
Abstract
Awake craniotomy with direct electrical stimulation (DES) is the standard treatment for patients with eloquent area gliomas. DES detects speech and language errors, which indicate functional boundaries that must be maintained to preserve quality of life. During DES, traditional object naming or other linguistic tasks such as tasks from the Dutch Linguistic Intraoperative Protocol (DuLIP) can be used. It is not fully clear which speech and language errors occur in which brain locations. To provide an overview and to update DuLIP, a systematic review was conducted in which 102 studies were included, reporting on speech and language errors and the corresponding brain locations during awake craniotomy with DES in adult glioma patients up until 6 July 2020. The current findings provide a crude overview on language localization. Even though subcortical areas are in general less often investigated intraoperatively, still 40% out of all errors was reported at the subcortical level and almost 60% at the cortical level. Rudimentary localization patterns for different error types were observed and compared to the dual-stream model of language processing and the DuLIP model. While most patterns were similar compared to the models, additional locations were identified for articulation/motor speech, phonology, reading, and writing. Based on these patterns, we propose an updated DuLIP model. This model can be applied for a more adequate “location-to-function” language task selection to assess different linguistic functions during awake craniotomy, to possibly improve intraoperative language monitoring. This could result in a better postoperative language outcome in the future.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Gliomas are primary brain tumors that are typically located in eloquent areas of the brain [1]. The current gold standard treatment for gliomas in eloquent areas is awake craniotomy with direct electrical stimulation (DES) [2]. By using DES in combination with various tasks, critical functional areas (e.g., language, motor) can be identified and preserved during tumor resection, resulting in a larger extent of resection while maintaining neurological and cognitive function [2,3,4,5,6]. This can result in an extension of survival time with preservation of quality of life [7].
DES has contributed significantly to the modern perspective on language localization [8,9,10,11,12]. Traditionally, a topological viewpoint of language localization was adopted in which two brain regions in the left hemisphere were described and associated with the production and the comprehension of speech and language: Broca’s [13, 14] and Wernicke’s area [15], respectively. Nowadays, however, a hodotopical viewpoint is accepted as many language mapping studies have shown that language functions are located in various cortical brain locations, well beyond the two classical language regions [16,17,18] and that subcortical pathways are crucial for language functions as well [19].
During DES and resection, different types of (temporary) speech and language errors (paraphasias) can be elicited. Examples are speech arrests, verbal apraxia, dysarthria, semantic paraphasias (related in meaning: “cat” for “dog”), phonemic paraphasias (substitution of phonemes: “lorse” for “horse”), difficulty with (initiation of) spontaneous speech, and (auditory) comprehension errors. The elicited errors suggest that the corresponding language function is (at least partially) localized in that specific brain location [20, 21]. Different locations of language errors have been observed between high-grade and low-grade glioma patients [22].
Intraoperative language mapping is traditionally mainly done with object naming [8, 23, 24]. Although sensitive, with the application of only object naming during DES and resection, other language functions could be left untested and the possible corresponding deficits thus unremarked [25, 26]. Dissociations in language impairments have been described, such as intact object naming in combination with impaired other linguistic modalities like auditory language comprehension [27]. Hence, various linguistic tests should be applied to preserve language at different modalities (production, comprehension, reading, writing) and/or linguistic levels (phonology, semantics, (morpho-)syntax).
The first Dutch linguistic intraoperative test battery with tasks at different linguistic modalities (production, comprehension, reading) and levels (phonology, semantics, syntax) is the Dutch Linguistic Intraoperative Protocol (DuLIP) [28]. These tasks can be selected according to tumor location in cortico-subcortical areas associated with specific linguistic functions. For example, while spontaneous speech involves a complex interplay between different language functions, it has been found to be partly localized in the supplementary motor area (SMA) [29], the insula, the subcallosal fascicle (also called the frontal striatal tract: FST), and the inferior longitudinal fascicle (ILF) [30]. To assess this language function in those specific locations, DuLIP includes a test in which a sentence must be completed in a grammatical and meaningful way (sentence completion). Another example is that semantics has been found to be partly localized in the temporal and prefrontal cortex and the inferior fronto-occipital fascicle (IFOF) [31]. To assess this language function in those specific locations, DuLIP includes a task in which three pictures are presented and the picture that is not semantically related to the other two must be named (odd picture out). DuLIP has been adapted to other languages, such as Portuguese [32]. Nowadays, other test batteries and tests for intraoperative use are available as well [33,34,35,36].
Considering that much research has been done on language localization during DES [37,38,39,40], it can be difficult to obtain a full picture of the localization of language functions at the cortical and subcortical level at one glance. A recent review by Young et al. [41] contributes to this field of research by providing a narrative overview. With the current systematic review, we aim to add more detailed information on language localization. The aims of this study are (1) to systematically review all specific speech and language errors elicited during awake surgery with DES and their corresponding cortical and subcortical brain locations, (2) to investigate whether brain localization patterns of these errors can be identified, (3) to interpret these error localization patterns and the corresponding language functions with the dual-stream model of language processing [42, 43] and the DuLIP model, and (4) to update the DuLIP model. Results can lead to a more theoretical understanding of where and how language is localized in the brain. Moreover, this knowledge could also be used in a clinical setting, to guide adequate task selection during awake craniotomies.
Materials and methods
Details of the protocol for this systematic review were registered in the PROSPERO database (CRD42020196727). During data collection, it became apparent that there would be too much data to describe in one article. Therefore, the original outline as displayed on PROSPERO was divided into two, resulting in the current article (focusing on intraoperative speech and language errors and brain location) and a second article (focusing on intraoperative speech and language errors and language outcome [44]).
Study selection
A systematic search of the literature was performed according to the PRISMA statement guidelines [45]. The following online databases were searched: Embase, Medline Ovid, Web of Science, Cochrane, and Google Scholar (for search terms, see Supplementary Materials 1). Articles with publication dates up until July 6, 2020 were included. A reviewer (EC) performed the search in collaboration with a biomedical information specialist from the Medical Library at the Erasmus Medical Centre. Difficult cases (e.g., when the type of error or brain location was not clear) were discussed with two co-authors (D.S. and A.V.).
Inclusion and exclusion criteria
The inclusion and exclusion criteria were defined according to the PICO (patient population, intervention, control, outcome) framework criteria. All articles were included that reported on adult monolingual patients with gliomas (WHO grade II–IV: Patient population) who underwent awake craniotomies with DES (intervention) and who produced specific intraoperative speech and language errors (outcome) while stimulating or resecting in a specific reported brain location (outcome). As long as DES was used, studies using additional imaging techniques (e.g., iMRI, CCEP, grids) were also included.
Articles were excluded if brain locations or speech/language errors were not reported, not further specified, or not clear. Articles were also excluded if they did not report: (original) patient data, intraoperative language information, on glioma patients, or if no language mapping occurred, another surgery protocol was used, when the article was an abstract, review, or editorial or was written in another language than English or Dutch. The PRISMA flowchart is shown in Fig. 1.

PRISMA flowchart of total records identified through database searching
Data extraction and organization
From the eligible studies, the number of patients, tumor grade, tumor locations, speech and language errors, and the corresponding brain locations of the errors were recorded.
