
Abstract
Cocoa hybridisation generates new varieties which are resistant to several plant diseases, but has individual chemical characteristics that affect chocolate production. Image analysis is a useful method for visual discrimination of cocoa beans, while deep learning (DL) has emerged as the de facto technique for image processing . However, these algorithms require a large amount of data and careful tuning of hyperparameters. Since it is necessary to acquire a large number of images to encompass the wide range of agricultural products, in this paper, we compare a Deep Computer Vision System (DCVS) and a traditional Computer Vision System (CVS) to classify cocoa beans into different varieties. For DCVS, we used a Resnet18 and Resnet50 as backbone, while for CVS, we experimented traditional machine learning algorithms, Support Vector Machine (SVM), and Random Forest (RF). All the algorithms were selected since they provide good classification performance and their potential application for food classification A dataset with 1,239 samples was used to evaluate both systems. The best accuracy was 96.82% for DCVS (ResNet 18), compared to 85.71% obtained by the CVS using SVM. The essential handcrafted features were reported and discussed regarding their influence on cocoa bean classification. Class Activation Maps was applied to DCVS’s predictions, providing a meaningful visualisation of the most important regions of the images in the model.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Fermented and dried cocoa (Theobroma cacao) beans are among the most important agricultural products in the world. “Witches’ broom disease”, caused by the fungus Moniliophthora perniciosa, caused severe economic losses to cocoa production. Hybridisation (genetic breeding) generates varieties that are resistant to this fungus [39], with different chemical compositions. Motamayor et al. [42] proposed a new grouping for the cocoa varieties of South and Central America, including Marañon, Curaray, Criollo, Iquitos, Nanay, Contamana, Amelonado, Purús, Nacional and Guiana. However, locally, these varieties can be much more diverse. Each of these varieties of cocoa beans has a unique chemical profile, which, after fermentation and drying, yields cocoa beans with specific flavour, determining its quality for the chocolate industry.
Different varieties of cocoa beans are grown and harvested together, making it difficult to identify and separate beans from different varieties, thus affecting the quality of the final product (chocolate). In the last decades, several methods have been proposed to identify cocoa varieties. Morphological properties are prominent quality descriptors, which can help this identification [12, 16].
Traditionally, cocoa beans are visually inspected by specialists, being a subjective method for quality identification. The visual perception does not encourage reliable results and standardisation of the raw material [28]. The industry requires precise and fast methods to distinguish cocoa varieties for quality control. Several works aimed to develop quick and accurate techniques to assess cocoa beans’ chemical composition and quality features from different varieties.
Computational tools have emerged to aid the agricultural and food industries as a cost-effective alternative to expedite product characterisation and classification. Computer vision systems (CVS) have been a useful technique to improve food quality assessment and control [13]. CVS is considered a suitable approach through digital imaging processing based on the combination of hardware and software for applications on automatic classification [11]. It is a non-destructive, rapid and low-cost method, with high accuracy and precision [49].
Computer vision solutions achieved significant results in the detection of image patterns. The predictive potential of computer vision and machine learning (ML) carry promising solutions to different agricultural products [6, 46, 47].
Pattern recognition is a challenge considering the structural description of image samples. Commonly, image analysis by ML involves robust techniques due to the complexity of the characteristics in distinguishing the different levels [40]. Deep learning (DL) extends the predictive potential of ML, extracting meaningful features directly from the data in a multi-level abstraction scheme [10, 23]. DL is considered a revolution to the computer vision community, and has become a dominant approach for image recognition. As explored in [24], DL has been widely applied in computer vision tasks. Although DL demands a large amount of data, it is possible to fine-tune a pre-trained model using little data from the desired problem using transfer learning [29, 31, 60, 70].
The approach introduced in this study is based on DL embedded in a CVS, composing a deep computer vision system (DCVS), to improve the predictive performance compared to traditional classification methods when distinguishing fermented cocoa beans. The proposed approach was designed to provide insights by using visual assessment of problem solutions based on Gradient-weighted Class Activation Mapping (Grad-CAM). A total of 1,239 cocoa bean samples from five different varieties were investigated. CVS was implemented using 92 image features to compare two different machine learning classifiers (Random Forest and Support Vector Machine). DCVS was built using a Convolutional Neural Network (CNN), exploring two different transfer learning strategies (fine-tuning the whole network or training a linear classifier on top of it) on two Residual Networks, ResNet 18 and ResNet 50.
The main contribution of our paper can be split into two different branches: food quality evaluation and computer vision. Determination of quality control is widely used in agriculture through image processing techniques. By introducing automated, comprehensive, and highly accurate solutions, we pave the way for a new wide range of applications. In our work, we proposed a DL classification solution able to fulfil the gap of comprehensiveness (i.e., DL provides a black-box model) of morphological features that lead to an automated decision. Regarding computer vision, DL solutions have been taking over the machine learning scenario, challenging the traditional CVS. However, we evaluated CVS and DVCS from the same problem perspective. Thus, using the classification of fermented cocoa beans as a case, we create a fair comparison using recent techniques of both approaches. We delivered a parallel comparison considering the advantages and disadvantages, which both achieved a high predictive rate and brought important insights on the requirements and achievements when selecting one of them.
