
Abstract
This paper presents a control strategy designed as a combination of a PD controller and a twisting-like algorithm to stabilize the damped cart pole system, provided that the pendulum is initially placed within the upper-half plane. To develop the strategy, the original system is transformed into a four-order chain of integrator form, where the damping force is included through an additional nonlinear perturbation. The strategy consists of simultaneously bringing the position and velocity of the pendulum to within a compact region by applying the PD controller. Meanwhile, the system state variables are brought to the origin by the twisting-like algorithm. The corresponding convergence analysis is done using several Lyapunov functions. The control strategy is illustrated with numerical simulations.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
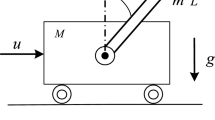
The cart pole system (CPS), also known as the inverted pendulum on a cart, is among the classic mechanical systems that have been studied extensively in control theory during the last four decades. This system was originally used as a benchmark for educational purposes, see [1, 6, 15, 33, 39, 43, 44, 46] .Through the years, this system has attracted attention as an important underactuated mechanical system, because the pendulum angular acceleration cannot be directly controlled [18, 42]. As the CPS dynamics resembles that of many underactuated robot systems, it has been studied as a simplified model such systems (see [7, 27, 30, 38, 40, 43] ). This system is made up of a cart that moves, forward and backward, over a straight line and has a free-moving pendulum hanging from it. The cart is moved by a horizontal force, which is the input of the system. It is well known that several control strategies that were initially conceived for fully actuated systems cannot be applied to drive this system. Actually, the system is not feedback linearizable [23, 42]; also, the system loses controllability when the pendulum passes through the horizontal plane [18, 41]. However, the system can be controlled when located near the unstable equilibrium point, by applying the direct pole placement procedure [25, 42].
In the present authors’ opinion, there are two important problems related to the control of the CPS. The first consists of the upward swing of the pendulum from the hanging position to the upright position. In general, this problem has been tackled by using methods based on energy control and hybrid schemes [2, 3, 8, 9, 22, 26, 31, 44, 45] . The second issue arises when the pendulum is located somewhere in the upper-half plane, and the goal is bringing it to its unstable equilibrium point. Usually, this control challenge has been solved by applying nonlinear control tools. A full review of these tools is beyond the scope of this work; however, we mention, for instance, the well-known energy-based controller or Lyapunov-based techniques, and methods based on the feedforward or the backforward forms, in conjunction with the saturation function or the bounded function approaches [3–5, 13, 14, 22, 30, 45].
In this work, we propose a control strategy to stabilize the damped CPS around to its unstable equilibrium point, assuming that the pendulum starts moving from some position located inside of the upper-half plane and that the damped coefficient is known. Considering the damping force in the non-actuated coordinate makes controlling this system a challenge, because this force can easily destroy the system stability [21, 32, 47]. In addition, managing this force is a very difficult task. Several works have neglected the damping coefficient for this reason.
To develop the proposed control strategy, we transformed the original system into a four-order chain of integrators, with an additional nonlinear perturbation. Then, we proposed the strategy as a combination of a linear PD controller and a modified version of the twisting algorithm [16, 28, 34–36] ,where the first acts over the pendulum position and velocity, while the second brings the whole system state to the origin. The corresponding stability analysis was carried out by using several Lyapunov functions. Convincing numerical simulations were done to assesses the performance of the proposed control strategy. Finally, we mention that this work was inspired by [35, 36]. However, our strategy, when the controller gains are adequately selected, may guarantee global convergence, as long as the position pendulum is initialized into the upper-half plane, though it has the disadvantage of being less robust in the presence of unmodeled perturbations. During the development of this study, we use the following functions:
The following sections are organized as follows. The nonlinear model of the system is presented in Sect. 2. In Sect. 3, we develop the control strategy. The numerical simulations and the conclusions are in Sects. 4 and 5, respectively.
2 Problem statement
Consider the damped inverted pendulum mounted on a cart. This system can be described by the following set of normalized differential equations [42]:
where \(x\) is the normalized cart displacement, \(\theta \), is the angle between the pendulum and the vertical, \(f\) is the normalized force applied to the cart, which is also the input to the system, and \(\mu >0\) is a scalar constant dependent on both the cart and pendulum masses. The pendulum viscous friction is considered as a linear function of the angular velocity, \(d\dot{\theta }\), with \(d \ge 0\).
