
Abstract
Deep reinforcement learning (RL) has achieved outstanding results in recent years. This has led to a dramatic increase in the number of applications and methods. Recent works have explored learning beyond single-agent scenarios and have considered multiagent learning (MAL) scenarios. Initial results report successes in complex multiagent domains, although there are several challenges to be addressed. The primary goal of this article is to provide a clear overview of current multiagent deep reinforcement learning (MDRL) literature. Additionally, we complement the overview with a broader analysis: (i) we revisit previous key components, originally presented in MAL and RL, and highlight how they have been adapted to multiagent deep reinforcement learning settings. (ii) We provide general guidelines to new practitioners in the area: describing lessons learned from MDRL works, pointing to recent benchmarks, and outlining open avenues of research. (iii) We take a more critical tone raising practical challenges of MDRL (e.g., implementation and computational demands). We expect this article will help unify and motivate future research to take advantage of the abundant literature that exists (e.g., RL and MAL) in a joint effort to promote fruitful research in the multiagent community.







Similar content being viewed by others


Notes
We have noted inconsistency in abbreviations such as: D-MARL, MADRL, deep-multiagent RL and MA-DRL.
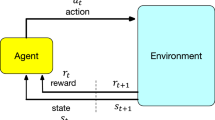
In this setting each agent independently executes a policy, however, there are other cases where this does not hold, for example when agents have a coordinated exploration strategy.
This algorithm is similar to CFR-BR [159] and has the main advantage that the current policy convergences rather than the average policy, so there is no need to learn the average strategy, which requires large reservoir buffers or many past networks.
The average strategy profile of fictitious players converges to a Nash equilibrium in certain classes of games, e.g., two-player zero-sum and potential games [222].
The vocabulary that agents use was arbitrary and had no initial meaning. To understand its emerging semantics they looked at the relationship between symbols and the sets of images they referred to [183].
Elo uses a normal distribution for each player skill, and after each match, both players’ distributions are updated based on measure of surprise, i.e., if a user with previously lower (predicted) skill beats a high skilled one, the low-skilled player is significantly increased.
Johanson et al. [160] also found “overfitting” when solving large extensive games (e.g., poker)—the performance in an abstract game improved but it was worse in the full game.
Bayesian policy reuse assumes an agent with prior experience in the form of a library of policies. When a novel task instance occurs, the objective is to reuse a policy from its library based on observed signals which correlate to policy performance [272].
Centralized planning and decentralized execution is also a standard paradigm for multiagent planning [239].
This idea was initially inspired by the Workshop “Critiquing and Correcting Trends in Machine Learning” at NeurIPS 2018 where it was possible to submit Negative results papers: “Papers which show failure modes of existing algorithms or suggest new approaches which one might expect to perform well but which do not. The aim is to provide a venue for work which might otherwise go unpublished but which is still of interest to the community.” https://ml-critique-correct.github.io/.
It is sometimes unclear in the literature what is the meaning of frame due to the “frame skip” technique. It is therefore suggested to refer to “game frames” and “training frames” [310].
One recent effort by Beeching et al. [29] proposes to use only “mid-range hardware” (8 CPUs and 1 GPU) to train deep RL agents.
NeurIPS 2019 hosts the “MineRL Competition on Sample Efficient Reinforcement Learning using Human Priors” where the primary goal of the competition is to foster the development of algorithms which can efficiently leverage human demonstrations to drastically reduce the number of samples needed to solve complex, hierarchical, and sparse environments [125].
Cuccu, Togelius and Cudré-Mauroux achieved state-of-the-art policy learning in Atari games with only 6 to 18 neurons [75]. The main idea was to decouple image processing from decision-making.
References
Achiam, J., Knight, E., & Abbeel, P. (2019). Towards characterizing divergence in deep Q-learning. CoRR arXiv:1903.08894.
Agogino, A. K., & Tumer, K. (2004). Unifying temporal and structural credit assignment problems. In Proceedings of 17th international conference on autonomous agents and multiagent systems.
Agogino, A. K., & Tumer, K. (2008). Analyzing and visualizing multiagent rewards in dynamic and stochastic domains. Autonomous Agents and Multi-Agent Systems, 17(2), 320–338.
Ahamed, T. I., Borkar, V. S., & Juneja, S. (2006). Adaptive importance sampling technique for markov chains using stochastic approximation. Operations Research, 54(3), 489–504.
Albrecht, S. V., & Ramamoorthy, S. (2013). A game-theoretic model and best-response learning method for ad hoc coordination in multiagent systems. In Proceedings of the 12th international conference on autonomous agents and multi-agent systems. Saint Paul, MN, USA.
Albrecht, S. V., & Stone, P. (2018). Autonomous agents modelling other agents: A comprehensive survey and open problems. Artificial Intelligence, 258, 66–95.
Alonso, E., D’inverno, M., Kudenko, D., Luck, M., & Noble, J. (2002). Learning in multi-agent systems. Knowledge Engineering Review, 16(03), 1–8.
Amato, C., & Oliehoek, F. A. (2015). Scalable planning and learning for multiagent POMDPs. In AAAI (pp. 1995–2002).
Amodei, D., & Hernandez, D. (2018). AI and compute. https://blog.openai.com/ai-and-compute.
Andre, D., Friedman, N., & Parr, R. (1998). Generalized prioritized sweeping. In Advances in neural information processing systems (pp. 1001–1007).
Andrychowicz, M., Wolski, F., Ray, A., Schneider, J., Fong, R., Welinder, P., McGrew, B., Tobin, J., Abbeel, P., & Zaremba, W. (2017). Hindsight experience replay. In Advances in neural information processing systems.
Arjona-Medina, J. A., Gillhofer, M., Widrich, M., Unterthiner, T., & Hochreiter, S. (2018). RUDDER: Return decomposition for delayed rewards. arXiv:1806.07857.
Arulkumaran, K., Deisenroth, M. P., Brundage, M., & Bharath, A. A. (2017). A brief survey of deep reinforcement learning. arXiv:1708.05866v2.
Astrom, K. J. (1965). Optimal control of Markov processes with incomplete state information. Journal of Mathematical Analysis and Applications, 10(1), 174–205.
Axelrod, R., & Hamilton, W. D. (1981). The evolution of cooperation. Science, 211(27), 1390–1396.
Azizzadenesheli, K. (2019). Maybe a few considerations in reinforcement learning research? In Reinforcement learning for real life workshop.
Azizzadenesheli, K., Yang, B., Liu, W., Brunskill, E., Lipton, Z., & Anandkumar, A. (2018). Surprising negative results for generative adversarial tree search. In Critiquing and correcting trends in machine learning workshop.
Babaeizadeh, M., Frosio, I., Tyree, S., Clemons, J., & Kautz, J. (2017). Reinforcement learning through asynchronous advantage actor-critic on a GPU. In International conference on learning representations.
Bacchiani, G., Molinari, D., & Patander, M. (2019). Microscopic traffic simulation by cooperative multi-agent deep reinforcement learning. In AAMAS.
Back, T. (1996). Evolutionary algorithms in theory and practice: Evolution strategies, evolutionary programming, genetic algorithms. Oxford: Oxford University Press.
Baird, L. (1995). Residual algorithms: Reinforcement learning with function approximation. Machine Learning Proceedings, 1995, 30–37.
Balduzzi, D., Racaniere, S., Martens, J., Foerster, J., Tuyls, K., & Graepel, T. (2018). The mechanics of n-player differentiable games. In Proceedings of the 35th international conference on machine learning, proceedings of machine learning research (pp. 354–363). Stockholm, Sweden.
Banerjee, B., & Peng, J. (2003). Adaptive policy gradient in multiagent learning. In Proceedings of the second international joint conference on Autonomous agents and multiagent systems (pp. 686–692). ACM.
Bansal, T., Pachocki, J., Sidor, S., Sutskever, I., & Mordatch, I. (2018). Emergent complexity via multi-agent competition. In International conference on machine learning.
Bard, N., Foerster, J. N., Chandar, S., Burch, N., Lanctot, M., & Song, H. F., et al. (2019). The Hanabi challenge: A new frontier for AI research. arXiv:1902.00506.
Barrett, S., Stone, P., Kraus, S., & Rosenfeld, A. (2013). Teamwork with Limited Knowledge of Teammates. In Proceedings of the Twenty-Seventh AAAI Conference on Artificial Intelligence, pp. 102–108. Bellevue, WS, USA.
Barto, A. G. (2013). Intrinsic motivation and reinforcement learning. In M. Mirolli & G. Baldassarre (Eds.), Intrinsically motivated learning in natural and artificial systems (pp. 17–47). Berlin: Springer.
Becker, R., Zilberstein, S., Lesser, V., & Goldman, C. V. (2004). Solving transition independent decentralized Markov decision processes. Journal of Artificial Intelligence Research, 22, 423–455.
Beeching, E., Wolf, C., Dibangoye, J., & Simonin, O. (2019). Deep reinforcement learning on a budget: 3D Control and reasoning without a supercomputer. CoRR arXiv:1904.01806.
Bellemare, M., Srinivasan, S., Ostrovski, G., Schaul, T., Saxton, D., & Munos, R. (2016). Unifying count-based exploration and intrinsic motivation. In Advances in neural information processing systems (pp. 1471–1479).
Bellemare, M. G., Dabney, W., Dadashi, R., Taïga, A. A., Castro, P. S., & Roux, N. L., et al. (2019). A geometric perspective on optimal representations for reinforcement learning. CoRR arXiv:1901.11530.
