
Abstract
The traditional image quality assessment (IQA) methods are usually based on convolutional neural networks (CNNs). For these IQA methods using CNNs, limited by the feature size of the fully connected layer, the input image needs be tailored to a pre-defined size, which usually results in destroying the original structure and content of the input image and thus reduces the accuracy of the quality assessment. In this paper, a blind image quality assessment method (named CSPP-IQA), which is based on multi-scale spatial pyramid pooling, is proposed. CSPP-IQA allows inputting the original image when assessing the image quality without any image adjustment. Moreover, by facilitating the convolutional block attention module and image understanding module, CSPP-IQA achieved better accuracy, generalization and efficiency than traditional IQA methods. The result of experiments running on real-scene IQA datasets in this study verified the effectiveness and efficiency of CSPP-IQA.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Due to the wide adoption of smart phones, the generation of digital images has shown explosive growth. Quality assessment is an essential for enhancing the quality of visual contents sent to the terminal users in a visual communication systems (VCSs). [1]. Video and images also play an important role in maintaining social stability and prosperity. For example, in the medical field, with the sudden outbreak of the novel coronavirus pneumonia (COVID-19), images play an extremely important role in fighting the epidemic. Experts across the country can conduct online medical analysis and diagnosis through images [2,3,4,5,6,7]. It is an essential to assess the quality of real-scene images to optimize the parameters and performance of the image-oriented systems, so as to ensure the quality of visual content delivered to the terminal users.
Methods for IQA could be grouped to objective ones and subjective ones. Objective methods are trained by using subjective assessment data. It can automatically predict content quality and is suitable for real-time scenarios. Human visual systems (HVS) are the ultimate receiver of visual signals in most of VCSs; hence, HVS-based subjective methods are reliable and accurate. However, it is time-consuming and usually cannot be directly integrated to other applications as an optimized factor.
Generally, objective IQA methods can be grouped to: (1) No-Reference (NR), which is also called Blind IQA (BIQA); (2) Reduced-Reference (RR) and (3) Full-Reference (FR), which is usually used as a metric to assess algorithms for image processing. RR-IQA methods are usually integrated into the other systems to optimize the algorithm performance. Usually, there is no possibility to acquire a reference image without any distortions. NR-IQA is the promising method in practice.
Recently, various kinds of IQA methods are proposed for the natural image quality assessment [8,9,10,11,12,13,14,15,16,17]. These features extracted by manual operations are not enough to perfectly achieve the IQA. Besides, the low-level features are not enough for representing the complex distortion in practice. Although these exist a number of NR-IQA methods [18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33] for distortion achieved, most of existing deep neural networks are not specially proposed for IQA tasks; therefore, these methods could only work with the global features rather than the local features. However, the image distortion mostly occurs in the local areas. Moreover, local distortions are sensitive for HVS; hence, both the global and local quality while designing an IQA algorithm must be taken into consideration. Moreover, these IQA methods usually introduce CNN to extract semantic features of the original images (as illustrated in Fig. 1b). Constrained by the image size, the original image must be tailored prior to inputting to the convolutional network. As illustrated in Fig. 1a, the overexposed frame missed due to the operation of cropping on the original image; the latter image is stretched, which indirectly introduces distortions and destroys the original content of the original image. In consequence, the caused distortion deviation weakens the performance of these methods.

Comparison of the workflow between traditional CNN-based methods and the proposed method
In this paper, a novel method for IQA, which is based on multi-scale spatial pyramid pooling, is proposed. In practices, such as capturing images with mobile phones, the proposed method could provide reliable and efficient image quality assessment for terminal users. The contributions in this work are as below:
-
We proposed a convolutional spatial pyramidal pooling structure to address the issue of size limitation of semantic features, and the structure is capable of assessing the image quality by directly inputting the original image without the operations tailoring image.
-
The ResNet50 is adopted as the backbone network to integrate the multi-scales semantic information of the image to efficiently capture the local distortion. In the proposed method, the Convolutional Block Attention Module is integrated to highlight important features while suppressing unimportant ones.