In this work, the physical parameters \(\mu \) and \(d\) are actually given by [42]:
where \(M\) and \(m\) stand for the cart and pendulum masses, respectively, the pendulum length is \(L\), \(g\) is the gravity constant, and \(\gamma \) is the actual dissipation coefficient presented in the non-actuated coordinated \( \theta \). The damping force presented in the actuated coordinate is neglected in order to simplify the methodology presented here. It is important to remark that this force can be easily compensated by using any adaptive control algorithm ([20, 29]).
The control objective consists of bringing the pendulum to its unstable equilibrium point,
under the following important considerations:
C1) The system is initialized inside of the following set:
C2) The state variables are available and the parameters are known.
It should be notice that C1 is not very restrictive, because the pendulum is assumed to be somewhere inside of the upper-half plane; in fact, it can be easily accomplished by using some suitable controller such as those proposed in [26].
Differential equations are understood in the Filippov sense [19] in order to provide for the possibility to use discontinuous signals in controls. Filippov solutions coincide with the usual solutions, when the right-hand sides are Lipschitzian. It is assumed also that all considered inputs allow the existence of solutions and their extension to the whole semi-axis \(t\ge 0\).
3 System transformation
After introducing the following feedback law:
the system can be rewritten as:
Now, in order to represent the system (3) as a four-order chain of integrators plus an additional nonlinear perturbation, we define the following new change of coordinates:
Then, the system (3) can be rewritten as:
where
and \(\upsilon \) is the new control variable, defined as:
It is important to remark that:
Now, to dominate the undesirable term \(d\beta (z_{3})z_{4}\), found in the second equation of (5), we use the following change of coordinates and the following scale of time:
where \(\epsilon \) is a strictly positive free parameter. Hence, the system (5) can be written in the new coordinates as:
where \(\rho (q)\) is a vanishing perturbation defined by:
Here, the symbol “dot” stands for differentiation with respect to the dimensionless time \(\tau \). We must underscore that the free parameter, \(\epsilon >0\), can be tuned as desired.
Finally, the above system can be expressed in a compact form as:
where \(v_{\epsilon }\in R, q\in R^{4}\) and \(f(q): \,R^{4}\rightarrow R^{4}\).
4 Control of the cart pole system
The control law is proposed as:
where \(v_{e}(q)\) is a linear controller devoted to bring the states \(q_{3}\) and \(q_{4}\) close enough to the origin, and \(v_{s}(q)\) is a bounded controller designed using the twisting sliding mode algorithm.
The linear control part of the controller, \(v_{\epsilon }\), is selected as:
Let us introduce the following auxiliary variables:
where the set of constants \(k_{i}>0\) should be selected such that they satisfy the following:
where \(\delta _{i}>0, i=\{1,2,3\}\).Footnote 1 The inequities in (14) are referred to in the sequel as assumption A1. Let us propose \(v_{s}\) as a discontinuous injection based on the twisting control algorithm [28, 34–36] .That is,
where \(\lambda _{1}>\lambda _{2}>0\).
Let us synthesize the main result of this work in the following theorem:
Theorem 1
Consider the system (9) in closed-loop with:
where
Under the assumption that the control parameters \(k_{i}>0\); with \( i=\{1,2,3\} \) and \(\lambda _{1}>\lambda _{2}>0\), satisfy the inequalities in (14), then the closed-loop system is asymptotically stable. In particular, the variables \(s_{1}\) converge to zero in finite time.
Proof
Following the application of the linear control, and after some simple algebra, the dynamics of \(s_{1}\) and \(s_{2}\) become:
Then, the system composed by (16) and the last two equations of (9) reads as:
To be able to carry out the convergence analysis, we analyze the boundedness of the states \(q_{3}\) and \(q_{4}\), when the system (17) is feedback by the twisting controller, to assure the boundedness of the vanishing nonlinear perturbation \(\rho (q)\). That is, the system (17), in closed-loop with (15), reads as
where
Before formally presenting the corresponding proof, we introduce the following auxiliary lemma:
Lemma 1
Consider the following second order system:
where the set of constants \(k_{i}>0\), for \(i=\{p,d\}\), with \(\left| \upsilon \right| \le \overline{\upsilon }\) . Then, there exits a finite time, \(t_{0}>0\) , such that:
where \(\delta _{0}>0\) is sufficiently small. The proof of this lemma is omitted due to its obviousness.