Bellemare, M. G., Naddaf, Y., Veness, J., & Bowling, M. (2013). The arcade learning environment: An evaluation platform for general agents. Journal of Artificial Intelligence Research, 47, 253–279.
Bellman, R. (1957). A Markovian decision process. Journal of Mathematics and Mechanics, 6(5), 679–684.
Bernstein, D. S., Givan, R., Immerman, N., & Zilberstein, S. (2002). The complexity of decentralized control of Markov decision processes. Mathematics of Operations Research, 27(4), 819–840.
Best, G., Cliff, O. M., Patten, T., Mettu, R. R., & Fitch, R. (2019). Dec-MCTS: Decentralized planning for multi-robot active perception. The International Journal of Robotics Research, 38(2–3), 316–337.
Bishop, C. M. (2006). Pattern recognition and machine learning. Berlin: Springer.
Bloembergen, D., Kaisers, M., & Tuyls, K. (2010). Lenient frequency adjusted Q-learning. In Proceedings of the 22nd Belgian/Netherlands artificial intelligence conference.
Bloembergen, D., Tuyls, K., Hennes, D., & Kaisers, M. (2015). Evolutionary dynamics of multi-agent learning: A survey. Journal of Artificial Intelligence Research, 53, 659–697.
Blum, A., & Monsour, Y. (2007). Learning, regret minimization, and equilibria. Chap. 4. In N. Nisan (Ed.), Algorithmic game theory. Cambridge: Cambridge University Press.
Bono, G., Dibangoye, J. S., Matignon, L., Pereyron, F., & Simonin, O. (2018). Cooperative multi-agent policy gradient. In European conference on machine learning.
Bowling, M. (2000). Convergence problems of general-sum multiagent reinforcement learning. In International conference on machine learning (pp. 89–94).
Bowling, M. (2004). Convergence and no-regret in multiagent learning. Advances in neural information processing systems (pp. 209–216). Canada: Vancouver.
Bowling, M., Burch, N., Johanson, M., & Tammelin, O. (2015). Heads-up limit hold’em poker is solved. Science, 347(6218), 145–149.
Bowling, M., & McCracken, P. (2005). Coordination and adaptation in impromptu teams. Proceedings of the nineteenth conference on artificial intelligence (Vol. 5, pp. 53–58).
Bowling, M., & Veloso, M. (2002). Multiagent learning using a variable learning rate. Artificial Intelligence, 136(2), 215–250.
Boyan, J. A., & Moore, A. W. (1995). Generalization in reinforcement learning: Safely approximating the value function. In Advances in neural information processing systems, pp. 369–376.
Brafman, R. I., & Tennenholtz, M. (2002). R-max-a general polynomial time algorithm for near-optimal reinforcement learning. Journal of Machine Learning Research, 3(Oct), 213–231.
Brockman, G., Cheung, V., Pettersson, L., Schneider, J., Schulman, J., Tang, J., & Zaremba, W. (2016). OpenAI gym. arXiv preprint arXiv:1606.01540.
Brown, G. W. (1951). Iterative solution of games by fictitious play. Activity Analysis of Production and Allocation, 13(1), 374–376.
Brown, N., & Sandholm, T. (2018). Superhuman AI for heads-up no-limit poker: Libratus beats top professionals. Science, 359(6374), 418–424.
Browne, C. B., Powley, E., Whitehouse, D., Lucas, S. M., Cowling, P. I., Rohlfshagen, P., et al. (2012). A survey of Monte Carlo tree search methods. IEEE Transactions on Computational Intelligence and AI in Games, 4(1), 1–43.
Bucilua, C., Caruana, R., & Niculescu-Mizil, A. (2006). Model compression. In Proceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining (pp. 535–541). ACM.
Bull, L. (1998). Evolutionary computing in multi-agent environments: Operators. In International conference on evolutionary programming (pp. 43–52). Springer.
Bull, L., Fogarty, T. C., & Snaith, M. (1995). Evolution in multi-agent systems: Evolving communicating classifier systems for gait in a quadrupedal robot. In Proceedings of the 6th international conference on genetic algorithms (pp. 382–388). Morgan Kaufmann Publishers Inc.
Busoniu, L., Babuska, R., & De Schutter, B. (2008). A comprehensive survey of multiagent reinforcement learning. IEEE Transactions on Systems, Man and Cybernetics, Part C (Applications and Reviews), 38(2), 156–172.
Busoniu, L., Babuska, R., & De Schutter, B. (2010). Multi-agent reinforcement learning: An overview. In D. Srinivasan & L. C. Jain (Eds.), Innovations in multi-agent systems and applications - 1 (pp. 183–221). Berlin: Springer.
Capture the Flag: The emergence of complex cooperative agents. (2018). [Online]. Retrieved September 7, 2018, https://deepmind.com/blog/capture-the-flag/ .
Collaboration & Credit Principles, How can we be good stewards of collaborative trust? (2019). [Online]. Retrieved May 31, 2019, http://colah.github.io/posts/2019-05-Collaboration/index.html.
Camerer, C. F., Ho, T. H., & Chong, J. K. (2004). A cognitive hierarchy model of games. The Quarterly Journal of Economics, 119(3), 861.
Camerer, C. F., Ho, T. H., & Chong, J. K. (2004). Behavioural game theory: Thinking, learning and teaching. In Advances in understanding strategic behavior (pp. 120–180). New York.
Carmel, D., & Markovitch, S. (1996). Incorporating opponent models into adversary search. AAAI/IAAI, 1, 120–125.
Caruana, R. (1997). Multitask learning. Machine Learning, 28(1), 41–75.
Cassandra, A. R. (1998). Exact and approximate algorithms for partially observable Markov decision processes. Ph.D. thesis, Computer Science Department, Brown University.
Castellini, J., Oliehoek, F. A., Savani, R., & Whiteson, S. (2019). The representational capacity of action-value networks for multi-agent reinforcement learning. In 18th International conference on autonomous agents and multiagent systems.
Castro, P. S., Moitra, S., Gelada, C., Kumar, S., Bellemare, M. G. (2018). Dopamine: A research framework for deep reinforcement learning. arXiv:1812.06110.
Chakraborty, D., & Stone, P. (2013). Multiagent learning in the presence of memory-bounded agents. Autonomous Agents and Multi-Agent Systems, 28(2), 182–213.
Chung, J., Gulcehre, C., Cho, K., & Bengio, Y. (2014). Empirical evaluation of gated recurrent neural networks on sequence modeling. In Deep learning and representation learning workshop.
Ciosek, K. A., & Whiteson, S. (2017). Offer: Off-environment reinforcement learning. In Thirty-first AAAI conference on artificial intelligence.
Clary, K., Tosch, E., Foley, J., & Jensen, D. (2018). Let’s play again: Variability of deep reinforcement learning agents in Atari environments. In NeurIPS critiquing and correcting trends workshop.
Claus, C., & Boutilier, C. (1998). The dynamics of reinforcement learning in cooperative multiagent systems. In Proceedings of the 15th national conference on artificial intelligence (pp. 746–752). Madison, Wisconsin, USA.
Conitzer, V., & Sandholm, T. (2006). AWESOME: A general multiagent learning algorithm that converges in self-play and learns a best response against stationary opponents. Machine Learning, 67(1–2), 23–43.
Costa Gomes, M., Crawford, V. P., & Broseta, B. (2001). Cognition and behavior in normal-form games: An experimental study. Econometrica, 69(5), 1193–1235.
Crandall, J. W., & Goodrich, M. A. (2011). Learning to compete, coordinate, and cooperate in repeated games using reinforcement learning. Machine Learning, 82(3), 281–314.
Crites, R. H., & Barto, A. G. (1998). Elevator group control using multiple reinforcement learning agents. Machine Learning, 33(2–3), 235–262.
Cuccu, G., Togelius, J., & Cudré-Mauroux, P. (2019). Playing Atari with six neurons. In Proceedings of the 18th international conference on autonomous agents and multiagent systems (pp. 998–1006). International Foundation for Autonomous Agents and Multiagent Systems.
de Weerd, H., Verbrugge, R., & Verheij, B. (2013). How much does it help to know what she knows you know? An agent-based simulation study. Artificial Intelligence, 199–200(C), 67–92.
de Cote, E. M., Lazaric, A., & Restelli, M. (2006). Learning to cooperate in multi-agent social dilemmas. In Proceedings of the 5th international conference on autonomous agents and multiagent systems (pp. 783–785). Hakodate, Hokkaido, Japan.
Deep reinforcement learning: Pong from pixels. (2016). [Online]. Retrieved May 7, 2019, https://karpathy.github.io/2016/05/31/rl/.
Do I really have to cite an arXiv paper? (2017). [Online]. Retrieved May 21, 2019, http://approximatelycorrect.com/2017/08/01/do-i-have-to-cite-arxiv-paper/.
Damer, S., & Gini, M. (2017). Safely using predictions in general-sum normal form games. In Proceedings of the 16th conference on autonomous agents and multiagent systems. Sao Paulo.
Darwiche, A. (2018). Human-level intelligence or animal-like abilities? Communications of the ACM, 61(10), 56–67.
Dayan, P., & Hinton, G. E. (1993). Feudal reinforcement learning. In Advances in neural information processing systems (pp. 271–278).
De Bruin, T., Kober, J., Tuyls, K., & Babuška, R. (2018). Experience selection in deep reinforcement learning for control. The Journal of Machine Learning Research, 19(1), 347–402.
