
Abstract
Pairwise comparisons have been a long-standing technique for comparing alternatives/criteria and their role has been pivotal in the development of modern decision-making methods. The evaluation is very often done linguistically. Several scales have been proposed to translate the linguistic evaluation into a quantitative evaluation. In this paper, we perform an experiment to investigate, under our methodological choices, which type of scale provides the best matching of the decision-maker’s verbal representation. The experiment aims to evaluate the suitability of eight evaluation scales for problems of different sizes. We find that the inverse linear scale provides the best matching verbal representation whenever the objective data are measured by means of pairwise comparisons matrices and a suitable distance between matrices is applied for computing the matching error.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Being able to make a good decision is fundamental for the survival of companies, people and societies. However, to make good decisions, we need to be able to measure performance. If a performance is not directly objectively measurable, then it can be evaluated. Subjective evaluations are often given in a linguistic scale (e.g., poor, good, excellent, etc) with a better result than numeric evaluations (Windschitl and Wells 1996). The question is how to convert a verbal scale into a numerical scale that can be used in the prioritization of actions. Although several scales have been proposed (Meesariganda and Ishizaka 2017), it is not clear which one to choose; indeed, the authors have seen that there is not a unique scale for the conversion of a fixed problem (i.e., cloud computing strategy selection): each person has its own representation. To investigate this question, we propose an experimental method to evaluate the same scales used by Meesariganda and Ishizaka (2017), but in further problems. Experiments are very popular in psychology (Wixted 2018). For example, experimental psychology employs human participants to study a variety of topics, including among others sensation and perception, memory, cognition, learning, motivation and emotion. Experiments have been also used in economics (Kagel and Roth 2017) and in operational research (Donohue et al. 2018). An experiment was performed by Keeney et al. (1990), who asked participants to provide a direct ranking of options. They then solved the problem with the Multi Attribute Utility (MAU). In the final ranking, 80\(\%\) of the participants changed their initial ranking, mostly in agreement with the MAU ranking. Huizingh and Vrolijk (1997) asked participants to select a room to rent. They observed that the participants were more satisfied with the AHP result than with a random selection. Linares (2009) asked 18 participants to rank cars with AHP. Then, an automatic algorithm removed the intransitivities and a new ranking was generated. In a questionnaire, the majority of the students said that when intransitivities were removed, their preferences were not better represented. Ishizaka et al. (2011) statistically compared three rankings: one given directly by the participants, a second by applying AHP, a third after having provided the information for AHP and a final after learning the ranking provided by AHP. Their results showed that the rankings were similar. Furthermore, it was found that if participants changed their ranking, then they followed the suggestion of AHP. Later, Ishizaka and Siraj (2018) renewed the experiment with a different decision problem solved with AHP, MACBETH and SMART, and the same results were found. Bozóki et al. (2013) conducted experiments for testing various characteristics of pairwise comparison matrices. Recently, Cavallo et al. (2019) measured the coherence of the participants when they express their subjective preferences by means of additive, multiplicative and fuzzy pairwise comparisons. They found that the worst level of coherence occurs when participants use the additive pairwise comparison. An algorithm for controlling the incoherence during the construction of the pairwise comparison matrix has been proposed by Ishizaka and Siraj (2020). Relations among several coherence conditions have been provided by Brunelli and Cavallo (2020b) and Cavallo and D’Apuzzo (2020).
When we have to solve a problem, we may do not know in advance the range of values in the problem. The goal of this paper is to investigate the existence of a scale that always provides the best matching verbal representation of the respondents; therefore, we have selected problems with different ranges to analyze whether a scale would always perform better whatever the range.
In this paper, we ask participants to evaluate three problems of different known dimensions with a verbal scale. Then, the verbal evaluations are matched with the real values of eight numerical scales. We find that, under our methodological choices, the inverse linear scale provides the best matching verbal representation of the respondents, followed shortly by the root square scale, while the power scale is the worst.
The remainder of this paper is organized as follows. Section 2 presents the different evaluation scales and provides basic theoretical notions about pairwise comparison matrices. The experimental part and its results are given in Sect. 3. Finally, Sect. 4 concludes this paper and outlines some future avenues of research.