According to this lemma, the last two equations of (17) satisfy the following inequity:
where \(t_{0}\) is a finite period of time and \(\delta _{0}\) is a small positive constant. That is, \(q_{3}\) and \(q_{4}\) are bounded after \(t\ge t_{0}\). This fact assures that the proposed closed-loop system is Lipschitzian, implying that the states \(s_{1}\) and \(s_{2}\) remain bounded during a finite time. Hence, the finite time of scape does not exist—see [24]. On the other hand, from the relations (7) and (10), the inequality,
is fulfilled. Having shown that \(q_{3}\) and \(q_{4}\) are uniformly bounded after some finite time, we are in a position to finally perform the convergence analysis of the whole system, using a continuous and differentiable almost everywhere Lyapunov function. Before to proceeding, we must remember that these kinds of Lyapunov functions have been introduced since the late nineties to prove the stability of discontinuous systems and systems with solutions intended in Filippov’s sense—see for example, [10–12]. Let us introduce our Lyapunov function, as:
with the vector state \(p=(s_{1},s_{2},q_{3},q_{4})\), whose time derivative around the trajectories of the system (17) is almost everywhere given by:
Notice that the derivative of the Lyapunov function (21) exists for all \(s_{1}\) values except the set of measure zero given by \(s_{1}=0\). Notice that \( W(p)\) can be expressed after using (16), as follows:
By using the inequality \(\left| q_{4}\mathfrak {v}_{s}\right| \le (q_{4}^{2}+\mathfrak {v}_{s}^{2})/2\), we have that (22) can be upperbounded, as:
It is easy to see, after some simple algebra that the following inequality
holds, for all \(t\ge t_{0}\); where for simplicity, we introduce, \( \overline{\rho }\), such thatFootnote 2
After substituting (24) into the relation (23), we obtain the following inequality:
Then, according to the conditions in assumption A1, we have that after a finite time \(t\ge t_{0}\), the following inequity is fulfilled:
From the above, it follows that \(V_{T}(p)<V_{T}(p(0))\) and, from its own definition, \(V_{T}(t)\) is radially bounded and differentially everywhere, except when \(s_{1}=0\). Consequently, the vector state \(p\) is bounded. On the other hand, as \(V_{T}\) is bounded from below, with strictly negative definite time derivative, then \(V\) converges and \(p\) has a limit. Also, \( \overset{.}{p}\) is bounded, according to (18). That is, \(p\) is uniformingly continuous. Now, integrating both sides of the last inequity and using simple algebra, we can claim that the following inequity:
holds, for \(t>t_{0}\). It implies that the signals \(s_{2}\) and \(q_{4}\) are, respectively, \(L_{1}\) and \(L_{2}\). According to Barbalat’s lemma, we have that \(s_{2}\rightarrow 0\) and \(q_{4}\rightarrow 0\), as long as \(t\rightarrow \infty \). We proceed to show that \(s_{1}\) converges to zero, in a finite time. So, as the values of \(\left| s_{2}\right| \) and \(\left| q_{4}\right| \) decreasing continuously toward the origin, always exists a finite time \(t_{1}>0\) and a constant \(\mu >0\), such that, \(\lambda _{1}>\left| \Delta (q(t))\right| +\mu \), for all \(t>t_{1}\), where:
because \(\lambda _{1}>>\lambda _{2}\). Hence, the first equation of (18) can be read, as:
Evidently, the dynamics of \(s_{1}\) concides with the dynamics of a first-order sliding mode.
To see the convergence of \(s_{1}\), we propose \(V_{1}=s_{1}^{2}/2\). According to (28), we have:
From the above inequity, we conclude that \(s_{1}\rightarrow 0\), in a finite time. That is, there is a time \(t_{2}>t_{1}\), such that, \( s_{1}(t)\rightarrow 0\), as long as \(t>t_{2}\). To prove that \(q_{3}\) converges to zero, we introduce the following auxiliary variable \( z=k_{3}q_{4}+k_{2}q_{3}-s_{2}\), whose time derivative can be written, after using simple algebra, as:
According to (20) and the fact that \(s_{1}\rightarrow 0\) and \( q_{4}\rightarrow 0\), the last differential equation turns out to be \(\overset{.}{z}=-k_{1}z/k_{2}\). It imples that \(z\rightarrow 0\) and \( q_{3}\rightarrow 0\). Therefore, the closed-loop system (18) asymptotically converges to the origin, if the control gains are selected according with A1.