Tumor locations were divided into hemisphere, resulting in the following four data sets: (1) patients with tumors in the left hemisphere, (2) patients with tumors in the right hemisphere, (3) patients with tumors in the left hemisphere + patients with tumors in the right hemisphere (i.e., these results were reported at group level, combining patients with a tumor in one hemisphere. These patients did not have tumors in both hemispheres), and (4) patients with tumors in an unstated hemisphere. Additionally, tumor grades were grouped as low-grades, high-grades, combined (group: patients with low-grades + patients with high-grades), or not reported.
In addition, the specific speech and language errors were taken from the articles as they were stated. They were grouped into types: speech arrest, dysarthria/anarthria, semantic errors, phonemic errors, (morpho-)syntactic errors, comprehension errors, reading errors, speech initiation difficulties, production errors, anomia/word finding difficulties, perseverations, writing errors, verbal apraxia, and irrelevant paraphasia (see Supplementary Materials 2 for more information), based on linguistic level (e.g., semantics, phonology, (morpho-)syntax) or modality (e.g., reading, production). In a few cases, speech and language errors occurred at the same time as a motor or visual response in which case only the speech and language errors were analyzed.
Analyses and visualization
The different analyses and visualization methods will be explained below (see Supplementary Materials 3 for an overview).
First analysis: subcortical/cortical location distribution of all errors
The speech and language errors from all four data sets were taken together (nT), and a percentage of how often an error occurred in a specific brain location (cortically and subcortically) was calculated based on the total number of errors (nT). Locations including gyrus, cortex, and lobe were seen as cortical. On the subcortical level, a distinction was made between general subcortical locations (e.g., white matter below inferior frontal gyrus: IFG, hippocampus) and subcortical tracts (e.g., IFOF). One location (Heschl’s gyrus fiber intersection area) was considered both cortical and subcortical. A similar analysis on tumor grade (low-grade vs. high-grade) was performed (nT = total high/low-grades), excluding combined and not reported grades (see “Data extraction and organization”). Cortical data was visualized using the DKT-atlas (see “Visualization of cortical data (DKT-atlas)”).
Second analysis: subcortical/cortical location distributions per error type
Data set 4 (hemisphere not stated) and irrelevant paraphasia were discarded from further analyses because they did not include enough instances to analyze them separately (n=18, n=1, respectively). In the first analysis (see “First analysis: subcortical/cortical location distribution of all errors”), we found that only a small part of the data was from high-grades (high-grades: nT=120 vs. low-grades: nT=710) and that the number of reported cortical errors in high-grades was notably low (high-grades: nC=84 vs. low-grades: nC=403). Considering that taking percentages of a small amount of total errors in the high-grade group can give distorted biased results, no distinction in tumor grade was made in the following analyses. Separate for each error type and remaining data set (1, 2, 3), a percentage of how often an error occurred in a specific brain location (cortically and subcortically) was calculated based on the total number of errors of that subgroup (e.g., total speech arrest: n=10, speech arrest in location x: n=5 =50%). These calculations resulted in percentages for different brain locations (cortical and subcortical) for each error type per data set (adding up to 100% for each error type and data set separately).
Due to the limitation of combining different visualization methods for different levels in the brain (i.e., cortical, subcortical), the cortical plots were categorized based on error type and the subcortical plot on tract type. Cortical data was visualized using the DKT-atlas (see “Visualization of cortical data (DKT-atlas)”). Subcortical data (subcortical tracts only) were visualized using DTI images from the open-source HCP-YA tractography atlas [46], which is based on a large group of healthy individuals (n=842). All tracts in the data were visualized except the middle longitudinal fascicle (MLF), corticospinal tract (CST), and pyramidal pathways since few speech and language errors occurred in these locations (1, 1, and 2 errors, respectively). FAT and FST were visualized using the same DTI tract image, as they are closely related, making distinction difficult [47].
Third analysis: cortical/subcortical division
The combination of each error type (all types minus irrelevant paraphasia) and data set (1, 2, 3) was seen as a separate subset. For each subset, the occurrences of errors per brain location (cortical or subcortical level) were calculated and visualized. Within the subcortical level, it was calculated how many subsets contained errors at the general subcortical or subcortical tract level. Plots were made in R [48] using the ggplot2 package [49]. One location (Heschl’s gyrus fiber intersection area) was considered both cortical and subcortical and was therefore not included in these division plots.
Visualization of cortical data (DKT-atlas)
The ggseg package [50] in R [48] was used to visualize speech and language errors in cortical brain areas. This package automatically plots brain areas and is based on the Desikan-Killiany-Tourville (DKT) atlas [51]. This is a free, open access parcellation atlas, which defines boundaries between brain areas based on anatomical landmarks. Some brain locations in our data needed to be grouped to be compatible with this atlas (see Supplementary Materials 4). The most important changes were that the premotor cortex (PMC), motor cortex (MC), SMA, and precentral gyrus (preCG) in our data were all mapped to the preCG. A few locations could not be converted to the (lateral) DKT-atlas, since they portrayed another layer of the brain (operculum, n=8; hippocampus, n=2; medial temporal gyrus, n=2; medial frontal gyrus, n=1). Since they did not occur often across all data sets, it was accepted that they would not be visualized in the cortical plots. Even though the DKT-atlas locations are less specific than the ones in our data at times, it was decided to use this method because these plots instantly give a general idea of where the different speech and language errors are located. The DKT-atlas locations were used to make plots, while the original locations in our data (i.e., the more specific ones) were used in the text to describe the plots.
Results
Data searching resulted in 1706 articles, of which 1015 remained after duplications were removed. Four hundred ninety-nine of these articles were excluded because they were irrelevant for our purpose. Of the 516 articles that were reviewed in full text, 414 were excluded due to multiple reasons (see Fig. 1). This resulted in the inclusion of 102 articles of which 70 reported on individual patients, 18 on patients in a group, and 14 on both an individual and group level (see Supplementary Materials 5 for the reference list of all included articles). Data from individual patients and patient groups were collapsed. If one article reported the same error in the same brain location for an individual patient and for the group (including that same patient), this error was only noted once.
Overview of included studies
Information collected from the articles is shown in Table 1. Tumor grade and location are based on the total errors, not the total number of patients.
First analysis: subcortical/cortical location distribution of all errors (nT=930)
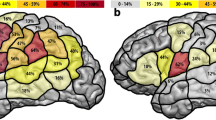
All speech and language errors across all four data sets (all data combined) resulted in a total of 930 errors: 549 at the cortical level (59.0%), 376 at the subcortical level (40.4%), and 5 which were seen as both cortical and subcortical (0.5%; see “First analysis: subcortical/cortical location distribution of all errors”). Nineteen of the 549 cortical locations were unplottable with the DKT-atlas (see “Visualization of cortical data (DKT-atlas)”), which resulted in the visualization of 530 cortical speech and language errors in Fig. 2A. In this plot, high occurrences of cortical errors in a specific brain location are shown in red, while lower occurrences are shown in orange and yellow. Speech and language errors occurred everywhere on the cortical surface of the DKT-atlas. Out of all 930 errors, most occurred in the preCG (n=208, 22.4%, note that more locations are combined in the preCG; see “Visualization of cortical data (DKT-atlas)”), pars opercularis (parsOp; n=95, 10.2%), pars triangularis (parsT; n=80, 8.6%), and superior temporal gyrus (STG; n=71, 7.6%). Additionally, most subcortical errors occurred at the level of the IFOF (n=96, 10.3%) and AF (n=70, 7.5%). The other subcortical errors occurred in less than 5% in the other tracts (SLF: n=38, 4.1%; FAT: n=20, 2.2%; ILF: n=12, 1.3%; UF: n=6, 0.6%; FST: n=5, 0.5%, pyramidal pathways: n=2, 0.2%; MLF: n=1, 0.1%, corticospinal tract: n=1, 0.1%).