The remainder of this work is organised as follows: Section 2 describes the DCVS used in this work. In Section 3, we present the material and methods; results and discussions are in Section 4, and Section 5 presents the main conclusions.
2 Deep computer vision system
Computer vision techniques are applied in the automation process considering the effectiveness obtained as high-quality control [3, 18]. For example, the agricultural sector increased the interest in improved food manufacturing methods [37, 46, 48, 63].
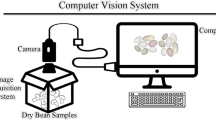
CVS is based on image processing from acquisition to data analysis. CVS is a reliable method that uses a computing solution to simulate the human visual and instrumental inspection [59]. As part of image processing, features are extracted to train ML models for classification based on handcrafted descriptors [62], Fig. 1.

Computer Vision System and Deep Computer Vision System
Alternatively, DL provides powerful features that incorporate raw data into high-dimensional representations [14]. Only recently applied in agriculture, this technique has advanced in other domains, reinforcing its vast potential [29]. In particular, there are some hybrid systems, i.e., combining CVS and DCVS, which improve the sample descriptive capacity by applying image processing methods, boosting the decision performance of DL models. These methods can emphasise the visual information using a more descriptive colour space, frequency domain, or applying image enhancement methods before DL application [17, 36].
2.1 Convolutional neural networks
Convolutional Neural Networks (CNNs) are particular kinds of neural networks (NN) designed for data where spatial information is essential, e.g., images, where pixels spatially close are highly correlated [20, 35]. Whereas older CNNs are usually composed of convolution layers, pooling layers and fully connected layers [25, 33, 61], newer architectures are usually convolution only, with a linear classifier at the end [25].
The convolutional layer corresponds to a set of learnable filters with height and width. These filters are slid through this layer’s input and, at each position, an element-wise multiplication is performed between the filter and the values in that spatial location of the input, and the results are summed. This multiplication usually occurs in the full depth of the input. For example, given an input of depth 3, a filter with spatial size 2 by 2 will have a depth of 3. Therefore, at each position that the filter is placed, the 12 values (2*2*3) are multiplied with their respective input values and added together to correspond to a single output. These learnable filters can also be seen as neurons in the biological analogy of neural networks. Note that the depth of the output will be given by the number of filters, whereas the spatial dimension is given by Wout = (Win − w + 2p)/s + 1 and Hout = (Hin − h + 2p)/s + 1, where Wout and Hout is the spatial size of the input, w and h the spatial size of the filter, p is the size of a zero-padding added around the input to keep the spatial size of the output and s is the stride that determines how much a filter moves when being slid through the input. A convolutional layer can also be viewed as a locally connected layer [35]. Each filter in a convolutional layer is trained to detect some characteristics in the image, e.g., corners, shape, or the presence of colour [20, 35] The deepest tthe convolutionallayer is located in the network, the more abstract are the characteristics that each filter is searching. For example, in the first few layers, filters may be searching for edges, while in deeper layers, filters may be looking for whole objects.
Pooling is a weightless layer which, operating independently at each layer (depth dimension) of the input, slides a filter of height and width in the input data and performs a mean or max operation on the values inside that filter [20, 53]. It is generally used to reduce the spatial size of its input, reducing the number of parameters in the network and controlling the output’s sensitivity to shifts and distortions [35]. However, note that the input’s depth is preserved since the mean or max operations are performed considering each layer separately. Recent architectures, such as Residual Networks [25] do not employ pooling layers in the hidden parts of the network, relying on increasing the stride of a convolutional layer to reduce the spatial size of the output. Only average pooling is applied at the end of the network to produce feature representations without spatial information.
The fully connected layer is used only as the last layer of modern CNNs, acting as a linear classifier using the image features extracted from previous convolutional layers [25, 35, 53].
CNNs are trained using back-propagation (backprop) to compute the gradients of a loss function, L, given its parameters [20, 35, 53] and using an update algorithm, such as stochastic gradient descent or adaptive moment estimation (Adam) [32], that uses those gradients to update the parameters of the network. Start by propagating the inputs to each layer (l) in the forward direction by calculating the outputs z(l) = a(W(l)x(l) + b(l)), where W is a weight matrix, x(l) is the input to this layer, b a bias term and a is a non-linearity.
The error gradients for the last layer n are computed as in (1), given a desired output y.
Backprop is a technique where the error gradients of each weight in the network are computed iteratively from the end of the network to its beginning using partial derivatives. To backpropagate the error to lower layers l = nl− 1,nl− 2,…, it is used the (2), where W(l) is the weight matrix for the layer l.
Likewise, to compute the gradients that are used to update the parameters W and b, we follow (3) and (4).
Finally, we compute the new parameter values of the network using ΔW and Δb and an update algorithm such as Adam [32].