De Hauwere, Y. M., Vrancx, P., & Nowe, A. (2010). Learning multi-agent state space representations. In Proceedings of the 9th international conference on autonomous agents and multiagent systems (pp. 715–722). Toronto, Canada.
De Jong, K. A. (2006). Evolutionary computation: A unified approach. Cambridge: MIT press.
Devlin, S., Yliniemi, L. M., Kudenko, D., & Tumer, K. (2014). Potential-based difference rewards for multiagent reinforcement learning. In 13th International conference on autonomous agents and multiagent systems, AAMAS 2014. Paris, France.
Dietterich, T. G. (2000). Ensemble methods in machine learning. In MCS proceedings of the first international workshop on multiple classifier systems (pp. 1–15). Springer, Berlin Heidelberg, Cagliari, Italy.
Du, Y., Czarnecki, W. M., Jayakumar, S. M., Pascanu, R., & Lakshminarayanan, B. (2018). Adapting auxiliary losses using gradient similarity. arXiv preprint arXiv:1812.02224.
Ecoffet, A., Huizinga, J., Lehman, J., Stanley, K. O., & Clune, J. (2019). Go-explore: A new approach for hard-exploration problems. arXiv preprint arXiv:1901.10995.
Elo, A. E. (1978). The rating of chessplayers, past and present. Nagoya: Arco Pub.
Erdös, P., & Selfridge, J. L. (1973). On a combinatorial game. Journal of Combinatorial Theory, Series A, 14(3), 298–301.
Ernst, D., Geurts, P., & Wehenkel, L. (2005). Tree-based batch mode reinforcement learning. Journal of Machine Learning Research, 6(Apr), 503–556.
Espeholt, L., Soyer, H., Munos, R., Simonyan, K., Mnih, V., Ward, T., Doron, Y., Firoiu, V., Harley, T., & Dunning, I., et al. (2018). IMPALA: Scalable distributed deep-RL with importance weighted actor-learner architectures. In International conference on machine learning.
Even-Dar, E., & Mansour, Y. (2003). Learning rates for Q-learning. Journal of Machine Learning Research, 5(Dec), 1–25.
Firoiu, V., Whitney, W. F., & Tenenbaum, J. B. (2017). Beating the World’s best at super smash Bros. with deep reinforcement learning. CoRR arXiv:1702.06230.
Foerster, J. N., Assael, Y. M., De Freitas, N., & Whiteson, S. (2016). Learning to communicate with deep multi-agent reinforcement learning. In Advances in neural information processing systems (pp. 2145–2153).
Foerster, J. N., Chen, R. Y., Al-Shedivat, M., Whiteson, S., Abbeel, P., & Mordatch, I. (2018). Learning with opponent-learning awareness. In Proceedings of 17th international conference on autonomous agents and multiagent systems. Stockholm, Sweden.
Foerster, J. N., Farquhar, G., Afouras, T., Nardelli, N., & Whiteson, S. (2017). Counterfactual multi-agent policy gradients. In 32nd AAAI conference on artificial intelligence.
Foerster, J. N., Nardelli, N., Farquhar, G., Afouras, T., Torr, P. H. S., Kohli, P., & Whiteson, S. (2017). Stabilising experience replay for deep multi-agent reinforcement learning. In International conference on machine learning.
Forde, J. Z., & Paganini, M. (2019). The scientific method in the science of machine learning. In ICLR debugging machine learning models workshop.
François-Lavet, V., Henderson, P., Islam, R., Bellemare, M. G., Pineau, J., et al. (2018). An introduction to deep reinforcement learning. Foundations and Trends® in Machine Learning, 11(3–4), 219–354.
Frank, J., Mannor, S., & Precup, D. (2008). Reinforcement learning in the presence of rare events. In Proceedings of the 25th international conference on machine learning (pp. 336–343). ACM.
Fudenberg, D., & Tirole, J. (1991). Game theory. Cambridge: The MIT Press.
Fujimoto, S., van Hoof, H., & Meger, D. (2018). Addressing function approximation error in actor-critic methods. In International conference on machine learning.
Fulda, N., & Ventura, D. (2007). Predicting and preventing coordination problems in cooperative Q-learning systems. In Proceedings of the twentieth international joint conference on artificial intelligence (pp. 780–785). Hyderabad, India.
Gao, C., Hernandez-Leal, P., Kartal, B., & Taylor, M. E. (2019). Skynet: A top deep RL agent in the inaugural pommerman team competition. In 4th multidisciplinary conference on reinforcement learning and decision making.
Gao, C., Kartal, B., Hernandez-Leal, P., & Taylor, M. E. (2019). On hard exploration for reinforcement learning: A case study in pommerman. In AAAI conference on artificial intelligence and interactive digital entertainment.
Gencoglu, O., van Gils, M., Guldogan, E., Morikawa, C., Süzen, M., Gruber, M., Leinonen, J., & Huttunen, H. (2019). Hark side of deep learning–from grad student descent to automated machine learning. arXiv preprint arXiv:1904.07633.
Gmytrasiewicz, P. J., & Doshi, P. (2005). A framework for sequential planning in multiagent settings. Journal of Artificial Intelligence Research, 24(1), 49–79.
Gmytrasiewicz, P. J., & Durfee, E. H. (2000). Rational coordination in multi-agent environments. Autonomous Agents and Multi-Agent Systems, 3(4), 319–350.
Goodfellow, I. J., Mirza, M., Xiao, D., Courville, A., & Bengio, Y. (2013). An empirical investigation of catastrophic forgetting in gradient-based neural networks. arXiv:1312.6211
Gordon, G. J. (1999). Approximate solutions to Markov decision processes. Technical report, Carnegie-Mellon University.
Greenwald, A., & Hall, K. (2003). Correlated Q-learning. In Proceedings of 17th international conference on autonomous agents and multiagent systems (pp. 242–249). Washington, DC, USA.
Greff, K., Srivastava, R. K., Koutnik, J., Steunebrink, B. R., & Schmidhuber, J. (2017). LSTM: A search space odyssey. IEEE Transactions on Neural Networks and Learning Systems, 28(10), 2222–2232.
Grosz, B. J., & Kraus, S. (1996). Collaborative plans for complex group action. Artificial Intelligence, 86(2), 269–357.
Grover, A., Al-Shedivat, M., Gupta, J. K., Burda, Y., & Edwards, H. (2018). Learning policy representations in multiagent systems. In International conference on machine learning.
Gu, S., Lillicrap, T., Ghahramani, Z., Turner, R. E., & Levine, S. (2017). Q-prop: Sample-efficient policy gradient with an off-policy critic. In International conference on learning representations.
Gu, S. S., Lillicrap, T., Turner, R. E., Ghahramani, Z., Schölkopf, B., & Levine, S. (2017). Interpolated policy gradient: Merging on-policy and off-policy gradient estimation for deep reinforcement learning. In Advances in neural information processing systems (pp. 3846–3855).
Guestrin, C., Koller, D., & Parr, R. (2002). Multiagent planning with factored MDPs. In Advances in neural information processing systems (pp. 1523–1530).
Guestrin, C., Koller, D., Parr, R., & Venkataraman, S. (2003). Efficient solution algorithms for factored MDPs. Journal of Artificial Intelligence Research, 19, 399–468.
Guestrin, C., Lagoudakis, M., & Parr, R. (2002). Coordinated reinforcement learning. In ICML (Vol. 2, pp. 227–234).
Gullapalli, V., & Barto, A. G. (1992). Shaping as a method for accelerating reinforcement learning. In Proceedings of the 1992 IEEE international symposium on intelligent control (pp. 554–559). IEEE.
Gupta, J. K., Egorov, M., & Kochenderfer, M. (2017). Cooperative multi-agent control using deep reinforcement learning. In G. Sukthankar & J. A. Rodriguez-Aguilar (Eds.), Autonomous agents and multiagent systems (pp. 66–83). Cham: Springer.
Gupta, J. K., Egorov, M., & Kochenderfer, M. J. (2017). Cooperative Multi-agent Control using deep reinforcement learning. In Adaptive learning agents at AAMAS. Sao Paulo.
Guss, W. H., Codel, C., Hofmann, K., Houghton, B., Kuno, N., Milani, S., Mohanty, S. P., Liebana, D. P., Salakhutdinov, R., Topin, N., Veloso, M., & Wang, P. (2019). The MineRL competition on sample efficient reinforcement learning using human priors. CoRR arXiv:1904.10079.
Haarnoja, T., Tang, H., Abbeel, P., & Levine, S. (2017). Reinforcement learning with deep energy-based policies. In Proceedings of the 34th international conference on machine learning (Vol. 70, pp. 1352–1361).
Haarnoja, T., Zhou, A., Abbeel, P., & Levine, S. (2018). Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In International conference on machine learning.
Hafner, R., & Riedmiller, M. (2011). Reinforcement learning in feedback control. Machine Learning, 84(1–2), 137–169.
Harsanyi, J. C. (1967). Games with incomplete information played by “Bayesian” players, I–III part I. The basic model. Management Science, 14(3), 159–182.
Hasselt, H. V. (2010). Double Q-learning. In Advances in neural information processing systems (pp. 2613–2621).
Hausknecht, M., & Stone, P. (2015). Deep recurrent Q-learning for partially observable MDPs. In International conference on learning representations.