-
In the proposed method, SmoothL1 loss is introduced in the process of quality scoring to address the issue that the original model is not smooth near the zero point.
The remainder of this paper is organized as follows. Section 2 introduces the related work. The proposed model is introduced in Sect. 3. Section 4 presents the experiments of the proposed method. We conclude the paper and discuss the future directions in Sect. 5.
2 Related work
2.1 NR-IQA-based synthetic distortion
NR-IQA can be grouped to synthetic distortion based on NR-IQA and authentic distortion based on NR-IQA. The synthetic distortion based on NR-IQA can be grouped to: (1) natural scene statistical-based models (NSS), (2) manual feature extraction-based models and (3) deep learning-based models. There are a number of NSS-based NR-IQA methods such as BRISQUE [8], NIQE [9], BIQI [10], DIIVINE [11], BLIINDS [12], ShearletIQM [13] and SPNSS [14]. Moreover, CORINA [15] is NR-IQA-based model. ILNIQE is a BIQA-based method [16]. Xu et al. [17] proposed a High Order Statistics Aggregation hybrid-based model. Rajevenceltha [34] proposed a rotation-invariant and efficient NR-IQA method, which extracts features using the modified local binary patterns and statistical methods and then employs support vector regression to measure image quality. Azam et al. concluded the fusion quality assessments metric of fused images with different imaging modalities [35].
The deep learning-based IQA methods adopt deep neural networks to extract the visual features of an image and then calculate the functional expression of the distorted image to get its quality score. Kang et al [18] introduced CNN to construct an IQA method. Kim [19] used an image block-based method to increase the amount of training data. Bosse et al. [20] performed random sampling operations to image dataset without the operation of normalization, so these global features (e.g., luminance, etc.) can be taken into considerations.
2.2 NR-IQA-based authentic distortion
The authentic distortion is usually randomly and mixed distributed in an image; therefore, traditional synthetic distortion-based NR-IQA methods cannot perfectly achieve the quality score of authentic distorted images. Ghadiyaram et al. [21] proposed a feature-map-based image quality assessment method. Bianco et al. [22] introduced a pre-trained CNN to build a function mapping CNN features to subjective quality scores. Li et al. [23] proposed a NR-IQA based method, which is only valid for authentic blurred. Zeng et al. [24] proposed a probabilistic model to predict the distribution of five different quality scores instead of only one score. HyperIQA [26] is proposed to predict the image quality of with an adaptation to scenarios. Zhang et al. [31] and Sun et al. [32] proposed a BIQA for in-the-wild images via hierarchical feature fusion and iterative mixed database training.
To address the cross-distortion-scenario challenges, [25] proposed a novel model consisting of two networks, in which one network is used for synthetic distortion and other network is used for authentic distortion. The change of image content and types of image distortions hinders the definition of image quality while assessing the blind quality of distorted images [36, 37].
3 The proposed model
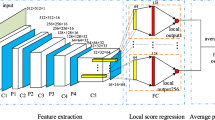
As shown in Fig. 2, the proposed model consists of (1) multi-scale semantic feature extraction, (2) quality prediction module and (3) adaptive content understanding. Firstly, four different scales of semantic features are extracted from the input image by ResNet50, and then four different scales of semantic feature vectors are generated, respectively, by spatial pyramid pooling. Then, these semantic feature vectors are integrated as the input of the quality prediction module. By introducing attention mechanism, the 4th scale semantic features are transferred to high-level semantic features, which will then be fed to the adaptive content understanding module. The image content understanding module is designed to generate the weights and biases for the quality prediction module. The quality prediction module is designed to calculate these weights and biases with a multi-scale semantic feature vector to get the image’s quality score.

The structure of the proposed image quality assessment model
3.1 Multi-scale semantic feature extraction
The ResNet50 [38] is adopted as the backbone network. The fully connected layer and average pooling layer are removed from the classical ResNet50 model and the output of this model is designated to the high-level semantic feature stream.
