
Abstract
Consider the directed polymer in one space dimension in log-gamma environment with boundary conditions, introduced by Seppäläinen (Ann Probab, 40(1):19–73, 2012). In the equilibrium case, we prove that the end point of the polymer converges in law as the length increases, to a density proportional to the exponent of a zero-mean random walk. This holds without space normalization, and the mass concentrates in a neighborhood of the minimum of this random walk. We have analogous results out of equilibrium as well as for the middle point of the polymer with both ends fixed. The existence and the identification of the limit relies on the analysis of a random walk seen from its infimum.
Similar content being viewed by others

1 Directed polymers and localization
The directed polymer model was introduced in the statistical physics literature by Huse and Henley [25] to mimic the phase boundary of Ising model in presence of random impurities, and it is frequently used to study the roughness statistics of random interfaces. Later, it has been mathematically formulated as a random walk in a random potential by Imbrie and Spencer [26]. In the \((1+1)\)-dimensional lattice polymer case, the random potential is defined by a field of random variables \(\{\omega (i,j):(i,j) \in \mathbb {Z}^2\}\) and a polymer \(\mathbf{x}=(x_t; t=0,\ldots n)\) is a nearest neighbor up-right path in \(\mathbb {Z}^2\) of length n. The weight of a path is equal to the exponent of the sum of the potential it has met on its way. There is a competition between the entropy of paths and the disorder strength, i.e., the inhomogeneities of the potential. If the potential is constant, the path behaves diffusively and spreads smoothly over distances of order of the square root of its length. On the contrary, if the potential has large fluctuations, the path is pinned on sites with large potential values, and it localizes on a few corridors with width of order of unity. An early example where this behavior was observed is the parabolic Anderson model yielding a rigourous framework to analyse intermittency [8]. Recently, significant efforts have been focused on planar polymer models (i.e. \((1+1)\)-dimensional) which fall in the KPZ universality class (named after Kardar, Parisi and Zhang), see Corwin’s recent survey [13]. In the line of specific first passage percolation models and interacting particle systems, a few explicitly solvable models were discovered, and they allow for detailed descriptions of new scaling limits and statistics. We namely mention Brownian queues [30], log-gamma polymer [35], KPZ equation [23, 33]. However, the theory of universality classes does not explain the localization phenomena. For instance, the wandering exponent 2 / 3 from the KPZ class accounts for the typical transverse displacement of order \(n^{2/3}\) of the polymer of length n, certainly an important information, however different in nature since it addresses the location of the corridor but not its width.
Let us start by defining the model of directed polymers in random environment. For each endpoint (m, n) of the path, we can define a point-to-point partition function
where the sum is over up-right paths \(\mathbf{x}\) that start at (0, 0) and end at (m, n). The model does not have a temperature in the strict sense of statistical mechanics, however the parameter \(\mu \) entering below the log-gamma distribution of \(\omega \) plays a similar role by tuning the strength of the disorder. The point-to-line partition function is given by
The point-to-line polymer measure of a path of length n is
It is known that the polymer at a vanishing temperature concentrates on its geodesics. However little information is known on the random geodesics [31], except under assumptions which are often hard to check [15, 19]. A less ambitious way to analyze this localization phenomenon is to consider the endpoint of the path, and study the largest probability for ending at a specific point,
which does not require any information on where the endpoint concentrates. Observe that \(I_n\) is small when the measure is spread out, for example if \(\omega \) is constant, but \(I_n\) should be much larger when \(Q_{n}^{\omega }\) concentrates on a small number of paths. In large generality it is proved that the polymer is localized and it is expected from the KPZ scaling that most of the endpoint density lies in a relatively small region around a random point at distance \(n^{2/3}\) from the mid-point of the transverse diagonal. The size of this region is much smaller than \(n^{2/3}\) and is believed that it is order one. Moreover, Carmona and Hu [7] and Comets, Shiga and Yoshida [10] showed that there is a constant \(c_0=c_0(\beta )>0\) such that the event
has \(\mathbb {P}\)-probability one. This property is called endpoint localization. In fact, the Césaro mean of the sequence \(I_n\) is a.s. lower bounded by a positive constant. Analyzing terms in semimartingale decompositions, the technique is quite general, but also very circuitous and thus it only provides rough estimates. Recently, Seppäläinen has introduced in [35] a new solvable polymer model with a particular choice of the law of the potential. In this paper, we consider the log-gamma model, taking advantage of its solvability to analyze the mechanism of localization and obtain an explicit description. The model can be defined with boundary conditions (b.c.), i.e., with a different law for vertices inside the quadrant or on the boundary, see (2). From now, we will consider this model. First, it is convenient to introduce multiplicative weights
As discovered in the seminal paper [35], some boundary conditions make the model stationary as in Burke’s theorem [32], and further, they make it explicitely sovable. In this setting, the point-to-point partition function for the paths with fixed endpoint is given by
where \(\Pi _{m,n}\) denotes the collection of up-right paths \(\mathbf{x}=(x_t)_{0\le t\le m+n}\) in the rectangle \(\Lambda _{m,n}=\{0,\dots ,m\}\times \{0,\dots ,n\}\) that go from (0, 0) to (m, n). We assign distinct weight distributions on the boundaries \((\mathbb {N}\times \{0\}) \cup (\{0\}\times \mathbb {N})\) and in the bulk \(\mathbb {N}^2\). In order to make it clear, we use the symbols U and V for the weights on the horizontal and vertical boundaries:
Model b.c.( \(\theta )\): Let \(\mu >0\) be fixed. For \(\theta \in (0,\mu )\), we will denote by b.c.(\(\theta \)) the model with
where \(\hbox {Gamma}(\theta ,r)\) distribution has density \(\Gamma (\theta )^{-1}r^{\theta }x^{\theta -1}e^{-rx}\) with \(\theta >0, r>0\).
The polymer model with boundary condition possesses a two-dimensional stationarity property. Using this property, Seppäläinen [35] obtains an explicit expression for the variance of the partition function, he proves that the fluctuation exponent of free energy is 1 / 3 and that the exponent for transverse displacement of the path is 2 / 3. This model has soon attracted a strong interest: large deviations of the partition function [21], explicit formula for the Laplace transform of the partition function at finite size [14], GUE Tracy-Widom fluctuations for \(Z_n\) at scale \(n^{1/3}\) [6], computations of Busemann functions [20].
In fact, the model of directed polymers can be defined in arbitrary dimension \(1+d\) and with general environment law, see [26], and we now briefly mention some results for comparison. In contrast with the above results for \(d=1\), if the space dimension is large and the potential has small fluctuations—the so-called weak disorder regime—this exponent is 0, and under \(Q_n^{\omega }\) the fluctuation of the polymer path is order \(\mathcal {O}(n^{1/2})\) with a Brownian scaling limit, see [5, 11, 26]. More precisely, if the space dimension \(d\ge 3\) and if the ratio \({\mathbb E} (e^{2 \omega } ) / ({\mathbb E} e^{\omega })^2\) is smaller than the inverse of the return probability for the simple random walk, the end point, rescaled by \(n^{-1/2}\), converges to a centered d-dimensional Gaussian vector. Moreover, under the previous assumptions, \(I_n \rightarrow 0\) a.s., at the rate \(n^{-d/2}\) according to the local limit theorem of [37, 39].
Let us come back to the case \(d=1\) of up-right polymer paths, more precisely, to the log-gamma model. We now give a flavour of our results with an explicit limit description of the endpoint distribution under the quenched measure.
For each n, denote by
the location maximizing the above probability, and call it the “favourite endpoint”.
