
Abstract
In most countries, systems are in place to analyse food products for the potential presence of genetically modified organisms (GMOs), to enforce labelling requirements and to screen for the potential presence of unauthorised GMOs. With the growing number of GMOs on the world market, a larger diversity of methods is required for informative analyses. In this paper, the specificity of an extended screening set consisting of 32 screening methods to identify different crop species (endogenous genes) and GMO elements was verified against 59 different GMO reference materials. In addition, a cost- and time-efficient strategy for DNA isolation, screening and identification is presented. A module for semiautomated analysis of the screening results and planning of subsequent event-specific tests for identification has been developed. The Excel-based module contains information on the experimentally verified specificity of the element methods and of the EU authorisation status of the GMO events. If a detected GMO element cannot be explained by any of the events as identified in the same sample, this may indicate the presence of an unknown unauthorised GMO that may not yet have been assessed for its safety for humans, animals or the environment.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
An increasing number of genetically modified organisms (GMOs), e.g. soy, maize, canola, potato, are currently grown worldwide, with many others in the process of development [1]. In the European Union (EU), strict labelling requirements are in place. Authorised GMOs are allowed up to a level of 0.9% in non-GMO material, provided their presence is unintentional [2]. There is a zero tolerance level for unauthorised GMOs in food products. In feed some GMOs that are not (yet) authorised but are in the process of authorisation are allowed up to a level of 0.1% [3]. This status can be given if there is already an authorisation in another country, if positive advice with relation to the safety of the particular GMO is given by the European Food Safety Authority (EFSA), and if reference materials and a method for identification of the GMO are available.
For enforcement of the labelling requirements practical detection and quantification methods for routine laboratories are needed. Several novel DNA-based techniques, including micro-arrays, digital PCR and next generation sequencing (NGS), are described for GMO detection and identification [4–10]. Nevertheless quantitative polymerase chain reaction (qPCR) is still the most widely used technique for GMO screening, identification and quantification in routine GMO laboratories. The availability of interlaboratory validated event-specific TaqMan PCR methods for all EU authorised GMOs is an important reason for this. For every GMO event that is authorised in the EU, an event-specific TaqMan qPCR method that targets the sequence bridging the GMO insert and the plant DNA and thus identifying one specific GMO is obligatorily provided by the manufacturer of the GMO in question. These methods were verified by the European Union Reference Laboratory for Genetically Modified Food and Feed (EURL-GMFF) and underwent interlaboratory validation by the EURL-GMFF with the aid of the European Network of GMO laboratories (ENGL) prior to their use for official control (http://gmo-crl.jrc.ec.europa.eu/StatusOfDossiers.aspx). Also for GMOs that are in the process of being authorised, EURL interlaboratory validated methods are available in several cases.
The GMO insert typically consists of a combination of a number of genetic elements derived from several species (promoter, regulator, coding sequence and terminator(s) from bacteria, viruses, plants) to obtain new characteristics in the plant, e.g. herbicide or insect resistance. The series of joint elements is called the genetic construct, and construct-specific methods identify two (or more) joint elements of a particular construct that may be present in different GMOs. Because testing on all possible GMO events is time consuming and impractical, laboratories first screen for elements and constructs that are commonly used, applying well-established qPCR methods. This strategy is called the matrix approach [11–14]. Several screening strategies for GMOs, using qPCR with TaqMan probes or SYBR Green I, have been described [15–20] and also pre-spotted screening plates have been developed on the basis of this strategy [21, 22]. For cost-efficient screening of non-GMO labelled samples for the presence of authorised and unauthorised GMOs, for which event-specific methods are available, a screening approach using a minimal amount of GM elements and constructs that detects all known GMOs may be used [12]. However, using this approach it is unlikely that indications for unknown unauthorised GMOs will be obtained. With only a few frequently used GMO elements, chances are considerable that the presence of unauthorised GMOs may be masked by the presence of (multiple) GMOs in the same sample. As a result, for the screening of GMO labelled samples that will contain GMOs, this minimal screening step is not informative enough to obtain indications for the presence of (unknown) unauthorised GMOs. For screening of whole series of GMO labelled samples this minimal screening step is not informative enough since the samples are bound to contain GMO elements. For GMO labelled samples an extended screening with many elements and constructs potentially reduces the number of subsequent event-specific tests needed. At the same time, when not all elements can be explained by known GMO events as identified in the same sample this gives an indication of the presence of an unknown unauthorised GMO in the sample.