2.2 Residual network
Deep CNNs are hard to train due to several problems, e.g., computational resources and vanishing gradients [19, 25, 61].
Vanishing gradients occur when the gradients get subsequently smaller when being backpropagated. , caused by the multiplication of loss by the weights, which generally have an absolute value of less than 1. Additionally, in theory, deeper networks should perform better or at least the same as shallower networks by being able to set unnecessary layers to the identity, i.e., a layer that outputs its input. However, in practice, this is not always trivial. The Residual Network (ResNet) [25], a type of CNN, was proposed to tackle both of these problems. To address them, it performs identity mapping to skip connections. Identity mapping consists of adding the output of multiple layers with weights (convolutional layers) to the input of the first weight layer in the block. In Fig. 2 a basic ResNet building block is depicted, where the output of the function \(\mathcal {F}(x)\) is added with x. Note that \(\mathcal {F}(x)\) can be any function such as z(l) = a(W(l)x(l) + b(l)). This acts as a path for the gradient to flow and allows the network to ignore the entire layer when necessary, instead of learning to perform an identity map. Furthermore, it also makes the network reuse useful abstract representations.

ResNet building block. (Adapted from [25])
More details about the exact structure of the different versions of ResNet can be found in [25].
The ideas behind the ResNet have been vastly used [51] and extended [26, 27, 65, 68, 69] in multiple works and in many different domains, since most models benefit from having skip connections.
We applied a transfer learning strategy to address the limited availability of labelled images for training a network from scratch. This strategy is based on adapting a pretrained ResNet to the ImageNet dataset and expanding the cocoa bean training dataset through augmentation procedures, as described in Section 3.1.
Transfer learning consists of adapting a model trained on a dataset with millions of labelled images to a target domain (the domain of interest in this work, cocoa bean classification) [55]. The idea is that the pretrained network learns many useful and generic feature extractors that can later be used for different tasks.
2.3 Visualising what CNNs are looking for
Many techniques have been proposed to visualise what deep CNNs are looking for when performing classification. Class Activation Mapping (CAM) [71] creates a heatmap on top of the input images relating them to their given predicted classes. Thus, it is possible to identify which regions of the image are more important to classify a sample into a given class. CAM obtains active regions by performing a global average pooling (GAP) and visualising the weighted combination based on feature maps of pre-softmax (penultimate layer).
Selvaraju et al. [56] propose a visualising technique based on the class-specific gradient information and the final convolutional layer of a CNN to discriminate regions in the image generating a local activation map. Gradient-weighted Class Activation Mapping (Grad-CAM) is considered a generalisation of CAM, which visualises a linear combination of the final convolutional layer of a CNN and class-specific weights to produce visual explanations.
3 Material and methods
In the experiments, we compared the performances of a CVS and DCVS based on CNN, as shown in Fig. 3. CVS was explored using five handcrafted image features, a total of 92 features, comparing Random Forest (RF) and Support Vector Machine (SVM). The RF Importance gives further information about each feature for the classification.

Overview of experimental evaluation
On the other hand, DCVS performances were compared among four classifiers based on ResNet 18 and ResNet 50 with two different transfer learning strategies over the full network or only the last layer. We selected those ResNet models since they strike a good balance between performance and the number of parameters. Moreover, these architectures have been successfully applied for classifying food quality. Here, we applied two transfer learning strategies: freezing the network and just training a linear classifier on top of it, or fine-tuning the whole network. In the first strategy, we froze the weights of the NN and replaced the classification layer (last layer) with a randomly initialised layer which is responsible for predicting the cocoa bean classification and later trained this layer using labelled data from cocoa bean images. In the second strategy, the classification layer is also replaced, but the whole network is fine-tuned (i.e., the weights are modified) to better adapt the network to our problem.
Additionally, the DCVS classifier produces a Grad-CAM visualisation to provide insights on the importance of specific image regions for the classification task. The techniques were applied to classify cocoa beans in five different varieties, as detailed in Section 3.1. Using Grad-CAM visualisation, an additional layer shows a heatmap on top of the original input images. The heatmap colours emphasise (from blue to red) the most critical regions to classify a given sample to the predicted class
3.1 Image collection and augmentation
A total of 1,239 cocoa beans were used in the current study. The samples were from five different cocoa varieties: PH16 (14 fruits); BN34 (16 fruits); SR162 (16 fruits); CEPC-2002 (16 fruits); Pará-Parazinho (PP) (18 fruits). Cocoa beans were removed from the fruits after harvest. The beans were fermented for five days and sun-dried for seven days until the moisture content reached between 6-10%. Unpeeled cocoa bean samples were packed and stored in an appropriate place at -18o̱C, protected from illumination, until the day of analyses.