Theorem 1
Consider the model b.c.(\(\theta \)) with \(\theta \in (0,\mu )\). Define the end-point distribution \(\tilde{\xi }^{(n)}\) centered around its mode, by
Thus, \(\tilde{\xi }^{(n)}\) is a random element of the set \({\mathcal M}_1\) of probability measures on \({\mathbb Z}\). Then, as \(n \rightarrow \infty \), we have convergence in law
where \(\Vert \mu -\nu \Vert _{TV}= \sum _k |\mu (k)-\nu (k)|\) is the total variation distance.
The definition of \(\xi _k\) is given as a functional of a random walk conditioned to stay positive on \({\mathbb Z}^+\) and conditioned to stay strictly positive on \({\mathbb Z}^-\). The explicit expression for \(\xi \) is formula (12) below. The convergence is not strong but only in distribution. The above result yields a complete description of the localization phenomenon revealed in [7, 10]. In particular, the mass of the favourite point is converging in the distributional sense.
Corollary 1
Consider the model b.c.\((\theta )\) from (2). With \(I_n\) from (1), it holds
as \(n \rightarrow \infty \). By consequence, \(\limsup _n I_n >0 \ \ \mathbb {P}\)-a.s.
Moreover, we derive that the endpoint density indeed concentrates in a microscopic region, i.e., of size \({\mathcal O}(1)\), around the favourite endpoint.
Corollary 2
(Tightness of polymer endpoint) Consider the model b.c.\((\theta )\) from (2) with \(\theta \in (0,\mu )\). Then we have
Our results call for a few comments.
Remark 1
(i) Influence of high peaks in the parabolic Anderson model: it is easy to check that the sequence \(Z_{m,n}\) is the unique solution of the parabolic Anderson equation
with initial condition \(Z_{0,0}=1\) and boundary conditions \(Z_{-1,n}=Z_{m,-1}=0\). Hence, \(Z_{m,n}\) can be interpreted as the mean density at time \(m+n\) and location (m, n) of a population starting from one individual at the origin, subject to the following discrete dynamics: each particle splits at each integer time into a random number (with mean \(2 e^{\omega (m,n)}\) at location (m, n)) of identical individual moving independently, and jumping instantaneously one step upwards or to the right. If \(e^{-\omega (m,n)} \sim Gamma(\mu ), e^{-\omega (m,0)} \sim Gamma(\theta ),\) and \( e^{-\omega (0,n)} \sim Gamma(\mu -\theta )\), our result applies, and shows that the population concentrates around the highest peak and spreads at distance O(1). In particular, the second high peak does not contribute significantly to the measure, a feature which is believed to hold in small space dimension only. In large time, the population density converges, without any scaling, to a limit distribution given by \(\xi \).
(ii) Corollary 2 states uniqueness of the favourite endpoint, in the sense that all the mass is concentrated in the neighborhood of the favourite point \(l_n\). This property is analogous to uniqueness of geodesics in planar oriented last passage percolation. We refer to [15, 19] for a detailed and recent account on this and related questions.
Besides the point-to-line polymer measure, we also study in this paper the point-to-point measure, for which the polymer endpoint is prescribed. Under this measure, we obtain similar localization results, that we will state in the next section. They deal with the location in the direction transverse to the overall displacement of the “point in the middle” of the polymer chain, and with the “middle edge”. They are the first results of this nature. The main reason is that the general approach via martingales in [7, 10] fails to apply if the endpoint of the path is fixed. We mention that the alternative method, introduced in [40] to deal with environment without exponential moments, could be applied to point-to-point measures. A similar comment holds for another approach, based on integration by parts, which has been recently introduced in [9] to extend localization results to the path itself—and then reveal the favourite corridors. So far, it is known to apply to Gaussian environment and Poissonian environment [12], but whether it covers the log-gamma case is still open.
As we will see in Sect. 2, the localization phenomena around the favourite point in the log-gamma model directly relates to the problem of splitting a random walk at its local minima. This coupling is also the main tool to study the recurrent random walk in random environment [18] in one dimension. In the literature, it was proved by Williams [41], Bertoin [1–3], Bertoin and Doney [4], Kersting and Memişoǧlu [28] that if the random walk is split at its local minimum, the two new processes will converge in law to certain limits which are related to a process called the random walk conditioned to stay positive/negative. The mechanism is reminiscent of that of the localization in the main valley of the one-dimensional random walk in random environment in the recurrent case, discovered by Sinaï [36] and studied by Golosov [22].
Our results only hold for boundary conditions ensuring stationarity. A possible way towards the model without boundary conditions could be via techniques of tropical combinatorics initiated in [14].
Organization of the paper: In Sect. 2, we recall the basic facts on the log-gamma model and state the main localization results both for point-to-line and point-to-point measures. In Sect. 3, we introduce the important properties of the random walk conditioned to stay positive that we need to define the limits. In Sect. 4 we give the proofs of Theorem 1, Corollaries 1 and 2. The last section contains the complete statements for the point-to-point measure, together with their proofs.
2 Polymer model with boundary conditions and results
2.1 Endpoint under the point-to-line measure
Assume the condition (2). Define for \((m,n)\in \mathbb {Z}_+^2\),
We can associate the U’s and V’s to edges of the lattice \(\mathbb {Z}_+^2\), so that they represent the weight distribution on a horizontal or vertical edge respectively. Let \(\mathbf{e_1}, \mathbf{e_2}\) denote the unit coordinate vectors in \(\mathbb Z^2\). For an horizontal edge \(f=\{y-\mathbf{e_1},y\}\) we set \(T_f=U_y\), and \(T_f= V_y\) if \(f=\{y-\mathbf{e_2},y\}\). Let \({\mathbf z}= (z_k)_{k \in \mathbb {Z}}\) be a nearest-neighbor down-right path in \(\mathbb {Z}_+^2\), that is, \(z_k \in \mathbb {Z}_+^2\) and \(z_k-z_{k-1}=\mathbf{e_1} \ \hbox {or} -\mathbf{e_2}\). Denoting the undirected edges of the path by \(f_k=\{z_{k-1},z_k\}\), we then have
Seppäläinen proved [35] that the choice of log-gamma distribution provides a stationary structure to the model:
Fact 1
(Theorem 3.3 in [35]) Assume (2). For any down-right path \((z_k)_{k\in \mathbb {N}}\) in \(\mathbb {Z}_+^2\), the variables \(\{T_{f_k}: k\in \mathbb {Z}\}\) are mutually independent with marginal distributions
By considering the down-right path along the vertices x with \(x\cdot ({\mathbf { e_1+e_2}})=n\), we deduce the following fact, which will be a fundamental ingredient in the next two sections.