Hauskrecht, M. (2000). Value-function approximations for partially observable Markov decision processes. Journal of Artificial Intelligence Research, 13(1), 33–94.
He, H., Boyd-Graber, J., Kwok, K., Daume, H. (2016). Opponent modeling in deep reinforcement learning. In 33rd international conference on machine learning (pp. 2675–2684).
Heess, N., TB, D., Sriram, S., Lemmon, J., Merel, J., Wayne, G., Tassa, Y., Erez, T., Wang, Z., Eslami, S. M. A., Riedmiller, M. A., & Silver, D. (2017). Emergence of locomotion behaviours in rich environments. arXiv:1707.02286v2
Heinrich, J., Lanctot, M., & Silver, D. (2015). Fictitious self-play in extensive-form games. In International conference on machine learning (pp. 805–813).
Heinrich, J., & Silver, D. (2016). Deep reinforcement learning from self-play in imperfect-information games. arXiv:1603.01121.
Henderson, P., Islam, R., Bachman, P., Pineau, J., Precup, D., & Meger, D. (2018). Deep reinforcement learning that matters. In 32nd AAAI conference on artificial intelligence.
Herbrich, R., Minka, T., & Graepel, T. (2007). TrueSkill\(^{{\rm TM}}\): a Bayesian skill rating system. In Advances in neural information processing systems (pp. 569–576).
Hernandez-Leal, P., & Kaisers, M. (2017). Learning against sequential opponents in repeated stochastic games. In The 3rd multi-disciplinary conference on reinforcement learning and decision making. Ann Arbor.
Hernandez-Leal, P., & Kaisers, M. (2017). Towards a fast detection of opponents in repeated stochastic games. In G. Sukthankar, & J. A. Rodriguez-Aguilar (Eds.) Autonomous agents and multiagent systems: AAMAS 2017 Workshops, Best Papers, Sao Paulo, Brazil, 8–12 May, 2017, Revised selected papers (pp. 239–257).
Hernandez-Leal, P., Kaisers, M., Baarslag, T., & Munoz de Cote, E. (2017). A survey of learning in multiagent environments—dealing with non-stationarity. arXiv:1707.09183.
Hernandez-Leal, P., Kartal, B., & Taylor, M. E. (2019). Agent modeling as auxiliary task for deep reinforcement learning. In AAAI conference on artificial intelligence and interactive digital entertainment.
Hernandez-Leal, P., Taylor, M. E., Rosman, B., Sucar, L. E., & Munoz de Cote, E. (2016). Identifying and tracking switching, non-stationary opponents: A Bayesian approach. In Multiagent interaction without prior coordination workshop at AAAI. Phoenix, AZ, USA.
Hernandez-Leal, P., Zhan, Y., Taylor, M. E., Sucar, L. E., & Munoz de Cote, E. (2017). Efficiently detecting switches against non-stationary opponents. Autonomous Agents and Multi-Agent Systems, 31(4), 767–789.
Hessel, M., Modayil, J., Van Hasselt, H., Schaul, T., Ostrovski, G., Dabney, W., Horgan, D., Piot, B., Azar, M., & Silver, D. (2018). Rainbow: Combining improvements in deep reinforcement learning. In Thirty-second AAAI conference on artificial intelligence.
Hinton, G., Vinyals, O., & Dean, J. (2014). Distilling the knowledge in a neural network. In NIPS deep learning workshop.
Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural Computation, 9(8), 1735–1780.
Hong, Z. W., Su, S. Y., Shann, T. Y., Chang, Y. H., & Lee, C. Y. (2018). A deep policy inference Q-network for multi-agent systems. In International conference on autonomous agents and multiagent systems.
Hu, J., & Wellman, M. P. (2003). Nash Q-learning for general-sum stochastic games. The Journal of Machine Learning Research, 4, 1039–1069.
Iba, H. (1996). Emergent cooperation for multiple agents using genetic programming. In International conference on parallel problem solving from nature (pp. 32–41). Springer.
Ilyas, A., Engstrom, L., Santurkar, S., Tsipras, D., Janoos, F., Rudolph, L., & Madry, A. (2018). Are deep policy gradient algorithms truly policy gradient algorithms? CoRR arXiv:1811.02553.
Ioffe, S., & Szegedy, C. (2015). Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd international conference on machine learning (pp. 448–456).
Isele, D., & Cosgun, A. (2018). Selective experience replay for lifelong learning. In Thirty-second AAAI conference on artificial intelligence.
Jaakkola, T., Jordan, M. I., & Singh, S. P. (1994). Convergence of stochastic iterative dynamic programming algorithms. In Advances in neural information processing systems (pp. 703–710)
Jacobs, R. A., Jordan, M. I., Nowlan, S. J., Hinton, G. E., et al. (1991). Adaptive mixtures of local experts. Neural Computation, 3(1), 79–87.
Jaderberg, M., Czarnecki, W. M., Dunning, I., Marris, L., Lever, G., Castañeda, A. G., et al. (2019). Human-level performance in 3d multiplayer games with population-based reinforcement learning. Science, 364(6443), 859–865. https://doi.org/10.1126/science.aau6249.
Jaderberg, M., Dalibard, V., Osindero, S., Czarnecki, W. M., Donahue, J., Razavi, A., Vinyals, O., Green, T., Dunning, I., & Simonyan, K., et al. (2017). Population based training of neural networks. arXiv:1711.09846.
Jaderberg, M., Mnih, V., Czarnecki, W. M., Schaul, T., Leibo, J. Z., Silver, D., & Kavukcuoglu, K. (2017). Reinforcement learning with unsupervised auxiliary tasks. In International conference on learning representations.
Johanson, M., Bard, N., Burch, N., & Bowling, M. (2012). Finding optimal abstract strategies in extensive-form games. In Twenty-sixth AAAI conference on artificial intelligence.
Johanson, M., Waugh, K., Bowling, M., & Zinkevich, M. (2011). Accelerating best response calculation in large extensive games. In Twenty-second international joint conference on artificial intelligence.
Johanson, M., Zinkevich, M. A., & Bowling, M. (2007). Computing robust counter-strategies. In Advances in neural information processing systems (pp. 721–728). Vancouver, BC, Canada.
Johnson, M., Hofmann, K., Hutton, T., & Bignell, D. (2016). The Malmo platform for artificial intelligence experimentation. In IJCAI (pp. 4246–4247).
Juliani, A., Berges, V., Vckay, E., Gao, Y., Henry, H., Mattar, M., & Lange, D. (2018). Unity: A general platform for intelligent agents. CoRR arXiv:1809.02627.
Kaelbling, L. P., Littman, M. L., & Moore, A. W. (1996). Reinforcement learning: A survey. Journal of Artificial Intelligence Research, 4, 237–285.
Kaisers, M., & Tuyls, K. (2011). FAQ-learning in matrix games: demonstrating convergence near Nash equilibria, and bifurcation of attractors in the battle of sexes. In AAAI Workshop on Interactive Decision Theory and Game Theory (pp. 309–316). San Francisco, CA, USA.
Kakade, S. M. (2002). A natural policy gradient. In Advances in neural information processing systems (pp. 1531–1538).
Kalai, E., & Lehrer, E. (1993). Rational learning leads to Nash equilibrium. Econometrica: Journal of the Econometric Society, 61, 1019–1045.
Kamihigashi, T., & Le Van, C. (2015). Necessary and sufficient conditions for a solution of the bellman equation to be the value function: A general principle. https://halshs.archives-ouvertes.fr/halshs-01159177
Kartal, B., Godoy, J., Karamouzas, I., & Guy, S. J. (2015). Stochastic tree search with useful cycles for patrolling problems. In 2015 IEEE international conference on robotics and automation (ICRA) (pp. 1289–1294). IEEE.
Kartal, B., Hernandez-Leal, P., & Taylor, M. E. (2019). Using Monte Carlo tree search as a demonstrator within asynchronous deep RL. In AAAI workshop on reinforcement learning in games.
Kartal, B., Nunes, E., Godoy, J., & Gini, M. (2016). Monte Carlo tree search with branch and bound for multi-robot task allocation. In The IJCAI-16 workshop on autonomous mobile service robots.
Khadka, S., Majumdar, S., & Tumer, K. (2019). Evolutionary reinforcement learning for sample-efficient multiagent coordination. arXiv e-prints arXiv:1906.07315.
Kim, W., Cho, M., & Sung, Y. (2019). Message-dropout: An efficient training method for multi-agent deep reinforcement learning. In 33rd AAAI conference on artificial intelligence.
Kok, J. R., & Vlassis, N. (2004). Sparse cooperative Q-learning. In Proceedings of the twenty-first international conference on Machine learning (p. 61). ACM.
Konda, V. R., & Tsitsiklis, J. (2000). Actor-critic algorithms. In Advances in neural information processing systems.
Konidaris, G., & Barto, A. (2006). Autonomous shaping: Knowledge transfer in reinforcement learning. In Proceedings of the 23rd international conference on machine learning (pp. 489–496). ACM.
Kretchmar, R. M., & Anderson, C. W. (1997). Comparison of CMACs and radial basis functions for local function approximators in reinforcement learning. In Proceedings of international conference on neural networks (ICNN’97) (Vol. 2, pp. 834–837). IEEE.
Kulkarni, T. D., Narasimhan, K., Saeedi, A., & Tenenbaum, J. (2016). Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation. In Advances in neural information processing systems (pp. 3675–3683).
Lake, B. M., Ullman, T. D., Tenenbaum, J., & Gershman, S. (2016). Building machines that learn and think like people. Behavioral and Brain Sciences, 40, 1–72.