Each image was acquired using a CCD camera (f/1.2/ 1X optical zoom) with image resolution of 12.6 megapixels (4096 x 3072, 10,485 pixels/cm) using an image acquisition system (L-PIX EX, Loccus, Brazil). After, each image was segmented to identify the region of interest (ROI), isolating the cocoa beans from the background and other components that can interfere in the image analysis. Beans were isolated from the background as the region of interest (ROI) by thresholding performed over the H channel of HSV (Hue, Saturation and Value) colour space and removal of small regions from the image mask.
Deep learning requires a significant amount and variety of training data to induce its structure and to achieve good classification performance. It is difficult and expensive to obtain a large amount of data, which requires intensive labour from specialists and domain expertise. Accordingly, most datasets are usually insufficient to train a CNN without overfitting [67]. To deal with this challenge, the strategy called data augmentation can increase the dataset by introducing slight distortions to the images [57]. In our work, we only employed image rotation as an augmentation strategy, since the cocoa beans’ shape and colour are important for its classification. A total of 3,468 images composed our final training dataset with rotations from the cardinal 0∘, 90∘, 180∘, and 270∘.
3.2 Computer Vision System
A CVS is built based on specific requirements, conditions, goals, and resources to provide a suitable tool for a particular domain. Here, we spot the cocoa bean discrimination by following the industrial constraints. Thus, the following sections provide the steps an instance capable of tackling our particular domain. Considering the CVS applied in the experiments, the traditional CVS can be split into two steps: Feature Extraction and Classification.
3.2.1 Feature Extraction
The description step was built by extracting relevant features from each image, which produces a vector of numerical values through an extract function [2, 8, 22]. In detail, for a given image, 92 image features were extracted from ROI selection. These 92 image features are based on four groups: colour [15], intensity [34], border [9, 58] and texture [21] (Table 1).
Concerning colour descriptors, to deal with the brightness information presented in colour channels from RGB (Red, Green and Blue), we considered HSV colour space to isolate the brightness by transforming the input images from RGB to HSV. Thus, 33 different features were extracted from RGB and HSV colour spaces, from where the statistical moments were obtained, such as mean and standard deviation. We also extracted correlations among channels to improve the properties’ descriptive capacity of each image. Those two statistical moments were used to describe the intensity information considering the Monochromatic channel, which corresponds to the average of RGB values. Additionally, the entropy value was calculated as in [30]. Standard deviation, kurtosis, and skewness were calculated from each channel’s histogram (grey level), comprising 21 features.
Sobel [58] and Canny [9] operators are widely used for extracting border information. Thus, 4 features were considered based on the number of white pixels and Hu moments to address the image’s properties.
Texture descriptors are also considered essential features that help identify patterns in an image [21]. We applied different approaches to texture analysis to have general applicability: Local Binary Patterns (LBP), which describes local image texture features based on binary vector encoded by comparing grey-scale pixels and neighbours; Gray Level Co-occurrence Matrix (GLCM) [21], that provides mapping patterns of the image; and Fast Fourier Transform (FFT) [44], which uncovers frequency domain characteristics.
3.2.2 Classification
The classification step is related to make an automatic decision when inputted with the extracted features using a classification model. The classification model is built using a labelled dataset of samples and the respective feature vector. There are several different machine learning algorithms able to build high accurate classification models. Focusing on the food industry, it is possible to observe a diversity of algorithms, from the simplest ones (e.g., the k-nearest neighbour in [11]) to more sophisticated deep learning classifiers as in [17]
Considering the particularities of the problem and algorithm robustness, we have chosen Support Vector Machine (SVM) and Random Forest (RF), as applied in [4, 38, 48]. In our experiments, we applied algorithms with the R environment to induce models for classification. Briefly, the algorithm description and the corresponding packages used to implement each ML algorithm are described in Table 2.
Additionally, it is possible to interpret the achieved results and image features using the Random Forest importance from the RF model [41]. RF importance estimates the significance of the extracted features through their prediction error inside the induced Random Forest.
3.3 Performance comparison
The same test set supported the performance comparison of the different approaches investigated. Test set (127 samples) was obtained using Kennard-Stone algorithm as in [5]. For DCVS, the training set was randomly divided into the validation set (247 samples) and the training set (3,468 samples). In detail, the validation set was built by samples from the training set without the augmentation process. The next step was augmenting training samples as described in Section 3.1. Thus the training set was used to induce the final model and the validation set to find the best configuration. CVS used the same training set augmented.
We compared CVS and DCVS based on predictive performance using a Confusion Matrix. Confusion Matrix (CM) consists of a matrix able to support several performance metrics computations. One of them was the Total Accuracy method (Accuracy Matrix) [1] which is defined by Equation (5). Total Accuracy metric is based on summarising the results of a classification model and comparing those approaches. The Total Accuracy is obtained from the sum of the elements in the main diagonal, True Positive (TP) and True Negative (TN), divided by the sum of the whole samples (n) of the matrix. Therefore, Total Accuracy allows estimating the performance of the method used to predict the image samples. Additionally, Precision (6), Recall (7) and F-Measure (8) were used to provide a more realistic comparison since the dataset is unbalanced. Those metrics are based on False Positives (FP) and False Negatives (FN).