Fact 2
For each n, the variables \((U_{k,n-k},V_{k,n-k})_{0\le k\le n}\) are independent, and
Now, define for each \(1\le k \le n\) the random variable \(X_k^n\)
and \(X_0^n =0\). By corollary 2, for each n, \((X_k^n)_{1\le k\le n}\) are i.i.d random variables, and satisfy
Defining \(S_k^n= \sum _{i=1}^k X_i^n\), for \(0\le k\le n\), we will express the mass at point \((k,n-k)\) as a function of \(S^n\),
From (7), the favourite point \(l_n\) defined in (3) is also the minimum of the random walk,
Since we are only interested in the law of \(Q_{n}^{\omega }\{x_n=(k,n-k)\}\), in order to simplify the notion, we consider a single set of i.i.d random variables \((X_k)_{k\in \mathbb {Z}_+}\), with the same distribution under \(\mathbb {P}\) as \(\log (U/V)\), where U and V are independent with the same distribution as in (6). The associated random walk is given by
and we define
Then one can check that for every n:
where \( \mathop {=}\limits ^{\mathcal {L}}\) means equality in law. Then instead of considering for each n a new set of i.i.d random variables to calculate \(\tilde{\xi }_k^{(n)}\), we just need the n first steps of the random walk \(S_n\) to compute the law of \(\xi _k^n\). Hence Theorem 1 can be reformulated as follows:
with
Since the environment has a continuous distribution, the minimum is a.s. unique. The complete construction of the limit \(\xi _k\) will be given in Sect. 4 below in two different cases when \(\theta =\mu /2\) and \(\theta \ne \mu /2\). However, for the convenience of the reader, we give an informal definition, starting with the case \( \theta =\mu /2\). Let \((S^\uparrow _k,k \ge 0), (S_k^\downarrow , k \ge 0)\) be two independent processes, with the first one distributed as the random walk S conditioned to be non-negative (forever), and the second one distributed as the random walk S conditioned to be positive (for positive k). Since we condition by a negligible event, the proper definition requires some care, it relies on Doob’s h-transform. Then,
In the case \(\theta <\mu /2\), then \(l_n = {\mathcal O}(1)\), but the limit is still given by the formula (12), provided that \(S^\downarrow \) has a lifetime (equal to the time for the walk to reach its absolute minimum), after which it is infinite. \(S^\uparrow \) is as before, and it is defined in a classical manner. Thus, the concatenated process is simply equal to S with a space shift by its minimum value, and time shift by the time to reach the minimum. The last case \(\theta >\mu /2\) is similar under the change \(k \mapsto n-k\).
In particular in the equilibrium case \(\theta =\mu /2\), \(S_k\) is a random walk with expectation zero. By Donsker’s invariance principle, the random walk has a scaling limit,
with W a Brownian motion with diffusion coefficient \(2 \Psi _1(\mu /2)\) (there, \(\Psi _1(\theta )= (\log \Gamma )\text {''}(\theta )\) is the trigamma function). By consequence, the scaling limit of the favourite endpoint is easy to compute in the present model with boundary conditions.
Theorem 2
Consider the model b.c.\((\theta )\) from (2).
-
(i)
When \(\theta =\mu /2\), we have
$$\begin{aligned} \frac{l_n}{n}\mathop {\longrightarrow }\limits ^{\mathcal {L}}\underset{t\in [0,1]}{\arg \min }\ W_t , \end{aligned}$$where the limit has the arcsine distribution with density \([\pi \sqrt{s(1-s)}]^{-1}\) on the interval [0, 1].
-
(ii)
When \(\theta <\mu /2\), \(n-l_n\) converges in law, so
$$\begin{aligned} \frac{l_n}{n}\mathop {\longrightarrow }\limits ^{\mathbb {P}} 1, \end{aligned}$$though when \(\theta >\mu /2\), \(l_n\) converges in law, so
$$\begin{aligned}\frac{l_n}{n}\mathop {\longrightarrow }\limits ^{\mathbb {P}} 0.\end{aligned}$$
In words, the favourite location for the polymer endpoint is random at a macroscopic level in the equilibrium case, and degenerate otherwise. Further, the (doubly random) polymer endpoint \(x_n\) has the same asymptotics under \(Q_n^\omega \), since, by (5), \(x_n/n\) and \(l_n/n\) are asymptotic as \(n \rightarrow \infty \). These results disagree with KPZ theory, where the endpoint fluctuates at distance \(n^{2/3}\) around the diagonal. A word of explanation is necessary. The difference comes from the boundary conditions. In the equilibrium case \(\mu /2=\theta \) the direction of the endpoint has a maximal dispersion, though in non equilibrium ones it sticks to one of the coordinate axes. In the model without boundary conditions –that we leave untouched in this paper–, we expect an extra entropy term to come into the play and balance the random walk \(S_n\) in the potential, a factor being of magnitude n and quadratic around its minimum (which is the diagonal by symmetry), making the localization happen close to the diagonal and with fluctuations of order \(n^{2/3}\).
Finally, we derive a large deviation principle for the endpoint distribution:
Theorem 3
Consider the model b.c.\((\theta )\) from (2).
-
(i)
Assume \(\theta =\mu /2\). In the Skorohod space \(D([0,1],\mathbb {R}^+)\) equipped with Skorohod topology,
$$\begin{aligned} \left( \frac{-1}{\sqrt{n}}\log Q_n^{\omega }\left\{ x_n=([ns], n-[ns])\right\} \right) _{s\in [0,1]} \mathop {\longrightarrow }\limits ^{\mathcal {L}} \left( W(s)-\min _{[0,1]} W\right) _{s\in [0,1]}.\nonumber \\ \end{aligned}$$(13)Moreover, for all segment \(A\subset \{(s,1-s); s \in [0,1]\}\) in the first quadrant,
$$\begin{aligned} \frac{-1}{\sqrt{n}}\log Q_n^{\omega }(x_n\in nA) \mathop {\longrightarrow }\limits ^{\mathcal {L}} \inf _A W- \min _{[0,1]} W. \end{aligned}$$(14) -
(ii)
Assume \(\theta > \mu /2\). Then, as \(n \rightarrow \infty \),
$$\begin{aligned} - \frac{1}{{n}}\log Q_n^{\omega }\left\{ x_n=([ns], n-[ns]) \right\} \mathop {\longrightarrow }\limits ^{\mathbb {P}} s \vert \Psi _0(\theta )-\Psi _0(\mu -\theta )\vert , \end{aligned}$$(15)where \(\Psi _0(\theta )= (\log \Gamma )'(\theta )\) is the digamma function. Similarly, if \(\theta < \mu /2\),
$$\begin{aligned} - \frac{1}{{n}}\log Q_n^{\omega }\left\{ x_n=([ns], n-[ns])\right\} \mathop {\longrightarrow }\limits ^{\mathbb {P}} (1-s) \vert \Psi _0(\theta )-\Psi _0(\mu -\theta )\vert . \end{aligned}$$
Then, at logarithmic scale, the large deviation probability for the endpoint is of order \( \sqrt{n}\) in the equilibrium case, whereas it is of order n otherwise. This is again specific to boundary conditions, since it is shown in [21] for the model without boundaries that the large deviation probabilities have exponential order n with a rate function which vanishes only on the diagonal (\(s=1/2\)).
2.2 Middle point under the point-to-point measure
In this section, we consider the point-to-point measure with boundary conditions. Fix \(\mu >0\), \((p,q)\in (\mathbb {Z}_+^*)^2\) and for each \(N\in \mathbb {N}\), let \(R_N\) be the rectangle with vertices (0, 0), (0, qN), (pN, 0) and (pN, qN). With some fixed
and denote \(\Theta =(\theta _N, \theta _S, \theta _E, \theta _W)\). To sites (i, j) strictly inside \(R_N\) we assign inverse Gamma variables \(Y_{i,j}\) with parameter \(\mu \), whereas to sites on the boundary we assign inverse Gamma variables with parameter \(\theta _N, \theta _S, \theta _E\) or \(\theta _W \) depending if the boundary is north, south, east or west.
Model P2P-b.c.( \(\Theta \) ): Assume
The point-to-point polymer measure is the probability measure on \(\Pi _{pN,qN}\) given by
For a path \(\mathbf{x}\in \Pi _{pN,qN}\) denote by
the “time it crosses the transverse diagonal”. The coordinate of the crossing point can be described up to a multiplicative factor by the integer
Theorem 4
Consider the model P2P-b.c.\((\Theta )\). Then, there exist a random integer \(m_N\) depending on \(\omega \) and a random probability measure \(\hat{\xi }\) on \(\mathbb Z\) such that, as \(N \rightarrow \infty \),
in the space \(({\mathcal M}_1, \Vert \cdot \Vert _{TV})\).
We recall that middle-point localization for the point-to-point measure is not covered by the usual martingale approach to localization, and this result is the first one of this nature. Here also the limit can be described in terms of the minimum of a functional of random walks. The appropriate form of the claim and the limit itself are given in Theorem 3, Sect. 5. We end with a complement.
