls, N., & Jackson, M. S. (1980). The development of a behavioral-assessment technique or evaluating gradual change in handwriting performance. Behavioral Assessment, 2(4), 369–387.
Danna, J, Velay, J. L., & Albaret, J. M. (2016). Dysgraphies. In S. Pinto & M. Santo (Eds.), Traité de Neurolinguistique. Du cerveau au langage. Deboek Superieur.
Danna, J., Paz-Villagrán, V., & Velay, J.-L. (2013). Signal-to-Noise velocity peaks difference: A new method for evaluating the handwriting movement fluency in children with dysgraphia. Research in Developmental Disabilities, 34(12), 4375–4384. https://doi.org/10.1016/j.ridd.2013.09.012
Di Brina, C., Niels, R., Overvelde, A., Levi, G., & Hulstijn, W. (2008). Dynamic time warping: A new method in the study of poor handwriting. Human Movement Science, 27(2), 242–255. https://doi.org/10.1016/j.humov.2008.02.012
Edelman, S., & Flash, T. (1987). A model of handwriting. Biological Cybernetics, 57(1–2), 25–36. https://doi.org/10.1007/BF00318713
Feder, K. P., & Majnemer, A. (2003). Children’s handwriting evaluation tools and their psychometric properties. Physical & Occupational Therapy in Pediatrics, 23(3), 65–84. https://doi.org/10.1080/J006v23n03
Fitjar, C. L., Rønneberg, V., Torrance, M., & Nottbusch, G. (2021). Learning handwriting: Factors affecting pen-movement fluency in beginning writers. Frontiers in Psychology, 12, 1–13. https://doi.org/10.3389/fpsyg.2021.663829
van Galen, G. P., Portier, S. J., Smits-Engelsman, B. C. M., & Schomaker, L. R. B. (1993). Neuromotor noise and poor handwriting in children. Acta Psychologica, 82(1–3), 161–178. https://doi.org/10.1016/0001-6918(93)90010-O
Graham, S., Harris, K. R., & Fink, B. (2000). Is handwriting causally related to learning to write? Treatment of handwriting problems in beginning writers. Journal of Educational Psychology, 92(4), 620–633. https://doi.org/10.1037/0022-0663.92.4.620
Graham, S., Harris, K. R., & Hebert, M. (2011). It is more than just the message: Presentation effects in scoring writing. Focus on Exceptional Children, 44(4), 1–12.
Habas, C., & Cabanis, E. A. (2008). Neural correlates of simple unimanual discrete and continuous movements: A functional imaging study at 3 T. Neuroradiology, 50(4), 367–375. https://doi.org/10.1007/s00234-007-0354-6
Helwig, J. J., Johns, J. C., Norman, J. E., & Cooper, J. O. (1976). The measurement of manuscript letter strokes. Journal of Applied Behavior Analysis, 9(2), 1311933. https://doi.org/10.1901/jaba.1976.9-231
Hepp-Reymond, M. C., Chakarov, V., Schulte-Mönting, J., Huethe, F., & Kristeva, R. (2009). Role of proprioception and vision in handwriting. Brain Research Bulletin, 79(6), 365–370. https://doi.org/10.1016/j.brainresbull.2009.05.013
Jones, J. C., Trap, J., & Cooper, J. O. (1977). Technical report: Students’ self-recording of manuscript letter strokes. Journal of Applied Behavior Analysis, 10(3), 509–514.
Kent, S. C., & Wanzek, J. (2016). The relationship between component skills and writing quality and production across developmental levels. Review of Educational Research, 86(2), 570–601. https://doi.org/10.3102/0034654315619491
Khalid, P. I., Yunus, J., & Adnan, R. (2010). Extraction of dynamic features from hand drawn data for the identification of children with handwriting difficulty. Research in Developmental Disabilities, 31(1), 256–262. https://doi.org/10.1016/j.ridd.2009.09.009
Kim, Y. S. G., & Schatschneider, C. (2017). Expanding the developmental models of writing: A direct and indirect effects model of developmental writing (DIEW). Journal of Educational Psychology, 109(1), 35–50. https://doi.org/10.1037/edu0000129
Klein, J., & Taub, D. (2005). The effect of variations in handwriting and print on evaluation of student essays. Assessing Writing, 10(2), 134–148. https://doi.org/10.1016/j.asw.2005.05.002
Kushki, A., Schwellnus, H., Ilyas, F., & Chau, T. (2011). Changes in kinetics and kinematics of handwriting during a prolonged writing task in children with and without dysgraphia. Research in Developmental Disabilities, 32(3), 1058–1064. https://doi.org/10.1016/j.ridd.2011.01.026
Kuznetsova, A., Brockhoff, P. B., & Christensen, R. H. B. (2017). lmerTest Package: Tests in Linear Mixed Effects Models. Journal of Statistical Software, 82(13), 1–26. https://doi.org/10.18637/jss.v082.i13
Larsen, S., & Hammill, D. (1989). Test of legible handwriting: An ecological approach to holistic assessment. Austin, TX: Pro-Ed.