4 Results and discussion
The results show that different DCVS approaches achieved distinct performance values depending on the transfer learning strategy. In some cases, the outcomes were inferior to CVS. Table 3 summarises the obtained results, where the best performances were highlighted (bold).
Variability in cocoa genotypes, both wild and domesticated, can turn the cocoa traceability into a challenge for researchers and producers. In this work, the classifiers’ best results ranged between 75.40% and 96.82% of accuracy, a precision value between 74.70% and 96.85% and recall 73.53% and 97.09%. The best performance has been obtained with ResNet18 (Full). The worst result was in the ResNet50 (Last Layer), which reached 22.12% the smallest value of accuracy and, consequently, low precision and recall values. Concerning CVS, RF and SVM performances were 82.54% and 85.71% of accuracy, respectively. These values were slightly similar to Resnet18 (Last Layer), which was 84.92%. It is relevant to mention that SVM reached competitive results with ResNet18 retrained in the last layer. Both fully retrained CNNs obtained superior results. Previously, [43] reported an error between 15 − 44% in the classification of cocoa germplasm from South America and Central America using morphological and agronomic characteristics. On the other hand, [52] used microsatellite markers to identify cocoa germplasm with a 30% error. Therefore, in addition to presenting a lower error rate, our results are very encouraging to show some advantages: (1) the image analysis does not destroy the sample and allows a bean to bean analysis, (2) the results are subjected to human error when trying to recognise patterns in cocoa varieties, and (3) the texture and colour characteristics of each hybrid are the result of the fermentation and drying process, which in turn is associated with the unique composition of cocoa beans, so, those characteristics must be kept constant and can be used to identify cocoa beans.
Table 4 shows the Precision, Recall, and F-Measure obtained with the best F-Measures highlighted in bold. When observing each different variety, it is possible to detect some peculiarities. G1, G2, and G3 were better classified by ResNet18 (full), while G4 and G5 obtained superior F-Measure results with ResNet50 (full).
Unsatisfactory results were achieved using the RF model for all varieties. However, it is possible to discuss insights from RF models using the RF feature importance for an in-depth analysis of how each cocoa variety can be classified. In Fig. 4, we grouped the feature types (Border, Colour, Histogram, Intensity, and Texture) and sorted their importance. At first, it is possible to see a superior “importance” of colour features and structural information. During the classification processes, the standard deviation of V, S (hue and saturation of HSV colour space) and standard deviation of intensity (std_I) were the most relevant features. This could be related to changes in the perception of cocoa bean colour among different varieties. On the other hand, the information obtained by CVS is from the cocoa bean shell, which contains high amounts of protein (116-181 g protein/g dried shell) and carbohydrates (≈ 178 g carbohydrates/kg dried shell) [45]. Thus, browning produced by the Maillard reaction during the drying of cocoa beans can have various colour tones in the cocoa bean shell. Therefore, the particularities in hue, saturation and intensity are reliable parameters to identify cocoa beans. The dynamics of the drying process are constant and always associated with each variety of cocoa. The bean structure was another important point, described here by nump_canny (border feature) and com_correlation, FFT_entropy and com_homogenety. The texture of the cocoa bean shell may be related to (1) high fibre content (504 - 606 g fibre / kg dried shell) [45], or (2) the dynamics of the drying process of cocoa beans. In the first case, the amount and distribution of fibre in the cocoa bean shell can generate particularities for each hybrid, although this could change with the tree’s age or agronomic factors. In the second case, [50] reported that cocoa hybrids have various drying tolerances, which are associated with the presence of oligosaccharides in the cocoa bean shell. Therefore, it is possible that this drying tolerance allowed to develop some peculiarities in the texture of the cocoa bean shell of each variety during the evaporation of water. Thus, it was possible to observe that CVS could take advantage of cocoa bean characteristics close to human visual perception.

RF importance of image features (Border, Colour, Histogram, Intensity and Texture) explored in CVS
Addressing human perception, Grad-CAM method provides the identification of relevant regions to classify the original image. These regions, highlighted in a heatmap, lead to a comprehensive abstraction of how to assess a sample of a particular class. Figure 5 exposes three random samples correctly classified with ResNet18 full retraining and their Grad-CAM view. Varieties G1, G2, and G5 share some important patterns highlighted by their Grad-CAM view: borders and extremities are important features when classifying samples. Mainly, G1 Grad-CAMs present multiple points of importance, focusing on serrated border aspects. On the other hand, G2 takes advantage of information from an extended border area. G5 is a mix of G1 and G2. Differently, G3 highlighted practically all sample regions. This fact is strongly correlated with the dark aspect of this variety. Finally, G4 presents importance in both extremities with important regions within the samples.

Three random samples per cocoa bean variety correctly classified with ResNet18 full retraining. Grad-CAM view showing regions of beans that had higher contribution for classification (from blue to red regarding low to high contribution)
5 Conclusion
Concerning pattern recognition, it is considered a challenge due to many image characteristics that have to be analysed to provide accurate performance. Moreover, this is in turn made difficult by complex properties over different sample levels. In this paper, we compared the traditional Computer Vision System and a Deep Computer Vision System for cocoa bean classification. The Grad-CAM and the importance of extracted features were investigated to provide insights by visualising essential image regions..