Lanctot, M., Zambaldi, V. F., Gruslys, A., Lazaridou, A., Tuyls, K., Pérolat, J., Silver, D., & Graepel, T. (2017). A unified game-theoretic approach to multiagent reinforcement learning. In Advances in neural information processing systems.
Lauer, M., & Riedmiller, M. (2000). An algorithm for distributed reinforcement learning in cooperative multi-agent systems. In Proceedings of the seventeenth international conference on machine learning.
Laurent, G. J., Matignon, L., Fort-Piat, L., et al. (2011). The world of independent learners is not Markovian. International Journal of Knowledge-based and Intelligent Engineering Systems, 15(1), 55–64.
Lazaridou, A., Peysakhovich, A., & Baroni, M. (2017). Multi-agent cooperation and the emergence of (natural) language. In International conference on learning representations.
LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. Nature, 521(7553), 436.
Lehman, J., & Stanley, K. O. (2008). Exploiting open-endedness to solve problems through the search for novelty. In ALIFE (pp. 329–336).
Leibo, J. Z., Hughes, E., Lanctot, M., & Graepel, T. (2019). Autocurricula and the emergence of innovation from social interaction: A manifesto for multi-agent intelligence research. CoRR arXiv:1903.00742.
Leibo, J. Z., Perolat, J., Hughes, E., Wheelwright, S., Marblestone, A. H., Duéñez-Guzmán, E., Sunehag, P., Dunning, I., & Graepel, T. (2019). Malthusian reinforcement learning. In 18th international conference on autonomous agents and multiagent systems.
Leibo, J. Z., Zambaldi, V., Lanctot, M., & Marecki, J. (2017). Multi-agent reinforcement learning in sequential social dilemmas. In Proceedings of the 16th conference on autonomous agents and multiagent systems. Sao Paulo.
Lerer, A., & Peysakhovich, A. (2017). Maintaining cooperation in complex social dilemmas using deep reinforcement learning. CoRR arXiv:1707.01068.
Li, S., Wu, Y., Cui, X., Dong, H., Fang, F., & Russell, S. (2019). Robust multi-agent reinforcement learning via minimax deep deterministic policy gradient. In AAAI conference on artificial intelligence.
Li, Y. (2017). Deep reinforcement learning: An overview. CoRR arXiv:1701.07274.
Lillicrap, T. P., Hunt, J. J., Pritzel, A., Heess, N., Erez, T., Tassa, Y., Silver, D., & Wierstra, D. (2016). Continuous control with deep reinforcement learning. In International conference on learning representations.
Lin, L. J. (1991). Programming robots using reinforcement learning and teaching. In AAAI (pp. 781–786).
Lin, L. J. (1992). Self-improving reactive agents based on reinforcement learning, planning and teaching. Machine Learning, 8(3–4), 293–321.
Ling, C. K., Fang, F., & Kolter, J. Z. (2018). What game are we playing? End-to-end learning in normal and extensive form games. In Twenty-seventh international joint conference on artificial intelligence.
Lipton, Z. C., Azizzadenesheli, K., Kumar, A., Li, L., Gao, J., & Deng, L. (2018). Combating reinforcement learning’s Sisyphean curse with intrinsic fear. arXiv:1611.01211v8.
Lipton, Z. C., & Steinhardt, J. (2018). Troubling trends in machine learning scholarship. In ICML Machine Learning Debates workshop.
Littman, M. L. (1994). Markov games as a framework for multi-agent reinforcement learning. In Proceedings of the 11th international conference on machine learning (pp. 157–163). New Brunswick, NJ, USA.
Littman, M. L. (2001). Friend-or-foe Q-learning in general-sum games. In Proceedings of 17th international conference on autonomous agents and multiagent systems (pp. 322–328). Williamstown, MA, USA.
Littman, M. L. (2001). Value-function reinforcement learning in Markov games. Cognitive Systems Research, 2(1), 55–66.
Littman, M. L., & Stone, P. (2001). Implicit negotiation in repeated games. In ATAL ’01: revised papers from the 8th international workshop on intelligent agents VIII.
Liu, H., Feng, Y., Mao, Y., Zhou, D., Peng, J., & Liu, Q. (2018). Action-depedent control variates for policy optimization via stein’s identity. In International conference on learning representations.
Liu, S., Lever, G., Merel, J., Tunyasuvunakool, S., Heess, N., & Graepel, T. (2019). Emergent coordination through competition. In International conference on learning representations.
Lockhart, E., Lanctot, M., Pérolat, J., Lespiau, J., Morrill, D., Timbers, F., & Tuyls, K. (2019). Computing approximate equilibria in sequential adversarial games by exploitability descent. CoRR arXiv:1903.05614.
Lowe, R., Foerster, J., Boureau, Y. L., Pineau, J., & Dauphin, Y. (2019). On the pitfalls of measuring emergent communication. In 18th international conference on autonomous agents and multiagent systems.
Lowe, R., Wu, Y., Tamar, A., Harb, J., Abbeel, P., & Mordatch, I. (2017). Multi-agent actor-critic for mixed cooperative-competitive environments. In Advances in neural information processing systems (pp. 6379–6390).
Lu, T., Schuurmans, D., & Boutilier, C. (2018). Non-delusional Q-learning and value-iteration. In Advances in neural information processing systems (pp. 9949–9959).
Lyle, C., Castro, P. S., & Bellemare, M. G. (2019). A comparative analysis of expected and distributional reinforcement learning. In Thirty-third AAAI conference on artificial intelligence.
Multiagent Learning, Foundations and Recent Trends. (2017). [Online]. Retrieved September 7, 2018, https://www.cs.utexas.edu/~larg/ijcai17_tutorial/multiagent_learning.pdf .
Maaten, Lvd, & Hinton, G. (2008). Visualizing data using t-SNE. Journal of Machine Learning Research, 9(Nov), 2579–2605.
Machado, M. C., Bellemare, M. G., Talvitie, E., Veness, J., Hausknecht, M., & Bowling, M. (2018). Revisiting the arcade learning environment: Evaluation protocols and open problems for general agents. Journal of Artificial Intelligence Research, 61, 523–562.
Mahadevan, S., & Connell, J. (1992). Automatic programming of behavior-based robots using reinforcement learning. Artificial Intelligence, 55(2–3), 311–365.
Matignon, L., Laurent, G. J., & Le Fort-Piat, N. (2012). Independent reinforcement learners in cooperative Markov games: A survey regarding coordination problems. Knowledge Engineering Review, 27(1), 1–31.
McCloskey, M., & Cohen, N. J. (1989). Catastrophic interference in connectionist networks: The sequential learning problem. In G. H. Bower (Ed.), Psychology of learning and motivation (Vol. 24, pp. 109–165). Amsterdam: Elsevier.
McCracken, P., & Bowling, M. (2004) Safe strategies for agent modelling in games. In AAAI fall symposium (pp. 103–110).
Melis, G., Dyer, C., & Blunsom, P. (2018). On the state of the art of evaluation in neural language models. In International conference on learning representations.
Melo, F. S., Meyn, S. P., & Ribeiro, M. I. (2008). An analysis of reinforcement learning with function approximation. In Proceedings of the 25th international conference on Machine learning (pp. 664–671). ACM.
Meuleau, N., Peshkin, L., Kim, K. E., & Kaelbling, L. P. (1999). Learning finite-state controllers for partially observable environments. In Proceedings of the fifteenth conference on uncertainty in artificial intelligence (pp. 427–436).
Mnih, V., Badia, A. P., Mirza, M., Graves, A., Lillicrap, T., Harley, T., Silver, D., & Kavukcuoglu, K. (2016). Asynchronous methods for deep reinforcement learning. In International conference on machine learning (pp. 1928–1937).
Mnih, V., Kavukcuoglu, K., Silver, D., Graves, A., Antonoglou, I., Wierstra, D., & Riedmiller, M. (2013). Playing atari with deep reinforcement learning. arXiv:1312.5602v1.
Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness, J., Bellemare, M. G., et al. (2015). Human-level control through deep reinforcement learning. Nature, 518(7540), 529–533.
Monderer, D., & Shapley, L. S. (1996). Fictitious play property for games with identical interests. Journal of Economic Theory, 68(1), 258–265.
Moore, A. W., & Atkeson, C. G. (1993). Prioritized sweeping: Reinforcement learning with less data and less time. Machine Learning, 13(1), 103–130.
Moravčík, M., Schmid, M., Burch, N., Lisý, V., Morrill, D., Bard, N., et al. (2017). DeepStack: Expert-level artificial intelligence in heads-up no-limit poker. Science, 356(6337), 508–513.
Mordatch, I., & Abbeel, P. (2018). Emergence of grounded compositional language in multi-agent populations. In Thirty-second AAAI conference on artificial intelligence.
Moriarty, D. E., Schultz, A. C., & Grefenstette, J. J. (1999). Evolutionary algorithms for reinforcement learning. Journal of Artificial Intelligence Research, 11, 241–276.
Morimoto, J., & Doya, K. (2005). Robust reinforcement learning. Neural Computation, 17(2), 335–359.
Nagarajan, P., Warnell, G., & Stone, P. (2018). Deterministic implementations for reproducibility in deep reinforcement learning. arXiv:1809.05676
Nash, J. F. (1950). Equilibrium points in n-person games. Proceedings of the National Academy of Sciences, 36(1), 48–49.