Theorem 5
Consider the model P2P-b.c.(\(\Theta \)), and recall \(m_N\) from Theorem 4.
-
(i)
When \(\theta _N=\theta _S\), as \(N \rightarrow \infty \),
$$\begin{aligned} \frac{m_N}{4Npq}+\frac{1}{2}\mathop {\longrightarrow }\limits ^{\mathcal {L}} \underset{t\in [0,1]}{\arg \min }\ W_t , \end{aligned}$$(18)where the limit has the arcsine distribution.
-
(ii)
When \(\theta _N < \theta _S\), then \(m_N+2pqN\) converges in law, so
$$\begin{aligned} \frac{m_N}{4Npq}+\frac{1}{2} \mathop {\longrightarrow }\limits ^{\mathbb {P}} 0, \end{aligned}$$but when \(\theta _N > \theta _S\), \(m_N-2pqN\) converges in law, so
$$\begin{aligned} \frac{m_N}{4Npq}+\frac{1}{2} \mathop {\longrightarrow }\limits ^{\mathbb {P}} 1, \end{aligned}$$
We stress that the equilibrium relation (18) holds whatever p and q are, provided that \(\theta _N=\theta _S\).
In order to prove all these results, the direct approach is to understand the growth of the random walk seen from its local minima. In the next section, we will present different results about the decomposition of random walk around its minima.
3 Splitting at the infimum and random walk conditioned to stay positive
Through this section, we will only consider the equilibrium case \(\theta =\mu /2\), i.e. when the random walk \(S=(S_k, k\ge 0)\) in (9) has mean 0. The problem of path decomposition for Markov chains at its infimum points is well studied in the literature by Williams [41], Bertoin [1–4], Kersting and Memişoǧlu [28]. We will follow the fine approach of Bertoin [3]. We mention at this point that the case of a walk drifting to infinity was considered by Doney [16]. However for our purpose, we do not need such sophisticated results when \(\theta \) is different from \(\mu /2\).
First we will introduce the random walk conditioned to stay non negative and explain how it relates to the decomposition of random walk at its minimum. Then we present Tanaka’s construction and its consequence on the growth of the walk around the minimum.
3.1 Random walk conditioned to stay non negative
Recall that \(S_0=0\). Define the event that the random walk stays non negative
As the random walk does not drift to \(+ \infty \) this event has probability \(\mathbb {P}[\Lambda ]=0\). In order to give a meaning for the conditioning with respect to \(\Lambda \), we can approximate \(\Lambda \) with some other event \(\Lambda _n\). The natural choice here is
and we would like to study the asymptotics for large n of the law of S conditioned by \(\Lambda _n\).
Let us introduce some basic notation. For every real number x, we denote by \(\mathbb {P}_x\) the law of the random walk S started at x, and we put \(\mathbb {P}=\mathbb {P}_0\). Let \(\tau \) be the first entrance time in \((-\infty ,0)\):
In particular \(\Lambda _n=\{\tau >n\}\). Let \((H,T)=((H_k,T_k),k\ge 0)\) be the strict ascending ladder point process of the reflected random walk \(-S\). That is, \(T_0=0\) and, for \(k=0,1,\ldots \),
with the convention \(H_k=\infty \) when \(T_k=\infty \). The variable \(H_1\) is called the first strict ascending height of \(-S\), they are depicted in Fig. 1. The renewal function associated with \(H_1\) is

The strict ascending ladder of the random walk \(-S\). Line segments represent jumps. \(T_1\) is the first time the walk is positive, \(-H_1=-S_{T_1}\) is the value. \(T_2\) is the next time the walk takes a larger value, denoted by \(-H_2\), etc.
By the duality lemma ([17], Sect. XII.2), we can rewrite the renewal function for \(x \ge 0\) as
where
Now we define Doob’s h-transform \(P_x^V\) of \(P_x\) by the function V, i.e., the law of the homogeneous Markov chain on the nonnegative real numbers with transition function:
Here \(p, P_x\) denote the transition density and the law of the chain S starting from x. By definition, if \(f(S)=f(S_0,S_1,\dots ,S_k)\) is a functional depending only on the k first steps of the random walk, then
(We use the standard notation \(E[Z,A]=E[Z {\mathbf 1}_A]\) for an integrable r.v. Z and an event A.) We denote by \((S_k^{\uparrow })_{k \ge 0}\) the chain starting from 0,
The following result shows that it yields the correct description of the random walk conditioned to stay non negative.
Proposition 1
For a bounded Borel function \(f(S)=f(S_1,\ldots ,S_k)\),
Proof
First we will prove the following lemma:
Lemma 1
For every \(x\ge 0\), we have
Proof of Lemma 1
Recall that \((H_k,T_k)\) denotes the kth ascending ladder point of \(-S\). Let \(a_{n,k}\) be the event \(\{H_k\le x,T_k\le n, T_{k+1}-T_k>n\}\). On the event \(a_{n,k}\), we have \(\max _{k\in [0,n]}\{-S_k\}=H_k\le x\). It implies that \(\min _{k\in [0,n]}S_k+x\ge 0\), and by consequence \(\tau >n\) under \(\mathbb {P}_x\). Moreover the events \(a_{n,k}\) are clearly disjoint, then we have:
By the Markov property at \(T_k\), we have:
By monotone convergence,
which yields the lemma. \(\square \)
Now, we can complete the proof of Proposition 1. Without loss of generality we may assume that \(0\le f \le 1\). By the Markov property, for \(k\le n\),
We deduce from Lemma 1 and Fatou’s lemma that
since \(V(0)=1\). Replacing f by \(1-f\), we get
which completes the proof of Proposition 1. \(\square \)
Now we will show that the random walk conditioned stay non negative is the natural limit for the random walk seen from its local minima. Recall \(\ell _n\) from (11). The following property is crucial.
Proposition 2
For a bounded function \(f(x_1,\ldots ,x_k)\) and \(\varepsilon \in (0,1)\), we have
Proof
We have
On the other hand we can write the event \(\{\ell _n=i\}\) as
Both random variables \(f(S_{i+1}-S_{i},\ldots ,S_{i+k}-S_{i})\) and \(1_{\{S_j\ge S_i, \forall j\in [ i,n]\}}\) are measurable with respect to \(\sigma (X_{i+1},\ldots ,X_n)\) and thus are independent of the event \(\{S_j\ge S_i, \forall j\le i\}\) which is in \(\sigma (X_1,\ldots ,X_i)\). Then we obtain:
Applying the Markov property at time \(i (0<i<n-n\varepsilon )\), we obtain
From Proposition 1, for fixed \(\delta >0\), there exists \(n(\delta )\) such that for \(n\ge n(\delta )\),
Combining (22), (23) and (24), we obtain
Thus, for \(n>n(\delta )\),
and by the same argument,
This yields the desired result. \(\square \)
In the above result we proved convergence of the post-infimum process. Since the random variables X are centered, by considering the reflected random walk \(-S\), we derive a similar convergence result for the pre-infimum process to a limit that we now introduce. Since the environment has a density, the model enjoys a simplification: conditioning the walk to be positive is the same as conditioning it to be non-negative. Define the process \((S_k^{\downarrow })\) as the homogeneous Markov chain starting from 0 with transition function \(p^{\hat{V}}\) given by (20) with
and
Corollary 3
For a bounded function \(f(x_1,\dots ,x_k)\) and \(\varepsilon \in (0,1)\), we have
Since the walk is centered, the event \(\{n\varepsilon <\ell _n<n-n\varepsilon \}\) will happen with high probability for \(\varepsilon \) small enough. Then Theorem 2 and Corollary 3 imply that
Corollary 4
For fixed K, the following convergence results hold as \(n\rightarrow \infty \):
3.2 Growth of random walk conditioned to stay positive
In the literature, it is well known that the random walk conditioned to stay positive can be constructed based on an infinite number of time reversal at the ladder time set of the walk \((S,\mathbb {P})\). The first proof is given by Golosov [22] for the case of random walk with expectation zero and later Tanaka [38] gave a proof for more general case. We first present Tanaka’s construction [38], and summarize the results.