CVS used 92 handcrafted features for machine learning classification. SVM overcame the RF model, reaching a competitive performance on a particular DCVS based on last layer retraining. DCVS with full retraining obtained superior results in both deep NNs, with ResNet18 and ResNet50 reaching (96.82%) and (94.44%) of accuracy, respectively. Observing the importance of handcrafted features, some important insights from colour, border, and texture indicate differences among the varieties. These observed patterns were corroborated using the Grad-CAM method, through which it was possible to identify specific regions capable of discriminating each class in a human-friendly exhibition.
When comparing CVS and DCVS, both leverage to highly accurate predictive results. DCVS was superior, as the current literature has been showing. However, it is worth mentioning that CVS provided relevant results in the industrial scenario. In terms of comprehensiveness, DCVS map supports the investigation of morphological aspects that lead to predicting a particular class. On the other hand, CVS can similarly present the feature importance when classifying samples, in general.
In this way, this paper provides relevant information for future studies based on comprehensive machine learning (applied to food industry), which contributes to building solutions by visualising techniques. Hence, this approach could be used as a rapid and objective method for the identification of cocoa beans from different varieties in the food industry. Furthermore, using visualization methods, the food industry can improve product tracking in the supply chain.
Change history
25 August 2022
Missing Open Access funding information has been added in the Funding Note.
References
Aggarwal CC (2014) Data classification: algorithms and applications. CRC Press
Aguiar GJ, Mantovani RG, Mastelini SM, de Carvalho AC, Campos GF, Junior SB (2019) A meta-learning approach for selecting image segmentation algorithm. Pattern Recogn Lett 128:480–487
Arefi A, Motlagh AM, Khoshroo A (2011) Recognition of weed seed species by image processing. J Food Agric Environ 9(1):379–383
Barbon APA, Barbon Jr S, Mantovani RG, Fuzyi EM, Peres LM, Bridi AM (2016) Storage time prediction of pork by computational intelligence. Comput Electron Agric 127:368–375
Barbon Jr S, Mastelini SM, Barbon APA, Barbin DF, Calvini R, Lopes JF, Ulrici A (2019) Multi-target prediction of wheat flour quality parameters with near infrared spectroscopy. Information Processing in Agriculture
Bhargava A, Bansal A (2020) Quality evaluation of mono & bi-colored apples with computer vision and multispectral imaging. Multimedia Tools and Applications
Breiman L (2001) Random forests. Machine learning 45(1):5–32
Campos GF, Barbon S, Mantovani RG (2016) A meta-learning approach for recommendation of image segmentation algorithms. In: Graphics, Patterns and Images (SIBGRAPI), 2016 29th SIBGRAPI Conference on, IEEE, pp 370–377
Canny JF (1986) A computational approach to edge detection. IEEE Trans Pattern Anal Mach Intell 8:679–698
da Costa AZ, Figueroa HE, Fracarolli JA (2020) Computer vision based detection of external defects on tomatoes using deep learning. Biosyst Eng 190:131–144
Da Costa Barbon APA, Barbon Jr S, Campos GFC, Seixas Jr JL, Peres LM, Mastelini SM, Andreo N, Ulrici A, Bridi AM (2017) Development of a flexible computer vision system for marbling classification. Comput Electron Agric 142:536–544
Cruz-Tirado J, Fernández Pierna JA, Rogez H, Barbin DF, Baeten V (2020) Authentication of cocoa (theobroma cacao) bean hybrids by nir-hyperspectral imaging and chemometrics. Food Control 118:107445. https://doi.org/10.1016/j.foodcont.2020.107445. https://www.sciencedirect.com/science/article/pii/S0956713520303613
Du CJ, Sun DW (2006) Learning techniques used in computer vision for food quality evaluation: a review. J Food Eng 72(1):39–55
Engilberge M, Chevallier L, Pérez P, Cord M (2018) Finding beans in burgers: Deep semantic-visual embedding with localization. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 3984–3993
Fan F, Ma Q, Ge J, Peng Q, Riley WW, Tang S (2013) Prediction of texture characteristics from extrusion food surface images using a computer vision system and artificial neural networks. J Food Eng 118(4):426–433
Fang W, Meinhardt LW, Mischke S, Bellato CM, Motilal L, Zhang D (2013) Accurate determination of genetic identity for a single cacao bean, using molecular markers with a nanofluidic system, ensures cocoa authentication. J Agri Food Chem 62(2):481–487
Gill HS, Khehra BS (2021) Hybrid classifier model for fruit classification. Multimedia Tools and Applications