Remark 1
The function \(V_{T}\) is continuous but not locally Lipschitz. Therefore, the usual version of the traditional Lyapunov theorem cannot be applied [10, 17]. However, it can be shown that function \(V_{T}(p)\)is absolutely continuous along the trajectories of the closed-loop equation (17), implying that \(V_{T}(p)\) is differentiable almost everywhere, monotone decreasing and converges to zero. These are the conditions needed by the theorem of Zubov [28, 37].
Remark 2
Should the damping parameter \(d\) be very large, assumption A1 becomes a strong condition, because assuring the positiveness of constants \(\delta _{i}\) and \(k_{i},\) \(i=\{1,2,3\}\), in a way that the inequities in (14) hold, needs the parameter \(\epsilon \) to be sufficiently small, which converts the controller into a high-gain controller—see (9). Another way to see it is that when the damping force is very strong, strong control actions must be taken.
It is important to note that the proposed controller has a very simple structure and does not presents singularities, if the system is initialized inside of the upper-half plane.
Tuning the control parameters The correct performance of the control strategy requires control parameters tuning according to the restriction (23). To illustrate this tuning, we fix the pendulum length, mass, and damping as \(L=0.35\) (m), \(m=0.250\) (Kg), and \(\gamma =4\,(\hbox {kgm}^{2}/\hbox {s})\), respectively. Then, according to the expression given in comment C1, the normalized damping coefficient is \(d=0.9\). Now, fixing the control gains as \(k_{1}=0.9, k_{2}=3.5, k_{3}=4, \lambda _{1}=6\), and \(\lambda _{2}=0.8\), and setting the rescale parameter as \(0<\epsilon <0.404\), it is easy to see in a plot that the inequities in (14) hold.
Summarizing Given \(d>0\) and \(\delta _{i}\thickapprox 0.1\), we need to find an admissible parameter vector
fulfilling the restrictions given in (23). This problem can be solved using any numerical optimization program.
5 Numerical simulations
In order to verify the proposed controller performance, we carried out some numerical simulations, where the above proposed control gains were used, with \(\epsilon =0.4\). To make this experiment more interesting, we assume that the knowledge of the damping force has an accuracy of \(85\%\). We ran two experiments with their own different initial conditions. The obtained closed-loop responses for \({p_{1}=(\theta (0)=1.2}\) (rad), \(\dot{\theta } (0)=-0.1\) (rad/s), \(x=0,\dot{x}=0)\) and \(p_{2}=(\theta (0)=-0.7\)[rad], \(\dot{ \theta }(0)=0\), \(x=0.2\) (m/s), \(\dot{x}=0)\) are shown in Fig. 1, where \(p_{i}\) correspond to \((\theta ,\overset{.}{\theta },x,\overset{.}{x})\). As we can see, the control strategy is able to render the system to the origin after 7 (s) elapsed, even when the value of the damping coefficient, \(d\), is partially known.

Closed-loop responses for two initial conditions (\(p_{1}, p_{2}\) ), and a partial knowledge of 85 % of the damping force
To provide an idea of how good the proposed control strategy OC is, we compared it with the control technique proposed by Riachy et al. in [35], here referred to as RC. The control parameters of RC were tuning heuristically, but to be fair, we tried to find the values that enable the best transient response. The initial conditions were fixed as \((\theta =0.9,0,0,0)\). The obtained results are shown in Fig. 2, where we can see that the closed-loop response of the propose control strategy is as good as the responses of RC. Furthermore, we can see that our strategy presents a better behavior in the angular variable, if compared with the RF strategy. However, the cart displacements in our strategy are larger that those in RC. Please keep in mind that this is a numeric comparison, a formal comparison is beyond the scope of this work, as is a comparative study between our control strategy and others found in the literature. We must underscore that all the simulations were carried out in the actual coordinates of the pendulum system. Finally, Fig. 3 shows numerically the asymptotic behavior the Lyapunov function \( V_{T}(p)\), and its derivative. To this experiment, we used the same setup as before, but normalized time, and the following two different sets of initial conditions: \((s_{1}=1,s_{2}=0,q_{3}=-5,q_{4}=1)\) and \( (s_{1}=0,s_{2}=0,q_{3}=1,q_{4}=4)\). The numerical similations shown in this figure are the expect results, because \(V_{T}\) converges asymptotically to zero and \(\overset{.}{V}_{T}\) is always strictly negative, with \(\overset{.}{V}_{T}\) tends to \(-4.9\).