An extended screening strategy for whole series samples, utilizing 32 screening PCRs, is presented in this paper. For GMO labelled samples, when all elements and constructs are explained by the known authorised and unauthorised events detected in the sample, no further events need to be tested, thus reducing the workload per sample. If an element cannot be explained by any of the known events identified in the sample, this is an indication of the potential presence of an unknown unauthorised GMO. A cost- and time-effective semiautomated strategy to screen and analyse a series of 11 samples using a DNA extraction robot, PCR plate pipetting robot and a semiautomated Microsoft Excel module for result analyses is presented here. The screening results of 11 samples and 32 tests can be copied into the Excel module. The Excel module predicts the potentially present events on the basis of detected screening elements. After the identified events are entered in the module it indicates if all elements are explained and summarizes the results of all tests performed on the 11 samples in a table. This table can be used to send all results to a laboratory information management system (LIMS).
Materials and methods
Reference materials for specificity verification
The Certified Reference Materials (CRM) were obtained from the Institute for Reference Materials and Measurements (IRMM, Geel, Belgium), the American Oil Chemists’ Society (AOCS, Urbana, Illinois, USA) and Fluka (Sigma-Aldrich, Saint Louis, MI, USA). Positive material of the unauthorised DAS59132 (E32) maize was obtained from the EURL-GMFF (Ispra VA, Italy). The CRMs used are described in Table 1. The reference materials are intended for detection and quantification of the specified GMO event and not for specificity testing. Low level contamination of these materials with other GMO events cannot be excluded.
DNA isolation
Several CRMs were obtained as leaf DNA and no further treatment was carried out. From CRMs that were obtained as powder, DNA was isolated from 100 ± 10 mg dry material using the DNeasy Plant Mini Kit (Qiagen, Venlo, Netherlands) according to the manufacturer’s protocol. For crops other than soy the lysis step with the manufacturer’s AP1 buffer was replaced with cetyl trimethylammonium bromide (CTAB) extraction buffer (20 g/L CTAB, 1.4 M NaCl, 0.1 M Tris, 20 mM Na2EDTA, pH 8.0). Incubation time of the CTAB extraction buffer is 30 min at 65 °C, and after 15 min of incubation 20 μL of 20 mg/mL proteinase K was added. Alternatively, DNA from soy, maize, canola and cotton was isolated from 100 ± 10 mg dry material using the Maxwell® 16 MDx instrument (Promega, Madison WI, USA) with the custom-made Maxwell® 16 Food Feed Seed (FFS) Nucleic Acid Extraction System according to the manufacturer’s protocol (now available as Maxwell® RSC PureFood GMO and Authentication Kit). The lysis step was performed with 1 mL CTAB extraction buffer, 40 μL Proteinase K 20 mg/mL (FFS kit) and 20 μL RNase A solution 4 mg/mL (Qiagen, 100 mg/mL). The incubation time is 90 min at 65 °C. After this step the cartridge from the FFS kit is loaded and fed into the Maxwell instrument according to manufacturer’s protocol. Extracted DNA concentrations and quality were measured on a NanoDrop spectrophotometer (Thermo Scientific, Waltham, MA, USA). The concentration was further diluted to 10 ng/μL in water (ultrapure distilled water, DNase and RNase free, Life Technologies, USA) and stored at 4 °C or −20 °C. DNA quality was checked using the A 260/A 280 and A 260/A 230 ratios. Although the Qiagen kit can be used for feed samples the Maxwell DNA extraction system is proposed for series of feed samples, because using the DNA extraction robot saves hands-on time. Feed samples include processed and unprocessed soy, maize, canola products and mixed feed.