Let \(\{(H_k^+,\sigma _k^+)\}_{k\ge 0}\) be the sequence of strictly increasing ladder heights and times respectively of \((S,\mathbb {P})\) with \(H_0^+=\sigma _0^+=0\). Define \(e_1,e_2,\dots \) the sequence of excursions of \((S,\mathbb {P})\) from its supremum that have been time reversed:
for \(n\ge 1\). Write for convenience \(e_n=(e_n(0),e_n(1),\dots ,e_n(\sigma _n^+-\sigma _{n-1}^+))\) as an alternative for the step of each \(e_n\). By Markov property, \(e_1,e_2,\dots \) are independent copies of \(e=(0,S_{\sigma ^+}-S_{\sigma ^+-1},S_{\sigma ^+}-S_{\sigma ^+-2},\dots ,S_{\sigma ^+}-S_{1},S_{\sigma ^+})\) where \(\sigma ^+=\inf \{k\ge 0: S_k\in (0,+\infty )\}\) is from (19). Tanaka’s construction for the reflected random walk \((-S)\) consists in the following process \(W^{\uparrow }=\{W_n^{\uparrow }: n\ge 0 \}\):
Under the condition \(\mathbb {P}\{\sigma ^+ <\infty \}=1\), the main theorem in [38] states that \(\{W_n^{\uparrow }\}\) is a Markov chain process on \([0,+\infty )\) with transition function \(\hat{p}(x,dy)\), which is given by
where
As we consider here log-gamma variables with \(\theta =\mu /2\), then we have \(\mathbb {P}\)-a.s \(\sigma ^+=\sigma (0)<1\) and \(g=V\) from (19). Therefore the process \(W^{\uparrow }\) has the same law as the random walk conditioned to stay non negative, i.e., \(S^{\uparrow }\) defined above Proposition 1. This identity provides an elegant way to determine the growth rate of the limit process \(S^{\uparrow }\).
Lemma 2
For every \(\varepsilon >0\), then we have:
As a consequence, for fixed \(\delta > 0\) there exists a constant \(k=k(\delta )\) such that
Proof
We follow the lines of [24]. Let \(\{M_k^+,v_k^+\}_{k\ge 0}\) be the space-time points of increase of the future minimum of \((W^{\uparrow },\mathbb {P})\). That is, \(M_0^+=v_0^+=0\),
for \(k\ge 1\). From the construction of \(W^{\uparrow }\), we can deduce that for each path, the sequence \(\{(M_k^+,v_k^+)\}_{k\ge 0}\) corresponds precisely to \(\{(H_k^+,\sigma _k^+)\}_{k\ge 0}\). Let \(L=\{L_n\}_{n\ge 0}\) be the local time at the maximum in \((S,\mathbb {P})\), that is
Because \(W^{\uparrow }\) is obtained by time reversal from S, then L is also the local time at the future minimum of \((W^{\uparrow },\mathbb {P})\). Hence it’s clear that:
Now we need the following lemma (e.g., Theorem 3 in [24]): \(\square \)
Lemma 3
Consider the random walk \((S,\mathbb {P})\). Now suppose that \(\Phi \downarrow 0\) and that \(\mathbb {E}(S_1)=0\) and \(\mathbb {E}(S_1^2)<\infty \). Then
according to
We use the standard notations “i.o.” for “infinitely often” and “ev.” for “eventually”. For \(\Phi (n) =n^{-\varepsilon } \), the integral converges and Lemma 3 yields
Again using the fact that we may replace \(\Phi \) by \(c\Phi \) for any \(c>0\), and that the integral in the lemma still converges, it follows easily that
\(\mathbb {P}\)-almost surely. As \(W^{\uparrow }\) and \(S^{\uparrow }\) have the same law under \(\mathbb {P}\), we get the first result. Then it’s clear for fixed \(\delta \), there exists k such that
\(\square \)
We complement Lemma 2 with the following version for the conditioned random walk, proved by Ritter [34].
Theorem 6
[34] Fixed \(\eta < 1/2\) then:
Note now that the time \(\ell _n\) of the first minimum of S on [0, n] is such that, for fixed \(\varepsilon \in (0,1)\) we have for large n,
Indeed, by the invariance principle of Donsker (1951), \(\ell _n/n\) converges in law to the time of the global minimum of the standard Brownian motion on [0, 1], which obeys the arcsine distribution [27, problem 8.18]. Therefore, conditionally on the event \(\{\ell _n<(1-\varepsilon ^2)n\}\), Theorem 6 gives us the growth of the random walk after the minimum:
Corollary 5
If \(\eta \in (0,1/2)\), then uniformly in n:
Proof
The proof is similar to the proof of Proposition 2. To simplify the notation define
and
Then we have
We know that the event \(\{\ell _n=i\}\) can be written as
Both random variables \( A_{\delta ,j}\) and \(1_{\{S_j\ge S_i, \forall j\in [ i,n]\}}\) are measurable with respect to \(\sigma (X_{i+1},\dots ,X_n)\) and are independent of the event \(\{S_j\ge S_i, \forall j\le i\}\). By the Markov property, it follows that
For \(\varepsilon >0\) by using Theorem 6, there exists \(\delta _{\varepsilon }\) and \(n_{\varepsilon }\) such that for all \(\delta <\delta _{\varepsilon }\), \(m> n_{\varepsilon }\)
By putting \(m=n-j\) and summing \(j\in \{1,2,\dots ,[(1-\varepsilon )n]\}\) we obtain
So by (27), for n large enough, we have
which implies easily the corollary. \(\square \)
4 Proof of the main results in the point-to-line case
We split the section according to \(\theta =\mu /2\) or not, starting with the first case, which is more involved than the second one. The reason why \(\theta =\mu /2\) is special is that the random variable X in (9) is centered, and even symmetric.
4.1 Equilibrium case
In the equilibrium setting \(\theta =\mu /2\), we know that the post- and pre-infimum chain converge in law to the random walk conditioned to stay positive. As these limit processes grow fast enough, we can indeed prove that the endpoint densities of the polymer converge when its length goes to infinity. Firstly we consider the distribution at the favourite endpoint, and we later extend the arguments to all the points:
Lemma 4
For \(n\rightarrow \infty \),
Proof
From Lemma 2, the random walk conditioned to stay positive is lower bounded by some factor of \(n^{1/2-\varepsilon }\), thus the random variable \(\xi _0\) is well defined and strictly positive. By the continuous mapping theorem, the claim is equivalent to convergence in law of the inverse random variables. Then, in order to prove the lemma, it suffices to show that, for all bounded and uniformly continuous function f, we have
as \(n \rightarrow \infty \). By (25) in Corollary 4, we already know that, for a fixed K,
By uniform continuity, given an \(\varepsilon >0\) there exists \(\rho >0\) such that \(|f(x)-f(y)|<\varepsilon \) for all x, y with \(|x-y|< \rho \). Now we will prove that, for all positive \(\varepsilon \), we can find finite \(K=K(\varepsilon )\) and \(n_0(\varepsilon )\) such that for \(n \ge n_0(\varepsilon )\), it holds
and
Then, by combining (29), (30) and (31) we get (28) and the proof is finished.
In order to get (30), it is enough to prove that for all positive \(\rho , \varepsilon \) there exists a finite K such that
for all n large enough, while, in order to get (31), it is enough to prove that for all positive \(\rho , \varepsilon \) there exists a finite K such that
for all n large enough.