Limpo, T., & Alves, R. A. (2013). Modeling writing development: Contribution of transcription and self-regulation to Portuguese students’ text generation quality. Journal of Educational Psychology, 105(2), 401–413. https://doi.org/10.1037/a0031391
Meulenbroek, R. G. J., & van Galen, G. P. (1990). Perceptual-Motor Complexity of Printed and Cursive Letters. Journal of Experimental Education, 28(2), 95–110.
Meulenbroek, R. G. J., & van Galen, G. P. (1986). Movement analysis of repetitive writing behaviour of first, Second and Third Grade Primary School Children. In Advances in Psychology (Vol. 37, pp. 71–92).
Molfese, V. J., Beswick, J. L., Jacobi-Vessels, J. L., Armstrong, N. E., Culver, B. L., White, J. M., Ferguson, M. C., Rudasill, K. M., & Molfese, D. L. (2011). Evidence of alphabetic knowledge in writing: Connections to letter and word identification skills in preschool and kindergarten. Reading and Writing, 24(2), 133–150. https://doi.org/10.1007/s11145-010-9265-8
Morasso, P., & Mussa Ivaldi, F. A. (1982). Trajectory Formation and Handwriting: A Computational Model. Biological Cybernetics, 45, 131–142.
Nakagawa, S., & Schielzeth, H. (2013). A general and simple method for obtaining R 2 from generalized linear mixed-effects models. Methods in Ecology and Evolution, 4(2), 133–142. https://doi.org/10.1111/j.2041-210x.2012.00261.x
The Norwegian Directorate for Education and Training. (2019). The Norwegian Education Mirror. https://www.udir.no/in-english/education-mirror-2019/school/#children-in-kindergarten
Overvelde, A., & Hulstijn, W. (2011). Learning new movement patterns: A study on good and poor writers comparing learning conditions emphasizing spatial, timing or abstract characteristics. Human Movement Science, 30(4), 731–744. https://doi.org/10.1016/j.humov.2010.08.016
Paz-Villagrán, V., Danna, J., & Velay, J. L. (2014). Lifts and stops in proficient and dysgraphic handwriting. Human Movement Science, 33(1), 381–394. https://doi.org/10.1016/j.humov.2013.11.005
Peirce, J., Gray, J. R., Simpson, S., MacAskill, M., Höchenberger, R., Sogo, H., Kastman, E., & Lindeløv, J. K. (2019). PsychoPy2: Experiments in behavior made easy. Behavior Research Methods, 51(1), 195–203. https://doi.org/10.3758/s13428-018-01193-y
Phelps, J., & Stempel, L. (1988). The children’s handwriting evaluation scale for manuscript writing. Reading Improvement, 25(4), 247.
Reisman, J. E. (1993). Development and reliability of the research version of the minnesota handwriting test. Physical & Occupational Therapy in Pediatrics, 13(2), 41–55. https://doi.org/10.1080/J006v13n02_03
Rosenblum, S., Dvorkin, A. Y., & Weiss, P. L. (2006). Automatic segmentation as a tool for examining the handwriting process of children with dysgraphic and proficient handwriting. Human Movement Science, 25(4–5), 608–621. https://doi.org/10.1016/j.humov.2006.07.005
Rosenblum, S., & Weiss, T. (2006). Tele-evaluation for the handwriting performance. Educational Psychology Review, 15(1), 41–81.
Rosenblum, S., & Werner, P. (2006). Assessing the handwriting process in healthy elderly persons using a computerized system. Aging Clinical and Experimental Research, 18(5), 433–439.
