
Abstract
Soil types mapping and the spatial variation of soil classes are essential concerns in both geotechnical and geoenvironmental engineering. Because conventional soil mapping systems are time-consuming and costly, alternative quick and cheap but accurate methods need to be developed. In this paper, a new optimized multi-output generalized feed forward neural network (GFNN) structure using 58 piezocone penetration test points (CPTu) for producing a digital soil types map in the southwest of Sweden is developed. The introduced GFNN architecture is supported by a generalized shunting neuron (GSN) model computing unit to increase the capability of nonlinear boundaries of classified patterns. The comparison conducted between known soil type classification charts, CPTu interpreting procedures, and the outcomes of the GFNN model indicates acceptable accuracy in estimating complex soil types. The results show that the predictability of the GFNN system offers a valuable tool for the purpose of soil type pattern classifications and providing soil profiles.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
The information on subsurface soil layers obtained from retrieved samples from drilled boreholes in a desired area can be used for several engineering purposes, including resolving geological, geotechnical, and environmental issues. However, both the number of drilled boreholes and extending the provided exploration database are essentially dependent on the importance, target of study, scale, and the finances of the project, which may require special laboratory and field procedures.
Soil type prediction and soil mapping can be used by a wide range of individuals, for example farmers, town and country planners, conservationists, foresters, researchers, and engineers. The comparisons of the cost, sample size, accuracy, and desired classification level can show the efficiency of different digital and conventional soil mapping approaches in producing categorical maps of soil types (e.g., Zeraatpisheh et al. 2017; Piikki and Söderström 2018; Camera et al. 2017). However, the small number of soil maps with adequate scale and the corresponding high costs associated with soil surveying and mapping are also reported (Rizzo et al. 2016). On the other hand, characterizing the soil types for a particular landscape with a set of soil parameters is a difficult task due to the large variation in soils in a space (Santra et al. 2017a, b). The lack of an adequate spatial coverage scale for planning applications and inappropriate soil mapping consistency across countries can therefore be observed in most of the soil mapping carried out in many countries, even in Europe (Freire et al. 2013; Tizpa et al. 2015; Piikki and Söderström 2018; Yiming et al. 2018; Carré and Girard 2002; Nagaraj 2000). Development of digital soil mapping through soil type prediction using field data integrated with geographic information systems (GIS), geostatistical, and soft computing techniques can be useful to cover the mentioned gaps for new kinds of spatial soil information for more general and target-specific soil maps, which cannot be fully satisfied by legacy soil maps or formerly elaborated databases (Pásztor et al. 2017; Sindayihebura et al. 2017). Such requirements for improving the soil mapping methods have, however, been pointed out in previous studies (e.g., Peterson 1991; Band and Moore 1995; Zhu and Mackay 2001). In recent years, soft computing methods such as fuzzy logic and in particular artificial neural networks (ANNs) have, due to their significant abilities, been used as desirable approaches to produce soil mapping systems through the available datasets (Dobos et al. 2006; Zhu et al. 2010; Pásztor et al. 2017). The ANNs have also successfully been developed to estimate soil classification (e.g., Olanloye 2014; Kurup and Griffin 2006; Bhattacharya and Solomatine 2006), soil mapping (e.g. Zhu et al. 2010; Arel 2012; Choobasti et al. 2015) and soil behavior modeling (Edincliler et al. 2013; Cevik et al. 2010). The data extracted from these generated soil mappings can be used to predict engineering properties, especially for preliminary design purposes (Cabalar et al. 2012; Jaksa 1995).
Among the various types of ANNs, the multi-layer percepteron (MLP) and self-organized featured map (SOFM) are the ones most commonly used in digital soil mapping due to their utilizing different classification approaches (Freire et al. 2013), and more accuracy has been observed in the results of MLP than SOFM (Albuquerque et al. 2009). However, in developing the MLP problems such as computational effort, time, proneness to over fitting, and the empirical nature of the model should be considered (Kumar Gupta et al. 2017). Moreover, previous studies have demonstrated that an appropriate combination of ANNs and soil map data in known landscape features and spatial variation of soils not only showed high accuracy (Sarmento et al. 2010) but can also be employed to predict soil types at locations where there are no current soil maps (e.g. Freire et al. 2013; Mcbratney et al. 2003; Tso and Mather 2001; Zhu 2000; Behrens et al. 2005; Carvalho Junior et al. 2011).