To prove (32), we use Corollary 5: For any fixed \(\eta <1/2\), choose \(\delta >0\), such that for all \(n\in \mathbb {N}\) :
Because the random variable X is symmetric, the pre-infimum process verifies the same properties, i.e for \(n\in \mathbb {N}\):
Then, choosing K such that \(\sum _{k=K}^\infty e^{-\delta k^\eta }< \rho /2\) yields (32). A similar argument leads to (33). This completes the proof of the lemma. \(\square \)
In the course of the proof we have discovered the limit endpoint densities \((\xi _k)_{k\in Z}\) is given by formula (12). Repeating the argument in the proof of Lemma 4, it is straightforward to extend the result to a finite set of points around the maximum point:
Lemma 5
For fixed K, \(n\rightarrow \infty \):
Proof of Theorem 1 in the case of
\(\theta =\mu /2\).
Recall that \(\tilde{\xi }^{(n)}\) and \(\xi ^n\) have the same law, and that the total variation distance between probability measures on \(\mathbb Z\) coincides with the \(\ell ^1\)-norm. Taking a function \(f:\ell ^1\rightarrow R\) bounded and uniformly continuous in the norm \(\vert .\vert _1\) and one needs to prove that
We will use almost the same idea as in the proof of Lemma 4. From Lemma 5 we have, with a slight abuse of notation,
Fixing \(\varepsilon >0\), there exists by continuity some \(\delta >0\) such that \(|x-y|_1<\delta \) implies \(|f(x)-f(y)|<\varepsilon \). Hence,
provided that
and similarly for \(\xi \) instead of \(\xi ^n\). Since \(\mathbb {E}[\xi _k]\) is a probability measure on \(\mathbb {Z}\), we can take K large enough so that \(\mathbb {E}[\sum _{k:|k|>K}\xi _k ]\le \delta \). Then, from Lemma 5, we see that, as \(n \rightarrow \infty \),
yielding (37). By combining (35) and (36), we obtain (34). \(\square \)
Proof of Corollary 2
It is enough to note that
which vanishes as \(K \rightarrow \infty \). \(\square \)
Proof of Corollary 1
Recall first that under \(Q_{n-1}^\omega \), the steps after the final time \(n-1\) are uniformly distributed, and independent from everything else. Then, it is enough to note that
with k determined by \((x-{\mathbf e_1})\cdot {\mathbf e_1}= l_{n-1}+k\). \(\square \)
Now we give the proof for Theorems 2 and 3:
Proof of Theorem 2 for
\(\theta =\mu /2\).
First, recall that \(l_n\) and \(\ell _n\) have the same law, so we can focus on the latter one. By definition of \(\ell _n\) and Donsker’s invariance principle, we have directly
By Lévy’s arcsine law [29], the location of the minimum of the Brownian motion, i.e. the above limit, has the density \(\pi ^{-1}(s(1-s))^{-1/2}\) on the interval [0, 1]. \(\square \)
Proof of Theorem 3 for
\(\theta =\mu /2\).
We can express the first term in (13) as
with \(\mathop {=}\limits ^\mathcal{L} \) the equality in law. As the second term in the right-hand side is almost surely dominated by \(\frac{\log n}{\sqrt{n}}\), then again, Donsker’s invariance principle yields (13).
On the other hand, let A be an interval. For all \(s\in A\), we have
which means that
From Donsker’s invariance principle it follows
which, in turn, yields (14). \(\square \)
4.2 Non-equilibrium case
Proof of Theorem 1 in the case of
\(\theta \ne \mu /2\).
Without loss of generality, we assume that \(\theta < \mu /2\), which implies that \(m=\mathbb {E}[X]>0\) and the random walk S drifts to \(+\infty \). By the law of large number, we have for all \(a \in (0,m)\),
It follows that \(\mathbb {P}\)-a.s for every integer n,
Then the sum of \(e^{-S_n}\) converges \(\mathbb {P}\)-a.s and we can identify the limit distribution \(\xi \) as
Indeed, it is clear that, for \(k\in \mathbb {Z}_+\),
Since the random walk drifts to \(+\infty \) the global minimizer
is \(\mathbb {P}\)-a.s finite. Moreover, for n large enough we have \(\ell _n=\ell \), and by centering the measure \(\xi ^n\) and \(\overline{\xi }\) around \(\ell _n\) and \(\ell \) respectively, we can easily obtain that
where \(\tilde{\xi }^{(n)}\) is defined as in (4) and \(\xi _k=\overline{\xi }_{\ell +k}\). This yields Theorem 1 in the case \(\theta <\mu /2\). \(\square \)
Proof of Theorem 2 for
\(\theta \ne \mu /2\).
It is a straightforward consequence of the above, since \(\ell _n={\mathcal O}(1)\) if \(\theta < \mu /2\) or \(n-\ell _n={\mathcal O}(1)\) if \(\theta > \mu /2\). \(\square \)
Proof of Theorem 3 for
\(\theta \ne \mu /2\).
Though it was already proved in [21, 35], we give another argument for completeness. Applying the law of large numbers for i.i.d. variables in (38), we directly obtain the claim. \(\square \)
5 Localization of the point-to-point measure
In this section, we consider the point-to-point measure with mirror boundary conditions. Recall the definition of the model P2P-b.c.\((\Theta )\) from (16).
In this situation, beside the usual partition function \(Z_{m,n}\), we will also define the reverse partition function \(\tilde{Z}_{m,n}\) for \((m,n) \in R_N\) as
where \(\tilde{\Pi }_{m,n}^N\) denotes the collection of up-right paths \(\mathbf{x}=(x_t; m+n\le t \le (p+q)N)\) in the rectangle \(R_N\) that go from (m, n) to (pN, qN). Note that in the reverse partition function we exclude the weight at (pN, qN). Also, it depends on N, p and q, but we omit to indicate it in the notation. Moreover, we can also define the ratios \(\tilde{U}\) and \(\tilde{V}\) as in the usual case,
If we take the point (pN, qN) as the initial point then the reverse environment \((\tilde{Z},\tilde{U},\tilde{V})\) is also a stationary log-gamma system with boundary conditions. Indeed one sees from (39), (40) and (41) that \( \tilde{U}_{m,qN}=Y_{m,qN}\) and \( \tilde{V}_{pN,v}=Y_{pN,n}\).