2 Preliminaries
In this section, we provide preliminaries useful in the sequel.
2.1 Evaluation scales
Pairwise comparisons have been used in psychology since the beginning of last century (Yokoyama 1921), (Thurstone 1927). They have also been adopted in multi-criteria decision analysis, for example in AHP (Saaty 1977) and BWM (Rezaei 2015). Decision items are compared in pairs and their evaluation is entered into a squared matrix. The priorities are then calculated from this matrix. It has previously been experimentally demonstrated that pairwise comparisons are more precise than direct evaluations (Millet 1997), (Por and Budescu 2017), (Whitaker 2007). Generally, the comparisons are expressed on a verbal scale because it is more familiar to decision-makers and they understand it better than numerical evaluations (Budescu and Wallsten 1985). The verbal scale is only converted into numerical values to calculate priorities in a second step without the decision-maker. Several scale conversions have been proposed. The most commonly used is the linear scale in Table 1 that was proposed by Saaty, probably because it is integrated into the leading Expert choice software program (Ishizaka and Labib 2009).
It has been demonstrated that different decision-makers may have different interpretations of the same verbal expression (Huizingh and Vrolijk 1997). Therefore, several scales have been proposed (Table 2). For example, another linear scale was proposed by Ma and Zheng (1991), where the inverse elements (i.e. \(\frac{1}{x}\)) are linear instead of the x that is used in the Saaty’s scale.
The power and root scale were proposed by Harker and Vargas (1987), but they then recognised that the linear scale would often outperform them. Inspired from auditory stimuli, the geometric scale was proposed to represent equidistant stimuli (Lootsma 1989). Salo and Hämäläinen (1997) observed that when two alternatives are compared on an integer scale one to nine, there is an uneven dispersion of local priorities. This means that there is a lack of sensitivity when comparing elements, which are preferentially close to each other. Based on this observation, the authors proposed a balanced scale where the local priorities are evenly dispersed between the range [0.1, 0.9]. Later, Elliott (2010) developed a balanced power scale. This scale is based on the same idea as Salo and Hämäläinen (1997) but with balanced priorities among three alternatives. To avoid the boundary problem that is incurred by the consistency rule (e.g., if the decision-maker enters \(a_{ij} = 4\) and \(a_{jk} = 5\), the user is forced to an inconsistent relation when the upper limit of the scale is 9, and therefore cannot enter \(a_{ik} = 20\)), Donegan et al. (1992) proposed an asymptotic scale. Ishizaka et al. (2011) observed that the existing scales disadvantage compromised solutions. To solve this problem, they suggested a logarithmic scale, which provides a better priority for compromised solutions.
Although these scales have advantages and disadvantages, the only question that counts is: what is the scale in the mind of the decision-maker? To solve this problem, individual scales have been developed. Dong et al. (2013) and Liang et al. (2008) proposed a method to calculate personalised scales that minimise the inconsistency of the matrix. However, these techniques are questionable because inconsistency in the pairwise matrix can have several origins in addition to the scale effect, including error, lack of information, distracted or undecided user, and so on. Another approach to choose the most appropriate scale has been to map verbal scale with comparisons given by the decision-maker on alternatives with known measures, such as the surface of geometrical figures. This technique has been used for fuzzy AHP (Ishizaka and Nguyen 2013), ANP (Rokou and Kirytopoulos 2014) and AHP (Meesariganda and Ishizaka 2017). However, the chosen scale may depend on the objective problem that is chosen to calibrate the scale. Scale invariance property has been the subject of some recent papers (Csató 2017, 2018, 2019).