Due to a lack of research on the performance of different ANN architectures and related aspects for soil spatial modeling on different scales and under different conditions (Freire et al. 2013), this study aims to examine the applicability of a developed multi-output generalized feed forward neural network (GFNN) based model using available peizocone penetration test data (CPTu) to provide a regional soil mapping in southwest Sweden. The soil behavior type (SBT) (Robertson et al. 1986) and soil type behavior index (IC) (Jefferies and Davies 1993) predicted by a GFNN model were converted to 2D soil type map distribution and then compared to known soil classification methods.
Applicability of CPTu information for soil type classification
The direct readings of CPTu, including depth, cone tip resistance (qc), sleeve friction (fs), and porewater pressure (u), can, after processing and correction operations, be converted to soil type classification charts (e.g., Robertson et al. 1986; Robertson 1990; Jefferies and Been 2006). Comparison of these charts with other laboratory based procedures such as a unified soil classification system (USCS) requires less detailed laboratory work (Abbaszadeh Shahri et al. 2015a; Arel 2012). The chart proposed by Robertson et al. (1986) consists of 12 zones that correspond to the USCS classes, whereas Robertson (1990) classifies the soils into nine zones. These charts use the processed and corrected CPTu data, including corrected cone tip resistance (qt) for pore pressure at the shoulder area (a), friction ratio (Rf), normalized cone resistance (Qt), and normalized friction factor (Fr), which can be obtained from Eqs. 1–4.
By referring to Ku et al. (2010) as indicated by Abbaszadeh Shahri et al. (2015a), the reliability of IC for mechanical behavior classification of soil has been approved (Eq. 5). In this relation, the pore pressure ratio (Bq) can be obtained from Eq. 6.
Where u0u0 is in situ pore pressure and σv and σv′ are total and effective overburden stresses, respectively.
Therefore, IC as an engineering concept can be implemented not only for soil classification using CPTu data but also to produce the soil profiles (Abbaszadeh Shahri et al. 2015a).
The Robertson et al. (1986) soil profiling chart uses qt, Rf, and Bq, whereas Robertson (1990) implemented Qt and Fr. The comparison of both these charts to identify the soil types using coded zones (SBT (Robertson et al. 1986) and SBTn (Robertson 1990)) is presented in Table 1, in which the boundary provided between the identified zones are used to present gradual conversion from fine-grained to coarse-grained soils. The results from these charts thus lead to the soil profile and identify the underlying soil types and their corresponding thickness.
Materials and datasets
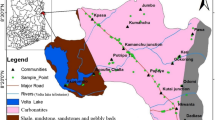
The selected area (Fig. 1a) lies around the Göta River in southwest Sweden, which has been subjected to several geotechnical and geophysical investigations (Löfroth et al. 2011; Malehmir et al. 2013; Abbaszadeh Shahri et al. 2015a, b; Abbaszadeh Shahri 2016). The CPTu provided by the Swedish Geotechnical Institute (SGI) as well as some executed laboratory and field test results (e.g., Rannka et al. 2004; Löfroth et al. 2011; Millet 2011) were used in this paper. The provided topography map of the studied area was obtained thorough the digital elevation model (DEM) and then the CPTu test points used as well as some nearby towns were located on it (Fig. 1b). To construct the datacenter for further analyses the implemented CPTu soundings were divided into three categories using randomized selection with 55%, 25%, and 20% for training, testing, and validation sets, respectively (Fig. 1b).

(a) Location of studied area in southwest Sweden (www.vidiani.com/large-detailed-topographical-map-of-sweden/) and (b) location of randomized used CPTu test points on the provided topography map from DEM
Applied ANN model
The ANNs are small scale computer models of the human brain that can be trained at high speed for different nonlinear problems using appropriate learning algorithms (e.g., Duda et al. 2001; Jordan and Bishop 2004; Theodoridis and Koutroumbas 2009; Arel 2012).