Constrained by the size of feature of the fully connected layer in the traditional IQA methods, a test image is randomly cropped into several blocks in the same size, and then these image blocks are subsequently fed into a network for semantic feature extraction. As presented in the SPPnet [39], spatial pyramid pooling structure could improve the model performance and speed up the model training; hence, in the proposed method, the convolutional spatial pyramidal pooling (CSPP) is adopted as the pooling structure in the process of semantic feature extraction.
As shown in Fig. 3, the CSPP is introduced for reducing dimensionalities by spatial pyramidal pooling and \(1 \times 1\) convolution. There is no constraint to the size of the input feature map, and the size of the output channels is set to 256. A three-level spatial pyramid structure is used for the operation of pooling. By merging the results from the three sources, the final feature size of \(14*256\) is obtained. So that, it is transformed to a one-dimensional matrix prior to being passed to the fully connected layer. Whatever the size of the input images, and with the operation of spatial pyramid pooling, the size will be finally set to \(1*3584\), which is the size of input feature in the fully connected layer.

The internal structure of the CSPP
The CBAM [40] is introduced to highlight the target features of channel and spatial axis as shown in Fig. 4a. Besides, the channel attention module and the spatial attention module in turn, whose functions are adopted to learn the content in the channel axis and the position in the spatial axis, respectively. Given an intermediate feature map \(F \in R^{C \times H \times W}\) as input (\(C\) for channel, \(H\) for height, \(W\) for width), CBAM calculates a 1D channel attention map \(M_{c} \in R^{C \times 1 \times 1}\) and a 2D spatial attention map \(M_{s} \in R^{1 \times H \times W}\) in turn, as shown in Fig. 4. The whole attention process can be summarized as follows:
where \(\otimes\) denotes the element-wise multiplication, \(M_{c} \left( \cdot \right)\) represents the calculation of channel attention module, and \(M_{s} \left( \cdot \right)\) represents the calculation of spatial attention module. The execution process of CBAM are as follows: first, the input \(F\) is multiplied by channel attention module to get the result \(F{^{\prime}}\); then, \(F{^{\prime}}\) is used as the input of spatial attention module, and the refined feature \(F^{\prime\prime}\) is calculated by the spatial attention module.

The internal structure of the convolutional block attention module
As shown in Fig. 4b, the channel attention module receives the average-pooled and max-pooled features and then feeds these features to a weight-sharing Multilayer Perceptron (MLP). The element-wise summation combining the output feature vectors is carried out. The core idea of channel attention module is to make up for the deficiency of channel attention. The channel attention module is formularized as:
where \(\sigma\) represents sigmoid activation function, \(MLP\) represents shared full connection layer, \(AvgPool\) represents average pooling, \(MaxPool\) represents maximum pooling, and '\(+\)' represents element-wise addition.
The structure of spatial attention module is shown in Fig. 4c, a feature map is obtained through max pooling and average pooling, then they are spliced into a 2D feature map and then sent to the standard \(7 \times 7\) convolution for parameter learning, and a 1D weight feature map is obtained. The spatial attention module is formularized as:
where \(\sigma\) is the sigmoid activation function and \(conv^{7 \times 7}\) is the convolution kernel of \(7 \times 7\).
The full workflow of the feature extraction module is as shown in Fig. 2. The original image is inputted to ResNet50 and then passed through the first convolutional layer and CBAM. Three strings of semantic feature streams in different scales are generated from convolutional layers. Next, these three feature streams are inputted into CSPP(3) to generate 3 semantic feature vectors. The high-level semantic feature streams generated in Stage 4 are further handled by SPP to generate the 4th semantic feature vector. By calculating these four semantic feature vectors, the \(C\left( I \right)\), which is the input of the quality prediction module, is obtained.