Séraphin-Thibon, L., Barbier, G., Vilain, C., Sawallis, T. R., Gerber, S., & Kandel, S. (2019). Investigating how children produce rotation and pointing movements when they learn to write letters. Human Movement Science, 65, 15–29. https://doi.org/10.1016/j.humov.2018.04.008
Simpson, S., Nottbusch, G., & Torrance, M. (2021). OpenHandWrite 0.4.9 (0.4.7). https://github.com/isolver/OpenHandWrite
Smits-Engelsman, B. C. M., Niemeijer, A. S., & van Galen, G. P. (2001). Fine motor deficiencies in children diagnosed as DCD based on poor grapho-motor ability. Human Movement Science, 20(1–2), 161–182. https://doi.org/10.1016/S0167-9457(01)00033-1
Smits-Engelsman, B. C. M., & Van Galen, G. P. (1997). Dysgraphia in children: Lasting psychomotor deficiency or transient developmental delay? Journal of Experimental Child Psychology, 67(2), 164–184. https://doi.org/10.1006/jecp.1997.2400
SSB. (2021). Barnehager. https://www.ssb.no/utdanning/barnehager/statistikk/barnehager
Sumner, E., Connelly, V., & Barnett, A. L. (2013). Children with dyslexia are slow writers because they pause more often and not because they are slow at handwriting execution. Reading and Writing, 26(6), 991–1008. https://doi.org/10.1007/s11145-012-9403-6
Wing, A. M. (2000). Motor control: Mechanisms of motor equivalence in handwriting. Current Biology, 10(6), R245–R248. https://doi.org/10.1016/S0960-9822(00)00375-4
Ziviani, J., & Elkins, J. (1984). An Evaluation of Handwriting Performance. Educational Review, 36(3), 249–261. https://doi.org/10.1080/0013191840360304
Ziviani, J., & Watson-Will, A. (1998). Writing speed and legibility of 7–14-year-old school students using modern cursive script. Australian Occupational Therapy Journal, 45(2), 59–64.
Acknowledgements
We wish to thank the children, parents, and schools for their participation. We also thank researchers and research assistants in the DigiHand project for collecting part of the data.
Funding
Open access funding provided by University Of Stavanger. This research was funded by the DigiHand project (RCN FINNUT-273422) and by the University of Stavanger.
Author information
Authors and Affiliations
Contributions
All authors contributed to the study conception and design. Material preparation, data collection and analysis were performed by Camilla L. Fitjar, Vibeke Rønneberg and Mark Torrance. The first draft of the manuscript was written by Camilla L. Fitjar, and all authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethical approval
The study involving human participants was reviewed and approved by Norwegian Centre for Research Data. Written informed consent to participate in this study was provided by the participants’ legal guardian/next of kin.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
The table below gives letter segmentation and coding scheme for upper and lowercase letters in the English alphabet. Unless specified, the tolerance for size difference 1/6 of the size of the preceding feature, and the tolerance for gaps/overlaps are 1/6 of letter height.