In this paper, a GFNN based model (Worden et al. 2007; Abbaszadeh Shahri et al. 2015b) is developed as a special class of MLP to predict the soil type classes. The GFNN is derived from the extended shunting inhibitory artificial neural networks (SIANNs) and includes two types of inputs: excitatory (equal to the number of shunting neurons) and inhibitory (Arulampalam and Bouzerdoum 2003). Shunting inhibition is a powerful computational mechanism that plays an important role in sensory information processing and provides more freedom in selecting the optimum network structure (Arulampalam and Bouzerdoum 2003). The GFNN classifier not only covers the motioned advantage but also uses a generalized shunting neuron (GSN) model that enables the connections to jump over one or more layers and allows neurons to operate as adaptive nonlinear filters (Arulampalam and Bouzerdoum 2003; Abbaszadeh Shahri et al. 2015b). Moreover, the GSN is able to reduce both computational effort and memory requirements and can arrange the variables that should be used as excitatory inputs. In the GSN, all the excitatory input is summed and passed through an activation function similar to a perceptron neuron (Eq. 7).
In the GFNN architecture, neurons in each layer receive inputs only from the preceding layer and calculate their outputs according to Eq. 7, and then transmit the resulting signals to the next layer. The hidden layers of GFNN can consist of generalized shunting inhibitory neurons or perceptron-type neurons (Arulampalam and Bouzerdoum 2003; Worden et al. 2007; Abbaszadeh Shahri et al. 2015b). The role of shunting inhibitory layers is to perform a nonlinear transformation on the inputs in which the results can easily be combined by output neurons to provide the correct decision. Moreover, GFNNs are capable of forming complex, nonlinear decision boundaries as well as being able to solve the problems much more efficiently than MLPs in the same number of processing elements (Abbaszadeh Shahri et al. 2015b).
Where:
xj: output (activity) of the jth neuron; Ij and Ii: inputs to the ith and jth neurons; aj: passive decay rate of the neuron (positive constant); wji and cji: connection weight from the ith inputs to the jth neuron; aj and bj: constant biases; g and f: activation functions.
To prevent network over-fitting, finding an optimum model both in structure and size for evaluating the results is an important task that depends on the quality of the implemented data (Wang and Strong 1996). The developed GFNN model in this paper was found through trial and error using Matlab (2016a) under an interactive computing environment with hundreds of functions. Moreover, the included neural network toolbox consists of source codes of various training algorithms, which depend on problems being able to be developed for adaptability in different situations.
Using the capabilities provided in Matlab, it can be connected to an Excel spreadsheet, which allows Matlab commands to be issued from Excel. This feature greatly enhances data manipulation and sharing between programs (Juang et al. 2001; Arel 2012). The number of neurons, activation transfer functions, network arrays, and training algorithms were the variables used to find the optimized model. The weights that minimize the error functions are then considered to be a solution to the learning problem, which can be found using the Delta-rule or gradient descent technique (Rojas 1996; Rumelhart et al. 1986). The quick propagation, conjugate gradient descent, step, momentum, and Levenberg-Marquardt were the implemented training algorithms. The logistic, hyperbolic tangent, linear, softmax axon, and bias axon functions were also used for activation of hidden and output layers and the sum of squares was employed as output error function, respectively.
The information from 58 located CPTu test points was implemented and randomized by 55%, 25%, and 20% to provide training, testing, and validation datasets (Fig. 3). Due to the widely approved efficiency of the proposed linked charts to cone parameters in determination of soil stratigraphy as well as identifying the soil type (Robertson et al. 1986; Robertson 1990) in practical oriented projects (Abbaszadeh Shahri et al. 2015a), in this paper, the SBT (Robertson et al. 1986) and IC were predicted as the output of the GFNN model. Using an iterative trial and error procedure, different GFNN structures were examined by changing the related components, including number of neurons, layers arrangements, training algorithms, and activation functions under different learning rates. For each of the tested structures, the network correlation (R2) and minimum root mean square error (RMSE) controlling criteria were calculated. However, if these criteria were not achieved, the number of epochs is then employed as the termination criterion. In this study, the number of epochs was set to 1000. Each structure was run three times. Among the 650 different tested models, two hidden layers including 14 neurons with 4-8-6-2 structure subjected to momentum algorithm and tangent hyperbolic activation function were found to be optimum. The information on inputs, outputs, training, and validation error as well as the calculated controlling criteria of the introduced model are given in Table 2, and the result of the predicted soil types for one of the training test points is presented in Fig. 4.