We partition the rectangle \(R_N\) according to the lower half space
and its complement. In order to simplify the notations, we denote for an edge f with endpoints in \(R_N\),

From Fact 1 of Sect. 2.1 and independence of the weights in \(H_{p,q}^{-,N}\) and its complement, for every down-right path z it follows that the variables \(\{T_f:f\in z\}\) are mutually independent. We stress that independence relies also on the expressions of \(Z_{m,n}\) and \(\tilde{Z}_{m',n'}\), where there are no shared weights. The marginal distribution of \(T_f\) is given by the stationary structure, it is a log-gamma distribution with the appropriate parameter. Let \(\partial H_{p,q}^{-,N}\) be the transverse diagonal in \(R_N\), which is given as

Consider the “lower transverse diagonal” given as
and the “upper transverse diagonal”,
see Fig. 2. Define also the set of up-right edges across the transverse diagonal,

Each up-right path \(\mathbf{x}\) that goes from (0, 0) to (pN, qN), intersects the transverse diagonal once and only once. Precisely, the mapping
is well defined, and it indicates where the crossing takes place. (We have \(i=t^-\) in (17).) Our main question in this section is the behaviour of the crossing edge when N increases. By definition of the polymer measure, for \(\langle z_1,z_2\rangle \in \mathcal {A}_{p,q}^N\) we can write, with the notation \(\sum _*\) for the sum over \(\mathbf{x}\in \Pi _{pN,qN}, x_{t^-}=z_1, x_{t^-+1}=z_2\),
where the last factor is the contribution of the last point \(x_{(p+q)N}=(pN,qN)\). In view of (40), (41), (42), this term can be expressed as
where \(\Pi _1(z_1)\) is the restriction of \( \mathcal {L}_{p,q}^N \) from (0, qN) to \(z_1\), and \(\Pi _2(z_2)\) is the restriction of \(\mathcal {U}_{p,q}^N \) from (1, qN) to \(z_2\). Note that, when computing the ratio of the left-hand side for two different values of the crossing edge \(\langle z_1,z_2\rangle \), both the first and last lines of the right-hand side cancel. Thus, we consider
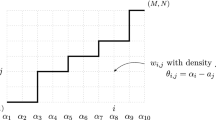
Observe that the variables \(\{T_f: f\in \Pi _1(z_1)\}\) and \(\{T_f: f\in \Pi _2(z_2)\}\) are independent but not identically distributed, so that in order to apply the same method as in previous section, we should divide \(\mathcal {U}_{p,q}^N\) and \(\mathcal {L}_{p,q}^N\) into identical blocks to obtain a centered random walk. Blocks are shifts of the right triangle with vertices \(\mathbf{0}, p\mathbf{e_1}, q\mathbf{e_2}\). Precisely we denote by
the vertices in \(R_N\) which sit on the line of equation \(qi_1+pi_2=pqN\), by
and by \(\mathcal {A}\) the set of crossing edges in the basic block \(R_1\) shifted by \(q\mathbf{e_2}\),
as shown in Fig. 3. Note that \(\langle \mathbf{0},\mathbf{e_1}\rangle \in \mathcal {A}\) and the shifted edge \((p,-q)+ \langle \mathbf{0},\mathbf{e_2}\rangle \in \mathcal {A}\) but  . We will use \(\mathcal {A}\) and the set \((\langle z_1^k,z_2^k\rangle )_k\) to parametrize the set \(\mathcal {A}_{p,q}^N\) as follows. For \(\langle z_1,z_2\rangle \in \mathcal {A}_{p,q}^N\) we can find a unique k such that, relative to any coordinate, \(z_1\) is between \(z_1^k\) and \(z_1^{k+1}\). Then by translation, there exists a unique edge \(a\in \mathcal {A}\) such that:
. We will use \(\mathcal {A}\) and the set \((\langle z_1^k,z_2^k\rangle )_k\) to parametrize the set \(\mathcal {A}_{p,q}^N\) as follows. For \(\langle z_1,z_2\rangle \in \mathcal {A}_{p,q}^N\) we can find a unique k such that, relative to any coordinate, \(z_1\) is between \(z_1^k\) and \(z_1^{k+1}\). Then by translation, there exists a unique edge \(a\in \mathcal {A}\) such that:

Upper and lower “transverse diagonal” with \(p=5, q=2, N=4\). Their vertices are indicated by dots and crosses respectively. \(H_{p,q}^{-,N}\) is the region below the diagonal. The boundary conditions are indicated on the boundaries of the rectangle

The set \(\mathcal A\) with \(p=5, q=2\) contains 7 crossing edges in the first block, indicated by solid lines
On the other hand, we have:
where
with \(\Pi _1(z_1^k,z_1^{k+1})\) the restriction of \(\mathcal {L}_{p,q}^N\) from \(z_1^k\) to \(z_1^{k+1}\) and \(\Pi _2(z_2^k,z_2^{k+1})\) the restriction of \(\mathcal {U}_{p,q}^N\) from \(z_2^k\) to \(z_2^{k+1}\).
Let \(\mathcal {B}=\{ \text{ edges } \ f \in \Pi _1(z_1^1)\cup \Pi _2(z_2^1)\}\), the edge set of the first block. Then it is clear that the edge set of a general block is a shift of that one,
By consequence, the variables \((X_i)_{i\le n}\) are i.i.d and moreover
We first consider the case \(\theta _N=\theta _S\). Then \(W_k\) is a centered random walk and we can define
as in the previous section. Before presenting the key lemma, we introduce the limit law. Denote by \(\nu (\cdot | u)\) a regular version of the conditional law of \((W(a), a\in \mathcal {A} )\) given \(\sum _{a \in {\mathcal A}} W(a)=u\). Let \((X_i, i \ge 1)\) be an i.i.d. sequence distributed as in (43), and \(S^{\uparrow }\) [resp. \(S^{\downarrow }\)] associated to X [resp., \(-X\)] as in (21), and \(\hat{S}\) the sequence with \(\hat{S}_0=0\) and
Consider also, on the same probability space, a random sequence \((Y_{k,a}: k\in \mathbb {Z}, a\in \mathcal {A})\) such that the vectors \({\mathcal Y}_k=(Y_{k,a}: a\in \mathcal {A})\) are, for \(k \in {\mathbb {Z}}\), independent conditionally on \(\hat{S}\) with conditional law \(\nu (\cdot | \hat{S}_{k+1} -\hat{S}_k)\).
Lemma 6
For fixed \(K\in \mathbb {Z}_+ \),
Proof
Applying Corollary 4 to the centered random walk \(W_k\) we obtain for fixed K
with \({\mathfrak l}_N\) from (44). On the other hand, by independence of the \(T_f\)’s we know that the vectors
Thus, with \(W_k=W(\langle z_1^{k},z_2^{k}\rangle )\), their joint law, conditionally on \((W_k; k \ge 0)\), is \(\otimes _k \nu (\cdot | W_{k+1}-W_k)\). Then the result follows from (45). \(\square \)
Now we can state the main result of our construction, which reformulates Theorem 4 in the equilibrium case.
Proposition 3
Assume \(\theta _N=\theta _S\). With the notations of Lemma 6, let
Then, as \(N \rightarrow \infty \),
on the space \((\ell _1( {\mathbb Z}\times \mathcal {A}), |\cdot |_1)\).
Proof
We will use the same method as in the Sect. 4.1 to prove (46). With Lemma 6 at hand, we only need here to control the tail of sums as in (32) and (33). Define
the minimum location of W. Now we consider the process \((k,a) \mapsto W( z_1^{k}+a)\) indexed by integer time \(t=kN+\ell \) if a is the \(\ell \) element in \(\mathcal A\), relative to its infimum, i.e., with the shift \(s \mapsto t=s + l_{N}^*\times N+a_{N}^*\). Note that \(t \mapsto W( z_1^{k}+a)\) is a sum of independent but not identically distributed random variables, it can be viewed as a Markov chain, which is not time-homogeneous but has periodic transitions with period equal by the cardinality of \(\mathcal A\). Then, the law of the post-infimum process
is also a Markov chain with a lifetime, i.e., a Markov chain killed at a stopping time. Similar to Proposition 2, we can prove that the law of this post-infimum process converges as \(N \rightarrow \infty \) to a Markov chain on \({\mathbb R}^+\), with non-homogeneous transitions but periodic with period given by the cardinality of \(\mathcal A\). The product of N consecutive transition kernels coincides with the one of \(S^{\uparrow }\), it is homogeneous. Similar to Theorem 6, we conclude that the post-infimum process grows algebraically: with probability arbitrarily close to 1, we have for some positive \(\delta \) and all large N,
Then, it is plain to check that \({\mathfrak l}_N-l_{N}^*= {\mathcal O}(1)\) in probability using that the former minimizes \(W_k=W(\langle z_1^k, z_2^k\rangle )\), and we derive (32) and (33) as well. The rest of the proof follows from similar arguments to those of Theorem 1 in the case of \(\theta =\mu /2\) and from Lemma 6. \(\square \)
Proof of Theorem 4
In the equilibrium case \(\theta _N=\theta _S\), the above proposition 3 yields the conclusion by taking
so that any path \(\mathbf{x}\) through the edge \(\langle z_1^{{\mathfrak l}_N},z_2^{{\mathfrak l}_N} \rangle \) has \(F(\mathbf{x})=m_M\).