Letter | Feature code | Shape and orientation | Size | Position |
|---|---|---|---|---|
A | A1_1 | Straight Diagonal | Similar length to A2 | Slant top to right Meet with A2 at top to create an acute angle |
A1_2 | Curve, Open | Arms must be similar length | Open end downwards | |
A2 | Straight Diagonal | Similar length to A1_1 | Slant top to left Meets with A1_1 at top to create an acute angle | |
A3 | Straight Horizonal | Must be long enough to meet with or slightly overlap with A1_1 and A2 or both arms of A1_2 | In the middle of A1 and A2 | |
B | B1 | Straight Vertical | Must be longer than the length of B2 | To the left of B2 and B3 Top meets upper arm of B2_1 Bottom meets lower arm of B3_1 |
B2_1 | Curve Open | The length of the curve must be half the length of B1 and similar to or shorter than B3 Width of curve should be similar to or narrower than width of B3 | Open end towards B1 Above B3 Both arms meet B1 Upper arm meets top of B1 | |
B2_2 | Curve, Closed | The length of the curve must be half the length of B1 and similar to or shorter than B3 Width of curve should be similar to or narrower than width of B3 | Above B3 The left side meets B1 in the upper half of B1 | |
B3_1 | Curve Open | The length of the curve must be half the length of B1, and similar to or longer than B2 Width of curve should be similar to or wider than width of B2 | Open end towards B1 Below B2 Both arms meet B1 Lower arm meets bottom of B1 | |
B3_2 | Curve, Closed | The length of the curve must be half the length of B1 and similar to or longer than B2 Width of curve should be similar to or wider than width of B2 | Below B2 The left side meets B1 in the lower half of B1 | |
C | C1 | Curve Open | Similar length and width, but length cannot exceed width | Open end towards the right |
D | D1 | Straight Vertical | Must be longer than the length of D2 Must be long enough to meet both arms of D2 | To the left of D2 Cannot extend top of 2 or descend below D2 |
D2 | Curve Open | Similar length and width, and length must be similar to or shorter than D1 length | Open end towards D1 Upper arm meets top of D1 Lower arm meets bottom of D1 | |
E | E1 | Straight Vertical | Must be longer than the lengths of E2, E3 and E4 | To the left of E2, E3, and E4 Cannot extend above E2 or descend below E4 |
E2 | Straight Horizontal | Shorter than E1, similar to E4 | To the right of E1 Left end meets with top of E1 | |
E3 | Straight Horizontal | Shorter than 1, similar or shorter than 2 and 4 | To the right of E1 Left end meets with the middle of E1 | |
E4 | Straight Horizontal | Shorter than E1, similar to E2 | To the right of E1 Left end meets with bottom of E1 | |
F | F1 | Straight Vertical | Must be longer than the lengths of F2 and F3 | To the left of F2 and F3 Top meets left end of F2 |
F2 | Straight Horizontal | Shorter than F1, similar or longer than F3 | To the right of F1 Left end meets with top of F1 | |
F3 | Straight Horizontal | Shorter than F1 and similar to or shorter than F2 | To the right of F1 Left end meets with the middle of F1 | |
G | G1 | Curve Open | Width must be wider than G2 Arms must be similar length, or bottom arm may be longer than upper arm Curve length cannot be longer than letter height | Open end towards the right |
G2 | Straight Horizontal | At least 1/6 of letter height and no longer than letter height | Right end meets with bottom arm of G1 Left end cannot intersect G1 | |
Optional | G3 | Straight Vertical | Length cannot extend above G2 or below G1 | Top end meets right end G2 Bottom end meets bottom arm of G1 |
H | H1 | Straight Vertical | Similar length to H2 | To the left of H2 and H3 The left end of H3 meets with the middle of H1 |
H2 | Straight Vertical | Similar length to H1 | To the right of H1 and H3 The right end of H3 meets with the middle of H2 | |
H3 | Straight Horizontal | Must be long enough to meet with or slightly overlap with H1 and H2 Cannot be longer than both H1 and H2 | Meets with H1 and H2 in the middle of H1 and H2 | |
I | I1 | Straight Vertical | ||
J | J1 | Curve Open | Uneven lengths, left arm must be no more than half the length of the right arm | Open end upwards Below J2 Top of J1 right arm meets J2 in the middle |
J2 | Straight Horizontal | Length must be shorter than letter height | Above J1 Middle meets the top of J1 right arm | |
K | K1 | Straight Vertical | Longer than K2 and K3 | To the left of K2 and K3 |