Mapping the predicted soil type classes
As presented in Table 2, the outputs of GFNN in prediction of SBT and IC were employed to produce the digitized distribution soil type maps at different depths. Due to observed matching between predicted values (SBT, IC) and field data (83.9 and 94.6%), the IC for soil mapping is selected and one example is shown in Fig. 4. Moreover, Robertson (2016) showed that using IC is more reliable for digitizing the soil classification in engineering applications and practices due to the predicted values being closer to those calculated using conventional methods (Eq. 5). Furthermore, the IC can delineate the clay or sand-like behavior of underlying soils and then can be converted to SBT using Table 1. This is an important issue to distinguish the area prone to slide or liquefaction, which is illustrated in the next section. A series of 2D soil type distributions based on the IC predicted by the GFNN model at different depth intervals for a characterized small scale of studied area including used test points (Fig. 3) were therefore provided and are reflected in Fig. 5(a–i). The mapped area in Fig. 5 was characterized using a rectangle in Figs. 2 and 3, respectively. Considering that IC > 2.6 can be assigned to susceptible soil layers, then the sensitivity (St) of the clayey materials in this area is increased with depth.

The generic architecture of feed forward SIANN structure (Arulampalam and Bouzerdoum 2003)

3D map of study area created from satellite image and location of randomized CPTu test points. The surrounded area in the white rectangle is used to represent the predicted 2D soil type map

Comparison between actual and predicted soil types in one of the training test points based on (a) SBT and (b) IC values


Data scattering of actual and predicted IC and SBT regarding the 1:1 slope line

Comparison of (a and b) predicted IC and SBT according to the defined boundaries (Table 1) using the GFNN model and CPTu interpretations with available USCS data (c) the classified soil classes using fuzzy approach (Zhang and Tumay 1999), and (d) classified soil types based on Douglas and Olsen (1981). The methods and used abbreviations were described in the text
Discussion
The introduced GFFN model was evaluated using validation datasets not previously fed or seen by the network. The compared results of predicted SBT and IC values in validation datasets with respect to interpreted CPTu data and conventional soil type charts showed 84.5 and 90.34% success in accuracy, whereas for all data sets 83.9 and 94.6% were observed. Moreover, the IC values are used to screen out layers susceptible to liquefaction (i.e., IC > 2.6) and also differentiate between clay-like and sand-like soils (Robertson 2016). This is an important issue in Sweden and also in areas which suffer from frequent landslides, which mainly occur in clayey soils and in quick clay in particular. As shown in Fig. 5, an expansion in clayey-like behavior zones with IC > 2.6 can be observed, which according to surveyed geological condition and landslides that have occurred in the area (Klingberg 2010) can be attributed to the presence of quick clay. The soil type distribution presented in Fig. 5 also showed a similar trend in geophysical and geotechnical investigations as well as laboratory tests (Abbaszadeh Shahri et al. 2015a; Malehmir et al. 2013; Löfroth et al. 2011), which aimed to provide high resolution subsurface layers and in particular distinguish the quick clays for a part of this area. It was thus discovered that soil type mapping based on IC can play an important role in detecting possible hazardous areas and delineating the clay-like behavior areas (i.e. IC > 2.6).
The data scattering conducted between actual and predicted SBT and IC values regarding the 1:1 slope line is shown in Fig. 6. The IC is a continuous range of numbers, whereas the SBT includes the integer values (Table 1). The aggregations of data around the slope line that express appropriate performance in IC are therefore more visible than SBT and the located data on the slope line indicate accurate prediction. The calculated coefficients of determination (R2) and the percentage of outputs classified correctly in prediction using the GFNN (Table 3) also showed better performance than SBT.
The accuracy of predicted IC in the soil type maps produced for each test point was also compared to and evaluated against other known soil classification procedures (Zhang and Tumay 1999; Douglas and Olsen 1981) as well as available field and laboratory tests in the study area. As an example, one of the investigated test points belonging to validation datasets is presented (Fig. 7). For the presented test points, USCS data was also available (Fig. 7). The USCS, which is expressed by two letter symbols, classifies the soils based on texture and grain size in different groups for engineering geology purposes and can be applied to most unconsolidated materials (the first indicates the soil type and the second corresponds to grading and plasticity conditions). The M and C express the silt and clay, while L shows low plasticity, respectively (Fig. 7). As can be seen from Fig. 7a, the IC predicted using GFNN showed appropriate adaption with both USCS data and CPTu conventional soil type charts. It can be observed that the chart by Robertson et al. (1986) is able to cover most of the classes defined in USCS, whereas Zhang and Tumay (1999) showed high clayey soils containing 5–6% sand and 43–44% silt, which can be classified as CL, ML, and CH in USCS (Fig. 7c). The method used by Douglas and Olsen (1981) also classified the soil types in the CL-CH group (Fig. 7d). Comparison of these analyses showed more appropriate conditions when subjected to Robertson et al. (1986) and Zhang and Tumay (1999). The results of these analyses also showed that using IC is not only more reliable but can also be a logical reason for soil classification in engineering applications and practices. The test point marked in Fig. 5, which belongs to validation datasets, has been the subject of both geophysical, geotechnical, and laboratory investigations (Abbaszadeh Shahri et al. 2015a; Malehmir et al. 2013; Löfroth et al. 2011).