3.2 Adaptive content understanding
The quality scoring in traditional deep learning-based IQA methods is defined in Eq. (5).
where \(P\) is a function mapping the original image \(I\) to the quality score \(s\). \(\theta\) denotes the weight of the network. When the training process completes, the weight parameter \(\theta\) is obtained for all test images.
With regard to the characteristics of HVS, we decode the content of the image and then customize different rules according to the content, and thus the calculation of the quality score is defined as follows:
where the parameter \(\theta_{I}\) is determined by the content of the test image.
The calculation of parameter \(\theta_{I}\) is defined as follows:
where \(U\) is a function mapping the high-level semantic features \(C\left( I \right)\) to network parameters \(\theta_{I}\), \(\lambda\) is the parameter in the adaptive content understanding module, and \(C\left( I \right)\) is from the input image.
The module is designed to learn the content of the image and generate the weights and biases for the fully connected layer. It consists of an adaptive average pooling layer, three \(1 \times 1\) convolutional layers and four weight generation branches. The weights of the fully connected layer are initiated by the operation of convolution.
An adaptive pooling operation is carried out prior to inputting the high-level semantic features into the adaptive content understanding module to ensure that the size of feature maps is subjected to the requirement. The maximum or average pooling is formularized as:
where \(S_{out}\) denotes the size of output, \(S_{in}\) denotes the size of input, and \(padding\) denotes the fill size. The operation of padding during the pooling process is used to maintain the boundary information of the feature map. \(S_{kernel}\) denotes the kernel size and \(stride\) denotes the step size.
Given the input and output dimensions, the adaptive pooling operation is defined as follows:
3.3 Quality prediction process
The calculation of image quality scoring is formularized in Eq. (11).
\(f_{I}\) denotes the multi-scale semantic feature stream extracted from ResNet50. \(C\left( I \right)\) denotes the high-level semantic features, which will be fed into the adaptive content understanding module to generates weights and biases for the image quality prediction module. These weights and biases will be calculated with \(f_{I}\) using fully connection to get the quality score.
4 Experiment
4.1 Dataset introduction
The datasets in this experiment includes Live-Challenge [41], KonIQ-10k [42], BID [43], SPAQ [44] and FLIVE [45]. The LIVE Challenge was developed by University of Texas at Austin. It contains 1162 authentic distortion images with more than 350,000 collected subjective scores. The values of these scores are from 3.42 to 92.43. The KonIQ-10k was developed by the University of Konstanz. It contains 10,073 authentic distorted images with 1,459 annotators and 1.2 million subjective data. BID contains 586 images with authentic blur distortion (such as complex motion blur, etc.). SPAQ contains 11,125 images covering a wide range of scene categories such as landscape, human, animal, etc. FLIVE is currently the largest database for IQA, and it contains over 40,000 authentic distorted images.
4.2 Training method
The training was carried out on a Windows 10 computer equipped with a GPU 2080Ti, and we took Pytorch library to develop the experimental programs. A single-size training method proposed in [39] was adopted for model training. To enhance the generalization of the model, each image is randomly sampled and horizontally flipped to get 25 blocks in the size \(224 \times 224\) pixels. In each round of training, 80% of the dataset are randomly selected as the training set and 20% of the dataset are used as the testing set. In the test, SmoothL1Loss is adopted as the loss function and is formularized as follows:
In Eq. (12), SmoothL1Loss will be assigned as L2Loss when the absolute value of \(t\) is less than 1. Then smaller loss is obtained because L2Loss squares the error, which is beneficial for model convergence. Otherwise, SmoothL1Loss is a translation of L1Loss. L1Loss is more insensitive to outliers compared to L2Loss, and the magnitude of the gradient is controllable. SmoothL1Loss is treated as the combination of L2Loss and L1Loss. Therefore, SmoothL1Loss is adopted as loss function. The \(t\) in Eq. (12) is defined as below:
The \(P\left( {f_{I} ,U\left( {C\left( I \right),\lambda } \right)} \right)\) in Eq. (13) denotes the predicted score, and \(q\) denotes the subjective score. Adam optimizer is adopted for performance optimization. The weight attenuation is set to \(5 \times 10^{ - 4}\); meanwhile, the learning rate is set to \(2 \times 10^{ - 5}\).