Primers and probes
The primers and probe sequences of all methods used in the routine screening strategy for GMO labelled feed samples are shown in Table 2. Primers and probes were ordered from Biolegio (Nijmegen, Netherlands) or Eurogentec (Belgium). All probes were labelled at the 5’ end with 6-carboxyfluorescein (FAM) dye and at the 3’ end with 6-carboxytetramethylrhodamine (TAMRA) quencher. The final concentrations of the primers and probes were as described in the literature or adjusted to 400 nM for both primers and 200 nM for the probes (Table 2). Using the QIAgility robot it was feasible to use optimal conditions for each method, but for several (older) methods 400 nM for both primers and 200 nM for the probes were used [23].
Limits of detection
The screening methods should be able to detect less than 0.045% or 25 copies [24]. For the published methods the limits of detection (LOD) were verified according to the ENGL method verification document [25] using 10-fold repetitions close to the expected LOD and found to be fewer than 20 copies (in-house validation data not shown). The LODs of methods designed and published by RIKILT Wageningen University & Research were not verified again because they were already validated in our laboratory on the basis of 60 repetitions at LOD level [8, 18]. To monitor the sensitivity of the methods in the sample analysis a positive sensitivity control for every screening method was used in each screening series at the level of 0.1% GMO or 25 copies (0.1% GMO CRM at 50 ng per PCR reaction, or higher percentage GMO diluted to 25 haploid genome equivalent copies per reaction in non-GMO background DNA). For practical reasons a control of 50 ng DNA isolated from 0.1% IRMM material was used where possible (=44 copies soy (1C = 1.13 pg), 18 copies maize (1C = 2.725 pg), 43 copies canola (1C = 1.15 pg). The actual number of copies in the 0.1% reference material depends on the zygosity.
The 32 positive sensitivity controls, one well for each screening method, were added to the eight screening plates with four different screening methods (see plate setup in Fig. 1). The positive control for a screening method was chosen from one of the certified GMO reference materials that contained this element. Some 0.1% GMO positive controls were used as control for several methods. The following CRMs were used as positive control for the screening methods at a level of 50 ng 0.1%, if available as CRM, or at 25 copies in a background of 50 ng non-GMO material: MON810 maize for Cry1A(b); MON863 maize for Cry3Bb1, nptII, I-rAct1; NK603 maize for P-Rice actin, T-nos, ctp2/CP4-epsps; MON810 maize for P-35S, CP4-epsps, ctp4/CP4-epsps; TC1507 maize for T-35S, Cry1F, pat; CaMV positive sample for CaMV; MON87701 soy for P-SSuAra, Cry1Ab/Ac; MON89034 maize for Cry1A.105, Cry2Ab2; MON89788 soy for P-FMV(2), T-E9; Rf1 canola for P-nos, T-g7 (T-ORF1), bar, barstar; MIR162 for Vip3a; common wheat for endogenous gene wheat Wx-1; non-modified canola (AOCS0306B) for endogenous gene canola FatA; DP305423 for endogenous gene soy Lec; H7-1 for endogenous gene sugar beet GS; MIR162 for endogenous gene maize hmg; non-modified rice (AOCS0306D) for endogenous gene rice SPS; A2704 for the general plant actin.

Uniform setup for eight 96-well PCR plates to screen 11 samples in duplicate (sample numbers indicated as 1-1 to 11-2), including positive sensitivity controls (0.1% or 25 copies) and negative controls (water), on four screening methods per plate
QIAgility robot
For pipetting the screening plates the QIAgility robot (Qiagen) was used with Qiagen QIAgility software version 4.17.1. The 32 screening methods were pipetted in eight 96-well plates (Table 3). Every run of the QIAgility prepares four PCR mixes to test four screening methods on 11 samples and a positive and negative control. The QIAgility robot is loaded with Mastermix (1 × 1.5-mL Eppendorf tube), water (1 × 5-mL tube), primers and probes for four screening methods (12 × 1.5-mL Eppendorf tube), four empty tubes to make the mixes (4 × 1.5-mL Eppendorf tube), four positive controls (4 × 1.5-mL Eppendorf tube), 11 samples in two isolations (22 × 1.5-mL Eppendorf tube), 1 × 200-μL conductive filtered tips (Qiagen, cat. #990522), 2 × 50-μL conductive filtered tips (Qiagen, cat. #990512) and an empty 96-well plate (Bio-Rad cat #HSP-9645). First the four mixes for four screening methods consisting of Mastermix, water, two primers and a probe were prepared and were divided over the 96-well plate in 4 × 24 wells by the QIAgility robot (Fig. 1). Then the DNA from two different DNA isolations per sample of 11 samples and the positive sensitivity controls (0.1% GMO or 25 copies) and a water control were pipetted by the QIAgility robot (Fig. 1).