Conclusions
In the current study a multi-output GFNN based model was developed to predict the distribution map of soil types at various depth intervals using recorded CPTu data in the southwest of Sweden. Two outputs consisting of SBT and IC were utilized for the GFNN, and the results were compared to different conventional soil classification charts and a statistical fuzzy approach. The analyses showed that a four layer multi-output GFNN under 4-8-6-2 structure with a 94.3% success rate can be considered the best model in this study. Comparison of predicted GFNN outputs showed that the IC values can be used for soil distribution mapping and distinguishing of soil types due to better conditions than SBT. The performance of the GFNN model in estimating the complex soil profile plots was also controlled by calculated correlation of determination in soil type distribution maps using both predicted outputs (SBT and IC). Comparison of predicted soil type classes using GFNN with other known soil identification procedures showed acceptable accuracy in estimated soil type classes and digital soil type maps. However, an appropriate similar trend or even better situations than the conventional methods in many test points were observed. The studied area is prone to landslide hazard and the generated soil mapping can therefore play an important role in construction and environment issues. The integrity of GFNN with chart based soil classification methods thus indicates a powerful tool in providing a reliable prediction process.
It should be noted that the artificial intelligence based models can always be updated and modified to improve the results if new examples or more data become available and thus more complex and mostly unpredictable situations and problems in geotechnical engineering may be handled more confidently.
References
Abbaszadeh Shahri A (2016) An optimized artificial neural network structure to predict clay sensitivity in a high landslide prone area using piezocone penetration test (CPTu) data: a case study in southwest of Sweden. Geotech Geol Eng 34(2):745–758
Abbaszadeh Shahri A, Malehmir A, Juhlin C (2015a) Soil classification analysis based on piezocone penetration test data a case study from a quick-clay landslide site in southwestern Sweden. Eng Geol 189:32–47
Abbaszadeh Shahri A, Larsson S, Johansson F (2015b) CPT-SPT correlations using artificial neural network approach—a case study in Sweden. Electron J Geotech Eng 20(28):13439–13460
Albuquerque VH, Alexandria AR, Cortez PC, Tavares JM (2009) Evaluation of multilayer perceptron and self-organizing map neural network topologies applied on microstructure segmentation from metallographic images. NDT & E Int 42(7):644–651
Arel E (2012) Predicting the spatial distribution of soil profile in Adapazari/Turkey by artificial neural networks using CPT data. J Comput Geosci 43:90–100
Arulampalam G, Bouzerdoum A (2003) A generalized feed forward neural network architecture for classification and regression. Neural Netw 16:561–568
Band LE, Moore ID (1995) Scale: landscape attributes and geographical information systems. Hydrol Process 9:401–422
Behrens T, Forster H, Scholten T, Steinrucken U, Spies E, Goldschmitt M (2005) Digital soil mapping using artificial neural networks. J Plant Soil Sci 168:1–13
Bhattacharya B, Solomatine DP (2006) Machine learning in soil classification. J Neural Netw 19(2):186–195
Cabalar AF, Cevik A, Gokceoglu C (2012) Some applications of adaptive neuro-fuzzy inference system (ANFIS) in geotechnical engineering. Comput Geotech 40:14–33
Camera C, Zomeni Z, Noller JS, Zissimos AM, Christoforou IC, Bruggeman A (2017) A high resolution map of soil types and physical properties for Cyprus: a digital soil mapping optimization. Geoderma 285:35–49
Carré F, Girard MC (2002) Quantitative mapping of soil types based on regression kriging of taxonomic distances with landform and land cover attributes. Geoderma 110(3–4):241–263