2.2 Pairwise comparison matrices
In this section, we provide the theoretical framework about Pairwise Comparison Matrices (PCMs) that we choose for the experiment; we adopt the multiplicative representation (Saaty 1977). Thus, from now on, we assume that each PCM satisfies the following reciprocity property:
Definition 2.1
\({{\textbf {M}}}=[m_{ij}]_{n \times n}\), with \(m_{ij}>0\), is a reciprocal PCM if, for all \( i,j\in \{1, \ldots , n\}\), it verifies the following condition:
The distance (Cavallo 2019) between \({{\textbf {M}}}^1=[m^1_{ij}]_{n \times n}\) and \({{\textbf {M}}}^2=[m^2_{ij}]_{n \times n}\) is:
where
is the distance between the entries \(m^1_{ij}\) and \(m^2_{ij}\) (Cavallo and D’Apuzzo 2009). Thus, the distance between \({{\textbf {M}}}^1=[m^1_{ij}]_{n \times n}\) and \({{\textbf {M}}}^2=[m^2_{ij}]_{n \times n}\) is the geometric mean of the component-wise distances in the upper triangles of \({{\textbf {M}}}^1=[m^1_{ij}]_{n \times n}\) and \({{\textbf {M}}}^2=[m^2_{ij}]_{n \times n}\).
It is nowadays widely acknowledged that seemingly different types of pairwise comparisons (e.g. additive (Barzilai 1998), multiplicative and fuzzy (Tanino 1984)) are mathematically equivalent (Cavallo and D’Apuzzo 2009; Ramík 2015) because they share the same algebraic structure; that is, they are pairwise comparisons defined over Abelian linearly ordered (Alo)-groups. It has been shown that, by means of proper isomorphisms, one can naturally extend concepts and properties from one representation to another. As an example, for two additive PCMs \({{\textbf {A}}}^1=[a^1_{ij}]_{n \times n}\) and \({{\textbf {A}}}^2=[a^2_{ij}]_{n \times n}\), the distance equivalent to (1) is the following one:
that is, the arithmetic mean of the component-wise absolute differences in the upper triangles of \({{\textbf {A}}}^1=[a^1_{ij}]_{n \times n}\) and \({{\textbf {A}}}^2=[a^2_{ij}]_{n \times n}\).
Because of its extensibility, e.g. to the additive and fuzzy PCMs, in our experiment we will use distance in (1) between multiplicative PCMs, in order to evaluate the scales in Table 3. Moreover, remaining in the same theoretical framework, the same distance could be also used, in a future work, for measuring several levels of coherence (Brunelli and Cavallo 2020a, b) of the PCMs in the experiment.
3 The experiment
Our experiment aims to evaluate the suitability of the evaluation scales in Table 3, that are the same scales used by Meesariganda and Ishizaka (2017), for problems of different sizes with known measures. For this purpose, we compare the scales against known measurable evaluations (i.e., distances between cities). In the next section, we will describe the problems in more detail.
3.1 Problem description
We deal with the following three problems:
- \(P_A\).:
-
Evaluating distance ratios between cities in Campania region;
- \(P_B\).:
-
Evaluating distance ratios between cities in Italy;
- \(P_C\).:
-
Evaluating distance ratios between cities in Europe.
Thus, given the following sets:
and the corresponding distances, expressed in km, between each city and Naples, that is:
for each pair in \(X_A\), \(X_B\) and \(X_C\), a decision maker has to select the farthest city from Naples, and to measure how much farther the selected city is from Naples than the other city; they have to express a verbal judgement among those given in Table 4.
The real distance ratios among the cities in \(X_A\), \(X_B\) and \(X_C\) are represented by the following multiplicative PCMs:
respectively. Our experiment aims to assess the suitability of the scales in Table 3 to represent the entries of the PCMs \({\mathbf {A}}=[a_{ij}]_{4 \times 4}\), \({\mathbf {B}}=[b_{ij}]_{5 \times 5}\) and \({\mathbf {C}}=[c_{ij}]_{5 \times 5}\).
3.2 Methodology
We use an opinion survey with a sample of 66 students of the Department of Architecture of University of Naples Federico II, Italy. The students received instructions on how to fill out the survey and they completed it during a class period. On average, the experiment lasted 20 minutes. The survey forms are as follows:
- \({\varvec{{Q_A}}}\):
-
The respondent has to perform four pairwise comparisons. For each pairwise comparison of cities in \(X_A\), they have to select the farthest from Naples and they also have to select a verbal judgement from Table 4 to express how much farther the selected city is from Naples than the other city;
- \({\varvec{{Q_B}}}\):
-
The respondent has to perform five pairwise comparisons. For each pairwise comparison of cities in \(X_B\), they have to select the farthest from Naples and they have to select a verbal judgement from Table 4 to express how much farther the selected city is from Naples than the other city;
- \({\varvec{{Q_C}}}\):
-
The respondent has to perform five pairwise comparisons. For each pairwise comparison of cities in \(X_C\), they have to select the farthest from Naples and they also have to select a verbal judgement from Table 4 to express how much farther the selected city is from Naples than the other city.