4.3 Assessment metrics
In order to validate the performance of the proposed method, Pearson Linear Correlation Coefficient (PLCC) and Spearman Rank Order Correlation Coefficient (SROCC) are taken as assessment metrics to compute the correlation between subjective and objective scores in this experiment. PLCC is adopted for assessing the prediction accuracy of the model, and SROCC is adopted to access the prediction monotonicity.
The quality scores achieved by different IQA methods are in different ranges, so a mapping function to regress these quality scores into a common space is defined as follows:
where \(x\) denotes the input score and \(\left( {\beta_{1} , \cdots ,\beta_{5} } \right)\) is the set of parameters to be fitted.
4.4 Experimental results
4.4.1 SROCC and PLCC Performance
The experiment is carried out on a group of datasets: Live-Challenge, KonIQ-10k dataset, BID, SPAQ and FLIVE dataset. The experiment compares the performance of SROCC and PLCC with the traditional manual feature extraction IQA methods [8, 16,17,18], synthetic distortion IQA methods [20, 21] and authentic distortion IQA methods [22, 24,25,26,27]. As shown in Table 1. The proposed method outperformed in the comparison, indicating that directly inputting the whole image into the network is helpful for reflecting the overall image quality. Because cropping/stretching the original image usually destroys the original structure and content of the image, it weakens the performance of quality scoring.
4.4.2 Comparison of MOS prediction
The MOS prediction was performed using BIECON, FRISQUEE, PQR, DBCNN, HyperIQA and CSPP-IQA on Live-Challenge dataset, respectively. As shown in Fig. 5, the result is illustrated in a group of scatter plots, where the horizontal coordinates are the true MOS values and the vertical coordinates are MOS values predicted by the objective IQA methods. The scatter plot can intuitively show the relationship between the two sets of data. The better the performance of the algorithm, the more the scatter distribution in the plot is clustered around the red fitting line. The scatter distribution of CSPP-IQA is more concentrated and regular than other methods, which also shows that the predicted MOS of CSPP-IQA is more consistent with subjective score.

Scatter plots of predicted MOS values of six different IQA methods on the Live-challenge
4.4.3 Analysis of model generalization
To evaluate the generalization of the proposed model, we took different image datasets for training and testing. The model is trained on a dataset, but tested on a different dataset. The proposed method outperforms the competition with PQR, DBCNN and HyperIQA (as shown in Table 2). Moreover, by integrating the CBAM into the proposed model, the achieved quality score of the model is close to human subjective perception.
4.4.4 Comparison of training time
We performed a 100-round experiment to evaluate the training time of the proposed model and others. The original image is inputted directly in the training phase on the KonIQ-10k dataset without cropping. As shown in the Table 3, compared with HyperIQA, under the premise of ensuring accuracy, the training speed of CSPP-IQA is improved by 4.88 times. Besides, the proposed model requires less computational resources.
4.4.5 Experimental analysis on SPP structure
By introducing the SPP, there is no need for stretching and cropping the original image, which could avoid causing extra distortions to the original image. Figure 6 shows the result of CSPP-IQA adopted different levels of SPP (i.e., SPP-3, SPP-4 and SPP-5). SPP-3 denotes three-level SPP structure and so on. The result indicates that the three-level SPP outperformed the performance comparison. That is because more features extracted by higher-level SPP could result in certain redundant features, which could affect the final quality assessment. Meanwhile, the introduction of higher-level SPP structure could hinder the converge process of the model.

Performance comparison of SPP structure in different levels: a Result based on the dataset Live-Challenge; b Result based on the dataset KonIQ-10k
In the experiment based on the dataset Live-Challenge, the maximum pooling and average pooling are introduced in the three-layer SPP structure respectively. As shown in Table 4, the comparative result indicates that average pooling achieved better performance as it retains the overall characteristics of the image. In this sense, the main function of average pooling is more consistent than maximum pooling, which aims to preserving texture features and reducing the impact of irrelative information. The idea of the proposed method is to learn the global and local semantic information by fusing multi-scale features, and thus average pooling is adopted in SPP structure.