Mastermixes
The QIAgility robot pipets a total reaction volume of 25 μL in every well consisting of 20 μL of the mix and 5 μL of the DNA (10 ng/μL). The mixes were prepared with 2× Diagenode Mastermix (Real time PCR Master Mix, cat. #DMMM-2X-A300, Seraing, Belgium), and the primers (10 μM) and probes (10 μM) were added to the final concentrations as mentioned in Table 2 and further diluted in water (ultrapure distilled water, DNase and RNase free, Life Technologies, USA) to a final volume of 20 μL per well. After the DNA was added, the 96-well plate is covered with a Bio-Rad seal (Microseal® 'B' Adhesive Seals cat. #MSB1001), vortexed briefly and centrifuged at 1000 rpm for 1 min to remove air bubbles.
PCR
Real-time PCR reactions were performed on Bio-Rad CFX 96 machines (Bio-Rad Laboratories Inc, Hercules, CA, USA) with Bio-Rad CFX Manager 3.1 software. The PCR program consisted of a decontamination step with UNG for 120 s at 50 °C, activation of the Taq polymerase for 600 s at 95 °C, followed by 45 cycles of 15 s at 95 °C and 60 s at 60 °C. Baseline and threshold were automatically calculated and only adjusted manually when necessary.
Results
The experimentally verified specificity of the screening PCRs which is needed for correct interpretation of the screening results in a given sample is shown in Table 4. The specificity of all screening methods included in the module was verified experimentally against a large set of reference materials (Table 1). In most cases the expected presence or absence of an element in the respective reference materials was confirmed (Table 4). Some element methods were not able to detect the related element as a result of sequence differences (indicated with an ”X” in Table 4) in the reference material tested. Most reactions that were expected to be negative were tested in practice as well. All element methods were able to detect the 25 copies of GMO sensitivity controls.
In some reference materials low level contaminations with other GMO events were detected that explained unexpected elements detected at high Cq values (ranging from 34 to 40). For example, in MON1445 reference material Cry1Ab/Ac and Cry1Ac elements were detected and confirmed by detection of traces of MON531 cotton. In MON531 and MON15985 cotton P-FMV, T-E9 CP4-epsps, and ctp2/CP4-epsps were detected and confirmed by detection of traces of MON1445 event. In the AOCS 1011-A and AOCS 0304-A, MON88302 DNA GT73 canola was detected, as well as traces of Rf3, Ms8 and the cotton event 3006-210-23.
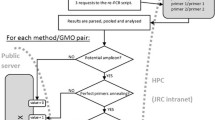
The Microsoft Excel 2010 module is available as Electronic Supplementary Material (ESM) including the detailed procedure for use of the module to analyse laboratory results. A screen shot of an empty result sheet for one sample can be seen in Fig. 2. The authorisation status of the events is shown with explanatory colouring. On the basis of the detected elements the possible GMO events to be tested are indicated with an “X” in the lane “possibly present GMO event” (Fig. 2). In the next lane the results of the event testing can be entered (D, detected; ND, not detected). When this is completed the elements or constructs that are explained by the events detected will get a green background. In this way one can assess whether more GMO event tests need to be carried out to explain the elements and constructs detected in the sample. For GMO labelled samples no further tests are needed when all elements and constructs are explained (all screening elements and constructs have a green background). For non-GMO labelled samples all events that are indicated with an “X” in the lane “possibly present GMO event” should be tested. All detected events need to be quantified using event-specific methods to check if they comply with the 0.9% labelling threshold. A more general overview to show the different steps in the analysis module is given in Fig. 3. A detailed description of the Excel module is given in Online Resource 1.