Neller, T. W., & Lanctot, M. (2013). An introduction to counterfactual regret minimization. In Proceedings of model AI assignments, the fourth symposium on educational advances in artificial intelligence (EAAI-2013).
Ng, A. Y., Harada, D., & Russell, S. J. (1999). Policy invariance under reward transformations: Theory and application to reward shaping. In Proceedings of the sixteenth international conference on machine learning (pp. 278–287).
Nguyen, T. T., Nguyen, N. D., & Nahavandi, S. (2018). Deep reinforcement learning for multi-agent systems: A review of challenges, solutions and applications. arXiv preprint arXiv:1812.11794.
Nowé, A., Vrancx, P., & De Hauwere, Y. M. (2012). Game theory and multi-agent reinforcement learning. In M. Wiering & M. van Otterlo (Eds.), Reinforcement learning (pp. 441–470). Berlin: Springer.
OpenAI Baselines: ACKTR & A2C. (2017). [Online]. Retrieved April 29, 2019, https://openai.com/blog/baselines-acktr-a2c/ .
Open AI Five. (2018). [Online]. Retrieved September 7, 2018, https://blog.openai.com/openai-five.
Oliehoek, F. A. (2018). Interactive learning and decision making - foundations, insights & challenges. In International joint conference on artificial intelligence.
Oliehoek, F. A., Amato, C., et al. (2016). A concise introduction to decentralized POMDPs. Berlin: Springer.
Oliehoek, F. A., De Jong, E. D., & Vlassis, N. (2006). The parallel Nash memory for asymmetric games. In Proceedings of the 8th annual conference on genetic and evolutionary computation (pp. 337–344). ACM.
Oliehoek, F. A., Spaan, M. T., & Vlassis, N. (2008). Optimal and approximate Q-value functions for decentralized POMDPs. Journal of Artificial Intelligence Research, 32, 289–353.
Oliehoek, F. A., Whiteson, S., & Spaan, M. T. (2013). Approximate solutions for factored Dec-POMDPs with many agents. In Proceedings of the 2013 international conference on Autonomous agents and multi-agent systems (pp. 563–570). International Foundation for Autonomous Agents and Multiagent Systems.
Oliehoek, F. A., Witwicki, S. J., & Kaelbling, L. P. (2012). Influence-based abstraction for multiagent systems. In Twenty-sixth AAAI conference on artificial intelligence.
Omidshafiei, S., Hennes, D., Morrill, D., Munos, R., Perolat, J., Lanctot, M., Gruslys, A., Lespiau, J. B., & Tuyls, K. (2019). Neural replicator dynamics. arXiv e-prints arXiv:1906.00190.
Omidshafiei, S., Papadimitriou, C., Piliouras, G., Tuyls, K., Rowland, M., Lespiau, J. B., et al. (2019). \(\alpha \)-rank: Multi-agent evaluation by evolution. Scientific Reports, 9, 9937.
Omidshafiei, S., Pazis, J., Amato, C., How, J. P., & Vian, J. (2017). Deep decentralized multi-task multi-agent reinforcement learning under partial observability. In Proceedings of the 34th international conference on machine learning. Sydney.
Ortega, P. A., & Legg, S. (2018). Modeling friends and foes. arXiv:1807.00196
Palmer, G., Savani, R., & Tuyls, K. (2019). Negative update intervals in deep multi-agent reinforcement learning. In 18th International conference on autonomous agents and multiagent systems.
Palmer, G., Tuyls, K., Bloembergen, D., & Savani, R. (2018). Lenient multi-agent deep reinforcement learning. In International conference on autonomous agents and multiagent systems.
Panait, L., & Luke, S. (2005). Cooperative multi-agent learning: The state of the art. Autonomous Agents and Multi-Agent Systems, 11(3), 387–434.
Panait, L., Sullivan, K., & Luke, S. (2006). Lenience towards teammates helps in cooperative multiagent learning. In Proceedings of the 5th international conference on autonomous agents and multiagent systems. Hakodate, Japan.
Panait, L., Tuyls, K., & Luke, S. (2008). Theoretical advantages of lenient learners: An evolutionary game theoretic perspective. JMLR, 9(Mar), 423–457.
Papoudakis, G., Christianos, F., Rahman, A., & Albrecht, S. V. (2019). Dealing with non-stationarity in multi-agent deep reinforcement learning. arXiv preprint arXiv:1906.04737.
Pascanu, R., Mikolov, T., & Bengio, Y. (2013). On the difficulty of training recurrent neural networks. In International conference on machine learning (pp. 1310–1318).
Peng, P., Yuan, Q., Wen, Y., Yang, Y., Tang, Z., Long, H., & Wang, J. (2017). Multiagent bidirectionally-coordinated nets for learning to play StarCraft combat games. arXiv:1703.10069
Pérez-Liébana, D., Hofmann, K., Mohanty, S. P., Kuno, N., Kramer, A., Devlin, S., Gaina, R. D., & Ionita, D. (2019). The multi-agent reinforcement learning in Malmö (MARLÖ) competition. CoRR arXiv:1901.08129.
Pérolat, J., Piot, B., & Pietquin, O. (2018). Actor-critic fictitious play in simultaneous move multistage games. In 21st international conference on artificial intelligence and statistics.
Pesce, E., & Montana, G. (2019). Improving coordination in multi-agent deep reinforcement learning through memory-driven communication. CoRR arXiv:1901.03887.
Pinto, L., Davidson, J., Sukthankar, R., & Gupta, A. (2017). Robust adversarial reinforcement learning. In Proceedings of the 34th international conference on machine learning (Vol. 70, pp. 2817–2826). JMLR. org
Powers, R., & Shoham, Y. (2005). Learning against opponents with bounded memory. In Proceedings of the 19th international joint conference on artificial intelligence (pp. 817–822). Edinburg, Scotland, UK.
Powers, R., Shoham, Y., & Vu, T. (2007). A general criterion and an algorithmic framework for learning in multi-agent systems. Machine Learning, 67(1–2), 45–76.
Precup, D., Sutton, R. S., & Singh, S. (2000). Eligibility traces for off-policy policy evaluation. In Proceedings of the seventeenth international conference on machine learning.
Puterman, M. L. (1994). Markov decision processes: Discrete stochastic dynamic programming. New York: Wiley.
Pyeatt, L. D., Howe, A. E., et al. (2001). Decision tree function approximation in reinforcement learning. In Proceedings of the third international symposium on adaptive systems: Evolutionary computation and probabilistic graphical models (Vol. 2, pp. 70–77). Cuba.
Rabinowitz, N. C., Perbet, F., Song, H. F., Zhang, C., Eslami, S. M. A., & Botvinick, M. (2018). Machine theory of mind. In International conference on machine learning. Stockholm, Sweden.
Raghu, M., Irpan, A., Andreas, J., Kleinberg, R., Le, Q., & Kleinberg, J. (2018). Can deep reinforcement learning solve Erdos–Selfridge-spencer games? In Proceedings of the 35th international conference on machine learning.
Raileanu, R., Denton, E., Szlam, A., & Fergus, R. (2018). Modeling others using oneself in multi-agent reinforcement learning. In International conference on machine learning.
Rashid, T., Samvelyan, M., de Witt, C. S., Farquhar, G., Foerster, J. N., & Whiteson, S. (2018). QMIX - monotonic value function factorisation for deep multi-agent reinforcement learning. In International conference on machine learning.
Resnick, C., Eldridge, W., Ha, D., Britz, D., Foerster, J., Togelius, J., Cho, K., & Bruna, J. (2018). Pommerman: A multi-agent playground. arXiv:1809.07124.
Riedmiller, M. (2005). Neural fitted Q iteration–first experiences with a data efficient neural reinforcement learning method. In European conference on machine learning (pp. 317–328). Springer.
Riemer, M., Cases, I., Ajemian, R., Liu, M., Rish, I., Tu, Y., & Tesauro, G. (2018). Learning to learn without forgetting by maximizing transfer and minimizing interference. CoRR arXiv:1810.11910.
Rosenthal, R. (1979). The file drawer problem and tolerance for null results. Psychological Bulletin, 86(3), 638.
Rosin, C. D., & Belew, R. K. (1997). New methods for competitive coevolution. Evolutionary Computation, 5(1), 1–29.
Rosman, B., Hawasly, M., & Ramamoorthy, S. (2016). Bayesian policy reuse. Machine Learning, 104(1), 99–127.
Rusu, A. A., Colmenarejo, S. G., Gulcehre, C., Desjardins, G., Kirkpatrick, J., Pascanu, R., Mnih, V., Kavukcuoglu, K., & Hadsell, R. (2016). Policy distillation. In International conference on learning representations.
Salimans, T., & Kingma, D. P. (2016). Weight normalization: A simple reparameterization to accelerate training of deep neural networks. In Advances in neural information processing systems (pp. 901–909).
Samothrakis, S., Lucas, S., Runarsson, T., & Robles, D. (2013). Coevolving game-playing agents: Measuring performance and intransitivities. IEEE Transactions on Evolutionary Computation, 17(2), 213–226.
Samvelyan, M., Rashid, T., de Witt, C. S., Farquhar, G., Nardelli, N., Rudner, T. G. J., Hung, C., Torr, P. H. S., Foerster, J. N., & Whiteson, S. (2019). The StarCraft multi-agent challenge. CoRR arXiv:1902.04043.
Sandholm, T. W., & Crites, R. H. (1996). Multiagent reinforcement learning in the iterated prisoner’s dilemma. Biosystems, 37(1–2), 147–166.