The survey forms have been developed by means of Google Forms in such a way that each question is mandatory. For example, Fig. 1 provides a question in the survey \(Q_A\); as we can see, the participants have full information: the map with the cities and the distance to Naples.

Example of question in the survey \(Q_A\)
We discard surveys where the students select a wrong city as the farthest from Naples because we assume a minimal level of coherence; thus, let m be the number of students who always select the correct city. Although discarding all surveys of a student committing a mistake in any survey \(Q_A\), \(Q_B\) or \(Q_C\) is selective, this choice ensures that, for each problem, we have the same number of surveys to analyze and that, for each student, we can obtain the type of scale that provides the best matching of his/her verbal representation for each problem.
To evaluate the suitability of the scales in Table 3 for the given problems, we perform the following steps:
- Step 1:
-
For each student (i.e., for each \(k \in \{1, \ldots , m\}\)), the verbal judgements provided in the surveys \(Q_A\), \(Q_B\) and \(Q_C\) are matched with the real values of the scales in Table 3 by building the PCMs \({{\textbf {A}}}^{ks}=[a_{ij}^{ks}]_{4 \times 4}\), \({{\textbf {B}}}^{ks}=[b_{ij}^{ks}]_{5 \times 5}\) and \({{\textbf {C}}}^{ks}=[c_{ij}^{ks}]_{5 \times 5}\), where \(s= \{1, \ldots , 8\}\) is the index of the scale in Table 3 (e.g., \(s=2\) refers to the power scale);
- Step 2:
-
For each student (i.e. for each \(k \in \{1, \ldots , m\}\)) and for each scale (i.e., for each \(s\in \{1, \ldots , 8\}\)), by applying (1), we compute the following matching errors:
$$\begin{aligned} d({\mathbf {A}},{\mathbf {A}}^{ks})= & {} \root 6 \of {\prod _{i=1}^{3}\prod _{j=i+1}^{4}\max \{{a_{ij}}/{a^{ks}_{ij}},{a^{ks}_{ij}}/{a_{ij}} \}}; \end{aligned}$$(7)$$\begin{aligned} d({\mathbf {B}},{\mathbf {B}}^{ks})= & {} \root 10 \of {\prod _{i=1}^{4}\prod _{j=i+1}^{5}\max \{{b_{ij}}/{b^{ks}_{ij}},{b^{ks}_{ij}}/{b_{ij}} \}}; \end{aligned}$$(8)$$\begin{aligned} d({\mathbf {C}},{\mathbf {C}}^{ks})= & {} \root 10 \of {\prod _{i=1}^{4}\prod _{j=i+1}^{5}\max \{{c_{ij}}/{c^{ks}_{ij}},{c^{ks}_{ij}}/{c_{ij}} \}}. \end{aligned}$$(9)
Example 3.1
Let us suppose that student k provides the following verbal judgements to the survey \(Q_A\):
-
1.
Avellino is weakly farther (i.e., value= \({{\textbf {c}}}\) in Table 4) from Naples than Caserta;
-
2.
Salerno is weakly farther (i.e., value= \({{\textbf {c}}}\) in Table 4) from Naples than Caserta;
-
3.
Benevento is weakly farther (i.e., value= \({{\textbf {c}}}\) in Table 4) from Naples than Caserta;
-
4.
Avellino and Salerno have the same distance (i.e., value= \({{\textbf {a}}}\) in Table 4) from Naples;
-
5.
Benevento is less than weakly farther (i.e., value= \({{\textbf {b}}}\) in Table 4) than Avellino from Naples;
-
6.
Benevento is less than weakly farther (i.e., value= \({{\textbf {b}}}\) in Table 4) than Salerno from Naples.