Overview of the analysis sheet (Online Resource 1). Authorised GMO events have a white background. GMOs that fall under the Regulation (EC) No. 619/2011 for low level presence (0.1%) in feed have an orange background. GMOs for which the authorisation has expired have a purple background and EU unauthorised GMOs have got a red background. The Cq values of the screening results are copied to the two upper lanes (Cq1 and Cq2). Then the results (D detected, ND not detected, S suspect) are automatically copied to the third line and to the green cells in the sheet. The boxes of screening results that are expected to be positive have a light green background, the results that are expected to be negative have a light yellow background

Extended screening strategy Excel module explained in ten steps (for more details see explanation tab in Online Resource 1)
Discussion
In this article a setup is presented to efficiently test series of samples for GMOs. Series of 11 samples can be tested in a cost-effective way based on 32 screening methods. The screening tests are pipetted using a QIAgility robot in eight 96-well plates. On the basis of the combination of the detected and undetected endogenous genes, elements and constructs, a limited number of GMO events can be present in the sample. Especially in samples containing multiple GMOs this approach can reduce the amount of event-specific methods needed after the screening. When all elements are explained no further events need to be tested for GMO labelled samples. This means that probably not all authorised GMO events will be tested for. For instance, if a sample contains MON89034 maize and MON810 maize, the following elements will be positive: P35S, P-FMV, T-nos, cry1A(b), Cry1A.105, cry2Ab2 and I-rActin1. After confirming the MON89034 event, which contains all of these elements, all elements have been explained and MON810 maize (P-35S and cry1Ab) will not be tested for and MON810 will thus not be identified. Although it is theoretically feasible that the combination of identified elements and related events may mask the presence of one or more unauthorised GMO events, it is considered that the chance is low, and it will entail much work to further assess the sample in this case, as there is no obvious starting point to look for unauthorised GMOs. If a detected element cannot be explained by any known event this is an indication of an unknown unauthorised GMO in the sample. This possibility of obtaining indications of unknown unauthorised GMOs is an advantage in terms of enforcement strategies compared with a screening strategy employing only the minimal amount of elements needed to screen for all known GMO events.
The samples are tested for the presence of maize, soy, canola, wheat, potato, sugar beet and several elements and constructs. As a control for the DNA quality the actin gene, which should be positive in all plant materials, is also included. The actin gene can also serve as a positive control for more exotic samples for which no endogenous gene is available in the laboratory. On the basis of the practical experience that GTS-40-3-2 is detected in most samples, the Roundup Ready construct method was added to the standard screening. The specificity of the screening methods was verified in practice against a set of 59 GMO reference materials. This practical verification was deemed necessary because elements with the same name do not always have the same DNA sequence in different GMOs. Although the specificity can also be predicted in silico on the basis of the sequences of the primers, probe and the element, it is not always certain what the specificity will be in the actual PCR reaction in a specific reference material. Moreover, DNA sequence data are not yet available for all elements in all GMO events.
Most element methods showed the expected specificity outcome in the CRMs. In several cases GMO elements that were expected to be positive on the presence of an element with the same name in that particular GMO (http://www.euginius.eu/) are not detected in practice. This does not hamper the GMO screening as long as the correct specificity information is used for the interpretation of the screening results and as long as enough other screening elements are available for a given GMO. In most cases where elements are not picked up because of sequence differences, several other screening elements are still at hand for screening. For example the rice actin promoter present in MON87460 maize is not detected, but there are four other screening elements left that can be detected in MON87460 maize. Seven GMO events (in italics and marked with an asterisk in Table 4) contain no GMO elements that are part of the screening strategy as applied and need to be tested with their event-specific method. As an alternative a P-35S method that does detect DP356043 soy is also available [12].