The combined cortical speech and language errors ratio in percentages for A all data combined, B low-grade gliomas, and C high-grade gliomas
The general localization patterns in low-grade gliomas (Fig. 2B, nT=710) were similar to the overall localization patterns based on all data (Fig. 2A; highest cortical: preCG; n=169, 23.8%, highest subcortical: IFOF; n=77, 10.8%). This is in contrast to the cortical localization patterns for high-grades; see Fig. 2C (nT=120), where the superior parietal lobe (n=25, 20.8%), pars opercularis (n=24, 20%), and pars triangularis (n=24, 20%) occurred most often. Subcortically, the IFOF (n=10, 8.3%) and AF (n=10, 8.3%) were found most often (see Supplementary Materials 6 for information per error including from which article it was taken, tumor location (lobe/hemisphere), tumor grade, and brain location).
Second analysis: subcortical/cortical location distributions per error type
The error types which occurred most often in the data sets (1, 2, 3) were speech arrest (23.6%), anomia (18.6%), dysarthria/anarthria (15.4%), semantic errors (14.0%), and phonemic errors (12.6%). Based on the three data sets (1, 2, 3), a total of 914 speech and language errors were found: 542 cortically (59.3%) and 367 subcortically (total: 40.2%; general: 115, 12.6%; tracts: 252, 27.6%). Five instances were interpreted as both cortical and subcortical (0.5%, see “First analysis: subcortical/cortical location distribution of all errors”). Of the 252 subcortical tract locations, most errors occurred at the IFOF (38.1%), AF (27.8%), SLF (15.1%), and FAT (7.9%).
The cortical error ratios are visualized in Fig. 3 (scale up to 60%) and Fig. 4 (scale up to 100%) and the subcortical error ratios in Fig. 5. Additionally, Fig. 7 shows the division between cortical and subcortical occurrences per error type. The most common brain locations in which a specific error occurred are described per type below. Types are ranked based on the frequency and the occurrence (absolute and percentage) of this type out of all 914 speech and language errors (nT=x, y%).
-
-Speech arrest (nT=216, 23.6%) occurred in both the left and right hemisphere. Speech arrests were found at the cortical and subcortical level, but mostly cortically (see Fig. 7). They mainly occurred in the ventral PMC but also in other locations like part of the IFG, the entire IFG, preCG, and the post central gyrus (postCG; see Fig. 3). At the subcortical tract level, they were mainly found at the FAT (see Fig. 5).
-
-Anomia (nT=170, 18.6%) occurred in both the left and right hemisphere. Anomia was found on the cortical and subcortical level but mainly cortically (see Fig. 7). The locations were widespread, but these errors occurred often in the STG (mainly posteriorly) and dorsal PMC (see Fig. 4). Subcortically, they occurred mainly at the AF and IFOF (see Fig. 5).
-
-Dysarthria/anarthria (nT=141, 15.4%) occurred in both the left and right hemisphere. These errors were found at the cortical and subcortical level but mostly cortically (see Fig. 7). They were mainly located in the ventral PMC and the general preCG. Additionally, they also occurred often in the SLF and in the fibers from the ventral PMC (see Fig. 3, Fig. 5).
-
-Semantic errors (nT=128, 14.0%) occurred in both the left and right hemisphere. They were found at the cortical and subcortical level but mostly subcortically at the tract level (see Fig. 7). They mainly occurred at the level of the IFOF (see Fig. 5). Cortically, they were mainly found at the STG (see Fig. 3).
-
-Phonemic errors (nT=115, 12.6%) occurred in both the left and right hemisphere. These errors were found at the cortical and subcortical level but mostly subcortically at the tract level (see Fig. 7). They mainly occurred at the AF but also at other tracts such as the SLF and UF (see Fig. 5). Cortically, they were mainly found at the IFG, STG, and middle temporal gyrus (MTG, see Fig. 3).
-
-Perseverations (nT=35, 3.8%) occurred in both the left and right hemisphere. They occurred more often, and in one data set even exclusively, at the subcortical level than at the cortical level (see Fig. 7). They were mainly found in/near the (head of the) caudate nucleus. At the subcortical tract level, they were mainly found at the IFOF (see Fig. 5). The cortical locations were widespread, with only one occurrence per location (see Fig. 4).
-
-Reading errors (nT=25, 2.7) occurred in both the left and right hemisphere. They were found at the cortical and subcortical level (varying from only cortical, to more subcortical than cortical, to equal cortical and subcortical locations, see Fig. 7). They mainly occurred at the ILF (see Fig. 5) but also in the MTG and inferior temporal gyrus (ITG, see Fig. 3).
-
-Comprehension errors (nT=22, 2.4%) occurred in both the left and right hemisphere. These errors were found at the cortical and subcortical level but mostly cortically (see Fig. 7). In general, they were found in the frontal, temporal, and parietal lobes (see Fig. 3) and the IFOF (see Fig. 5).
-
-Verbal apraxia (nT=18, 2.0%) occurred in both the left and right hemisphere. These errors occurred at the cortical and subcortical level, but they were mainly found cortically (see Fig. 7). They mainly occurred at the postCG and the SLF. Other cortical and subcortical locations were widespread, with mostly one occurrence per location (see Fig. 4, Fig. 5).
-
-Morphosyntactic errors (nT=15, 1.6%) only occurred in the left hemisphere. These errors were found at the cortical and subcortical level but mostly cortically (see Fig. 7). They occurred mainly in the IFG, MTG, and (near) the head of the caudate nucleus (see Fig. 3). At the subcortical tract level, this error was found once at the FAT and once at the IFOF (see Fig. 5).
-
-Production errors (nT=13, 1.4%) occurred only in the left hemisphere. These errors occurred cortically and subcortically but mainly at the subcortical tract level (see Fig. 7). They mainly occurred at the FAT (see Fig. 5). Cortically, they were mainly found in the STG (see Fig. 3).
-
-Speech initiation difficulties (nT=9, 1.0%) occurred in both the left and right hemisphere. They occurred cortically and subcortically but mainly at the subcortical tract level (see Fig. 7). They occurred mainly at the FAT, FST, and SMA (see Fig. 3, Fig. 5).
-
-Writing errors (nT=7, 0.8%) occurred only in the left hemisphere. They occurred at the cortical and subcortical level, but they were mainly found cortically (see Fig. 7). They mainly occurred at the superior parietal gyrus (SPG, see Fig. 4). At the subcortical tract level, this error was only found once, at the IFOF (see Fig. 5).

The cortical speech and language error ratios in percentages of nine error types divided by hemisphere/data set

The cortical speech and language error ratios in percentages of four error types divided by hemisphere/data set

The occurrences in percentages of different speech and language errors at subcortical tracts, divided by hemisphere/data set
Third analysis: cortical/subcortical division
When regarding each error type and hemisphere (i.e., left, right, left+right) as a separate subset, there were 13 (error types) × 3 (hemispheres) = 39 subsets. Of these subsets, 32 contained speech and language errors. Of these 32 subsets (see Fig. 6a), most contained more cortical than subcortical error locations (43.8%). Additionally, 31.2% of the subsets with errors contained more subcortical than cortical error locations. Some subsets exclusively contained cortical locations (12.5%). Only one subset (3.1%) contained exclusively subcortical locations.