The verbal judgements can be synthesized by the following matrix:
Then, by applying this methodology, we obtain the following eight different matrices (i.e., one for each scale):
- Step 1:
-
$$\begin{aligned} {{\textbf {A}}}^{k1}= & {} \left[ \begin{array}{cccc} 1 &{} \frac{1}{3} &{} \frac{1}{3} &{} \frac{1}{3}\\ 3 &{}1 &{} 1 &{}\frac{1}{2} \\ 3 &{} 1&{}1 &{}\frac{1}{2}\\ 3 &{} 2 &{} 2 &{} 1 \end{array}\right] \; {{\textbf {A}}}^{k4}=\left[ \begin{array}{cccc} 1 &{} \frac{1}{2} &{} \frac{1}{2} &{} \frac{1}{2}\\ 2 &{}1 &{} 1 &{}\frac{1}{1.58} \\ 2 &{} 1&{}1 &{}\frac{1}{1.58}\\ 2 &{} 1.58 &{} 1.58 &{} 1 \end{array}\right] \;{{\textbf {A}}}^{k7}=\left[ \begin{array}{cccc} 1 &{} \frac{1}{1.5} &{} \frac{1}{1.5} &{} \frac{1}{1.29}\\ 1.5 &{}1 &{} 1 &{}\frac{1}{1.22} \\ 1.5&{} 1&{}1 &{}\frac{1}{1.22}\\ 1.5 &{} 1.22 &{} 1.22 &{} 1 \end{array}\right] \\ {{\textbf {A}}}^{k2}= & {} \left[ \begin{array}{cccc} 1 &{} \frac{1}{9} &{} \frac{1}{9} &{} \frac{1}{9}\\ 9 &{}1 &{} 1 &{}\frac{1}{4} \\ 9 &{} 1&{}1 &{}\frac{1}{4}\\ 9 &{} 4 &{} 4 &{} 1 \end{array}\right] \; {{\textbf {A}}}^{k5}=\left[ \begin{array}{cccc} 1 &{} \frac{1}{1.73} &{} \frac{1}{1.73} &{} \frac{1}{1.73}\\ 1.73 &{}1 &{} 1 &{}\frac{1}{1.41} \\ 1.73 &{} 1&{}1 &{}\frac{1}{1.41}\\ 1.73 &{} 1.41 &{} 1.41 &{} 1 \end{array}\right] \; \;{{\textbf {A}}}^{k8}=\left[ \begin{array}{cccc} 1 &{} \frac{1}{1.73} &{} \frac{1}{1.73} &{} \frac{1}{1.73}\\ 1.73 &{}1 &{} 1 &{}\frac{1}{1.32} \\ 1.73&{} 1&{}1 &{}\frac{1}{1.32}\\ 1.73 &{} 1.32 &{} 1.32 &{} 1 \end{array}\right] \\ {{\textbf {A}}}^{k3}= & {} \left[ \begin{array}{cccc} 1 &{} \frac{1}{4} &{} \frac{1}{4} &{} \frac{1}{4}\\ 4 &{}1 &{} 1 &{}\frac{1}{2} \\ 4 &{} 1&{}1 &{}\frac{1}{2}\\ 4 &{} 2 &{} 2 &{} 1 \end{array}\right] \; {{\textbf {A}}}^{k6}=\left[ \begin{array}{cccc} 1 &{} \frac{1}{1.29} &{} \frac{1}{1.29} &{} \frac{1}{1.29}\\ 1.29 &{}1 &{} 1 &{}\frac{1}{1.13} \\ 1.29 &{} 1&{}1 &{}\frac{1}{1.13}\\ 1.29 &{} 1.13 &{} 1.13 &{} 1 \end{array}\right] ; \end{aligned}$$
- Step 2:
-
$$\begin{aligned} d({\mathbf {A}},{\mathbf {A}}^{k1})= & {} 1.5,\quad d({\mathbf {A}},{\mathbf {A}}^{k2})= 3.27, \quad d({\mathbf {A}},{\mathbf {A}}^{k3})=1.73,\\ d({\mathbf {A}},{\mathbf {A}}^{k4})= & {} 1.15, \quad d({\mathbf {A}},{\mathbf {A}}^{k5})=1.11, \quad d({\mathbf {A}},{\mathbf {A}}^{k6})=1.24,\\ d({\mathbf {A}},{\mathbf {A}}^{k7})= & {} 1.14, \quad d({\mathbf {A}},{\mathbf {A}}^{k8})=1.09. \end{aligned}$$
Thus, for this student, the less suitable scale (i.e., the worst fitting scale) is the power scale because the matching error \( d({\mathbf {A}},{\mathbf {A}}^{k2})= 3.27\) is the biggest, and the most suitable scale is the balanced power scale because the matching error \(d({\mathbf {A}},{\mathbf {A}}^{k8})=1.09\) is the smallest; note that there is a very small difference among logarithmic, root square, balanced and balanced power scales.