Giraldo-Zuluaga JH, Salazar A, Daza JM (2016) Semi-supervised recognition of the diploglossus millepunctatus lizard species using artificial vision algorithms. arXiv:161102803
Glorot X, Bengio Y (2010) Understanding the difficulty of training deep feedforward neural networks. In: Teh YW, Titterington M (eds) Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, PMLR, Chia Laguna Resort, Sardinia, Italy, Proceedings of Machine Learning Research. http://proceedings.mlr.press/v9/glorot10a.html, vol 9, pp 249–256
Goodfellow I, Bengio Y, Courville A (2016) Deep Learning. MIT Press. http://www.deeplearningbook.org
Haralick RM, Shanmugam K, Dinstein I (1973) Textural features for image classification. IEEE Trans Syst Man Cybern SMC-3(6):610–621
Hassaballah M, Awad AI (2016) Detection and description of image features: an introduction. In: Image feature detectors and descriptors, Springer, pp 1–8
Hassaballah M, Awad AI (2020) Deep learning in computer vision: principles and applications. CRC Press
Hassaballah M, Hosny KM (2019) Recent advances in computer vision. Studies in Computational Intelligence
He K, Zhang X, Ren S, Sun J (2015) Deep residual learning for image recognition. CoRR arXiv:1512.03385
He K, Zhang X, Ren S, Sun J (2016) Identity mappings in deep residual networks. CoRR arXiv:1603.05027
Huang G, Liu Z, Weinberger KQ (2016) Densely connected convolutional networks. CoRR arXiv:1608.06993
Jentzsch PV, Ciobotă V, Salinas W, Kampe B, Aponte PM, Rösch P, Popp J, Ramos LA (2016) Distinction of ecuadorian varieties of fermented cocoa beans using raman spectroscopy. Food chemistry 211:274–280
Kamilaris A, Prenafeta-Boldú FX (2018) Deep learning in agriculture: a survey. Comput Electron Agric 147:70–90
Kapur J, Sahoo P, Wong A (1985) A new method for gray-level picture thresholding using the entropy of the histogram. Comput Vis Graph Image Process 29(3):273–285
Kaur T, Gandhi TK (2020) Deep convolutional neural networks with transfer learning for automated brain image classification. Mach Vis Appl 31:1–16
Kingma DP, Ba J (2014) Adam: A method for stochastic optimization. CoRR arXiv:1412.6980
Krizhevsky A, Sutskever I, Hinton GE (2012) Imagenet classification with deep convolutional neural networks. In: Proceedings of the 25th International Conference on Neural Information Processing Systems - Volume 1, Curran Associates Inc., USA, NIPS’12. http://dl.acm.org/citation.cfm?id=2999134.2999257, pp 1097–1105
Laddi A, Sharma S, Kumar A, Kapur P (2013) Classification of tea grains based upon image texture feature analysis under different illumination conditions. J Food Eng 115(2):226–231
Lecun Y, Bottou L, Bengio Y, Haffner P (1998) Gradient-based learning applied to document recognition. Proc IEEE 86(11):2278–2324. https://doi.org/10.1109/5.726791
Liu Y, Pu H, Sun DW (2021) Efficient extraction of deep image features using convolutional neural network (cnn) for applications in detecting and analysing complex food matrices. Trends in Food Science & Technology
Lopes JF, Ludwig L, Barbin DF, Grossmann MVE, Barbon S (2019) Computer vision classification of barley flour based on spatial pyramid partition ensemble. Sensors 19(13):2953
Lopes JF, Barbon APA, Orlandi G, Calvini R, Fiego DPL, Ulrici A, Barbon Jr S (2020) Dual stage image analysis for a complex pattern classification task: Ham veining defect detection. Biosyst Eng 191:129–144
Lopes UV, Monteiro WR, Pires JL, Clement D, Yamada MM, Gramacho KP (2011) Cacao breeding in bahia, brazil: strategies and results. Crop breeding and applied biotechnology 11(SPE):73–81
Mancini R, Hunt M (2005) Current research in meat color. Meat science 71(1):100–121
Mastelini SM, Sasso MGA, Campos GFC, Schmiele M, Clerici MTPS, Barbin DF, Barbon S (2018) Computer vision system for characterization of pasta (noodle) composition. J Electron Imaging 27(5):053021
Motamayor JC, Lachenaud P, e Mota JWdS, Loor R, Kuhn DN, Brown JS, Schnell RJ (2008) Geographic and genetic population differentiation of the amazonian chocolate tree (theobroma cacao l). PloS one 3(10):e3311
Motilal L, Butler D (2003) Verification of identities in global cacao germplasm collections. Genet Resour Crop Evol 50(8):799–807
Nixon M, Aguado AS (2012) Feature extraction and image processing for computer vision. Academic Press
Okiyama DC, Navarro SL, Rodrigues CE (2017) Cocoa shell and its compounds: Applications in the food industry. Trends Food Sci Technol 63:103–112
Oliveira MM, Cerqueira BV, Barbon S, Barbin DF (2021) Classification of fermented cocoa beans (cut test) using computer vision, vol 97. https://doi.org/10.1016/j.jfca.2020.103771. https://www.sciencedirect.com/science/article/pii/S0889157520314769