The percentage of subsets containing speech and language errors in cortical and/or subcortical locations
Notably, 28 of the subsets with errors (87.5%) contained subcortical locations (see Fig. 6b). Of these, 28.6% contained only tract locations. In addition, 28.6% of the subsets contained more tracts than general subcortical locations, while 25.0% contained more general than tract locations. Some subsets exclusively contained general subcortical locations (17.9%).
Zooming in, Fig. 7 shows the cortical/subcortical divisions for each error type and subset (1 bar = 1 subset). Examples of subsets containing more cortical than subcortical errors are the speech arrest subsets (see more gray than blue in Fig. 7). The other divisions from Fig. 6a are also illustrated in Fig. 7: more subcortical than cortical locations (e.g., phonemic errors), exclusively cortical locations (e.g., LH-verbal apraxia), and exclusively subcortical locations (LH+RH-perseveration).

The division of the absolute number of errors between cortical and subcortical (general and tracts) locations for each error type and hemisphere/data set
Focusing on the subcortical portions of the subsets only (dark and light blue in Fig. 7), some exclusively contain subcortical tracts and no general subcortical locations, such as most semantic and phonemic error subsets. The other divisions from Fig. 6b are also shown in Fig. 7: more tracts than general subcortical locations (e.g., LH-anomia), more general than tract locations (LH-dysarthria/anarthria), and exclusively general subcortical locations (LH+RH-perseveration).
Discussion
General overview of speech and language errors
This is the first extensive systematic review of the literature investigating language localization building on many different specific intraoperative speech and language errors attained during awake craniotomy with our specific approach. The first aim of this study was to systematically collect all specific speech and language errors elicited during awake craniotomy with DES mapping and the corresponding brain locations from the literature, resulting in 102 articles reporting 930 errors in total. Errors were found cortically and subcortically (see “The importance of subcortical mapping”). Different error types were found, of which speech arrest, anomia, dysarthria/anarthria, semantic errors, and phonemic errors occurred most often.
The second aim was to investigate potential brain localization patterns of different speech and language error types. As expected, our findings show that speech and language errors occurred in many different cortical and subcortical locations. However, several patterns were identified when looking at all data. Cortically, errors occurred most often in the preCG. This can (partly) be explained by the high occurrence of speech arrest, dysarthria/anarthria, and anomia in our data (58.7% in total) and because this area collapses multiple smaller areas (see “Visualization of cortical data (DKT-atlas)”). Subcortically, errors occurred most often at the level of the IFOF.
The localization patterns for low-grade gliomas were similar to the overall pattern based on all data (including high-grades, low-grades, group of combined grades and not stated grades). Another localization pattern seemed to emerge for high-grade gliomas. However, the total number of errors by high-grades (nT= 120, nC=84) and low-grades (nT=710, nC=403) was substantially different and thus unbalanced, making comparison difficult. Moreover, the group of high-grades was too small in this data set, and considering that percentages were taken from this low total, a distorted localization pattern for high-grades emerged. Therefore, these results should be approached cautiously. However, in general, these results may suggest that there are differences in language localization between tumor grades, which have been reported before [22]: high-grade glioma patients seem to show a more mixed range of language difficulties than strictly expected based on tumor location compared to low-grade glioma patients. This may be explained by differences in neuroplasticity between grades. Low-grade gliomas often lead to more functional recovery than high-grade tumors, due to the characteristic slow tumor growth of low-grades [52]. Localization patterns for specific speech and language errors were also found.
The third aim was to interpret the error localization patterns and the corresponding language functions with the dual-stream model of language processing and the Dutch Linguistic Intraoperative Protocol (DuLIP). Most of the found patterns are in line with the models, but interestingly, some additional patterns of language localization seemed to have emerged. In line with aim 4, these will be discussed and added to the DuLIP model below.
Patterns of language localization and selection of intraoperative language tasks
Based on speech and language errors, many localization patterns were found in our data. However, no clear pattern was found for the error type anomia. Anomia was found in the most widespread brain locations at the cortical (in the frontal, parietal, temporal, and occipital lobes) and subcortical level (6/7 of the reported tracts). These results are similar to Ojemann et al. [53], who included 117 glioma patients and showed that naming errors during DES were found in almost the entire language dominant hemisphere (frontal, parietal, and temporal lobes). Similar results concerning anomia were found by Sanai et al. [16]. It is therefore fully grounded that object naming, a test to monitor word retrieval, remains standardly used during awake brain surgery. However, more standardized intraoperative tests that tap into different language modalities and linguistics levels should also be used, such as DuLIP.
Our data compared to the dual-stream model
First, we will compare our data to the seminal neuroanatomic model of language processing by Hickok & Poeppel [42, 43] or the so-called dual-stream model, which includes two pathways: the dorsal and the ventral pathway. The dorsal pathway projects from the posterior STG to the frontal regions, which is assumed to correspond to the AF [54]. It is assumed to be involved in mapping sound to articulation (phonological processing). A way to investigate the function of this structure concerns an auditority production task, such as word repetition. Schwartz et al. [55] used another task, object naming, and found that phonological errors in this object naming task were linked to the dorsal stream as well. In line with this, we found phonemic errors in this pathway (STG, IFG). We also found them at the level of the AF.
The ventral pathway is involved in mapping sound to meaning (semantic processing). It projects from the posterior MTG and ITG to the anterior MTG and is assumed to correspond to the IFOF and the intratemporal networks [9]. In line with this, we found some comprehension errors in part of the ventral pathway (STG, MTG, ITG). In line with Swartz et al. [55], who detected semantic errors in object naming pointing to the ventral stream, we found some semantic errors in this pathway (STG, MTG, ITG). We also found many semantic errors at the level of the IFOF. In general, our results seem to be in line with the dual-stream model.
Our data compared to the DuLIP model
Second, we will compare our data to the DuLIP model, since this model was based on the knowledge and available literature at the time but not on a systematic literature search. Interestingly, the results confirm but also reveal additional localizations of language functions, which can be added to the DuLIP model. We suggest an updated “location-function-task” model which can be applied to better select appropriate language tests to assess different linguistic functions during awake brain surgery.
Similarities between cortical data and the DuLIP model
When comparing the cortical speech and language errors and thus the corresponding language functions from this review to the cortical DuLIP language model (see Table 2), most main functions of different brain areas are similar. Examples are as follows:
-
-Articulatory processing and motor speech: speech arrest (nT=216), dysarthria/anarthria (nT=141), production errors (nT=13), IFG & preCG. These results are consistent with the literature. Speech arrest has been found in the IFG and preCG [56]. However, other studies suggest that articulation is not supported by the IFG [18]. This is part of the current debate on the functionality of the classical Broca’s area. This in-depth debate is beyond the scope of the current article and will therefore not be discussed further. Dysarthria/anarthria and production errors are linked to motor function, which is localized in the preCG.
-
-Semantics: semantic errors (nT=128), STG. This is consistent with the classical language localization view [15]. However, more recent studies implicate that the STG is involved in phonological based processes [57]. In line with this, we found phonemic errors at the STG. However, the current in-depth debate on the functionality of the classical Wernicke’s area specifically is too detailed for the current purpose and will therefore not be discussed further.
-
-Syntax: morphosyntactic errors (nT=15), IFG. This is consistent with the classical language localization view [13, 14, 58].