K2 | Straight Diagonal | Shorter than K1 Similar to K3 | Slant top to right Bottom meets in the middle of K1 | |
K3 | Straight Diagonal | Shorter than K1 Similar to K2 | Slant down to right Top meets in the middle of K1 | |
L | L1 | Straight Vertical | Longer than L2 | To the left of L2 Bottom meets with left end of L2 |
L2 | Straight Horizontal | Shorter than L1 | To the right of L1 Left end meets with bottom part of L1 | |
M | M1 | Straight Vertical | Similar to M4 | To the left of M2, M3, and M4 Meet with M2 at top to create an acute angle |
M2_1 | Straight Diagonal | Must be at least 1/6 of both 1 and 4 Length similar to length of M3 | Slant top to left Top meets with top of 1 to create acute angle Bottom meets with bottom of M3_1, meeting point below the upper 1/6 of letter height | |
M2_2 | Curve Open | The arms should be similar length, or the right arm may be shorter | Bottom of right arm overlaps with bottom of left arm of M3_2 | |
M3_1 | Straight Diagonal | Must be at least 1/6 of both 1 and 4 Length similar to length of M2 | Slant top to right Bottom meets with bottom of M2_1, meeting point below the upper 1/6 of letter height | |
M3_2 | Curve Open | The arms should be similar length, or the left arm may be shorter | Bottom of left arm overlaps with bottom of right arm of M2_1 | |
M4 | Straight Vertical | Longer than M2_1 and M3_1 Length similar to M1 | To the right of M1, M2 and M3 Meet with M3_1 at top to create an acute angle | |
N | N1 | Straight Vertical | Length similar to N2 and N3 | To the left of N2, and N3 Meets with N2 at top to create an acute angle |
N2 | Straight Diagonal | Length similar to N1 and N3 | Slant top to left Meets with N1 at top and N3 within lower half to create acute angles | |
N3 | Straight Vertical | Length similar to 1 and 2 | To the right of N1 and N2 Meets with N2 within the lower half to create an acute angle | |
O | O1 | Curve Closed | Similar width and length | |
P | P1 | Straight Vertical | Length twice the width of the curve in P2 | To the left of P2 |
P2_1 | Curve Open | Width: half the length of P1 Length: shorter or similar to height of P1 | To the right of P1 Open end towards P1 Top arm meets with top of P1, and bottom arm meets P1 in the middle | |
P2_2 | Curve Closed | Width: half the length of P1 Length: shorter or similar to height of P1 | To the right of P1 In the upper half of P1 | |
Q | Q1 | Curve Closed | Similar width and length | |
Q2 | Straight Diagonal | Shorter than the letter height | Slant top to left Meets with or intersects Q1 only once and in the right lower quadrant | |
R | R1 | Straight Vertical | Length twice the width of the curve in R2 | To the left of R2 and R3 |
R2_1 | Curve Open | Width: half the length of R1 Length: shorter or similar to length of R1 | To the right of R1 Open end towards R1 Top arm meets with top of R1 Bottom arm meets R1 in the middle | |
R2_2 | Curve Closed | Width: half the length of R1 Length: shorter or similar to length of R1 | To the right of R1 In the upper half of R1 | |
R3 | Straight Diagonal | Shorter than R1 | To the right of R1 Slant bottom to right Meets lower arm of R2 and or middle of R1 | |
S | S1 | Curve Open | Similar to S2 Tolerance: half or double the size of S2 | Open end towards right Directly above S2 Lower arm merges into upper arm of S2 |
S2 | Curve Open | Similar to S1 Tolerance: half or double the size of S1 | Open end towards left Directly below S1 Upper arm merges into lower arm of S1 | |
T | 1 | Straight Vertical | Similar to T2 Tolerance: half or double the size of T2 | Below T2 Top meets the middle of T2 |
2 | Straight Horizontal | Similar to T1 Tolerance: half or double the size of T1 | Above T1 Middle meets the top of T1 | |
U | U1 | Curve Open | Arms have similar length Length should be longer or similar to width | Open end upwards |
V | V1 | Straight Diagonal | Similar to V2 | Slant top to left Bottom meets with bottom part of V2 to create an acute angle |
V2 | Straight Diagonal | Similar to V1 | Slant top to right Bottom meets with bottom part of V1 to create an acute angle | |
W | W1 | Straight Diagonal | Longer than or similar to W2 and W3 Similar to W4 | Slant top to left Bottom meets with bottom part of W2 to create an acute angle |
W2 | Straight Diagonal | Shorter than or similar to W1 and W4 Similar to W3 | Slant top to right Bottom meets with bottom part of W1 to create an acute angle Top meets with top of W3 to create an acute angle or intersects upper part of W3 | |