Carvalho Junior W, Chagas C, FernandesFilho E, Francelino M (2011) Digital soil scape mapping of tropical hill slope areas by neural networks. Sci Agric (Piracicaba, Braz) 68(6):691–696
Cevik A, Cabalar A, Guzelbey I (2010) Constitutive modeling of Leighton Buzzard Sands using genetic programming. Neural Comput Applic 19(5):657–665
Choobasti AJ, Farrokhzad F, Rahim Mashaei S, Azar PH (2015) Mapping of soil layers using artificial neural network (case study of Babol, northern Iran). J South Afr Inst Civil Eng 57(1):59–66
Dobos E, Carré F, Hengl T, Reuter HI, Tóth H (2006) Digital soil mapping as a support to production of functional maps, EUR 22123 EN. Office for Official Publications of the European Communities, Luxemburg
Douglas BJ, Olsen RS (1981) Soil classification using electric cone penetrometer. American Society of Civil Engineers, ASCE, Proceedings of conference on cone penetration testing and experience, St. Louis, pp 209–227
Duda RO, Hart PE, Stork DG (2001) Unsupervised learning and clustering. Pattern classification (2nd edn). Wiley, New York
Edincliler A, Cabalar AF, Cevik A (2013) Modelling dynamic behaviour of sand–waste tires mixtures using neural networks and neuro-fuzzy. Eur J Environ Civ Eng 17(8):720–741
Freire S, Fonseca I, Brasil R, Rocha J (2013) Using artificial neural networks for digital soil mapping – a comparison of MLP and SOM approaches. AGILE 2013 – Leuven
Jaksa MB (1995) The influence of spatial variability on the geotechnical design properties of a stiff, over consolidated clay. PhD thesis, The University of Adelaide
Jefferies MG, Been K (2006) Soil liquefaction a critical state approach. Taylor & Francis/CRC, Boca Raton
Jefferies MG, Davies MP (1993) Use of CPTU to estimate equivalent SPT N60. Geotech Test J ASTM 16(4):458–468
Jordan MI, Bishop CM (2004) Neural networks. Computer science handbook, second edition (section VII: intelligent systems). Chapman & Hall/CRC , Boca Raton
Juang CH, Jiang T, Christopher RA (2001) Three-dimensional site characterization: neural network approach. Geotechnique 51(9):799–809
Klingberg F (2010) Bottenf örhållanden i Göta Älv. SGU-rapport 2010: 7, Sveriges Geologiska Undersökning, Göteborg
Ku CS, Juang CH, Ou CY (2010) Reliability of CPT Ic as an index for mechanical behavior classification of soils. Geotechnique 60(11):861–875
Kumar Gupta D, Prasad R, Kumar P, Kuamr Vishwakarma A (2017) Soil moisture retrieval using ground based bistatic scatterometer data at X-band. Adv Space Res 59(4):996–1007. https://doi.org/10.1016/j.asr.2016.11.032
Kurup PU, Griffin EP (2006) Prediction of soil composition from CPT data using general regression neural network. J Comput Civ Eng 20(4):281–289
Löfroth H, Suer P, Dahlin T, Leroux V, Schälin D (2011) Quick clay mapping by resistivity-surface resistivity, CPTU-R and chemistry to complement other geotechnical sounding and sampling. Swedish Geotechnical Institute, report GÄU 30
Malehmir A, Saleem UM, Bastani M (2013) High-resolution reflection seismic investigations of quick-clay and associated formations at a landslide scar in Southwest Sweden. J Appl Geophys 92:84–102
Mcbratney AB, Mendonça Santos ML, Minasny B (2003) On digital soil mapping. Geoderma 117:3–52
Millet D (2011) River erosion, landslides and slope development in Göta River. Master thesis, Chalmers University of Technology
Nagaraj (2000) Prediction of engineering properties of fine-grained soils from their index properties. Can Geotech J 37:712–722
Olanloye DO (2014) An intelligent system for soil classification using supervised learning approach. J Comput Eng Intell Syst 5(11):13–24
Pásztor L, Laborczi A, Takács K, Szatmári G, Fodor N, Illés G, Farkas-Iványi K, Bakacsi Z, Szabó J (2017) Compilation of functional soil maps for the support of spatial planning and land management in Hungary. Soil Mapp Proc Model Sustain Land Use Manag 9:293–317. https://doi.org/10.1016/B978-0-12-805200-6.00009-8
Peterson C (1991) Precision GPS navigation for improving agricultural productivity. GPS World 2:38–44