3.3 Results and discussion
We discarded about \(20\% \) of the surveys; that is, 14 surveys where the evaluations were not transitive or an incorrect ranking of the cities was provided. The selection of the wrong city shows incoherence or an error that does not depend on the kind of scale in Table 3. Thus, we analyze \(m=52\) surveys.
By performing Step 1 and Step 2 described in the previous section, and by counting how many times a scale provides the smallest matching errors (7), (8) and (9), we obtain Table 5; it shows that the inverse linear scale is always the best fitting scale, followed by the root square scale. As obtained by Meesariganda and Ishizaka (2017) for a strategy selection problem, we obtain that the traditional linear scale used by Saaty and the power and geometric scales provide the worst matching verbal representation of the students.
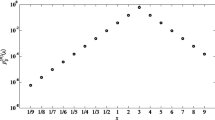
Figures 2, 3, and 4 provide further information, in addition to the count provided in Table 5. In particular, it shows that although the linear scale has never been found to be the best matching verbal representation of the participants, its matching errors are less than the errors provided by the power and geometric scales. In order to highlight the scales with the best matching verbal representations, Figures 2b, 3b and 4b provide a zoom on all the scales with the exclusion of the worst scales (i.e. geometric and power).

Matching errors in problem \(P_A\) computed by applying (7)

Matching errors in problem \(P_B\) computed by applying (8)

Matching errors in problem \(P_C\) computed by applying (9)
In order to analyze the matching errors averages, we provide Table 6; in particular, it confirms that the average error of the linear scale is less than the average errors of the power and geometric scales.
To analyze if the differences among the means in Table 6 are significant, we performed ANalysis Of VAriance (ANOVA) tests. Table 7 shows that the differences among all the scales are significant with an ANOVA test at a confidence threshold \(p_t = 0.05\). Indeed, p value is always smaller than \(p_t\) and F value is always higher than critical value \(F_{crit}\). In particular, there are highly significant differences among all the scales because \(p=0\).
In order to know exactly which means are significantly different from the other ones, we performed a pairwise multiple comparisons; the results are shown in Table 8.
Tables 6 and 8 show that the geometric scale (3.) provides a smaller matching error mean than the power scale (2.) in both \(P_A\) and \(P_B\), but not in \(P_C\), and that there is a significant difference between the two means in \(P_A\) and no significant differences in \(P_B\) and \(P_C\). Note that the difference between these two means and the other ones is always significant. Thus, we can conclude that the power scale provides the worst matching verbal representation of the respondents.
Let us focus now on the scales with the smallest matching errors averages. Tables 6 and 8 show that the inverse linear scale provides the smallest matching errors mean in both \(P_A\) and \(P_C\); moreover, in \(P_A\) there is not significant difference with the root square scale, and in \(P_C\) there is not significant difference with the balanced scale and the balanced power scale. Concerning \(P_B\), the inverse linear and the root square provide the smallest matching errors means and there is not significant difference between them.
Thus, we can confirm the results provided in Table 5: the inverse linear scale provides the best matching verbal representation of the respondents.