W3 | Straight Diagonal | Shorter than or similar to W1 and W4 Similar to W2 | Slant top to left Top meets with top part of W2 to create an acute angle or intersects with upper part of W2 Bottom meets with bottom of W4 to create an acute angle | |
W4 | Straight Diagonal | Longer than or similar to W2 and W3 Similar to W1 | Slant top to right Bottom meets with bottom part of W3 to create an acute angle | |
X | X1 | Straight Diagonal | Similar to X2 | Slant top to left The middle intersects the middle of X2 |
X2 | Straight Diagonal | Similar to X1 | Slant top to right The middle intersects the middle of X1 | |
Y | Y1 | Straight Diagonal | Half the length of Y2 | Slant top to left Bottom meets middle of Y2 |
Y2 | Straight Diagonal | Double the length of Y1 | Slant top to right Middle meets end of Y1 | |
Z | Z1 | Straight Horizontal | Similar to or shorter than Z2 and similar to or longer than Z3 | Above Z2 and Z3 Right end meets top of Z2 to create an acute angle |
Z2 | Straight Diagonal | Similar to Z1 and Z3 | Between Z1 and Z3 Slant top to right Top meets right end of Z1 to create an acute angle Bottom meets left end of Z3 to create an acute angle | |
Z3 | Straight Horizontal | Similar to Z1 and Z2 | Below Z1 and Z2 Left end meets bottom of Z2 to create an acute angle | |
a | a1_1 | Curve Open | Length similar to a2 length Width similar to length of a2 | Open end to the right Aligned with and to the left of a2 Top arm meets top of a2 Bottom arm meets bottom of a2 |
a1_2 | Curve Closed | Similar length as a2 | Top and bottom aligned with a2 top and bottom To the left of a2 | |
a2_1 | Straight Vertical | Similar length as a1 | To the right of a1 Overlaps with the right side of a1 OR The top meets end of upper arm of a1_1 and the bottom meets end of lower arm of a1_1 | |
a2_2 | Curve Open | Left arm similar length as a1 Right arm cannot extend the middle of letter height | To the right of a1 Overlaps with the right side of a1 OR The top meets end of upper arm of a1_1, the bottom meets end of lower arm of a1_1 | |
b | b1 | Vertical | Length twice the width of the curve in b2 | To the left of b2 Meets with arms of b2_1 OR the left side of b2 |
b2_1 | Curve Open | Width: half the length of b1 Length: shorter than length of b1 | Open end towards the left To the right of the bottom half of b1 | |
b2_2 | Curve Closed | Width: half the length of b1 Length: shorter than length b1 | To the right of the bottom half of b1 | |
c | c1 | Curve Open | Similar length and width, but length cannot exceed width | Open end towards the right |
d | d1_1 | Straight Vertical | Length twice the width of the curve in d2 | To the right of d2 and meets d2_1 end of arms OR right side of d2_2 |
d1_2 | Curve Open | Left arm length twice the width of the curve in d2 Right arm length cannot extend the middle of letter height | To the right of d2 and meets d2_1 end of arms OR right side of d2_2 | |
d2_1 | Curve Open | Length and width: half the length of d1 | Open end towards the right Upper arm meets the middle of d1 lower arm meets the bottom of d1 | |
d2_2 | Curve Closed | Length and width: half the length of d1 | Meets d1 to the left of the bottom half of d1 | |
e | e1 | Straight Horizontal | Length: similar to length of e2 and no more than double the width of e2 | Right end meets upper arm of e2 Left arm meets bottom curve of e2 |
e2 | Curve Open | Length: similar to length of e1 Width: must be at least half of e1 length, but no more than double length of e1 The lower arm must exceed the middle of the upper arm but cannot meet the right end of e1 | Open end towards the right The upper arm continues downward to meet the right end of e1 | |
f | f1 | Curve Open | Arms are uneven lengthwise Right arm must be between 1/6 and 1/2 of the length of the left arm Must be longer than f2 | Open end downwards Left arm must be in the middle of f2 |
f2 | Straight Horizontal | Shorter than f1 and longer than 1/3 of f1 | Placed cross sectional in the middle of f1, but below endpoint of f1 right arm | |
g | g1 | Curve Open | Arms are uneven lengthwise Left arm must be between 1/6 and 1/2 the length of the right arm Must be longer than g2 | Open end upwards Must be placed visibly below the bottom curve of g2 |
g2_1 | Curve Open | Width: half the length of g1 Length: shorter or similar to length of g1 | To the left of g1 End of upper arm meets top of g1 Lower arm must be visibly above the bottom of the curve in g1 | |