-
-Speech initiation: speech initiation difficulty (nT=9), SMA. Apart from problems with motor initiation, the SMA is also associated with self-initiated speech [59]. Lesions in the SMA can result in dynamic aphasia [60, 61], which is a syndrome characterized by reduced spontaneous speech and speech initiation in the context of intact naming, repetition, and comprehension.
Differences between cortical data and the DuLIP model
There are also differences between our cortical data and the DuLIP model. Based on this, we make suggestions for adjustments to the cortical DuLIP model. These suggestions are shown in Table 2 (in underlined italic print) and Fig. 8 (adjustments are based on the occurrence of ≤18 errors).
-
-Articulatory processing and motor speech: speech arrest (nT=216), verbal apraxia (nT=18), PostCG. We suggest adding the postCG to the cortical DuLIP model with the corresponding function of articulatory processing/motor speech. This is based on the occurrence of speech arrests and verbal apraxia (n=10) in this location. When resecting in this area, it may be useful to additionally select a production task like verbal diadochokinesis.
-
-Reading: reading errors (nT=25), MTG & ITG. Our data showed that 12 out of 13 cortical reading errors occurred in the temporal lobe (mainly MTG/ITG). Therefore, reading as a function of the MTG and ITG is suggested as an addition to the original DuLIP model. This can be tested intraoperatively with a reading test, for example, with the Written language battery, which includes reading and spelling tests [62]. A recent review by Young et al. [41] also suggests using a reading test in the ITG.
-
-Writing: writing errors (nT=7), SPG. Although not reported frequently (7x total, 6x cortically), writing errors were exclusively found in the parietal lobe (5x SPG, 1x general parietal lobe), whereas the original DuLIP model links writing specifically to the angular gyrus and frontal lobe. The model does not suggest a test to assess writing in the angular gyrus and frontal lobe. Since we did not find any writing errors there specifically, we do not suggest a test for those locations either. Further research should investigate whether this newly found trend is accurate. The result is in line with data from a systematic review by Van Ierschot et al. [12], which showed that spelling interferences were found in the SPG during intraoperative writing tests during awake craniotomies. Therefore, the SPG with the corresponding function of writing was added to the DuLIP model. DuLIP does not include a writing test, since it is difficult to test this modality from a practical point of view during surgery. However, subtests from the previously mentioned Written language battery [62] could be of added value when resecting near the SPG.

The updated Dutch Linguistic Intraoperative Protocol (DuLIP) model for cortical brain locations
Similarities between subcortical data and the DuLIP model
When comparing the subcortical speech and language errors and their corresponding language functions from this review to the subcortical DuLIP model (see Table 3), many similarities are again observed. Examples are as follows:
-
-Semantics: semantic errors (nT=128), IFOF. This is in line with the literature that semantics is linked to the IFOF [63].
-
-Phonology: phonemic errors (nT=115), AF. This is in line with the literature that phonology is linked to the AF [64].
-
-Reading: reading errors (nT=25), ILF. This is in line with previous studies that showed that reading is linked to the ILF [65, 66].
-
-Speech initiation: speech initiation difficulties (nT=9), FST. Spontaneous speech disorders with initiation difficulties have been found to be linked to the FST [64].
Differences between subcortical data and the DuLIP model
There are also differences between the DuLIP model and our subcortical data, on which suggestions for modifications to the subcortical DuLIP model are based. These suggestions are shown in Table 3 and are based on the occurrence of ≤18 errors (underlined italic print) or 60 errors (underlined bold print). Table 3 corresponds to Fig. 9.
-
-Articulatory processing: dysarthria/anarthria (nT=141), phonological errors (nT=115), verbal apraxia (nT=18), SLF vs. phonology: phonemic errors (nT=115), AF. While the SLF and AF are taken together in the subcortical DuLIP model with the function of articulatory processing and phonology, we suggest separating these tracts as a modification to the DuLIP model for two reasons. First, our data showed many errors (n=70) elicited at the AF, which was always specified as a distinct tract. Second, while articulatory (dysarthria/anarthria (n=18), verbal apraxia (n=3)) and phonemic errors (n=11) were found at the SLF, only phonemic errors (n=60) were found at the AF. This is in line with the idea that the AF corresponds to the function of phonology [64]. We have therefore deleted the function of articulatory processing for the AF, leaving the function of phonology. Since this addition is based on a notably more substantial number of errors (n=60) than other additions (n≤18), we underlined it in bold for emphasis in the updated model below.
-
-Motor speech: speech arrests (nT=216), production errors (nT=13), speech initiation difficulties (nT=9), FAT/FST. We suggest adding the FAT to the DuLIP model since this tract was found multiple times (n=20) in our data. The FAT is a recently discovered tract associated with speech control and speech initiation running between the SMA and parsOp [67,68,69]. We suggest adding the FAT in the DuLIP model next to the FST (called the subcallosal fascicle in the original model), since similar speech and language errors were found at both tracts and because the tracts are difficult to distinguish [47]. Next to (the expected) speech initiation difficulties at the FAT and FST (n=5), speech arrests and production errors (n=13) were also found. Therefore, motor speech is added as a function of these tracts to the DuLIP model. Consequently, a production test, such as verbal diadochokinesis, can be useful to additionally select when operating close to these tracts.
-
-Phonology: phonological errors (nT=115), ILF. Some phonological errors (n=2) were found at the ILF, which is in line with the DuLIP model. However, the model does not suggest a test to monitor phonology at this tract. Therefore, we suggest that repetition could be a useful additional test to use when the tumor infiltrates this tract.
-
-Phonology: phonological errors (nT=115), UF. Adding phonology as a function of the UF to the subcortical DuLIP model is the next modification. Interestingly, 3/6 errors elicited at the UF were phonemic errors. Even though this is a small number, it may be useful to test phonology through repetition when resecting close to this tract. Additionally, no semantic errors were found at the UF, although the DuLIP model assumes that semantics is the main function of this tract. Future research should investigate this (lack of a) link to semantics further focusing on more errors.

The Dutch Linguistic Intraoperative Protocol (DuLIP) model for subcortical brain locations
This article is a confirmation of the current knowledge on language localization, based on many articles, bundled in one review article. By updating the DuLIP model, the current understanding of language localization (theory) is transferred to the clinic and used during awake craniotomy (practice). Based on this updated DuLIP model, the selection of pre, post, and especially intraoperative language tests at different linguistic modalities and levels may be more patient-tailored with possible better language outcomes for patients with gliomas.
A general subcortical pattern
Even though the discussed DuLIP model focuses exclusively on subcortical tracts, our data revealed non-tract (or general) subcortical areas related to language functions. Interestingly, 71.9% of the 32 subcortical perseverations were found in/near the head of the caudate nucleus. Previous work by Mandonnet et al. [70] found the same main localization pattern for perseverations. They propose a striatal deafferentation model in which the striatum (including the caudate nucleus) is part of a loop that ultimately inhibits competitors and amplifies the current target word. If this loop is malfunctioning, or disrupted by DES, the new information on the current target word is not passed on in the loop, and the systems remain in the previous state, which leads to a perseveration. During awake craniotomy, this phenomenon could for example be tested with an object naming task (among other language production tasks at word level).