Comparison between the closed-loop responses of the OC and the RC strategies, represented with a solid line and a dotted line, respectively

Asymptotic behavior of \(V_{T}\) and \(\overset{.}{V}_{T}\), for the initial conditions: \((s_{1}=1,s_{2}=0,q_{3}=-5,q_{4}=1)\) and \( (s_{1}=0,s_{2}=0,q_{3}=1,q_{4}=4)\). The plot on the left side corresponds to the first initial conditions, and the one on the right side to the second initial conditions
6 Conclusions
In this work, we introduced a control strategy, based on a PD controller in conjunction with a twisting-like algorithm, to solve the stabilization of the damped cart pole system, assuming that the pendulum is initialized somewhere inside of the upper-half plane. To this end, we first used some nonlinear transformations over the original pendulum system to express it as a four-order chain of integrators, with an additional perturbation that vanishes at the origin. The PD controller was designed to bring the pendulum position and its velocity inside of a compact region simultaneously. At the same time, the twisting-like algorithm renders the whole system state to the origin. For the convergence analysis, we used several Lyapunov functions, thereby assuring that our strategy converges asymptotically once the pendulum position and its velocity are inside of the compact region. The effectiveness and robustness of the strategy was tested running numerical simulations, where uncertainties in the parameters’ values were included. The obtained results allow us to claim that the performance of our controller is satisfactory.
Notes
With \(\overline{q}_{4}=\frac{\lambda _{1}+\lambda _{2}}{k_{2}}\) and \(\delta _{i}\) can be fixed as needed inside of a suitable range.
Notice that by definition
$$\begin{aligned} \left| \rho (q)\right| \le \kappa _{0}\epsilon \left| q_{4}\right| +d\le \kappa _{0}\epsilon \overline{q}_{4}+d;\forall t\ge t_{0}. \end{aligned}$$
References
Abedinnasab, M.H., Yoon, Y.J., Saeedi-Hosseiny, M.S.: High performance fuzzy-padé controllers: introduction and comparison to fuzzy controllers. Nonlinear Dyn. 71(1–2), 141–157 (2013)
Acosta, J., Ortega, R., Astolfi, A., Sarras, I.: A constructive solution for stabilization via immersion and invariance: the cart and pendulum system. Automatica 44(9), 2352–2357 (2008)
Acosta, J.A., Ortega, R., Astolfi, A., Mahindrakar, A.D.: Interconnection and damping assignment passivity-based control of mechanical systems with underactuation degree one. IEEE Trans. Autom. Control 50(12), 1936–1955 (2005)
Aguilar-Ibañez, C.F., Gutiérrez-Frias, O.O.: Controlling the inverted pendulum by means of a nested saturation function. Nonlinear Dyn. 53(4), 273–280 (2008)
Aguilar-Ibañez, C.F., Gutiérrez-Frias, O.O.: A simple model matching for the stabilization of an inverted pendulum cart system. Int. J. Robust Nonlinear Control 18(6), 688–699 (2008)
Aguilar-Ibánez, C., Sossa-Azuela, J.H.: Stabilization of the furuta pendulum based on a lyapunov function. Nonlinear Dyn. 49(1–2), 1–8 (2007)
Almutairi, N.B., Zribi, M.: On the sliding mode control of a ball on a beam system. Nonlinear Dyn. 59(1–2), 221–238 (2010)
Aracil, J., Gordillo, F., Astrom, K.J.: A familiy of pumping–damping smooth strategies for swinging up a pendulum. In: Third IFAC Workshop on Lagrangian and Hamiltonian Methods for Nonlinear Control. Negoya, Japan (2006)
Aström, K.J., Aracil, J., Gordillo, F.: A family of smooth controllers for swinging up a pendulum. Automarica 44(7), 1841–1848 (2008)
Bacciotti, A., Ceragioli, F.: Stability and stabilization of discontinuous systems and nonsmooth lyapunov functions. ESAIM: Control Optim. Calc. Var. 4, 361–376 (1999)
Bacciotti, A., Ceragioli, F.: Nonpathological lyapunov functions and discontinuous carathéodory systems. Automatica 42(3), 453–458 (2006)