Schaul, T., Quan, J., Antonoglou, I., & Silver, D. (2016). Prioritized experience replay. In International conference on learning representations.
Schmidhuber, J. (1991). A possibility for implementing curiosity and boredom in model-building neural controllers. In Proceedings of the international conference on simulation of adaptive behavior: From animals to animats (pp. 222–227).
Schmidhuber, J. (2015). Critique of Paper by “Deep Learning Conspiracy” (Nature 521 p 436). http://people.idsia.ch/~juergen/deep-learning-conspiracy.html.
Schmidhuber, J. (2015). Deep learning in neural networks: An overview. Neural Networks, 61, 85–117.
Schulman, J., Abbeel, P., & Chen, X. (2017) Equivalence between policy gradients and soft Q-learning. CoRR arXiv:1704.06440.
Schulman, J., Levine, S., Abbeel, P., Jordan, M. I., & Moritz, P. (2015). Trust region policy optimization. In 31st international conference on machine learning. Lille, France.
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., & Klimov, O. (2017). Proximal policy optimization algorithms. arXiv:1707.06347.
Schuster, M., & Paliwal, K. K. (1997). Bidirectional recurrent neural networks. IEEE Transactions on Signal Processing, 45(11), 2673–2681.
Sculley, D., Snoek, J., Wiltschko, A., & Rahimi, A. (2018). Winner’s curse? On pace, progress, and empirical rigor. In ICLR workshop.
Shamma, J. S., & Arslan, G. (2005). Dynamic fictitious play, dynamic gradient play, and distributed convergence to Nash equilibria. IEEE Transactions on Automatic Control, 50(3), 312–327.
Shelhamer, E., Mahmoudieh, P., Argus, M., & Darrell, T. (2017). Loss is its own reward: Self-supervision for reinforcement learning. In ICLR workshops.
Shoham, Y., Powers, R., & Grenager, T. (2007). If multi-agent learning is the answer, what is the question? Artificial Intelligence, 171(7), 365–377.
Silva, F. L., & Costa, A. H. R. (2019). A survey on transfer learning for multiagent reinforcement learning systems. Journal of Artificial Intelligence Research, 64, 645–703.
Silver, D., Huang, A., Maddison, C. J., Guez, A., Sifre, L., van den Driessche, G., et al. (2016). Mastering the game of go with deep neural networks and tree search. Nature, 529(7587), 484–489.
Silver, D., Lever, G., Heess, N., Degris, T., Wierstra, D., & Riedmiller, M. (2014). Deterministic policy gradient algorithms. In ICML.
Silver, D., Schrittwieser, J., Simonyan, K., Antonoglou, I., Huang, A., Guez, A., et al. (2017). Mastering the game of go without human knowledge. Nature, 550(7676), 354.
Singh, S., Jaakkola, T., Littman, M. L., & Szepesvári, C. (2000). Convergence results for single-step on-policy reinforcement-learning algorithms. Machine Learning, 38(3), 287–308.
Singh, S., Kearns, M., & Mansour, Y. (2000). Nash convergence of gradient dynamics in general-sum games. In Proceedings of the sixteenth conference on uncertainty in artificial intelligence (pp. 541–548). Morgan Kaufmann Publishers Inc.
Singh, S. P. (1992). Transfer of learning by composing solutions of elemental sequential tasks. Machine Learning, 8(3–4), 323–339.
Song, X., Wang, T., & Zhang, C. (2019). Convergence of multi-agent learning with a finite step size in general-sum games. In 18th International conference on autonomous agents and multiagent systems.
Song, Y., Wang, J., Lukasiewicz, T., Xu, Z., Xu, M., Ding, Z., & Wu, L. (2019). Arena: A general evaluation platform and building toolkit for multi-agent intelligence. CoRR arXiv:1905.08085.
Spencer, J. (1994). Randomization, derandomization and antirandomization: three games. Theoretical Computer Science, 131(2), 415–429.
Srinivasan, S., Lanctot, M., Zambaldi, V., Pérolat, J., Tuyls, K., Munos, R., & Bowling, M. (2018). Actor-critic policy optimization in partially observable multiagent environments. In Advances in neural information processing systems (pp. 3422–3435).
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., & Salakhutdinov, R. (2014). Dropout: a simple way to prevent neural networks from overfitting. The Journal of Machine Learning Research, 15(1), 1929–1958.
Steckelmacher, D., Roijers, D. M., Harutyunyan, A., Vrancx, P., Plisnier, H., & Nowé, A. (2018). Reinforcement learning in pomdps with memoryless options and option-observation initiation sets. In Thirty-second AAAI conference on artificial intelligence.
Stimpson, J. L., & Goodrich, M. A. (2003). Learning to cooperate in a social dilemma: A satisficing approach to bargaining. In Proceedings of the 20th international conference on machine learning (ICML-03) (pp. 728–735).
Stone, P., Kaminka, G., Kraus, S., & Rosenschein, J. S. (2010). Ad Hoc autonomous agent teams: Collaboration without pre-coordination. In 32nd AAAI conference on artificial intelligence (pp. 1504–1509). Atlanta, Georgia, USA.
Stone, P., & Veloso, M. M. (2000). Multiagent systems - a survey from a machine learning perspective. Autonomous Robots, 8(3), 345–383.
Stooke, A., & Abbeel, P. (2018). Accelerated methods for deep reinforcement learning. CoRR arXiv:1803.02811.
Strehl, A. L., & Littman, M. L. (2008). An analysis of model-based interval estimation for Markov decision processes. Journal of Computer and System Sciences, 74(8), 1309–1331.
Suarez, J., Du, Y., Isola, P., & Mordatch, I. (2019). Neural MMO: A massively multiagent game environment for training and evaluating intelligent agents. CoRR arXiv:1903.00784.
Suau de Castro, M., Congeduti, E., Starre, R. A., Czechowski, A., & Oliehoek, F. A. (2019). Influence-based abstraction in deep reinforcement learning. In Adaptive, learning agents workshop.
Such, F. P., Madhavan, V., Conti, E., Lehman, J., Stanley, K. O., & Clune, J. (2017). Deep neuroevolution: Genetic algorithms are a competitive alternative for training deep neural networks for reinforcement learning. CoRR arXiv:1712.06567.
Suddarth, S. C., & Kergosien, Y. (1990). Rule-injection hints as a means of improving network performance and learning time. In Neural networks (pp. 120–129). Springer.
Sukhbaatar, S., Szlam, A., & Fergus, R. (2016). Learning multiagent communication with backpropagation. In Advances in neural information processing systems (pp. 2244–2252).
Sunehag, P., Lever, G., Gruslys, A., Czarnecki, W. M., Zambaldi, V. F., Jaderberg, M., Lanctot, M., Sonnerat, N., Leibo, J. Z., Tuyls, K., & Graepel, T. (2018). Value-decomposition networks for cooperative multi-agent learning based on team reward. In Proceedings of 17th international conference on autonomous agents and multiagent systems. Stockholm, Sweden.
Sutton, R. S. (1996). Generalization in reinforcement learning: Successful examples using sparse coarse coding. In Advances in neural information processing systems (pp. 1038–1044).
Sutton, R. S., & Barto, A. G. (2018). Reinforcement learning: An introduction (2nd ed.). Cambridge: MIT Press.
Sutton, R. S., McAllester, D. A., Singh, S. P., & Mansour, Y. (2000). Policy gradient methods for reinforcement learning with function approximation. In Advances in neural information processing systems.
Sutton, R. S., Modayil, J., Delp, M., Degris, T., Pilarski, P. M., White, A., & Precup, D. (2011). Horde: A scalable real-time architecture for learning knowledge from unsupervised sensorimotor interaction. In The 10th international conference on autonomous agents and multiagent systems (Vol. 2, pp. 761–768). International Foundation for Autonomous Agents and Multiagent Systems.
Szepesvári, C. (2010). Algorithms for reinforcement learning. Synthesis Lectures on Artificial Intelligence and Machine Learning, 4(1), 1–103.
Szepesvári, C., & Littman, M. L. (1999). A unified analysis of value-function-based reinforcement-learning algorithms. Neural Computation, 11(8), 2017–2060.
Tamar, A., Levine, S., Abbeel, P., Wu, Y., & Thomas, G. (2016). Value iteration networks. In NIPS (pp. 2154–2162).
Tambe, M. (1997). Towards flexible teamwork. Journal of Artificial Intelligence Research, 7, 83–124.
Tampuu, A., Matiisen, T., Kodelja, D., Kuzovkin, I., Korjus, K., Aru, J., et al. (2017). Multiagent cooperation and competition with deep reinforcement learning. PLoS ONE, 12(4), e0172395.
Tan, M. (1993). Multi-agent reinforcement learning: Independent vs. cooperative agents. In Machine learning proceedings 1993 proceedings of the tenth international conference, University of Massachusetts, Amherst, 27–29 June, 1993 (pp. 330–337).
Taylor, M. E., & Stone, P. (2009). Transfer learning for reinforcement learning domains: A survey. The Journal of Machine Learning Research, 10, 1633–1685.
Tesauro, G. (1995). Temporal difference learning and TD-Gammon. Communications of the ACM, 38(3), 58–68.
Tesauro, G. (2003). Extending Q-learning to general adaptive multi-agent systems. In Advances in neural information processing systems (pp. 871–878). Vancouver, Canada.