g2_2 | Curve Closed | Width: half the length of g1 Length: shorter or similar to length of g1 | To the left of g1 The right side of the curve meets g1 in the upper half The closed curve must be visibly above the bottom of the curve in g1 | |
h | h1 | Straight Vertical | Length: double the length of h2 | (Potentially) overlapping with the left arm of h2 Bottom part of h1 should be aligned with end of h2 right arm |
h2 | Curve Open | Length: Half the length of h1 Width: shorter or similar to length of h1 | Endpoints of h2 arms should be aligned with bottom part of h1 The left arm of h2 may be shorter than the right arm but should be connected to h1 | |
i | i1 | Straight Vertical | Ignore tittle | |
j | j1 | Curve Open | Uneven lengths, left arm must be no more than half the length of the right arm | Open end upwards Ignore tittle |
k | k1 | Straight Vertical | Length: longer than k2 and k3 | To the left of k2 and k3 |
k2 | Straight Diagonal | Shorter than k1, Similar to or shorter than k3 | Slant top to right Bottom meets in the lower half of k1 | |
k3 | Straight Diagonal | Shorter than k1, similar to or longer than k2 | Slant down to right Top meets in the lower half of k1, but not above k2 bottom | |
l | l1_1 | Straight Vertical | ||
l1_2 | Curve Open | Uneven lengths, right arm must be no more than half the length of the left arm | Open end upwards | |
m | m1 | Straight Vertical | Length: similar to or longer than m2 and m3 | (Potentially) overlapping with the left arm of m2 Top should be aligned with top of m2 and m3 curves Bottom part of m1 should be below or aligned with endpoint of m2 right arm and aligned with endpoint of m3 right arm |
m2 | Curve Open | Length: similar to or shorter than m1 Left arm length: similar or shorter than m1, similar or longer than m2 right arm Right arm length: similar or shorter than m2 left arm Width: shorter than length, but at least half the length of feature length | Open end downwards Top of curve should be aligned with m3 and top of m1 Left arm should overlap with m1, or start in the upper half of m1 Right arm should overlap with m3 left arm | |
m3 | Curve Open | Length: similar to or shorter than m1 Left arm: similar or shorter than m3 right arm Right arm: similar or longer than m3 left arm Width: shorter than length, but at least half the length of feature length | Open end downwards Top of curve should be aligned with m3 and top of m1 Left arm should overlap with m2 right arm Right arm endpoint should be below or aligned with endpoint of left arm and aligned with bottom om m1 | |
n | n1 | Straight Vertical | Length: similar to or longer than length of n2 | (Potentially) overlapping with n2 left arm Top should be aligned with top of n2 curve Bottom part of n1 should be below or aligned with endpoint of n2 left arm and aligned with endpoint of n2 right arm |
n2 | Curve Open | Left arm length: similar to or shorter than n1 and n2 right arm Right arm length: similar to or longer than n2 left arm Width: shorter than length, but at least half the length of feature length | Open end downwards Left arm (potentially) overlapping with n1 Right arm endpoint should be below or aligned with endpoint of left arm and aligned with bottom om n1 | |
o | o1 | Curve Closed | Similar width and length | |
p | p1 | Straight Vertical | Length twice the width of the curve on p2 | Meets p2 to the left of p2 |
p2_1 | Curve Open | Length and width: half the length of p1 | To the right of p1 Open end towards p1 Upper arm meets top of p1 Lower arm meets middle of p1 | |
p2_2 | Curve Closed | Length and width: half the length of p1 | To the right of p1 Meets in the upper half of p1 | |
q | q1 | Straight Vertical | Length twice the width of the curve on q2 | Meets q2 to the right of q2 |
q2_1 | Curve Open | Length and width: half the length of p1 | Meets q1 to the left of q1 Open end towards q1 Upper arm meets top of q1 Lower arm meets middle of q1 | |
q2_2 | Curve Closed | Length and width: half the length of p1 | To the right of q1 In the upper half of q1 | |
r | r1 | Straight Vertical | Length: similar to or longer than length of n2 | (Potentially) overlapping with left arm of r2 |
r2 | Curve Open | Arms are potentially uneven lengthwise, ie left arm may be similar to r1 OR arms are similar in length Right arm must be between 1/6 and 1/2 of the length of the left arm OR r1 length | Open end downwards Left arm overlaps potentially with r1, it may be shorter but must be connected to upper half of r1 | |