The screening strategy contains several elements derived from donor organisms (e.g. nptII which is present in e.g. Escherichia coli and T-g7 from Agrobacterium tumefaciens). If such an element is found to be positive it is necessary to take into account the possibility that the donor organism is the cause of the positive signal and not a GMO. This problem can also occur with elements derived from other plants (e.g. T-E9 from pea, P-Rice actin and I-rAct1 from rice). The screening strategy cannot detect stacked events (and neither can other screening strategies), although similar Cq values for individual events can be an indication of the presence of a stack.
Some of the specificity results did not agree with information published earlier [20]. The P-35S [26] was not detected by us in DP98140 maize but was reported as detected by Block et al. [20] The DP98140 maize contains no P-35S according to the EUginius database. T-35S [17] was found to be positive in T45 canola and DAS59122 maize and reported as unexpectedly positive by Block et al. According to the EUginius database both GMOs contain a T-35S so a positive signal can be expected in T45 canola and DAS59122 maize. For Bt11 maize T-35S signals with comparable Cq as the other elements were found (marked with + * in Table 4). As these signals are too low to suspect contamination with other reference these may be caused by sequence similarities between Bt11 maize and the T-35S primers and probe. The table from Block et al. does not contain T-35S information on Bt11 maize.
The screening results can be evaluated in a semiautomatic way using a Microsoft Excel module which is available as ESM (Online Resource 1). This module can also be used to plan the subsequent event-specific testing. Depending on the sample labelling all possible GMO events indicated by the Excel module need to be tested for and quantified (non-GMO labelling) or only the event tests that explain all detected elements need to be carried out (for GMO labelled samples). The screening results per sample can be seen graphically in relation to the detected GMO events and their authorisation status. In case not all elements are explained extra events may need to be tested, or the (unknown) GMO needs to be identified using other techniques like next generation sequencing [8]. All analysis results are automatically summarised in an overall table by the Excel module, in a format that will allow the laboratory to send the data in one action to a laboratory information management system that is compatible with Excel. In this way this GMO analysis protocol and data analysis module can help enforcement as well as other laboratories to analyse series of samples in a highly informative and time- and cost-effective way.
References
Parisi C, Tillie P, Rodriguez-Cerezo E. The global pipeline of GM crops out to 2020. Nat Biotechnol. 2016;34(1):31–6. doi:10.1038/nbt.3449.
European Commission. Regulation (EC) No 882/2004 of the European Parliament and of the Council of 29 April 2004 on official controls performed to ensure the verification of compliance with feed and food law, animal health and animal welfare rules. 2004.
European Commission. Commission Regulation (EU) No 619/2011 of 24 June 2011 laying down the methods of sampling and analysis for the official control of feed as regards presence of genetically modified material for which an authorisation procedure is pending or the authorisation of which has expired. Off J Eur Union L. 2011;166:7.
Li X, Wu Y, Li J, Li Y, Long L, Li F, et al. Development and validation of a 48-target analytical method for high-throughput monitoring of genetically modified organisms. Sci Rep. 2015;5:7616. doi:10.1038/srep07616.
Koppel R, Bucher T, Frei A, Waiblinger HU. Droplet digital PCR versus multiplex real-time PCR method for the detection and quantification of DNA from the four transgenic soy traits MON87769, MON87708, MON87705 and FG72, and lectin. Eur Food Res Technol. 2015;241(4):521–7. doi:10.1007/s00217-015-2481-3.
Brod FC, van Dijk JP, Voorhuijzen MM, Dinon AZ, Guimaraes LH, Scholtens IM, et al. A high-throughput method for GMO multi-detection using a microfluidic dynamic array. Anal Bioanal Chem. 2014;406(5):1397–410. doi:10.1007/s00216-013-7562-1.
Liang C, van Dijk JP, Scholtens IM, Staats M, Prins TW, Voorhuijzen MM, et al. Detecting authorized and unauthorized genetically modified organisms containing vip3A by real-time PCR and next-generation sequencing. Anal Bioanal Chem. 2014;406(11):2603–11. doi:10.1007/s00216-014-7667-1.