The importance of subcortical mapping
Some speech and language error types occurred only or mainly cortically. This could be because some articles did not perform subcortical mapping, since it is not standard procedure. However, this does not mean that language functions are less often supported by subcortical compared to cortical brain areas but simply that subcortical functionality is less often investigated. Still 40.4% of all errors were reported at the subcortical level in our data. Some error types, such as phonemic errors and semantic errors, even occurred more often subcortically than cortically. Moreover, one perseveration subset even occurred exclusively subcortically. These findings emphasize that language functions are mediated by subcortical tracts, as has been shown by many studies.
Importantly, permanent neurological and language deficits can occur when subcortical tracts are damaged [71]. When subcortical mapping is administered, studies have shown better language outcomes [19, 72], which can increase the quality of life of the patient. Keeping this in mind, it is surprising that subcortical mapping during awake craniotomies is not standardly performed. We advise applying DES during awake craniotomies at the subcortical level as a standard addition to the routine cortical mapping.
Limitations and future research
A limitation of this study is that articles varied greatly in how specifically they reported speech and language errors, brain locations, stimulation parameters, and used language tests. Information was often lacking or not clear. For example, some articles reporting on the SLF did not specify which part (I, II, III) they meant. Since older articles have also been included, the reported SLF could perhaps also refer to the AF, considering that the distinctions used to be less clear. Future prospective research should report on the different parts of the SLF and report it separately from the AF. This will give more insight in the functioning of the different parts of the tracts.
Additionally, many articles did not report which language test they used, and many others only used object naming. This poses a problem, since one language test may not be sensitive enough to detect language disturbances at different linguistic modalities and/or levels. Therefore, errors may have been missed. Further research should focus on the sensitivity of a wider range of language tasks (apart from object naming) and their relation to specific intraoperative speech and language errors.
Another limitation is that the localization patterns for high-grade glioma patients must be regarded with caution in this review, considering that the group of high-grades was too small in this data set, giving a distorted impression. Prospective research should pay attention to tumor grade and should strive to include a large balanced amount of speech and language errors by high-grade and low-grade glioma patients to systematically investigate possible localization differences between grades.
Another limitation is that the used DKT-atlas grouped some brain areas together (notably: PMC, MC, SMA, preCG as preCG), resulting in a crude interpretation of language localization. A final limitation is that some suggestions for changes to the DuLIP model are based on only a few occurrences of speech or language errors in that location. Future prospective research should investigate further if these patterns can be confirmed.
As a next step, we investigated the relation between different intraoperative speech and language errors and the postoperative language outcome in a separate second article based on the current systematic search [44]. This relation could be the foundation of a prognostic severity scale for speech and language errors on postoperative language outcome, which could guide the intraoperative procedure and may potentially reduce postoperative language deficits.
Conclusion
This systematic review provides a crude overview of language localization based on the occurrence of speech and language errors during awake craniotomy with DES. Localization patterns were compared to the dual-stream model of language processing and the DuLIP model. We propose an updated DuLIP model which can be considered for future selection of perioperative language tasks, to possibly improve language testing and monitoring. This may result in a better postoperative language outcome for glioma patients in the future.
Data availability
Data is available from the corresponding author on request.
Change history
06 February 2023
The article was modified to remove the e-mail addresses of the other authors.
References
Duffau H, Capelle L (2004) Preferential brain locations of low-grade gliomas: comparison with glioblastomas and review of hypothesis. Cancer 100(12):2622–2626. https://doi.org/10.1002/cncr.20297
De Witt Hamer PDW, Robles SG, Zwinderman AH, Duffau H, Berger MS (2012) Impact of intraoperative stimulation brain mapping on glioma surgery outcome: a meta-analysis. J Clin Oncol 30(20):2559–2565. https://doi.org/10.1200/JCO.2011.38.4818
Gerritsen JKW, Arends L, Klimek M, Dirven CMF, Vincent AJPE (2019) Impact of intraoperative stimulation mapping on high grade glioma surgery outcome: a meta-analysis. Acta Neurochir 161(1):99–107. https://doi.org/10.1007/s00701-018-3732-4
Gupta DK, Chandra PS, Mahapatra AK, Mehta VS, Ojha BK, Sharma BS (2007) Awake craniotomy versus surgery under general anesthesia for resection of intrinsic lesions of eloquent cortex – a prospective randomized study. Clin Neurol Neurosurg 109:335–343. https://doi.org/10.1016/j.clineuro.2007.01.008
Sacko O, Brauge D, Brenner A, Lauwers-Cances V, Roux FE, Sesay M (2011) Awake craniotomy vs surgery under general anesthesia for resection of supratentorial lesions. Neurosurgery 68(5):1992–1998. https://doi.org/10.1227/NEU.0b013e31820c02a3
Sanai N, Berger MS (2008) Glioma extent of resection and its impact on patient outcome. Neurosurgery 62(4):753–766. https://doi.org/10.1227/01.NEU.0000310769.20996.BD
Duffau H, Mandonnet E (2013) The “onco-functional balance” in surgery for diffuse low-grade glioma: integrating the extent of resection with quality of life. Acta Neurochir 155(6):951–957. https://doi.org/10.1007/s00701-013-1653-9
De Witte E, Mariën P (2013) The neurolinguistic approach to awake surgery reviewed. Clin Neurol Neurosurg 115(2):127–145. https://doi.org/10.1016/j.clineuro.2012.09.015
Fujii M, Maesawa S, Ishiai S, Iwami K, Futamura M, Saito K (2016) Neural basis of language: an overview of an evolving model. Neurol Med Chir 56(7):379–386. https://doi.org/10.2176/nmc.ra.2016-0014
Ojemann GA (1983) Brain organization for language from the perspective of electrical stimulation mapping. Behav Brain Sci 6(2):189–206. https://doi.org/10.1017/S0140525X00015491
Rofes A, Miceli G (2014) Language mapping with verbs and sentences in awake surgery: a review. Neuropsy Rev 24(2):185–199. https://doi.org/10.1007/s11065-014-9258-5
van Ierschot F, Bastiaanse R, Miceli G (2018) Evaluating spelling in glioma patients undergoing awake surgery: a systematic review. Neuropsy Rev 28(4):470–495. https://doi.org/10.1007/s11065-018-9391-7