4.4.6 Comparison of SROCC performance for loss functions
Figure 7 shows the comparative results of different loss functions running on Live-Challenge dataset. Compared with L1 / L2 loss function, the SmoothL1 loss function achieved the best performance thanks to the integration of L1 and L2 loss functions.

The comparison of loss functions adopted in this experiment on the dataset Live-challenge
4.4.7 Comparison of quality scoring accuracy
As shown in Fig. 8, we took 5 randomly selected images from the SPAQ dataset for the experiment, and the predicted MOS of four IQA methods (BIECON, DBCNN, HyperIQA and CSPP-IQA) for these images are listed in Table 5. CSPP-IQA achieved better performance in terms of consistency with MOS while assessing the quality of inputting images of different contents (e. g. animals, landscapes, portraits, buildings, etc.). As shown in Table 5, DBCNN achieved poor scores on Fig. 8e because the traditional IQA model that predicts the score directly without content understanding is prone to mistakenly treat flat regions (e. g. the sky) as distorted images [24].

A group of randomly selected images from the SPAQ dataset
4.4.8 Ablation Analysis
As shown in Table 6, ablation experiment was carried out based on the datasets Live-Challenge and KonIQ-10k to verify the effectiveness of each component. With Live-Challenge dataset, the introduction of either the SPP structure or CBAM could contribute to the improvement of SROCC by 1.5% and by 0.7% and PLCC by 2.5% and by 0.9%, respectively. With the dataset KonIQ-10k, the introduction of SPP structure could contribute an improvement of SROCC by 0.4% and PLCC by 0.5%, and the introduction of CBAM mechanism could contribute an improvement of PLCC by 0.6%.
5 Conclusion
In this study, we proposed a blind image quality assessment method (named CSPP-IQA) for distorted images. It introduces the spatial pyramid pooling, as well as the attention mechanism to successfully address the issue caused by the constraint of the image size in the fully connected layer. In the proposed method, by introducing the CBAM and adaptive content understanding module, the assessment accuracy is further improved, and it archives stronger generalization and less time cost compared with these existing IQA methods. Besides, CSPP-IQA requires less training time and computational resources and could be widely used in many real-time applications.
Because the human eye is easy to be attracted by the salient areas of the image when observing an image, the quality of these areas has great impact on the overall quality of the image. In the future, the visual attention could be taken into the basis of current study to further improve the prediction performance for the IQA tasks.
Data availability
The datasets generated during and analyzed during the current study are available from the corresponding author on reasonable request.
References
Zhai G, Min X (2020) Perceptual image quality assessment: a survey. Sci China Inf Sci 63(11):1–52
Rajevenceltha J (2022) Gaidhane V (2022) An efficient approach for no-reference image quality assessment based on statistical texture and structural features. Eng Sci Technol Int J 30:101039
Zhao L, Li K, Pu B, Chen J, Li S, Liao X (2022) An ultrasound standard plane detection model of fetal head based on multi-task learning and hybrid knowledge graph. Futur Gener Comput Syst 135:234–243
Wu X, Tan G, Zhu N, Chen Z, Li K (2021) CacheTrack-YOLO: Real-time detection and tracking for thyroid nodules and surrounding tissues in ultrasound videos. IEEE J Biomed Health Inform 25(10):3812–3823
Fang Y, Zhu H, Zeng Y, Ma K, Wang Z (2020) Perceptual quality assessment of smartphone photography. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp 3677–3686.