Consider now the opposite case where, by symmetry, we may assume \(\theta _N<\theta _S\) without loss of generality. Then, the walk \((W_k)_{k \ge 0}\) has a global minimum. Interpolating \((W_k)_{k \ge 0}\) with independent pieces with law \(\nu \) defined as above, we construct a process \(\hat{\xi }\). Repeating the arguments of Sect. 4.2, we check that it is the desired limit. \(\square \)
Similar to that of Theorem 2, the proof of Theorem 5 is straightforward and left to the reader.
References
Bertoin, J.: Décomposition du mouvement brownien avec dérive en un minimum local par juxtaposition de ses excursions positives et négatives. In: Séminaire de Probabilités, XXV, Lecture Notes in Math., vol. 1485, pp. 330–344. Springer, Berlin (1991)
Bertoin, J.: Sur la décomposition de la trajectoire d’un processus de Lévy spectralement positif en son infimum. Ann. Inst. H. Poincaré Probab. Statist. 27(4), 537–547 (1991)
Bertoin, J.: Splitting at the infimum and excursions in half-lines for random walks and Lévy processes. Stochastic Process. Appl. 47(1), 17–35 (1993)
Bertoin, J., Doney, R.A.: On conditioning a random walk to stay nonnegative. Ann. Probab. 22(4), 2152–2167 (1994)
Bolthausen, E.: A note on the diffusion of directed polymers in a random environment. Commun. Math. Phys. 123(4), 529–534 (1989)
Borodin, A., Corwin, I., Remenik, D.: Log-gamma polymer free energy fluctuations via a Fredholm determinant identity. Commun. Math. Phys. 324(1), 215–232 (2013)
Carmona, P., Hu, Y.: On the partition function of a directed polymer in a Gaussian random environment. Probab. Theory Related Fields 124(3), 431–457 (2002)
Carmona, R., Molchanov, S.: Parabolic Anderson problem and intermittency. Mem. Am. Math. Soc. 108(518) (1994)
Comets, F., Cranston, M.: Overlaps and pathwise localization in the Anderson polymer model. Stochastic Process. Appl. 123(6), 2446–2471 (2013)
Comets, F., Shiga, T., Yoshida, N.: Directed polymers in a random environment: path localization and strong disorder. Bernoulli 9(4), 705–723 (2003)
Comets, F., Yoshida, N.: Directed polymers in random environment are diffusive at weak disorder. Ann. Probab. 34(5), 1746–1770 (2006)
Comets, F., Yoshida, N.: Localization transition for polymers in Poissonian medium. Commun. Math. Phys. 323(1), 417–447 (2013)
Corwin, I.: The Kardar–Parisi–Zhang equation and universality class. Random Matrices Theory Appl. 1(1), 1130001–11300076 (2012)
Corwin, I., O’Connell, N., Seppäläinen, T., Zygouras, N.: Tropical combinatorics and Whittaker functions. Duke Math. J. 163(3), 513–563 (2014)
Damron, M., Hanson, J.: Busemann functions and infinite geodesics in two-dimensional first-passage percolation. Commun. Math. Phys. 325(3), 917–963 (2014)
Doney, R.A.: Last exit times for random walks. Stochastic Process. Appl. 31(2), 321–331 (1989)
Feller, W.: An Introduction to Probability Theory and its Applications, 2nd edn, vol. II. Wiley, New York (1971)
Gantert, N., Peres, Y., Shi, Z.: The infinite valley for a recurrent random walk in random environment. Ann. Inst. Henri Poincaré Probab. Stat. 46(2), 525–536 (2010)
Georgiou, N., Rassoul-Agha, F., Seppäläinen, T.: Stationary cocycles for the corner growth model. arXiv:1404.7786 (2014, preprint)
Georgiou, N., Rassoul-Agha, F., Seppäläinen, T., Yilmaz, A.: Ratios of partition functions for the log-gamma polymer. arXiv:1303.1229 (2013, preprint)
Georgiou, N., Seppäläinen, T.: Large deviation rate functions for the partition function in a log-gamma distributed random potential. Ann. Probab. 41(6), 4248–4286 (2013)
Golosov, A.O.: Localization of random walks in one-dimensional random environments. Commun. Math. Phys. 92(4), 491–506 (1984)
Hairer, M.: Solving the KPZ equation. Ann. Math. (2) 178(2), 559–664 (2013)
Hambly, B.M., Kersting, G., Kyprianou, A.E.: Law of the iterated logarithm for oscillating random walks conditioned to stay non-negative. Stochastic Process. Appl. 108(2), 327–343 (2003)
Huse, D.A., Henley, C.L.: Pinning and roughening of domain wall in Ising systems due to random impurities. Phys. Rev. Lett. 54, 2708–2711 (1985)
Imbrie, J.Z., Spencer, T.: Diffusion of directed polymers in a random environment. J. Statist. Phys. 52(3–4), 609–626 (1988)
Karatzas, I., Shreve, S.: Methods of Mathematical Finance, Applications of Mathematics (New York), vol. 39. Springer, New York (1998)
Kersting, G., Memişoǧlu, K.: Path decompositions for Markov chains. Ann. Probab. 32(2), 1370–1390 (2004)
Lévy, P.: Sur certains processus stochastiques homogènes. Composit. Math. 7, 283–339 (1939)
Moriarty, J., O’Connell, N.: On the free energy of a directed polymer in a Brownian environment. Markov Process. Related Fields 13(2), 251–266 (2007)
Newman, C.: Topics in Disordered Systems, Lectures in Mathematics ETH Zürich. Birkhäuser Verlag, Basel (1997)
O’Connell, N., Yor, M.: Brownian analogues of Burke’s theorem. Stochastic Process. Appl. 96(2), 285–304 (2001)
Quastel, J.: Weakly asymmetric exclusion and KPZ. In: Proceedings of the International Congress of Mathematicians, vol. IV, pp. 2310-2324. Hindustan Book Agency, New Delhi (2010)
Ritter, G.A.: Growth of random walks conditioned to stay positive. Ann. Probab. 9(4), 699–704 (1981)
Seppäläinen, T.: Scaling for a one-dimensional directed polymer with boundary conditions. Ann. Probab. 40(1), 19–73 (2012)
Sinaĭ, Ya G.: The limit behavior of a one-dimensional random walk in a random environment. Teor. Veroyatnost. i Primenen 27(2), 247–258 (1982)
Sinaĭ, Ya G.: A remark concerning random walks with random potentials. Fund. Math 147(2), 173–180 (1995)
Tanaka, H.: Time reversal of random walks in one-dimension. Tokyo J. Math. 12(1), 159–174 (1989)
Vargas, V.: A local limit theorem for directed polymers in random media: the continuous and the discrete case. Ann. Inst. H. Poincaré Probab. Statist. 42(5), 521–534 (2006)
Vargas, V.: Strong localization and macroscopic atoms for directed polymers. Probab. Theory Related Fields 138(3–4), 391–410 (2007)
Williams, D.: Path decomposition and continuity of local time for one-dimensional diffusions. I. Proc. Lond. Math. Soc. 3(28), 738–768 (1974)
Acknowledgments
We thank the referee for a careful reading, many useful comments and numerous suggestions to improve the paper.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Comets, F., Nguyen, VL. Localization in log-gamma polymers with boundaries. Probab. Theory Relat. Fields 166, 429–461 (2016). https://doi.org/10.1007/s00440-015-0662-4
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00440-015-0662-4