Broca P (1861) Nouvelle observation d’aphe´mie produite par une lesion de la troisieme circonvolution frontale. Bull Soc Anat Paris 6:398–407
Broca P (1861) Perte de la parole: ramollissement chronique et destruction partielle du lobe anterieur gauche du cerveau. Bull Soc Anthropol 2:235–238
Wernicke C (1874/1969) The symptom complex of aphasia: a psychological study on an anatomical basis. Boston studies in philosophies of science. D. Reidel Publishing Company, Dordrecht
Sanai N, Mirzadeh Z, Berger MS (2008) Functional outcome after language mapping for glioma resection. New Engl J Med 358(1):18–27. https://doi.org/10.1056/NEJMoa067819
Lubrano V, Draper L, Roux FE (2010) What makes surgical tumor resection feasible in Broca’s area? Insights into intraoperative brain mapping. Neurosurgery 66:868–875. https://doi.org/10.1227/01.NEU.0000368442.92290.04
Tate MC, Herbet G, Moritz-Gasser S, Tate JE, Duffau H (2014) Probabilistic map of critical functional regions of the human cerebral cortex: Broca’s area revisited. Brain 137(10):2773–2782. https://doi.org/10.1093/brain/awu168
Duffau H, Gatignol P, Mandonnet E, Capelle L, Taillandier L (2008) Intraoperative subcortical stimulation mapping of language pathways in a consecutive series of 115 patients with grade II glioma in the left dominant hemisphere. J Neurosurg 109(3):461–471. https://doi.org/10.3171/JNS/2008/109/9/0461
Borchers S, Himmelbach M, Logothetis N, Karnath HO (2012) Direct electrical stimulation of human cortex—the gold standard for mapping brain functions? Nature Rev Neurosci 13(1):63–70. https://doi.org/10.1038/nrn3140
Desmurget M, Song Z, Mottolese C, Sirigu A (2013) Re-establishing the merits of electrical brain stimulation. Trends Cog Sci 17(9):442–449. https://doi.org/10.1016/j.tics.2013.07.002
Donders-Kamphuis M, Vincent A, Schouten J, Smits M, Docter-Kerkhof C, Dirven C, Satoer D (2022) Feasibility of awake brain surgery in glioblastoma patients with severe aphasia: five case illustrations. Aphasiology 1–20
Hamberger MJ, Tamny TR (1999) Auditory naming and temporal lobe epilepsy. Epilepsy Res 35(3):229–243. https://doi.org/10.1016/S0920-1211(99)00023-6
Papatzalas C, Fountas K, Kapsalaki E, Papathanasiou I (2021) The use of standardized intraoperative language tests in awake craniotomies: a scoping review. Neuropsy Rev 32:1–31. https://doi.org/10.1007/s11065-021-09492-6
Sierpowska J, Gabarrós A, Fernandez-Coello A et al (2017) Words are not enough: nonword repetition as an indicator of arcuate fascicle integrity during brain tumor resection. J Neurosurg 126(2):435–445. https://doi.org/10.3171/2016.2.JNS151592
Zanin E, Riva M, Bambini V, Cappa SF, Magrassi L, Moro A (2017) The contribution of surgical brain mapping to the understanding of the anatomo-functional basis of syntax: a critical review. Neurol Sci 38(9):1579–1589. https://doi.org/10.1007/s10072-017-3016-4
De Witte E, Satoer D, Colle H, Robert E, Visch-Brink E, Mariën P (2015) Subcortical language and non-language mapping in awake brain surgery: the use of multimodal tests. Acta Neurochir 157(4):577–588. https://doi.org/10.1007/s00701-014-2317-0
De Witte E, Satoer D, Robert E, Colle H, Verheyen S, Visch-Brink E, Mariën P (2015) The Dutch linguistic intraoperative protocol: a valid linguistic approach to awake brain surgery. Brain Lang 140:35–48. https://doi.org/10.1016/j.bandl.2014.10.011
Fontaine D, Capelle L, Duffau H (2002) Somatotopy of the supplementary motor area: evidence from correlation of the extent of surgical resection with the clinical patterns of deficit. Neurosurgery 50(2):297–303. https://doi.org/10.1097/00006123-200202000-00011
Bello L, Gallucci M, Fava M, Carrabba G, Giussani C, Acerbi F, Baratta P, Songa V, Conte V, Branca V, Stocchetti N, Papagno C, Gaini SM (2007) Intraoperative subcortical language tract mapping guides surgical removal of gliomas involving speech areas. Neurosurgery 60(1):67–82. https://doi.org/10.1227/01.NEU.0000249206.58601.DE
Moritz-Gasser S, Herbet G (1814) Duffau H (2013) Mapping the connectivity underlying multimodal (verbal and non-verbal) semantic processing: a brain electrostimulation study. Neuropsychologia 51(10):1822. https://doi.org/10.1016/j.neuropsychologia.2013.06.007
Alves J, Cardoso M, Morgado M, De Witte E, Satoer D, Hall A, Jesus LM (2021) Language assessment in awake brain surgery: the Portuguese adaptation of the Dutch linguistic intraoperative protocol (DuLIP). Clin Ling Phon 35(12):1113–1131. https://doi.org/10.1080/02699206.2020.1868022
Gisbert-Muñoz S, Quiñones I, Amoruso L, Timofeeva P, Geng S, Boudelaa S, Pomposo I, Gil-Robles S, Carreiras M (2021) MULTIMAP: multilingual picture naming test for mapping eloquent areas during awake surgeries. Behav Res Methods 53(2):918–927. https://doi.org/10.3758/s13428-020-01467-4
Verst SM, de Castro I, Scappini-Junior W, de Melo MN, de Oliveira JR, de Almeida SS, Alvarez NRC, Sucena ACB, Barros MR, Marrone CD, Maldaun MVC (2021) Methodology for creating and validating object naming and semantic tests used by Verst-Maldaun Language Assessment during awake craniotomies. Clin Neurol Neurosurg 202:106485. https://doi.org/10.1016/j.clineuro.2021.106485
Dragoy O, Chrabaszcz A, Tolkacheva V, Buklina S (2016) Russian intraoperative naming test: a standardized tool to map noun and verb production during awake neurosurgeries. Rus J Cog Sci 3(4):4–25
Ohlerth AK, Valentin A, Vergani F, Ashkan K, Bastiaanse R (2020) The verb and noun test for perioperative testing (VAN-POP): standardized language tests for navigated transcranial magnetic stimulation and direct electrical stimulation. Acta Neurochir 162(2):397–406. https://doi.org/10.1007/s00701-019-04159-x
Mandonnet E, Herbet G (eds) (2021) Intraoperative mapping of cognitive networks: which tasks for which locations. Springer Nature, Paris, France
Sarubbo S, De Benedictis A, Merler S, Mandonnet E, Balbi S, Granieri E, Duffau H (2015) Towards a functional atlas of human white matter. Hum Brain Map 36(8):3117–3136. https://doi.org/10.1002/hbm.22832
Sarubbo S, Tate M, De Benedictis A, Merler S, Moritz-Gasser S, Herbet G, Duffau H (2020) Mapping critical cortical hubs and white matter pathways by direct electrical stimulation: an original functional atlas of the human brain. Neuroimage 205:116237. https://doi.org/10.1016/j.neuroimage.2019.116237
Sarubbo S, Annicchiarico L, Corsini F, Zigiotto L, Herbet G, Moritz-Gasser S, Dalpiaz C, Vitali L, Tate M, De Benedictis A, Amorosino G, Olivetti E, Rozzanigo U, Petralia B, Duffau H, Avesani P (2021) Planning brain tumor resection using a probabilistic atlas of cortical and subcortical structures critical for functional processing: a proof of concept. Operative Neurosurg 20(3):E175–E183
Young JS, Lee AT, Chang EF (2021) A review of cortical and subcortical stimulation mapping for language. Neurosurgery 89(3):331–342. https://doi.org/10.1093/neuros/nyaa436
Hickok G, Poeppel D (2000) Towards a functional neuroanatomy of speech perception. Trends Cog Sci 4(4):131–138. https://doi.org/10.1016/S1364-6613(00)01463-7
Hickok G, Poeppel D (2004) Dorsal and ventral streams: a framework for understanding aspects of the functional anatomy of language. Cognition 92(1–2):67–99. https://doi.org/10.1016/j.cognition.2003.10.011