Liu X, Yang L, Chen J, Yu S, Li K (2022) Region-to-boundary deep learning model with multi-scale feature fusion for medical image segmentation. Biomed Signal Process Control. https://doi.org/10.1016/j.bspc.2021.103165
Zhou X, Liang W, Wang K, Yang L (2021) Deep correlation mining based on hierarchical hybrid networks for heterogeneous big data recommendations. IEEE Trans Comput Soc Syst 8(1):171–178
Mittal A, Moorthy AK, Bovik AC (2012) No-reference image quality assessment in the spatial domain. IEEE Trans Image Process 21(12):4695–4708
Mittal A, Soundararajan R, Bovik AC (2012) Making a “completely blind” image quality analyzer. IEEE Signal Process Lett 20(3):209–212
Moorthy AK, Bovik AC (2010) A two-step framework for constructing blind image quality indices. IEEE Signal Process Lett 17(5):513–516
Moorthy AK, Bovik AC (2011) Blind image quality assessment: From natural scene statistics to perceptual quality. IEEE Trans Image Process 20(12):3350–3364
Saad MA, Bovik AC, Charrier C (2010) A DCT statistics-based blind image quality index. IEEE Signal Process Lett 17(6):583–586
Mahmoudpour S, Kim M (2016) No-reference image quality assessment in complex-shearlet domain. SIViP 10(8):1465–1472
Lu F, Zhao Q, Yang G (2015) A no-reference image quality assessment approach based on steerable pyramid decomposition using natural scene statistics. Neural Comput Appl 26(1):77–90
Ye P, Kumar J, Kang L, Doermann D (2012) Unsupervised feature learning framework for no-reference image quality assessment. In: 2012 IEEE conference on computer vision and pattern recognition. IEEE, pp 1098–1105
Zhang L, Zhang L, Bovik AC (2015) A feature-enriched completely blind image quality evaluator. IEEE Trans Image Process 24(8):2579–2591
Xu J, Ye P, Li Q, Du H, Liu Y, Doermann D (2016) Blind image quality assessment based on high order statistics aggregation. IEEE Trans Image Process 25(9):4444–4457
Kang L, Ye P, Li Y, Doermann D (2014) Convolutional neural networks for no-reference image quality assessment. In: IEEE conference on computer vision and pattern recognition, pp 1733–1740
Kim J, Lee S (2016) Fully deep blind image quality predictor. IEEE J Sel Topics Signal Process 11(1):206–220
Bosse S, Maniry D, Müller KR, Wiegand T, Samek W (2017) Deep neural networks for no-reference and full-reference image quality assessment. IEEE Trans Image Process 27(1):206–219
Ghadiyaram D, Bovik AC (2015) Scene statistic of authentically distorted images in perceptually relevant color spaces for blind image quality assessment. In 2015 IEEE International conference on image processing (ICIP), pp 3851–3855
Bianco S, Celona L, Napoletano P, Schettini R (2017) On the use of deep learning for blind image quality assessment. SIViP 12(2):355–362
Li D, Jiang T, Lin W, Jiang M (2019) Which has better visual quality: The clear blue sky or a blurry animal? IEEE Trans Multimedia 21(5):1221–1234
Zeng H, Zhang L, Bovik AC (2017) A probabilistic quality representation approach to deep blind image quality prediction. arXiv preprint arXiv:1708.08190
Zhang W, Ma K, Yan J, Deng D, Wang Z (2020) Blind image quality assessment using a deep bilinear convolutional neural network. IEEE Trans Circuits Syst Video Technol 30(1):36–47
Su S, Yan Q, Zhu Y, Zhu Y, Zhang C, Ge X, Sun J, Zhang Y (2020) Blindly assess image quality in the wild guided by a self-adaptive hyper network. In: IEEE/CVF Conference on computer vision and pattern recognition, pp 3667–3676
Zhou X, Li Y, Liang W (2021) CNN-RNN based intelligent recommendation for online medical pre-diagnosis support. IEEE/ACM Trans Comput Biol Bioinf 18(3):912–921
Zhou X, Liang W, Wang K, Huang R, Jin Q (2021) Academic influence aware and multidimensional network analysis for research collaboration navigation based on scholarly big data. IEEE Trans Emerg Top Comput 9(1):246–257