Fraiture MA, Herman P, Taverniers I, De Loose M, Deforce D, Roosens NH. Current and new approaches in GMO detection: challenges and solutions. Biomed Res Int. 2015;2015:392872. doi:10.1155/2015/392872.
Wahler D, Schauser L, Bendiek J, Grohmann L. Next-generation sequencing as a tool for detailed molecular characterisation of genomic insertions and flanking regions in genetically modified plants: a pilot study using a rice event unauthorised in the EU. Food Anal Method. 2013;6(6):1718–27. doi:10.1007/s12161-013-9673-x.
Xu J, Miao H, Wu H, Huang W, Tang R, Qiu M, et al. Screening genetically modified organisms using multiplex-PCR coupled with oligonucleotide microarray. Biosens Bioelectron. 2006;22(1):71–7.
Randhawa GJ, Morisset D, Singh M, Zel J. GMO matrix: a cost-effective approach for screening unauthorized genetically modified events in India. Food Control. 2014;38:124–9. doi:10.1016/j.foodcont.2013.10.013.
Waiblinger HU, Grohmann L, Mankertz J, Engelbert D, Pietsch K. A practical approach to screen for authorised and unauthorised genetically modified plants. Anal Bioanal Chem. 2010;396(6):2065–72. doi:10.1007/s00216-009-3173-2.
Gerdes L, Busch U, Pecoraro S. GMOfinder-a GMO screening database. Food Anal Method. 2012;5(6):1368–76. doi:10.1007/s12161-012-9378-6.
CEN. Foodstuffs - methods of analysis for the detection of genetically modified organisms and derived products - polymerase chain reaction (PCR) based screening strategies. NPR-CEN/TS 16707:2014 en. 2014-06.
Koppel R, Sendic A, Waiblinger HU. Two quantitative multiplex real-time PCR systems for the efficient GMO screening of food products. Eur Food Res Technol. 2014;239(4):653–9. doi:10.1007/s00217-014-2261-5.
Debode F, Janssen E, Berben G. Development of 10 new screening PCR assays for GMO detection targeting promoters (pFMV, pNOS, pSSuAra, pTA29, pUbi, pRice actin) and terminators (t35S, tE9, tOCS, tg7). Eur Food Res Technol. 2013;236(4):659–69. doi:10.1007/s00217-013-1921-1.
Dinon A, Prins T, van Dijk J, Arisi A, Scholtens I, Kok E. Development and validation of real-time PCR screening methods for detection of cry1A.105 and cry2Ab2 genes in genetically modified organisms. Anal Bioanal Chem. 2011;400(5):1433–42. doi:10.1007/s00216-011-4875-9.
Morisset D, Novak PK, Zupanic D, Gruden K, Lavrac N, Zel J. GMOseek: a user friendly tool for optimized GMO testing. BMC Bioinformatics. 2014;15(1):258. doi:10.1186/1471-2105-15-258.
Block A, Debode F, Grohmann L, Hulin J, Taverniers I, Kluga L, et al. The GMOseek matrix: a decision support tool for optimizing the detection of genetically modified plants. BMC Bioinformatics. 2013;14:256.
Broeders S, Fraiture M-A, Vandermassen E, Delvoye M, Barbau-Piednoir E, Lievens A, et al. New qualitative trait-specific SYBR®Green qPCR methods to expand the panel of GMO screening methods used in the CoSYPS. Eur Food Res Technol. 2015;241(2):275–87. doi:10.1007/s00217-015-2454-6.
Rosa SF, Gatto F, Angers-Loustau A, Petrillo M, Kreysa J, Querci M. Development and applicability of a ready-to-use PCR system for GMO screening. Food Chem. 2016;201:110–9.
Zagon J, Kurth S, Ehlers A, Linke B, Lampen A, Broll H. Preservation of primer and probes on "ready-to-use" 96-well microtiter plates: A step forward towards enhancing throughput and harmonization of real-time PCR applications in food and feed control. Food Control. 2012;25(2):709–16. doi:10.1016/j.foodcont.2011.12.006.