Todorov, E., Erez, T., & Tassa, Y. (2012). MuJoCo - A physics engine for model-based control. In Intelligent robots and systems( pp. 5026–5033).
Torrado, R. R., Bontrager, P., Togelius, J., Liu, J., & Perez-Liebana, D. (2018). Deep reinforcement learning for general video game AI. arXiv:1806.02448
Tsitsiklis, J. (1994). Asynchronous stochastic approximation and Q-learning. Machine Learning, 16(3), 185–202.
Tsitsiklis, J. N., & Van Roy, B. (1997). Analysis of temporal-diffference learning with function approximation. In Advances in neural information processing systems (pp. 1075–1081).
Tucker, G., Bhupatiraju, S., Gu, S., Turner, R. E., Ghahramani, Z., & Levine, S. (2018). The mirage of action-dependent baselines in reinforcement learning. In International conference on machine learning.
Tumer, K., & Agogino, A. (2007). Distributed agent-based air traffic flow management. In Proceedings of the 6th international conference on autonomous agents and multiagent systems. Honolulu, Hawaii.
Tuyls, K., & Weiss, G. (2012). Multiagent learning: Basics, challenges, and prospects. AI Magazine, 33(3), 41–52.
van Hasselt, H., Doron, Y., Strub, F., Hessel, M., Sonnerat, N., & Modayil, J. (2018). Deep reinforcement learning and the deadly triad. CoRR arXiv:1812.02648.
Van der Pol, E., & Oliehoek, F. A. (2016). Coordinated deep reinforcement learners for traffic light control. In Proceedings of learning, inference and control of multi-agent systems at NIPS.
Van Hasselt, H., Guez, A., & Silver, D. (2016). Deep reinforcement learning with double Q-learning. In Thirtieth AAAI conference on artificial intelligence.
Van Seijen, H., Van Hasselt, H., Whiteson, S., & Wiering, M. (2009). A theoretical and empirical analysis of Expected Sarsa. In IEEE symposium on adaptive dynamic programming and reinforcement learning (pp. 177–184). Nashville, TN, USA.
Vezhnevets, A. S., Osindero, S., Schaul, T., Heess, N., Jaderberg, M., Silver, D., & Kavukcuoglu, K. (2017). FeUdal networks for hierarchical reinforcement learning. In International conference on machine learning.
Vinyals, O., Babuschkin, I., Chung, J., Mathieu, M., Jaderberg, M., Czarnecki, W. M., Dudzik, A., Huang, A., Georgiev, P., Powell, R., Ewalds, T., Horgan, D., Kroiss, M., Danihelka, I., Agapiou, J., Oh, J., Dalibard, V., Choi, D., Sifre, L., Sulsky, Y., Vezhnevets, S., Molloy, J., Cai, T., Budden, D., Paine, T., Gulcehre, C., Wang, Z., Pfaff, T., Pohlen, T., Wu, Y., Yogatama, D., Cohen, J., McKinney, K., Smith, O., Schaul, T., Lillicrap, T., Apps, C., Kavukcuoglu, K., Hassabis, D., & Silver, D. (2019). AlphaStar: Mastering the real-time strategy game StarCraft II. https://deepmind.com/blog/alphastar-mastering-real-time-strategy-game-starcraft-ii/
Vodopivec, T., Samothrakis, S., & Ster, B. (2017). On Monte Carlo tree search and reinforcement learning. Journal of Artificial Intelligence Research, 60, 881–936.
Von Neumann, J., & Morgenstern, O. (1945). Theory of games and economic behavior (Vol. 51). New York: Bulletin of the American Mathematical Society.
Walsh, W. E., Das, R., Tesauro, G., & Kephart, J. O. (2002). Analyzing complex strategic interactions in multi-agent systems. In AAAI-02 workshop on game-theoretic and decision-theoretic agents (pp. 109–118).
Wang, H., Raj, B., & Xing, E. P. (2017). On the origin of deep learning. CoRR arXiv:1702.07800.
Wang, Z., Bapst, V., Heess, N., Mnih, V., Munos, R., Kavukcuoglu, K., & de Freitas, N. (2016). Sample efficient actor-critic with experience replay. arXiv preprint arXiv:1611.01224.
Wang, Z., Schaul, T., Hessel, M., Van Hasselt, H., Lanctot, M., & De Freitas, N. (2016). Dueling network architectures for deep reinforcement learning. In International conference on machine learning.
Watkins, J. (1989). Learning from delayed rewards. Ph.D. thesis, King’s College, Cambridge, UK
Wei, E., & Luke, S. (2016). Lenient learning in independent-learner stochastic cooperative games. Journal of Machine Learning Research, 17, 1–42.
Wei, E., Wicke, D., Freelan, D., & Luke, S. (2018). Multiagent soft Q-learning. arXiv:1804.09817
Weinberg, M., & Rosenschein, J. S. (2004). Best-response multiagent learning in non-stationary environments. In Proceedings of the 3rd international conference on autonomous agents and multiagent systems (pp. 506–513). New York, NY, USA.
Weiss, G. (Ed.). (2013). Multiagent systems. Intelligent robotics and autonomous agents series (2nd ed.). Cambridge, MA: MIT Press.
Whiteson, S., & Stone, P. (2006). Evolutionary function approximation for reinforcement learning. Journal of Machine Learning Research, 7(May), 877–917.
Whiteson, S., Tanner, B., Taylor, M. E., & Stone, P. (2011). Protecting against evaluation overfitting in empirical reinforcement learning. In 2011 IEEE symposium on adaptive dynamic programming and reinforcement learning (ADPRL) (pp. 120–127). IEEE.
Wiering, M., & van Otterlo, M. (Eds.) (2012). Reinforcement learning. Adaptation, learning, and optimization (Vol. 12). Springer-Verlag Berlin Heidelberg.
Williams, R. J. (1992). Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine Learning, 8(3–4), 229–256.
Wolpert, D. H., & Tumer, K. (2002). Optimal payoff functions for members of collectives. In Modeling complexity in economic and social systems (pp. 355–369).
Wolpert, D. H., Wheeler, K. R., & Tumer, K. (1999). General principles of learning-based multi-agent systems. In Proceedings of the third international conference on autonomous agents.
Wunder, M., Littman, M. L., & Babes, M. (2010). Classes of multiagent Q-learning dynamics with epsilon-greedy exploration. In Proceedings of the 35th international conference on machine learning (pp. 1167–1174). Haifa, Israel.
Yang, T., Hao, J., Meng, Z., Zhang, C., & Zheng, Y. Z. Z. (2019). Towards efficient detection and optimal response against sophisticated opponents. In IJCAI.
Yang, Y., Hao, J., Sun, M., Wang, Z., Fan, C., & Strbac, G. (2018). Recurrent deep multiagent Q-learning for autonomous brokers in smart grid. In Proceedings of the twenty-seventh international joint conference on artificial intelligence. Stockholm, Sweden.
Yang, Y., Luo, R., Li, M., Zhou, M., Zhang, W., & Wang, J. (2018). Mean field multi-agent reinforcement learning. In Proceedings of the 35th international conference on machine learning. Stockholm Sweden.
Yu, Y. (2018). Towards sample efficient reinforcement learning. In IJCAI (pp. 5739–5743).
Zahavy, T., Ben-Zrihem, N., & Mannor, S. (2016). Graying the black box: Understanding DQNs. In International conference on machine learning (pp. 1899–1908).
Zhang, C., & Lesser, V. (2010). Multi-agent learning with policy prediction. In Twenty-fourth AAAI conference on artificial intelligence.
Zhao, J., Qiu, G., Guan, Z., Zhao, W., & He, X. (2018). Deep reinforcement learning for sponsored search real-time bidding. In Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining (pp. 1021–1030). ACM.
Zheng, Y., Hao, J., & Zhang, Z. (2018). Weighted double deep multiagent reinforcement learning in stochastic cooperative environments. arXiv:1802.08534.
Zheng, Y., Meng, Z., Hao, J., Zhang, Z., Yang, T., & Fan, C. (2018). A deep bayesian policy reuse approach against non-stationary agents. In Advances in Neural Information Processing Systems (pp. 962–972).
Zinkevich, M., Greenwald, A., & Littman, M. L. (2006). Cyclic equilibria in Markov games. In Advances in neural information processing systems (pp. 1641–1648).
Zinkevich, M., Johanson, M., Bowling, M., & Piccione, C. (2008). Regret minimization in games with incomplete information. In Advances in neural information processing systems (pp. 1729–1736).
Acknowledgements
We would like to thank Chao Gao, Nidhi Hegde, Gregory Palmer, Felipe Leno Da Silva and Craig Sherstan for reading earlier versions of this work and providing feedback, to April Cooper for her visual designs for the figures in the article, to Frans Oliehoek, Sam Devlin, Marc Lanctot, Nolan Bard, Roberta Raileanu, Angeliki Lazaridou, and Yuhang Song for clarifications in their areas of expertise, to Baoxiang Wang for his suggestions on recent deep RL works, to Michael Kaisers, Daan Bloembergen, and Katja Hofmann for their comments about the practical challenges of MDRL, and to the editor and three anonymous reviewers whose comments and suggestions increased the quality of this work.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Hernandez-Leal, P., Kartal, B. & Taylor, M.E. A survey and critique of multiagent deep reinforcement learning. Auton Agent Multi-Agent Syst 33, 750–797 (2019). https://doi.org/10.1007/s10458-019-09421-1
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10458-019-09421-1