Bacciotti, A., Rosier, L.: Liapunov functions and stability in control theory. Commun. Control Eng. Springer, Berlin (2001)
BenAbdallah, A., Mabrouk, M.: Semi-global output feedback stabilization for the cart-pendulum system. In: 50th IEEE Conference on Decision and Control and European Control Conference, vol. 50. December 12–15, 2011, Orlando, FL, USA (2011)
Bloch, A.M., Chang, D., Leonard, N., Marsden, J.E.: Controlled lagrangians and the stabilization of mechanical systems II: potential shaping. IEEE Trans. Autom. Control 46(10), 1556–1571 (2001)
Chung, C.C., Hauser, J.: Nonlinear control of a swinging pendulum. Automatica 31(6), 851–862 (1995)
Dávila, A., Moreno, J.A., Fridman, L.: Optimal lyapunov function selection for reaching time estimation of super twisting algorithm. In: Proceedings of the 48th IEEE Conference on Decision and Control, 2009 Held Jointly with the 2009 28th Chinese Control Conference. CDC/CCC 2009, pp. 8405–8410. IEEE (2009)
Edwards, C., Spurgeon, S.: Sliding Mode Control: Theory and Applications. CRC Press, Cleveland (1998)
Fantoni, I., Lozano, R.: Non-linear Control for Underactuated Mechanical Systems. Communications and Control Engineering. Springer, London (2002)
Filippov, A.F.: Differential equations with discontinuous righthand sides: control systems, vol. 18. Springer, Berlin (1988)
Garćıa-Alarćon, O., Puga-Guzan, S., Moreno-Valenzuela, J.: On parameter identification of the furuta pendulum. Procedia Eng. 35, 77–84 (2012)
Gomez-Estern, F., Van der Schaft, A.J.: Physical damping in ida-pbc controlled underactuated mechanical systems. Eur. J. Control 10(Special Issue on Hamiltonian and Lagrangian Methods for Nonlinear Control), 451–468 (2004)
Gordillo, F., Aracil, J.: A new controller for the inverted pendulum on a cart. Int. J. Robust Nonlinear Control 18(17), 1607–1621 (2008). doi:10.1002/rnc.1300
Jakubczyk, B., Respondek, W.: On the linearization of control systems. Bull. Acad. Polon. Sci. Math. 28, 517–522 (1980)
Khalil, H.K.: Nonlinear Systems, 2n edn. Prentice Hall, Englewood Cliffs (1996)
Lozano, R., Fantoni, I., Block, D.J.: Stabilization of the inverted pendulum around its homoclinic orbit. Syst. Control Lett. 40(5), 197–204 (2000)
Lozano, R., Fantoni, I., Block, D.J.: Stabilization of the inverted pendulum around its homoclinic orbit. Syst. Control Lett. 40(3), 197–204 (2000)
Martinez, R., Alvarez, J.: A controller for 2-dof underactuated mechanical systems with discontinuous friction. Nonlinear Dyn. 53(3), 191–200 (2008)
Moreno, J.A.: A linear framework for the robust stability analysis of a generalized super-twisting algorithm. In: 2009 6th International Conference on Electrical Engineering, Computing Science and Automatic Control, CCE. IEEE, pp. 1–6 (2009)
Moreno-Valenzuela, J., Kelly, R.: A hierarchical approach to manipulator velocity field control considering dynamic friction compensation. J. Dyn. Syst. Meas. Control 128(3), 670–674 (2006)
Olfati-Saber, R.: Fixed point controllers and stabilization of the cart-pole and rotating pendulum. In: Proceedings of the 38th IEEE Conference on Decision and Control, vol. 2. Phoenix Az, , pp. 1174–1181 (1999)
Ordaz-Oliver, J.P., Santos-Sánchez, O.J., López-Morales, V.: Toward a generalized sub-optimal control method of underactuated systems. Optim. Control Appl. Methods 33(3), 338–351 (2011)
Ortega, R., Garcia-Canseco, E.: Interconnection and damping assignment passivity-based control: a survey. Eur. J. Control 10(5), 432–450 (2004)
Pilipchuk, V.N., Ibrahim, R.A.: Dynamics of a two-pendulum model with impact interaction and an elastic support. Nonlinear Dyn. 21(3), 221–247 (2000)
