
Abstract
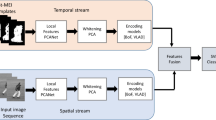
Deep learning models have attained great success for an extensive range of computer vision applications including image and video classification. However, the complex architecture of the most recently developed networks imposes certain memory and computational resource limitations, especially for human action recognition applications. Unsupervised deep convolutional neural networks such as PCANet can alleviate these limitations and hence significantly reduce the computational complexity of the whole recognition system. In this work, instead of using 3D convolutional neural network architecture to learn temporal features of video actions, the unsupervised convolutional PCANet model is extended into (PCANet-TOP) which effectively learn spatiotemporal features from Three Orthogonal Planes (TOP). For each video sequence, spatial frames (XY) and temporal planes (XT and YT) are utilized to train three different PCANet models. Then, the learned features are fused after reducing their dimensionality using whitening PCA to obtain spatiotemporal feature representation of the action video. Finally, Support Vector Machine (SVM) classifier is applied for action classification process. The proposed method is evaluated on four benchmarks and well-known datasets, namely, Weizmann, KTH, UCF Sports, and YouTube action datasets. The recognition results show that the proposed PCANet-TOP provides discriminative and complementary features using three orthogonal planes and able to achieve promising and comparable results with state-of-the-art methods.
















Similar content being viewed by others


References
Abdelbaky A, Aly S (2020) Human action recognition based on simple deep convolution network pcanet. In: 2020 International conference on innovative trends in communication and computer engineering (ITCE). IEEE, pp 257–262
Abdelbaky A, Aly S (2020) Human action recognition using short-time motion energy template images and PCANet features. Neural Comput Applic 32 (16):12561–12574. https://doi.org/10.1007/s00521-020-04712-1
Abdelbaky A, Aly S (2020) Two-stream spatiotemporal feature fusion for human action recognition. Vis Comput, pp 1–15. https://doi.org/10.1007/s00371-020-01940-3
Ahmad M, Lee SW (2008) Human action recognition using shape and clg-motion flow from multi-view image sequences. Pattern Recogn 41(7):2237–2252
Aly S, Aly W (2020) DeepArSLR: A novel signer-independent deep learning framework for isolated arabic sign language gestures recognition. IEEE Access 8:83199–83212
Aly S, Sayed A (2019) Human action recognition using bag of global and local zernike moment features. Multimed Tools Appl 78:24923–24953
Aly W, Aly S, Almotairi S (2019) User-independent american sign language alphabet recognition based on depth image and PCANet features. IEEE Access 7:123138–123150
Andrearczyk V, Whelan PF (2018) Convolutional neural network on three orthogonal planes for dynamic texture classification. Pattern Recogn 76:36–49
Arashloo SR, Amirani MC, Noroozi A (2017) Dynamic texture representation using a deep multi-scale convolutional network. J Vis Commun Image Represent 43:89–97
Aslan MF, Durdu A, Sabanci K (2020) Human action recognition with bag of visual words using different machine learning methods and hyperparameter optimization. Neural Comput Applic 32(12):8585–8597
Chan TH, Jia K, Gao S, Lu J, Zeng Z, Ma Y (2015) Pcanet: A simple deep learning baseline for image classification. IEEE Trans Image Process 24(12):5017–5032
Chang CC, Lin CJ (2011) Libsvm: A library for support vector machines. ACM Trans Intell Syst Technol (TIST) 2(3):27
Dalal N, Triggs B (2005) Histograms of oriented gradients for human detection. In: IEEE Computer society conference on computer vision and pattern recognition, 2005. CVPR 2005, vol 1. IEEE, pp 886–893
Fan RE, Chang KW, Hsieh CJ, Wang XR, Lin CJ (2008) Liblinear: A library for large linear classification. J Mach Learn Res 9:1871–1874