Scholtens I, Laurensse E, Molenaar B, Zaaijer S, Gaballo H, Boleij P, et al. Practical experiences with an extended screening strategy for genetically modified organisms (GMOs) in real-life samples. J Agric Food Chem. 2013;61(38):9097–109. doi:10.1021/jf4018146.
European Network of GMO Laboratories (ENGL). Definition of minimum performance requirements for analytical methods of GMO testing. Ispra: ENGL; 2015.
ENGL working group on "method verification". Verification of analytical methods for GMO testing when implementing interlaboratory validated methods: guidance document from the European Network of GMO Laboratories (ENGL). Ispra: ENGL; 2011.
Kuribara H, Shindo Y, Matsuoka T, Takubo K, Futo S, Aoki N, et al. Novel reference molecules for quantitation of genetically modified maize and soybean. J AOAC Int. 2002;85(5):1077–89.
Laube I, Hird H, Brodmann P, Ullmann S, Schone-Michling M, Chisholm J, et al. Development of primer and probe sets for the detection of plant species in honey. Food Chem. 2010;118(4):979–86. doi:10.1016/j.foodchem.2008.09.063.
European Union Reference Laboratory for GM Food and Feed. Status of dossiers. 2016. http://gmo-crl.jrc.ec.europa.eu/StatusOfDossiers.aspx. http://gmo-crl.jrc.ec.europa.eu/StatusOfDossiers.aspx. Accessed 1 Jan 2017.
Ding J, Jia J, Yang L, Wen H, Zhang C, Liu W, et al. Validation of a rice specific gene, sucrose phosphate synthase, used as the endogenous reference gene for qualitative and real-time quantitative PCR detection of transgenes. J Agric Food Chem. 2004;52(11):3372–7. doi:10.1021/jf049915d.
Iida M, Yamashiro S, Yamakawa H, Hayakawa K, Kuribara H, Kodama T, et al. Development of taxon-specific sequences of common wheat for the detection of genetically modified wheat. J Agr Food Chem. 2005;53(16):6294–300. doi:10.1021/jf0505731.
Grohmann L, Reiting R, Made D, Uhlig S, Simon K, Frost K, et al. Collaborative trial validation of cry1Ab/Ac and Pubi-cry TaqMan-based real-time PCR assays for detection of DNA derived from genetically modified Bt plant products. Accredit Qual Assur. 2015;20(2):85–96. doi:10.1007/s00769-015-1108-5.
Mano J, Shigemitsu N, Futo S, Akiyama H, Teshima R, Hino A, et al. Real-time PCR array as a universal platform for the detection of genetically modified crops and its application in identifying unapproved genetically modified crops in Japan. J Agric Food Chem. 2009;57(1):26–37. doi:10.1021/jf802551h.
Chaouachi M, Fortabat MN, Geldreich A, Yot P, Kerlan C, Kebdani N, et al. An accurate real-time PCR test for the detection and quantification of cauliflower mosaïc virus (CaMV): applicable in GMO screening. Eur Food Res Technol. 2007;227(3):789–98. doi:10.1007/s00217-007-0787-5.
Grohmann L, Brunen-Nieweler C, Nemeth A, Waiblinger HU. Collaborative trial validation studies of real-time PCR-based GMO screening methods for detection of the bar gene and the ctp2-cp4epsps construct. J Agric Food Chem. 2009;57(19):8913–20. doi:10.1021/jf901598r.
ISO. ISO21579:2005/Amd.1:2013(E). Foodstuffs - methods of analysis for the detection of genetically modified organisms and derived products - quantitative nucleic acid based methods. Geneva: International Organization for Standardization.
Acknowledgements
This research was funded by the Dutch Ministry of Economic Affairs as part of the WOT-02-004-005 project Validation and accreditation of detection methods for genetically modified organisms.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare to have no conflict of interest.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Scholtens, I.M.J., Molenaar, B., van Hoof, R.A. et al. Semiautomated TaqMan PCR screening of GMO labelled samples for (unauthorised) GMOs. Anal Bioanal Chem 409, 3877–3889 (2017). https://doi.org/10.1007/s00216-017-0333-7
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00216-017-0333-7