Piikki K, Söderström M (2018) Digital soil mapping of arable land in Sweden – validation of performance at multiple scales. Geoderma. https://doi.org/10.1016/j.geoderma.2017.10.049
Rannka K, Andersson-Sköld Y, Hulten C, Larsson R, Leroux V, Dahlin T (2004) Quick clay in Sweden. Report No 65, SGI-R--04/65-SE, Linköping
Rizzo R, Demattê JAM, Lepsch IF, Gallo BC, Fongaro CT (2016) Digital soil mapping at local scale using a multi-depth Vis–NIR spectral library and terrain attributes. Geoderma 274:18–27
Robertson PK, Campanella RG, Gillespie D, Greig J (1986) Use of piezometer cone data. In-Situ '86 use of in-situ testing in geotechnical engineering, GSP 6, ASCE, Reston, VA, Specialty Publication, pp 1263–1280
Robertson PK (1990) Soil classification using the cone penetration test. Can Geotech J 27(1):151–158
Robertson PK (2016) Cone penetration test (CPT)-based soil behaviour type (SBT) classification system- an update. Can Geotech J 53:1910–1927. https://doi.org/10.1139/cgj-2016-0044
Rojas R (1996) Neural networks a systematic introduction. Chap 7, the back propagation algorithm. Springer, Berlin
Rumelhart DE, Hinton GE, Williams RJ (1986) Learning internal representation by error propagation parallel distribution processing: exploration in the microstructure of cognition, Vol 1, Chap (8). MIT Press, Cambridge
Santra P, Kumar M, Panwar NR, Das BS (2017a) Digital soil mapping and best management of soil resources: a brief discussion with few case studies. Rakshit A, Abhilash PC, Singh HB, Ghosh S (Eds) Adaptive soil management: from theory to practices, Chap 3–38
Santra P, Kumar M, Panwar N (2017b) Digital soil mapping of sand content in arid western India through geostatistical approaches. Geoderma Reg 9:56–72
Sarmento EC, Giasson E, Weber E, Flores CA, Hasenack H (2010) Comparison of four machine learning algorithms for digital soil mapping in the Vale dos Vinhedos, RS, Brasil. In: International workshop on digital soil mapping, 4. Anais. CRA-RPS, Rome
Sindayihebura A, Ottoy S, Dondeyne S, Van Meirvenne M, Van Orshoven J (2017) Comparing digital soil mapping techniques for organic carbon and clay content: case study in Burundi's central plateaus. Catena 156:161–175
Theodoridis S, Koutroumbas K (2009) Pattern recognition, 4th edn. Academic, Cambridge
Tizpa P, Jamshidi R, Mehran C, Karimpour F, Machado S (2015) ANN prediction of some geotechnical properties of soil from their index parameters. Arab J Geosci 8(5):2911–2920
Tso B, Mather PM (2001) Classification methods for remotely sensed data. Taylor and Francis, London
Wang RY, Strong D (1996) What data quality means to data consumers. J Manag Inf Syst 12(4):5–34
Worden K, Wong CX, Parlitz U, Hornstein A, Engster D, Tjahjowidodo T, Al-Bender A (2007) Identification of pre-sliding and sliding friction dynamics: grey box and black-box models. Mech Syst Signal Process 21:514–534
Yiming A, Lin Y, Xing ZA, Chengzhi Q, JingJing S (2018) Identification of representative samples from existing samples for digital soil mapping. Geoderma 311:109–119
Zeraatpisheh M, Ayoubi S, Jafari A, Finke P (2017) Comparing the efficiency of digital and conventional soil mapping to predict soil types in a semi-arid region in Iran. Geomorphology 285:186–204
Zhang Z, Tumay MT (1999) Statistical to fuzzy approach toward CPT soil classification. J Geotech Geoenviron 25(3):179–186
Zhu X, Yang L, Li B, Qin C, Pei T, Liu B (2010) Construction of membership functions for predictive soil mapping under fuzzy logic. Geoderma 155:164–174
Zhu A (2000) Mapping soil landscape as spatial continua: the neural network approach. J Water Resour Res 36(3):663–677
Zhu AX, Mackay DS (2001) Effects of spatial detail of soil information on watershed modeling. J Hydrol 248:54–57
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Ghaderi, A., Abbaszadeh Shahri, A. & Larsson, S. An artificial neural network based model to predict spatial soil type distribution using piezocone penetration test data (CPTu). Bull Eng Geol Environ 78, 4579–4588 (2019). https://doi.org/10.1007/s10064-018-1400-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10064-018-1400-9