Polyakov, A., Poznyak, A.: Reaching time estimation for super-twisting second order sliding mode controller via lyapunov function designing. IEEE Trans. Autom. Control 54(8), 1951–1955 (2009)
Riachy, S., Orlov, Y., Floquet, T., Santiesteban, R., Richard, J.P.: Second-order sliding mode control of underactuated mechanical systems I: local stabilization with application to an inverted pendulum. Int. J. Robust Nonlinear Control 18(4–5), 529–543 (2008)
Santiesteban, R., Floquet, T., Orlov, Y., Riachy, S., Richard, J.P.: Second-order sliding mode control of underactuated mechanical systems II: orbital stabilization of an inverted pendulum with application to swing up/balancing control. Int. J. Robust Nonlinear Control 18(4–5), 544–556 (2008)
Santiesteban, R., Fridman, L., Moreno, J.A.: Finite-time convergence analysis for twisting controller via a strict lyapunov function. In: 2010 11th International Workshop on Variable Structure Systems (VSS), pp. 1–6. IEEE (2010)
Saranlı, U., Arslan, Ö., Ankaralı, M.M., Morgül, Ö.: Approximate analytic solutions to non-symmetric stance trajectories of the passive spring-loaded inverted pendulum with damping. Nonlinear Dyn. 62(4), 729–742 (2010)
Semenov, M.E., Shevlyakova, D.V., Meleshenko, P.A.: Inverted pendulum under hysteretic control: stability zones and periodic solutions. Nonlinear Dynamics pp. 1–10 (2013). doi: 10.1007/s11071-013-1062-x
She, J., Zhang, A., Lai, X., Wu, M.: Global stabilization of 2-dof underactuated mechanical systems an equivalent-input-disturbance approach. Nonlinear Dyn. 69(1–2), 495–509 (2012)
Shiriaev, A.S., Pogromsky, A., Ludvigsen, H., Egeland, O.: On global properties of passivity-based control of an inverted pendulum. Int. J. Robust Nonlinear Control 10(4), 283–300 (2000)
Sira-Ramirez, H., Agrawal, S.K.: Differentially Flat Systems. Marcel Dekker, New York (2004)
Spong, M.W.: Energy based control of a class of underactuated mechanical systems. In: IFAC World Congress. San Francisco CA (1996)
Spong, M.W., Praly, L.: Coordinated-Science, Centre-Automatique: Control of Underactuated Mechanical Systems Using Switching and Saturation. Springer, Berlin (1996)
Udhayakuma, K., Lakshmi, P.: Design of robust energy control for cart-inverted pendulum. Int. J. Eng. Technol. 4(1), 66–76 (2007)
Weibel, S., Kaper, T., Baillieul, J.: Global dynamics of a rapidly forced cart and pendulum. Nonlinear Dyn. 13(2), 131–170 (1997)
Woolsey, C., Bloch, A.M., Leonard, N.E., Marsden, J.E.: Physical dissipation and the method of controlled lagrangians. In: Proc. Eur. Control Conf., pp. 2570–2575. Port, Portugal (2001)
Acknowledgments
This research was supported by the Centro de Investigación en Computación of the Instituto Politécnico Nacional (CIC-IPN), by the Escuela Superior de Ingeniería Mecánica y Eléctrica (ESIME-IPN), by the Secretaría de Investigación y Posgrado of the Instituto Politécnico Nacional (SIP-IPN), under Research Grants 20144330 and 20141003, and by the mexican CONACyT under grant 151855. Carlos Aguilar-Ibanez wants to express its gratitude to the reviewer because their comments help to greatly improve this work. Also, he thanks to Dr. Fernando Castaños for the time devoted to discuses key issues of this study, resulting in considerable technical improvements to it.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution License which permits any use, distribution, and reproduction in any medium, provided the original author(s) and the source are credited.
About this article

Cite this article
Aguilar-Ibáñez, C., Mendoza-Mendoza, J. & Dávila , J. Stabilization of the cart pole system: by sliding mode control. Nonlinear Dyn 78, 2769–2777 (2014). https://doi.org/10.1007/s11071-014-1624-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11071-014-1624-6