Girshick R, Donahue J, Darrell T, Malik J (2014) Rich feature hierarchies for accurate object detection and semantic segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 580–587
Gorelick L, Blank M, Shechtman E, Irani M, Basri R (2007) Actions as space-time shapes. IEEE Trans Pattern Anal Mach Intell 29(12):2247–2253
Hasan M, Roy-Chowdhury AK (2014) Incremental activity modeling and recognition in streaming videos. In: Proceedings of the IEEE conference on computer vision pattern recognition, pp 796–803
Hou R, Chen C, Shah M (2017) Tube convolutional neural network (t-cnn) for action detection in videos. In: Proceedings of the IEEE international conference on computer vision, pp 5822–5831
Ibrahim MS, Muralidharan S, Deng Z, Vahdat A, Mori G (2016) A hierarchical deep temporal model for group activity recognition. In: Proceedings of the IEEE conference on computer vision pattern recognition, pp 1971–1980
Jhuang H, Serre T, Wolf L, Poggio T (2007) A biologically inspired system for action recognition. In: IEEE 11th international conference on Computer vision, 2007. ICCV 2007. IEEE, pp 1–8
Ji S, Xu W, Yang M, Yu K (2013) 3d convolutional neural networks for human action recognition. IEEE Trans Pattern Anal Mach Intell 35 (1):221–231
Jia K, Yeung DY (2008) Human action recognition using local spatio-temporal discriminant embedding. In: IEEE Conference on computer vision and pattern recognition 2008, CVPR, 2008. IEEE, pp 1–8
Kessy A, Lewin A, Strimmer K (2018) Optimal whitening and decorrelation. Am Stat 72(4):309–314
Klaser A, Marszałek M, Schmid C (2008) A spatio-temporal descriptor based on 3d-gradients. In: BMVC 2008-19th british machine vision conference. British machine vision association, pp 275–1:10
Koohzadi M, Charkari NM (2017) Survey on deep learning methods in human action recognition. IET Comput Vis 11(8):623–632
Krizhevsky A, Sutskever I, Hinton GE (2012) Imagenet classification with deep convolutional neural networks. In: Advances in neural information processing systems, pp 1097–1105
Laptev I, Marszalek M, Schmid C, Rozenfeld B (2008) Learning realistic human actions from movies. In: 2008 IEEE Conference on computer vision and pattern recognition. IEEE, pp 1–8
Le QV, Zou WY, Yeung SY, Ng AY (2011) Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis. In: 2011 IEEE Conference on computer vision and pattern recognition (CVPR). IEEE, pp 3361–3368
Li X, Choo Chuah M (2017) Sbgar: Semantics based group activity recognition. In: Proceedings of the IEEE international conference on computer vision, pp 2876–2885
Liu J, Luo J, Shah M (2009) Recognizing realistic actions from videos in the wild. In: 2009 IEEE Conference on computer vision and pattern recognition. IEEE, pp 1996–2003
Mangai UG, Samanta S, Das S, Chowdhury PR (2010) A survey of decision fusion and feature fusion strategies for pattern classification. IETE Tech Rev 27(4):293–307
Mikolajczyk K, Schmid C (2005) A performance evaluation of local descriptors. IEEE Trans Pattern Anal Mach Intell 27(10):1615–1630
Mota VF, Souza JI, Araújo AdA, Vieira M.B (2013) Combining orientation tensors for human action recognition. In: 2013 XXVI IEEE Conference on graphics, patterns and images. IEEE, pp 328–333
Nadeem A, Jalal A, Kim K (2020) Human actions tracking and recognition based on body parts detection via artificial neural network. In: 2020 3rd International conference on advancements in computational sciences (ICACS). IEEE, pp 1–6
Naveed H, Khan G, Khan AU, Siddiqi A, Khan MUG (2019) Human activity recognition using mixture of heterogeneous features and sequential minimal optimization. Int J Mach Learn Cybern 10(9):2329–2340
Niebles JC, Wang H, Fei-Fei L (2008) Unsupervised learning of human action categories using spatial-temporal words. Int J Comput Vision 79 (3):299–318
Rodriguez MD, Ahmed J, Shah M (2008) Action mach a spatio-temporal maximum average correlation height filter for action recognition. In: IEEE Conference on computer vision and pattern recognition, 2008. CVPR 2008. IEEE, pp 1–8