s | s1 | Curve Open | Similar to s2 Tolerance: half or double the size of s2 | Open end towards right Directly above s2 Lower arm merges into upper arm of s2 |
s2 | Curve Open | Similar to s1 Tolerance: half or double the size of s1 | Open end towards left Directly below s1 Upper arm merges into lower arm of s1 | |
t | t1_1 | Straight Vertical | Must be longer than t2 | Placed in the middle of t2 |
t1_2 | Curve Open | Arms are uneven lengthwise Right arm must be between 1/6 and 1/2 of the length of the left arm Must be longer than t2 | Open end upwards Left arm in the middle of t2 | |
t2 | Straight Horizontal | Shorter than t1 but longer than 1/3 of t1 | Placed cross sectional in the middle of t1, but above endpoint of t1_2 right arm | |
u | u1 | Curve Open | Length: longer than width, but no more than double the feature width Width: shorter than length, but at least half the length of feature length | Open end upwards Left arm (potentially) overlapping with u2 Arm endpoints must be aligned |
u2_1 | Straight Vertical | Length similar to u1 length | Overlapping with u1 to the right of u1 | |
u2_2 | Curve Open | Left arm similar length as u1 Right arm cannot extend the middle of letter height | To the right of u1 Left arm overlapping with the right arm of u1 | |
v | v1 | Straight Diagonal | Similar to v2 | Slant top to left Bottom meets with bottom part of v2 to create an acute angle |
v2 | Straight Diagonal | Similar to v1 | Slant top to right Bottom meets with bottom part of v1 to create an acute angle | |
w | w1 | Straight Diagonal | Length shorter than or similar to w1 and w4 Length similar to w3 | Slant top to right Bottom meets with bottom part of w1 to create an acute angle Top meets with top of w3 to create an acute angle or intersects upper part of w3 |
w2 | Straight Diagonal | Length shorter than or similar to w1 and w4 Length similar to w2 | Slant top to left Top meets with top part of w2 to create an acute angle or intersects with upper part of w2 Bottom meets with bottom of w4 to create an acute angle | |
w3 | Straight Diagonal | Longer than or similar to w2 and w3 Similar to w1 | Slant top to right Bottom meets with bottom part of w3 to create an acute angle | |
w4 | Straight Diagonal | Shorter than or similar to w1 and w4 Similar to w3 | Slant top to right Bottom meets with bottom part of w1 to create an acute angle Top meets with top of w3 to create an acute angle or intersects upper part of w3 | |
x | × 1 | Straight Diagonal | Similar to × 2 | Slant top to left The middle intersects the middle of × 2 |
× 2 | Straight Diagonal | Similar to × 1 | Slant top to right The middle intersects the middle of × 1 | |
y | y1_1 | Straight Diagonal | Half the length of y2_1 | Slant top to left The bottom endpoint meets the middle of y2_1 |
y1_2 | Curve Open | Length: longer than width, but no more than double the feature width Width: shorter than length, but at least half the length of feature length | Open end upwards Arm endpoints must be aligned Left arm overlaps (potentially) with upper part of y2_2 left arm | |
y2_1 | Straight Diagonal | Double the length of y1_1 | Slant top to right The middle meets the bottom endpoint of y1_1 | |
y2_2 | Curve Open | Arms are uneven lengthwise Left arm must be between 1/6 and 1/2 the length of the right arm Must be longer than y1_2 | Open end upwards Left arm overlaps (potentially) with left arm of y1_2 Must be placed visibly below the bottom curve of y1_2 | |
z | z1 | Straight Horizonal | Similar to or shorter than z2 Similar to or longer than z3 | Above z2 and z3 Right end meets top of z2 to create an acute angle |
z2 | Straight Diagonal | Similar to z1 and z3 | Between z1 and z3 Slant top to right Top meets right end of z1 to create an acute angle Bottom meets left end of z3 to create an acute angle | |
z3 | Straight Horizontal | Similar to z1 and z2 | Below z1 and z2 Left end meets bottom of z2 to create an acute angle |
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Fitjar, C.L., Rønneberg, V. & Torrance, M. Assessing handwriting: a method for detailed analysis of letter-formation accuracy and fluency. Read Writ 37, 291–327 (2024). https://doi.org/10.1007/s11145-022-10308-z
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11145-022-10308-z