4 Conclusions
Pairwise comparisons have been used extensively for evaluations in decision-making. However, because they often use linguistic evaluations, conversion to a numerical scale is not obvious. In this paper we use an opinion survey to evaluate the suitability of eight numerical scales to represent the decision maker’s verbal representations in problems of different sizes. For this purpose, we compare the scales against known measurable evaluations (i.e. distances between cities). By analyzing the results by means of ANOVA tests, under our methodological choices, we found that the power scale provides the worst matching verbal representation, followed by the geometric scale. The inverse linear scale provides the best matching verbal representation. However, problem-specific scales can be used if the decision-maker has exogenous information on the likely distribution of the pairwise comparisons.
Different parameters on the scales and different distance functions can also be evaluated in a future work. Experiments has been proven to be effective in psychology, economics and recently in behavioral operation research (such as in this paper). In the future, we plan to design more experiments to validate subjective decision techniques; for example, to investigate the suitability of the same numerical scales for subjective decision-making problems.
Change history
22 July 2022
Missing Open Access funding information has been added in the Funding Note.
References
Barzilai, J. (1998). Consistency measures for pairwise comparison matrices. Journal of Multi-Criteria Decision Analysis, 7(3), 123–132.
Bozóki, S., Dezsö, L., Poesz, A., et al. (2013). Analysis of pairwise comparison matrices: An empirical research. Annals of Operations Research, 211(1), 511–528.
Brunelli, M., & Cavallo, B. (2020). Distance-based measures of incoherence for pairwise comparisons. Knowledge-Based Systems, 187, 104808.
Brunelli, M., & Cavallo, B. (2020). Incoherence measures and relations between coherence conditions for pairwise comparisons. Decisions in Economics and Finance, 43(2), 613–635.
Budescu, D. V., & Wallsten, T. S. (1985). Consistency in interpretation of probabilistic phrases. Organizational Behavior and Human Decision Processes, 36(3), 391–405.
Cavallo, B. (2019). \({\cal{G}}\)-distance and \({\cal{G}}\)-decomposition for improving \({\cal{G}}\)-consistency of a pairwise comparison matrix. Fuzzy Optimization and Decision Making, 18(1), 57–83.
Cavallo, B., & D’Apuzzo, L. (2009). A general unified framework for pairwise comparison matrices in multicriterial methods. International Journal of Intelligent Systems, 24(4), 377–398.
Cavallo, B., & D’Apuzzo, L. (2020). Relations between coherence conditions and row orders in pairwise comparison matrices. Decisions in Economics and Finance, 43(2), 637–656.
Cavallo, B., Ishizaka, A., Olivieri, M. G., et al. (2019). Comparing inconsistency of pairwise comparison matrices depending on entries. Journal of the Operational Research Society, 70(5), 842–850.
Csató, L. (2017). On the ranking of a Swiss system chess team tournament. Annals of Operations Research, 254(1–2), 17–36.
Csató, L. (2018). Characterization of an inconsistency ranking for pairwise comparison matrices. Annals of Operations Research, 261(1–2), 155–165.
Csató, L. (2019). Axiomatizations of inconsistency indices for triads. Annals of Operations Research, 280(1–2), 99–110.
Donegan, H. A., Dodd, F. J., & McMaster, T. B. M. (1992). A new approach to AHP decision-making. Journal of the Royal Statistical Society: Series D (The Statistician), 41(3), 295–302.
Dong, Y., Hong, W. C., Xu, Y., et al. (2013). Numerical scales generated individually for analytic hierarchy process. European Journal of Operational Research, 229(3), 654–662.
Donohue, K., Katok, E., & Leider, S. (2018). The handbook of behavioral operations. Hoboken: Wiley.
Elliott, M. A. (2010). Selecting numerical scales for pairwise comparisons. Reliability Engineering & System Safety, 95(7), 750–763.
Harker, P. T., & Vargas, L. G. (1987). The theory of ratio scale estimation: Saaty’s analytic hierarchy process. Management Science, 33(11), 1383–1403.
Huizingh, E. K., & Vrolijk, H. C. (1997). A comparison of verbal and numerical judgments in the Analytic Hierarchy Process. Organizational Behavior and Human Decision Processes, 70(3), 237–247.
Ishizaka, A., & Labib, A. (2009). Analytic hierarchy process and expert choice: Benefits and limitations. OR Insight, 22(4), 201–220.