Schindler K, Van Gool L (2008) Action snippets: How many frames does human action recognition require?. In: 2008 IEEE Conference on computer vision and pattern recognition. IEEE, pp 1–8
Schuldt C, Laptev I, Caputo B (2004) Recognizing human actions: a local svm approach. In: Proceedings of the 17th international conference on pattern recognition, 2004. ICPR 2004, vol 3. IEEE, pp 32–36
Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. In: Advances in neural information processing systems, pp 568–576
Sun L, Jia K, Chan TH, Fang Y, Wang G, Yan S (2014) Dl-sfa: Deeply-learned slow feature analysis for action recognition, pp 2625–2632
Ta AP, Wolf C, Lavoue G, Baskurt A, Jolion JM (2010) Pairwise features for human action recognition. In: 2010 20th International conference on pattern recognition. IEEE, pp 3224–3227
Taylor GW, Fergus R, LeCun Y, Bregler C (2010) Convolutional learning of spatio-temporal features. In: European conference on computer vision. Springer, pp 140–153
Tran D, Bourdev L, Fergus R, Torresani L, Paluri M (2015) Learning spatiotemporal features with 3d convolutional networks. In: Proceedings of the IEEE international conference on computer vision, pp 4489–4497
Tran D, Ray J, Shou Z, Chang SF, Paluri M (2017) Convnet architecture search for spatiotemporal feature learning. arXiv:1708.05038
Wang L, Xu Y, Cheng J, Xia H, Yin J, Wu J (2018) Human action recognition by learning spatio-temporal features with deep neural networks. IEEE Access 6:17913–17922
Wang T, Chen Y, Zhang M, Chen J, Snoussi H (2017) Internal transfer learning for improving performance in human action recognition for small datasets. IEEE Access 5:17627–17633
Wang W, Shen J, Guo F, Cheng MM, Borji A (2018) Revisiting video saliency: A large-scale benchmark and a new model. In: Proceedings of the IEEE Conference on computer vision and pattern recognition, pp 4894–4903
Wang Y, Song J, Wang L, Van Gool L, Hilliges O (2016) Two-stream sr-cnns for action recognition in videos. In: BMVC
Whytock T, Belyaev A, Robertson N (2012) Gei+ hog for action recognition. In: Fourth UK computer vision student workshop
Wu J, Qiu S, Zeng R, Kong Y, Senhadji L, Shu H (2017) Multilinear principal component analysis network for tensor object classification. IEEE Access 5:3322–3331
Yao G, Lei T, Zhong J (2019) A review of convolutional-neural-network-based action recognition. Pattern Recogn Lett 118:14–22
Yao T, Wang Z, Xie Z, Gao J, Feng DD (2017) Learning universal multiview dictionary for human action recognition. Pattern Recogn 64:236–244
Ye J, Wang L, Li G, Chen D, Zhe S, Chu X, Xu Z (2018) Learning compact recurrent neural networks with block-term tensor decomposition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 9378–9387
Yi Y, Lin M (2016) Human action recognition with graph-based multiple-instance learning. Pattern Recogn 53:148–162
Yuan C, Li X, Hu W, Ling H, Maybank S (2013) 3d r transform on spatio-temporal interest points for action recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 724–730
Zare A, Moghaddam HA, Sharifi A (2020) Video spatiotemporal mapping for human action recognition by convolutional neural network. Pattern Anal Applic 23(1):265–279
Zhang K, Zhang L (2018) Extracting hierarchical spatial and temporal features for human action recognition. Multimed Tools Appl 77(13):16053–16068
Zhao G, Pietikainen M (2007) Dynamic texture recognition using local binary patterns with an application to facial expressions. IEEE Trans Pattern Anal Mach Intell 29(6):915–928
Acknowledgements
Saleh Aly would like to thank the Deanship of Scientific Research at Majmaah University for supporting this work under Project No. R-2021-21
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Abdelbaky, A., Aly, S. Human action recognition using three orthogonal planes with unsupervised deep convolutional neural network. Multimed Tools Appl 80, 20019–20043 (2021). https://doi.org/10.1007/s11042-021-10636-2
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-021-10636-2