Patrício DI, Rieder R (2018) Computer vision and artificial intelligence in precision agriculture for grain crops: a systematic review. Comput Electron Agric 153:69–81
Pereira LFS, Barbon Jr S, Valous NA, Barbin DF (2018) Predicting the ripening of papaya fruit with digital imaging and random forests. Comput Electron Agric 145:76–82
Pu H, Sun DW, Ma J, Cheng JH (2015) Classification of fresh and frozen-thawed pork muscles using visible and near infrared hyperspectral imaging and textural analysis. Meat Sci 99:81–88
Rangel F, Córdova T, López A, Delgado A, Zavaleta M, Villegas M et al (2011) Desiccation tolerance in seeds from three genetic origins of cocoa (theobroma cacao l.) Rev Fitotec Mex 34(3):175–182
Razzak MI, Naz S, Zaib A (2018) Deep Learning for Medical Image Processing: Overview, Challenges and the Future, Springer International Publishing, Cham. https://doi.org/10.1007/978-3-319-65981-7_12
Risterucci AM, Eskes A, Fargeas D, Motamayor JC, Lanaud C (2001) Use of microsatellite markers of germplasm identity analysis in cocoa. Ingenic
Schmidhuber J (2015) Deep learning in neural networks: an overview. Neural Networks 61:85–117. https://doi.org/10.1016/j.neunet.2014.09.003, published online 2014; based on TR arXiv:1404.7828 [cs.NE]
Scornet E, Biau G, Vert JP et al (2015) Consistency of random forests. Ann Statist 43(4):1716–1741
Scott GJ, England MR, Starms WA, Marcum RA, Davis CH (2017) Training deep convolutional neural networks for land–cover classification of high-resolution imagery. IEEE Geosci Remote Sens Lett 14(4):549–553
Selvaraju RR, Cogswell M, Das A, Vedantam R, Parikh D, Batra D (2017) Grad-cam: Visual explanations from deep networks via gradient-based localization. In: Proceedings of the IEEE International Conference on Computer Vision, pp 618–626
Sladojevic S, Arsenovic M, Anderla A, Culibrk D, Stefanovic D (2016) Deep neural networks based recognition of plant diseases by leaf image classification. Computational intelligence and neuroscience
Sobel I (1978) Neighborhood coding of binary images for fast contour following and general binary array processing. Computer Graphics and Image Processing 8:127–135
Sun D (2016) Computer Vision Technology for Food Quality Evaluation. Elsevier Science
Sun J, Radecka K, Zilic Z (2019) Exploring better food detection via transfer learning. In: 2019 16Th international conference on machine vision applications (MVA), IEEE, pp 1–6
Szegedy C, Liu W, Jia Y, Sermanet P, Reed SE, Anguelov D, Erhan D, Vanhoucke V, Rabinovich A (2015) Going deeper with convolutions. 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Szeliski R (2010) Computer vision: algorithms and applications. Springer Science & Business Media
Tian H, Wang T, Liu Y, Qiao X, Li Y (2020) Computer vision technology in agricultural automation—a review. Inf Process Agric 7(1):1–19
Vapnik VN (1995) The nature of statistical learning theory. Springer, NY
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser L, Polosukhin I (2017) Attention is all you need. CoRR arXiv:1706.03762
Wang L (2005) Support vector machines: theory and applications, vol (177). Springer Science & Business Media
Xie S, Yang T, Wang X, Lin Y (2015) Hyper-class augmented and regularized deep learning for fine-grained image classification. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 2645–2654
Xie S, Girshick RB, Dollár P, Tu Z, He K (2016) Aggregated residual transformations for deep neural networks. CoRR arXiv:1611.05431
Zagoruyko S, Komodakis N (2016) Wide residual networks. CoRR arXiv:1605.07146
Zhang YD, Dong Z, Chen X, Jia W, Du S, Muhammad K, Wang SH (2019) Image based fruit category classification by 13-layer deep convolutional neural network and data augmentation. Multimed Tools Appl 78(3):3613–3632
Zhou B, Khosla A, A L, Oliva A, Torralba A (2016) Learning deep features for discriminative localization. CVPR
Acknowledgements
This study was financed in part by the Coordenação de Aperfeiçoamento de Pessoal de Nível Superior - Brasil (CAPES) - Finance Code 001; São Paulo Research Foundation (FAPESP) (project no. 2015/24351-2, 2019/04833-3, 2018/02500-4); National Council for Scientific and Technological Development - Brazil (CNPq) - Grant of Project 420562/2018-4 and 309863/2020-1.
Funding
Open access funding provided by Università degli Studi di Trieste within the CRUI-CARE Agreement.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Lopes, J.F., da Costa, V.G.T., Barbin, D.F. et al. Deep computer vision system for cocoa classification. Multimed Tools Appl 81, 41059–41077 (2022). https://doi.org/10.1007/s11042-022-13097-3
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-022-13097-3