Ishizaka, A., & Nguyen, N. H. (2013). Calibrated fuzzy AHP for current bank account selection. Expert Systems with Applications, 40(9), 3775–3783.
Ishizaka, A., & Siraj, S. (2018). Are multi-criteria decision-making tools useful? An experimental comparative study of three methods. European Journal of Operational Research, 264(2), 462–471.
Ishizaka, A., & Siraj, S. (2020). Interactive consistency correction in the analytic hierarchy process to preserve ranks. Decisions in Economics and Finance, 43(2), 443–464.
Ishizaka, A., Balkenborg, D., & Kaplan, T. (2011). Influence of aggregation and measurement scale on ranking a compromise alternative in AHP. Journal of the Operational Research Society, 62(4), 700–710.
Kagel, J., & Roth, A. (2017). The handbook of experimental economics (Vol. 2). Princeton: Princeton University Press.
Keeney, R. L., von Winterfeldt, D., & Eppel, T. (1990). Eliciting public values for complex policy decisions. Management Science, 36(9), 1011–1030.
Liang, L., Wang, G., Hua, Z., et al. (2008). Mapping verbal responses to numerical scales in the analytic hierarchy process. Socio-Economic Planning Sciences, 42(1), 46–55.
Linares, P. (2009). Are inconsistent decisions better? An experiment with pairwise comparisons. European Journal of Operational Research, 193(2), 492–498.
Lootsma, F. (1989). Conflict resolution via pairwise comparison of concessions. European Journal of Operational Research, 40(1), 109–116.
Ma D, Zheng X (1991) 9/9-9/1 scale method of AHP. In: 2nd Int. Symposium on AHP, pp 197–202.
Meesariganda, B. R., & Ishizaka, A. (2017). Mapping verbal AHP scale to numerical scale for cloud computing strategy selection. Applied Soft Computing, 53, 111–118.
Millet, I. (1997). The effectiveness of alternative preference elicitation methods in the analytic hierarchy process. Journal of Multi-Criteria Decision Analysis, 6(1), 41–51.
Por, H. H., & Budescu, D. V. (2017). Eliciting subjective probabilities through pair-wise comparisons. Journal of Behavioral Decision Making, 30(2), 181–196.
Ramík, J. (2015). Isomorphisms between fuzzy pairwise comparison matrices. Fuzzy Optimization and Decision Making, 14(2), 199–209.
Rezaei, J. (2015). Best-worst multi-criteria decision-making method. Omega, 53, 49–57.
Rokou, E., & Kirytopoulos, K. (2014). Calibrated group decision process. Group Decision and Negotiation, 23, 1369–1384.
Saaty, T. L. (1977). A scaling method for priorities in hierarchical structures. Journal of Mathematical Psychology, 15(3), 234–281.
Salo, A. A., & Hämäläinen, R. P. (1997). On the measurement of preferences in the analytic hierarchy process. Journal of Multi-Criteria Decision Analysis, 6(6), 309–319.
Tanino, T. (1984). Fuzzy preference orderings in group decision making. Fuzzy Sets and Systems, 12(2), 117–131.
Thurstone, L. L. (1927). A law of comparative judgment. Psychological Review, 34(4), 273–286.
Whitaker, R. (2007). Validation examples of the analytic hierarchy process and analytic network process. Mathematical and Computer Modelling, 46(7), 840–859.
Windschitl, P. D., & Wells, G. L. (1996). Measuring psychological uncertainty: Verbal versus numeric methods. Journal of Experimental Psychology: Applied, 2(4), 343–364.
Wixted, J. (2018). Stevens’ handbook of experimental psychology and cognitive neuroscience. Hoboken: Wiley.
Yokoyama, M. (1921). The nature of the affective judgment in the method of paired comparisons. The American Journal of Psychology, 32(3), 357–369.
Funding
Open access funding provided by Universitá degli Studi di Napoli Federico II within the CRUI-CARE Agreement.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Cavallo, B., Ishizaka, A. Evaluating scales for pairwise comparisons. Ann Oper Res 325, 951–965 (2023). https://doi.org/10.1007/s10479-022-04682-8
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10479-022-04682-8