Collée E, Vincent A, Dirven C, Satoer D (2022) Speech and language errors during awake brain surgery and postoperative language outcome in glioma patients: a systematic review. Cancers 14(21):5466
Page MJ, JE MK, Bossuyt PM, Boutron I, Hoffmann TC, Mulrow CD, Shamseer L, Tetzlaff JM, Akl EA, Brennan SE, Chou R (2021) The PRISMA 2020 statement: an updated guideline for reporting systematic reviews. Syst. Rev. 10:1–11
Yeh F (2018) HCP-YA tractography atlas (figures). Zenodo. https://doi.org/10.5281/zenodo.3627770
Middlebrooks EH, Yagmurlu K, Szaflarski JP, Rahman M, Bozkurt B (2017) A contemporary framework of language processing in the human brain in the context of preoperative and intraoperative language mapping. Neuroradiology 59(1):69–87. https://doi.org/10.1007/s00234-016-1772-0
R Core Team (2020) R: a language and environment for statistical computing. R Foundation for StatisticalComputing, Vienna
Wickham H (2016) ggplot2: elegant graphics for data analysis. Springer-Verlag, New York
Mowinckel A, Vidal-Pieiro D (2020) Visualisation of brain statistics with R-packages ggseg and ggseg3d. Advances in Methods and Practices in Psychological Science 3(4):466–483
Klein A, Tourville J (2012) 101 labeled brain images and a consistent human cortical labelling protocol. Front Neurosci 6:171. https://doi.org/10.3389/fnins.2012.00171
Cirillo S, Caulo M, Pieri V (2019) Falini A, & Castellano A (2019) Role of functional imaging techniques to assess motor and language cortical plasticity in glioma patients: a systematic review. Neural Plasticity 2019:1–16
Ojemann G, Ojemann J, Lettich E, Berger M (1989) Cortical language localization in left, dominant hemisphere: an electrical stimulation mapping investigation in 117 patients. J Neurosurg 3:316–326. https://doi.org/10.3171/jns.1989.71.3.0316
Wong FC, Chandrasekaran B, Garibaldi K, Wong PC (2011) White matter anisotropy in the ventral language pathway predicts sound-to-word learning success. J Neurosci 31(24):8780–8785. https://doi.org/10.1523/JNEUROSCI.0999-11.2011
Schwartz MF, Faseyitan O, Kim J, Coslett HB (2012) The dorsal stream contribution to phonological retrieval in object naming. Brain 135(12):3799–3814. https://doi.org/10.1093/brain/aws300
Chang EF, Breshears JD, Raygor KP, Lau D, Molinaro AM, Berger MS (2017) Stereotactic probability and variability of speech arrest and anomia sites during stimulation mapping of the language dominant hemisphere. J Neurosurg 126(1):114–121. https://doi.org/10.3171/2015.10.JNS151087
Binder JR (2015) The Wernicke area: modern evidence and a reinterpretation. Neurology 85(24):2170–2175. https://doi.org/10.1212/WNL.0000000000002219
Rofes A, Miceli G (2014) Language mapping with verbs and sentences in awake surgery: a review. Neuropsy Rev 24(2):185–199. https://doi.org/10.1007/s11065-014-9258-5
Bohland JW, Guenther FH (2006) An fMRI investigation of syllable sequence production. Neuroimage 32(2):821–841. https://doi.org/10.1016/j.neuroimage.2006.04.173
Costello AL, Warrington EK (1989) Dynamic aphasia: the selective impairment of verbal planning. Cortex 25(1):103–114. https://doi.org/10.1016/S0010-9452(89)80010-3
Satoer D, Kloet A, Vincent A, Dirven C, Visch-Brink E (2014) Dynamic aphasia following low-grade glioma surgery near the supplementary motor area: a selective spontaneous speech deficit. Neurocase 20(6):704–716. https://doi.org/10.1080/13554794.2013.841954
Van Ierschot FC (2018) Monitoring of reading and spelling in glioma patients undergoing awake surgery (Doctoral dissertation,. University of Trento)
Duffau H, Gatignol P, Mandonnet E, Peruzzi P, Tzourio-Mazoyer N, Capelle L (2005) New insights into the anatomo-functional connectivity of the semantic system: a study using cortico-subcortical electrostimulations. Brain 128(4):797–810. https://doi.org/10.1093/brain/awh423
Duffau H, Capelle L, Sichez N, Denvil D, Lopes M, Sichez JP, Fohanno D (2002) Intraoperative mapping of the subcortical language pathways using direct stimulations. An anatomofunctional study. Brain 125:199–214. https://doi.org/10.1093/brain/awf016
Zemmoura I, Herbet G, Moritz-Gasser S, Duffau H (2015) New insights into the neural network mediating reading processes provided by cortico-subcortical electrical mapping. Hum Brain Map 36(6):2215–2230. https://doi.org/10.1002/hbm.22766
Epelbaum S, Pinel P, Gaillard R et al (2008) Pure alexia as a disconnection syndrome: new diffusion imaging evidence for an old concept. Cortex 44(8):962–974. https://doi.org/10.1016/j.cortex.2008.05.003
Kinoshita M, De Champfleur NM, Deverdun J, Moritz-Gasser S, Herbet G, Duffau H (2015) Role of fronto-striatal tract and frontal aslant tract in movement and speech: an axonal mapping study. Brain Struct Funct 220(6):3399–3412. https://doi.org/10.1007/s00429-014-0863-0
Dragoy O, Zyryanov A, Bronov O, Gordeyeva E, Gronskaya N, Kryuchkova O, Klyuev E, Kopachev D, Medyanik I, Mishnyakova L, Pedyash N, Pronin I, Reutov A, Sitnikov A, Stupina E, Yashin K, Zhirnova V, Zuev A (2020) Functional linguistic specificity of the left frontal aslant tract for spontaneous speech fluency: evidence from intraoperative language mapping. Brain Lang 208:104836. https://doi.org/10.1016/j.bandl.2020.104836
Chernoff BL, Sims MH, Smith SO, Pilcher WH, Mahon BZ (2019) Direct electrical stimulation of the left frontal aslant tract disrupts sentence planning without affecting articulation. Cog Neuropsy 36(3-4):178–192. https://doi.org/10.1080/02643294.2019.1619544
Mandonnet E, Herbet G, Moritz-Gasser S, Poisson I, Rheault F, Duffau H (2019) Electrically induced verbal perseveration: a striatal deafferentation model. Neurology 92(6):e613–e621. https://doi.org/10.1212/WNL.0000000000006880
Naeser MA, Palumbo CL, Helm-Estabrooks N, Stiassny-Eder D, Albert ML (1989) Severe nonfluency in aphasia: role of the medial subcallosal fascicle and other white matter pathways in recovery of spontaneous speech. Brain 112(1):1–38. https://doi.org/10.1093/brain/112.1.1
Trinh VT, Fahim DK, Shah K et al (2013) Subcortical injury is an independent predictor of worsening neurological deficits following awake craniotomy procedures. Neurosurgery 72(2):160–169. https://doi.org/10.1227/NEU.0b013e31827b9a11
Acknowledgements
The authors wish to thank Sabrina Meertens-Gunput from the Erasmus MC Medical Library for developing and updating the search strategies.
Author information
Authors and Affiliations
Contributions
EC, DS, and AV contributed to the study conception and design. EC wrote the main manuscript text, and all authors reviewed the manuscript.
Corresponding author
Ethics declarations
Ethical approval and consent to participate
Not applicable
Human and animal ethics
Not applicable
Consent for publication
Not applicable
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Collée, E., Vincent, A., Visch-Brink, E. et al. Localization patterns of speech and language errors during awake brain surgery: a systematic review. Neurosurg Rev 46, 38 (2023). https://doi.org/10.1007/s10143-022-01943-9
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10143-022-01943-9