Sun W, Min X, Zhai G, Ma S (2021) Blind quality assessment for in-the-wild images via hierarchical feature fusion and iterative mixed database training. arXiv preprint arXiv:2105.14550
Zhai G, Sun W, Min X, Zhou J (2021) Perceptual quality assessment of low-light image enhancement. ACM Trans Multimedia Comput Commun Appl (TOMM) 17(4):1–24
Zhang W, Ma K, Zhai G, Yang X (2020) Learning to blindly assess image quality in the laboratory and wild. In: International conference on image processing (ICIP), IEEE, pp 111–115
Zhou X, Liang W, Wang K, Shimizu S (2019) Multi-modality behavioral influence analysis for personalized recommendations in health social media environment. IEEE Trans Comput Soc Syst 6(5):888–897
Jiang Q, Xu J, Zhou W, Min X, Zhai G (2022) Deep decomposition and bilinear pooling network for blind night-time image quality evaluation. arXiv preprint arXiv:2205.05880
Pu B, Li K, Li S, Zhu N (2021) Automatic fetal ultrasound standard plane recognition based on deep learning and IIoT. IEEE Trans Indus Inf 17(11):7771–7780
Zhou X, Xu X, Liang W, Zeng Z, Yan Z (2021) Deep-learning-enhanced multitarget detection for end-edge-cloud surveillance in smart IoT. IEEE Internet Things J 8(16):12588–12596
Azam M et al (2022) A review on multimodal medical image fusion: compendious analysis of medical modalities, multimodal databases, fusion techniques and quality metrics. Comput Biol Med. https://doi.org/10.1016/j.compbiomed.2022.105253
Chen J, Yang N, Zhou M, Zhang Z, Yang X (2022) A configurable deep learning framework for medical image analysis. Neural Comput Appl 34(10):7375–7392
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: IEEE conference on computer vision and pattern recognition, pp 770–778
He K, Zhang X, Ren S, Sun J (2015) Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans Pattern Anal Mach Intell 37(9):1904–1916
Woo S, Park J, Lee, JY, Kweon S (2018) CBAM: Convolutional block attention module. In: Proc. ECCV, pp 3–19
Ghadiyaram D, Bovik AC (2015) Massive online crowdsourced study of subjective and objective picture quality. IEEE Trans Image Process 25(1):372–387
Hosu V, Lin H, Sziranyi T, Saupe D (2020) KonIQ-10k: An ecologically valid database for deep learning of blind image quality assessment. IEEE Trans Image Process 29:4041–4056
Ciancio A, Targino da Costa ALN, da Silva EAB, Said A, Samadani R, Obrador P (2010) No-reference blur assessment of digital pictures based on multifeature classifiers. IEEE Trans Image Process 20(1):64–75
Chen J, Li K, Zhang Z, Li K, Yu PS (2022) A survey on applications of artificial intelligence in fighting against COVID-19. ACM Comput Surv. https://doi.org/10.1145/3465398
Ying Z, Niu H, Gupta P, Mahajan D, Ghadiyaram D, and Bovik AC (2020) From patches to pictures (PaQ-2-PiQ): mapping the perceptual space of picture quality. In: IEEE Conference on computer vision and pattern recognition, pp 3575–3585.
Acknowledgements
This work was supported by Ministry of Education humanities social sciences research project (20YJC760101); China Postdoctoral Science Foundation (2020T130102ZX); Natural Science Foundation of Zhejiang Province (LQ20E080021, LQ21H190004); and the Educational Commission of Zhejiang Province of China (Y202147553).
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Conflict of interests
The authors declare that they have no interest conflict.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Jingjing Chen and Feng Qin contributed equally to this article.
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Chen, J., Qin, F., Lu, F. et al. CSPP-IQA: a multi-scale spatial pyramid pooling-based approach for blind image quality assessment. Neural Comput & Applic (2022). https://doi.org/10.1007/s00521-022-07874-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00521-022-07874-2